BAB II
DASAR TEORI
2.1 Sistem Pakar
Sistem pakar adalah program komputer yang mampu merepresentasikan dan memberikan penalaran atas pengetahuan pada bidang tertentu dengan tujuan untuk dapat memecahkan masalah atau memberikan saran [JAC99].
Sebuah sistem pakar dikatakan berbeda dari program konvensional karena [JAC99]:
1. Sistem pakar mensimulasikan penalaran manusia pada ranah masalah tertentu, bukan mensimulasikan ranah itu sendiri.
2. Sistem pakar melakukan penalaran atas representasi pengetahuan manusia, selain melakukan kalkulasi numerik atau temu balik informasi.
3. Sistem pakar memecahkan masalah secara heuristic atau memakai metode perkiraan. Dikatakan metode perkiraan karena tidak memerlukan data yang sempurna dan solusi yang dihasilkan dapat bervariasi kepastiannya.
Pada umumnya, sistem pakar memiliki dua modul utama yang terpisah, yaitu basis pengetahuan dan mesin inferensi [JAC99]. Basis pengetahuan adalah pengetahuan pada program yang diekspresikan dalam bentuk bahasa tertentu, sedangkan mesin inferensi merupakan kode program yang melakukan penalaran/pemecahan masalah.
Siklus hidup sistem pakar secara garis besar meliputi 4 tahap, yaitu [KHO98]:
1. Inisialisasi basis pengetahuan, meliputi pemilihan ranah masalah, pendefinisian tujuan pembuatan sistem pakar, dan penentuan sumber pengetahuan.
2. Akuisisi pengetahuan, meliputi identifikasi masalah, penentuan faktor-faktor yang dapat mempengaruhi struktur sistem secara keseluruhan, formalisasi, dan representasi pengetahuan, serta pemasukan pengetahuan ke dalam basis pengetahuan.
3. Verifikasi basis pengetahuan yang dilakukan untuk menjamin bahwa sistem bebas dari kesalahan internal dan memenuhi spesifikasi.
4. Validasi basis pengetahuan yang dilakukan untuk menjamin bahwa sistem memenuhi keinginan pengguna.
Ada dua macam cara akuisisi pengetahuan, yaitu manual dan otomatis. Dalam tugas akhir ini, metode yang akan dibahas hanya akuisisi pengetahuan otomatis.
2.2 Akuisisi Pengetahuan Otomatis
Akuisisi pengetahuan otomatis merupakan salah satu teknik akuisisi pengetahuan di mana pengetahuan didapatkan dari hasil ekstraksi kasus-kasus yang terjadi dengan menggunakan kakas bantu (program atau aplikasi). Munculnya akuisisi pengetahuan otomatis ini dilatarbelakangi oleh adanya bottleneck pada proses akuisisi pengetahuan secara manual, yaitu:
1. Proses akuisisi yang mahal dan lambat. Akuisisi dikatakan mahal karena keterbatasan pakar dan dikatakan lambat karena dikarenakan adanya perbedaan pemahaman antara perekayasa pengetahuan dan pakar.
2. Representasi dari sumber pengetahuan sulit dilakukan, pakar tidak dapat menuliskan pengetahuan mereka dalam kata-kata.
Beberapa hal yang dilakukan dalam akuisisi pengetahuan otomatis:
1. Pengetahuan tidak didapatkan dari pakar secara langsung, melainkan dari kasus-kasus yang sudah diselesaikan oleh pakar (data dari tiap kasus dan keputusannya).
2. Peran perekayasa pengetahuan dihilangkan dan diganti dengan program yang dapat menganalisis kasus-kasus tersebut dan menghasilkan sekumpulan rule yang menghasilkan keputusan yang sama seperti pada kasus.
Proses pembentukan sekumpulan rule dari sejumlah kasus pada proses akuisisi pengetahuan otomatis disebut dengan pembelajaran induksi. Dalam induksi tersebut, dilakukan penalaran dari khusus menjadi umum (dari kasus menjadi rule).
