Hal 217
Sistem Pencarian Data Teks dengan Menggunakan Metode
Klasifikasi Rocchio(Studi Kasus:Dokumen Teks Skripsi)
Favorisen Rosyking Lumbanraja
Jurusan Ilmu Komputer, FMIPA Universitas Lampung E-mail: [email protected]
Abstrak.Dengan semakin banyaknya koleksi dokumen teks, pencarian merupakan tantangan tersendiri. Banyak metode yang dikembangkan untuk proses pencarian, salah satu metode yang umum adalah dengan metode klasifikasi. Beberapa contoh teknik yang menggunakan metode klafisifikai antara lain, NaïveBayes, K-Nearest Neighbor, Decision Tree, dan Vector Space Model.Teknik Rocchio merupakan contoh lain yang mengimplementasikan metode klasifikasi untuk proses pencarian teks. Teknik ini menggunakan Vector Space Model untuk merepresentasikan setiap dokumen dalam korpus. Tujuan utama karya ilmiah ini adalah mengembangkan sistem temu kembali informasi dengan menggunakan metode text mining (Klasifikasi Rocchio) untuk merekomendasikan data teks yang sesuai dengan pencarian yang dilakukan oleh pengguna sistem. Proses pertama yang dilakukan untuk mengembangan sistem dengan metode klasifikasi ini, yaitu tahap pra-proses.Pra-proses terdiri dari beberapa tahap, yaitu: parsering, pembersihan data, pemotongan kata berimbuhan, dan pembuatan inverted index dengan pembobot nilai itf.idf. Korpus dokumen pada karya ilmiah adalah data skripsi S1 Ilmu Komputer yang terdiri dari 150 dokumen abstrak skripsi. Korpus dokumen dibagi menjadi 12 bidang keilmuwan di dalam Ilmu Komputer. Untuk menguji akurasi hasil pencarian, maka 30 dokumen tersebut dijadikan data uji. Hasil dari pengujian adalah 76,67% dokumen terkelompokan secara benar sesusai dengan bidang keilmuwan. Dalam karya tulis ini, juga dilakukan proses evaluasi dari hasil pencarian dari sistem temu kembali sesuai dengan kueri pencarian pengguna sistem. Hasil pencarian yang akan relevan, jika kueri dari pengguna sesuai dengan bidang keilmuwan. Sebaliknya, jika pengguna menggunakan kueri dengan kata-kata umum, maka hasil pencarian akan memiliki tingkat relevansi yang rendah. Nilai precision dan recall juga dicatat berdasarkan panjang kueri pencarian. Hasil dari nilai-nilai tersebut cenderung konstan.
Kata Kunci.Data Mining, Text Mining, Text Classification, Rocchio Classification.
PENDAHULUAN
Perkembangan teknologi internet yang ditandai dengan munculnya teknologi web
2.0 dan semakin pesat kapasitas
penyimpanan digital serta semakin murah, membuat semakin banyak dan beragam konten (khususnya konten yang berupa data teks) yang ada di dalam situs web. Salah satu permasalahan yang muncul dengan semakin banyaknya informasi yang ada di dalam situs adalah bagaimana mengorganisasi dan mengolah data dan konten yang ada menjadi informasi yang dapatdigunakan oleh pengguna.
Terdapat beberapa teknik untuk
pengklasifikasian teks, antara lain:
NaïveBayes, K-Nearest Neighbor, Decision Tree,dan vector space model[5].
Setiap teknik memiliki karaktersik
masing-masing yang unik. Salah satu teknik yang ada adalah teknik Rocchio yang merupakan teknik klasifikasi yang menggunakan vektor space model.
Dengan menggunakan Text
Classification and Mining dan teknik
temu kembali informasi diharapkan dapat
membantupengguna mendapatkan
informasi implisit yang ada pada data konten teks.
Hal 218
Oleh karena itu, diperlukan aplikasi yang dapat membantu pengunjung sebuah situs web untuk mencari konten yang sesuai dengan keinginan pengguna.
Ruang lingkup penelitian adalah
pengembangan sistem rekomendasi
pencarian berbasis web pada dokumen abstrak skripsi S1 Jurusan Ilmu Komputer yang disimpan dalam database.
