Jurnal Informatika Kaputama (JIK), Vol. 5 No. 1, Januari 2021 P-ISSN : 2548-9739 E-ISSN : 2685-5240
129
ANALISA SENTIMEN TERHADAP BELAJAR ONLINE PADA MASA
COVID-19 MENGGUNAKAN ALGORITMA SUPPORT VECTOR
MACHINE BERBASIS PARTICLE SARM OPTIMIZATION
Hermanto1), Astrid Noviriandini2) 12Universitas Bina Sarana Informatika
Jl. Kramat Raya No. 98, Senen, Jakarta Pusat Email : [email protected], [email protected]
ABSTRACT
Coronavirus 19 (COVID-19) is a contagious viral infection that has now spread to various countries, one of which is Indonesia. Monitoring the spread of COVID-19 in Indonesia, direct services by the Government of Indonesia, especially. The Indonesian government immediately followed up on the case. One of the government’s actions is to carry out Social Distancing for 14 days to minimize the spread of the virus. This online learning activity is carried out to replace direct learning activities. Online learning has weaknesses in the use of internet networks, adequate infrastructure, requires a lot of money, communication via the internet which has various networks is slow. There are quite a lot of public comments on twitter about online learning. Based on comments from the general public who are hurt, it is easy, based on very many orders to leave so that you can see the extent to which the analysis of public sentiment is based on positive and negative comments using classification techniques, namely using the Particle Swarm Optimization-Based Support Vector Machine. The test result with accuracy values and AUC values by means of SVM + PSO accuracy value = 71.39% and AUC value = 0.762. for this reason, in this study it can be stated that the use of Particle Swarm Optimization (PSO) in the Support Vector Machine (SVM) algorithm model can be a solution to improve accuracy and AUC analysis of public sentiment regarding online learning during the Covid-19 period can be used to provide solutions to problems. Sentiment analysis on public comments on twitter during the Covid-19 period.
Keywords: Text Mining, Online Learning, Covid-19, Support Vector Machine Algorithm
ABSTRAK
Coronavirus 19 (COVID-19) merupakan infeksi virus menular yang saat ini sudah merambah ke berbagai negara salah satunya di Indoenesia. Pemantauan penyebaran COVID-19 di Indonesia ditangani langsung oleh Pemerintah Indonesia terutama. Pemerintah Indonesia langsung menindak lanjuti kasus tersebut. Salah satu tindakan pemerintah adalah melakukan Social Distancing selama 14 hari untuk meminimalisir penyebaran virus tersebut. Kegiatan pembelajaran online ini dilakukan untuk mengganti kegiatan pembelajaran secara langsung. Pembelajaran online memiliki beberapa kelemahan yakni penggunaan jaringan internet membutuhkan infrastruktur yang memadai, membutuhkan banyak biaya, komunikasi memalui internet terdapat berbagai kendala/lamban. Komentar masyarakat di twitter mengenai belajar online cukup banyak. Namun memantau komentar dari masyarakat umum bukanlah hal yang mudah, dikarenakan jumlahnya sangat banyak untuk diproses sehingga peneliti ingin mengetahui sejauh mana analisa sentimen masyarakat berdasarkan komentar positif dan negatif dengan menggunakan teknik klasifikasi yaitu menggunakan Algoritma Support Vector Machine Berbasis Particle Swarm Optimization. Hasil
Jurnal Informatika Kaputama (JIK), Vol. 5 No. 1, Januari 2021 P-ISSN : 2548-9739 E-ISSN : 2685-5240
130 pengujian dengan nilai akurasi dan nilai AUC yaitu yaitu untuk SVM + PSO nilai akurasi = 71.39% dan nilai AUC = 0.762. Untuk itu, Dalam penelitian ini dapat disimpulkan bahwa penggunaan Particle Swarm Optimization (PSO) pada model algoritma support vector machine (SVM) dapat menjadi solusi meningkatkan akurasi dan AUC analisa sentiment masyarakat mengenai belajar online pada masa covid-19 dapat digunakan untuk memberikan solusi terhadap permasalahan analisis sentimen Komentar masyarakat di twitter ada masa covid-19.
