BAB 2 LANDASAN TEORI
2.1 Database 2.1.1 Basis Data
Menurut Connolly (2002, p14), basis data adalah kumpulan data yang terhubung secara logis, yang dapat digunakan secara bersama, dan deskripsi dari data ini dirancang untuk memenuhi kebutuhan. Sedangkan menurut O’Brien (2003, p145), basis data adalah sebuah kumpulan terintegrasi dari elemen data yang terhubung secara logis. Maka dapat disimpulkan bahwa basis data adalah suatu kumpulan data yang memiliki pola tertentu yang logis.
2.1.2 Model Relasional
Menurut Subekti (1998, p23), dalam model basis data relasional maka data diorganisir dalam bentuk tabel-tabel dua dimensi (seperti halnya bentuk konvensional dari file sequential). Organisasi data dalam bentuk tabel atau disebut juga relation, terdiri atas baris (row/tuple) yang merepresentasikan
record dan kolom (column) yang merepresentasikan field (atribut).
Berbagai keuntungan yang dimiliki oleh basis data relasional adalah: - Bentuknya sederhana sehingga mudah dimengerti (representasi tabel)
- Bentuknya alami (natural) mudah bagi pengguna untuk melakukan berbagai operasi data (insert, update, delete).
Menurut Kadir (1998, p25) model relasional merupakan model yang paling sederhana sehingga mudah dipahami oleh pengguna, serta merupakan
tabel dua dimensi atau berupa baris dan atribut. Relasi dirancang sedemikian rupa sehingga dapat menghilangkan kemubaziran data dan menggunakan kunci tamu untuk berhubungan dengan relasi lain.
Kesimpulannya model relasional merupakan data yang ditampilkan dalam bentuk dua dimensi yang berupa beberapa baris dan kolom. Pada tiap relasi terdapat kunci yang menghubungkan antara satu relasi dengan relasi yang lain.
2.1.3 Kunci Relasional
Menurut Connolly (2002, p78-79) kunci relasi sangat dibutuhkan untuk mengidentifikasi satu atau lebih atribut (disebut kunci relasi) yang memiliki nilai unik setiap tuple dalam relasi. Macam-macam kunci relasi:
1. Kunci Sederhana (Simple Key)
Kunci sederhana adalah suatu kunci yang dibentuk oleh satu atribut. 2. Kunci Komposit (Composite Key)
Kunci Komposit adalah kunci yang disusun berdasarkan lebih dari satu atribut.
3. Kunci Kandidat (Candidate Key)
Kunci Kandidat adalah satu atribut atau satu set minimal atribut yang mengidentifikasikan secara unik suatu kejadian spesifik dari entity.
4. Kunci Primer (Primary Key)
Kunci Primer adalah satu atribut atau satu set minimal atribut yang tidak hanya mengidentifikasikan secara unik suatu kejadian spesifik, tapi juga dapat mewakili setiap kejadian dari suatu entity.
5. Kunci Alternatif (Alternate Key)
Kunci Alternatif adalah kunci kandidat yang tidak dipakai sebagai kunci primer.
6. Kunci Tamu (Foreign Key)
Kunci Tamu adalah satu atribut yang melengkapi satu hubungan (relationship) yang menunjukkan ke induknya.
2.1.4 Struktur Data Relasional
Menurut Connolly (2002, p72-74) struktur data relasional terdiri dari: • Relasi
Suatu relasi adalah sebuah tabel dengan kolom-kolom dan baris-baris. • Atribut
Suatu atribut adalah sebuah nama kolom dari suatu relasi. • Domain
Sebuah domain merupakan sekumpulan nilai-nilai yang diperbolehkan bagi satu atau lebih atribut.
• Tuple
Tuple merupakan sebuah baris dari sebuah relasi.
• Derajat (degree)
Derajat dari suatu relasi adalah sejumlah atribut yang terkandung di dalamnya.
• Kardinalitas (cardinality)
• Relasi Basis Data
Suatu koleksi dari sejumlah relasi normalisasi dengan nama-nama relasi yang jelas.
2.1.5 Tahapan Perancangan Basis Data
Menurut Connolly (2002, p419), proses perancangan dibagi menjadi 3 tahap utama:
1. Perancangan basis data secara konseptual
Perancangan konseptual merupakan proses konstruksi suatu informasi yang digunakan dalam sebuah organisasi. Fase perancangan konseptual bermula dari pembuatan data model konseptual dari organisasi, yang sepenuhnya bebas dari pengimplementasian rincian– rincian seperti mengenai sasaran dari manajemen sistem basis data (DBMS), program–program aplikasi, bahasa pemrograman, platform perangkat keras, persoalan kinerja atau pertimbangan–pertimbangan fisik lainnya.
2. Perancangan Basis Data secara logikal
Perancangan basis data logikal adalah proses konstruksi suatu informasi yang digunakan dalam sebuah perusahaan berdasarkan pada sebuah model data yang spesifik, tetapi bebas dari pertimbangan– pertimbangan fisik lainnya.
Fase perancangan basis data secara logikal memerlukan modal perancangan konseptual pada sebuah model logikal, yang mana dipengaruhi oleh model data untuk target basis data (contohnya, model
relasional). Model data logikal adalah sumber informasi bagi fase perancangan fisik, menyediakan perancangan fisik yang sangat penting untuk sebuah perancangan basis data yang efisien.
3. Perancangan Basis Data secara fisikal
Perancangan basis data secara fisik merupakan proses pembuatan deskripsi dari implementasi basis data pada media penyimpanan sekunder, fase ini mendeskripsikan dasar relasi, berkas organisasi dan indeks untuk mencapai pengaksesan data yang efisien, dan beberapa batasan hubungan yang utuh dan tingkat keamanan.
Fase perancangan basis data secara fisik memperbolehkan perancang membuat keputusan–keputusan berdasarkan bagaimana basis data diimplementasikan, agar perancangan fisikal ditoleransi sebuah untuk sebuah manajemen sistem basis data yang spesifik. Ada timbal balik antara perancangan logical dan perancangan fisikal, karena keputusan–keputusan diambil selama perancangan fisikal mengembangkan kinerja yang bisa mempengaruhi model data logikal.
