Fakultas Ilmu Komputer
Universitas Brawijaya 2195
Analisis Sentimen pada Ulasan Pengguna MRT Jakarta Menggunakan Metode Neighbor-Weighted K-Nearest Neighbor dengan Seleksi Fitur
Information Gain
Firda Oktaviani Putri1, Indriati2, Randy Cahya Wihandika3
Program Studi Teknik Informatika, Fakultas Ilmu Komputer, Universitas Brawijaya Email: 1[email protected], 2[email protected], 3[email protected]
Abstrak
Keberadaan MRT Jakarta diharapkan dapat mengurangi jumlah penggunaan transportasi pribadi yang membuat angka kemacetan di daerah Jakarta terus mengalami peningkatan. Ulasan dari para pengguna MRT Jakarta membantu pihak MRT Jakarta dalam meningkatkan pelayanannya, karena dengan kualitas pelayanan yang baik dapat menarik minat masyarakat untuk menggunakan MRT sebagai transportasi umum dalam berpergian. Namun saat ini, pada akun resmi media sosial MRT Jakarta belum dijumpai keberadaan sebuah fitur untuk memilah ulasan antara ulasan positif atau negatif. Jika hal tersebut dilakukan secara manual akan menguras waktu, maka dari itu perlu dilakukan proses automasi dalam pemilihan ulasan-ulasan tersebut. Proses automasi ini dikenal sebagai analisis sentimen. Dalam penelitian ini, sistem analisis sentimen menggunakan kombinasi metode klasifikasi Neighbor-Weighted K-Nearest Neighbor (NWKNN) dengan seleksi fitur Information Gain. Pengujian yang dilakukan dalam penelitian ini menggunakan 5-Fold Cross Validation. Hasil pengujian mencapai titik optimal pada Fold ke-5, saat nilai k = 100, nilai exponent = 2, dan nilai threshold untuk seleksi fitur = 100% (tanpa seleksi fitur dan tanpa menggunakan stopword removal), dengan nilai precision, recall, f-measure, dan accuracy sebesar 1; 0,94; 0,97; dan 0,97.
Kata kunci: analisis sentimen, ulasan, MRT, neighbor-weighted k-nearest neighbor, information gain Abstract
The existence of the MRT Jakarta is expected to reduce the number of private transportation uses, which causes the congestion rate in the Jakarta area to continue to increase. Reviews from MRT Jakarta users help MRT Jakarta in improving its services, because good service quality can attract people to use MRT as public transportation for traveling. However, at this time, MRT Jakarta's official social media accounts had not yet found a feature to sort reviews between positive and negative reviews. If this is done manually it will take time, therefore it is necessary to carry out an automation process in the selection of these reviews. This automation process is known as sentiment analysis. In this study, the sentiment analysis system uses a combination of the Neighbor-Weighted K- Nearest Neighbor (NWKNN) classification method with the Information Gain feature selection. Tests conducted in this study using 5-Fold Cross Validation. The test results reach the optimal point at the 5th Fold, when the k value = 100, the exponent value = 2, and the threshold value for feature selection
= 100% (without feature selection and without using stopword removal), with values of precision, recall, f- measure, and accuracy is 1; 0.94; 0.97; and 0.97.
Keywords: sentiment analysis, review, MRT, neighbor-weighted k-nearest neighbor, information gain
1. PENDAHULUAN
Kemacetan adalah sebuah permasalahan yang sering dialami di berbagai wilayah, khususnya di wilayah Kota Jakarta yang telah menghadapi masalah kemacetan menahun.
Berdasarkan survei yang dilakukan oleh
TomTom Traffic Index tingkat kemacetan Kota Jakarta pada tahun 2019 berada pada angka 53%. Adanya permasalahan kemacetan yang tak kunjung rampung, pihak Pemerintah Provinsi DKI Jakarta melakukan perkembangan dan pembangunan di bidang transportasi, salah satunya contohnya adalah dengan adanya MRT
(Widadio, 2019). Keberadaan MRT sebagai salah satu transportasi umum diharapkan dapat mengurangi jumlah penggunaan transportasi pribadi yang membuat angka kemacetan di daerah Jakarta terus mengalami peningkatan.
Pihak MRT Jakarta memperbolehkan para pengguna untuk memberikan aspirasi mereka dalam bentuk ulasan terkait pelayanan yang telah diberikan oleh pihak MRT Jakarta. Ulasan ini dapat memengaruhi keputusan masyarakat dalam memilih MRT Jakarta sebagai pilihan transportasi umum dalam berpergian. Saat ini pada akun resmi media sosial MRT Jakarta belum ditemukan keberadaan sebuah fitur untuk menyeleksi antara ulasan positif dan ulasan negatif. Jika proses tersebut dilakukan secara manual dapat menghabiskan waktu, maka dari itu perlu dilakukan proses analisis sentimen guna mengetahui kelas atau kategori dari ulasan tersebut.
Terdapat berbagai macam algoritme klasifikasi yang telah banyak mengalami perkembangan, salah satunya adalah K-Nearest Neighbor (KNN) (Sahara & Wahyudi, 2015).
