Fakultas Ilmu Komputer
Universitas Brawijaya
7119
Klasifikasi Status Gunung Berapi dengan Metode Learning Vector
Quantization (LVQ)
Chelsa Farah Virkhansa1, Budi Darma Setiawan2, Candra Dewi3
Program Studi Teknik Informatika, Fakultas Ilmu Komputer, Universitas Brawijaya Email: 1[email protected], 2[email protected], 3[email protected]
Abstrak
Ada 129 gunung api yang masih aktif serta 500 gunung api yang tidak aktif yang terletak di Indonesia. Warga yang bertempat tinggal di sekitar daerah yang rentan terhadap letusan gunung api cukup banyak yaitu sebanyak 10% dari penduduk Indonesia. Dari jumlah gunung api yang masih aktif tersebut hanya terdapat 69 gunung yang terpantau, maka masih banyak gunung api yang aktif yang tidak terpantau secara baik yaitu sekitar 40%. Sehingga dibutuhkan informasi status gunung berapi secepat dan seakurat mungkin untuk mengurangi dampak yang disebabkan oleh letusan gunung berapi tersebut. Pada penelitian bertujuan untuk melakukan pengklasifikasian status gunung berapi dengan menggunakan metode Learning Vector Quantization. Penelitian ini menggunakan data berjumlah 110 data. Data tersebut diperoleh dari website Pusat Vulkanogi dan Mitigasi Bencana Geologi (PVMBG). Dari pengujian yang sudah dilakukan, didapatkan hasil akurasi tertinggi sebesar 88% saat memakai learning
rate 0.1, pengurang learning rate 0.1 serta minimum learning rate 0.01.
Kata kunci: Gunung berapi, klasifikasi, learning vector quantization Abstract
There are 129 active volcanoes and 500 inactive volcanoes located in Indonesia. Residents who live around areas that are susceptible to volcanic eruptions are quite numerous, which is as much as 10% of Indonesia's population. From the number of volcanoes that are still active there are only 69 mountains monitored, so there are still many active volcanoes which are not well monitored, which is around 40%. So that information on the status of the volcano is needed as quickly and accurately as possible to reduce the impact caused by the volcanic eruption. In this research, volcanic status classification will be carried out using the Learning Vector Quantization method. this study uses data totaling 110 data. The data was obtained from the website of the Volcanology Center and Geological Disaster Mitigation (PVMBG). From the tests that have been done, the highest accuracy is 88% when using the learning rate 0.1, the learning rate deduction is 0.1 and the minimum learning rate is 0.01.
Keywords: volcanoes, classification, learning vector quantization
1. PENDAHULUAN
Ada 129 gunung api yang masih aktif serta 500 gunung api yang tidak aktif yang terletak di Indonesia. Banyaknya jumlah gunung api yang masih aktif tersebut dimana jumlah tersebut 13% dari total gunung api aktif yang ada dalam dunia. Banyak warga yang tinggal di daerah yang rentan terhadap letusan gunung api yaitu sebanyak 10% dari penduduk Indonesia. Terdapat 175.000 yang telah menjadi korban akibat dari bencana letusan gunung api sejak lebih dari 100 tahun (Noor, 2014). Dari jumlah gunung api yang masih aktif tersebut hanya terdapat 69 gunung yang terpantau, maka masih
banyak gunung api yang aktif yang tidak terpantau secara baik yaitu sekitar 40% (Tempola, Arief, & Muhammad, 2017). Sehingga dibutuhkan informasi status gunung berapi secepat dan seakurat mungkin untuk mengurangi dampak yang disebabkan oleh letusan gunung berapi tersebut.
Di Indonesia terdapat badan yang mengeluarkan rekomendasi status gunung berapi yaitu Pusat Vulkanogi dan Mitigasi Bencana Geologi (PVMBG). Mereka memantau aktifitas dari setiap gunung untuk mengetahui status aktivitas gunung. Pemantauan dilakukan dengan mengamati secara visual dan dari faktor kegempaannya.
terkait status gunung berapi yaitu dengan menerapkan kombinasi metode Case Based
Reasoning dan nearest neigbour. Klasifikasi
status gunung berapi yang dilakukan dengan menggunakan 4 faktor kegempaan yang terdiri dari gempa vulkanik dangkal, gempa tektonik jauh, gempa vulkanik dalam, gempa hembusan. Kemudian ditambahkan 1 fitur lain yaitu status sebelumnya. Hasil dari sistem tersebut mendapatkan akurasi maksimal 80,91%, namun saat diterapkan k-fold validation akurasinya menurun menjadi 66,64% (Tempola, Arief, & Muhammad, 2017).
