DAN MODIFIKASI ALGORITMA HUFFMAN
ABSTRAK
Permasalahan ukuran file dan waktu yang dibutuhkan menjadi suatu kendala tersendiri dalam proses penyimpanan atau perpindahan antar media. Solusi permasalahan tersebut telah ditemukan oleh David A. Huffman dengan algoritma yang didasarkan pada pohon biner. Algoritma Huffman mempunyai dua jenis yaitu Huffman Statis dan Huffman Dinamis. Algoritma ini terkenal dalam bidang kompresi data, akan tetapi perkembangan zaman membuktikan algoritma ini memiliki hasil kompresi yang kurang maksimal.
DYNAMIC HUFFMAN ALGORITHM AND MODIFICATION HUFFMAN ALGORITHM
ABSTRACT
Problems file size and time taken into an obstacle in the process of storage or displacement between media. Solution these problems have been found by David A . Huffman with the algorithms that based on binary tree. Huffman algorithm have two types is huffman static and huffman dynamic. This algorithm famous in the field of compression data, but time progress prove this algorithm having results compression not optimal.
i HALAMAN JUDUL
PERBANDINGAN KOMPRESI TEKS MENGGUNAKAN
ALGORITMA HUFFMAN STATIS, HUFFMAN DINAMIS
DAN MODIFIKASI ALGORITMA HUFFMAN
SKRIPSI
Diajukan Untuk Memenuhi Salah Satu Syarat Memperoleh Gelar Sarjana Komputer
Program Studi Teknik Informatika
Disusun oleh: Yohanes Beny Prasetyo
115314040
PROGRAM STUDI TEKNIK INFORMATIKA JURUSAN TEKNIK INFORMATIKA FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA YOGYAKARTA
ii
HALAMAN JUDUL (English)
COMPARISON TEXT COMPRESSION USING STATIC
HUFFMAN ALGORITHM, DYNAMIC HUFFMAN
ALGORITHM AND MODIFICATION HUFFMAN
ALGORITHM
A Thesis
Presented as Partial Fulfillment of The Requirements To Obtain Sarjana Komputer Degree
In Informatics Engineering Study Program
Written by: Yohanes Beny Prasetyo
115314040
INFORMATICS ENGINEERING STUDY PROGRAM DEPARTMENT OF INFORMATICS ENGINEERING
FACULTY OF SCIENCE AND TECHNOLOGY SANATA DHARMA UNIVERSITY
v
HALAMAN PERSEMBAHAN
“ Mintalah, maka akan diberikan kepadamu; carilah, maka kamu akan mendapat;
ketoklah, maka pintu akan dibukakan bagimu ” – Yesus Kristus
“ Orang muda terkasih,
jangan mengubur talenta-talenta, karunia yang diberikan Allah padamu. Jangan takut memimpikan hal-hal besar “ – Paus Fransiskus
vi
PERNYATAAN KEASLIAN KARYA
Saya menyatakan dengan sesungguhnya bahwa skripsi yang saya tulis ini tidak memuat karya atau bagian karya orang lain, kecuali yang telah disebutkan dalam kutipan dan daftar pustaka sebagaimana layaknya karya ilmiah
Yogyakarta, 11 Januari 2016 Penulis
vii
LEMBAR PERNYATAAN PERSETUJUAN PUBLIKASI KARYA ILMIAH UNTUK KEPENTINGAN AKADEMIS
Yang bertanda tangan di bawah ini, saya mahasiswa Universitas Sanata Dharma: Nama : Yohanes Beny Prasetyo
NIM : 115314040
Demi pengembangan ilmu pengetahuan, saya memberikan kepada perpustakaan Universitas Sanata Dharma karya ilmiah yang berjudul:
PERBANDINGAN KOMPRESI TEKS MENGGUNAKAN ALGORITMA HUFFMAN STATIS, HUFFMAN DINAMIS
DAN MODIFIKASI ALGORITMA HUFFMAN
Beserta perangkat yang diperlukan (bila ada). Dengan demikian saya memberikan kepada perpustakaan Universitas Sanata Dharma hak untuk menyimpan, mengalihkan dalam bentuk media lain, mengelolanya dalam bentuk pangkalan data, mendistribusikan secara terbatas, dan mempublikasikan di internet atau media lain untuk kepentingan akademis tanpa perlu meminta ijin dari saya maupun memberikan royalty kepada saya selama tetap mencantumkan nama saya sebagai penulis.
Demikian pernyataan ini saya buat dengan sebenarnya.
Yogyakarta, 11 Januari 2016 Yang menyatakan,
viii
PERBANDINGAN KOMPRESI TEKS MENGGUNAKAN ALGORITMA HUFFMAN STATIS, HUFFMAN DINAMIS
DAN MODIFIKASI ALGORITMA HUFFMAN
ABSTRAK
Permasalahan ukuran file dan waktu yang dibutuhkan menjadi suatu kendala tersendiri dalam proses penyimpanan atau perpindahan antar media. Solusi permasalahan tersebut telah ditemukan oleh David A. Huffman dengan algoritma yang didasarkan pada pohon biner. Algoritma Huffman mempunyai dua jenis yaitu Huffman Statis dan Huffman Dinamis. Algoritma ini terkenal dalam bidang kompresi data, akan tetapi perkembangan zaman membuktikan algoritma ini memiliki hasil kompresi yang kurang maksimal.
ix ABSTRACT
COMPARISON TEXT COMPRESSION USING STATIC HUFFMAN ALGORITHM, DYNAMIC HUFFMAN ALGORITHM AND
MODIFICATION HUFFMAN ALGORITHM
ABSTRACT
Problems file size and time taken into an obstacle in the process of storage or displacement between media. Solution these problems have been found by David A . Huffman with the algorithms that based on binary tree. Huffman algorithm have two types is huffman static and huffman dynamic. This algorithm famous in the field of compression data, but time progress prove this algorithm having results compression not optimal.
x
KATA PENGANTAR
Dengan kerendahan hati, penulis mengucapkan puji dan syukur atas segala berkat dan karunia Tuhan Yesus Kristus sehingga dapat menyelesaikan tugas akhir ini. Selama pengerjaan tugas akhir ini, penulis tidak akan bisa menyelesaikan sendirian tanpa orang-orang hebat yang telah membantu. Terucap terima kasih kepada :
1. Kedua orang tua, bapak Yustinus Sugito dan ibu Chatarina Sutini yang selalu memberikan semangat dan mendoakan setiap malam untuk penulis.
2. Br. Sarju selaku ketua LKM dan Mbak Iput yang telah memberikan kesempatan dan membantu saya untuk menyelesaikan studi ini.
3. Bapak Alb. Agung Hadhiatma, S.T., M.T. selaku dosen pembimbing yang telah memberikan pencerahan kepada penulis sehingga dapat menyelesaikan tugas akhir ini.
4. Ibu Sri Hartati Wijono, S.Si., M.Kom. selaku wakil kepala program studi Teknik Informatika yang juga telah memberikan pencerahan terhadap penulis untuk dapat menyelesaikan studi ini.
5. Bapak Drs. Haris Sriwindono, M.Kom. selaku penguji tugas akhir penulis telah memberikan masukan dan arahan yang bermanfaat dalam penulisan tugas akhir ini.
6. Seluruh teman-teman seperjuangan Teknik Informatika angkatan 2011, yang telah membuat penulis tertawa dan senang ketika pusing menyelesaikan tugas akhir ini.
7. Semua pihak, baik langsung maupun tidak, yang telah membantu penyelesaian tugas akhir ini.
Penulis menyadari bahwa masih banyak kekurangan dalam tugas akhir ini. Saran dan kritik diharapkan untuk perbaikan-perbaikan pada masa yang akan datang. Semoga bermanfaat.
