OPTIMASI PARAMETER PADA KLASIFIKASI FUZZY ARTMAP
BERBOBOT BERBASIS ALGORITMA GENETIKA
Bain Khusnul Khotimah1*, Agus Zainal Arifin2, Anny Yuniarti3
Pascasarjana Teknik Informatika, Fakultas Teknologi Informasi ITS, Surabaya Indonesia1*, email: [email protected]
Pascasarjana Teknik Informatika, Fakultas Teknologi Informasi ITS, Surabaya, Indonesia2, 3
ABSTRAK
Klasifikasi menggunakan fuzzy ARTMAP berbobot adalah metode baru dalam klasifikasi yang diperoleh dengan mengkombinasikan simplified fuzzy ARTMAP dan symmetric fuzzy ART ditambah pembobotan feromon sesuai konsep koloni semut. Metode ini memiliki kelebihan dalam hal efisiensi dan toleran dalam mencari kedekatan kelas serta menyesuaikan node output dengan pola. Kelemahan metode ini sangat dipengaruhi estimasi parameter significant pada saat melakukan training sehingga mempengaruhi kinerja classifier. Untuk mengatasi masalah tersebut perlu dilakukan pemilihan parameter yang signifikant yang sangat berpengaruh dalam meningkatkan nilai akurasi pada klasifikasi. Penelitian ini melakukan optimasi parameter pada klasifikasi fuzzy ARTMAP berbobot menggunakan algoritma genetika atau disebut GA-FAMB. Algoritma ini melakukan pencarian parameter dengan menentukan pembobotan pheromon, pembobotan likenessIntensity dan nilai batas vigilance untuk mendapatkan hasil akurasi yang optimal. Pada algoritma genetika mampu mendapatkan nilai parameter optimal secara otomatis pada klasifikasi FAMB dengan tingkat akurasi yang lebih tinggi untuk set data uci repository menghasilkan ± 92%, sedangkan dengan menggunakan algoritma grid search yang digunakan sebagai algoritma pembanding menghasilkan nilai akurasi ± 88%.
kata kunci : fuzzy ARTMAP, simplified fuzzy ARTMAP, symmetric fuzzy ART, fuzzy ARTMAP berbobot, algoritma genetika , algoritma grid search
1. Pendahuluan
Klasifikasi adalah suatu kegiatan
menggolongkan sebuah obyek ke kategori atau kelas tertentu. Proses klasifikasi dilakukan dengan menggunakan model klasifikasi. Sebuah obyek yang belum diketahui kelasnya diprediksi kelasnya berdasarkan model klasifikasi dengan menyesuaikan nilai attribut-attribut atau fitur-fiturnya (Pang Ning Tang, 2005)..
Saat ini terdapat banyak algoritma
pembelajaran untuk membangun model
klasifikasi seperti Adaptive Resonance Theory
(ART) merupakan jenis klasifikasi baru dari
neural network (Grossberg, 1976). ART
dikembangkan menjadi ART-1 untuk
mengkluster data biner (Grossberg, 1987).. Selanjutnya dilakukan ART-2 yang mempunyai
kelemahan dalam proses searching dimana
seluruh output neuron uncummited. Kelemahan
ART dapat diperbaiki menggunakan fuzzy
ARTMAP dengan cara mengkonversi searching
problem menuju optimization problem (Baraldi,
2002).
Fuzzy ARTMAP diperoleh dengan
mengkombinasikan antara simplified fuzzy
ARTMAP dan symmetric fuzzy ART yang
mempunyai fungsi aktifasi dan fungsi mach
yang terpengaruh jumlah data di dalam node,
hal ini menimbulkan ketidakadilan terhadap
node yang memiliki jumlah pattern lebih
banyak. Untuk mengatasi masalah tersebut dilakukan modifikasi pembobotan dengan menambahkan konsep algoritma koloni semut
pada fuzzy ARTMAP sehingga disebut FAM
berbobot atau fuzzy ARTMAP berbobot.