Kemudian Tempola, Muhammad, dan Khairan (2018) juga telah melakukan penelitian terkait prediksi status gunung berapi di Indonesia dengan menerapkan metode Naive
Bayes Classifier. Data latih yang digunakan
sejumlah 23 dan data ujinya sejumlah 46. Akurasi yang didapatkan tanpa menggunakan validasi data yaitu sebesar 82,61%. Namun pada saat dilakukan k-fold validation, akurasi rata-rata yang dihasilkan sebesar 79,71%.
Metode Naive Bayes menggunakan probabilitas untuk melakukan klasifikasi. Sehingga apabila data latih yang digunakan hanya terbatas akan memungkinkan terjadi kegagalan dalam pengklasifikasian. Seperti pada penelitian terkait klasifikasi penyakit kandungan yang melakukan perbandingan antara probabilistik Naive Bayes Classifier dengan
Learning Vector Quantization didapatkan hasil
yakni Learning Vector Quantization
memperoleh akurasi yang lebih baik dibandingkan Naïve Bayesian Classifier saat tidak menggunakan Laplacian Smoothing. Hasil akurasi yang diperoleh Naïve Bayesian
Classifier tanpa Laplacian Smoothing yaitu
32%; 67.8%; 79%; dan 89.6%. Sedangkan
Learning Vector Quantization mendapatkan
akurasi 82.4%; 88.8%; 89.4%; dan 95.2% (Nugraha, Saptono & Sulistyo, 2013).
LVQ adalah metode yang termasuk
dalam neural network. Metode Learning Vector
Quantization (LVQ) ialah metode yang simpel
selain itu waktu pelatihannya cepat. LVQ juga sudah pernah digunakan pada penelitian terkait mitigasi bencana banjir. Data yang digunakan terdiri dari ketinggian, drainase serta curah hujan. Dari penelitian tersebut diperoleh hasil akurasi 95,29%. Sehingga dapat disimpulkan bahwa metode LVQ baik dalam mengidentifikasi bencana banjir (Ashar, et al., 2018).
Berdasarkan uraian tersebut, maka
dibuatlah skripsi untuk klasifikasi status gunung berapi dengan mengimplementasikan algoritme
Learning Vector Quantization (LVQ). Fitur
yang dipakai untuk klasifikasi ialah jumlah gempa vulkanik dangkal, gempa tektonik jauh, gempa vulkanik dalam, gempa hembusan dan status gunung sebelumnya. Dengan adanya sistem ini diharapkan mampu membatu dalam mendeteksi status gunung berapi.
2. LANDASAN KEPUSTAKAAN 2.1. Gunung Berapi
Gejala kegiatan gunungapi menyebabkan gempa yang biasa disebut Gempa Vulkanik. Menurut Kristianto & Budianto (2008) berdasarkan kedalaman terjadinya gempa dan sifat-sifat gelombangnya, maka gempa vulkanik dikelompokkan menjadi :
1. Gempa Vulkanik Dalam (VA)
Merupakan gempa yang memiliki frekuensi antara 4-7Hz dengan tempo yang pendek. Mekanisme dari gempa ini adalah di dalam tubuh gunung berapi terjadi retakan batuan akibat dari magma yang mengalami gerakan naik ke permukaan. Terdapat 2 macam gempa tipe A berdasarkan penyebabnya diantaranya gempa yang terjadi akibat sebelum terjadi letusan terdapat tekanan dari bawah ke atas dan penyebab lainnya terjadi karena tekanan mengalami penurunan setelah letusan terjadi.
2. Gempa Vulkanik Dangkal (VB)
Gempa ini menandakan terjadinya pergerakan magma yang mendekati permukaan. Gempa ini sering ditemukan pada gunung api yang bertipe letusan Volcano.
3. Gempa Hembusan
Mekanisme jenis gempa hembusan mirip dengan gempa letusan. Perberdaannya yaitu kekuatan gempa dan disertai dengan material vulkanik yang ikut terlempar. Kekuatan gempa hembusan lebih kecil dari gempa letusan. Gempa hembusan biasanya juga disertai dengan peristiwa emisi gas uap air.