2.1.6 Entity-Relational Diagram (ERD)
Menurut Date (2000, p427–429), entity relational diagram (ER Diagram) merupakan sebuah teknik untuk menggambarkan struktur logis dari sebuah basis data dalam suatu cara bergambar. Tentu saja, popularitas dari sebuah model ER seperti sebuah pendekatan pada perancangan basis data dapat dilengkapi lebih untuk keberadaan tehnik diagram ER daripada untuk beberapa kasus lainnya.
2.2 Normalisasi
2.2.1 Pengertian Normalisasi
Normalisasi adalah sebuah teknik formal untuk menganalisis relasi berdasarkan primary key (candidate key) dan ketergantungan fungsional (Connolly, 2002, p386). Teknik tersebut mencakup serangkaian aturan yang dapat digunakan untuk menguji relasi individual, sehingga sebuah basis data dapat dinormalisasi pada derajat tertentu. Ketika syarat tidak terpenuhi, relasi yang tidak sesuai syarat harus diuraikan ke dalam relasi yang secara individu memenuhi syarat-syarat normalisasi. Tujuan dari proses normalisasi adalah untuk menghilangkan redundansi data (misalnya menyimpan data yang sama di beberapa tabel) dan memastikan ketergantungan data yang ada sudah benar (hanya menyimpan data yang berhubungan ke dalam sebuah tabel). Normalisasi mendukung para perancang basis data dengan memberikan serangkaian percobaan yang dapat digunakan dalam relasi individual sehingga skema relasi tersebut dapat dinormalisasi ke dalam bentuk yang lebih spesifik untuk menghindari kejadian yang memungkinkan terjadinya update anomaly (Connolly, 2002, p377). Normalisasi biasanya dilakukan dalam beberapa tahap. Masing-masing tahap berkaitan dengan bentuk normal tertentu yang telah diketahui propertinya. Dalam pemodelan data, sangatlah penting untuk mengenal normalisasi tingkat pertama (1NF) yang merupakan kondisi kritis untuk membuat relasi-relasi yang diperlukan, sedangkan bagian bentuk normal yang lain merupakan pilihan (optional). Namun, untuk menghindari terjadinya update
normal ketiga (Connolly, 2002, p386).
2.2.2 Pengertian Anomali
Menurut Connolly (2002, p376), anomali, adalah suatu masalah yang timbul seperti: data ganda, data hilang, tempat pemborosan memori, dan data yang tidak konsisten akibat proses penghapusan data, pembaruan data, pemasukan data, dan penggantian data.
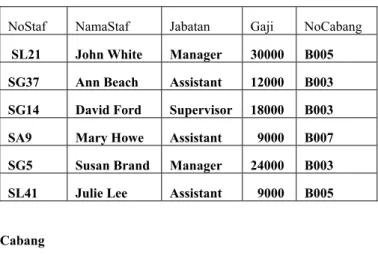
Staf
NoStaf NamaStaf Jabatan Gaji NoCabang SL21 John White Manager 30000 B005
SG37 Ann Beach Assistant 12000 B003 SG14 David Ford Supervisor 18000 B003 SA9 Mary Howe Assistant 9000 B007 SG5 Susan Brand Manager 24000 B003 SL41 Julie Lee Assistant 9000 B005
Cabang
NoCabang AlamatCabang B005 22 Deer Rd, London B007 16 Argyll St, Aberdeen B003 163 Main St, Glasgow
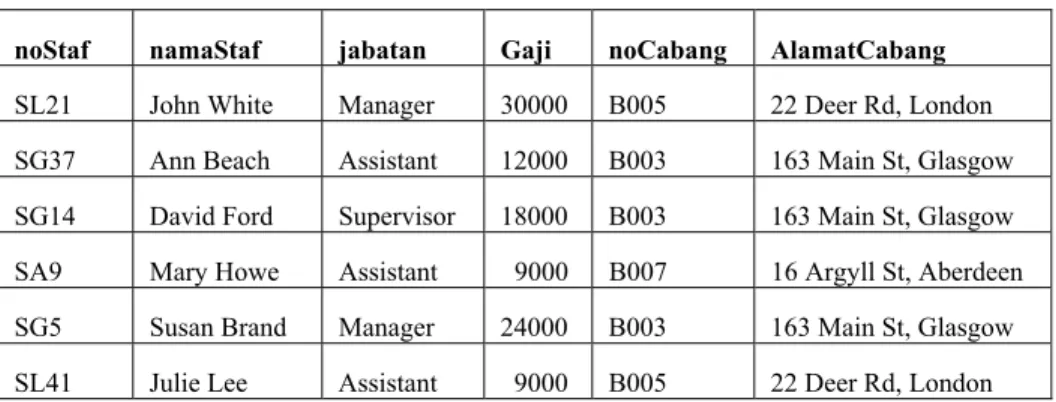
StafCabang
noStaf namaStaf jabatan Gaji noCabang AlamatCabang SL21 John White Manager 30000 B005 22 Deer Rd, London SG37 Ann Beach Assistant 12000 B003 163 Main St, Glasgow SG14 David Ford Supervisor 18000 B003 163 Main St, Glasgow SA9 Mary Howe Assistant 9000 B007 16 Argyll St, Aberdeen SG5 Susan Brand Manager 24000 B003 163 Main St, Glasgow SL41 Julie Lee Assistant 9000 B005 22 Deer Rd, London
Tabel 2.2 Relasi StafCabang
Menurut Subekti (1998, p22), anomali (kejanggalan) akan muncul terhadap operasi dasar karena adanya fakta hubungan many to many (baik untuk operasi insert, delete, maupun update):
• Anomali insert
Ada dua jenis insertion anomaly yang dapat digambarkan dengan menggunakan relasi pada contoh tabel 2.2 di atas.
