BUKITTINGGI SUMATERA BARAT TAHUN 2005
MELLYNA EKA YAN FITRI
0302017029
UNIVERSITAS INDONESIA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
DEPARTEMEN MATEMATIKA
SUMATERA BARAT TAHUN 2005
Skripsi diajukan sebagai salah satu syarat untuk memperoleh gelar Sarjana Sains
Oleh:
MELLYNA EKA YAN FITRI
0302017029
DEPOK
BUKITTINGGI SUMATERA BARAT TAHUN 2005
NAMA : MELLYNA EKA YAN FITRI
NPM : 0302017029
SKRIPSI INI TELAH DIPERIKSA DAN DISETUJUI
DEPOK, Juli 2006
Dra. Titin Siswantining D.E.A. Dra. Yekti Widyaningsih M. Si
PEMBIMBING I PEMBIMBING II
Tanggal lulus Ujian Sidang Sarjana: Juli 2006
Penguji I : Dra. Yekti Siswantingsih M.Si
Penguji II : Dra. Dian Lestari
Alhamdulillahirabbil’alamin, penuliskan ucapkan puji dan syukur kehadirat Allah SWT yang telah melimpahkan rahmat dan karunia-Nya bagi penulis, hingga penulis dapat menyelesaikan tugas akhir ini. Penulis sangat bersyukur pada Allah SWT, karena mendapatkan dukungan yang luar biasa dari berbagai pihak.
Untuk itu penulis mengucapkan terima kasih kepada :
1. Ibu Dra. Titin Siswantining DEA, dan Ibu Dra. Yekti Widyaningsih Msi. sebagai pembimbing I dan pembimbing II, beliau berdua sudah seperti orang tua bagi penulis, banyak membantu, memotivasi, mengajarkan hal-hal positif, kesabaran, pengertian dan perhatian yang beliau berikan selalu membuat penulis terus bersemangat, terima kasih.
2. Bapak Al Haji dan Ibu Titin selaku dosen pembimbing akademik penulis, terima kasih atas perhatian, semangat dan nasehat yang Bapak dan Ibu berikan, sehingga penulis bisa bertahan di Math UI hingga selesai tugas akhir ini.
3. Kepada dosen-dosen penguji seminar tugas akhir penulis, Ibu Sakya, Ibu Dian, Ibu Ida, Ibu Nur, Uni Milla, Mba Sarini,Mba Rahmi, dan Mba Fevi, terima kasih yang sebesar-besarnya atas semua masukan dan
Mba Santi, Mba Rusmi, Mas Ratmin, Mas Iwan, Pak Anshori dan Da Salman, terima kasih atas kerjasama yang baik.
4. Orang tercinta, Papa Ir. Mawardi dan Mama Dasnamiwati S.E., yang menjadi tempat mengadu, yang tak henti-hentinya mendoakan,
memberikan kepercayaan, mendukung dan selalu menyemangati penulis sampai saat ini. Terima kasih yang sebesar-besarnya atas semua yang diberikan pada penulis. Dan juga terima kasih untuk almarhum Kakek, untuk Nenek, Nek Datuk, Aki Datuk, Ibu, Ayah, Makdang, Maiadang, Makngah, Maketek, Pakngah, Angah, Paketek, Tekti, Ante Des, Ante Id, Uniang, Makuncu, Taci, Ngah Dewi yang selalu memberikan semangat dan doa pada penulis hingga saat ini. Begitu juga kepada adik-adik penulis, Rissa, Rizki, Putri, Repi, Febri, Niva, Rio, Andini, Rasyid, Fikri, Dian, Dedi, Zikri, Andi yang selalu menghibur dan menyemangati penulis. 5. Untuk Paketek Am, Tante Linda, Ibu, Abah, Om Nova dan Ante yang
selalu memberikan nasehat dan semangat untuk penulis. Dan terima kasih untuk semua keluarga yang tidak bisa penulis sebutkan satu persatu.
nonton lagi. Untuk Dessa, Ani, Winny dan Emi terima kasih atas nasehat dan masukannya. Untuk teman-teman 2002 lainnya, Hendy yang selalu membantu menangani masalah komputer penulis, Nala, Arisha, Da en, Riri, Yeyen, Mamad, Nuts, Dhini, Zilham, Sofyan, Arif, Fuad, Iif, QQ, Henri, Ando, Naro, Santoso, Syariat dan Thamrin, terima kasih. Untuk Ni Leni dan Kak Yana yang telah membantu penulis. Untuk Kak Aurora, Kak Diyut, Kak Nia, Kak Yuni, Kak Onggo, Herman, Tile dan semua anak Math UI yang ga bisa penulis sebutkan satu persatu.
7. Untuk Om Budi yang membantu kelancaran tugas akhir penulis ini. Terima kasih yang sebesar-besarnya.
8. PDAM Kota Bukittinggi yang telah bersedia memberikan data hasil Survey Kepuasan Pelanggan tahun 2005.
karena itu penulis menerima masukan berupa kritik dan saran atas tulisan ini. Akhir kata, selamat membaca, semoga bermanfaat
Depok, Juli 2006
Kepuasan adalah perasaan seseorang yang berhubungan dengan
kenyamanan atau kekecewaan sebagai akibat perbandingan antara
pelayanan yang dirasakan dengan harapannya. Penelitian ini bertujuan untuk
mengukur tingkat kepuasan pelanggan PDAM dan menentukan faktor-faktor
yang perlu diperhatikan PDAM kota Bukittinggi dalam meningkatkan kualitas
pelayanannya dalam penyediaan air bersih. Pengambilan data dalam
penelitian ini menggunakan metode survey. Metode statistik yang digunakan
untuk menganalisis data adalah analisis faktor, analisis diskriminan dan
analisis gap. Dengan analisis faktor, diperoleh tujuh aspek yang
mempengaruhi kepuasan pelanggan. Analisis diskriminan dikerjakan pada
ketujuh aspek tersebut. Hasilnya terdapat perbedaan pelayanan yang
diberikan PDAM pada lima wilayah layanannya. Analisis gap (kesenjangan)
memberi kesimpulan bahwa terdapatnya faktor-faktor yang harus
ditingkatkan PDAM agar sesuai dengan harapan pelanggan.
Kata kunci: kepuasan, kepentingan, analisis faktor, komponen utama, analisis
diskriminan, analisis gap, tingkat kesesuaian.
Xii + 87 hlm.; lamp.
DAFTAR ISI
Halaman
KATA PENGANTAR……… i
ABSTRAK………. v
DAFTAR ISI……….. vi
DAFTAR GAMBAR……….. x
DAFTAR TABEL………... x
DAFTAR LAMPIRAN……… xi
BAB I. PENDAHULUAN... 1
1.1 Latar Belakang Masalah……….. 1
1.2 Perumusan Masalah………. 4
1.3 Pembatasan Masalah……….. 4
1.4 Hipotesis………. 4
1.5 Tujuan Penelitian……….. 4
1.6 Manfaat Penelitian……… 5
1.7 Metode Penelitian……….……… 5
1.8 Sistimatika Pembahasan……….……… 6
BAB II LANDASAN TEORI………. 7
2.1 Analisis Komponen Utama……….. 7
2.1.1 Pengertian………. 7
2.1.3 Komponen Utama untuk Data yang
Distandardisasi………. 13
2.1.4 Peringkasan Variasi Sampel oleh Komponen Utama………. 15
2.1.5 Penentuan Jumlah Komponen Utama………. 18
2.1.6 Komponen Utama untuk Sampel yang Distandarisasi... 19
2.2 Analisis Faktor………... 21
2.2.1 Pengertian ……….. 21
2.2.2 Model dan Asumsi Analisis Faktor……….. 22
2.2.3 Metode Estimasi………. 26
2.2.4 Menguji Kesesuaian Model………... 26
2.2.5 Penentuan Jumlah Faktor……….. 28
2.2.6 Rotasi Faktor……… 29
2.2.7 Menghitung Skor Faktor………. 32
2.3 Analisis Diskriminan………. 33
2.3.1 Pengertian dan Tujuan……… 33
2.3.2 Asumsi-Asumsi……… 34
2.3.3 Struktur Data……… 34
2.3.4 Mengidentifikasi Variabel secara Univariat…………. 36
2.3.6 Fungsi Diskriminan Linear………... 39
2.3.7 Uji Signifikansi Fungsi Diskriminan……….. 41
2.4 Analisis Gap (Kesenjangan)………... 42
2.4.1 Pengertian Analisis Gap………. 42
2.4.2 Tingkat Kesesuaian………. 43
2.4.3 Pemetaan Hasil Penelitian………..……… 45
BAB III ANALISIS DATA……….………. 48
3.1 Latar Belakang Perusahaan……… 48
3.1.1 Sejarah Perusahaan……… 48
3.1.2 Proses Produksi………... 49
3.1.3 Wilayah Layanan PDAM………. 50
3.2 Analisis Karakteristik Responden………... 50