4. Gempa Tektonik
Pelepasan energi yang merupakan dampak dari aktivitas tektonik dalam bentuk patahan ataupun rekahan mengakibatkan gempa yang disebut dengan gempa tektonik. Energi gempa ini lebih besar daripada gempa vulkanik. Jenis gempa tektonik terbagi menjadi 3 berdasarkan letak sumber gempanya antara lain:
a. Teleseismik merupakan gempa yang mempunyai jarak sumbernya diatas 500 Km.
b. Gempa Tektonik-Jauh merupakan gempa yang mempunyai jarak sumbernya diantara 100-500 Km.
c. Gempa Tektonik-Lokal merupakan gempa yang mempunyai jarak sumbernya kurang dari 100 Km dan disekitar gunung api. Dalam aktititasnya gunung berapi mempunyai empat tingkatan status yang ada yaitu normal (level 1), waspada (Level II), siaga (Level III), dan awas (Level 4). Penjelasan mengenai status tersebut sebagai berikut (PVMBG,2014):
a) Normal (Level 1): Kegiatan gunung api tidak terlihat adanya kelainan yang didasarkan dari pengamatan visual, faktor kegempaan dan gejala vulkanik yang lain.
b) Waspada (Level II): Kegiatan menunjukkan kelainan yang terlihat secara visual atau berdasar hasil peninjauan kawah, kegempaan dan gejala vulkanik yang lain mengalami peningkatan.
c) Siaga (Level III): Peningkatan menjadi semakin jelas dari hasil pemantauan secara visual atau peninjauan kawah, kegempaan dan metoda lainnya yang mendukung satu sama lain. Didasarkan dari analisis, letusan biasanya mengikuti perubahan kegiatan tersebut.
d) Awas (Level IV): Letusan awal berupa abu atau asap mulai terjadi pada saat mendekati terjadinya letusan utama. Berdasarkan analisis data pemantauan, letusan utama akan segera mengikuti.
2.2. Normalisasi
Normalisasi dilakukan terhadap data yang mempunyai rentang nilai yang jauh. Seperti pengukuran tinggi dari satuan meter ke inci atau pengukuran berat dari satuan kilogram ke poun, semakin kecil satuan pengukuran maka akan menghasilkan jarak yang lebih besar pada atribut tersebut. Data akan ditransformasi ke dalam rentang yang lebih kecil. Pada umumnya data akan diubah ke dalam rentang 0 hingga 1 atau -1 hingga 1.
Normalisasi sangat berguna untuk algoritma klasifikasi diantaranya jaringan syaraf tiruan atau perhitungan jarak seperti pada
nearest-neighbor dan clustering. Penelitian ini akan
menggunakan jenis normalisasi min-max yang dengan rumus pada Persamaan (1) (Han, Kamber dan Pei, 2012).
𝑣𝑖′ = 𝑚𝑎𝑥𝑣𝑖− 𝑚𝑖𝑛𝐴
𝐴−𝑚𝑖𝑛𝐴 (𝑛𝑒𝑤_𝑚𝑎𝑥𝐴−
𝑛𝑒𝑤_𝑚𝑖𝑛𝐴) + 𝑛𝑒𝑤_𝑚𝑖𝑛𝐴 (1)
Dimana 𝑣𝑖′ merupakan data normalisasi dari data 𝑣𝑖 , 𝑚𝑎𝑥𝐴 ialah nilai maksimal dari data, 𝑚𝑖𝑛𝐴 ialah nilai minimal dari data, 𝑛𝑒𝑤_𝑚𝑎𝑥𝐴 adalah nilai maksimal yang diinginkan untuk rentang data baru dan 𝑛𝑒𝑤_𝑚𝑖𝑛𝐴 merupakan nilai minimal yang diingikan untuk rentang data baru.
