(M.3)
CLUSTERING PENGGUNA WEBSITE BPS MENGGUNAKAN
ALGORITMA SEQUENCE DBSCAN (SEQDBSCAN)
DENGAN JARAK SIMILARITAS S
3M
1Toza Sathia Utiayarsih, 2Yadi Suprijadi, 3Bernik Maskun
1Mahasiswa Magister Statistika Terapan, FMIPA Universitas Padjajaran, Bandung,
Indonesia
2,3Dosen Jurusan Statistika, FMIPA Universitas Padjajaran, Bandung, Indonesia
e-mail: 1[email protected]
ABSTRAK
Perkembangan dunia web sangat pesat, banyak organisasi yang memberikan informasi dan menyediakan layanan melalui web. Sehingga dunia web menjadi lahan yang luas dalam penelitian data mining, yang disebut sebagai web mining. Salah satu pengembangan dari web
mining, web usage mining, berguna untuk mencari pola penggunaan dari akses web log. Pola
penggunaan akses web log dapat dianalisis dengan menggunakan analisis klaster. Web data
clustering merupakan suatu proses pengelompokkan (clustering) data web berdasarkan
kemiripan karakteristik data tersebut. Struktur data web memiliki karakteristik yang berbeda dengan data pada umumnya. Pada data web, data disusun berdasarkan urutan (sequence) dalam mengakses halaman web. Sehingga diperlukan algoritma yang mempertimbangkan urutan data dan jarak antar klaster, yang dapat dipenuhi oleh algoritma Sequence DBSCAN (SeqDBSCAN). Dalam pembentukan klaster melalui algoritma tersebut, digunakan ukuran similaritas S3M (Set and Sequence Similarity) yang mempertimbangkan baik urutan pada
halaman web yang dikunjungi sebagaimana juga isi dari halaman tersebut. Algoritma ini diterapkan dalam menganalisis pola pengguna data website BPS (Badan Pusat Statistik) yang volumenya sangat besar.
Kata kunci: Data Mining, Web Usage Mining, Similarity Measure, Sequence Clustering, Density Based Clustering
1. PENDAHULUAN
Dengan pesatnya perkembangan dari web, banyak organisasi yang memberikan informasi dan menyediakan layanan melalui web, seperti on-line shopping, pelayanan teknis, tanya jawab, maupun pelayanan data. Untuk memberikan pelayanan yang terbaik, perlu diketahui tentang pola penggunaan situs web itu sendiri dalam rangka memberikan kemudahan sesuai kebutuhan pengguna. Pola penggunaan situs web dapat dianalisis dengan
web mining.
Web mining merupakan salah satu bagian dari data mining, merupakan
pengembangan data mining pada data berbasis web. Selanjutnya, penelitian tentang web
mining berkembang menjadi web content mining dan web usage mining, dimana sebelumnya
dapat menjembatani antara pengguna dengan pengelola situs web, yaitu melalui web usage
session.
Web usage session adalah interaksi antara pengguna dan web server dalam satu
periode waktu tertentu yang berisi halaman web yang dikunjungi dan lamanya waktu mengunjungi halaman tersebut. Karena jumlah dan keragaman pengguna situs web yang sangat besar, maka diperlukan suatu metode yang dapat menganalisis web usage session. Salah satu metode yang diterapkan adalah web data clustering.
Web data clustering adalah suatu proses pengelompokkan data web berdasarkan
kemiripan karakteristik data tersebut. Pada proses pengelompokkannya, analisis klaster memiliki beberapa algoritma yang dapat digunakan, salah satunya adalah algoritma baru yang diperkenalkan oleh Sathisree dan Damodaram (2010), yaitu algoritma Sequence DBSCAN (Density-Based Spatial Clustering of Applications with Noise).
