A. PENGERTIAN REGRESI 1. PENGERTIAN REGRESI
Analisis regresi digunakan untuk mempelajari dan mengukur statistik yang terjadi antara dua variabel atau lebih. Regresi adalah suatu analisis yang digunakan untuk mengetahui hubungan antara variabel bebas (x) dan variabel terikat (y). Dalam analisis regresi, suatu persamaan regresi hendak ditentukan dan digunakan untuk menggambarkan pola atau fungsi hubungan yang terjadi antara variabel. Dalam regresi majemuk dikaji lebih dari dua variabel. Variabel yang akan dioptimasi nilainya disebut variabel terikat (dependent variabel) atau response variabel dan biasanya diplot pada sumbu tegak (sumbu y), sedangkan variabel bebas (independent variabel) atau explanatory variabel adalah variabel yang diasumsikan memberikan pengaruh terhadap variasi variabel terikat dan biasanya diplot pada sumbu datar (sumbu x).
(sumber: http://skripsimahasiswa.blogspot.com/2010/10/regresi-linier.html) 2. PENGERTIAN REGRESI MENURUT PARA AHLI
a. Fancis Galton, analisis regresi berkenaan dengan studi ketergantungan dari suatu variabel yang disebut variabel tak bebas (dependet variable), pada satu atau variabel yang menerangkan dengan tujuan untuk memperkirakan ataupun meramalkan nilai-nilai dari variabel tak bebas apabila nilai variabel yang menerangkan sudah diketahui.
b. Analisis regresi pada dasarnya adalah studi mengenai ketergantungan variabel dependen (terikat) dengan satu atau lebih variabel independen (variabel penjelas/bebas), dengan tujuan untuk mengestimasi dan/atau memprediksi rata-rata populasi atau nilai rata-rata-rata-rata variabel dependen berdasarkan nilai variabel independen yang diketahui (Gujarati, 2003).
(sumber: http://digilib.unpas.ac.id/files/disk1/12/jbptunpaspp-gdl-ajiefauzia-579-3-bab3.pdf)
B. PENGERTIAN KORELASI 1. PENGERTIAN KORELASI
Korelasi adalah metode untuk mengetahui tingkat keeratan hbungan antara dua peubah atau lebih yang digambarkan oleh besarnya korelasi. Koefisien korelasi adalah koefisien yang menggambarkan tingkat keeratan hubungan antar dua peubah atau lebih.
Besaran dari koefisien korelasi tidak menggambarkan hubungan sebab akibat antara dua peubah (lebih) tapi semata-mata menggambarkan keterlibatan linier antar peubah.
Nilai koefisien korelasi berkisar antara (-1) sampai 1
Nilai -1 berati terdapat hubungan negatif (berkebalikan) yang sempurna.
Nilai 0 berarti tidak terdapat hubungan sama sekali.
Nilai 1 berarti terdapat hubungan positif yang sempurna. (sumber: http://skripsimahasiswa.blogspot.com/2010/10/regresi-linier.html)
2. PENGERTIAN KORELASI MENURUT PARA AHLI a. Faenkel dan Wallen, 2008:328)
korelasi adalah suatu penelitian untuk mengetahui hubungan dan tingkat hubungan antara dua variabel atau lebih tanpa ada upaya untuk mempengaruhi varaibel tersebut sehingga tidak terdapat manipulasi variabel.
b. Mc Millan dan Schumacher, dalam Syamsuddin dan Vismala, 2009:25
Korelasi adalah adanya hubungan dan tingkat variabel penting karena dengan mengetahui tingkat hubungan yang ada, peneliti akan dapat mengembangkannya sesuai dengan tujuan penelitian. jenis penelitian ini biasanya melibatkan ukuran statistik/tingkat hubungan.
C. JENIS- JENIS REGRESI 1. Regresi Linier
Regresi linier adalah alat statik yang digunakan untuk mengetahui pengaruh antara satu atau beberapa variabel terhadap satu buah variabel. Variabel yang mempengaruhi disebut variabel bebas dan variabel yang dipengaruhi disebut variabel terikat.
Secara umum regresi linier terdiri atas dua yaitu regresi linier sederhana dan regresi linier berganda.
a. Regresi Linier Sederhana
Regresi dengan satu buah variabel bebas terhadap satu buah variabel terikat. Persamaan umumnya adalah:
Y= a + bX Dimana:
Y = variabel terikat
b = koefisien regresi X = variabel bebas
Sifat-Sifat Garis Regresi Linier:
terdapat dua (2) sifatt yang harus dipenuhi sebuah garis lurus untuk dapat menjadi garis yang cocok (fit) dengan titik-titik data pada diagram pencar, yaitu:
Jumlah simpangan (deviasi) positif dari titik-titik yang tersebar di atas garis regresi sama dengan (saling menghitung langkah) jumlah simpangan negatif dari titik-titik yang tersebar di bawah garis regresi dengan kata lain
∑
∆ y=∑
(
y−y')=
0lny=ln
(
e−ax+b)
y=¿ax+b ln¿
atau dapat dikatakan:
s=ax+b dimana s=lny
dengan demikian dapat digunakan regresi linier dalam menentukan fungsi eksponensial yang paling sesuai dengan data.
kuadrat dari simpangan-simpangan mencapai nilai minimum (least square value of deviation) jadi:
∑
∆ y=∑
(y−y)2=minimumdengan sifat kedua, metode regresi ini seringg juga disebut sebagai metode least square. dengan menggunakan kedua sifat di atas dan menggabungkannya dengan prinsip-prinsip kalkulus differensial untuk enetukan nilai-nilai konstanta a dan b pada persamaan garis regresi, yang hasilnya sebagai berikut:
xy x
∑
¿ ¿ y∑
¿ ¿ ¿ ¿ x2 x∑
¿ ¿ ¿2 ¿∑
¿−¿∑
¿−¿ ¿ b=¿ dimana:n = jumlah titik (pasangan pengamatan (x,y))
´
x = mean dari variabel x ´
y = mean dari variabel y
(sumber: www.eepis.its.edu/nalfuragi/numerik/bobot.pdf) contoh 1:
Berdasarkan hasil pengambilan sampel secara acak tentag pengaruh lamanya belajar (x) terhadap nilai ujian (y) adalah seperti pada tabel 1.1 berikut:
Tabel 1.1
Nilai Ujian (y) Lama Belajar (x) X2 xy
40 4 16 169 60 6 36 360 50 7 49 350 70 10 100 700 90 13 169 1170 y = 310 Ʃ Ʃx = 40 Ʃx2 = 370 Ʃxy = 2740
penyelesaian: a=
(
Ʃy. xƩ 2)−(
Ʃx. xyƩ )(
N . xƩ 2)
−(Ʃx)2 ¿(310.370)−(40.2740) (5.370)−1600 =20,4 b=N(Ʃxy)−(Ʃx. yƩ )(
N . xƩ 2)
−(Ʃx)2 ¿(5.2740)−(40.310) (5.370)−1600 =5,4sehingga persamaan regresi sederhananya adalah: y = 20,4 + 5,4X
berdasarkan hasil perhitungan dari persamaan regresi sederhana tersebut diatas, maka dapat diketahui bahwa:
lamanya belajar mempunyai pengaruh positif (koefisien regresi sederhana (b)=5,2) terhadap nilai ujian, artinya jika semakin lama dalam belajar maka akan semakin baik atau tinggi nilainya.
