yang tidak berarti sebagai pembeda antar dokumen.
c. Pembobotan indeks yaitu pembobotan secara lokal dan global. Pembobotan lokal dilakukan dengan cara menghitung frekuensi kemunculan kata dan total seluruh kata pada kelas dari dokumen. Pembobotan global akan menghasilkan total kata dan jumlah total kata unik yang ada pada dokumen latih.
Naïve Bayes Classifier (NBC) dengan Background Smoothing
Proses pengklasifikasian dokumen pada penelitian ini menggunakan algoritme klasifikasi NBC yang merupakan multinomial model. Agar mudah dalam implementasinya maka digunakan teknik background smoothing sebagai pengontrol dari penghitungan maximum likelihood estimator melalui pendekatan simple language model agar hasil klasifikasinya lebih akurat.
Pada tahap ini diawali dengan penghitungan peluang setiap kata dalam dokumen latih menggunakan Maximum Likelihood Estimation (MLE) berdasarkan kata pada dokumen uji. Proses penghitungan tersebut dimulai dengan pendugaan parameter peluang kata pada dokumen kelas ci sesuai dengan formula (2). Selanjutnya melakukan kombinasi linier pada unigram class model menggunakan collection background model dengan parameter pengontrol λ sesuai dengan formula (3) pada dokumen latih. Setelah didapatkan peluang tiap kata dari dokumen uji berdasarkan dokumen latih, proses akhir adalah penghitungan peluang dari masing-masing kelas terhadap dokumen uji dengan formula (1).
Evaluasi Hasil Klasifikasi
Evaluasi hasil klasifikasi dokumen dilakukan untuk menganalisis tingkat keakurasian klasifikasi dokumen dengan metode background smoothing pada parameter pengontrol λ yang berbeda. Hal ini dimaksudkan untuk menentukan nilai ideal dari parameter pengontrol λ yang sesuai dengan data training.
Setelah diperoleh nilai koefisien λ yang terbaik untuk short dan long query, evaluasi dilanjutkan pada perbandingan klasifikasi dokumen antara NBC dengan NBC+ Background Smoothing. Pengukuran kesamaan dokumen yang digunakan adalah tingkat akurasi, recall, precision, dan F-1
menggunakan formula (4) dan (5) untuk setiap kelasnya berdasarkan tabel confusion matrix.
HASIL DAN PEMBAHASAN
Dokumen yang digunakan sebagai dokumen latih dan uji perlu dikompilasi karena hasil klasifikasi bergantung pada koleksi dokumen yang akan dijadikan dokumen latih. Hasil kompilasi menghasilkan 249 dokumen. Isi dari koleksi dokumen tersebut merupakan judul penelitian, kata kunci dan abstrak dari 3 (tiga) kelas, yaitu:
a) Kelas Ekofisiologi dan Agronomi b) Kelas Pemuliaan dan Teknologi Benih c) Kelas Proteksi (Hama dan Penyakit)
Masing-masing kelas terdiri atas 83 dokumen. Dokumen tersebut dibagi lagi untuk dijadikan sebagai data latih dan data uji. Data latih untuk setiap kelas terdiri atas 58 dokumen, sedangkan untuk data uji terdiri atas 25 dokumen. Pembagian tersebut sesuai dengan proporsi dokumen pada Bab Metodologi Penelitian, yaitu 70 % untuk data latih dan 30 % untuk data uji.
Setelah melalui proses indexing, diperoleh pembobotan indeks yang diperlukan dalam proses klasifikasi dokumen. Bagian penting dari tahap ini adalah penentuan stoplist atau kata yang akan dibuang sebagai stopword. Penghilangan stopword disesuaikan dengan kebutuhan penelitian, yaitu kata yang sering muncul dalam koleksi dokumen dan tidak memunyai arti dan dilanjutkan dengan menghilangkan kata-kata yang tidak berarti dalam membedakan dokumen. Hasil dari penghilangan stopword dan pembobotan indeks kata, diperoleh total jumlah kata sebanyak 20605 dan jumlah kata unik sebanyak 2949 untuk pembobotan global.
Uji Coba Klasifikasi Dokumen
Uji coba dilakukan dengan dua kombinasi perlakuan, yaitu:
1. NBC+Background Smoothing dengan parameter pengontrol λ= 0.1 sampai dengan 0.9, agar diperoleh nilai koefisien λ terbaik pada short dan long query.
