i
Perbandingan Kinerja Algoritma Decision Tree ID3 Dan CART
Pada Penjurusan Siswa SMA
Berdasarkan Nilai Ujian SMP Dan Nilai Rapor Kelas X
(Studi Kasus Pada SMA Kristen Bentara Wacana Muntilan)
Skripsi
Diajukan untuk Memenuhi Salah Satu Syarat
Memperoleh Gelar Sarjana Komputer
Oleh :
Maria Anindita Febri Apsari
07 5314 017
PROGRAM STUDI TEKNIK INFORMATIKA
FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA
YOGYAKARTA
ii
Comparison Performance of Decision Tree Algorithm ID3 and CART at Field of Study Senior High School Based on Examination Value Junior
High School and Report Value in Ten Class
(Case Study at Bentara Wacana Christian Senior High School Muntilan)
A Thesis
Presented as Partial Fullfillment of the Requirements To Obtain the Sarjana Teknik Degree
In Study Program of Informatics Engineering
By :
Maria Anindita Febri Apsari
07 5314 017
INFORMATICS ENGINEERING STUDY PROGRAM
FACULTY OF SCIENCE AND TECHNOLOGY
SANATA DHARMA UNIVERSITY
YOGYAKARTA
v
HALAMAN PERSEMBAHAN
Se g al a pe r kar a d apat
ku t an g g u n g d i d al am Di a y an g
me mb e r i ke ku at an ke pad aku
(Fi l i pi 4 : 13 )
Skripsi ini saya persembahkan untuk
x
PERBANDINGAN KINERJA ALGORITMA DECISION TREE ID3
DAN CART PADA PENJURUSAN SISWA SMA BERDASARKAN NILAI UJIAN SMP DAN NILAI RAPOR KELAS X
Studi Kasus SMA Kristen Bentara Wacana Muntilan
Maria Anindita Febri Apsari
ABSTRAK
Penelitian ini bertujuan untuk membandingkan kinerja dua algoritma
decision tree yaitu algoritma ID3 dan CART yang diterapkan pada kasus
penentuan jurusan SMA. Adapun jurusan yang dihasilkan adalah jurusan IPA dan IPS. Data yang digunakan adalah data nilai ujian SMP dan nilai rapor kelas X SMA Kristen Bentara Wacana tahun ajaran 2005/2006-2008/2009. Sistem yang dibangun diuji menggunakan tiga macam kriteria pengujian yaitu 3-fold
validation, 5-fold validation dan perbandingan jumlah data. Pengujian dengan
k-fold validation menggunakan tiga macam cara pembagian data yaitu indeks,
random dan per jurusan. Dari hasil pengujian yang telah dilakukan dapat disimpulkan bahwa algoritma CART lebih baik daripada algoritma ID3 pada kasus penentuan jurusan siswa dengan jumlah data training 229 record. Prosentase hasil akurasi dari tiga macam pengujian menunjukkan angka yang tinggi sehingga membuktikan bahwa nilai ujian SMP dan nilai rapor kelas X berpengaruh terhadap penjurusan. Hasil perbandingan akurasi sistem dengan WEKA menunjukan selisih hasil yang tidak terlalu jauh sehingga bisa dikatakan system sudah berjalan dengan baik.
viii
COMPARISON PERFORMANCE OF DECISION TREE ALGORITHM ID3 AND CART AT FIELD OF STUDY SENIOR HIGH SCHOOL BASED ON EXAMINATION VALUE JUNIOR HIGH SCHOOL AND
REPORT VALUE IN TEN CLASS
Case Study Bentara Wacana Christian Senior High School
Maria Anindita Febri Apsari
ABSTRACT
This study aims to compare the performance of two decision tree algorithms ID3 and CART algorithms are applied to the case of the determination of high school majors. The majors that are generated are science and social studies majors. The data used is the junior high school exam value and value class X 2005/2006-2008/2009 academic year. The system built was tested using three different testing criteria that is 3-fold validation, 5-fold validation and comparison of the amount of data. Testing with the k-fold validation using three different ways of data sharing is an index, random and major. From the results of the testing that has been done can be concluded that the CART algorithm is better than ID3 algorithm in the case of students majoring in the determination of the amount of training data 229 record. Percentage accuracy of the results of three kinds of tests showed a high rate thus proving that the junior high school test scores and class X affect determination of high school major. The results of accuracy comparison with the Weka system shows the difference in results is not too far away so they can say the system is running well.
x
KATA PENGANTAR
Puji dan syukur penulis panjatkan ke hadirat Tuhan Yang Maha Esa atas segala limpahan berkat dan penyertaan sehingga penulis bisa menyelesaikan tugas akhir yang berjudul “Perbandingan Kinerja Algoritma Decision Tree ID3 dan
CARTPada Penjurusan Siswa SMA Berdasarkan Nilai Ujian SMP dan Nilai
Rapor Kelas X (Studi Kasus SMA Kristen Bentara Wacana)”. Tugas akhir
ini ditulis sebagai salah satu syarat memperoleh gelar sarjana program studi Teknik Informatika, Fakultas Sains dan Teknologi Universitas Sanata Dharma.
Terima kasih sebesar-besarnya kepada semua pihak yang turut memberikan dukungan, semangat dan bantuan sehingga terselesaikannya skripsi ini :
1. Ibu Ridowati Gunawan, S.Kom, M.T. selaku dosen pembimbing serta kaprodi Teknik Informatika yang sudah membantu dan membimbing saya dalam menyelesaikan tugas akhir ini.
2. Ibu P.H. Prima Rosa, S.Si, M.Sc, dan Romo Dr. C. Kuntoro Adi, S.J, M.A, M.Sc sebagai dosen penguji atas kritik dan saran yang telah diberikan. 3. Seluruh staff pengajar dan laboran serta pihak sekretariat Prodi Teknik
Informatika Fakultas Sains dan Teknologi Universitas Sanata Dharma. 4. Kedua orang tua, Bapak Laurentius Sutikno, S.Pd dan Veronica Susiwi
Triwahyuni, S,Pd yang selalu memberikan doa, semangat, perhatian dan dukungan sehingga penulis dapat menyelesaikan tugas akhir ini.
5. Kedua adik, Willybrordus Aditya Yudistira dan Stefani Sekar Bela Jati yang telah memberika doa, semangat dan dukungan sehingga penulis dapat menyelesaikan tugas akhir ini.
6. Kekasihku, Yohanes Aditya Galih Kurniawan, yang selalu setia menemani serta memberikan semangat dan dukungan sehingga penulis dapat menyelesaikan tugas akhir ini.
xii
DAFTAR ISI
HALAMAN JUDUL……… i HALAMAN JUDUL (INGGRIS)……….……… ii HALAMAN PERSETUJUAN……….. iii HALAMAN PENGESAHAN ... Error! Bookmark not defined.
HALAMAN PERSEMBAHAN ... Error! Bookmark not defined.
HALAMAN KEASLIAN KARYA ... Error! Bookmark not defined.
ABSTRAK ... Error! Bookmark not defined.
ABSTRACT ... Error! Bookmark not defined.
LEMBAR PERSETUJUAN
PUBLIKASI……….……….. ix KATA PENGANTAR ... Error! Bookmark not defined.
DAFTAR ISI ... xii DAFTAR TABEL ... xv DAFTAR GAMBAR ... xix BAB I ... Error! Bookmark not defined.
PENDAHULUAN ... Error! Bookmark not defined.
1.1 Latar Belakang ... Error! Bookmark not defined.
1.2 Rumusan Masalah ... Error! Bookmark not defined.
1.3 Tujuan ... Error! Bookmark not defined.
1.4 Batasan Masalah ... Error! Bookmark not defined.
1.5 Metodologi Penelitian ... Error! Bookmark not defined.
1.6 Sistematika Penulisan ... Error! Bookmark not defined.
BAB II ... Error! Bookmark not defined.
LANDASAN TEORI ... Error! Bookmark not defined.
xiii
2.2 Teknik Data Mining ... Error! Bookmark not defined.
2.2.1 Klasifikasi ... Error! Bookmark not defined.
2.3 Pohon Keputusan (Decision Tree) ... Error! Bookmark not defined.
2.4 Pohon Keputusan Induksi ... Error! Bookmark not defined.
2.4.1 ID3 (Iterative Dichotomiser) ... Error! Bookmark not defined.
2.4.2 CART (Classification and Regression Tree) ...Error! Bookmark not defined.
2.5 Attribute Selection Measures ... Error! Bookmark not defined.
2.5.1 Information Gain ... Error! Bookmark not defined.
2.5.2 Gain Ratio ... Error! Bookmark not defined.
2.5.3 Gini Index ... Error! Bookmark not defined.
2.6 Korelasi dan Regresi ... Error! Bookmark not defined.
2.7 Perbandingan Performasi Algoritma ... Error! Bookmark not defined.
2.7.1 Pengukuran Kinerja Berdasarkan Komposisi DataError! Bookmark not defined.
2.7.2 Pengukuran Kinerja Berdasarkan Jumlah Data ....Error! Bookmark not defined.
BAB III ... Error! Bookmark not defined.
ANALISIS DAN PERANCANGAN SISTEM ... Error! Bookmark not defined.