nilai konstanta adalah sebesar 20,4 artinya jika tidak belajar atau lama belajar sama dengan nol, maka nilai ujian adalah sebesar 20,4 dengan asumsi variabel-variabel lain yang dapat mempengaruhi dianggap tetap.
(sumber: susanto.blogspot.com/2006/06/analisis-regresi-dan korelasi-materi.html) contoh 2:
mengetahui pengaruh upah terhadap motivasi kerja karyawan PT Benir Berlian.
dimana X atau variabel bebasnya adalah upah, sedangkan variabel Y atau variabel terikatnya adalah motivasi kerja karyawan PT Benir. Berlian.
b. Regresi Linier Berganda
merupakan regresi dengan beberapa variabel bebas dan satu buah variabel terikat. Persamaan umumnya adalah:
+¿… .+bnXn y=a+b1X1+b2X2¿
dimana:
y = variabel terikat
X1 dan X2 = variabel bebas a = titik potong
b = koefisien regresi
misalnya pertumbuhan mikroba merupakan fungsi dari suhu, nutrient, dan space. jika total mikroba merupakan symbol y, besarnya suhu dengan X1, jumlah nutrient dengan X2, dan space dengan X3. maka pendugaan nilai y diperoleh dengan menggunakan prosedur kuadrat terkecil terhadap data hasil pengukuran suhu, nutrient, dan space dalam bentuk variabel x dan y dapat diberikan bahwa y dipengaruhi X1, X2, dan X3. bentuk persamaannya adalah:
μy∨x1x2x3=β0+β1x1+β2x2+β3x3 secara umum bentuk persamaannya adalah:
μy∨x1x2….xn=β0+β1x1+β2x2+β3x3+..+βnxn
dengan mengganti β0, β1,…., βn dengan b0, b1,…., bn nilai μy∨x1x2….xn dapat diduga dari persamaan regresi, yaitu:
yn=b0+b1x1+b2x2+bnxn
selanjutnya akan dibahas kasus dengan satu peubah bebas X1dan X2 persamaan regresi untuk 2 peubah bebas X1 dan X2 adalah:
^y=b0+b1x1+b2x2+e1
JKG dari persamaan ini adalah: JKG=
∑
e12=
∑
(
x−b0−b1x1−b2x2)
2denggan menurunkan persamaan ini terhadap b0, b1, dan b2 secara berturut-turut, maka diperoleh ketiga persamaan linier simultan berikut:
b1
∑
y1i+b2∑
x2i=∑
yi b0∑
x1i+b1∑
x1i2
+b2
∑
x1ix2i=∑
yi1yi1nilai dengan kuadrat terkecil untuk b0, b1, dan b2 dapat diperoleh dengan menggunakan matriks setelah nilai b2 dan b1 diperoleh nilai b0 dapat ditentukan dengan menggunakan rumus berikut:
b0=^y−b1x1−b2x2 contoh 1:
sebuah percobaan dilakukan untuk menduga berat akhir ternak setelah diberi pakan, dengan menggunakan variabel bebas berat awal ternak sejumlah pakan yang dihabiskan oleh ternak tersebut (kg)
tabel 1.2
Batas akhir (y) Batas awal (X1) Jumlah pakan (X2)
55 42 272 70 30 226 80 33 259 100 45 192 97 30 311 70 36 183 50 32 173 80 41 236 92 40 220 84 38 235
a. buatlah persamaan regresi berganda!
b. ramal berat akhir ternak, jika berat awal 55kg dan jumlah pakan yang dihabiskan 250kg jawab: X Ʃ 1i=379 ƩX2i = 2417 ƩX1iX2i = 92628 X Ʃ 12i = 14535 ƩX22i = 601365 X1 = 35,9 X Ʃ 1iYi = 31276 ƩX2iYi = 204569 y = 82, 5 Y2 = 242,7 ƩYi = 825 ƩX2i = 70083 persamaan (1): 10b0 + 379b1 + 2417b2 = 825 persamaan (2): 379b0 + 14535b1 + 92628b2 = 31726 persamaan (3): 2417b0 + 92628b1 + 601365b2 = 204969
dengan menyelesaikan ketiga persamaan ini dengan matematika biasa, maka diperoleh:
nilai b1 dan b2 ini dimasukkan ke dalam persamaan b0 sehingga diperoleh: b0 = y – b1X1 – b2X2 = -15,6396869
persamaan regresinya adalah y = -15,64 + 5,11 X1-X2 y = -15,64 + 5,11 (35) – 0,4 (200) = 63,21
(sumber: http://eepis.tts.edu/nalfangi/numerik/bab9tm.pdf) contoh 2:
jika kita ingin mengukur faktor-faktor yang berpengaruh terhadap penjualan produk mobil, mungkin faktor-faktor yang mempengaruhinya dapat berupa citra merk, layanan purna jual, harga yang kompetitif, pengaruh lingkungan, iklan media, dan lain sebagainya. dari contoh tersebut, maka penjualan produk mobil disebut variabel dependent, sedangkanvariabel lainnya merupakan variabel independent.
persamaan yang digunakan yaitu persamaan regresi bergamda: y=+a¿+….b+bnXn+e
1X1+b2X2¿
dimana:
y = penjualan produk mobil X4 =pengaruh liingkungan
X1 = citra merk X5 = iklan media
X2 = layanan purna jual b = koefisien regresi X3 = harga kompetitif e = error
(sumber: http://skripsimahasiswa.blogspot.com/2010/10/regresi-linier.html)
Hubungan antara variabel y dan x yang tidak linier, tidak linier maksudnya laju perubahan y akibat perubahan x tidak konstan untuk nilai tertentu.
