III-1 BAB III
ANALISIS DAN PERANCANGAN
3.1 Analisis Dan Kebutuhan Sistem
Pada penelitian ini dibutuhkan data training dan data testing. Data yang digunakan diambil dari twitter yang diambil secara acak sesuai dengan kategori yang dibutuhkan. Kemudian setelah mendapatkan data yang dibuthkan selanjutnya menentukan jumlah data yang akan digunakan sebagai data training dan data testing.
Pada penelitian ini selain data yang dibutuhkan untuk melakukan penelitian ada juga aspek penunjang kebutuhan untuk melakukan penelitian ini. Berikut aspek penunjang yang digunakan pada penelitian :
1. Perangkat Lunak (Software)
Sistem ini didukung oleh perangkat lunak (Software) seperti yang dibawah ini :
a. Sublime Text 3 b. XAMPP c. Windows 10
2. Perangkat Keras (Hardware)
Perangkat keras yang digunakan untuk inputoutput data sebagai berikut : a. CPU Intel Core i5 dan RAM 4 GB
b. Monitor c. Keyboard d. Mouse 3.2 Fungsi Sistem
Aplikasi ini memiliki beberapa fungsi utama yaitu : a. Mengklasifikasi data komentar negatif maupun positif
3.3 Batasan Sistem
Pengembangan aplikasi berbasis web ini mempunyai batasan yaitu : a. User hanya dapat melihat hasil data training dan testing
b. Aplikasi ini hanya menampilkan hasil akurasi klasifikasi data komentar dari twitter.
c. Sistem hanya mengolah data 1 calon kandidat 3.4 Input
Pada tahap ini data masukan yang digunakan adalah data tweet atau komentar dari akun kandidat calon gubernur jawa barat. Data tweet tersebut diambil secara manual dari komentar pada kandidat calon gubernur jawa barat. Data yang didapat berupa sebuah kalimat dengan panjang maksimal 140 karakter. Contoh data tweet yang didapat dari twitter dapat dilihat pada gambar
Gambar 3.1 contoh tweet positif Ridwan Kamil
3.5 Proses
Pada tahap ini proses yang dilakukan yaitu mengumpulkan data terlebih dahulu Setelah data yang didapatkan dari Twitter kemudian dilakukan tahap Preprocessing.
3.5.1 Text Preprocessing
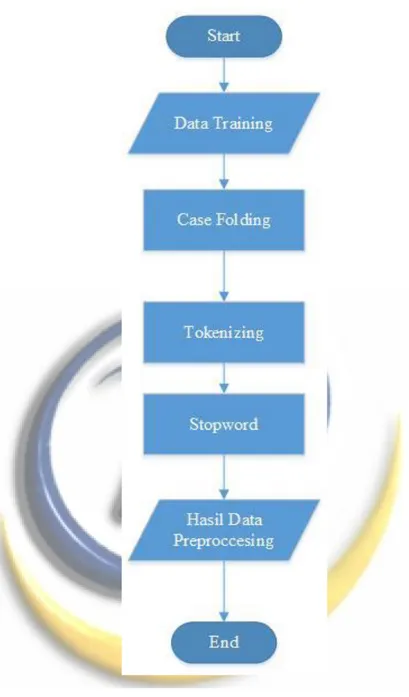
Text preprocessing merupakan bagian dari proses data preparation, Text preprocessing digunakan untuk melakukan filter terhadap dokumen. Agar data tweets tersebut dapat dimanfaatkan dengan baik untuk analisis sentimen, proses text preprocessing dapat dilihat pada gambar di bawah ini.