2. TINJAUAN PUSTAKA
Pada proses pengelompok data, analisis klaster memiliki beberapa algoritma yang dapat digunakan, salah satunya adalah algoritma DBSCAN (Density-Based Spatial Clustering of
Applications with Noise) yang diperkenalkan oleh Ester dkk. (1996). Menurut Sathisree dan
Damodaram (2010), analisis klaster mempertimbangkan 2 (dua) aspek penting, yaitu jumlah optimal dari klaster dan perbandingan ukuran terbaik antara dua set klaster. Pada algoritma DBSCAN, kedua aspek tersebut dapat dipenuhi dengan menggunakan konsep density
reachability dan density connectability. Density reachability adalah satu set titik (klaster) yang
berkumpul pada jarak radius tertentu yang dapat dicapai dari satu set klaster lainnya, sedangkan density connectability adalah dua set titik yang berkumpul pada radius tertentu yang terhubung melalui satu set titik lainnya.
Struktur data web memiliki karakteristik yang berbeda dengan data pada umumnya. Pada data web, data disusun berdasarkan urutan (sequence) dalam mengakses halaman web. Sehingga diperlukan algoritma yang mempertimbangkan urutan data dan jarak antar klaster. Menurut Sathisree dan Damodaram (2010), algoritma DBSCAN tidak mempertimbangkan urutan data. Sehingga diperlukan modifikasi pada algoritma DBSCAN yang disebut Sequence
DBSCAN (SeqDBSCAN).
Dalam membangun set klaster diperlukan jarak similaritas untuk mengelompokkan data. Karena struktur data web yang memiliki karakteristik yang berbeda, maka diperlukan juga jarak yang mempertimbangkan hal tersebut. Untuk penerapan pada algoritma SeqDBSCAN digunakan jarak similaritas S3M (Set and Sequence Similarity).
3. DATA WEB USAGE SESSION SITUS WEB BPS
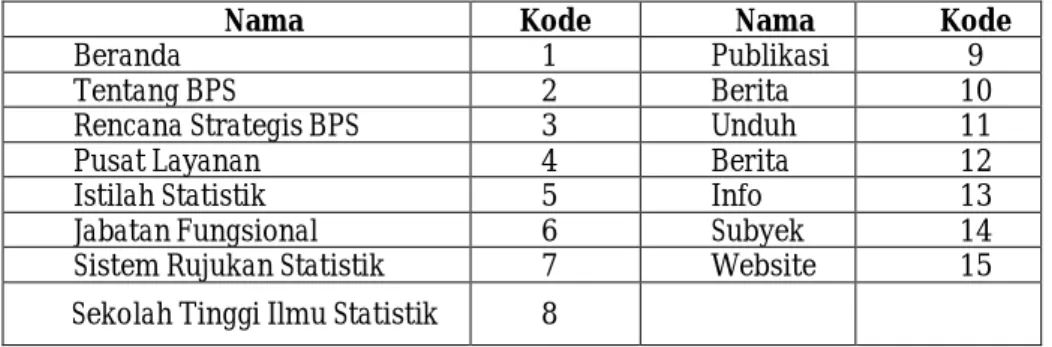
Kategori halaman yang digunakan pada penelitian ini berasal dari peta situs web BPS yang merupakan kerangka dasar dalam sebuah situs web yang berisi informasi mengenai halaman-halaman yang ada dalam situs. Halaman pada situs web BPS terdapat 15 kategori. Setiap kategori halaman direpresentasikan dengan label integer. Contohnya, “Beranda” diberi kode 1, “Tentang BPS” diberi kode 2, dan seterusnya, seperti terlihat dalam Tabel 1.
Sumber data sebagian besar web usage mining adalah web server log, yang menyediakan data mentah untuk mengidentifikasi kumpulan data web atau web usage
session. Web server log berisi catatan akses dari pengguna. Setiap record mewakili sebuah
halaman yang diakses oleh pengguna dan umumnya berisi alamat IP (Internet Protocol) pengguna, tanggal dan waktu akses diterima, alamat URL yang diakses, kode balasan dari
server yang menunjukkan status akses, dan ukuran file (byte) dari halaman yang diakses
sempurna.