Yogyakarta, 11 Januari 2016 Penulis,
xi DAFTAR ISI
1
HALAMAN JUDUL ...i
HALAMAN JUDUL (English) ... ii
HALAMAN PERSETUJUAN ... iii
HALAMAN PENGESAHAN ... iv
HALAMAN PERSEMBAHAN ... v
PERNYATAAN KEASLIAN KARYA ... vi
LEMBAR PERNYATAAN PERSETUJUAN PUBLIKASI KARYA ILMIAH UNTUK KEPENTINGAN AKADEMIS ... vii
ABSTRAK ... viii
1.7 Sistematika Penulisan ... 5
2 BAB II LANDASAN TEORI ... 6
2.1 Kompresi ... 6
2.1.1 Pengertian ... 6
xii
3 BAB III METODOLOGI DAN PERANCANGAN ... 25
3.1 Metode Pengembangan Sistem ... 25
3.2 Gambaran Umum Sistem ... 26
3.3 Analisa Kebutuhan Proses ... 27
3.3.1 Baca Teks ... 28
3.3.2 Pembentukan Pohon Huffman ... 28
3.3.3 Analisis Biner ... 29
3.3.4 Simpan File ... 30
3.3.5 Baca File ... 33
3.3.6 Pengubahan Kode ... 34
3.3.7 Simpan File (Proses Decoding) ... 34
3.4 Optimalisasi Algoritma Huffman ... 35
3.5 Desain User Interface ... 38
3.6 Spesifikasi Software dan Hardware ... 39
4 BAB IV IMPLEMENTASI DAN ANALISIS ... 41
4.1 Proses Encoding ... 41
4.1.1 Implementasi Proses Baca Teks ... 41
4.1.2 Implementasi Proses Pembentukan Pohon Biner ... 43
4.1.3 Implementasi Proses Analisis Biner ... 47
4.1.4 Implementasi Proses Encoding ... 55
xiii
4.2 Proses Decoding ... 62
4.2.1 Implementasi Proses Baca Teks File Kompresi ... 62
4.2.2 Implementasi Proses Pengubahan Kode (Decoding) ... 64
4.2.3 Implementasi Proses Pembentukan File Hasil Decoding ... 68
5 BAB V PENGUJIAN DAN ANALISIS ... 70
5.1 Perbandingan Jumlah Bit ... 70
5.2 Perbandingan Ukuran File Kompresi dan Waktu Proses ... 73
5.3 Hubungan Peluang Kemuculan Setiap Karakter dengan Jumlah Bit Hasil Kompresi ... 79
5.3.1 Data Bahasa Indonesia ... 80
5.3.2 Data Bahasa Inggris ... 82
6 BAB VI PENUTUP ... 85
6.1 Kesimpulan ... 85
6.2 Saran ... 86
xiv
DAFTAR GAMBAR
Gambar 2.1 Penentuan pivot dan cara kerja Quick Sort ... 11
Gambar 2.2 Pohon biner sempurna dan beberapa contoh pohon biner ... 13
Gambar 2.3 Flowchart pembentukan pohon biner Huffman ... 14
Gambar 2.4 Hasil dari pohon Huffman ... 18
Gambar 2.5 Proses pembentukan pohon Huffman Dinamis FGK ... 20
Gambar 2.6 Pembentukan pohon Huffman Dinamis ... 21
Gambar 2.7 Proses dekompresi dengan pohon Huffman ... 24
Gambar 3.1 Diagram konteks ... 27
Gambar 3.2 Block diagram encoding... 27
Gambar 3.3 Block diagram decoding... 28
Gambar 3.4 Pembentukan pohon Huffman modifikasi... 37
Gambar 3.5 Interface encoding ... 38
Gambar 3.6 Interface decoding ... 39
Gambar 4.1 Implementasi proses memilih file encoding ... 42
Gambar 4.2 Implementasi proses membaca file encoding ... 42
Gambar 4.3 Implementasi pembentukan pohon Huffman Statis ... 43
Gambar 4.4 Implementasi pembentukan pohon Huffman Dinamis ... 44
Gambar 4.5 Implementasi pembentukan pohon Huffman Modifikasi ... 46
Gambar 4.6 Source code kelas KodeHuffman.java ... 48
Gambar 4.7 Implementasi analisis biner Huffman Statis dan Modifikasi ... 49
Gambar 4.8 Implementasi analisis biner Huffman Statis method find() ... 50
Gambar 4.9 Implementasi analisis biner Huffman Modifikasi method find() . 51-52 Gambar 4.10 Implementasi analisis biner Huffman Dinamis ... 53
Gambar 4.11 Implementasi analisis biner Huffman Dinamis ... 54
Gambar 4.12 Implementasi encoding Huffman Statis dan Dinamis ... 55
Gambar 4.13 Implementasi encoding Huffman Modifikasi ... 56
Gambar 4.14 Implementasi preprocessing ... 58
xv
Gambar 4.16 Implementasi proses simpan file kompresi ... 61
Gambar 4.17 Implementasi proses memilih file decoding ... 62
Gambar 4.18 Implementasi proses membaca file decoding ... 63
Gambar 4.19 Implementasi proses decoding header ... 64
Gambar 4.20 Implementasi proses decoding isi ... 65
Gambar 4.21 Implementasi proses decoding Huffman Dinamis dan Statis... 66
Gambar 4.22 Implementasi proses decoding Huffman Modifikasi ... 67
Gambar 4.23 Implementasi proses pembentukan file decoding... 68
Gambar 5.1 Kelas pengujian perbandingan jumlah bit ... 71
Gambar 5.2 Capture hasil pengujian jumlah bit ... 71
Gambar 5.3 Lanjutan capture hasil pengujian jumlah bit ... 72
Gambar 5.4 Frame pengujian jumlah bit dan ratio compression ... 73
Gambar 5.5 Tampilan awal aplikasi ... 74
Gambar 5.6 Tampilan klik browse untuk memilih file ... 74
Gambar 5.7 Tampilan encoding untuk memilih salah satu algoritma ... 75
Gambar 5.8 Tampilan loading proses encoding ... 75
Gambar 5.9 Pemberitahuan jika proses encoding berhasil ... 76
Gambar 5.10 Grafik waktu yang dibutuhkan untuk kompresi ... 78
xvi
DAFTAR TABEL
Tabel 2.1 Tabel kode Huffman ... 18
Tabel 5.1 Tabel hasil perbandingan jumlah bit ... 72
Tabel 5.2 Tabel hasil pengujian jumlah bit dan ratio compression ... 73
Tabel 5.3 Data ukuran file pengujian ... 77
Tabel 5.4 Tabel hasil pengujian ... 77
Tabel 5.5 Hasil pengujian jumlah bit data bahasa Indonesia ... 81
Tabel 5.6 Peluang karakter terbanyak data bahasa Indonesia ... 81
Tabel 5.7 Hasil pengujian jumlah bit data bahasa Inggris ... 83
1
1
BAB I
PENDAHULUAN
1.1 Latar Belakang
Pada zaman sekarang ukuran suatu file menjadi bertambah semakin besar dan membutuhkan memori penyimpanan yang lebih serta membutuhkan waktu transfer yang lama. Ukuran file yang besar tidak terlalu menjadi masalah karena ukuran hard disk semakin lama semakin besar dengan harga yang semakin terjangkau. Tetapi jika mengenai file transfer, masalah ukuran file yang besar menjadi penghambat dalam waktu transfer yang menjadi semakin lama.
pembuatan Huffman Tree karena pohon Huffman akan otomatis berubah menyesuaikan kode yang sering muncul dan akan ditempatkan di dekat root sehingga tidak membutuhkan waktu preprocessing yang lama. Hal ini berbeda dengan algoritma Huffman Statis yang harus melakukan preprocessing dengan memindai setiap karakter dan mengurutkannya dari yang paling sering muncul sampai yang paling sedikit muncul.
Dalam ilmu komputer dan informasi, Huffman coding adalah suatu entropi algoritma yang digunakan untuk teknik lossless compression [3]. Data yang dikompres menggunakan algoritma ini akan menghasilkan hasil dekompresi yang sama dengan aslinya. Penggunaan teknik ini banyak digunakan untuk kompresi data teks serta informasi penting lainnya yang tidak diperbolehkan adanya data informasi yang hilang.
pengembangan algoritma dari Huffman yang dapat berguna bagi optimalisasi transfer data dan mengoptimalkan kapasitas penyimpanan memori.
1.2 Rumusan Masalah
Berdasarkan latar belakang yang dipaparkan sebelumnya maka dapat dibuat beberapa rumusan masalah antara lain:
1. Bagaimana cara mengecilkan ukuran suatu file teks untuk mempercepat transfer data antar media penyimpanan?
2. Bagaimana cara mengecilkan ukuran suatu file teks untuk mempercepat proses upload atau download?
3. Bagaimana cara mengecilkan ukuran suatu file teks untuk menghemat kapasitas memori penyimpanan serta mengoptimalkan kapasitas memori?
1.3 Tujuan
Tujuan dari penelitian ini adalah menemukan optimalisasi dari algoritma Huffman untuk kompresi data teks sebagai suatu cara untuk mempercepat proses transfer antar media penyimpanan, serta untuk menghemat dan mengoptimalkan kapasitas memori penyimpanan.
1.4 Batasan Masalah
1. Algoritma yang dibahas dalam tulisan ini hanya digunakan untuk data bertipe teks. Data yang dimaksud adalah data berisi huruf, angka atau karakter yang terdapat dalam standar ASCII.
2. Data teks yang digunakan hanya untuk file betipe .TXT (Text Document).
1.5 Manfaat Penelitian
Manfaat yang didapat dari penelitian ini, antara lain :
1. Memberikan analisis sejauh mana algoritma Huffman dapat dikembangkan untuk menghasilkan algoritma kompresi yang lebih baik.