Prinsip algoritma ini mirip dengan
penyelesaian kasus terpendek dimana setiap semut akan mengikuti jalan yang mengandung
jumlah pheromon lebih banyak dibanding
lainnya. Semakin dekat jalur yang dilalui semut maka semut yang lewat akan semakin
banyak dan jejak pheromon yang ditinggalkan
juga semakin banyak, begitu juga sebaliknya.
Sehingga cluster node yang dihasilkan akan
menyesuaikan dengan jumlah pattern dan
dapat menampung pattern lebih banyak
(Darlis, 2009).
Kelemahan metode fuzzy ARTMAP
berbobot optimization problem sangat
dipengaruhi oleh inisialisasi parameter pada
saat training yang mempengaruhi hasil
melakukan estimasi parameter dengan
menggunakan algoritma genetika yang
tujuannya dapat meningkatkan kinerja pada
classifier. Algoritma genetika sangat baik untuk menyelesaikan permasalahan optimasi dan
melakukan search point dengan mencari pola
baru yang diharapkan memiliki nilai fitness
yang lebih baik dari seluruh kromosom dan
dapat meningkatkan kinerja pada classifier
(Limai, 2009). Dalam melakukan estimasi
parameter pada klasifikasi fuzzy ARTMAP
berbobot menggunakan algoritma genetika atau
disebut metode GA-FAMB dibandingkan
dengan algoritma grid search yang disebut
GS-FAMB. Algoritma grid search yaitu salah satu
algoritma umum yang sering digunakan untuk estimasi parameter, dengan prinsip kerjanya dengan menentukan beberapa nilai parameter pada rentang tertentu, kemudian memilih parameter pada nilai terbaik pada rentang tersebut dan melakukan pencarian berulang
pada grid (rentang nilai) yang lebih kecil, dst.
Kelemahan algoritma ini pada pencarian grid
yang terlalu kecil dapat mengakibatkan
overfitting.
2 Tinjauan Pustaka
2.1 Simplified Fuzzy ARTMAP (SFAM)
SFAM pada dasarnya merupakan sequential
counterpart dari parallel fuzzy ARTMAP yaitu dengan menyederhanakan algoritma dengan
hasil yang sama. Sebagai classifier, network
training digunakan untuk mencari himpunan
template yang berupa hiperrectangle yang
mengelompokkan/mengklasifikasikan dari suatu pola sedemikan rupa sehingga mampu memberi Gambaran terbaik tentang data anggota yang ada didalamnya [3]. Misalkan himpunan
templateW = {w1, w2, …, wC} dan jumlah pola
dari X yang sesuai dengan setiap template N
={N1, N2, …, NC}. Yang perlu dicatat bahwa
jumlah output node, himpunan W dan N akan
bertambah (growing) secara dinamis. Tiga
fungsi utama Algoritma SFAM adalah fungsi T
(), M () and U (). Sedangkan NEWNODE(new)
dalam algoritma tersebut adalah sebuah macro
routine yang mengalokasikan new node
(template) untuk network, yaitu T (x, w) disebut
sebagai choice function atau activation function,
yang digunakan untuk mengukur derajat dari
resemblance dari x dengan w.
wj w x w x T j j
) , ( (2.1)Dimana a adalah choice parameter, a > 0
M( x, wj) disebut match function, yang
digunakan untuk menentukan seberapa jauh
kesamaan wj dengan x. x w x w x M j j ) , ( (2.2)
Fungsi ini digunakan sebagai conjunction
untuk vigilance parameter
0
,
1
, dimana
x wj
M , yang berarti resonansi.
Vigilance merupakan parameter network
terpenting untuk menentukan resolusinya :
larger vigilance value normally yields larger number dari output nodes dan presisi yang bagus.
