Langkah – langkah uji F dengan data SPSS Dasar Cara Melihat F tabel
Untuk melihat F tabel dalam pengujian hipotesis pada model regresi, perlu menentukan derajat bebas atau degree of freedom (df) atau dikenal dengan df2 dan juga dalam F tabel disimbolkan dengan N2. Hal ini ditentukan dengan rumus:
df1 = k - 1 df2 = n - k
Dimana n = Banyaknya observasi dalam kurun waktu data. Dimana k = Banyaknya variabel (bebas dan terikat).
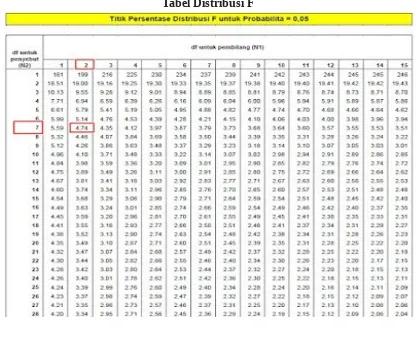
Dalam pengujian ini dilakukan dengan tingkat kepercayaan 5% atau 0,05, dalam hal ini bisa kita uji dengan rumus tersebut. Pada df1 = 3 - 1 = 2 dan pada df2 = 10 - 3 = 7, maka nilai F tabel adalah 4,74.
Tabel Distribusi F
Dasar Pengambilan Keputusan Untuk Uji F (Simultan) Dalam Analisis Regresi
Berdasarkan nilai F hitung dan F tabel :
Jika nilai F hitung > F tabel maka variabel bebas (X) berpengaruh terhadap variabel terikat (Y). Jika nilai F hitung < F tabel maka variabel bebas (X) tidak berpengaruh terhadap variabel
Berdasarkan nilai signifikansi hasil output SPSS :
Jika nilai Sig. < 0,05 maka variabel bebas (X) berpengaruh signifikan terhadap variabel terikat
(Y).
Jika nilai Sig. > 0,05 maka variabel bebas (X) tidak berpengaruh signifikan terhadap variabel terikat (Y).
Ada beberapa langkah yang harus anda lakukan untuk mempraktekkan uji F atau uji simultan ini, Berikut langkah-langkah yang harus anda lakukan :
Langkah-langkahnya :
Buka data yang ingin anda uji !
Pada kotak Dependent, isikan variabel Y (PAD) dan pada kotakIndependent isikan variabel X1, X2 (Pajak Daerah, Retribusi Daerah).
Selanjutnya abaikan yang lain dan kemudian klik Ok. Tampilan hasil output SPSS.
Interpretasi Output
Langkah langkah uji Test t dengan SPSS
Independen T Test adalah uji komparatif atau uji beda untuk mengetahui adakah perbedaan mean atau rerata yang bermakna antara 2 kelompok bebas yang berskala data interval/rasio. Dua kelompok bebas yang dimaksud di sini adalah dua kelompok yang tidak berpasangan, artinya sumber data berasal dari subjek yang berbeda. Misal Kelompok Kelas A dan Kelompok kelas B, di mana responden dalam kelas A dan kelas B adalah 2 kelompok yang subjeknya berbeda. Bandingkan dengan nilai pretest dan posttest pada kelas A, di mana nilai pretest dan posttest berasal dari subjek yang sama atau disebut dengan data berpasangan. Apabila menemui kasus yang data berpasangan, maka uji beda yang tepat adalah uji paired t test.
Asumsi yang harus dipenuhi pada independen t test antara lain: 1. Skala data interval/rasio.
2. Kelompok data saling bebas atau tidak berpasangan. 3. Data per kelompok berdistribusi normal.
4. Data per kelompok tidak terdapat outlier. 5. Varians antar kelompok sama atau homogen.
Untuk asumsi poin no. 1 dan 2, anda tidak perlu mengujinya dengan SPSS. Sedangkan untuk asumsi no. 3 dan no. 5 anda harus mengujinya dengan SPSS. Untuk uji normalitas secara lengkap baca DISINI. Untuk uji homogenitas secara lengkap, baca DISINI.
