http://research. pps.dinus.ac.id , 135
PEMISAHAN
VOICE DAN UNVOICE MENGGUNAKAN TEKNIK
OVERLAPING BLOCK, ZERO CROSSING RATE, DAN SHORT TIME
ENERGY DALAM PENGENALAN SUARA
Ade Yusupa1, Abdul Syukur 2, Ricardus Anggi Pramunendar 3
123Pasca Sarjana Teknik Informatika Universitas Dian Nuswantoro
ABSTRAK
Dalam proses speech recognition, speech syntesis dan speech enhancement, signal suara yang diinputkan tidak dapat langsung dikenali atau diindentifikasi sebagai gelombang signal voice atau unvoice. Proses analisis ucapan dalam menetapkan voice dan unvoice biasanya dilakukan dengan ekstrasi dari speech signal atau signal suara. Dalam penelitian ini, kami melakukan dan membandingkan 3 akurasi metode yakni: penentuan manual dengan software
Adobe Audition dibandingkan pada tool matlab dengan metode separation of voice and unvoice using non overlapping block, zero-crossing rate and energy of a speech signal, dan juga membandingkan dengan metode
peneliti yaitu penggabungan teknik overlapping blocks, zero crossing rate dan short time energy dalam menentukan
voice dan unvoice untuk memisahkan bagian unvoice dan voice ucapan dari sinyal suara. Dengan ada perbedaan pada overlapping block dan non-overlapping block. Kami mengevaluasi hasil dari semua metode tersebut bahwa teknik
yang digunakan peneliti dengan overlapping blocks, zero crossing rate dan short time energy terbukti lebih efektif dalam pemisahan voice dan unvoice.
Kata Kunci: Speech signal, Overlapping blocks, Zero crossing rate, Short time energy, Voice dan Unvoice
1. PENDAHULUAN
Ucapan merupakan cara paling alami untuk pertukaran informasi. Dengan demikian, merancang mesin cerdas yang dapat mengenali informasi lisan telah menjadi topik penelitian bagi para ilmuwan dan insinyur selama lebih dari lima dekade[2]. Hal ini dapat digunakan secara efisien dalam berbagai keseharian untuk meningkatkan lingkungan kerja, atau untuk memecahkan masalah nyata dalam kehidupan seperti untuk membuat teknologi modern yang dapat diakses dalam kegiatan sehari-hari bagi orang-orang yang menderita cacat fisik. Keunggulan teknologi pengenalan suara memasukkan informasi dengan berbicara terhadap komputer merupakan dua kali lebih cepat dibandingkan oleh juru ketik terampil.Teknologi pengenalan suara meningkatkan kemampuan untuk berkomunikasi dengan orang-orang yang memiliki cacat fisik.[1][3]
Pita suara merupakan sumber untuk memproduksi ucapan pada manusia. Ini menghasilkan dua jenis suara ucapan ini voice dan unvoice. Getaran pita suara menghasilkan suara yang merupakan voice ,dan
unvoice karena turbulensi aliran udara pada penyempitan di semua bagian dalam saluran vokal
[7]. Frekuensi getaran suara ditentukan oleh beberapa faktor seperti ketegangan yang diberikan oleh otot, massa, dan durasi. Faktor-faktor ini bervariasi antara jenis kelamin dan sesuai dengan umur. Dalam beblkerapa tahun terakhir upaya besar telah dilakukan oleh para peneliti dalam memecahkan masalah memisahkan atau segmentasi bagian voice dan unvoice[8]. Pendekatan pengenalan pola dengan teknik statistik, dan nonstatistik telah diterapkan untuk memutuskan segmen tertentu dari speech signal harus diklasifikasikan sebagai ucapan voice dan unvoice [9].
Zero Crossing Rate (ZCR) merupakan algoritma penentuan phonem atau pengenalan frekuensi suara,
dapat bekerja dengan baik tanpa adanya noise, dan dirancang untuk menjadi sangat sederhana dalam hal perhitungan. Dalam hal ini ZCR merupakan salah satu solusi dalam permasalahan klasifikasi suara berdasarkan dua kategori phonem yaitu voice dan unvoice. ZCR bekerja dengan baik untuk gelombang suara yang bebas dan sederhana seperti gelombang sinus, gagasan untuk menghitung berapa kali gelombang melintasi nol-sumbu dalam waktu tertentu jumlah penyeberangan per-detik akan sama dengan dua kali frekuensi [10][11][12][13].
