TUGAS MATA KULIAH
(PENGANTAR ARSITEKTUR DAN SISTIM OPERASI KOMPUTER)
BAB 6
SYSTEM INTEGRATION AND
PERFORMANCE
O L E H:
EMANUEL JANDO (7205000865)
Magister Teknologi Informasi
Fakultas Ilmu Komputer
Universitas Indonesia
DAFTAR ISI:
SYTEM BUS ---4
BUS CLOCK AND DATA TRANSFER RATE ---4
BUS PROTOCOL ---6
LOGICAL DAN PHISICAL ACCESS ---10
TECHNOLOGY FOCUS: SCSI ---12
PERANGKAT KERAS I/O ---16
POLLING ---16
INTERRUPT PROCESSING ---17
MEKANISME DASAR INTERRUPT---17
FITUR TAMBAHAN KOMPUTER MODERN---17
INTERRUPT REQUEST LINE ---18
INTERRUPT VECTOR DAN INTERRUPT CHAINING ---18
PENYEBAB INTERRUPT---18
DMA ---19
TRANSFER DMA ---19
HANDSHAKING ---20
INTERRUPT APLIKASI I/O ---21
PERALATAN BLOK DAN KARAKTER ---22
PERALATAN JARINGAN ---22
JAM DAN TIMER---22
BLOCKING DAN NON BLOCKING I/O ---23
KERNEL I/O SUBSISTEM---23
I/O SCHEDULLING ---23
BUFFER AND CACHE DATA ---24
BUFFERS---25
CACHING---26
SPOOLING DAN RESERVASI DEVICE ---27
ERROR HANDLING ---28
PENANGANAN PERMINTAAN I/O---30
PENGARUH I/O PADA KINERJA---32
CARA MENINGKATAKAN EFISIENSI I/O ---32
IMPLEMENTASI FUNGSI I/O ---32
TECHNOLOGY FOCUS: ITANIUM MEMORY CACHE---33
PERFORMA ---34
CLOCK PROSESSOR---36
SYSTEM BUS
Bus adalah kumpulan jalur komunikasi paralel yang menghubungkan dua atau lebih peralatan. System bus menghubungkan CPU dengan memori utama dan komponen sistem lainnya.
Data Bus Address bus Control bus
Gambar: Komponen sistem bus dan kaitan antar device
Peralatan lain dari CPU dan penyimpanan utama disebut peripheral device. Setiap jalur bus membawa sebuah nilai bit tunggal selama bus melakukan operasi pengiriman. Sistem komputer mempunyai beberapa bagian jalur bus termasuk data bus, address bus, dan control bus dengan jenis informasi yang dibawa secara khusus.
Data bus memindahkan data antara komponen sistem komputer. Secara khusus jumlah jalurnya sama dan bermacam-macam sesuai dengan ukuran kata (word size) CPU. Misalnya sistem komputer 64-bit CPU mempunyai 64 atau 128 jalur data bus.
Adsress bus membawa bit dari alamat memori. Alamat bus modern empunyai sedikitnya 32 jalur. Ketika peralatan peripheral mengirim data ke memori utama, address bus mengirimkan data item melalui data bus dan secara simultan mengirimkan alamat data item melalui address bus. Address bus digunakan oleh bus untuk mengirim ke target atau tujuan yang mana dari peralatan di dalam memori utama.
Control bus membawa perintah, respons perintah, kode status, dan pesan yang sesuai. Seluruh aktifitas dikoordinasi oleh komponen sistem komputer dengan mengirim signal yang tepat di atas control bus.
BUS CLOCK DAN DATA TRANSFER RATE
Satu atau lebih jalur control bus membawa pulsa bus clock, bersamaan patokan waktu untuk semua peralatan. Frekuensi pulasa bus clock diukur dalam satuan megahertz
Primary Storage
CPU Secondary
Storage
(NHz). Bisa sepadan dengan CPU clock rate atau pecahan dari clock rate. Setiap pulsa clock ditandai dengan dimulainya kesempatan baru untuk mengirimkan data atau pengendali pesan.
Interval waktu antara satu pulsa clock ke pulsa clock berikutnya disebut bus cycle. Bus cycle time merupakan invers dari bus clock rate. Contohnya, jika bus clock rate sebesar 200 MHz maka lama setiap bus cycle adalah:
Bus cycle time =
rate clock bus_ _ 1 = Hz 000 , 000 , 2000 1 = 5 nanoseconds
Sangat alami, bus harus panjang secara relatif sebab bus menghubungkan banyak komponen sistem komputer yang berbeda. Miniatur dari semua komponen sistem komputer mengurangi panjang tipikal sistem bus, tetapi masih 10 centimeter atau lebih panjang sebagaian besar sistem komputer. Bus cycle tidak boleh lebih pendek dari waktu yang dibutuhkan untuk sinyal elektrik melintasi bus dari ujung ke ujung. Panjang bus menentukan maksimum teoritis pada bus clock rate dan minimum teoritis pada bus cycle
time.
Dalam praktek, bus clock rate biasanya diset jauh di bawah maksimum teoritis untuk memperhitungkan noise, interference dan waktu yang dibutuhkan untuk beroperasinya putaran interface pada peralatan peripheral. Bus clock rate lebih pendek juga memberikan kemampuan pabrik pembuatan komponen komputer untuk meningkatkan peralatan peripheral secara nyata selama biaya pada tingkatan yang layak. Kecepatan maksimum sebuah bus atau chanel komunikasi lainnya menghasilkan clock
rate dan data transfer unit. Sebagai contoh kapasitas teoritis sebuah bus dengan 64 jalur
data dan 200 MHz clock rate adalah:
Kapasitas bus = data transfer unit x clock rate = 64 bits x 200,000,000 Hz
= 1,600,000,000 bytes per second
Sama halnya mengukur kapasitas komunikasi yang disebut data transfer rate. Data
transfer rate dinyatakan dalam bits atau bytes per second, sebagai contoh 10 MB per
second. Hanya dua cara untuk meningkatkan data transfer rate bus maksimum: meningkatkan clock rate atau meningkatkan ukuran unit transfer data (jumlah jalur data). Untuk diskusi, panjang bus, mesin yang lama juga terbatas pada jumlah jalur data bus.
Tetapi jumlah jalur data bus selalu minimal sama dengan word size CPU. Hal ini membantu menghindari CPU menunggu proses transfer data bus. Lebar bus data yang besar dari word size CPU dapat memberikan performa jika CPU dapat secara efektif menggunakan masukan multiple-word.
BUS PROTOCOL
Bus protocol menentukan format, isi dan timing data, alamat memori, dan mengirim kendali pesan melewati bus. Setiap peralatan peripheral harus mengikutu aturan protokol. Dalam pengertian sederhana, sebuah bus adalah sebuah kumpulan jalur komunikasi. Dalam pengertian yang luas bus adalah kombinasi antara jalur komunikasi, protokol bus, dan peralatan yang mengimplementasikan protokol bus. Protokol bus mempunyai dua dampak penting pada data transfer rate maksimum. Pertama, mengontrol pengiriman sinyal melewati bus yang dipakai bus cycle, mengurangi ketersediaan putaran pengiriman data. Contoh, sebuah disk drive mengirim data ke memori utama sebagai hasil dari penegasan perintah CPU. Mengirimkan perintah membutuhkan sebuah bus cycle. Kebanyakan perintah protokol bus telah diikuti dengan pengesahan dari disk drive dan kemudian melalui konfirmasi bahwa perintah telah keluar. Setiap sinyal (perintah, pengesahan, dan konfirmasi) memakai sepenggal bus cycle.
Agar efisien protokol bus memakai jumlah minimum bus cycle untuk perintah - perintah, memaksimalkan ketersediaan bus untuk mengirimkan data. Sayangnya, protokol bus yang efisien pemeliharaannya kompleks, meningkatkan kompleksitas dan biaya dan dari semua peralatan peripheral.
Bus protokol mengatur akses bus untuk mencegah peralatan dari gangguan antara satu dengan yang lain. Jika dua peralatan peripheral mencoba mengirimkan sebuah pesan dalam waktu yang sama, pesan bertabrakan dan menghasilakan gangguan elektrik. Protokol bus mengembalikan tumbukan dengan satu atau dua pendekatan akses kontrol: pendekatan master-slave dan multiple master, atau pendekatan peer-to-peer.
Pada arsitektur komputer tradisional, CPU merupakan fokus dari semua aktivitas komputer. Sebagian dari peranan ini, CPU juga bus master dan semua peralatan lain adalah bus slave. Tidak ada peralatan lain selain CPU dapat mengakses bus, keculai pada tanggapan untuk instruksi yang tegas dari CPU. Tidak ada tumbukan selama CPU
menunggu untuk menanggapi dari satu peralatan sebelum pokok persoalan sebuah perintah untuk peralatan lain.
Karena hanya satu bus master, maka protokol bus sederhana dan efisien. Akan tetapi secara keseluruhan performa sistem berkurang secara signifikan sebab pengiriman antar peralatan, sperti dari disk ke memori, harus melalui CPU. Semua pengiriman memakai sekurang-kurangnya dua bus cycle; satu untuk mengirim data dari peralatan sumber ke CPU dan yang lain mengirim data dari CPU ke peralatan tujuan. CPU tidak dapat mengeksekusi perhitungan dan instruksi logic selama berlangsungnya pengiriman data antara peralatan lain. Performa telah berubah jika peralatan penyimpanan dan I/O dapat mengirim data antara mereka tanpa keterlibatan CPU secara tegas. Ada dua pendekatan yang biasa digunakan untuk mengimlementasikan pengiriman: direct memory access dan multiple master bus. Di bawah direct memory access (DMA), sebiah peralatan yang disebut DMA controller meletakkann ke bus dan memori utama. DMA controller memakai aturan bus master untuk semua pengiriman antara memori dan penyimpanan lain atau peralatan I/O. Selama DMA mengatur lalulintas bus, CPU bebas untuk melaksanakan perhitungan dan instrukasi perpindahan data.
