2. LANDASAN TEORI
2.1Pengertian Data Mining
Data Mining adalah suatu metode untuk mengambil atau menggali pengetahuan dari sejumlah besar data-data. Data Mining seharusnya lebih sesuai disebut “knowledge mining from data”. Mining menggambarkan suatu proses yang menemukan sebuah bongkah kecil yang sangat berharga dari tumpukan raw material.
Gambar 2.1. Menggali pengetahuan dari tumpukan data-data.
Sumber : Data Mining Concepts and Techniques (Jiawei Han, Micheline Kamber).
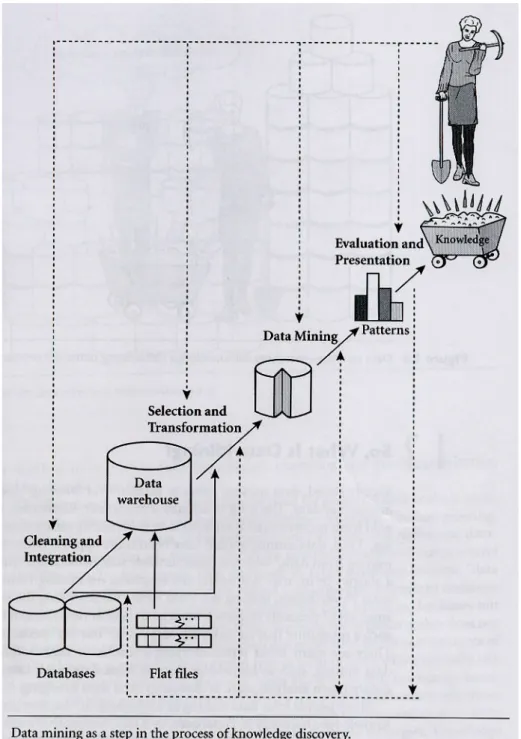
Pandangan lain menganggap Data Mining sebagai suatu langkah penting dalam proses penemuan pengetahuan di dalam database. Penemuan pengetahuan sebagai suatu proses, digambarkan dalam Gambar 2.2.
Gambar 2.2. Proses menemukan pengetahuan dari database.
Sumber : Data Mining Concepts and Techniques (Jiawei Han, Micheline Kamber).
- Data cleaning : untuk menghilangkan data yang tidak diperlukan.
- Data integration : tempat dimana sumber-sumber multiple data bisa digabungkan.
6
- Data transformation : dimana data diubah atau dikonsolidasikan ke dalam bentuk-bentuk yang sesuai untuk menggali dengan melakukan ringkasan atau operasi-operasi gabungan.
- Data mining : suatu proses penting dimana metode-metode cerdas diaplikasikan untuk mengekstrak pola-pola data.
- Pattern evaluation : untuk mengidentifikasi pola-pola yang sungguh-sungguh menarik yang menunjukkan pengetahuan berdasarkan atas beberapa pengukuran-pengukuran ketertarikan.
- Knowledge presentation : dimana visualisasi dan teknik-teknik penyajian pengetahuan digunakan untuk mengadakan pengetahuan pikiran kepada pemakai.
