2BAB 2
LANDASAN TEORI
2.1.Peringkasan Teks Otomatis
Sering kali kita membutuhkan ringkasan dari sebuah bacaan untuk mendapatkan secara ringkas dan cepat isi dari bacaan. Konsep sederhana dari ringkasan adalah mengambil bagian penting yang menggambarkan keseluruhan isi dari dokumen asal. Menurut Mani dan Maybury (Mani and Maybury, 1999), ringkasan adalah mengambil isi yang paling penting dari sumber informasi yang kemudian menyajikan kembali dalam bentuk yang lebih ringkas bagi penggunanya.Dalam Hovy (2001), summary atau ringkasan didefinisikan sebagai sebuah teks yang dihasilkan dari satu atau lebih teks, mengandung informasi dari teks asli dan panjangnya tidak lebih dari setengah teks asli.
Peringkasan teks otomatis (automatic text summarization) adalah pembuatan versi yang lebih singkat dari sebuah teks dengan memanfaatkan aplikasi yang dijalankan pada komputer. Hasil peringkasan ini mengandung poin -poin penting dari teks asli.
2.1.1. Tipe Ringkasan
Berdasar teknik pembuatan, suatu ringkasan diambil dari bagian terpenting dari teks aslinya (Mani, 2001), terdapat 2 tipe yaitu :
1. Abstraktif
Tipe peringkasan abstraktif menghasilkan sebuah interpretasi terhadap teks aslinya. Dimana sebuah kalimat akan ditransformasikan menjadi kalimat yang lebih singkat dan kalimat baru yang tidak terdapat dalam dokumen yang asli atau dengan kalimat yang berbeda.
2. Ekstraktif
Tipe peringkasan ekstraktif menghasilkan suatu ringkasan dengan memilih sebagian dari kalimat yang ada dalam dokumen asli. Metode ini menggunakan metode statistical, linguistical dan heuristic atau kombinasi dari semuanya dalam menetapkan ringkasan suatu teks.
Berdasarkan teori, hasil ringkasan ekstraktif lebih baik dibandingkan dengan ringkasan abstraktif. Hal ini dikarenakan peringkasan abstraktif, seperti representasi semantik, inferens dan pembangun natural language relatif lebih sulit, dibandingkan pendekatan data driven, seperti ekstraksi kalimat (Erkan dan Radev, 2004). Sehingga kebanyakan penelitian dilakukan menggunakan metode ekstraktif.
Sedangkan model peringkasan teks otomatis ada dua yaitu ringkasan yang umum (generic summary) merupakan perwakilan dari teks asli yang mencoba untuk mempresentasikan semua fitur penting dari sebuah teks asal. Mengikuti pendekatan bottom up (information retrieval) dan yang kedua ringkasan berpusat pada pemakai (query driven) yaitu peringkasan bersandar pada spesifikasi kebutuhan informasi pemakai, seperti topik atau query dan mengikuti pendekatan top down (information extraction).
Tujuan dari peringkasan teks (teks summarization) dapat dikategorikan berdasarkan maksud, fokus dan cakupannya (Firmin dan Chrzanowski, 1999), sebagai berikut :
1. Informatif
Informatif, ringkasan ini menyatakan informasi - informasi penting yang terdapat pada dokumen asal.
2. Indikatif
Indikatif, tujuan dari ringkasan ini adalah untuk dijadikan sebuah referensi, yang membantu pembaca untuk mengetahui isi dari teks daripada membaca keseluruhan teks yang ada. Ringkasan ini meliputi topik kunci dari teks asal. 3. Evaluatif
Evaluatif, atau ringkasan yang melibatkan pembuatan sebuah pertimbangan pada teks asal, seperti suatu tinjauan ulang atau opini.
4. User-focused (query-relevant)
User-focused, ringkasan yang dibuat berdasarkan topik yang dipilih oleh user, sering merupakan jawaban dari query yang dimiliki oleh user.
5. Generic
Generic, disebut juga author-focused, sifatnya lebih umum dan berdasarkan pada teks aslinya.