2. Membantu masyarakat dalam melakukan pengoptimalan memori penyimpanan serta mempermudah dan mempercepat dalam proses transfer (upload dan download) suatu file teks.
1.6 Luaran Penelitian
1.7 Sistematika Penulisan
BAB I PENDAHULUAN
Berisi latar belakang, rumusan masalah, tujuan, batasan masalah, manfaat penelitian, luaran penelitian dan sistematika penulisan untuk mempermudah pemahamannya.
BAB II LANDASAN TEORI
Bab ini berisi mengenai berbagai macam landasan teori yang digunakan untuk penelitian ini.
BAB III METODOLOGI DAN PERANCANGAN
Bab ini berisi analisa dan gambaran umum dari perancangan algoritma yang akan dibuat dari pengembangan algoritma Huffman.
BAB IV IMPLEMENTASI
Berisi implementasi dari algoritma serta rancangan yang telah dibuat.
BAB V PENGUJIAN DAN ANALISIS
Berisi pengujian dari algoritma yang telah dibuat kedalam beberapa kondisi pengujian.
BAB VI PENUTUP
6
2
BAB II
LANDASAN TEORI
Pada bab ini penulis akan membahas serta menjelaskan mengenai teori-teori yang mendukung penelitian dalam proses analisa dan implementasi algoritma. Hal yang dibahas mencakup : pengertian kompresi file, jenis-jenis kompresi file, struktur data, binary tree, pengurutan data, algoritma Huffman Statis dan algoritma Huffman Dinamis.
2.1 Kompresi 2.1.1 Pengertian
Kompresi adalah mengurangi jumlah data dalam file, gambar atau video tanpa mengurangi kualitas dari data asli. Itu juga berarti mengurangi jumlah bit yang diperlukan untuk menyimpan dan atau mengirimkan melalui media digital[1]. Dalam kompresi, jika data tersebut akan dipergunakan kembali maka harus dilakukan proses dekompresi. Dekompresi adalah suatu proses pengubahan kembali kode-kode yang digunakan untuk mengurangi jumlah bit menjadi data awal.
Pemilihan algoritma yang tepat dalam kompresi tidak hanya bagaimana algoritma itu dapat mengembalikan data menjadi seperti semula, tetapi ada beberapa faktor lain yang dipertimbangkan. Faktor tersebut antara lain :
2. Kecepatan kompresi
3. Ukuran hasil kompresi
4. Besarnya redudansi
5. Ketepatan hasil dekompresi
6. Kompleksitas algoritma
2.1.2 Jenis Kompresi
Teknik kompresi itu sendiri terdiri dari dua jenis yaitu Lossless Compression dan Lossy Compression. Kedua jenis kompresi tersebut akan dijelaskan sebagai berikut :
2.1.2.1 Lossless Compression
Jika data dikompresi menggunakan teknik Lossless Compression, hasil dekompresiakan menghasilkan data yang sama dengan aslinya. Teknik ini biasa digunakan untuk aplikasi yang tidak diperbolehkan adanya perbedaan antara data asli dengan data hasil dekompresi. Contoh : ZIP, RAR, GZIP, 7-ZIP.
Kelemahan dari metode ini adalah ratio kompresi yang rendah. Rasio dapat dihitung dengan persamaan :
�� � = ( −� � � � � � � � ) � � � %
karena itu secara umum, compression ratio yang tinggi tidak akan mungkin terjadi jika menggunakan teknik lossless compression[2].
2.1.2.2 Lossy Compression
Teknik Lossy Compression memperbolehkan adanya informasi dan data yang hilang setelah proses dekompresi. Contoh : MP3, JPEG, MPEG dan WMA.
Kelebihan dari teknik ini adalah ukuran file yang lebih kecil namun masih dapat memenuhi syarat setelah di dekompresi. Teknik ini sebenarnya membuang bagian-bagian yang tidak berguna, tidak begitu dirasakan dan tidak begitu dilihat sehingga manusia masih beranggapan bahwa data tersebut masih memenuhi syarat dan masih bisa digunakan.
Jika dilihat dari contoh di atas, sebagian besar produk hasil dari teknik ini merupakan file multimedia seperti lagu, gambar dan video. Hal itu didasarkan karena file multimedia hanya untuk didengar atau dilihat, sehingga data yang hilang tidak akan terlalu mempengaruhi selagi masih dalam batas wajar.
2.2 Struktur Data
Selain konsep pohon biner, dalam algoritma Huffman juga terdapat konsep pengurutan data. Pengurutan data digunakan untuk preprocessing dalam algoritma Huffman Statis di mana setelah data di cek frekuensi kemunculannya, maka data akan diurutkan secara descending (dari besar ke kecil). Seperti yang telah dibahas sebelumnya, data dengan kemunculan terbanyak ditempatkan dekat dengan akar.
2.2.1 Pohon Biner (Binary Tree)
Sebuah pohon biner terbuat dari titik – titik (nodes), di mana setiap titik mempunyai pointer kiri dan kanan serta data element. Pointer akar terletak di paling atas dari pohon. Pointer kiri dan kanan secara rekursif membentuk subtree
[5]
.
Dalam setiap pohon biner, terdapat sifat – sifat pohon antara lain [8]:
1. Node / simpul : obyek sederhana elemen dari senarai berantai yang dapat memiliki elemen dan penunjuk ke node lain.
2. Edge : garis yang menghubungkan dua buah node.
3. Path : sederetan node / edge dari awal node ke node lain (target). 4. Root node : node pertama dalam sebuah tree / subtree.
5. Subtree : tree yang merupakan bagian dari sebuah tree yang lebih besar. 6. Left Subtree : subtree yang berada di sebelah kiri sebuah tree.
7. Right subtree : subtree yang berada di sebelah kanan sebuah tree. 8. Parent : node yang berada tepat di atas sebuah node.
10. Left Child : node pertama dalam seuah left subtree / parentnode dari left subtree.
11. Right Child : node pertama dalam seuah right subtree / parentnode dari right subtree.
12. Sibling : node dengan parent yang sama.
13. Leaf Node / terrminal simpul : node yang tidak memiliki child. 14. Internal Node : node yang bukan leaf node.
Pohon biner secara umum mempunyai ciri bahwa setiap node hanya mempunyai anak paling banyak dua. Sering kali pohon biner yang baik dan sempurna adalah pohon biner yang seimbang. Pohon biner seimbang yaitu pohon yang mempunyai tinggi subtree kanan dan kiri tidak lebih dari satu, semua daun terisi dan semua simpul memiliki dua anak [8].
2.2.2 Quick Sort
Dari ide dasar metode quick sort tersebut, dapat dipahami bahwa inti dari pengurutannya adalah membagi data menjadi dua bagian. Cara kerja quick sort [9]: 1. Tentukan elemen sebagai pivot dari array, misalkan elemen awal.
2. Atur array sehingga semua elemen yang lebih kecil atau sama dengan pivot di sebelah kiri pivot dan semua elemen yang lebih besar dari pivot berada di sebelah kanan.
3. Secara rekursif quick sort subarray (kiri) dengan elemen yang lebih kecil atau sama dengan dari pivot dan subarray (kanan) dengan elemen yang lebih besar dari pivot.
Gambar 2.1 Penetuan pivot dan cara kerja Quick Sort
atau dengan kata lain semua data berdiri sendiri. Algoritma quick sort itu sendiri adalah sebagai berikut [9] :
Larik A dengan N elemen akan diurutkan secara menaik (ascending).
Pemanggilan fungsi quick sort rekursif dengan parameter array x, indek awal dan indek akhir.
Parameter : x adalah array bertipe int.
awal = indek awal dari vektor / subvektor yang akan diurutkan = 0
akhir = indek akhir dari vektor / subvektor yang akan diurutkan = N-1
Test apakah indek awal < akhir, jika ya kerjakan langkah – langkah sebagai berikut:
Langkah 1 : tentukan i = awal + 1, j = akhir.
Langkah 2 : tambahkan nilai i dengan 1 selama i <= akhir dan x[i] <= x[awal]. Langkah 3 : kurangi nilai j dengan 1 selama j > awal dan x[j] > x[awal]. Langkah 4 : kerjakan langkah 5 sampai 7 selama i < j.
Langkah 5 : tukarkan nilai x[i] dengan x[j].
Langkah 6 : tambahkan nilai i dengan 1 selama i <= akhir dan x[i] <= x[awal]. Langkah 7 : kurangi nilai j dengan 1 selama j > awal dan x[j] > x[awal]. Langkah 8 : tukarkan nilai x[awal] dengan x[j].
