IV-1
BAB IV
EKSPERIMEN
4.1 Tujuan Eksperimen
Terdapat beberapa hal yang menjadi tujuan eksperimen, yaitu:
1. Membandingkan performansi hasil eksperimen dengan hasil penelitian [LI05a], menggunakan dataset dan skenario yang sama. Dengan demikian dapat diketahui apakah implementasi SVM untuk ekstraksi informasi sudah benar.
2. Menganalisis performansi hasil eksperimen jika implementasi SVM untuk ekstraksi informasi digunakan pada dataset berbahasa campuran, yaitu Bahasa Inggris dan Bahasa Indonesia-Inggris. Adapun analisis yang dilakukan mencakup: - Performansi hasil eksperimen terhadap dataset berbahasa campuran
- Pengujian parameter terbaik untuk dataset berbahasa campuran
- Perbandingan algoritma klasifikasi SVM dengan algoritma klasifikasi lain, yaitu Naïve Bayes dan KNN
- Aplikasi model ekstraksi hasil pembelajaran terhadap dokumen teks baru
4.2 Lingkungan Eksperimen
Berikut ini adalah lingkungan perangkat keras dan perangkat lunak tempat eksperimen dilakukan:
1. Microsoft Windows XP SP2
2. Processor Intel Pentium 4, 3.00 Ghz 3. RAM 1.5 GB
4. Harddisk 80 GB
4.3 Hasil Eksperimen
4.3.1 Perbandingan Performansi dengan Paper Acuan [LI05a]
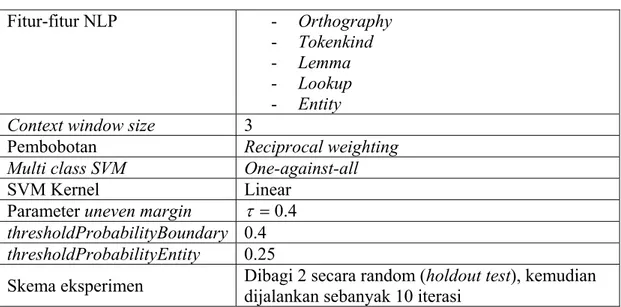
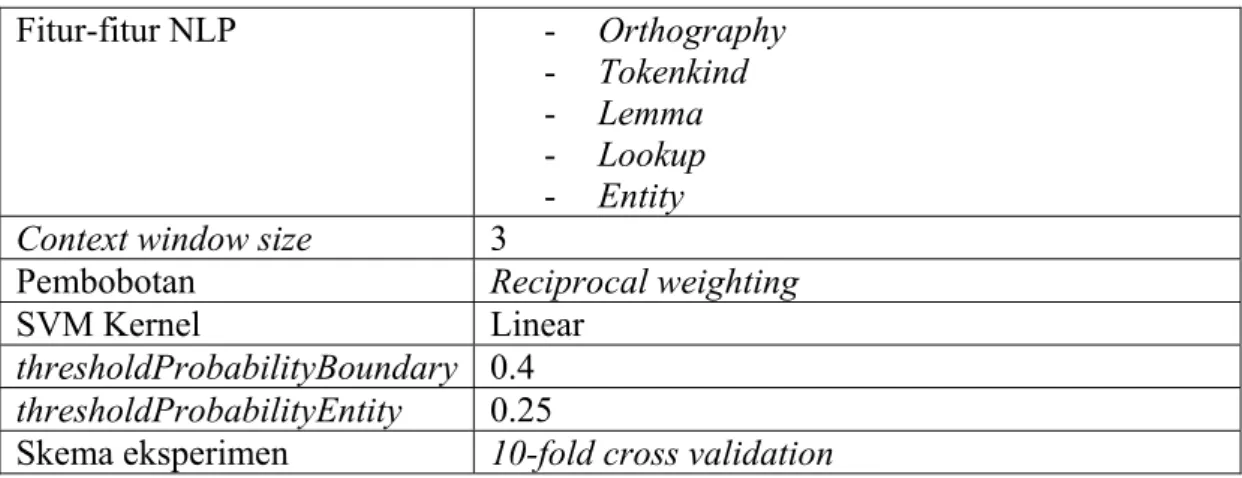
Dataset yang digunakan adalah job postings corpus, dataset yang sama dengan yang digunakan pada [LI05a]. Penjelasan dataset dapat dilihat pada bagian 3.2.1. Sedangkan skenario eksperimen adalah sebagai berikut:
Fitur-fitur NLP - Orthography
- Tokenkind
- Lemma
- Lookup
- Entity
Context window size 3
Pembobotan Reciprocal weighting
Multi class SVM One-against-all
SVM Kernel Linear
Parameter uneven margin τ =0.4
thresholdProbabilityBoundary 0.4
thresholdProbabilityEntity 0.25
Skema eksperimen Dibagi 2 secara random (holdout test), kemudian dijalankan sebanyak 10 iterasi
Total jumlah instance atau token di dalam dataset adalah sebanyak 135.286 token. Dengan menggunakan fitur-fitur NLP yang disebutkan sebelumnya, maka jumlah atribut untuk dataset ini adalah 4.968 atribut. Karena menggunakan window size = 3, maka jumlah seluruh dimensi vektor fitur adalah 4968×7=34776.