beberapa model regresi non linier: a. model parabola
rumus persamaan regresi non linier parabola, yaitu: y = a + bx +cx2
b. model hiperbola
Pada regresi hiperbola, di mana variabelbebas X atau variabel tak bebas Y, dapat berfungsi sebagai penyebut sehinggaregresi ini disebut regresi dengan fungsi pecahan atau fungsi resiprok.
persamaan regresi hiperbola (lengkung cekung): y= 1
(a+bx)
diman garis persamaa akan memotong sumbu y, ini berarti bahwa nilai x ada yang negatif atau bahkan keduanya (x dan y) sama-sama negatif.
c. model fungsi pangkat tiga y = a + bx + cx2 + dx3 d. model eksponensial
Regresi eksponensial ialah regresi di mana variabelbebas X berfungsi sebagai pangkat atau eksponen.
log y = log a (log b) x
namun jika log-nya dihilangkan, maka: y = axbx e. model geometri
Pada regresi ini mempunyaibentuk fungsi yang berbeda dengan fungsi polinomial maupun fungsi eksponensial.
y = a +(x) b y = log a + b log x 3. Regresi eksponensial
Regresi eksponensial adalah regresi linier yang variabel responnya terdistribusi eksponensial. model regresi ekksponensial mempunyai peranan penting pada beberapa bidan statistik dan telah banyak digunakan pada beberapa penelitian data survival. penelitian tentang ketahanan benda-benda produksi dan penelitian pada bidang kedokteran.
regresi eksponensial digunakan untuk menetukan fungsi eksponensial yang paling sesuai dengan kumpulan titik data (X2Y2) yang diketahui. regresi eksponensial ini merupakan pengembangan dari regresi linier dengan memanfaatkan fungsi logaritma:
dengan melogaritmakan persamaan di atas akan diperoleh: b log¿x ¿ a+¿ y=log¿ log¿ (sumber: http://statistielasakel114.blogspot.com) contoh:
Tabel dibawah ini menunjukan data pengukuran debet dan
sedimen melayang DPS Citarum – Nanjung pada bulan Maret
1981. Tentukanlah besarnya koefisien korelasi, persamaan
eksponensialnya dan uji ?
Debet
(m
3/det)-X
Sedimen
Melayang (juta
m
3/det)-Y
Debet
(m
3/det)-X
Sedimen
Melayang (juta
m
3/det)-Y
35
39
43
54
56
1,73
2,45
3,31
6,83
6,99
119
88
95
105
112
10,44
16,36
27,47
29,06
33,96
Jawab.
Buat tabel pembentu seperti:
N
o.
(m
Debet
3/det)-X
Sedimen
Melayang
1.
2.
3.
4.
5.
6.
7.
8.
9.
1
0
35
39
43
54
56
88
95
105
112
119
1,73
2,45
3,31
6,83
6,99
10,44
16,36
27,47
29,06
33,96
0,55
0.90
1,20
1,92
1,94
2,35
2,79
3,31
3,37
3,53
19,25
35,10
51,60
103,68
108,64
206,80
265,05
347,55
377,44
420,07
746
21,46
Di dapat:
P 2,186,
86 , 21 P,
58,083 2 P, S
P=1,096
6 , 74 X,
X 746,
65146 2 X, S
X= 32,48 dan
XY 1935,18sehingga:
10
65146
746
0,018 18 , 1935 746 65146 186 , 2 2 2 2 2
X X n XP X X P A
2 2 X X n Y X XY n Batau
0,0296 6 , 74 018 , 0 186 , 2 X A P BA=lna atau –0,018=lna maka a=0,98 dan B=b maka b=0,0295.
Jadi persamaan regresi eksponensialnya adalah:
Y = a e
bX= 0,98e
0,0295XD. JENIS-JENIS KORELASI 1. korelasi bivariat
korelasi bivariat merupakan hubungan antara dua buah vaiabel jika nilai suatu variabel naik, sedangkan nilai variabel yang lain turun, maka dikatakan terdapat hubungan negatif begitupun sebaliknya. korelasi bivariat mengukur keeratan antara hasil-hasil pengamatan dari populasi yang mempunyai dua variansi.
Contoh kasus: jika terdapat hubungan korelasi antara variabel citra merek dengan kepuasan konsumen motor merek Honda.
2. korelasi parsial
korelasi parsial membahas mengenai hubungan linier antara dua variabel dengan melakkukan kontrol terhadap satu atau lebih variabel tambahan.
adapun rumusnya sebagai berikut:
korelasi X1 dengan y dikontrol oleh X2 r y1.2= ry1−ry2−r12
√
(
1−ry12)
(
1−r12)
2 korelasi X2 dengan y dokontrol oleh X1 r y2.1= ry2−ry1−r12
√
(
1−ry12)
(
1−r12)
2uji signifikansi korelasi parsial
th=r
√
N−3√
1−r2th < tt : korelasi tidak signifikan th > tt : korelasi signifikan
contoh:
dengan menggunakan data dalam tabel diperoleh hasil perhitungan:
ry12= 0,987−0,959−0,971
(
1−0,9592)
−(1−0,9712)
ry12=0,0558
0,0677 ry12=0,8242
korelasi X2 dengan y dokontrol oleh X1 ry21= 0,959−0,987−0,971
√
(
1−0,9872)−(
1−0,9712)
ry21=0,00062
0,03842 ry21=0,0161
3. Koefisien Korelasi Rangking Spearman
merupakan ukuran korelasi yang menuntut kedua tabel pengamatan sekurang-kurangnya diukur dalam skala ordinal, sehingga obje-objek atau individu-individu yang diamati dapat dirangking dalam dua rangkaian berturut-turut.
nilai korelasi yang dihasilkan berkisar antara -1 sampai +1. angka pada nilai korelasi menunjukkan keeratan hubunan antara variabel yang diuji. jika angka korelasi main mendekati 1, maka korelasi dua variabel akan makin kuat, sedangkan jika angka korelasi makin mendekati 0, maka korelasi dua variabel makin lemah.
sedangkan tanda minus dan positif pada nilai korelasi menyatakan sifat hubungan. jika nilai korelasi bertanda minus berarti hubungan diantara kedua tabel bersifat searah, sedangkan jika nilai korelasi bertanda positif, berarti hubungan antara kedua tabel bersifat berlawanan arah.