Langkah 10 : panggil fungsi quick sort rekursif dengan parameter indek awal = j + 1 dan indek akhir = akhir.
Langkah 11 : selesai.
2.3 Algoritma Huffman 2.3.1 Pohon Biner Huffman
Pohon adalah graf tak-berarah terhubung yang tidak mengandung sirkuit. Sedangkan pohon biner adalah pohon berakar dimana setiap simpul cabangnya mempunyai paling banyak dua anak. Pohon biner teratur adalah pohon biner dimana setiap simpul cabangnya mempunyai dua buah anak[4].
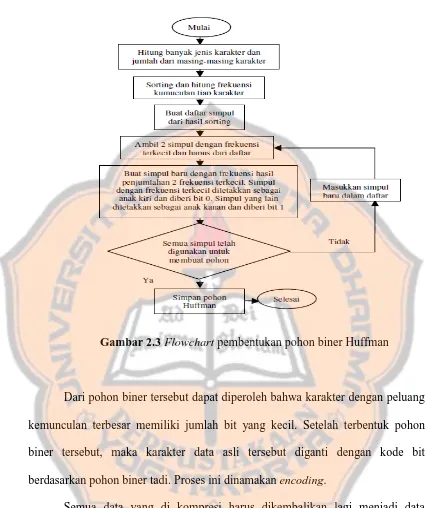
Gambar 2.3 Flowchart pembentukan pohon biner Huffman
Dari pohon biner tersebut dapat diperoleh bahwa karakter dengan peluang kemunculan terbesar memiliki jumlah bit yang kecil. Setelah terbentuk pohon biner tersebut, maka karakter data asli tersebut diganti dengan kode bit berdasarkan pohon biner tadi. Proses ini dinamakan encoding.
2.3.1.1 Menggunakan Pohon Biner Huffman
Langkah-langkah yang dilakukan dalam proses decoding dengan pohon biner Huffman adalah :
a. Baca bit pertama dari string biner masukan
b. Lakukan traversal pada pohon Huffman mulai dari akar sesuai dengan bit yang dibaca. Jika bit yang dibaca adalah 0, baca anak kiri. Tetapi jika yang dibaca adalah 1, baca anak kanan.
c. Jika anak dari pohon bukan daun, baca bit berikutnya dari string biner. d. Traversal hingga ditemukan daun.
e. Pada daun tersebut, simbol ditemukan dan proses penguraian kode selesai. f. Proses penguraian kode dilakukan hingga seluruh string biner masukan
diproses.
2.3.1.2 Menggunakan Tabel Kode Huffman
Kode Huffman itu sendiri disusun menggunakan kode awalan (prefiks code) yang berarti kode awalan dari sebuah simbol/karakter tidak boleh menjadi awalan suatu simbol lain. Oleh karena itu rangkaian bit hasil enkripsi dapat dengan mudah diuraikan menjadi data semula. Yang perlu dilakukan hanyalah melihat rangkaian setiap bit hasil enksripsi di dalam tabel kode Huffman.
� log , dan proses tersebut dilakukan berulang kali sampai hanya tersisa satu buah pohon Huffman, yang berarti dilakukan sebanyak n kali [5].
2.3.2 Huffman Statis
Algoritma Huffman Statis merupakan algoritma dasar dari Huffman Coding. Untuk mendapatkan kode Huffman, mula-mula kita harus menghitung dahulu peluang kemunculan tiap karakter dalam teks. Pada Huffman Statis pembentukan pohon Huffman adalah sebagai berikut :
1. Pilih dua karakter dengan peluang terkecil. Kedua simbol tadi dikombinasikan sebagai simpul orangtua sehingga menjadi simbol 2 karakter dengan peluang yang dijumlahkan.
2. Selanjutnya pilih 2 simbol berikutnya termasuk simbol baru yang mempunyai peluang terkecil.
3. Prosedur yang sama dilakukan pada dua simbol berikutnya yang mempunyai peluang terkecil [4].
Contoh :
Data teks : EBCDAAEA = 8 huruf
Membutuhkan memori : 8 x 8 bit = 64 bit (8 byte) Kode ASCII :
A = 01000001 A = 01000001 E = 01000101 A = 01000001
Frekuensi kemunculan data string di atas A = 3, E = 2, B=1, C = 1 dan D = 1.
Maka peluang yang didapat :
C dan D menjadi 1 (CD) sehingga probabilitas menjadi 1/8 + 1/8 =
2/8
CD dan B menjadi 1 (BCD) sehingga probabilitas menjadi 1/8 + 2/8
= 3/8
BCD dan E menjadi 1 (EBCD) sehingga probabilitas menjadi 2/8 +
3/8 = 5/8
EBCD dan A menjadi 1 (AEBCD) sehingga probabilitas menjadi 3/8
+ 5/8=8/8
A
Gambar 2.4 Hasil dari pohon Huffman
Huruf Kode
Tabel 2.1 Tabel Kode Huffman
Dengan melakukan pengkodean di atas, maka didapat sebuah kode yang sangat pendek. Sebagai contoh untuk karakter A yang sebelumnya berjumlah 8 bit hanya menjadi 1 bit.
Sehingga kapasitas memori yang diperlukan : Sebelum : 8 x 8 bit = 64 bit
2.3.3 Huffman Dinamis
Algoritma Huffman Dinamis atau Adaptive Huffman Coding (AHC) merupakan suatu lanjutan dari algoritma Huffman Statis di mana AHC merupakan algoritma yang lebih efisien dan mampat. AHC lebih sering dilakukan pada proses transfer data (streaming). Berikut algoritma AHC FGK (Faller-Gallager-Knuth)[6] :
1. Buat suatu simbol yang bernama NYT (Not Yet Transmitted) atau berarti belum ditransmisi.
2. Jika simbol adalah NYT, tambahkan 2 anak NYT tersebut, satunya akan menjadi NYT baru dan yang lainnya adalah untuk simbol, akan menambahkan nilai dari NYT akar dan daun akan terbentuk. Jika daun baru terbentuk lanjutkan langkah 4, jika telah ada sebelumnya periksa dulu di langkah 3.
3. Jika simbol yang dimasukan terakhir memiliki probabilitas yang lebih tinggi maka akan ditukar dengan yang sebelumnya menempati tempat kemunculan tertinggi.
4. Tambahkan nilai dari akar tersebut.
5. Jika bukan akar, kembali ke akar inang lalu lanjutkan ke langkah 2, selain itu selesai.
Gambar 2.5 Proses pembentukan pohon Huffman Dinamis FGK
1. Pohon Huffman kosong dan berisi NYT 256 (2 byte).
2. Karakter pertama adalah a, dan disimpan pada anak NYT 256 yang bobotnya bertambah 1 dan menambah anak NYT 254. Simbol a memiliki bobot 1 dengan alamat 255.
3. Karakter kedua adalah b, dan disimpan pada anak NYT 254. Simbol b memiliki bobot 1 dengan alamat 253 serta NYT 254 memiliki anak NYT 252.
4. Karakter berikutnya adalah b lagi, maka akan dimasukan ke 253 (proses searching) dan bobotnya menjadi 2. Lalu dibandingkan dengan karakter a, karena bobot b lebih besar dari a maka posisi a dan b ditukar.
Dari pohon di atas maka dapat disimpulkan bahwa karakter A memiliki
code “01” dan karakter B memiliki code “1”.
E
Gambar 2.6 Pembentukan pohon Huffman Dinamis
1. Karakter pertama ‘E’ masuk, dan menempati posisi dekat dengan akar.
Bobot atau jumlah ‘E’ adalah 1.
2. Karakter kedua ‘B’ masuk dan mengecek posisi, karena posisi dekat
dengan akar sudah ditempati ‘E’ maka ‘B’ membentuk posisi di bawah
3. Karakter ketiga ‘C’ masuk maka akan mengecek dan membuat posisi di bawah ‘B’. Bobot karakter ‘C’ adalah 1.
4. Karakter keempat ‘D’ masuk maka akan mengecek dan membuat posisi di
bawah ‘C’. Bobot karakter ‘D’ adalah 1.
5. Karakter kelima ‘A’ masuk maka akan mengecek dan membuat posisi di
bawah ‘D’. Bobot karakter ‘A’ adalah 1.
6. Karakter keenam ‘A’ masuk dan akan mengecek setiap node. Karena
karakter ‘A’ sudah membuat node di posisi paling bawah maka bobot ‘A’
akan bertambah menjadi 2. Perubahan bobot ini akan mengubah posisi ‘A’
menjadi dekat dengan akar dan bertukar posisi dengan karakter ‘E’.