136 http://research.pps.dinus.ac.id Di dalam penelitian ini peneliti akan mencoba memisahkan antara voice dan unvoice. Speech atau ucapan dapat dibagi menjadi beberapa daerah voice dan unvoice. Klasifikasi speech signal menjadi voice dan unvoice memberikan segmentasi akustik awal untuk aplikasi pengolahan ucapan seperti contoh :
speech synthesis, speech enhancement, dan speech recognition[11]. Sebagian besar algoritma speech processing membingkai signal ucapan menjadi frame dan mengolahnya secara berurutan , menganalisis speech signal dengan frame rate yang tetap. Algoritma ini biasanya mengolah sinyal dengan rate tetap
yang memberikan hasil pada sinyal yang dijadikan sampel secara merata. Pengolahan rate tetap tidak konsisten dengan persepsi ucapan.tidak handal dalam mengambil keputusan membingkai spektrum informasi berdasarkan rentang waktu yang lebih lama dan kurang sensitive to noise[14]. Sehingga akurasi pengenalan speech signal jarang dicapai dalam praktiknya [15]. Peneliti melakukan pendekatan baru untuk deteksi yang tepat mengenai speech signal terisolasi tertentu terutama terbatas dalam satu suku kata. Peneliti akan mencoba memisahkan antara voice dan unvoice dengan menggunakan metode pendekatan yang sederhana, cepat dan dapat mengatasi masalah segmentasi atau separated ucapan dalam voice/
unvoice dengan menggunakan teknik overlapping blocks, zero crossing rate dan energy dari speech signal.
2. METODE PENELITIAN
Metode pemisahan voice dan unvoice menggunakan teknik overlaping block, zero crossing rate and short
time energy dalam pengenalan suara dilakukan dengan menggunakan perkakas / tool matlab R2012a dan
dibuat dengan Graphical User Interface (GUI) untuk mempermudah interaksi antara user dengan metode pemisahan yang digunakan.
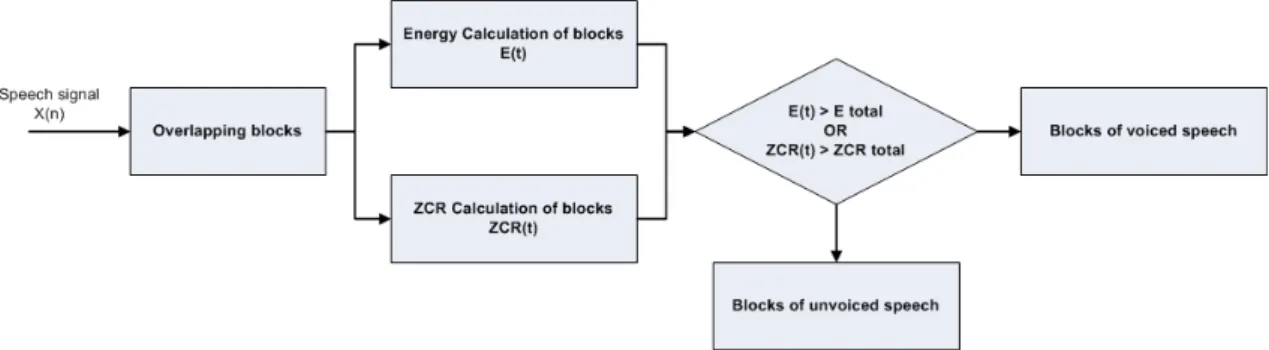
Metode yang diusulkan sederhana namun tangguh dalam pengenalan speech signal. Dalam proses pelaksanaan didasarkan pada gambar di bawah ini. Perhatikan bahwa seluruh skema akan dilaksanakan dengan menggunakan perangkat lunak MATLAB, dengan mengolah semua format data 32 bit. Metode ini digunakan untuk mengekstrak dengan membatasi sinyal ucapan dengan mengabaikan suasana pra dan pasca. Untuk melayani tujuan ini teknik overlapping block digunakan. Dalam teknik ini, sinyal yang ditangkap dibagi menjadi beberapa blok tumpang tindih. Ukuran setiap blok dan tumpang tindih antara dua blok berturut turut memiliki dua nilai tetap yang berbeda. Dalam kasus ini bisa diset agar nilai N dan M bisa diganti-ganti. Metode yang diterapkan seperti pada gambar di bawah ini yang hasilnya dibandingkan dengan metode yang digunakan pada penelitian sebelumnya.