4. korelai Rank Kendall
digunakan sebagai ukuran korelasi dengan jenis data yang sama dengan data yang lain, dimana koefisien korelasi rangking spearmannya dapat digunakan. untuk uji signifikan, diperlukan pembentukan hipotesis sebagai berikut:
Ho : tabel x dan tabel y tidak saling berhubungan Hi : tabel x dan tabel y saling berhubungan 5. korelasi phi
merupakan ukuran keeratan hubungan antar dua variabel dengan skala nominal yang bersifat dikotomi (terpisah atau dipisahkan).
nilai korelasi yang dihasilkan berkisar antara 0 sampai dengan 1. angka pada nilai korelasi menunjukkan keeratan hubungan antar 2 variabel yang diuji. jika angka
korelasi mendekati 1, maka korelasi 2 variabel akan makin kuat. sedangkan jika angka korelasi makin mendekati 0, maka korelasi 2 variabel akan makin lemah. sifat hubungan antara kedua tabel yang diuji, tidak dapat ditunjukkan dari nilai korelasi phi, karena tabel yang diukur mempunyai skala nominal.
6. koefisien kontingensi
merupakan ukuran korelasi antara dua variabel/ tabel kategori yang disusun dalam tabel kontingensi berukuran rxc. dalam menggunakan koefisien kontingensi C, kita ridak perlu membuat anggapan kontingensitas untuk berbagai kategori yang dipergunakan. penyusunan terhadap koefisien kontingensi digunakan sebagai uji kebebasan (uji indepedensi) antara dua tabel.
(sumber: BAB_VII_statistika_non_parametrik_uji_hubungan) E. UJI KELINIEARAN REGRESI
hubungan linier diberikan pada variabel x dan y, jika dari diagram pencarnya sebuah garis lurus yang dapat digambarkan. cara yang dapat digunakan untuk menunjukkan apakah variabel x dan y berhubungan secara linier. cara ini disebut dengan uji kelinieran regresi. jika uji kelinieran menunjukkan bahwa garis liniernya pada tingkat kepercayaannya (1 – a) 100%, maka selanjutnya sifat-sifat keinieran dapat digunakan.
pertama-tama asumsikan linier sehingga parameter a dan b dapat ditentukan. misalnya, contoh acak n diambil dari k buah nilai x yang berbeda yaitu : X1, X2, X3 dimana untuk X = X1 ada n1 buah pengamatan untuk X = X2 ada n2 buah pengamatan, dan seterusnya.
n=Ʃni
didefinisikan:
n = Nilai ke-J bagi peubah acak yi n
Ʃ i = jumlah nilai-nilai y dalam contoh
statistik F dengan V1 = k . 2 dan V2 = n.k digunakan untuk menentukan wilayah kritik, dan nilai uji dihitung berdasarkan rumus berikut:
f=x1 2 /(k−2) x/(n−k) , dimana x12=
∑
(
y12 n1)
∙ Ʃy1 n ∙ b 2 (n−1)s2x dan x2 2 =Ʃy1 2 J ∙∑
(
y1 2 ni)
bila H0 benar X12/(k-2) dan X22/(n-k) keduanya merupakan nilai dengan bagi σ2, dan bersifat bebas atau sama yang lain, tetapi bila H0 salah, X12/(k-2) menduga σ2 secara berlebihan dengan demikian H0 ditolak pada taraf nyata a bila nilai f jatuh pada wilayah kritik yang berukuran a yang terletak di ujung kanan sebaran f-nya.
(sumber:elearning.gunadarma.ac.id/doc.modul-pengantar-statistika-bab8-regresi-dan-korelasi.pdf)
F. INFERENSIA MENGENAI KOEFISIEN KORELASI
persamaan regresi y = a + bx adalah persamaan regresi dugaan berdasarkan data-data contohnya. persamaan regresi contohnya diharapkan mendekati persamaan regresi populasinya.
μy∨X0=a+bx
parameter a dan b disebut sebagai koefisien regresi, untuk meentukan rumus selang kepercayaan bagi a dan b, lihat kembali persamaan untuk JKG.
JKG=Ʃ
(
y1−abx)
2JKG=(n−1)
(
s2y −b2s2x)
dimana: sx2=nƩx 2 1−(
Ʃx1)
2 n(1−1) dan sy 2 =nƩy1 2 −(
Ʃy1)
2 n(1−1)nilai dugaan tak bebas bagi 02 dengan n – 2 derajat bebas diberikan oleh rumus: Se2 =JKG n−2atau Se 2 =n−1 n−2
(
s 2y −b2s2x)
jika A dan B merupakan peubah acak dari a dan b yang diperoleh melalui pengambilan contoh berukuran n beberapa kali, maka nilai A dan B tergantung pada keragaman nilai y karena x bersifat tetap. bila diasumsikan y1, y2,…,yn bebas dan mnyebar normal, maka peubah acak A juga menyebar normal dengan nilai tengah:
μA=a dan σ2A=
∑
i=1 n xi2 n(n−1)s2xσ 2dengan menggunakan transformasi 2, maka: z= A−a σ
√
Ʃx1 2 sx−√
n(n−1) =(A−a)sx√
n(n−1) σ√
∑
x2ijika σ tidak diketahui, Se digunakan sebagai pengganti σ dan sebaran peubah acaknya menjadi sebaran t (dengan v = n – 2) dan rumus:
T=(A−a)sx
√
n(n−1)Se
√
∑
x2idengan menggunakan rumus ini, selang kepercayaan (1-a) 100% bagi parameter a dalam garis regresi µy|x = a + b adalah:
a= ta 2Se
√
Ʃx1 2 Sx√
n(n−1)<a<a+ ta 2Se√
Ʃx1 2 Sx√
n(n−1)paremeter a yang diduga adalah intersep garis regresi populasi, sedangkan a dalam t a/2 adalah taraf nyata uji.
untuk menguji hipotesis na (H0) bahwa a = a0 lawan alternatif yang dikehendaki dapat digunakan sebaran t dengan derajat bebas v=n-2 untuk menentukan wilayah kritis dan kemudian mendasarkan keputusan kepada nilai t yang diperoleh dari rumus:
t=
(
a−a0)
Sx√
n(n−1)Se
√
ƩX12contoh:
buat selang kepercayaan 0,5% bagi a dan garis regresi µy|x=a+bx yang didasarkan pada contoh 1.