Gambar 3.2 Flowchart Prepocessing
1. Casefolding
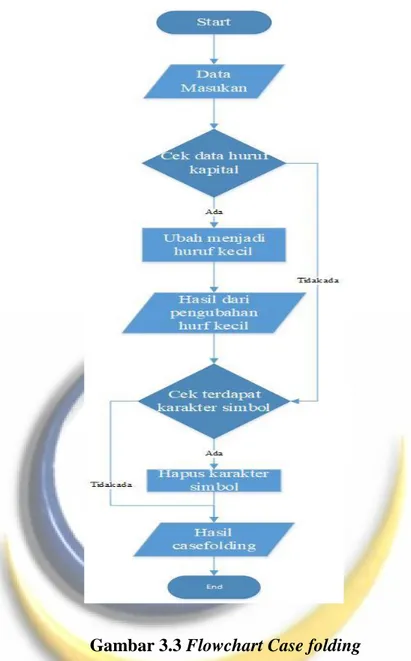
Casefolding yaitu mengubah semua huruf dalam teks dokumen menjadi huruf kecil, serta menghilangkan karakter selain a-z, kecuali karakter pemecah kalimat, seperti spasi, tab, dan newline (lompat baris). Berikut flowchart dari tahapan Casefolding dapat di lihat pada Gambar berikut:
Gambar 3.3 Flowchart Case folding
Adapun contoh tahapan proses data training dari casefolding bisa dilihat pada tabel berikut :
Tabel 3.1 Proses Casefolding
Penjelasan dari tabel 3.1 sebagai berikut : 1. Pengecekan huruf kapital pada kalimat
Pernyataan
Tahap Case Folding Ubah Menjadi Huruf Kecil Hapus Karakter Simbol Hasil Casefolding
Data masukan P1 dan P2 dilakukan pengecakan apakah ada huruf kapital atau tidak, ternyata pada P1 terdapat huruf kapital yaitu pada huruf M pada kata pertama dan pada P2 juga terdapat huruf kapital pada kata KETIKA, JABATAN, Nasdem, RidwanKamil, Ancang, Nyagub, Lewat, Jalur, Independen.
2. Pengubahan menjadi huruf kecil
Pada P1 Huruf M pada kata pertama di ganti menjadi huruf kecil m, dan P2 dari kalimat KETIKA, JABATAN, Nasdem, RidwanKamil, Ancang, Nyagub, Lewat,Jalur, Independen di ganti menjadi ketika, jabatan, nasdem, ridwankamil, ancang, nyagub, lewat, jalur, independen.
Mari terus berupaya dan berdoa dalam mendukung @ridwankamil untuk mewujudkan mimpi kita bersama untuk menjadikan. #jabarjuara
mari terus berupaya dan berdoa dalam mendukung
@ridwankamil untuk mewujudkan mimpi kita bersama untuk menjadikan. #jabarjuara mari terus berupaya dan berdoa dalam mendukung @ridwankamil untuk mewujudkan mimpi kita bersama untuk menjadikan jabarjuara mari terus berupaya dan berdoa dalam mendukung @ridwankamil untuk mewujudkan mimpi kita bersama untuk menjadikan jabarjuara KETIKA otak manusia terasuki JABATAN ? Nasdem > independen @RidwanKamil Ancang-ancang Nyagub Lewat Jalur Independen ketika otak manusia terasuko jabatan ? nasdem > independen @ridwankamil ancang-ancang nyagub lewat jalur independen ketika otak manusia terasuko jabatan nasdem independen @ridwankamil ancang ancang nyagub lewat jalur independen ketika otak manusia terasuko jabatan nasdem independen @ridwankamil ancang ancang nyagub lewat jalur independen
3. Pengecekan karakter simbol
Data hasil dari perubahan menjadi huruf kecil dilakukan pengecekan apakah ada karakter simbol atau tidak, dan ternyata pada P1 terdapat titik (.) hastag (#) dan pada P2 terdapat tanda tanya (?), kurung siku (>), tanda strip (-).
4. Penghapusan karakter simbol
Data dari hasil pengecekan pada simbol ternyata terdapat karakter simbol seperti titik (.), hastag (#),tanda tanya (?), kurung siku (>), tanda strip (-), kemudian karakter simbol tersebut dihapus dan hasil akhir penghapusan karakter simbol itu disimpan sebagai data hasil casefolding
2. Tokenizing
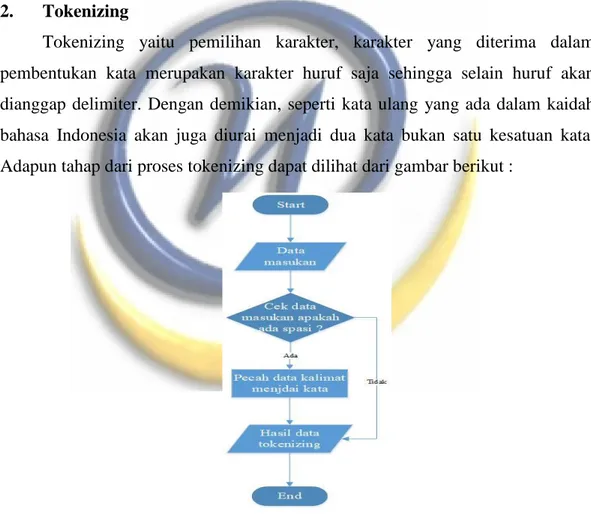
Tokenizing yaitu pemilihan karakter, karakter yang diterima dalam pembentukan kata merupakan karakter huruf saja sehingga selain huruf akan dianggap delimiter. Dengan demikian, seperti kata ulang yang ada dalam kaidah bahasa Indonesia akan juga diurai menjadi dua kata bukan satu kesatuan kata. Adapun tahap dari proses tokenizing dapat dilihat dari gambar berikut :
Gambar 3.4 Flowchart Tokenizing
Adapun contoh tahapan proses data training dari tokenizing bisa dilihat pada tabel berikut.