Kata Kunci: Text Mining, Belajar Online, Covid-19, Algoritma Support Vector Machine 1. PENDAHULUAN
Coronavirus 19 (COVID-19) merupakan sebuah virus yang menyerang pernafasan manusia (Kementrian Kesehatan, 2020). Covid-19 ini pertaman kali meyebar luas di Wuhan, Provinsi Hubei, Cina. Beberapa hal yang harus dilakukan dalam pencegahan virus ini menurut (Kementrian Dalam Negeri, 2020) yaitu melakukan kebersihan tangan menggunakan hand sanitizer atau mencuci tangan menggunakan sabun, menghindari menyentuh mata, hidung dan mulut, terapkan etika batuk atau bersin dengan menutup hidung dan mulut dengan lengan atas bagian dalam atau menggunakan tisu, lalu buanglah tisu ke tempat sampah, pakailah masker medis jika memiliki gejala berat dan melakukan kebersihan tangan setelah membuang masker, menjaga jarak (minimal 1 meter) dari orang yang mengalami gejala gangguan pernapasan.
Penyebaran virus Covid-19 ini pada awalnya sangat berdampak pada dunia ekonomi yang mulai lesu, tetapi kini dmapaknya dirasakan juga oleh dunia pendidikan. Kebijakan yang diambil oleh banyak Negara termasuk Indonesia dengan meliburkan seluruh aktivitas pendidikan membuat pemerintah dan lembaga terkait harus menghadirkan alternatif proses pendidikan bagi peserta didik maupun mahasiswa yang tidak dapat melaksanakan proses pendidikan pada lembaga pendidikan. Hasil keputusan dari Menteri Pendidikan bahwa seluruh kegiatan pembelajaran baik sekolah maupun perguruan tinggi dilaksanakan dirumah masing-masing melalui aplikasi yang tersedia. Menteri Pendidikan mengeluarkan Surat Edaran Nomor 3 Tahun 2020 Tentang Pencegahan Corona Virus Disease (COVID-19) Pada Satuan Pendidikan yang menyatakan
bahwa meliburkan sekolah dan perguruan tinggi (Kemdikbud RI, 2020). Seluruh jenjang pendidikan dari sekolah dasar sampai perguruan tinggi yang berada dibawah Kementerian Pendidikan dan Kebudayaan RI semuanya memperoleh dampak negative karena pelajar, siswa dan mahasiswa dipaksa belajar dari rumah karena pembelajaran tatap muka ditiadakan untuk mencegah penularan Covid-19. Padahal tidak semua pelajar, siswa dan mahasiswa terbiasa belajar melalui online apalagi guru dan dosen masih banyak yang belum mahir mengajar menggunakan teknologi internet atau media social terutama di berbagai daerah.
Kegiatan pembelajaran online ini dilakukan untuk mengganti kegiatan pembelajaran secara langsung. Pembelajaran online memiliki beberapa kelemahan yakni penggunaan jaringan internet yang membutuhkan infrastruktur yang memadai dan membutuhkan banyak biaya. Meskipun terdapat beberapa kendala, pembelajaran online dapat dikatakan efektif apabila siswa atau mahasiswa dapat mencapai tujuan pembelajaran dan aktif berinteraksi dengan guru atau dosen.
Dari serangkaian latar belakang yang telah diuraikan diatas, peneliti akan melakukan analisis sentimen terhadap belajar online pada masa pandemi Covid-19 menggunakan metode
Support Vector Machine (SVM) berbasis
Particle Swarm Optimization (PSO). Dari
proses pengujian data pada Rapidminer dimulai dengan pembentukan model data pada bagian pertama pembagian data training dan data testing. Setelah melakukan pengujian akurasi dapat diukur dengan menggunakan cond=fusion matrix, dan performance diukur
Jurnal Informatika Kaputama (JIK), Vol. 5 No. 1, Januari 2021 P-ISSN : 2548-9739 E-ISSN : 2685-5240
131 menggunakan accuracy dan AUC serta akan
ditampilkan dalam bentuk kurva ROC, tentunya dapat diketahui akurasi manakah yang memiliki tingkat akurasi yang paling tinggi sesuai dengan hasil penelitian menggunakan model Algoritma Support Vector Machine (SVM) berbasis Particle Swarm Optimization (PSO).
