Lingkungan Implementasi
Lingkungan implementasi yang digunakan adalah sebagai berikut :
Perangkat lunak :
• Sistem operasi Windows XP Professional • Microsoft Visual Basic.NET 2005 • SQL Srever 2000
Perangkat keras :
• Prosesor AMD Turion, 2.2 GHz • RAM 512 MB
• Harddisk dengan kapasitas 80 GB
HASIL DAN PEMBAHASAN
Koleksi Dokumen Pengujian
Dokumen yang digunakan sebagai dokumen uji diambil dari korpus yang sudah tersedia di Laboratorium Temu Kembali Informasi Departemen Ilmu Komputer IPB. Sumbernya adalah media koran, media majalah, media internet, dan lain-lain. Dari 958 dokumen dan 30 topik yang dibicarakan dalam dokumen, penulis hanya mengambil 60 dokumen dan 5 topik (bencana kekeringan, pertanian organik, flu burung, gagal panen dan kelangkaan pupuk) yang dibicarakan di dalamnya sebagai koleksi dokumen. Pengambilan dokumen dan topik dilakukan secara acak atau tidak memiliki aturan tertentu.
Dokumen sebagai koleksi memiliki format teks (*.txt) dan terdapat struktur tag XML didalamnya. Dokumen disimpan dalam satu direktori. Nama dokumen berdasarkan sumber data dan tanggal data tersebut diterbitkan, misalnya Gatra070203.txt yang berarti data berasal dari majalah Gatra dan diterbitkan oleh Gatra pada tanggal 07 bulan Februari tahun 2003.
Satu dokumen dapat berisi beberapa artikel bacaan. Satu dokumen berisi minimal satu kalimat dan sebuah kalimat harus diakhiri dengan tanda titik (.). Sementara untuk kalimat yang diakhiri dengan tanda tanya (?), tanda seru (!) dan tidak berhubungan dengan kalimat sesudahnya maka dilakukan penambahan tanda titik (.) secara manual. Indexing
Hal yang pertama dilakukan pada saat Indexing adalah menyimpan nama dokumen yang digunakan sebagai dokumen uji ke tabel tb_dokumen. Struktur tabel tb_dokumen dapat dilihat pada Tabel 1.
Tabel 1 Struktur tabel tb_dokumen Nama
Kolom
Tipe Data Keterangan
idDok INT Primary key
namaDok VARCHAR (100)
-
Proses penyimpanan nama dokumen tidak berurutan karena pengambilan nama dokumen oleh sistem dilakukan secara acak. Kolom idDok merupakan urutan penyimpanan dokumen berdasarkan jumlah dokumen yang digunakan. Nama dokumen disimpan dalam kolom namaDok.
Parsing yang dilakukan pada dokumen diawali dengan memisahkan kalimat-kalimat dokumen berdasarkan separator titik (.). Hasil proses ini berupa array kalimat yang kemudian disimpan dalam tabel tb_kalimat. Struktur tabel tb_kalimat dapat dilihat pada Tabel 2.
Tabel 2 Struktur tabel tb_kalimat Nama
Kolom
Tipe Data Keterangan
idKal INT Primary key
idDok INT Primary key
kalimat VARCHAR(8000) -
score INT -
Kolom idKal menunjukkan urutan kalimat pada dokumen bersangkutan. Kolom idDok mengacu ke kolom idDok pada tabel tb_dokumen. Kolom kalimat berisi array kalimat yang dihasilkan oleh proses parsing. Kolom score digunakan untuk menyimpan nilai yang diperoleh masing-masing kalimat dari proses WordMatch dan pembobotan berdasarkan rule. Pada Indexing dokumen dan awal proses pengolahan terhadap kueri pengguna, kolom score masing-masing kalimat diberi nilai nol (0).
Parsing pada kalimat diawali dengan proses case folding (membuat semua huruf pada teks yang akan diparsing menjadi huruf kecil). Penelitian ini tidak melakukan penghilangan stopwords karena semua kata dianggap penting dan masih akan mengalami proses stemming. Penulis memanfaatkan algoritme parsing Ikhsani (2006). Proses ini akan menghasilkan token-token yang disimpan pada array sementara untuk
kemudian dilanjutkan dengan proses stemming.
