SEQUENTIAL PATTERN MINING
DALAM
EVENT
LOG
DENGAN
METODE GSP, PREFIX SPAN DAN
CM-SPADE
TUGAS AKHIR
Disusun oleh:
Syarah Mulyati 3311501037
Disusun untuk memenuhi salah satu syarat kelulusan Program Diploma III
PROGRAM STUDI TEKNIK INFORMATIKA JURUSAN TEKNIK INFORMATIKA
POLITEKNIK NEGERI BATAM BATAM
HALAMAN PENGESAHAN
SEQUENTIAL PATTERN MINING DALAM EVENT LOG DENGAN METODE GSP, PREFIX SPAN, DAN CM-SPADE
Disusun oleh: Syarah Mulyati
3311501037
Telah dikonsultasikan dengan dosen pembimbing sebagai persyaratan untuk melaksanakan sidang Tugas Akhir II
Batam, 17 September 2017 Disetujui oleh: Pembimbing Metta Santiputri, S.T., M.Sc., Ph. D NIP. 197707202012122004 HALAMAN PERNYATAAN
Dengan ini, saya:
NIM : 3311501037 Nama : Syarah Mulyati
adalah mahasiswa Program Studi Teknik Informatika Politeknik Negeri Batam menyatakan bahwa Tugas Akhir dengan judul:
disusun dengan:
SEQUENTIAL PATTERN MINING DALAM EVENT LOG DENGAN METODE
GSP, PREFIX SPAN, DAN CM-SPADE
1. Tidak melakukan plagiat terhadap naskah karya orang lain 2. Tidak melakukan pemalsuan data
3. Tidak menggunakan karya orang lain tanpa menyebut sumber asli atau tanpa ijin pemilik
Jika kemudian terbukti terjadi pelanggaran terhadap pernyataan di atas, maka saya bersedia menerima sanksi apapun termasuk pencabutan gelar akademik.
Lembar pernyataan ini juga memberikan hak kepada Politeknik Negeri Batam untuk mempergunakan, mendistribusikan ataupun memproduksi ulang seluruh hasil Tugas Akhir ini.
Batam, 17 September 2018
Syarah Mulyati 3311501037
ABSTRAK
SEQUENTIAL PATTERN MINING DALAM EVENT LOG DENGAN METODE GSP, PREFIX SPAN, DAN CM-SPADE
Didalam sebuah perusahaan atau organisasi tentu memiliki informasi data dengan jumlah rekaman yang besar, dimana rekaman tersebut berupa event log
yang merupakan hasil eksekusi di dalam sebuah perusahaan atau organisasi, yang berisi sejumlah aktivitas yang terjadi. Teknik data mining yang dilakukan adalah
Sequential Patern Mining, dimana teknik ini digunakan untuk menentukan pola sequensial yang terdapat pada database dalam suatu perusahaan atau organisasi. semua proses pendekatan mining mengambil log peristiwa sebagai masukan dan sebagai titik awal untuk penemuan proses yang mendasarinya.
Software yang di kembangkan adalah SPMF, yaitu berupa kumpulan
library yang tergabung di dalam software tersebut, dimana software ini nantinya dapat membantu penggguna dalam menganalisis data dari dalam event log, dengan menggunakan metode data mining yaitu GSP, Prefix Span dan CM-Spade, Dengan mengembangkan library yang telah ada di SPMF, kemudian dapat menerima masukan berupa event log dan menghasilkan keluaran berupa pattern aktivitas, sehingga nantinya dapat menghasilkan informasi-informasi yang baru dengan mudah.
ABSTRACT
SEQUENTIAL PATTERN MINING IN EVENT LOG WITH GSP, PREFIX SPAN, AND CM-SPADE METHODS
In a company or organization certainly has data information with a large number of recordings, where the recording is an event log that is the result of execution within a company or organization, which contains a number of activities that occur. Data mining techniques performed are Sequential Patern Mining, which is used to determine the sequential patterns contained in the database within a company or organization. all the mining approach takes the event log as input and as a starting point for the discovery of the underlying process.
Software developed is SPMF, which is a collection of libraries incorporated in the software, where this software will be able to assist users in analyzing data from within the event log, using data mining methods that are GSP, Prefix Span and CM-Spade, By developing libraries that already exist in the SPMF, then can receive input in the form of event log and produce output in the form of activity pattern, so that later can generate new information easily.
KATA PENGANTAR
Puji Syukur atas rahmat Tuhan Yang Maha Esa, karena atas rahmat dan hidayatnya penulis dapat menyelesaikan Tugas Akhir ini dengan judul ”Sequential Pattern Mining dalam Event Log dengan Metode GSP, Prefix Span, dan CM-Spade”. Penulisan Tugas Akhir ini ditujukan untuk memenuhi salah satu
persyaratan kelulusan program Diploma III pada jurusan Teknik Informatika di Politeknik Negeri Batam.
Selama proses pengerjaan tugas akhir ini penulis telah banyak menerima bantuan, petunjuk dan saran dari berbagai pihak. Pada kesempatan ini penulis ingin menyampaikan ucapan terima kasih yang sebesar-besarnya kepada semua pihak yang terlibat, antara lain:
1. Kedua orang tua yang selalu memberikan dorongan semangat dan doa-doa yang tulus.
2. Ibu Metta Santiputri, S.T., M.Sc., Ph.D Selaku pembimbing dalam mengerjakan penulisan Laporan Tugas Akhir.
3. Seluruh rekan - rekan mahasiswa khususnya Teknik Informatika.
4. Seluruh staff pengajar Politeknik Negeri Batam yang telah memberikan materi perkuliahan sehingga menunjang pengerjaan Laporan Tugas Akhir. 5. Serta seluruh pihak yang telah memberikan bantuan yang berguna bagi
kelancaran penyusunan Tugas Akhir ini.
Penulis menyadari sepenuhnya bahwa Laporan Tugas Akhir ini masih banyak kekurangan dalam penyusunannya, sehingga penulis sangat mengharapkan kritik dan saran yang bersifat membangun demi kesempurnaan penyusunan Laporan Tugas Akhir ini.
Batam, 17 September 2018
DAFTAR ISI HALAMAN PENGESAHAN ... i HALAMAN PERNYATAAN ... i ABSTRAK ... iii ABSTRACT ... iv KATA PENGANTAR ... v
DAFTAR ISI ... vii
DAFTAR TABEL ... x DAFTAR GAMBAR ... xi BAB I ... 1 PENDAHULUAN ... 1 1.1 Latar Belakang ... 1 1.2 Rumusan Masalah ... 2 1.3 Batasan Masalah ... 2 1.4 Tujuan ... 2 1.5 Manfaat ... 2 1.6 Sistematika Penulisan ... 3 BAB II ... 4 LANDASAN TEORI ... 4 2.1 Dasar Teori ... 4
2.1.1 Sequential Pattern Mining Framework (SPMF) ... 4
2.1.2 Netbeans ... 5
2.1.3 GSP (Generalized Sequential Pattern) ... 6
2.1.4 CM-Spade ... 7
2.1.5 Prefix Span ... 8
2.1.6 Event Log ... 9
2.1.7 Contoh Event Log ... 10
BAB III ... 16
ANALISIS DAN PERANCANGAN ... 16
3.1 Analisis Sistem ... 16
3.1.1 Format Input ... 16
3.1.2 Format Output ... 18
3.1.3 Analisis spesifikasi kebutuhan software dan hardware ... 18
3.2 Perancangan Sistem ... 20
3.2.2 Rancangan Kelas ... 21
3.2.3 Algoritma ... 21
3.3 Rancangan Antar Muka ... 23
3.3.1 Antarmuka Beranda ... 24
3.3.2 Antarmuka Data Event Log ... 25
3.3.3 Antarmuka Activity List ... 26
3.3.4 Antarmuka Trace Activity ... 26
3.3.5 Antarmuka Save Trace ... 27
3.3.6 Antarmuka SPMS ... 28
3.4 Rancangan Pengujian ... 28
3.4.1 Data Uji ... 28
3.4.2 Deskripsi Pengujian ... 29
BAB IV HASIL DAN PEMBAHASAN ... 31
4.1 Implementasi Antarmuka ... 31
4.1.1 Halaman Beranda ... 31
4.1.2 Halaman Antarmuka Data Event Log ... 32
4.1.3 Halaman Antarmuka Activitylist ... 33
4.1.4 Halaman Antarmuka Trace Activity ... 33
4.1.5 Halaman Antarmuka Save Trace ... 34
4.1.6 Halaman Antarmuka SPMS ... 35
4.2 Pengujian ... 35
4.2.1 Hasil Pengujian ... 35
4.2.2 Pegujian Aplikasi Dengan Metode GSP ... 36
4.2 3 Pegujian Aplikasi Dengan Metode Prefix Span ... 38
4.2.4 Pegujian Aplikasi Dengan Metode CM-Spade ... 40
4.2.5 Pegujian Aplikasi Dengan Metode GSP ... 42
4.2.6 Pegujian Aplikasi Dengan Metode Prefix Span ... 43
4.2.7 Pegujian Aplikasi Dengan Metode CM-Spade ... 45
4.2.8 Pegujian Aplikasi Dengan Metode GSP ... 46
4.2.9 Pegujian Aplikasi Dengan Metode Prefix Span ... 48
4.2.11 Pegujian Aplikasi Dengan Metode GSP ... 50