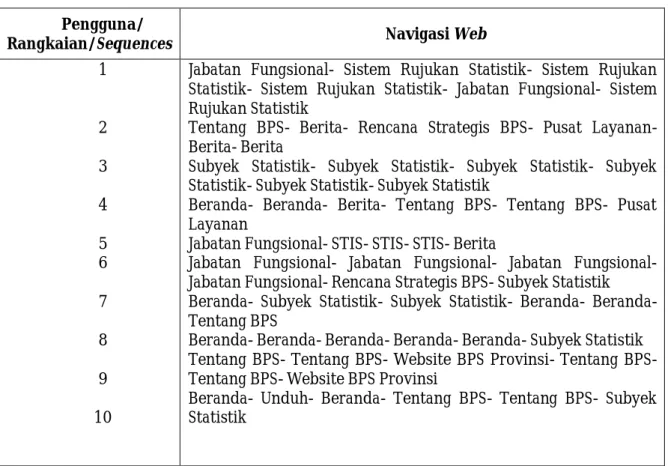
Untuk mengidentifikasi session pengguna, data mentah dari log harus dipilih atau ditransformasikan menjadi daftar halaman yang diakses. Memilih dari server log termasuk juga menghilangkan semua file yang berulang, sehingga hanya menyisakan satu record per halaman yang diakses. Kemudian session file dapat disaring untuk menghilangkan transaksi yang sangat kecil. Contoh dari user session file yang menunjukkan referensi navigasi dapat dilihat pada Tabel 2.
Tabel 1. Kategori Halaman yang Diberi Label Kode Angka
Nama Kode Nama Kode
Beranda 1 Publikasi 9
Tentang BPS 2 Berita 10
Rencana Strategis BPS 3 Unduh 11
Pusat Layanan 4 Berita 12
Istilah Statistik 5 Info 13
Jabatan Fungsional 6 Subyek 14
Sistem Rujukan Statistik 7 Website 15
Sekolah Tinggi Ilmu Statistik 8
Berdasarkan pengkodean seperti pada Tabel 1 di atas, maka untuk contoh referensi navigasi situs web BPS seperti pada Tabel 2 dapat dituliskan sebagai berikut:
Pengguna 1: “Jabatan Fungsional “ diberi kode “6”; “Sistem Rujukan Statistik” diberi kode “7”; “Sistem Rujukan Statistik” diberi kode “7”; “Sistem Rujukan Statistik” diberi kode “7”; “Jabatan Fungsional” diberi kode “6”; Sistem Rujukan Statistik” diberi kode “7”, kemudian dituliskan dalam navigasi web menjadi “6-7-7-7-6-7” .
Tabel 2. Contoh Navigasi Pengguna Web BPS Pengguna/
Rangkaian/Sequences Navigasi Web
1 2 3 4 5 6 7 8 9 10
Jabatan Fungsional- Sistem Rujukan Statistik- Sistem Rujukan Statistik- Sistem Rujukan Statistik- Jabatan Fungsional- Sistem Rujukan Statistik
Tentang BPS- Berita- Rencana Strategis BPS- Pusat Layanan- Berita- Berita
Subyek Statistik- Subyek Statistik- Subyek Statistik- Subyek Statistik- Subyek Statistik- Subyek Statistik
Beranda- Beranda- Berita- Tentang BPS- Tentang BPS- Pusat Layanan
Jabatan Fungsional- STIS- STIS- STIS- Berita
Jabatan Fungsional- Jabatan Fungsional- Jabatan Fungsional- Jabatan Fungsional- Rencana Strategis BPS- Subyek Statistik Beranda- Subyek Statistik- Subyek Statistik- Beranda- Beranda- Tentang BPS
Beranda- Beranda- Beranda- Beranda- Beranda- Subyek Statistik Tentang BPS- Tentang BPS- Website BPS Provinsi- Tentang BPS- Tentang BPS- Website BPS Provinsi
Beranda- Unduh- Beranda- Tentang BPS- Tentang BPS- Subyek Statistik
4. JARAK SIMILARITAS S3M (SET AND SEQUENCE SIMILARITY MEASURE)
Ukuran/ jarak similaritas S3M mempertimbangkan baik similaritas set maupun
similaritas data berurutan (sequence) diantara dua urutan. Ukuran ini didefinisikan sebagai kombinasi linier tertimbang dari besaran subsequence terpanjang seperti pada ukuran Jaccard. Rangkaian tersusun atas set dari beberapa item yang diurutkan berdasarkan waktu atau item yang terakhir berlangsung setelah kemunculan item sebelumnya, yaitu secara posisi tetapi tidak selalu berhubungan dengan waktu. Dapat dikatakan rangkaian adalah urutan dari sekumpulan item. Rangkaian dinotasikan sebagai berikut : S = {a1, a2, ..., an}, dengan a1, a2, ..., an adalah beberapa item dengan urutan dalam rangkaian/sequence (S). Panjang rangkaian didefinisikan sebagai jumlah dari kumpulan item dalam rangkaian tersebut, dinotasikan dengan |S|. Untuk mencari pola pada rangkaian, penting untuk melihat urutan kemunculan dari item pada rangkaian, bukan pada isinya saja.