Stemming dilakukan pada setiap token hasil parsing kalimat dengan menggunakan algoritme stemming Ikhsani (2006). Dalam prosesnya, stemming menghasilkan beberapa kata yang tidak sesuai dengan tata bahasa baku misalnya kata leta. Proses stemming melakukan penghilangan huruf k di awal dan akhir kata. Sehingga kata letak menjadi leta. Padahal ketika menjadi kata leta, kata tersebut menjadi tidak memiliki makna apa-apa. Tetapi hal tersebut tidak mempengaruhi sistem yang dibangun karena setiap kueri pertanyaan yang akan diproses oleh sistem juga mengalami proses parsing dan stemming. Proses selanjutnya, hasil stemming dimasukkan ke dalam tabel tb_kata. Struktur tabel tb_kata dapat dilihat pada Tabel 3. Tabel 3 Struktur tabel tb_kata
Nama Kolom
Tipe Data Keterangan
idKata INT Primary key
idKal INT -
kata VARCHAR(100) -
Kolom idKal mengacu pada kolom idKal pada tabel tb_kalimat. Hasil parsing dan stemming untuk masing-masing kalimat pada tabel tb_kalimat disimpan di kolom kata pada tabel tb_kata. Setelah proses Indexing selesai dilakukan diperoleh hasil seperti yang ada di Lampiran 2.
Algoritme Rule
Mengacu pada algoritme yang dibuat Riloff & Thelen (2000) dan algoritme yang diimplementasikan oleh Ikhsani (2006), penulis membuat algoritme rule dengan melakukan beberapa modifikasi. Algoritme rules yang dibuat dan diimplementasikan ke dalam sistem adalah algoritme “APA”, “SIAPA”, “KAPAN”, “MANA” dan “MENGAPA”. Seperti yang dituliskan di bawah.
1 “KAPAN”
Score(S) += WordMatch(Q,S)
If contains(S,{saat, ketika, kala,
semenjak, sejak, waktu, setelah, sebelum, sesudah,selama, pada}) and
contains(S, TIME) then Score(S) += slam_dunk If contains(Q,TIME) Or
containsS(S, TIME) then Score(S) += good_clue If contains(S,{saat, ketika, kala,
semenjak, sejak, waktu, setelah, sebelum}) then
Score(S) +=good_clue
Untuk algoritme rule menggunakan kata tanya “KAPAN”, juga memiliki perbedaan dengan algoritme rule yang sudah dibuat oleh Ikhsani (2006). Selain pada pemberian nilai score, untuk kondisi if yang pertama, penulis menambahkan kata “sesudah”, “selama” dan “pada”.
2 “MANA”
Score(S) += WordMatch(Q,S) If contains(S,LOCATION) and
contains(S,{dalam, dari, pada}) then Score(S) += slam_dunk
If contains(S,{dalam, dari, pada}) then Score(S) += clue If contains(S,LOCATION) then Score(S) += good_clue 3 “MENGAPA” Score(S) += WordMatch(Q,S) If contains(S,{karena, sebab, akibat, maka, agar, supaya}) then
Score(S) += clue
Untuk kueri pertanyaan dengan menggunakan kata tanya “MANA” algoritme rule yang dibuat sama dengan yang sudah dibuat oleh Ikhsani (2006). Sementara untuk kueri pertanyaan dengan menggunakan kata tanya “MENGAPA”, perbedaannya terletak pada kondisi if yaitu pemberian nilai score untuk dan penambahan kata “agar” dan “supaya”.
4 “SIAPA”
Score(S) += WordMatch(Q,S)
If contains(Q,HUMAN) then Score(S) += confident
Berbeda dengan kueri pertanyaan dengan kata tanya “APA”, algortima rule untuk kueri pertanyaan dengan kata tanya “SIAPA” yang diimplementasikan pada sistem yang dibangun oleh penulis berbeda dengan algoritme rule yang telah diimplementasikan oleh Ikhsani (2006). Perbedaannya terletak pada pemberian nilai score.