4.2.12 Pegujian Aplikasi Dengan Metode Prefix Span ... 52
4.2.13 Pegujian Aplikasi Dengan Metode CM-Spade ... 53
4.2.14 Pegujian Aplikasi Dengan Metode GSP ... 54
4.2.15 Pegujian Aplikasi Dengan Metode Prefix Span ... 56
4.2.16 Pegujian Aplikasi Dengan Metode CM-Spade ... 57
4.2.17 Pegujian Aplikasi Dengan Metode GSP ... 58
4.2.18 Pegujian Aplikasi Dengan Metode Prefix Span ... 60
4.2.19 Pegujian Aplikasi Dengan Metode CM-Spade ... 61
BAB V KESIMPULAN DAN SARAN... 63
5.1 Kesimpulan ... 63
5.2 Saran ... 63
DAFTAR TABEL
Tabel 1 Cuplikan sebuah event log: setiap baris menunjukkan sebuah event ... 12
Tabel 2 Contoh Trace Clustering ... 15
Tabel 3 Hasil Pengujian Data dengan Metode GSP ... 36
Tabel 4 Hasil Pengujian Data dengan Metode Prefix Span ... 38
Tabel 5 Hasil Pengujian Data dengan Metode CM-Spade ... 40
Tabel 6 Hasil pengujian data dengan menggunakan metode GSP ... 42
Tabel 7 Hasil pengujian data dengan menggunakan metode Prefix Span... 44
Tabel 8 Hasil pengujian data dengan menggunakan metode CM-Spade ... 45
Tabel 9 Hasil pengujian data dengan menggunakan metode GSP ... 47
Tabel 10 Hasil pengujian data dengan menggunakan metode Prefix Span... 48
Tabel 11 Hasil pengujian data dengan menggunakan metode CM-Spade ... 49
Tabel 12 Hasil Pengujian Data dengan Metode GSP ... 51
Tabel 13 Hasil Pengujian Data dengan Metode Prefix Span ... 52
Tabel 14 Hasil Pengujian Data dengan Metode CM-Spade ... 53
Tabel 15 Hasil pengujian data dengan menggunakan metode GSP ... 55
Tabel 16 Hasil pengujian data dengan menggunakan metode Prefix Span... 56
Tabel 17 Hasil pengujian data dengan menggunakan metode CM-Spade ... 57
Tabel 18 Hasil pengujian data dengan menggunakan metode GSP ... 59
Tabel 19 Hasil pengujian data dengan menggunakan metode Prefix Span... 60
DAFTAR GAMBAR
Tabel 1 Cuplikan sebuah event log: setiap baris menunjukkan sebuah event ... 12
Tabel 2 Contoh Trace Clustering ... 15
Tabel 3 Hasil Pengujian Data dengan Metode GSP ... 36
Tabel 4 Hasil Pengujian Data dengan Metode Prefix Span ... 38
Tabel 5 Hasil Pengujian Data dengan Metode CM-Spade ... 40
Tabel 6 Hasil pengujian data dengan menggunakan metode GSP ... 42
Tabel 7 Hasil pengujian data dengan menggunakan metode Prefix Span... 44
Tabel 8 Hasil pengujian data dengan menggunakan metode CM-Spade ... 45
Tabel 9 Hasil pengujian data dengan menggunakan metode GSP ... 47
Tabel 10 Hasil pengujian data dengan menggunakan metode Prefix Span... 48
Tabel 11 Hasil pengujian data dengan menggunakan metode CM-Spade ... 49
Tabel 12 Hasil Pengujian Data dengan Metode GSP ... 51
Tabel 13 Hasil Pengujian Data dengan Metode Prefix Span ... 52
Tabel 14 Hasil Pengujian Data dengan Metode CM-Spade ... 53
Tabel 15 Hasil pengujian data dengan menggunakan metode GSP ... 55
Tabel 16 Hasil pengujian data dengan menggunakan metode Prefix Span... 56
Tabel 17 Hasil pengujian data dengan menggunakan metode CM-Spade ... 57
Tabel 18 Hasil pengujian data dengan menggunakan metode GSP ... 59
Tabel 19 Hasil pengujian data dengan menggunakan metode Prefix Span... 60
BAB I PENDAHULUAN 1.1Latar Belakang
Data mining adalah proses ekstraksi/menggali informasi atau pola dalam database yang berukuran besar. Salah satu teknik data mining adalah sequential pattern mining yang berguna untuk menentukan pola sequensial yang terdapat pada database. Sequential pattern mining bertujuan untuk mencari dan menemukan hubungaan antar item yang ada pada suatu dataset. Metode ini bertujuan untuk menemukan informasi antar item yang saling berhubungan kedalam bentuk rule.
Pada sisi yang lain, dalam suatu perusahaan atau organisasi sendiri biasanya terdapat beberapa proses bisnis, dimana pada pelaksanaan proses bisnis tersebut akan menghasilkan rekaman data dengan jumlah besar. Salah satu bentuk rekamannya adalah yang disebut sebagai event log yang merupakan rekaman eksekusi seluruh aktivitas di dalam sebuah enterprise. Event log tersebut merekam urutan atau rangkaian aktivitas yang terjadi.
Untuk menggali adanya pola atau pattern yang terjadi dalam pelaksanaan aktivitas dalam sebuah organisasi atau enterprise, maka perlu digunakan metode
sequential pattern mining ini. Manfaat penggalian pola atau pattern dari event log
ini misalnya untuk menemukan hubungan antara seorang aktor dengan aktor yang lain dalam organisasi (Ghose dkk, 2014), menemukan hubungan antar event dalam
log yang berbeda (Saraswati, dkk, 2015).
Oleh karena itu dalam penelitian ini, di kembangkan sebuah aplikasi yang dapat membantu memudahkan pengguna dalam menggali pattern dari data dalam
event log menggunakan berbagai metode sequential pattern mining. Perangkat lunak yang digunakan yaitu berupa kumpulan library perangkat lunak berbagai metode data mining yang tergabung dalam SPMF, Library ini mulai dibangun oleh Philippe Fournier-Viger pada tahun 2008. Meskipun telah tersedia banyak metode data mining yang dapat digunakan, namun library ini tidak memfasilitasi mining
akan menjembatani masalah tersebut yaitu mengembangkan library yang telah ada di SPMF sehingga dapat menerima masukan berupa event log dan menghasilkan keluaran berupa pattern aktivitas.
1.2Rumusan Masalah
Berdasarkan latar belakang tersebut dapat dirumuskan masalah untuk membangun aplikasi, yaitu bagaimana cara memudahkan pengguna dalam melakukan
Sequential Pattern Mining terhadap eventlog dengan metode GSP, Prefix Span dan CM-Spade.
1.3Batasan Masalah
1. Tugas Akhir ini menerima masukan berupa event log yang berbentuk CSV (Comma Separated Values).
2. Metode yang digunakan dalam Tugas Akhir ini adalah metode GSP, Prefix Span, dan CM-Spade.
1.4Tujuan
Tujuannya adalah membangun aplikasi sequential patern mining berbasis dekstop dengan masukan berupa event log dengan metode GSP, Prefix Span dan CM-Spade dengan menggunakan library spmf.
1.5Manfaat
Manfaat dari pengembangan perangkat lunak ini adalah proses mining
terhadap event log dapat dilakukan dengan lebih mudah, sehingga diharapkan banyak informasi-informasi baru yang dapat dihasilkan.
1.6Sistematika Penulisan
Sistematika penulisan tugas akhir ini disusun dengan urutan sebagai berikut:
BAB I : Pendahuluan. Berisi tentang latar belakang, rumusan masalah, batasan masalah, tujuan penelitian dan sistematika penulisan untuk memberikan gambaran isi laporan tugas akhir.
BAB II : Landasan Teori, Berisi tentang ulasan penelitia-penelitian yang pernah dikerjakan sebelumnya sebagai referensi dari tugas akhir dan teori-teori yang mendukung pembuatan tugas akhir.
BAB III : Analisis dan perancangan . Berisi tentang analisis, perancangan sistem dan perancangan antarmuka tugas akhir ini
BAB IV : Implementasi dan Pengujian. Berisi tentang hasil implementasi, dan pengujian pada tugas akhir.
BAB V : Kesimpulan dan Saran. Berisi tentang kesimpulan dari tugas akhir beserta saran yang sifatnya membangun untuk pembuatan dan pengembangan aplikasi
BAB II
LANDASAN TEORI 2.1 Dasar Teori
2.1.1 Sequential Pattern Mining Framework (SPMF)
SPMF adalah sebuah library metode data mining open-source yang ditulis menggunakan bahasa pemrograman Java. Perangkat lunak yang dibuat oleh Philippe Fournier-Viger pada tahun 2008 ini menawarkan implementasi lebih dari 130 algoritma data mining untuk menemukan pola sekuensial, aturan sekuensial, peraturan asosiasi, pola utilitas tinggi,
frequentents itemset, pola periodik, cluster, dan banyak lagi.
