METODE PREDIKSI TAK-BIAS LINEAR
TERBAIK DAN BAYES BERHIRARKI UNTUK
PENDUGAAN AREA KECIL BERDASARKAN
MODEL STATE SPACE
KUSMAN SADIK
SEKOLAH PASCASARJANA
INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI DISERTASI
DAN SUMBER INFORMASI
Dengan ini saya menyatakan bahwa disertasi yang berjudul ‘Metode
Prediksi Tak-bias Linear Terbaik dan Bayes Berhirarki untuk Pendugaan Area Kecil Berdasarkan Model State Space’ adalah hasil karya saya sendiri
dengan arahan komisi pembimbing dan belum pernah diajukan kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya penulis lain telah dicantumkan di dalam teks dan Daftar Pustaka disertasi ini.
Bogor, November 2009
Kusman Sadik NIM. G161050021
ABSTRACT
KUSMAN SADIK. Best Linear Unbiased Prediction and Hierarchical Bayes Methods for Small Area Estimation Using State Space Models. Under guidance of KHAIRIL ANWAR NOTODIPUTRO, BUDI SUSETYO, and I WAYAN MANGKU.
There have been two main topics developed by statisticians in a survey, i.e. sampling techniques and estimation methods. The current issues are estimation methods related to estimation of a particular domain having small size of samples or, in more extreme cases, there is no sample available for direct estimation. Sample survey data provide effective reliable estimators of totals and means for large area and domains. But it is recognized that the usual direct survey estimator for a parameter of small area, have unacceptably large standard errors, due to the circumstance of small sample size in the area. The most commonly used models for this case, usually in small area estimation, are based on generalized linear mixed models. Some time happened that some surveys are carried out periodically so that the estimation could be improved by incorporating both the area and time random effects. In this dissertation we propose a state space model which accounts for the two random effects and is based on two equations, namely transition equation and measurement equation. Based on an evaluation criterion, the proposed hierarchical Bayes estimator turns out to be superior to both estimated best linear unbiased prediction (BLUP) and the direct survey estimator. The posterior variances which measure accuracy of the hierarchical Bayes estimates are always smaller than the corresponding variances of the BLUP and the direct survey estimates.
Keywords: Generalized linear mixed model, hierarchical Bayes, best linear
unbiased prediction, prior and posterior function, generalized variance function, block diagonal covariance, state space model.
RINGKASAN
KUSMAN SADIK. Metode Prediksi Tak-bias Linear Terbaik dan Bayes Berhirarki untuk Pendugaan Area Kecil Berdasarkan Model State Space. Dibimbing oleh KHAIRIL ANWAR NOTODIPUTRO, BUDI SUSETYO, dan I WAYAN MANGKU.
Terkait dengan persoalan survei, ada dua topik utama yang menjadi perhatian para statistisi selama tahun-tahun terakhir ini. Topik tersebut menyangkut persoalan pengembangan teknik penarikan contoh dan pengembangan metodologi pendugaan parameter pupulasi. Sebagaimana diketahui, pada umumnya survei rutin yang dilakukan oleh pemerintah suatu negara didesain untuk memperoleh statistik nasional. Artinya, survei semacam ini didesain untuk inferensia bagi daerah yang luas.
Persoalan muncul ketika dari survei seperti ini ingin diperoleh informasi untuk area yang lebih kecil, misalnya informasi pada level propinsi, kabupaten, bahkan mungkin level kecamatan. Ukuran contoh pada level area tersebut biasanya sangat kecil sehingga statistik yang diperoleh akan memiliki ragam yang besar. Bahkan bisa saja pendugaan tidak dapat dilakukan karena area tersebut tidak terpilih menjadi contoh dalam survei. Oleh karena itu dikembangkan metode pendugaan parameter yang dapat mengatasi hal ini. Metode tersebut dikenal dengan metode pendugaan area kecil (small area estimation, SAE).
Berbagai metode pendugaan area kecil telah dikembangkan khususnya menyangkut metode yang berbasis model. Area kecil tersebut didefinisikan sebagai himpunan bagian dari populasi dimana suatu peubah menjadi perhatian. Pendekatan klasik untuk menduga parameter area kecil didasarkan pada aplikasi model desain penarikan contoh (design-based) yang dikenal sebagai pendugaan langsung (direct estimation). Namun, metode pendugaan langsung pada sub-populasi tidak memiliki presisi yang memadai karena kecilnya jumlah contoh yang digunakan untuk memperoleh dugaan tersebut. Oleh karena itu dikembangkan metode pendugaan secara tidak langsung (indirect estimation) di suatu area yang relatif kecil dalam percontohan survei.
Tujuan tulisan ini adalah untuk mengkaji konsep dan sifat-sifat statistik pada model campuran linear terampat (generalized linear mixed model) untuk SAE serta mengkaji konsep dan sifat-sifat statistik model SAE yang memasukkan pengaruh acak area dan waktu berdasarkan model state space melalui pendekatan kemungkinan maksimum dan Bayes berhirarki.
Nilai tengah pada area kecil dapat diekspresikan sebagai kombinasi linear dari pengaruh tetap dan pengaruh acak. Prediksi tak-bias linear terbaik (best linear unbiased prediction) dilakukan dengan cara meminimumkan fungsi kuadrat tengah galat (mean square of error), sehingga penduga bagi prediksi tak-bias
linear terbaik (PTLT) memiliki kuadrat tengah galat (KTG) yang paling kecil diantara semua penduga tidak bias linear. Metode kemungkinan maksimum terkendala (restricted maximum likelihood) dapat digunakan untuk menduga komponen ragam atau koragam. Penggunaan komponen dugaan ini dalam penduga PTLT akan diperoleh penduga secara dua tahap sebagai PTLT empirik atau PTLTE.
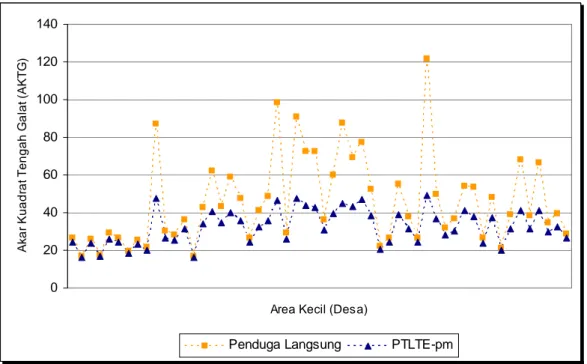
Penerapan metode pendugaan tidak langsung pada area kecil untuk data Susenas menunjukkan bahwa nilai akar kuadrat tengah galatnya (AKTG) lebih kecil dibandingkan dengan AKTG pada metode pendugaan langsung. Sementara pada data deret waktu (time series data) Susenas, AKTG lebih kecil pada metode pemodelan area kecil PTLTE deret waktu dibandingkan dengan AKTG pada metode PTLTE data penampang melintang (cross-sectional data). Ini menunjukkan bahwa pengaruh acak area dan waktu maupun pengaruh sintetik vektor kovariat berfungsi memperbaiki hasil pendugaan metode PTLTE yang hanya didasarkan pada data survei pada satu tahun saja.
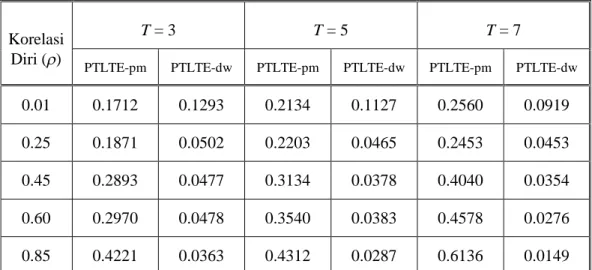
Berdasarkan data simulasi dapat diketahui bahwa nilai akar kuadrat tengah galat relatif (AKTGR) metode PTLTE deret waktu cenderung jauh mengecil dibandingkan dengan nilai AKTGR metode PTLTE non-time series pada waktu T dan korelasi diri yang sama-sama besar. Artinya, pengaruh pengamatan antar waktu yang diakibatkan oleh banyaknya waktu T dan korelasi diri dapat memperbaiki pendugaan parameter pada area kecil yang diindikasikan dengan menurunnya nilai AKTGR tersebut.
Metode PTLT pada SAE memerlukan banyak kondisi tertentu yang harus dipenuhi, diantaranya adalah pengasumsian bahwa parameter peubah tetap dan ragam penarikan contohnya adalah konstanta atau tidak memiliki fungsi sebaran tertentu. Padahal kenyataannya, sangat dimungkinkan parameter tersebut bukan suatu konstanta, melainkan memiliki suatu fungsi sebaran tertentu. Metode Bayes dapat digunakan untuk mengatasi persoalan tersebut. Sehingga motode Bayes lebih fleksibel daripada metode PTLT yang memerlukan berbagai kondisi tertentu.
Penerapan pada data deret waktu Susenas, diketahui bahwa nilai AKTG lebih kecil pada metode pemodelan area kecil Bayes berhirarki dibandingkan dengan AKTG pada metode PTLTE. Hal ini mengindikasikan bahwa metode Bayes berhirarki lebih baik daripada PTLTE dalam menurunkan AKTG. Penurunan AKTG ini sebagai akibat adanya penguraian komponen ragam yang terdapat di dalam model, termasuk komponen ragam yang diakibatkan oleh fluktuasi tingkat pengeluaran perkapita antar tahun.
Berdasarkan kajian analitik pada model SAE yang memasukkan pengaruh acak area dan waktu, penduga PTLT yang berbasis pada metode kemungkinan maksimum terbatas dan penduga Bayes berhirarki sama-sama bersifat tidak bias. Namun, resiko atau KTG yang dihasilkan penduga Bayes lebih kecil daripada penduga PTLT, artinya dalam hal ini penduga Bayes lebih baik daripada penduga PTLT.
@ Hak Cipta Milik Institut Pertanian Bogor (IPB), Tahun 2009 Hak Cipta Dilindungi Undang-undang
1. Dilarang mengutip sebagian atau seluruh karya tulis ini tanpa mencantumkan atau menyebutkan sumber:
a. Pengutipan hanya untuk kepentingan pendidikan, penelitian, penulisan karya ilmiah, penyusunan laporan, penulisan kritik atau tinjauan suatu masalah.
b. Pengutipan tidak merugikan kepentingan yang wajar IPB.