• Untuk memasukkan anggota baru staf ke dalam relasi StafCabang, perincian Cabang di mana staf ditempatkan perlu dimasukkan. Sebagai contohnya, untuk memasukkan perincian staf baru yang akan ditempatkan pada cabang nomor B007, perincian cabang nomor B007 perlu dimasukkan dengan benar, sehingga perincian cabang konsisten dengan nilai cabang B007 di tuple lain dalam relasi StafCabang. Relasi yang ditunjukkan pada tabel 2.1 tidak mengalami data yang tidak konsisten, karena hanya memasukkan nomor cabang dengan tepat untuk masing-masing staf dalam relasi Staf. Sedangkan
perincian cabang nomor B007 disimpan dalam basis data sebagai
tuple tersendiri dalam relasi Cabang.
• Untuk memasukkan perincian cabang baru yang tidak mempunyai nomor anggota staf pada relasi StafCabang, perlu memasukkan nilai
null pada atribut staf, seperti noStaf. noStaf adalah primary key dari
relasi StafCabang, sehingga memasukkan nilai null pada noStaf akan melanggar konsep integritas data, dan hal semacam ini tidak diperbolehkan. Oleh karena itu, nilai null tidak bisa dimasukkan pada noStaf ke dalam cabang baru pada relasi StafCabang. Perancangan yang ditunjukkan pada tabel 2.1 menghindari masalah ini karena perincian cabang yang dimasukkan pada relasi Cabang terpisah dari perincian staf.
• Anomali delete
Jika ingin menghapus sebuah tuple dari relasi StafCabang yang merepresentasikan anggota staf yang ditempatkan pada cabang, maka perincian tentang cabang juga hilang dari basis data. Sebagai contohnya, jika ingin menghapus tuple NoStaf SA9 (Mary Howe) dari relasi StafCabang, perincian yang berhubungan dengan cabang nomor B007 akan hilang dari basis data. Rancangan pada relasi yang ditunjukkan pada tabel 2.1 menghindari masalah ini, karena tuple cabang disimpan secara terpisah dari tuple staf dan hanya atribut NoCabang yang berhubungan dengan kedua relasi tersebut. Jika ingin menghapus tuple NoStaf SA9 dari relasi Staf, perincian cabang nomor B007 tetap tidak terpengaruh dalam relasi
Cabang.
• Anomali update:
Jika ingin mengubah nilai dari salah satu atribut untuk cabang tertentu pada relasi StafCabang, contohnya AlamatCabang dari cabang nomor B003,
tuple dari semua staf yang ditempatkan pada cabang tersebut perlu
diperbaharui (update). Jika perubahan ini tidak mengubah semua tuple pada relasi StafCabang dengan tepat, maka basis data menjadi tidak konsisten. Pada contoh ini, cabang nomor B003 akan mempunyai AlamatCabang yang berbeda untuk tuple staf yang berbeda.
2.2.3 Dependensi (Ketergantungan)
Menurut Kadir (1999, p680), dependensi merupakan konsep yang mendasari normalisasi. Dependensi menjelaskan hubungan antara atribut, atau secara lebih khusus menjelaskan nilai suatu atribut yang menentukan nilai atribut lainnya. Dependensi ini kelak menjadi acuan bagi pendekomposian data ke dalam bentuk yang paling efisien.
Untuk menentukan cara yang sistematik dalam mengambil ketergantungan, perlu diketahui sejumlah inference rule yang dapat digunakan untuk mengambil ketergantungan baru dari sejumlah ketergantungan yang diberikan. Enam aturan yang dikenal sebagai inference rule untuk ketergantungan fungsional adalah sebagai berikut (Elmasri, 2000, p479).
1. Reflektif : Jika A ⊇ B, maka A Æ B 2. Augmentasi : Jika A Æ B, maka A,C Æ B,C
4. Dekomposisi : Jika A Æ B,C, maka A Æ B dan A Æ C 5. Union : Jika A Æ B dan A Æ C, maka A Æ B,C 6. Pseudotransitif : Jika A Æ B dan DB Æ E, maka AD Æ E
Misalnya skema R = (A, B, C, G, H ,I) dan sejumlah ketergantungan fungsional F {A Æ B, A Æ C, CG Æ H, CG Æ I, B Æ H}. Dengan menggunakan inference rule tersebut maka akan didapatkan F+ sebagai berikut : • A Æ H didapat dari A Æ B dan B Æ H dengan menggunakan aturan
transitif.
• CG Æ HI didapat dari CG Æ H dan CG Æ I dengan menggunakan aturan union.
• AG Æ I didapat dari A Æ C dan CG Æ I dengan menggunakan aturan pseudotransitif.
Terdapat cara lain juga untuk mendapatkan AG Æ I. Dengan menggunakan aturan augmentasi, A Æ C menjadi AG Æ CG, kemudian menggunakan CG Æ I dengan aturan transitif diperoleh AG Æ I.
Macam-macam dependensi:
• Dependensi fungsional, adalah jenis dependensi yang banyak diulas pada literatur basis data. Dependensi fungsional didefinisikan sebagai berikut: Suatu atribut Y mempunyai dependensi fungsional terhadap atribut X jika dan hanya jika setiap nilai X berhubungan dengan sebuah nilai Y (XÆY). • Dependensi fungsional sepenuhnya, dapat dijelaskan sebagai berikut:
Suatu atribut Y mempunyai dependensi fungsional penuh terhadap atribut X jika:
Y mempunyai dependensi fungsional terhadap X. Y tidak memiliki dependensi terhadap bagian dari X. • Dependensi total, dapat didefinsikan sebagai berikut:
Suatu atribut Y mempunyai dependensi total terhadap atribut X jika: Y mempunyai dependensi fungsional terhadap X.
X mempunyai dependensi fungsional terhadap Y. Dependensi ini dapat dinyatakan dengan notasi XÅÆY • Dependensi multivalued
Suatu kondisi di mana terdapat ketergantungan antara atribut (contohnya, A, B, and C) di suatu relasi, di mana untuk setiap nilai dari A terdapat sejumlah nilai dari B dan sejumlah nilai dari C. Tetapi, antara B dan C tidak saling tergantung atau tidak ada hubungan satu sama lainnya
Terjadinya multivalued dependencies dalam suatu relasi dikarenakan pada bentuk 1NF tidak diperbolehkan adanya repeating groups (atribut dalam satu baris mempunyai nilai lebih dari satu). Contohnya, jika dalam suatu relasi terdapat dua multivalued atribut, kita harus mengulang setiap nilai dari satu atribut dengan setiap nilai dari atribut lain, untuk menjaga konsistensinya. Hal ini menyebabkan multivalued dependencies dan menghasilkan redundansi data.