6. Dokumen tunggal (single document)
Dokumen tunggal, ringkasan merupakan ringkasan dari satu dokumen. 7. Banyak dokumen (multi document)
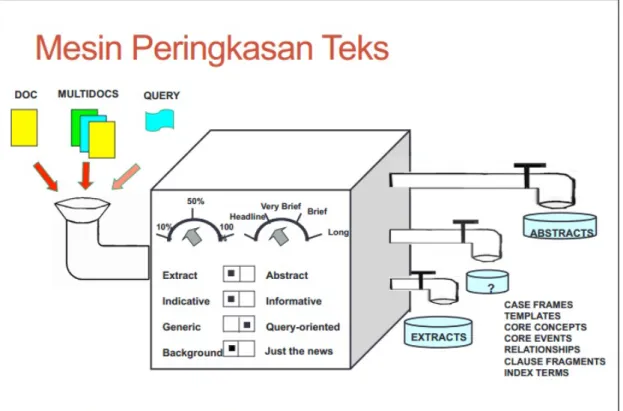
Banyak dokumen, ringkasan merupakan hasil ringkasan dari banyak dokumen. Berikut gambar mesin dan modul peringkasan teks menurut (Hovy dan Marcu, 1998) :
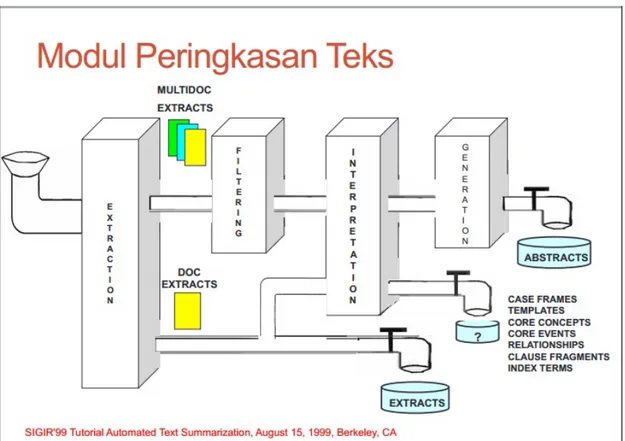
Serta gambar modul peringkasan teks :
Gambar 2.2 Modul Peringkas Teks 2.2.Berita
Kata "berita" berasal dari bahasa sansekerta yaitu dari kata "vrit" yang sebenarnya berarti "terjadi" atau "ada" (Djuroto, 2004). Berita (news) adalah laporan mengenai suatu peristiwa atau kejadian yang terbaru (aktual); laporan mengenai fakta-fakta yang aktual, menarik perhatian, dinilai penting, atau luar biasa (Budiman, 2011).
Berita adalah informasi baru tentang kejadian yang baru, penting, dan bermakna, yang berpengaruh pada para pendengarnya serta relevan dan layak dinikmati (Maeseneer, 1999).
2.2.1. Nilai-Nilai Berita
Dalam menulis berita, ada beberapa hal yang perlu diperhatikan terkait nilai berita itu sendiri (Djuroto, 2004). Ada beberapa nilai berita yang dapat dikelompokkan sebagai acuan dalam sebuah penulisan. Beberapa nilai berita tesebut adalah sebagai berikut :
1. Magnitude (pengaruh) artinya seberapa luas pengaruh suatu berita terhadap khalayak.
2. Significant (Arti) artinya seberapa penting arti dari suatu kejadian atau peristiwa.
3. Actuality (Aktualitas) artinya seberapa besar tingkat aktualitas suatu kejadian atau peristiwa.
4. Proximity (Kedekatan) artinya bertia lokal lebih pas diberitakan di daerah bersangkutan.
5. Prominence (Keakraban) artinya akrabnya suatu peristiwa terhadap khalayak. 6. Surprise (Kejutan).
7. Clarity (Kejelasan) kejadian atau peristiwa.
8. Dampak (Impact) artinya berdampak apakah berita tersebut terhadap khalayak. 9. Konflik.
10. Human Interest artinya kemampuan suatu peristiwa menyentuh perasaan
khalayak.