Tabel 3.2 Proses Tokenizing Tahap Tokenizing
Pernyataan Pecah Data menjadi Kata Hasil Tokenizing mari terus berupaya dan berdoa dalam mendukung @ridwankamil untuk mewujudkan mimpi kita bersama untuk menjadikan jabarjuara Mari Mari Terus Terus Berupaya Berupaya Dan Dan Berdoa Berdoa Dalam Dalam Mendukung Mendukung @ridwankamil @ridwankamil Untuk Untuk Mewujudkan Mewujudkan Mimpi Mimpi Kita Kita Bersama Bersama Untuk Untuk Menjadikan Menjadikan Jabarjuara Jabarjuara
Berikut ini adalah penjelasan dari Tabel 3.2 di atas: a. Pengecekan spasi
Data latih P1 hasil change username dilakukan pengecekan apakah data bertemu spasi atau tidak. Setiap kata pada P1 bertemu spasi.
b. Pemecahan data menjadi kata
Pemecahan data menjadi kata setiap bertemu spasi. Data hasil pemecahan data menjadi kata tersebut disimpan sebagai data hasil tokenizing yang nantinya akan digunakan pada tahap stopword removal.
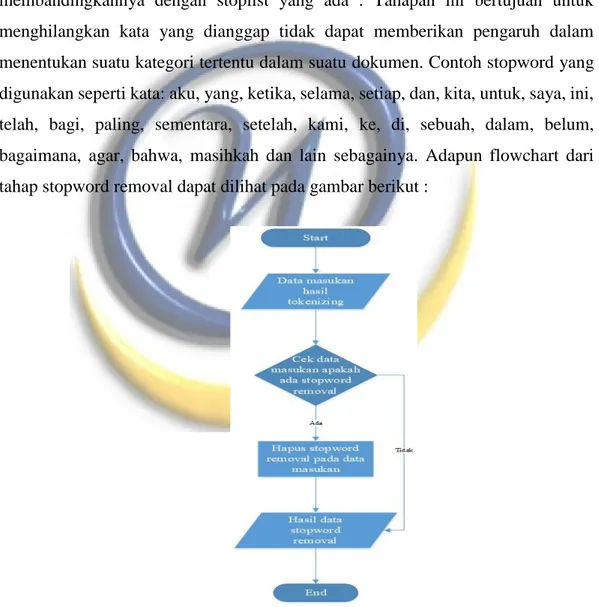
3. Stopword removal
Stopwords removal adalah sebuah proses untuk menghilangkan kata yang 'tidak relevan' pada hasil parsing sebuah dokumen teks dengan cara membandingkannya dengan stoplist yang ada . Tahapan ini bertujuan untuk menghilangkan kata yang dianggap tidak dapat memberikan pengaruh dalam menentukan suatu kategori tertentu dalam suatu dokumen. Contoh stopword yang digunakan seperti kata: aku, yang, ketika, selama, setiap, dan, kita, untuk, saya, ini, telah, bagi, paling, sementara, setelah, kami, ke, di, sebuah, dalam, belum, bagaimana, agar, bahwa, masihkah dan lain sebagainya. Adapun flowchart dari tahap stopword removal dapat dilihat pada gambar berikut :
Gambar 3.5 Flowchart Stopword
Adapun contoh tahapan proses data training dari stopword removal bisa dilihat pada tabel berikut.