Sedangkan tujuan penelitian ini adalah
mengembangkan dan
mengimplementasikan sistem
rekomendasi pencarian yang dapat
membantu pengguna mencari isi konten informasi suatu situs web berberbahasa Indonesia menggunakan Teknik Rocchio.
Text Mining Dan Klasifikasi Teks
Text Mining merupakan salah satu aplikasi dari bidang data mining, yang khusus mengolah data dalam bentuk teks [6]. Tujuan text mining adalah mencari informasi implisit dari data teks sehingga bisa digunakan oleh pengguna untuk mengambil keputusan.
Klasifikasi Teks merupakan teknik dalam teks mining yang bertujuan mengelompokkan dokumen-dokumen ke dalam kelompok kategori tertentu. Setiap dokumen yang ada di dalam korpus diberi kategori yang spesifik. Kemudian sistem
akan menemu-kembalikan (retrieve)
dokumen yang dianggap sesuai dengan kueri yang diberikan oleh pengguna. Secara umum, teknik ini merupakan
supervised clustering, karena data
dokumen perlu diklasifikasi oleh
seseorang yang dianggap pakar terlebih dahulu. Tujuan utama klasifikasi adalah
mengelompokkan dokumen-dokumen
yang memiliki karakteristik yang mirip.
Parsering
Parsing merupakan proses memilah isi dokumen menjadi unit-unit kecil yang akan menjadi penciri misalnya berupa kata, frase atau kalimat. Unit terkecil ini yang disebut sebagai token. Proses parsing merujuk pada proses pengidentifikasian token dalam rangkaian teks [1]. Sehingga
bagian dasar dalam parsing dari dokumen
teks disebut tokenizer. Proses ini
memerlukan pengetahuan tentang bahasa untukmenangani karakter-karakter khusus dan menentukan batasan satuan unit dalam dokumen.Proses Parsing akan
menghasilkan daftar isitilah beserta
informasi tambahan seperti frekuensi dan posisi yang akan digunakan untuk proses selanjutnya.
Stemming
Stemming merupakan proses
penghilangan/ pemotongan prefiks
(awalan) dan sufiks (akhiran) dari kata dan istilah-istilah dokumen [1]. Stemming diakukan atas dasar asusmi bahwa kata-kata yang memilik stem yang sama memiliki makna dasar yang sama.
Teknik stemming dapat dikategorikan menjadi 3, yaitu:
• berdasarkan aturan dalam bahasa tertentu
• berdasarkan kamus
• berdasarkan kemunculan bersama Salah satu tujuan utama dilakukan proses stemming adalah meningkatkan efesiensi. Stemming mengurangi jumlah kata-kata unik dalam indeks sehingga menghemat sumber daya komputasi dan sumber daya penyimpanan.
Inverted Index
Inverted Index adalah struktur yang
dioptimasi untuk proses
penemukembalian (retrieve) dokumen sedangkan proses update hanya menjadi pertimbangan sekunder. Struktur tersebut
membalik teks sehingga indeks
memetakan kata ke posisi didalam dokumen (seperti bagian index dalam buku memetakan kata atau isitilah tertentu ke halaman dalam buku) [1].
Interveted Index terdiri dari dua bagian yaitu sebuah index kata/term yang berisikan daftar istilah unik dalam dokumen, dan untuk setiap kata/term terdapat posting list, yaitu memuat posisi kata tersebut adalah dokumen.
Hal 219
Misalkan kata/term T1terdapat di dokumen D1 pada posisi kata 3 dan 189, Dokumen D2 pada posisi kata 56, 11, 389 dan Dokumen D3 pada posisi kata 10. Sedang kata/term T2 terdapat pada dokumen D1 pada posisi kata 29 dan dokumenD3 pada posisi kata 1,45, dan 290, maka inverted index yang dihasilkan adalah:
T1→D1:[3;189];D2:[56; 11; 389];D3:[10] T2→D1:[29];D3:[1;45;290]
Vector Space Model
Dalam Pemodelan pada Temu Kembali Informasi setiap dokumen dideskripsikan sebagai sekumpulan kata-kata keyword yang disebut sebagai kata index. Kata index merupakan kata yang yang secara semantik membantu mendeskripsikan isi dari dokumen. Sehingga kata index
digunakan dalam proses pencarian
searching dan summarization pada
dokumen teks.