3.1 Identifikasi Sistem ... Error! Bookmark not defined.
3.2 Sumber Data ... Error! Bookmark not defined.
3.3 Tahap-Tahap KDD (Knowledge Discovery in Database)Error! Bookmark not defined.
3.3.1 Data Praproses ... Error! Bookmark not defined.
3.3.2 Data Mining ... Error! Bookmark not defined.
3.4 Perancangan Umum Sistem ... Error! Bookmark not defined.
3.4.1 Diagram Use Case ... Error! Bookmark not defined.
3.4.2 Narasi Use Case ... Error! Bookmark not defined.
xiv
3.4.4 Diagram Aktivitas ... Error! Bookmark not defined.
3.4.5 Diagram Kelas Desain ... Error! Bookmark not defined.
3.4.6 Algoritma dan Method ... Error! Bookmark not defined.
3.4.7 Desain Basis Data ... Error! Bookmark not defined.
3.4.8 Diagram Analisis dan Sekuensial ... Error! Bookmark not defined.
3.4.9 Perancangan Struktur Data ... Error! Bookmark not defined.
3.4.10 Desain Antarmuka ... Error! Bookmark not defined.
BAB IV ... Error! Bookmark not defined.
IMPLEMENTASI SISTEM ... Error! Bookmark not defined.
4.1 Spesifikasi Software dan Hardware ... Error! Bookmark not defined.
4.2 Implementasi ... Error! Bookmark not defined.
4.2.1 Implementasi Data ... Error! Bookmark not defined.
4.2.2 Implementasi Use Case ... Error! Bookmark not defined.
4.2.3 Implementasi Diagram Kelas ... Error! Bookmark not defined.
5.1 Penyelesaian Rumusan Masalah ... Error! Bookmark not defined.
5.2 Pengukuran Kinerja Sistem ... Error! Bookmark not defined.
5.2.1 Pengukuran Kinerja 3-Fold Validation .. Error! Bookmark not defined.
5.2.2 Pengukuran Kinerja 5-Fold Validation .. Error! Bookmark not defined.
5.2.4 Evaluasi Pengukuran Kinerja Sistem... Error! Bookmark not defined.
5.2.5 Analisis Bentuk Pohon Keputusan ... Error! Bookmark not defined.
5.3 Kelebihan dan Kelemahan Sistem ... Error! Bookmark not defined.
5.3.1 Kelebihan Sistem ... Error! Bookmark not defined.
5.3.2 Kelemahan Sistem ... Error! Bookmark not defined.
DAFTAR PUSTAKA ... Error! Bookmark not defined.
LAMPIRAN 1 ... Error! Bookmark not defined.
LAMPIRAN 2 ... Error! Bookmark not defined.
2.6.1 Perhitungan ID3 ... Error! Bookmark not defined.
xv
DAFTAR TABEL
Tabel 3.1 Jumlah Record Data dengan Missing Value……… 26
Tabel 3.2 Jumlah Record Data Integrasi……….. 26
Tabel 3.3 Atribut yang Relevan dalam Penelitian……… 27
Tabel 3.4 Perhitungan Rata-Rata Nilai Rapor Semester 1 dan Semester 2………. 28 Tabel 3.5 Penamaan Atribut………. 28
Tabel 3.6 Transformasi Data Nilai……… 29
Tabel 3.7 Deskripsi Masukan Untuk Data Pelatihan……… 30
xvi
Tabel 3.9 Narasi Use Case Input Data Nilai Siswa………. 37 Tabel 3.10 Narasi Use Case Preprocessing………………… 38 Tabel 3.11 Narasi Use Case Pembentukan Pohon Keputusan….……. 39 Tabel 3.12 Narasi Use Case Pengujian Algoritma……… 40 Tabel 3.13 Kelas Analisis Diagram Sekuensial Input Nilai Siswa…… 56 Tabel 3.14 Kelas Analisis Diagram Sekuensial Preprocessing………. 57 Tabel 3.15 Kelas Analisis Diagram Sekuensial Pembentukan Pohon
Keputusan………
59
Tabel 3.16 Kelas Analisis Diagram Sekuensial Pengujian Algoritma.. 60 Tabel 3.17 Struktur Data……… 61 Tabel 5.1 Tabel Data dan Pola Pohon Keputusan……… 163
Tabel 5.2 Hasil Uji Korelasi………. 164 Tabel 5.3 Tabel Pengujian menggunakan ID3 3-Fold Validation
BerdasarkanIndeks……………..
167
Tabel 5.4 Tabel Pengujian menggunakan CART 3-Fold Validation
Berdasarkan Indeks……….…..
167
xvii
Berdasarkan Indeks ………..
Tabel 5.9 Tabel Pengujian menggunakan CART 5-Fold Validation
Berdasarkan Indeks………
170
Tabel 5.10 Tabel Pengujian 5-Fold Validation Secara Random……… 171 Tabel 5.11 Tabel Pengujian 5-Fold Validation Per Jurusan………….. 171 Tabel 5.12 Hasil Pengujian Kinerja Sistem 5-Fold Validation………….. 172 Tabel 5.13 Tabel Pengujian Algoritma ID3 Berdasarkan Jumlah Data
Uji 1………
172
Tabel 5.14 Tabel Pengujian Algoritma CART Berdasarkan Jumlah Data Uji 1……….
173
Tabel 5.15 Hasil Pengujian Kinerja Berdasarkan Jumlah Data Uji 1……. 173 Tabel 5.16 Tabel Pengujian Algoritma ID3 Berdasarkan Jumlah Data
Uji 2………
174
Tabel 5.17 Tabel Pengujian Algoritma CART Berdasarkan Jumlah Data Uji 2………..
174
Tabel 5.18 Hasil Pengujian Kinerja Berdasarkan Jumlah Data Uji 2……. 175
Tabel 5.19 Tabel Pengujian Algoritma ID3 Berdasarkan Jumlah Data Uji 3………..
175
Tabel 5.20 Tabel Pengujian Algoritma CART Berdasarkan Jumlah Data Uji 3……….
176
xviii
Tabel 5.23 Pengujian Kinerja Sistem Berdasarkan Komposisi Data dan Perbandingan Jumlah Data………
178
Tabel 5.24 Hasil Pengujian Akurasi Algoritma Decision Tree ………. 181 Tabel 5.25 Perbandingan Hasil k-Fold Validation dengan Weka…….. 181 Tabel 5.26 Penyebaran Node Pohon Keputusan………. 184
xix
DAFTAR GAMBAR
Gambar 2.1 Tahap-tahap Data Mining……… 8
Gambar 2.2 Contoh Pohon Keputusan..……….. 11
Gambar 2.3 Jika Atribut A di Simpul Uji Bernilai Diskrit….……… 14
Gambar 2.4 Jika Atribut A di Simpul Uji Bernilai Kontinu……… 14
Gambar 2.5 Jika Atribut A di Simpul Uji Bernilai Diskrit dan Pohon Keputusan yang Dihasilkan Harus Biner………. 15 Gambar 3.1 Contoh Pembagian Data Algoritma ID3………. 33
Gambar 3.2 Contoh Pembagian Data Algoritma CART………. 33
Gambar 3.3 Pengelompokan Data Untuk Proses Evaluasi Komposisi Data.. 34
Gambar 3.4 Pengelompokan Data Untuk Proses Evaluasi Komposisi Data.. 35
Gambar 3.5 Diagram Model Use Case……….. 37
Gambar 3.6 Diagram Konteks………. 41
Gambar 3.7 Diagram Aktivitas Input Nilai Siswa……… 41
Gambar 3.8 Diagram Aktivitas Preprocessing………. 42
xx
Gambar 3.10 Diagram Aktivitas Pengujian Algoritma..……….. 43
Gambar 3.11 Diagram Kelas Keseluruhan……… 44
Gambar 3.12 Diagram Kelas Input Data Nilai Siswa……….. 45
Gambar 3.13 Diagram Kelas Preprocessing……….. 46
Gambar 3.14 Diagram Kelas Pembentukan Pohon Keputusan………... 47
Gambar 3.15(a) Diagram Kelas Pengujian Algoritma………. 48
Gambat 3.15(b) Diagram Kelas Pengujian Algoritma……… 49
Gambar 3.16 Desain Fisik Basis Data………. 56
Gambar 3.17 Diagram Sekuensial Input Nilai Siswa………. 57
Gambar 3.18 Diagram Sekuensial Preprocessing……..………. 58
Gambar 3.19 Diagram Sekuensial Pohon Keputusan………. 59
Gambar 3.20 Diagram Sekuensial Pengujian Algoritma……… 61
Gambar 3.21 Desain Antarmuka Halaman Utama…….……….. 62
Gambar 3.22 Pesan Belum Melakukan Input Data Siswa……… 62
Gambar 3.23 Desain Antarmuka Halaman Input Nilai Siswa….……….. 63
Gambar 3.24 Pesan Belum Melakukan Transformasi……….. 63 Gambar 3.25 Desain Antarmuka Halaman Kriteria
xxi
Gambar 3.26 Pesan Belum Pilih Pengujian………. 64
Gambar 3.27 Desain Antarmuka Halaman Lihat Pohon Keputusan…………. 65
Gambar 3.28 Desain Antarmuka Halaman Hasil Pengujian……….. 65
Gambar 3.29 Desain Antarmuka Halaman Bantuan……….. 66
Gambar 3.30 Desain Antarmuka Halaman Tentang Kami………. 66
Gambar 4.1 Tampilan Halaman Utama……… 68
Gambar 4.2 Tampilan Halaman Input Nilai Siswa………. 69
Gambar 4.3 Tampilan Jika Menekan Tombol Browse……….. 69
Gambar 4.4 Tampilan Hasil Input Nilai Siswa………. 70
Gambar 4.5 Pesan Nilai Asli Tersimpan di Database……… 70
Gambar 4.6 Tampilan Hasil Preprocessing……….. 71
Gambar 4.7 Tampilan Halaman Lihat Pohon Keputusan……… 72
Gambar 4.8 Pesan Belum Input Data Siswa……… 73
Gambar 4.9 Pesan Belum Tranformasi……… 73
Gambar 4.10 Tampilan Halaman Kriteria Pengujian……… 74
Gambar 4.11 Pesan Belum Memilih Kriteria Pengujian………. 74
xxii
Gambar 4.15 Tampilan Halaman Tentang Kami……… 77 Gambar 5.1 Hasil Penentuan Jurusan dengan Pohon Keputusan ID3 dan
CART………...