http://research. pps.dinus.ac.id , 137 3. HASIL DAN PEMBAHASAN
3.1. Persiapan Dataset
Dataset yang digunakan adalah speech signal dengan format WAV dan total berjumlah 24 buah speech
signals. Objek speech signal dataset merupakan suara ucapan manusia dengan kata Yes dan No. Objek
tersebut akan dipisahkan antara voice dan unvoice dalam speech signals. Ukuran dari suara speech
signal.wav bervariasi, tetapi pada umumnya adalah moderat artinya tidak terlalu besar maupun tidak
terlalu kecil. Daftar lengkap dari keseluruhan dataset akan disertakan pada lampiran dari laporan penelitian ini. Dataset speech signals dengan format wav sebagai berikut:
Gambar 4.1 Dataset public speech sound
Gambar 2. Dataset Speech signals
3.2. Proses Eksperimen GUI
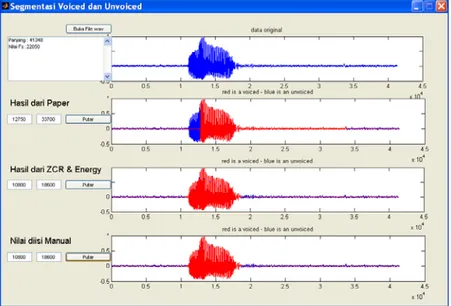
Berikut merupakan tampilan grapich user interface (GUI) untuk berinteraksi dengan user yang terdiri dari beberapa button, axes, dan edit text.
138 http://research.pps.dinus.ac.id Berikut tampilan pada saat dijalankan. Agar jelas terlihat perbedaan antara metode pada penelitian terkait (hasil dari paper) dengan penelitian ini (hasil dari ZCR & energy), maka digunakan plot grafik dan warna yang berbeda yaitu biru untuk dikategorikan sebagai unvoiced dan merah sebagai voiced.
Gambar 4. GUI Segmentasi Voice and Unvoice dengan Objek anna-no.wav
Kedua component figure yaitu edit text menampilkan informasi nilai indeks awal dan akhir dari sebuah sinyal suara yang dikategorikan sebagai voiced.
http://research. pps.dinus.ac.id , 139 Deskripsi perhitungan:
a. Nama file: anna-no.wav.
b. Menghitung kolom D yaitu dengan menghitung perbedaan absolut (abs(B-C)/A * 100) sehingga terdapat selisih 5%
c. Menghitung kolom E dengan batas sebesar 25% yang berarti jika nilai perbedaan (kolom D) lebih dari 25% maka akan menghasilkan 1 (sehingga dianggap CUKUP berbeda)
d. Cara di atas juga diterapkan untuk menghitung kolom H (sama dengan kolom D) dan I (sama dengan kolom E)
e. Sedangkan untuk kolom J didapatkan dari penjumlahan kolom E dan I
Dari tabel di atas dapat disimpulkan kolom J merupakan hasil penjelasan untuk mengetahui ada perbedaan hasil antarkeduanya atau tidak. Jika menghasilkan 0, maka sama. Jika menghasilkan lebih dari 0, maka ada beda, maka komparasi hasil akhir menghasilkan prosentase keberhasilan 50% sedangkan pada versi revisi menghasilkan prosentase validasi 100%.
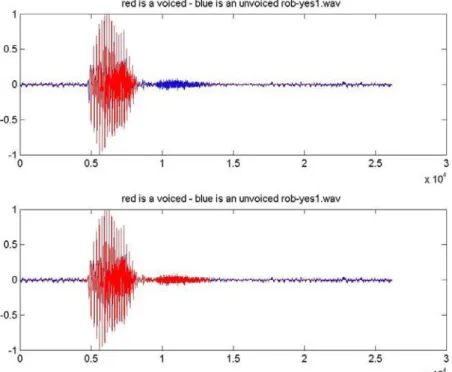
Gambar 5. Sample GUI Segmentasi Voice and Unvoice
Dari hasil eksperimen didapatkan hasil bahwa metode paper telah gagal ketika posisi start index atau
end index pada grafik tidak bisa melakukan segmentasi unvoice dan voice secara sempurna. Hal ini bisa
dikarenakan block unvoice teridentifikasi sebagai voice ataupun sebaliknya. Metode peneliti dapat menentukan start index dan end index lebih akurat, koefisien perbedaan yang terdapat di 12 file di atas yang rata rata mencapai 25% dapat dilihat pada gambar Plot Grafik perbandingan hasil pemisahan suara di atas. Dalam penelitian ini dapat diidentifikasi daerah voice dengan menggunakan persepsi visual dan
voice, langkah berikutnya dengan pendekatan otomatis. Jika gelombang sinyal suara terlihat secara
berkala alami, maka dapat ditandai sebagai voice tetapi dapat juga dilihat dari beberapa struktur secara periodik. Jika tidak, mungkin ditandai sebagai unvoice pada wilayah berdasarkan energi terkait. Jika amplitudo sinyal rendah atau diabaikan, maka dapat ditandai sebagai diam, jika tidak ditandai sebagai sebagai unvoice.