2. Setelah diperoleh parameter pengontrol koefisien λ yang terbaik, selanjutnya dilakukan perbandingan klasifikasi dokumen NBC dengan NBC+Background Smoothing. Tujuannya adalah untuk mengetahui apakah akurasi klasifikasi dokumen menggunakan
Background Smoothing lebih baik daripada NBC.
NBC+Background Smoothing
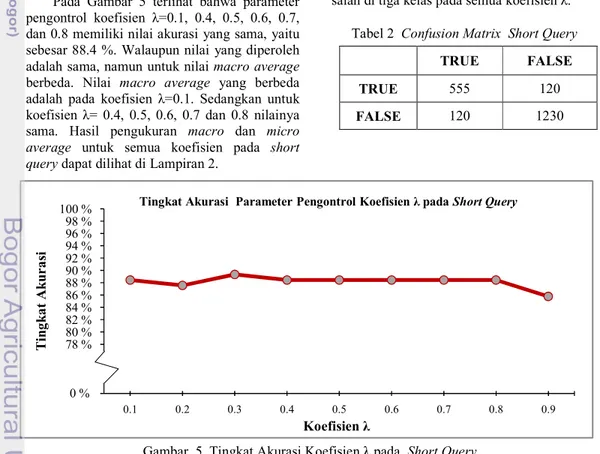
Tingkat keakurasian yang paling baik untuk short query diperoleh pada parameter pengontrol koefisien λ=0.3, seperti yang terlihat pada Gambar 5. Rata-rata nilai recall, precision dan F-measure untuk semua kelas atau micro average pada koefisien λ=0.3 adalah 84 % dan akurasi yang didapat adalah 89.3 %. Hasil penghitungan pada micro average untuk semua nilai koefisien λ dapat dilihat pada Tabel 1. Hasil klasifikasi dokumen untuk semua koefisien λ pada short query dalam bentuk confusion matrix ada pada Lampiran 1.
Tabel 1 Micro Average untuk Short Query
≠
rec=recall (%); pre=Precision (%); F-1= F-measure (%); acc= Accuracy (%) Pada Gambar 5 terlihat bahwa parameter pengontrol koefisien λ=0.1, 0.4, 0.5, 0.6, 0.7, dan 0.8 memiliki nilai akurasi yang sama, yaitu sebesar 88.4 %. Walaupun nilai yang diperoleh adalah sama, namun untuk nilai macro average berbeda. Nilai macro average yang berbeda adalah pada koefisien λ=0.1. Sedangkan untuk koefisien λ= 0.4, 0.5, 0.6, 0.7 dan 0.8 nilainya sama. Hasil pengukuran macro dan micro average untuk semua koefisien pada short query dapat dilihat di Lampiran 2.
Perbedaan tersebut nampak pada kelas b (Pemuliaan dan Teknologi Benih) dan kelas c (Proteksi). Sedangkan untuk kelas a (Fisiologi dan Agronomi) nilai yang diperoleh adalah sama. Pada Koefisien λ=0.1, nilai pada kelas c lebih tinggi dan pada kelas b nilainya lebih rendah. Hal ini disebabkan karena pada kelas c dokumen yang dikenali dengan benar lebih tinggi daripada koefisien λ= 0.4, 0.5, 0.6, 0.7, dan 0.8. Demikian pula sebaliknya yang terjadi pada kelas b, dokumen yang dikenali dengan benar lebih rendah dibandingkan dengan λ= 0.1.
Pada Tabel 2 terlihat bahwa total pengujian untuk tiga kelas a, b, dan c yang diklasifikasi-kan benar adalah 555, dan yang diklasifikasi salah adalah sebanyak 120. Sedangkan untuk dokumen yang diklasifikasikan dari total tiga kelas dengan banyaknya koefisien λ yang diujikan, diperoleh nilai sebanyak 1230. Nilai tersebut diperoleh dengan penghitungan sebagai berikut:
((75 x 3)*9) - (555+120+120) = 2025 - 796 = 1230
Nilai 75 adalah total dokumen uji dan nilai 3 merupakan jumlah kelas atau kategori. Nilai 555 adalah total dokumen yang diklasifikasikan benar di tiga kelas pada semua koefisien λ, dan 120 adalah total dokumen yang diklasifikasikan salah di tiga kelas pada semua koefisien λ.