Pada multiple master bus, beberapa peralatan dapat memakai pengendali bus atau bertindak sesuai master bus untuk mentransfer ke peralatan lain. Single master harus memilih ketika multiple device ingin menjadi bus master pada waktu yang sama. Unit bus arbitration adalah prosesor sederhana yang telah terpasang pada multiple master bus dan memutuskan peralatan mana yang harus menunggu ketika multiple device ingin menjadi bus master. Protokol multiple master bus secara substansi lebih kompleks dan mahal dibandigkan protokol master-slave bus, namun kompleksitas mereka tergantikan dengan menggunakan CPU dan bus.
LOGICAL dan PHYSICAL ACCESS
Di beberapa sistem komputer, sistem bus diimplementasikan pada cetakan papan sirkuit dengan mencantumkan berbagai titik peralatan. Beberapa peralatan, seperti bus dan memori controller secara sirkuit tertanam secara permanen pada board. Yang lainnya seperti CPU, memori modul, dan beberapa pengendali
I/O port adalah jalur komunikasi dari CPU ke peralatan peripheral. Pada beberapa komputer I/O port berupa alamat memori, atau suatu kumpulan alamat memori yang saling berdampingan, dan dapat membaca atau menulis oleh CPU dan peralatan peripheral tunggal. Setiap peralatan peripheral memiliki multiple I/O port dan penggunaanya untuk tujuan yang beerbeda, sebagai contoh, mengirim data, perintah, dan kode kesalahan. CPU berkomunikasi dengan peralatan peripheral melalui perpindahan data ke atau dari alamat memori I/O port. Sirkuit antar muka bus yang ada memonitor perubahan akan isi memori I/O port dan secara otomatis meng-copy isi yang telah ter-update ke port bus yang layak.
I/O port terdiri dari alamat memori atau saluran data; yang juga merupakan sebuah abstraksi logika yang digunakan oleh CPU dan bus untuk berinteraksi dengan keyboard yang tepat sekali dengan cara yang sama berinteraksi dengan disk drive atau video display. I/O port menyederhanakan set instrukasi CPU dan protokol bus sebab instruksi-instrukasi khusus dan sirkuit bus tidak diperlukan untuk setiap peralatan peripheral yang berbeda. Sistem komputer pun lebih fleksibel, sebab jenis peralatan yang baru dapat digabung dengan sistem komputer lama melalui pengalokasian I/O yang baru. Meskipun antar muka CPU dan bus sama, peralatan peripheral merupakan hal yang sangat berbeda, termasuk kapasitas penyimpanan, data transfer rate, metode pengkodean data internal, dan penyimpanan atau I/O device. Rincian peralatan fisik seperti bagaimana sebuah disk membaca/menulis pada posisi head, bagaimana warna ditampilkan di layar, atau font dan posisi karakter printer, secara tidak langsung bersepakat dengan antar muka sederhana antara peralatan peripheral dan CPU lebih jauh.
Esensinya CPU dan bus berinteraksi dengan setiap peralatan peripheral jika peralatan penyimpanan mengandung satu atau lebih byte tersimpan dalam penomoraN alamat secara sequential. Sebuah operasi baca atau tulis dari peralatan penyimpanan secara hipotetis disebut logical acsess. Kumpulan penomoran lokasi penyimpanan secara sequential disebut linear address space. Logical access untuk peralatan peripheral adalah sama untuk mengakses ke memori. Satu atau
lebih byte “baca” atau “tulis” sebagai instruksi I/O yang telah dijalankan. Jalur alamat bus membawa posisi dengan linear address space yang telah membaca atau menulis, dan jalur data bus membawa data. Perintah rumit dan status sinyal pun dapat di encoded dan mengirim melalui jalur data.
Sebagai contoh sebuah logical access, ibarat sebuah disk drive secara fisik erorganisir ke dalam sektor, track, dan keping. Ketika CPU menjalankan instruksi untuk memabaca pada sektor tertentu, tidak dapat melakukan pengiriman piringan, track dan nomor sektor sebagai parameter perintah pembacaan. Malahan “pemikiran” disk sebagai linear terurut dari lokasi penyimpanan, setiap kepemilikan satu sektor data, dan mengirim sebuah nomor tunggal untuk mengidentifikasi lokasi yang ingin dibaca.
Untuk mengakses secara fisik sektor yang sesuai, bersama lokasi diasumsikan linear address space harus dikonversikan ke dalam koresponden piringan, sektor, dan trak, dan perangkat keras disk harus diinstruksikan untuk mengakses lokasi tertentu. Alamat liniear dapat ditugaskan untuk sektor fisik di beberapa cara penomoran seperti diperlihatkan pada gambar di bawah ini:
Platter 1 Platter 2 Platter 3
Penugasan nomor logical sektor untuk meminimize switch head-to-head dan pencarian track-to-track.
Disk drive sendiri adalah pengendali peralatan, menterjemahkan alamat linear sektor ke dalam koresponden lokasi sektor fisik pada piringan dan trak tertentu.
Dengan pita drive, menterjemahkan alamat logois ke alamat fisik dan secara jelas sebab blok pada pita terorganisir secara fisik dalam urutan linier. Sebuah akses logika ke sebuah lokasi penyimpanan (blok) diterjemahkan ke dalam perintah pada bagian posisi yang sesuai dari pita secara fisik di bawah head baca/tulis.
Beberapa peralatan I/O seperti keyboard dan komunikasi sound card hanya dalam termin aliran terurut dari byte yang mengisi lokasi memori yang sama. Dengan peralatan ini konsep pengalamatan atau lokasi tidak relevan. Dari titik pandang CPU, peralatan I/O adalah peralatan penyimpanan dengan lokasi tunggal yang membaca atau menulis secara berulang.
Peralatan I/O yang lain mempunyai lokasi penyimpanan dalam pengertian tradisional. Sebagai contoh, karakter individu atau posisi pixel dari video display atau halaman pencetakan adalah lokasi penyimpanan logika. Setiap posisi menugaskan sebuah alamat dengan linear address space, dan alamat-alamat ini digunakan untuk memanipulasi pixel individu atau posisi karakter. Peralatan pengendali menterjemahkan logika operasi penulisan ke dalam aksi fisik yang diperlukan untuk menerangkan koresponden pixel video display atau menempatkan tinta pada koresponden posisi di atas halaman.
Penyimpanan dan peralatan I/O secara normal dihubungkan ke sistem bus melewati peralatan pengendali seperti terlihat pada gambar di bawah ini. Peralatan pengendali melakukan fungsin di bawah ini:
Sebagai bus interface dan protokol akses
Menterjemahkan logikal akses ke phicical akses
Mengijinkan beberapa peralatan untuk membagi akses ke koneksi bus
Gambar: Penyimpanan sekunder dan koneksi peralatan I/O menggunakan peralatan pengendali
Peralatan pengendali memonitor jalur pengendali bus terhadap sinyal ke peralatan peripheral dan menterjemahkan sinyal tersebut ke dalam perintah yang sesuai untuk penyimpan atau peralatan I/O. Dengan cara yang sama peralatan pengendali menterjemahkan dat dan status sinyal dari peralatan ke kendali bus dan sinyal data yang sesuai. Sebuah pengendali menjalankan semua fungsi antar muka bus untuk peralatan peripheral yang terpasang.
Peralatan pengendali melaksanakan beberapa atau semua konversi antara perintah logical access dan physical access. Pengendali peralatan “mengetahui” detail fisik dari peralatan yang terpasang dan isu instruksi tertentu ke pengatahuan peralatan dasar. Sebagai contoh, sebuah disk controller mengkonver sebuah logical access ke sektor disk tertentu dengan sebuah linear address space ke dalam sebuah perintah untuk membaca dari head, trak, dan sektor tertentu.
Pengendali peralatan mengikutu multiple peripheral device untuk membagi port bus. Fungsi ini penting karena jumlah port bus dalam sistem bus biasanya terbatas untuk 16 atau lebih. Sistem komputer, secara khusus minikomputer dan mainframe, mungkin mempunyai beberapa lusin penyimpanan dan peralatan I/O. Sebagian besar penyimapanan dan peralatan I/O tidak dapat menunjang sistem bus data transfer rate untuk meningkatkan periode. Membagi
Primary storage CPU Secondary storage controller I/O controller I/O controller I/O unit I/O unit Secondary storage
pakai koneksi bus tunggal antara multiple device yang lebih rendah alokasi secara efisien dan relatif terhadap kapasitas komunikasi yang besar dari sebuah bus port ke banyak kapasitas yang rendah.
TECHNOLOGY FOCUS: SCSI
Akronim SCSI merupakan singkatan dari Smmall Computer System Interface. Akronim tersebut mengacu pada bus standar yang di identifikasikan oleh American National Standarts Institute (ANSI) dengan nomor X3.131. Dalam spesifikasi asli standar tersebut, perangkat seperti disk dihubungkan ke komputer melalui kabel 50-wire, yang dapat mencapai panjang 25 meter dan dapat mentransfer data hingga kecepatan 5 megabyte / detik.
Standar bus SCSI telah mengalami banyak revisi, dan kemampuan transfer datanya telah meningkat sangat besar, hampir dua kali setiap dua tahun. SCSI-2 dan SCSI-3 telah didefinisikan, dan masing-masing memiliki beberapa opsi. Bus SCSI memiliki delapan jalur data, yang disebut narrow bus dan mentrasfer data satu byte pada satuwaktu. Sebagai alternatif, bus wide SCSI memiliki 16 jalur data bit pada satu waktu. Terdapat pula beberapa opsi untuk skema signaling elektrik yang digunakan. Bus dapat menggunakan transmisi single-ended (SE), dimana tiap sinyal menggunakan satu wire, dengan common ground return untuk semua sinyal. Dalam opsi lain, digunakan signaling diferensial, dimana disediakan return wire terpisah untuk tiap sinyal. Dalam hal ini, dimungkinkan dua tingkat tegangan. Versi yang lebih awal menggunakan 5 V (tingkat TTL) dan dikenal sebagai High Voltage Differential (HVD). Yang lebih baru, versi 3,3V telah diperkenalkan dan dikenal sebagai Low Voltage Differential (LVD).