2. METODOLOGI PENELITIAN
Dari penelitian yang dilakukan oleh Hermanto dkk dengan judul “Sentiment Analysis On Gojek and Grab User Reviews Using SVM Algorithm Based on Particle
Swarm Optimization” kesimpulan dari
penelitian ini adalah hasil evaluasi dan validasi diketahui bahwa nilai akurasi untuk menentukan Analisis review aplikasi Gojek dan Grab komentar pengguna dapat dibuktikan dengan nilai keakuratannya dan nilai AUC masing-masing yaitu untuk aplikasi Gojek dengan nilai akurasi sebesar 65,59% dan nilai AUC 0,680, sedangkan untuk aplikasi Grab nilai akurasi sebesar 73,09% dan nilai AUC 0,804 dengan kinerja akurasi yang sangat baik. Didalam mempelajari dapat diketahui bahwa tingkat akurasi yang diperoleh aplikasi Grab menggunakan Algoritma Support Vector Machine berbasis Particle Swarm Optimization lebih unggul dibandingkan aplikasi Gojek. Algoritma Support Vector Machine berbasis Particle Swarm Optimization ini memiliki akurasi yang lebih tinggi dari penelitian sebelumnya sehingga dapat dimanfaatkan untuk memberikan solusi pada masalah analisis sentimen dalam ulasan komentar pengguna aplikasi online[1].
2.1.Data Mining
Data Mining adalah proses untuk
mendapatkan informasi yang berguna dari gudang basis data yang besar. Teknik dalam Data Mining yaitu bagaimana menelusuri data yang ada untuk membangun sebuah model. Model tersebut digunakan untuk mengenali pola data yang lain yang tidak berada dalam basis data yang tersimpan[2].
Data Mining sebenarnya merupakan salah satu bagian proses Knowledge-discovery in
Database (KDD) yang bertugas untuk
mengesktrak pola atau model dari data dengan menggunakan satu algoritma yang spesifik[2]. 2.2.Text Mining
Text Mining yang juga dikenal dengan text data mining atau pencarian pengetahuan di basis data textual adalah sebuah proses untuk melakukan pencarian pengetahuan yang berfokus kepada data yang berbentuk dokumen atau teks, dengan tujuan untuk mengekstrak informasi yang berguna dan mengidentifikasinya. Text Mining mempunyai kesamaan dengan data mining. Keduanya memiliki tujuan yang sama yaitu untuk memperoleh pengetahuan dan informasi dari sekumpulan data yang besar. Yang membedakan antara text mining dengan data mining adalah pada data mining masukan data terstruktur sedangkan text mining masukan datanya tidak terstruktur[3].
2.3.Analisis Sentimen
Analisis sentimen adalah sebuah proses untuk menentukan sentimen atau opini dari seseorang yang diwujudkan dalam bentuk teks dan bisa dikategorikan sebagai sentimen positif atau negatif[4]. Pengguna internet banyak menuliskan pengalaman, opini dan segala hal yang menjadi perhatian mereka. Tulisan tentang apa yang mereka rasakan ini berupa perasaan positif, netral maupun negatif yang bisa diungkapkan dengan cara yang cukup kompleks.
2.4.Support Vector Machine (SVM)
Support Vector Machine (SVM) adalah
metode pembelajaran terbimbing yang menganalisis data dan mengenali pola, digunakan untuk klasifikasi dan analisis regresi. Metode ini dikembangkan oleh Boser, Guyon, Vapnik dan pertama kali dipresentasikan pada tahun 1992 di Annual Workshop on Computational Learning Theory[5].
Jurnal Informatika Kaputama (JIK), Vol. 5 No. 1, Januari 2021 P-ISSN : 2548-9739 E-ISSN : 2685-5240
132
Support Vector Machine (SVM) termasuk
klasifikasi yang memberikan aturan untuk mengubah dokumen teks menjadi vector sebelum diklasifikasi. Biasanya teks dokumen diubah menjadi vector multidimensional tf-idf.
Support Vector Machine (SVM)
memperkenalkan strategi baru dengan menemukan hyperplane terbaik pada ruang input[5].
2.5.Particle Swarm Optimization (PSO) Particle Swarm Optimization (PSO) adalah metode optimasi global yang diperkenalkan oleh Kennedy dan Eberhart pada tahun 1995 berdasarkan penelitian terhadap perilaku kawanan burung dan ikan. Setiap partikel dalam Particle Swarm Optimization memiliki kecepatan partikel bergerak dalam ruang pencarian dengan kecepatan yang dinamis disesuaikan dengan perilaku historis mereka. Oleh karena itu, partikel memiliki kecenderungan untuk bergerak menuju daerah pencarian yang lebih baik selama proses pencarian[6].