Sebuah alat ukur baru, disebut sequence and set similarity measure (S3M),
diperkenalkan untuk network security domain (Kumar et al., 2005). Secara umum ukuran S3M
di antara rangkaian/sequence ke-i dan rangkaian/sequence ke-j adalah:
, = ( , )
(| |, )+
| ∩ |
| ∪ |
dengan:
adalah rangkaian/sequence ke-i. adalah rangkaian /sequence ke-j.
p adalah penimbang urutan susunan (sequence similarity).
q adalah penimbang komposisi (set similarity).
p + q = 1; p, q 0
( , ) adalah panjang dari sub-sequence terlama diantara kedua sequence. (| |, ) adalah nilai maksimum dari rangkaian/sequence dan . | ∩ | adalah jumlah rangkaian/sequence yang sama.
| ∪ | adalah jumlah rangkaian/sequence gabungan.
S3M terdiri dari dua bagian, yaitu:
1. Menghitung kuantitas dari komposisi rangkaian (set similarity).
2. Menghitung kuantitas dari keberadaan rangkaian (sequence similarity). Sequence similarity menghitung jumlah similaritas pada urutan kemunculan kumpulan item dalam dua rangkaian.
S3M memiliki sifat-sifat sebagai berikut:
1. Non-negatif: Sim (si,sj) ≥ 0
2. Simetri: Sim (si,sj) = Sim (sj,si)
3. Normalisasi: Sim (si,sj) ≤ 1
Besaran dari sub urutan umum terpanjang/length of longest common subsequence (LLCS) dengan memperhatikan besaran dari rangkaian terpanjang menentukan aspek similaritas rangkaian diantara dua rangkaian. LLCS antara dua rangkaian dapat dicari melalui pendekatan dynamic programming (Bergroth et al., 2000).
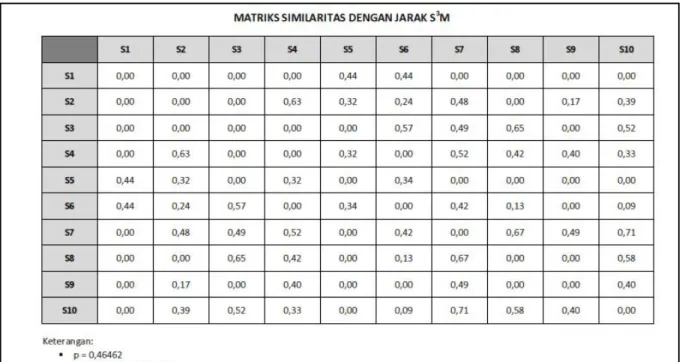
Contoh matriks similaritas dengan jarak similaritas S3M pada data yang terdapat pada
Gambar 1. Matriks Similaritas dengan Jarak S3M
5. ALGORITMA SEQDBSCAN (SEQUENCE DBSCAN)
Pada data web, data disusun berdasarkan rangkaian/sequence dalam mengakses halaman web sebagaimana dijelaskan sebelumnya. Menurut Sathisree dan Damodaram (2010), algoritma DBSCAN tidak mempertimbangkan urutan pada data, sehingga diperlukan modifikasi yang disebut Sequence DBSCAN (SeqDBSCAN).
Algoritma Sequence DBSCAN didasari pendekatan center-based, yang memiliki tiga konsep. Sebuah titik dikatakan core point apabila jumlah titik dalam suatu lingkungan yang ditentukan oleh fungsi jarak, yang ditentukan sebelumnya, atau dapat disebut Eps, melebihi jumlah tertentu, atau dapat disebut Minpts.