U ( x, wj) disebut update function, yang
digunakan untuk mengupdate sebuah template setelah resonansi dengan sebuah pola:
U(x,wj)(1)wj (x wj) (2.3)
dimana
adalah learning rate,0
1
.Nilai yang lebih tinggi dari
dihasilkandalam faster learning. Disebut sebagai fast
learning dalam ART ketika
= 1.Operator dalam persamaan (2.1) hingga
(2.2) adalah bitwise AND operator, yaitu a
b = (a1 AND b1, a2 AND b2, … acCAND bc) ,
dan|| a|| adalah dirumuskan sebagai berikut,
D i i a a 1 (2.4)2.2 Simmetric Fuzzy ART (S-Fuzzy ART)
ART-1 menggunakan inherently
nonsymmetrical architecture untuk
menghitung intrinsically symmetric fuzzy ART
(S-Fuzzy ART) yang mengadopsi symmetric
activation dan match function, yaitu
T(x,wj)=T(wj,x) dan T(x,wj)=M(x,wj) (Baraldi,
2002). Dua bentuk dari symmetric activation
dan match function adalah: 2 1 1 ) , ( ) , ( j j j w x w x M w x T (2.5) atau
D d D d d d D d d d j j w x w x w x M w x T 1 1 1 } , min{ ) , ( ) , ( (2.6)S-Fuzzy ART dapat diimplementasikan
menggunakan skema EART-2. Hal ini
daripada fuzzy ART dalam hal akurasi
klaterisasi dan robust terhadap perubahan dari
urutan representasi data. Setelah S-Fuzzy ART
menemukan tujuan awalnya, Andrew Baraldi dan Ethem Alpaydin mengusulkan group baru
dari ART networks yang disebut simplified
ART (SART), merupakan generalisasi dari
S-Fuzzy ART dan dapat diimplementasikan
menggunakan skema EART, GART dan
S-Fuzzy ART adalah dua contoh dari SART.
2. 3 Fuzzy ARTMAP Berbobot
Metode ini merupakan pengembangan dari
SFAM dan fuzzy ARTMAP yang mana
algoritma ini secara umum mengkombinasikan
antara fuzzy ARTMAP dan synmetric fuzzy
ART serta ditambah dengan pembobotan node
cluster berdasarkan jumlah pola dan size dari
node cluster tersebut. Ada beberapa hal yang
perlu diperhatikan dalam fuzzy ARTMAP
sebagai berikut dimana nilai fungsi dari aktifasi
T() dan match (M) pada suatu node output tidak
terpengaruh terhadap jumlah data yang ada
dalam node terxebut, dengan kata lain jika ada
dua node output yang memiliki bentuk dan
ukuran yang sama, tetapi memiliki jumlah
pattern yang ada tidak sama, maka nilai T() maka menimbulkan ketidakadilan terhadap node yang memiliki jumlah pattern yang lebih
banyak. Sehingga ide dasar fuzzy ARTMAP
berbobot adalah mencari bentuk formula baru dari T() dan M() yang merupakan hasil relaksasi
fungsi pada SFAM dan S-fuzzy ART dengan
mengalikan dengan parameter likenessintensity
(Li). Serta dijumlahkan dengan bobot pheromon
dengan maksud memberi nilai lebih besar pada
ukuran cluster node yang memiliki pattern lebih
banyak.
Proses pembobotan dalam algoritma ini
mengadopsi sistem pheromon dan peluruhannya
pada sistem koloni semut, dan penerapan jejak
pheromon pada metodeARTMAP terletak pada
seberapa pertambahan size (pola baru sudah didalam cluster). Jika tidak terjadi pertambahan
size (pola baru sudah didalam cluster) maka
tingkat kepekatan pheromon dalam node
tersebut semakin besar walaupun terjadi peluruhan karena waktu. Akan tetapi, jika pola
baru menyebabkan ukuran cluster node
bertambah besar, maka tingkat
peluruhan/evaporasi kepekatan pheromon juga
semakin besar karena harus disebar ke ruang
baru sehingga tingkat kepekatan pheromon
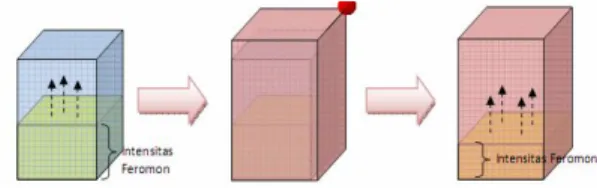
menjadi berkurang [2]. Ilustrasi dari perubahan
kepekatan pheromon seperti ditunjukkan pada
Gambar 2.1.