Khusus dalam pertambangan pola. Kode sumber setiap algoritma yang tedapat pada SPMF dapat dengan mudah diintegrasikan ke dalam perangkat lunak Java lainnya. Selain itu, SPMF dapat digunakan sebagai program mandiri dengan userinterface yang sederhana atau dari command line. Versi SPMF yang penulis gunakan saat ini yaitu v2.17 yang diris pada 3 juli 2017.
Perangkat lunak SPMF secara native menggunakan file teks sebagai masukan. File input sampel ini dapat didownload dari halaman download
(test_files.zip) untuk versi rilis SPMF, dan disertakan dengan kode sumber, untuk versi kode sumber SPMF.
Masukan dari library SPMF berupa file teks, seperti terlihat pada contoh berikut:
1 -1 1 2 3 -1 1 3 -1 4 -1 3 6 -1 -2 1 4 -1 3 -1 2 3 -1 1 5 -1 -2 5 6 -1 1 2 -1 4 6 -1 3 -1 2 -1 -2 5 -1 7 -1 1 6 -1 3 -1 2 -1 3 -1 -2
Keluaran dari library SPMF berupa file teks, seperti terlihat pada contoh di bawah:
-1 #SUP: 4 #SID: 0 1 2 3 3 -1 #SUP: 4 #SID: 0 1 2 3 4 -1 #SUP: 3 #SID: 0 1 2 5 -1 #SUP: 3 #SID: 1 2 3 6 -1 #SUP: 3 #SID: 0 2 3
Arti nilai output yang di hasilkan dari software SPMF. -2 : Akhir dari nilai sebuah urutan / nilai di akhir setiap baris -1 : Akhir dari item set
1 ,2,3,4,5,6 : Sequences / urutan data
#SUP : muncul diikuti oleh sebuah integer yang mengindikasikan dukungan dari pola
#SID : Parameter ini memungkinkan untuk menentukan bahwa id sekuensi urutan yang mengandung pola harus menghasilkan output untuk setiap pola yang ditemukan, kemudian menghasilkan bilangan bulat yang dipisahkan oleh spasi
2.1.2 Netbeans
Netbeans merupakan sebuah aplikasi Integrated Development Environment (IDE) yang berbasiskan java dari Sun Microsystem yang berjalan di atas swing. Swing merupakan sebuah teknologi java untuk pengembangan aplikasi desktop yang dapat berjalan pada berbagai macam platformns seperti windows, linux, Mac OS X dan solaris. Sebuah IDE merupakan lingkup pemograman yang diitegrasikan ke dalam suatu aplikasi perangkat lunak yang menyediakan Graphic User Interface (GUI), suatu kode editor atau text, suatu compiler dan suatu
2.1.3 GSP (Generalized Sequential Pattern)
GSP adalah algoritma mining yang memakai pendekatan candidat-and-test, yaitu dengan membangkitkan pola-pola yang kemudian dihitung jumlah kemunculannya. Apabila melebihi nilai threshold, pola tersebut menjadi sequential pattern, dan bila tidak, pembangkitan pola-pola merupakan supersequence dari pola tersebut tidak akan pernah dilakukan. Hal ini dimaksudkan untuk semakin membatasi pembangkitan kandidat.
GSP juga merupakan format data horizontal berurutan Algoritma penambangan pola. Berdasarkan properti penutupan ke bawah dari pola sekuensial, GSP mengadopsi pendekatan multiple-pass, candidate generation-and-test di pertambangan berurutan. Algoritma GSP menciptakan banyak cara dalam database. Salah satu caranya, setiap item
atau produk tunggal (urutan pertama) dihitung. Dari item yang sering keluar atau muncul, tercipta sebuah kumpulan kandidat urutan kedua, dan cara lain dibuat untuk melengkapi urutan tersebut. Urutan kedua yang sering keluar digunakan untuk menghasilkan kandidat urutan ketiga.
Struktur dasar algoritma GSP adalah algoritma dapat membuat beberapa data. Pertama menentukan dukungan dari setiap item, yaitu jumlah data yang mencangkup item. Setiap item seperti menghasilkan 1 elemen urutan.
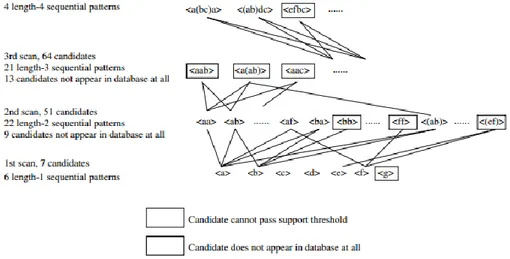
Contoh 1 (GSP) Mengingat urutan database Din Tabel ( ) dan
Min_suppor t = 2, pemindaian pertama GSP, mengumpulkan dukungan untuk setiap item, dan Menemukan kumpulan item yang sering, yaitu, sering terjadi kemunculan-1 (dalam bentuk "Item: support"): <a>: 4, <b>: 4, <c>: 4, <d>: 3, <e>: 3, <f>: 3, <g>: 1.
Gambar 1 Kandidat, calon generasi, dan pola sekuensial di GSP
Dengan menyaring item yang jarang, kita mendapatkan benih pertama yang ditetapkan L1 ={<a>, <b>, <c>, <d>, <e>, <f>}, dengan setiap anggota di set mewakili elemen-1 Pola berurutan Setiap lulus berikutnya dimulai dengan set benih yang ditemukan di jalur sebelumnya dan menggunakannya untuk menghasilkan pola sekuensial potensial baru, yang disebut kandidat urutan.
ForL1, satu set dari 6 panjang-1 pola sekuensial menghasilkan satu set 6×6+ = 51 urutan kandidat, C2 = {<aa>, <ab>, ...,<af>, <ba>, <bb>, ..., <ff>,<(ab)>, <(ac)>, ..., <(ef)>}.
2.1.4 CM-Spade
CM-Spade Memakai pendekatan berbasis kandidat-and-test, sehingga algoritma ini perlu melakukan sekali scan terhadap basis data untuk menemukan pola dengan satu elemen yang sering muncul. Untuk membangkitkan kandidat pola dengan dua elemen, dilakukan dengan cara menggabungkan seluruh pola satu elemen pola apabila pola tersebut melebihi nilai threshold dan memiliki identitas sequence yang sama. Hal
ini dilakukan terus menerus hingga tidak ada lagi pembangkitan kandidat pola, yang berarti seluruh sequential pattern telah di temukan.
Spade memetakan database urutan ke dalam format data vertikal yang mengambil setiap item sebagai pusat pengamatan dan mengambil urutan terkait dan pengidentifikasi acara sebagai kumpulan data. Untuk menemukan urutan panjang-2 item, itu hanya perlu untuk menggabungkan dua item tunggal jika mereka sering dan mereka berbagi pengenal urutan yang sama dan pengenal acara mereka (yang pada dasarnya adalah perangko waktu relatif) mengikuti urutan pemesanan. Demikian pula, SPADE dapat menumbuhkan urutan dari panjang dua sampai tiga, dan seterusnya.
SPADE bergantung pada kisi urutan yang sering dihasilkan dengan menerapkan teori kisi pada urutan yang sering dan urutannya. Ini juga membusuk Ruang pencarian asli (kisi) menjadi potongan-potongan kecil (sub-kisi) yang disebute quivalence kelas, yang bisa dimuat dan diproses secara mandiri di memori utama. Dua urutan dianggap berada di kelas yang sama jika mereka memiliki panjang k yang sama awalan. Setiap sub-kisi dapat dilalui melalui pencarian baik pertama maupun pertama untuk menghitung urutan yang sering, yang menghitung kemudian dihitung melalui sederhana temporal bergabung (atau persimpangan) on id-list.
2.1.5 Prefix Span
PrefixSpan (Prefix Sequential Pattern Growth) adalah algoritma yang memakai pendekatan pengembangan sequence untuk mencari sequential pattern. PrefixSpan akan mencari frequent sequence satu elemen dan kemudiian mengembangkan sequence-sequence tersebut dengan cara menambahkan elemen satu persatu. PrefixSpan dirancang sedemikian rupa sehingga sequence hasil penambahan elemen tersebut tetap
merupakan frequent sequence. Dengan cara ini, tidak diperlukan pembangkit dan pengujian kandidat.
PrefixSpan dibangun di atas konsep FreeSpan namun bukan
memproyeksikan database urutan yang hanya memeriksa awalan dan hanya memproyeksikan proyek mereka. Akhiran sufiks yang sesuai ke dalam database yang diproyeksikan. Dengan cara ini, sekuensial Pola ditanam di setiap database yang diproyeksikan dengan hanya mengeksplorasi urutan umum lokal. Ide utama dari PrefixSpan adalah dengan memproyeksi database yang memiliki prefix frequent. Ide ini dikembangkan karena adanya prinsip yang menyatakan bahwa setiap
frequent sequence selalu dapat di hasilkan dari prefix yang frequent.
Perbedaan antara GSP, Prefix Span dan CM-SPADE dapat dilihat di Lampiran A.
2.1.6 Event Log
Pendekatan proses mining bertujuan untuk menemukan model yang tepat. Namun, urutan clustering dapat memberikan wawasan berharga tentang jenis urutan yang sedang dieksekusi. Secara umum, semua proses pendekatan mining mengambil log peristiwa sebagai masukan dan sebagai titik awal untuk penemuan proses yang mendasarinya.