2. Dilarang mengumumkan atau memperbanyak sebagian atau seluruh karya tulis ini dalam bentuk apapun tanpa izin IPB.
METODE PREDIKSI TAK-BIAS LINEAR TERBAIK
DAN BAYES BERHIRARKI UNTUK PENDUGAAN
AREA KECIL BERDASARKAN
MODEL STATE SPACE
KUSMAN SADIK
Disertasi
sebagai salah satu syarat untuk memperoleh gelar Doktor
pada
Program Studi Statistika
SEKOLAH PASCASARJANA
INSTITUT PERTANIAN BOGOR
Penguji Luar Komisi pada Ujian Tertutup, 30 Oktober 2009
1. Prof. Dr. Ir. Aunuddin, MSc. (Dosen Dept. Statistika IPB) 2. Dr. Ir. Aji Hamim Wigena, MSc. (Dosen Dept. Statistika IPB)
Penguji Luar Komisi pada Ujian Terbuka, 23 November 2009
1. Dr. Bambang Heru Santosa, MEc. (Badan Pusat Statistik, Jakarta) 2. Dr. Ir. Anik Djuraidah, MS. (Dosen Dept. Statistika IPB)
Judul Disertasi : Metode Prediksi Tak-bias Linear Terbaik dan Bayes Berhirarki untuk Pendugaan Area Kecil Berdasarkan Model State Space
Nama Mahasiswa : Kusman Sadik
NIM : G161050021
Program Studi : Statistika
Disetujui, Komisi Pembimbing
Prof. Dr. Ir. Khairil Anwar Notodiputro, MS Ketua
Dr. Ir. Budi Susetyo, MS Dr. Ir. I Wayan Mangku, MSc
Anggota Anggota
Diketahui,
Ketua Program Studi Statistika, Dekan Sekolah Pascasarjana IPB,
PRAKATA
Puji syukur penulis panjatkan ke hadirat Allah SWT, karena atas rahmat dan hidayah-Nyalah akhirnya disertasi ini dapat diselesaikan.
Selama pelaksanaan penelitian dan penyelesaian tulisan ini, penulis banyak mendapatkan bantuan dari berbagai pihak diantaranya adalah Komisi Pembimbing, seluruh dosen dan karyawan Departemen Statistika FMIPA IPB, seluruh staf dan karyawan Sekolah Pascasarjana IPB, peneliti dan karyawan di BPS Jakarta, dosen dan karyawan di Joint Program in Survey Methodology (JPSM) University of Maryland Amerika Serikat, keluarga, dan berbagai pihak yang tidak dapat penulis sebutkan semuanya. Dengan segala keterbatasan dan kekurangannya, akhirnya disertasi yang berjudul “Metode Prediksi Tak-bias Linear Terbaik dan Bayes Berhirarki untuk Pendugaan Area Kecil Berdasarkan Model State Space” dapat diselesaikan dengan baik.
Pada kesempatan ini, secara khusus penulis mengucapkan terima kasih kepada:
1. Bapak Prof. Dr. Ir. Khairil Anwar Notodiputro, Bapak Dr. Ir. Budi Susetyo, dan Bapak Dr. Ir. I Wayan Mangku, selaku dosen pembimbing yang telah banyak memberikan arahan, saran, dan bimbingan.
2. Bapak Prof. Dr. Ir. Aunuddin dan Bapak Dr. Ir. Aji Hamim Wigena selaku penguji luar komisi pada saat Ujian Tertutup.
3. Bapak Dr. Bambang Heru Santosa, MEc dan Ibu Dr. Ir. Anik Djuraidah selaku penguji luar komisi pada saat Ujian Terbuka.
4. Seluruh dosen dan karyawan Departemen Statistika FMIPA IPB yang telah menjadi teman diskusi, memberikan saran, dan dorongan moril. 5. Seluruh dosen dan karyawan Sekolah Pascasarjana IPB yang telah
memberikan layanan pengajaran dan administrasi yang baik.
6. Para peneliti dan karyawan di BPS Jakarta yang banyak membantu memberikan data dan penjelasannya terkait data Susenas dan Podes.
7. Prof. Partha Lahiri, yang telah memberikan arahan dan pengajaran terkait konsep teori dan metodologi Small Area Estimation selama penulis melaksanakan Program Sandwich di Joint Program in Survey Methodology, University of Maryland, Amerika Serikat.
8. Direktorat Pendidikan Tinggi, yang telah memberikan berbagai bantuan biaya pendidikan dan penelitian.
9. Seluruh anggota keluarga penulis, yang senantiasa memberikan dorongan semangat dan doa yang ikhlas.
10. Serta berbagai pihak lain yang tidak dapat penulis sebutkan seluruhnya secara satu persatu.
Akhir kalam, dengan segala kerendahan hati, penulis menyadari bahwa disertasi ini masih jauh dari kesempurnaan. Namun demikian, penulis berharap tulisan ini dapat bermanfaat bagi mereka yang memerlukannya. Aamiin.
RIWAYAT HIDUP
Penulis dilahirkan di Sumenep pada tanggal 12 September 1969, sebagai anak kedua dari pasangan Muhammad Durri (alm) dan Siti Ahmadiyah (almh). Pendidikan sarjana ditempuh di Jurusan Statistika, Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor (IPB), lulus pada tahun 1995. Pada tahun 1996 penulis diterima di Program Magister Statistika pada Program Pascasarjana IPB, dan menyelesaikannya pada tahun 1999. Pada tahun 2005 penulis mendapat kesempatan untuk mengikuti Program Doktor pada Program Studi Statistika, Sekolah Pasacasarjana IPB, dengan beasiswa pendidikan (BPPS) diperoleh dari Direktorat Jendral Pendidikan Tinggi, Depdiknas RI. Pada tahun 2008, penulis mengikuti Program Sandwich ke University of Maryland, Amerika Serikat, untuk mengikuti kuliah dan melakukan penelitian terkait dengan metode pendugaan area kecil yang menjadi fokus dalam disertasi ini.
Pada saat ini penulis bekerja sebagai dosen pada Departemen Statistika, Fakultas Matematika dan Ilmu Pengetahuan Alam, IPB. Penulis menikah dengan Kurniawati Rahmi Wijaya, S.Si dan telah dikaruniai tiga orang anak, yaitu Firyali Rahmani Shidqi, Muhammad Sayyidurrahman Ash Shidqi, dan Radhwa Rahmaniyah Ash Shidqi.
Selama mengikuti program S3, penulis telah mempresentasikan beberapa karya ilmiah dalam seminar nasional dan internasional, dan sebagiannya dipublikasikan dalam jurnal ilmiah nasional. Karya-karya ilmiah tersebut adalah:
1. Sadik, K. and Notodiputro, K.A. 2009. Hierarchical Bayes Estimation Using Time Series and Cross-sectional Data : A Case of Per-capita Expenditure in Indonesia. Conference of Small Area Estimation, 29 Juni – 01 Juli 2009, Elche, Spanyol.
2. Sadik, K. 2008. Hierarchical Bayes Approach in Small Area Estimation. Makalah Seminar Reguler di Joint Program in Survey Methodology, University of Maryland, USA. Oktober, 2008.
3. Sadik, K., Notodiputro, K.A., Susetyo, B., Mangku, I.W. 2008. Small Area Estimation With Time and Area Effects Using A Dynamic
Linear Model. The 3rd International Conference on Mathematics and Statistics (ICoMS-3). Institut Pertanian Bogor, Indonesia, 5-6 August 2008.
4. Sadik, K. and Notodiputro, K.A. 2007. A State Space Model in Small Area Estimation. The 9th Islamic Countries Conference on Statistical Sciences 2007 (ICCS-IX), Kuala Lumpur: 12-14 December 2007.
5. Sadik, K. dan Notodiputro, K.A. 2007. Model State Space pada GLMM untuk Pendugaan Area Kecil (Small Area Estimation). Prosiding pada Seminar Nasional Statistika: 24 Mei 2007, Unisba – Bandung.
6. Sadik, K. dan Notodiputro, K.A. 2006. Pendekatan P-Spline M-Quantile dalam Pendugaan Area Kecil (Small Area Estimation). Jurnal Matematika Aplikasi dan Pembelajaran, Vol. 5 No.2 Jilid 1, p:142-147, Universitas Negeri Jakarta, Jakarta.
7. Sadik, K. dan Notodiputro, K.A. 2006. Small Area Estimation with Time and Area Effects Using Two Stage Estimation. Proceeding at the First International Conference on Mathematics and Statistics, MSMSSEA, 19-21 June 2006, Bandung.
8. Sadik, K., Notodiputro, K.A., Susetyo, B., Mangku, I.W. 2006. Pendugaan Area Kecil (Small Area Estimation) Berdasarkan Model yang Mengandung Langkah Acak (Random Walk). Prosiding Seminar Nasional Matematika dan Konferda IndoMS wilayah Jabar & Banten, 22 April 2006, Jurusan Matematika UNPAD, Bandung.