• Dependensi transitif, adalah sebagai berikut
Atribut Z mempunyai dependensi transitif terhadap X bila: Y mempunyai dependensi fungsional terhadap X. Z mempunyai dependensi fungsional terhadap Y.
2.2.6 Proses Normalisasi
Pertama kali dikembangkan oleh E.F.Codd (1972 b). Proses normalisasi sering dilakukan sebagai rangkaian test terhadap suatu hubungan untuk menentukan apakah memenuhi atau melanggar kebutuhan dari bentuk normal yang ditentukan.
1. Bentuk normal kesatu (1NF)
Mengidentifikasikan dan membuang atribut yang berulang (repeating
groups) dan memiliki nilai yang lebih dari satu (multivalued). Grup yang
berulang (repeating groups) disini maksudnya adalah sebuah atribut atau sekumpulan atribut dalam tabel yang mengandung banyak nilai untuk satu kejadian.
Ada dua pendekatan yang umum digunakan untuk menghilangkan grup yang berulang dalam tabel yang tidak normal (Connolly, 2002, p388) : a. Menghilangkan grup yang berulang dengan memasukkan data yang
tepat pada kolom kosong dari baris yang mengandung data yang berulang. Dengan kata lain, kolom yang kosong tersebut diisi dengan menggandakan data yang tidak berulang (jika diperlukan). Tabel yang dihasilkan merupakan suatu relasi yang mengandung nilai tunggal pada irisan untuk tiap baris dan kolom, dan tabel yang dihasilkan sudah berada dalam bentuk normal pertama.
b. Menghilangkan grup yang berulang dengan menempatkan data yang berulang bersama dengan salinan atribut key asli. Sebuah primary key diidentifikasi untuk relasi baru. Kadang-kadang tabel yang tidak normal
mengandung lebih dari satu grup yang berulang. Dalam kasus tersebut, pendekatan ini digunakan berulang-ulang sampai tidak ada grup yang berulang lagi.
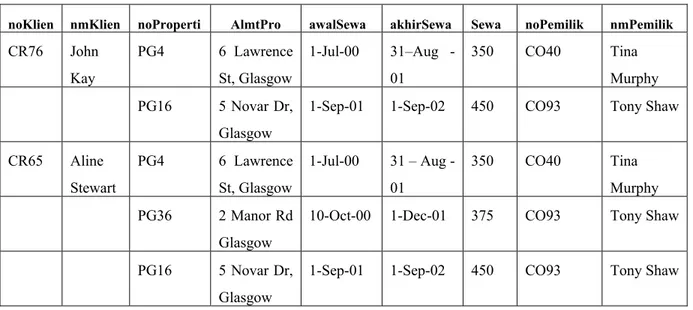
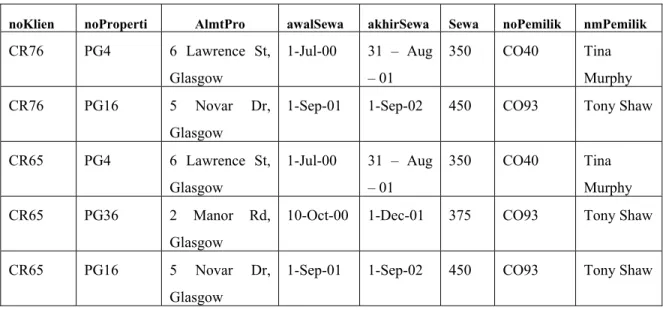
SewaKlien
noKlien nmKlien noProperti AlmtPro awalSewa akhirSewa Sewa noPemilik nmPemilik
CR76 John Kay PG4 6 Lawrence St, Glasgow 1-Jul-00 31–Aug - 01 350 CO40 Tina Murphy PG16 5 Novar Dr, Glasgow
1-Sep-01 1-Sep-02 450 CO93 Tony Shaw CR65 Aline Stewart PG4 6 Lawrence St, Glasgow 1-Jul-00 31 – Aug - 01 350 CO40 Tina Murphy PG36 2 Manor Rd Glasgow
10-Oct-00 1-Dec-01 375 CO93 Tony Shaw PG16 5 Novar Dr,
Glasgow
1-Sep-01 1-Sep-02 450 CO93 Tony Shaw
Tabel 2.3 Tabel SewaKlien yang belum dinormalisasi
noKlien diidentifikasi sebagai kunci atribut dalam tabel yang tidak normal (sewaKlien). Struktur dari grup yang berulang adalah {noProperti, AlmtPro, awalSewa, akhirSewa, Sewa, noPemilik, nmPemilik}.
Akibatnya, terdapat beberapa nilai pada irisan untuk baris dan kolom tertentu. Sebagai contohnya, untuk klien yang bernama John Kay terdapat dua nilai noProperti (PG4 dan PG16). Untuk mengubah tabel yang tidak normal ke dalam bentuk normal pertama, perlu dipastikan bahwa hanya terdapat nilai yang tunggal pada irisan dari masing-masing baris dan kolom. Oleh karena itu grup yang berulang harus dihilangkan.