Namun dalam implementasinya, algoritme KNN memiliki kelemahan yakni tidak dapat mengatasi permasalahan pada kumpulan data yang dalam pendistribusian kelasnya tidak merata (Indriati & Ridok, 2016). Permasalahan tersebut dapat diatasi oleh algoritme Neighbor- Weighted K-Nearest Neighbor (NWKNN).
Algoritme NWKNN dikenalkan oleh Sangbo Tan, dalam algoritme ini menerapkan prinsip pembobotan (Tan, 2005). Dalam penelitian Indriati dan Ridok, algoritme NWKNN dapat melakukan klasifikasi pada dokumen review aplikasi mobile dengan baik ketika data latih tidak seimbang. Hal tersebut terjadi karena adanya penambahan bobot pada kelas minoritas. Hasil pengujian menunjukkan, algoritme NWKNN memiliki hasil akurasi yang lebih baik sebesar 0,27 dibandingkan dengan algoritme KNN (Indriati & Ridok, 2016).
Sementara itu, data uji maupun data latih yang berasal dari ulasan-ulasan pengguna MRT Jakarta dapat memiliki ukuran dataset yang cukup besar. Beberapa fitur yang tidak diperlukan ini dapat menyebabkan kompleksitas komputasi yang tinggi dalam proses pengklasifikasiannya. Sehingga dibutuhkan sebuah proses seleksi fitur.
Information Gain (IG) merupakan bagian dari metode seleksi fitur untuk mengatasi permasalahan tersebut (Nugraha, et al., 2018).
Penelitian oleh Uğuz menunjukkan, dengan
adanya seleksi fitur IG dapat mengurangi term- term yang kurang relevan dengan cara melakukan pemeringkatan terhadap term, dengan mengabaikan term-term yang tidak relevan tadi dapat menghasilkan nilai evaluasi sistem yang optimal (Uğuz, 2011).
Berdasarkan paparan penelitian yang telah dilakukan tersebut, penulis menentukan untuk menggunakan kombinasi dari metode klasifikasi Neighbor-Weighted K-Nearest Neighbor (NWKNN) dengan seleksi fitur menggunakan Information Gain (IG) dalam penelitian skripsi ini. Dengan adanya kombinasi metode tersebut diharapkan dapat memperoleh hasil evaluasi sistem yang optimal.
2. DASAR TEORI 2.1. Ulasan
Ulasan dapat berupa pendapat atau komentar terhadap sebuah kejadian, dengan adanya ulasan pengguna dapat memutuskan untuk menggunakan atau tidak menggunakannya suatu produk (Onantya, et al., 2019).
2.2. Media Sosial
Media sosial digunakan untuk melakukan proses sosial antara pengguna yang satu dengan pengguna yang lainnya (Mulawarman &
Nurfitri, 2017). Facebook, Twitter, Instagram, Line, LinkedIn, dsb merupakan bagian dari media sosial.
2.3. Text Mining
Sebuah proses dalam penambangan data dimana sumber data yang diperoleh berasal dari suatu dokumen serta data yang diproses berupa teks merupakan penjelasan dari text mining.
Tujuan dari text mining yakni, mendapatkan sebuah kata dimana kata tersebut mampu mewakili isi dari suatu dokumen (Onantya, et al., 2019).
2.4. Analisis Sentimen
Analisis sentimen adalah bagian dari dari data mining. Dalam analisis sentimen data tekstual berupa opini terhadap entitas seperti, produk, servis, organisasi, individu, dan topik tertentu akan dilakukan proses menganalisis, memahami, mengolah, dan mengekstrak data (Novantirani, et al., 2015).
2.5. Preprocessing
Untuk menghilangkan noise pada data serta mengurangi volume kata dan menyeragamkan bentuk kata perlu dilakukan proses preprocessing (Putranti & Winarko, 2014).
Preprocessing yang ada dalam penelitian ini terdiri dari beberapa tahapan, yakni:
Case Folding
Untuk mengubah semua huruf menjadi huruf kecil semua pada dokumen memerlukan proses case folding (Onantya, et al., 2019).
Tokenizing
Sebuah proses dalam memisahkan atau memecah sebuah kalimat (string) yang terdapat di dalam dokumen menjadi token/term dikenal dengan istilah tokenizing. Proses ini menghilangkan semua karakter selain huruf (Indriati & Ridok, 2016).
Filtering
Filtering merupakan sebuah proses menghapus term berdasarkan stoplist/stopword list. Term yang dihapuskan dalam hal ini merupakan term yang tidak penting seperti kata penghubung atau kata ganti (Indriati & Ridok, 2016). Dalam penelitian ini menggunakan stopword list Tala.
Stemming
Stemming merupakan sebuah proses mengubah bentuk kata. Dimana term yang memiliki imbuhan akan diubah menjadi kata dasarnya (Onantya, et al., 2019). Library sastrawi dalam penelitian ini digunakan untuk proses stemming.
2.6. Feature Selection dan Information Gain Feature selection digunakan untuk memilih fitur-fitur yang berguna atau relevan pada term, dimana fitur tersebut merupakan target dari data learning pada suatu permasalahan. Salah satu metode seleksi fitur yang cukup populer yakni Information gain (IG) (Pristiyanti, et al., 2018).
Persamaan (1) merupakan formula untuk menemukan nilai IG (Uğuz, 2011).