2.2.2. Unsur-Unsur Berita
Dalam penulisan berita kita harus memahami unsur dari suatu berita supaya memberi kemudahan kita dalam mendeskripsikan berita tersebut dan berita yang kita buat mudah untuk dipahami oleh khalayak ramai (Olii, 2007). Unsur-unsur berita tersebut adalah:
1. What (apa) artinya apa yang tengah terjadi. Peristiwa apa yang tengah terjadi. 2. Who (siapa) artinya siapa saja yang terlibat dalam peristiwa itu.
3. Where (dimana) artinya dimana lokasi terjadinya peristiwa itu. 4. When (kapan) artinya kapan perisitiwa itu berlangsung.
5. Why (mengapa) artinya mengapa kejadian itu bisa terjadi.
6. How (bagaimana) artinya bagaimana kejadian itu bisa berlangsung. 2.2.3. Anatomi Berita
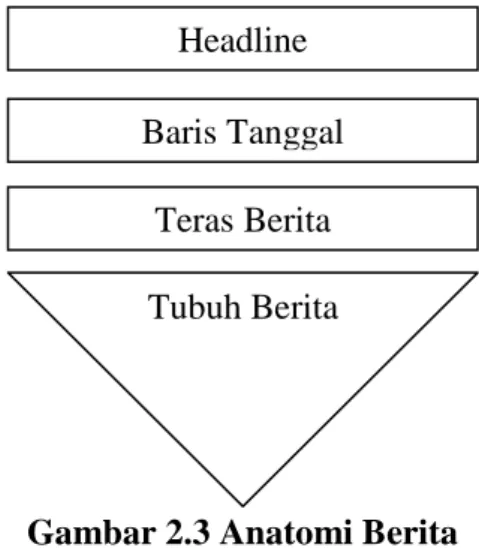
Seperti tubuh manusia, berita juga mempunyai bagian-bagian, diantaranya adalah sebagai berikut (Budiman, 2011) :
1. Judul atau Kepala Berita (Headline)
Headline mewakili isi berita yang ingin disampaikan dan memiliki daya tarik yang kuat.
2. Baris Tanggal (Dateline)
Dateline terdiri atas nama media massa, tempat kejadian dan tanggal kejadian. Tujuannya adalah untuk menunjukkan tempat kejadian dan inisial media. 3. Teras Berita (Lead atau Intro)
Lead biasanya ditulis pada paragrap pertama sebuah berita. Lead merupakan unsur yang paling penting dari sebuah berita, yang menentukan apakah isi berita akan dibaca atau tidak.
4. Tubuh Berita (Body)
Body isinya menceritakan peristiwa yang dilaporkan dengan bahasa yang singkat, padat, dan jelas baik yang sudah dikemukakan dalam teras maupun yang belum diungkapkan.
Gambar 2.3 Anatomi Berita
Bagian yang disebutkan membentuk anatomi yang tersusun sebagai sebuah struktur yang utuh dan terpadu, yang sering dinamakan sebagai gaya piramida terbalik (inverted pyramid style) seperti yang terlihat pada Gambar 2.3. Disebut demikian karena bagian tubuh berita disusun dengan pola pengembangan umum ke khusus (dimulai dari hal umum, lalu secara berangsur-angsur menuju ke hal-hal yang semakin khusus) atau klimaks-antiklimaks (dari yang paling pokok atau penting beralih secara berturut-turut ke yang kurang pokok atau penting). Tujuannya adalah untuk memudahkan atau mempercepat pembaca dalam mengetahui apa yang diberitakan.
Headline Baris Tanggal
Teras Berita Tubuh Berita
2.3.Text Mining
Text mining (penambangan teks) adalah penambangan yang dilakukan oleh komputer untuk mendapatkan sesuatu yang baru, sesuatu yang tidak diketahui sebelumnya atau menemukan kembali informasi yang tersirat secara implisit, yang berasal dari informasi yang di-ekstrak secara otomatis dari sumber-sumber data teks yang berbeda-beda (Feldman & Sanger, 2007). Text mining merupakan teknik yang digunakan untuk menangani masalah klasifikasi, clustering, information extraction dan information retrival (Berry & Kogan, 2010).