3.2.1 Pelanggan Rumah Tangga………. 50
3.2.2 Pelanggan Non Rumah Tangga……… 55
3.3 Analisis Data Kepuasan Pelanggan……….. 57
3.3.1 Struktur Data………. 57
3.3.2 Analisis Data Pelanggan Rumah Tangga……… 58
3.3.2.1 Analisis Faktor……….. 59
3.3.2.2 Analisis Diskriminan……… 62
3.3.2.3 Analisis Gap……….. 71
3.3.3 Analisis Data Pelanggan Non Rumah Tangga…….. 76
BAB IV KESIMPULAN DAN SARAN………. 81
DAFTAR GAMBAR
Gambar Halaman
1 . Diagram kartesius tingkat kesesuaian pelanggan ... 47
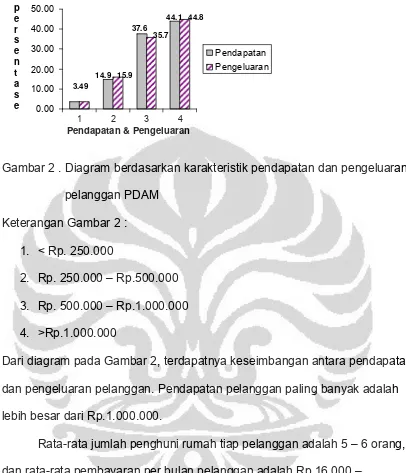
2 . Diagram berdasarkan karakteristik pendapatan dan pengeluaran pelanggan PDAM... 54
3 . Diagram kartesius tingkat kesesuaian pelanggan rumah tangga ... 78
4 . Diagram kartesius tingkat kepuasan pelanggan non rumah tangga. 81
DAFTAR TABEL Tabel Halaman 1. Interpretasi dari nilai KMO..……… ....28
2. Struktur data dalam analisis diskriminan... ... 35
3. Karakteristik pelanggan berdasarkan pendidikan terakhir... 51
4. Karakteristik pelanggan berdasarkan jenis pekerjaan ... 52
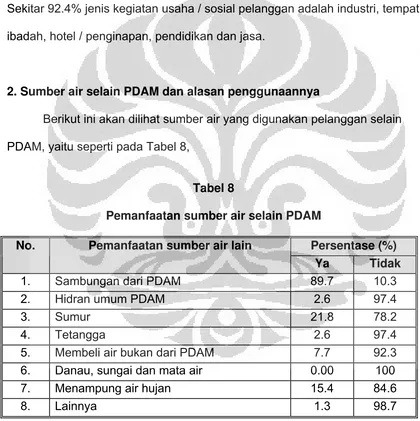
5. Pemanfaatan sumber selain PDAM... 54
6. Alasan pelanggan menggunakan sumber air selain PDAM... 54
8. Pemanfaatan sumber air selain
PDAM... ... 56 9. Alasan pelanggan menggunakan sumber air selain PDAM... 57 10. Kepuasan Pelanggan Berdasarkan Mean dan Standar Deviasi
masing-masing faktor kepuasan... ... 63 11 Tingkat kesesuaian persepsi pelanggan rumah tangga... ... 72 12. Kepuasan pelanggan berdasarkan wilayah layanan PDAM... .... 82
DAFTAR LAMPIRAN
Halaman Lampiran 1 Pembuktian Maksimization of Quadratic Forms For
Points On The Unit Sphere... 88 Lampiran 2 Uji variabilitas dan validitas variabel-variabek kepuasan
pelanggan PDAM ... 90 Lampiran 3 Output hasil analisis faktor untuk pelanggan rumah
tangga... 97 Lampiran 4 Output hasil analisis diskriminan untuk pelanggan rumah
tangga... 101 Lampiran 5 Analisis tingkat kesesuaian antara kepuasan dan
bahan acuan lokasi SKP-PDAM Bukittinggi tahun 2005... 112 Lampiran 7 Pembagian variabel-variabel yang mempengaruhi
kepuasan pelanggan serta analisis karakteristik secara
deskriptif... 113 Lampiran 8 Kuisioner pelanggan rumah tangga, non pelanggan dan
1.1 Latar Belakang Masalah
Salah satu ciri perekonomian dinamis ditandai dengan keikutsertaan perusahaan-perusahaan yang berperan aktif dalam menunjang
pembangunan. Tujuan perusahaan adalah memenuhi kebutuhan sosial masyarakat dan mempertahankan hidup perusahaan tersebut. Perusahaan Daerah Air Minum (PDAM) adalah salah satu perusahaan yang memiliki tujuan tersebut.
Perusahaan Daerah Air Minum bertujuan untuk memberikan
pelayanan umum berupa jasa kepada masyarakat dengan jalan memenuhi dan mengusahakan kebutuhan air minum yang bersih dan sehat bagi kesehatan masyarakat. PDAM sebagai perusahaan daerah yang eksistensi dan fungsinya sangat penting bagi masyarakat dan pemerintahan daerah, pimpinan dan segenap karyawannya harus mempunyai komitmen yang tinggi dalam mengembangkan, meningkatkan, serta memperbaiki sistim
manajemen yang ada dengan cara yang profesional dan jelas, serta berkesinambungan.
pelangganlah yang memberikan kesempatan produsen untuk melayaninya. Oleh karena itu merupakan suatu keharusan bagi produsen, untuk
memberikan pelayanan yang memuaskan bagi pelanggan.
Secara umum, kepuasan adalah nilai yang diperoleh pelanggan dengan membandingkan manfaat yang dirasakan terhadap harga yang dikeluarkan saat membeli suatu produk. Jika manfaat yang dirasakan pelanggan semakin besar dibandingkan biaya yang dikeluarkan, maka nilai dari tingkat kepuasan akan semakin besar, sehingga perusahaan akan selalu memperbesar manfaat, apabila harga tetap atau tidak dapat diturunkan.
Menurut Kotler (1997), kepuasan adalah perasaan seseorang yang berhubungan dengan kenyamanan atau kekecewaan sebagai akibat dari perbandingan antara pelayanan yang dirasakan dengan harapannya. Jadi kepuasan tergantung pada kinerja yang ditawarkan, yang dikaitkan dengan terpenuhi atau tidak terpenuhinya harapan pelanggan.
Sehubungan dengan tingkat kepuasan, banyak perusahaan yang berusaha untuk mencapai tingkat kepuasan pelanggan yang tinggi. Karena jika pelanggan sudah sangat puas maka mereka tidak mudah untuk
berpindah kepada suatu penawaran lain yang lebih baik.
Konsep kepuasan pelanggan lebih diutamakan pada tingkat
1. Undang-Undang tentang perlindungan konsumen (No.8 Th.1999) 2. Surat edaran Menteri Dalam Negeri melalui Dirjen PUMDA,
No.690/947/PUMDA, tentang Buku Petunjuk Pelaksanaan Survey Kepuasan Pelanggan (SKP) bagi PDAM di Indonesia.
Sejak dikeluarkannya undang-undang tentang perlindungan hak konsumen, disadari oleh pihak PDAM bahwa hak-hak konsumen sebagai pengguna produk akan dilindungi dengan hukum yang pasti. Kesadaran masyarakat akan hak-hak konsumen selama ini kurang mendapat perhatian untuk menjadikannya sebagai faktor utama yang mendorong PDAM dalam menjalankan kebijakan di bidang manajemen, baik internal maupun
eksternal. Dengan didasari oleh undang-undang perlindungan hak
konsumen, maka PDAM seluruh Indonesia, khususnya Bukittinggi melakukan suatu survey untuk mengukur kepuasan pelanggan. Melalui Survey
Kepuasan Pelanggan (SKP), PDAM mengharapkan untuk memperoleh umpan balik secara langsung dari pelanggan, dan sekaligus memberikan upaya positif bagi PDAM untuk meningkatkan pelayanannya.
1.2 Perumusan Masalah
Permasalahan dalam penelitian ini, adalah
1. Bagaimanakah tingkat kepuasan atas pelayanan yang diberikan PDAM selama ini.
2. Apakah ada perbedaan kepuasan pelanggan PDAM pada lima wilayah layanan di Bukittinggi dan wilayah layanan manakah yang harus
ditingkatkan.
1.3 Pembatasan Masalah
Penelitian ini hanya berlaku untuk PDAM Daerah Tingkat II Kota Bukittinggi, Sumatera Barat.
1.4 Hipotesis
Hipotesis dalam penelitian ini adalah:
Ada perbedaan tingkat kepuasan pelanggan PDAM di tiap wilayah layanan Daerah Tingkat II Kota Bukittinggi.
1.5 Tujuan Penelitian
1. Untuk mengetahui faktor-faktor yang mempengaruhi kepuasan
pelanggan PDAM Bukittinggi, dilakukan dengan menggunakan analisis faktor.
2. Untuk mengetahui tingkat kepuasan pelanggan di tiap wilayah layanan dilakukan, dengan menggunakan analisis diskriminan.
3. Untuk mengetahui kesesuaian antara pelayanan yang diharapkan dengan pelayanan yang dirasakan pelanggan, dilakukan dengan menggunakan analisis gap.
1.6 Manfaat Penelitian
Manfaat dari penelitian ini dapat memberikan saran-saran dan perbaikan pelayanan bagi PDAM Bukittinggi.