2.2 Decision Tree (Pohon Keputusan)
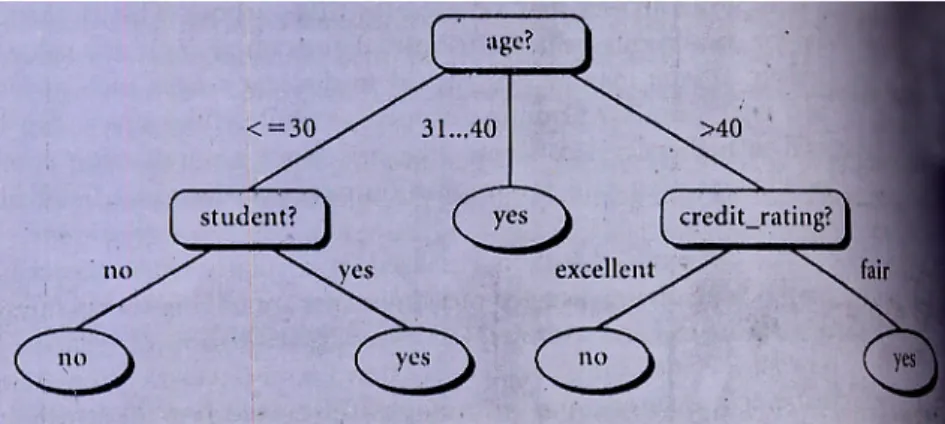
Pohon Keputusan (Decision Tree) adalah suatu flow chart seperti struktur pohon, dimana setiap internal node menunjukkan sebuah tes di sebuah atribut, setiap branch (ranting) mewakili sebuah hasil/output dari tes, dan leaf nodes mewakili kelas-kelas atau ditribusi-distribusi kelas. Titik paling atas dalam sebuah pohon adalah titik root. Contoh pohon keputusan dapat dilihat pada gambar 2.3.
Gambar 2.3.Salah satu contoh Decision Tree mengenai konsep membeli komputer. Sumber : Data Mining Concepts and Techniques (Jiawei Han, Micheline Kamber).
Diagram di atas memprediksi seorang konsumen di AllElectronics, apakah suka atau tidak membeli sebuah komputer. Internal nodes ditunjukkan oleh kotak-kotak
dan mewakili sebuah tes di sebuah atribut, dan leaf nodes ditunjukkan dengan elips dan mewakili sebuah kelas (salah satu dari beli komputer = ya atau beli komputer = tidak).
Dalam tujuan untuk mengklasifikasi sebuah sampel yang tidak diketahui, nilai-nilai atribut dari sampel dites berlawanan dengan pohon keputusan. Sebuah alur dicari dari akar sumbernya ke sebuah titik daun yang memegang prediksi kelas untuk sampel. Pohon keputusan dapat dengan mudah diubah ke aturan klasifikasi.
2.3 Tree Pruning
Ketika suatu pohon keputusan dibuat, maka banyak cabang-cabang akan menggambarkan keanehan-keanehan dalam data percobaan. Metode-metode tree pruning menyebut masalah ini sebagai data overfitting. Metode tree pruning
menggunakan pengukuran-pengukuran statistik untuk menghilangkan cabang-cabang yang tidak berguna.
Ada 2 pendekatan umum untuk tree pruning. Dalam pendekatan
prepruning, suatu pohon dipangkas dengan menghentikan pembuatannya
secepatnya (dengan memutuskan tidak melanjutkan membagi atau memisah subset dari sampel-sampel percobaan di sebuah titik yang ditentukan). Ketika membuat suatu pohon, pengukuran seperti statistical significance, X2, information gain, dll, dapat digunakan untuk menilai kelebihan dari suatu pembagian.
Pendekatan yang kedua, postpruning, menghilangkan cabang-cabang dari suatu pohon yang “fully grown”. Sebuah titik pohon dipangkas dengan menghilangkan cabang-cabangnya. Algoritma pemangkasan cost complexity adalah suatu contoh dari pendekatan postpruning.
2.4 Information Gain
Information gain adalah algoritma yang menggunakan sebuah pengukuran dasar entropy sebagai heuristic untuk memilih atribut terbaik dalam memisahkan sampel-sampel ke dalam kelas-kelas individu. Pengukuran
information gain digunakan untuk memilih tes atribut di setiap titik dalam pohon. Atribut dengan information gain tertinggi (atau pengurangan entropy terbaik) dipilih sebagai tes atribut untuk titik yang sedang diukur.