Detil hasil eksperimen per iterasi/run dapat dilihat pada Lampiran E. Pada Tabel IV-1 dapat dilihat hasil rata-rata untuk 10 runs, diperoleh setelah program dijalankan selama 6 jam 18 menit 52 detik. Berikut ini adalah penjelasan kolom yang terdapat di dalam Tabel IV-1:
- field berisi tipe-tipe pengisi slot yang didefinisikan di dalam job postings corpus.
- correct berisi jumlah hasil prediksi yang benar untuk setiap tipe pengisi slot. - partial berisi jumlah hasil prediksi yang benar sebagian untuk setiap tipe
pengisi slot.
- spurious berisi jumlah hasil falsePositive, yaitu hasil prediksi salah. - missing berisi jumlah hasil falseNegative, yaitu tidak terdeteksi.
- strict F-1, lenient F-1, dan average F-1 berisi nilai F-measure masing-masing untuk pendekatan strict, lenient, dan average.
- microAverage dan macroAverage berisi nilai rata-rata untuk semua tipe pengisi slot, dengan pendekatan micro average dan macro average.
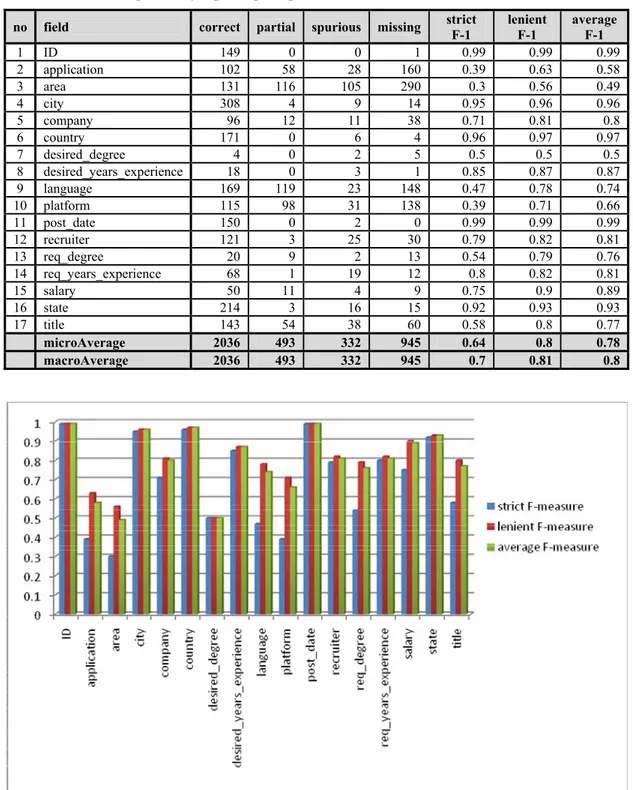
Tabel IV-1 Hasil eksperimen job postings corpus
no field correct partial spurious missing strict F-1 lenient F-1 average F-1
1 ID 149 0 0 1 0.99 0.99 0.99 2 application 102 58 28 160 0.39 0.63 0.58 3 area 131 116 105 290 0.3 0.56 0.49 4 city 308 4 9 14 0.95 0.96 0.96 5 company 96 12 11 38 0.71 0.81 0.8 6 country 171 0 6 4 0.96 0.97 0.97 7 desired_degree 4 0 2 5 0.5 0.5 0.5 8 desired_years_experience 18 0 3 1 0.85 0.87 0.87 9 language 169 119 23 148 0.47 0.78 0.74 10 platform 115 98 31 138 0.39 0.71 0.66 11 post_date 150 0 2 0 0.99 0.99 0.99 12 recruiter 121 3 25 30 0.79 0.82 0.81 13 req_degree 20 9 2 13 0.54 0.79 0.76 14 req_years_experience 68 1 19 12 0.8 0.82 0.81 15 salary 50 11 4 9 0.75 0.9 0.89 16 state 214 3 16 15 0.92 0.93 0.93 17 title 143 54 38 60 0.58 0.8 0.77 microAverage 2036 493 332 945 0.64 0.8 0.78 macroAverage 2036 493 332 945 0.7 0.81 0.8
Pada Gambar IV-1 dapat dilihat bahwa performansi yang tidak terlalu baik terjadi pada beberapa field atau tipe slot yang memiliki beberapa nilai (multi-valued fields), seperti language, platform, application, dan area. Pada beberapa field tersebut, nilai F-measure dengan pendekatan strict dan F-measure dengan pendekatan lenient sangat berbeda jauh, hal ini dikarenakan banyaknya jumlah partial correct yang hampir mendekati jumlah correct.