Dalam algoritma Particle Swarm Optimization (PSO) terdapat beberapa proses sebagai berikut[6]:
1. Inisialisasi
2. Update kecepatan
3. Update posisi dan hitung fitness 4. Update pBest dan gBest
3. HASIL DAN PEMBAHASAN 3.1.Business Understanding
Pada tahap business understanding bisa disebut juga sebagai tahap pemahaman penelitian, menentukan tujuan proyek penelitian dalam perumusan mendefinisikan masalah data mining. Semakin banyak masyarakat yang menggunakan media sosial maka semakin banyak data berupa opini yang di hasilkan, dalam opini-opini tersebut tidak hanya membicarakan satu topik saja yang di sampaikan.
Pada penelitian ini memiliki tujuan untuk membuat sebuah Analisis sentimen untuk mengetahui komentar masyarakat terhadap belajar online pada masa covid-19 melalui opini
yang disampaikan dalam media sosial seperti twitter dan mengimplementasikan metode klasifikasi dalam text mining.
3.2.Data Understanding
Tahap ini adalah proses memahami data yang Tapahan ini adalah proses memahami data yang akan digunakan sebagai bahan yang akan diteliti untuk bisa dilakukan ke tahap setelahnya yaitu processing. Data yang dikumpulkan dalam proses crawling data tweet ini kemudian disimpan dalam format file excel. Adapun sumber data utama yang digunakan dalam penelitian ini menggunakan dataset twitter dari opini-opini masyarakat mengenai belajar online pada masa covid-19 yang disampaikan dalam media sosial twitter. Dataset yang diambil sejumlah 615 data. Dari komentar dari opini-opini masyarakat tersebut kemudian membagi statusnya menjadi dua bagian yaitu 219 dengan label negatif dan 396 label positif agar status menjadi kondisi normal dalam penelitian text mining. Semua data komentar tersebut dikelompokan menjadi satu baik itu positif atau negatif dan disimpan dalam bentuk ekstensi .xls.
3.3.Data Preparation
Tahap selanjutnya adalah melakukan persiapan data sebelum data akan dilakukan modelling atau disebut dengan Data Preparation. Untuk tahap yang ke-2 ini yaitu mempersiapkan data untuk melakukan langkah-langkah yang disebut dengan text preprocesing, dengan menggunakan dua aplikasi preprocessing, pertama menggunakan Gata Framework yang diakses melalui link
http://gataframework.com/textmining yang
dapat digunakan secara gratis juga mudah dalam penggunaan dikarenakan tidak harus membuat account untuk memakai servicenya dan dilanjutkan preprocessing dari rapidminer, berikut adalah tahapannya:
Jurnal Informatika Kaputama (JIK), Vol. 5 No. 1, Januari 2021 P-ISSN : 2548-9739 E-ISSN : 2685-5240
133 Sumber:[1]
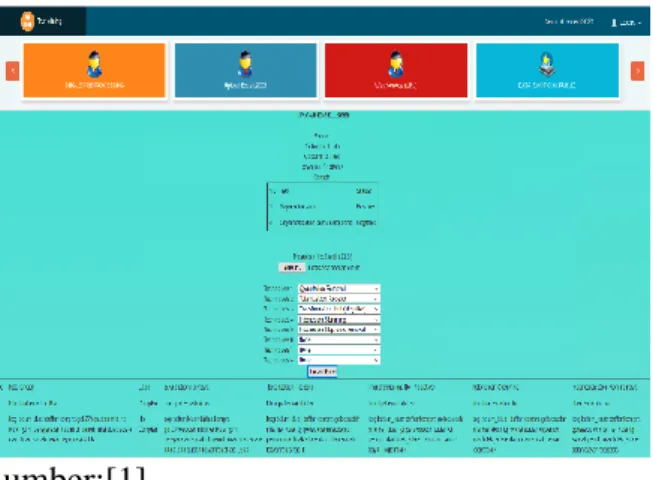
Gambar 1. Tampilan tools Gata Framework Textmining
Gata Framework merupakan alternatif dalam pre-processing teks berbahasa Indonesia yang dikombinasikan dengan aplikasi RapidMiner untuk memproses kata-kata dalam bahasa Indonesia, hal ini dikarenakan dalam aplikasi RapidMiner sudah ada fasilitas kamus untuk mengubah akronim, dan stopword, tetapi masih terbatas pada bahasa Inggris, Cina, dan Arab, sedangkan untuk bahasa Indonesia masih belum tersedia. Dari hasil pre-processing dengan menggunakan Gata Framework, maka data set akan dilakukan pre-processing lagi dengan menggunaan tools RapidMiner untuk membersihkan data agar lebih baik lagi hasilnya.