Vector space model adalah salah satu
teknik yang digunakan dalam
merepresentasikan dokumen dalam
korpus. Representasi vektor dapat
menggunakan boolean (teknik Naive
Bayes) atau angka numerik untuk
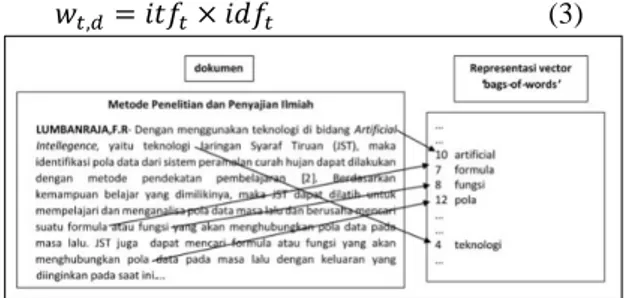
merepresentasikan isi dokumen teks. Setiap dokumen dipandang sebagai vektor berdimensi n, dimana n adalah jumlah term yang ada pada himpunan dokumen. Representasi seperti ini sering kali disebut
seb g i ‟b g-of-words‟ [4] karena
susunankata dan struktur kalimat tidak diperhatikan (seperti terlihat pada Gambar 1).
Berbeda dengan teknik Naive Bayes
dalam merepresentasikan dokumen
sebagai sekuens dari term atau sebagai vektor binari. Vector space model memiliki beberapa metode lain dalam menentukan bobot dari vektor dokumen. Pada umumnya teknik bobot yang digunakan adalah tf-idf untuk setiap term. Namun untuk paper ni, digunakan
itf-idfuntuk setiap term [2].
{ (1)
dan
( ) (2)
Dimana, tf adalah jumlah kemunculan term pada korpus dan df merupakan
jumlah dokumen yang berisi term
tersebut.Dan bobot sebuah term dalam koleksi korpus dokumen teks adalah perkalian antara itf dan idf.
(3)
Gambar 7 Ilustrasi Representasi Dokumen Menggun k n ‟B g Of Words‟ Deng n
Pembobotan Menggunakan Frekuensi
Kata Yang Muncul
Teknik Rocchio
Dalam menggunakan vector space
model diperlukan batas-batas antar kelas
untuk mengetahui klasifikasi yang
sesuai.Teknik Rocchio menerapkan batas-batas tersebut dalam bentuk centroid untuk memberi batasan tersebut. Centroid sebuah kelas c adalah rata-rata semua vektor yang berada pada kelas c.
⃗ | |∑ ⃗ (4)
Dimana Dc adalah himpunan dokumen di dalam korpus pada kelas c. sedangkan ⃗ merupakan vektor dokumen yang telah dinormalisasi.Untuk menentukan kemiripan dua vektor space model ada dua cara yaitu dengan mengukur jarak atau
dengan mengukur kemiripan.Dalam
menentukan jarak (distance) antara dua vektor space model digunakan jarak euclidean.
√∑ ( ) (5)
Dan dengan menghitung kemiripan (similarity) antara dua vektor dokumen adalah sebagai berikut:
⃗⃗⃗ ⃗⃗⃗
Hal 220
Jika terdapat suatu kueri diproses menjadi sebuah vektor space, maka dapat
dibandingkan dengan masing-masing
centroid kelas yang ada pada korpus.
Dengan dua pendekatan mencari
kemiripan dua vektor space., vektor kueri dianggap mirip dengan sebuah centorid
kelas dapaat dilakukan dengan
menggunakan jarak (distance) atau
menggunakan kemiripan (similarity). Jika menggunakan jarak, yang dicari adalah kelas yang memiliki jarak yang terkecil dengan kueri.