jawab:
Se2 = 310,16 Se = 17,61
Sx2 = 218,38 Sx = 14,78 t a/2 = 2,131
Sy2 = 555,18 a = 91
maka selang kepercayaan bagi a adalah: 91−2,131(17,61)
√
13376 14,78√
16×15 <a<91+ 2,131(17,6)√
13376 14,78√
16×15 ¿72,0449<a<109,9551 (sumber: http://www.eepis.its.edu/nalafarugi/numerik/bab9tm.pdf.com) G. REGRESI DUMMY DAN REGRESI LOGISTIKnama lain dari regresi dummy adalah regresi kategori. Regresi ini menggunakan predictor kualitatif (yang bukan dummy dinamai predictor kuantitatif). Pembahasan pada regresi ini mempunyai hanya untuk satu macam variabel dummy dan dikhususkan pada penafsiran parameter dan kemaknaan pengaruh predictor.
secara implisit, teknik penggunaan variabel dummy pada dasarnya mengandung asumsi bahwa variabel kuantitatif mempengaruhi intersep tetapi tidak mempengaruhi koefisien kemiringan dan berbagai regresi sub kelompok.
(sumber:
http://jurnaldichaniago.wordpress.com/2008/09/22/regresi.atas.variabel.dummy) Tujuan menggunakan regresi berganda dummy adalah memprediksi besarnya nilai variabel tergantung/dependent atas dasar satu atau lebih variabel bebas/independent, di mana satu atau lebih variabel bebas yang digunakan bersifat dummy. Variabel dummy adalah variabel yang digunakan untuk membuat kategori data yang bersifat kualitatif (data kualitatif tidak memiliki satuan ukur), agar data kualitatif dapat digunakan dalam analisa regresi maka harus lebih dahulu di transformasikan ke dalam bentuk Kuantitatif. contoh data kualitatif misal jenis kelamin adalah laki-laki dan perempuan, harus di transform ke dalam bentuk Laki-laki = 1 ; Perempuan = 0. atau tingkat pendidikan misal SMA dan Sarjana, maka diubah menjadi SMA = 0 ; Sarjana = 1, skala yang terdiri dari dua yakni 0 dan 1 disebut kode Binary, sedangkan persamaan model yang terdiri dari Variabel Dependentnya Kuantitatif dan variabel Independentnya skala campuran : kualitatif dan kuantitatif, maka persamaan tersebut disebut persamaan regresi berganda Dummy. Dalam kegiatan penelitian, kadang variabel yang akan diukur bersifat Kualitatif, sehingga muncul kendala dalam pengukuran, dengan adanya variabel dummy tersebut, maka besaran atau nilai variabel yang bersifat Kualitatif tersebut dapat di ukur dan diubah menjadi kuantitatif.
Berikut akan dijelaskan mengenai bagaimana cara menggunakan persamaan estimasi yang telah di peroleh melalui analisa regresi berganda Dummy, ingat ada tiga variabel yang digunakan dalam persamaan model yakni : variabel Gaji
merupakan variabel kuantitatif, variabel Gender terdiri dari 0 : perempuan dan 1 : pria ; variabel Pendidikan terdiri dari 0 : SMA dan 1 : Sarjana (variabel Gender dan
Didik adalah variabel kualitatif) dan variabel yang terakhir adalah variabel Usia
merupakan variabel kuantitatif.
(Sumber : http://putuartayasa.blogspot.com/2011/05/estimasi-melalui-persamaan-dalam.html)
Contoh kasus:
Seorang peneliti tertarik untuk memprediksi laba 2 macam perusahaan (swasta asing dan swasta nasional) bila ditinjau dari besarnya biaya iklan yang dikeluarkan oleh perusahaan untuk membuat iklan mengenai produknya. (Untuk perusahaan swasta asing, laba yang diamati adalah laba yang diperoleh dari hasil penjualan produknya di wilayah Indonesia saja.)
Kasus semacam ini dapat diselesaikan dengan metode regresi menggunakan variabel dummy. Hanya saja yang perlu diperhatikan adalah teknik menyusun variabel dummy dalam analisis regresinya.
Dari contoh kasus di atas, variabel respon (Y) adalah Laba perusahaan, variabel bebas (X) adalah biaya iklan, sedangkan variabel dummy-nya adalah tipe perusahaan, yaitu swasta asing dan swasta nasonal. Kita sebut terdapat 2 tipe/kategori perusahaan. Untuk menyusun variabel dummy-nya, maka kita perlu menentukan terlebih dahulu banyaknya variabel dummy yang digunakan. Banyaknya variabel dummy yang digunakan adalah sebanyak kategori dikurangi satu.
Rumus: banyaknya var dummy = banyaknya kategori – 1.
Dalam kasus kita di atas, maka banyaknya variabel dummy adalah = 2-1 = 1 buah. Misalkan jika perusahaan swasta asing dilambangkan dengan angka 1, sedangkan swasta nasional 0.
(sumber: http://ineddeni.wordpress.com/2007/08/17/analisis-regresi-dengan-variabel-dummy/#more-20)
2. Regresi Logistik
regresi logistic adalah bagian dari analisis regresi yang digunakan ketika variabel dependent (respon) merupakan variabel dikotomi. variabel dikotomi biasanya hanya terdiri atas dua nilai, yang mewakili kemunculan atau tidak adanya suatu kejadian yang biasanya diberi angka 0 dan 1. tidak seperti regresi linier biasa, regresi logistic
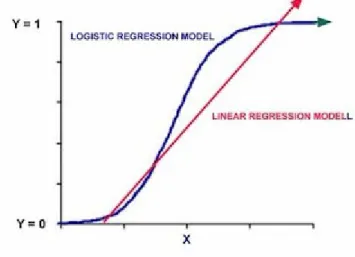
tidak mengasumsikan hubungan antara variabel independent dan dependent secar linier. Regresi logistik merupakan regresi non linier dimana model yang ditentukan akan mengikuti pola kurva seperti gambar di bawah ini.
Gambar 1.1 kurva regresi logistik
model yang digunakan pada regresi logistic adalah: log
(
p1−p
)
=β0+β1x1+β2x2+..+βnxndimana P adalah kemungkinan bahwa y = 1 dan X1, X2, X3 adalah variabel independent, dan b adalah koefisien regresi.
regresi logistic akan membentuk variabel predictor/ respon (log(p/1-p)) yang merupakan kombinasi linier dari variabel independent. nilai variabel predictor ini kemudian ditransformasikan menjadi probabilitas fungsi logit.