3.4.Remove Duplicates
Ini merupakan tahapan data preparation selanjutnya yang digunakan pada
software rapidminer. Remove duplicates
digunakan untuk menghilangkan text yang sama atau duplikat. Hal ini dilakukan agar data tidak dipenuhi oleh text yang sama sehingga memperlambat proses running software untuk menganalisa model.
3.5.Nominal to Text
Ini merupakn operator yang ada dalam rapidminer yang berfungsi untuk mengubah semua angka yang ada dalam text menjadi sebuah text. Sehingga angka yang ada akan dianggap jenis data text bukan numeric atau nominal. Gambar 2 memperlihatkan bagaimana
penggunaan operator ini digunakan pada proses yang ada pada rapidminer.
Sumber:[7]
Gambar 2. Desain Model Preprocessing Data Local menggunakanoperator Remove
Duplicates dan Nominal to Text 3.6.Transform Case.
Operator yang digunakan pada tahapan ini adalah untuk mengubah huruf kapital yang masih ada pada text akan diubah menjadi huruf kecil semua. Hal ini dilakukan agar ketikan dilakukan proses ke dalam model klasifikasi terdapat keseragaman huruf dan tidak terjadi kesalahan dalam proses tokenize.
3.7.Filter Token ( by Length )
Ini adalah proses yang ada pada data preparation untuk menghilangkan sejumlah kata ( setelah proses tokenize ) dengan panjang karakter tertentu. Pada penelitian ini panjang minimum karakter yang digunakan adalah 3 karakter dan panjang maksimum 25 karakter. Artinya kata yang panjangnya kurang dari 3 karakter dan lebih dari 25 karakter akan dihilangkan. Untuk mendapatkan hasil seperti ini maka dilakukan setting pada Parameters dari operator ini (Gambar 3).
Sumber:[7]
Gambar 3. Parameters dari Filter Tokens (by Length)
Jurnal Informatika Kaputama (JIK), Vol. 5 No. 1, Januari 2021 P-ISSN : 2548-9739 E-ISSN : 2685-5240
134 3.8.Filter Stopword ( Dictionary )
Selanjutnya adalah penggunaan operator Stopword Removal (by Directory) yang berfungsi untuk menghilangkan kata-kata yang tidak hubungan dengan isi text. Pada tahapan sebelumnya dengan menggunakan service text mining Gataframework telah dilakukan namun ada beberapa kata yang belum dapat bisa dihilangkan oleh service sebelumnya karena belum dimasukkan sebagai kata yang harus dihapus. Maka dengan operator Stopword
Removal (by Directory) peneliti dapat
mendaftarkan kata yang harusnya dihapus dari text. Gambar 4. merupakan penjelasan dari penggunaan operator pada proses rapidminer.
Sumber:[1]
Gambar 4. Desain dari Penggunaan operator untuk Data Preparation. 3.9.Tahapan Pemodelan
Merupakan tahap pemilihan teknik mining dengan menentukan algoritma yang akan digunakan. Tool yang digunakan adalah RapidMiner versi 9.1. Hasil pengujian model yang dilakukan adalah menganalisa komentar twitter dari opini-opini masyarakat mengenai belajar online pada masa covid-19 dengan label data komentar positif dan negatif menggunakan algoritma Support Vector Machine (SVM) Berbasis Particle Swarm Optimization untuk mendapatkan nilai akurasi terbaik. Berikut adalah desain model Rapidminer yang digunakan yaitu :
Pengujian Model dengan Algoritma SVM Pengaturan dan penggunaan operator serta parameter dalam frameworks RapidMiner sangat berpengaruh terhadap akurasi dan model yang terbentuk, secara lebih jelas pengujian terhadap algoritma Naive Bayes dan
Support Vector Machine (SVM) Berbasis Particle Swarm Optimization tersebut adalah sebagai berikut.