165
Gambar 5.2 Hasil Pengujian Berdasarkan Perbandingan Jumlah Data Uji 1 173 Gambar 5.3 Hasil Pengujian Berdasarkan Perbandingan Jumlah Data Uji 2 176 Gambar 5.4 Hasil Pengujian Berdasarkan Perbandingan Jumlah Data Uji 3 177 Gambar 5.5 Grafik Akurasi Pengujian Berdasarkan Komposisi Data…….. 179 Gambar 5.6 Grafik Kecepatan Komputasi Pengujian Berdasarkan Komposisi
Data……… 180
1
BAB I
PENDAHULUAN
1.1 Latar Belakang
Salah satu cara untuk mencerdaskan kehidupan bangsa yaitu dengan cara memberikan pendidikan yang baik bagi para penerus bangsa. Mengenai arti dari pendidikan itu sendiri, Kustejo (2010) menyatakan bahwa pendidikan merupakan usaha sadar dan terencana untuk mewujudkan suasana belajar dan proses pembelajaran agar peserta didik secara aktif mengembangkan potensi dirinya untuk memiliki kekuatan spiritual keagamaan, pengendalian diri, kepribadian, kecerdasan, akhlak mulia, serta ketrampilan yang diperlukan dirinya, masyarakat, bangsa dan negara.
Untuk mendapatkan pendidikan yang baik salah satu cara yang bisa ditempuh yaitu dengan bersekolah. Menurut Ramli (2008) bersekolah merupakan kebutuhan setiap manusia dalam upaya menambah kualitas hidupnya. Dengan bersekolah maka akan didapatkan suatu ilmu pengetahuan yang nantinya bisa menjadi bekal seseorang dalam menghadapi masa depannya. Pada jenjang sekolah menengah atas atau sering disebut SMA diberlakukan penjurusan bagi siswa-siswanya. Penjurusan diperkenalkan sebagai upaya untuk lebih mengarahkan siswa berdasarkan minat dan kemampuan akademiknya. Siswa-siswa yang mempunyai kemampuan sains dan ilmu eksakta yang baik, biasanya akan memilih jurusan IPA, dan yang memiliki minat pada sosial dan ekonomi akan memilih jurusan IPS.
bagi seorang siswa pun bukan merupakan hal yang mudah bagi pihak sekolah karena banyak faktor harus dipertimbangkan sesuai dengan kemampuan akademis yang dimiliki seorang siswa. Kemampuan akademis seorang siswa yang menonjol di bidangnya dapat diukur dengan melihat nilai rapor. Padahal setiap tahunnya ada puluhan siswa yang harus ditentukan jurusan yang tepat untuknya. Kesalahan dalam perhitungan bisa menyebabkan siswa tersebut terjebak dalam penjurusan yang tidak sesuai dengan kemampuan akademisnya sehingga mempengaruhi siswa dalam menentukan masa depannya kelak.
Dengan melihat masalah yang ada, maka dilakukan suatu penelitian untuk mengelompokkan penjurusan siswa SMA berdasarkan nilai ujian SMP dan nilai rapor kelas X. Nilai rapor digunakan karena menyatakan hasil belajar siswa, sedangkan nilai ujian SMP digunakan karena latar belakang pendidikan ketika di SMP juga bisa berpengaruh terhadap penjurusan SMA.
Nilai ujian SMP yang digunakan hanyalah nilai ujian yang berpengaruh terhadap penjurusan SMA yaitu nilai Matematika, IPA dan IPS. Nilai rapor yang digunakan juga yang mempengaruhi penjurusan yaitu nilai Matematika, Sejarah, Ekonomi, Geografi, Sosiologi, Fisika, Kimia dan Biologi. Penelitian ini mengambil objek SMA Kristen Bentara Wacana Muntilan yang setiap tahunnya memberikan rekomendasi penjurusan kepada siswa-siswinya sehingga dari penelitian ini diharapkan akan muncul suatu pola yang dapat membantu mengelompokkan jurusan yang tepat bagi seorang siswa. Untuk mendapatkan suatu pola pengelompokan penjurusan diperlukan teknik data mining. Dalam penelitian ini akan digunakan teknik decision tree.
Teknik pengembangan dengan decision tree menjadi teknik yang popular karena decision tree yang dihasilkan mudah diinterpretasikan dan divisualisasikan. Menurut Kusrini (2009), ada beberapa algoritma decision tree
yaitu ID3, C4.5, CART dan CHAID yang dapat membangun model tree.
kedua algoritma ini memberikan visualisasi pohon yang berbeda. Dengan model yang berbeda dapat memberikan keakuratan yang berbeda juga. Untuk itu akan dilakukan penelitian Perbandingan Kinerja Algoritma Decision Tree ID3 dan CART pada Penjurusan SMA Berdasarkan Nilai Ujian SMP dan Nilai Kelas X.
1.2 Rumusan Masalah
Permasalahan yang akan dirumuskan dalam penelitian ini adalah :
1. Bagaimanakah menentukan jurusan bagi siswa SMA dengan menerapkan algoritma ID3 dan CART?
2. Bagaimana membangun suatu sistem untuk menentukan jurusan bagi siswa SMA dengan menerapkan algoritma ID3 dan CART?
3. Bagaimanakah perbandingan kinerja algoritma ID3 dengan CART?
Tujuan dari penelitian ini yaitu membangun suatu sistem yang dapat membandingkan kinerja algoritma ID3 dan CART pada kasus penentuan penjurusan siswa SMA berdasarkan pada nilai ujian SMP dan nilai rapor kelas X untuk melihat akurasi dan kecepatan komputasi dengan membandingkan komposisi data yang berbeda dan perbandingan jumlah data yang berbeda.
1.3 Tujuan
Sesuai dengan rumusan masalah di atas, maka batasan yang diberlakukan dalam penelitian ini adalah :
1.4 Batasan Masalah
1. Sistem ini hanya digunakan untuk menentukan penjurusan SMA untuk jurusan IPA dan IPS.
3. Sistem ini hanya digunakan untuk membandingkan akurasi dan kecepatan komputasi sistem berdasarkan komposisi dan perbandingan jumlah data. 4. Data yang digunakan berasal dari nilai ujian SMP dan nilai rapor kelas X
siswa tahun ajaran 2005/2006 – 2008/2009
1.5 Metodologi Penelitian
1. Studi Pustaka
Metode yang digunakan dalam penelitian ini adalah :
Mempelajari bahan-bahan tertulis seperti buku cetak, makalah dan tutorial yang ada kaitannya dengan pengembangan sistem.
2. Wawancara
Melakukan studi dengan metode wawancara kepada dosen, kepala sekolah, guru ataupun pihak-pihak yang berhubungan dengan permasalahan yang dibahas dalam penelitian ini.
3. Pengumpulan data
Mengumpulkan data-data yang berkaitan dengan sistem yang dikerjakan. 4. Perancangan Model Decision Tree
Perancangan model Decision Tree menggunakan Metode KDD (Knowledge Discovery in Database) meliputi :
a.
Pada tahap ini akan dilakukan pengisian data yang kosong dan penghilangan data yang tidak konsisten.
Data Cleaning
b.
Pada tahap ini dilakukan penggabungan data dari berbagai sumber data yang berbeda. Data mining tidak hanya berasal dari satu sumber
database tetapi juga berasal dari beberapa database atau file teks. Data Integration
c.
d.
Pada tahap ini akan dilakukan pemilihan data untuk menentukan kualitas data mining, sehingga data dapat diubah menjadi bentuk yang sesuai untuk di-Mining.
Data Transformation
e.
Proses esensial untuk mengekstrak pola dari data dengan metode
data mining.
Data Mining
f.
Pada tahap ini, knowledge atau pola yang didapat dari proses penambangan data akan dievaluasi dengan hipotesa yang telah dibentuk sebelumnya.
Pattern Evaluation
g.
Penyajian pengetahuan yang digali kepada pengguna dengan menggunakan visualisasi dan teknik representasi pengetahuan.
Knowledge Presentation
Penulisan penelitian ini tersusun dari 5 (lima) bab dengan sistematika penulisan sebagai berikut :
1.6 Sistematika Penulisan
BAB I PENDAHULUAN
Bab I Pendahuluan berisi latar belakang, rumusan masalah, tujuan penelitian, batasan masalah, metodologi penelitian, dan sistematika penulisan.
BAB II LANDASAN TEORI
BAB III ANALISA DAN PERANCANGAN SISTEM
Bab ini berisi tentang identifikasi sistem, tahap-tahap KDD
(Knowledge Discovery in Database), perancangan umum sistem, perancangan basis data dan perancangan antar muka.
BAB IV IMPLEMENTASI SISTEM
Bab ini berisi tentang spesifikasi software dan hardware, implementasi sistem yang meliputi implementasi data, implementasi use case dan implementasi diagram kelas.
BAB V ANALISIS SISTEM
Bab ini berisi tentang pembahasan program yang telah dibangun.