Sedangkan pada field atau tipe slot desired degree, walaupun nilai F-measure antara
strict, lenient, dan average tidak berbeda jauh, namun hasilnya masih di bawah 0.5. Hal ini disebabkan oleh jumlah data untuk tipe slot desired degree di dalam dataset terlalu sedikit.
F-measure rata-rata menggunakan macroAverage yang diperoleh oleh GATE-SVM [LI05a] adalah 80.8 (±1.0). Sayangnya pada [LI05a] tidak disebutkan pendekatan yang digunakan apakah strict, lenient, atau average. Dengan asumsi bahwa hasil yang diperoleh oleh GATE-SVM menggunakan pendekatan average, dapat disimpulkan bahwa hasil eksperimen yang dilakukan sudah menyamai GATE-SVM.
4.3.2 Eksperimen Menggunakan Dataset Lowongan Pekerjaan
Dataset yang digunakan adalah dataset lowongan pekerjaan, merupakan dataset berbahasa campuran dengan komposisi 90 dokumen berbahasa Inggris dan 90 dokumen berbahasa Indonesia-Inggris. Penjelasan dataset dapat dilihat pada bagian 3.2.2. Eksperimen dibagi menjadi 4 bagian, yaitu:
1. Menganalisis performansi pada dataset berbahasa campuran 2. Menguji parameter terbaik
3. Membandingkan algoritma klasifikasi SVMUM dengan algoritma klasifikasi Naïve Bayes dan KNN
4. Mengaplikasikan model ekstraksi pada dokumen teks baru
Total jumlah instance atau token di dalam dataset adalah sebanyak 44.834 token. Dengan menggunakan fitur-fitur NLP yang disebutkan sebelumnya, maka jumlah atribut untuk dataset ini adalah 3.397 atribut. Karena menggunakan window size = 3, maka jumlah seluruh dimensi vektor fitur adalah 3397×7=23779.
4.3.2.1 Analisis Performansi
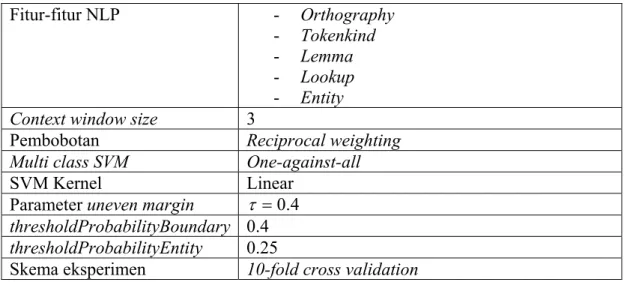
Skenario eksperimen adalah sebagai berikut:
Fitur-fitur NLP - Orthography
- Tokenkind
- Lemma
- Lookup
- Entity
Context window size 3
Pembobotan Reciprocal weighting
Multi class SVM One-against-all
SVM Kernel Linear
Parameter uneven margin τ =0.4
thresholdProbabilityBoundary 0.4
thresholdProbabilityEntity 0.25
Skema eksperimen Dibagi 2 secara random (dijalankan sebanyak 10 iterasi holdout test), kemudian
Detil hasil eksperimen per iterasi/run dapat dilihat pada Lampiran F. Pada Tabel IV-2 dapat dilihat hasil rata-rata untuk 10 runs, diperoleh setelah program dijalankan selama 1 jam 30 menit 34 detik. Penjelasan kolom yang terdapat di dalam Tabel IV-2 sama seperti penjelasan kolom untuk Tabel IV-1 yang dapat dilihat pada bagian 4.3.1.