DAFTAR ISI
DAFTAR TABEL ... xvii
DAFTAR GAMBAR ... xviii
DAFTAR LAMPIRAN ... xix
I. PENDAHULUAN ... 1
1.1. Latar Belakang ... 1
1.2. Tujuan Penelitian ... 3
1.3. Ruang Lingkup ... 3
1.4. Kebaruan / Novelty ... 4
II. TINJAUAN METODE PENDUGAAN AREA KECIL ... 5
2.1. Pendahuluan ... 5
2.1.1. Keuntungan dan Keterbatasan Penarikan Contoh ... 6
2.1.2. Validitas, Reliabilitas, dan Keakuratan ... 6
2.1.3. Pendugaan Ukuran Contoh ... 7
2.2. Perkembangan Metode SAE ... 9
2.2.1. Metode Pendugaan Tidak Langsung untuk Area Kecil ... 12
2.2.2. Pendekatan Model Campuran Linear Terampat ... 14
2.2.3. Pengaruh Penarikan Contoh pada Pendugaan Tidak Langsung ... 16
2.3. Metode SAE dan Model State Space ... 23
2.4. Statistik Area Kecil untuk Data BPS ... 23
2.4.1. Jenis Data yang Dikumpulkan ... 24
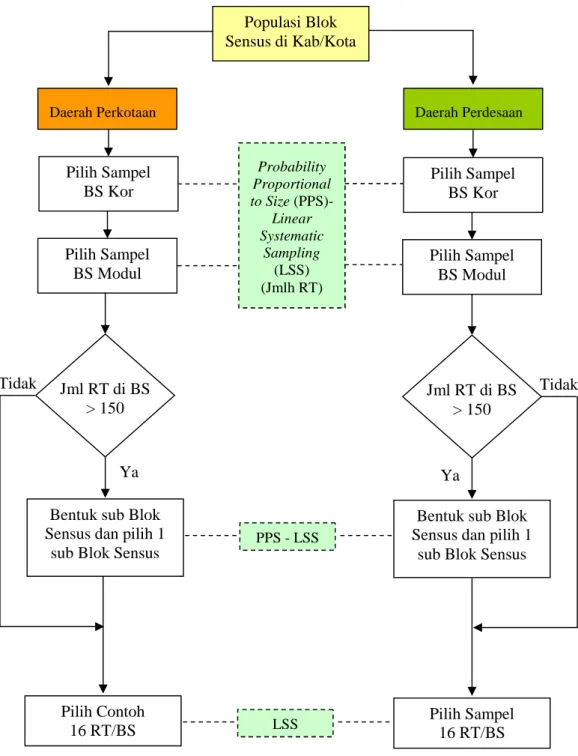
2.4.2. Rancangan Penarikan Contoh Susenas ... 25
2.4.3. Pendugaan Data Rumah Tangga ... 27
2.4.4. Persoalan Ukuran Contoh pada Susenas ... 28
III. METODE PREDIKSI TAK-BIAS LINEAR TERBAIK UNTUK PENDUGAAN AREA KECIL BERDASARKAN MODEL STATE SPACE …… . ... 31
3.1. Pendahuluan ... 31
3.3. Model State Space pada Pendugaan Area Kecil ... 41
3.4. Pendugaan Parameter Model dengan KMT ... 44
3.4.1. Penduga Tak-bias Linear Terbaik (PTLT) ... 44
3.4.2. Penduga Dua Tahap ... 46
3.5. Pendekatan Orde Kedua untuk KTG ... 48
3.6. Evaluasi terhadap Penduga KTG ... 51
3.7. Penerapan pada Data Susenas dan Simulasi ... 59
3.7.1. Data Susenas ... 59
3.7.2. Data Simulasi ... 64
3.8. Simpulan ... 66
IV. METODE BAYES BERHIRARKI UNTUK PENDUGAAN AREA KECIL BERDASARKAN MODEL STATE SPACE ... 68
4.1. Pendahuluan ... 68
4.2. Metode Bayes Empirik ... 68
4.3. Metode Bayes Berhirarki ... 73
4.3.1. Kasus2 Diketahui ... 76
4.3.2. Kasus2 Tidak Diketahui ... 77
4.4. Bayes Berhirarki untuk Model State Space ... 78
4.5. Penduga Bagi KTG ... 85
4.6. Metode Gibbs Sampling ... 89
4.7. Penerapan pada Data Susenas dan Simulasi ... 90
4.7.1. Data Susenas ... 90
4.7.2. Data Simulasi ... 96
4.8. Simpulan ... 101
V. PEMBAHASAN UMUM ... 103
5.1. Pendahuluan ... 103
5.2. Keunggulan Metode Bayes daripada Metode PTLT pada Model SAE Secara Analitik ... 104
5.3. Hasil Studi Kasus pada Data ... 107
5.4. Lesson Learned ... 112
VI. SIMPULAN DAN SARAN ... 113
DAFTAR PUSTAKA ... 116 DAFTAR ISTILAH DAN SINGKATAN ... 121 LAMPIRAN ... ... 122
DAFTAR TABEL
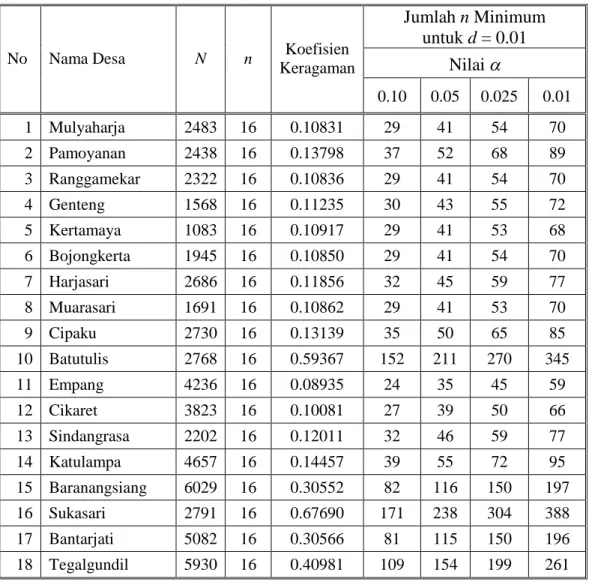
Tabel 2.1. Perbandingan Antara Ukuran Contoh Susenas 2005 (n) dengan
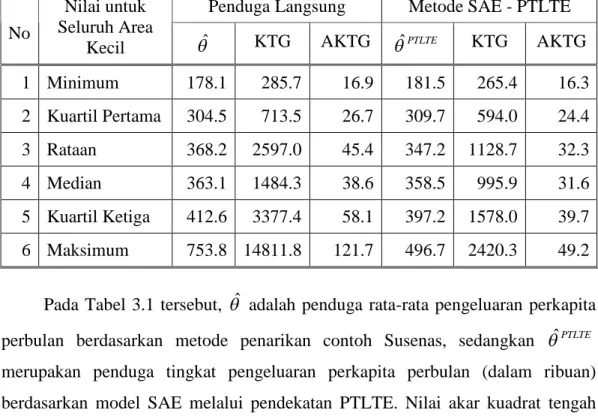
Jumlah n Minimum pada Batas d = 0.01. ... 28 Tabel 3.1. Perbandingan Antara Metode Pendugaan Langsung dengan
Metode Pendugaan Tidak Langsung untuk Rata-rata Pengeluaran Perkapita Perbulan (dalam Ribuan Rupiah),
Susenas 2005 Wilayah Kota Bogor ... 61 Tabel 3.2. Perbandingan Antara Metode PTLTE Penampang Melintang
dengan Metode PTLTE Deret Waktu untuk Data Tingkat Pengeluaran Perkapita Perbulan (dalam Ribuan Rupiah),
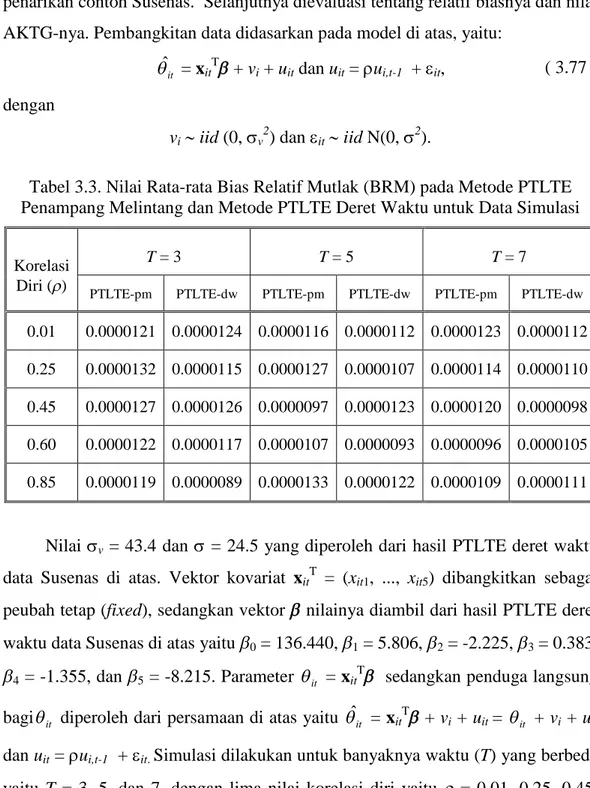
Susenas Wilayah Kota Bogor ... 62 Tabel 3.3. Nilai Rata-rata Bias Relatif Mutlak (BRM) pada Metode
PTLTE Penampang Melintang dan Metode PTLTE Deret
Waktu untuk Data Simulasi ... 64 Tabel 3.4. Nilai Rata-rata AKTGR pada Metode PTLTE Penampang
Melintang dan Metode PTLTE Deret Waktu untuk Data
Simulasi ... 65 Tabel 4.1. Perbandingan Antara Metode PTLTE dengan Metode Bayes
Berhirarki Model 1 pada Data Deret Waktu Tingkat Pengeluaran Perkapita Perbulan (dalam Ribuan Rupiah),
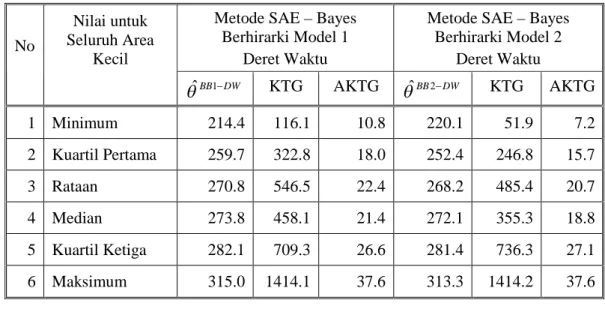
Susenas Wilayah Kota Bogor ... 92 Tabel 4.2. Perbandingan Antara Metode Bayes Berhirarki Model 1
dengan Model 2 pada Data Deret Waktu Tingkat Pengeluaran Perkapita Perbulan (dalam Ribuan Rupiah), Susenas Wilayah
Kota Bogor ... 94 Tabel 4.3. Nilai Rata-rata Bias Relatif Mutlak (BRM) pada Metode Bayes
Berhirarki Model 1 dengan Model 2 untuk Data Simulasi ... 97 Tabel 4.4. Nilai Rata-rata AKTGR pada Metode Bayes Berhirarki Model
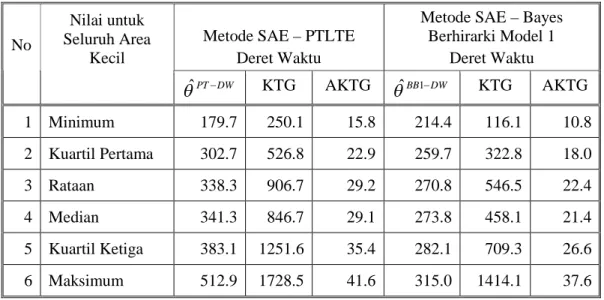
1 dengan Model 2 untuk Data Simulasi ... 98 Tabel 5.1. Perbandingan KTG dan AKTG Antara Metode PTLT dengan
Bayes Berhirarki pada Data Deret waktu Tingkat Pengeluaran Perkapita Perbulan (dalam Ribuan Rupiah), Susenas Wilayah
Kota Bogor ... 109 Tabel 5.2. Perbandingan KTG dan AKTG Antara Metode PTLT dengan
Bayes Berhirarki pada Data Deret waktu Tingkat Pengeluaran Perkapita Perbulan (dalam Ribuan Rupiah), Susenas Wilayah
Kota Bogor ... 110 Tabel 5.3. Nilai Rata-rata AKTGR pada Metode PTLTE dan Bayes
DAFTAR GAMBAR
Gambar 2.1. Diagram Alur Metode Penarikan Contoh Susenas ... 27 Gambar 3.1. Plot Antara AKTG Penduga Langsung dengan AKTG Hasil
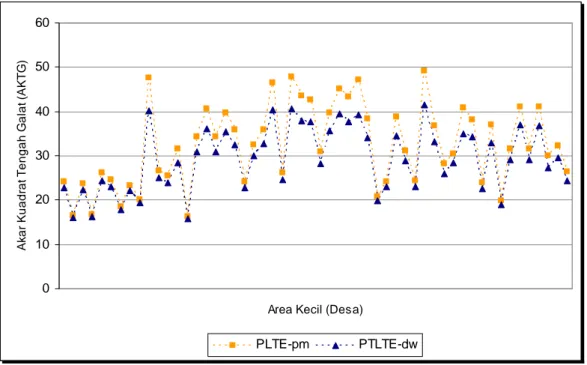
Metode PTLTE Data Penampang Melintang ... 62 Gambar 3.2. Plot Antara AKTG Metode PTLTE Penampang Melintang
dengan AKTG Metode PTLTE Deret Waktu ... 63 Gambar 4.1. Plot Antara AKTG Metode PTLTE dengan AKTG Metode
Bayes Berhirarki Model 1 ... 93 Gambar 4.2. Plot Antara AKTG Metode Bayes Berhirarki Model 1 dan
Model 2 ... 95 Gambar 4.3. Karakteristik Penduga Parameter Peubah Tetap (Fixed) 0
untuk Metode Bayes Berhirarki Model 1 dan Model 2 ... 98 Gambar 4.4. Karakteristik Penduga Parameter Peubah Tetap (Fixed) 1
untuk Metode Bayes Berhirarki Model 1 dan Model 2 ... 99 Gambar 4.5. Karakteristik Penduga Parameter Peubah Tetap (Fixed) 2
untuk Metode Bayes Berhirarki Model 1 dan Model 2 ... 99 Gambar 4.6. Karakteristik Penduga Parameter Peubah Tetap (Fixed) 3
untuk Metode Bayes Berhirarki Model 1 dan Model 2 ... 100 Gambar 4.7. Karakteristik Penduga Parameter Peubah Tetap (Fixed) 4