Tabel 3.3 Proses Stopword Proses Stopword
Hasil Tokenizing Hapus Stopword Hasil Stopword
Mari Mari berupaya
Terus Terus berdoa
berupaya Berupaya dalam
Dan Dan mendukung
berdoa Berdoa ridwankamil
Dalam Dalam menjadikan
mendukung mendukung jabarjuara
@ridwankamil @ridwankamil Untuk Untuk mewujudkan mewujudkan mimpi Mimpi Kita Kita bersama bersama Untuk Untuk Menjadikan menjadikan Jabarjuara jabarjuara
Berikut ini adalah penjelasan dari Tabel 3.3 di atas: 1. Pengecekan stopword removal
Data latih P1 hasil tokenizing dilakukan pengecekan apakah terdapat stopword removal atau tidak. Dan ternyata pada P1 terdapat stopword yaitu mari, terus, dan, untuk, mewujudkan, mimpi, bersama.
2. Penghapusan stopword removal
Pada tahap ini akan dilakukan penghapusan stopword removal seperti pada di P1 yaitu mari, terus, dan, untuk, mewujudkan, mimpi, bersama. Hasil dari data dari stopword removal akan dilanjutkan ke tahap stemming.
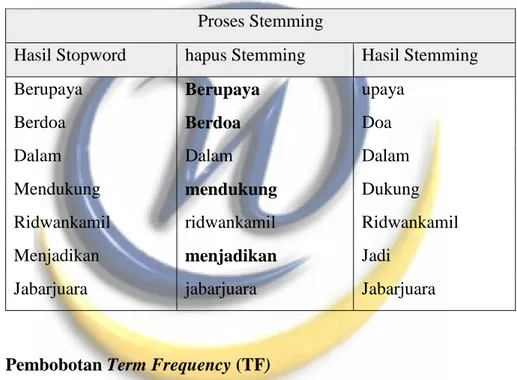
4 Stemming
Stemming merupakan suatu proses untuk menemukan kata dasar dari sebuah kata. Dengan menghilangkan semua imbuhan (affixes) baik yang terdiri dari awalan (prefixes), sisipan (infixes), akhiran (suffixes) dan confixes (kombinasi dari awalan dan akhiran) pada kata turunan. Stemming digunakan untuk mengganti bentuk dari suatu kata menjadi kata dasar dari kata tersebut yang sesuai dengan struktur morfologi Bahasa Indonesia yang baik dan benar.
Tabel 3.4 Proses Stemming Proses Stemming
Hasil Stopword hapus Stemming Hasil Stemming
Berupaya Berupaya upaya
Berdoa Berdoa Doa
Dalam Dalam Dalam
Mendukung mendukung Dukung
Ridwankamil ridwankamil Ridwankamil
Menjadikan menjadikan Jadi
Jabarjuara jabarjuara Jabarjuara
3.5.2 Pembobotan Term Frequency (TF)
Term frequency merupakan salah satu model untuk menhitung bobot tiap term dalam teks. Dalam metode ini, tiap term diaseumsikan memiliki nilai kepentingan yang sebanding dengan jumlah kemunculan term tersebut pada teks [12]. Bobot sebuah term pada sebuah teks dirumuskan dalam persamaan berikut :
𝑊(𝑑, 𝑡) = 𝑇𝑓(𝑑, 𝑡)
Dimana TF(d,t) adalah term frequency dari term t di teks d. Term frequency dapat memparbaiki nilai recall pada information retrieval, tetapi tidak selalu memperbaiki nilai precision. Hal ini disebabkan term yang frequency cenderung
muncul di banyak teks, sehingga term-term tersebut memiliki kekuatan diskriminatif/keunikan yang kecil. Untuk memperbaiki permasalahan ini, term dengan nilai frekuensi yang tunggi sebaiknya dibuang dari set term. Menemukan threshold yang optimal merupakan fokus dari metode ini.
Dalam mengetahui nilai pada tweet, pembobotan kata harus melalui tahap TF-IDF, tapi disini penulis hanya menggunakan TF,TF adalah Term
Gambar 3.6 Flowchart Pembobotan Tf
Berikut adalah data latih yang sudah melewati tahap preprocessing dapat dilihat pada tabel berikut :
Tabel 3.5 Data Latih Setelah Preprocessing
Contoh perhitungan pembobotan TF akan diterapkan pada kalimat negative dalam pernyataan pertama (P1).