BAB VI PENUTUP
7
BAB II
LANDASAN TEORI
Pada bab ini akan dipaparkan teori-teori yang menjadi landasan proses pengerjaan penelitian ini. Penelitian ini bertujuan untuk membandingkan kinerja algoritma data mining. Dalam hal ini akan dibandingkan dua algoritma decision tree yaitu algoritma ID3 (Iterative Dichotomiser) dan CART (Classification and Regression Tree). Dengan dua model algoritma yang berbeda akan memberikan keakuratan yang berbeda pula. Kinerja kedua algoritma tersebut akan diukur berdasarkan komposisi data dan jumlah data sehingga akan didapatkan akurasi dan kecepatan sistem untuk masing-masing algoritma.
2.1 Data Mining
Menurut Kusnawi (2007) pengertian dari data mining adalah sebagai berikut “data mining merupakan salah satu bidang yang berkembang pesat karena adanya kebutuhan akan nilai tambah dari database skala besar yang makin banyak terakumulasi sejalan dengan berkembangnya teknologi informasi”. Pertumbuhan akumulasi data menciptakan suatu kondisi yang sering disebut “rich of data but poor information” karena data yang terkumpul tidak dapat digunakan untuk aplikasi yang berguna. Kusnawi juga menyatakan bahwa “data mining adalah serangkaian proses untuk menggali nilai tambah berupa pengetahuan yang selama ini tidak diketahui secara manual dari suatu kumpulan data. Selain itu data mining
Salah satu tuntutan dari data mining ketika diterapkan pada data berskala besar adalah diperlukan metodologi sistematis tidak hanya ketika melakukan analisa saja tetapi juga ketika mempersiapkan data dan juga melakukan interpretasi dari hasilnya sehingga dapat menjadi keputusan yang bermanfaat.
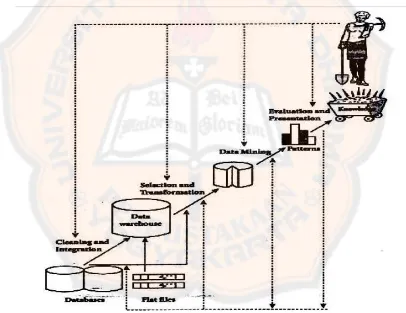
Data mining seharusnya dipahami sebagai suatu proses yang memiliki tahapan-tahapan tertentu dan juga ada umpan balik dari setiap tahapan ke tahapan sebelumnya. Pada umumnya proses data mining berjalan interaktif karena tidak jarang hasil data mining pada awalnya tidak sesuai dengan harapan analisnya sehingga perlu dilakukan desain ulang prosesnya. Tahap-tahap data mining
menurut Han, Kamber (2006 ) dipaparkan pada gambar 2.1 berikut ini :
1. Data Cleaning / Pembersihan data
Digunakan untuk pengisian data yang kosong dan membuang data yang tidak konsisten.
2. Data Integration / Intergrasi Data
Data yang diperlukan untuk data mining tidak hanya berasal dari satu
database tetapi juga berasal dari beberapa database atau file teks. Hasil integrasi data sering diwujudkan dalam sebuah data warehouse karena dengan
data warehouse, data dikonsolidasikan dengan struktur khusus yang efisien. Selain itu data warehouse juga memungkinkan tipe analisa seperti OLAP. 3. Data Transformation / Transformasi data
Transformasi dan pemilihan data ini untuk menentukan kualitas dari hasil
data mining, sehingga data diubah menjadi bentuk sesuai untuk di-Mining. 4. Data Mining / Aplikasi Teknik Data Mining
Aplikasi teknik data mining sendiri hanya merupakan salah satu bagian dari proses data mining. Ada beberapa teknik data mining yang sudah umum dipakai yaitu klasifikasi, clustering dan asosiasi.
5. Pattern Evaluation / Evaluasi pola yang ditemukan
Dalam tahap ini hasil dari teknik data mining berupa pola-pola yang khas maupun model prediksi dievaluasi untuk menilai apakah hipotesa yang ada memang tercapai.
6. Knowledge Presentation / Presentasi Pengetahuan
Presentasi pola yang ditemukan untuk menghasilkan aksi tahap terakhir dari proses data mining adalah bagaimana memformulasikan keputusan atau aksi dari hasil analisa yang didapat.
2.2 Teknik Data Mining
2.2.1 Klasifikasi
Suatu teknik dengan melihat pada kelakuan dan atribut dari kelompok yang telah didefinisikan.Teknik ini dapat memberikan klasifikasi pada data baru dengan memanipulasi data yang ada yang telah diklasifikasi dan dengan menggunakan hasilnya untuk memberikan sejumlah aturan. Aturan-aturan tersebut digunakan pada data-data baru untuk diklasifikasi. Teknik ini menggunakan supervised induction, yang memanfaatkan kumpulan pengujian dari
record yang terklasifikasi untuk menentukan kelas-kelas tambahan. Salah satu contoh yang mudah dan popular adalah dengan decision tree.
2.3 Pohon Keputusan (Decision Tree)
Tentang pohon keputusan Kusrini (2009) menyatakan bahwa “pohon keputusan merupakan metode klasifikasi dan prediksi yang sangat kuat dan terkenal. Metode pohon keputusan ini mengubah fakta yang sangat besar menjadi pohon keputusan yang merepresentasikan aturan”.
Sebuah pohon keputusan adalah sebuah struktur yang dapat digunakan untuk membagi kumpulan data yang besar menjadi himpunan-himpunan record
yang lebih kecil dengan menerapkan serangkaian aturan keputusan. Dengan masing-masing rangkaian pembagian, anggota himpunan hasil menjadi mirip satu dengan yang lain (Berry & Linoff, 2004).
Proses pada pohon keputusan adalah mengubah bentuk data (tabel) menjadi model pohon, mengubah model pohon menjadi rule dan menyederhanakan rule (Basuki & Syarif, 2003).
menginterpretasikan solusi dari permasalahan, bisa dijadikan tool pengambilan keputusan terakhir dan dapat mengubah keputusan yang kompleks menjadi lebih
simple, spesifik dan mudah.
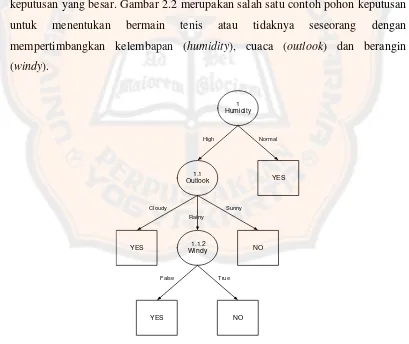
Adapun kekurangan pohon keputusan diantaranya kesulitan dalam mendesain pohon keputusan yang optimal, hasil keputusan yang didapat dari metode pohon keputusan sangat tergantung pada bagaimana pohon keputusan tersebut didesain, terjadi overlap terutama kelas-kelas dan kriteria yang digunakan jumlahnya sangat banyak. Hal tersebut juga dapat menyebabkan meningkatnya waktu pengambilan keputusan dan jumlah memori yang diperlukan. Tetapi ketika kriterianya lebih simple tentu saja pengambilan keputusannya menjadi lebih cepat serta pengakumulasian jumlah error dari setiap tingkat dalam sebuah pohon keputusan yang besar. Gambar 2.2 merupakan salah satu contoh pohon keputusan untuk menentukan bermain tenis atau tidaknya seseorang dengan mempertimbangkan kelembapan (humidity), cuaca (outlook) dan berangin (windy).
1 Humidity
1.1 Outlook
1.1.2 Windy
YES
YES
YES
NO
NO
High Normal
Cloudy
Rainy
Sunny
False True
2.4 Pohon Keputusan Induksi
Sejak akhir tahun 1970 sampai awal tahun 1980, J.RossQuinlan, peneliti mesin pembelajaran, mengembangkan algoritma pohon keputusan yang dikenal dengan nama ID3 (Iterative Dichotomiser). Quinlan kemudian memperkenalkan C4.5 (pengganti ID3) yang menjadi tolak ukur pembanding supervised learning algorithm. Pada tahun 1984 kelompok ahli statistic (L. Breiman, J.Friedman, R. Olshen, and C. Stone) menerbitkan buku Classification and Regression Trees
(CART), dideskripsikan sebagai generasi pohon keputusan biner.
Menurut Han,J., Kamber,M (2006) ID3, C45 dan CART memiliki karakteristik yang sama dalam membangun pohon keputusan, yaitu top-down dan
divide-conquer. Top-down artinya pohon keputusan dibangun dari simpul akar ke simpul daun. Divide-conquer artinya training data secara rekursif dipartisi ke dalam bagian-bagian yang lebih kecil saat pembangunan pohon. Biner tidaknya pohon keputusan ditentukan oleh attribbute selection measures atau algoritma yang digunakan. Secara umum algoritma dasar dalam pembangunan pohon keputusan adalah sebagai berikut.
Algoritma dasar untuk pohon keputusan menurut Han,J., Kamber,M (2006) :
Algorithm: Generate_decision_tree.
Narative : Generate a decision tree from the given training data.
Input: The training samples, samples, represented by discrete-valued attribute; the
set of candidate attributes, attribute-list.
Output: A decision tree.