Karena berbagai pilihan ini, maka konektor SCSI dapat memiliki 50, 68, atau 80 pin. Kecepatan transfer maksimum dalam perangkat komersial yang saat ini tersedia bervariasi dari 5 megabyte / detik hingga 160
megabyte / det. Versi terbaru dari standar tersebut dimaksudkan untuk mendukung kecepatan transfer hingga 320 megabyte/det, dan 640 megabyte / det diantisipasi kemudian. Kecepatan transfer maksimum pada bus tertentu sering merupakan fungsi panjang kabel dan jumlah perangkat yang lebih sedikit. Untuk mencapai kecepatan transfer data puncak, panjang bus biasanya dibatasi hingga 1,6 m untuk signaling SE dan 12 m untuk signaling LVD. Akan tetapi produsen sering menyediakan bus expander khusus untuk menghubungkan perangkat yang jauh letaknya. Kapasitas maksimum bus adalah 8 perangkat untuk narrow bus dan 16 perangkat untuk wide bus.
Perangkat yang dihubungkan ke SCSI bukanlah bagian dari ruang alamat prosesor seperti perangkat yang terhubung ke bus prosesor. Bus SCSI dihubungkan ke bus prosesor melalui kontroler SCSI, sebagaimana ditunjukan pada Gambar 4.38. Kontroler ini menggunakan DMA untuk mentransfer paket data dari memori utama ke perangkat tersebut, atau sebaliknya. Suatu paket dapat berisi blok data, perintah dari prosesor ke perangkat, atau informasi status tentang perangkat tersebut.
Untuk mengilustrasikan operasi bus SCSI, marilah kita memperhatikan bagaimana bus tersebut digunakan bersama disk drive. Komunikasi dengan disk drive berbeda secara substansial dari komunikasi dengan memori utama. Data disimpan pada disk dalam blok yang disebut sector, dimana tiap sektor dapat berisi beberapa ratus byte. Data tersebut mungkin tidak perlu disimpan dalam sektor yang berbatasan. Beberapa sektor dapat berisi data yang disimpan sebelumnya; yang lain mungkin rusak dan harus dilompati. Karenaya, request baca atau tulis dapat menghasilkan pengaksesan beberapa sektor disk yang tidak harus berdekatan. Karena batasan gerakan mekanik disk, maka terdapat jeda yang panjang, dalam order beberapa milidetik, sebelum mencapai sektor pertama ke atau dari mana data ditransfer. Kemudian, burst data ditransfer pada kecepatan tinggi. Jeda lain mungkin terjadi, diikuti oleh burst data. Request baca atau
tulis tungal dapat melibatkan bebrapa burst semacam itu. Protokol SCSI didesain untuk memfasilitasi mode operasi lain..
Kontroler yang dihubungkan ke bus SCSI adalah salah satu dari dua tipe-initator atau target. Initiator memiliki memampuan untuk memilih target tertentu dan mengirim perintah yang menetapkan operasi yang akan dilakukan. Kontroler pada sisi prosesor, seperti kontroler SCSI pada Gambar 4.38, harus mampu beroperasi sebagai initiator. Kontroler disk beroperasi sebagai target. Kontroler tersebut menetapkan koneksi logika dengan target yang dimaksud. Setelah koneksi terbentuk, koneksi tersebut dapat ditangguhkan dan dipulihkan seperlunya untuk mentransfer perintah dan burst data. Pada saat koneksi tertentu ditangguhkan, perangkat lain dapat menggunakan bus tersebut untuk mentransfer informasi. Kemampuan untuk mengoverlap request transfer data ini adalah salah satu fitur utama dalam bus SCSI yang menghasilkan performa tinggi.
Transfer data pada bus SCSI selalu dikontrol ole target kontroler target. Untuk mengirim perintah ke target, suatu initiator me-request kontrol bus dan, setelah memenangkan arbitration, memilih kontroler yang akan diajak berkomunikasi dan menyerahkan kontrol bus padanya. Kemudian kontroler memulai operasi transfer data untuk menerima perintah dari initiator.
Marilah kita menganalisa operasi baca disk lengkap sebagai contah. Dalam pembahasan diperjelas bahwa kontroler melakukan tindakan ini setelah menerima perintah yang tepat dari prosesor. Asumsikan bahwa prosesor ingin membaca blok data dari disk drive dan data tersebut disimpan dalam dua sektor disk yang tidak berbatasan. Prosesor mengirim perintah ke kontroler SCSI, yang menghasilkan rangkaian event berikut :
1. Kontroler SCSI, yang bertindak sebagai initiator, berjuang untuk mendapatakan kontrol bus.
2. Pada saat initiator memenangkan proses arbitration, initiator memilih kontroler target dan menyerahkan kontrol bus padanya.
3. Target memulai operasi output (dari initiator ke target); sebagai respon terhadap hal ini, initiatror mengirim perintah yang menentukan operasi baca yang diminta.
4. Target, yang mengerti bahwa harus melakukan operasi disk seek terlebih dahulu, mengirim pesan ke initiator yang mengindikasikan akan menangguhkan sementara konekai antara initator dan target. Kemudian target membebaskan bus tersebut.
5. Kontroler target mengirim perintah ke disk drive untuk memindahkan head baca ke sektor pertama yang terlibat dalam operasi baca yang dimaksud. Kemudian membaca data yang disimpan dalam sektor tersebut dan menyimpannya dalam buffer data. Pada saat target siap mentransfer ke initiator, target me-request kontrol bus. Setelah memenangkan arbitration, target me-reselect kontroler initiator, sehingga memulihkan koneksi yang ditangguhkan.
6. Target mentransfer isi buffer data ke initiator dan kemudian menangguhkan lagi koneksi tersebut. Data ditransfer 8 atau 16 bit secara paralel, tergantung pada lebar bus.
7. Kontroler target mengirim perintah ke disk drive untuk melakukan operasi seek lainnya. Kemudian mentransfer isi sektor disk kedua ke initiator, seperti sebelumnya. Pada akhir transfer ini, koneksi logika antara dua kontroler tersebut diterminasi.
8. Pada saat kontroler utama menggunakan pendekatan DMA.
9. Kontroler SCSI mengirim interrupt ke prosesor untuk memberitahu bahwa operasi yang diminta telah selesai.
Skenario ini menunjukkan bahwa pesan yang dipertukarkan melalui bus SCSI berada pada tingkat yang kebih tinggi daripada yang dipertukarkan melalui prosesor bus. Dalam konteks ini, “tingkat yang lebih tinggi” berarti bahwa pesan yang mengacu pada operasi yang meminta beberapa langkah penyelesaian, tergantung pada perangkat tersebut. Prosesor maupun kontroler SCSI harus waspada terhadap detil operasi perangkat
tertentu yang terlibat dalam transfer data. Pada contoh sebelumnya, prosesor tidak perlu dilibatkan dalam operasi disk seek.
Standar bus SCSI mendefinisikan rentang pesan kontrol yang luas, yang dapat dipertukarkan antar-kontroler untuk menangani berbagai error atau kondisi kegagalan yang mungkin muncul selama operasi perangkat atau transfer data.
PERANGKAT KERAS I/O
Secara umum, terdapat beberapa jenis seperti device penyimpanan (disk, tape), transmission device (network card, modem), dan human-interface device (screen, keyboard, mouse). Device tersebut dikendalikan oleh instruksi I/O. Alamat-alamat yang dimiliki oleh device akan digunakan oleh direct I/O instruction dan memory-mapped I/O. Beberapa konsep yang umum digunakan ialah port, bus (daisy chain/ shared direct access), dan controller (host adapter). Port adalah koneksi yang digunakan oleh device untuk berkomunikasi dengan mesin. Bus adalah koneksi yang menghubungkan beberapa device menggunakan kabel-kabel. Controller adalah alat-alat elektronik yang berfungsi untuk mengoperasikan port, bus, dan device.
Langkah yang ditentukan untuk device adalah command-ready, busy, dan error. Host mengeset command-ready ketika perintah telah siap untuk dieksekusi oleh controller. Controller mengeset busy ketika sedang mengerjakan sesuatu, dan men clear busy ketika telah siap untuk menerima perintah selanjutnya. Error diset ketika terjadi kesalahan.
POLLING
Busy-waiting / polling adalah ketika host mengalami looping yaitu membaca status register secara terus-menerus sampai status busy di-clear. Pada dasarnya polling dapat dikatakan efisien. Akan tetapi polling menjadi tidak efisien ketika setelah berulang-ulang melakukan looping, hanya menemukan sedikit device yang siap untuk men-service, karena CPU processing yang tersisa belum selesai.
INTERRUPT PROCESSING Mekanisme Dasar Interupsi
Ketika CPU mendeteksi bahwa sebuah controller telah mengirimkan sebuah sinyal ke interrupt request line (membangkitkan sebuah interupsi), CPU kemudian menjawab interupsi tersebut (juga disebut menangkap interupsi) dengan menyimpan beberapa informasi mengenai state terkini CPU--contohnya nilai instruksi pointer, dan memanggil interrupt handler agar handler tersebut dapat melayani controller atau alat yang mengirim interupsi tersebut.
Fitur Tambahan pada Komputer Modern
Pada arsitektur komputer modern, tiga fitur disediakan oleh CPU dan interrupt controller (pada perangkat keras) untuk dapat menangani interrupsi dengan lebih bagus. Fitur-fitur ini antara lain adalah kemampuan menghambat sebuah proses interrupt handling selama prosesi berada dalam critical state, efisiensi penanganan interupsi sehingga tidak perlu dilakukan polling untuk mencari device yang mengirimkan interupsi, dan fitur yang ketiga adalah adanya sebuah konsep multilevel interupsi sedemikian rupa sehingga terdapat prioritas dalam penanganan interupsi (diimplementasikan dengan interrupt priority level system).