1.7 Metode Penelitian
rumah tangga. Dari 1331 responden, yang dapat digunakan sebagai ukuran sampel adalah 774 responden untuk pelanggan rumah tangga dan 78 responden pelanggan non rumah tangga. Sehingga total ukuran sampel adalah 852 responden.
1.8 Sistimatika Pembahasan
Agar pembahasan permasalahan dapat dibahas dengan lebih jelas, maka penulis menyajikannya dalam susunan bab sebagai berikut:
Bab I, pendahuluan yang berisi penjelasan mengenai dasar pemilihan judul, perumusan masalah, tujuan penelitian, manfaat penelitian dan metode penelitian yang dipilih.
Bab II, berisi landasan teori mengenai analisis faktor dengan metode komponen utama, analisis diskriminan dan analisis gap (kesenjangan). Bab III, merupakan latar belakang PDAM kota Bukittinggi, analisis karakteristik responden dan analisis data kepuasan pelanggan PDAM.
2.1 Analisis Komponen Utama
2.1.1 Pengertian
Analisis komponen utama adalah suatu teknik untuk membentuk
variabel baru yang merupakan kombinasi linier dari variabel mula-mula. Variabel-variabel baru yang terbentuk ini disebut juga komponen utama.
Secara geometri, kombinasi linier ini mewakili pemilihan sistim koordinat baru yang diperoleh dengan merotasi sistim koordinat mula-mula, dengan variabel mula-mula sebagai sumbu koordinat. Masing-masing sumbu koordinat
diusahakan dapat memberikan informasi sebanyak mungkin mengenai variasi-variasi di dalam variabel-variabel mula-mula. Oleh sebab itu,
diinginkan agar hasil proyeksi data pada masing-masing sumbu koordinat menjadi maksimum.
Variabel baru dalam komponen utama merupakan kombinasi linier dari
2.1.2 Model Matematik dan Struktur Kovariansi
Pandang vektor acak X' =[X1,X2,...,Xp] memiliki matriks kovariansi
Σ (matriks definit positif) dengan nilai eigen λ1¡Ýλ2 ¡Ý...¡Ýλp ¡Ý0. Maka
Y1=a1X=a11X1+a12X2+...+a1pXp '
Y2=a2'X=a21X1+a22X2+...+a2pXp
M
Yp =ap'X=ap1X1+ap2X2+...+appXp (2.1-1)
dengan
Yj = nilai komponen ke-j
Xi = nilai variabel acak mula-mula ke-i
aij = koefisien variabel acak mula-mula ke-i terhadap komponen ke-j i, j = 1, 2, ..., p
dalam bentuk persamaan matriks
= p 2 1 pp p2 p1 2p 22 21 1p 12 11 p 2 1 X X X a a a a a a a a a Y Y Y M L M O M M L L M dengan i i i)
Var(Y =a'Σa i = 1, 2, …, p (2.1-2)
k i k i,Y
Komponen utama yang terbentuk memiliki variansi maksimum, sedangkan antar komponen tidak berkorelasi. Komponen ke-1 memiliki
variansi terbesar pertama, komponen ke-2 memiliki variansi terbesar kedua setelah komponen ke-1, komponen ke-i memiliki variansi terbesar ke-i
setelah komponen ke-k jika k < i.
Komponen utama ke-1 = kombinasi linier a1’X yang memaksimumkan Var(a1’X) dengan a1’a1= 1
Komponen utama ke-2 = kombinasi linier a2’X yang memaksimumkan
Var(a2’X) dengan a2’a2= 1 dan Cov(a1X,a2X)=0
' '
pada langkah ke-i
Komponen utama ke- i = kombinasi linier ai’X yang memaksimumkan
Var(ai’X) dengan ai’ai = 1 dan Cov(a X,a X)=0 ' k ' i
untuk k < i.
Akibat (2-1):
Pandang vektor acak X' =[X1,X2,...,Xp], Misalkan matriks
kovariansi Σ memiliki pasangan nilai eigen dan vektor eigen
(
λ1,e1) (
, λ2,e2)
,....,(
λp,ep)
dimana λ1 ¡Ýλ2 ¡Ý...¡Ýλp ¡Ý0, maka komponenke-i adalah
p 2
i2 1 i
i e X e X ... e X
Y =e'X= i1 + + + ip i = 1, 2, …, p (2.1-4)
Var(Yi)=ei'Σei =λi i = 1, 2, …, p
0 =
= i k
k i,Y )
Cov(Y e'Σe i≠k (2.1-5)
Jika beberapa nilai eigen λi sama, maka pemilihan vektor eigen ei yang
berpadanan dan nilai komponen Yi tidak unik.
Bukti:
Dari Lampiran 1, apabila B =Σ, maka
1 λ max = a a Σa a 0 a ' ' ‚
Untuk a = e1, dan vektor eigen ortonormal yaitu e1’e1 = 1, sehingga
) Var(Y λ max 1 = = = = 1 ' 1 1 1 1 1 1
‚ e e e e
Σe e a a Σa a 0 a ' ' ' '
Dengan cara yang sama,
1 k λ max + =
⊥ aa
Σa a e e e a ' ' k ,..., , 2 1
k = 1, 2, …, p-1
untuk a=ek+1 dengan ek+1ei =0
' ; i = 1, 2, …, k dan k = 1, 2, …, p-1, ,maka
) Y ( Var λ ) λ
( k 1 k 1 k 1 k 1 k 1 k 1 k 1 ' 1 k 1 k 1 k 1 k 1 k 1 k 1 k + + + + + + + + + + + + +
+ =e Σe =e e =λ e e = =
e e
Σe
e ' '
' ' dan 0 ) ( ' ' ' = = =
= i λk k λk i k
) Y ,
Cov(Yi k eiΣek e e e e untuk i≠k, 0λ ‚ diperoleh
0
'
=
k ie
Akibat (2-2):
Pandang vektor acak X' =[X1,X2,...,Xp] dengan matriks kovariansi Σ
yang memiliki pasangan nilai eigen dan vektor eigen
(
λ1,e1) (
, λ2,e2)
,....,(
λp,ep)
dengan syarat λ1¡Ýλ2 ¡Ý...¡Ýλp ¡Ý0. Misalkankomponen utama Y1 = e1’X, Y2 = e2’X, …, Yp = ep’X,, maka
‡” ‡” p 1 i i p 2 1 p 1 i i pp 22
11+σ +...+σ Var(X ) λ λ ... λ Var(Y) σ = = = + + + = =
dengan σii adalah variansi variabel ke-i.
Bukti:
Menurut definisi matriks kovariansi Σ, elemen diagonal utama adalah variansi dari masing-masing variabel mula-mula, sehingga
) ( tr σ + ... + σ +
σ11 22 pp = Σ
Hubungan antara matriks kovariansi Σ, nilai eigenλi dan vektor eigen ei,
dapat dinyatakan dalam bentuk persamaan matriks
pxp) (pxp) (pxp) (pxp) ( '
P
Λ
P
Σ
=
; P’P = PP’ =I(pxp)dengan
Σ = matriks kovariansi (p x p) dengan elemen diagonal utama adalah
variansi variabel mula-mula
P = matriks (p x p) dengan kolom-kolomnya adalah vektor eigen Λ = matriks (p x p) dengan elemen diagonal utama adalah nilai eigen
diperoleh tr(Σ)=tr(PΛP')=tr(ΛPP')= tr(Λ)=λ1+λ2 +...+λp
Oleh karena itu dari persamaan (2.1-5) diperoleh hubungan
‡”
) ( ) ( p 1 i i p 1 ii) tr tr Var(Y)
Var(X
=
= = = =
∑
Σ Λ (2.1-6)atau
∑
∑
= = = + + + = =p1 i i p 1 i
i) σ +σ +...+σ λ λ ... λ Var(Y)
Var(X p 2 1 pp 22 11
Variansi total dari populasi adalah σ11+σ22 +...+σpp=λ1+λ2+...+λp
dan proporsi variansi total populasi yang diberikan komponen utama ke-k
adalah p 2 1 k λ ... λ λ λ k -komponen dari asi standardis variabel total variansi proporsi + + + =
; k = 1, 2, …,p (2.1-7)
Akibat (2-3):
Jika komponen utama Y1 = e1’X, Y2 = e2’X, …, Yp = ep’X dihasilkan dari matriks kovariansi Σ yang memiliki pasangan nilai eigen dan vektor eigen
(
λ1,e1) (
, λ2,e2)
,....,(
λp,ep)
dengan syarat λ1¡Ýλ2 ¡Ý...¡Ýλp ¡Ý0, makakk i ik σ λ e ρ k X , i
Y = i, k =1, 2, …, p (2.1-8)
adalah koefisien korelasi antara komponen Yi dan variabel Xk
Bukti:
Kovariansi antara variabel ke-k, Xkdan komponen utama ke-i, Yiadalah
)) ( Cov Cov
) Y ,
Cov(Xk i = (ak'X,ei'X)= (ak'X ei'X
=Cov(ak'XX'ei)=ak'Cov(XX')ei =ak'Σei
Jika Σei =λiei, maka Cov(Xk,Yi)=ak'λiei =λiakei =λieik
Dari akibat (2-1) diperoleh Var(Yi)=λi dan Var(Xk)=σkk, maka diperoleh
( )
( )
kki ik
kk i
ik i
k i
k i X
, Y
σ λ σ
λ λ X
Var Y
Var
) X , Cov(Y
ρ i k = = e = e i, k =1, 2, …, p
Koefisien korelasi
k i,X Y
ρ memberikan interpretasi besarnya kontribusi
univariat variabel mula-mula terhadap komponen, sedangkan koefisien eik memberikan interpretasi seberapa pentingnya variabel mula-mula terhadap
komponen. Nilai mutlak koefisien eik yang besar akan memiliki korelasi yang kuat.