5 “APA”
Score(S) += WordMatch(Q,S)
If contains(Q,{tujuan, manfaat}) and contains(S,{untuk, guna}) then
Elseif contains(Q,{maksud}) and contains(S,{adalah, ialah, yaitu}) then
Score(S) += slam_dunk
Elseif contains(S,{adalah, ialah}) then
Score(S) += confident
Algortima rule untuk kueri pertanyaan dengan kata tanya “APA” yang diimplementasikan pada sistem yang dibangun oleh penulis sama dengan algoritme rule yang telah diimplementasikan oleh Ikhsani (2006).
Fungsi dan notasi yang digunakan dalam rules tersebut adalah sebagai berikut : • Notasi S = sentence (kalimat dokumen). • Notasi Q = query (kalimat kueri).
• Fungsi contains adalah fungsi untuk memeriksa kalimat dokumen dan kalimat kueri pertanyaan, apakah mengandung kata yang telah ditentukan.
• Fungsi WordMatch adalah fungsi untuk memeriksa kesamaan kata.
• Fungsi score adalah fungsi pemberian nilai pada kalimat dokumen.
Parsing dan WordMatch
Algoritme parsing dokumen menjadi kalimat-kalimat berdasarkan separator titik (”.”) dibuat sendiri oleh penulis. Namun untuk parsing kalimat-kalimat dokumen dan kalimat kueri menjadi token-token serta algoritme stemming, penulis memanfaatkan algoritme yang sudah ada di Laboratorium Temu Kembali Informasi, Departemen Ilmu Komputer, Institut Pertanian Bogor (IPB). Algoritme WordMatch memanfaatkan algoritma yang sudah digunakan pada penelitian yang dilakukan oleh Ikhsani (2006).
Algoritme WordMatch membandingkan token-token pada setiap kalimat dokumen dengan token-token pada kalimat kueri, yang telah melalui proses stemming. Setiap token yang sama akan menambahkan nilai clue (+3) pada kalimat dokumen tersebut.
Hasil Percobaan
Percobaan dilakukan pada seluruh dokumen yang ada. Dokumen yang digunakan sebanyak 60 dokumen. Seluruh dokumen diberi lima tipe kueri pertanyaan yang kalimat pertanyaannya menggunakan kata tanya “APA”, “SIAPA”, “KAPAN”, “MENGAPA” dan “MANA”. Untuk masing-masing tipe pertanyaan diberikan empat kueri pertanyaan
yang sudah dibuat sebelumnya oleh penulis. Antarmuka prototipe Question Answering System dapat dilihat pada Lampiran 3.
Penghitungan persentase hasil jawaban yang benar yang berhasil dikembalikan oleh sistem dilakukan untuk masing-masing tipe pertanyaan. Penghitungan dilakukan dengan cara membandingkan jumlah kalimat yang benar yang ditemukembalikan oleh sistem dengan jumlah keseluruhan kalimat yang ditemukembalikan oleh sistem pada masing-masing nilai ambang batas yang ditentukan.
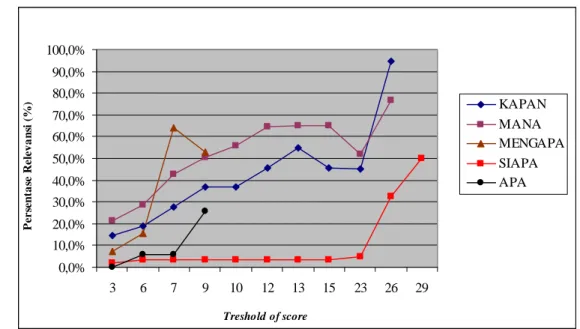
Yang dimaksud dengan hasil yang benar adalah jika ada jawaban yang relevan yang berhasil dikembalikan walaupun tidak memiliki nilai tertinggi. Hasil percobaan berdasarkan nilai ambang batas dapat dilihat pada Gambar 3 dan berdasarkan Recall Precision dapat dilihat pada Gambar 4.