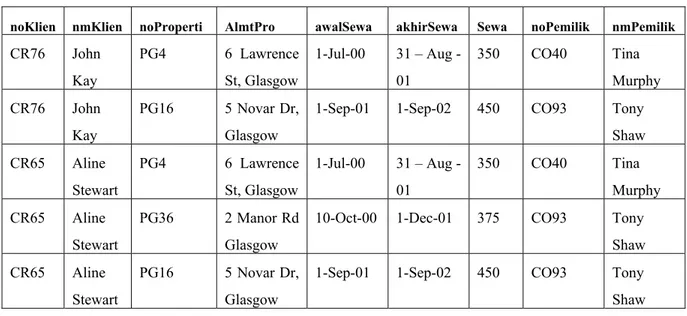
noKlien nmKlien noProperti AlmtPro awalSewa akhirSewa Sewa noPemilik nmPemilik CR76 John Kay PG4 6 Lawrence St, Glasgow 1-Jul-00 31 – Aug - 01 350 CO40 Tina Murphy CR76 John Kay PG16 5 Novar Dr, Glasgow
1-Sep-01 1-Sep-02 450 CO93 Tony Shaw CR65 Aline Stewart PG4 6 Lawrence St, Glasgow 1-Jul-00 31 – Aug - 01 350 CO40 Tina Murphy CR65 Aline Stewart PG36 2 Manor Rd Glasgow
10-Oct-00 1-Dec-01 375 CO93 Tony Shaw CR65 Aline
Stewart
PG16 5 Novar Dr, Glasgow
1-Sep-01 1-Sep-02 450 CO93 Tony Shaw
Tabel 2.4 Relasi SewaKlien pada bentuk normal pertama
Dengan menggunakan pendekatan pertama, grup yang berulang dihilangkan dengan memasukkan data klien yang tepat ke tiap baris. Hasil bentuk normal pertama relasi SewaKlien dapat dilihat pada tabel 2.4.
Candidate key untuk relasi SewaKlien diidentifikasi sebagai key gabungan
(composite key) yang terdiri dari (noKlien, noProperti), (noKlien,awalSewa) dan (noProperti, awalSewa). Key yang dipilih sebagai
primary key adalah (noKlien, noProperti) dan untuk lebih jelasnya, atribut
yang dipilih sebagai primary key diletakkan di sebelah kiri dalam relasi. Atribut akhirSewa tidak tepat sebagai komponen dari candidate key karena mungkin berisi nilai null. Relasi SewaKlien dapat didefinisikan sebagai berikut : SewaKlien (noKlien, noProperti, nmKlien, AlmtPro, awalSewa, akhirSewa, sewa, noPemilik, nmPemilik)
mengandung data yang mendeskripsikan klien, properti yang disewakan, dan pemilik properti secara berulang-ulang. Sebagai hasilnya, relasi SewaKlien mengandung redundansi data. Jika relasi dalam bentuk normal pertama diimplementasikan, maka akan terjadi update anomaly. Untuk mengatasi hal tersebut maka relasi harus diubah ke dalam bentuk normal kedua.
Dengan menggunakan pendekatan kedua, grup yang berulang dihilangkan dengan menempatkan data yang berulang bersama dengan salinan atribut key asli (noKlien) dalam relasi yang terpisah seperti yang ditunjukkan pada tabel 2.5. Kemudian primary key dapat diidentifikasi untuk relasi yang baru, dan hasil relasi dalam bentuk normal pertama adalah sebagai berikut :
Klien (noKlien, nmKlien)
PemilikPropertiSewa (noKlien, noProperti, AlmtPro,awalSewa,akhirSewa, Sewa, noPemilik, nmPemilik)
Kedua relasi Klien dan PemilikPropertiSewa berada dalam bentuk normal pertama di mana terdapat nilai tunggal pada irisan dari tiap baris dan kolom. Relasi Klien berisi data yang mendeskripsikan klien dan relasi PemilikPropertiSewa berisi data yang mendeskripsikan properti yang disewa oleh klien dan pemilik properti. Relasi pada tabel 2.5 juga berisi redundansi data yang menyebabkan terjadinya update anomaly.
noKlien noProperti AlmtPro awalSewa akhirSewa Sewa noPemilik nmPemilik CR76 PG4 6 Lawrence St, Glasgow 1-Jul-00 31 – Aug – 01 350 CO40 Tina Murphy CR76 PG16 5 Novar Dr, Glasgow
1-Sep-01 1-Sep-02 450 CO93 Tony Shaw CR65 PG4 6 Lawrence St, Glasgow 1-Jul-00 31 – Aug – 01 350 CO40 Tina Murphy CR65 PG36 2 Manor Rd, Glasgow
10-Oct-00 1-Dec-01 375 CO93 Tony Shaw CR65 PG16 5 Novar Dr,
Glasgow
1-Sep-01 1-Sep-02 450 CO93 Tony Shaw
Klien
noKlien nmKlien
CR76 John Kay CR56 Aline Stewart
Tabel 2.5 Relasi Klien dan PemilikPropertiSewa pada 1NF Suatu hubungan dinyatakan normal pertama apabila :
a. Setiap dari baris dan kolom berisi atribut yang bernilai tunggal. b. Kunci primer telah ditentukan
c. Attribut yang mempunyai nilai banyak (multivalued) telah dihilangkan. 2. Bentuk normal kedua (2NF)
Ketergantungan Fungsional (Functional Dependency)
Bergantung fungsional dapat didefinisikan sebagai berikut : Jika A dan B merupakan bagian atribut dari suatu hubungan, B bergantung penuh pada A, jika dan hanya jika setiap nilai A berhubungan dengan sebuah nilai B.
Gambar 2.3 contoh Functional Dependency
Bergantung fungsional penuh dapat didefinisikan sebagai berikut : Jika A dan B adalah atribut dari suatu hubungan , B bergantung fungsional sepenuhnya kepada A jika B bergantung fungsional terhadap A, tetapi tidak memiliki ketergantungan kepada subset A lainnya.
Suatu hubungan berada dalam bentuk normal kedua jika : a. Berada pada bentuk normal pertama
b. Atribut bukan kunci primer (non primary key) telah dihilangkan atau semua atribut bukan kunci primer bergantung fungsional sepenuhnya kepada kunci primer.