Dan jika menggunakan kemiripan yang
dicari adalah kelas yang memiliki
kemiripan yang paling besar dengan kueri, seperti yang ada di bawah:
• menggunakan jarak
| ⃗ ⃗ | (7)
• menggunakan kemiripan
( ⃗ ⃗ ) (8)
Precision Dan Recall
Untuk menggukur kualitas hasil
dokumen yang ditemukembalikan perlu ada suatu tolak ukur. Dua parameter yang umum digunakan untuk mengukur kinerja sebuah sistem temu kembali informasi adalah precision dan recall[2].
Precision adalah nilai perbandingan
antara jumlah dokumen relevan yang ditemukembalikan terhadap jumlah semua dokumen yang ditemukembalikan. Sedang Recall adalah nilai perbandingan jumlah dokumen relevan yang ditemukembalikan terhadap jumlah semua dokumen yang dianggap relevan.
Tabel 5 Hubungan Precision Dan Recall (Manning, 2008)
Relevant non relevant
retrieved true positives
(tp) false positives (fp) not retrieved false negative (fn) true negative (tn)
Berdasarkan Tabel 1, dapat
merumuskan Precision (P) dan Recall (R) menjadi sebagai berikut:
P = tp/(tp + f p) (9)
R = tp/(tp + f n) (10)
METODE PENELITIAN
Tujuan penelitian ini adalah membuat suatu sistem temu kembali informasi dengan menggunakan vector space model dengan teknik rocchio. Dalam mengembangkan sistem ini, sistematika tahap yang dilakukan adalah sebagai berikut:
Penentuan Data Korpus
Dokumen-dokumen yang digunakan dalam sistem ini adalah dokumen abstrak skripsi S1 Jurusan Ilmu Komputer pada
perpustakaan. Dokumen-dokumen
tersebut diklasifikasikan menjadi 12 kelas
keilmuan yaitu, Data Mining,Temu
Kembali Informasi, Sistem Informasi, Sistem Informasi Geografi, Rekayasa Perangkat Lunak, Kripografi, Jaringan Komputer, Pemrograman Paralel, Sistem
Pakar, Pengolahan Citra Digital,
Pengenalan Pola dan Komputasi Lunak.
Tokenisasi
Tokenizer menerima input string dan memilahnya menjadi token (unit terkecil) sebagai penciri dokumen dengan aturan sebagai berikut:
- Token dipisahkan oleh karakter
whitespace (spasi)
- T nd b c (seperti ‟!‟, ‟?‟, ‟.‟, ‟,‟) dihilangkan
- Suatu token dimulai dengan huruf atau angka
Output dari tokenisasi adalah token serta informasi tambahan informasi lain seperti frekuensi kata, posisi kata dalam dokumen.
Stemming
Stemming merupakan tahapan yang
memerlukan pengetahuan terhadap strukur dan grammer suatu bahasa karena penentuan aturan stem suatu kata berbeda-beda bergantung terhadap tata bahasa
bahasa yang digunakan dalamsystem
kembali informasi. Pada paper ini
digunakan algoritme stemming untuk Bahasa Indonesia.
Hal 221
Ridha (2002) telah mengembangkan sistem stemming prefiks dan sufiks untuk kata-kata dalam bahasa Indonesia yang mengimplementasikan algoritma Porter. Sebagaimana algoritma Proter, digunakan fungsi untuk mengukur ukuran kata untuk mencegah stemming menghasil stem yang terlalu pendek.
Aturan pemotongan kata dinyatakan sebagai berikut:P1(kondisi)S1 → P2S2 yang berarti jika sebuah kata yang memiliki prefiks P1 dan prefiks S1dan bagian kata antara P1dan S1 memenuhi syarat kondisi maka P1 dan S1diganti menjadi P2 dan S2.
Beberapa notasi yang digunakan dalam proses ini adalah:
- W, seluruh kata termasuk prefiks dan sufiks
- M, ukuran kata
- L, seluruh kata termasuk prefiks dan sufiks
- V , huruf vokal - C, huruf konsonan - V *, diawali huruf vokal - C*, diawali huruf konsonan - *CC, diakhiri dua huruf kononan - V (x), huruf ke-x adalah vokal - C(x), huruf ke-x adalah Konsonan Sebagai contoh, dalam aturan:
(M > 1) nya →
S1 d l h ‟n ‟ d n S2 d l h null
(tidak ada), sehingga kata seperti
‟komputern ‟ dipotong menj di
‟komputer‟, k ren k t ‟komputer‟ berukuran 3 (M>1).