Salah satu metode yang menggunakan pembelajaran induksi ini adalah Induct/RDR dan Induct/MCRDR Kedua metode ini tidak melibatkan pakar secara langsung dan hanya menggunakan kumpulan kasus yang ada untuk membentuk rule.
2.3 Induct/Multiple Classification Ripple-Down Rules
(Induct/MCRDR)
Induct/MCRDR merupakan metode akuisisi pengetahuan otomatis hasil pengembangan dari MCRDR (Lampiran C) untuk mengatasi keterbatasan MCRDR yang masih membutuhkan campur tangan pakar. Dengan Induct/MCRDR, basis pengetahuan dibangkitkan secara
otomatis menggunakan algoritma Induct sehingga tidak membutuhkan peran pakar. Metode akuisisi ini juga tidak membutuhkan bantuan perekayasa pengetahuan untuk mengatasi permasalahan klasifikasi majemuk. Proses akuisisi Induct/MCRDR dapat dilihat pada Lampiran B.
Seperti telah dijelaskan pada [ARM07], Induct/MCRDR diperlukan sebagai solusi permasalahan yang dihadapi oleh penggunaan MCRDR, yaitu:
1. Induct/MCRDR digunakan untuk membangkitkan basis pengetahuan awal yang melibatkan data klasifikasi majemuk ukuran besar. Proses ini akan menghemat banyak waktu dalam proses akuisisi pengetahuan awal. Perawatan basis pengetahuan, termasuk manipulasi pengetahuan, dilakukan secara manual oleh pakar atau perekayasa pengetahuan.
2. Induct/MCRDR digunakan untuk memperbaiki basis pengetahuan MCRDR dengan melakukan pembangunan ulang pengetahuan dari awal menggunakan seluruh data yang telah diperoleh untuk menjamin basis pengetahuan yang lebih ringkas dan akurat. Hal ini dapat terjadi jika basis pengetahuan MCRDR telah mengalami banyak manipulasi sehingga pengetahuan yang terbentuk menjadi tidak ringkas dan akurat lagi.
2.3.1 Metode
Induct
Pengertian dari Induct yaitu suatu metode pembelajaran yang menghasilkan ruang hipotesa H dari sekumpulan instans X untuk mendefinisikan konsep target c. Setiap hipotesa h dalam H menunjukkan sebuah fungsi boolean terhadap X, yaitu h: X _ {0,1}. Tujuan pembelajaran inductive yaitu untuk memperoleh sebuah hipotesa h sedemikian sehingga h(x) = c(x) untuk semua x dalam X [MIT97].
Metode induct yang digunakan dalam Induct/MCRDR sama dengan metode induct yang digunakan pada Induct/RDR. Berikut adalah penjelasan mengenai metode Induct.
Gambar II-1 Induksi pada Induct/RDR [GAI92]
Gambar II-1 menggambarkan analisis kesalahan untuk statistical control dari algoritma yang digunakan pada Induct. Suatu ruang kasus dibagi berdasarkan diagnosis, yaitu D0, D1, D2, dan seterusnya, dengan D0 adalah diagnosis sasaran yang digunakan Induct untuk membangkitkan sebuah kaidah. Kasus yang dicakup sebelum diubah ditunjukkan dengan elips bagian luar, sedangkan elips bagian dalam menunjukkan kumpulan kasus yang telah tereduksi saat klausa tambahan diberikan pada premis. Hal ini menunjukkan bahwa kaidah yang semakin spesifik menyebabkan semakin spesifik pula jumlah kasus yang dapat dicakup oleh kaidah tersebut.