8
2.5 Perhitungan Information Gain
S adalah sebuah kumpulan dari sampel-sampel percobaan, dimana label kelas dari tiap sampel diketahui. Setiap sampel dalam kenyataannya adalah sebuah tuple. Satu atribut digunakan untuk menentukan kelas dari sampel-sampel percobaan. Contohnya, atribut status dapat digunakan untuk menetapkan label kelas dari tiap sampel, seperti salah satu dari “lulus” atau “tidak lulus”. Andaikan ada m kelas-kelas. S berisi si sampel-sampel dari kelas-kelas i, untuk i = 1, ..., m. Sebuah sampel yang berubah-ubah termasuk kelas i dengan probabilitas si/s, dimana s adalah jumlah dari sampel-sampel dalam kumpulan S. Expected information yang dibutuhkan untuk mengklasifikasi sebuah sampel yang diberikan adalah: I(s1,s2, ..., sm) = - log2 . 1 s s s s i m i i = (2.1)
Sebuah atribut A dengan nilai-nilai {a1,a2, ..., av} dapat digunakan untuk membagi S ke dalam subset-subset {S1,S2, ..., Sv}, dimana Sj berisi sampel-sampel tersebut dalam S yang mempunyai nilai aj dari A. Sj berisi sij sampel-sampel dari kelas Ci.
Expected information berdasarkan atas pembagian ke dalam subset-subset dengan A diketahui sebagai entropy dari A, sebagai berikut:
E(A) = ... ( 1 ,..., ). 1 1 mj j v j mj j I s s s s s = + + (2.2) Istilah s s s1j +...+ mj
bertindak sebagai bobot dari subset j dan adalah jumlah dari sampel-sampel dalam subset yang dibagi dengan total jumlah dari sampel-sampel S.
Information gain didapatkan dari pembagian di A ditetapkan dengan:
Dengan kata lain, Gain(A) adalah expected reduction dalam entropy yang disebabkan dengan mengetahui nilai dari atribut A.
Dalam pendekatan ini untuk analisa yang sesuai, kita dapat menghitung
information gain untuk tiap-tiap atribut. Atribut dengan information gain tertinggi dipilih sebagai atribut tes untuk kumpulan S yang diberikan.
2.6 Klasifikasi Bayes
klasifikasi Bayes adalah klasifikasi statistik. Klasifikasi-klasifikasi Bayes dapat memprediksi kelas anggota probabilitas.
Klasifikasi Bayes berdasarkan atas teorema Bayes. Studi-studi perbandingan algoritma-algoritma klasifikasi dapat menemukan sebuah klasifikasi Bayes sederhana yang dikenal sebagai “naive Bayesian classifier“ dapat diperbandingkan dalam penampilan dengan decision tree dan neural network classifier.
Naive Bayesian classifier mengasumsi bahwa efek dari sebuah nilai atribut di sebuah kelas yang diberikan adalah bebas dari nilai-nilai atribut lain. Asumsi ini disebut class conditional independence. Itu dibuat untuk memudahkan perhitungan-perhitungan yang dilibatkan dan dalam pengertian ini, dianggap “naive.”
2.7 Teorema Bayes
X adalah sebuah sampel data yang label kelasnya tidak diketahui. C
adalah kelas yang spesifik. Untuk masalah-masalah klasifikasi, kita menginginkan untuk menentukan P(C|X).
P(C|X) adalah posterior probability, atau sebuah posteriori probability, dari C dikondisikan di X. Sebaliknya, P(C) adalah prior probability, atau sebuah
priori probability, dari C. Posterior probability, P(C|X), berdasarkan atas lebih banyak informasi daripada prior probability, P(C), dimana bebas dari X.
P(X), P(C), dan P(C|X) dapat diestimasi dari data yang diberikan. Teorema Bayes sangat berguna, karena teorema Bayes menyediakan suatu cara menghitung posterior probability, P(C|X), dari P(C), P(X), dan P(X|C). Teorema Bayes:
10 P(C|X) = ) ( ) ( ) | ( X P C P C X P . (2.4)
Karena P(X) sama dengan konstan sehingga dapat dihilangkan dan persamaannya menjadi:
P(C|X) = P(X|C) P(C) (2.5)
2.8 Naive Bayesian Classification
Andaikata ada data terdiri dari buah-buahan, digambarkan dengan warna dan bentuk. Penggolongan Bayesian beroperasi dengan mengatakan "Jika kita melihat suatu buah yang berwarna merah dan bentuknya bulat, jenis buah apakah itu yang paling mungkin, berdasarkan pada contoh data yang kita amati tadi?" Suatu kesulitan muncul ketika kita mempunyai lebih dari beberapa kelas dan variabel. Kita akan memerlukan pengamatan yang sangat banyak untuk meramalkan kemungkinan-kemungkinan ini.