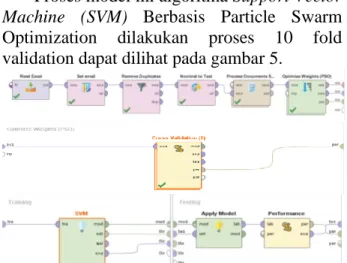
Proses model ini algoritma Support Vector Machine (SVM) Berbasis Particle Swarm Optimization dilakukan proses 10 fold validation dapat dilihat pada gambar 5.
Gambar 5. Desain Model Algoritma (SVM) +PSO
Gambar 5 diatas adalah model pengujian algoritma Support Vector Machine (SVM) Berbasis Particle Swarm Optimization menggunakan rapidminer, diawali dari memasukan data kemudian mengatur set role yang nantinya menentukan label disana dan nominal text lalu keproses dokumen. Pada pengujian ini, data digunakan adalah data bersih yang telah melalui preprocessing. Data tersebut diambil dari operator Read Excel, hal ini dilakukan karena dataset disimpan dalam bentuk Excel (.xlsx). Process documents from files untuk mengkonversi files menjadi dokumen. Process validasi terdiri dari data training dan data testing. Kemudian masuk ke model desain algoritmanya diproses ke dalam operator cross validation Support Vector Machine (SVM) Berbasis Particle Swarm Optimization didalamnya ada perhitungan algoritmanya kemudian modelnya diapply setelah itu masuk ke penilaian performancenya barulah muncul hasil nilai accuracy dan aucnya. Model Evaluasi
Tahapan evaluasi bertujuan untuk menentukan nilai kegunaan dari model yang telah berhasil dibuat pada langkah sebelumnya. Untuk evaluasi digunakan 10-fold cross
Jurnal Informatika Kaputama (JIK), Vol. 5 No. 1, Januari 2021 P-ISSN : 2548-9739 E-ISSN : 2685-5240
135 validation. Dari hasil pengujian model dari dua
algoritma yang dipakai adalah untuk menghasilkan sebuah nilai Accuracy
(Confusion Matrix) dan AUC (Area Under
Curve). Maka mendapatkan hasil grafik ROC dengan nilai AUC (Area Under Curve).
Nilai Accuracy algoritma Support Vector Machine (SVM) Berbasis Particle Swarm Optimization
Berdasarkan hasil percobaan yang dilakukan dengan menggunakan data komentar twitter dari opini-opini masyarakat mengenai belajar online pada masa covid-19 dimana dalam percobaan ini menggunakan Algoritma
Support Vector Machine (SVM) Berbasis
Particle Swarm Optimization dengan
menggunakan 615 data komentar opini- opini masyarakat maka dihasilkan nilai Accuracy (Confusion Matrix) sebagai beikut:
Tabel 6. Nilai Accuracy Algoritma SVM
Jumlah True Positif (TP) adalah 389 record diklasifikasikan sebagai Positif dan False Negatif (FN) adalah 50 record diklasifikasikan sebagai Negatif. Berikutnya 169 False Positif diklasifikasikan sebagai Positif dan 7 record True Negatif diklasifikasikan sebagai Negatif. Berdasarkan gambar 6 diatas menunjukan bahwa, tingkat akurasi dengan menggunakan algoritma SVM Berbasis Particle Swarm Optimization adalah sebesar 71.39%.
Nilai AUC dari Algoritma SVM+PSO
Berikut ini akan dijelaskan Kurva ROC dan Confusion Matrix dari algoritma Support
Vector Machine Berbasis Particle Swarm Optimization:
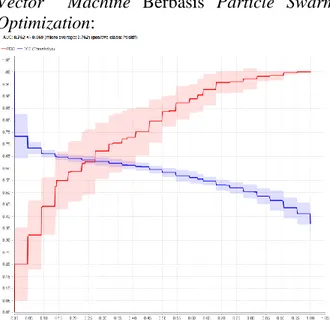
Gambar 7. Nilai AUC dalam Algoritma SVM+PSO
Dari hasil pengujian model yang telah dilakukan adalah untuk mendapatkan hasil akurasi dan Area Under Curve (AUC). Maka mendapatkan hasil grafik ROC dengan nilai Area Under Curve (AUC) sebesar 0.762 dengan performance akurasi yaitu excellent.