3. Bentuk normal ketiga (3NF)
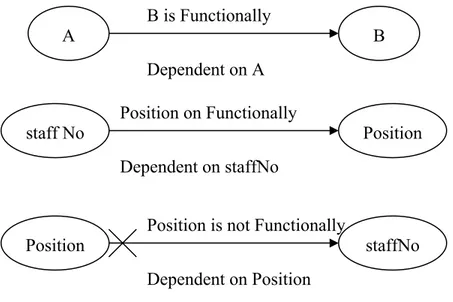
Ketergantungan Transitif (Transitive Dependency)
Ketergantungan transitif dapat didefinisikan sebagai berikut : Pada kondisi dimana A , B dan C adalah atribut dari suatu hubungan. Jika AÆB dan BÆC, maka C merupakan ketergantungan transitif pada A dan B
staff No Position
Position on Functionally Dependent on staffNo
Position Position is not Functionally staffNo Dependent on Position
A B is Functionally B
(dimana A tidak bergantung fungsional terhadap B atau C) Suatu hubungan berada pada bentuk normal ketiga jika :
a. Berada pada bentuk normal pertama dan kedua
b. Setiap atribut bukan kunci tidak memiliki dependensi transitif terhadap kunci primer.
4. Bentuk normal Boyce – Codd Normal Form (BCNF)
Pertama kali diperkenalkan oleh R.Boyce dan E.F.Codd (Codd, 1974). Suatu hubungan berada pada bentuk normal BCNF (Boyce Codd Normal Form) jika hanya jika setiap determinan adalah kunci kandidat. Bentuk normal BCNF merupakan perbaikan dari bentuk normal yang ketiga. Tetapi tidak menutup kemungkinan bahwa bentuk normal ketiga memiliki anomali, sehingga perlu dinormalisasi lagi. Suatu relasi yang memenuhi BCNF selalu memenuhi 3NF, tetapi belum tentu bentuk normal 3NF memenuhi bentuk normal BCNF
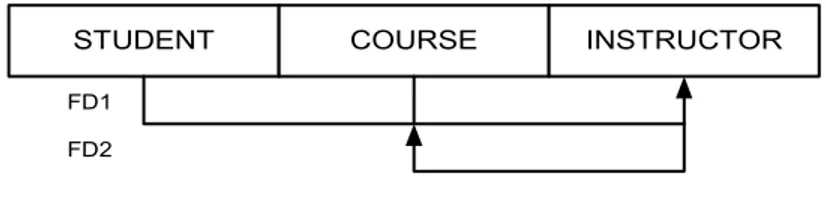
Contoh (Elmasri, 2000, p495):
Asumsinya adalah setiap INSTRUCTOR hanya mengajar satu COURSE
STUDENT COURSE INSTRUCTOR
FD1 FD2
Tabel 2.6 Relasi Teach
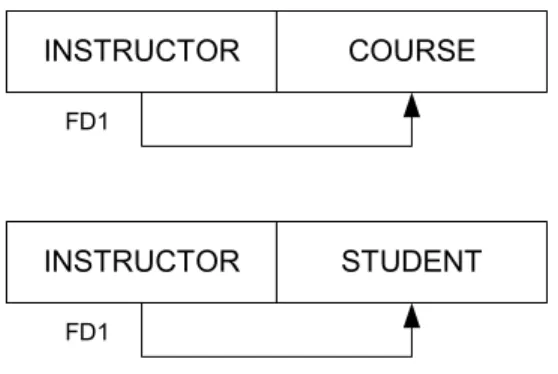
Karena determinant pada FD2 bukan kunci kandidat, maka relasi ini melanggar ketentuan BCNF. Untuk mengubahnya ke dalam bentuk BCNF, relasi di atas harus di dekomposisi menjadi dua relasi yaitu:
INSTRUCTOR COURSE
FD1
INSTRUCTOR STUDENT
FD1
Tabel 2.7 Relasi Teach setelah didekomposisi 5. Bentuk normal keempat (4NF)
Ketergantungan nilai banyak (MultiValued Atribut)
Menurut Connolly (2002, p407-408) MultiValued Dependecy adalah suatu kondisi di mana terdapat ketergantungan antara atribut (contohnya, A, B, and C) di suatu relasi, di mana untuk setiap nilai dari A terdapat sejumlah nilai dari B dan sejumlah nilai dari C. Tetapi, antara B dan C tidak saling tergantung atau tidak ada hubungan satu sama lainnya.
Terjadinya multivalued dependencies dalam suatu relasi dikarenakan pada bentuk 1NF tidak diperbolehkan adanya repeating groups (atribut dalam satu baris mempunyai nilai lebih dari satu). Contohnya, jika dalam suatu relasi terdapat dua multivalued atribut, kita harus mengulang setiap nilai dari satu atribut dengan setiap nilai dari atribut lain, untuk menjaga konsistensinya. Hal ini menyebabkan multivalued dependencies dan menghasilkan redundansi data.
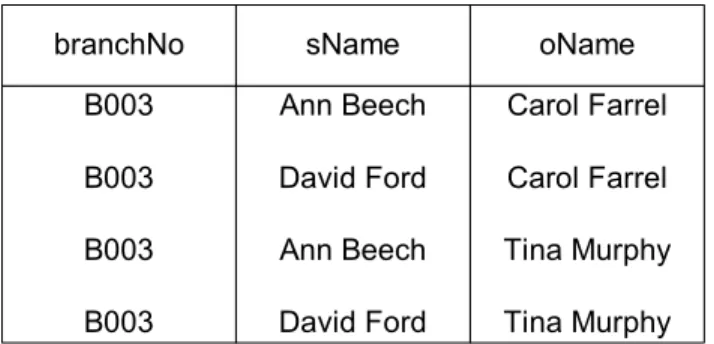
branchNo sName oName B003 B003 B003 B003 Ann Beech David Ford Ann Beech David Ford Carol Farrel Carol Farrel Tina Murphy Tina Murphy
Tabel 2.8 Relasi BranchStaffOwner
Seperti terlihat, MVD timbul karena ada dua hubungan 1:* yang independent dalam relasi BranchStaffOwner yaitu:
branchNo sName branchNo oName
Suatu relasi dikatakan sudah berada dalam 4NF jika relasi tersebut sudah dalam BCNF dan tidak mengandung nontrivial multivalued dependencies. Sebuah MVD A B dalam suatu relasi R dikatakan trivial jika B adalah subset dari A dan A U B = R. Sebuah MVD dikatakan nontrivial jika kedua kondisi pada trivial tidak dipenuhi .Seperti pada contoh di atas terdapat nontrivial MVD, maka untuk mengubahnya ke dalam 4NF, relasi di atas perlu didekomposisi menjadi relasi BranchStaff dan BranchOwner.