Langsung saja kita buat data sebagai berikut: Data di bawah ini menunjukkan bahwa ada 2 kelompok yaitu 1 dan 2, di mana tiap kelompok terdapat 10 responden/observasi.
Langkah pertama adalah menguji asumsi normalitas, outlier dan homogenitas. Yaitu pada menu SPSS, klik Analyze, Descriptive Statistics, Explore. Maka akan muncul jendela seperti berikut:
Explore Independen T Test
Klik tombol Plots, setelah muncul jendela, centang Factor levels together, Stem-and-leaf, Histogram, Normality plots with tests dan Power estimation. Kemudian Klik Continue.
Plot Independen T Test
Normalitas Independen T Test
Tabel di atas menunjukkan hasil uji Shapiro Wilk dan Lilliefors. Nilai p value (Sig) lilliefors 0,200 pada 2 kelompok di mana > 0,05 maka berdasarkan uji lilliefors, data tiap kelompok berdistribusi normal. P value uji Shapiro wilk pada kelompok 1 sebesar 0,884 > 0,05 dan pada kelompok 2 sebesar 0,778 > 0,05. Karena semua > 0,05 maka kedua kelompok sama-sama berdistribusi normal berdasarkan uji Shapiro wilk.
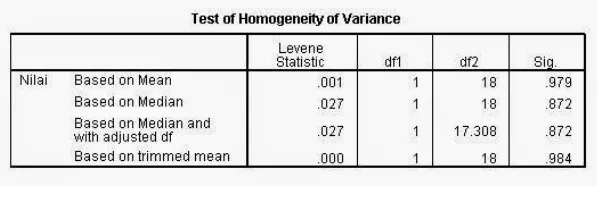
Homogenitas Independen T Test
Stem-leaf Independen T Test
Diagram di atas adalah diagram stem-leaf yang berfungsi untuk mendeteksi adanya outlier. Ada outlier apabila terdapat nilai Extrem di atas dan di bawah stem-leaf. Pada data anda tidak terdapat nilai exkstrem, maka tidak terdapat outlier. Deteksi outlier juga bisa dinilai dengan Box-plot seperti di bawah ini:
Box-Plot di atas tidak menunjukkan terdapat plot-plot di atas dan/atau di bawah boxplot yang berarti tidak terdapat outlier.
Oleh karena semua asumsi terpenuhi, maka dapat dilanjutkan ke uji selanjutnya yaitu uji Independen T Test.
Pada menu SPSS, klik Analyze, Compare Means, Independen Samples T Test. Maka akan muncul jendela sebagai berikut: Kemudian masukkan variabel terikat anda yaitu Nilai ke kotak Test Variable(s) dan masukkan variabel bebasanda yaitu Kelompok ke kotak Grouping Variables.
Independen T Test
Klik tombol Define Groups kemudian masukkan kode 1 dan 2.
Grouping Independen T Test
Klik Continue. Dan pada jendela utama klik OK kemudian lihat Output!
Tabel di atas menunjukkan Mean atau rerata tiap kelompok, yaitu pada kelompok 1 nilainya 56 di mana lebih rendah dari kelompok 2 yaitu 73,1. Apakah perbedaan ini bermakna? lihat di bawah ini:
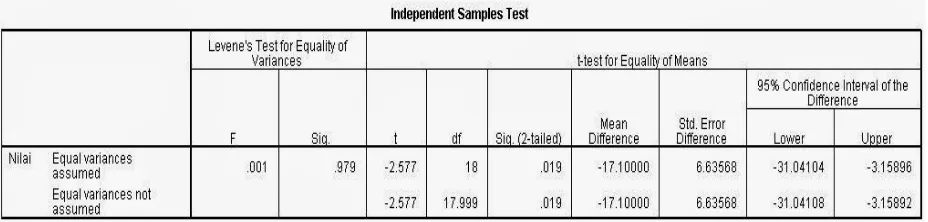
Output Independen T Test
Nilai hasil uji levene test untuk homogenitas sama dengan bahasan di atas, yaitu homogen. Karena homogen, maka gunakan baris pertama yaitu nilai t hitung -2,577 pada DF 18. DF pada uji t adalah N-2, yaitu pada kasus ini 20-2=18. Nilai t hitung ini anda bandingkan dengan t tabel pada DF 18 dan probabilitas 0,05.