2.3. Klasifikasi
Klasifikasi ialah metode yang berfungsi untuk mengelompokan data kedalam beberapa kategori dengan menggunakan data latih yang sudah mempunyai katergori sebelumnya (Adinugroho & Sari, 2018). Berikut adalah beberapa algoritme klasifikasi yang populer digunakan diantaranya yaitu:
1. Decision tree 2. Naive bayes
3. K-nearest neighbor (KNN) 4. Jaringan syaraf tiruan 5. Algoritme genetik
6. Support vector machine (SVM)
Algoritme-algoritme klasifikasi dapat dikelompokkan menjadi 2 jenis menurut cara pelatihannya antara lain eager learner dan lazy
learner. Algoritme eager learner merupakan
algoritme yang dimodelkan yang digunakan untuk melakukan pembelajaran terhadap data latih yang kemudian petakan dengan benar pada masing-masing vektor masukan menuju label kelas keluarannya. Sehingga model tersebut bisa memetakan secara benar seluruh data latih ke label kelas keluarannya pada hasil akhir dari proses pembelajarannya. Sedangkan algoritme
lazy learner yaitu algoritme yang memerlukan
sedikit proses pelatihan. Hanya sebagian atau semua data yang akan disimpan, lalu data latih tersebut digunakan pada saat proses prediksi. Model dari algoritme ini adalah semua data latih harus dibaca kembali untuk memberikan label kelas keluaran yang sesuai terhadap data ujinya, sehingga berakibat proses prediksi berjalan lama. Namun untuk proses pelatihannya berlangsung secara cepat.
2.3. Jaringan Saraf Tiruan
Jaringan Saraf Tiruan (JST) ialah suatu sistem pengolahan informasi yang didasarkan dengan menyerupai kriteria dari jaringan saraf manusia. Jaringan Saraf Tiruan (JST) juga dikenal sebagai model free-estimator karena
jaringa saraf tiruan tidak membutuhkan suatu model yang sistematis untuk masalah yang sedang dihadapinya. Algoritme jaringan saraf tiruan tidak sama dengan algoritme yang lain, dimana operasi dilakukan secara langsung dalam bentuk angka. Sehingga data yang tidak numerik perlu dikonversikan menjadi numerik terlebih dahulu (Hermawan, 2006).
Jaringan saraf tiruan tersusun dari 3 lapisan antara lain lapisan input, lapisan tesembunyi, dan lapisan keluaran. Lapisan input merupakan unit-unit input yang mempunyai tugas menerima pola inputan dari luar. Sedangkan lapisan tersembunyi merupakan unit-unit tersembunyi yang tidak dapat terlihat langsung nilai ouput-nya. Dan lapisan keluaran yaitu unit-unit output dari solusi JST dalam memecahkan suatu masalah.
2.4. Algoritme LVQ
Learning Vector Quantization (LVQ) termasuk ke dalam supervised learning dan arsitektur jaringannya adalah berlayer tunggal. LVQ yaitu suatu metode klasifikasi yang setiap keluarannya menunjukkan suatu kelas atau kategori tertentu. Selama proses pelatihan, unit keluaran ditempatkan dengan kelas yang sesuai. Setelah pelatihan, sebuah vektor masukan dilakukan klasifikasi dengan menentukan kelas berdasarkan dengan kelas unit keluaran yang memiliki jarak terdekat antara vektor bobot dan vektor masukan.
Konsep utama algoritme ini adalah menemukan unit keluaran yang terdekat dengan vektor masukan. Bobot akan didekatkan ke vektor masukan apabila vektor masukan (x) dan vektor bobot (w) mempunyai kelas yang sama. Sedangkan jika vektor vektor masukan (x) dan vektor bobot (w) mempunyai kelas yang berbeda, maka bobot harus dijauhkan dari vektor masukan (Fausett, 1994).
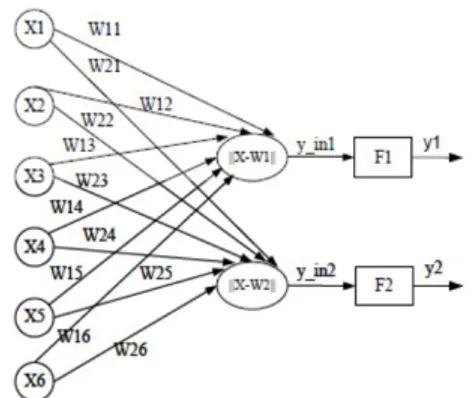
Gambar 1 merupakan contoh arsitektur jaringan LVQ dengan 4 vektor masukan dan 2 unit keluaran.
Gambar 1. Contoh Arsitektur Jaringan LVQ Sumber: (Fakhrurrifqi, Wardoyo,2013)
Tahapan langkah pada algoritme pelatihan LVQ antara lain (Fausett, 1994):
1. Menginisialisasi vektor bobot awal (w),
maxEpoch, learning rate (α), pengurang learning rate (dec_α) dan minimum α.