Method:
(1) create a node N;
(2) if samples are all of the same class, C then
(3) return N as a leaf node labeled with the class C;
(4) if attribute-list is empty then
(5) return N as a leaf node labeled with the most common class in
samples;//majority voting
information gain;
(7) label node N with test-attribute;
(8) for each known value ai of test-attribute;
(9) grow a branch from node N for the condition test-attribute = ai;
(10) let si be the set of samples in samples for which test-attribute = ai; // a
partition
(11) if si is empty then
(12) attach a leaf labeled with the most common class in samples;
(13) else attach the node returned by Generate_decision_tree (si, attribute-listtest-
attribute);
Algoritma di atas dapat dijelaskan sebagai berikut. Awalnya pohon hanya memiliki sebuah simpul, N, yang mewakili seluruh training data di D. Jika seluruh tuples di D memiliki kelas yang sama, maka simpul N diubah menjadi daun dan dilabeli dengan nama kelas tersebut. Sebaliknya, jika tuple-tuple di D memiliki kelas yang berbeda-beda, maka dipanggil attribute_selection_method
untuk menentukan kriteria terbaik dalam mempartisi data dengan menggunakan
attribute selection measures. Kemudian, simpul N dilabeli dengan splitting attribute yang diperoleh dari Attribute_selection_method dan sebuah cabang akan dibangkitkan untuk setiap hasil pengujian pada simpul N. Selanjutnya, tuple-tuple di D akan dipartisi sesuai dengan hasil pengujian tersebut. Terdapat tiga skenario yang mungkin dalam mempartisi D. Misalkan A adalah
splitting attribute pada simpul N dan A memiliki sejumlah k nilai berbeda {a1, a2, ..., ak} pada training data.
Color ?
orange purple blue green
red
Gambar 2.3 Jika atribut A di simpul uji bernilai diskrit (Sumber : Han,J., Kamber,M (2006))
ii. Jika A memiliki nilai-nilai yang kontinu, maka hasil pengujian pada simpul N akan menghasilkan dua cabang, yaitu untuk A ≤ split point dan A > split point. Split point merupakan keluaran dari attribute_selection_method
sebagai bagian dari kriteria untuk melakukan partisi. Selanjutnya, D dipartisi sehingga D1 terdiri dari tuple-tuple di mana A ≤ split point dan D2 adalah sisanya. Gambar 2.4 memperlihatkan pembagian atribut A yang bernilai kontinu.
Income?
>42000 <=42000
Gambar 2.4 Jika atribut A di simpul uji bernilai kontinu (Sumber : Han,J., Kamber,M (2006))
color ε {red,green}?
yes no
Gambar 2.5 Jika atribut A di simpul uji bernilai diskrit dan pohon keputusan yang dihasilkan harus biner
(Sumber : Han,J., Kamber,M (2006))
Algoritma akan melakukan proses yang sama secara rekursif terhadap setiap partisi yang dihasilkan. Proses ini berakhir hanya jika salah satu dari kondisi berikut dipenuhi.
(i) Seluruh tuples di D memiliki kelas yang sama.
(ii) Tidak ada lagi atribut yang tersisa di attribute_list. Pada kasus ini, simpul N akan diubah menjadi daun dan dilabeli dengan mayoritas kelas di D.
(iii) Tidak terdapat tuple di suatu cabang (Di kosong). Pada kasus ini, sebuah daun dibuat dan dilabeli dengan mayoritas kelas di D.
2.4.1 ID3 (Iterative Dichotomiser)
Menurut Santosa, B (2007) ID3 menggunakan kriteria information gain untuk memilih atribut yang akan digunakan untuk pemisahan obyek. Atribut yang mempunyai information gain tertinggi dibandingkan dengan atribut yang lain relatif terhadap set y dalam suatu data, dipilih untuk melakukan pemecahan. Adapun untuk menghitung information gain digunakan persamaan 2.4 pada subbab 2.5 tentang Attribute Selection Measures.
2.4.2 CART (Classification and Regression Tree)
dua langkah penting yang harus diikuti untuk mendapatkan tree dengan performansi yang optimal. Yang pertama adalah pemecahan obyek secara berulang berdasarkan atribut tertentu. Yang kedua, pruning (pemangkasan) dengan menggunakan data validasi. Misalkan kita mempunyai variabel independent x1, x2, x3, ... , xn
Pemecahan secara berulang berarti membagi obyek ke dalam kotak-kotak bernilai variabel x
dan variabel dependent atau output y.
1, x2 atau xp. Cara ini diulang sehingga dalam suatu kotak
sebisa mungkin berisi observasi dari kelompok / kelas yang sama. Misalkan untuk pemecahan pertama, kita buat kotak yang memuat semua observasi dengan xi ≤ si,
sementara kotak lain berisi observasi dengan nilai xi > si. Selanjutnya satu kotak
dipecah lagi menjadi dua kotak dengan cara yang sama dengan menggunakan variabel xi
Langkah berikutnya sesudah dilakukan pemecahan obyek/data secara berulang adalah melakukan pruning. Pruning dilakukan untuk memangkas tree
yang mungkin terlalu besar dan terjadi fenomena overfitting. Overfitting
merupakan noise yang ada di dalam data training, bukan pola yang termasuk ke dalam data testing atau data validasi. Pruning terdiri dari beberapa langkah pemilihan secara berulang simpul yang akan dijadikan simpul daun. Dengan mengubah simpul menjadi simpul daun artinya tidak akan dilakukan pemecahan lagi. Dengan demikian ukuran tree akan berkurang. Proses pruning akan menghasilkan tawar-menawar antara kesalahan klasifikasi (misclassification error) dalam data validasi dan jumlah simpul pohon keputusan dalam tree yang dipangkas untuk mencapai tree yang bisa menangkap pola sesungguhnya dan bukan hanya noise dalam data training. Untuk itu perlu digunakan suatu kriteria. Kriteria itu dinamakan kompleksitas ongkos (cost complexity). Yaitu, ongkos yang dibutuhkan untuk membuat tree secara berurutan dipangkas menjadi lebih kecil hingga tinggal simpul akar. Dalam urutan ini akan dipilih tree yang memberi kesalahan klasifikasi paling kecil dalam data validasi.
Kriteria kompleksitas ongkos yang digunakan dalam CART adalah jumlah antara kesalahan klasifikasi untuk data validasi dengan faktor pinalti yang berhubungan dengan ukuran tree. Faktor pinalti ini didasarkan pada suatu parameter, α, yaitu pinalti untuk setiap simpul. Semakin besar ukuran tree, semakin banyak jumlah simpul, semakin tinggi pinalti yang dikenakan. Sehingga kriteria kompleksitas ongkos untuk suatu tree adalah seperti persamaan 2.1 berikut.
C = Err(T) + α|L(T)|...2.1
dimana Err(T) adalah kesalahan klasifikasi pada data validasi yang dihasilkan tree T, L(T) adalah jumlah daun (leaf) dan α adalah ongkos tiap
simpul. Nilai α ini bervariasi mulai dari nol. Jika α = 0 maka tidak ada pinalti untuk tree yang dihasilkan dan tidak perlu ada pemangkasan. Jika nilai α lebih
besar maka komponen ongkos dari pinalti akan mendominasi kompleksitas ongkos dan tree terbaik adalah tree dengan satu simpul. Jadi akan dicari kombinasi terbaik antara besarnya tingkat kesalahan klasifikasi dengan jumlah daun.
2.5 Attribute Selection Measures
Attribute selection measures menurut Han,J., Kamber,M (2006)
selection measures yang banyak digunakan, yaitu information gain, gain ratio, dan gini index.
Notasi yang digunakan adalah sebagai berikut. D merupakan partisi yang berisi training data. Sebuah atribut yang menyatakan kelas memiliki sejumlah m
nilai berbeda, yang berarti bahwa terdapat sebanyak m kelas yang terdefinisi, Ci (i
= 1, …, m). Ci,D menyatakan tuples di D yang memiliki kelas Ci.
2.5.1 Information Gain
ID3 menggunakan information gain sebagai attribute selection measure.
Simpul N mewakili tuples di dalam D. Atribut dengan information gain tertinggi dipilih sebagai splitting attribute pada simpul N. Atribut seperti ini diharapkan mampu meminimalkan informasi yang dibutuhkan untuk mengklasifikasi seluruh
tuples di D serta mencerminkan tingkat impurity yang rendah pada partisi-partisi yang dihasilkan. Dengan kata lain, jumlah pengujian yang dibutuhkan untuk mengklasifikasi sebuah tuple menjadi berkurang dan pohon keputusan yang dihasilkan pun menjadi lebih sederhana. Informasi yang dibutuhkan untuk mengklasifikasi sebuah tuple didefinisikan pada persamaan 2.2 sebagai berikut :
𝐼𝐼𝐺𝐺𝐼𝐼𝑙𝑙 (𝐷𝐷) = − ∑𝐺𝐺𝑗𝑗=1𝑝𝑝𝐺𝐺𝑙𝑙𝑙𝑙𝑙𝑙2(𝑝𝑝𝐺𝐺)
………..2.2 Dimana p(i) adalah peluang sebuah tuple D memiliki kelas C
Pada saat akan mempartisi tuple-tuple di D terhadap atribut A yang memiliki v nilai berbeda, jika A diskrit, akan terbentuk sebanyak v hasil pengujian dan v partisi di mana Dj adalah partisi yang terdiri dari tuple-tuple di D yang memiliki nilai aj untuk atribut A. Idealnya, setiap partisi yang dihasilkan akan bersifat pure. Namun pada kenyataannya, partisi yang dihasilkan sering impure.
Oleh karena itu, setelah partisi dilakukan, masih dibutuhkan informasi untuk memperoleh klasifikasi yang pure yang dapat diukur dengan rumus 2.3 berikut.
. Nilai peluang ini dapat didekati dengan cara menghitung |Ci,D|/|D|. Info(D) hanyalah jumlah rata-rata informasi yang dibutuhkan untuk memprediksi kelas dari sebuah tuple.
𝐼𝐼𝐺𝐺𝐼𝐼𝑙𝑙𝐴𝐴(𝐷𝐷) = ∑𝑣𝑣𝑗𝑗=1||𝐷𝐷𝐷𝐷𝑗𝑗||𝑥𝑥𝐼𝐼𝐺𝐺𝐼𝐼𝑙𝑙 (𝐷𝐷𝑗𝑗)……….2.3
InfoA(D) adalah informasi yang dibutuhkan untuk mengklasifikasi sebuah
tuple di D berdasarkan hasil partisi di A. Semakin kecil jumlah informasi yang dibutuhkan ini, semakin tinggi tingkat purity dari partisi yang dihasilkan.