Untuk menjawab hipotesis ada 2 cara:
Dengan membandingkan antara t hitung dengan t tabel:
Apabila nilai t hitung positif: Ada perbedaan bermakna apabila t hitung > t tabel. Apabila nilai t hitung negatif: ada perbedaan bermakna apabila t hitung < t tabel.
Cara kedua adalah dengan melihat nilai Sig (2 tailed) atau p value. Pada kasus di atas nilai p value sebesar 0,019 di mana < 0,05. Karena < 0,05 maka perbedaan bermakna secara statistik atau signifikan pada probabilitas 0,05.
Perhitungan uji chi square SPSS
SPSS merupakan program pengolahan data statistik yang memudahkan pengguna dalam
memakainya. Uji Chi Square SPSS tentunya bisa dikerjakan dengan mudah dengan program ini. Berikut ini, beberapa langkah yang bisa dijadikan petunjuk dalam mengolah data untuk uji Chi Square dengan SPSS:
1. Input data ke dalam “Data View”, namun sebelumnya isi kamus data yang berisi karakteristik variable pada “Variable View”.
2. Setelah selesai menginput data, klik menu “Analyze”, lalu pilih “Descriptive Statistics” dan pilih “Crosstabs”
3. Maka akan muncul tampilan “Crosstabs”, dimana akan terdapat kotak di sebelah kiri yang berisi variable yang akan dipindahkan ke dalam kotak “Rows” dan “Columns”
4. Cara memindahkan variabel dengan mengklik variable kemudian klik panah yang terdapat di samping kiri kotak “rows” dan “column”.
5. Kemudian klik menu “Statistic” yang terdapat di sisi kanan kotak “Row(s)”.
6. Akan muncul kotak dialog “Statistic”.
7. Pilih dengan mengklik Chi-Square lalu pilih pada menu “Nominal” dan “Ordinal” sesuai dengan kebutuhan pengujian.
8. Klik tombol “Continue”, maka akan kembali ke kotak dialog “Crosstabs”.
9. Lalu klik tombol “Cells” dan muncul tampilan kotak dialog “Crosstabs:Cell Display” dan pilih dengan mengklik “Observed” pada menu “Counts”, lalu klik “Row”,”Column”, “Total” pada menu Percentages. Kemudian klik tombol “continue”.
10. Tampilan kotak dialog “Crosstabs” akan muncul kembali dan klik tombol “Format”.
11. Kotak dialog “Crosstabs:Table Format” akan muncul dan pilih akan ditampilkan secara “Ascending” atau “Descending” hasilnya.
12. Kemudian klik “ok” dan output akan ditampilkan.
Contoh Uji t, F, dan Chi yang ada di Skripsi Perpustakaan
ANALISIS UJI t-test
Uji t digunakan untuk mengetahui tingkat signifikan masing-masing koefisien regresi dari variable bebas terhadap variable terkait. Nilai thitung diperoleh dengan bantuan SPSS. Adapun
nilai thitung dan ttabel dapat dilihat pada tabel dibawah ini ;
Gambar 1.1 Tabel hasil uji t hitung
Variabel thitung Signifikansi ttabel
Lingkungan kerja (X1) 7,974 0,000 1,658
Komunikasi (X2) 7,655 0,000 1,658
Berdasarkan table diatas selanjutnya dibahas pengaruh dari masing-masing variable bebas terhadap variable terikat dapat dijelaskan sebagai berikut ;
1. Pengaruh lingkungan kerja terhadap kinerja karyawan PT. Cocacola Botlling Indonesia Balinusa, formulasi hipotesis sebagai berikut ;
a) Merumuskan hipotesis
Ho1 : β1 = 0, berarti tidak ada pengaruh yang signifikansecara persial dari
variable lingkungan kerja terhadap kinerja karyawan PT Cocacola Botlling Indonesia Balinusa.