Interrupt Request Line
Pada peranti keras CPU terdapat kabel yang disebut interrupt request line, kebanyakan CPU memiliki dua macam interrupt request line, yaitu nonmaskable interrupt dan maskable interrupt. Maskable interrupt dapat dimatikan/ dihentikan oleh CPU sebelum pengeksekusian deretan critical instruction (critical instruction sequence) yang tidak boleh diinterupsi. Biasanya, interrupt jenis ini digunakan oleh device controller untuk meminta pelayanan CPU.
Interrupt Vector dan Interrupt Chaining
Sebuah mekanisme interupsi akan menerima alamat interrupt handling routine yang spesifik dari sebuah set, pada kebanyakan arsitektur komputer yang ada sekarang ini, alamat ini biasanya berupa sekumpulan bilangan yang menyatakan offset pada sebuah tabel (biasa disebut interrupt vector). Tabel ini menyimpan alamat-alamat interrupt handler spesifik di dalam memori. Keuntungan dari pemakaian vektor adalah untuk mengurangi kebutuhan akan sebuah interrupt handler yang harus mencari semua kemungkinan sumber interupsi untuk menemukan pengirim interupsi.
Akan tetapi, interrupt vector memiliki hambatan karena pada kenyataannya, komputer yang ada memiliki device (dan interrupt handler) yang lebih banyak dibandingkan dengan jumlah alamat pada interrupt vector. Karena itulah, digunakanlah teknik interrupt chaining dimana setiap elemen dari interrupt vector menunjuk / merujuk pada elemen pertama dari sebuah daftar interrupt handler. Dengan teknik ini, overhead yang dihasilkan oleh besarnya ukuran tabel dan inefisiensi dari penggunaan sebuah interrupt handler (fitur pada CPU yang telah disebutkan sebelumnya) dapat dikurangi, sehingga keduanya menjadi kurang lebih seimbang.
Penyebab Interupsi
Interupsi dapat disebabkan berbagai hal, antara lain exception, page fault, interupsi yang dikirimkan oleh device controllers, dan system call Exception adalah suatu kondisi dimana terjadi sesuatu/ dari sebuah operasi didapat hasil tertentu yang dianggap khusus sehingga harus mendapat perhatian lebih, contoh nya pembagian dengan 0 (nol), pengaksesan alamat memori yang restricted atau bahkan tidak valid, dan lain-lain.
System call adalah sebuah fungsi pada aplikasi (perangkat lunak) yang dapat mengeksekusikan instruksi khusus berupa software interrupt atau trap.
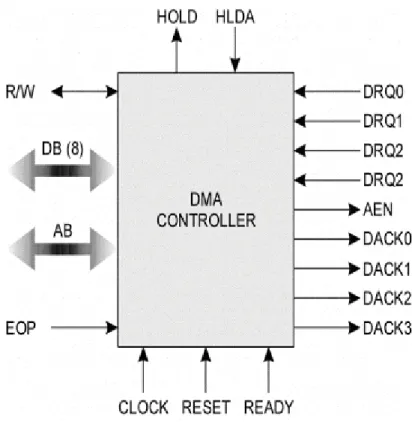
DMA
DMA adalah sebuah prosesor khusus (special purpose processor) yang berguna untuk menghindari pembebanan CPU utama oleh program I/O (PIO).
Transfer DMA
Untuk memulai sebuah transfer DMA, host akan menuliskan sebuah DMA command block yang berisi pointer yang menunjuk ke sumber transfer, pointer yang menunjuk ke tujuan/ destinasi transfer, dan jumlah byte yang ditransfer, ke memori. CPU kemudian menuliskan alamat command block ini ke DMA controller, sehingga DMA controller dapat kemudian mengoperasikan bus memori secara langsung dengan menempatkan alamat-alamat pada bus tersebut untuk melakukan transfer tanpa bantuan CPU. Tiga langkah dalam transfer DMA:
1. Prosesor menyiapkan DMA transfer dengan menyedia kan data-data dari device, operasi yang akan ditampilkan, alamat memori yang menjadi sumber dan tujuan data, dan banyaknya byte yang di transfer.
2. DMA controller memulai operasi (menyiapkan bus, menyediakan alamat, menulis dan membaca data), sampai seluruh blok sudah di transfer.
3. DMA controller meng-interupsi prosesor, dimana selanjutnya akan ditentukan tindakan berikutnya.
Pada dasarnya, DMA mempunyai dua metode yang berbeda dalam mentransfer data. Metode yang pertama adalah metode yang sangat baku dan simple disebut HALT, atau Burst Mode DMA, karena DMA controller memegang kontrol dari sistem bus dan mentransfer semua blok data ke atau dari memori pada single burst. Selagi transfer masih dalam progres, sistem mikroprosessor di-set idle, tidak melakukan instruksi operasi untuk menjaga internal register. Tipe operasi DMA seperti ini ada pada kebanyakan komputer. Metode yang kedua, mengikut-sertakan DMA controller untuk memegang kontrol dari sistem bus untuk jangka waktu yang lebih pendek pada periode dimana mikroprosessor
ini disebut cycle stealing mode. Cycle stealing DMA lebih kompleks untuk diimplementasikan dibandingkan HALT DMA, karena DMA controller harus mempunyai kepintaran untuk merasakan waktu pada saat sistem bus terbuka.
Gambar 6-3. DMA Controller. Sumber: . . .
Handshaking
Proses handshaking antara DMA controller dan device controller dilakukan melalui sepasang kabel yang disebut DMA-request dan DMA-acknowledge. Device controller mengirimkan sinyal melalui DMA-request ketika akan mentransfer data sebanyak satu word. Hal ini kemudian akan mengakibatkan DMA controller memasukkan alamat-alamat yang dinginkan ke kabel alamat memori, dan mengirimkan sinyal melalui kabel acknowledge. Setelah sinyal melalui kabel DMA-acknowledge diterima, device controller mengirimkan data yang dimaksud dan mematikan sinyal pada DMA-request. Hal ini berlangsung berulang-ulang sehingga disebut handshaking. Pada saat DMA controller mengambil alih memori, CPU sementara tidak dapat mengakses memori (dihalangi), walau pun masih dapat mengaksees data pada cache primer dan sekunder. Hal ini disebut cycle stealing, yang walau pun memperlambat
komputasi CPU, tidak menurunkan kinerja karena memindahkan pekerjaan data transfer ke DMA controller meningkatkan performa sistem secara keseluruhan.
Cara-cara Implementasi DMA
Dalam pelaksanaannya, beberapa komputer menggunakan memori fisik untuk proses DMA , sedangkan jenis komputer lain menggunakan alamat virtual dengan melalui tahap "penerjemahan" dari alamat memori virtual menjadi alamat memori fisik, hal ini disebut direct virtual-memory address atau DVMA. Keuntungan dari DVMA adalah dapat mendukung transfer antara dua memory mapped device tanpa intervensi CPU.
INTERFACE APLIKASI I/O
Ketika suatu aplikasi ingin membuka data yang ada dalam suatu disk, sebenarnya aplikasi tersebut harus dapat membedakan jenis disk apa yang akan diaksesnya. Untuk mempermudah pengaksesan, sistem operasi melakukan standarisasi cara pengaksesan pada peralatan I/O. Pendekatan inilah yang dinamakan interface aplikasi I/O.
Interface aplikasi I/O melibatkan abstraksi, enkapsulasi, dan software layering. Abstraksi dilakukan dengan membagi-bagi detail peralatan-peralatan I/O ke dalam kelas-kelas yang lebih umum. Dengan adanya kelas-kelas yang umum ini, maka akan lebih mudah untuk membuat fungsi-fungsi standar (interface) untuk mengaksesnya. Lalu kemudian adanya device driver pada masing-masing peralatan I/O, berfungsi untuk enkapsulasi perbedaan-perbedaan yang ada dari masing-masing anggota kelas-kelas yang umum tadi. Device driver mengenkapsulasi tiap -tiap peralatan I/O ke dalam masing-masing 1 kelas yang umum tadi (interface standar). Tujuan dari adanya lapisan device driver ini adalah untuk menyembunyikan perbedaan-perbedaan yang ada pada device controller dari subsistem I/O pada kernel. Karena hal ini, subsistem I/O dapat bersifat independen dari hardware. Karena subsistem I/O independen dari hardware maka hal ini akan sangat menguntungkan dari segi pengembangan hardware. Tidak perlu menunggu vendor sistem operasi untuk mengeluarkan support code untuk hardware-hardware baru yang akan dikeluarkan oleh vendor hardware.
PERALATAN BLOCK DAN KARAKTER
Peralatan block diharapkan dapat memenuhi kebutuhan akses pada berbagai macam disk drive dan juga peralatan block lainnya. Block device diharapkan dapat memenuhi/mengerti perintah baca, tulis dan juga perintah pencarian data pada peralatan yang memiliki sifat random-access.
Keyboard adalah salah satu contoh alat yang dapat mengakses stream-karakter. System call dasar dari interface ini dapat membuat sebuah aplikasi mengerti tentang bagaimana cara untuk mengambil dan menuliskan sebuah karakter. Kemudian pada pengembangan lanjutannya, kita dapat membuat library yang dapat mengakses data/pesan per-baris. PERALATAN JARINGAN
Karena adanya perbedaan dalam kinerja dan pengalamatan dari jaringan I/O, maka biasanya sistem operasi memiliki interface I/O yang berbeda dari baca, tulis dan pencarian pada disk. Salah satu yang banyak digunakan pada sistem operasi adalah interface socket. Socket berfungsi untuk menghubungkan komputer ke jaringan. System call pada socket interface dapat memudahkan suatu aplikasi untuk membuat local socket, dan menghubungkannya ke remote socket. Dengan menghubungkan komputer ke socket, maka komunikasi antar komputer dapat dilakukan.