Evaluasi Question Answering System Berdasarkan Nilai Ambang Batas
Tujuan dari temu kembali informasi yaitu menemukembalikan informasi yang relevan dan sesedikit mungkin menemukembalikan informasi yang tidak relevan.
Hasil dari Gambar 3 dapat diuraikan sebagai berikut :
1 Tipe pertanyaan “KAPAN”, terlihat bahwa kinerja sistem paling tinggi dicapai saat pemakaian nilai ambang batas 26. Dengan ambang batas 26, persentase hasil yang benar mencapai 94,44 % dan nilai persentase yang paling kecil dicapai saat pemakaian ambang batas 3 yaitu 14,67 %. 2 Tipe pertanyaan “MANA”, terlihat bahwa
kinerja sistem yang tinggi dicapai saat pemakaian nilai ambang batas 13, 15 dan 26. Dengan ambang batas 13, 15, persentase hasil yang benar mencapai 64,95% dan ambang batas 26 mencapai 76,8 %. Nilai persentase yang paling kecil dicapai saat pemakaian ambang batas 3 yaitu 21,55 %.
3 Tipe pertanyaan “MENGAPA”, terlihat bahwa kinerja sistem paling tinggi dicapai saat pemakaian ambang batas 7. Dengan ambang batas 7, persentase hasil yang benar mencapai 64,19% dan nilai persentase yang paling kecil dicapai saat pemakaian ambang batas 3 yaitu 7,22%. 4 Tipe pertanyaan “SIAPA”, terlihat bahwa
kinerja sistem paling tinggi dicapai saat pemakaian ambang batas 26 dan 29.
Dengan ambang batas 26 dan 29, persentase hasil yang benar mencapai 50% dan nilai persentase yang paling kecil dicapai saat pemakaian ambang batas 3 yaitu 7,22 %.
5 Tipe pertanyaan “APA”, terlihat bahwa kinerja sistem kurang baik dengan nilai persentase yang sangat kecil. Nilai tertinggi yaitu sebesar 25,88% dicapai saat pemakaian ambang batas 9.
Nilai persentase untuk ambang batas 3 sangat kecil karena sistem mengembalikan sedikit jawaban yang benar dari semua kalimat jawaban yang terdapat pada relevance judgement dan mengembalikan semua kalimat pada basis data yang memiliki score = 3. Evaluasi Sistem Berdasarkan Rule
Setiap rule yang dibuat pasti tidak memiliki kinerja yang sama dengan rule yang lain. Gambar 4 menunjukkan perbedaan Gambar 3 Persentase hasil yang benar
0,0% 10,0% 20,0% 30,0% 40,0% 50,0% 60,0% 70,0% 80,0% 90,0% 100,0% 3 6 7 9 10 12 13 15 23 26 29 Treshold of score P e r se n ta se R e le v a n si (% ) KAPAN MANA MENGAPA SIAPA APA
Gambar 4 Recall Precision 0,0 0,1 0,2 0,3 0,4 0,5 0,6 0,7 0,8 0,9 1,0 0,1 0,2 0,3 0,4 0,5 0,6 0,7 0,8 0,9 1,0 Recall P reci si o n KAPAN MANA MENGAPA SIAPA APA
kinerja sistem untuk masing-masing rule menggunakan rumus Recall Precision.
Berdasarkan Gambar 3 dan Gambar 4 terlihat bahwa kinerja sistem yang paling buruk adalah kueri pertanyaan dengan menggunakan kata tanya “APA”. Berbeda dari sistem yang telah diimplementasikan oleh Ikhsani (2007), rule APA memiliki kinerja yang paling baik dibandingkan dengan rules yang lain yaitu mencapai 81,94%. Sementara untuk sistem ini, persentase hasil jawaban yang benar hanya mencapai 25,88% dan nilai Recall Precision tertinggi mencapai 0.46.