Hi1 : β1 > 0, berarti ada pengaruh signifikan secara persial dan variable
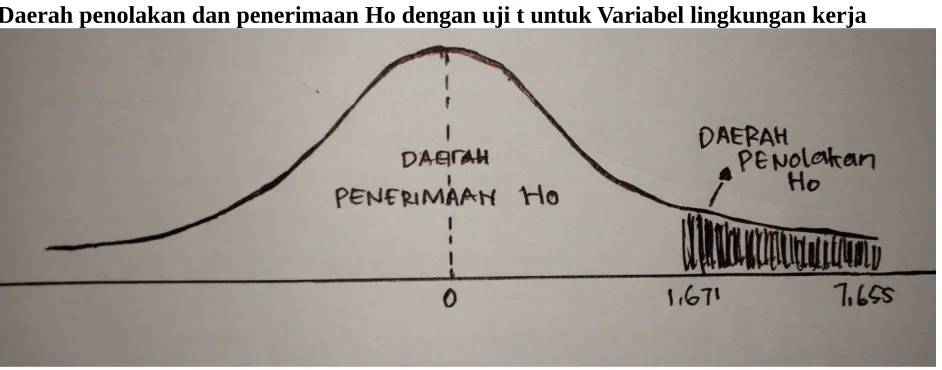
d) Membandingkan t hitung dengan t table pada gambar dibawah ini ;
Daerah penolakan dan penerimaan Ho dengan uji t untuk Variabel lingkungan kerja
e) Hasil uji thitung yang dapat dilihat pada tabel diperoleh t hitung sebesar 7,794
dengan tingkat signifikasi 0,000 yang lebih kecil dari 0,5 selain itu t hitung (7,974) lebih besar dari t tabel (1,671) yang berarti lingkungan kerja signifikan dan positif terhadap tenaga kinerja karyawan PT. Cocacola Botlling Indonesia Balinusa. Jadi hipotesis pertama yang menyatakan bahwa lingkungan kerja komunikasi secara parsial erpengaruh signifikan dan positif terhadap kinerja karyawan PT. Cocacola Botlling Indonesia Balinusa diterima.
2. Pengaruh komunikasi terhadap kinerja karyawan PT. Cocacola Botlling Indonesia Balinusa.
a) Merumuskan hipotesis
Ho2 : β2 = 0, berarti tidak ada pengaruh yang signifikan dan positif secara parsial
dari variable komunikasi terhadap kinerja karyawan PT. Cocacola Botlling Indonesia Balinusa.
Hi2 : β2 > 0, berarti berpengaruh signifikan dan positif secara parsial dari variable
Daerah penolakan dan penerimaan Ho dengan uji t untuk variable komunikasi
e) Membuat keputusan uji hipotesis
Dari hasil penghitungan t hitung yang dapat dilihat pada tabel 1.1 diperoleh t2
hitung sebesar 7,655 dengan tingkat signifikasi sebesar 0,000. Yang lebih kecil
dari 0,5 selain itu t2 hitung (7,655) lebih besar dari t table (1,671) yang berarti
komunikasi berpengaruh signifikan dan positif terhadap kinerja pegawai PT. Cocacola Botlling Indonesia Balinusa, jadi hipotesis kedua yang menyatakan bahwa komunikasi secara parsial berpengaruh signifikan dan positif terhadap kinerja karyawan PT. Cocacola Botlling Indonesia Balinusa diterima.
ANALISIS UJI F-test
Uji F-test dilakukan untuk menguji hipotesis pertama yaitu untuk mengetahui tingkat signifikan variable bebas yang terdiri dari, lingkungan kerja (X1) dan komunikasi (X2) terhadap kinerja karyawan (Y) hasil perhitungan SPSS 17,0 for windows dapat diketahui dengan formulasi hipotesis sebagai berikut :
1. Merumuskan hipotesis = (65-3) = 62 sehingga nilai Ftabel sebesar F 0,05 (2;62) = 3,15 merumuskan
Apabila Fhitung ≤ Ftabel, Maka Ho3 ditolak.
Apabila Fhitung ≥ Ftabel, Maka Ho3 diterima.