2. Apabila syarat kondisi pemberhentian masih tidak sesuai, lakukan tahap 3 hingga 6
3. Pada masing-masing vektor input data latih (x), lakukan tahap 4 hingga 6 4. Menemukan J yang mempunyai jarak
terkecil antara vektor masukan dengan vektor bobot ║xi-wj║ dengan rumus perhitungan jarak euclidian pada Persamaan (2).
Dj= Σ(wj−xi)2 (2) 5. Melakukan perbaikan vektor bobot wj
dengan kriteria:
Ketika T = Cj lalu rumus yang digunakan Persamaan (3)
wj(baru)=wj(lama)+α(x–wj(lama)) (3) Ketika T≠Cj lalu rumus yang digunakan Persamaan (4)
wj(baru)=wj(lama)-α(x–wj(lama)) (4) 6. Melakukan pengurangan nilai learning
rate (α) memakai rumus pada
Persamaan (5):
α = α × Decα (5) 7. Cek kondisi untuk berhenti yaitu hingga sampai iterasi yang sudah ditentukan atau learning rate mempunyai nilai sampai pada nilai terkecil yang sudah ditentukan sebelumnya.
Dimana:
T: kelas vektor data latih x: adalah vektor data latih
wj: vektor bobot sebanyak j unit keluaran (w1j,...,wij,....wnj)
2.5. Evaluasi
Pengukuran evaluasi pada penelitian ini dengan melakukan perhitungan akurasi dari jumlah dari data uji yang terklasifikasikan secara benar yang kemudian dibagi oleh jumlah keseluruhan data uji setelah itu dilakukan perkalian dengan 100%. Pengujian ini mempunyai tujuan supaya mengetahui keakuratan sistem yang telah dibuat. Pengujian akurasi tersebut bisa dilihat pada Persamaan 6. Akurasi= = 𝐷𝑎𝑡𝑎 𝑢𝑗𝑖 𝑦𝑎𝑛𝑔 𝑠𝑒𝑠𝑢𝑎𝑖
𝑇𝑜𝑡𝑎𝑙 𝑗𝑢𝑚𝑙𝑎ℎ 𝑑𝑎𝑡𝑎 𝑢𝑗𝑖 x 100% (6)
3. METODOLOGI 3.1. Data Penelitian
Data yang digunakan ialah bertipe sekunder. Data tersebut didapatkan dari data yang sudah ada dari sebuah institusi atau lembaga. Data tersebut bersifat publik yang tersedia secara online pada halaman web pusat vulkanologi dan mitigasi bencana geologi (PVBMG). Data yang diambil yaitu data dari tahun 2013 hingga 2017. Data tersebut berasal dari sekumpulan berita yang kemudian diolah kedalam bentuk excel. Data gunung berapi yang digunakan mempunyai 5 kriteria diantaranya jumlah gempa vulkanik dangkal, gempa tektonik jauh, gempa vulkanik dalam, gempa hembusan dan status gunung sebelumnya.
3.2. Metode LVQ
Penelitian ini menggunakan metode
Learning Vector Quantization (LVQ). Pada
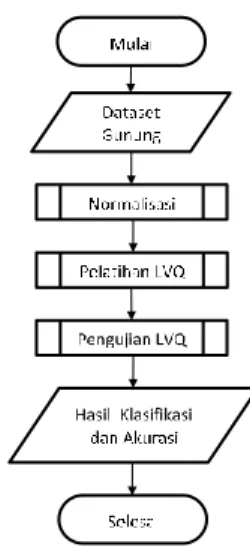
proses LVQ terdapat 2 proses utama antara lain proses pelatihan serta pengujian. Dari proses pelatihan akan memperoleh bobot akhir yang berfungsi untuk proses klasifikasi. Sementara itu proses pengujian akan mendapatkan akurasi keakuratan hasil penelitian. Secara umum alur dari proses dalam penelitian dapat dijelaskan melalui Gambar 2.
Gambar 2. Diagram Alir Proses Secara Umum
3.1.1. Normalisasi
Proses normalisasi merupakan perhitungan yang bertujuan untuk melakukan perubahan nilai data asli agar data berubah menjadi dalam rentang 0 dan 1. Penelitian akan menggunkan jenis metode normalisasi min-max.