Stemming dilakukan pada bagian kata-kata sebagai berikut:
- prefiks: mem-, meny-, meng-, me-, di-, per-, ber-ter-,
- peng, -per, se-
- sufiks:-an, -kan, -i, -nya - konfiks:ke-an, ke-i - partikel:-kah, -lah
- kata ganti: -ku, -mu, -nya
Indexing
Pengindeksan dilakukan dengan
menggunakan inverted index. Dilanjutkan
dengan pembobotan index dilakukan dengan nilai itf.idf.
Pembuatan Centroid
Setelah mendapatkan masing-masing vektor untuk setiap dokumen, dilakukan penentuan pusat kluster (centroid) pada setiap kelas. Centroid setiap kelas
merupakan rata-rata masing vektor
dokumen pada setiap kelas/kategori.
Centroid dari kelas ini yang akan menjadi
vektor penciri dari kelas yang akan
dibandingkan dengan vektor kueri
pencarian dari pengguna.
Pencarian Berdasarkan Kueri
Setelah dimasukan kueri, maka kueri akan diubah menjadi vector space. Lalu
vektor kueri dibandingkan dengan
masing-masing centroid kelas yang ada. Vektor kueri juga dilakukan proses normalisasi, kemudian yang dipilih adalah
centroid kelas yang paling memiliki
kemiripan yang paling besar dengan vektor kueri.
Lalu vektor kueri dibandingkan dengan masing-masing vektor dokumen pada kelas yang memiliki kemiripian yang paling besar. Proses perbandingan antara vektor kueri dan vektor dokumen juga dilakukan dengan mencari kemiripan. Lalu ditampilkan semua dokumen dari kelas tersebut, dengan urutan kemiripan terbesar hingga kemiripan yang terkecil.
HASIL DAN PEMBAHASAN
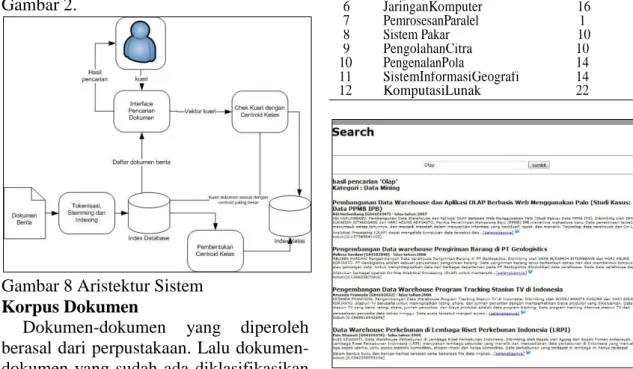
Rancangan Arsitektur Sistem
Sebelum sistem ini dijalankan untuk melakukan proses pencarian, dokumen-dokumen abstrak S1 dikumpulkan ke dalam database untuk membentuk index database. Kemudian setiap dokumen dikelompokan berdasarkan kelas keilmuan yang ada, lalu ditentukan kata-kata
stopword yang akan menjadi filter dari
term-term yang ada pada dokumen (terdapat 3.891 term kata dan terdapat 128 kata stopword di dalam). Secara umum,
Hal 222
arsitektur sistem ini dapat dilihat pada Gambar 2.
Gambar 8 Aristektur Sistem
Korpus Dokumen
Dokumen-dokumen yang diperoleh berasal dari perpustakaan. Lalu dokumen-dokumen yang sudah ada diklasifikasikan ke dalam 12 kelas keilmuan yang ada pada Jurusan Ilmu Komputer yang berjumlah 150 dokumen (seperti yang terlihat pada Tabel 2) .