Log peristiwa (juga disebut event log) adalah daftar catatan hasil eksekusi beberapa proses. Persyaratan pada log, yaitu jenis informasi yang harus dikandungnya, bervariasi sesuai dengan algoritma yang digunakan salah satunya algoritma α, sebuah algoritma yang mampu menciptakan kembali alur kerja Petri-net dari hubungan pemesanan yang ditemukan di log genap. Agar algoritma bekerja, log harus berisi instance identifier proses (case id) dan harus agak lengkap dalam artian semua relasi pemesanan harus ada di log.
2.1.7 Contoh Event Log
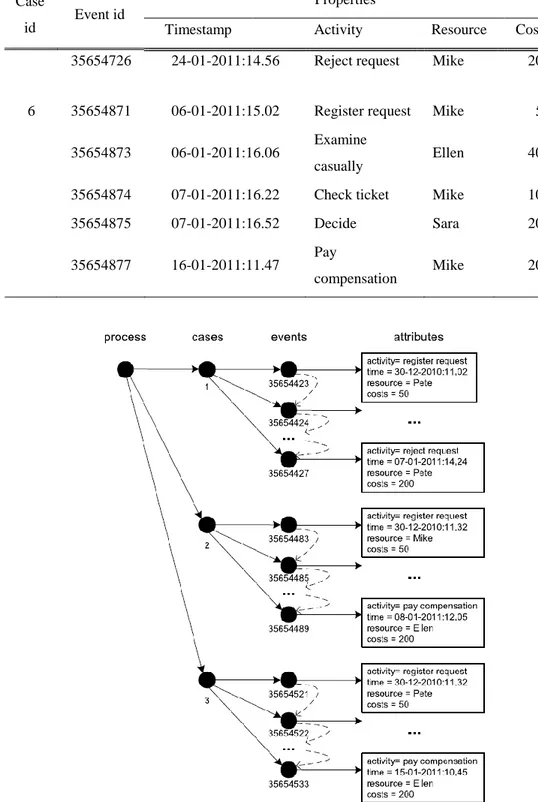
Gambar 2 memperlihatkan model proses yang mendeskripsikan penanganan permintaan kompensasi dalam sebuah perusahaan penerbangan. Pelanggan dapat mengajukan permintaan kompensasi dengan berbagai alasan, misalnya terjadi delay atau pembatalan penerbangan. Proses ini dimulai dengan mendaftarkan permintaan. Aktivitas ini dinamakan dengan register request. Setelah permintaan didaftarkan, maka berikutnya adalah melakukan cek administrative untuk memeriksa apakah pelanggan tersebut berhak mengajukan permintaan kompensasi. Aktivitas ini dinamakan dengan check ticket. salah satu dari dua aktivitas, yaitu (1) jika permintaan dinilai mencurigakan atau kompleks, maka dilakukan pemeriksaan secara mendalam (examine thoroughly), atau (2) jika permintaan dianggap tidak mencurigakan atau cukup jelas, maka dilakukan pemeriksaan secukupnya (examine casually). Hasilnya kemudian diputuskan dalam aktivitas decide. Ada tiga kemungkinan keputusan, yaitu permintaan kompensasi dipenuhi (pay compensation), permintaan ditolak (reject request), atau diperlukan pemrosesan lebih lanjut (reinitiate request). Jika diperlukan pemrosesan lebih lanjut, maka proses kembali ke setelah register request, atau dengan kata lain, tidak diperlukan pendaftaran lagi. Proses akan berakhir ketika kompensasi dibayarkan atau ditolak. Gambar memperlihatkan struktur dari sebuah event log, yaitu:
Sebuah proses terdiri dari banyak case.
Sebuah case terdiri dari banyak event, dimana setiap event
terhubung dengan satu case.
Event di dalam case terurut.
Event dapat memiliki atribut, contohnya aktivitas, waktu, biaya, dan resource.
Gambar 2 Model proses penanganan permintaan kompensasi
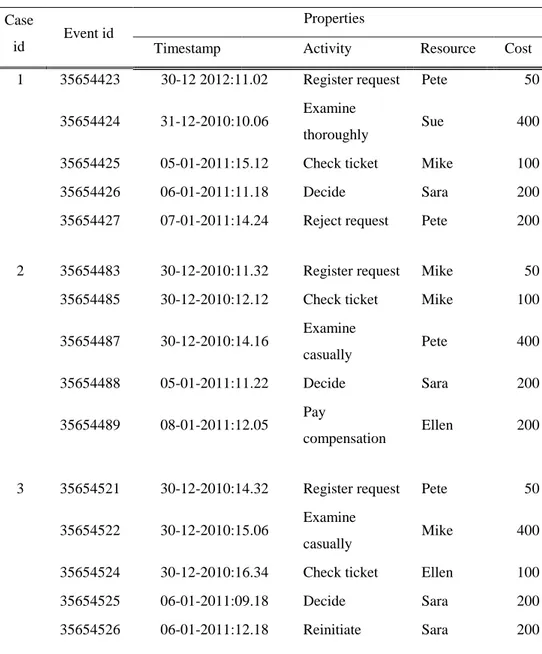
Tabel 1 memperlihatkan cuplikan log yang merekam proses penanganan permintaan kompensasi tersebut. Setiap baris mewakili satu event. beberapa event dikelompokkan menjadi sebuah case. Case 1 memiliki lima
event. Event pertama dalam case 1 adalah pelaksanaan aktivitas mendaftarkan permintaan (register request) oleh Pete pada 30 Desember 2010. Tabel tersebut juga menunjukkan id khusus untuk event ini: 35654423. Id ini digunakan agar dapat mengidentifikasi sebuah event, misalnya untuk membedakan event tersebut dengan event 35654483 yang juga merupakan pelaksanaan aktivitas register request (event pertama dari
case kedua). Tabel tersebut juga menampilkan tanggal dan waktu (timestamp) untuk setiap event. Ada kemungkinan dalam beberapa event log, informasi ini tidak diberikan secara detail dan hanya tanggal atau urutan event yang ada. Namun mungkin juga dalam kasus lain, terdapat informasi waktu yang lebih detil seperti kapan sebuah aktivitas dimulai, kapan selesai, serta kapan hasilnya ditampilkan pada user. Kolom waktu atau timestamp yang ada dalam tabel tersebut menunjukkan waktu selesainya sebuah aktivitas. Dalam event log ini, aktivitas dianggap atomik dan tabel tersebut tidak merekam durasi aktivitas. Dalam tabel tersebut setiap event berhubungan dengan sebuah resource. Dalam beberapa log, mungkin saja informasi ini tidak tersedia. Sedangkan dalam log yang lain, terdapat informasi yang mendetail mengenai resource, misalnya rule atau jabatan dari resource tersebut atau mengenai autorisasi yang terjadi antar
biaya untuk setiap event. Informasi ini merupakan contoh atribut data. Ada banyak atribut data yang lain, seperti outcome atau hasil dari setiap event, atau dalam contoh di tabel, dapat disertakan jumlah kompensasi yang diminta. Atribut ini dapat merupakan atribut dari seluruh case atau disimpan sebagai atribut dari event register request. Tabel 1 memperlihatkan informasi yang biasanya ada dalam sebuah event log. Informasi bagian mana yang digunakan tergantung pada teknik dan pertanyaan yang akan dijawab.
