5
BAB II
LANDASAN TEORI
2.1 Text Mining
Menurut Feldman dan Sanger (Feldman dan Sanger, 2007), text mining dapat didefinisikan secara luas sebagai proses pengetahuan intensif yang memungkinkan pengguna berinteraksi dengan koleksi dokumen dari waktu ke waktu menggunakan berbagai macam analisis. Dalam cara yang sejalan dengan data mining, text mining berusaha mengekstrak informasi yang berguna dari sumber data melalui identifikasi dan eksplorasi patterns. Text mining menjadi menarik karena sumber data koleksi dokumen dan pola yang menarik tidak ditemukan dari database formal namun ditemukan dalam data tekstual yang tidak terstruktur pada kumpulan dokumen.
Selain itu, Feldman dan Sanger (Feldman dan Sanger, 2007) juga berpendapat bahwa text mining juga merupakan bidang baru dalam cabang ilmu komputer yang berupaya untuk mengatasi krisis informasi yang berlebihan dengan cara menggabungkaan beberapa teknik dari data mining, mesin pembelajaran (machine learning), pengolahan bahasa alami (natural language processing), information retrieval dan pengelolaan ilmu pengetahuan (knowledge management).
Franke dalam Langgeni dkk. (Langgeni dkk., 2010) menjelaskan bahwa text mining didefinisikan sebagai menambang data berupa teks yang bersumber dari dokumen. Text mining bertujuan untuk mencari kata-kata yang dapat mewakili isi dari dokumen sehingga dapat dilakukan analisis keterhubungan antar dokumen. Text mining juga dapat diartikan sebagai sebuah proses untuk menemukan suatu informasi atau tren baru yang sebelumnya tidak terungkap dengan memroses dan menganalisis data dalam jumlah besar (Feldman dan Sanger, 2007).
6
Tahap-tahap text mining secara umum adalah text preprocessing, feature selection dan pembobotan (term weighting). Penjelasan dari tahap tersebut adalah sebagai berikut.
2.1.1 Text Preprocessing
Tahap text preprocessing merupakan tahap awal dari text mining. Text preprocessing merupakan proses menggali, mengolah dan mengatur informasi dengan cara menganalisis hubungannya dengan aturan-aturan yang ada di data tekstual semi terstruktur atau tidak terstruktur (Luhulima, Marji, dan Muflikhah, 2013). Untuk lebih efektif dalam proses text preprocessing, dilakukan langkah transformasi data ke dalam suatu format yang memudahkan untuk kebutuhan pemakai. Proses ini disebut text preprocessing. Setelah dalam bentuk yang lebih terstruktur dengan adanya proses di atas, data dapat dijadikan sumber data yang dapat diolah lebih lanjut. Tahapan text preprocessing, di antaranya sebagai berikut.
1. Case Folding
Case Folding adalah mengubah semua karkater huruf menjadi huruf kecil (lowercase).
2. Tokenizing
Tokenizing yaitu proses penguraian deskripsi yang semula berupa kalimatkalimat menjadi kata-kata dan menghilangkan delimiter-delimiter seperti tanda titik (.), koma (,), spasi dan karakter angka yang ada pada kata tersebut.
3. Stopword Removal
Stopword removal yaitu proses penghapusan kata-kata yang terdapat pada stoplist. Stoplist itu sendiri berisi kosakata-kosakata yang bukan merupakan ciri dari suatu dokumen (Dragut dkk. dalam Manalu, 2014).
7 4. Stemming
Stemming adalah proses pemetaan dan penguraian berbagai bentuk (variants) dari suatu kata menjadi bentuk kata dasarnya (stem) (Tala dalam Manalu, 2014). Stemming bertujuan untuk menghilangkan imbuhan imbuhan baik itu berupa prefiks, sufiks, maupun konfiks yang ada pada setiap kata.
2.1.2 Feature Selection
Kata-kata yang tidak relevan dengan proses pengkategorisasian dapat dibuang tanpa mempengaruhi kinerja classifier bahkan meningkatkan kinerja karena mengurangi noise. Langkah preprocessing dengan menghilangkan kata-kata yang tidak relevan disebut feature Selection (Feldman dan Sanger, 2007). Tahap ini merupakan tahap yang sangat penting dalam tahap preprocessing karena pada tahap ini dilakukan proses yang bisa digunakan pada machine learning. Sekumpulan dari features yang dimiliki data digunakan untuk pembelajaran algoritma. Salah satu fungsi dari feature Selection adalah pemilihan term atau kata-kata apa saja yang dapat mewakili dokumen yang akan dianalisis dengan melakukan pembobotan terhadap setiap term. Term dapat berupa kata atau frasa dalam suatu dokumen yang dapat digunakan untuk mengetahui konteks dari dokumen tersebut.