JAM DAN TIMER
Adanya jam dan timer pada hardware komputer, setidaknya memiliki tiga fungsi, memberi informasi waktu saat ini, memberi informasi lamanya waktu sebuah proses, sebagai trigger untuk suatu operasi pada suatu waktu. Fungsi fungsi ini sering digunakan oleh sistem operasi. Sayangnya, system call untuk pemanggilan fungsi ini tidak di-standarisasi antar sistem operasi
Hardware yang mengukur waktu dan melakukan operasi trigger dinamakan programmable interval timer. Dia dapat di set untuk menunggu waktu tertentu dan kemudian melakukan interupsi. Contoh penerapannya ada pada scheduler, dimana dia akan melakukan interupsi yang akan memberhentikan suatu proses pada akhir dari bagian waktunya.
Sistem operasi dapat mendukung lebih dari banyak timer request daripada banyaknya jumlah hardware timer. Dengan kondisi seperti ini, maka kernel atau device driver mengatur list dari interupsi dengan urutan yang duluan datang yang duluan dilayani.
BLOCKING DAN NONBLOCKING I/O
Ketika suatu aplikasi menggunakan sebuah blocking system call, eksekusi aplikasi itu akan diberhentikan untuk sementara. aplikasi tersebut akan dipindahkan ke wait queue. Dan setelah system call tersebut selesai, aplikasi tersebut dikembalikan ke run queue, sehingga pengeksekusian aplikasi tersebut akan dilanjutkan. Physical action dari peralatan I/O biasanya bersifat asynchronous. Akan tetapi, banyak sistem operasi yang bersifat blocking, hal ini terjadi karena blocking application lebih mudah dimengerti dari pada nonblocking application.
KERNEL I/O SUBSYSTEM
Kernel menyediakan banyak service yang berhubungan dengan I/O. Pada bagian ini, kita akan mendeskripsikan beberapa service yang disediakan oleh kernel I/O
subsystem, dan kita akan membahas bagaimana caranya membuat infrastruktur hardware dan device-driver. Service yang akan kita bahas adalah I/O scheduling, buffering,
caching, spooling, reservasi device, error handling.
I/O SCHEDULING
Untuk menjadualkan sebuah set permintaan I/O, kita harus menetukan urutan yang bagus untuk mengeksekusi permintaan tersebut. Scheduling dapat meningkatkan kemampuan sistem secara keseluruhan, dapat membagi device secara rata di antara proses-proses, dan dapat mengurangi waktu tunggu rata-rata untuk menyelesaikan I/O. Ini adalah contoh sederhana untuk menggambarkan definisi di atas. Jika sebuah arm disk terletak di dekat permulaan disk, dan ada tiga aplikasi yang memblokir panggilan untuk membaca untuk disk tersebut. Aplikasi 1 meminta sebuah blok dekat akhir disk, aplikasi 2 meminta blok yang dekat dengan awal, dan aplikasi 3 meminta bagian tengah dari disk. Sistem operasi dapat mengurangi jarak yang harus ditempuh oleh arm disk dengan
melayani aplikasi tersebut dengan urutan 2, 3, 1. Pengaturan urutan pekerjaan kembali dengan cara ini merupakan inti dari I/O scheduling. Sistem operasi mengembangkan implementasi scheduling dengan menetapkan antrian permintaan untuk tiap device. Ketika sebuah aplikasi meminta sebuah blocking sistem I/O, permintaan tersebut dimasukkan ke dalam antrian untuk device tersebut. Scheduler I/O mengatur urutan antrian untuk meningkatkan efisiensi dari sistem dan waktu respon rata-rata yang harus dialami oleh aplikasi. Sistem operasi juga mencoba untuk bertindak secara adil, seperti tidak ada aplikasi yang menerima service yang buruk, atau dapat seperti memberi prioritas service untuk permintaan penting yang ditunda. Contohnya, pemintaan dari subsistem mungkin akan mendapatkan prioritas lebih tinggi daripada permintaan dari aplikasi. Beberapa algoritma scheduling untuk disk I/O akan dijelaskan ada bagian Disk Scheduling.
Satu cara untuk meningkatkan efisiensi I/O subsistem dari sebuah komputer adalah dengan mengatur operasi I/O. Cara lain adalah dengan menggunakan tempat penyimpanan pada memori utama atau pada disk, melalui teknik yang disebut buffering, caching, dan spooling.
BUFFER / CACHE DATA
Disk drive dihubungkan ke bagian lain sistem komputer menggunakan beberapa skema interkoneksi standar. Biasanya, digunakan bus standar, seperti bus SCSI. Disk drive yang menggabungkan sirkuit antar muka SCSI biasanya disebut sebagai drive SCSI. Bus SCSI mampu mentransfer data pada kecepatan data dibaca dari track disk. Cara yang efisien untuk menangani perbedaan kecepatan transfer antara disk dan bus SCSI adalah dengan menyertakan buffer data dalam unit disk. Buffer ini adalah memori semikonduktor. Yang mampu menyimpan beberapa megabyte data. Data yang direquest ditransfer antara track disk dan buffer pada kecepatan lain dihubungkan ke bus, biasanya memori utama, kemudian dapat berlangsung pada kecepatan maksimum yang dimungkinkan oleh bus tersebut.
Buffer data dapat juga menyediakan mekanisme caching untuk disk. Pada saat request baca tiba pada disk, kontroler dapat terlebih dahulu melihat apakah data yang
dan diletakkan pada bus SCSI dalam mikodetik bukan milidetik. Sebaliknya, data dibaca dari track disk dengan cara yang biasa dan disimpan didalam cache. Karena tampaknya akan ada request baca selanjutnya untuk data yang berurutan setelah data yang sedang diakses, maka kontroler disk dapat memerintahkan lebih banyak data yang diperlukan dibaca dan ditempatkan dalam cache, sehingga secara potensial memperpendek waktu respon untuk request berikutnya. Cache biasanya cukup besar untuk menyimpan seluruh track data, sehingga strategi yang mungkin adalah dengan mulai mentransfer isi track ke dalam buffer data segera setelah head baca/tulis ditempatkan pada track yang dimaksud. BUFFERS
Buffer adalah area memori yang menyimpan data ketika mereka sedang dipindahkan antara dua device atau antara device dan aplikasi. Buffering dilakukan untuk tiga buah alasan. Alasan pertama adalah untuk men-cope dengan kesalahan yang terjadi karena perbedaan kecepatan antara produsen dengan konsumen dari sebuah stream data. Sebagai contoh, sebuah file sedang diterima melalui modem dan ditujukan ke media penyimpanan di hard disk. Kecepatan modem tersebut kira-kira hanyalah 1/1000 daripada hard disk. Jadi buffer dibuat di dalam memori utama untuk mengumpulkan jumlah byte yang diterima dari modem. Ketika keseluruhan data di buffer sudah sampai, buffer tersebut dapat ditulis ke disk dengan operasi tunggal. Karena penulisan disk tidak terjadi dengan instan dan modem masih memerlukan tempat untuk menyimpan data yang berdatangan, maka dipakai 2 buah buffer. Setelah modem memenuhi buffer pertama, akan terjadi request untuk menulis di disk. Modem kemudian mulai memenuhi buffer kedua sementara buffer pertama dipakai untuk penulisan ke disk. Pada saat modem sudah memenuhi buffer kedua, penulisan ke disk dari buffer pertama seharusnya sudah selesai, jadi modem akan berganti kembali memenuhi buffer pertama dan buffer kedua dipakai untuk menulis. Metode double buffering ini membuat pasangan ganda antara produsen dan konsumen sekaligus mengurangi kebutuhan waktu di antara mereka.
Alasan kedua dari buffering adalah untuk menyesuaikan device-device yang mempunyai perbedaan dalam ukuran transfer data. Hal ini sangat umum terjadi pada jaringan komputer, dimana buffer dipakai secara luas untuk fragmentasi dan pengaturan kembali pesan-pesan yang diterima. Pada bagian pengirim, sebuah pesan yang besar akan dipecah
ke paket-paket kecil. Paket-paket tersebut dikirim melalui jaringan, dan penerima akan meletakkan mereka di dalam buffer untuk disusun kembali.
Alasan ketiga untuk buffering adalah untuk mendukung copy semantics untuk aplikasi I/O. Sebuah contoh akan menjelaskan apa arti dari copy semantics. Jika ada sebuah aplikasi yang mempunyai buffer data yang ingin dituliskan ke disk. Aplikasi tersebut akan memanggil sistem penulisan, menyediakan pointer ke buffer, dan sebuah integer untuk menunjukkan ukuran bytes yang ingin ditulis. Setelah pemanggilan tersebut, apakah yang akan terjadi jika aplikasi tersebut merubah isi dari buffer, dengan copy semantics, keutuhan data yang ingin ditulis sama dengan data waktu aplikasi ini memanggil sistem untuk menulis, tidak tergantung dengan perubahan yang terjadi pada buffer. Sebuah cara sederhana untuk sistem operasi untuk menjamin copy semantics adalah membiarkan sistem penulisan untuk mengkopi data aplikasi ke dalam buffer kernel sebelum mengembalikan kontrol kepada aplikasi. Jadi penulisan ke disk dilakukan pada buffer kernel, sehingga perubahan yang terjadi pada buffer aplikasi tidak akan membawa dampak apa-apa. Mengcopy data antara buffer kernel data aplikasi merupakan sesuatu yang umum pada sistem operasi, kecuali overhead yang terjadi karena operasi ini karena clean semantics. Kita dapat memperoleh efek yang sama yang lebih efisien dengan memanfaatkan virtual-memori mapping dan proteksi copy-on-wire dengan pintar. CACHING
Tempat penyimpanan sementara (volatile) sejumlah kecil data untuk meningkatkan kecepatan pengambilan atau penyimpanan data di memori oleh prosesor yang berkecepatan tinggi. Dahulu cache disimpan di luar prosesor dan dapat ditambahkan. Misalnya pipeline burst cache yang biasa ada di komputer awal tahun 90-an. Akan tetapi seiring menurunnya biaya produksi die atau wafer dan untuk meningkatkan kinerja, cache ditanamkan di prosesor. Memori ini biasanya dibuat berdasarkan desain memori statik. Sebuah cache adalah daerah memori yang cepat yang berisikan data kopian. Akses ke sebuah kopian yang di-cached lebih efisien daripada akses ke data asli. Sebagai contoh, instruksi-instruksi dari proses yang sedang dijalankan disimpan ke dalam disk, dan ter-cached di dalam memori physical, dan kemudian dicopy lagi ke dalam cache secondary and primary dari CPU. Perbedaan antara sebuah buffer
dan ache adalah buffer dapat menyimpan satu-satunya informasi datanya sedangkan sebuah cache secara definisi hanya menyimpan sebuah data dari sebuah tempat untuk dapat diakses lebih cepat.