Tabel 2 Confusion Matrix Short Query
TRUE FALSE
TRUE 555 120
FALSE 120 1230
parameter pengontrol koefisien λ
0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 rec 82,7 81,3 84,0 82,7 82,7 82,7 82,7 82,7 83,1 pre 82,7 81,3 84,0 82,7 82,7 82,7 82,7 82,7 74,7 F-1 82,7 81,3 84,0 82,7 82,7 82,7 82,7 82,7 78,7 acc 88,4 87,6 89,3 88,4 88,4 88,4 88,4 88,4 85,8 70 % 72 % 74 % 76 % 78 % 80 % 82 % 84 % 86 % 88 % 90 % 92 % 94 % 96 % 98 % 100 % 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 T in g k a t A k u r a si Koefisien λ
Tingkat Akurasi Parameter Pengontrol Koefisien λ pada Short Query
0 %
70 % 72 % 74 % 76 % 78 % 80 % 82 % 84 % 86 % 88 % 90 % 92 % 94 % 96 % 98 % 100 % 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 Ti n gk at A k u r as i Koefisien λ
Tingkat Akurasi Parameter Pengontrol Koefisien λ pada Long Query
0 %
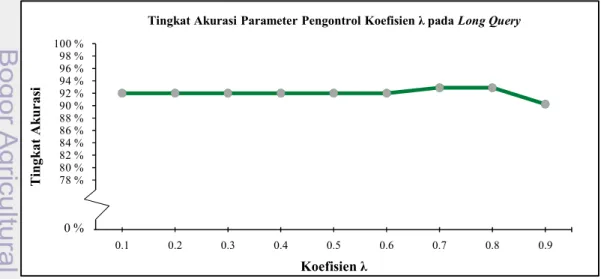
Pada long query, tingkat keakurasian terbaik diperoleh pada parameter pengontrol koefisien λ=0.7 dan λ=0.8. Nilai micro average untuk recall, precision dan F-measure adalah 89.3 %. Sedangkan akurasi yang didapat adalah 92.8 %. Hasil penghitungan micro average tersebut dapat pada tabel dibawah ini.
Tabel 3 Micro Average untuk Long Query
≠
rec = recall (%); pre=Precision (%); F-1= F1 (%); acc= Accuracy (%)
Hasil klasifikasi dokumen untuk semua koefisien λ pada long query dalam bentuk confusion matrix dapat dilihat pada Lampiran 3 dan hasil pengukuran untuk semua koefisien λ pada long query ada di Lampiran 4. Dari Gambar 6 terlihat bahwa parameter pengontrol koefisien λ=0.1 sampai dengan 0.6 memiliki nilai akurasi yang sama, sebesar 92 %. Demikian juga untuk recall, precision dan F-measure pada micro average adalah sama, yaitu 88 %. Perbedaan yang tampak pada koefisien λ=0.1 sampai dengan 0.3, dan koefisien λ=0.4 sampai 0.6.
Perbedaan tersebut tidak terlalu berarti, hanya pada koefisien λ=0.1 sampai 0.3, kelas a dikenali salah ke dalam kelas b sebanyak satu dokumen uji dan kelas c sebanyak dua dokumen uji. Sebaliknya pada koefisien λ=0.4 sampai
0.6, kelas a salah dikenali ke dalam kelas b sebanyak 2 (dua) dokumen uji dan kelas c sebanyak satu dokumen uji. Nilai Micro Average untuk total seluruh nilai parameter pengontrol koefisien λ mulai dari 0.1 sampai dengan 0.9, dapat dilihat pada tabel 4.
Tabel 4 Confusion Matrix Long Query
TRUE FALSE
TRUE 594 81
FALSE 81 1269
Pada Tabel 4 terlihat bahwa total pengujian untuk kelas a, b, dan c yang diklasifikasikan benar adalah 594, dan yang diklasifikasikan salah adalah sebanyak 81. Dari total kelas dengan banyaknya koefisien λ yang diujikan sebanyak 1269.
NBC dan NBC+Background Smoothing
Perbedaan antara klasifikasi dokumen NBC dengan NBC+Background Smoothing adalah Maximum Likelihood Estimation (MLE). Penghitungan MLE pada NBC seperti pada formula (2), menggunakan jumlah seluruh kata unik dokumen latih di semua kelas, sedangkan pada Background Smoothing tidak menambahkan jumlah seluruh kata unik dalam dokumen uji untuk penghitungannya.