3.1.2. Pelatihan LVQ
Proses pelatihan algoritme LVQ diawali dengan inisialisasi bobot awal, data latih, kelas target(T), learning rate, dec_alfa, maxEpoch dan min_alfa. Kemudian dilakukan perhitungan jarak euclidean antara vektor bobot dengan vektor input yang didapatkan dari data latih. Selanjutnya dilakukan pencarian untuk mendapatkan jarak terdekat dari jarak euclidean yang telah dihitung sebelumnya. Lalu melakukan perbaikan perubahan vektor bobot. Proses-proses tersebut dilakukan secara berulang sebanyak data latih dan juga dilakukan secara terus menerus apabila masih memenuhi kondisi yang telah ditentukan. Pada saat proses sudah berhenti maka akan didapatkan hasil akhir vektor bobot akhir untuk digunakan saat proses pengujian.
3.1.3. Pengujian LVQ
Setelah proses pelatihan pada LVQ sudah selesai, maka selanjutnya dilakukan proses pengujian. Vektor bobot yang merupakan hasil pada proses pelatihan LVQ akan digunakan dalam proses pengujian ini. Kemudian melakukan proses hitung jarak euclidean antara vektor bobot dengan vektor masukan dari data uji. Setelah itu melakukan pencarian nilai minimum dari sejumlah jarak euclidean tersebut. Data uji akan diklasifikasikan ke kelas yang mempunyai jarak terkecil. Apabila data uji sudah
diklasifikasikan semuanya, maka akan dihitung akurasinya.
4. HASIL PENGUJIAN DAN ANALISIS
Proses pengujian yang dilakukan antara lain pengujian learning rate, pengurang learning
rate dan minimal learning rate. Tujuan dari
pengujian ini adalah agar dapat diketahui dan kemudian dilakukan analisis nilai-nilai parameter yang paling baik pada algoritme LVQ yang digunakan. Selain itu juga terdapat pengujian dan analisis hasil apabila data yang digunakan hanya terdiri dari satu jenis gunung saja.
Setiap pengujian yang dilakukan akan diambil nilai yang paling baik dan akan digunakan untuk pengujian parameter selanjutnya. Data uji yang dipakai sejumlah 25 dari keseluruhan data sejumlah 110. Bobot awal yang dipakai pada pengujian ini merupakan bobot optimum yang sudah dipilih sebelumnya. Sehingga bobot awal untuk setiap dilakukan pengujian selalu sama. Parameter awal yang digunakan pada pengujian learning rate adalah pengurang learning rate (Dec α) 0.9, maksimal epoch 20 dan minimum learning rate 1 × 10-10.
4.1. Pengujian Learning Rate (α)
Pengujian ini dilakukan agar memperoleh hasil analisis terhadap parameter learning rate (α) dalam penggunaan metode LVQ untuk klasifikasi status gunung berapi. Learning rate
mempunyai perngaruh terhadap perubahan bobot. Hasil pengujian learning rate dapat dilihat pada Gambar 3.
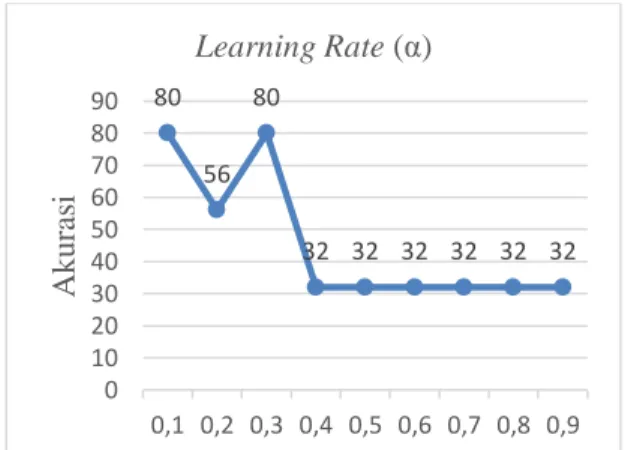
Gambar 3. Pengujian Learning Rate (α) Hasil akurasi tertinggi pada pengujian ini yaitu sebesar 80% pada saat learning rate bernilai 0,1 dan akurasi paling rendah 32% yang berlangsung stabil. Dari proses pengujian ini mendaptkan akurasi sebesar 32% karena proses
pembalajaran akan menjadi semakin lama apabila nilai learning rate semakin besar. Namun data yang digunakan kurang baik sehingga semakin banyak proses pelatihan akan memperngaruhi akurasi yang semakin buruk. Kesimpulan dari hasil tersebut adalah nilai semakin besar nilai dari learning rate mengakibatkan pengaruh pada akurasi yang akan menjadi semakin rendah. Learning rate mempunyai pengaruh terhadap eksplorasi perbaikan bobot yang dilakukan, apabila nilainya semakin besar maka jangkauan explorasi semakin jauh. Hal itu mengakibatkan akan ada proses perbaikan bobot yang dilewatkan sehingga memungkinkan pada saat proses pembelajaran tidak dapat menemukan bobot yang optimal. Berdasarkan pengujian nilai parameter learning rate yang telah dilakukan maka akan menggunakan nilai parameter learning rate yaitu 0,1 untuk proses pengujian selanjutnya.