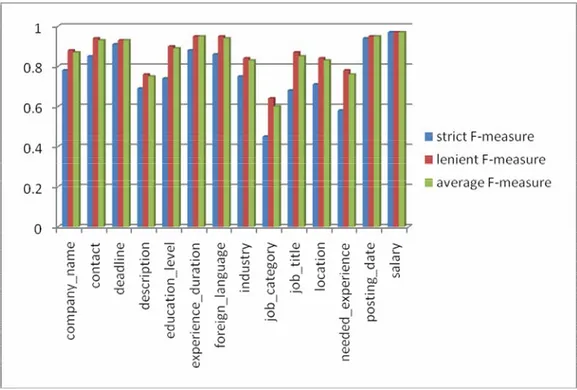
Tabel IV-2 Hasil eksperimen dataset lowongan pekerjaan
no field correct partial spurious missing strict F-1 lenient F-1 average F-1 1 company_name 26 3 2 6 0.78 0.88 0.87 2 contact 15 1 0 2 0.85 0.94 0.93 3 deadline 4 0 0 0 0.91 0.93 0.93 4 description 5 0 0 4 0.69 0.76 0.75 5 education_level 15 3 0 3 0.74 0.9 0.89 6 experience_duration 13 1 0 1 0.88 0.95 0.95 7 foreign_language 8 0 0 0 0.86 0.95 0.94 8 industry 8 1 1 2 0.75 0.84 0.83 9 job_category 6 2 3 7 0.45 0.64 0.6 10 job_title 14 3 1 4 0.68 0.87 0.85 11 location 15 2 2 4 0.71 0.84 0.83 12 needed_experience 8 2 1 4 0.58 0.78 0.76 13 posting_date 7 0 0 0 0.94 0.95 0.95 14 salary 3 0 0 0 0.97 0.97 0.97 microAverage 153 24 13 42 0.75 0.86 0.85 macroAverage 153 24 13 42 0.77 0.87 0.86
Gambar IV-2 Distribusi nilai F-measure untuk setiap tipe slot pada dataset lowongan pekerjaan
Dari hasil eksperimen dapat disimpulkan bahwa performansi untuk dataset berbahasa campuran secara keseluruhan sangat baik. Hal ini disebabkan oleh jumlah data pelatihan yang cukup banyak untuk setiap tipe slot. Selain itu, dokumen berbahasa Inggris yang memiliki fitur-fitur NLP yang lengkap dapat meningkatkan performansi secara keseluruhan. Tingkat keragaman dokumen berbahasa Inggris yang rendah juga mengakibatkan meningkatnya performansi dokumen berbahasa Inggris.
Dari Gambar IV-2 dapat terlihat bahwa performansi untuk setiap tipe slot sangat baik. Akan tetapi, performansi paling rendah dimiliki oleh tipe slotjob_category. Dari hasil eksperimen diperoleh bahwa seringkali terjadi partial correct, misalnya: seharusnya
Accounting, hasil prediksi adalah Finance & Accounting Staff.
Untuk mengetahui pengaruh multi-bahasa di dalam dataset, dilakukan eksperimen dengan berbagai komposisi data pelatihan dan data pengujian. Terdapat 3 komposisi data pelatihan, yaitu:
- 80 dokumen berbahasa Inggris + 10 dokumen berbahasa Indonesia-Inggris - 45 dokumen berbahasa Inggris + 45 dokumen berbahasa Indonesia-Inggris - 10 dokumen berbahasa Inggris + 80 dokumen berbahasa Indonesia-Inggris
Setiap data pelatihan diuji sebanyak dua kali, dengan menggunakan data pengujian yang berbeda, yaitu:
- 10 dokumen berbahasa Inggris
- 10 dokumen berbahasa Indonesia-Inggris
Adapun skenario eksperimen adalah sebagai berikut:
Fitur-fitur NLP - Orthography
- Tokenkind
- Lemma
- Lookup
- Entity
Context window size 3
Pembobotan Reciprocal weighting
Multi class SVM One-against-all
SVM Kernel Linear
Parameter uneven margin τ =0.4
thresholdProbabilityBoundary 0.4
thresholdProbabilityEntity 0.25 Skema eksperimen
3 komposisi data pelatihan diuji sebanyak dua kali, dengan menggunakan 2 komposisi data pengujian
Performansi untuk setiap skema eksperimen dapat dilihat pada Lampiran J. Pada Tabel IV-3 dapat dilihat perbandingan performansi untuk setiap skema eksperimen. Pada Tabel IV-3 metrik evaluasi yang dibandingkan adalah nilai F-measure yang dihitung menggunakan pendekatan strict, lenient, dan average. Nilai F-measure
tersebut terisi pada kolom strict F-1, lenient F-1, dan average F-1 untuk masing-masing pendekatan.