𝐼𝐺(𝑡) = − ∑|𝑐|𝑖=1 𝑃(𝑐𝑖)𝑙𝑜𝑔𝑃(𝑐𝑖) + 𝑃(𝑡) ∑|𝑐|𝑖=1 𝑃(𝑐𝑖|𝑡)𝑙𝑜𝑔𝑃(𝑐𝑖|𝑡) + 𝑃(𝑡̅) ∑|𝑐|𝑖=1 𝑃(𝑐𝑖|𝑡̅)𝑙𝑜𝑔𝑃(𝑐𝑖|𝑡̅) (1) Keterangan:
𝑐𝑖 : kategori kelas.
𝑃(𝑐𝑖) : peluang dari kategori kelas.
𝑃(𝑡) dan 𝑃(𝑡̅) : peluang dari term t yang ada atau tidak ada dalam dokumen.
𝑃(𝑐𝑖|𝑡) : peluang dari kondisi bersyarat kategori kelas pada term t yang ada dalam dokumen.
𝑃(𝑐𝑖|𝑡̅) : peluang dari kondisi bersyarat kategori kelas pada term t yang tidak ada di dokumen.
2.7. Pembobotan Kata
Sebuah proses yang mampu mengubah bentuk nilai dari suatu term dikenal dengan pembobotan kata. Nilai term awalnya berupa data kualitatif diubah menjadi data kuantitatif.
Proses ini dilakukan agar komputer dapat melakukan proses komputasi. Salah satu bagian dari metode pembobotan kata yakni TF-IDF (Indriati & Ridok, 2016).
Langkah awal dalam metode TF-IDF yakni mencari nilai Term frequency (TF) (Indriati &
Ridok, 2016). Persamaan (2) merupakan formula untuk mencari nilai TF.
Jika 𝑥(𝑡, 𝑑) = 0, maka:
𝑇𝐹(𝑡,𝑑)= 0
Jika 𝑥(𝑡, 𝑑) > 0, maka:
𝑇𝐹(𝑡,𝑑)= 1 + 𝑙𝑜𝑔 𝑥(𝑡, 𝑑) (2) Keterangan:
𝑇𝐹(𝑡,𝑑) : bobot dari term t terhadap dokumen d.
𝑥(𝑡,𝑑) : jumlah kemunculan term t terhadap dokumen d.
Setelah mendapatkan nilai TF, langkah selanjutnya mencari nilai inverse document frequency (IDF) serta nilai TF-IDF nya (Indriati
& Ridok, 2016). Persamaan (3) merupakan formula dari pembobotan kata menggunakan TF-IDF (Feldman & Sanger, 2007).
𝑇𝐹 − 𝐼𝐷𝐹(𝑡,𝑑)= 𝑇𝐹(𝑡,𝑑)∗ 𝑙𝑜𝑔 𝐷
𝐷𝑡 (3) Keterangan:
𝑇𝐹 − 𝐼𝐷𝐹(𝑡,𝑑) : bobot kata t terhadap dokumen d.
𝑇𝐹(𝑡,𝑑) : bobot term t terhadap
dokumen d.
𝐷 : jumlah dari keseluruhan dokumen
𝐷𝑡 : jumlah dari dokumen yang memuat term t.
2.8. Klasifikasi
Untuk mendapatkan suatu fungsi atau model yang dapat membedakan kelas data dibutuhkan proses klasifikasi. Pada saat pengklasifikasian data terdapat beberapa proses yakni proses training, proses testing, dan proses validasi (Indriati & Ridok, 2016).
2.9. Neighbor-Weighted K-Nearest Neighbor (NWKNN)
Neighbor-Weighted K-Nearest Neighbor (NWKNN) merupakan peningkatan dari metode K-Nearest Neighbor (KNN). Konsep dari metode NWKNN adalah memberikan nilai bobot besar pada kelas minoritas serta memberikan nilai bobot kecil pada kelas mayoritas (Tan, 2005).
Tahapan awal pada metode NWKNN yakni melakukan penghitungan jarak atau kemiripan antara kumpulan k dokumen latih dengan obyek pada dokumen uji. Cara paling umum yang digunakan untuk mengukur kedekatan jarak antara dokumen lama dengan dokumen baru yakni dengan Cosine Similarity (Indriati &
Ridok, 2016). Formula dari menghitung nilai Cosine Similarity terdapat di Persamaan (4) (Suguna & Thanushkodi, 2010).
𝑆𝐼𝑀 (𝑋, 𝑑𝑖) = ∑ 𝑥𝑗 . 𝑑𝑖𝑗
𝑚𝑗=1
√(∑𝑚𝑗=1𝑥𝑗)2 √(∑𝑚𝑗=1𝑑𝑖𝑗)2 (4) Keterangan:
𝑋 : dokumen uji.
𝑑𝑖 : dokumen latih.
𝑥𝑗 dan 𝑑𝑖𝑗 : bobot yang diberikan pada setiap term dokumen uji dan dokumen latih.
Dalam algoritme NWKNN untuk menghitung skor akhir tahapan pertama yang dilakukan yaitu menghitung nilai bobot pada setiap kelas atau kategori 𝐶𝑖. Nilai bobot besar diberikan kepada kelas minoritas, sedangkan nilai bobot kecil diberikan kepada kelas mayoritas (Indriati & Ridok, 2016). Formula untuk menghitung bobot kategori atau 𝑊𝑒𝑖𝑔ℎ𝑡 𝑖 dapat dilihat pada Persamaan (5) (Tan, 2005).