Gambar 2.1. Size cluster node bertambah
karena beresonansi dengan pola baru
Dari ilustrasi Gambar 2.1, jejak pheromon
dapat ditulis dengan persamaan :
) 1 ( ) ( t w t w r j j (2.1)
( ( () ( ())) ( 1) || ( 1)|| ) 1 ( 1)
1
(
tr t if t w t else t w j j j j j jt
(2.2) Dimana :r =ratio pertambahan size cluster node baru
dengan size clusternode lama.
= constant pheromon yang ditinggalkansetiap terjadi update clusternode.
=constant evaporasi/peluruhan setiap terjadiupdate clusternode.
) 1 (t j
= jejak pheromon jika terjadi
resonansi antara pola dengan node output.
Pengembangan lainnya dari algoritma SFAM ini dengan menggabung antara nilai yang dihasilkan dari T() dan M() pada persamaan
dengan nilai dari symmetric fuzzy ARTMAP,
dimana T() dan M() berbobot ditunjukkan pada persamaan berikut ini:
2 1 1 * * ) 1 ( ) , ( j j j j i w x w n w x w x T (2.7) j j j j j i w x w w x w x M 2 1 1 * * ) 1 ( ) , ( (2.8)
Dimana nilai
adalah bobot kesimetrisanyang jika nilainya
1berarti sama denganpersamaan fuzzy ARTMAP ditambah
pembobotan dan jika nilai
0maka prinsip3. Optimasi parameter menggunakan Algoritma Genetika
Algoritma genetika atau GA (Genetic Algorithm) adalah jenis nonpolynomial (NP) Secara khusus dapat di terapkan untuk memecahkan masalah optimasi yang kompleks, sehingga baik untuk aplikasi yang memerlukan startegi pemecahan masalah secara adaptif. Penggunaan algoritma ini secara inheren paralel, karena pencarian pemecahan yang terbaik dilakukan melalui struktur genetik yang
menyatakan sejumlah kemungkinan
penyelesaian (Godberg, 1989).
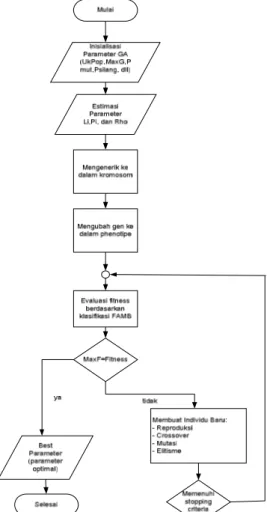
Diagram alir optimasi parameter dengan menggunakan algoritma genetika ditunjukkan pada Gambar 3.1
Gambar 3.1. Optimasi parameter menggunakan algoritma genetika
3.1 Inisialisasi Parameter
Sebelum menganalisa fitness, maka perlu
menganalisa parameter yang berpengaruh
terhadap classifier diantaranya analisa fungsi
pada metode fuzzy ARTMAP berbobot
diantaranya RHO= vigilance untuk tingkat
resonansi pada saat learning , PI =
PheromonIntensity untuk pembobotan nilai
bias, dan LI = LikenessIntensity untuk
menentukan kisimetrisan yang menentukan
jumlah node cluster yang terbentuk.
3.2Fitness Function
Kromosom pada individu mewakili
parameter fungsi fuzzy ARTMAP untuk
menghasilkan nilai fitness. Nilai fitness
dihitung pada setiap populasi kromosom dan diambil nilai fitness tertinggi pada setiap populasi [4]. Fitness yang digunakan untuk mengukur performansi klasifikasi.
fitness = accuracy klasifikasi (3.1)
3.3 Desain Kromosom
Algoritma genetika digunakan untuk
menentukan estimasi parameter yang
tujuannya untuk meningkatkan akurasi
klasifikasi. Pendekatan fitur diperoleh dari hasil ekstraksi fitur dan hasil analisa parameter
fungsi fuzzy ARTMAP berbobot yang terdiri
dari parameter
=vigilance (Rho), Pi =pheromonintensity dan Li = likenessintensity.