Hasil pengukuran ini dilakukan pada nilai parameter pengontrol koefisien λ yang terbaik untuk background smoothing. Dari hasil pengukuran sebelumnya telah diperoleh nilai koefisien terbaik untuk short query adalah λ=0.3 dan long query pada λ=0.7.
parameter pengontrol koefisien λ 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 rec 88,0 88,0 88,0 88,0 88,0 88,0 89,3 89,3 85,3
pre 88,0 88,0 88,0 88,0 88,0 88,0 89,3 89,3 85,3
F-1 88,0 88,0 88,0 88,0 88,0 88,0 89,3 89,3 85,3
acc 92,0 92,0 92,0 92,0 92,0 92,0 92,9 92,9 90,2
Hasil klasifikasi dokumen untuk
terlihat pada Tabel 5 dan Gambar 7 bahwa tingkat akurasi NBC+Background Smoothing dengan koefisien λ=0.3 lebih baik dibandingkan dengan NBC. Hasil pengukuran selengkapnya dapat dilihat pada Lampiran 6
measure pada tabel macro average
a dan kelas b, lebih tinggi dibandingkan dengan F-measure pada NBC. Hanya kelas
uji diklasifikasikan dengan baik terhadap kelas a dan b oleh NBC.
Tabel 5 Micro Average NBC dan NBC+ Background Smoothing
Gambar 7 Perbandingan Tingkat pada Short Query
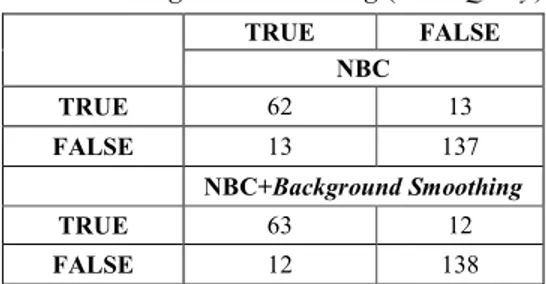
Berdasarkan Tabel 6 pengujian dokumen untuk tiga kelas a, b, dan c pada NBC yang diklasifikasikan dengan benar adalah 62, dan yang diklasifikasikan salah yaitu 13 dokumen uji dari total 75 dokumen yang diujikan. Sedangkan dokumen uji yang diklasifikasikan dari total dokumen pada tiga kelas sebanyak 137. Sedangkan pada NB
Smoothing mengklasifikasikan dokumen dengan benar sebanyak 63 dokumen uji. Hal inilah yang membuat tingkat akurasi NBC+Background Smoothing 0 % 10 % 20 % 30 % 40 % 50 % 60 % 70 % 80 % 90 % 100 % Ti n g k a t K in er ja
Tingkat Kinerja NBC dan NBC+ Background Smoothing pada Short Query
Pengukuran Micro Average (%) recall precision
NBC 82,67 82,67
NBC+BgS 84,00 84,00
Hasil klasifikasi dokumen untuk short query dan Gambar 7 bahwa Background Smoothing lebih baik dibandingkan dengan NBC. Hasil pengukuran selengkapnya dimana nilai F-macro average untuk kelas lebih tinggi dibandingkan dengan pada NBC. Hanya kelas c dokumen ifikasikan dengan baik terhadap kelas
NBC dan NBC+ Background Smoothing λ=0.3
7 Perbandingan Tingkat Akurasi Short Query
pengujian dokumen pada NBC yang diklasifikasikan dengan benar adalah 62, dan yang diklasifikasikan salah yaitu 13 dokumen uji dari total 75 dokumen yang diujikan. Sedangkan dokumen uji yang diklasifikasikan dari total dokumen pada tiga kelas sebanyak 137. Sedangkan pada NBC+Background mengklasifikasikan dokumen dengan benar sebanyak 63 dokumen uji. Hal inilah yang membuat tingkat akurasi
Background Smoothing lebih baik
daripada NBC, walaupun tidak terlalu berbeda. Hasil klasifikasi dokumen pada tiap kelas, selengkapnya dapat dilihat pada Lampiran 5.
Tabel 6 Confusion Matrix NBC dan NBC+ Background Smoothing (Short Query
TRUE NBC TRUE 62 FALSE 13 NBC+Background Smoothing TRUE 63 FALSE 12
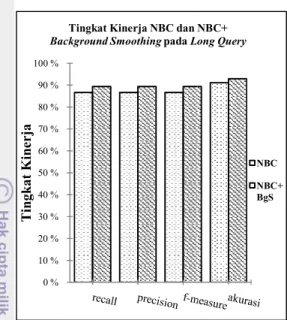
Hasil klasifikasi untuk long query dilihat pada Tabel 7 dan Gambar 8. Terlihat bahwa tingkat akurasi klasifikasi dokumen NBC+Background Smoothing dengan koefisien λ=0.7 lebih baik dibandingkan dengan NBC. Dimana nilai micro average untuk precision, dan F-measure pada Background Smoothing dengan koefisien adalah sebesar 89.3 %, sedangkan pada NBC diperoleh sebesar 86.6 %. Tingkat akurasi +Background Smoothing mencapai 92.9 %, sedangkan NBC menghasilkan tingkat akurasi sebesar 91.1 %.