𝑊𝑒𝑖𝑔ℎ𝑡𝑖 = 1
( 𝑁𝑢𝑚 (𝐶𝑖𝑑) 𝑀𝑖𝑛{𝑁𝑢𝑚(𝐶𝑗𝑑) | 𝑗 = 1,...,𝑘∗)
1/𝑒𝑥𝑝 (5)
Keterangan:
𝑁𝑢𝑚 (𝐶𝑖𝑑) : jumlah dari dokumen latih 𝑑 di kategori / kelas 𝑖.
𝑁𝑢𝑚(𝐶𝑗𝑑) : jumlah dari dokumen latih 𝑑 di kategori / kelas 𝑗, dimana 𝑗 merupakan anggota pada kumpulan 𝑘 tetangga terdekat.
𝑒𝑥𝑝 : nilai eksponen, dimana nilai ini harus lebih dari 1.
Jika nilai bobot dari setiap kategorinya sudah diperoleh, selanjutnya adalah menghitung score pada setiap kategori kelas berdasarkan dokumen uji. Persamaan (6) merupakan formula penghitungan skor pada metode NWKNN disetiap dokumen uji 𝑞 terhadap kategori/kelas 𝑖 (Tan, 2005).
𝑆𝑐𝑜𝑟𝑒(𝑞 , 𝐶𝑖) = 𝑊𝑒𝑖𝑔ℎ𝑡𝑖×
(∑𝑑𝑗∈𝐾𝑁𝑁(𝑞)𝑆𝑖𝑚(𝑞, 𝑑𝑗)𝛿(𝑑𝑗, 𝐶𝑖)) (6) Keterangan:
𝑊𝑒𝑖𝑔ℎ𝑡𝑖 : bobot pada kategori / kelas ke- 𝑖.
𝑑𝑗 ∈ 𝐾𝑁𝑁(𝑞) : dokumen latih 𝑑𝑗 yang berada pada kelompok tetangga terdekat (nearest neighbor) dari dokumen uji 𝑞.
𝑆𝑖𝑚(𝑞, 𝑑𝑗) : nilai kedekatan jarak (similarity) antara antara dokumen latih 𝑑𝑗 dengan dokumen uji 𝑞.
𝛿(𝑑𝑗, 𝐶𝑖) : {𝑑𝑗 ∈ 𝐶𝑖 = 1 𝑑𝑗 ∉ 𝐶𝑖 = 0 𝐶𝑖 : Kelas / kategori 𝑖. 2.10. Evaluasi
Untuk menguji hasil dari klasifikasi sistem terdapat berbagai metode, berikut adalah metode pengujian yang digunakan pada penelitian ini:
K-Fold Cross Validation
Banyak fold yang diujikan pada pengujian ini yakni sebanyak 5 Fold atau dikenal juga dengan istilah 5-Fold Cross Validation. Konsep dari pengujian ini membagi dataset menjadi 5 bagian yang berisikan data latih dan data uji.
Pada setiap fold nya, urutan penggunaan data uji tidak boleh sama antara fold yang satu dengan yang lainnya. Untuk data latih di setiap fold nya menggunakan sisa dari data yang tidak terpakai untuk data uji.
Evaluasi Precision, Recall, F-measure, dan Accuracy
Tabel confusion matrix digunakan untuk mempermudah dalam proses perhitungan nilai precision, recall, f-measure, dan accuracy.
Berikut bentuk dari tabel confusion matrix yang dapat diperhatikan pada Tabel 1.
Tabel 1. Tabel Confusion Matrix Actual Positif Actual Negatif Classified
Positif
True Positives (TP)
False Positives (FP) Classified
Negatif
False Negatives (FN)
True Negatives (TN)
Precision merupakan tingkat ketepatan antara informasi yang diminta oleh pengguna dengan jawaban yang diberikan oleh sistem (Sugiharto & Lhaksmana, 2018). Untuk menghitung nilai precision formulanya ada di Persamaan (7).
𝑝𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛 = 𝑇𝑃
𝑇𝑃 + 𝐹𝑃 (7)
Recall merupakan tingkat keberhasilan sistem dalam menampilkan atau menemukan kembali sebuah informasi dalam bentuk analisis sentimen (Onantya, et al., 2019). Untuk menghitung nilai recall formulanya ada di Persamaan (8).
𝑟𝑒𝑐𝑎𝑙𝑙 = 𝑇𝑃
𝑇𝑃 + 𝐹𝑁 (8)
F-measure merupakan perhitungan evaluasi dalam informasi temu kembali yang mengkombinasikan recall dan precision (Sugiharto & Lhaksmana, 2018). Untuk menghitung nilai f-measure formulanya ada di Persamaan (9).
𝑓 − 𝑚𝑒𝑎𝑠𝑢𝑟𝑒 = 2 × 𝑝𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛 × 𝑟𝑒𝑐𝑎𝑙𝑙
𝑝𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛 + 𝑟𝑒𝑐𝑎𝑙𝑙 (9) Accuracy merupakan kedekatan antara nilai aktual dengan nilai prediksi dari sistem (Onantya, et al., 2019). Untuk menghitung nilai accuracy formulanya ada di Persamaan (10).