2.1.3 Komponen Utama untuk Data yang Distandardisasi
Sekumpulan variabel tidak selalu memiliki satuan pengukuran yang sama. Perbedaan yang sangat besar antara satuan pengukuran akan
Pandang variabel acak X1, X2, …, Xp dengan mean masing-masing
p 2 1,µ ,...,µ
µ , dan variansi σ11,σ22,....,σpp. Maka bentuk variabel yang
distandardisasi adalah:
(
)
11 1 1 1 σ µ XZ = −
(
)
22 2 2 2 σ µ XZ = −
M
(
)
pp p p p σ µ XZ = − (2.1-9)
dalam notasi matriks,
(
X µ)
V
Z = −
−1 2 1
(2.1-10)
dengan matriks standar deviasi V12=
pp 22 11 σ 0 0 0 σ 0 0 0 σ L M O M M L L mean dan
kovariansi dari variabel yang distandardisasi, Z adalah E(Z) = 0 dan
( ) ( )
ρ )Cov(Z = V12 −1ΣV12 −1 =
Berikut ini adalah komponen utama yang merupakan kombinasi linier
dari variabel mula-mula yang distandardisasi,
Y = e’Z ; Z=[Z1 ,Z2 ,… ,Zp]
Akibat (2-4):
Untuk variabel mula-mula yang distandardisasi terlebih dahulu,
) -( ) ( ' i = i = i
Y e'Z e V12 -1 x µ i = 1, 2, …, p
identik dengan persamaan (2.1-6), maka diperoleh
p 1 ... 1 1 ) Var(Z ) Var(Y p 1 i i p 1 i
i = = + + + =
= =
‡”
‡”
(2.1-11)dan identik dengan persamaan (2.1-8), diperoleh
i λ ik e 1 i λ ik e kk σ i λ ik e k X , i Y
ρ = = = i = 1, 2, …, p
maka
i ik ,Z
Y e λ
ρ i k = i, k = 1, 2, …, p
Dari persamaan (2.1-11), variansi total populasi dengan variabel
yang distandardisasi adalah p, dan
p λ k komponen dari variansi proporsi k =
− k =1, 2, …, p (2.1-12)
k
λ adalah nilai eigen dari matriks korelasi ρ.
2.1.4 Peringkasan Variasi Sampel oleh Komponen Utama
Pandang pengamatan x1, x2, …, xp yang saling bebas, yang diambil
kovariansi Σ. Dari pengamatan tersebut diperoleh vektor mean sampel xdan matriks kovariansi sampel S (matriks korelasi sampel R). Analisis komponen
utama membentuk komponen-komponen yang tidak saling berkorelasi sebagai kombinasi linier dari variabel mula-mula yang memiliki variansi
terbesar dalam sampel, komponen-komponen tersebut dinamakan komponen utama sampel.
Misalkan n-nilai dari setiap kombinasi linier, dinyatakan dengan
jp 1p j2
12 j1
11x a x ... a x
a + + +
=
x
a1' j = 1, 2, …, n
memiliki mean sampel a1'x dan variansi sampel a1'Sa1, untuk pasangan
nilai
(
a1'xj,a2'xj)
memiliki kovariansi sampel a1'Sa2.Komponen utama ke-1 = kombinasi linier a1’xj yang memaksimumkan Var(a1’xj) dengan a1’a1 = 1
Komponen utama ke-2 = kombinasi linier a2’xj yang memaksimumkan
Var(a2’xj) dengan a2’a2 = 1 dan Cov(a1xj a2xj)=0
' '
,
pada langkah ke-i
Komponen utama ke-i = kombinasi linier ai’xj yang memaksimumkan Var(ai’xj)
dengan ai’ai = 1 dan Cov(aixj ak xj)=0
' '
,
untuk k < i
Jika matriks S ={sik}yang berukuran (p x p) adalah matriks kovariansi sampel
yang memiliki pasangan nilai eigen dan vektor eigen
( )( ) ( )
λˆi,eˆi , λˆ2,eˆ ,...,λˆp,eˆp2 ,
p ip 2 i2 1 i1
i e x e x ... e x
yˆ =eˆi'x = ˆ + ˆ + + ˆ i =1, 2, …, p
dengan λˆ1 ¡Ýλˆ2 ¡Ý...λˆp ¡Ý0 dan x adalah nilai pengamatan untuk setiap variabel X1, X2,…, Xp.
Variansi sampel (yˆk)=
k
λˆ k = 1, 2, …, p (2.1-13)
Kovariansi sampel
(
yˆi,yˆk)
=0 i ‚kVariansi total sampel = 1 2 p
p
1 = i
ii =λˆ +λˆ +...+λˆ
s
‡”
Dan korelasi antara komponen utama sampel ke-i dan pengamatan ke-k dari
setiap variabel mula-mula adalah
kk i ik x , y s λ r k i ˆ ˆ ˆ e
= i, k, = 1, 2, …, p
Pemusatan pengamatan xj oleh mean sampel x tidak akan mengubah
matriks kovariansi sampel S. Maka komponen ke-i adalah
(
x x)
eˆ
-ˆ '
i =
i
y i = 1, 2, …, p (2.1-14)
untuk setiap vektor pengamatan x. Nilai pengamatan komponen utama ke-i menjadi
( )
x xeˆ
-ˆ '
j i ji
y = j = 1, 2, …, n (2.1-15)
Dengan substitusi tiap pengamatan xj pada persamaan (2.1-14), maka diperoleh mean sampel tiap komponen nol, yaitu
(
)
ˆ 0ˆ = ) -( ˆ ˆ
‡”
' n 1 j= i 'i = =
−
∑
= x x e 0 ex x
e i'
dan variansi sampel tetap yaituλi
2.1.5 Penentuan Jumlah Komponen Utama
Secara umum, tujuan dari analisis komponen utama adalah mereduksi
jumlah variabel dan menginterpretasikannya. Dalam mereduksi jumlah variabel, banyaknya variabel baru atau komponen utama yang terbentuk
dapat mewakili variansi terbesar dari variabel mula-mula.
Prosedur untuk menentukan banyaknya komponen yang diinginkan, salah satunya adalah berdasarkan nilai eigen. Suatu nilai eigen dari matriks
kovariansi Σmewakili besarnya sumbangan variansi dari variabel mula-mula yang dapat dijelaskan oleh setiap komponen utama. Jika nilai eigennya
kurang dari satu, maka komponen utama tersebut tidak diiukutsertakan dalam analisis, sebaliknya jika nilai eigen lebih besar dari satu, maka komponen utama tersebut diikutsertakan dalam analisis. Aturan ini
didasarkan pada data yang distandardisasi, dimana besarnya variansi variabel mula-mula yang diekstraksi oleh tiap komponen adalah minimum.
2.1.6 Komponen Utama untuk Sampel yang Distandardisasi
Komponen utama sampel bergantung pada skala. Jika skala pengukuran variabel mula-mula sampel berbeda maka dilakukan
standardisasi terhadap variabel tersebut, yaitu
⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ − − − = − = pp p jp 22 2 j2 11 1 j1 s x x s x x s x x M ) (
j D x x
z -12 j j = 1, 2, …, n
matriks data (n x p) dari variabel yang distandardisasi, yaitu
menghasilkan vektor mean sampel
dan matriks kovariansi sampel adalah − − −
= Z 11'Z Z 11'Z
SZ n 1 n 1 1 n 1 '
(
')(
')
z 1 Z z 1Z− −
− = ' 1 n 1 Z Z' 1 n 1 −
= =R
⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ − − − − − − − − − − = pp pp pp 22 p 2 pp 11 p 1 pp 22 p 2 22 22 22 11 112 pp 11 p 1 22 11 12 11 11 s s ) 1 n ( s s s ) 1 n ( s s s ) 1 n ( s s s ) 1 n ( s s ) 1 n ( s s s ) 1 n ( s s s ) 1 n ( s s s ) 1 n ( s s ) 1 n ( 1 n 1 L M O M M L L
Jika z1, z2, …, zn adalah pengamatan dari variabel yang
distandardisasi dengan matriks korelasi R, maka komponen utama sampel
adalah p ip 2 2 i 1 1 i i
i ˆ eˆ z eˆ z ... eˆ z
yˆ =e'z= + + + i = , 1, 2, …, p
Pasangan nilai eigen dan vektor eigen dari matriks korelasi R adalah
( )( ) (
λˆi,eˆi , λˆ2,eˆ2 ,..., λˆp,eˆp)
dengan λˆ1 ¡Ýλˆ2 ¡Ý...λˆp ¡Ý0.Variansi sampel (yˆi)=λˆik i =1, 2, …, p (2.1-13)
Kovariansi sampel
(
yˆi,yˆk)
=0 i ‚k Variansi total sampel = tr(R) =p= λˆ1 +λˆ2 +...+λˆpi ik z ,
yˆ ˆ ˆ
r
k
i =e λ i, k, = 1, 2, …, p
Proporsi variansi total populasi yang diberikan komponen utama ke-k adalah
p
λˆi
asi standardis
variabel
dengan i
-komponen dari
variansi
proporsi
=
i=1, 2, …,p. (2.1-30)
Nilai eigen kecil yang diperoleh dari matriks kovariansi sampel S
(matriks korelasi sampel R) mengindikasikan bahwa sekumpulan data tidak
bebas linier, sehingga terjadi pengulangan variabel. Sebaliknya jika nilai eigen yang diperoleh besar, mengindikasikan bahwa sekumpulan data bebas linier sehingga interpretasi menjadi lebih mudah.