140 http://research.pps.dinus.ac.id 4. KESIMPULAN
Berdasarkan hasil penelitian ini didapatkan bahwa pemisahan suara voice dan unvoice menggunakan teknik overlaping block zero crossing rate, and short time energy dalam pengenalan suara berhasil memisahkan antara voice dan unvoice lebih baik dan akurat. Hal ini dibuktikan pada metode paper terjadi kesalahan 12 file dari 24 file dengan tingkat 50%. Kelemahan ini berhasil diperbaiki dengan metode ZCR & energy. Pada metode ZCR & energy terjadi 0 kesalahan dari 24 file dengan tingkat 100% berhasil. DAFTAR PUSTAKA
[1] V. Goel and W. J. Byrne, “Minimum Bayes-risk automatic speech recognition,” no. 10, pp. 115– 135, 2000.
[2] C. Y. Fook, M. Hariharan, S. Yaacob, and A. Ah, “A Review : Malay Speech Recognition and Audio Visual Speech Recognition,” no. February, pp. 27–28, 2012.
[3] A. K. Paul, D. Das, and M. M. Kamal, “Bangla Speech Recognition System Using LPC and ANN,”
2009 Seventh Int. Conf. Adv. Pattern Recognit., pp. 171–174, Feb. 2009.
[4] K. Nishikawa and H. Takanobu, “Modeling and Analysis of Elastic Tongue Mechanism of Talking Robot for Acoustic Simulation,” no. October, 2003.
[5] I. McLoughlin, Applied speech and audio processing: with Matlab examples. 2009.
[6] M. Kitani and H. Sawada, “Mechanical Reproduction of Human-Like Expressive Speech Using a Talking Robot,” 2013 Int. Conf. Biometrics Kansei Eng., pp. 229–234, Jul. 2013.
[7] B. Atal and L. Rabiner, “A pattern recognition approach to voiced-unvoiced-silence classification with applications to speech recognition,” IEEE Trans. Acoust., vol. 24, no. 3, pp. 201–212, Jun. 1976.
[8] T. Toda, M. Nakagiri, and K. Shikano, “Statistical Voice Conversion Techniques for Body-Conducted Unvoiced Speech Enhancement,” IEEE Trans. Audio. Speech. Lang. Processing, vol. 20, no. 9, pp. 2505–2517, Nov. 2012.
[9] F. Daaboul and J. Adoul, “Parametric segmentation of speech into voiced-unvoiced-silence intervals,” ICASSP ’77. IEEE Int. Conf. Acoust. Speech, Signal Process., vol. 2, pp. 327–331. [10] S. J. An, R. M. Kil, S. Member, and Y. Kim, “Zero-Crossing-Based Speech Segregation and
Recognition for Humanoid Robots,” no. Cc, 2009.
[11] R. G. Bachu, S. Kopparthi, B. Adapa, and B. D. Barkana, “Separation of Voiced and Unvoiced using Zero crossing rate and Energy of the Speech signal,” pp. 1–7.
[12] W. Bezdel, C. Eng, J. S. Bridle, and B. Sc, “Control & Science Speech recognition using zero-crossing measurements and sequence information,” vol. 116, pp. 617–623.
[13] L. P. Bhaiya and A. U. Khan, “Hindi Speaking Person Identification using Zero Crossing rate and Short-Term Energy,” no. 4, pp. 101–104, 2012.
[14] “Entropy-Based Variable Frame Rate Analysis Of Speech signals And Its Application To Asr H . You , Q . Zhu and A . Alwan Los Angeles CA90095 , USA,” no. 2, pp. 2–5.
[15] A. Mitra, B. K. Mitra, and B. Chatterjee, “Recognition of Isolated Speech signals using Simplified Statistical Parameters,” no. 8, pp. 1222–1225, 2007.