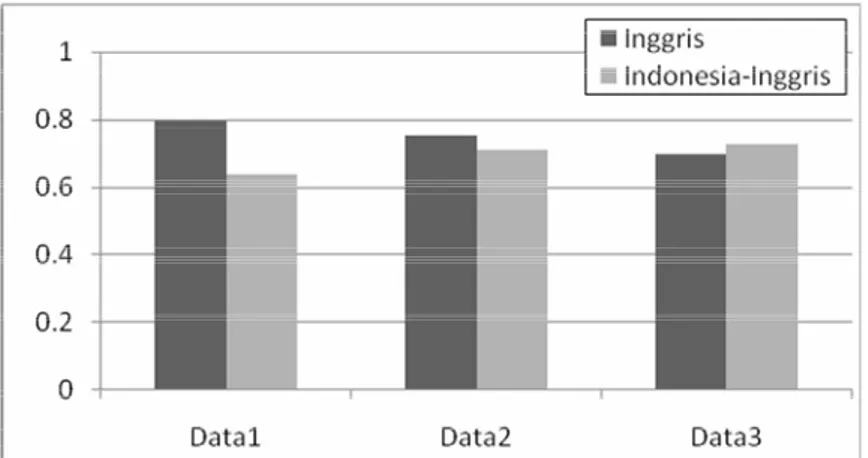
Tabel IV-3 Perbandingan performansi dengan berbagai komposisi data pelatihan dan pengujian Data Pengujian Inggris Indonesia-Inggris Data Pelatihan strict F-1 lenient F-1 average F-1 strict F-1 lenient F-1 average F-1 Data1 0.77 0.87 0.79 0.6 0.69 0.63 Data2 0.72 0.7 0.75 0.61 0.76 0.71 Data3 0.64 0.78 0.7 0.68 0.82 0.73
Gambar IV-3 Performansi untuk setiap komposisi data pelatihan dan pengujian
Dari Gambar IV-3 dapat terlihat bahwa walaupun untuk dokumen berbahasa Indonesia terdapat banyak fitur-fitur NLP yang tidak diketahui, performansi dapat ditingkatkan dengan menambah jumlah data pelatihan. Performansi data pengujian Indonesia-Inggris meningkat sebanyak 14% ketika jumlah data pelatihan dimodifikasi dari Data1 (10 dokumen Inggris) ke Data3 (80 dokumen Indonesia-Inggris). Hal ini disebabkan oleh meningkatnya jumlah vocabulary token di dalam data pelatihan.
Dengan menggunakan data pelatihan Data1 (80 dokumen Inggris + 10 dokumen Indonesia-Inggris), performansi data pengujian Inggris hampir 20% lebih tinggi dibandingkan performansi data pengujian Indonesia-Inggris. Namun dengan menggunakan data pelatihan Data3 (10 dokumen Inggris + 80 dokumen Indonesia-Inggris), performansi data pengujian Indonesia-Inggris hanya 3% lebih tinggi dibandingkan performansi data pengujian Inggris. Hal ini menunjukkan bahwa selain jumlah data pelatihan, vektor fitur yang baik, dalam hal ini memiliki informasi fitur-fitur NLP yang lengkap, juga mempengaruhi performansi sebuah sistem ekstraksi informasi.
4.3.2.2 Pengujian Parameter Terbaik
Adapun parameter yang diuji antara lain:
- Teknik implementasi multi class SVM: one-against-all dan one-against-one
- Parameter uneven margin: τ =0.2, τ =0.4, τ =0.6, τ =0.8, dan τ =1
Sedangkan parameter lainnya akan mengikuti parameter yang memberikan performansi optimal pada job postings corpus [LI05a]. Dataset lowongan pekerjaan
memiliki domain sama dengan job postings corpus, sehingga diasumsikan parameter yang memberikan performansi optimal pada job postings corpus juga akan memberikan performansi optimal pada dataset lowongan pekerjaan.