Pernyataan Kata
P1 sampai ridwankamil sesat dukung warga depok dukung maaf P2 upaya doa dalam dukung ridwankamil jadi jabarjuara
Gambar 3.7 Contoh Hasil TF
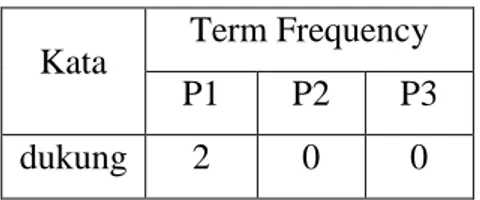
1. Perhitungan Term Frequency
Data hasil preprocessing dilakukan perhitungan kemunculan kata tangan (term frequency (tf)) pada setiap dokumen. Dokumen pada contoh kasus ini adalah P1, P2, dan P3.
Tabel 3.6 Term Frequency
Dari tabel dijelaskan bahwa kata tangan pada pernyataan P1 kemunculan nya sebanyak 2 kali, sedangakan pada P2, dan P3 kata tangan tidak muncul (0).
Kata Term Frequency P1 P2 P3
3.6 Output
Setelah melalui tahap input dan proses diharuskan adanya output dalam sebuah sistem karena output sangatlah dibutuhkan untuk mengolah data mentah menjadi sebuah informasi. Begitupun dengan sistem yang dibuat nanti, sesuai dengan judul pada laporan yaitu penerapan analisis sentimen pada komentar di twitter untuk mengatahui hasil persentase dukungan kandidat calon gubernur jawa barat dengan algoritma artificial neural network (ANN) Perceptron.
Maka dari itu hasil output pada sistem ini diharapkan akan menghasilkan sebuah informasi.
3.7 Perancangan 3.7.1 Context Diagram
Context diagram merupakan diagram yang menggambarkan sitem secara umum, yaitu menggambarkan hubungan antara entitas luar, masukan dan keluaran dari sitem. Pada sistem yang akan dibangun terdapat satu pengguna yang menggunakan sistem ini, yaitu user. Berikut gambaran diagram konteks dari sitem yang akan dibangun.
Gambar 3.8 Context Diagram
3.7.2 Data Flow Diagram (DFD)
Setelah terbentuk diagram konteks, maka dibuat rancangan proses selanjutnya dengan menggunakan Data Flow Diagram (DFD). Data flow Diagram (DFD) adalah diagram yang menggambarkan sistem dalam bentuk lambang-lambang tertentu yang menunjukan aliran data, entitas eksternal, proses, dan tempat penyimpanan data
3.7.2.1 Data Flow Diagram Level 0
3.7.2.2 Data Flow Diagram Level 1 Proses 2
Gambar 3.10 Data Flow Diagram Level 1 Proses 2
3.7.3 Kamus Data a. Data Storage 1. tb_komentar = @id+komentar+target 2. tb_katadasar = @id+katadasar+tipe_katadasar 3. tb_stpword = @id+stopword 4. user = @id+usename+Password
d. Data flow
1. jumlah data = angka
2. hasil klasifikasi = akurasi, data negatif, data positif 3. data komentar = kata, hasil stemming, jumlah kata 3.7.4 Proses Specification (P-Spec)
3.7.4.1 Proses Specification (P-Spec ) Data Flow Diagram Level 0 1. Nama Proses : Login
Nomor proses : 1
Deskripsi proses : Proses ini digunakan untuk masuk ke halaman tambah komentar
Data input : username, password Data output : -
Kondisi error : username atau password salah maka tidak bisa masuk kehalaman tambah komentar
2. Nama Proses : Pengelolaan Data Komentar Nomor proses : 2
Deskripsi proses : Proses ini digunakan untuk menambah data komentar, menyimpan data komentar, menghapus data komentar, dan target.