Caching dan buffering adalah dua fungsi yang berbeda, tetapi terkadang sebuah daerah memori dapat digunakan untuk keduanya. sebagai contoh, untuk menghemat copy semantics dan membuat scheduling I/O menjadi efisien, sistem operasi menggunakan buffer pada memori utama untuk menyimpan data. Buffer ini juga digunakan sebagai cache, untuk meningkatkan efisiensi I/O untuk file yang digunakan secara bersama-sama oleh beberapa aplikasi, atau yang sedang dibaca dan ditulis secara berulang-ulang. Ketika kernel menerima sebuah permintaan file I/O, kernel tersebut mengakses buffer cacheuntuk melihat apakah daerah memori tersebut sudah tersedia dalam memori utama. Jika iya, sebuah physical disk I/O dapat dihindari atau tidak dipakai. penulisan disk juga terakumulasi ke dalam buffer cache selama beberapa detik, jadi transfer yang besar akan dikumpulkan untuk mengefisiensikan schedule penulisan. Cara ini akan menunda penulisan untuk meningkatkan efisiensi I/O akan dibahas pada bagian Remote File Access.
SPOOLING DAN RESERVASI DEVICE
Sebuah spool adalah sebuah buffer yang menyimpan output untuk sebuah device, seperti printer, yang tidak dapat menerima interleaved data streams. Walau pun printer hanya dapat melayani satu pekerjaan pada waktu yang sama, beberapa aplikasi dapat meminta printer untuk mencetak, tanpa harus mendapatkan hasil output mereka tercetak secara bercampur. Sistem operasi akan menyelesaikan masalah ini dengan meng-intercept semua output kepada printer. Tiap output aplikasi sudah di-spooled ke disk file yang berbeda. Ketika sebuah aplikasi selesai mengeprint, sistem spooling akan melanjutkan ke antrian berikutnya. Di dalam beberapa sistem operasi, spooling ditangani oleh sebuah sistem proses daemon. Pada sistem operasi yang lain, sistem ini ditangani oleh in-kernel thread. Pada kedua kasus, sistem operasi menyediakan interfacekontrol yang membuat users and system administrator dapat menampilkan antrian tersebut, untuk mengenyahkan antrian-antrian yang tidak diinginkan sebelum mulai di-print.
Untuk beberapa device, seperti drive tapedan printer tidak dapat me-multiplex permintaan I/O dari beberapa aplikasi. Spooling merupakan salah satu cara untuk mengatasi masalah ini. Cara lain adalah dengan membagi koordinasi untuk multiple concurrent ini. Beberapa sistem operasi menyediakan dukungan untuk akses device secara eksklusif, dengan mengalokasikan proses ke device idledan membuang device yang sudah tidak diperlukan lagi. Sistem operasi lainnya memaksakan limit suatu file untuk menangani device ini. Banyak sistem operasi menyediakan fungsi yang membuat proses untuk menangani koordinat exclusive akses diantara mereka sendiri.
ERROR HANDLING
Sebuah sistem operasi yang menggunakan protected memory dapat menjaga banyak kemungkinan error akibat hardware mau pun aplikasi. Devices dan transfer I/O dapat gagal dalam banyak cara, bisa karena alasan transient, seperti overloaded pada network, mau pun alasan permanen yang seperti kerusakan yang terjadi pada disk controller. Sistem operasi seringkali dapat mengkompensasikan untuk kesalahan transient. Seperti, sebuah kesalahan baca pada disk akan mengakibatkan pembacaan ulang kembali dan sebuah kesalahan pengiriman pada network akan mengakibatkan pengiriman ulang apabila protokolnya diketahui. Akan tetapi untuk kesalahan permanent, sistem operasi pada umumnya tidak akan bisa mengembalikan situasi seperti semula. Sebuah ketentuan umum, yaitu sebuah sistem I/O akan mengembalikan satu bit informasi tentang status panggilan tersebut, yang akan menandakan apakah proses tersebut berhasil atau gagal. Sistem operasi pada UNIX menggunakan integer tambahan yang dinamakan errno untuk mengembalikan kode kesalahan sekitar 1 dari 100 nilai yang mengindikasikan sebab dari kesalahan tersebut. Akan tetapi, beberapa perangkat keras dapat menyediakan informasi kesalahan yang detail, walau pun banyak sistem operasi yang tidak mendukung fasilitas ini.
KERNEL DATA STRUCTURE
Kernel membutuhkan informasi state tentang penggunakan komponen I/O. Kernel menggunakan banyak struktur yang mirip untuk melacak koneksi jaringan, komunikasi karakter-device, dan aktivitas I/O lainnya.
UNIX menyediakan akses sistem file untuk beberapa entiti, seperti file user, raw devices, dan alamat tempat proses. Walau pun tiap entiti ini didukung sebuah operasi baca, semantics-nya berbeda untuk tiap entiti. Seperti untuk membaca file user, kernel perlu memeriksa buffer cache sebelum memutuskan apakah akan melaksanakan I/O disk. Untuk membaca sebuah raw disk, kernel perlu untuk memastikan bahwa ukuran permintaan adalah kelipatan dari ukuran sektor disk, dan masih terdapat di dalam batas sektor. Untuk memproses citra, cukup perlu untuk mengkopi data ke dalam memori. UNIX mengkapsulasikan perbedaan-perbedaan ini di dalam struktur yang uniform dengan menggunakan teknik object oriented.
Beberapa sistem operasi bahkan menggunakan metode object oriented secara lebih extensif. Sebagai contoh, Windows NT menggunakan implementasi message-passing untuk I/O. Sebuah permintaan I/O akan dikonversikan ke sebuah pesan yang dikirim melalui kernel kepada I/O manager dan kemudian ke device driver, yang masing-masing bisa mengubah isi pesan. Untuk output, isi message adalah data yang akan ditulis. Untuk input, message berisikan buffer untuk menerima data. Pendekatan message-passing ini dapat menambah overhead, dengan perbandingan dengan teknik prosedural yang men-share struktur data, tetapi akan mensederhanakan struktur dan design dari sistem I/O tersebut dan menambah fleksibilitas.
Kesimpulannya, subsistem I/O mengkoordinasi kumpulan-kumpulan service yang banyak sekali, yang tersedia dari aplikasi mau pun bagian lain dari kernel. Subsistem I/O mengawasi:
1. Manajemen nama untuk file dan device. 2. Kontrol akses untuk file dan device.
3. Kontrol operasi, contoh: model yang tidak dapat dikenali. 4. Alokasi tempat sistem file.
5. Alokasi device.
6. Buffering, caching, spooling. 7. I/O scheduling
8. Mengawasi status device, error handling, dan kesalahan dalam recovery. 9. Konfigurasi dan utilisasi driver device.
Penanganan Permintaan I/O
Di bagian sebelumnya, kita mendeskripsikan handshaking antara device driver dan device controller, tapi kita tidak menjelaskan bagaimana Sistem Operasi menyambungkan permintaan aplikasi untuk menyiapkan jaringan menuju sektor disk yang spesifik.
Sistem Operasi yang modern mendapatkan fleksibilitas yang signifikan dari tahapan-tahapan tabel lookup di jalur diantara permintaan dan physical device controller. Kita dapat mengenalkan device dan driver baru ke komputer tanpa harus meng-compile ulang kernelnya. Sebagai fakta, ada beberapa sistem operasi yang mampu untuk me-load device drivers yang diinginkan. Pada waktu boot, sistem mula-mula meminta bus piranti keras untuk menentukan device apa yang ada, kemudian sistem me-load ke dalam driver yang sesuai; baik sesegera mungkin, mau pun ketika diperlukan oleh sebuah permintaan I/O.
UNIX Sistem V mempunyai mekanisme yang menarik, yang disebut streams, yang membolehkan aplikasi untuk men-assemble pipeline dari kode driver secara dinamis. Sebuah stream adalah sebuah koneksi full duplex antara sebuah device driver dan sebuah proses user-level. Stream terdiri atas sebuah stream head yang merupakan antarmuka dengan user process, sebuah driver end yang mengontrol device, dan nol atau lebih stream modules diantara mereka. Modules dapat didorong ke stream untuk menambah fungsionalitas di sebuah layered fashion. Sebagai gambaran sederhana, sebuah proses dapat membuka sebuah alat port serial melalui sebuah stream, dan dapat mendorong ke sebuah modul untuk memegang edit input. Stream dapat digunakan untuk interproses dan komunikasi jaringan. Faktanya, di Sistem V, mekanisme soket diimplementasikan dengan stream.
Berikut dideskripsikan sebuah lifecycle yang tipikal dari sebuah permintaan pembacaan blok.
1. Sebuah proses mengeluarkan sebuah blocking read system call ke sebuah file deskriptor dari berkas yang telah dibuka sebelumnya.
2. Kode system-call di kernel mengecek parameter untuk kebenaran. Dalam kasus input, jika data telah siap di buffer cache, data akan dikembalikan ke proses dan permintaan I/O diselesaikan.