Gambar II-2 Basis pengujian statistik pada Induct [GAI92]
Gambar II-2 menggambarkan basis dari pengujian statistik yang digunakan pada Induct. Diberikan himpunan semesta predikat E, Q menunjukkan data benar yang seharusnya tercakupi oleh rule yang diajukan, S menunjukkan data yang tercakupi oleh rule yang diajukan, dan C menunjukkan data benar yang tercakupi oleh rule tersebut. Bila kardinalitas E, Q, S, dan C dinyatakan dengan e, q, s, dan c, probabilitas pemilihan entitas dari E secara acak yang memenuhi Q adalah:
e
q
Probabilitas suatu rule terpilih secara acak untuk memilih s dan memperoleh sejumlah c atau lebih entitas bernilai benar dinyatakan dengan r. Nilai r merupakan penjumlahan distribusi binomial standar untuk memperoleh fungsi berikut:
i s r c i i p) (1 p i s r − = − ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ =
∑
... (II-2)Penggunaan r untuk mengukur kualitas suatu kaidah adalah dengan mengambil pasangan atribut-nilai yang mempunyai nilai r terkecil, yaitu pasangan atribut-nilai yang mempunyai kemungkinan paling kecil untuk terpilih secara acak. Asumsi yang digunakan dalam memilih nilai probabilitas ini adalah bahwa kualitas suatu rule semakin baik jika kemungkinan rule tersebut terpilih secara acak semakin kecil [LIT96]. Jadi, semakin kecil nilai r, maka akan semakin baik pula kualitas rule yang dihasilkan.
2.3.2
Representasi Pengetahuan Induct/MCRDR
Struktur pengetahuan Induct/MCRDR berupa pohon n-ary, di mana setiap simpul merepresentasikan sebuah kaidah. Struktur ini memungkinkan setiap simpul memiliki lebih dari 1 cabang. Perkecualian hanya terjadi pada simpul daun yang tidak memiliki cabang sama sekali. Seluruh cabang yang dimiliki oleh Induct/MCRDR adalah cabang except IF-TRUE yang hanya ditelusuri bila kasus masukan memenuhi kondisi pada kaidah. Contoh representasi pengetahuan dari Induct/MCRDR dapat dilihat pada Gambar II-3.
Gambar II-3 Contoh representasi pengetahuan Induct/MCRDR [ARM07]
2.3.3
Proses Inferensi Induct/MCRDR
Proses inferensi pada pohon Induct/MCRDR sama dengan proses inferensi pada pohon MCRDR. Proses tersebut dimulai dari simpul akar. Kondisi pada simpul akar (kaidah 0)
selalu dipenuhi oleh seluruh kasus masukan. Solusi ini menjadi solusi sementara sekaligus menjadi solusi paling umum. Setelah itu, seluruh kaidah pada tingkat pertama akan dievaluasi. Evaluasi berikutnya hanya dilakukan pada kaidah-kaidah yang dipenuhi pada tingkat sebelumnya, dan seterusnya. Proses inferensi berhenti ketika tidak ada kaidah yang dapat dievaluasi lagi, atau ketika tidak ada kaidah yang dapat memenuhi kasus masukan. Contoh inferensi Induct/MCRDR dapat dilihat pada Gambar II-4.
Gambar II-4 Contoh inferensi dari Induct/MCRDR untuk kasus masukan [tear-prod = normal, astigmatism = no, age = young]
Jika terdapat basis pengetahuan Induct/MCRDR seperti pada gambar II-5 yang mendapat kasus masukan [tear-prod = normal, astigmatism = no, age = young], maka solusi yang dihasilkan adalah [lens = soft]. Rule 5 dan Rule 6 pada gambar II-5 merupakan stopping rule yang menghasilkan solusi null. Penjelasan mengenai stopping rule dapat dilihat pada subbab 2.3.4.
2.3.4 Proses
Pembelajaran Induct/MCRDR
Induct/MCRDR mengadopsi seluruh konsep MCRDR (Lampiran C), dengan perbedaan terletak pada penentuan kaidah rule baru, Kaidah rule baru pada Induct/MCRDR ditentukan dengan parameter r untuk mencari klausa terbaik yang memiliki probabilitas kemungkinan terpilih secara acak paling kecil. Penghitungan nilai r dapat dilihat pada persamaan II-2.