2.1.3 Pembobotan Kata (Term Weighting)
Pembobotan dilakukan untuk mendapatkan nilai dari kata term yang telah diekstrak. Term dapat berupa kata atau frasa dalam suatu dokumen yang dapat digunakan untuk mengetahui konteks dari dokumen tersebut. Karena setiap kata memiliki tingkat kepentingan yang berbeda dalam dokumen, maka untuk setiap kata tersebut diberikan sebuah indikator, yaitu term weight. Term weighting atau pembobotan kata sangat dipengaruhi oleh hal-hal berikut ini (Mandala dalam Zafikri, 2010).
8 1. Document Frequency (df)
Metode document frequency (df) merupakan salah satu metode pembobotan dalam bentuk sebuah metode yang merupakan perhitungan jumlah dokumen yang mengandung suatu term tertentu. Tiap term akan dihitung nilai document frequency-nya (df).
2. Term Frequency (tf)
Term frequency (tf) yaitu faktor yang menentukan bobot term pada suatu dokumen berdasarkan jumlah kemunculannya dalam dokumen tersebut. Nilai jumlah memunculan suatu kata (term frequency) diperhitungkan dalam pemberian bobot terhadap suatu kata. Semakin besar jumlah kemunculan suatu term (tf tinggi) dalam dokumen, semakin besar pula bobotnya dalam dokumen atau akan memberikan nilai kesesuaian yang semakin besar.
3. Inverse Document Frequency (idf)
Inverse Document Frequency (idf) yaitu pengurangan dominasi term yang sering muncul di berbagai dokumen. Hal ini diperlukan karena term yang banyak muncul di berbagai dokumen, dapat dianggap sebagai term umum sehingga tidak penting nilainya. Sebaliknya, faktor jarangnya munculnya kata dalam kumpulan dokumen harus diperhatikan dalam pemberian bobot. Menurut Wittern dalam Zafikri (2010), kata yang muncul pada sedikit dokumen harus dipandang sebagai kata yang lebih penting daripada kata yang muncul pada banyak dokumen. Pembobotan akan memperhitungkan faktor kebalikan frekuensi dokumen yang mengandung suatu kata (Inverse Document Frequency). Metode tf-idf merupakan metode pembobotan term yang banyak digunakan sebagai metode pembanding terhadap metode pembobotan baru. Pada metode ini, perhitungan bobot term t dalam sebuah dokumen dilakukan dengan mengalikan nilai Term Frequency dengan Inverse Document Frequency. Metode tf-idf dapat dirumuskan sebagai berikut.
9
( , ) = ( , ) x ,
= log
( )
Sumber: Feldman dan Sanger (2007)
Notasi TermFreq (t,d) adalah jumlah kemunculan kata t dalam dokumen d, N adalah jumlah seluruh dokumen dan DocFreq(t) adalah jumlah dokumen yang mengandung term t.
Fungsi metode ini adalah untuk mencari representasi nilai dari tiap-tiap dokumen dari suatu kumpulan data training yang nantinya akan dibentuk suatu vektor antara dokumen dengan kata (documents with terms) Yong, Youwen dan Xhixion dalam Luhulima dkk. (Luhulima dkk, 2013).
2.2 Sentiment Analysis atau Opinion Mining
Menurut Liu (Liu, 2010), analisis sentimen adalah riset komputasional dari opini, sentimen, dan emosi yang diekspresikan secara tekstual. Sebuah dokumenteks dapat dilihat sebagai kumpulan pernyataan subjektif dan objektif. Pernyataan objektif tersebut berkenaan dengan informasi faktual yang ada dalam teks dan subjektivitas berkaitan dengan ekspresi dari opini dan spekulasi (Wiebi dalam Ohana, 2009).