Regresi logistik juga menghasilkan rasio peluang (odds ratios) terkait dengan nilai setiap prediktor. Peluang (odds) dari suatu kejadian diartikan sebagai probabilitas hasil yang muncul yang dibagi dengan probabilitas suatu kejadian tidak terjadi. Secara umum, rasio peluang (odds ratios) merupakan sekumpulan peluang yang dibagi oleh peluang lainnya. Rasio peluang bagi prediktor diartikan sebagai jumlah relatif dimana peluang hasil meningkat (rasio peluang > 1) atau turun (rasio peluang < 1) ketika nilai variabel prediktor meningkat sebesar 1 unit.
(sumber: http://statistik4file.blogspot.com/2009/12/regresi.logistik.html) Contoh Kasus
Seorang peneliti ingin mengetahui bagaimana pengaruh kualitas pelayanan public terhadap kepuasan pengguna (masyarakat). Kualitas pelayanan publik diteliti melaluji variabel Daya Tanggap (X1) dan Empati (X2). Kepuasan penggunana layanan (Y)
sebagai variabel dependent adalah variabel dummy dimana dimana jika responden menjawab puas maka kita beri skor 1 dan jika menjawab tidak puas kita beri skor 0. H. DIAGRAM PENCAR DAN BENTUK-BENTUKNYA
diagram pencar adalah suatu diagram yang menggambarkan titik-titik plot dari data yang diperoleh. diagram pencar juga merupakan Sebuah grafik yang menggambarkan hubungan dari satu variabel numerik lain pada sumbu horizontal dan vertikal, dan menentukan tingkat ketergantungan atau saling ketergantungan. diagram pencar berguna untuk:
1. membantu melihat apakah data relasi berguna antar variabel.
2. membantu menentukan jenis persamaan yang akan digunakan untuk menentukan hubungan tersebut.
Bentuk-Bentuk Diagram Pencar: 1) Linier Positif
Diagram pencar ini memiliki hubungan yang saling searah/ sejalan dan membentuk garis lurus dari persamaan yang didapatkan, dimana apabila nilai X naik, maka nilai Y pun naik.
Gambar 1.2 Linier Positif 2) Linier Negatif
diagram pencar ini memiliki hubungan yang berlawanan dengan kedua variabelnya. dimana nilai X naik, maka nilai y-nya menurun. dan persamaannya membentuk garis lurus. oleh karena itu dikatakan diagram pencar negatif.
Gambar 1.3 Linier Negatif 3) Kurva Linier Positif
Diagram ini hamper sama dengan linier positif hanya saja garis yang dihasilkan membentuk kurva karena persamaannya dari persamaan kuadrat.
Gambar 1.4 Kurva Linier Positif 4) Kurva Linier Negatif
Hampir sama dengan linier negatif, hanya saja garisnya berbentuk kurva karena persamaannya menggunakan persamaan kuadrat.
Gambar 1.5 Kurva Linier Negatif 5) Kurva Linier
Diagram pencar ini menggambarka kondisi dimana didapatkan hubungan antara x dn y, seolah meningkat, namun saat mencapai puncak maksimum keduanya mengalami penurunan. jadi garis yang dihasilkan membentuk kurva persamaan kuadrat juga.
Gambar 1.6 Kurva Linier 6) Tak Tentu
diagram pencar ini menggambarkan seolah-olah tidak adanya hubungan antara variabel x dan y, seolah-olah keduanya tidak saling mempengaruhi, arena adanya diagram yang didapatkan tersebar secara acak dan tidak berpola.
Gambar 1.7 Tak Tentu
(sumber: Dr. Ir. Hariadi. meng. prinsip-prinsip statistik untuk teknik dan sains) Hal terpenting dalam pembuatan atau penggunaan Scatter Diagram adalah :
Bagaimana memilih ukuran yang tepat, agar hubungan yang ter-gambarkan tidak menghasilkan hubungan yang bias ? Meskipun demikian, dalam kenyataannya kita tidak pernah dapat benar-benar mendapatkan penjelasan : Mengapa terjadi hubungan tersebut ?”, karena analisa pada Scatter Diagram hanya terbatas pada menunjukkan adanya hubungan dan kekuatan dari hubungan tersebut.
Membaca Scatter Diagram
Pada umumnya data dalam gambar diagram akan berpencar dan membentuk pola tertentu, dan pola pencaran data tersebutlah, dapat dilakukan analisa kecenderungan hubungan kedua faktor yang diuji, misalnya : Pola pencaran data dari bagian bawah kiri naik ke arah kanan seolah membentuk sudut. Dan bila ditarik suatu garis imajiner (bayangan), maka kita bisa membuat garis linear sebagai wakil dari kelompok atau pencaran data tersebut.Garis ini dalam istilah statistik dinamakan sebagai Garis Regresi.
Dalam Scatter Diagram dikenal 2 macam hubungan, yaitu : i. Ada Korelasi yang ditandai dengan korelasi Kuat dan Lemah ii. Tidak Ada Korelasi
Bila ADA korelasi, hubungan ini masih dibagi dengan Korelasi yang Positif dan Korelasi yang Negatif. Korelasi Positif diartikan : bila faktor “A” muncul semakin besar, maka faktor “B” akan muncul semakin besar pula. Sedangkan Korelasi Negatif diartikan : bila faktor “A” muncul semakin besar, faktor “B” justru akan muncul semakin kecil. Kedua korelasi tersebut (positif dan negatif) dapat ditandai dengan kuat dan lemah, sehingga dalam Scatter Diagram sebenarnya dapat ditandai 5 jenis korelasi, yaitu :
1. Korelasi Positif Kuat 2. Korelasi Positif Lemah 3. Korelasi Negatif Kuat 4. Korelasi Negatif Lemah 5. Tanpa Korelasi
Cara Membuat Scatter Diagram
1. Tentukan faktor-faktor yang akan diamati, misalnya “A” dan “B” (faktor sebab vs akibat atau akibat 1 vs akibat 2 atau sebab 1 vs sebab 2). Pedoman : salah satu variabel / faktor ditempatkan sebagai Variabel Independen (PENYEBAB), yang di dalam diagram ditempatkan pada Sumbu X, variabel lainnya sebagai Variabel Dependen (AKIBAT), yang ditempatkan pada Sumbu Y.