𝑎𝑐𝑐𝑢𝑟𝑎𝑐𝑦 = 𝑇𝑃 + 𝑇𝑁
𝑇𝑃+𝑇𝑁+𝐹𝑃+𝐹𝑁 (10)
Berikut merupakan keterangan untuk Persamaan (7) – (10):
𝑇𝑃 : jumlah dari data positif yang terklasifikasi dengan benar oleh sistem.
𝑇𝑁 : jumlah dari data negatif yang terklasifikasi dengan benar oleh sistem.
𝐹𝑃 : jumlah dari data yang nilai sebenarnya negatif namun terklasifikasi ke kelas positif oleh sistem.
𝐹𝑁 : jumlah data yang nilai sebenarnya positif namun terklasifikasi ke kelas negatif oleh sistem.
3. METODOLOGI PENELITIAN 3.1. Pengumpulan Data
Data yang digunakan dalam penelitian ini menggunakan data sekunder. Data tersebut diperoleh dari kolom komentar akun resmi media sosial (Facebook, Instagram, Twitter, dan Youtube) MRT Jakarta. Total data yang digunakan dalam penelitian ini sebanyak 650 data, yang terdiri dari 350 data dengan sentimen positif dan 300 data dengan sentimen negatif.
Data ulasan tersebut disimpan ke dalam sebuah file (.txt). Untuk data yang ada di dalam dataset penelitian ini telah terlabeli semua, data tersebut dilabeli oleh 4 orang pakar.
3.2. Perancangan Algoritme
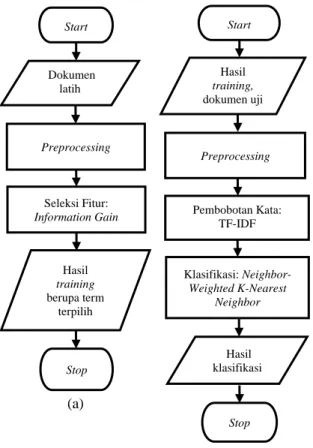
Sistem yang dibangun dalam penelitian ini yakni sebuah sistem analisis sentimen terhadap ulasan pengguna MRT Jakarta. Sistem analisis sentimen ini terbagi menjadi 2 proses, yakni:
proses training data dan testing data. Dalam proses training data terdiri dari 2 tahapan, yakni: tahapan awal dilakukannya proses preprocessing data dan tahapan terakhir dilakukan proses seleksi fitur menggunakan Information Gain. Dalam proses testing data terdiri dari beberapa tahapan, yakni: tahapan awal dilakukan proses preprocessing data, tahapan selanjutnya melakukan proses pembobotan kata atau term weighting menggunakan metode TF-IDF, dan tahapan yang terakhir adalah melakukan proses klasifikasi menggunakan metode NWKNN.
Alur dari perancangan sistem analisis sentimen pada penelitian ini dapat diperhatikan dalam Gambar 1.
Gambar 1. Diagram Alir Perancangan Algoritme untuk (a) Proses Training; serta (b) Proses Testing 4. PENGUJIAN DAN ANALISIS
4.1. Pengujian Sistem
Nilai F-measure dijadikan acuan untuk mencari parameter yang mempunyai hasil evaluasi sistem terbaik. Pemilihan F-measure ini dilakukan karena hasil jumlah data false positive (FP) dan false negative (FN) dalam penelitian ini tidak mendekati (asymmetric).
Dalam sistem analisis sentimen ini, pengujian sistem menggunakan 5-Fold Cross Validation digunakan untuk menguji nilai k dan nilai exponent pada metode Neighbor-Weighted K- Nearest Neighbor (NWKNN) serta menguji nilai threshold pada seleksi fitur Information Gain (IG). Sedangkan untuk pengujian pengaruh stopword removal menggunakan data pada Fold terbaik yang telah didapat dari pengujian sebelumnya. Penelitian ini menggunakan data sebanyak 650 dokumen, yang mana pengujian dilakukan sebanyak 5 kali pada 5 Fold data latih dan data uji yang berbeda. Komposisi pembagian data setiap Fold nya yakni 520 data sebagai data latih dan 130 data sebagai data uji.
Dalam mengukur kinerja algoritme NWKNN diujikan beberapa variasi nilai k dan exponent. Setelah itu dicari nilai rata-rata pengujian pada keseluruhan fold, nilai k dan exponent yang memiliki nilai f-measure tertinggi diambil dan dijadikan sebagai variabel kontrol. Untuk melihat pengaruh seleksi fitur IG pada hasil pengujian sistem, menggunakan beberapa variasi nilai threshold untuk diujikan serta menggunakan nilai k dan exponent terbaik yang telah diperoleh dari pengujian sebelumnya. Untuk melihat pengaruh penggunaan stopword pada sistem analisis sentimen ini, dilakukan perbandingan antara sistem yang menggunakan stopword dan yang tanpa menggunakan stopword.
Berikut ini merupakan hasil rata-rata pengujian 5-Fold Cross Validation pada nilai 𝑘 yang dapat diperhatikan pada Tabel 2.