Liu juga berpendapat bahwa opinion mining adalah proses klasifikasi dokumen tekstual ke dalam dua kelas, yaitu kelas sentimen positif dan negatif. Besarnya pengaruh dan manfaat dari analisis sentimen, menyebabkan penelitian ataupun aplikasi mengenai analisis sentimen berkembang pesat, bahkan di Amerika kurang lebih 20-30 perusahaan yang memfokuskan pada layanan analisis sentiment.
Pang dan Lee (Pang dan Lee, 2008) menjelaskan sentiment analysis atau dikenal sebagai opinion mining adalah proses memahami, mengekstrak dan mengolah data tekstual secara otomatis untuk mendapatkan informasi. Secara umum, opinion mining diperlukan untuk mengetahui sikap seorang pembicara atau penulis sehubungan dengan beberapa topik atau polaritas kontekstual keseluruhan dokumen.
10
Sikap yang diambil mungkin menjadi pendapat atau penilaian atau evaluasi (teori appraisal), keadaan afektif (keadaan emosional penulis saat menulis) atau komunikasi emosional (efek emosional penulis yang ingin disampaikan pada pembaca) (Saraswati, 2011).
Secara umum, Sentiment analysis ini dibagi menjadi 2 kategori besar : 1. Coarse-grained sentiment analysis
Melakukan proses analisis pada level dokumen. Singkatnya adalah kita mencoba mengklasifikasikan orientasi sebuah dokumen secara keseluruhan. Orientasi ini ada 3 jenih : Positif, Netral, Negatif. Akan tetapi, ada juga yang menjadikan nilai orientasi ini bersifat kontinu / tidak diskrit.
2. Fined-grained sentiment analysis
Maksudnya adalah para researcher sebagian besar fokus pada jenis ini. Obyek yang ingin diklasifikasi bukan berada pada level dokumen melainkan sebuah kalimat pada suatu dokumen. Kategori kedua ini yang sedang Naik Daun sekarang.
Contoh :
Saya tidak suka programming. (negatif)
Hotel yang baru saja dikunjungi sangat indah sekali. (positif) Hingga sekarang, hampir sebagian besar penelitian di bidang sentiment analysis hanya ditujukan untuk bahasa Inggris karena memang Tools/Resources untuk bahasa Inggris sangat banyak sekali. Beberapa resources yang sering digunakan untuk sentiment analysis adalah SentiWordNet dan WordNet.
Sentiment analysis terdiri dari 3 subproses besar. Masing-masing subproses ini bisa kita jadikan bahan/topik riset secara terpisah karena masing-masing subproses ini membutuhkan teknik yang tidak mudah :
11
1. Subjectivity Classification, menentukan kalimat yang merupakan opini.
2. Orientation Detection, setelah berhasil diklasifikasi untuk kategori opini, sekarang kita tentukan apakah dia positif, negatif, netral.
3. Opinion Holder and Target Detection, menentukan bagian yang merupakan Opinion Holder dan bagian yang merupakan Target.
Pada dasarnya sentiment analysis atau opinion mining merupakan klasifikasi. Kenyataannya tidak semudah proses klasifikasi biasa karena terkait penggunaan bahasa, yaitu adanya ambigu dalam penggunaan kata dan tidak adanya intonasi dalam sebuah teks dan perkembangan dari bahasa itu sendiri.
2.3 Support Vector Machine (SVM)
Menurut Santoso (2007) Support Vector Machine (SVM) adalah suatu teknik untuk melakukan prediksi, baik dalam kasus klasifikasi maupun regresi. SVM berada dalam satu kelas dengan Artificial Neural Network (ANN) dalam hal fungsi dan kondisi permasalahan yang bisa diselesaikan. Keduanya masuk dalam kelas supervised learning.
Dalam penelitian ini, teknik SVM digunakan untuk menemukan fungsi pemisah (clasifier) yang optimal yang bisa memisahkan dua set data dari dua kelas yang berbeda. Penggunaan teknik machine learning tersebut, karena performansinya yang meyakinkan dalam memprediksi kelas suatu data baru.