Naive Bayesian Classification mendapatkan bahwa di sekitar masalah ini dengan tidak menuntut, bahwa kita harus mempunyai banyak pengamatan untuk masing-masing kombinasi variabel yang mungkin. Bahkan, variabel diasumsikan untuk menjadi bebas antara satu sama lain, oleh karena itu kemungkinan bahwa suatu buah yang merah, bulat, keras, memiliki garis tengah 3 inci, dan lain-lain akan menjadi sebuah apel yang dapat dihitung dari kemungkinan-kemungkinan bebas yaitu sebuah buah merah, bahwa itu bulat, bahwa itu kuat, bahwa itu memiliki garis tengah 3 inci, dll.
Dengan kata lain, Naive Bayesian Classification berasumsi bahwa efek suatu nilai variabel di sebuah kelas yang ditentukan adalah tidak terikat pada nilai-nilai dari variabel lain. Asumsi ini disebut kelas kondisi bebas/tidak terikat. Itu dibuat untuk menyederhanakan perhitungan dan dalam hal ini dianggap sebagai
"Naive". Asumsi ini adalah suatu asumsi yang hampir kuat dan sering tidak bisa diterapkan. Bagaimanapun juga, penyimpangan di dalam peramalan kemungkinan
sering tidak bisa membuat perbedaan dalam praktek, bukan nilai-nilai tepat mereka, yang menentukan penggolongan.
Studi yang membandingkan algoritma-algoritma klasifikasi sudah menemukan bahwa Naive Bayesian Classification dapat diperbandingkan dalam
performance dengan pohon-pohon klasifikasi. Naive Bayesian Classification juga telah mempertunjukkan ketelitian yang tinggi dan kecepatan ketika diaplikasikan untuk database-database besar.
2.9 Maximum Conditional Expectation Of The Bayesian Posterior Distribution Langkah-langkah Maximum Conditional Expectation Of The Bayesian Posterior Distribution adalah sebagai berikut:
1. Setiap sampel data diwakili dengan sebuah n-dimensional feature vector, X = (x1,x2, ..., xn).
2. Andaikata ada m kelas-kelas, C1, C2, ..., Cm.
3. Catatan bahwa kemungkinan-kemungkinan prior kelas dapat diestimasikan dengan P(Ci) =
s si
. (2.6)
dimana si adalah jumlah dari sampel-sampel percobaan kelas Ci, dan s adalah total jumlah dari sampel-sampel percobaan.
4. Gunakan fungsi kepadatan Gaussian (normal) di bawah ini.
) | (xk Ci P = g(xk, Ci, Ci) = − − 2 2 1 2 2 ) ( 2 1 i C i C k i x C e µ
π
. (2.7)dimana Ci dan Ci adalah rata-rata dan covarian untuk sampel-sampel
percobaan dari kelas Ci.
5. Untuk mengklasifikasi suatu sampel X yang tidak diketahui, maka dicari nilai ekspektasi dari sampel X di dalam kelas Ci, dengan menggunakan persamaan berikut.
12
6. Setelah mendapatkan nilai ekspektasi diatas, maka selanjutnya dicari nilai maksimumnya diantara kelas-kelas yang dibandingkan.
E(Ci|X) > E(Cj|X) ; for1 < j < m, j i. (2.9)
Maka kita dapat mengetahui, sampel X termasuk di golongan kelas yang memiliki nilai ekspektasi maksimum.