Tabel 1 Cuplikan sebuah event log: setiap baris menunjukkan sebuah event Case
id
Event id
Properties
Timestamp Activity Resource Cost
1 35654423 30-12 2012:11.02 Register request Pete 50
35654424 31-12-2010:10.06 Examine
thoroughly
Sue 400
35654425 05-01-2011:15.12 Check ticket Mike 100
35654426 06-01-2011:11.18 Decide Sara 200
35654427 07-01-2011:14.24 Reject request Pete 200
2 35654483 30-12-2010:11.32 Register request Mike 50
35654485 30-12-2010:12.12 Check ticket Mike 100
35654487 30-12-2010:14.16 Examine casually Pete 400 35654488 05-01-2011:11.22 Decide Sara 200 35654489 08-01-2011:12.05 Pay compensation Ellen 200
3 35654521 30-12-2010:14.32 Register request Pete 50
35654522 30-12-2010:15.06 Examine
casually
Mike 400
35654524 30-12-2010:16.34 Check ticket Ellen 100
35654525 06-01-2011:09.18 Decide Sara 200
Case
id Event id
Properties
Timestamp Activity Resource Cost
request
35654527 06-01-2011:13.06 Examine
thoroughly Sean 400
35654530 08-01-2011:11.43 Check ticket Pete 100
35654531 09-01-2011:09.55 Decide Sara 200
35654533 15-01-2011:10.45 Pay
compensation Ellen 200
4 35654641 06-01-2011:15.02 Register request Pete 50
35654643 07-01-2011:12.06 Check ticket Mike 100
35654644 08-01-2011:14.43 Examine
thoroughly Sean 400
35654645 09-01-2011:12.02 Decide Sara 200
35654647 12-01-2011:15.44 Reject request Ellen 200
5 35654711 06-01-2011:09.02 Register request Ellen 50
35654712 07-01-2011:10.16
Examine
casually Mike 400
35654714 08-01-2011:11.22 Check ticket Pete 100
35654715 10-01-2011:13.28 Decide Sara 200
35654716 11-01-2011:16.18 Reinitiate reque
st Sara 200
35654718 14-01-2011:14.33 Check ticket Ellen 100
35654719 16-01-2011:15.50 Examine casually Mike 400 35654720 19-01-2011:11.18 Decide Sara 200 35654721 20-01-2011:12.48 Reinitiate request Sara 200 35654722 21-01-2011:09.06 Examine casually Sue 400
35654724 21-01-2011:11.34 Check ticket Sara 100
Case
id Event id
Properties
Timestamp Activity Resource Cost
35654726 24-01-2011:14.56 Reject request Mike 200
6 35654871 06-01-2011:15.02 Register request Mike 50
35654873 06-01-2011:16.06 Examine
casually Ellen 400
35654874 07-01-2011:16.22 Check ticket Mike 100
35654875 07-01-2011:16.52 Decide Sara 200
35654877 16-01-2011:11.47 Pay
compensation
Mike 200
Gambar 3 Struktur sebuah event log
Informasi yang mewakili aturan minimum tersebut adalah “case id” dan “activity”
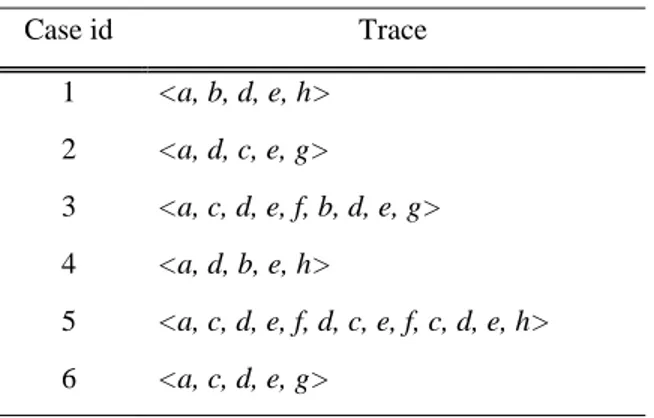
maka kita mendapatkan bentuk yang lebih singkat seperti dipelihatkan dalam Tabel 2. Dalam tabel tersebut, setiap case diperlihatkan sebagai urutan aktivitas yang disebut sebagai trace. Untuk mempermudah, setiap nama aktivitas telah diubah menjadi label yang terdiri dari satu huruf, misalnya a melambangkan aktivitas register request. (Aggarwa, 2014).
Tabel 2 Contoh Trace Clustering
Case id Trace 1 <a, b, d, e, h> 2 <a, d, c, e, g> 3 <a, c, d, e, f, b, d, e, g> 4 <a, d, b, e, h> 5 <a, c, d, e, f, d, c, e, f, c, d, e, h> 6 <a, c, d, e, g>
BAB III
ANALISIS DAN PERANCANGAN 3.1Analisis Sistem
3.1.1 Format Input
Untuk proses analisis data, aplikasi perangkat lunak ini menggunakan
file input dengan format CSV (Comma Separated Values ), format data tersebut seperti Gambar 4.
Gambar 4 Data event log
Pada format input dengan format excel/csv terdiri dari
1. Case id ialah beberapa event dikelompokkan menjadi sebuah case. 2. Event id digunakan agar dapat mengidentifikasi sebuah event, 3. Activity merupakan aktivitas.
Contohnya seperti 1;35654423;register request, 1 merupakan case id, 35654423 merupakan event id, dan request merupakan aktivitas yang terjadi.
Untuk proses menjalankan metode data mining, aplikasi perangkat lunak ini menggunakan file input dengan format CSV (Comma Separated Values ), agar output yang dihasilkan berupa activityformat data tersebut seperti Gambar 5.
Gambar 5 Format input untuk menjalankan metode data mining
3.1.2 Format Output
Aplikasi akan menghasilkan output dengan fomat text file. Format
output tersebut seperti di bawah ini:
Register request #SUP: 3 #SID: 5,6
Register request, Decide #SUP: 3
Pada format output tersebut terdiri dari : 1. Activity merupakan aktivitas. 2. SUP : Aktivitas minimum support.
3. SID sama dengan Case Id : untuk menentukan id sequence
3.1.3 Analisis spesifikasi kebutuhan software dan hardware 3.1.3.1 Analisis Kebutuhan perangkat keras (Hardware)
Tidak diperlukan hardware khusus, untuk membangun dan menjalankan, hardware yang digunakan untuk membangun aplikasi ini adalah dengan spesifikasi sebagai berikut :
b) Memory 2048Mb RAM d) Mouse
3.1.3.2 Analisis Perangkat Lunak/Software
Spesifikasi perangkat lunak yang dibutuhkan untuk mendukung aplikasi yang akan dibangun adalah sebagai berikut:
a) Sistem Operasi: Microsoft Windows 7 b) Microsoft Office 2010
c) NetBeans IDE 8.2 d) Microsoft Visio 2010 e) StarUML
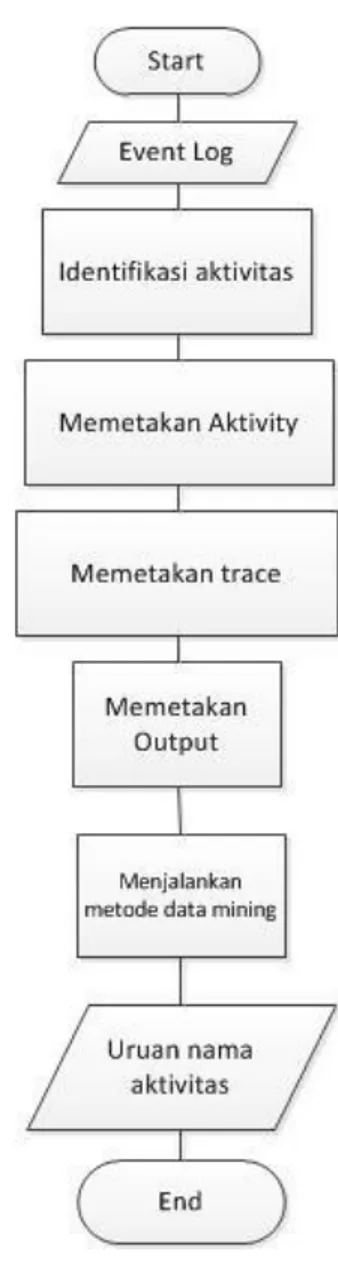
3.2Perancangan Sistem 3.2.1 Flowchart
Proses data dalam aplikasi ini ditampilkan menggunakan flowchart pada Gambar 6.
Gambar 6 Flowchart aplikasi SPMS (Sequential Pattern Mining Software
Masing-masing langkah dalam flowchart akan dijelaskan secara detil dalam bab 3.2.3 mengenai algoritma. Algoritma untuk tiap langkah tersebut akan dituliskan menggunakan pseudocode.
3.2.2 Rancangan Kelas
Rancangan kelas untuk aplikasi sequential pattern mining dengan menggunakan metode GSP, Prefix Span, dan CM-Spade dapat dilihat pada Gambar 7.
Gambar 7 Rancangan kelas
3.2.3 Algoritma
1. Algoritma untuk method identifikasi activity
Mengidentifikasi nama-nama activity dalam event log.
Dengan mengindetifikasi urutan dalam event log, sehingga nama activity tersebut yang akan menjadi output dalam pengembangan. Jika di lakukan masukan dengan memanggil
event log dengan format csv, setelah di proses dengan menggunakan algoritma yang ada maka output yang akan di tampilkan akan berupa nama activity dengan format file teks.
Input : Event log Output : Activity list
For each activity in the event log if not in activity list
append activity to activity list
end end
2. Algoritma untuk method memetakan nama activity menjadi
activity id
Input : Event log, Activity list Output :Event log
3. Algoritma untuk method memetakan trace
Memetakan trace dalam event log menjadi format masukan
library, Trace yang berisi data event log dengan menggunakan format file teks, yang akan di dijadikan format masukan di dalam library yang di gunakan.
Input: event log Output: trace
4. Menjalankan metode data mining menggunakan library.
Menjalankan metode data mining (GSP,Prefix Span dan CM-Spade) menggunakan library pada perangkat lunak SPMF.
a. Input :Trace Output : Sequence
for each activity do
if activity = activity in activity list append activity id
end end
for each activity
If case id identical Append to trace end
Algoritma : GSP ( Trace ) b. Input :Trace
Output :Sequence
Algoritma : Prefix Span ( Trace ) c. Input : Trace
Output :Sequence
Algoritma : CM-Spade ( Trace )
5. Algoritma memetakan output library menjadi nama activity
dalam event log.
Dengan memasukkan input yang berupa data event log yang terdiri dari event id dan activity, di lakukan trace, kemudian akan mendapatkan hasil yang berupa patternactivity dari data
event log tersebut.