Support Vector Machine (SVM) juga dikenal sebagai teknik pembelajaran mesin (machine learning) paling mutakhir setelah pembelajaran mesin sebelumnya yang dikenal sebagai Neural Network (NN). Baik SVM maupun NN tersebut telah berhasil digunakan dalam pengenalan pola. Pembelajaran dilakukan dengan menggunakan pasangan data input dan data output berupa sasaran yang diinginkan. Pembelajaran dengan cara ini disebut dengan pembelajaran terarah (supervised learning). Dengan pembelajaran terarah ini akan diperoleh fungsi yang menggambarkan bentuk ketergantungan input dan output-nya. Selanjutnya, diharapkan fungsi yang diperoleh mempunyai kemampuan generalisasi yang baik,
12
dalam arti bahwa fungsi tersebut dapat digunakan untuk data input di luar data pembelajaran.
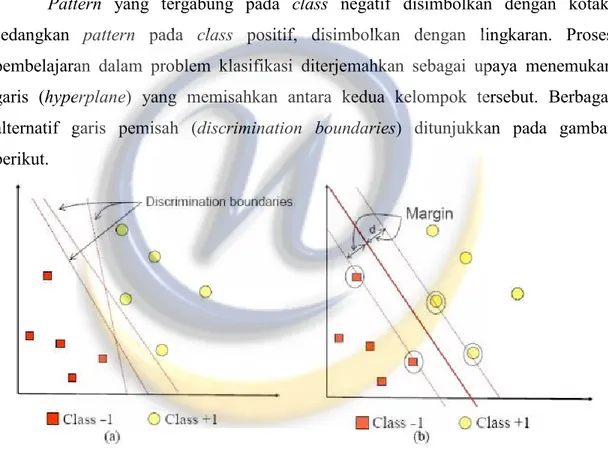
Konsep SVM dapat dijelaskan secara sederhana sebagai usaha mencari hyperplane terbaik yang berfungsi sebagai pemisah dua buah class pada input space. Gambar di bawah memperlihatkan beberapa pattern yang merupakan anggota dari dua class : positif (dinotasikan dengan +1) dan negatif (dinotasikan dengan -1).
Pattern yang tergabung pada class negatif disimbolkan dengan kotak, sedangkan pattern pada class positif, disimbolkan dengan lingkaran. Proses pembelajaran dalam problem klasifikasi diterjemahkan sebagai upaya menemukan garis (hyperplane) yang memisahkan antara kedua kelompok tersebut. Berbagai alternatif garis pemisah (discrimination boundaries) ditunjukkan pada gambar berikut.
Gambar 2.1 Hyperplane SVM
Hyperplane pemisah terbaik antara kedua class dapat ditemukan dengan mengukur margin hyperplane tersebut dan mencari titik maksimalnya. Margin adalah jarak antara hyperplane tersebut dengan data terdekat dari masing-masing class. Subset data training set yang paling dekat ini disebut sebagai support vector. Garis solid pada Gambar 2.1b menunjukkan hyperplane yang terbaik, yaitu yang terletak tepat pada tengah-tengah kedua class, sedangkan titik kotak dan lingkaran yang
13
berada dalam lingkaran hitam adalah support vector. Upaya mencari lokasi hyperplane optimal ini merupakan inti dari proses pembelajaran pada SVM
Data yang tersedia dinotasikan sebagai x1∈Rd sedangkan label masing-masing
yi∈{-1,+1} dinotasikan untuk i = 1,2,…,l , yang mana l adalah banyaknya data.
Diasumsikan kedua class –1 dan +1 dapat terpisah secara sempurna oleh hyperplane berdimensi d , yang didefinisikan:
2.3.1 Karakteristik SVM
Algoritma SVM juga memiliki beberapa karakteristik. Berikut merupakan karakteristik dari Support Vector Machine (SVM) :
1. Secara prinsip SVM adalah linear classifier
2. Pattern recognition dilakukan dengan mentransformasikan data pada input space ke ruang yang berdimensi lebih tinggi, dan optimisasi dilakukan pada ruang vector yang baru tersebut. Hal ini membedakan SVM dari solusi pattern recognition pada umumnya, yang melakukan optimisasi parameter pada ruang hasil transformasi yang berdimensi lebih rendah daripada dimensi input space.
3. Menerapkan strategi Structural Risk Minimization (SRM)
4. Prinsip kerja SVM pada dasarnya hanya mampu menangani klasifikasi dua class.
2.3.2 Kelebihan dan Kekurangan SVM
Selain memiliki karakteristik, algoritma SVM juga memiliki beberapa kelebihan dan kekurangan.