Tabel 2. Rata-rata Pengujian 5-Fold Cross Validation pada nilai 𝑘
Nilai
k Precision Recall F-
measure Accuracy
2 0,84 0,90 0,87 0,85
4 0,85 0,92 0,88 0,87
6 0,84 0,94 0,89 0,87
8 0,84 0,94 0,89 0,87
10 0,84 0,95 0,89 0,87
20 0,85 0,95 0,90 0,88
30 0,87 0,95 0,91 0,89
40 0,88 0,94 0,91 0,90
50 0,87 0,94 0,90 0,89
60 0,87 0,94 0,90 0,89
70 0,87 0,94 0,90 0,89
80 0,87 0,94 0,91 0,90
90 0,88 0,94 0,91 0,90
100 0,89 0,94 0,91 0,90
150 0,88 0,94 0,91 0,90
200 0,88 0,95 0,91 0,90
Berikutnya merupakan hasil rata-rata pengujian 5-Fold Cross Validation pada nilai exponent berdasarkan nilai k terbaik yang dapat diperhatikan pada Tabel 3.
Tabel 3. Rata-rata Pengujian 5-Fold Cross Validation pada nilai exponent
Nilai
exponent Precision Recall F-
measure Accuracy
2 0,89 0,94 0,91 0,90
3 0,88 0,94 0,91 0,90
4 0,87 0,94 0,90 0,89
5 0,87 0,94 0,90 0,89
6 0,87 0,94 0,90 0,89
7 0,87 0,94 0,90 0,89
8 0,86 0,95 0,90 0,89
9 0,86 0,95 0,90 0,89
10 0,86 0,95 0,90 0,89
Start
Dokumen latih
Preprocessing
Hasil training berupa term
terpilih
Stop Seleksi Fitur:
Information Gain
(a)
Start
Hasil training, dokumen uji
Preprocessing
Pembobotan Kata:
TF-IDF
Klasifikasi: Neighbor- Weighted K-Nearest
Neighbor
Hasil klasifikasi
Stop
(b)
Berikutnya merupakan hasil rata-rata pengujian 5-Fold Cross Validation pada nilai threshold berdasarkan nilai k dan exponent terbaik yang dapat diperhatikan pada Tabel 4.
Tabel 4. Rata-rata Pengujian 5-Fold Cross Validation pada nilai threshold Thres
hold Precision Recall F-
measure Accuracy
25% 0,56 0,94 0,70 0,56
50% 0,64 0,87 0,73 0,66
60% 0,64 0,84 0,73 0,66
75% 0,73 0,73 0,73 0,71
90% 0,84 0,75 0,79 0,79
100% 0,89 0,94 0,91 0,90
Berikutnya merupakan hasil pengujian pengaruh stopword removal pada Fold kelima (fold terbaik) berdasarkan nilai k dan exponent terbaik yang dapat diperhatikan pada Tabel 5.
Tabel 5. Hasil Pengujian Pengaruh Stopword Removal
Memakai Stopword Threshold Precision Recall F-
Measure Accuracy
25% 0,54 0,99 0,70 0,54
50% 0,58 0,90 0,71 0,60
60% 0,64 0,87 0,74 0,67
75% 0,68 0,86 0,76 0,71
90% 0,85 0,87 0,86 0,85
100% 0,93 0,94 0,94 0,93
Tanpa Memakai Stopword Threshold Precision Recall F-
measure Accuracy
25% 0,53 0,86 0,66 0,52
50% 0,61 0,89 0,73 0,64
60% 0,72 0,77 0,74 0,72
75% 0,79 0,87 0,83 0,81
90% 0,88 0,76 0,82 0,82
100% 1 0,94 0,97 0,97
4.2. Analisis Pengujian Sistem
Berdasarkan hasil pengujian sistem, parameter terbaik yang bisa digunakan pada sistem analisis sentimen pada penelitian ini yakni, nilai k = 100, nilai exponent = 2, serta tanpa menggunakan seleksi fitur dan stopword removal.
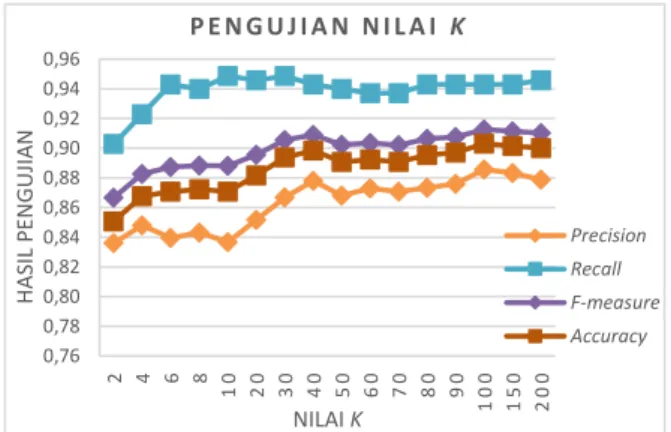
Untuk melihat hasil pengujian nilai k pada keseluruhan Fold dapat diperhatikan pada Gambar 2.
Gambar 2. Grafik Rata-rata Pengujian 5-Fold Cross Validation pada Nilai k
Besarnya nilai k dapat mempengaruhi hasil evaluasi sistem. Dapat dilihat pada grafik di atas, nilai f-measure dan accuracy terus mengalami peningkatan seiring dengan besarnya nilai k dan memperoleh hasil optimal pada nilai k = 100. Dengan nilai k yang rendah membuat hasil evaluasi sistem tidak optimal, karena nilai ketetanggaan yang diambil hanya sedikit.