4.2. Pengujian Pengurang Learning Rate (dec α)
Bertujuan agar memperoleh analisis terhadap parameter pengurang learning rate (Dec α) dalam penggunaan algoritme LVQ. Perbaikan pada nilai learning rate (α) dipengaruhi oleh pengurang learning rate. Hasil dari pengujian ini dapat dilihat melalui Gambar 4.
Gambar 4. Pengujian Pengurang Learning Rate (dec α)
Akurasi tertinggi sebesar 84% diperoleh pada saat pengurang learning rate bernilai 0,1 serta 0,2. Sementara akurasi terendahnya ialah 80%. Pada saat nilai parameter pengurang learning rate 0,3 hingga 0,8 hasilnya konstan. Berdasarkan hasil pengujian ini maka nilai parameter learning rate yang dipakai untuk proses pengujian selanjutnya yaitu 0,1.
80 56 80 32 32 32 32 32 32 0 10 20 30 40 50 60 70 80 90 0,1 0,2 0,3 0,4 0,5 0,6 0,7 0,8 0,9 A k u ra si Learning Rate (α) 84 84 80 80 80 80 80 80 80 0 10 20 30 40 50 60 70 80 90 0,1 0,2 0,3 0,4 0,5 0,6 0,7 0,8 0,9 A k u ra si
4.3. Pengujian Minimum Learning Rate (min α)
Pengujian ini dilakukan agar memperoleh hasil analisis terhadap parameter minimum
learning rate (α) dalam penggunaan metode
LVQ untuk klasifikasi status gunung berapi. Hasil dari pengujian pada parameter minimum learning rate dapat dilihat melalui Gambar 5.
Gambar 5. Pengujian Minimum Learning Rate (min α)
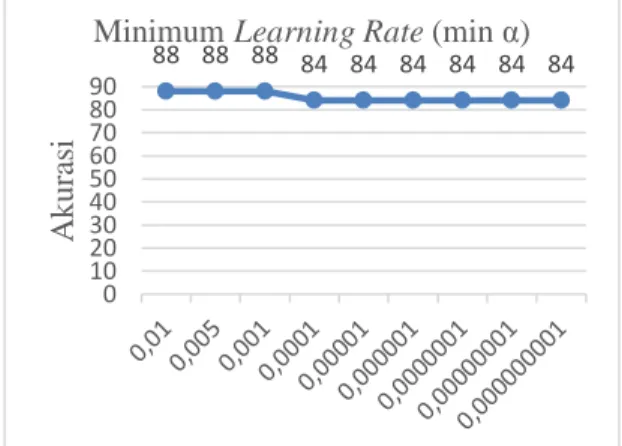
Akurasi paling tinggi ialah sebesar 88% pada saat nilai parameter minimum learning rate 0,1 hingga 0,001. Kemudian akurasi terendah yaitu sebesar 84% saat nilai parameter minimum
learning rate 0,001 dan berlangsung konstan
hingga 0,000000001. Minimum learning rate mempengaruhi banyaknya proses konvergensi bobot untuk mendapatkan bobot optimum. Proses untuk menemukan bobot optimum akan menjadi semakin lama jika nilainya semakin kecil. Kesimpulan dari hasil pengujian ini yaitu bahwa pada saat minimum learning rate 0,01 sudah didapatkan bobot yang optimum.