Kelebihan SVM antara lain sebagai berikut : 1. Generalisasi
Generalisasi didefinisikan sebagai kemampuan suatu metode (SVM, neural network, dsb.) untuk mengklasifikasikan suatu pattern, yang tidak termasuk
14
data yang dipakai dalam fase pembelajaran metode itu. Vapnik menjelaskan bahwa generalization error dipengaruhi oleh dua faktor: error terhadap training set, dan satu faktor lagi yang dipengaruhi oleh dimensi VC (Vapnik-Chervokinensis). Berbagai studi empiris menunjukkan bahwa pendekatan SRM pada SVM memberikan error generalisasi yang lebih kecil daripada yang diperoleh dari strategi ERM pada network maupun metode yang lain. 2. Curse of dimensionality
Curse of dimensionality didefinisikan sebagai masalah yang dihadapi suatu metode pattern recognition dalam mengestimasikan parameter (misalnya jumlah hidden neuron pada neural network, stopping criteria dalam proses pembelajaran dsb). Dikarenakan jumlah sampel data yang relatif sedikit dibandingkan dimensional ruang vector data tersebut. Semakin tinggi dimensi dari ruang vector informasi yang diolah, membawa konsekuensi dibutuhkannya jumlah data dalam proses pembelajaran. Vapnik membuktikan bahwa tingkat generalisasi yang diperoleh oleh SVM tidak dipengaruhi oleh dimensi dari input vector. Hal ini merupakan alasan mengapa SVM merupakan salah satu metode yang tepat dipakai untuk memecahkan masalah berdimensi tinggi, dalam keterbatasan sampel data yang ada.
3. Landasan teori
Sebagai metode yang berbasis statistik, SVM memiliki landasan teori yang dapat dianalisa dengan jelas, dan tidak bersifat kuliah umum.
4. Feasibility
SVM dapat diimplementasikan relatif mudah, karena proses penentuan support vector dapat dirumuskan dalam QP problem. Dengan demikian jika kita memiliki library untuk menyelesaikan QP problem, dengan sendirinya SVM dapat diimplementasikan dengan mudah. Selain itu dapat diselesaikan dengan metode sekuensial sebagaimana penjelasan sebelumnya.
15
SVM memiliki kelemahan atau keterbatasan, antara lain:
1. Sulit dipakai dalam problem berskala besar. Skala besar dalam hal ini dimaksudkan dengan jumlah sampel yang diolah.
2. SVM secara teoritik dikembangkan untuk problem klasifikasi dengan dua class. Dewasa ini SVM telah dimodifikasi agar dapat menyelesaikan masalah dengan class lebih dari dua, antara lain strategi one versus rest dan strategi tree structure. Namun demikian, masing-masing strategi ini memiliki kelemahan, sehingga dapat dikatakan penelitian dan pengembangan SVM pada multiclass-problem masih merupakan tema penelitian yang masih terbuka.
2.4 Evaluation Model
Diperlukan cara yang sistematis untuk mengevaluasi kinerja dari suatu metode/ model. Evaluasi klasifikasi didasarkan pengujian pada objek yang benar dan salah (Gorunescu, 2011). Validasi data digunakan untuk menentukan jenis terbaik dari skema pembelajaran yang digunakan, berdasarkan data pelatihan untuk melatih skema pembelajaran (Witten, Frank dan Hall, 2011).
2.4.1 Confusion Matrix
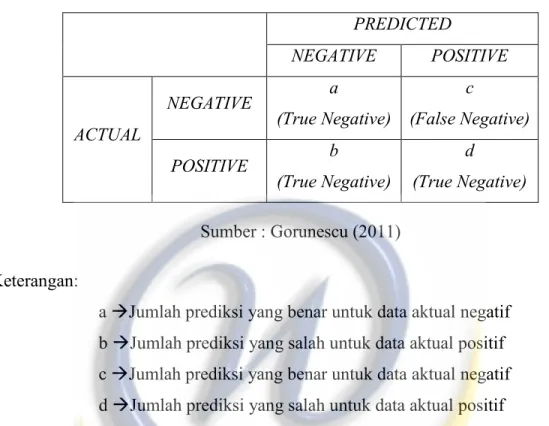
Confusion matrix menurut Kohavi dan Provost dalam Visa, Ramsay, Ralescu, dan Van Der Knaap (Visa, Ramsay, Ralescu, dan Van Der Knaap, 2011) berisi informasi mengenai hasil klasifikasi aktual dan yang telah diprediksi oleh sistem klasifikasi. Performa dari sistem tersebut biasanya dievaluasi menggunakan data dalam sebuah matriks. Tabel dibawah ini menampilkan sebuah confusion matrix untuk pengklasifikasian ke dalam dua kelas.