Hasil pengukuran macro dan micro average untuk long query dapat dilihat pada
Pada tabel macro average terlihat bahwa nilai F-measure pada kelas a dan kelas b
dibandingkan dengan F-measure
Namun sebaliknya pada kelas c terlihat bahwa nilai F-measure yang diperoleh NBC lebih tinggi dibandingkan dengan NBC+
Smoothing. Hal inilah yang menyebabkan hasil klasifikasi dokumen menggunakan
Background Smoothing tidak terlalu berbeda dengan NBC karena pada tabel macro average (Lampiran 6) terlihat bahwa nilai
kelas c lebih tinggi dibandingkan dengan NBC+Background Smoothing.
Tabel 7 Micro Average NBC dan NBC+ Background Smoothing
Pengukuran Micro Average (%) recall precision F
NBC 86,67 86,67 86,67
NBC+BgS 89,33 89,33 89,33
Tingkat Kinerja NBC dan NBC+ Short Query
NBC
NBC +BgS
Pengukuran Micro Average (%) F-1 Akurasi
82,67 88,44 84,00 89,33
, walaupun tidak terlalu berbeda. Hasil klasifikasi dokumen pada tiap kelas,
lengkapnya dapat dilihat pada Lampiran 5. NBC dan NBC+ Short Query) FALSE 13 137 Background Smoothing 12 138 long query dapat dilihat pada Tabel 7 dan Gambar 8. Terlihat bahwa tingkat akurasi klasifikasi dokumen
dengan koefisien lebih baik dibandingkan dengan NBC. untuk recall, pada NBC+ dengan koefisien λ=0.7 adalah sebesar 89.3 %, sedangkan pada NBC diperoleh sebesar 86.6 %. Tingkat akurasi NBC mencapai 92.9 %, sedangkan NBC menghasilkan tingkat akurasi
micro average dapat dilihat pada Lampiran 6.
erlihat bahwa nilai b lebih tinggi pada NBC. terlihat bahwa yang diperoleh NBC lebih NBC+Background . Hal inilah yang menyebabkan hasil klasifikasi dokumen menggunakan NBC+ tidak terlalu berbeda macro average ) terlihat bahwa nilai recall untuk lebih tinggi dibandingkan dengan
NBC dan NBC+ Background Smoothing λ=0.7
Pengukuran Micro Average (%) F-1 Akurasi
86,67 91,11 89,33 92,89
Gambar 8 Perbandingan Tingkat pada Long Query Selain dari hasil pengukuran pada average, terlihat juga pada Tabel 8 matrix, bahwa tingkat akurasi
Background Smoothing lebih baik daripada NBC, walaupun hasil yang diperoleh tidak terlalu berbeda seperti halnya pada
Dimana total pengujian dokumen untuk tiga kelas a, b, dan c pada NBC yang diklasifikasikan dengan benar sebanyak 65, dan yang diklasifikasikan salah yaitu 10 dokumen dari total 75 dokumen yang diujikan. Sedangkan NBC+Background Smoothing mengklasifikasikan dokumen dengan benar sebanyak 67 dokumen.