Nilai minimum dan maksimum pada parameter
dibatasi oleh user. Kromosom gen
diilustrasikan pada Gambar 3.2 dan dinyatakan
dalam bit string dengan ghenotype yang
disimbolkan n g g1 ~ menyatakan nilai
parameter vigilance, npi
pi pi g g1 ~ menyatakan nilai parameter pi, nli li li g g1 ~ menyatakan parameter li.
Gambar 3.2 desain kromosom pada inisialisasi parameter Rho, Pi dan Li
Proses pengubahan ghenotype menjadi
phenotype dinyatakan sebagai berikut:
xd p p pl p 1 2 min max min (3.2) dimana :
p = phenotype pada bit string
minp= nilai minimum pada parameter
maxp= nilai maksimum pada
parameter
d = nilai desimal pada bit string l = panjang bit string
3.4. Pindah Silang (Crossover)
Pindah silang bisa juga berakibat buruk jika ukuran populasinya sangat kecil. Dalam suatu populasi yang sangat kecil, suatu kromosom dengan gen-gen yang mengarah ke solusi akan
sangat cepat menyebar ke
kromosom-kromosom lainnya. Untuk mengatasi masalah ini digunakan suatu aturan bahwa pindah silang hanya bisa dilakukan dengan suatu probabilitas
tertentu Pc. Artinya pindah silang bisa
dilakukan hanya jika suatu bilangan random
(0,1) yang dibangkitkan kurang dari Pc yang
ditentukan. Peluang crossover yang digunakan
adalah 0.9. Pindah silang bisa dilakukan dalam beberapa cara berbeda. Pindah silang yang digunakan adalah pindah silang satu titik potong (one-point crossover). Suatu titik potong dipilih secara random, kemudian bagian pertama dari orang tua 1 digabungkan dengan bagian kedua dari orang tua 2 (Utami, 2008).
3.5. Mutasi
Mutasi digunakan untuk memperkenal-kan beberapa penyebaran tiruan dalam populasi untuk mencegah konvergensi dini pada titik optimum lokal. Prosedur mutasi sangatlah sederhana dan untuk semua gen yang ada jika bilangan random yang dibangkitkan kurang dari
probabilitas mutasi Pmut yang ditentukan maka
ubah gen tersebut menjadi nilai kebalikannya (dalam binary encoding, 0 diubah 1, dan 1
diubah 0). Besarnya Pmut diset sebagai 1/n, di
mana n adalah jumlah gen dalam kromosom.
Dengan Pmut sebesar ini berarti mutasi hanya
terjadi sekitar satu gen saja (Utami, 2008)..
3.7. Elitisme
Karena seleksi dilakukan secara random, maka tidak ada jaminan bahwa suatu individu bernilai fitness tertinggi akan selalu terpilih. Kalaupun individu bernilai fitness tertinggi terpilih, mungkin saja individu tersebut akan rusak (nilai fitnessnya menurun) karena proses pindah silang. Untuk menjaga agar individu bernilai fitness tertinggi tersebut tidak hilang selama evolusi, maka perlu dibuat satu atau beberapa kopinya. Prosedur ini dikenal sebagai
elitisme (Utami, 2008).