Skenario eksperimen adalah sebagai berikut:
Fitur-fitur NLP - Orthography
- Tokenkind
- Lemma
- Lookup
- Entity
Context window size 3
Pembobotan Reciprocal weighting
SVM Kernel Linear
thresholdProbabilityBoundary 0.4
thresholdProbabilityEntity 0.25
Skema eksperimen 10-fold cross validation
Performansi untuk teknik one-against-all dan one-against-one dapat dilihat pada Lampiran G (performansi rata-rata untuk 10 runs). Pada Tabel IV-4 dapat dilihat perbandingan performansi antara teknik kombinasi one-against-all dan one-against-one.
Tabel IV-4 Perbandingan performansi teknik one-against-all dan teknik one-against-one one-against-all one-against-one no Field
strict
F-1 lenient F-1 average F-1 strict F-1 lenient F-1 average F-1
1 company_name 0.78 0.88 0.87 0.8 0.83 0.83 2 contact 0.85 0.94 0.93 0.73 0.87 0.86 3 deadline 0.91 0.93 0.93 0.83 0.85 0.85 4 description 0.69 0.76 0.75 0.66 0.68 0.67 5 education_level 0.74 0.9 0.89 0.5 0.54 0.53 6 experience_duration 0.88 0.95 0.95 0.04 0.04 0.04 7 foreign_language 0.86 0.95 0.94 0 0.02 0.01 8 industry 0.75 0.84 0.83 0.36 0.36 0.36 9 job_category 0.45 0.64 0.6 0.14 0.22 0.19 10 job_title 0.68 0.87 0.85 0.71 0.78 0.77 11 location 0.71 0.84 0.83 0.19 0.23 0.22 12 needed_experience 0.58 0.78 0.76 0.5 0.64 0.61 13 posting_date 0.94 0.95 0.95 0.93 0.93 0.93 14 salary 0.97 0.97 0.97 0.71 0.71 0.71 microAverage 0.75 0.86 0.85 0.56 0.62 0.61 macroAverage 0.77 0.87 0.86 0.51 0.55 0.54 waktu 1 jam 30 menit 55 detik 1 jam 28 menit 25 detik
Dari hasil eksperimen dapat disimpulkan bahwa teknik kombinasi one-against-all
memiliki performansi yang lebih baik jika dibandingkan dengan teknik kombinasi
one-against-one, dan dengan waktu proses yang tidak berbeda jauh.
Dari detil hasil eksperimen pada Lampiran G dapat dilihat bahwa untuk teknik kombinasi one-against-one, nilai precision cukup tinggi, yaitu berkisar pada angka 0.71-0.94. Sementara nilai recall sangat rendah, yaitu berkisar pada angka 0.41-0.47. Nilai recall yang rendah inilah yang menyebabkan nilai F-measure untuk teknik one-against-one menjadi turun. Nilai recall yang rendah ini disebabkan oleh banyaknya jumlah missing atau falseNegative.
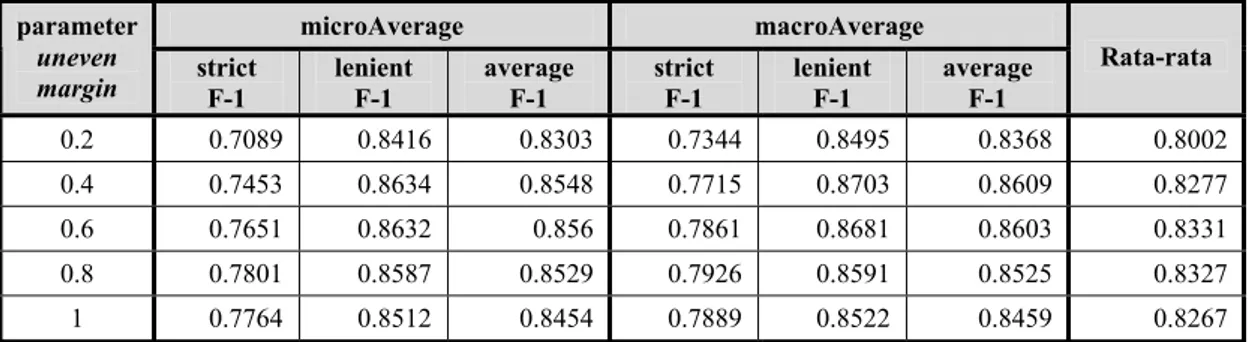
Performansi untuk setiap nilai parameter uneven margin dapat dilihat pada Lampiran H (performansi rata-rata untuk 10 runs). Pada Tabel IV-5 dapat dilihat perbandingan performansi untuk setiap nilai parameter uneven margin.