2.2 Analisis Faktor
2.2.1 Pengertian
Metode statistik dapat dibagi atas dua kelompok berdasarkan jumlah variabel yang dianalisis yaitu analisis univariat dan analisis multivariat.
Analisis univariat adalah analisis yang melibatkan satu variabel, sedangkan analisis multivariat adalah analisis yang melibatkan lebih dari satu variabel. Analisis faktor adalah salah satu analisis multivariat digunakan untuk
mereduksi jumlah variabel menjadi dimensi lebih kecil dan masih
adalah p, setelah dilakukan analisis faktor, diperoleh m variabel yang disebut juga m faktor dengan m < p.
Analisis faktor banyak digunakan pada bidang pemasaran,
manajemen, kedokteran, psikologi dan ilmu sosial lainnya. Dalam skripsi ini,
analisis faktor digunakan untuk mereduksi variabel-variabel yang dapat mempengaruhi kepuasan pelanggan PDAM kota Bukittinggi.
2.2.2 Model dan Asumsi Analisis Faktor
Secara matematis, analisis faktor mirip dengan regresi linier berganda,
yaitu setiap variabel dapat dinyatakan sebagai kombinasi linier dari faktor-faktor. Variabel terobservasi X bergantung linier terhadap variabel tak
terobservasi atau commonfaktor F1, F2, … , Fmdan faktor unik ε1,ε2,...,εp
Model faktor dari suatu sistim variabel ganda yang mengandung p variabel acak X1, X2, …, Xp , adalah
1 m m 2
12 1 11 1
1 µ F F ... F ε
X − =l +l + +l1 +
2 m 2m 2
22 1 21 2
2 µ F F ... F ε
X − =l +l + +l +
M
p m pm 2
p2 1 p1 p
p µ F F ... F ε
X − =l +l + +l + (2.2-1)
dengan
Xi = variabel terobservasi ke-i
Fj = variabel tak terobservasi ke-j atau commonfaktor ke-j
ij
l = koefisien loading dari variabel ke-j dan commonfaktor ke-j.
εi = faktor unik untuk variabel ke-i
i = 1, 2, …, p j = 1, 2, …,m
Persamaan (2.2.-1) dapat dinyatakan dalam bentuk matriks, yaitu
(px1) (mx1)
(pxm) (px1)
(px1) µ L F ε
X − = + (2.2-2)
dengan
X = vektor variabel (p x 1)
µ = vektor mean (p x 1)
L = matriks loading dari faktor (p x m)
F = matriks faktor (m x 1) ε = vektor faktor unik (p x 1)
i = 1, 2, …, p dan j = 1, 2, …, m
Analisis faktor akan memberikan hasil yang signifikan jika memenuhi
asumsi, yaitu
1. Terdapat korelasi yang signifikan antar variabel-variabel terobservasi 2. Mean common faktorF dan faktor unik εadalah nol
E(F) = 0(mx1) dan Cov(FF’) = I(mxm)
E(ε) = 0(px1)dan Cov(εε’) = Ψ(pxp) (2.2-3)
3. Variansi variabel terobservasi dan variansi common faktor adalah satu.
4. Faktor unik ε tidak berkorelasi dengan common faktorF dan antar sesamanya.
Cov(ε,F) = E(εF’) = 0 dan Cov(εi, εj) = 0 untuk i = 1, 2, …, p dan j = 1, 2, …, m.
Dari persamaan X−µ=LF+ε, maka diperoleh
1. Σ=Cov(X)=LL'+Ψ
Atau
i im
i2
i1 Ψ
Xi) = 2 + 2 +...+ 2 +
var( l l l (2.2-4)
km im k2
i2 k1 i1 k
i, )=l l +l l +...+l l
Cov(X X dengan i = 1, 2, …, p
Bukti:
(
LF+ε)(
LF+ε)
' =(LF)(LF)' +(LF)ε' +ε(LF)' +εε'εε' L
εF' LFε L'
LFF' + + +
= ' '
ε) LL µ
X
Σ=Cov( - )=Cov( '+
(
)(
)
[
X µ X µ]
[
(
LF ε) (
, LF ε)
,]
Σ=E - , - =E + +
[
LFF'L' LFε' εF'L' εε'] [
ELFF'L'] [ ] [
ELFε' Eε'F'L'] [ ]
Eεε'E + + + = + + +
=
[ ]
FF' L' L[ ] [ ]
Fε ε'F' L'[ ]
εε'LE + E ' +E +E
=
Ψ
LL'+
=
2. Cov(X,F)=L
atau
Cov(Xi,Fj)=lij dengan i = 1, 2, …, p dan j = 1, 2, …, m (2.2-5)
Bukti:
(
)
[
X µF']
[
(
LF ε)
F'] [
LFF' εF']
FX, )=E − =E + =E +
Cov(
[ ] [ ]
LFF' + εF' =L[ ]
FF' +0=L=E E E
Variansi dari variabel terobservasi X berasal dari dua komponen yaitu
common faktorF dan faktor unik ε. Variansi yang berasal dari common faktor F, disebut communality yaitu besarnya kontribusi variansi suatu faktor
terhadap variansi seluruh variabel. Dalam hal ini, communality sebut ci2 sama
dengan jumlah kuadrat dari loading faktor, yaitu
2 im 2
i2 2 i1 2
i ...
c =l +l + +l dengan i = 1, 2, …, p (2.2-6)
Sehingga dari persamaan (2.2-4), σii =Var(Xi)=communality+var(εi)
dengan i = 1, 2, …,p
Variansi yang berasal dari faktor unik diakibatkan oleh dua faktor yaitu
faktor unik dan faktor unreliability. Pengaruh faktor unreliability dapat dikurangi dengan cara mengadakan pengamatan yang berulang-ulang.
Tetapi misalnya pengamatan dalam bidang psikologi dan ilmu sosial lainnya tidak memungkinkan bagi peneliti untuk melakukan pengamatan ulang. Maka untuk memudahkan perhitungannya, segala bentuk kesalahan digabung
2.2.3 Metode Estimasi
Metode estimasi analisis faktor yang digunakan dalam penulisan skripsi ini adalah metode analisis komponen utama. Analisis faktor dan
analisis komponen utama memiliki tujuan yang sama, yaitu mereduksi
sekumpulan variabel menjadi variabel baru yang jumlahnya lebih sedikit. Ada dua perbedaan antara analisis faktor dengan analisis komponen utama.
Pertama, analisis komponen utama bertujuan untuk mereduksi sejumlah variabel menjadi beberapa komponen yang dapat menerangkan sebagian besar variansi dari data, sedangkan analisis faktor selain bertujuan untuk
mereduksi variabel, juga mengidentifikasi faktor yang muncul karena adanya korelasi yang kuat antar variabel. Kedua, dalam analisis komponen utama,
variabel hanya membentuk sebuah indeks, sedangkan dalam analisis faktor, variabel dapat dinyatakan sebagai kombinasi linier dari faktor-faktor yang diperoleh disebut juga variabel balikan.
1.2.4 Uji Kesesuaian Model
Langkah awal yang perlu diperhatikan sebelum melakukan analisis faktor adalah memeriksa korelasi antar variabel-variabelnya. Jika korelasi
antar variabel cukup tinggi, maka analisis faktor dapat dilakukan pada data tersebut. Pengujian hipotesis untuk korelasi tersebut dilakukan sebagai
Ho : Variabel tidak saling berkorelasi dalam populasi H1 : Variabel saling berkorelasi dalam populasi
Statistik ujinya dinyatakan dengan koreksi Bartlett, yaitu
(2.2-7)
dengan
L = matriks loading faktor (p x m)
Ψ = matriks kovariansi faktor unik (p x p)
Sn= matriks kovariansi sampel berukuran n
n = ukuran sampel
p = ukuran variabel mula-mula
m = ukuran faktor yang diperoleh
Statistik uji (2.2-7) didekati dengan distribusi Chi-square (χ2) dengan derajat
bebas [( ) ]
2 1 2 m p m p
v= − + − .
Pada tingkat signifikansi α , H0 ditolak jika koreksi Bartlett lebih besar dari
α,ν 2
χ dan lainnya H0 tidak ditolak. H0 ditolak berarti data tidak sesuai untuk
analisis faktor.