Dari Tabel 2 dapat dilihat bahwa jumlah dokumen tiap kelas keilmuan tidak s m . Dim n kel s ‟Komput si Lun k‟ yang memiliki jumlah dokumen yang p ling b n k d n kel s ‟Pemroses n P r lel‟ memiliki juml h dokumen ng paling sedikit.
Pada saat pengguna memasukan kueri pencarian, maka sistem akan akan
membandingkannya dengan
masing-masing centroid kelas. Lalu dipilih kelas yang memiliki nilai bobot yang paling besar.
Kemudian ditamplikan semua
dokumen pada kelas tersebut, cara pengurutannya adalah dari dokumen yang
memiliki kemiripan terbesar hingga
terkecil (decending) seperti yang terlihat pada Gambar 2.
Tabel 6 Jumlah Dokumen Yang Ada Pada Masing-Masing Kategori Keilmuan
No Kelaskeilmuan Jumlahdokumen
1 Temu Kembali Informasi 7
2 DataMining 20 3 RekayasaPerangkatLunak 16 4 SistemInformasi 7 5 Kriptografi 13 6 JaringanKomputer 16 7 PemrosesanParalel 1 8 Sistem Pakar 10 9 PengolahanCitra 10 10 PengenalanPola 14 11 SistemInformasiGeografi 14 12 KomputasiLunak 22
Gambar 9 Halaman Hasil Pencarian
Fungsi Sistem
Dari Arstiktur Sistem seperti yang terlihat di Gambar 2, maka dikembangkan beberapa modul fungsi yang digunakan dalam sistem temu kembali informasi, meliputi:
- Tokenisasi dan indexing. Merupakan fungsi untuk melakukan pembentukan vektor space dokumen dari file- file dokumen berita.
- Pembentukan Centroid. Merupakan fungsi membentuk vektor centroid
masing-masing kelas yang ada
dokumen korpus.
- Rekomendasi. Merupakan fungsi untuk merekomendasi klasifikasi dokumen berdasarkan kelas keilmuan yang ada. - Pemeriksaan kueri. Merupakan fungsi
untuk memband- ingkan vektor kueri dengan centroid kelas.
- Interface Pencarian. Merupakan fungsi untuk memasukan kueri dan
menampilkan hasil kueri pencarian.
Implementasi
Sistem temu kembali informasi dengan
menggunakan teknik Rocchio ini
Hal 223
• XAMPP yang meliputi: Web Server
Apache, Database MySQL,
pemrograman web PHP, dan
pemrograman Perl • Smarty dan Adodb
Pengujian Dan Evaluasi
Untuk menguji akurasi dari data
dokumen abstrak yang telah
diklasifikasikan sebelumnya sebagai data trainning, maka dilakukan pengujian terhadap 30 dokumen data uji (seperti yang terlihat pada Gambar 4) . Hasil pengujian menunjukkan ada 23 dokumen
yang sesuai dengan kategori yang
direkomendasi (hit) dan 7 dokumen yang tidak sesuai dengan rekomendasi (miss), sehingga akurasinya adalah 76,67%.
Gambar 10 Halaman Hasil Rekomendasi Kemudian dilakukan pengujian terhadap hasil pencarian dari kueri yang dimasukan oleh pengguna. Untuk kueri yangmengandung term-term spesifik pada keilmuan tertentu hasilnya akan baik, sebagai contoh jika pengguna mencari
k t ‟OLAP‟ sistem k n
merekomendasikan dokumen-dokumen p d kel s ‟D t Mining‟ ng meng ndung k t ‟OLAP‟. N mun jik kueri bersifat umum untuk terminologi di dalam ilmu komputer, hasilnya tidak baik. sebagai contoh jika pengguna mencari ‟OLAP berb sis web‟, hasil pencariannya
justru merekomendasikan
dokumen-dokumen pada kel s ‟Sistem Informasi Geogr fi‟ ng tid k relev n deng n kueri pencarian. Lalu dilakukan pengujian terhadap precision dan recall terhadap hasil dokumen yang ditemukembalikan berdasarkan kueri pencarian. Untuk itu
dilakukan pengujian terhadap 3 jenis kueri, yaitu: kueri pendek(kueri yang terdiri dari beberapa kata atau frase), sedang (kueri yang terdari 1 kalimat) dan panjang (kueri yang terdiri dari lebih dari 1 kalimat). Setiap jenis kueri dihitung tingkat percision dan recall. Proses diulang sebanyak 3 kali, lalu dihitung rata-ratanya hasilnya sebagaiberikut: Tabel 7 Perbandingan Precision Dan Recall Berdasarkan Panjang Kueri
JenisKueri Precision Recall KueriPendek 0.26 0.5 KueriSedang 0.31 0.49 KueriPanjang 0.33 0.47
Dari Tabel 3, Dapat dilihat panjang kueri tidak terlalu mempengaruhi nilai precision dan nilai recall. Tapi secara umum, nilai precision berbanding terbalik dengan nilai recall.