4.4. Pengujian dengan Menggunakan Satu Jenis Gunung
Pengujian ini dilakukan agar memperoleh hasil analisis terhadap penggunaan data yang digunakan untuk proses pelatihan dan pengujian. Data yang digunakan yaitu data gunung Raung , gunung Agung dan Gunung Lokon. Hasil pengujian dapat dilihat pada Tabel 1.
Tabel 1. Pengujian dengan Data Satu Jenis Gunung
Nama Gunung Akurasi
Gunung Agung 100%
Gunung Lokon 100%
Gunung Raung 50%
Data yang digunakan sejumlah 9 untuk gunung Agung dan gunung Lokon sedangkan pada gunung Lokon berjumlah 10. Sehingga data yang digunakan sebagai data uji yaitu sebanyak 2 data pada saat pengujian data gunung Agung dan juga gunung Lokon. Sementara itu saat pengujian dengan menggunakan data gunung Lokon menggunakan data sebanyak 3 sebagai data ujinya. Dari hasil tersebut membuktikan bahwa apabila menggunakan data dari satu jenis gunung saja akan menghasilkan akurasi yang baik. Hal itu terjadi karena karakteristik dari gunung berbeda-beda. Namun akurasi pada gunung Raung akurasinya hanya 50% karena terdapat fitur lain yaitu gempa tremor yang mempengaruhi untuk penentuan status pada gunung tersebut sehingga akurasi yang didapatkan kurang maksimal.
5. KESIMPULAN DAN SARAN
Maka dapat ditarik kesimpulan yakni parameter yang learning rate mempengaruhi tingkat akurasi, semakin besar nilai learning rate akan mengakibatkan akurasi yang rendah. Parameter pengurang learning rate juga mempunyai pengaruh terhadap hasil akurasi menjadi semakin rendah karena semakin besar nilainya sehingga mengakibatkan nilai learning
rate juga semakin besar. Sedangkan untuk
pengujian terkait pengaruh nilai minimum
learning rate menghasilkan akurasi yang
konstan karena saat nilainya 0,01 sudah mendapatkan bobot yang optimum. Pada penelitian ini diperoleh akurasi paling tinggi yaitu sebesar 88% dengan memakai nilai
learning rate 0,1, pengurang learning rate 0,1
serta minimum learning rate 0,01.
Saran untuk perkembangan penelitian berikutnya ialah Mengembangkan sistem dengan metode klasifikasi lainnya serta Dilakukan optimasi terhadap bobot pada LVQ agar memperoleh vektor bobot yang lebih optimal dengan cepat karena penentuan bobot secara manual membutuhkan waktu yang lama.
6. DAFTAR PUSTAKA
Adinugroho, S. & Sari, Y. A., 2018.
Implementasi Data Mining Menggunakan WEKA. Malang: UB Press.
Fausett, L., 1994. Fundamental of Neural
Network : Architectures, Algorithms, and Applications. New Jersey: PrenticeHall,
Inc. 88 88 88 84 84 84 84 84 84 0 10 20 30 40 50 60 70 80 90 A k u ra si
Hamidi, R., Furqon, M. T. & Rahayudi, B., 2015. Implementasi Learning Vector
Quantization (LVQ) untuk Klasifikasi Kualitas Air Sungai. S1. Universitas
Brawijaya.
Kristianto & Budianto, A., 2008. Evaluasi Seismik dan Visual Kegiatan Vulkanik G. Egon, April 2008. Bulletin Vulkanologi
dan Mitigasi Bencana Geologi, 3(2), pp.
9-17.
Noor, D., 2014. Pengantar Mitigasi Bencana
Geologi. Yogyakarta: Deepublish.
Nurkhozin, A., Irawan, M. I. & Mukhlash, I., 2011. Klasifikasi Penyakit Diabetes
Mellitus Menggunakan Jaringan Syaraf Tiruan Backpropagation dan Learning Vector Quantization. Yogyakarta, s.n.
Tempola, F., Arief, A. & Muhammad, M., 2017.
Combination of Case-Based Reasoning and Nearest Neighbour for Recommendation of Volcano Status.
Yogyakarta, IEEE, pp. 348-352.
Tempola, F., Muhammad, M. & Khairan, A., 2018. Naive Bayes Classifier For
Prediction Of Volcanic Status In Indonesia. Ternate, ICITACEE.
Han, J., Kamber, M. & J. P., 2012. Data Mining:
Concepts and Techniques. USA: Elsevier.
Hermawan, A., 2006. Jaringan Saraf Tiruan,