Input : event log
Output :Urutan nama activity
3.3Rancangan Antar Muka
Aplikasi ini akan dibangun sedemikian rupa dengan perancangan antarmuka. Terdapat 7 perancangan antarmuka dari aplikasi yang akan dibangun.
for each id in the sequence
If id equals activity id then Append activity to trace end
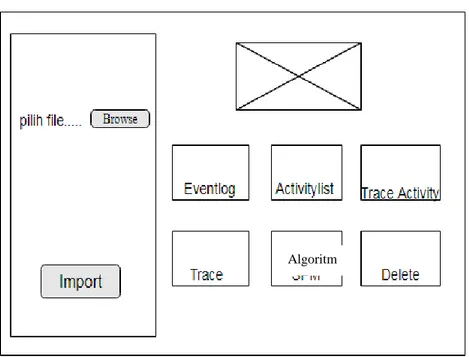
3.3.1 Antarmuka Beranda
Gambar 8 Rancangan antarmuka beranda
Pada gambar 8 rancangan antarmuka beranda dirancang sederhana agar pengguna dapat dengan mudah menggunakan aplikasi tersebut. Tombol untuk meng-import
data berada di samping agar lebih praktis.
3.3.2 Antarmuka Data Event Log
Gambar 9 Rancangan antarmuka data event log
Pada gambar 9 dibuat untuk menampilkan seluruh data yang telah di masukkan ke dalam aplikasi, kemudian terdapat tombol activitylist, dimana tombol tersebut akan menghubungkan ke antarmuka activitylist.
3.3.3 Antarmuka Activity List
Gambar 10 Rancangan antarmuka activity list
Pada gambar 10 dibuat untuk mecari jumlah activity yang sama dari seluruh data di eventlog,
3.3.4 Antarmuka Trace Activity
Pada gambar 11 dibuat setelah antarmuka activity list, dimana antarmuka ini akan bekerja untuk mengelompokkan activity berdasarkan ID sesuai dengan data
activitylist. -1 menandakan akhir dari setiap item, sedanglan -2 menandakan akhir dari sebuah urutan.
3.3.5 Antarmuka Save Trace
Gambar 12 Rancangan antarmuka save trace
Gambar 12 dibuat untuk melakukan penyimpanan data berupa urutan activity yang merupakan masukan dari SPMS.
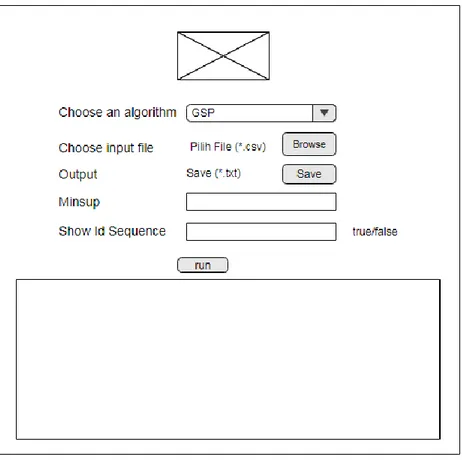
3.3.6 Antarmuka SPMS
Gambar 13 Rancangan antarmuka metode data mining
Gambar 13 dibuat untuk menjalankan metode data mining yaitu GSP, Prefix Span
dan CM-Spade untuk mencari urutan activity yang sering muncul dari data
eventlog.
3.4Rancangan Pengujian
Untuk membuktikan bahwa aplikasi dapat melakukan Sequential Pattern Mining dengan menggunakan metode GSP, Prefix Span dan CM-Spade dilakukan pengujian dengan rancangan sebagai berikut.
3.4.1 Data Uji
Data uji diambil dari buku karya Wil van der Aalst berjudul "Process Mining: Data Science in Action." terbitan Springer Berlin Heidelberg (2016) halaman 3-23. Contoh data uji dapat dilihat pada Gambar 20.
Gambar 14 Contoh data uji
Pada data uji ini terdiri dari :
1. Case id merupakan sebuah angka yang digunakan untuk memberi atau mengidentifikasi sebuah event
2. Event id digunakan agar dapat mengidentifikasi sebuah event,
3. Timestamp (dd-MM-yyyy:HH.mm) menunjukkan waktu sebuah aktivitas, 4. Activity merupakan rangakaian kegiatan,
5. Resource merupakan nama-nama orang yang bertanggung jawab dalam pelaksanaan dalam suatu kegiatan,
6. Costs harga dalam sebuah event
7. Outcome merupakan hasil dari setiap event
3.4.2 Deskripsi Pengujian
Pengujian dilakukan 2 kali dengan 3 metode, yaitu GSP, Prefix Span dan CM-Spade, 100 data , 200 data, 300 data, 400 data, 500 data, 600 data, 700 data, 800 data, 900 data dan 1000 data dengan min support 20%, 40%, dan 60%. Dalam
masing-masing data uji tersebut, dimasukkan data dengan jumlah Event, Jumlah
Case dan jumlah Activity yang berbeda, untuk setiap pengujian terdapat waktu dimana waktu tersebut menunjukkan lamanya proses pengurutan data yang sering muncul dari eventlog, lama waktu saat melakukan pengurutan data berbeda-beda karena tergantung kondisi lingkungan sistem saat mengurutkan data.
BAB IV
HASIL DAN PEMBAHASAN
Setelah melakukan tahap perancangan maka tahap selanjutnya adalah implementasi dan pengujian terhadap produk. Implementasi dari tahap perancangan tersebut adalah sebagai berikut:
4.1 Implementasi Antarmuka 4.1.1 Halaman Beranda
Pada halaman beranda terdapat tombol untuk meng-import data event log ke dalam aplikasi dalam format csv.
Gambar 15 Implementasi antarmuka beranda
Pada gambar 14 dibuat sederhana namun tetap memiliki keindahan dan seni dari segi tampilannya. Terdapat enam tombol utama untuk memproses data, di sebelah kiri ditempatkan khusus untuk meng-import data. Enam tombol utama di buat berurut yang dimulai dari kiri tombol “Event Log” hingga tombol “Delete All
Data” agar memudahkan penggunaan yang sesuai dengan alur proses yang di tetapkan.
4.1.2 Halaman Antarmuka Data Event Log
Gambar 16 Implementasi antarmuka data event log
Pada gambar 15 dibuat untuk menampilkan seluruh data yang telah di masukkan ke dalam aplikasi, kemudian terdapat tombol activitylist, dimana tombol tersebut akan menghubungkan ke antarmuka activitylist
4.1.3 Halaman Antarmuka Activitylist
Gambar 17 Implementasi antarmuka activity list
Pada gambar 16 ini dibuat untuk mecari jumlah activity yang sama dari seluruh data di eventlog,
4.1.4 Halaman Antarmuka Trace Activity
Pada gambar 17 dibuat setelah antarmuka activity list, dimana antarmuka ini akan bekerja untuk mengelompokkan activity berdasarkan ID sesuai dengan data
activitylist. -1 menandakan akhir dari setiap item, sedanglan -2 menandakan akhir dari sebuah urutan.
4.1.5 Halaman Antarmuka Save Trace
Gambar 19 Implementasi antarmuka save trace
Pada gambar 18 dibuat untuk melakukan penyimpanan data berupa urutan activity
4.1.6 Halaman Antarmuka SPMS
Gambar 20 Implementasi antarmuka SPMS
Pada gambar 19 dibuat untuk menjalankan metode data mining yaitu GSP, Prefix Span dan CM-Spade untuk mencari urutan activity yang sering muncul dari data
eventlog.
4.2 Pengujian 4.2.1 Hasil Pengujian
Pengujian yang dilakukan dengan mengamati hasil eksekusi melalui data uji dan memerikasa fungsionalitas suatu system secara lengkap.
4.2.2 Pegujian Aplikasi Dengan Metode GSP
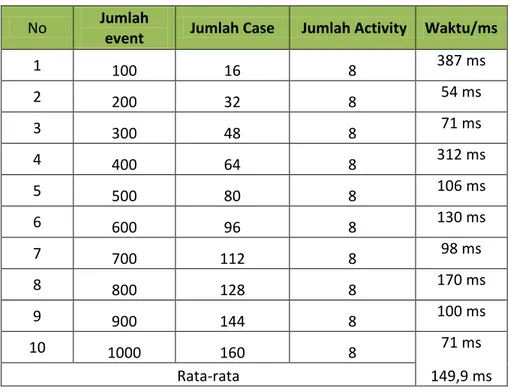
Aplikasi diuji dengan memasukkan data jumlah event dan jumlah case yang berbeda tetapi dengan jumlah activity yang sama untuk mengetahui kecepatan dan akurasi aplikasi dalam mendeteksi urutan data yang sering muncul. Tabel 3 merupakan hasil pengujian data dengan menggunakan metode GSP dengan min support 20%.
Tabel 3 Hasil Pengujian Data dengan Metode GSP
No Jumlah
event Jumlah Case Jumlah Activity Waktu/ms
1 100 16 8 387 ms 2 200 32 8 54 ms 3 300 48 8 71 ms 4 400 64 8 312 ms 5 500 80 8 106 ms 6 600 96 8 130 ms 7 700 112 8 98 ms 8 800 128 8 170 ms 9 900 144 8 100 ms 10 1000 160 8 71 ms Rata-rata 149,9 ms
Gambar 21 Grafik pengujian data dengan metode GSP min support 20%
Pada gambar 21 dapat disimpulkan bahwa pada pengujian dengan mtode CM-Spade dengan jumlah event dan jumlah case yang berbeda tetapi jumlah activity
yang sama dengan min support 20% rata-rata waktu yang diperlukan adalah 149.9 ms. Hasil output dari metode GSP dapat dilihat pada gambar 22.