KESIMPULAN
Sistem temu kembali informasi ini menggunakan teknik Rocchio. Teknik ini menggunakan vektor space model dalam merepresentasikan dokumen, centroid dan
kueri. Pembobotan dokumen
menggunakan nilai idf-itf yang telah dilakukan proses normalisasi nilai vektor.
Vektor kueri akan dibandingkan
dengan masing-masing centroid kelas
menggunakan kemiripan kueri, dan
menentukan kelas dengan mencari
kemiripan yang paling besar. Kemudian dokumen dalam kelas itu ditampilkan secara decending dari bobot kemiripan dengan vektor kueri. Pengklasifikasian data training pada kelas-kelas yang telah ditentukan sangat mem- pengaruhi hasil rekomendasi dan hasil pencarian.
Untuk menguji klasifikasi dokumen dilakukan pengujan rekomendasi kelas terhadap data trainning. Dari hasil
pengujian terhadap data trainning
menunjukkan akurasi hasil rekomendasi sebesar 76,67%. Untuk pengujian sistem pencar- ian, hasil dokumen yang
ditemu-Hal 224
kembalikan akan baik untuk kueri pencarian yang spesifik terhadap kelas
keilmuan, namun akan cenderung
menemu-kembalikan dokumen yang
kurang relevan untuk kueri yang umum. Panjang kueri secara umum tidak terlalu mempengaruhi tingkat precision dan recall, namun secara umum semakin tinggi tingkat precision semakin rendah nilai recall.
Kelemahan utama dalam teknik
Klasifikasi Rocchio ini adalah setiap dokumen hanya dapat diklasifikasikan ke dalamsatu kelas kategori saja. Padahal
dalam abstrak penelitian bisa saja
melibatkan lebih dari satu kategori keilmuan. Kelemahan yang kedua adalah teknik ini tidak mengenal makna semantik pada kata. sebagai contoh, jika pengguna
memasukkan kueri pencarian
‟K lim nt n‟ m k h n men mpilk n dokumen ng berisi k t ‟K lim nt n‟ dan tidak menampilkan doku- men yang berisi k t ‟Borneo‟. P d h l k t ‟K lim nt n‟ d n ‟Borneo‟ memiliki makna semantik yang sama. Perlu ada
penelitian lanjutan untuk
pengklasifikasian dengan teknik Roc- chio pada dokumen dengan multi-class dan
memperhatikan makna semantik pada kata. DAFTAR PUSTAKA Grossman,D.2002.IR Book.http://ir.iit.edu/~dagr/cs529/ir_bo ok.html [29 Januari 2013] Manning, C.D.,et-al.2008.Introduction to
Information Retrieval. Cambridge
University Press.USA.
Ridha, A.2002.Pengindeksan Otomatis
dengan Istilah Tunggal untuk
Dokumen Berbahasa
Indonesia.Skripsi.Departemen Ilmu
Komputer IPB.Bogor
Uchyigit, G. dan Clark, K.2008.An
Experimental Study of Feature Selection Methods for Text Classifica- tion.Personalization Techniques dan Recommendation Systems.hal.303-320.Word Scientific.USA wikipedia.2010.Document Classifica- tion.http://en.wikipedia.org/wiki/docu ment_classification [30 Januari 2013] wikipedia.2010.Text Mining.http://en.wikipedia.org/wiki/tex t_mining [30 Januari2010]