Untuk melihat hasil pengujian nilai exponent pada keseluruhan Fold dapat diperhatikan pada Gambar 3.
Gambar 3. Grafik Rata-rata Pengujian 5-Fold Cross Validation pada Nilai exponent
Dapat dilihat pada grafik di atas, nilai f- measure dan accuracy terus mengalami penurunan seiring dengan besarnya nilai exponent. Penurunan tersebut mengalami perubahan nilai yang tidak signifikan. Hal tersebut dibuktikan dengan selisih rata-rata nilai precision, recall, f-measure, dan accuracy pada masing-masing nilai exponent hanya berselisih sedikit (semuanya berselisih kurang dari 1%).
0,76 0,78 0,80 0,82 0,84 0,86 0,88 0,90 0,92 0,94 0,96
2 4 6 8 10 20 30 40 50 60 70 80 90 100 150 200
HASIL PENGUJIAN
NILAI K P E N G U J I A N N I L A I K
Precision Recall F-measure Accuracy
0,82 0,84 0,86 0,88 0,90 0,92 0,94 0,96
2 3 4 5 6 7 8 9 1 0
HASIL PENGUJIAN
NILAI EXPONENT
P E N G U J I A N N I L A I E X P O N E N T
Precision Recall F-measure Accuracy
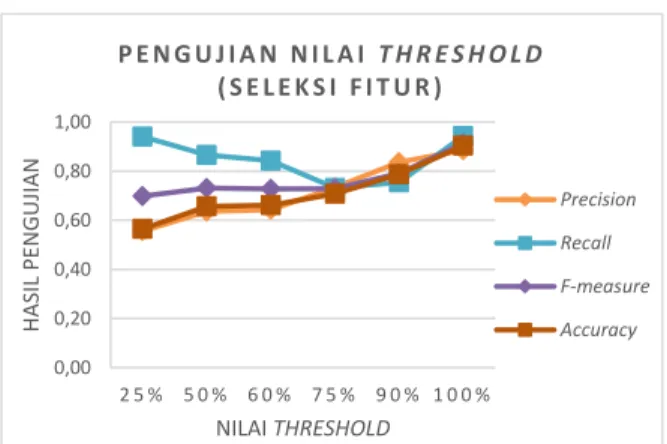
Untuk melihat hasil pengujian nilai threshold pada keseluruhan Fold dapat diperhatikan pada Gambar 4.
Gambar 4. Grafik Rata-rata Pengujian 5-Fold Cross Validation pada Nilai Threshold
Berdasarkan grafik di atas, hasil evaluasi sistem yang tanpa menggunakan seleksi fitur Information Gain (IG) lebih optimal daripada yang menggunakan seleksi fitur IG. Hal tersebut terjadi karena adanya pengambilan banyaknya fitur atau term berdasarkan persentase nilai threshold yang tidak berimbang. Apabila persen nilai threshold memiliki nilai yang kecil maka semakin sedikit term yang diambil untuk proses selanjutnya.
Dengan term yang lebih sedikit ini tidak dapat merepresentasikan banyak dokumen, sehingga bisa jadi sistem salah mengklasifikasikan kategori kelas. Tetapi dengan term yang lebih sedikit dapat membuat waktu komputasi (berdasarkan runtime program) lebih cepat. Di sisi lain, nilai threshold yang besar mengambil lebih banyak term untuk proses selanjutnya yang dapat menyebabkan waktu komputasi lebih lama.
Untuk melihat perbandingan hasil pengujian pengaruh stopword removal di Fold 5 dapat diperhatikan pada Gambar 5.
Gambar 5. Grafik Hasil Pengujian Pengaruh Stopword Removal pada Fold Kelima
Nilai F-measure pada sistem tanpa menggunakan stopword (serta tanpa menggunakan seleksi fitur IG) lebih optimal daripada sistem yang menggunakan stopword.
Hal ini terjadi karena adanya penghilangan kata negasi (seperti kata: tidak, bukan, enggak) pada ulasan ketika proses filtering. Dengan adanya penghapusan kata bernegasi dapat membuat ulasan tersebut kehilangan makna sebenarnya (kehilangan sentimennya). Sehingga bisa saja sistem salah mengklasifikasikan kelas pada ulasan tersebut.
5. KESIMPULAN DAN SARAN
Kesimpulan dari sistem analisis sentimen pada penelitian ini yakni hasil pengujian 5-Fold Cross Validation mencapai titik optimal pada Fold kelima saat nilai k = 100, nilai exponent = 2, dan nilai threshold = 100% (tanpa seleksi fitur dan tanpa menggunakan stopword removal), dengan nilai precision, recall, f- measure, dan accuracy sebesar 1; 0,94; 0,97;
dan 0,97. Seleksi fitur IG cukup berpengaruh dalam sistem analisis sentimen ini. Hal tersebut terbukti dengan adanya seleksi fitur IG dapat mempengaruhi waktu komputasi (berdasarkan runtime program) lebih cepat dibandingkan dengan tanpa menggunakan seleksi fitur IG.
