Fakultas Ilmu Komputer
Universitas Brawijaya
8772
Klasifikasi Video
Clickbait
pada YouTube Berdasarkan Analisis Sentimen
Komentar Menggunakan
Learning Vector Quantization
(LVQ) dan
Lexicon-Based Features
Dwi Wahyu Puji Lestari1, Rizal Setya Perdana2, Putra Pandu Adikara3
Program Studi Teknik Informatika, Fakultas Ilmu Komputer, Universitas Brawijaya Email: 1[email protected], 2[email protected], 3[email protected]
Abstrak
Clickbait adalah suatu konten di media sosial yang bertujuan untuk menarik perhatian dan memikat pengunjung situs agar dapat mengunjungi konten mereka dengan cara membuat umpan klik yaitu berupa judul yang menarik atau provokatif tetapi dengan isi konten yang biasanya tidak sesuai. Hal tersebut membuat pengunjung situs merasa tertipu dan kecewa sehingga mereka biasanya melampiaskan rasa kesalnya dengan menuliskan komentar atau opini (dokumen, kata, kalimat) yang bersifat positif ataupun negatif. Dokumen teks yang digunakan pada penelitian ini berasal dari komentar YouTube yang berkaitan dengan konten clickbait dan non clickbait yang berbahasa Indonesia. Penelitian ini menggunakan metode Learning Vector Quantization (LVQ) dan Lexicon-Based Features sebagai pembobotan kata selain menggunakan TF-IDF. Data yang digunakan pada penelitian ini sejumlah 300 data yang terdiri dari dua jenis data yaitu data latih dan data uji dengan perbandingan 70% data latih dan 30% data uji. Akurasi sistem yang diperoleh dari hasil klasifikasi dengan metode Learning Vector Quantization tanpa Lexicon-Based Features sebesar 54,54%, precision sebesar 1, recall sebesar 0,1667, dan f-measure sebesar 0,2858. Hasil akurasi sistem dengan menggunakan Learning Vector Quantization
dan Lexicon-Based Features sebesar 90,91%, precision sebesar 0,8571, recall sebesar 1, dan f-measure
sebesar 0,9231 sehingga dapat disimpulkan bahwa metode Learning Vector Quantization dan Lexicon-Based Features dapat digunakan untuk klasifikasi sentimen.
Kata kunci: klasifikasi, video clickbait, YouTube, analisis sentimen, Learning Vector Quantization, Lexicon-Based Features
Abstract
Clickbait is social media content that aims to attract website visitors in order to visit their content by creating clickbait in form of appealing or provoking title but with irrelevant content. It makes the visitor decieved and disappointed, so they usually vent their frustation by writing their positive or negative opinion on the comment section. The document that is used in the research comes from YouTube comments that is related with Indonesian clickbait and non-clickbait content. This research used Learning Vector Quantization (LVQ) method and Lexicon-Based Features as word weighting other than using TF-IDF. This research uses 300 data consisting 2 type of data, training and testing data with the ratio of 70% training data and 30% testing data. The accuracy of the system that is obtained by classification using LVQ without Lexicon-Based Features is 54.54%, 1 precission, 0.1667 recall and 0.2858 f-measure. The result of the accuracy of the system using LVQ and Lexicon-Based Features is 90.91%, 0.8571 precission, 1 recall, and 0.9231 f-measure. The conclution is that LVQ method and Lexicon-Based Features can be used for sentiment classification.
Keywords: classification, clickbait video, YouTube, sentiment analysis, Learning Vector Quantization, Lexicon-Based Features
1. PENDAHULUAN
Berdasarkan data dari lembaga riset pasar e-Marketer, Indonesia berada pada peringkat
Komunikasi dan informatika, 2014). Menurut survei yang dilakukan oleh Asosiasi Penyelenggara Jasa Internet Indonesia (APJII) pada tahun 2016, YouTube1 merupakan media
sosial ketiga yang paling banyak dikunjungi oleh pengguna internet Indonesia setelah Instagram dan Facebook (Liputan6, 2016).
Semakin populernya media daring saat ini menjadi sebuah ajang perlombaan yang digunakan untuk mencari pendapatan tambahan. Seperti halnya clickbait yang sering kali dijumpai. Clickbait adalah konten di media daring yang bertujuan untuk menarik perhatian dan memikat pengunjung agar mengunjungi konten mereka. Clickbait memiliki ciri salah satunya yaitu dengan menciptakan judul eye catching yang berguna untuk menarik perhatian agar pengunjung mengekliknya, sehingga mereka akan menghasilkan pendapatan dari pengunjung yang sudah mengeklik tersebut (Agrawal, 2016). Hal ini mengakibatkan pengunjung merasa kecewa dan kesal sehingga mereka biasanya melampiaskan rasa kesalnya dengan mengisi kolom komentar. Komentar-komentar tersebut adalah sumber informasi yang dapat digunakan untuk mengelompokkan opini pengunjung yang berupa teks.