Perbedaan kedua terdapat pada kemungkinan penambahan stopping rule untuk setiap penambahan rule ke samping. Bila kondisi rule baru memiliki atribut yang berbeda dengan kondisi rule pada sibling-nya, maka penambahan stopping rule diperlukan untuk menjamin
hanya data bersesuaian yang memenuhi kondisi untuk memperoleh solusi dari simpul orangtua stopping rule tersebut.
Berikut adalah algoritma umum untuk pembangunan pengetahuan Induct/MCRDR.
BuildMCRDR(Default_Class,Attrs,Training_Set)
{Menghasilkan pohon pengetahuan MCRDR dengan simpul bernilai T} type T = {Class: nilai kelas
Clause: nilai klausa
Cov: pohon perkecualian positif NotCov: pohon perkecualian negatif} for Class = (set of class values)
if Class = Default_Class
TempClause ← BestClause(Class,Attr,Training_Set) if r(TempClause) < r(T.Clause)
T.Clause ← TempClause T.Class ← Class
Bentuk simpul dengan klausa T.Clause dan solusi Default_Class Covered ← himpunan semua entitas e dalam Training_Set dengan
T.Clause(e) bernilai benar
NotCovered ← himpunan semua entitas e dalam Training_Set dengan T.Clause(e) bernilai salah
if e berada dalam Covered dan e.Class = Class
T.Cov ← BuildMCRDR(Class,Attrs,Covered) ;pada level selanjutnya
if e berada dalam NotCovered dan e.Class = Class
T.NotCov ← BuildMCRDR(Class,Attrs,NotCovered) ;pada level sama if T.Class berbeda dengan T.Class simpul siblingnya
for i = jumlah simpul dengan T.Class berbeda S.Clause ← Sib.Clause – T.Clause
Bentuk stopping rule dengan kondisi S.Clause dan
solusi none ;pada level selanjutnya end BuildMCRDR
Algoritma II-1 Algoritma BuildMCRDR untuk pembangkitan struktur MCRDR
Dalam proses pembelajaran Induct/MCRDR, terdapat tiga proses utama dalam penambahan pengetahuan, yaitu : penentuan klasifikasi yang benar, penentuan lokasi, dan penentuan kondisi.
2.3.4.1 Penentuan Klasifikasi yang Benar
Induct/MCRDR tidak memerlukan pakar dalam menentukan klasifikasi yang benar. Klasifikasi ditentukan dari dataset masukan dan diasumsikan bahwa dataset mengandung klasifikasi yang benar. Perbaikan klasifikasi dilakukan dengan mengubah dataset dan mengulang pembangkitan basis pengetahuan dari awal.
Jika proses penentuan klasifikasi ini dilihat berdasarkan kasus covered dan not covered seperti pada algoritma II-1, maka rule yang dibangkitkan dari data covered akan ditambahkan pada tingkatan di bawah simpul yang mempartisi. Rule yang dibangkitkan dari data not covered akan ditambahkan sebagai sibling (berada dalam satu tingkat) dari simpul yang mempartisi data tersebut.
2.3.4.2 Penentuan Lokasi
Penentuan lokasi untuk simpul baru pada Induct/MCRDR mengacu pada aturan:
1. Seluruh rule yang menhasilkan solusi baru akan ditambahkan di bawah simpul akar. 2. Penambahan stopping rule dilakukan di bawah seluruh rule yang menghasilkan
kesimpulan yang salah. Stopping rule di sini hanya bertujuan mencegah pemberian klasifikasi yang salah dengan menambahkan simpul solusi null atau none.