7. Karakter ketujuh ‘E’ masuk dan mengecek setiap node. Karakter ‘E’ juga
telah dibuat maka bobot ‘E’ bertambah menjadi 2. Karakter ‘E’ kembali
mengecek dari akar untuk mengubah posisi. Posisi dekat akar telah
ditempati ‘A’ dengan bobot sama, maka ‘E’ mengecek dengan turun satu
node. Karakter ‘B’dengan bobot 1 ditukar posisinya dengan karakter ‘E’ .
2.4 Dekompresi
Proses dekompresi (decoding) merupakan suatu proses kebalikan dari proses kompresi (encoding). Dimana kode hasil kompresi dikembalikan dan disusun kembali seperti data awal. Proses dekompresi seperti yang telah disebutkan di awal, dapat dilakukan dengan 2 cara yaitu dengan menggunakan pohon Huffman atau dengan tabel Huffman. Langkah-langkah dekompresi string biner dengan pohon Huffman adalah sebagai berikut[7] :
1. Baca sebuah bit dari string biner. 2. Mulai dari akar.
3. Periksa kiri. 4. Periksa kanan.
5. Ulangi langkah 1,2 dan 3 sampai bertemu daun. Kodekan rangkaian bit yang telah dibaca dengan karakter di daun.
6. Ulangi dari langkah 1 sampai semua bit di dalam string habis.
Sebagai contoh sebuah biner “01001” akan di dekompresi, dengan pohon
Gambar 2.7 Proses dekompresi dengan pohon Huffman
Dengan menggunakan algoritma di awal tadi, maka jika kita telusuri dari
akar ditemukan bahwa kode “01” merupakan B dan kode “001” merupakan D.
Hal ini dengan mudah ditemukan karena dalam Huffman kode akhir suatu biner
bukan merupakan kode awalan biner lain. Jadi kode “01001” adalah kode
Huffman untuk string BD.
3
BAB III
METODOLOGI DAN PERANCANGAN
Pada bab analisis dan desain ini akan dibahas mengenai analisa terhadap kompresi data teks dengan algoritma Huffman serta desain program yang akan dibuat. Hal–hal yang dibahas antara lain proses–proses yang dibutuhkan dalam penelitian meliputi beberapa hal : gambaran umum sistem yang akan dikembangkan, prosedur pengembangan sistem, gambaran algoritma pengembangan dari Huffman, model analisis dan model desain.
3.1 Metode Pengembangan Sistem
Metodologi pengembangan yang penulis gunakan untuk pembuatan sistem ini adalah metodologi model waterfall. Terdapat beberapa tahapan dalam metodologi tersebut, antara lain :
1. System Engineering
Pada tahap ini merupakan tahap untuk mengumpulkan dan menentukan semua kebutuhan elemen sistem.
2. Analisis
Pada tahap untuk menentukan analisis terhadap permasalahan yang dihadapi.
Gambaran program yang akan diterjemahkan menjadi sebuah sistem. Meliputi desain tampilan, diagram konteks dan block diagram.
4. Implementasi
Proses menterjemahkan desain ke dalam bentuk yang dapat dieksekusi. Pada tahap ini juga merupakan proses coding program.
5. Pengujian
Memastikan apakah semua fungsi-fungsi program dapat berjalan dengan baik dan menghasilkan output yang sesuai dengan yang dibutuhkan.
3.2 Gambaran Umum Sistem
Sistem yang akan dibangun merupakan sebuah sistem berbasis Java dengan Netbeans sebagai Intregated Development Environment (IDE). Secara umum sistem yang berjalan akan menitikberatkan pada operasi algoritma Huffman sebagai proses kompresi dan dekompresi data. Dalam sistem ini hanya terdapat satu tipe data yang digunakan sebagai masukan user yaitu data teks dengan keluaran hasil dari sistem adalah sebuah file hasil kompresi data masukan tersebut.
User
Kompresi Data
Sistem
1. Data teks 2. File hasil kompresi
1. File hasil kompresi 2. Data teks
Gambar 3.1 Diagram konteks
Selain masukan berupa data teks, dari diagram konteks tersebut user juga bisa memasukan file hasil kompresi agar dapat di dekompresi kembali menjadi data teks sebagai keluarannya. File hasil kompresi yang akan digunakan sebagai masukan adalah file kompresi hasil dari sistem ini, karena file tipe hasil kompresi sistem ini akan berbeda dari sistem kompresi yang lain.
3.3 Analisa Kebutuhan Proses
Setelah melihat gambaran umum sistem, maka tahap selanjutnya adalah menganalisa semua proses yang dibutuhkan dalam sistem. Terdapat dua proses sistem yaitu proses encoding dan decoding. Gambaran proses tersebut akan di tampilkan dalam block diagram berikut :
Gambar 3.3 block diagram decoding
Dari gambar detail proses encoding dan decoding tersebut maka diperoleh beberapa proses di dalamnya antara lain : baca teks, pembentukan pohon Huffman, analisis biner, simpan file, baca file dan pengubahan kode.
3.3.1 Baca Teks
Proses baca teks merupakan sebuah proses awal dimana user memilih data yang akan di kompresi. Data yang dipilih hanya tipe data yang sesuai dengan batasan masalah seperti telah disebutkan pada bab 1. Proses pemilihan menggunakan kelas JFileChooser yang merupakan kelas bawaan pada Java untuk membuka kotak dialog browse file.
File yang telah dipilih, akan di read setiap byte secara detail. Proses baca akan membaca secara keseluruhan seperti karakter spasi, tanda baca hingga enter. Hasil dari proses ini adalah berupa Arraylist bertipe String yang akan diolah diproses selanjutya.
3.3.2 Pembentukan Pohon Huffman
encoding karena dari data teks tersebut disusun sebuah pohon biner Huffman untuk membuat sebuah kode baru yang lebih singkat untuk masing-masing karakter.
Proses ini akan berbeda di setiap algoritma, karena pembentukan pohon biner yang memiliki ciri khas di masing-masing algoritma.Arraylist hasil proses baca teks akan di loop dan diambil setiap karakternya lalu dibentuk pohon binernya. Setelah terbentuk pohon biner, maka akan di identifikasi setiap karakter beserta kode yang baru. Hasil proses identifikasi dimasukan ke dalam Arraylist objek sebuah kelas yang berisi atribut karakter dan kode karakter. Hasil tersebut juga merupakan keluaran dari proses ini.
3.3.3 Analisis Biner
Proses analisis biner adalah suatu proses yang meliputi proses identifikasi kode baru tiap karakter serta proses pembentukan rangkaian kode biner baru. Proses ini dapat juga disebut sebagai proses pembentukan sebuah file baru hasil kompresi data yang dimasukan.
3.3.4 Simpan File
Proses simpan file adalah sebuah proses untuk menyimpanan file hasil kompresi tersebut atau dengan kata lain file yang telah di buat dalam proses analisis biner akan di-stream di media penyimpanan.
Dalam proses ini terdapat 3 sub proses di dalamnya, proses-proses tersebut antara lain stream byte, simpan log, dan buat file kompresi.
3.3.4.1 Simpan Log
Proses simpan log ini merupakan sebuah proses yang saya buat untuk menyimpan tabel kode (Arraylist objek) dari hasil proses pembentukan pohon Huffman. Proses ini nantinya akan membantu pada saat decoding dengan mengambil tabel kode yang tersimpan dalam file log. File ini berada di dalam project tepatnya di folder logs. Untuk menyimpan tabel kode di dalam file log, saya menggunakan stream bertipe objek dengan implements Serializable pada kelasnya.
Aturan penamaan file log ini adalah tanggal ditambah waktu pada saat proses kompresi. Sebagai contoh kompresi dilakukan pada tanggal 24 Desember 2014 pukul 11:21:40, maka nama file log menjadi 24122014112140. Penamaan ini secara singkatnya adalah tanggal dalam format angka ditambah waktu dari format jam, menit dan detik yang semuanya digabung tanpa spasi.
3.3.4.2 Stream Byte
Pada awalnya, untuk proses stream hasil kompresi akan menggunakan stream bit yaitu stream dengan menggunakan ukuran terkecil dalam data. Ukuran terkecil yang dimaksud adalah jika program mencetak angka 1, maka yang ditulis adalah biner angka 1 bukan angka 1 yang mempunyai kode biner (00000001) seperti halnya String atau Integer. Melihat sangat sulit dilakukan dengan pemrograman berbasis Java, maka stream untuk hasil kompresi menggunakan stream byte.