Border point bukan merupakan core point, tetapi sebagian daerahnya berada dalam
daerah core point. Sedangkan noise point adalah titik manapun yang bukan merupakan core
Sesuai dengan definisi dari ketiga konsep tersebut di atas, maka secara informal algoritma SeqDBSCAN dapat disimpulkan menjadi, setiap dua core point yang berdekatan, dalam jarak Eps, diletakkan ke dalam klaster yang sama. Begitu juga dengan border point yang berdekatan dengan core point, dalam jarak Eps, diletakkan ke dalam klaster yang sama. Sedangkan noise point diabaikan.
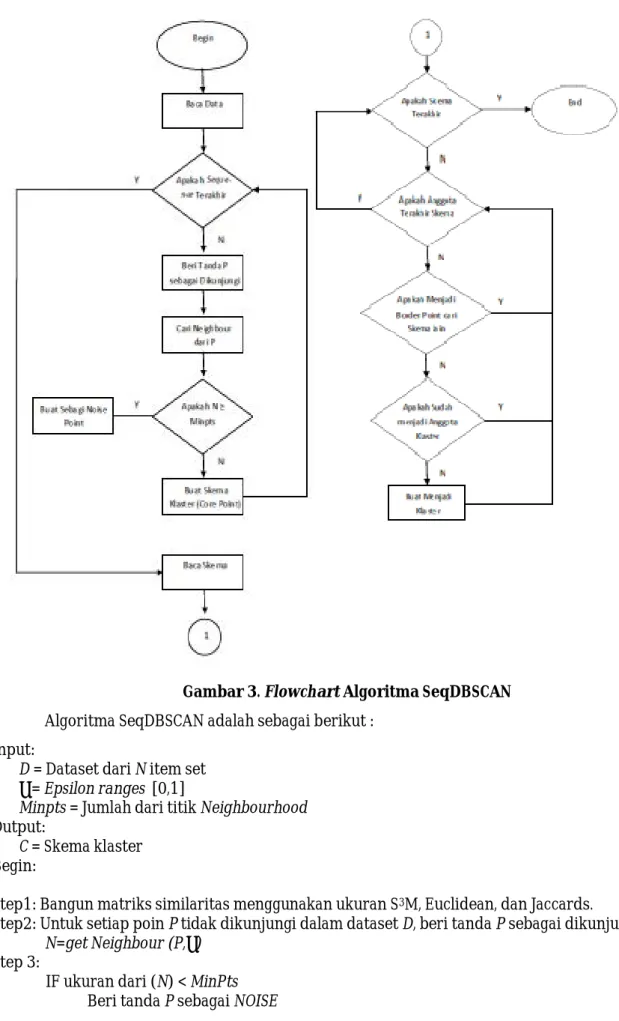
Algoritma SeqDBSCAN adalah sebuah analisis klaster density-based dengan mempertimbangkan data sequential. Secara inisial proses dimulai dengan memilih setiap rangkaian dari matriks similaritas dengan jarak kurang dari nilai radius (Eps). Lalu pilih setiap poin/titik P yang tidak dikunjungi, hitungan jumlah titik yang berdekatan disekelilingnya. Jika jumlah titik pada lingkungan P lebih besar dari nilai minimum yang ditentukan (Minpts) maka masukkan ke dalam klaster C. Lakukan pada semua titik P sampai ditemukan keseluruhan klaster C. Flowchart untuk algoritma tersebut dapat dilihat pada Gambar 3.
Flowchart tersebut menggambarkan proses yang dikerjakan pada algoritma
SeqDBSCAN. Misalkan sebuah data set D = {d1, d2,d3,..., dN} sebanyak N item set, dan data set
tersebut adalah transaksi dari akses website dengan di = {u1, u2,u3,..., um} dengan u2 setelah
u1dan u3 setelah u2, dan seterusnya. Proses dimulai dengan memilih setiap rangkaian data
dari mariks similaritas yang memiliki jarak kurang dari radius (eps). Kemudian pilih titik P yang belum dikunjungi, kemudian cari titik Neighbourhood (wilayah) dari P. Jika nilai
Neighbourhood lebih besar dari Minpts, masukkan pada inisial klaster C (skema klaster),
begitu juga pada setiap titik P’ pada N. Ulangi proses yang sama sampai semua titik dikunjungi dan didapat hasil klaster C.