Agar dapat mengetahui video YouTube yang termasuk clickbait berdasarkan komentar pengguna, maka diperlukan suatu analisis sentimen pada komentar-komentar YouTube yang berkaitan dengan clickbait dan non-clickbait. Penelitian yang terkait dengan analisis sentimen pada sosial media YouTube yaitu yang dilakukan oleh Al-Tamimi, Shatnawi dan Bani-Issa (2017) yaitu analisis sentimen komentar berbahasa Arab pada YouTube. Pada penelitian ini menggunakan metode Support Vector Machine (SVM) dengan Radial Bases Function
(RBF), K-Nearest Neighbor (KNN) dan klasifikasi Naïve Bayes Bernoulli dengan nilai f-measure terbaik mencapai 88% dengan menggunakan SVM-RBF.
Dalam hal ini clickbait memiliki pengaruh yang sangat negatif terhadap pengunjung situs
web. Oleh karena itu, terdapat penelitian yang berkaitan dengan deteksi clickbait dan non-clickbait. Penelitian yang dilakukan oleh Chakraborty,et al., (2016) yaitu mendeteksi dan mencegah clickbait pada berita daring. Penelitian ini membandingkan tiga metode untuk mendeteksi clickbait yaitu metode Support Vector Machine (SVM), Decision Tree, dan
1 https://www.youtube.com/
Random Forest. Dari perbandingan metode-metode tersebut dengan menggunakan metode-metode SVM dapat memperoleh nilai akurasi tertinggi yaitu 93%.
Berdasarkan penelitian yang dilakukan oleh Hadnanto (1996 yang disitasi dalam Hariri, et al., 2015 p.129) algortime LVQ memiliki tingkat akurasi yang tinggi dalam klasifikasi dan waktu komputasinya cepat, sehingga penelitian ini membahas mengenai klasifikasi video clickbait pada YouTube berdasarkan analisis sentimen komentar menggunakan Learning Vector Quantization (LVQ) dan menggunkan Lexicon-Based Features karena fitur ini memiliki peranan yang sangat penting dalam analisis sentimen (Siddiqua, Ahsan dan Chy, 2016).
2. METODE USULAN
Klasifikasi video clickbait pada YouTube berdasarkan analisis sentimen komentar menggunakan Learning Vector Quantization
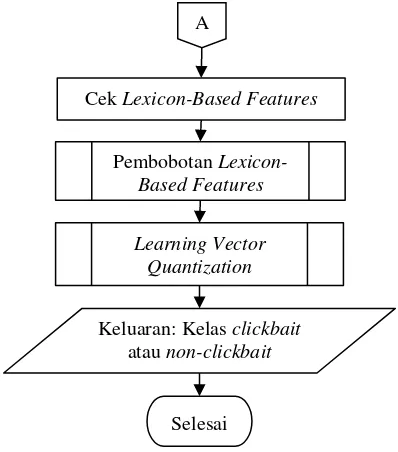
Gambar 1. Diagram Alir Sistem
2.1. Pre–processing
Tahap awal yang dilakukan dalam proses
text mining adalah pre–processing. Tahap ini digunakan untuk tujuan mengubah data yang tidak terstruktur menjadi data yang terstruktur (Pabeta, 2016). Pre–processing memiliki beberapa tahapan yaitu:
1. Tokenisasi 2. Case folding
3. Filtering 4. Stemming
2.2. Pembobotan Kata
Pemberian bobot pada setiap kata yang
muncul yang terdapat pada suatu dokumen
teks adalah tujuan dari pembobotan kata.
Pembobotan kata mempunyai
tahapan-tahapan yang dilakukan:
1. Term Frequency (TF) 2. Document Frequency (DF)
3. Inverse Document Frequency (IDF)
4. Term Frequency – Inverse Document Frequency (TF-IDF)
2.3. Pembobotan Lexicon-Based Features
Setelah tahap pembobotan kata, tahap selanjutnya yang dilakukan adalah pembobotan
lexicon-based features. Lexicon adalah kumpulan kosakata atau istilah yang sudah diketahui dan terkumpul (Desai dan Mehta, 2016). Pembobotan lexicon-based features
digunakan untuk memberikan bobot positif atau
negatif pada setiap fitur kata yang muncul berdasarkan lexicon atau kamus yang menyimpan kata-kata yang bersentimen positif dan negatif.