untuk Metode Bayes Berhirarki Model 1 dan Model 2 ... 100 Gambar 4.8. Karakteristik Penduga Parameter Peubah Tetap (Fixed) 5
DAFTAR LAMPIRAN
Lampiran 1. Program R untuk Bayes Berhirarki Model 1 ... 123 Lampiran 2. Program R untuk Bayes Berhirarki Model 2 ... 128 Lampiran 3. Program R untuk Simulasi Data ... 134 Lampiran 4. Perbandingan Antara Metode Pendugaan Langsung dengan
Metode Pendugaan Tidak Langsung untuk Rata-rata Pengeluaran Perkapita Perbulan (dalam Ribuan Rupiah),
Susenas 2005 Wilayah Kota Bogor ... 139 Lampiran 5. Perbandingan Antara Metode PTLTE Penampang Melintang
dengan Metode PTLTE Deret Waktu untuk Data Tingkat Pengeluaran Perkapita Perbulan (dalam Ribuan Rupiah),
Susenas Wilayah Kota Bogor ... 141 Lampiran 6. Perbandingan Antara Metode PTLTE dengan Metode Bayes
Berhirarki Model 1 pada Data Deret Waktu Tingkat Pengeluaran Perkapita Perbulan (dalam Ribuan Rupiah),
Susenas Wilayah Kota Bogor ... 143 Lampiran 7. Perbandingan Antara Metode Bayes Berhirarki Model 1
dengan Model 2 pada Data Deret Waktu Tingkat Pengeluaran Perkapita Perbulan (dalam Ribuan Rupiah), Susenas Wilayah
Kota Bogor ... 145 Lampiran 8. Perbandingan KTG dan AKTG Antara Metode PTLT dengan
Bayes Berhirarki pada Data Deret Waktu Tingkat Pengeluaran Perkapita Perbulan (dalam Ribuan Rupiah),
Susenas Wilayah Kota Bogor ... 147 Lampiran 9. Metode Pendugaan Langsung yang digunakan oleh BPS
BAB I
1.
Pendahuluan
1.1. Latar Belakang
Survei merupakan salah satu bagian penting dari proses pengambilan keputusan yang berbasis pada data. Karena itu, survei sering dilakukan secara rutin baik di lembaga penelitian swasta maupun negeri. Terkait dengan persoalan survei tersebut, ada dua topik utama yang menjadi perhatian para statistisi pada tahun-tahun terakhir ini. Topik tersebut menyangkut persoalan pengembangan teknik penarikan contoh dan pengembangan metodologi pendugaan parameter populasi untuk area dengan contoh kecil.
Survei rutin yang dilakukan oleh pemerintah suatu negara, umumnya didesain untuk memperoleh statistik nasional. Artinya, survei semacam ini didesain untuk inferensia bagi daerah yang luas. Persoalan muncul ketika dari survei seperti ini ingin diperoleh informasi untuk area yang lebih kecil, misalnya informasi pada level propinsi, kabupaten, bahkan mungkin level kecamatan. Ukuran contoh pada level area tersebut biasanya sangat kecil sehingga statistik yang diperoleh akan memiliki ragam yang besar. Bahkan bisa saja pendugaan tidak dapat dilakukan karena area tersebut tidak terpilih menjadi contoh dalam survei. Oleh karena itu dikembangkan metode pendugaan parameter yang dapat mengatasi hal ini. Metode tersebut dikenal dengan metode pendugaan area kecil (small area estimation, SAE).
Statistik area kecil semacam itu telah menjadi perhatian para statistisi dunia secara sangat serius sejak sepuluh tahun terakhir ini (misalnya Ghosh and Rao, 1994; Chand dan Alexander, 1995; You dan Rao, 2000; Rao, 2003; Russo et.al., 2005; Chambers dan Chandra, 2006; Lahiri, 2008). Berbagai metode SAE telah dikembangkan khususnya menyangkut metode yang berbasis model. Area kecil tersebut didefinisikan sebagai himpunan bagian dari populasi dimana suatu peubah menjadi perhatian. Pendekatan klasik untuk menduga parameter area kecil
didasarkan pada aplikasi model desain penarikan contoh (design-based) yang dikenal sebagai pendugaan langsung (direct estimation). Namun, metode pendugaan langsung pada sub-populasi tidak memiliki presisi yang memadai karena kecilnya jumlah contoh yang digunakan untuk memperoleh dugaan tersebut. Oleh karena itu dikembangkan metode pendugaan secara tidak langsung (indirect estimation) di suatu area yang relatif kecil dalam percontohan survei (Lahiri dan Rao, 1995; Russo et al, 2005)
Menurut Lahiri (2008), metode pendugaan tidak langsung pada area kecil pada dasarnya memanfaatkan kekuatan area sekitarnya (neighbouring areas) dan sumber data di luar area yang statistiknya ingin diperoleh. Dalam hal ini, model dikembangkan dengan asumsi bahwa keragaman didalam area kecil peubah respon dapat diterangkan oleh hubungan keragaman yang bersesuaian pada informasi penyerta (auxiliary) yang berupa pengaruh tetap, sedangkan keragaman specifik area kecil diasumsikan dapat diterangkan oleh informasi tambahan yang berupa pengaruh acak area.
Meningkatnya kebutuhan terhadap metode SAE saat ini terjadi seiring dengan meningkatnya kebutuhan pemerintah dan para pengguna statistik (termasuk dunia bisnis) terhadap informasi yang lebih rinci, cepat, dan handal, tidak saja untuk lingkup negara tetapi pada lingkup yang lebih kecil seperti provinsi, kabupaten, bahkan kecamatan atau kelurahan. Di Indonesia pentingnya statistik area kecil semakin dirasakan seiring dengan era otonomi daerah dimana sistem ketatanegaraan bergeser dari sistem sentralisasi ke sistem desentralisasi. Pada sistem desentralisasi pemerintah daerah memiliki kewenangan yang lebih besar untuk mengatur dirinya sendiri. Kebutuhan statistik pada level kabupaten, dengan demikian, menjadi keniscayaan sebagai dasar bagi pemerintah daerah untuk menyusun sistem perencanaan, pemantauan dan penilaian pembangunan daerah atau kebijakan penting lainnya.
Menurut Sadik et al (2006, 2008), model pendugaan parameter area kecil akan sangat membantu khususnya dalam menyediakan kebutuhan data dan informasi yang akurat untuk kebutuhan daerah di Indonesia seperti level propinsi, kabupaten/kota atau bahkan kecamatan dengan memanfaatkan keakuratan data
mengumpulkan data sendiri. Dengan demikian, secara nasional akan cukup banyak biaya yang bisa dihemat sehingga dapat dialokasikan untuk pembiayaan pembangunan lainnya.