Stream byte adalah program mencetak hasil ke dalam sebuah file dengan menulis tiap karakter. Deretan kode hasil proses analisis biner yang berisi 1 dan 0, akan dipotong menjadi beberapa Stringdengan panjang masing-masing 7 karakter. Pemotongan menjadi 7 karakter ini didasarkan pada jumlah bit yang terdapat di sebuah karakter maksimal adalah 8 yaitu 10000000. Jika pemotongan berjumlah 8 karakter, akan menjadi masalah jika terdapat angka 1 selain di depan dan otomatis tidak akan ada karakter yang sesuai. Sebagai standar, saya menggunakan ASCII dengan maksimal jumlah bit adalah 8.
3.3.4.3 Buat File Kompresi
Untuk file baru hasil kompresi ini, saya akan memberi sebuah extension dengan format .NFC(New File Compression). Tujuan dari pemberian format file ini dengan nama yang baru adalah untuk membedakan file hasil kompresi dengan file hasil kompresi yang lainnya seperti RAR, ZIP, TAR atau sebagainya. Karena proses kompresi ini berbeda dari aplikasi kompresi lainnya, sehingga akan terjadi error jika file ini dibuka dengan aplikasi kompresi pada umumnya.
Seperti halnya file hasil kompresi umumnya, pada file ini juga terdapat sebuah informasi yang terdapat di dalamnya. Informasi dalam file ini meliputi nama file log untuk data tersebut. Secara singkat, file hasil kompresi akan berpasangan dengan file log-nya masing-masing. Selain itu juga terdapat informasi tentang metode atau algoritma yang dipakai. Saya memberikan ketentuan sebagai berikut :
1. Algoritma Huffman Statis, diberi kode ‘S’. 2. Algoritma Huffman Dinamis, diberi kode ‘D’. 3. Algoritma Huffman Modifikasi, diberi kode ‘M’.
Pemberian kode tersebut digunakan untuk mempermudah program dalam proses decoding sehingga otomatis akan memilih cara yang sesuai. Untuk mempermudah proses pengambilan data atau tokenizer, maka saya menggunakan
kata ‘sb’ yang merupakan singkatan dari sub. Alasan saya menggunakan sebuah
Secara garis besar format penulisan dalam file hasil kompresi adalah sebagai berikut :
nama file logsbkode metodesb isi karakter
Untuk penamaan file hasil kompresi, saya menyamakan dengan nama file asli ditambah dengan metode yang dipakai. Sebagai contoh file bernama coba.txt di kompresi dengan metode Huffman Dinamis, menghasilkan file hasil coba_dinamis.nfc.
3.3.5 Baca File
Proses baca file adalah proses user untuk memilih file hasil kompresi untuk kemudian di dekompresi menjadi file baru seperti file aslinya. Pada proses ini hanya file berekstensi .NFC yang dapat dibuka, karena output file hasil dari sistem ini adalah file berformat .NFC. Sistem tidak bisa men-decoding jika masukan file tidak berformat seperti aturan tersebut.
3.3.6 Pengubahan Kode
Proses ini merupakan kebalikan dari proses pembentukan pohon Huffman pada saat encoding. Di dalam proses ini, ketiga komponen yang sudah diambil pada proses baca file akan diolah. Isi karakter akan di loop dan di proses per karakter lalu diubah menjadi bentuk biner. Hasil pengubahan ini adalah sebuah String yang berisi deretan kode 1 dan 0 seperti kode pada saat encoding.
Setelah terbentuk deret tersebut, maka akan dicocokan dengan Arraylist yang berisi tabel kode sehingga akan terbentuk sebuah kata yang sesuai dengan kata aslinya. Hasil dari proses ini adalah sebuah String yang nantinya akan diolah pada proses selanjutnya.
3.3.7 Simpan File (Proses Decoding)
Proses simpan file pada saat decoding berbeda dengan proses simpan file pada saat encoding. Pada proses ini, String hasil dari pengubahan kode akan langsung di stream ke dalam sebuah file baru. Karena melihat dari batasan masalah di mana file masukan hanya untuk berekstensi .TXT, maka file hasil decoding akan langsung diberi extension .TXT.
3.4 Optimalisasi Algoritma Huffman
Seperti yang telah disebutkan dari awal, bahwa algoritma Huffman merupakan dasar dari algoritma kompresi yang ada pada saat ini. Melihat posisi tersebut bukan tidak mungkin dilakukan suatu modifikasi untuk mengoptimalkan hasil kompresi dari algoritma Huffman. Algoritma Huffman mempunyai dua macam algoritma, yaitu Huffman Dinamis dan Huffman Statis.
Kedua algoritma tersebut mempunyai persamaan yaitu terbuat dari pohon biner yang dikenal dengan pohon biner Huffman, hanya saja kedua algoritma tersebut mempunyai perbedaan pada preprocessing data. Algoritma Huffman Dinamis lebih fleksibel dan tanpa preprocessing karena data yang masuk akan diolah penempatannya ketika berada di pohon biner, sedangkan algoritma Huffman Statis melakukan pengurutan frekuensi kemunculan dahulu sebelum membuat pohon biner. Kedua algoritma mempunyai persamaan menempatkan karakter yang sering muncul berada di dekat akar sehingga mempunyai kode terpendek.
Pada penelitian ini mencoba untuk memodifikasi algoritma Huffman supaya lebih optimal dalam mendapatkan hasil ukuran kompresi. Secara garis besar, modifikasi ini merupakan turunan dari algoritma Huffman Statis. Untuk lebih memahaminya, maka sebuah contoh akan penulis berikan.
Data : E B C D A A E A
Langkah 2 : urutkan data dari frekuensi kemunculan terbanyak hingga sedikit :
Hasil : A = 3, E = 2, B = 1, C = 1, D = 1
Langkah 3 : pembentukan pohon biner berdasarkan letak setiap karakter, jika pada posisi ganjil maka akan menuju ke sebelah kanan pohon. Jika terletak pada posisi genap maka akan menuju ke sebelah kiri pohon.
Secara umum dapat dinyatakan dengan pseudecode sebagai berikut : 1. Cek frekuensi kemunculan tiap karakter.
2. Urutkan frekuensi dari yang terbanyak muncul hingga paling sedikit muncul.
3. Cek posisi karakter yang telah diurutkan, variabel cursor == akar : Ganjil :
Jika cursor.getKanan( ) == null, buat node baru.
Jika cursor.getKanan( ) != null, maka cursor = cursor.getKanan( ).
Genap :
Jika cursor.getKiri( ) == null, buat node baru.
Jika cursor.getKiri( ) == null, maka cursor = cursor.getKiri( ).
4. Lakukan nomor 3 hingga semua karakter ditempatkan pada pohon biner.
Langkah 4 : membuat pohon biner dari data yang telah diurutkan.
Gambar 3.4 Pembentukan pohon Huffman modifikasi 1. Pada awalnya hanya akar dan data belum masuk.
2. Kemudian masuk karakter A, karena posisinya di awal (ganjil) dan data belum ada maka langsung membuat node A di sebelah kanan akar.
3. Kemudian masuk karakter E, karena posisinya kedua (genap) dan data belum ada maka langsung membuat node E di sebelah kiri akar.
4. Masuk karakter B yang berada pada urutan ketiga (ganjil), tetapi sudah ada data A di sebelah kanan maka cursor turun 1 langkah dan membuat node B di bawah node A.
6. Karakter terakhir adalah D dengan posisi kelima (ganjil). Karakter tersebut menempati di sebelah kanan akar, tetapi sudah ada data A dan B maka currsor turun 2 langkah dan membuat node D.
3.5 Desain User Interface
Tampilan atau user inteface merupakan komponen yang penting dalam sebuah aplikasi atau program, oleh karena itu untuk mempermudah penggunaan aplikasi kompresi ini penulis membuat sebuah rancangan untuk user interface. Tampilan aplikasi ini dibuat menggunakan kelas form dalam Java. Penggunaan kelas JTabedPane untuk tampilan berguna mempersingkat dan mengurangi banyaknya form yang digunakan. Untuk lebih memperjelasnya, berikut rancangan yang akan dibuat :
Gambar 3.6 Interface decoding
Secara garis besar, tampilan untuk encoding dan decoding hampir sama. Kedua tampilan mempunyai jumlah tombol dan susunan panel yang sama. Untuk panel detail pada encoding, akan saya tampilkan ukuran asli dan ukuran file setelah dikompresi beserta compression ratio. Selain itu pada tampilan encoding juga ditambahkan panel untuk memilih algoritma yang akan digunakan. Pada panel detail untuk decoding akan ditampilkan ukuran setelah di decoding beserta metode atau algoritma yang digunakan.