2. Tetapkan waktu pengamatan dan kumpulkan sejumlah data (umumnya > 30).
3. Gambarkanlah Sumbu “X” dan Sumbu “Y” dalam kertas diagram atau millimeterpaper
4. Tetapkanlah bidang bujur sangkar untuk menempatkan seluruh data yang dikumpulkan dengan cara :
Tentukan Nilai Tertinggi dan Nilai Terendah masing-masing data.
Hitunglah bedanya, dan tetapkan skalanya, baik sumbu X, maupun sumbu Y.
Masukkan data, dimulai pada sumbu X (penyebab) dan pada sumbu Y (akibat). (http://ikhtisar.com/scatter-diagram-untuk-menentukan-faktor-korelasi/)
I. TEKNIK-TEKNIK REGRESI
1. Model Seemingly Unrelated Regretions (SUR)
diperkenalkan oleh Zehner pada tahun 1912, yang merupakan bahasan dari model regresi multivariate dan merupakan bagian regresi linier. model SUR terdiri atas beberapa sistem persamaan yang tidak berhubungan (unrelated). artinya setiap variasi (dependent maupun independent) terdapat dalam satu sistem yang berbeda saling terkolerasi (berhubungan). singkatnya sistem persamaan linier beberapa regresi dapat diselesaikan menjadi satu set persamaan saja. beberapa persamaan regresi yang berbeda dapat disatukan untuk mendapatkan parameter yan efisiensi dengan SUR.
jika kita memiliki, beberapa persamaan garis seperti berikut ini: y1t = β11 x1t1 + β12 x2t2 + …. + β1k1 x1tk1 + ε1t
y2t = β21 x2t.1 + β22 x2t2.2 + …. + β2k2 x2t.k2 + ε2t ymt = βm xmt.1 + βm2 xm2 + …. + βmk+ dxmk + d+ εmt 2. Uji Heteroskedastisitas
pada analisis regresi, heteroskedastisitas berarti situasi dimana keseragaman variabel independent bervariasi pada data yang kita miliki. salah satu asumsi kunci pada metode regresi biasa adalah bahwa error memiliki keragaman yang sama pada tiap-tiap sampelnya. asumsi inilah yang disebut heteroskedastisitas. jika keragaman residual error tidak bersifat konstan, data dapat dikatakan bersifat eteroskedastisitas karena pada metode regresi ordinary least square mengasumsikan keragaman error yang konstan, heteroskedastisitas menyebabkan estimasi ols menjadi tidak efisien. model yang memperhitungkan perubahan keragaman dapat membuat penggunaan estimasi data menjadi lebih efisien.
Uji heteroskedastisitas digunakan untuk mengetahui ada atau tidaknya penyimpangan asumsi klasik heteroskedastisitas yaitu adanya ketidaksamaan varian dari residual untuk semua pengamatan pada model regresi. Prasyarat yang harus terpenuhi dalam model regresi adalah tidak adanya gejala heteroskedastisitas. Ada beberapa metode pengujian yang bisa digunakan diantaranya yaitu Uji Park, Uji Glesjer, Melihat pola grafik regresi, dan uji koefisien korelasi Spearman.
a) Uji Park
Metode uji Park yaitu dengan meregresikan nilai residual (Lnei2) dengan
masing-masing variabel dependen (LnX1 dan LnX2).
Kriteria pengujian adalah sebagai berikut:
Ho : tidak ada gejala heteroskedastisitas Ha : ada gejala heteroskedastisitas
Ho diterima bila –t tabel < t hitung < t tabel berarti tidak terdapat
heteroskedastisitas dan Ho ditolak bila t hitung > t tabel atau -t hitung < -t tabel yang berarti terdapat heteroskedastisitas.
b) Uji Glejser
Uji Glejser dilakukan dengan cara meregresikan antara variabel independen dengan nilai absolut residualnya. Jika nilai signifikansi antara variabel independen dengan absolut residual lebih dari 0,05 maka tidak terjadi masalah heteroskedastisitas.
(sumber: http://duwiconsultant.blogspot.com/2011/11/uji-heteroskedastisitas.html)
3. Persamaan Berbasis Regresi
model kausal mengasumsikan bahwa variabel yang diramalkan (variabel dependent) terkait dengan variabel lain (variabel independent) dalam tabel. pendekatan ini mencoba untuk melakukan proyeksi berdasarkan hubungan tersebut. dalam bentuknya yang paling sederhana, regresi linier digunakan untuk mencocokkan baris ke data. baris itu kemudian digunakan untuk meramalkan variabel dependent yang dipilih untuk beberapa nilai dari variabel independent. model yang digunakan sama dengan model pada regresi linier berganda, yaitu:
+¿….+bnXn y=b0+b1X1+b2X2¿
dimana:
y = nilai observasi dari variabel yang diukur b0 = konstanta
X = variabel pengukur (independent) ∂ = variabel sugrogales (dummy) ε = error
4. Regresi Stepwise
model regresi terbaik terkadang didapatkan dari beberapa tahapan pemikiran. daftar sejumlah variabel penjelas tersedia dan dari data itu dicari variabel mana yang seharusnya dimasukkan ke dalam model. variabel penjelas terbaik akan digunakan pertama kali, dan kemudian yang kedua, dan seterusnya. prosedur ini dikenal dengan regresi stepwise.