1.2. Tujuan Penelitian
Secara umum tujuan penelitian ini adalah untuk mengkaji sifat-sifat statistik pada:
a. Model campuran linear terampat (generalized linear mixed model) sebagai model dasar SAE.
b. Model SAE yang memasukkan pengaruh acak area dan waktu (state space) melalui pendekatan prediksi tak-bias linear terbaik (best linear unbiased prediction).
c. Model SAE yang memasukkan pengaruh acak area dan waktu (state space) melalui pendekatan Bayes berhirarki.
1.3. Ruang Lingkup
Fokus penelitian ini adalah kajian terhadap metode SAE yang memasukkan pengaruh acak area dan waktu berdasarkan model state space. Pendekatan yang digunakan untuk pendugaan parameter model tersebut adalah metode prediksi tak-bias linear terbaik (PTLT) dan Bayes berhirarki. Penelaahan terhadap konsep dan sifat-sifat statistik model dilakukan secara analitik dan empirik.
Pada Bab II dibahas tinjauan metode SAE secara umum mencakup perkembangan metode SAE, metode pendugaan tidak langsung pada area kecil, pendekatan model campuran linear terampat (MCLT) pada SAE, pengaruh penarikan contoh pada pendugaan tidak langsung, serta persoalan statistik area kecil pada data Badan Pusat Statistik (BPS). Sementara kajian tentang metode PTLT pada pendugaan area kecil berdasarkan model state space dipaparkan pada Bab III yang mencakup pendekatan MCLT pada model SAE dengan pengaruh acak area dan waktu, metode PTLT, pendekatan kuadrat tengah galat / KTG (mean square error / MSE) dengan orde kedua, evaluasi terhadap penduga KTG, serta studi kasus penerapan pada data Susenas dan data simulasi.
Metode Bayes berhirarki pada pendugaan area kecil berdasarkan model state space dibahas pada Bab IV. Pembahasan tersebut mencakup konsep metode Bayes empirik dan berhirarki, pendekatan Bayes berhirarki pada model state space, penduga bagi KTG, metode Gibbs sampling, serta studi kasus penerapan pada data Susenas dan data simulasi. Pembahasan umum pada Bab V bertujuan untuk membandingkan sifat-sifat statistik model SAE state space antara metode PTLT dengan metode Bayes berhirarki baik secara empirik maupun analitik. Sementara Bab VI memaparkan simpulan dari penelitian secara keseluruhan dan saran untuk penelitian selanjutnya khususnya menyangkut hal-hal keterbatasan pada penelitian ini.
1.4. Kebaruan / Novelty
Pemikiran tentang SAE yang berbasis pada model telah mendapatkan perhatian para statistisi dunia hingga saat ini khususnya setelah JNK Rao (2003) mengeluarkan buku tentang SAE. Buku tersebut merupakan buku pertama yang membahas tentang pendugaan area kecil dengan cara mengkompilasi beberapa hasil penelitian yang telah dipublikasikan di berbagai jurnal ilmiah internasional. Sampai saat ini banyak dilakukan konferensi statistika internasional terkait dengan pengembangan metode pendugaan area kecil tersebut.
Penelitian yang menjadi topik dalam disertasi ini merupakan perluasan kajian SAE dari beberapa hasil kajian para statistisi dunia yang mereka publikasikan dalam jurnal ilmiah. Ada dua kebaruan yang disajikan dalam disertasi ini. Pertama adalah penjabaran dan pembuktian secara analitik terhadap sifat-sifat statistik pada model SAE yang berbasis pada model state space.
Kedua, kajian metode PTLT dan Bayes berhirarki untuk SAE berdasarkan model state space serta penerapannya pada data Susenas BPS merupakan kajian yang pertama kali dilakukan di Indonesia. Sehingga hasil kajian dalam disertasi ini diharapkan dapat memberikan sumbangsih pemikiran pada perkembangan perstatistikaan di Indonesia.
BAB II
2.
Tinjauan Metode Pendugaan Area Kecil
2.1. Pendahuluan
Survei digunakan untuk mendapatkan informasi mengenai parameter populasi dengan mengefektifkan biaya yang tersedia. Secara lebih luas survei secara praktis tidak hanya digunakan untuk menduga total populasi tetapi juga untuk menduga keragaman subpopulasi atau domain. Domain dapat didefinisikan sebagai daerah geografik, sosio-demografi, dan sebagainya. Dalam konteks survei, penduga dikatakan langsung (direct estimator) apabila pendugaan terhadap parameter populasi di suatu domain hanya didasarkan pada data contoh yang diperoleh dari domain tersebut. Misalnya, pendugaan rata-rata tingkat pengeluaran rumah tangga perbulan di suatu kabupaten didasarkan hanya pada data survei yang diperoleh dari kabupaten tersebut. Informasi lain yang berada di luar domain kabupaten tersebut tidak diperhitungkan.
Pendugaan langsung umumnya didasarkan pada teknik penarikan contohnya (sampling technique). Teknik semacam ini telah dikembangkan oleh Cochran (1977), Swenson dan Wretman (1989), dan Thompson (1997). Metode yang didasarkan pada pemodelan (model-based) juga telah dikembangkan.
Survei contoh termasuk dalam kelompok non-percobaan (non-experimental) yang lazim disebut studi observasional. Tujuan utamanya adalah menduga nilai sejumlah peubah yang terdapat dalam populasi. Meskipun sejumlah hipotesis dapat diuji berdasarkan data yang diperoleh dari suatu survei, namun hal ini umumnya merupakan tujuan sekunder dalam survei (Levy dan Lemeshow, 1999).
Survei contoh dapat dikategorikan kedalam dua kelompok besar berdasarkan pada metode pemilihan contoh, yaitu contoh berpeluang (probability samples) dan contoh tak-berpeluang (nonprobability samples). Contoh berpeluang memiliki karakteristik bahwa setiap elemen dalam populasi diketahui peluangnya untuk terpilih sebagai contoh. Sedangkan pada contoh tak-berpeluang tidak
memiliki karakteristik ini, yaitu peluang suatu elemen dalam populasi untuk terpilih sebagai contoh tidak diketahui berapa besar peluangnya. Pada penarikan contoh berpeluang, karena setiap elemen diketahui peluangnya untuk terpilih, maka penduga tidak bias parameter populasi yang berupa fungsi linear dari pengamatan (rataan populasi, proporsi, total) dapat diformulasikan dari data contoh. Demikian juga, galat baku bagi penduga ini bisa diperoleh sehingga reliabilitas dan validitas dapat dievaluasi.
Pada survei contoh mencakup dua hal penting, yaitu perencanaan penarikan contoh (sampling plan) dan prosedur pendugaan parameter. Perencanaan penarikan contoh adalah metodologi yang digunakan untuk pemilihan contoh dari populasi. Sedangkan prosedur pendugaan parameter merupakan algoritma atau formula yang digunakan untuk memperoleh dugaan nilai populasi dari data contoh dan untuk menduga reliabilitas dari penduga tersebut (Levy and Lemeshow, 1999).
2.1.1. Keuntungan dan Keterbatasan Penarikan Contoh
Penarikan contoh memiliki beberapa keuntungan dibandingkan dengan enumerasi secara lengkap terhadap populasi, diantaranya adalah lebih ekonomis, lebih pendek jedah waktunya (time-lag), cakupannya lebih luas, dan mutu pekerjaan lebih baik karena lebih terencana (Som, 1996). Penarikan contoh memerlukan sumberdaya yang lebih baik untuk merancang dan melaksanakannya sehingga biaya per unit pengamatan adalah lebih tinggi daripada enumerasi secara lengkap. Namun total biaya untuk penarikan contoh adalah lebih kecil daripada enumerasi secara lengkap dalam suatu cakupan populasi tertentu. Demikian juga, dengan jumlah pengamatan yang lebih kecil, penarikan contoh memungkinkan untuk lebih cepat dibandingkan dengan enumerasi secara lengkap. Penarikan contoh memiliki cakupan yang lebih luas daripada enumerasi secara lengkap
2.1.2. Validitas, Reliabilitas, dan Keakuratan
Sebagaimana disebutkan sebelumnya bahwa pada contoh berpeluang, reliabilitas dan validitas penduga dapat dievaluasi. Reliabilitas (reliability)
apabila survei yang sama dilakukan secara berulang-ulang. Apabila diasumsikan bahwa tidak ada kesalahan pengukuran dalam survei, maka reliabilitas suatu penduga parameter dapat digambarkan oleh ragam penarikan contohnya atau ekuivalen dengan galat bakunya. Sehingga penduga yang memiliki galat baku terkecil, maka penduga tersebut memiliki reliabilitas terbesar.
Validitas (validity) penduga parameter populasi ( θˆ ) merupakan gambaran tentang bagaimana rataan dari penduga-penduga suatu parameter yang diperoleh dari proses survei yang dilakukan secara berulang-ulang berbeda dari nilai parameter yang sebenarnya (). Apabila diasumsikan bahwa tidak ada kesalahan pengukuran dalam survei, maka validitas suatu penduga parameter dapat dievaluasi dari nilai bias penduga tersebut, yaitu E( - θˆ ). Penduga yang memiliki bias terkecil merupakan penduga yang memiliki validitas terbesar.
Sementara keakuratan (accuray) suatu penduga menunjukkan tentang seberapa jauh penyimpangan nilai dugaan dari nilai parameter yang sebenarnya. Keakuratan suatu penduga umumnya dievaluasi berdasarkan nilai kuadrat tengah galat / KTG (mean square error / MSE) atau berdasarkan nilai akar kuadrat
tengah galat / AKTG (root mean square error / RMSE) yaitu E(θθˆ)2 .
2.1.3. Pendugaan Ukuran Contoh
Salah satu persoalan penting dalam perancangan contoh adalah menentukan berapa besar contoh yang diperlukan untuk memperoleh penduga yang memiliki tingkat reliabilitas tertentu sesuai dengan tujuan survei. Secara umum, ukuran contoh yang lebih besar akan memberikan tingkat reliabilitas yang juga lebih besar terhadap hasil pendugaan.