3. Jika data tidak berada dalam buffer cache, sebuah physical I/O akan bekerja, sehingga proses akan dikeluarkan dari antrian jalan (run queue) dan diletakkan di antrian tunggu (wait queue) untuk alat, dan permintaan I/O pun dijadwalkan. Pada akhirnya, subsistem I/O mengirimkan permintaan ke device driver. Bergantung pada sistem operasi, permintaan dikirimkan melalui call subrutin atau melalui pesan in-kernel.
4. Device driver mengalokasikan ruang buffer pada kernel untuk menerima data, dan menjadwalkan I/O. Pada akhirnya, driver mengirim perintah ke device controller dengan menulis ke register device control.
5. Device controller mengoperasikan piranti keras device untuk melakukan transfer data.
6. Driver dapat menerima status dan data, atau dapat menyiapkan transfer DMA ke memori kernel. Kita mengasumsikan bahwa transfer diatur oleh sebuah DMA controller, yang meggunakan interupsi ketika transfer selesai.
7. Interrupt handler yang sesuai menerima interupsi melalui tabel vektor-interupsi, menyimpan sejumlah data yang dibutuhkan, menandai device driver, dan kembali dari interupsi.
8. Device driver menerima tanda, menganalisa permintaan I/O mana yang telah diselesaikan, menganalisa status permintaan, dan menandai subsistem I/O kernel yang permintaannya telah terselesaikan.
9. Kernel mentransfer data atau mengembalikan kode ke ruang alamat dari proses permintaan, dan memindahkan proses dari antrian tunggu kembali ke antrian siap. 10. Proses tidak diblok ketika dipindahkan ke antrian siap. Ketika penjadwal
(scheduler) mengembalikan proses ke CPU, proses meneruskan eksekusi pada penyelesaian dari system call.
PENGARUH I/O PADA KINERJA
I/O sangat berpengaruh pada kinerja sebuah sistem komputer. Hal ini dikarenakan I/O sangat menyita CPU dalam pengeksekusian device driver dan penjadwalan proses, demikian sehingga alih konteks yang dihasilkan membebani CPU dan cache perangkat keras. Selain itu, I/O juga memenuhi bus memori saat mengkopi data antara controller dan physical memory, serta antara buffer pada kernel dan application space data. Karena besarnya pengaruh I/O pada kinerja komputer inilah bidang pengembangan arsitektur komputer sangat memperhatikan masalah-masalah yang telah disebutkan diatas.
CARA MENINGKATKAN EFISIENSI I/O Menurunkan jumlah alih konteks.
1. Mengurangi jumlah pengkopian data ke memori ketika sedang dikirimkan antara device dan aplikasi.
2. Mengurangi frekuensi interupsi, dengan menggunakan ukuran transfer yang besar, smart controller, dan polling.
3. Meningkatkan concurrency dengan controller atau channel yang mendukung DMA.
4. Memindahkan kegiatan processing ke perangkat keras, sehingga operasi kepada device controller dapat berlangsung bersamaan dengan CPU.
5. Menyeimbangkan antara kinerja CPU, memory subsystem, bus, dan I/O. IMPLEMENTASI FUNGSI I/O
Pada dasarnya kita mengimplementasikan algoritma I/O pada level aplikasi. Hal ini dikarenakan kode aplikasi sangat fleksible, dan bugs aplikasi tidak mudah menyebabkan sebuah sistem crash. Lebih lanjut, dengan mengembangkan kode pada level aplikasi, kita akan menghindari kebutuhan untuk reboot atau reload device driver setiap kali kita mengubah kode. Implementasi pada level aplikasi juga bisa sangat tidak efisien. Tetapi, karena overhead dari alih konteks dan karena aplikasi tidak bisa mengambil keuntungan dari struktur data kernel internal dan fungsionalitas dari kernel (misalnya, efisiensi dari kernel messaging, threading dan locking.
Pada saat algoritma pada level aplikasi telah membuktikan keuntungannya, kita mungkin akan mengimplementasikannya di kernel. Langkah ini bisa meningkatkan kinerja tetapi perkembangannya dari kerja jadi lebih menantang, karena besarnya kernel dari sistem operasi, dan kompleksnya sistem sebuah perangkat lunak. Lebih lanjut , kita harus men-debug keseluruhan dari implementasi in-kernel untuk menghindari korupsi sebuah data dan sistem crash.
Kita mungkin akan mendapatkan kinerja yang optimal dengan menggunakan implementasi yang special pada perangkat keras, selain dari device atau controller. Kerugian dari implementasi perangkat keras termasuk kesukaran dan biaya yang ditanggung dalam membuat kemajuan yang lebih baik dalam mengurangi bugs, perkembangan waktu yang maju dan fleksibilitas yang meningkat. Contohnya, RAID controller pada perangkat keras mungkin tidak akan menyediakan sebuah efek pada kernel untuk mempengaruhi urutan atau lokasi dari individual block reads dan write, meski pun kernel tersebut mempunyai informasi yang spesial mengenai workload yang dapat mengaktifkan kernel untuk meningkatkan kinerja dari I/O.
Technology Focus: Itanium Memory Cache
Prosesor Itanium adalah implementasi pertama arsitektur IA-64. Prosesor ini memiliki sejumlah unit replicated funcional yang relatif bear untu berbagai tipe operasi; integer, foating-point, dan mutimedia (seperti operasi MMX pada arsitektur IA-32). Eksekusi superskalar dicapai dengan kemampuan untuk mengeluarkan sampai dengan enam instruksi (dua 3-instruction bundle) pada tiap 800-MHz clock cycle ke dalam 10-stage pipeline. Unit fungsional tersebut adalah: 4 unit integer, 4 unit floating-point, 4 unit multimedia (MMX), 2 unit load / store, dan 3 load / store, dan 3 unit branch. Integer register bank memiliki 8 read port dan 6 write port untuk mempertukarkan data secara simultan dengan unit multiple function.
Terdapat tiga level unit cache. Cache L1 dan L2 berada pada chip yang sama dengan prosesor, dan L3 diimplementasikan pada chip terpisah pada paket cartridge yang sama dengan prosesor tersebut. Level cache L1 terdiri dari cache data dan instruksi terpisah, masing-masing berisi 16K byte. Cache tersebutadalah 4-way seet associative dan memiliki 32 byte blok. Cache intruksi dapat mengirimkan dua 3-instruction bundle (256 bit) ke prosesor per clock cycle. Cache L2 berisi 96K byte. Cahe ini adalah 6-way set associative dan memiliki 64-byte blok. Cache L3 berisi total 4 M byte , dengan 64 byte clock. Cache ini adalah 4-way set
128-bit pada clock rate prosesor, menghasilkan transfer rate 12.8 gigabyte / det.
Interaksi antara cache dan antara cache L1 dan prosesor diatur dalam satu cara yang meminimalisasi efek processor pipeline atall dn cache miss pada tingkat eksekusi instruksi rata-rata. Beberapa dari interaksi ini tidak berguna. Terdapat decoupling buffer antara cache instruksi L1 dan prosesor. Buffer tersebut dapat dapat berisi sampai dengan 3-instruction bundle. Hal ini memungkinkan prefetching instruksi dari cache L1 ke dalam buffer untuk terus berjalan pada saat prosesor stall dalam mengeluarkan instruksi. Sebaliknya, prosesor dapat terus mengambil dan mngeluarkan instruksi dari buffer pada saat terjadi cache miss dalam proses prefetching. Terdapat juga buffer antara cache L1 dan L2 untuk memungkinkan prefetching instruksi dari L2 ke L1. Buffer ini berukuran dua kali ukuran buffer antara cache L1 dan hardware pengeluaran instruksi prosesor. Cache L1 hanya memberi masukan ke integer register bank. Floating-point operand di-load ke dalam floating-point register langsung dari cache L2.
Terdapat bus sistem 64-bit yang menghubungkan paket yang berisi prosesor dan cache ke komponen sistem lain misalnya memori utama dan perangkat I/O. Bus tersebut dapat mendukung 266-MHz transfer rate, yaitu 2.1 giga byte/det.
Kontroler bus eksternal dapat mengakomodasi koneksi langsung sampai dengan empat prosesor Itanium dalam konfigurasi multiprosesor. Kontroler tersebut menangani operasi koheren cache yang diperlukan pada saat banyak prosesor menggunakan bersama unit memori eksternal.
PERFORMA
Pengukuran performa komputer yang paling penting adalah seberapa cepat komputer tersebut mengeksekusi program. Kecepatan komputer mengeksekusi program dipengaruhi oleh desain hardware dan instruksi bahasa mesin-nya. Karena biasanya ditulis dalam bahasa tingkat tinggi,maka performa juga dipengaruhi oleh compiler yang mentranslasikan program ke dalam bahasa mesin. Untuk performa terbaik, perlu untuk mendesain compiler, set instruksi mesin,dan haerware dengan cara yang terkoordinasi. Kita tidak mendeskripsikan detil desain compiler dalam buku ini. Kita berfokus pada desain set instruksi dan hardware.
Waktu total yang diperlukan untuk mengeksekusi program dalam Gambar [Sharing program user & rutin OS pada prosesor] adalah t -t . elapsed time iniadalah ukuran
performa seluruh sistem komputer. Waktu tersebut dipengaruhi oleh kecepatan prosesor, disk, dan printer. Untuk membahas performa prosesor, kita sebaiknya hanya memperhatikan periode selama prosesor aktif. Periode tersebut adalah periode yang brlabel Program dan Rutin OS pada Gambar [Sharing program user & rutin OS pada prosesor].
Kita akan mengacu pada jumlah periode tersebut sebagai waktu prosesor yang diperlukan untuk mengeksekusi program. Selamjutnya kita akan mengidentifikasi beberapa parameter utama yang mempengaruhi waktu prosesor dan mengacu bab yang akan membahas persoalan yang relevan. Kami mendorong pembaca untuk mengingat ulasan umum tentang performa ini pada saat mempelajari materi yang ditampilkan pada bab-bab selanjutnya.