4. KESIMPULAN
Dalam penelitian ini setelah dilakukan preprocessing dan dilakukan pengujian model dengan metode data mining yaitu support vector machine (SVM) Berbasis Particle Swarm Optimization, hasil evaluasi dan validasi, diketahui bahwa nilai akurasi untuk menentukan bahwa komentar twitter dari opini-opini masyarakat mengenai belajar online pada masa covid-19 tersebut dengan kategori label positif dan negatif, dapat dibuktikan dengan nilai akurasi dan nilai AUC dari algoritma yaitu untuk SVM+PSO nilai akurasi = 71.39% dan nilai AUC = 0.762. Dalam penelitian dapat disimpulkan bahwa penggunaan Particle Swarm Optimization (PSO) pada model algoritma support vector machine (SVM) dapat menjadi solusi meningkatkan akurasi dan AUC analisa sentiment masyarakat mengenai belajar online pada masa covid-19. Pada penelitan [19] dengan menggunakan SVM dengan data lain dihasilkan akurasi 69.18%. Untuk itu, penerapan Support Vector Machine berbasis
Jurnal Informatika Kaputama (JIK), Vol. 5 No. 1, Januari 2021 P-ISSN : 2548-9739 E-ISSN : 2685-5240
136 PSO pada peneltian ini memiliki akurasi yang
lebih tinggi sehingga dapat digunakan untuk memberikan solusi terhadap permasalahan analisis sentimen pada komentar masyarakat mengenai belajar online pada masa covid-19. 5. SARAN
Untuk Penelitian lanjutan dengan mengambil jumlah data yang lebih besar lagi dalam kurun waktu lebih dari 3 bulan pada google play, sehingga akan mendapatkan nilai akurasi yang lebih baik lagi. Selain itu Menambahkan metode klasifikasi lain untuk membandingkan dengan metode dari Supervised Learning lainnya dari model yang diusulkan, seperti penggunaan Algoritma C-45, Random Forest dan lainnya.
DAFTAR PUSTAKA
[1] H. Hermanto, A. Y. Kuntoro, T. Asra, N. Nurajijah, L. Effendi, and R. Ocanitra, “Sentiment Analysis on Gojek and Grab User Reviews Using Svm Algorithm Based on Particle Swarm Optimization,” J. Pilar Nusa Mandiri, vol. 16, no. 1, pp.
117–122, 2020, doi:
10.33480/pilar.v16i1.1304.
[2] A. Noviriandini, P. Handayani, and Syahriani, “Prediksi Penyakit Liver Dengan Menggunakan Metode,” Pros. TAU SNAR-TEK Semin. Nas. Rekayasa dan Teknol., no. November, 2019. [3] M. Rivki and A. M. Bachtiar,
“Implementasi Algoritma K-Nearest Neighbor Dalam Pengklasifikasian Follower Twitter Yang Menggunakan Bahasa Indonesia,” J. Sist. Inf., vol. 13, no. 1, p. 31, 2017, doi: 10.21609/jsi.v13i1.500.
[4] M. S. Hadna, P. I. Santosa, and W. W. Winarno, “Studi Literatur Tentang Perbandingan Metode Untuk Proses Analisis Sentimen Di Twitter,” Semin. Nas. Teknol. Inf. dan Komun., vol. 2016,
no. Sentika, pp. 57–64, 2016, [Online]. Available:
https://fti.uajy.ac.id/sentika/publikasi/m akalah/2016/95.pdf.
[5] J. Ipmawati, Kusrini, and E. Taufiq Luthfi, “Komparasi Teknik Klasifikasi Teks Mining Pada Analisis Sentimen,” Indones. J. Netw. Secur., vol. 6, no. 1, pp. 28–36, 2017.
[6] H. Muhamad, C. A. Prasojo, N. A. Sugianto, L. Surtiningsih, and I. Cholissodin, “Optimasi Naïve Bayes Classifier Dengan Menggunakan Particle Swarm Optimization Pada Data Iris,” J. Teknol. Inf. dan Ilmu Komput., vol. 4, no. 3, p. 180, 2017, doi: 10.25126/jtiik.201743251.
[7] H. Hermanto, A. Mustopa, and A. Y. Kuntoro, “Algoritma Klasifikasi Naive Bayes Dan Support Vector Machine Dalam Layanan Komplain Mahasiswa,” JITK (Jurnal Ilmu Pengetah. dan Teknol. Komputer), vol. 5, no. 2, pp. 211–220, 2020, doi: 10.33480/jitk.v5i2.1181.