Gambar 3. Flowchart Algoritma SeqDBSCAN Algoritma SeqDBSCAN adalah sebagai berikut :
Input:
D = Dataset dari N item set Є = Epsilon ranges [0,1]
Minpts = Jumlah dari titik Neighbourhood
Output:
C = Skema klaster
Begin:
Step1: Bangun matriks similaritas menggunakan ukuran S3M, Euclidean, dan Jaccards.
Step2: Untuk setiap poin P tidak dikunjungi dalam dataset D, beri tanda P sebagai dikunjungi.
N=get Neighbour (P,Є)
Else BEGIN
C = klaster berikutnya
Beri tanda P sebagai dikunjungi END
Step 4:
Tambahkan P ke klaster C Step 5:
FOR setiap poin P’ dalam N IF P tidak dikunjungi
Beri tanda P’ sebagai dikunjungi N’=get Neighbour (P’,Є)
Step 6:
IF ukuran dari (N’) >= MinPts N = N bergabung dengan N’
P’ belum menjadi anggota klaster manapun Step 7: Tambahkan P’ ke klaster C Step 8: Kembali ke C End Step 9:
FOR semua klaster BEGIN
Hitung jarak inter klaster dan intra klaster menggunakan ALD End FOR
6. HASIL YANG DIHARAPKAN
Pada pengklasteran dengan algoritma SeqDBSCAN, akan dibentuk beberapa klaster yang berdasarkan densitas pada data dengan memperhatikan urutan. Jumlah dari klaster bergantung kepada densitas pada data itu sendiri, sehingga tidak ada jumlah klaster yang ditentukan dari awal. Sejak awal pembentukan klaster, algoritma ini telah mempertimbangkan urutan dengan memasukkan jarak similaritas yang dihitung berdasarkan urutan data. Sehingga pada data situs web BPS akan membentuk beberapa klaster yang sesuai dengan karakteristik data pada web.
7. PENUTUP
Algoritma SeqDBSCAN dengan jarak similaritas S3M adalah metode pengklasteran
yang tepat untuk data yang memiliki urutan seperti pada data situs web. Sehingga klaster yang terbentuk bukan hanya memperhatikan isi dari data tetapi juga mempertimbangkan waktu kemunculan data dibandingkan dengan data lainnya. Penelitian algoritma ini pada data situs web BPS masih berlangsung pada tahap proses pengolahan data, sehingga belum dapat ditampilkan secara langsung hasil dari pengklasteran tersebut.
8. DAFTAR PUSTAKA
Afifi, A. & Clark, V. 1984. Computer-Aided Multivariate Analysis. Belmont, CA: Wadsworth. E-book.
Bergroth dkk. 2000. A Survey of Longest Common Subsequence Algorithms. E-Journal on-line Melalui http://dl.acm.org/citation.cfm?id=829519.830817.
Ester dkk. 1996. A Density-Based Algorithm for Discovering Clusters in Large Spatial Databases
with Noise. E-Journal on-line Melalui http://citeseerx.ist.psu.edu/viewdoc/download.
Kumar, P., dkk. 2005. SeqPAM: A Sequence Clustering Algorithm for Web Personalization. E-Journal on-line. Melalui http://www.irma-international.org/viewtitle/1777/.
Santhisree, K. & Damodaram, A. 2010. SeqDBSCAN: A New Sequence DBSCAN Algorithm for
Clustering of Web Usage Data. E-Journal on-line. Melalui
http://journals.griet.ac.in/images/8v2i2a10.pdf.
Schime, A. 2005. Web Mining: Applications and Techniques. Hershey: Idea Group, Inc. E-book. Srivastava, dkk. 2000. Web Usage Mining: Discovery and Applications of Usage Patterns from
Web Data. E-Journal on-line Melalui