16
Tabel 2.1 Confusion Matrix Dua Kelas PREDICTED NEGATIVE POSITIVE ACTUAL NEGATIVE a (True Negative) c (False Negative) POSITIVE b (True Negative) d (True Negative) Sumber : Gorunescu (2011) Keterangan:
a Jumlah prediksi yang benar untuk data aktual negatif b Jumlah prediksi yang salah untuk data aktual positif c Jumlah prediksi yang benar untuk data aktual negatif d Jumlah prediksi yang salah untuk data aktual positif
Beberapa term standar yang telah ditetapkan untuk matriks dua kelas di atas adalah sebagai berikut.
1. Accuracy (AC) adalah proporsi jumlah prediksi yang benar. Hal ini ditentukan dengan menggunakan persamaan.
= +
+ + +
2. Sensitivity atau Recall atau True Positive Pate (TP) adalah proporsi dari kasus positif yang diidentifikasi dengan benar, dihitung dengan menggunakan persamaan.
= +
3. False Positive Rate (FP) adalah proporsi dari kasus negatif yang salah diklasifikasikan sebagai positif, dihitung dengan menggunakan persamaan.
= +
17
4. Specificity atau True Negative Rate (TN) didefinisikan sebagai proporsi untuk kasus negatif yang diklasifikasikan dengan benar, dihitung dengan menggunakan persamaan.
= +
5. False Negative Rate (FN) adalah proporsi dari kasus positif yang salah diklasifikasikan sebagai negatif, dihitung dengan menggunakan persamaan.
= +
6. Precision (P) adalah proporsi kasus dengan hasil positif yang benar, dihitung dengan menggunakan persamaan.
= + 2.5 MySQL
MySQL adalah sistem manajemen database SQL yang bersifat Open Source dan paling populer saat ini. Sistem database MySQL mendukung beberapa fitur seperti multithreaded, multi-user, dan SQL database management system (DBMS). Database ini dibuat untuk keperluan sistem database yang cepat, handal dan mudah digunakan.
Ulf Micheal Widenius adalah penemu awal versi pertama MySQL yang kemudian pengembangan selanjutnya dilakukan oleh perusahaan MySQL AB. MySQL AB yang merupakan sebuah perusahaan komersial yang didirikan oleh para pengembang MySQL.MySQL sudah digunakan lebih dari 11 millar instalasi saat ini. Berikut ini beberapa keistimewaan MySQL sebagai database server antara lain :
1. Source MySQL dapat diperoleh dengan mudah dan gratis. 2. Sintaksnya lebih mudah dipahami dan tidak rumit.
18
4. MySQL merupakan program yang multithreaded, sehingga dapat dipasang pada server yang memiliki multiCPU.
5. Didukung programprogram umum seperti C, C++, Java, Perl, PHP, Python, dsb.
6. Bekerja pada berbagai platform. (tersedia berbagai versi untuk berbagai sistem operasi).
7. Memiliki jenis kolom yang cukup banyak sehingga memudahkan konfigurasi sistem database.
8. Memiliki sistem sekuriti yang cukup baik dengan verifikasi host. 9. Mendukung ODBC untuk sistem operasi Windows.
10.Mendukung record yang memiliki kolom dengan panjang tetap atau panjang bervariasi.
2.6 PHP
PHP sendiri sebenarnya merupakan singkatan dari Hypertext Preprocessor, yang merupakan sebuah bahasa scripting tingkat tinggi yang dipasang pada dokumen HTML. Sebagian besar sintaks dalam PHP mirip dengan bahasa C, Java dan Perl, namun pada PHP ada beberapa fungsi yang lebih spesifik. Sedangkan tujuan utama dari penggunaan bahasa ini adalah untuk memungkinkan perancang web yang dinamis dan dapat bekerja secara otomatis.