Tabel 1.Karakteristik data set UCI repository
Set Data Jumlah
Sample Jumlah Attribut Jumlah Kelas Wine Ionosphere Sonar WBCD 178 155 208 351 13 34 60 10 3 2 2 2
IV. Uji Coba dan Hasil Penelitian 4.1 Data Dan Skenario Uji Coba
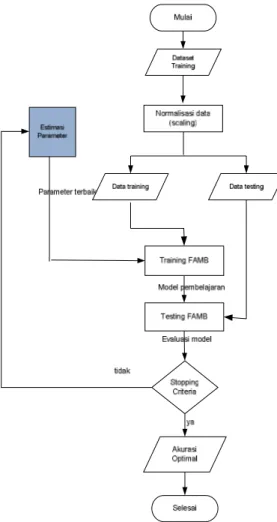
Tahapan klasifikasi dilakukan pelatihan (training) untuk mendapatkan pemodelan, sedangkan tahapan testing untuk mengukur pemodelan yang menghasilkan akurasi. Hasil akhir dari proses pengklasifikasian menggunakan metode fuzzy ARTMAP berbobot, dilakukan analisis terhadap hasil akurasi, serta dilakukan uji performansi k-folds cross-validation untuk membandingkan antara hasil yang dicapai oleh metode FAMB berbasis GA atau GA-FAMB dan FAMB berbasis Grid Search atau disebut GS-FAMB. Sedangkan diagram alur estimasi parameter ditunjukkan pada Gambar 4.1. Uji coba yang dilakukan pada penelitian ini menggunakan 4 dataset UCI repository yang terdiri data wine, sonar, WBCD, dan ionosphere. Uji coba dilakukan pada sebagian set data UCI machine learning repository pada Tabel 1. Data tersebut didapat di alamat
http://www.ics.uci.edu/~mlearn-/databases.
Algoritma genetika digunakan untuk
mendapatkan parameter terbaik yang
digunakan untuk training menghasilkan
pemodelan. Sedangkan algoritma grid search ditunjukkan pada Gambar 4.2. Prinsip GS yaitu memilih parameter terbaik dengan menentukan nilai parameter pada rentang
tertentu untuk setiap parameter untuk
menghitung performansi dengan k-fold cross
validation, kemudian pilih nilai terbaik.
Selanjutnya lakukan pencarian ulang pada grid (rentang nilai) yang lebih kecil. Kelemahan dari metode ini melakukan pencarian pada grid yang terlalu kecil yang mengakibatkan
overfitting.
4.2 Hasil Penelitian
Hasil uji coba ditunjukkan pada Tabel 1. menunjukkan hasil uji coba pembelajaran data set WBCD, nilai fitness tertinggi maksimal sebanding nilai akurasi training yang diperoleh pada fold1 dan fold 5. Berdasarkan uji coba pada Gambar 4.1 maka nilai fitness diperoleh dari nilai akurasi training klasifikasi fuzzy ARTMAP berbobot pada fold 1. Uji coba dilakukan hingga mencapai n iterasi yang sama sampai memperoleh nilai fitness tertinggi dan nilai sama untuk setiap iterasi yaitu kondisi konvergen (Godberg, 1989).
Gambar 4.1 Sistem arsitektur algoritma genetika pada optimasi parameter klasifikasi fuzzy berbobot
Gambar 4.2 Estimasi parameter dengan algoritma Grid Search
Tabel 4.2. Hasil uji coba data set WBCD menggunakan algoritma genetika
Uji ke- Sensitifitas Spesifisitas Akurasi Fitness rho P I