Langkah selanjutnya sebelum menggunakan analisis faktor adalah menguji kelayakan data dengan menggunakan statistik uji Keiser
Meyer-Olkin, dengan hipotesis,
Ho : Sampel belum memadai untuk dianalisis lebih lanjut H1 : Sampel sudah memadai untuk dianalisis lebih lanjut
Statistik uji dari Kaiser Meyer-Olkin (KMO), adalah
+
=
∑∑
∑∑
∑∑
= = = =
= =
p
1 i
p
1 j
2 ij p
1 i
p
1 j
2 ij p
1 i
p
1 j
2 ij
a r
r KMO
dimana
aij = korelasi parsial variabel ke-i dengan ke-j rij = korelasi antara variabel ke-i dengan ke-j
Tabel 1 berikut ini memberikan interpretasi dari nilai KMO yaitu
Tabel 1
Interpretasi dari nilai KMO
Nilai KMO Interpretasi
0.90 to 1.00 sangat bagus
0.80 to 0.89 Bagus
0.70 to 0.79 Sedang
0.60 to 0.69 Kurang bagus
0.50 to 0.59 Tidak bagus
0.00 to 0.49 Sangat tidak bagus
2.2.5 Penentuan Banyaknya Faktor
Setelah menguji kelayakan data, selanjutnya adalah menentukan jumlah faktor yang akan dibentuk yaitu sesuai dengan metode komponen
Kontribusi variansi faktor yang terbentuk seharusnya besar.
Sumbangan variansi sampel dari faktor ke-j terhadap variabel ke-i adalah
2 ij
l , maka variansi total sampel yang diberikan oleh faktor-j adalah
= + + + R S matriks untuk ; p λˆ matriks untuk ; s ... s s λˆ j pp 22 11 j (2.2-8)
2.2.6 Rotasi Faktor
Rotasi faktor adalah suatu rotasi yang dilakukan pada loading faktor
yang bertujuan memudahkan interpretasi faktor yang terbentuk. Prosedur rotasi faktor dilakukan dengan mentransformasikan matriks loading faktor L
menjadi matriks L* yang mempunyai sifat yang sama dengan matriks L. Transformasi tersebut dilakukan dengan persamaan
LT L*=
dengan
L = matriks loading faktor (p x m)
L* = matriks loading faktor yang dirotasi
T = matriks orthogonal (m x m) dengan TT’ = T’T =I
Dari persamaan (2.2-2) diperoleh ε
LIF
ε
LF µ
ε
F) (LT)(T'
ε
)F
L(TT' + = +
= ; I = T’T = TT’, F* = T’F dan
L* = LT
ε
F L* * +
= (2.2-9)
Akan ditunjukkan bahwa persamaan (2.2-9) memenuhi asumsi analisis faktor yaitu mean dari F* adalah nol dan kovariansi dari F* adalah I.
Mean dari faktor yang dirotasi adalah E
( )
F* =E( )
T'F =T'E( )
F =0dan kovariansi dari faktor rotasi adalah
( )
( )
( )
(mxm)* Cov T'F T'Cov F T T'IT T'T I
F
Cov = = = = =
Selanjutnya matriks kovariansi faktor rotasi adalah Ψ
LIL'
Ψ
LL'
Σ= + = +
Ψ
) L' (LT)(T'
Ψ
L
LTT' + = +
=
Ψ
)' (L
L* * +
=
dengan jumlah elemen diagonal utama dari matriks L*(L*)' adalah
communality dari faktor rotasi.
Rotasi faktor dapat dikelompokkan menjadi rotasi orthogonal dan rotasi non orthogonal. Rotasi orthogonal merupakan rotasi faktor yang
menghasilkan faktor yang saling orthogonal, sedangkan rotasi non orthogonal merupakan rotasi faktor yang menghasilkan faktor yang tidak orthogonal,
Metode rotasi yang sering digunakan adalah rotasi orthogonal yang terbagi menjadi tiga jenis rotasi, yaitu rotasi quartimax, rotasi varimax dan
rotasi equamax. Analisis data dalam skripsi ini menggunakan rotasi varimax.
Rotasi Varimax
Rotasi varimax merupakan metode rotasi orthogonal yang
meminimumkan jumlah variabel dengan memilih faktor yang memiliki loading
faktor tinggi. Misalkan model faktor Fj =l1jX1+l2jX2 +...+lpjXp dengan
j = 1, 2, …, m. Tujuan dari rotasi varimax adalah memaksimumkan variansi
dari kuadrat loading variabel lij2, yaitu untuk setiap faktor ke-j, didefinisikan
(
)
p V
p
1 i
2 2
j . 2 ij j
∑
= − =l l
(2.2–10)
dengan
Vj = variansi dari communality faktor ke-j
2 ij
l = kuadrat loading dari variabel ke-i dan faktor ke-j
2 j .
l = rata-rata loading kuadrat dari faktor ke-j
2.2.7 Menghitung Skor Faktor
Skor faktor umumnya digunakan untuk analisis multivariat selanjutnya. Metode yang digunakan dalam menghitung skor faktor adalah metode regresi
linier berganda.
Metode Regresi Linier Berganda
Skor faktor untuk pengamatan ke-i dan faktor ke–j dinyatakan sebagai berikut
ip p i2
2 i1 1
ij β x β x ... β x
Fˆ = ˆ +ˆ + + ˆ (2.2-11)
dengan
ij
Fˆ = skor faktor untuk pengamatan ke-i dan faktor ke-j
xip = pengamatan ke-i pada variabel ke-j
p
βˆ = koefisien estimasi skor faktor untuk variabel ke-p
Persamaan di (2.2-11) dapat disederhanakan dalam bentuk matriks,
(pxm) (nxp) (nxm) X β
Fˆ = ˆ (2.2-12)
dengan
Fˆ = matriks skor faktor (n x m)
X = matriks variabel (n x p)
Untuk variabel yang distandardisasi, maka matriks persamaan skor faktor menjadi,
(pxm) (nxp (mxn) Z β
Fˆ = )ˆ (2.2-13)
dengan Z adalah matriks (n x p) dari variabel terobservasi yang distandardisasi (n x p).
2.3 Analisis Diskriminan
2.3.1 Pengertian dan Tujuan
Analisis diskriminan merupakan salah satu metode analisis multivariat yang membagi variabel ke dalam dua kelompok, yaitu variabel bebas dan variabel tak bebas. Secara teknik, analisis diskriminan mirip dengan analisis
regresi. Walaupun demikian, terdapat perbedaan antara analisis diskriminan dan analisis regresi. Dalam analisis diskriminan, variabel tak bebas berupa
data non metrik, sedangkan dalam analisis regresi, variabel tak bebas berupa data metrik. Selain itu, analisis regresi memprediksi nilai variabel tak bebas y, sedangkan dalam analisis diskriminan nilai variabel tak bebas y adalah
kelompok dan analisis ini memprediksi suatu objek masuk ke dalam kelompok yang tepat.
1. Mengidentifikasi sekumpulan variabel yang mampu memisahkan atau mengelompokkan suatu pengamatan.
2. Membentuk fungsi diskriminan untuk menempatkan suatu pengamatan ke dalam kelompok yang sesuai.
2.3.2 Asumsi-Asumsi
Asumsi-asumsi dalam analisis diskriminan adalah 1. Variabel bebas berdistribusi normal multivariat.
2. Matriks kovariansi dari variabel bebas sama untuk setiap kelompok.
Jika kedua asumsi dipenuhi maka fungsi diskriminan yang terbentuk memberikan hasil yang optimal, yaitu memiliki kesalahan pengelompokan
yang kecil. Jika asumsi diskriminan tidak dipenuhi, tidak berarti analisis yang dilakukan adalah sia-sia, tetapi hasilnya tidak optimal.
2.3.3 Struktur Data
Tabel 2
Struktur data dalam analisis diskriminan
Variabel bebas
Kelompok Individu
X1 X2 … X32
2.3.4 Mengidentifikasi Variabel secara Univariat
Secara deskriptif perbedaan mean dan standar deviasi variabel bebas tertentu pada setiap kelompok menunjukkan bahwa variabel tersebut
berpengaruh pada pengelompokan. Untuk menguji variabel yang signifikan dalam membedakan setiap kelompok secara univariat digunakan uji F. Nilai F dihitung berdasarkan analisis variansi satu arah dengan variabel bebas
sebagai variabel kelompok. Model untuk variabel ke-j, yaitu
ijk k
ijk µ e
x = +
dengan
ijk
x = nilai pengamatan ke-i untuk variabel ke-j pada kelompok ke-k
k
µ = mean kelompok ke-k
ijk
e = error, diasumsikan N~
( )
2, 0σ
Hipotesis ujinya, yaitu
H0 : Mean dari setiap kelompok adalah sama H1 : Minimal terdapat dua mean yang berbeda
Statistik ujinya adalah
w b
MSS MSS
F= ,
dengan
Ho ditolak pada tingkat signifikansi α dan jika F > Fα,g−1,n−g dengan Fα,g−1,n−g
adalah suatu nilai dari tabel F yang mempunyai derajat kebebasan (g-1) dan (n-g) untuk g kelompok dan n observasi.