Pada dasarnya proses kerja dari text mining banyak mengapdopsi dari penelitian data mining namun yang menjadi perbedaan adalah pola yang digunakan oleh text mining diambil dari sekumpulan bahasa alami yang tidak terstruktur sedangkan dalam data mining pola yang diambil dari database yang terstruktur (Han & Kamber, 2006).
2.3.1. Tahap – Tahap Text Mining
Tahap-tahap text mining secara umum adalah text preprocessing dan feature selection (Feldman & Sanger 2007, Berry & Kogan 2010) . Dimana penjelasan dari tahap-tahap tersebut adalah sebagai berikut :
1. Text Preprocessing
Tahap text preprocessing adalah tahap awal dari text mining. Tahap ini mencakup semua rutinitas, dan proses untuk mempersiapkan data yang akan digunakan pada operasi knowledge discovery sistem text mining (Feldman & Sanger, 2007). Tindakan yang dilakukan pada tahap ini adalah toLowerCase, yaitu mengubah semua karakter huruf menjadi huruf kecil, dan Tokenizing yaitu proses penguraian deskripsi yang semula berupa kalimat – kalimat menjadi kata-kata dan menghilangkan delimiter-delimiter seperti tanda titik (.), koma (,), spasi dan karakter angka yang ada pada kata tersebut (Weiss et al, 2005).
2. Feature Selection
Tahap seleksi fitur (feature selection) bertujuan untuk mengurangi dimensi dari suatu kumpulan teks, atau dengan kata lain menghapus kata-kata yang dianggap tidak penting atau tidak menggambarkan isi dokumen sehingga
proses pengklasifikasian lebih efektif dan akurat (Do et al, 2006., Feldman & Sanger, 2007., Berry & Kogan 2010). Pada tahap ini tindakan yang dilakukan adalah menghilangkan stopword ( stopword removal ) dan stemming terhadap kata yang berimbuhan (Berry & Kogan 2010., Feldman & Sanger 2007). Namun pada penelitian ini proses stemming tidak dilakukan.
Stopword adalah kosakata yang bukan merupakan ciri ( kata unik ) dari suatu dokumen (Dragut et al. 2009). Misalnya “di”, “oleh”, “pada”, “sebuah”, “karena” dan lain sebagainya. Sebelum proses stopword removal dilakukan, harus dibuat daftar stopword (stoplist). Jika termasuk di dalam stoplist maka kata-kata tersebut akan dihapus dari deskripsi sehingga kata-kata yang tersisa di dalam deskripsi dianggap sebagai kata-kata yang mencirikan isi dari suatu dokumen atau keywords. Daftar kata stopword di penelitian ini bersumber dari Tala (2003).
2.4.Kata
Kata adalah kesatuan terkecil yang diperoleh sesudah kalimat dibagi atas bagian-bagiannya dan mengandung suatu ide.
Kategori kata berdasarkan sintaksisnya terdiri dari lima kata (Putrayasa, 2007), yaitu :
1. Kata Benda (Nomina)
Kata benda adalah kata yang mengacu pada manusia, binatang, benda dan konsep atau pengertian.
2. Kata Kerja (Verba)
Kata kerja adalah kata yang menyatakan tindakan. 3. Kata Sifat (Adjektiva)
Kata sifat adalah kata yang memberi keterangan yang lebih khusus tentang sesuatu yang dinyatakan oleh nomina dalam kalimat.
4. Kata Keterangan (adverbia)
Kata keterangan adalah kategori yang dapat mendampingi adjektiva, numeralia atau preposisi dalam konstruksi sintaksis.
5. Kata Tugas
Kata tugas adalah kata yang hanya memiliki arti gramatikal dan tidak memiliki arti leksikal.
2.5.Kalimat
Kalimat adalah satuan bahasa terkecil dalam wujud lisan atau tulisan, yang mengungkapkan pikiran yang utuh. Kalimat terdiri atas deret kata yang dimulai dengan huruf kapital dan diakhiri dengan tanda titik (.), tanda tanya (?), atau tanda seru (!).