Tabel IV-5 Perbandingan performansi beberapa nilai parameter uneven margin microAverage macroAverage parameter
uneven
margin strict F-1 lenient F-1 average F-1 strict F-1 lenient F-1 average F-1 Rata-rata
0.2 0.7089 0.8416 0.8303 0.7344 0.8495 0.8368 0.8002 0.4 0.7453 0.8634 0.8548 0.7715 0.8703 0.8609 0.8277 0.6 0.7651 0.8632 0.856 0.7861 0.8681 0.8603 0.8331 0.8 0.7801 0.8587 0.8529 0.7926 0.8591 0.8525 0.8327 1 0.7764 0.8512 0.8454 0.7889 0.8522 0.8459 0.8267
Secara umum, dapat dikatakan bahwa SVM dengan uneven margin memiliki performansi yang lebih baik jika dibandingkan dengan SVM standar (τ =1). Namun dengan catatan bahwa nilai parameter uneven margin sebaiknya disesuaikan dengan rasio imbalance pada dataset. Dalam eksperimen ini dataset yang digunakan memiliki rasio imbalance yang tidak terlalu tinggi, sehingga pada nilai parameter uneven margin τ =0.2, performansinya menjadi kurang baik, lebih rendah daripada SVM standar.
Dari hasil rata-rata total, dapat disimpulkan bahwa untuk dataset yang digunakan di dalam eksperimen ini, parameter uneven margin τ =0.6 memiliki performansi yang paling unggul dibandingkan dengan nilai parameter uneven margin lainnya.
4.3.2.3 Perbandingan Performansi Algoritma Klasifikasi SVM, Naïve Bayes, dan KNN
Skenario eksperimen adalah sebagai berikut:
Fitur-fitur NLP - Orthography
- Tokenkind
- Lemma
- Lookup
- Entity
Context window size 3
Pembobotan Reciprocal weighting
Multi class SVM One-against-all
SVM Kernel Linear
Parameter uneven margin τ =0.4
thresholdProbabilityBoundary 0.4
thresholdProbabilityEntity 0.25
Skema eksperimen 10-fold cross validation
Algoritma yang digunakan untuk klasifikasi adalah SVM dengan uneven margin, Naïve Bayes, dan K-Nearest Neighbor. Untuk algoritma K-Nearest Neighbor, jumlah tetangga yang digunakan adalah k =1.
Performansi untuk algoritma Naïve Bayes dan KNN dapat dilihat pada Lampiran I (performansi rata-rata untuk 10 runs). Sedangkan untuk algoritma SVM, yang digunakan adalah hasil eksperimen pada bagian 4.3.2.1. Pada Tabel IV-6 dapat dilihat perbandingan performansi untuk setiap algoritma klasifikasi.
Tabel IV-6 Perbandingan performansi algoritma SVMUM, Naïve Bayes dan KNN
microAverage macroAverage Algoritma klasifikasi strict F-1 lenient F-1 average F-1 strict F-1 lenient F-1 average F-1 Waktu (detik) SVMUM 0.75 0.86 0.85 0.77 0.87 0.86 5455 Naïve Bayes 0.37 0.42 0.41 0.25 0.28 0.28 2844 KNN 0.71 0.8 0.79 0.72 0.79 0.78 51084
Dari Tabel IV-6 dapat dilihat bahwa SVM dengan uneven margin merupakan algoritma klasifikasi yang memiliki performansi paling tinggi dibandingkan dengan kedua algoritma klasifikasi lainnya. Algoritma Naïve Bayes, walaupun waktu eksekusinya lebih cepat dibandingkan dengan SVM, namun performansinya kalah jauh. Sedangkan KNN, walaupun performansinya cukup tinggi, namun masih kalah jika dibandingkan dengan SVM, dan dengan waktu eksekusi yang jauh lebih lama.
4.3.2.4 Hasil Aplikasi Model Ekstraksi
Model ekstraksi dihasilkan dari pembelajaran dengan data pelatihan adalah seluruh dataset lowongan pekerjaan sebanyak 180 dokumen teks. Sedangkan data pengujian adalah dokumen teks baru yang berisi iklan lowongan pekerjaan di PT. Tata Bisnis Solusi.