Kesalahan relatif,, dalam pendugaaan parameter dapat dikontrol pada saat melakukan penarikan contoh. Pada penarikan contoh acak sederhana dapat dinyatakan bahwa α ξ ˆ P
dimana adalah nilai peluang tertentu. Sebagaimana telah dijabarkan sebelumnya bahwa ˆ dapat diasumsikan menyebar normal dengan ragam V(ˆ) yaitu
V(ˆ) = n N n N N n y N n N y N i i 2 1 2 σ ) 1 ( ) ( ) (
sehingga = z/2 V(ˆ) = z/2 n N n N y 2 σ .Penyelesain untuk ukuran contoh n adalah
n = 2 2 2 2 / 2 2 2 / 2 2 / 2 2 / ξ ψ ) ( ψ ) ( ξ σ 1 1 ξ σ N z z N Y z N Y z y y y y
dimana ψ =y σy/ merupakan koefisien keragaman.
Sebuah pendekatan untuk menentukan ukuran contoh kadang-kadang dapat dikembangkan bila keputusan praktis dibuat dari hasil-hasil contoh. Dasar keputusan akan menjadi lebih jelas jika pendugaan contoh mempunyai kesalahan yang rendah daripada jika mempunyai kesalahan yang tinggi. Masih memungkinkan untuk menghitung masalah keuangan, kerugian l(h) yang muncul dalam sebuah keputusan dengan sebuah kasalahan dalam pendugaannya. Meskipun nilai sebenarnya dari h tidak dapat diramalkan sebelumnya, teori penarikan contoh menunjukkan bahwa untuk mendapatkan sebaran frekuensi f(h, n) dari h, yang untuk metode penarikan contoh tertentu akan tergantung pada ukuran contoh n. Dengan demikian kerugian yang diharapkan untuk ukuran contoh tertentu adalah:
l h f h n dh n
L( ) ( ) ( , ) .
Tujuan dari pengambilan contoh adalah untuk mengurangi kerugian ini. Jika C(n) adalah biaya dari ukuran contoh n, sebuah prosedur yang beralasan adalah dengan memilih n untuk meminimumkan:
C(n) + L(n)
karena ini adalah total biaya yang diperlukan dalam pengambilan contoh dan dalam pembuatan keputusan berdasarkan hasil-hasil contoh. Pemilihan ukuran ( 2.2 )
contoh n ditentukan oleh ukuran contoh yang optimum dan tingkat ketelitian yang paling tinggi.
Sebagai alternatif, pendekatan yang sama dapat disajikan dalam keuntungan ekonomis (monetary gain) yang diperoleh dari contoh yang dimiliki, bukannya kerugian yang timbul dari kesalahan informasi contoh. Jika keuntungan keuangan yang digunakan, maka dapat dibentuk suatu harapan keuntungan G(n) dari sebuah contoh berukuran n, dengan G(n) adalah nol jika tidak ada contoh yang diambil. Berarti harus memaksimumkan
G(n) - C(n).
Aplikasi yang sangat sederhana terjadi bila fungsi kerugian, l(h), adalahh2, dengan adalah konstanta, sehingga dapat dinyatakan bahwa
L(n) =E(h2).
Misalkanˆadalah penduga dari dan h = ˆ - , maka
N n V n L y 1 1 λσ ) ˆ ( λ ) ( 2
jika yang digunakan adalah penarikan contoh acak sederhana. Sementara bentuk sederhana dari fungsi biaya untuk contoh adalah
C(n) = c0+ c1n
dimana c0adalah biaya tetap. Berdasarkan fungsi biaya dan kerugian, nilai dari n
yang meminimumkan biaya dan kerugian adalah
1 2 σ λ c n y .
2.2. Perkembangan Metode SAE
Persoalan statistik area kecil telah menjadi perhatian serius para statistisi sejak 10 tahun terakhir ini, meskipun dasar pemikirannya telah dimulai jauh sebelumnya. Pendugaan karakteristik area kecil berdasarkan model pengaruh tetap merujuk pada synthetic estimator (Levy, 1971), composite estimator (Schaible et. al., 1977) dan prediction estimator (Holt et. al., 1979). Model pengaruh tetap menerangkan seluruh keragaman peubah respon di dalam area kecil oleh keragaman faktor-faktor yang diketahui.
Fay dan Herriot (1979) mengajukan suatu metode pemodelan untuk menduga pendapatan perkapita untuk suatu area kecil berdasarkan data survei Biro Sensus Amerika Serikat (U.S. Bureau of the Cencus). Area kecil yang dimaksudkan oleh Fay dan Herriot sama dengan Levy dan Holt di atas, yaitu suatu area survei dimana ukuran contoh pada area tersebut sangat kecil. Perbedaannya, Fay dan Herriot memasukkan pengaruh acak pada modelnya. Asumsi dasar dalam pengembangan model untuk pendugaan area kecil (SAE) tersebut adalah bahwa keragaman di dalam area kecil peubah respon dapat diterangkan oleh hubungan keragaman yang bersesuaian pada informasi tambahan yang disebut sebagai pengaruh tetap. Asumsi lainnya adalah bahwa keragaman specifik area kecil tidak dapat diterangkan oleh informasi tambahan dan merupakan pengaruh acak area kecil. Gabungan dari dua asumsi tersebut membentuk model pengaruh campuran (mixed models).
Dibandingkan dengan model pengaruh tetap, model campuran memiliki cakupan aplikasi yang lebih luas. Model Fay-Herriot tersebut menggunakan model campuran yang telah menjadi kajian para statistisi sebelumnya. Salah satu sifat yang menarik dalam model campuran adalah kemampuannya dalam menduga kombinasi linear dari pengaruh tetap dan pengaruh acak. Henderson (1949-1975) mengembangkan teknik penyelesaian model pengaruh campuran untuk memperoleh prediksi tak-bias linear terbaik / PTLT (best linear unbiased prediction / BLUP). Metode PTLT yang dikembangkan tersebut mengasumsikan diketahuinya ragam pengaruh acak dalam model campuran (komponen ragam). Padahal dalam prakteknya, komponen ragam tidak bisa diketahui dan harus diduga berdasarkan data. Selanjutnya, Harville (1977) melakukan kajian terhadap beberapa metode pendugaan komponen ragam, dengan memasukkan metode maximum likelihood dan residual maximum likelihood. Penduga PTLT yang diperoleh dengan cara terlebih dahulu menduga komponen ragamnya disebut sebagai prediksi tak-bias linear terbaik empirik / PTLTE (empirical best linear unbiased prediction / EBLUP) seperti yang dikembangkan Harville (1990) dan Robinson (1991).
Clayton (1993), Breslow dan Lin (1995), McGilchrist (1994), dan Marker (1999) mengembangkan PTLTE untuk model linear terampat (generalized linear models) yang pengaruh acaknya diasumsikan memiliki sebaran keluarga eksponensial. Zeger dan Karim (1991) memperkenalkan pendekatan Gibbs sampling untuk penyelesaian model campuran. Teknik komputasi Monte Carlo Expectation-Maximization dan Monte Carlo Newton-Raphson digunakan oleh McCulloch (1994 dan 1997). Sementara Datta dan Ghosh (1991), Ghosh dan Rao (1994), Pfeffermann (1999), Ghosh dan Lahiri (1987), Rao (1999, 2003), serta Chambers dan Tzavidis (2006) menggunakan model campuran untuk meningkatkan akurasi pendugaan pada kasus area kecil berdasarkan data survey atau data sensus.
Selain PTLTE, pendugaan dan inferensia pada SAE juga menggunakan Bayes empirik (empirical Bayes) dan Bayes berhirarki (hierarchical Bayes). Pada pendekatan Bayes empirik, pendugaan dan inferensia berdasarkan pada sebaran posterior yang diduga dari data. Adapun pada pendekatan Bayes berhirarki, parameter model yang tidak diketahui (termasuk komponen ragam) diperlakukan sebagai komponen acak yang masing-masing memiliki sebaran prior tertentu. Sebaran posterior untuk parameter yang menjadi perhatian diperoleh berdasarkan seluruh sebaran prior tersebut. Ghos dan Rao (1994) mengulas penggunaan Bayes berhirarki pada SAE. Deely dan Lindley (1991), Maiti (1998), Datta et al (1996, 1999) menggunakan non-informative prior untuk kasus hiperparameter pada penggunaan Bayes berhirarki. You dan Rao (2000) menggunakan Bayes berhirarki untuk menduga rataan area kecil berdasarkan model pengaruh acak. Malec et al (1999) mengembangkan model yang digunakan pada Malec et al (1997) dengan memasukkan komponen oversampling di dalam likelihood. Farrell et al (1997) mengembangkan model logistik campuran yang digunakan oleh MacGibbon dan Tomberlin (1989). Moura dan Mignon (2001) lebih mengembangkan model tersebut dengan memasukkan komponen struktur korelasi spasial pada data respon biner.
Saat ini penelitian dan pengembangan metode SAE semakin meningkat semenjak JNK Rao menerbitkan buku yang berjudul ’Small Area Estimation’ pada tahun 2003, sebagai buku pertama di dunia yang membahas tentang metode SAE. Seminar dan konferensi internasional tentang SAE saat ini banyak
diselenggarakan di berbagai negara. Salah satunya diselenggarakan di Spanyol pada Juli 2009 yang dihadiri oleh berbagai statistisi dunia termasuk JNK Rao. Pada konferensi tersebut didiskusikan berbagai problem SAE termasuk aplikasinya pada data survei di berbagai negara. Perkembangan dan aplikasi metode SAE di Indonesia pada konferensi tersebut dikemukakan oleh Sadik dan Notodiputro (2009).
2.2.1. Metode Pendugaan Tidak Langsung untuk Area Kecil
Ukuran contoh pada sub-area survei terkadang berukuran kecil sehingga statistik yang diperoleh akan memiliki ragam yang besar atau bahkan pendugaan bisa saja tidak dapat dilakukan pada sub-area tertentu karena sub-area tersebut tidak terpilih menjadi contoh. Metode SAE dikembangkan untuk menyelesaikan masalah tersebut. Area kecil tersebut didefinisikan sebagai himpunan bagian dari populasi dimana suatu peubah menjadi perhatian. Pendekatan klasik untuk menduga parameter area kecil didasarkan pada aplikasi model desain penarikan contoh yang menghasilkan metode pendugaan langsung (Rao, 2003; Chambers dan Chandra, 2006; Lahiri, 2008).