Information gain merupakan selisih antara kebutuhan informasi awal (yang hanya bergantung pada jumlah dan proporsi tiap kelas di dalam D) dan kebutuhan informasi baru (yang diperoleh setelah melakukan partisi terhadap atribut A). Adapun rumus information gain didefinisikan pada rumus 2.4 berikut.
)
Gain(A) akan menginformasikan seberapa banyak informasi yang didapat dengan melakukan pembagian di A. Atribut dengan Gain(A) terbesar dipilih sebagai splitting attribute di simpul N. Dengan kata lain, atribut yang terbaik adalah yang meminimalkan jumlah informasi yang dibutuhkan untuk menyelesaikan klasifikasi dari seluruh tuple di D.
2.5.2 Gain Ratio
Pada uraian di atas, dapat dilihat bahwa information gain lebih mengutamakan pengujian yang menghasilkan banyak keluaran. Dengan kata lain, atribut yang memiliki banyak nilailah yang dipilih sebagai splitting attribute. Sebagai contoh, pembagian terhadap atribut yang berfungsi sebagai unique identifier, seperti product_ID¸ akan menghasilkan keluaran dalam jumlah yang banyak, di mana setiap keluaran hanya terdiri dari satu tuple. Partisi semacam ini tentu saja bersifat pure, sehingga informasi yang dibutuhkan untuk mengklasifikasi D berdasarkan partisi seperti ini adalah sebesar
Infoproduct_ID(D) = 0. Sebagai akibatnya, information gain yang dimiliki atribut
product_ID menjadi maksimal. Padahal, jelas sekali terlihat bahwa partisi semacam ini tidaklah berguna.
Algoritma C4.5 yang merupakan suksesor dari ID3 menggunakan gain ratio
pada information gain dengan menggunakan apa yang disebut sebagai split information seperti terlihat pada rumus 2.5.
𝑆𝑆𝑝𝑝𝑙𝑙𝐺𝐺𝑡𝑡𝐼𝐼𝐺𝐺𝐼𝐼𝑙𝑙𝐴𝐴 = − ∑ ||𝐷𝐷𝐷𝐷𝑗𝑗|| 𝑥𝑥𝑙𝑙𝑙𝑙𝑙𝑙2( |𝐷𝐷𝑗𝑗|
|𝐷𝐷|
𝑣𝑣
𝑗𝑗=1 ………2.5
Nilai ini menyatakan jumlah informasi yang dihasilkan akibat pembagian
training data ke dalam partisi-partisi, berkaitan dengan pengujian yang dilakukan terhadap atribut A.
𝐺𝐺𝑘𝑘𝐺𝐺𝐺𝐺𝐺𝐺𝑘𝑘𝑡𝑡𝐺𝐺𝑙𝑙(𝐴𝐴) = 𝐺𝐺𝑘𝑘𝐺𝐺𝐺𝐺 (𝐴𝐴)
𝑆𝑆𝑝𝑝𝑙𝑙𝐺𝐺𝑡𝑡𝐼𝐼𝐺𝐺𝐼𝐼𝑙𝑙(𝐴𝐴) ………2.6
Atribut dengan gain ratio maksimal dengan perhitungan menggunakan rumus 2.6 di atas, akan dipilih sebagai splitting attribute. Perlu diperhatikan bahwa jika split information mendekati 0, maka perbandingan tersebut menjadi tidak stabil. Oleh karena itu, perlu ditambahkan batasan untuk memastikan bahwa
information gain dari sebuah pengujian haruslah besar, dan minimal sama besar dengan information gain rata-rata dari seluruh pengujian.
2.5.3 Gini Index
Attribute selection measure jenis ini digunakan pada algoritma CART.
Giniindex akan menghasilkan pembagian yang bersifat biner pada setiap atribut, baik yang memiliki nilai diskrit ataupun kontinu. Gini index mengukur impurity
dari suatu partisi, D, dengan rumus 2.7 berikut.
𝐺𝐺𝐺𝐺𝐺𝐺𝐺𝐺(𝐷𝐷) = 1− ∑𝑗𝑗𝐺𝐺=1𝑝𝑝𝐺𝐺2 ………2.7
Dimana pi adalah peluang bahwa sebuah tuple di D berada pada kelas Ci. Peluang tersebut dapat didekati dengan hasil perhitungan |Ci,D|/|D| di mana. |Ci,D| merupakan jumlah tuple pada D yang memiliki kelas Ci dan |D| adalah jumlah seluruh tuple di D. Perhitungan ini dilakukan untuk setiap kelas.
Misalkan A merupakan atribut bernilai diskrit yang memiliki sejumlah v
”A Є SA ?”. Sebuah tuple memenuhi pengujian jika nilai untuk atribut A pada
tuple tersebut merupakan bagian dari SA. Dengan tidak mempertimbangkan himpunan kuasa dan himpunan kosong, maka akan terdapat 2v – 2 cara untuk melakukan pembagian biner dari D.
Pemeriksaan sebuah pembagian biner dilakukan dengan cara menjumlahkan impurity dari setiap partisi yang dihasilkan oleh pembagian tersebut. Misalkan sebuah pembagian yang dilakukan terhadap atribut A
mempartisi D menjadi D1 dan D2. Gini index dari D dapat dihitung dengan rumus 2.8 berikut.
𝐺𝐺𝐺𝐺𝐺𝐺𝐺𝐺𝐴𝐴(𝐷𝐷) = ||𝐷𝐷𝐷𝐷1|| 𝐺𝐺𝐺𝐺𝐺𝐺𝐺𝐺 (𝐷𝐷1) + |𝐷𝐷2|
|𝐷𝐷| 𝐺𝐺𝐺𝐺𝐺𝐺𝐺𝐺 (𝐷𝐷2)………2.8
Untuk atribut bernilai diskrit, himpunan bagian yang memberikan nilai gini index terkecil untuk atribut A akan dipilih sebagai splitting subset. Seluruh pembagian biner yang mungkin terjadi pada suatu atribut harus diperiksa.
Sementara untuk atribut bernilai kontinu, setiap split point yang mungkin harus diperiksa. Untuk nilai-nilai suatu atribut yang telah diurutkan, titik tengah di antara setiap pasangan nilai yang saling berseberangan dapat diambil sebagai sebuah split point. Titik yang memberikan nilai gini index terkecil untuk suatu atributlah yang akhirnya diambil sebagai split point.
Penurunan tingkat impurity yang diperoleh dari sebuah pembagian biner terhadap atribut A dapat dihitung dengan rumus 2.9 berikut.
∆𝐺𝐺𝐺𝐺𝐺𝐺𝐺𝐺(𝐴𝐴) = 𝐺𝐺𝐺𝐺𝐺𝐺𝐺𝐺(𝐷𝐷)− 𝐺𝐺𝐺𝐺𝐺𝐺𝐺𝐺𝐴𝐴(𝐷𝐷) ……….2.9
Atribut yang memaksimalkan penurunan tingkat impurity inilah yang dipilih sebagai splitting attribute. Atribut ini, bersama dengan splitting subset
2.6 Korelasi dan Regresi
Analisis hubungan antar variable secara garis besar dikemukakan oleh Trihendradi,C (2005) dibagi menjadi dua, yaitu analisis korelasi dan analisis regresi. Kedua analisis tersebut saling terkait. Analisis korelasi menyatakan derajat keeratan antar variabel, sedangkan analisis regresi digunakan dalam peramalan variabel dependent berdasarkan variabel-variabel independent-nya.
Menurut Teguh,W (2004) ada banyak macam analisis korelasi tergantung pada jenis data yang akan dianalisis. Beberapa uji korelasi yang banyak digunakan antara lain uji korelasi sederhana (bivariate correlation) dan uji korelasi parsial
(partial correlation) dari person product.
Korelasi bivariate menurut Trihendradi,C (2005) digunakan untuk mencari derajat keeratan hubungan dan arah hubungan. Semakin tinggi nilai korelasi, semakin tinggi keeratan hubungan kedua variabel. Nilai korelasi memiliki rentang antara 0 sampai 1 atau 0 sampai -1. Tanda positif dan negative menunjukkan arah hubungan. Tanda positif menunjukkan arah hubungan searah. Jika satu variabel naik, variabel yang lain naik. Tanda negative menunjukkan hubungan berlawanan, jika satu variabel naik, variabel yang lain turun.
Ada tiga macam uji Bivariate, yaitu Pearson yang digunakan untuk mengukur hubungan dengan data distribusi normal. Tes dikatakan normal bila nilai signifikan lebih dari nilai probabilitas yaitu 0,05. Sedangkan uji Kendall dan Spearman mengukur hubungan berdasarkan urutan ranking dua variabelskala atau ordinal. Uji dilakukan tanpa memandang distribusi variabel.
2.7 Perbandingan Performasi Algoritma
2.7.1 Pengukuran Kinerja Berdasarkan Komposisi Data
D1, D2, …Dk, masing-masing D mempunyai jumlah yang sama. Pada iterasi ke – i partisi Di digunakan sebagai data uji, sedangkan sisa partisi digunakan sebagai data pelatihan. Maka dari itu pada iterasi pertama, D1 digunakan sebagai data uji dan D2, D3, ….Dk digunakan sebagai data pelatihan. Pada iterasi kedua, D2 digunakan sebagai data uji, sedangakan D1, D3, ….Dk digunakan sebagai data pelatihan. Pada iterasi ketiga, D3 digunakan sebagai data uji, sedangkan D1, D2, …Dk digunakan sebagai data pelatihan dan seterusnya. Setiap sample D, hanya digunakan sekali sebagai data uji dan berkali-kali sebagai data pelatihan. Untuk pengklasifikasian, pengukuran keakurasian dapat dihitung dengan cara seluruh jumlah klasifikasi yang benar dari k iterasi, dibagi dengan seluruh data.