1 100 91.6667 97.1014 100 0.2416 0.0415 0.4417 2 97.7778 100 98.5507 99.8371 0.0061 0.0175 0.2149 3 97.7778 95.8333 97.1014 99.5114 0.1982 0.0131 0.4809 4 98.0456 100 98.5507 99.8371 0 .3067 0.3755 0.6626 5 97.7273 95.8333 97.0588 100 0.0544 0.0025 0.1661 6 97.7273 95.8333 97.0588 99.8374 0.0258 0.0109 0.178 7 95.4545 95.8333 96.1882 99.8374 0.0643 0.0236 0.2612 8 97.7273 95.8333 97.0588 99.5122 0.2401 0.0396 0.332 9 95.4545 100 97.0588 99.6748 0.0533 0.004 0.2382 10 100 91.3043 97.0149 99.6753 0.1935 0.0107 0.3403 Rata-rata 97.52134 96.21375 97.27425
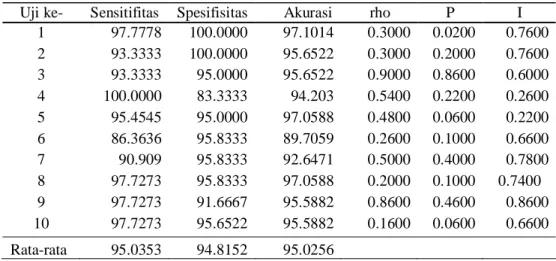
Tabel 4.3. Hasil uji coba data set WBCD menggunakan algoritma Grid Search
Uji ke- Sensitifitas Spesifisitas Akurasi rho P I
1 97.7778 100.0000 97.1014 0.3000 0.0200 0.7600 2 93.3333 100.0000 95.6522 0.3000 0.2000 0.7600 3 93.3333 95.0000 95.6522 0.9000 0.8600 0.6000 4 100.0000 83.3333 94.203 0.5400 0.2200 0.2600 5 95.4545 95.0000 97.0588 0.4800 0.0600 0.2200 6 86.3636 95.8333 89.7059 0.2600 0.1000 0.6600 7 90.909 95.8333 92.6471 0.5000 0.4000 0.7800 8 97.7273 95.8333 97.0588 0.2000 0.1000 0.7400 9 97.7273 91.6667 95.5882 0.8600 0.4600 0.8600 10 97.7273 95.6522 95.5882 0.1600 0.0600 0.6600 Rata-rata 95.0353 94.8152 95.0256
Pada Gambar 4.3 menunjukkan nilai ujicoba pada GA dari keempat data set. Pembelajaran dilakukan hingga konvergen dengan parameter yang berbeda untuk setiap data set menyesuaikan karakteristik data set yang digunakan. Pada wine maksimal generasi sebanyak 10, sonar sebanyak 50 generasi, WBCD dan ionosphere mencapai
100 generasi. Sedangkan perbandingan nilai iterasi ketika mencapai konvergen diperoleh pada data wine mulai iterasi 1 sampai 10 nilai konvergen, sonar pada itersi ke-14, WBCD pada iterasi ke-78 dan ionosphere pada iterasi ke-24. semakin banyak atribut dari data set semakin banyak iterasi yang dibutuhkan untuk mencapai konvergen.
Gambar 4.3 Perbandingan nilai fitness dengan generasi fold 1
Tabel 4.3 Rekapitulasi hasil uji coba ten fold cross validation
Dari rekapitulasi hasil uji coba yang ditunjukkan pada Tabel 4.3 dapat diketahui
bahwa metode GA-FAMB memiliki mean
selisih akurasi positif untuk seluruh 4 dataset
(wine, sonar, WBCD, dan ionosphere) mean
selisih akurasinya sigifikan pada confidence
level 95%. Dari 4 sisanya, pada 1 dataset
(ionosphere) signifikan pada confidence level
98%. Sedang pada dataset sonar mean
selisihnya tidak signifikan secara statistic
Keterangan Wine Sonar WBCD Ionos phere Rata-rata selisih akurasi (GA- FAMB)-(GS-FAMB) + + + + Fold GA-FAMB menang 7 6 7 7 Fold GA-FAMB seri 2 1 3 1 Fold GA-FAMB kalah 1 3 0 2 Significant pada tingkat kepercayaan 95% ya ya ya Tidak
ditunjukkan pada Gambar 4.5 dan Gambar 4.6.
Dari uji coba pembelajaran, dapat disimpulkan bahwa secara umum metode GA-FAMB memiliki akurasi yang lebih baik dari metode GS-FAMB pada parameter
optimal. Pada Gambar 4.4 grafik
menunjukkan rata-rata nilai akurasi metode GA-FAMB lebih tinggi dibandingkan metode GS-FAMB. Nilai akurasi tertinggi diperoleh pada data set WBCD sedangkan terendah pada akurasi data sonar.