3.6 Spesifikasi Software dan Hardware
Spesifikasi perangkat keras dan perangkat lunak yang digunakan untuk proses implementasi adalah sebagai berikut :
1) Processor : Intel(R) Core(TM) i3 CPU M380 @ 2.53GHz
2) Memory : 2048 MB
4) Operating System :Windows 7 Ultimate
@ 2013 Microsoft Corporation. All Rights Reserved
41
4
BAB IV
IMPLEMENTASI DAN ANALISIS
Pada bab ini akan dibahas tentang implementasi rancangan yang telah dijelaskan pada bab sebelumnya dan hasil analisa dari pengujian program. Implementasi tersebut meliputi ketiga algoritma yang akan dibuat dengan bahasa pemrograman Java. Pada bab sebelumnya telah dijelaskan proses-proses yang akan dilakukan oleh sistem, berikut adalah implementasi dari tiap proses tersebut.
4.1 Proses Encoding
Proses yang pertama adalah proses encoding yaitu proses data teks awal akan diubah menjadi kode-kode biner yang baru. Proses ini menghasilkan keluaran berupa file hasil kompresi.
4.1.1 Implementasi Proses Baca Teks
4.1.1.1 Memilih File
Gambar 4.1 Implementasi proses memilih file encoding
Penulis menggunakan kelas JFileChooser untuk menampilkan kotak dialog browse, serta menggunakan WindowsLookAndFeel yang memberi kesan seperti halnya kotak dialog pada aplikasi umumnya yang berjalan di Windows. Penggunaan kelas FileFilter berfungsi untuk menyaring dan hanya menampilkan file yang telah diatur. Pada program, file yang akan di-filter atau diperbolehkan hanya file berekstensi .TXT atau Text Format. Setelah file dipilih, maka file akan disimpan pada sebuah variabel.
4.1.1.2 Membaca File
Gambar 4.2 Implementasi proses membaca file encoding
dan memasukannya ke dalam kelas. Fungsi tersebut hampir sama seperti fungsi Stream yaitu membaca file, hanya saja pada fungsi ini program akan membaca seluruh karakter yang ada di dalam file masukan sehingga nantinya tidak akan ada karakter yang tidak terbaca.
4.1.2 Implementasi Proses Pembentukan Pohon Biner
Pada proses ini akan ada tiga implementasi dari proses pembentukan pohon biner. Ketiga implementasi tersebut menyesuaikan dengan jumlah algoritma yang akan diuji pada skripsi ini yaitu pembentukan pohon biner algoritma Huffman Statis, Huffman Dinamis dan Huffman Modifikasi.
4.1.2.1 Pohon Biner Huffman Statis
Pada implementasi pembentukan pohon biner Huffman Statis, node yang berisi karakter selalu ditempatkan di lengan sebelah kanan. Implementasi dari ciri khas Huffman Statis, program akan mengecek terlebih dahulu apakah lengan sebelah kanan kosong (null) atau tidak, jika kosong maka karakter membuat node baru. Tetapi jika di sebelah kanan terdapat node atau tidak kosong, maka cursor akan bergerak ke bawah melewati node tersebut untuk mencari hingga posisi lengan sebelah kanan kosong.
4.1.2.2 Pohon Biner Huffman Dinamis
Implementasi pembentukan pohon biner Huffman Dinamis terlihat lebih panjang dan rumit, hal ini dikarenakan pohon biner akan selalu berubah menyesuaikan jumlah frekuensi kemunculan setiap karakter yang masuk. Langkah pertama program akan mengecek lengan sebelah kanan kosong atau tidak, jika kosong maka karakter akan membentuk node baru dengan jumlah diisi 1 (cursor.setJumlah(1)). Jumlah ini merupakan frekuensi kemunculan karakter, hal ini juga yang membedakan Huffman Dinamis dengan metode Huffman yang lain.
4.1.2.3 Pohon Biner Huffman Modifikasi
Gambar 4.5 Implementasi pembentukan pohon Huffman Modifikasi Pembentukan pohon biner Huffman Modifikasi penulis implementasikan mirip seperti pembentukan pohon biner Huffman Statis, hanya saja terdapat perbedaan pada peletakan node setiap karakter. Ciri khas yang saya berikan pada algoritma ini adalah posisi tiap karakter (ganjil dan genap) akan menentukan peletakan pada pohon biner,pada implementasi terdapat variabel boolean yaitu isKanan_Ganjil. Variabel ini mempunyai arti jika posisi karakter adalah ganjil, maka akan ditempatkan pada lengan sebelah kanan.
menjadi false karena pasti posisi karakter berikutnya adalah genap. Jika tidak kosong maka cursor akan menuju ke bawah dan melewati node tersebut.
Kemudian jika sebelah kiri dari cursor kosong dan isKanan_Ganjil adalah false maka akan membentuk node baru serta memberi nilai isKanan_Ganjil menjadi true. Jika tidak kosong akan melewati node tersebut dan cursor menuju ke bawah.
4.1.3 Implementasi Proses Analisis Biner
Gambar 4.6 Source code kelas KodeHuffman.java
4.1.3.1 Implementasi Huffman Statis dan Huffman Modifikasi
Gambar 4.7 Implementasi analisis biner Huffman Statis dan modifikasi method generateKode()
Gambar 4.8 Implementasi analisis biner Huffman Statis method find() Method find() tersebut digunakan untuk algoritma Huffman Statis, di mana jika dilihat hanya mengecek sebelah kanan dari pohon biner. Cara kerja dari proses ini, pertama program akan terus berulang hingga cursor sama dengan null. Program akan mengecek sebelah kanan, apakah data di node sama dengan data yang dicari. Jika sesuai maka kode akan berisi 1 sertacursor akan berubah menjadi null dan looping berhenti.
berulang untuk kembali mengecek dari awal. Tetapi jika sebelah kiri tidak
ada kata “simpul” hal itu berarti tidak ada cabang di bawahnya maka
Gambar 4.9 Implementasi analisis biner Huffman Modifikasi method find()
Method find() tersebut digunakan untuk algoritma Huffman Modifikasi, terlihat lebih panjang karena program harus mengecek lengan sebelah kanan dan kiri. Hal itu dikarenakan pohon biner pada algoritma ini menggunakan semua lengannya untuk menyimpan karakter. Pada program tersebut terdapat variabel boolean kanan yang diberi nilai awal true. Variabel ini berfungsi supaya program mengecek lengan sebelah kanan terlebih dahulu, jika sebelah kanan sudah tidak ada data dan karakter yang dicari belum ditemukan maka variabel kanan menjadi false.
4.1.3.2 Implementasi Huffman Dinamis
Gambar 4.10 Implementasi analisis biner Huffman Dinamis method generateCode()
Gambar 4.11 Implementasi analisis biner Huffman Dinamis method prosesGenerate()
frekuensi jumlahnya menjadi 0. Program akan melewati node jika jumlahnya adalah 0 dan akan berhenti looping jika sudah tidak ada node di sebelah kanan.
4.1.4 Implementasi Proses Encoding
Proses encoding merupakan sebuah proses di mana program akan mengubah setiap karakter pada data teks menjadi sekumpulan kode biner yang baru. Pada implementasi proses ini, akan dibagi menjadi dua bagian yaitu implementasi encoding pada Huffman Modifikasi, implementasi encoding pada Huffman Statis dan Huffman Dinamis.
4.1.4.1 Implementasi Encoding Huffman Statis dan Huffman Dinamis
Gambar 4.12 Implementasi encoding Huffman Statis dan Dinamis
mempermudah dalam proses ini. Dampak yang dihasilkan adalah tidak adanya kode biner yang bersifat ambigu, yang berarti akhiran dari sebuah kode bukan merupakan awalan dari kode yang lain.
Pada method tersebut terdapat dua buah parameter yaitu Arraylist kelas KodeHuffman dan data seluruh isi teks bertipe String. Cara kerja dari method ini adalah membandingkan setiap karakter pada data teks dengan Arraylist KodeHuffman, sehingga hasil dari proses ini berupa data String yang berisi kumpulan kode biner.
4.1.4.2 Implementasi Encoding Huffman Modifikasi
Gambar 4.13 Implementasi encoding Huffman Modifikasi
struktur pohon biner yang berbeda dari algoritma lain. Algoritma ini menggunakan semua lengannya untuk menyimpan node. Dampak dari penggunaan semua lengan pada pohon biner, mengakibatkan adanya sifat ambigu. Oleh karena itu penulis membuat sebuah aturan untuk pembatas antar kode yaitu :
Kanan separator 0 Kiri separator 1
Aturan tersebut merupakan kebalikan dari kode di setiap lengan. Jika data berada di sebelah kanan mempunyai kode 1, maka akan selalu diakhiri dengan 0 sebagai pembatas untuk kode berikutnya. Jika data berada di sebelah kiri mempunyai kode 0, maka akan diakhiri dengan 1 sebagai pembatasnya. Implementasi dari aturan tersebut dapat dilihat dengan penggunaan fungsi endsWithyang merupakan fungsi dari Java untuk mengecek apakah sebuah data diakhiri oleh karakter yang ditentukan.