Unsur-unsur kalimat terdiri dari kata, kelompok kata dan lagu kalimat. Di dalam kalimat terdapat pengaturan hubungan kedudukan antara bagian-bagiannya. Ada bagian didalam kalimat yang menunjukkan sebagai “pelaku”, ada bagian yang menunjukkan sebagai “perbuatan”, ada bagian yang menunjukkan “bagaimana perbuatan itu dilakukan”. Berdasarkan jabatannya kalimat terdiri dari :
1. Subyek, yaitu bagian yang menjadi pangkal atau pokok pembicaraan.
2. Predikat, yaitu bagian yang menerangkan subyek, biasanya berdiri sesudah subyek.
3. Obyek, yaitu bagian yang menjadi tujuan.
4. Keterangan, yaitu bagian yang menunjukkan waktu (keterangan waktu), tempat (keterangan tempat), alat (keterangan alat) dan sebagainya.
Sedangkan kalimat berdasarkan fungsinya, dapat dikategorikan sebagai berikut: 1. Kalimat pernyataan 2. Kalimat pertanyaan 3. Kalimat perintah 4. Kalimat seruan 2.6.Paragraf
Paragraf disebut juga alinea. Kata paragraf merupakan kata serapan dari bahasa Inggris paragraph, sedangkan kata alinea dari bahasa Belanda dengan ejaan yang sama. Paragraf adalah seperangkat kalimat yang membicarakan suatu gagasan atau topik. Terdapat dua syarat dalam membentuk paragraf :
1. Menulis pernyataan (kalimat) tentang pokok bahasan dengan baik. 2. Mengangkat pola susunan rincian dengan patut.
2.7. Term Frequency Inverse Document Frequency (TF-IDF)
Metode Term Frequency-Inverse Document Frequency (TF-IDF) adalah cara pemberian bobot hubungan suatu kata (term) terhadap dokumen. Untuk dokumen tunggal tiap kalimat dianggap sebagai dokumen. Metode ini menggabungkan dua konsep untuk perhitungan bobot, yaitu Term frequency (TF) merupakan frekuensi kemunculan kata (t) pada kalimat (d). Document frequency (DF) adalah banyaknya kalimat dimana suatu kata (t) muncul. Frekuensi kemunculan kata di dalam dokumen yang diberikan menunjukkan seberapa penting kata itu di dalam dokumen tersebut. Frekuensi dokumen yang mengandung kata tersebut menunjukkan seberapa umum kata tersebut. Bobot kata semakin besar jika sering muncul dalam suatu dokumen dan semakin kecil jika muncul dalam banyak dokumen (Robertson, 2004). Pada Metode ini pembobotan kata dalam sebuah dokumen dilakukan dengan mengalikan nilai TF dan IDF.
Pada penelitian ini, peringkasan teks otomatis yang di kembangkan merupakan sistem peringkasan dengan inputan berupa single dokumen dan secara otomatis menghasilkan ringkasan (summary). Proses text preprosessing yang dilakukan pada peringkasan teks otomatis ini hanya proses tokenizing yaitu proses pemotongan string input berdasarkan tiap kata yang menyusunnya. Pemecahan kalimat menjadi kata-kata tunggal dilakukan dengan me-scan kalimat dengan pemisah (delimiter) white space (spasi, tab dan newline)( Tala, 2003).
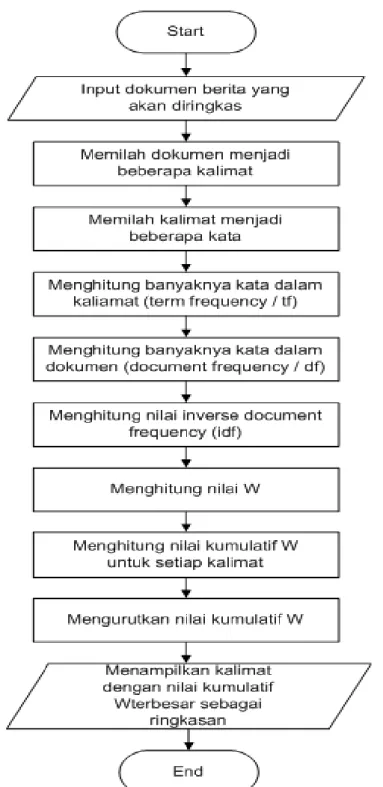
Adapun tahapan-tahapan peringkasan teks otomatis metode TF-IDF adalah sebagai berikut :