Hal ini disebabkan oleh rule “APA” yang hanya membatasi kalimat jawaban yang dikembalikan mengandung kata ialah, adalah, maksud, untuk, guna, manfaat dan tujuan. Sementara di dokumen yang digunakan sebagai dokumen uji jarang sekali ditemukan kalimat yang mengandung kata-kata tersebut. Dengan demikian sistem akan mengembalikan kalimat jawaban yang relevan lebih sedikit. dibandingkan dengan kalimat jawaban yang tidak relevan. Selain itu koleksi dokumen yang menggunakan bahasa yang tidak baku (tidak sesuai dengan EYD) juga mempengaruhi kinerja rule APA.
Kinerja sistem yang paling tinggi dicapai oleh kueri pertanyaan “KAPAN”. Terlihat bahwa nilai persentase hasil jawaban yang benar mencapai 94,44 % dan nilai Recall Precision mencapai 0,93. Kenaikan cukup drastis dicapai pada nilai ambang batas 26 dan membuat nilai Recall Precision mencapai nilai tertinggi. Hal ini disebabkan oleh karena sistem mengembalikan kalimat jawaban yang relevan lebih banyak dibandingkan dengan kalimat jawaban yang tidak relevan dan rule yang digunakan sudah cukup baik.
Kinerja sistem untuk kueri pertanyaan “MANA” sudah cukup baik dengan nilai Recall Precision tertinggi sebesar 0,88 dan nilai ambang batas tertinggi sebesar 76,86 %. Dengan menggunakan nilai ambang batas tertinggi yaitu 26, sistem mengembalikan cukup banyak kalimat jawaban yang relevan yang membuat nilai Recall Precision cukup tinggi.
Untuk kueri pertanyaan “MENGAPA”, nilai Recall Precision yang dicapai sebesar 0.65 dan dicapai saat pemakaian nilai ambang batas = 7.
Kueri pertanyaan “SIAPA”, nilai Recall Precision yang dicapai sebesar 0,84 dan nilai tersebut dicapai ketika menggunakan nilai
ambang batas = 26. Masih banyak kalimat jawaban yang tidak relevan yang dikembalikan oleh sistem. Hal ini mungkin disebabkan rule yang masih belum sempurna. Kelebihan dan Kekurangan Sistem
Kelebihan dan kekurangan Question Answering System (QAS) yang telah dibangun adalah sebagai berikut :
Kelebihan:
• Indexing dokumen hanya dilakukan satu kali yaitu di awal pembangunan sistem. • Kueri pertanyaan menggunakan bahasa
yang alami.
• Penggunaan nilai ambang batas yang memudahkan pengguna untuk menentukan sendiri score minimal yang harus dikembalikan dan memutuskan sendiri kalimat jawaban yang relevan menurut pengguna.
Kekurangan:
• Jika terdapat penambahan dokumen, maka harus dilakukan pengindeksan ulang. • Tidak dilakukan kajian terhadap makna
semantik dalam dokumen.
• Kamus yang digunakan belum dibuat otomatis tapi secara manual dibuat penulis. • Masih harus ada penyempurnaan untuk
algoritme rule agar dokumen yang dikembalikan nilai persentasenya lebih bagus.
KESIMPULAN DAN SARAN
Kesimpulan
Berdasarkan penelitian yang dilakukan, dapat disimpulkan bahwa metode rule-based dapat diterapkan untuk implementasi QAS (Question Answering System) untuk temu kembali banyak dokumen berbahasa Indonesia. Kinerja sistem sangat berbeda satu sama lain. Kinerja sistem tertinggi dengan penggunaan nilai ambang batas 23, yang mengembalikan rata–rata 0,5 atau sebagian kalimat jawaban yang relevan dari keseluruhan kalimat jawaban yang relevan yang seharusanya dikembalikan oleh sistem. Berdasarkan evaluasi menggunakan ”KAPAN”, ”MANA”, ”MENGAPA”, ”SIAPA” dan ”APA”, rule “KAPAN” memiliki kinerja tertinggi.