wine sonar WBCD Ionosphere
GS 90.4 71.9 95.0 89.8 GA 93.9 76.4 97.5 93.7 0.0 20.0 40.0 60.0 80.0 100.0 120.0 A k u r a s i (% )
Gambar 4.4 Grafik perbandingan Nilai Akurasi Klasifikasi GA-FAMB vs GS-FAMB 60 65 70 75 80 85 90 95 100 1 2 3 4 5 6 7 8 9 10 A k u r a s i (% ) Fold
ke-Wine WBCD Ionosphere Sonar
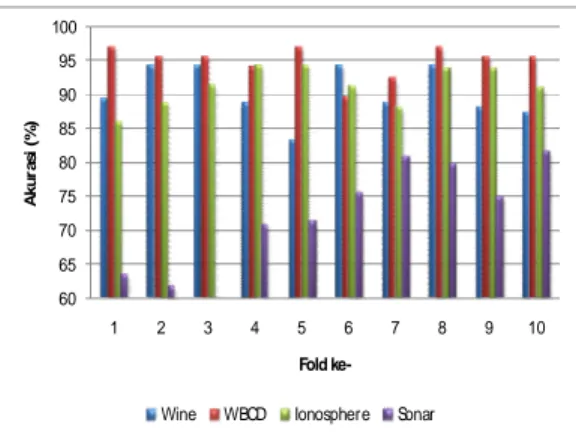
Gambar 4.5 Grafik Perbandingan Nilai Akurasi metode GA-FAMB
60 65 70 75 80 85 90 95 100 1 2 3 4 5 6 7 8 9 10 A k u ra si ( % ) Fold
ke-Wine WBCD Ionosphere Sonar
Gambar 4.6. Grafik Perbandingan Nilai Akurasi metode GS-FAMB
5. Kesimpulan
1. Algoritma genetika mampu mendapatkan
nilai parameter optimal secara otomatis dengan hasil yang lebih tinggi untuk set data wine sebesar 93.88%, sonar sebesar
76.35%, WBCD sebesar 97.51%,
ionosphere sebesar 93.74% dibandingkan algoritma grid search untuk set data wine sebesar 90.41%, sonar sebesar 71.86% , WBCD sebesar 95.03%, ionosphere sebesar 89.80%.
2 Dari hasil uji t-test berpasangan, algoritma
genetika menunjukkan bahwa nilai
akurasi, sensitifitas dan spesifisitas rata terbukti nilainya lebih besar dan rata-rata selisih akurasinya signifikan pada tingkat kepercayaan 95% dibandingkan pada algoritma grid search.
3. Algoritma GA-FAMB mampu mencapai kondisi konvergen pada 10 kali uji coba dengan nilai akurasi yang lebih tinggi dari metode GS-FAMB pada data UCI
repository kecuali data sonar dipengaruhi
jumlah fitur yang banyak.
4. Algoritma GA-FAMB mampu melakukan proses klasifikasi dengan baik dan menghasilkan nilai akurasi yang lebih baik dibandingkan metode GS-FAMB
7. Pustaka
Baraldi and Ethem Alpaydm (1998)
”Simplified ART-A new class of ART
Science Institute, Berkeley, CA, TR-98-004
Herumurti, Darlis (2009). ”Klasifikasi
Individu Penderita Osteoporosis dengan
Menggunakan Fuzzy ARTMAP
Berbobot. Tesis, Jurusan Informatika,
Pasca Sarjana, Institut Teknologi
Surabaya
Kasuba, T. (1993) ”Simplified Fuzzy
ARTMAP” AL Expert, 8, (11), pp 18-25
Whitley, Darrell (1993). ”A Genetic
Algorithm Tutorial”, Colorado State Univirsity.
Goldberg, David E (1989), Genetic
Algorithms in Search, Optimization and
Machine Learning, Kluwer Academic
Publishers, Boston, MA.
Huang, et al (2006). A GA-based feature selection and parameters optimization for
support vector machines. Elsevier,
Expert Systems with Applications, pp. 231–240.
Tan, P.N., Steinbach, M. dan Kumar, V.,
(2006), Introduction to Data Mining,
Pearson Education, Inc., Boston.
Utami, N.D. (2008). Analisis Teknik
Crossover Pada Penyelesaian
Penjadwalan Praktikum Dengan
Algoritma Genetika, Skripsi, Fakultas
Matematika dan Ilmu Pengetahuan Alam, Universitas Brawijaya, Malang.
Whitley, Darrell (1993). ”A Genetic
Algorithm Tutorial”, Colorado State University.