2.3.4.3 Penentuan Kondisi
Induct/MCRDR menggunakan parameter nilai r (Rumus II-2) dalam menentukan kondisi, yaitu klausa terbaik untuk simpul baru yang akan ditambahkan. Kondisi penambahan simpul baru ini harus tepat, sehingga tidak ada kasus lain yang dapat dipenuhi oleh rule tersebut. Untuk memastikan kondisi tersebut, maka ditambahkan stopping rule sehingga rule yang baru hanya dipenuhi oleh kasus yang bersesuaian dan tidak oleh kasus lainnya, kecuali bila dipenuhi oleh kasus yang memberikan solusi yang sama.
Stopping rule ditempatkan sebagai anak dari rule baru yang memenuhi kriteria tersebut. Kondisi stopping rule ini ditentukan dari simpul pada tingkat parent-nya, yaitu dengan cara mengurangi antara klausa simpul orangtua dengan klausa simpul-simpul pada level yang sama (simpul-simpul sibiling dari simpul orangtua), kecuali bila simpul tersebut memberikan solusi yang sama dengan simpul orangtua dari stopping rule. Sibling yang memiliki jenis atribut yang sama tetapi berbeda nilainya dapat diabaikan, karena nilai dari atribut yang berbeda tidak akan dipenuhi oleh kasus lainnya. Oleh karena itu, kondisi rule tersebut tidak perlu diperhitungkan sebagai stopping rule.
Contoh dari penentuan kondisi dari stopping rule [ARM07]:
kondisi_rule_1 = (atr1 = nilai1a, atr2 = nilai2a) kondisi_rule_2 = (atr1 = nilai1b, atr3 = nilai3a)
Penentuan kondisi stopping rule dilakukan dengan membandingkan kondisi rule 1 dan rule 2. Kondisi dari rule tersebut dapat diabaikan karena kedua rule tersebut memiliki atribut yang sama (atr1) tetapi berbeda nilainya (nilai1a dan nilai1b).
2.4 Shell Induct/MCRDR
Pada [ARM07], telah dikembangkan sebuah shell Induct/MCRDR dalam bahasa pemrograman Java.
2.4.1 Format
Dataset
Shell Induct/MCRDR ini menerima masukan file dataset dari pengguna. Dataset ini berisi daftar atribut dan kelas yang muncul dalam suatu pengetahuan beserta dataset yang berupa daftar nilai atribut dan nilai kelas majemuknya. Berikut ini adalah format dataset masukan yang dapat diterima oleh sistem:
#induct/MCRDR #names
attribute att1 {nilai_att_1a, ..., nilai_att_1z} ...
attribute att100 {nilai_att_100a, ..., nilai_att_100z} class class_name {class_value_1, ..., class_value_100} #data
nilai_att_1a, ..., nilai_att100a, class_value_1, ..., class_value_50 ...
nilai_att_1z, ..., nilai_att100z, class_value_51, ..., class_value_100
Gambar II-5 Format file dataset masukan
Identitas file dataset masukan ditandai dengan #Induct/MCRDR. Dari identitas, dilanjutkan dengan penulisan #names yang menandai awal penulisan daftar atribut berikut jenis kelas dalam suatu dataset. Urutan penulisan harus diawali dengan daftar atribut dan diakhiri dengan satu buah daftar kelas. Format daftar atribut ditandai dengan penulisan attribute, dilanjutkan dengan nama atribut, dan diakhiri dengan nilai-nilai atribut yang dipisahkan koma dan dibatasi dengan kurung kurawal. Aturan yang sama berlaku untuk penulisan nama kelas dan nilai-nilai kelas. Perbedaan hanya terdapat pada penanda yang diawali dengan penulisan
Pendaftaran atas dataset diawali dengan tanda #data. Setiap penulisan sebuah dataset harus mengikuti urutan kemunculan atribut dan kelas seperti yang telah dituliskan sebelumnya. Untuk memisahkan antara nilai yang satu dengan yang lainnya digunakan separator koma.