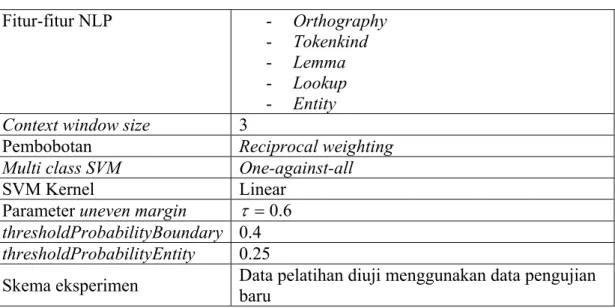
Skenario eksperimen adalah sebagai berikut:
Fitur-fitur NLP - Orthography
- Tokenkind
- Lemma
- Lookup
- Entity
Context window size 3
Pembobotan Reciprocal weighting
Multi class SVM One-against-all
SVM Kernel Linear
Parameter uneven margin τ =0.6
thresholdProbabilityBoundary 0.4
thresholdProbabilityEntity 0.25
Skema eksperimen Data pelatihan diuji menggunakan data pengujian baru
Adapun teknik multi class SVM dan parameter uneven margin dipilih berdasarkan hasil pengujian parameter terbaik. Berikut ini adalah hasil aplikasi model ekstraksi.
Dibutuhkan Staff Administrasi di TataSolusi Posted on June 7th, 2008 by admin
Kami perusahaan yang bergerak di bidang konsultan IT membutuhkan karyawan untuk posisi :
Staf Administrasi Kualifikasi :
- Wanita, max 35 tahun. - Pendidikan min. D3.
- Memiliki pengalaman min. 1 tahun di posisi yang sama. - Dapat melakukan kegiatan surat-menyurat.
- Teratur, rapi dan teliti.
- Diutamakan berdomisili di daerah Jakarta Pusat. CV lengkap dapat dikirimkan ke : [email protected] Atau ke alamat :
PT. Tata Bisnis Solusi Jl. Alaydrus no.73B Jakarta Pusat 10130 job_title industry location education_level experience_duration needed_experience contact
Seperti yang dapat dilihat pada Gambar IV-4, terdapat 7 buah tipe pengisi slot yang berhasil diekstrak dari dokumen teks baru tersebut, yaitu: job_title, industry, location,
education_level, experience_duration, needed_experience, dan contact. Sementara 7 tipe pengisi slot lainnya tidak berhasil diekstrak, antara lain:
1. company_name, seharusnya terdapat nama perusahaan di dokumen teks tersebut, yaitu ‘PT. Tata Bisnis Solusi’.
2. job_category, karena memang tidak terdapat kategori pekerjaan di dalam dokumen teks. Namun dari judul pekerjaan dapat disimpulkan bahwa kategori pekerjaan adalah ‘administrasi’.
3. foreign_language, karena memang tidak terdapat persyaratan bahasa asing yang harus dikuasai di dalam dokumen teks.
4. description, karena memang tidak terdapat deskripsi mengenai pekerjaan (job description) di dalam dokumen teks.
5. salary, karena memang tidak terdapat nilai gaji yang ditawarkan oleh perusahaan di dalam dokumen teks. Kebanyakan iklan lowongan pekerjaan di Indonesia memang tidak mencantumkan gaji yang ditawarkan.
6. deadline, karena memang tidak terdapat tanggal deadline lowongan pekerjaan dikirimkan.
7. posting_date, seharusnya terdapat tanggal lowongan pekerjaan di-publish, yaitu ‘June 7th, 2008’. Hal ini mungkin disebabkan oleh penulisan format tanggal seperti ini tidak terdapat di dalam data pelatihan.
Pada tipe slot location, hasil ekstraksi adalah ‘Jakarta’, padahal frase lengkapnya adalah ‘Jakarta Pusat’. Hal ini dikarenakan pada proses pemberian anotasi untuk dataset lowongan pekerjaan, ditetapkan bahwa yang dimaksud dengan lokasi adalah negara, propinsi, atau kota, sedangkan ‘Jakarta Pusat’ merupakan area yang terdapat di dalam kota ‘Jakarta’.
Dengan demikian, jika diukur dengan metrik evaluasi, performansi sistem untuk dokumen teks baru tersebut dapat dilihat pada Tabel IV-7.
Tabel IV-7 Performansi hasil aplikasi terhadap dokumen baru
correct partial spurious missing strict F-1 lenient F-1 average F-1
Dimana:
- correct berisi jumlah hasil prediksi yang benar.
- partial berisi jumlah hasil prediksi yang benar sebagian.
- spurious berisi jumlah hasil falsePositive, yaitu hasil prediksi salah. - missing berisi jumlah hasil falseNegative, yaitu tidak terdeteksi.
- strict F-1, lenient F-1, dan average F-1 berisi nilai F-measure masing-masing untuk pendekatan strict, lenient, dan average.