Informasi tambahan dapat digunakan untuk meningkatkan akurasi dan presisi suatu penduga. Pada SAE, informasi tambahan tersebut dapat berupa nilai parameter dari area kecil lain yang memiliki karakteristik serupa dengan area kecil yang menjadi perhatian, atau nilai pada waktu yang lalu, atau nilai dari peubah yang memiliki hubungan dengan peubah yang sedang diamati. Pendugaan paramater dan inferensianya yang berdasarkan pada informasi tambahan tersebut, dinamakan pendugaan tidak langsung atau model-based. Metode dengan memanfaatkan informasi tambahan tersebut secara statistik memiliki sifat penguatan (borrowing strength) dari hubungan antara nilai peubah respon dan informasi tambahan tersebut.
Asumsi dasar dalam pengembangan model untuk SAE adalah bahwa keragaman didalam area kecil peubah respon dapat diterangkan oleh hubungan keragaman yang bersesuaian pada informasi tambahan yang disebut sebagai pengaruh tetap. Asumsi lainnya adalah bahwa keragaman specifik area kecil tidak
kecil. Gabungan dari dua asumsi tersebut membentuk model pengaruh campuran (mixed models). Model pengaruh tetap menerangkan seluruh keragaman peubah respon di dalam area kecil oleh keragaman faktor-faktor yang diketahui. Pendugaan karakteristik area kecil berdasarkan model pengaruh tetap merujuk pada synthetic estimator (Levy, 1971), composite estimator (Schaible et. al., 1977) dan prediction estimator (Holt et. al., 1979; Sarndal, 1984; dan Marker, 1999).
Pendugaan langsung umumnya didasarkan pada teknik penarikan contohnya. Teknik semacam ini telah dikembangkan oleh Cochran (1977), Swenson dan Wretman (1989), dan Thompson (1997). Metode yang didasarkan pada pemodelan juga telah dikembangkan, misalnya seperti yang dilakukan oleh You dan Rao (2000).
Pada pendugaan yang berbasis pada rancangan survei, pembobot rancangan wj(s) memiliki peranan penting dalam membentuk penduga berbasis rancangan Yˆ bagi Y. Pembobot ini tergantung pada s dan elemen j (js). Salah satu bentuk pembobot yang penting adalah wj(s)=1/j, dimana j = {s:js}p(s), j=1, 2, .., N. Apabila tidak informasi penyerta, maka penduga langsung dapat diekspresikan sebagai Yˆ= {s:js}wj(s)yj. Dalam kasus ini, rancangan tidak berbias apabila terpenuhi{s:js}p(s)wj(s) = 1 untuk j=1, 2, …, N. Pembobot ini merupakan bentuk umum dari penduga Horvitz-Thompson (Cochran, 1977).
Pendugaan langsung ini dapat pula menggunakan informasi penyerta yang ada pada domain yang bersangkutan. Misalkan informasi penyerta dalam domain tertentu, X = (X1, …, Xp)T, tersedia dan vektor xj untuk js terobservasi, sehingga
data (yj, xj) untuk setiap elemen js terobservasi. Suatu penduga yang mengefisienkan informasi penyerta ini adalah generalized regression (GREG) yang bisa ditulis sebagai berikut:
B X X ˆ) ˆ ( ˆ ˆ T GR Y Y dimana Xˆ= {s:js}wj(s)xj dan T p B Bˆ ,..., ˆ ) ( ˆ 1
B adalah solusi dari persamaan
kuadrat terkecil terboboti dari contoh, yaitu ({s:js}wj(s)xjxjT/cj)Bˆ=
{s:js}wj(s)xjyj/cjdengan cj(>0) sebagai konstanta spesifik.
Pendugaan tidak langsung dapat menggunakan pendekatan model secara umum. Misalkan diasumsikan bahwa i = g(Yi) untuk beberapa spesifikasi g(.)
dihubungkan dengan data penyerta spesifik pada area i, xi = (x1i, …, xpi)Tmelalui suatu model linear
i= xiT + bivi, i = 1, …, m
dimana bi adalah konstanta positif yang diketahui dan adalah vektor berukuran px1. Sedangkan vi adalah pengaruh acak spesifikasi area yang diasumsikan bebas dan menyebar identik dengan
Em(vi) = 0 dan Vm(vi) =v2( 0), atau vi iid (0, v2).
Pendugaan tidak langsung untuk rataan populasi di area kecil i, (Yi), diperlukan
informasi mengenai penduga langsungnya yaitu Yˆ. Dengan menggunakan metode James-Stein akan diperoleh:
ˆi g(Y ˆ) = i+ ei ˆi xiT + bivi+ ei, i = 1, …, m
dimana galat penarikan contoh (sampling error) eiadalah bebas dengan Ep(ei|i) = 0 dan Vp(ei|i) =i, atau vi iid (0, v2).
2.2.2. Pendekatan Model Campuran Linear Terampat
Rao(2003) mengaitkan model-model pendugaan tidak langsung (model-based) di atas sebagai bagian dari model campuran linear terampat / MCLT (generalized linear mixed model / GLMM) yang menggabungkan antara pengaruh tetap dan pengaruh acak dalam suatu model umum. Datta dan Ghosh (1991) mengemukakan formulasi model MCLT sebagai berikut :
yP= XP + ZPv + eP.
Pada model ini v dan eP bebas dengan eP N(0, 2P) dan v N(0, 2
D()), dimana P adalah matriks definit positif yang diketahui dan D() adalah
matriks definit positif yang strukturnya diketahui. Sedangkan XP dan ZP adalah matriks rancangan dan YP adalah vektor N x 1 dari nilai y populasi. Matriks koragam bagi v dan e masing-masing adalah G dan R. Persamaan di atas dapat ( 2.5 )
* e e v * Z Z * X X * y y yP
dimana bagian yang ditandai asterisk (*) menunjukkan unit yang tidak tercakup dalam contoh. Vektor untuk total (Yi) pada area kecil adalah berbentuk Ay + Cy*
dengan A = mi Tn i 1 1 dan C = mi TN n i i 11 dimana im1 Au= blockdiag(A1, …, Am).
Pada MCLT ini dilakukan pendugaan terhadap kombinasi linear dari parameter yaitu = 1T + mTv. Rao (2003) mengemukakan bahwa untuk
tertentu yang diketahui maka penduga PTLT bagi adalah
H ~ = t(, y) = 1T ~ + mT~v = 1T~ + mTGZTV-1(y - X~) dimana ~ = ~() = (XTV-1X)-1XTV-1y v ~ = v~() = GZT V-1(y - X~). Model untuk pendugaan tidak langsung, yaitu ˆi xi
T + b
ivi + ei, i = 1, …, m, sebenarnya merupakan kasus khusus dari model MCLT, yaitu
yi= ˆ , Xi i= xi T , Zi= bi dan vi= vi, ei= ei, = (1, …,p)T sedangkan Gi=v2, Ri=i sehingga Vi=i+v2bi2 dan i=i= xiT + bivi.
Apabila persamaan pendugaan tidak langsung disubstitusikan ke dalam pendugaan MCLT akan diperoleh penduga PTLT bagiiataui yaitu:
H i ~ = xiT ~ +i(ˆ - xi i T~ ), dimanai=v2bi2/(i+v2bi2), dan ~ = ~(v2) =
m i i v i i i m i i v i T i i b b 1 2 2 1 1 2 2 ˆ x x x .Ada tiga pendekatan standar untuk SAE didasarkan pada model MCLT tersebut, yaitu PTLTE, Bayes empirik, dan Bayes berhirarki. Metode PTLTE biasanya membutuhkan metode kemungkinan maksimum terkendala / KMT ( 2.7 )
( 2.8 )
(restricted maximum likelihood / REML) untuk pendugaan parameternya yang berkaitan dengan pengaruh area acak, yang identik dengan Bayes empirik dan Bayes berhirarki dalam beberapa keadaan.
2.2.3. Pengaruh Penarikan Contoh pada Pendugaan Tidak Langsung
Sebagaimana dijabarkan di atas bahwa pada pendugaan tidak langsung, metode penarikan contoh akan mempengaruhi metode penghitungan nilai kuadrat tengah galatnya. Artinya, pada pendugaan tidak langsung juga mempertimbangkan metode pendugaan langsungnya bagi penduga parameternya maupun keragaman yang terdapat dalam penduga langsung tersebut. Pada model di atas yaitu,
ˆi g(Yˆ) =i+ ei
ˆi xiT + bivi+ ei, i = 1, …, m
pengaruh penarikan contoh diperhitungkan pada komponen ei sebagai galat penarikan contoh (sampling error) yang bebas dengan
Ep(ei|i) = 0 dan Vp(ei|i) =i, atau vi iid (0, v2).
Pada persamaan ( 2.10 ) di atas, penduga langsung yang berbasis pada metode penarikan contoh tertentu berkontribusi pada nilai ˆ dan Vi p(ei|i) = i. Untuk penarikan contoh acak sederhana (simple random sampling) yang memilih n unit dari N sehingga setiap elemen dari NCn contoh yang berbeda mempunyai kesempatan yang sama untuk dipilih maka ˆ = y pada suatu area kecil tertentu dimana E( y ) = ( ... ) ! )! ( ! )! ( )! 1 ( )! 1 ( 2 1 y yN y nN n N n n N n N = Y N y y y ... N) ( 1 2 .