1. Menginput dokumen yang akan dibuat ringkasannya 2. Memilah dokumen menjadi beberapa kalimat.
Pemilahan kalimat dilakukan dengan memecah string teks dari dokumen yang panjang menjadi kalaimat-kalimat mengunakan fungsi split(), dengan tanda titik ”.”, tanda tanya ”?” dan tanda seru ”!” sebagai delimiter untuk memotong string dokumen.
3. Memilah kalimat yang terbentuk menjadi beberapa kata dan simpan dalam variable array. Untuk memilah kalimat menjadi kata digunakan proses tokenizing.
4. Pembobotan TF-IDF
Pembobotan diperoleh berdasarkan jumlah kemunculan term dalam kalimat (TF) dan jumlah kemunculan term pada seluruh kalimat dalam dokumen (IDF). Bobot suatu istilah semakin besar jika istilah tersebut sering muncul dalam suatu dokumen dan semakin kecil jika istilah tersebut muncul dalam banyak dokumen (Grossman, 1998). Nilai IDF sebuah term dihitung menggunakan persamaan 1.
(1) dengan:
N = jumlah kalimat yang berisi term(t)
dfi = jumlah kemunculan kata (term) terhadap D
5. Menghitung bobot (W) masing-masing dokumen dengan persamaan 2 (Mustaqhfiri, 2011). (2) dengan : d = kalimat ke-d t = kata(term) ke –t TF = term freqency
W = bobot kalimat ke-d terhadap kata(term)ke- t IDF = inverse document f reqency
6. Melakukan proses pengurutan (sorting) nilai kumulatif dari W untuk setiap kalimat.
7. Tiga kalimat dengan nilai W terbesar dijadikan sebagai hasil dari ringkasan atau sebagai output dari peringkasan teks otomatis.
Tahapan-tahapan Peringkasan Teks Otomatis dengan metode TF -IDF di atas ditunjukan pada Gambar 2.4.
Gambar 2.4 Tahapan-tahapan peringkasan teks otomatis metode TF-IDF 2.8.Flowchart
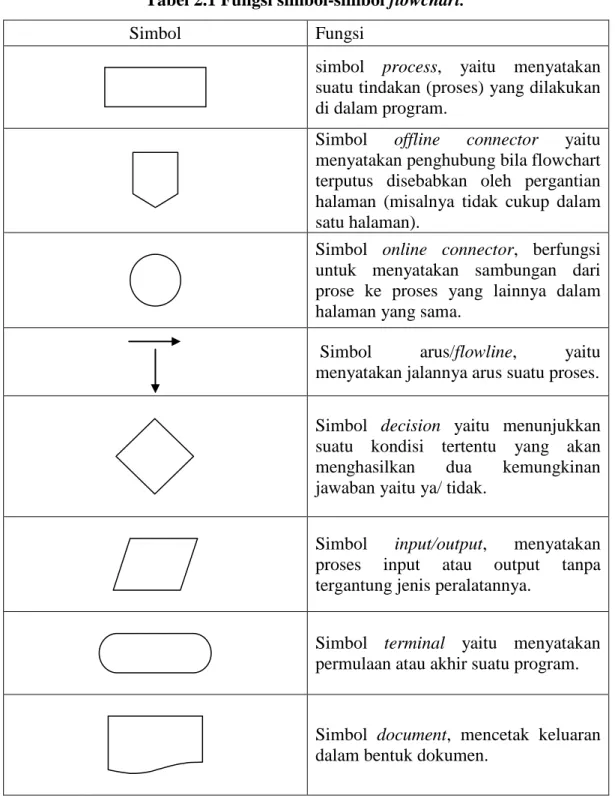
Flowchart adalah penggambaran secara grafik dari langkah-langkah dan urutan-urutan prosedur suatu program (Setiawan, 2006). Simbol-simbol dari flowchart memiliki fungsi yang berbeda antara satu simbol dengan simbol lainnya (Davis, 1999). Fungsi dari simbol-simbol flowchart adalah sebagai berikut :
Tabel 2.1 Fungsi simbol-simbol flowchart.