2.4. Learning Vector Quantization (LVQ)
Tahap selanjutnya yang dilakukan adalah proses klasifikasi dengan algoritme Learning Vector Quantization (LVQ). LVQ adalah salah satu dari beberapa algoritme yang ada di Jaringan Saraf Tiruan (JST). Algoritme LVQ adalah suatu algoritme pelatihan yang menerapkan pembelajaran secara terawasi (supervised learning) dan jaringannya memiliki layer tunggal (single layer). Pengklasifikasian vektor-vektor inputan akan secara otomatis dilakukan oleh lapisan kompetitif dengan cara pembelajaran. Lapisan kompetitif tersebut akan menghasilkan kelas-kelas yang tergantung pada jarak antara vektor-vektor inputan. Jika terdapat dua vektor input yang mendekati sama, maka kedua vektor input tersebut akan diletakkan ke dalam kelas yang sama oleh lapisan kompetitif (Hamidi, Furqon dan Rahayudi, 2017).
Langkah-langkah pelatihan algoritme LVQ adalah sebagai berikut (Fausett, 1994):
1. Inisialisasi nilai learning rate (α), pengurangan learning rate (dec α), α minimum (minimal learning rate yang diperoleh), iterasi maksimum (MaxEpoch) dan bobot awal.
2. Inisialisasi iterasi awal = 0.
3. Lakukan a sampai c bila epoch < MaxEpoch
atau α > α minimum.
a. Lakukan penambahan nilai iterasi. Rumus perhitungan iterasi ditunjukkan pada Persamaan (1).
𝑒𝑝𝑜𝑐ℎ = 𝑒𝑝𝑜𝑐ℎ + 1 (1) b. Lakukan langkah i sampai iii untuk
semua vektor masukan pada 𝓍 indeks ke
𝑖 = 1 sampai 𝑛.
i. Hitung jarak antara data dengan bobot awal setiap kelas dengan Persamaan (2).
𝐷(𝑗) = √∑ (𝑥𝑛𝑖=1 𝑖− 𝑤𝑖,𝑗)2 (2)
ii.Tentukan nilai minimal dari setiap jarak kelas sehingga menjadi keluaran Cj.
iii.Perbarui bobot Wjdengan rumus berikut:
- Jika T = Cj, maka gunakan
Persamaan (3).
𝑊𝑗(𝑏𝑎𝑟𝑢) = 𝑊𝑗(𝑙𝑎𝑚𝑎) +
𝛼(𝑥 − 𝑊𝑗(𝑙𝑎𝑚𝑎) (3)
Cek Lexicon-Based Features
Pembobotan Lexicon-Based Features
Learning Vector Quantization
Keluaran: Kelas clickbait atau non-clickbait
- Jika T ≠ Cj, maka gunakan Persamaan
(4).
𝑊𝑗(𝑏𝑎𝑟𝑢) = 𝑊𝑗(𝑙𝑎𝑚𝑎) − 𝛼(𝑥 −
𝑊𝑗(𝑙𝑎𝑚𝑎)) (4)
c. Kurangi α dengan Persamaan (5).
𝛼 (𝑏𝑎𝑟𝑢) = 𝛼 × 𝑑𝑒𝑐 𝛼 (5) Keterangan tata nama (Fausett, 1994):
• x = vektor pelatihan.
• T = kategori atau kelas yang benar untuk vektor pelatihan.
• Wj = vektor berat untuk unit keluaran ke-j.
• Cj = kategori atau kelas yang ditunjukkan
oleh unit keluaran ke-j.
• || x-wj || = jarak Euclidean antara vektor
masukan dan vektor bobot untuk unit keluaran ke-j.
3. HASIL DAN PEMBAHASAN
Penelitian ini menggunakan empat jenis pengujian yang dilakukan yaitu pengujian pengaruh parameter LVQ yang berupa pengaruh nilai learning rate, nilai decrement alfa (decα), nilai maksimum epoch (iterasi), dan pengujian pengaruh lexicon-based features.
3.1. Pengujian Pengaruh Learning Rate
Pada pengujian ini terlebih dahulu menentukan parameter awal yang digunakan untuk indikator awal pengujian yaitu nilai decα = 0,1, maksimum epoch = 50 dan 10 jenis nilai
learning rate. Hasil pengujian ditunjukkan pada Gambar 2.