2.4.2 Struktur
Data
2.4.2.1 Struktur Data ListAtribut dan ListData
Struktur data untuk ListAtribut dan ListData adalah two dimensional array list. Bentuk array list dipilih karena kebutuhan ukuran list yang dinamis. Dibutuhkan list dua dimensi untuk dapat menyimpan dalam ruang baris dan kolom. Library two dimensional array list diperoleh dari [FOR07]. Berikut adalah sketsa struktur data dari ListAtribut dan ListData.
Gambar II-6 Struktur data ListAtribut
Nilai atribut
Nilai kelas Data 1
Data n
Gambar II-7 Struktur data ListData
Pada struktur data ListData jumlah kolom nilai kelas berukuran sama dengan jumlah nilai kelas pada ListAtribut. Bila suatu data mengandung nilai_kelas_1, maka ListData akan mengisi kolom kelas pertama dengan nilai ’yes’, sebaliknya akan diisi dengan nilai ‘no’.
2.4.2.2 Struktur Data Condition
Condition merupakan struktur data untuk meyimpan kondisi dari suatu rule. Struktur data Condition merupakan array list yang bersifat dinamis karena jumlah kondisi rule yang tidak tetap. Setiap elemen array list akan mengandung array of string dengan elemen pertama berisi nama atribut, dan elemen kedua berisi nilai atribut.
Gambar II-8 Struktur data Condition
2.4.2.3 Struktur Data Rules
Rules merupakan struktur data yang mengandung kondisi dan sebuah solusi. Sama seperti Condition, Rules juga menggunakan array list yang bersifat dinamis karena jumlah rule yang tidak tetap. Elemen pada Rules terdiri dari Condition dan array of string yang menyimpan sebuah solusi. Array of string solusi memiliki dua elemen, dengan elemen pertama bernilai nama kelas, dan elemen kedua berisi nilai kelas.
Condition Rule 1
Nama kelas Nilai kelas
Rule n
Gambar II-9 Struktur data Rules
2.4.2.4 Struktur Data Node
Node merupakan struktur data berupa simpul dari pohon, di mana setiap simpul mengandung sebuah Rules. Pohon Induct/MCRDR yang akan dibangun dalam Tugas Akhir ini bersifat dinamis karena jumlahnya yang tidak tetap. Pembangunan pohon dinamis ini menggunakan library JDOTS (Java Dynamic Object Tree System) 1.5 dari [SQU07]. Untuk membuat objek JDOTS, sebuah kelas harus didefinisikan sebagai turunan dari kelas JD_Object. Setiap simpul pada JDOTS dianggap sebagai objek pohon, dan pembangunannya dapat dilihat pada contoh berikut ini:
test1_JDots t1 = new test1_JDots( "t1" ); test1_JDots t2 = new test1_JDots( "t2"); test1_JDots t3 = new test1_JDots( "t3"); test1_JDots t4 = new test1_JDots( "t4"); test1_JDots t = new test1_JDots( "t5"); t1.JD_addObject(t2);
t1.JD_addObject(t3); t1.JD_addObject(t4); t4.JD_addObject(t5);
Maka pohon yang akan terbentuk adalah sebagai berikut:
Gambar II-10 Contoh pohon dinamik JDOTS
Isi tiap Node adalah sebuah Rules sebagai berikut:
Node 1
Node n Rule
Gambar II-11 Struktur data Node
2.4.3 Kelas
Pada
Shell Induct/MCRDR
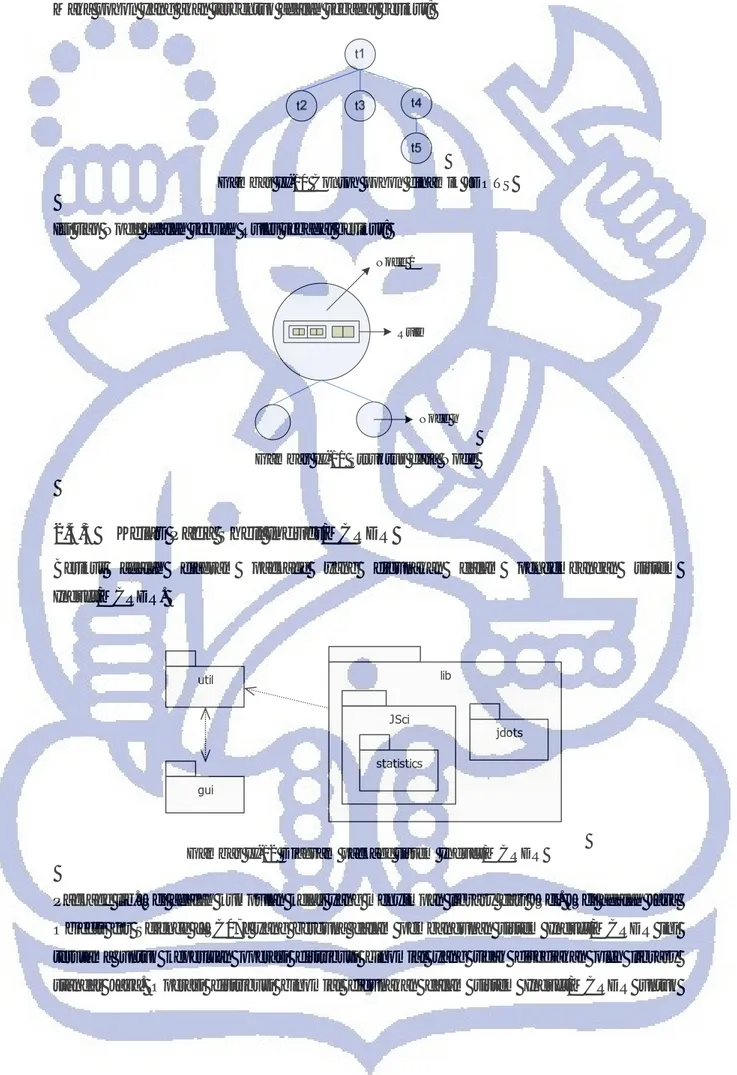
Berikut adalah diagram package yang digunakan dalam pengembangan sistem Induct/MCRDR. gui lib jdots JSci statistics util
Gambar II-12 Diagram package sistem Induct/MCRDR
Package lib.JSci adalah kumpulan kelas yang menyimpan library dari JSci. JSci adalah Java Objects for Science [JSC07] yang berguna dalam pembangunan sistem Induct/MCRDR ini terutama untuk keperluan operasi distribusi binomial yang tidak disediakan oleh library standar Java. Operasi distribusi binomial digunakan dalam sistem Induct/MCRDR untuk
menghitung nilai r yang menjadi parameter pemilihan kondisi terbaik dari suatu rule. Rumus lengkap dari nilai r dapat dilihat pada Subbab 2.3.1.
Berikut adalah pembagian kelas untuk tiap package yang digunakan:
Tabel II-1 Daftar kelas untuk tiap package yang digunakan dalam shell Induct/MCRDR No Nama Package Deskripsi Daftar Kelas
1. gui Berisi kelas-kelas antarmuka MainFrame.java
2. lib.jdots Berisi kelas-kelas pada library JDOTS Kelas-kelas dalam library JDOTS
3. lib.JSci Berisi kelas-kelas pada library JSci
(Java Objects for Science)
Kelas-kelas dalam library JSci
4. util Berisi kelas-kelas utama sistem
Induct/MCRDR TwoDimArrList.java ListAttrb.java ListData.java Condition.java Rules.java Node.java MainMCRDR.java
2.5 Diagnosis Penyakit dan Pemberian Terapi oleh Pakar
Secara umum, tahapan diagnosis dan pemberian terapi oleh pakar adalah sebagai berikut:1. Anamnesis
Anamnesis atau wawancara medis merupakan tahap awal dari rangkaian pemeriksaan pasien, baik secara langsung pada pasien yang bersangkutan atau secara tidak langsung melalui keluarga maupun relasi terdekatnya.