Pengukuran tingkat kecepatan komputasi dapat dilihat dengan membandingkan kecepatan waktu kerja dari sebelum proses pembuatan pohon keputusan, terbentuknya pohon keputusan sampai terbentuknya keputusan pada data testing.
2.7.2 Pengukuran Kinerja Berdasarkan Jumlah Data
Berdasarkan penelitian Raghavan, R (2006) dinyatakan bahwa untuk mengukur kinerja algoritma berdasarkan jumlah data yaitu dengan membagi data ke dalam beberapa bagian yang berbeda dimana setiap data set mempunyai rasio perbandingan 50:50 sampai 97.5 : 2.5. Perbandingan yang di depan digunakan sebagai data training, dan perbandingan yang belakang digunakan sebagai data testing. Data training digunakan untuk membangun model, sedangkan data testing digunakan untuk perhitungan akurasi. Tiap perbandingan rasio dari data set, lima perbedaan error rate akan dirata-rata untuk membentuk seluruh error rate. Ini digunakan untuk mengurangi variasi error rate.
24
BAB III
ANALISIS DAN PERANCANGAN SISTEM
3.1 Identifikasi Sistem
Setiap tahun SMA Bentara Wacana melakukan proses penjurusan kepada siswa-siswinya yang akan naik ke kelas XI. Ada dua jurusan yang ditawarkan yaitu IPA dan IPS. Setiap siswa yang akan naik ke kelas XI mempunyai data nilai ujian SMP dan nilai rapor kelas X yang didokumentasikan oleh pihak sekolah.
Data nilai ujian SMP dan nilai rapor kelas X tersebut akan dipakai untuk menentukan penjurusan bagi siswa yang akan naik ke kelas XI. Untuk melakukan penjurusan dengan menggunakan data nilai ujian SMP dan nilai rapor kelas X akan dilakukan proses penambangan data. Dari proses penambangan data ini akan dibandingkan kinerja dua algoritma decision tree yaitu algoritma ID3 dan CART dari segi akurasi algoritma dan kecepatan komputasi algoritma.
Sistem ini akan diimplementasikan ke dalam sebuah aplikasi yang dibangun menggunakan bahasa pemrograman Java dan sistem manajemen basis data MySQL.
3.2 Sumber Data
Pada penelitian ini dibutuhkan data yang akan digunakan sebagai data
training pada proses klasifikasi jurusan SMA. Data yang diperoleh dari SMA Bentara Wacana adalah sebagai berikut :
a. Data nilai rapor kelas X semester 1 tahun ajaran 2005/2006 – 2008/2009 meliputi Nomor Induk Siswa (NIS), nama siswa,nilai Bahasa Indonesia, Bahasa Inggris, Matematika, Sejarah, Geografi, Ekonomi, Sosiologi, Fisika, Kimia dan Biologi.
b. Data nilai rapor kelas X semester 2 tahun ajaran 2005/2006 – 2008/2009 meliputi Nomor Induk Siswa (NIS), nama siswa,nilai Bahasa Indonesia, Bahasa Inggris, Matematika, Sejarah, Geografi, Ekonomi, Sosiologi, Fisika, Kimia dan Biologi.
c. Jurusan siswa tahun ajaran 2005/2006 – 2008/2009.
3.3 Tahap-Tahap KDD (Knowledge Discovery in Database)
Tahap KDD ini dibagi menjadi dua tahap yaitu data praproses dan data mining. Sebelum melakukan proses data mining terlebih dahulu melakukan data praproses.
3.3.1 Data Praproses
Tahap-tahap dalam data praproses dijelaskan sebagai berikut :
3.3.1.1 Pembersihan Data
Tabel 3.1 Jumlah Record Data dengan Missing Value
Sheet Tahun
Ajaran
Jumlah Record
dengan Missing Value
1 2005/2006 2
2 2006/2007 6
3 2007/2008 2
4 2008/2009 1
Total Record 11
3.3.1.2 Integrasi Data
Pada langkah ini dilakukan penggabungan data. Data mentah yang diterima disajikan secara terpisah untuk setiap tahun ajaran (disajikan per sheet). Data yang disajikan secara terpisah tersebut disatukan dan disimpan dalam satu tabel pada satu sheet. Sehingga satu sheet menyimpan kumpulan data nilai siswa tahun ajaran 2005/2006 sampai 2008/2008. Adapun rincian jumlah record data tiap tahun ajaran terdapat pada tabel 3.2 berikut :
Tabel 3.2 Jumlah Record Data Integrasi
Sheet Tahun
Ajaran Jumlah Record
1 2005/2006 79
2 2006/2007 54
3 2007/2008 46
4 2008/2009 50
3.3.1.3 Seleksi Data
Pada tahap seleksi data, tahap-tahap yang dilakukan adalah : a. Memilih atribut-atribut yang relevan dengan penelitian
Atribut yang digunakan dalam penjurusan yaitu nilai matematika dan nilai ciri khas IPA dan IPS jadi atribut NIS, nama dan nilai selain itu tidak dipakai karena tidak relevan dengan penelitian. Adapun atribut yang digunakan adalah ditampilkan pada tabel 3.3 sebagai berikut :
Tabel 3.3 Atribut yang Relevan dalam Penelitian
Jenis Mata Pelajaran
Nilai Ujian SMP Matematika
IPA IPS
Nilai Rapor Matematika
Sejarah Geografi Ekonomi Sosiologi Fisika Kimia Biologi
Jurusan -
Contoh perhitungan rata-rata dalam satu record dapat dilihat pada tabel 3.4 berikut :
Tabel 3.4 Perhitungan Rata-Rata Nilai Rapor Semester 1 dan Semester 2 Mata Pelajaran Nilai Semester 1 Nilai Semester 2 Nilai Rata-Rata
Matematika 70 68 69
c. Menambahkan nama atribut dengan huruf U untuk nama mata pelajaran ujian SMP dan R untuk nama mata pelajaran rapor kelas X. Tabel 3.5 berikut merupakan penamaan atribut dalam sistem.
Tabel 3.5 Penamaan Atribut
Jenis Mata Pelajaran Nama Atribut Nilai Ujian
SMP
Matematika UMTK
IPA UIPA
IPS UIPS
Nilai Rapor Matematika RMTK
Sejarah RSEJ
Geografi RGEO
Ekonomi REKO
Sosiologi RSOS
Fisika RFIS
Kimia RKIM
Biologi RBIO
Jurusan - JURUSAN
3.3.1.4 Transformasi Data
dalam suatu nama. Dalam proses ini tiap atribut nilai siswa dibagi menjadi 4 interval yang dinyatakan dalam huruf A, B, C dan D. Pembagian intervalnya dilakukan dengan cara berikut :
D jika nilai < ratanilai – 1,5 * st_devnilai
C jika ratanilai – 1,5 * st_devnilai ≤ nilai < ratanilai B jika ratanilai ≤ nilai < ratanilai + 1,5 * st_devnilai A jika nilai ≥ ratanilai + 1,5 * st_devnilai
Hasil dari transformasi data untuk setiap atribut ditampilkan pada tabel 3.6 Transformasi Data Nilai berikut.
Tabel 3.6 Transformasi Data Nilai
RSOS rsos < 63.33 63.33≤ rsos
Seperti yang telah disebutkan sebelumnya, data akan dibagi menjadi dua bagian yaitu data yang digunakan untuk pelatihan dan data yang digunakan untuk data uji. Kedua data tersebut akan menjadi masukan sistem. Data pelatihan terdiri dari 12 atribut, 11 atribut yaitu UMTK, UIPA, UIPS, RMTK, RSEJ, RGEO, REKO, RSOS, RFIS, RKIM dan RBIO adalah atribut input, sedangkan atribut ke-12 yaitu JURUSAN merupakan atribut target. Tabel 3.7 berikut adalah masukan untuk data pelatihan.
Tabel 3.7 Deskripsi Masukan Untuk Data Pelatihan No Nama Atribut Keterangan Nilai Atribut
6 RGEO Nilai Rapor Kelas X Geografi
A, B,C,D
7 REKO Nilai Rapor Kelas
X Ekonomi
A, B,C,D
8 RSOS Nilai Rapor Kelas
X Sosiologi
A, B,C,D
9 RFIS Nilai Rapor Kelas
X Fisika
A, B,C,D
10 RKIM Nilai Rapor Kelas X Kimia
A, B,C,D
11 RBIO Nilai Rapor Kelas X Biologi
A, B,C,D
12 JURUSAN Jurusan IPA, IPS
Sedangkan untuk masukan data uji masukannya ditambah dengan atribut status. Masukan untuk data uji juga terdiri dari 12 atribut, 11 atribut yaitu UMTK, UIPA, UIPS, RMTK, RSEJ, RGEO, REKO, RSOS, RFIS, RKIM, RBIO adalah atribut input. Sedangkan jurusan sebagai atribut tujuan. Untuk atribut status akan diisi ketika didapatkan prediksi jurusan, bila prediksi jurusan sama dengan jurusan asli maka nilai status 1 dan bila berbeda nilai status 0. Tabel 3.8 berikut merupakan masukan untuk data uji.