branchNo sName B003 B003 Ann Beech David Ford branchNo oName B003 B003 Carol Farrel Tina Murphy
Sekarang kedua relasi tersebut sudah dalam 4NF karena relasi
BranchStaff mengandung trivial MVD branchNo sName, dan relasi BranchOwner juga mengandung trivial MVD branchNo oName. 6. Bentuk normal kelima ( 5NF )
Satu hubungan dikatakan berada pada bentuk kelima jika dan hanya jika suatu hubungan tidak memiliki join dependensi. Bentuk normal keempat dan kelima diperkenalkan oleh Fagin, hanya dipakai pada kasus–kasus khusus, terdapat hubungan yang mengandung dependensi nilai banyak.
2.2.7 Overnormalisasi
Tabel–tabel yang memenuhi 5NF terkadang didekomposisi lagi. Prosesnya dikenal dengan sebutan overnormalisasi. Tujuannya adalah untuk meningkatkan kinerja, caranya adalah dengan memperlihatkan permintaan terhadap data yang sering dilakukan. Kolom–kolom data yang sering diperlukan diletakkan pada tabel tersendiri, terpisah dengan kolom–kolom data yang jarang diperlukan. Alasan yang lain , tabel yang terlalu banyak memiliki kolom dapat menimbulkan persoalan yang disebut deadlock (saling mengunci) pada pengaksesan yang serentak (sejumlah pengguna mengakses baris yang sama).
Namun perlu juga diperlihatkan bahwa tidak selamanya pendekomposisian terhadap tabel yang telah memenuhi 5NF dapat meningkatkan kinerja. Pada kenyataannya tabel yang terlalu pendek (sedikit memiliki kolom) juga menimbulkan persoalan peningkatan waktu CPU dan juga memerlukan banyak
2.3 Algoritma Normalisasi BCNF dan 4NF 2.3.1 Algoritma Normalisasi BCNF
Algoritma yang dipakai untuk menghasilkan bentuk BCNF menurut Elmasri (2000, p509) :
Set D := {R};
While there is a relation schema Q in D that is not in BCNF do {
choose a relation schema Q in D that is not in BCNF;
find a functional dependency X Æ Y in Q that violates BCNF; replace Q in D by two relation schemas (Q – Y) and (X U Y);
}
Keterangan : untuk melakukan testing bahwa suatu relation schema dalam bentuk BCNF atau tidak dapat dilakukan dengan 2 cara :
a. Setiap functional dependency X -> Y di Q, apabila X bukan berisi semua
attribute di Q, maka X -> Y menyalahi BCNF karena X bukan superkey
dari Q
b. Jika suatu relational schema Q menyalahi BCNF , terdapat sepasang
attribute A dan B di Q berupa {Q – {A,B}} -> A. Dengan melihat closure {Q – {A,B}}* untuk setiap {A,B} dari Q dan memeriksa setiap closure terdapat A (atau B) maka kita dapat memperkirakan apakah Q
pada BCNF.
Set G := F
Replace each functional dependency X -> {A1,A2,…,An} in G by the n functional dependencies X -> A1, X -> A2, …, X -> An.
For each functional dependency X -> A in G For each attribute B that is an element of X
If ((G – {X->A}) U {(X – {B}) -> A}) is equivalent to G Then replace X -> A with (X – {B}) -> A in G
For each remaining functional dependency X -> A in G If (G – {X – A}) is equivalent to G
Then remove X -> A from G
For each left hand side X of a functional dependency that appears in G create a relation schema in D with attributes { X U {A1} U {A2} … U {An}}, where X -> A1 , X -> A2, … , X -> Ak are only dependencies in G with X as left-hand-side ( X is the key of this relation ).
If none of the relation schemas in D contains a key of R, then create one more relation schema in D that contains attributes that form a key of R.
2.3.2 Algoritma Normalisasi 4NF
Algoritma yang dipakai untuk menghasilkan bentuk 4NF menurut Elmasri (2000, p519) :
Set D := {R};
While there is a relation schema Q in D that is not in 4NF do { choose a relation schema Q in D that is not in 4NF;
analysis design code test System/information
engineering
find a nontrivial MVD X Æ Y in Q that violates 4NF;
replace Q in D by two relation schemas (Q – Y) and (X U Y);
}
Asumsi : tabel-tabel masukan sudah dalam bentuk BCNF.
2.4 Perancangan Piranti Lunak
Menurut Pressman (2001, p6), yang dimaksud dengan piranti lunak adalah (1) kumpulan instruksi (program komputer) yang jika dieksekusi akan menyediakan fungsi dan dayaguna yang diinginkan, (2) kumpulan struktur data yang memungkinkan program untuk memanipulasi informasi dengan memadai, dan (3) kumpulan dokumen yang menggambarkan operasi dan penggunaan program. Dalam perancangan piranti lunak terdapat beberapa macam model seperti linier , spiral , incremental , dll. Penyusun memilih model waterfall (
linier ) karena langkah – langkahnya berurutan dan sistematis.
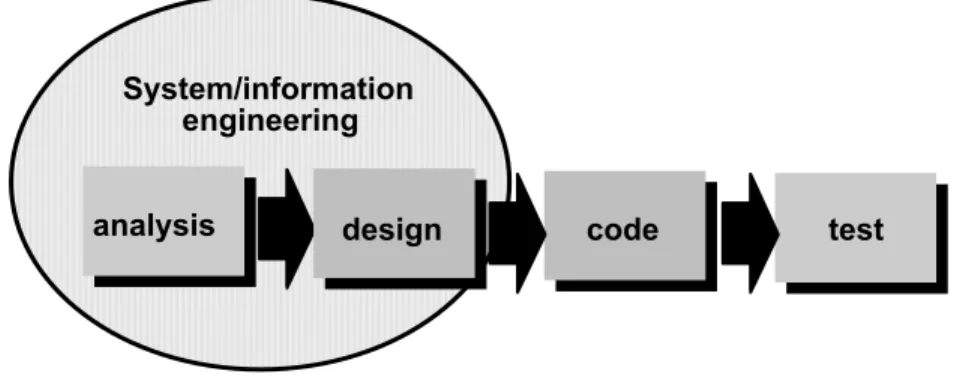
Gambar 2.2 Model linear sekuensial
Langkah-langkah dalam model waterfall adalah sebagai berikut: 1. Rekayasa dan penyusunan sistem/informasi
untuk seluruh elemen sistem dan kemudian mengalokasikan beberapa subset dari kebutuhan tersebut pada piranti lunak (software). Proses ini sangat penting ketika piranti lunak harus berinteraksi dengan elemen yang lainnya seperti, perangkat keras (hardware), manusia, dan basis data (database).