+b3X3+¿….+bnXn y=b0+b1X1+b2X2¿
sedangkan hipotesis yang digunakan dalam regresi stepwise adalah: H0=β1, β2, β3=0
dengan hipotesisnya alternatif adalah: H0=β1, β2, β3≠0
5. Uji Multikolinieritas
multikolinieritas adalah kondisi terdapatnya hubungan linier atau korelasi yang tinggi antara masing-masing variabel independent dalam model regresi. oleh karena itu multikolinieritas biasanya terjadi ketika sebagian besarr variabel yang digunakan saling terkait dalam suatu model regresi. oleh karena itu masalah multikolinieritas tidak terjadi pada regresi linier sederhana yang hanya melibatkan satu variabel independent. indikasi terhadap masalah multikolinieritas dapat kita lihat dari kasus-kasus berikut:
a. nilai R2 yang tinggi (signifikan) namun nilai standar error dan tingkat signifikan masing-masing variabel sangat rendah.
b. perubahan kecil sekalipu pada data akan menyebabkan perubahan signifikan pada variabel yang dialami.
c. nilai koefisien variabel tidak sesuai dengan hipotesis, misalnya variabel yang seharusnya memiliki pengaruh positif ditunjukkan dengan nilai negatif.
memang belum ada kriteria yang jelas dalam mendekati masalah multikolinieritas dalam model regresi linier. selain itu, hubungan korelasi yang tinggi belum tentu berimplikasi terhadap masalah multikolinieritas. tetapi kita dapat melihat indikasi multikolinieritas dengan tolerance value (TOL), rigenvalue, dan yang paling umum diguanakan adalah Variansi Inflarium Factor (VIF). Hingga saat ini tidak ada kriteria formal untuk menentukan batas terendah dari nilai toleransi atau VIP. beberapa ahli berpendapat bahwa nilai toleransi kurang dari , atau lebih besar dari 10 menunjukkan multikolinieritas signifikan, sementara itu para ahli lainnya menegaskan bahwa R2 model dianggap mengindikasikan adanya multikolinieritas.
Klein (1962) menunjukkan bahwa, jika VIF lebih besar dari 1/(t – R2) atau nilai toleransi kurang dari (1 – R2), maka multikolinieritas dapat dianggap signifikan secara satistik.
Ciri-ciri yang sering ditemui apabila model regresi linier kita mengalami multikolinieritas adalah:
a. Terjadi perubahan yang berarti pada koefisien model regresi (misal nilainya menjadi lebih besar atau kecil) apabila dilakukan penambahan atau pengeluaran sebuah variabel bebas dari model regresi.
b. Diperoleh nilai R-square yang besar, sedangkan koefisien regresi tidak signifikan pada uji parsial.
c. Tanda (+ atau -) pada koefisien model regresi berlawanan dengan yang disebutkan dalam teori (atau logika). Misal, pada teori (atau logika) seharusnya b1 bertanda (+), namun yang diperoleh justru bertanda (-).
d. Nilai standard error untuk koefisien regresi menjadi lebih besar dari yang sebenarnya (overestimated)
contoh:
Seorang mahasiswa bernama Bambang melakukan penelitian tentang faktor-faktor yang mempengaruhi harga saham pada perusahaan di BEJ. Data-data yang di dapat berupa data rasio dan ditabulasikan sebagai berikut:
Tabel. Tabulasi Data (Data Fiktif)
Tahun Harga Saham (Rp) PER (%) ROI (%)
1990 8300 4.90 6.47 1991 7500 3.28 3.14 1992 8950 5.05 5.00 1993 8250 4.00 4.75 1994 9000 5.97 6.23 1995 8750 4.24 6.03 1996 10000 8.00 8.75 1997 8200 7.45 7.72 1998 8300 7.47 8.00
1999 10900 12.68 10.40 2000 12800 14.45 12.42 2001 9450 10.50 8.62 2002 13000 17.24 12.07 2003 8000 15.56 5.83 2004 6500 10.85 5.20 2005 9000 16.56 8.53 2006 7600 13.24 7.37 2007 10200 16.98 9.38
Bambang dalam penelitiannya ingin mengetahui bagaimana hubungan antara rasio keuangan PER dan ROI terhadap harga saham. Dengan ini Bambang menganalisis dengan bantuan program SPSS dengan alat analisis regresi linear berganda.
(sumber: http://duwiconsultant.blogspot.com/2011/11/uji-multikolinearitas.html)
6. Auto Korelasi
uji auto korelasi digunakan utnuk melihat apakah ada hubungan linier antara Error dengan serangkaian observasi yang diurutkan berdasarkan waktu (data time series). uji autokorelasi perlu dilakukan apabila yang dianalisis merupakan data time series (Gujari, 1993)
d=
∑
(
e1−e2.1)
2
∑
e1dimana:
d = nilai durbin Watson e = jumlah kuadrat sisa
Ʃ
nilai durbin Watson kemudian dibandingkan dengan nilai drabel. hasil perbandingan akan menghasilkan kesimpulan seperti kriteria sebagai berikut:
a. jika d < d, berarti terdapat autokorelasi positif. b. jika d > (α – d1), berarti terdapat autokorelasi negatif. c. jika du ( d < (α – d1)), berarti tidak terdapat autokorelasi. d. jika d1 < d < du atau ( α – du), berarti tidak dapat disimpulkan. (sumber: ariyoso.wordpress.com/category/teknik-regresi.html)
Contoh data timeseries (terdapat urutan waktu) misalnya pengaruh biaya iklan terhadap penjualan dari bulan januari hingga bulan desember. Sedangkan data cross-sectional adalah data
yang tidak ada urutan waktu, misal pengaruh konsentrasi zat X terhadap kecepatan reaksi suatu senyawa kimia.
(sumber: http://ineddeni.wordpress.com/category/regresi-linier-dan-korelasi/) J. STANDARD ERROR ESTIMASI
dalam menggunakan persamaan linier untuk melakukan suatu perkiraan, terdapat satu pertanyaan penting mengenai seberapa kuat hubungan antar variabel bebas dan terikatnya, atau dengan kata lain, seberapa besar derajat ketergantungan hasil perkiraan tersebut. hal ini dapat lebih dimengerti dengan mmperhatikan gambar dibawah, yang menunjukkan dua diagram pencar yang memiliki persamaan garis regresi yang sama. pada gambar (a) terlihat bahwa titik-titik data pencar lebih rapat disekitar garis regresi dibandingkan dengan titik-titik data pada gambar (b). dengan begitu, kita dapat mengatakan bahwa suatu estimasi yang dilakukan dengan persamaan garis regresi untuk keadaan pada gambar (b).
ukuran yang mengidentifikasi derajat variasi, sebaran data disekitar garis regresi data menunjukkan seberapa besar derajat keterikatan perkiraan yang dieroleh dengan menggunakan persamaan regresi tersebut. ukuran ini dinamakan sebagai standar error estmas (sy,x) adalah deviasi standar yang memberikan ukuran penyebaran nilai-nilai yang teramati disekitar garis regresi dirumuskan sebagai berikut:
y− ´y ¿ ¿2 ¿ ¿ ¿ y xy
∑
¿ ¿ ¿∑
¿−b¿ ¿ ¿∑
¿ √¿ sy , x=¿Gambar:
Derajat variasi dari sebaran (pencaran data)