Gambar 2. Pengujian Pengaruh Learning Rate
Nilai akurasi terbaik yang didapat berdasarkan grafik pada Gambar 2 yang diperoleh dari 10 kali percobaan adalah 90,91%. Pada grafik tersebut menunjukkan bahwa akurasi terbaik didapat pada nilai learning rate
sebesar 10-2 dan mengalami penurunan yang
selanjutnya stabil sampai nilai 10-9.
3.2. Pengujian Pengaruh Decrement Alfa
Parameter awal yang digunakan untuk pengujian ini adalah nilai learning rate = 0,1, maksimum epoch = 50 dan 10 jenis nilai decα. Hasil pengujian ditunjukkan pada Gambar 3.
Gambar 3. Pengujian Pengaruh Decrement α
Berdasarkan dari grafik pada Gambar 3 bahwa akurasi mengalami perubahan, semakin tinggi pengurangan learning rate maka akurasi sistem akan semakin buruk. Akurasi sistem stabil mulai dari nilai decα 10-1 sampai 10-9.
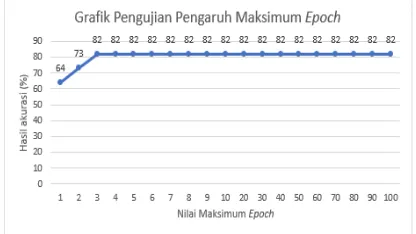
3.3. Pengujian Pengaruh Maksimum Epoch
Pengujian ini menggunakan parameter awal sebagai indikator awal pengujian yaitu nilai
learning rate = 0,1, nilai decα = 0,1 dan 20 kali percobaan yang dilakukan. Hasil percobaan ditunjukkan pada Gambar 4.
Gambar 4. Pengujian Pengaruh Maksimum Epoch
Nilai akurasi terbaik dihasilkan pada maksimum epoch sebesar 3 sampai 100 dengan nilai akurasi 82%. Pada grafik tersebut menunjukkan perubahan nilai akurasi pada
epoch 1 dan epoch 2, selanjutnya nilai akurasi sama yaitu mulai dari epoch 3 sampai 100 yang telah mencapai konvergen. Hal tersebut dikarenakan pengaruh nilai learning rate dan
kecil.
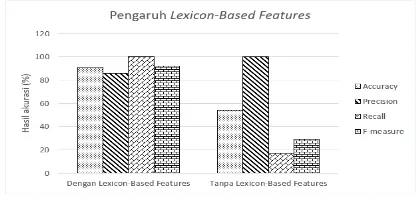
3.4. Pengujian Pengaruh Lexicon-Based Features
Pada pengujian kali ini yaitu menguji pengaruh Lexicon-Based Features terhadap hasil klasifikasi berdasarkan analisis sentimen dengan menggunakan Learning Vector Quantization
dan dilakukan perbandingan hasil akurasi sistem yang menggunakan Lexicon-Based Features dan tanpa menggunakan Lexicon-Based Features. Parameter yang digunakan pada pengujian ini menggunakan parameter yang telah digunakan pada pengujian sebelumnya yang telah mencapai optimal yaitu learning rate = 0,01, decα = 0,1 dan maksimum epoch = 50. Hasil pengujian pengaruh Lexicon-Based Features ditunjukkan pada Tabel 1 dan Gambar 5.
Tabel 1. Hasil Pengujian Pengaruh Lexicon-Based Features
F-Measure 0,9231 0,2858
Berdasarkan hasil pengujian yang ditunjukkan pada Gambar 5 menunjukkan bahwa hasil nilai akurasi sistem dengan menggunakan Lexicon-Based Features sangat bagus yaitu sebesar 90,91%, precision sebesar 0,8571, recall sebesar 1, dan f-measure sebesar 0,9231 sedangkan hasil akurasi sistem tanpa menggunakan Lexicon-Based Features yaitu sebesar 54,54%, precision sebesar 1, recall
sebesar 0,1667, dan f-measure 0,2858. Hal ini
menunjukkan bahwa Lexicon-Based Features
cocok digunakan untuk klasifikasi berdasarkan analisis sentimen. Perbandingan antara nilai akurasi sistem yang menggunakan Lexicon-Based Features dan tanpa menggunakan
Lexicon-Based Features sangatlah signifikan, namun hasil klasifikasi yang diperoleh pada Tabel 2 menunjukkan bahwa masih terdapat kesalahan dalam analisis sentimen karena terdapat kata yang seharusnya bersentimen positif tetapi masuk ke dalam sentimen negatif sehingga sistem salah dalam mengklasifikasi
.