Gambar 22 Contoh output dengan metode GSP
Pada data uji dihasilkan :
1. Activity merupakan rangkaian activity yang sering terjadi dalam eventlog.
2. SUP merupakan activity minimum support yaitu memberitahu berapa jumlah kemunculan activity yang terjadi.
3. SID berguna untuk menentukan ID sequence, yaitu menentukan caseid urutan yang sering muncul dari data event log. SID akan muncul jika parameter sequence
Pada data diatas #SID yang diikuti oleh daftar nomor urut (bilangan bulat dipisahkan oleh spasi). Misalnya, garis yang diakhiri oleh "#SID: 0 2" berarti bahwa pola pada baris ini muncul di urutan pertama dan ketiga dari basis data urutan (urutan dengan id 0 dan 2).
4.2 3 Pegujian Aplikasi Dengan Metode Prefix Span
Aplikasi diuji dengan memasukkan data jumlah event dan jumlah case yang berbeda tetapi dengan jumlah activity yang sama untuk mengetahui kecepatan dan akurasi aplikasi dalam mendeteksi urutan data yang sering muncul. Tabel 4 merupakan hasil pengujian data dengan menggunakan metode Prefix Span dengan
min support 20%.
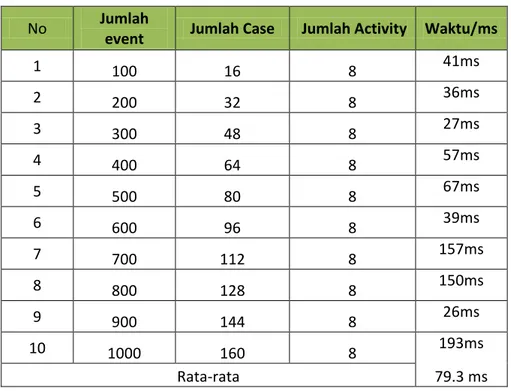
Tabel 4 Hasil Pengujian Data dengan Metode Prefix Span
No Jumlah
event Jumlah Case Jumlah Activity Waktu/ms
1 100 16 8 41ms 2 200 32 8 36ms 3 300 48 8 27ms 4 400 64 8 57ms 5 500 80 8 67ms 6 600 96 8 39ms 7 700 112 8 157ms 8 800 128 8 150ms 9 900 144 8 26ms 10 1000 160 8 193ms Rata-rata 79.3 ms
Gambar 23 Grafik pengujian data dengan Prefix Span min support 20%
Pada gambar 23 dapat disimpulkan bahwa pada pengujian dengan mtode CM-Spade dengan jumlah event dan jumlah case yang berbeda tetapi jumlah activity
yang sama dengan min support 20% rata-rata waktu yang diperlukan adalah 79.3 ms. Hasil output dari metode Prefix Span dapat dilihat pada gambar 24.
Gambar 24 Contoh output metode Prefix span
Pada data uji dihasilkan :
1. Activity merupakan rangkaian activity yang sering terjadi dalam eventlog.
2. SUP merupakan aktivitas minimum support yaitu memberitahu berapa jumlah kemunculan activity yang terjadi.
3. SID berguna untuk menentukan ID sequence, yaitu menentukan caseid urutan yang sering muncul dari data event log. SID akan muncul jika parameter sequence
Pada data diatas #SID yang diikuti oleh daftar nomor urut (bilangan bulat dipisahkan oleh spasi). Misalnya, garis yang diikuti oleh
"#SID: 1 3" berarti
bahwa pola pada baris ini muncul di urutan pertama dan ketiga dari basis
data urutan
4.2.4 Pegujian Aplikasi Dengan Metode CM-Spade
Aplikasi diuji dengan memasukkan data jumlah event dan jumlah case yang berbeda tetapi dengan jumlah activity yang sama untuk mengetahui kecepatan dan akurasi aplikasi dalam mendeteksi urutan data yang sering muncul. Tabel 5 merupakan hasil pengujian data dengan menggunakan metode Prefix Span dengan
min support 20%.
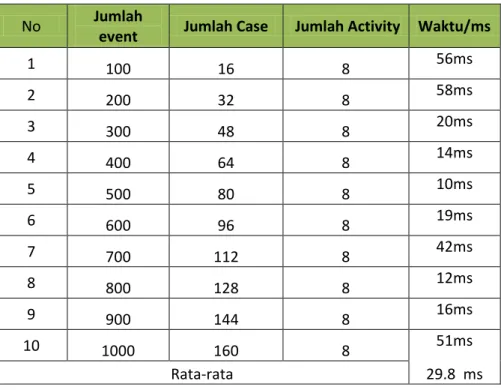
Tabel 5 Hasil Pengujian Data dengan Metode CM-Spade
No Jumlah
event Jumlah Case Jumlah Activity Waktu/ms
1 100 16 8 56ms 2 200 32 8 58ms 3 300 48 8 20ms 4 400 64 8 14ms 5 500 80 8 10ms 6 600 96 8 19ms 7 700 112 8 42ms 8 800 128 8 12ms 9 900 144 8 16ms 10 1000 160 8 51ms Rata-rata 29.8 ms
Gambar 25 Grafik pengujian data dengan CM-Spade min support 20%
Pada gambar 25 dapat disimpulkan bahwa pada pengujian dengan mtode CM-Spade dengan jumlah event dan jumlah case yang berbeda tetapi jumlah activity
yang sama dengan min support 20% rata-rata waktu yang diperlukan adalah 29.8 ms. Hasil output dari metode GSP dapat dilihat pada gambar 26.
Gambar 26 Contoh output metode CM-Spade
Pada data uji dihasilkan :
1. Activity merupakan rangkaian activity yang sering terjadi dalam eventlog.
2. SUP merupakan aktivitas minimum support yaitu memberitahu berapa jumlah kemunculan activity yang terjadi.
3. SID berguna untuk menentukan ID sequence, yaitu menentukan caseid urutan yang sering muncul dari data event log. SID akan muncul jika parameter sequence
Pada data diatas #SID yang diikuti oleh daftar nomor urut (bilangan bulat dipisahkan oleh spasi). Misalnya, garis yang diikuti oleh "#SID: 1 3" berarti bahwa pola pada baris ini muncul di urutan pertama dan ketiga dari basis data urutan
4.2.5 Pegujian Aplikasi Dengan Metode GSP
Aplikasi diuji dengan memasukkan data jumlah event dan jumlah case yang berbeda tetapi dengan jumlah activity yang sama untuk mengetahui kecepatan dan akurasi aplikasi dalam mendeteksi urutan data yang sering muncul. Tabel 6 merupakan hasil pengujian data dengan menggunakan metode GSP dengan min support 40%.
Tabel 6 Hasil pengujian data dengan menggunakan metode GSP
No Jumlah
event Jumlah Case Jumlah Activity Waktu/ms
1 100 16 8 75 ms 2 200 32 8 29 ms 3 300 48 8 28 ms 4 400 64 8 15 ms 5 500 80 8 14 ms 6 600 96 8 26 ms 7 700 112 8 18 ms 8 800 128 8 57 ms 9 900 144 8 19 ms 10 1000 160 8 35 ms Rata-rata 31.6 Ms
Gambar 27 Grafik pengujian data dengan metode GSP min support 40%
Pada gambar 28 dapat disimpulkan bahwa pada pengujian dengan mtode CM-Spade dengan jumlah event dan jumlah case yang berbeda tetapi jumlah activity
yang sama dengan min support 40% rata-rata waktu yang diperlukan adalah 31.6 ms.
4.2.6 Pegujian Aplikasi Dengan Metode Prefix Span
Aplikasi diuji dengan memasukkan data jumlah event dan jumlah case yang berbeda tetapi dengan jumlah activity yang sama untuk mengetahui kecepatan dan akurasi aplikasi dalam mendeteksi urutan data yang sering muncul. Tabel 7 merupakan hasil pengujian data dengan menggunakan metode GSP dengan min support 40%.
Tabel 7 Hasil pengujian data dengan menggunakan metode Prefix Span
No Jumlah
event Jumlah Case Jumlah Activity Waktu/ms
1 100 16 8 53ms 2 200 32 8 16ms 3 300 48 8 19ms 4 400 64 8 31ms 5 500 80 8 15ms 6 600 96 8 16ms 7 700 112 8 31ms 8 800 128 8 31ms 9 900 144 8 16ms 10 1000 160 8 15ms Rata-rata 24.3 ms
Gambar 28 Grafik pengujian data dengan metode Prefix Span min support 40%
Pada gambar 29 dapat disimpulkan bahwa pada pengujian dengan mtode CM-Spade dengan jumlah event dan jumlah case yang berbeda tetapi jumlah activity
yang sama dengan min support 40% rata-rata waktu yang diperlukan adalah 8.4 ms.
4.2.7 Pegujian Aplikasi Dengan Metode CM-Spade
Aplikasi diuji dengan memasukkan data jumlah event dan jumlah case yang berbeda tetapi dengan jumlah activity yang sama untuk mengetahui kecepatan dan akurasi aplikasi dalam mendeteksi urutan data yang sering muncul. Tabel 8 merupakan hasil pengujian data dengan menggunakan metode GSP dengan min support 40%.