Saran yang dapat menunjang penelitian berikutnya, yakni: melakukan perbaikan pada singkatan kata dan kata yang tidak baku.
Melakukan pemilihan ulasan yang hanya mengandung 1 sentimen (positif atau negatif), sehingga terhindar dari ulasan yang mengandung makna ambigu. Serta membuat sebuah kamus yang berisikan persamaan kata dari kata yang mengandung negasi. Misalkan terdapat ulasan “AC nya kurang dingin”, kata bernegasi ‘kurang dingin’ bisa digantikan dengan kata ‘panas’, sehingga ulasan tersebut tetap mempunyai arti yang sebenarnya.
6. DAFTAR PUSTAKA
Anon., 2019. mrt jakarta. [Online] Available at:
https://www.jakartamrt.co.id/2019/06/2 4/jumlah-penumpang-harian-ratangga- tembus-108-ribu/ [Diakses 26 Agustus 2019].
Feldman, R. & Sanger, J., 2007. The Text Mining Handbook: Advanced Approaches to Analyzing Unstructured Data. 1st penyunt. Cambridge:
Cambridge University Press.
Indriati & Ridok, A., 2016. SENTIMENT
0,00 0,20 0,40 0,60 0,80 1,00
2 5 % 5 0 % 6 0 % 7 5 % 9 0 % 1 0 0 %
HASIL PENGUJIAN
NILAI THRESHOLD
P E N G U J I A N N I L A I T H R E S H O L D ( S E L E K S I F I T U R )
Precision Recall F-measure Accuracy
0,00 0,20 0,40 0,60 0,80 1,00 1,20
2 5 % 5 0 % 6 0 % 7 5 % 9 0 % 1 0 0 %
HASIL PENGUJIAN F-MEASURE
NILAI THRESHOLD
P E N G U J I A N S T O P W O R D R E M O V A L
Stopword Tanpa Stopword
ANALYSIS FOR REVIEW MOBILE APPLICATIONS USING NEIGHBOR METHOD WEIGHTED K-NEAREST NEIGHBOR (NWKNN). Journal of Environmental Engineering &
Sustainable Technology (JEEST UB), 03(1), pp. 23-32.
Mulawarman & Nurfitri, A. D., 2017. Perilaku Pengguna Media Sosial beserta Implikasinya Ditinjau dari Perspektif Psikologi Sosial Terapan. Buletin Psikologi Jurnal UGM, 25(1), pp. 36- 44.
Novantirani, A., Sabariah, M. K. & Effendy, V., 2015. Analisis Sentimen pada Twitter untuk Mengenai Penggunaan Transportasi Umum Darat Dalam Kota dengan Metode Support Vector Machine. Bandung, e-Proceeding of Engineering.
Nugraha, P. D., Faraby, S. A. & Adiwijaya, 2018. Klasifikasi Dokumen Menggunakan Metode k-Nearest Neighbor (kNN) dengan Information Gain. Bandung, e-Proceeding of Engineering.
Onantya, I. D., Indriati & Adikara, P. P., 2019.
Analisis Sentimen Pada Ulasan Aplikasi BCA Mobile Menggunakan BM25 Dan Improved K-Nearest Neighbor. Jurnal Pengembangan Teknologi Informasi dan Komputer (JPTIIK UB), 3(3), pp. 2575-2580.
Pristiyanti, R. I., Fauzi, M. A. & Muflikhah, L., 2018. Sentiment Analysis Peringkasan Review Film Menggunakan Metode Information Gain dan K-Nearest Neighbor. Jurnal Pengembangan Teknologi Informasi dan Ilmu Komputer (JPTIIK UB), 2(3), pp. 1179- 1186.
Putranti, N. D. & Winarko, E., 2014. Analisis Sentimen Twitter untuk Teks Berbahasa Indonesia dengan Maximum Entropy dan Support Vector Machine.
Indonesian Journal of Computing and Cybernetics Systems (IJCCS), 8(1), pp.
91-100.
Sahara, S. & Wahyudi, M., 2015. K-NEAREST NEIGHBORS SEBAGAI ANALISIS SENTIMENT REVIEW PRODUK APPSTORE FOR ANDROID. Bekasi, Konferensi Nasional Ilmu Pengetahuan dan Teknologi (KNIT).
Sugiharto, K. R. & Lhaksmana, K. M., 2018.
Analisis Sentimen terhadap Toko Online menggunakan Naïve Bayes pada Media Sosial Twitter. Bandung, e- Proceeding of Engineering.
Suguna, N. & Thanushkodi, D. K., 2010. An Improved k-Nearest Neighbor Classification Using. IJCSI International Journal of Computer Science Issues, 7(4), pp. 18-21.
Tan, S., 2005. Neighbor-weighted K-nearest neighbor for unbalanced text corpus.
Expert Systems with Applications: An International Journal, 28(4), pp. 667- 671.
Uğuz, H., 2011. A two-stage feature selection method for text categorization by using information gain, principal component analysis and genetic algorithm. Journal Knowledge-Based Systems, 24(7), pp.
1024-1032.
Widadio, N. A., 2019. Anadolu Agency.
[Online] Available at:
https://www.aa.com.tr/id/nasional/surve i-tingkat-kemacetan-jakarta-turun-8- persen-pada-2018/1506436 [Diakses 26 Agustus 2019].