Ada dua tujuan utama dalam anamnesis, yaitu mendapatkan informasi menyeluruh dari pasien yang bersangkutan (data medis organobiologis, psikososial, serta lingkungan pasien). Dari informasi ini, diharapkan dapat disimpulkan dugaan organ/sistem yang terganggu, bahkan rumusan masalah klinik. Tujuan kedua dari anamnesis adalah membina hubungan dokter pasien yang profesional dan optimal. Hubungan ini diharapkan dapat menimbulkan kepercayaan pasien terhadap dokternya dan sebaliknya.
Dari anamnesis ini, biasanya didapatkan informasi berupa riwayat penyakit pasien dan keluhan pasien saat ini Adapun riwayat penyakit pasien meliputi alergi, penyakit
berat yang pernah diderita, operasi, diabetes, darah tinggi, darah rendah, dan lain sebagainya.
2. Pemeriksaan umum
Setelah melakukan anamnesis, pakar melihat keadaan fisik pasien secara umum, gemuk atau kurus, pucat, merasa kesakitan, kesadaran turun, batuk-batuk, dan lain sebagainya. Setelah itu, dokter melakukan pengukuran tekanan darah, suhu tubuh, berat badan, dan frekuensi pernapasan jika diperlukan.
3. Pemeriksaan fisik
Pemeriksaan fisik merupakan pemeriksaan mendetil sehubungan dengan keluhan pasien. Sebagai contoh, seorang pasien mengeluhkan sakit pada lengan kanan, maka pakar memeriksa lengan kanan pasien dengan menekan-nekan dengan jari tangannya. Dari aktivitas tersebut, pakar menyimpulkan terdapat nyeri tekan pada lengan kanan pasien. Hal seperti ini juga disebut inspeksi.
4. Diagnosis kerja (working diagnosis) / diagnosis sementara
Dari riwayat penyakit, keluhan, dan inspeksi pasien, pakar menyimpulkan penyakit yang diderita pasien, disertai dengan pemberian terapi yang sesuai. Untuk kasus-kasus yang memerlukan pemeriksaan penunjang untuk mengetahui kepastian penyakit yang diderita, tahap ini disebut sebagai diagnosis sementara.
5. Follow up / pemberian anjuran / saran untuk melakukan pemeriksaan penunjang Setelah pakar memberikan diagnosis dan terapi, biasanya pasien juga diberi anjuran sehubungan dengan terapi tersebut. Anjuran tersebut dapat berupa aktivitas yang menunjang terapi, ataupun berupa follow up (pasien diminta datang kembali pada waktu yang ditentukan). Jika hasil diagnosis merupakan diagnosis sementara, biasanya pasien diminta untuk melakukan pemeriksaan penunjang, misalnya tes kadar gula darah di laboratorium.
6. Diagnosis pasti
Diagnosis pasti dilakukan berdasarkan hasil pemeriksaan laboratorium, dilanjutkan dengan pemberian terapi yang sesuai.
![Gambar II-1 Induksi pada Induct/RDR [GAI92]](https://thumb-ap.123doks.com/thumbv2/123dok/4214736.3108496/4.892.90.818.94.1182/gambar-ii-induksi-pada-induct-rdr-gai.webp)
![Gambar II-3 Contoh representasi pengetahuan Induct/MCRDR [ARM07]](https://thumb-ap.123doks.com/thumbv2/123dok/4214736.3108496/5.892.82.820.106.1180/gambar-ii-contoh-representasi-pengetahuan-induct-mcrdr-arm.webp)
![Gambar II-4 Contoh inferensi dari Induct/MCRDR untuk kasus masukan [tear-prod = normal, astigmatism = no, age = young]](https://thumb-ap.123doks.com/thumbv2/123dok/4214736.3108496/6.892.84.820.96.1189/gambar-contoh-inferensi-induct-mcrdr-masukan-normal-astigmatism.webp)