Simbol Fungsi
simbol process, yaitu menyatakan suatu tindakan (proses) yang dilakukan di dalam program.
Simbol offline connector yaitu menyatakan penghubung bila flowchart terputus disebabkan oleh pergantian halaman (misalnya tidak cukup dalam satu halaman).
Simbol online connector, berfungsi untuk menyatakan sambungan dari prose ke proses yang lainnya dalam halaman yang sama.
Simbol arus/flowline, yaitu menyatakan jalannya arus suatu proses. Simbol decision yaitu menunjukkan suatu kondisi tertentu yang akan menghasilkan dua kemungkinan jawaban yaitu ya/ tidak.
Simbol input/output, menyatakan proses input atau output tanpa tergantung jenis peralatannya.
Simbol terminal yaitu menyatakan permulaan atau akhir suatu program.
Simbol document, mencetak keluaran dalam bentuk dokumen.
2.9.Penelitian Terdahulu
Metode Term Frequency Inverse Document Frequency telah banyak digunakan dalam menyelesaikan berbagai macam permasalahan dalam hal pembobotan kata. Dari permasalahan yang kecil hingga permasalahan yang cukup kompleks dengan berbagai metode dalam penyelesaiannya.
Zafikri, (2008) melakukan penelitian untuk menyelesaikan permasalahan dalam pencarian informasi yang akurat dan efektif pada mesin pencari. Dalam penelitiannya mencoba menerapkangabungan antara metode Term Frequency Inverse Document Frequency (TF-IDF) dan model ruang vektor (vector space model) pada mesin pencari. Hasilnya metode pembobotan dokumen TF-IDF tidak selalu memberikan hasil performansi yang baik.
Akbar (2011) dalam penelitiannya menyelesaikan permasalahan dalam menentukan nilai tes esai online. Dalam halini Akbar (2011) menggunakan algoritma
Latent Semantic Analysis (LSA) dengan pembobotan Term Frequency/Inverse
Document Frequency (TF/IDF) untuk menyelesaikan permasalahannya yakni sebagai alternatif solusi penilaian esai kepada user ssecara konsisten tanpa mengikutsertakan subjektivitas penilai, seperti suasana hati dan tingkat pengetahuan. Algoritma TF/IDF-LSA memiliki tingkat keakuratan cukup tinggi dalam pemeriksaan jawaban esai dengan jumlah kata yang banyak.
Sulthan (2012) menggunakan algoritma Hill Climbing dalam meringkas teks, hasil dari peringkasan menggunakan algoritma Hill Climbing cukup baik. Metode text mining juga pernah dilakukan Kurniawan (2012) dalam klasifikasi berita, dan hasil dari metode text mining cukup berhasil.
Aristoteles (2013) melakukan penelitian peringkasan teks dokumen bahasa Indonesia menggunakan algoritma genetika, hasilnya bahwa algoritma genetika dapat digunakan untuk mencari tingkat kepentingan yang optimal dari tiap fitur teks. Nilai akurasi 47.46% pada pemampatan 30%. Sedangkan hasil tidak optimal pada pemampatan 10%.
Tabel 2.2 Penelitian terdahulu
No Peneliti / Tahun Judul Keterangan
1 Zafikri (2008) Implementasi Metode Term Frequency Inverse Document Frequency (TF-IDF) pada Sistem Temu Kembali informasi. 2 Akbar (2011) Menentukan Nilai Tes Esai Online
Menggunakan AlgoritmaLatent Semantic Analysis (LSA) dengan Pembobotan Term Frequency/ Inverse Document Frequency
3 Sulthan (2012) Peringkasan Teks Otomatis Berbasis Web Menggunakan AlgoritmaHill Climbing
4 Kurniawan (2012) Klasifikasi Konten Berita menggunakan Text Mining
5 Aristoteles (2013) Penerapan Algoritma Genetika pada Peringkasan Teks Dokumen Bahasa Indonesia