Selain uji F, untuk menguji variabel yang signifikan dalam
membedakan kelompok secara univariat dapat digunakan nilai Wilk’s
Lambda (λ), dengan uji hipotesis sama dengan uji F di atas. H0 ditolak pada
tingkat signifikansi α dan jika
(
)
( )
( )
Fα;g 1,n gλ λ 1 1 g g n − − > − −
− untuk 0<λ≤1.
Jika nilai Lambda mendekati nol berarti variabilitas dalam kelompok kecil
dibandingkan variabilitas keseluruhan. Jika nilai Lambda mendekati satu berarti variabel tersebut tidak menunjukkan pebedaan antar kelompok.
Hubungan antara F dan λ adalah berdasarkan definisi
( )
(
n g)
SS 1 g SS MSS MSS F w b w b − − == dan
t w SS SS = λ
Maka
( )
( )
t b SS 1 g SS g n λ 1 F − − = dengan bSS = jumlah kuadrat antar kelompok
w
SS = jumlah kuadrat dalam kelompok
t
SS = jumlah kuadrat total
b
w
MSS = rata-rata jumlah kuadrat dalam kelompok
Jadi F dan λ berbanding terbalik. Sehingga semakin kecil nilai λ semakin
besar nilai F dan sebaliknya.
2.3.5 Wilk’s Lambda, Nilai Eigen dan Korelasi Kanonikal
Untuk menguji variabel secara multivariat dapat digunakan Wilk’s Lambda yang didekati dengan uji Chi Square. Wilk’s Lambda adalah rasio
antar jumlah kuadrat dalam kelompok terhadap jumlah kuadrat total. Nilai Wilk’s Lambda berkisar antara nol dan satu. Jika nilainya mendekati nol menunjukkan bahwa variabel secara bersamaan membedakan kelompok dan
fungsi diskriminan yang terbentuk adalah fungsi yang baik dalam
membedakan kelompok. Sedangkan jika nilai Wilk’s Lambda mendekati satu
menunjukkan bahwa variabel secara bersamaan tidak memberikan perbedaan dalam kelompok. Hipotesis uji adalah
H0 : Tidak terdapat perbedaan mean antar kelompok untuk tiap variabel
H1 : Terdapat perbedaan mean minimal untuk dua kelompok
Statistik ujinya adalah
t w
SSCP SSCP =
Λ , nilai Wilk’s Lambda didekati dengan
distribusi Chi Square
( )
χ2 , yaitu χ2 =−[n−1−(p+g)/2)lnΛ dengan derajatNilai eigen adalah rasio antara jumlah kuadrat antar kelompok terhadap jumlah kuadrat dalam kelompok. Nilai eigen yang besar
menyatakan fungsi diskriminan yang baik.
Korelasi kanonikal adalah akar dari rasio jumlah kuadrat antar
kelompok terhadap jumlah kuadrat total. Korelasi kanonikal menunjukkan ukuran tingkat hubungan antara skor diskriminan dengan skor kelompok. Nilai korelasi kanonikal mendekati satu menunjukkan fungsi diskriminan yang
baik.
2.3.6 Fungsi Diskriminan Linier
Misalkan pada data terdapat g kelompok dengan p variabel bebas, ni
adalah jumlah pengamatan kelompok ke-i. Suatu pengamatan baru akan ditempatkan pada salah satu kelompok berdasarkan fungsi diskriminan, berikut
ip 1 2
i 1 1 i 1 0
i b b X b X ... b X
D = + + + + (2.3-1)
dengan
Di = skor diskriminan dari pengamatan ke-i Xij = nilai pengamatan ke-i dari variabel ke-j bj = koefisien diskriminan dari variabel ke-j
Notasikan vektor mean untuk kelompok ke-k adalah µk dan
Selanjutnya, matriks jumlah kuadrat antar kelompok adalah
(
)(
)
∑
= − − = g 1 k µ µ µµk k '
b
SSCP
Pandang kombinasi linier D=b'X
dengan
D = matriks skor diskriminan (n x p)
b = vektor koefisien diskriminan (1 x n)
X = vektor variabel bebas (1 x p)
k
µ = vektor mean untuk kelompok ke-k
µ = vektor mean total sampel
Maka mean D untuk kelompok ke-k adalah µˆkD =b'µkdan mean D
untuk keseluruhan adalah b'µ b'µ µ
µ k
D = = =
∑
= g g g 1 k kDˆ . Sedangkan variansi
dari D sama untuk setiap kelompok, yaitu
( )
D =Cov( )
b'X =b'Cov( )
X b=b'ΣbVar maka
(
)
Σb b' µ µ∑
= − = g k 1 2 D D k Var(D) n keseluruha dan kelompok setiap D mean jarak kuadrat(
)(
)
(
)(
)
Σb b' Bb b' Σb b' b µ µ µ µ b' Σb b' µ b' µ b' µ b' µ b' = − − = − − =∑
=∑
= g k g k 1 k k 1 k k ' 'Koefisien b dipilih sedemikian sehingga Σb b'
Bb b'
Didefinisikan nilai =a Σb b'
Bb b'
diperoleh Bb−aΣb=0 yaitu Bb=aΣb.
Jadi a adalah nilai eigen dari Σ−1b sedangkan b adalah vektor eigen yang bersesuaian.
Dipilih b1 adalah vektor eigen yang bersesuaian dengan nilai eigen terbesar
a1 dari Σ−1b, dan b2 adalah vektor eigen yang bersesuaian dengan nilai
eigen terbesar a2 dari Σ−1b, dan seterusnya. Karena rank dari Σ−1badalah min(p, g-1) maka diperoleh jumlah fungsi diskriminan sebanyak min(p, g-1).
Fungsi diskriminan yang terbentuk digunakan untuk mengelompokkan suatu observasi baru pada salah satu kelompok yang tepat. Jika jumlah
kelompok lebih besar dari dua, maka pengelompokan berdasarkan jumlah
kuadrat jarak D terhadap µˆkD, yaitu
(
)(
)
D k D
k D-µ
µ
-D ˆ ' ˆ . Suatu observasi
digolongkan ke dalam kelompok ke-k, jika kuadrat jarak D terhadap µˆiD
adalah minimum.
2.3.7 Uji Signifikansi Fungsi Diskriminan
Fungsi diskriminan yang baik memiliki variabilitas antar kelompok yang besar dibandingkan variabilitas dalam kelompok. Hal ini dapat dilihat dari rata-rata skor diskriminan pada setiap kelompok. Jika rata-rata skor
Hal ini juga dapat dilihat dari nilai Wilk’s Lambda yang telah dijelaskan sebelumnya (pada sub bab 2.3.5). Selanjutnya adalah menentukan fungsi
diskriminan yang signifikan memisahkan antara kelompok. Fungsi
diskriminan ke-r memiliki variabilitas antar kelompok terbesar dibandingkan
dengan fungsi diskriminan ke-(r-1). Dengan hipotesis uji,
H0 : Hanya fungsi diskriminan ke-r yang berpengaruh dalam pengelompokan
H1 : Semua fungsi diskriminan berpengaruh dalam pengelompokan
Dapat digunakan statistik uji, yaitu
( )
(
)
∑
( )
= +
+ −
−
= p
1 j
j
b 1 ln } g p 2 1 1 n {
v .
H0 ditolak pada tingkat signifikansi α, jika 2( )( ) 2 g 1 p
α;
v >χ − − .
Jika semua fungsi diskriminan yang terbentuk berpengaruh maka digunakan
secara bersamaan.
2.4 Analisis Gap
2.4.1 Pengertian Analisis Gap
Salah satu metode analisis pengukuran kepuasan pelanggan dalam
dunia bisnis adalah analisis gap (kesenjangan) yang dikembangkan oleh Berry, Zeithaml dan Parasuraman pada akhir tahun 80-an. Analisis gap diformulasikan dalam riset yang panjang dan mendalam dan disertai dengan
setiap faktor pelayanan, yaitu kepuasan dan kepentingan. Kepuasan pelanggan adalah selisih antara pelayanan yang dirasakan dengan
pelayanan yang diharapkan, dengan demikian tingkat kepuasan pelanggan ditentukan oleh besarnya gap antara kepentingan.dengan kepuasan.
Gap positif akan diperoleh apabila skor kepuasan lebih besar dari skor kepentingan, sedangkan gap negatif diperoleh apabila skor kepuasan lebih kecil dari skor kepentingan. Semakin besar selisih skor kepentingan dengan
skor kepuasan berarti gap semakin besar.