Sehingga y merupakan penduga tidak bias bagi nilai tengah populasi Y . Sedangkan = ragam bagi y untuk area kecil tertentu yang dapat dinyatakan sebagai E( y Y )2, yaitu
( 2.10 )
=
N i i Y y N nN n N 1 2 ) ( ) 1 ( = n N n N N n Y y N n N N i i 2 1 2 y σ ) 1 ( ) ( ) (
dimana ) 1 ( ) ( σ 1 2 2
N Y y N i iy , sedangkan penduga bagi ragam y adalah
) ( ˆ 2 n s N n N y V y
pada penduga ragam bagi y tersebut,
) 1 ( ) ( 1 2 2
n y y s n i iy merupakan penduga tidak
bias bagi ragam populasi σ2y. Untuk penarikan contoh dengan pengembalian, ragam bagi y yaitu
= V( y ) = 12 n
N i N j i j i i N n y y N N n y 1 2 2 2 2 ) 1 ( = 1 ) ( 1 ) ( 1 1 2 1 2
N Y y nN N Y y nN N i i N i i = n N N y 2 σ 1 .Pada penarikan acak contoh berlapis, populasi N unitnya dibagi ke dalam subpopulasi, masing-masing N1, N2, ..., NL unit, dimana N N
L i
1 , sehingga subpopulasi ini tidak boleh tumpang tindih. Penduga langsung bagi yaitu ˆ pada persamaan pendugaan area kecil ( 2.10 ) adalah ˆ = y , yaitust
L h h h L h h h st W y N y N y 1 1dimana Wh = Nh/N merupakan pembobot lapisan. Apabila dalam setiap lapisan penduga contohnya, y , adalah tidak bias, makah yst merupakan penduga tidak bias bagi nilai tengah populasi Y , yaitu
( 2.13 )
( 2.14 ) ( 2.12 )
E(y ) =st
L h h h L h h hy WY W E 1 1karena penduganya, y , adalah tidak bias pada tiap lapisan. Sementara itu, nilaih
tengah populasi dapat dinyatakan sebagai berikut:
L h h h L h h h L h N i hi Y W N Y N N y Y h 1 1 1 1berdasarkan penjabaran di atas, maka yst merupakan penduga tidak bias bagi nilai tengah populasi Y , karena E(y ) = Y .st
Ragam penarikan contoh yang berkontribusi pada pendugaan area kecil di atas dapat dinyatakan sebagai ragam bagi yst yaitu
= V(y ) =st ( ) 2 ( , ) 1 1 2 1 j h L h L h j j h L h h h L h h hy W V y WWCov y y W V
Apabila penarikan contohnya dilakukan secara bebas antar lapisan yang berbeda seluruh koragam di atas sama dengan nol, sehigga
= V(y ) =st
L h h h L h h hy W V y W V 1 2 1 ) ( =
L h h h h h h h N n N n W 1 2 2σ dimana 1 ) ( σ 1 2 2
h N i h hi h N Y y h .Pada penarikan contoh sistematik yang mengambil sebuah unit secara acak dari k unit yang pertama, dan selanjutnya mengambil setiap kelipatan k, Penduga langsung bagi yaitu ˆ pada persamaan pendugaan area kecil ( 2.10 ) adalah ˆ =
sy
y . Pendekatan pada contoh sistematik adalah berupa penarikan contoh berkelompok dimana kelompoknya mengandung n elemen dan contohnya terdiri dari satu kelompok, sehingga dapat dianggap bahwa N = nk. Berdasarkan hal ini, ˆ = y merupakan penduga tidak bias bagi nilai tengah populasi Y untuk ( 2.15 )
Misalkan yijmenyatakan anggota ke-j dari contoh sistematik ke-i, sehingga j = 1, 2, . . ., n ; i = 1, 2, . . ., k, dan rata-rata contoh ke-i dinotasikan dengan
.
i
y maka adalah ragam dari ysy yaitu:
2 1 1 2 . 1 2 . 1 1 2 2 ) 1 ( ) ( ) ( ) ( ) ( ) 1 ( wsy sy k i n j i ij k i i k i n j ij S n k y nkV y y Y y n Y y S N
sehingga = 1 2 ( 1) 2 ) ( sy Swsy N n k S N N y V dimana
k i n j ij Y y N S 1 1 2 2 ) ( 1 1 dan
k i n j i ij wsy y y n k S 1 1 2 . 2 ) ( ) 1 ( 1 . 2 wsyS merupakan ragam antara unit-unit yang terletak di dalam contoh sistematik yang sama. Pembagi dari ragam ini, k(n - 1) dibentuk dengan aturan yang umum dalam analisis ragam yaitu masing-masing dari k contoh memberikan (n - 1) derajat bebas pada jumlah kuadrat dalam pembilangnya.
Bentuk lain untuk pada penarikan contoh acak berlapis ini dapat dijabarkan sebagai berikut:
= ( ) 1 [1 ( 1) ] 2 w sy n ρ n S N N y V .
Pada persamaan di atas, adalah koefisien korelasi antara pasangan dariw unit-unit yang berada dalam contoh sistematik yang sama, yaitu
2 ) ( ) )( ( Y y E Y y Y y E ρ ij iu ij w .
Dimana pembilangnya adalah rata-rata seluruh kn(n – 1)/2 pasangan yang berlainan, dan penyebutnya keseluruhan nilai N dari yij. Karena penyebutnya adalah (N – 1)S2/N, maka
k i n u j iu ij w y Y y Y S N n ρ 1 2 ( )( ) ) 1 )( 1 ( 2 .Pada penarikan contoh acak bergerombol, penduga langsung bagi yaitu ˆ pada persamaan pendugaan area kecil ( 2.10 ) dapat dijelaskan sebagai berikut. ( 2.17 )
( 2.18 )
Misalnya yij adalah nilai yang diamati untuk elemen ke-j dalam unit atau kelompok ke-i, dan yi =
M
j 1yij adalah total pada kelompok ke-i, dimana i = 1, 2, ..., N dan j = 1, 2, ..., M. Apabila sebuah contoh acak sederhana kelompok berukuran n diambil dari N kelompok pada populasi dan pada masing-masing kelompok berisi M elemen. Misalkan yi menyatakan total pada kelompok ke-i dan ˆ = y =
ni 1yi/ , sertan adalah ragam y , yaitu
= V( y ) = 1 ) ( 1 2
N Y y nN n N n i i .Karena y = My dan Y = M Y , maka y merupakan penduga tidak bias bagi Y dengan ragam sebagai berikut:
V(y ) = 1 ) ( 1 2 2
N Y y nNM n N n i iMisalkan bahwa setiap unit dalam populasi dapat dibagi ke dalam sejumlah unit-unit atau sub-unit yang lebih kecil. Sebuah contoh dari n unit dipilih. Jika sub-unit dalam unit yang dipilih memberikan hasil yang sama, hal ini menjadi tidak efisien untuk mengukur sebuah contoh dari sub-unit dalam setiap unit yang dipilih. Pada kondisi demikian dapat diterapkan sub-penarikan contoh atau penarikan contoh dua tahap, karena contohnya diambil dalam dua tahap. Tahap pertama memilih sebuah contoh dari unit-unit utama dan tahap kedua memilih sebuah contoh dari unit-unit tahap pertama atau sub-unit dari setiap unit utama yang terpilih.
Pada penarikan contoh dua tahap, penarikan contoh tahap pertama merupakan sebuah metode pemilihan n unit. Kemudian untuk setiap unit terpilih, digunakan metode untuk memilih sejumlah tertentu subunit-subunit. Dalam mencari rata-rata dan penduga ragam, rata-ratanya harus meliputi seluruh contoh yang dapat diturunkan dengan proses dua tahap ini. Salahsatu cara penghitungan rata-ratanya adalah dengan menghitung rata-rata seluruh contoh tahap kedua yang dapat diambil dari sekumpulan n unit. Kemudian dirata-ratakan seluruh pemilihan
yang mungkin dari n unit tersebut. Untuk sebuah penduga, ˆ, metode ini dapat dinyatakan sebagai
E(ˆ) = E1[E2(ˆ)].
Dimana E merupakan nilai harapan seluruh contoh, E2 meruapakan nilai
harapan seluruh pemilihan yang mungkin pada tahap kedua dari sekumpulan n unit tetap, dan E1 merupakan nilai harapan seluruh pemilihan yang mungkin pada
tahap pertama. Sedangkan ragam bagi ˆ dapat dinyatakan sebagai berikut: V(ˆ) = E(ˆ )2= E1[E2(ˆ )2] dimana E2(ˆ )2= E2(ˆ2) 2E2(ˆ) +2 = [E2(ˆ)]2+ V2(ˆ) 2E2(ˆ) +2 karena E1[E2(ˆ)] = , maka V(ˆ) = E1[E2(ˆ)]2+ E1[V2(ˆ)] 2 = V1[E2(ˆ)] + E1[V2(ˆ)] .
Hal serupa dapat dilanjutkan untuk penarikan contoh tiga tahap atau lebih. Misalnya, untuk penarikan contoh tiga tahap, ragam bagi ˆ dapat dinyatakan sebagai berikut:
V(ˆ) = V1{E2[E3(ˆ)]} + E1{V2[E3(ˆ)]} + E1{E2[V3(ˆ)]}.
Misalkan yijmerupakan nilai yang diperoleh untuk subunit ke-j (j = 1, 2, ..., m) pada unit utama ke-i (i = 1, 2, ..., n). Apabila n unit dan m subunit dari masing-masing unit yang telah diambil dipilih dengan penarikan contoh acak sederhana, maka nm y y n i m j ij
1 1merupakan penduga tidak bias bagi Y dengan ragam
mn S M m M n S N n N y V 2 2 2 1 ) ( ) 1 ( ) ( dan 1 ) ( 1 2 1 2 2 1 2 2 1
M N Y y S N Y Y S N i i M j ij N i i ( 2.20 ) ( 2.21 )dimana S12 merupakan ragam diantara rata-rata unit utama dan S22 merupakan
ragam diantara subunit-subunit dalam unit utama. Hal ini dapat ditunjukkan sebagai berikut: E(y ) = E1[E2(y )] = E1 Y Y N Y n N i i n i i
1 1 1 1 V(y ) = V1[E2(y )] + E1[V2(y )] karena E2(y ) =Yi/n, maka n S N n N y E V 2 1 2 1[ ( )] .Selanjutnya, dengan y = y /n dan penarikan contoh acak sederhanai digunakan pada tahap kedua,
m S Mn m M y V n i i
1 2 2 2 2( ) dimana 1 ) ( 2 1 2 2
M Y y S i M j ij imerupakan ragam diantara subunit utama ke-i. Apabila dirata-ratakan seluruh contoh tahap pertama,
2 2 1 2 2 S N S N i i
.Oleh karena itu,
mn S M m M y V E 2 2 2 1[ ( )] sehingga ragam bagi y adalah
mn S M m M n S N n N y V 2 2 2 1 ) ( . ( 2.22 ) ( 2.23 ) ( 2.24 )