Tabel 3.8 Deskripsi Masukan Untuk Data Uji
No Nama Atribut Keterangan Nilai Atribut
1 UMTK Nilai ujian SMP Matematika A, B,C,D
2 UIPA Nilai ujian SMP IPA A, B,C,D
3 UIPS Nilai ujian SMP IPS A, B,C,D
7 REKO Nilai Rapor Kelas X Ekonomi A, B,C,D 8 RSOS Nilai Rapor Kelas X Sosiologi A, B,C,D 9 RFIS Nilai Rapor Kelas X Fisika A, B,C,D 10 RKIM Nilai Rapor Kelas X Kimia A, B,C,D 11 RBIO Nilai Rapor Kelas X Biologi A, B,C,D
12 Jurusan Jurusan IPA, IPS
13 Status Nilai awal adalah kosong. Jika jurusan prediksi sama hasilnya dengan jurusan yang ada maka status akan berisi 1 dan jika hasilnya berbeda statusnya akan
berisi 0.
1,0
3.3.2.2 Proses Sistem
Masukan sistem akan diproses dengan menggunakan algoritma ID3 dan CART. Adapun proses dari sistem adalah sebagai berikut :
a. Pengguna melakukan proses input data nilai siswa untuk memindahkan nilai asli dari file excel ke database.
b. Data nilai asli akan ditransformasi ke dalam range nilai A, B, C dan D dan disimpan ke tabel nilai transformasi.
c. Data pada nilai transformasi akan digunakan untuk membangun pohon keputusan.
d. Pada pembentukan pohon keputusan langkah awal yang dilakukan adalah menghitung attribute selection measures untuk menentukan
root node.
1. Algoritma ID3 menggunakan Information Gain dengan persamaan 2.4.
2. Algoritma CART menggunakan Gini Index dengan persamaan 2.9.
e. Bagi data berdasarkan atribut terpilih sehingga didapatkan partisi data untuk setiap cabang pohon. Gambar 3.1 merupakan contoh pembagian data algoritma ID3 dan gambar 3.2 merupakan contoh pembagian data algoritma CART.
Gambar 3.1 Contoh Pembagian Data Algoritma ID3
Gambar 3.2 Contoh Pembagian Data Algoritma CART
f. Algoritma melakukan proses perhitungan attribute selection measures
dan pembagian data secara rekursif terhadap setiap partisi yang dihasilkan sampai seluruh data memiliki kelas.
g. Setelah perhitungan selesai akan ditampilkan bentuk pohon yang dihasilkan
h. Pada proses pengujian disediakan dua macam pengujian yaitu pengujian berdasarkan komposisi data dan pengujian berdasarkan jumlah data. Hasil akhir dari proses pengujian yaitu hasil akurasi serta kecepatan komputasi algoritma ID3 dan CART.
3.3.2.3 Metode Evaluasi Pengujian Pohon Keputusan
Langkah evaluasi merupakan langkah pengujian kebenaran pohon keputusan. Ada dua macam cara pengujian yaitu pengujian berdasarkan pengujian berdasarkan komposisi data dan pengujian berdasarkan jumlah data. Adapun cara pengujiannya akan dijelaskan pada subbab 3.3.2.3.1 dan 3.3.2.3.2 berikut :
3.3.2.3.1 Kriteria Pengujian Berdasarkan Komposisi Data
Pengujian berdasarkan komposisi data menggunakan teknik k-fold validation dimana seluruh data yang ada akan dibagi menjadi sejumlah k bagian data.
1. Penentuan k kelompok data
Terdapat 229 data nilai siswa yang akan dibagi menjadi k kelompok. Dan diberi label 1,2,3,4, dan 5.
1 2 3 k
...
Gambar 3.3 Pengelompokan Data Untuk Proses Evaluasi Komposisi Data 2. Pengujian akurasi
Pengujian akurasi dilakukan dengan dua cara, yaitu langkah
training dan testing. Langkah training dikenali untuk membentuk pohon keputusan. Langkah testing digunakan untuk mengklasifikasi jurusan siswa. Dalam satu kali pengujian, terdapat sejumlah k set
training dan testing yang menghasilkan satu bagian kelompok jurusan siswa.
3. Penghitungan akurasi
kemudian dibagi dengan jumlah data testing dikalikan dengan 100%. Akumulasi dari akurasi tiap kelompok akan dicari rata-ratanya untuk mendapatkan jumlah akurasi.
4. Kecepatan komputasi
Kecepatan komputasi didapatkan dari durasi proses pembentukan pohon keputusan tiap algoritma sampai didapatkan akurasi pengujian dengan cara mengurangkan waktu akhir proses dengan waktu awal proses.
3.3.2.3.2 Kriteria Pengujian Berdasarkan Jumlah Data
1. Penentuan kelompok data dengan ratio perbandingan training dan
testing 50 : 50 sampai 90: 10.
Terdapat 229 data nilai siswa yang akan dibagi menjadi 5 kelompok. Dan diberi label 1,2,3,4, dan 5.
1 2 3 5
...
Gambar 3.4 Pengelompokan Data Untuk Proses Evaluasi Komposisi Data 2. Pengujian akurasi
Pengujian akurasi dilakukan dengan dua cara, yaitu langkah
training dan testing. Langkah training dikenali untuk membentuk pohon keputusan. Langkah testing digunakan untuk mengklasifikasi jurusan siswa. Dalam satu kali pengujian, terdapat sejumlah 5 set
3. Penghitungan akurasi
Angka akurasi dapat dihitung dengan cara menghitung jumlah jurusan yang sesuai. Penghitungan ini dilakukan dengan cara membandingkan data hasil testing dengan data testing yang sesuai kemudian dibagi dengan jumlah data testing dikalikan dengan 100%. Untuk mengurangi variasi error rate maka tiap perbandingan rasio dari data dirata-rata untuk membentuk seluruh error rate.
4. Kecepatan komputasi
3.4 Perancangan Umum Sistem
Pada perancangan umum sistem akan dijelaskan rancangan dari sistem yang akan dibangun berupa usecase, narasi usecase, diagram konteks, diagram aktivitas, diagram kelas desain, algoritma dan method, desain basis data, diagram analisis dan sekuensial , dan desain antarmuka.
3.4.1 Diagram Use Case
Preprocessing
USER
Input Data Nilai Siswa
Pembentukan Pohon Keputusan
<<depends on>>
Pengujian Algoritma
<<depends on>>
Data mining
Gambar 3.5 Diagram Model Use Case
3.4.2 Narasi Use Case
Tabel 3.9 Narasi Use Case Input Data Nilai Siswa
ID Use Case : UC-01
Nama Use Case : Input Data Nilai Siswa
Aktor : Pengguna
Deskripsi Use Case : Use case ini berfungsi untuk menyimpan data nilai
asli siswa dari file excel ke database
Trigger : Use case ini digunakan sebelum melakukan proses
preprocessing
Langkah Umum : Kegiatan Aktor Respon Sistem
1. Pengguna menekan menu ”Input Data Siswa” pada Halaman Utama
3. Pengguna memilih file yang akan disimpan ”Data Nilai Berhasil Tersimpan” serta menampilkan tabel data nilai asli yang tersimpan di database
Langkah Alternatif : Alt- Langkah 4 : Bila file yang dipilih bukan file dengan ekstensi .csv maka akan muncul pesan ”Format File Tidak Sesuai” dan bila jumlah kolom pada file tidak sama dengan 13 maka akan muncul pesan ”Jumlah kolom tidak sesuai”. Bila proses penyimpanan gagal akan muncul pesan ”Nilai Gagal Disimpan”
Kesimpulan Use case ini berhenti data nilai asli sudah ditampilkan
dalam bentuk tabel.
Tabel 3.10 Narasi Use CasePreprocessing
ID Use Case : UC-02
Nama Use Case : Preprocessing
Aktor : Pengguna
Deskripsi Use Case : Use case ini berfungsi untuk mengubah data nilai asli ke dalam range nilai (A, B, C, D) sehingga mudah untuk digunakan dalam proses penambangan data
Prakondisi : Tabel nilai asli sudah terisi
Trigger : Use case ini digunakan sebelum proses pembentukan
pohon keputusan
1. Pengguna menekan tombol ”Transformasi” pada Halaman Input Nilai Siswa
2. Mengambil data nilai asli dan ditransformasi ke dalam range nilai dan menyimpan dalam tabel nilai transformasi 3. Menampilkan hasil
preprocessing dalam tabel pada Halaman Input Nilai Siswa
Langkah Alternatif : Alt- Langkah 2 : Bila proses transformasi nilai gagal dijalankan maka akan muncul pesan ”Nilai gagal ditransformasi”
Kesimpulan Use case berhenti apabila nilai sudah berhasil
ditransformasi dan muncul tabel nilai hasil transformasi pada Halaman Input Nilai Siswa.
Tabel 3.11 Narasi Use Case Pembentukan Pohon Keputusan
ID Use Case : UC-03
Nama Use Case : Pembentukan Pohon Keputusan
Aktor : Pengguna
Deskripsi Use Case : Use case ini berfungsi untuk membentuk pohon
keputusan ID3 dan CART dari data transformasi
Prakondisi : Nilai asli berhasil ditrasnformasi dan tersimpan di
tabel nilai_transformasi
Trigger : Use case ini digunakan jika pengguna ingin
membentuk pohon keputusan
Langkah Umum : Kegiatan Aktor Respon Sistem
1. Pengguna menekan tombol ”Buat Pohon”
pada Halaman Input Nilai Siswa atau menu ”Pohon Keputusan” dari pohon keputusan ID3 dan CART pada Halaman Lihat Pohon Keputusan
Langkah Alternatif : Alt- Langkah 1 : Bila pengguna belum melakukan