Analisis gap menggunakan data berskala likert, dalam skripsi ini terdapat lima skala likert. Kelima penilaian tersebut diberikan bobot sebagai
berikut:
1. Jawaban 1 diberi bobot 1
2. Jawaban 2 diberi bobot 2 3. Jawaban 3 diberi bobot 3 4. Jawaban 4 diberi bobot 4
5. Jawaban 5 diberi bobot 5
2.4.2 Tingkat Kesesuaian
Berdasarkan hasil penilaian tingkat kepentingan dan tingkat kepuasan
maka akan dihasilkan suatu perhitungan tingkat kesesuaian antara
kepentingan dan kepuasan. Tingkat kesesuaian adalah hasil perbandingan
menentukan urutan prioritas peningkatan variabel-variabel yang
mempengaruhi kepuasan pelanggan. Dalam hal ini terdapat dua variabel
yang diwakilkan oleh X dan Y, yaitu X mewakili tingkat kepuasan pelanggan dan Y mewakili tingkat kepentingan pelanggan. Formula yang digunakan
adalah % 100 Y X TK i i
i = × (2.4-1)
dengan
TKi = Tingkat kesesuaian pelanggan pada variabel ke-i Xi = Skor penilaian kepuasan pelanggan pada variabel ke-i Yi = Skor penilaian kepentingan pelanggan pada variabel ke-i
Setiap variabel yang mempengaruhi kepuasan dan kepentingan, dihitung rata-ratanya, yaitu
n X X n 1 i i
∑
== dan
n Y Y n 1 i i
∑
== (2.4-2)
dengan
X = skor rata-rata tingkat kepuasan
Y = skor rata-rata tingkat kepentingan n = jumlah responden
k X X k 1 j j
∑
== dan
k Y Y k 1 j j
∑
== (2.4-3)
X = skor rata-rata dari rata-rata tingkat kepuasan
Y = skor rata-rata dari rata-rata tingkat kepentingan k = jumlah variabel
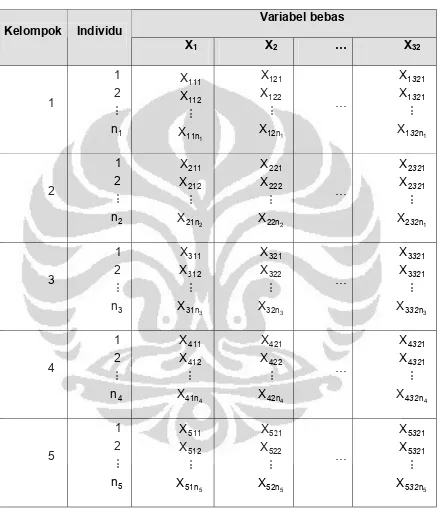
2.4.3 Pemetaan Hasil Penelitian
Pemetaan variabel-variabel yang ada pada tiap dimensi yang mempengaruhi kepuasan pelanggan dilakukan dengan memplot nilai rata-rata tingkat kepuasan dan rata-rata-rata-rata tingkat kepentingan pada diagram
kartesius. Diagram kartesius merupakan diagram yang membagi wilayah atas empat bagian yang dibatasi oleh dua garis yang berpotongan saling tegak
lurus pada suatu titik
( )
X,Y . Sumbu koordinat dari diagram kartesius yaitusumbu-X adalah tingkat kepuasan dan sumbu-Y adalah tingkat kepentingan. Selanjutnya, langkah untuk mengisi diagram kartesius, sebagai berikut
1. Menjumlahkan nilai kepentingan (Y) setiap variabel dari seluruh pengamatan, kemudian menghitung rata-rata seluruh pengamatan
diperoleh rata-rata kepentingan
( )
Y .2. Menjumlahkan nilai kepuasan (X) setiap variabel dari seluruh pengamatan, kemudian menghitung rata-rata seluruh pengamatan
diperoleh rata-rata kepuasan
( )
X .4. Menghitung rata-rata dari rata-rata kepuasan
( )
X , yaitu X .5. Membuat diagram dengan menggunakan X sebagai sumbu-X dan Y sebagai sumbu-Y.
6. Memplot hasil rata-rata
( )
X,Y tiap variabel pada diagram dan membuatdua garis yang saling tegak lurus dan berpotongan pada
( )
X,Y .7. Menginterpretasi hasil yang diperoleh.
Adapun diagram kartesiusnya, seperti pada Gambar 1,
Gambar 1. Diagram kartesius tingkat kesesuaian pelanggan
Keterangan dari Gambar 1, sebagai berikut :
A. Kuadran A
Menunjukkan variabel yang dianggap mempengaruhi kepuasan pelanggan, tetapi belum sesuai dengan yang diharapkan sehingga
mengecewakan pelanggan. Tingkat
Kepentingan
Tingkat Kepuasan Y
X
prioritas utama
A
pertahankan prestasi
B
prioritas rendah
C
berlebihan
D
X
B. Kuadran B
Menunjukkan variabel yang berhasil dilaksanakan perusahaan, untuk itu
wajib dipertahankan, dianggap sangat penting dan sangat memuaskan.
C. Kuadran C
Menunjukkan beberapa variabel yang kurang penting bagi pelanggan dan pelaksanaannya kurang memuaskan pelanggan.
D. Kuadran D
Menunjukkan variabel yang mempengaruhi kepuasan pelanggan kurang penting akan tetapi pelaksanaannya berlebihan sehingga sangat
3.1 Latar Belakang Perusahaan
Perusahaan Daerah Air Minum Kota Bukittinggi memiliki tujuan utama
memberikan pelayanan umum berupa jasa dengan jalan memenuhi dan
mengusahakan kebutuhan air minum yang bersih dan sehat bagi kesehatan
masyarakat kota Bukittinggi.
3.1.1 Sejarah Perusahaan
Sebelum menjadi Perusahaan Daerah Air Minum, kegiatan dalam
pengadaan dan pendistribusian air bersih merupakan salah satu tugas Biro
VII / usaha dari sekretariat Kotamadya Bukittinggi. Sesuai dengan
Undang-Undang No. 5 Th 1962 yo Undang-Undang-Undang-Undang No. 6 Th 1969 dan seterusnya
Undang-Undang No. 5 Th.1974 tentang pokok-pokok di daerah, kegiatan
penyediaan air minum selama ini merupakan salah satu seksi dari biro VII /
usaha dari sekretariat Kotamadya Bukitinggi dan ditingkatkan statusnya
menjadi perusahaan daerah. Berdasarkan Peraturan Daerah TK II No.3 Th
1975 berdirilah PDAM kota Bukittinggi pada tanggal 31 Juli 1975 yang
3.1.2 Proses Produksi
Sumber air baku PDAM Kota Bukittinggi berasal dari sumber mata air
Sungai Tanang yang terletak di desa Sungai Tanang dengan ketinggian dari
permukaan laut ± 1.000 meter dan kapasitas sumber 150 liter/detik. Mata air
Sungai Tanang merupakan air tanah yang muncul ke permukaan bumi di
bawah tekanan hidrolis. Kualitasnya secara fisik sesuai dengan standar
kualitas air minum karena tidak berwarna, tidak berasa dan tidak berbau
serta secara kimiawi memenuhi syarat. Namun secara bakteriologi, air baku
dari mata air ini perlu diberlakukan proses enfeksi dengan bahan
des-enfekton Ca(OCl)2 atau lebih dikenal dengan kaporit. Proses ini dilakukan
dengan cara melarutkan kaporit dalam bak berukuran 1 x 1 m2 dengan
keenceran 1% dan pembubuhan tetesan larutan ke dalam pipa transmisi,
diharapkan pada ujung pipa masih ada sisa Chlor sebesar 0.1 ppm yang
berguna untuk membunuh bakteri merugikan dan merusak kesehatan.
Setelah melalui proses ini, air dialirkan melalui pipa transmisi berdiameter
300 mm, 250 mm dan 150 mm menuju reservoir Bengkawas, Birugo,
Benteng dan Mandiangin yang selanjutnya didstribusikan melalui pipa tertier
3.1.3 Wilayah Layanan PDAM
Pada saat ini PDAM kota Bukittingi sudah memiliki pelanggan
sebanyak 9054 pelanggan (rumah tangga dan non rumah tangga). Jumlah
pelanggan PDAM kota Bukittinggi yang sudah tercatat sampai sekarang
dapat dilihat pada Lampiran 7.
3.2 Analisis Karakteristik Responden
Penelitian ini menggunakan data sekunder yang diambil dari PDAM
kota Bukittinggi. Survey dilakukan pada bulan Desember tahun 2005, atas
kerjasama PDAM kota Bukittinggi dengan United States Agency Internasional
Development (USAID) dan Environmental Service Program (ESP). Survey
dilakukan di lima wilayah layanan dengan sampel sebanyak 852 responden,
yang terdiri dari 774 responden pelanggan rumah tangga dan 78 responden
pelanggan non rumah tangga.
Analisis data ini terbagi atas dua, yaitu analisis karakteristik responden
secara deskriptif dan analisis data kepuasan pelanggan dengan metode yang
dijelaskan pada Bab II sebelumnya.
3.2.1 Pelanggan Rumah Tangga
1. Karakteristik berdasarkan pendidikan terakhir pelanggan
Berikut ini adalah karakteristik pelanggan berdasarkan pendidikan
terakhirnya, seperti pada Tabel 3,
Tabel 3
Karakteristik pelanggan berdasarkan pendidikan terakhir
No. Pendidikan terakhir pelanggan Persentase (%)
1 Tidak pernah sekolah 0.65 2 Tidak tamat SD / Ibtidayah 3.36 3 Tamat SD / Ibtidayah 9.3 4 Tidak tamat SMP / Tsanawiyah 1.16 5 Tamat SMP / Tsanawiyah 15.5 6 Tidak tamat SMA / Aliyah 4.39 7 Tamat SMA / Aliya