Gambar: Struktur bus tunggal
Seperti halnya elapsed time untuk eksekusi program tergantung pada semua unit dalam sistem komputer,maka waktu prosesor tergantung pada hardware yang terlibat dalam eksekusi instruksi mesin individu. Hardware tersebut meliputi prosesor dan memori, yang biasanya dihubungkan dengan bus, sebagaimana yang ditunjukkan pada Gambar Struktur bus tunggal. Bagian yang berhubungan dengan Gambar ini diulang dalam Gambar 1.5, termasuk memori cache sebagai bagian dari unit prosesor. Marilah kita memperhatikan aliran instruksi program dan data antara memori dan prosesor. Pada awal eksekusi, semua instruksi program dan data yang diuperlukan disimpan di memori utama. Selama eksekusi berjalan, instruksi diambil satu demi satu melalui bus ke dalam prosesor dan copy-annya diletakkan di cache. Pada saat eksekusi S suatu instruksi meminta data yang berada dalam memori uatama, data tersebut diambil dan copy-annya ditempatkan di cache. Selanjutnya, jika instruksi atau item data sama diperlukan untuk kedua alinya, maka akan langsung dibaca dari cache.
t0 t1 t2 t3 t4 t5
Gambar: Sharing program user dan rutin OS pada prosesor
Printer Disk OS routine Program Waktu
Prosesor dan memori cache yang relatif kecil pada chip sirkuit terintegrasi tunggal. Kecepatan internal untuk melaksanakan langkah dasar pengolahan instruksi pada chip semacam itusangat tinggi dan dianggap lebih cepat daripada kecepatan pengambilan instruksi dan data dari memori utama. Suatu program akan dieksekusi lebih cepat jika perpindahan instruksi dan data antara memori utama dan prosesor diminimalisasi, yang dicapai dengan menggunakan cache. Misalnya, suatu instruksi dieksekusi berulang kali selama periode waktu yang singkat, sebagaimana yang terjadi pada loop program. Jika instruksi ini tersedia dalam cache maka diambil dengan cepat selama periode pengulangan penggunaan. Hal yang sama diterapkan pada data yang digunakan berulang kali.
CLOCK PROSESOR
Sirkuit prosesor dikontrol oleh sinyal timing yang disebut clock. Clock menetapkan interval waktu reguler, yang disebut siklus clock. Untuk mengeksekusi instruksi mesin, prosesor membagi tidakan yang akan dilakukan ke dalam rangkaian langkah dasar,
sehingga tiap langkah dapat diselesaikan dalam siklus clock. Panjang P dari satu siklus clock adalah parameter penting yang mempengaruhi s performa prosesor. Kebalikannya adalah clock rate, R = 1/P yang diukur dalam siklus per detik. Prosesor yang digunakan dalam personal computer dan workstation saat ini memiliki clock rate yang berada dalam rentang beberapa ratus juta hingga lebih dari milyaran siklus per detik. Dalam terminologi teknik elektro standar, istilah “siklus per detik” disebut hertz (Hz) istilah “juta” ditunjukkan oleh awalan Mega (M). dan “milyar” ditunjukkan oelh awalah Giga (G). karena itu 500 juta siklus per detik biasanya disingkat menjadi 500 Megahertz (MHz), dan 1250 juta siklus per detik disingkat menjadi 1,25 Giga Hertz (GHz). Periode clock yang sesuai masing-masing adalah 2 dan 0,58 nano second (n).
PERSAMAAN PERFORMA DASAR
Sekarang kita memusatkan perhatian pada komponen waktu prosesor dari elapsed time total. Misalkan T adalah waktu prosesor yang diperlukan untuk mengeksekusi suatu progaram yang telah dipersiapkan dalam beberapa bahasa tingkat tinggi. Compiler menghasilkan program objek bahsa mesin yang sesuai dengan program source. Asumsikan bahwa eksekusi lengkap dari program memerlukan N instruksi bahasa mesin. Jumlah N adalah aktual eksekusi instruksi, dan tidak harus setara dengan jumlah eksekusi instruksi-instruksi mesin dalam program objek. Beberapa instruksi dapat dieksekusi lebih dari sekali, yaitu untuk instruksi yang berada di dalam loop. Instruksi yang lain mungkin tidak dieksekusi sama sekali, tergantung data input yang digunakan,misalkan jumlah langkah dasar rata-rata yang diperlukan untuk mengeksekusi satu instruksi mesin adalh S, dimana tiap langkah dasar diselesaikan dalam satu siklus clock. Jika clock rate adalah R siklus per detik, maka waktu eksekusi program dinyatakan sebagai berikut R S x N T =
Rumusan ini sering disebut sebagai persamaan performa dasar.
Parameter performa T untuk program aplikasi jauh lebih penting bagi user daripada nilai individu parameter N, S, atau R. untuk mencapai performa tinggi, desainer komputer harus mencari cara untuk mengurangi nilai T, yang berarti mengurangi N dan S,dan
meningkatkan R. Nilai N berkurang jika program source dikompilasi menjadi instruksi mesin yang lebih sedikit. Nilai S berkurang jika instruksi memiliki jumlah langkahdasar yang lebih kecil untuk dilaksanakan atau jika eksekusi instruksi ditumpangtindihkan. Menggunakan clock frekuensi tinggi meningkatkan nilai tersebut atau R, yang berarti bahwa waktu yang diperlukan untuk menyelesaikan kangkah eksekusi dasdar berkurang.
Kita harus menekankan bahwa N, S, dan R, bukanlah parameter bebas; perubahan pada salah satunya dapat mempengaruhi yang lain. Memperkenalkan fitur baru dalam desain suatu prosesor akan menuju pada peningkatan performa hanya jika hasil keseluruhannya mengurangi nilai T. Prosesor yang diiklankan memiliki clock 900 Mhz belum tentu memberikan performa yang lebih baik daripada prosesor 700 MHz karena prosesor tersebut mungkin memiliki nilai S yang berbeda.
OPERASI PIPELINING DAN SUPERSCALAR
Dalam pembahasan di atas, kita mengasumsikan bahwa instruksi dieksekusi satu demi satu. Karena itu, nilai S adalah jumlah total langkah dasar, atau siklus clock, yang diperlukan untuk mengeksekusi suatu instruksi. Peningkatan yang substansial pada performa dapat dicapai dengan menumpangtindihkan eksekusi instruksi yang beurutan, menggunakan teknik yang disebut pipelining. Misalkan suatu instuksi.
Add R1 , R2 , R3
yang menambahkan isi register R1 dan R2, dan menempatkan jumlahnya dalam R3. isi R1 dan R2 mula-mula ditransfer ke input ALU. Setelah operasi penabahan dilakukan, jumlahnya ditarnsfer ke R3. prosesor dapat membaca instruksi selanjutnya dari memori sementara operasi penambahan dilakukan. Kemudian jika instruksi tersebut juga menggunakan ALU,operandnya dapat ditransfer ke input ALU pada waktu yang sama dengan hAsil instruksi Add ditransfer ke R3. Pada kasus ideal, jika semua instruksi ditumpangyindihkan ke derajat maksimum yang mungkin, maka eksekusi dilanjutkan pada kecepatan penyelesaian satu instruksi dalam tiap siklus clock. Instruksi individual masih memerlukan beberapa siklus clock untuk penyelesaian. Tetapi, untuk tujuan perhitungan T, maka nilai efektif S adalah 1.
Nilai ideal S = 1 tidak dapat dicapai dalam praktek karena berbagai alasan. Akan tetapi, pipelining meningkatkan kecepatan eksekusi instruksi secara signifikan dan menyebabkan nilai efektif S mendekati 1.
Derajat konkurensi yang lebih tinggi dapat dicapai jika banyak pipeline instruksi diterapkan pada prosesor. Hal ini berarti digunakannya bayak unit fungsional, menciptakan jalur paralel dimana berbagai instruksi yang berbeda dapat dapat dieksekusi secara paralel. Dengan pengaturan tersebut, maka dimungkinkan untuk memulai beberapa instruksi pada tiap siklus clock. Mode operasi in disebut eksekusi superscalar. Jika mode ini dapat bertahan dalam waktu yang lama selama eksekusi program, maka nilai efektif S dapat dikurangi hingga kurang hasil dari satu. Tentu saja, eksekusi paralel harus mempertahankan kebenaran logika program, sehingga hasil yang diperoleh harus sama dengan hasil dari eksekusi serial instruksi program. Banyak dari prosesor performa tinggi saat ini didesain untuk bekerja dengan cara tersebut.
CLOCK RATE
Terdapat dua kemungkinan untuk clock rate, R. Pertama, meningkatkan teknologi integrated-circuit (IC) menjadikan sirkuit logika yang lebih cepat, sehingga mengurangi waktu yang diperlukan untuk menyelesaikan suatu langkah dasar. Hal ini memungkinkan periode clock, P, dikurangi dan clock rate, R, ditingkatkan. Kedua, mengurangi periode clock, P. Akan tetapi jika tindakan yang harus dilakukan oleh suatu instruksi tetap sama, maka jumlah langkah dasar yang diperlukan dapat bertambah.
Peningkatan nilai R yang sepenuhnya disebabkan oleh peningkatan teknologi IC mempengaruhi secara seimbang seluruh aspek operasi prosesor dengan pengecualian pada waktu yang diperlukan untuk mengakses memori utama. Dengan adanya cache, persentase akses ke memori utama menjadi kecil. Karena itu kebanyakan peningkatan performa yang diharapkan dari penggunaan teknologi yang lebih cepat dapat direalisasikan. Nilai T akan berkurang dengan faktor yang sama dengan peningkatan nilai R karena S dan N tidak terpengaruh. Pengaruh pada performa dari perubahan cara pembagian instruksi menjadi langkah dasar lebih sulit untuk diperkirakan.