Cara kerja dari proses encoding algoritma Huffman Modifikasi mirip dengan proses pada algoritma Huffman Statis atau Huffman Dinamis,yaitu dengan mencocokan setiap karakter pada data teks dengan Arraylist Kode Huffman. Perbedaandari ketiga algoritma, pada algoritma Huffman Modifikasi hanya ditambah dengan aturan pembatas.
4.1.5 Implementasi Proses Simpan File Hasil Kompresi
kode biner akan di simpan dalam bentuk bit yang merupakan satuan terkecil dalam file. Proses ini penulis membuat menjadi tiga bagian yaitu proses preprocessing, proses simpan file log dan proses simpan file kompresi. Ketiga proses tersebut diimplementasikan ke dalam tiga method yang semuanya berada di kelas EncoderStream.java.
4.1.5.1 Implementasi Preprocessing
Ketiga proses yang terdapat pada tahap ini, proses inilah yang paling penting dan utama karena kode biner bertipe String tersebut akan dipecah menjadi 7 karakter. Dasar dari pemecahan ini, karena panjang maksimal setiap karakter menurut standar ASCII yaitu 8 = 256 bit atau ditulis dalam biner 10000000. Pemecahan menjadi 7 karakter ini berguna untuk mengantisipasi jika terdapat kode biner yang lebih dari 256 bit. Sebagai contoh :
Kode biner = 10000001001
Pemecahan 8 karakter = 10000001 001 Pemecahan 7 karakter = 1000000 1001
Jika dilakukan pemecahan 8 karakter maka akan membentuk sebuah karakter yang mempunyai nilai biner 257 atau lebih dari standar ASCII. Jika terdapat sebuah karakter yang lebih dari 256 nilai binernya, maka standar harus diubah menjadi Unicode di mana panjang maksimal setiap karakter adalah 6. Standar pembentukan karakter pada penelitian ini menggunakan ASCII.
Pada implementasi program, pemecahan dilakukan dengan ekspresi modulo. Setelah dilakukan pemecahan, program akan mengubah kode biner yang bertipe String menjadi bertipe Integer dengan perintah Integer.parseInt(String code,2). Perintah tersebut mempunyai arti mengubah data menjadi kode biner dan hasilnya bertipe Integer. Angka 2 diambil dari bilangan yang di pangkat dalam penghitungan biner.
secara otomatis mendapatkan karakter yang sesuai dengan nilai biner. Langkah terakhir adalah menyimpan karakter yang telah diperoleh ke dalam Arraylist untuk diproses selanjutnya.
4.1.5.2 Implementasi Simpan File Log
Gambar 4.15 Implementasi proses simpan file log
Proses ini berfungsi untuk menyimpan data huruf dan kode biner yang baru berupa Arraylist dengan tipe kelas KodeHuffman.java. Pada method ini menggunakan stream bertipe objek untuk memudahkan dalam menyimpannya supaya tidak terpisah antara data huruf dan kode biner.
4.1.5.3 Implementasi Simpan File Kompresi
Gambar 4.16 Implementasi proses simpan file kompresi
Proses selanjutnya berfungsi untuk menyimpan file hasil kompresi yang telah diubah kodenya ke dalam sebuah file baru bertipe .NFC yang telah dibahas pada bab sebelumnya. Di dalam method ini menggunakan kelas dari Java yaitu PrintWriter yang merupakan salah satu cara dalam melakukan proses stream. Salah satu keunggulan menggunakan kelas tersebuat adalah kita dapat menentukan tipe dari hasil encoding teks.
Dalam method tersebut menggunakan tipe “windows-1252” yang berarti encoding yang digunakan menggunakan standard ANSI (American National Standards Institute). Alasan saya menggunakan ANSI, karena pada skripsi ini hanya menggunakan 8 bit atau dengan total hanya 256 kombinasi. Jika saya
menggunakan tipe “utf-8” akan terlalu banyak bit yang tidak digunakan karena
dalam tipe tersebut menggunakan 32 bit.
dalam proses decoding. Pemisah tersebut memisahkan nama file log, jenis algoritma yang digunakan dan isi dari kode biner yang baru.
4.2 Proses Decoding
Proses yang kedua adalah proses decoding yaitu proses mengembalikan data biner hasil kompresi menjadi data awal. Terdapat beberapa proses yang ada, antara lain sebagai berikut.
4.2.1 Implementasi Proses Baca Teks File Kompresi
Setelah proses encoding sudah dilakukan semua, maka akan menghasilkan file hasil kompresi bertipe .NFC. Untuk mengubah kode seperti semula maka harus dilakukan tiga tahap yaitu proses baca file kompresi, pengubahan kode dan yang terakhir adalah membuat file bertipe .TXT seperti format teks awal. Pada proses ini terdapat dua proses yaitu memilih file dan membaca file.
4.2.1.1 Memilih File
Sama seperti cara memilih file pada saat akan mengkompresi, saya menggunakan kelas JFileChooser dan menggunakan WindowsLookAndFeel untuk menampilkan kotak dialog seperti aplikasi yang berjalan pada sistem operasi Windows. Perubahan hanya terjadi di FileFilter yang dirubah menjadi .NFC yang berarti hanya menampilkan file berekstensi .NFC.
4.2.1.2 Membaca File
Gambar 4.18 Implementasi proses membaca file decoding
Proses berikutnya adalah membaca file kompresi, penulis menggunakan method dari Java yaitu Files.readAllBytes yang mempunyai keunggulan membaca semua karakter di dalam sebuah file tanpa terkecuali. Setelah semua karakter terbaca maka akan dilakukan pembagian menjadi tiga data yang telah dipisahkan
oleh kata “sb” tadi.
4.2.2 Implementasi Proses Pengubahan Kode (Decoding)
Pada proses pengubahan kode ini, tiga data hasil dari proses sebelumnya akan diolah sesuai kebutuhan masing-masing. Dari tiga data tersebut akan terbentuk dua sub proses yaitu proses decoding header dan proses decoding isi. Selain itu akan dibahas juga proses decoding untuk ketiga algoritma Huffman.
4.2.2.1 Proses Decoding Header
Gambar 4.19 Implementasi proses decoding header
4.2.2.2 Proses Decoding Isi
Gambar 4.20 Implementasi proses decoding isi
Di dalam method terdapat variabel akhir yang berisi sisa dari pembagian. Jika nilai akhir adalah 0, maka data biner tersebut habis di bagi tujuh dan dapat langsung diubah kembali karakter-karakter di dalam data menjadi biner. Jika nilai akhir tidak 0 maka karakter terakhir akan di proses terpisah setelah karakter lain telah diubah menjadi biner. Pemisahan ini dilakukan karena harus menggunakan syntax yang berbeda. Di dalam method tersebut, perintah yang menjadi inti adalah String.format(“%7s”, Integer.toBinaryString(c)).replace(‘ ‘,’0’).
Perintah tersebut berarti mengubah karakter c menjadi Integer biner
dengan jumlah bit sebanyak 7, ditulis dengan perintah “%7s”. Perintah “replace(‘
‘,’0’)” berarti mengganti tempat yang kosong dengan angka 0, karena secara
default setelah proses pengubahan tersebut angka 0 akan menjadi kosong.
4.2.2.3 Proses Decoding Huffman Dinamis dan Huffman Statis
Proses decoding untuk Huffman Statis dan Huffman Dinamis memiliki cara yang sama, karena tidak memakan separator seperti pada Huffman modifikasi yang penulis buat. Dalam membentuk hasil, penulis menggunakan StringBuilder untuk memudahkan dalam menggabungkan setiap String sehingga menjadi sebuah kata.
Langkah pertama adalah membentuk sebuah objek StringBuilder dan kemudian melakukan loop hingga semua data habis. Dalam melakukan loop, data akan dicocokan dengan data header. Jika kode sesuai maka akan menambahkan karakter yang sesuai ke objek StringBuilder hingga membentuk sebuah kata atau kalimat.
4.2.2.4 Proses Decoding Huffman Modifikasi
Pada proses decoding Huffman Modifikasi ini berbeda dengan proses decoding Huffman Dinamis dan Huffman Statis. Proses yang dilakukan harus mengecek bit selanjutnya. Penulis membuat suatu kondisi jika bit selanjutnya tidak sama maka akan mengecek dengan data yang tersimpan pada log. Kondisi ini dibuat penulis karena pada dasarnya algoritma Huffman Modifikasi ini setiap karakter memiliki bit yang sama, satu karakter bisa bernilai 1 atau 0 semua. Dalam menggabungkan setiap karakter, method ini juga menggunakan StringBuilder.
4.2.3 Implementasi Proses Pembentukan File Hasil Decoding