Banyak sekali kelebihan yang dimiliki PHP dibandingkan dengan bahasa pemrograman yang lain, Diantaranya :
1. Bisa membuat web menjadi dinamis.
2. PHP bersifat open source yang berarti dapat digunakan oleh siapa saja secara gratis.
19
3. Program yang dibuat dengan PHP bisa dijalankan oleh semua sistem operasi, karena PHP berjalan secara web base yang artinya semua sistem operasi bahkan HP yang mempunyai web browser dapat menggunakan program PHP. 4. Aplikasi PHP lebih cepat dibandingkan dengan ASP maupun Java.
5. Mendukung banyak paket database seperti MySQL, Oracle, PostgrSQL, dan lain-lain.
6. Bahasa pemrograman PHP tidak memerlukan Kompilasi dalam penggunaannya.
7. Banyak web server yang mendukung PHP seperti Apache, Lighttpd, IIS dan lain-lain.
8. Pengembangan Aplikasi PHP mudah karena banyak dokumentasi, refrensi dan developer yang membantu dalam pengembangannya.
9. Banyak bertebaran aplikasi dan program PHP yang gratis dan siap pakai seperti WordPress, PrestaShop, dan lain-lain.
Selain kelebihan PHP, PHP juga mempunyai kekurangan. Namun masalah kekurangannya sangat sedikit. Berikut diantaranya :
1. PHP tidak mengenal package.
2. Jika tidak di-encoding, maka kode PHP dapat dibaca semua orang dan untuk meng-encoding dibutuhkan tool dari Zend yang mahal sekali biayanya.
3. PHP memiliki kelemahan keamanan. Jadi Programmer harus jeli dan berhati-hati dalam melakukan pemrograman dan Konfigurasi PHP.
2.7 Flowchart
Flowchart adalah adalah suatu bagan dengan simbol-simbol tertentu yang menggambarkan urutan proses secara mendetail dan hubungan antara suatu proses (instruksi) dengan proses lainnya dalam suatu program.
20 Flowchart terbagi atas lima jenis, yaitu :
1. System Flowchart
Flowchart ini merupakan bagan yang menunjukkan alur kerja atau apa yang sedang dikerjakan di dalam sistem secara keseluruhan dan menjelaskan urutan dari prosedur-prosedur yang ada di dalam sistem. Dengan kata lain, flowchart ini merupakan dekripsi secara grafik dari urutan prosedur-prosedur yang terkombinasi yang membentuk suatu sistem.
2. Dokument Flowchart
Bagan alir dokumen (document flowchart) atau disebut juga bagan alir formulir (form flowchart) atau paperwork flowchart merupakan bagan alir yang menunjukkan arus dari laporan dan formulir termasuk tembusan-tembusannya. Bagan alir dokumen ini menggunakan simbol-simbol yang sama dengan yang digunakan di dalam bagan alir sistem.
3. Schematic Flowchart
Bagan alir skematik (schematic flowchart) merupakan bagan alir yang mirip dengan bagan alir sistem, yaitu untuk menggambarkan prosedur di dalam sistem. Perbedaannya adalah, bagan alir skematik selain menggunakan simbol-simbol bagan alir sistem, juga menggunakan gambar-gambar komputer dan peralatan lainnya yang digunakan. Maksud penggunaan gambar-gambar ini adalah untuk memudahkan komunikasi kepada orang yang kurang paham dengan simbol-simbol bagan alir.
4. Program Flowchart
Bagan alir program (program flowchart) merupakan bagan yang menjelaskan secara rinci langkah-langkah dari proses program. Bagan alir program dibuat dari derivikasi bagan alir sistem.
Bagan alir program dapat terdiri dari dua macam, yaitu bagan alir logika program (program logic flowchart) dan bagan alir program komputer terinci (detailed computer program flowchart). Bagan alir logika program digunakan
21
untuk menggambarkan tiap-tiap langkah di dalam program komputer secara logika. Bagan alir logika program ini dipersiapkan oleh analis sistem.
5. Process Flowchart
Flowchart ini merupakan teknik penggambaran rekayasa industrial yang memecah dan menganalisis langkah-langkah selanjutnya dalam suatu prosedur atau sistem. Flowchart jenis ini digunakan oleh perekayasa industrial dalam mempelajari dan mengembangkan proses-proses manufacturing. Dalam analisis sistem, flowchart ini digunakan secara efektif untuk menelusuri alur suatu laporan atau form.