2. Analisis kebutuhan piranti lunak
Proses pengumpulan kebutuhan pada tahap ini lebih diintensifkan dan difokuskan pada piranti lunak Pengembang piranti lunak harus memahami tentang fungsi yang dibutuhkan, perilaku, dayaguna dan tampilan layar dari piranti lunak yang akan dikembangkan.
3. Perancangan (Design)
Perancangan piranti lunak sesungguhnya merupakan proses bertahap yang berfokus pada empat atribut dari sebuah program: struktur data, arsitektur piranti lunak, representasi tampilan layar, dan detail prosedural (algoritmik). Proses desain menerjemahkan kebutuhan menjadi suatu representasi dari piranti lunak yang dapat diakses sebelum pengkodean dimulai.
4. Pembuatan kode (code generation)
Proses penerjemahan bentuk desain menjadi bentuk yang dapat dibaca oleh mesin.
5. Pengujian (testing)
Pengujian program dilakukan setelah kode dihasilkan. Proses pengujian difokuskan pada bagian internal software secara logis, memastikan bahwa setiap pernyataan (statement) telah diuji, dan pada
bagian eksternal fungsi, di mana dilakukan pengujian untuk menemukan
error dan memastikan bahwa masukan yang ditentukan akan memberikan
hasil yang diharapkan. 6. Pemeliharaan (Maintenance)
Ketika piranti lunak telah selesai dikembangkan dan dikirimkan kepada pelanggan, piranti lunak tersebut mungkin akan mengalami masalah atau error yang tidak diharapkan sebelumnya. Untuk itu, tahapan pemeliharaan dilakukan dengan tujuan melakukan penyesuaian dan perbaikan pada piranti lunak tersebut.
2.5 Alat Bantu Perancangan Sistem 2.2.1 Use Case Diagram
Use Case Diagram adalah diagram yang menggambarkan interaksi antara
sistem dengan sistem luar dan user. Dengan kata lain, secara grafik menggambarkan siapa yang akan menggunakan sistem dan dengan cara bagaimana user bisa berinteraksi dengan sistem. Diagram ini secara grafik menggambarkan sistem sebagai kumpulan use case, actor (user) dan hubungan yang terjadi. (Whitten, 2004, p271)
2.2.1.1 Use Case
Use case adalah alat untuk menggambarkan fungsi-fungsi sistem dari
perspektif pengguna luar dan dalam cara dan istilah yang mereka mengerti (Whitten, 2004, p272). Use case digambarkan secara grafik oleh sebuah elips horizontal dengan nama yang muncul di atas, di bawah atau di dalam elips.
interaksi yang dilakukan user dalam mencapai tujuan tersebut. Use case merupakan hasil penguraian batasan-batasan fungsionalitas sistem ke dalam pernyataan – pernyataan yang lebih pendek.
2.2.1.2 Actor
Actor adalah segala sesuatu yang perlu berinteraksi dengan sistem untuk
pertukaran informasi (Whitten, 2004, p273).
2.2.1.3 Relationship
Relationship digambarkan dengan garis di antara dua simbol di dalam diagram use case. Arti hubungan yang terjadi bisa bervariasi tergantung bagaimana garis
digambarkan dan tipe simbol apa yang mereka hubungkan (Whitten, 2004, p273).
Jenis – jenis hubungan yang terjadi ada lima, yaitu • Association
Sebuah hubungan antara sebuah actor dengan sebuah use case dimana interaksi terjadi di antara mereka (Whitten, 2004, p274).
• Extend
Sebuah use case yang terdiri dari langkah-langkah yang dikutip dari use
case yang lebih kompleks untuk menyederhanakan use case asli dan
memperluas fungsionalitasnya. Biasanya ditandai dengan label “<<extend>>” (Whitten, 2004, p274).
• Include
Sebuah use case yang mengurangi redundansi di antara dua atau lebih use
Hubungannya digambarkan dengan “<<uses>>” (Whitten, 2004, p274). • Depends on
Hubungan yang menggambarkan ketergantungan antar use case. Jenis hubungan ini digambarkan dengan garis yang berpanah dimulai dari satu
use case menunjuk ke use case tempat ia bergantung. Garis hubungan
ditandai dengan label “<<depends on>>” (Whitten, 2004, p275). • Inheritance
Hubungan yang terjadi jika terdapat dua atau lebih actor yang memiliki sifat yang sama (Whitten, 2004, p275).
2.2.2 Diagram Alir (flowchart)
Menurut O’Brien (2003, pG-8), diagram alir merupakan suatu representasi grafis di mana simbol-simbol digunakan untuk merepresentasikan operasi, data, aliran, logika, perlengkapan, dan seterusnya. Suatu diagram alir program mengilustrasikan struktur dan bagian dari operasi program tersebut, sementara sebuah diagram alir sistem mengilustrasikan komponen-komponen dan aliran sistem informasi.
Tiga konsep utama dalam pemrograman terstruktur yaitu sekuensial, kondisi (condition), dan pengulangan (repetition) (Pressman, 2001, p424-425). Sekuensial mengimplementasikan langkah-langkah proses yang penting dalam spesifikasi algoritma-algoritma. Kondisi menyediakan kemudahan untuk memilih proses berdasarkan logika, dan pengulangan untuk melakukan proses perulangan.