3. Membandingkan nilai Fhitung dengan Ftabel
Dapat dilihat pada gambar dibawah
Daerah penolakan dan penerimaan Ho dengan Uji F
4. Membuat keputusan uji hipotesis
Berdasarkan perhitungan dengan menggunakan program SPSS yaitu F hitung sebesar 146,938 dan dengan tingkat signifikan sebesar 0,000 yang lebih kecil dari 0,05. Selain itu jika dibandingan maka F hitung (146,938) lebih besar daripada f tabel (3,15) yang berarti lingkungan kerja dan komunikasi berpengaruh signifikan terhadap kinerja karyawan PT. Cocacola Botlling Indonesia Balinusa.
ANALISIS UJI CHI SQUARE
( Berhubung kemarin saya mencari contoh uji ini diskripsi tidak ada maka saya ambil contoh ini dari internet )
Sumber : http://www.statistikolahdata.com/2013/04/analisis-chi-square.html
Uji Chi-square atau qai-kuadrat digunakan untuk melihat ketergantungan antara variabel bebas dan variabel tergantung berskala nominal atau ordinal. Prosedur uji chi-square menabulasi satu atau variabel ke dalam kategori-kategori dan menghitung angka statistik chi-square. Untuk satu variabel dikenal sebagai uji keselarasan atau goodness of fit test yang berfungsi untuk membandingkan frekuensi yang diamati (fo) dengan frekuensi yang diharapkan (fe). Jika terdiri dari 2 variabel dikenal sebagai uji independensi yang berfungsi untuk hubungan dua variabel. Seperti sifatnya, prosedur uji chi-square dilkelompokan kedalam statistik uji non-parametrik.
Semua variabel yang akan dianalisa harus bersifat numerik kategorikal atau nominal dan dapat juga berskala ordinal. Prosedur ini didasarkan pada asumsi bahwa uji nonparametrik tidak membutuhkan asumsi bentuk distribusi yang mendasarinya. Data diasumsikan berasal dari sampel acak. Frekuensi yang diharapkan (fe) untuk masing-masing kategori harus setidaknya :
Tidak boleh lebih dari dua puluh (20%) dari kategori mempunyai frekuensi yang diharapkan kurang dari 5.
Formula uji Chi Square :
Dimana :
X2 = Nilai khai-kuadrat
fo = frekuensi observasi/pengamatan fe = frekuensi ekspetasi/harapan
Contoh kasus
Perusahaan penyalur alat elektronik AC ingin mengetahui apakah ada hubungan antara gender dengan sikap mereka terhadap kualitas produk AC. Untuk itu mereka meminta 25 responden mengisi identitas mereka dan sikap atau persepsi mereka terhadap produknya.
Hipotesis :
H0 = Tidak ada hubungan antara gender dengan sikap terhadap kualitas AC H1 = Ada hubungan antara gender dengan sikap terhadap kualitas AC
Tolak hipotesis nol (H0) apabila nilai signifikansi chi-square < 0.05 atau nilai chi-square hitung lebih besar (>) dari nilai chi-square tabel.
Data dari keduapuluh lima responden dapat dilihat pada tabel di bawah ini.
Data responden
Ket. :
Langkah-langkah SPSS
1. Analyze > Descriptive Statistics > Crosstab
2. Masukkan variabel Gender ke dalam kotak Row
3. MAsukkan variabel Sikap ke dalam kotak Column
4. Klik untuk pilihan Statistics
5. Pilih menu Chi-square, tekan Continue
6. Pilih Cell, Observed, tekan Continue
7. Klik Ascending, tekan Continue
8. Tekan OK Hasil output SPSS
Pada tabel case processing summary diatas menunjukkan bahwa input data ada 25 responden dan tidak ada data yang tertinggal.
STATISTIK EKONOMI 2
“
Analisis uji t, F, dan X
2(Chi Square)
“
DISUSUN OLEH :
Aria sudarte
NPM: 14.02.01.1884
Prodi: Manajemen 4B Pagi
UNIVERSITAS HINDU INDONESIA
Jl. Sangalangit, Tembau, Penatih, Kota Denpasar, Bali