Gambar 5. Pengujian Pengaruh Lexicon-Based Features
4. KESIMPULAN
Berdasarkan dari hasil pengujian sistem klasifikasi video clickbait pada YouTube berdasarkan analisis sentimen komentar menggunakan Learning Vector Quantization
dan Lexicon-Based Features dapat disimpulkan bahwa algoritme Learning Vector Quantization
dapat digunakankan pada klasifikasi video
clickbait pada YouTube berdasarkan analisis sentimen komentar dengan hasil klasifikasi
clickbait atau non-clickbait. Penelitian ini menggunakan data teks yang diperoleh dari YouTube Data API v3. Jumlah data yang digunakan sebanyak 300 data yang dibagi menjadi data latih dan data uji dengan perbandingan 70%:30.
Tabel 2. Hasil Klasifikasi
No Video Sebenarnya Prediksi
Positif Negatif Kelas Positif Negatif Kelas
Pembobotan Lexicon-Based Features sangat berpengaruh untuk analisis sentimen pada penelitian ini. Tingkat akurasi sistem lebih tinggi dibandingkan dengan analisis sentimen tanpa menggunakan Lexicon-Based Features, namun masih terdapat kesalahan dalam analisis sentimen.
Pada penelitian klasifikasi video clickbait
pada YouTube berdasarkan analisis sentimen komentar menggunakan Learning Vector Quantization (LVQ) dan Lexicon-Based Features menghasilkan nilai accuracy 90,91%,
precision sebesar 0,8571, recall sebesar 1 dan F-measure sebesar 0,9231. Hal ini membuktikan bahwa klasifikasi dengan metode Learning Vector Quantization dan Lexicon-Based Features baik digunakan untuk klasifikasi video berdasarkan analisis sentimen.
5. DAFTAR PUSTAKA
Agrawal, A., 2016. Clickbait Detection using Deep Learning. In: 2016 2nd International Conference on Next Generation Computing Technologies (NGCT-2016). [daring] Dehradun: IEEE, hal.268–272. Tersedia pada: <http://ieeexplore.ieee.org/document/787 7426/>.
Desai, M. dan Mehta, M.A., 2016. Techniques for Sentiment Analysis of Twitter Data: A Comprehensive Survey. In: International Conference on Computing, Communication and Automation (ICCCA2016). [daring] Noida: IEEE, hal.149–154. Tersedia pada: <http://ieeexplore.ieee.org/document/781 3707/>.
Fausett, L., 1994. Fundamental of Neural Network: Architectures, Algorithms, and Apllication.
Hamidi, R., Furqon, M.T. dan Rahayudi, B., 2017. Implementasi Learning Vector Quantization ( LVQ ) untuk Klasifikasi Kualitas Air Sungai. Jurnal Pengembangan Teknologi Informasi dan Ilmu Komputer, [daring] 1(12), hal.1758– 1763. Tersedia pada: <http://j-
ptiik.ub.ac.id/index.php/j-ptiik/article/view/635>.
Kementerian Komunikasi dan informatika, 2014. Kominfo : Pengguna Internet di
Indonesia 63 Juta Orang. [daring]
Tersedia pada:
<https://www.kominfo.go.id/content/deta il/3415/Kominfo+%3A+Pengguna+Inter net+di+Indonesia+63+Juta+Orang+/0/ber ita_satker> [Diakses 4 Jan 2018].
Kementerian Komunikasi dan Informatika, 2014. Pengguna Internet Indonesia Nomor Enam Dunia. [daring] Kementerian Komunikasi dan Informatika. Tersedia pada: <https://www.kominfo.go.id/content/deta il/4286/pengguna-internet-indonesia-nomor-enam-dunia/0/sorotan_media> [Diakses 4 Jan 2018].
Liputan6, 2016. Media Sosial Favorit Pengguna internet Indonesia. [daring] Tersedia pada:
<http://tekno.liputan6.com/read/2634027/
3-media-sosial-favorit-pengguna-internet-indonesia> [Diakses 4 Jan 2018]. Pabeta, H.A.M., 2016. Klasifikasi Konten Berita Menggunakan Metode Naive Bayes dan K-Nearest Neighbor. [daring] Bandung: Universitas Widyatama. Tersedia pada: <https://repository.widyatama.ac.id/xmlu i/handle/123456789/8416>.