Tabel 8 Confusion Matrix NBC dan NBC+ Background Smoothing TRUE NBC TRUE 65 FALSE 10 NBC+Background Smoothing TRUE 67 FALSE 8
Dari hasil penelitian ini menunjukkan bahwa hasil klasifikasi menggunakan
smoothing tidak bergantung pada panjang atau pendeknya query karena hasil yang hampir sama dicapai pula oleh NBC, baik untuk maupun long query. Hal yang mempengaruhi hasil klasifikasi dengan background smoothing adalah adanya nilai parameter pengontrol
0 % 10 % 20 % 30 % 40 % 50 % 60 % 70 % 80 % 90 % 100 % Ti n gk at K in e r ja
Tingkat Kinerja NBC dan NBC+ Background Smoothing pada Long Query
8 Perbandingan Tingkat Akurasi Long Query
Selain dari hasil pengukuran pada macro terlihat juga pada Tabel 8 confusion bahwa tingkat akurasi NBC+ lebih baik daripada walaupun hasil yang diperoleh tidak berbeda seperti halnya pada short query. total pengujian dokumen untuk tiga pada NBC yang diklasifikasikan dengan benar sebanyak 65, dan ah yaitu 10 dokumen dari total 75 dokumen yang diujikan. Background Smoothing mengklasifikasikan dokumen dengan benar
NBC dan NBC+ Background Smoothing (Long Query)
FALSE NBC 10 140 NBC+Background Smoothing 8 142 Dari hasil penelitian ini menunjukkan bahwa hasil klasifikasi menggunakan background tidak bergantung pada panjang atau karena hasil yang hampir sama dicapai pula oleh NBC, baik untuk short . Hal yang mempengaruhi background smoothing adalah adanya nilai parameter pengontrol λ
yang disesuaikan dengan data
sehingga hasilnya lebih baik dibandingkan dengan NBC kendati tidak terlalu berbeda. Sedangkan nilai λ terbaik pada short
query, terkait dengan domain klasifikasi dokumen yang digunakan sebagai
background model. Pada penelitian ini menggunakan domain tanaman hortikultura pada penelitian tentang pertanian. Bisa saja nilai koefisien λ untuk domain selain hortikultura, misalnya untuk domain tanaman pangan nilai koefisien λ pada short query bukan di dan sebaliknya untuk long query λ=0.7.
KESIMPULAN DAN SARAN
KesimpulanBackground smoothing merupakan teknik smoothing dengan pendekatan
model. Pada penelitian ini,
smoothing memodelkan seluruh dokumen latih sebagai collection background model
klasifikasi terlihat bahwa tingkat akurasi NBC+ Background Smoothing tidak banyak pengaruhnya dibandingkan dengan NBC. Peningkatan akurasi tersebut hanya sebesar 1.78% dari hasil yang diperoleh pada NBC. Untuk dapat menambah tingkat keakurasia perlu melibatkan keterkaitan antar kata atau semantic.
Hasil klasifikasi dengan
smoothing dipengaruhi oleh nilai parameter pengontrol λ yang disesuaikan dengan data training. Nilai λ terbaik yang diperoleh pada short dan long query bergantung pada domain klasifikasi dokumen yang digunakan sebagai collection background model. Hasil pengukuran klasifikasi pada dokumen bidang kajian pertanian untuk domain hortikultura menunjukkan bahwa nilai parameter koefisien λ yang terbaik pada short query
λ=0.3 dengan akurasi sebesar 89.3 % dan pada long query diperoleh pada λ=0.7 dengan akurasi 92.8 %. Oleh karena itu, nilai λ
sebaiknya digunakan pada data training kecil untuk klasifikasi short query untuk long query dibutuhkan nilai besar.
Saran
Pada penelitian selanjutnya metod Background Smoothing perlu di
koleksi dokumen selain domain pertanian
Tingkat Kinerja NBC dan NBC+ Long Query
NBC
NBC+ BgS
yang disesuaikan dengan data training, sehingga hasilnya lebih baik dibandingkan dengan NBC kendati tidak terlalu berbeda.
short dan long , terkait dengan domain klasifikasi dokumen yang digunakan sebagai collection . Pada penelitian ini enggunakan domain tanaman hortikultura pada penelitian tentang pertanian. Bisa saja nilai untuk domain selain hortikultura, misalnya untuk domain tanaman pangan nilai bukan di λ=0.3, long query tidak pada
KESIMPULAN DAN SARAN
merupakan teknik dengan pendekatan languange . Pada penelitian ini, background memodelkan seluruh dokumen latih model. Dari hasil klasifikasi terlihat bahwa tingkat akurasi NBC+ tidak banyak pengaruhnya dibandingkan dengan NBC. Peningkatan akurasi tersebut hanya sebesar 1.78% dari hasil yang diperoleh pada NBC. Untuk dapat menambah tingkat keakurasian perlu melibatkan keterkaitan antar kata atau Hasil klasifikasi dengan background dipengaruhi oleh nilai parameter yang disesuaikan dengan data terbaik yang diperoleh pada ng pada domain klasifikasi dokumen yang digunakan sebagai . Hasil pengukuran klasifikasi pada dokumen bidang kajian pertanian untuk domain hortikultura menunjukkan bahwa nilai parameter koefisien adalah pada =0.3 dengan akurasi sebesar 89.3 % dan pada =0.7 dengan akurasi λ yang kecil training yang short query. Sebaliknya dibutuhkan nilai λ yang lebih
Pada penelitian selanjutnya metode perlu diujikan pada domain pertanian