Data input : Data komentar, Target Data output : Data tersimpan di database Kondisi error : -
3. Nama Proses : Pemrosesan Klasifikasi ANN Perceptron Nomor proses : 3
Deskripsi proses : Proses ini digunakan untuk mengetahui hasil klasifikasir Data input : Jumlah data, data training, data testing, mulai data testing Data output : Hasil klasifikasi, akurasi
Kondisi error : -
3.7.4.2 Proses Specification (P-Spec ) Data Flow Diagram Level 1 Proses 2
1. Nama Proses : Tambah Komentar Nomor proses : 1.2
Deskripsi proses : Proses ini digunakan untuk enambah data komentar yang diambil dari twitter
Data input : Data komentar, Target Data output :
Kondisi error : -
2. Nama Proses : Hapus komentar Nomor proses : 2.2
Deskripsi proses : Proses ini digunakan untuk menghapus data komentar Data input : -
Data output : - Kondisi error : -
3. Nama Proses : Pilih target Nomor proses : 3.2
Deskripsi proses : Proses ini digunakan untuk memilih target pada data komentar
Data input : pilih target
Data output : target berupa angka 0 untuk komentar negatif dan 1 untuk komentar positif
Kondisi error : - 3.7.5 Penyimpanan Data
Pada perancangan sistem ini hanya menggunakan tiga table pada mysql yaitu Tabel 3.7 Database tb_komentar
Nama Field Tipe Data Ukuran
Id Int 11 Not Null
Komentar Text - Not Null
Tabel 3.8 Database tb_katadasar
Tabel 3.9 Database tb_Stpword
Tabel 3.10 Database User
Nama Field Tipe Data Ukuran
Id_ktdasar Int 10 Not Null
Katadasar Varchar - Not Null
Tipe_katada sar
Varchar - Not Null
Nama Field Tipe Data Ukuran
Id Int 11 Not Null
Stopword Text - Not Null
Nama Field Tipe Data Ukuran
id Int 11 Not Null
Username Varchar 11 Not Null
3.7.6 Perancangan Antarmuka
Perancangan antar muka menjelaskan rutinitas program yang akan dijalankan oleh sebuah sistem komputerisasi untuk menjelaskan interaksi antar pengguna (user) dengan program yang dibuat. Rancangan antar muka yang akan digunakan dalam sistem, dapat dilihat pada gambar dibawah ini:
a. Tampilan Halaman Login
Gambar 3.11 Tampilan Halaman Login
Pada halaman ini berfungsi untuk login yang dimana halaman ini digunkana oleh admin untuk mengelola data komentar
b. Tampilan Halaman Home
Pada halaman ini berfungsi untuk menginputkan jumlah data, jumlah data training, dan jumlah data testing yang dimana nantinya akan di proses untuk di klasifikasi.
c. Tampilan Halaman Text Preprocessing
Gambar 3.13 Tampilan Text Preprocessing
Pada halaman ini berfungsi menampilkan . tahap-tahap mulai dari data kalimat Asal lalu melewati proses Case Folding, Tokenizing, Stopword, dan Stemming, Sehingga mengahasilkan data kalimat yang baku.
d. Tampilan Halaman Term Frequency (Tf)
Pada halaman ini berfungsi untuk menampilkan hasil pembobotan Term Frequency (Tf), pembobotan tersebut didapat dari perhitungan dokumen yang melalui tahap text preprocessing
e. Tampilan Halaman ANN Perceptron Training
Gamabar 3.15 Tampilan Halaman ANN Perceptron Training
Pada halaman ini berfungsi untuk menampilkan data hasil perhitungan metode Artificial Neural Network (ANN) perceptron training
f. Tampilan Halaman ANN Perceptron Testing
Gamabar 3.16 Tampilan Halaman ANN Perceptron Testing
g. Tampilan halaman Insert Data
Gambar 3.17 Tampilan Halaman Insert Data
Pada halaman ini berfungsi untuk menginputkan data komentar yang dimana data komentar tersebut di dadapatkan dari twitter dan terdapat combo box yang diisi apakah kalimat tersebut termasuk kalimat negatif atau positif. Kemudian ada tombol submit yang dimana komentar tersebut nantinya akan tersimpan di dalam database. Ada juga tombol hapus yang dimana fungsi nya untuk mengahpus data komentar yang salah.
h. Tampilan halaman Hasil ANN Perceptron
pada halaman ini berfungsi menampilkan hasil klasifikasi menggunakan ANN Perceptron yang dimana hasil nya ada data dokumen dan hasil dari apakah komentar tersebut negatif atau positif jika angka 0 berarti negatif dan angka 1 positif.