Tabel 8 Hasil pengujian data dengan menggunakan metode CM-Spade
No Jumlah
event Jumlah Case Jumlah Activity Waktu/ms
1 100 16 8 30 ms 2 200 32 8 25 ms 3 300 48 8 7 ms 4 400 64 8 12 ms 5 500 80 8 16 ms 6 600 96 8 13 ms 7 700 112 8 12 ms 8 800 128 8 14 ms 9 900 144 8 9 ms 10 1000 160 8 22 ms Rata-rata 16 ms
Gambar 29 Grafik pengujian data dengan metode CM-Spade min support 40%
Pada gambar 30 dapat disimpulkan bahwa pada pengujian dengan mtode CM-Spade dengan jumlah event dan jumlah case yang berbeda tetapi jumlah activity
yang sama dengan min support 40% rata-rata waktu yang diperlukan adalah 16 ms.
4.2.8 Pegujian Aplikasi Dengan Metode GSP
Aplikasi diuji dengan memasukkan data jumlah event dan jumlah case yang berbeda tetapi dengan jumlah activity yang sama untuk mengetahui kecepatan dan akurasi aplikasi dalam mendeteksi urutan data yang sering muncul. Tabel 9 merupakan hasil pengujian data dengan menggunakan metode GSP dengan min support 60%.
Tabel 9 Hasil pengujian data dengan menggunakan metode GSP
No Jumlah
event Jumlah Case Jumlah Activity Waktu/ms
1 100 16 8 30ms 2 200 32 8 6ms 3 300 48 8 11ms 4 400 64 8 14ms 5 500 80 8 19ms 6 600 96 8 10ms 7 700 112 8 19ms 8 800 128 8 22ms 9 900 144 8 17ms 10 1000 160 8 89ms Rata-rata 23.7 ms
Gambar 30 Grafik pengujian data dengan metode CM-Spade min support 60%
Pada gambar 31 dapat disimpulkan bahwa pada pengujian dengan mtode CM-Spade dengan jumlah event dan jumlah case yang berbeda tetapi jumlah activity
yang sama dengan min support 60% rata-rata waktu yang diperlukan adalah 23.7 ms.
4.2.9 Pegujian Aplikasi Dengan Metode Prefix Span
Aplikasi diuji dengan memasukkan data jumlah event dan jumlah case yang berbeda tetapi dengan jumlah activity yang sama untuk mengetahui kecepatan dan akurasi aplikasi dalam mendeteksi urutan data yang sering muncul. Tabel 10 merupakan hasil pengujian data dengan menggunakan metode GSP dengan min support 60%.
Tabel 10 Hasil pengujian data dengan menggunakan metode Prefix Span
No Jumlah
event Jumlah Case Jumlah Activity Waktu/ms
1 100 16 8 7ms 2 200 32 8 10ms 3 300 48 8 8ms 4 400 64 8 10ms 5 500 80 8 7ms 6 600 96 8 5ms 7 700 112 8 7ms 8 800 128 8 6ms 9 900 144 8 6ms 10 1000 160 8 50ms Rata-rata 11.6 ms
Pada gambar 32 dapat disimpulkan bahwa pada pengujian dengan mtode CM-Spade dengan jumlah event dan jumlah case yang berbeda tetapi jumlah activity
yang sama dengan min support 60% rata-rata waktu yang diperlukan adalah 11.6 ms.
4.2.10 Pegujian Aplikasi Dengan Metode CM-Spade
Aplikasi diuji dengan memasukkan data jumlah event dan jumlah case yang berbeda tetapi dengan jumlah activity yang sama untuk mengetahui kecepatan dan akurasi aplikasi dalam mendeteksi urutan data yang sering muncul. Tabel 11 merupakan hasil pengujian data dengan menggunakan metode GSP dengan min support 60%.
Tabel 11 Hasil pengujian data dengan menggunakan metode CM-Spade
No Jumlah
event Jumlah Case Jumlah Activity Waktu/ms
1 100 16 8 3ms 2 200 32 8 12ms 3 300 48 8 12ms 4 400 64 8 2ms 5 500 80 8 3ms 6 600 96 8 13ms 7 700 112 8 11ms 8 800 128 8 16ms 9 900 144 8 6ms 10 1000 160 8 6ms Rata-rata 8.4 ms
Gambar 32 Grafik pengujian data dengan metode CM-Spade min support 60%
Pada gambar 33 dapat disimpulkan bahwa pada pengujian dengan metode CM-Spade dengan jumlah event dan jumlah case yang berbeda tetapi jumlah activity
yang sama dengan min support 60% rata-rata waktu yang diperlukan adalah 8.4 ms.
4.2.11 Pegujian Aplikasi Dengan Metode GSP
Aplikasi diuji dengan memasukkan data jumlah event dan jumlah case yang sama tetapi dengan jumlah activity yang berbeda untuk mengetahui kecepatan dan akurasi aplikasi dalam mendeteksi urutan data yang sering muncul. Tabel 12 merupakan hasil pengujian data dengan menggunakan metode GSP dengan min support 20%.
Tabel 12 Hasil Pengujian Data dengan Metode GSP
No Jumlah
event Jumlah Case Jumlah Activity Waktu/ms
1 624 100 9 15ms 2 624 100 11 14ms 3 624 100 12 15ms 4 624 100 13 18ms 5 624 100 14 15ms 6 624 100 15 16ms 7 624 100 16 21ms 8 624 100 18 19ms 9 624 100 21 37ms Rata-rata 18.89 ms
Gambar 33 Grafik pengujian data dengan GSP 20%
Pada gambar 34 dapat disimpulkan bahwa pada pengujian dengan mtode CM-Spade dengan jumlah event dan jumlah case yang sama tetapi jumlah activity yang berbeda dengan min support 20% rata-rata waktu yang diperlukan adalah 18.89 ms.
4.2.12 Pegujian Aplikasi Dengan Metode Prefix Span
Aplikasi diuji dengan memasukkan data jumlah event dan jumlah case yang sama tetapi dengan jumlah activity yang berbeda untuk mengetahui kecepatan dan akurasi aplikasi dalam mendeteksi urutan data yang sering muncul. Tabel 13 merupakan hasil pengujian data dengan menggunakan metode GSP dengan min support 20%.
Tabel 13 Hasil Pengujian Data dengan Metode Prefix Span
No Jumlah
event Jumlah Case Jumlah Activity Waktu/ms
1 624 100 9 4ms 2 624 100 11 5ms 3 624 100 12 8ms 4 624 100 13 10ms 5 624 100 14 5ms 6 624 100 15 15ms 7 624 100 16 7ms 8 624 100 18 7ms 9 624 100 21 4ms Rata-rata 7.44 ms
Pada gambar 35 dapat disimpulkan bahwa pada pengujian dengan mtode CM-Spade dengan jumlah event dan jumlah case yang sama tetapi jumlah activity yang berbeda dengan min support 20% rata-rata waktu yang diperlukan adalah 7.44 ms.
4.2.13 Pegujian Aplikasi Dengan Metode CM-Spade
Aplikasi diuji dengan memasukkan data jumlah event dan jumlah case yang berbeda tetapi dengan jumlah activity yang sama untuk mengetahui kecepatan dan akurasi aplikasi dalam mendeteksi urutan data yang sering muncul. Tabel 14 merupakan hasil pengujian data dengan menggunakan metode Prefix Span dengan
min support 20%.
Tabel 14 Hasil Pengujian Data dengan Metode CM-Spade
No Jumlah
event Jumlah Case Jumlah Activity Waktu/ms
1 624 100 9 3ms 2 624 100 11 2ms 3 624 100 12 2ms 4 624 100 13 1ms 5 624 100 14 9ms 6 624 100 15 3ms 7 624 100 16 2ms 8 624 100 18 1ms 9 624 100 21 1ms Rata-rata 2.67ms
Gambar 35 Grafik pengujian dengan CM-Spade min support 20%
Pada gambar 36 dapat disimpulkan bahwa pada pengujian dengan mtode CM-Spade dengan jumlah event dan jumlah case yang sama tetapi jumlah activity yang berbeda dengan min support 20% rata-rata waktu yang diperlukan adalah 2.67 ms.
4.2.14 Pegujian Aplikasi Dengan Metode GSP
Aplikasi diuji dengan memasukkan data jumlah event dan jumlah case yang berbeda tetapi dengan jumlah activity yang sama untuk mengetahui kecepatan dan akurasi aplikasi dalam mendeteksi urutan data yang sering muncul. Tabel 15 merupakan hasil pengujian data dengan menggunakan metode GSP dengan min support 40%.
Tabel 15 Hasil pengujian data dengan menggunakan metode GSP
No Jumlah
event Jumlah Case Jumlah Activity Waktu/ms
1 624 100 9 15ms 2 624 100 11 16ms 3 624 100 12 31ms 4 624 100 13 15ms 5 624 100 14 16ms 6 624 100 15 47ms 7 624 100 16 78ms 8 624 100 18 31ms 9 624 100 21 16ms Rata-rata 29.44 ms
Gambar 36 Grafik pengujian data dengan metode GSP min support 40%
Pada gambar 37 dapat disimpulkan bahwa pada pengujian dengan mtode CM-Spade dengan jumlah event dan jumlah case yang sama tetapi jumlah activity yang berbeda dengan min support 40% rata-rata waktu yang diperlukan adalah 29.44 ms.