An Application of Handwriting Recognition System for
Recognizing Students ID and Score on the Examination
Paper Using WebCam
Aryuanto1, Yusuf Ismail Nakhoda2 Department of Electrical Engineering
Institut Teknologi Nasional Malang, Jl.Raya Karanglo Km. 2 Malang, I ndonesia Tel. + 62-341-417636
1
[email protected], [email protected]
AbstractThis paper presents an automatic data entry
system which is used to read and recognize the students ID and score on the examination paper automatically. The system uses a W ebcam to capture the image and a numeral handwriting recognition technique to recognize the students I D and score. A simple effective image projection technique is employed to localize the students ID and score from an image, followed by the classsification technique using vector distance and box-method for classifying the numeral chartacters. The experimental results show that the algorithm works properly in finding and extracting students and score from the examination paper. Further, the classification technique shows a good result in classifying numeral handwriting characters.
I ndex Termsautomatic data entry, handwriting
recognition, image projection, vector distance, box-method.
I. INTRODUCTION
Recently, most of educational institutions have implemented the academic information sytem which provides the information of academic matters to the students easily and in short time. One key feature in this system is the application of computer and networking systems to store, process, and produce the data, resuts a paperless system. It requires that the data should be available (or converted) in digital format. Unfortunately, in several cases this requirement creates some burdens for implementation of a fully efficient academic information system. One of such problem is to convert or digitalize
the students ID and score on the examination paper. It is
well known that for engineering programs, most of examination given to students should be answered by handwriting on the paper. In this case, a data entry process is needed to enter the score and the corresponding
students ID into computer that needs extra time and works, also facing the accuration problem due to the human error.
In this research, we propose an automatic data entry system to solve the above problems. The proposed system utilizes the handwriting recognition technique to
recognize the students ID and score written on the
examination paper.
Handwriting recognition techniques have been implemented in several areas such as for automatic data entry of passport [1], to extract and recognize handwritten characters from application forms [2], to recognize handwritten postal codes for automatic sorting of mails [3]. In those applications, the characters are extracted from a whole document automatically, before they are recognized by the recognition system. Since the character extractions play an important process in the handwritten recognition system, they are also investigated intensively by researchers. In [4], they proposed a method by a syntactical structure of the numerical field to extract zip codes, phone numbers and customer codes from handwritten incoming mail documents. A robust connected component based character locating method is proposed in [5] for locating characters in scene image taken from digital camera.
The appplications of character recognition described above require the high performance of the accuracy and speed. The problems of handwritten character recognition are more complex than the machine printed characters, due to the different writing styles. Many approaches have been proposed to recognize the handwritten characters [6]. In [6], they compared several popular classification techniques for handwritten character recognition, i.e. the k-nearest neighbor classifier, neural classifiers, learning vector quantization classifier, and support vector classifiers. They concluded that all the classifiers give high recognition accuracies. Furthermore, they noted that the feature extraction is primarily important to the performance of character recognition. A n innovative approach for feature extration called box-method is proposed by [7] to deal with the variability of writing styles. In [7], both fuzzy logic and neural network are used for character recognition.
The approaches for characters extraction described above are application dependent. It is difficult to find a general method to extract characters for all scenarios. In
our research, we propose a method to extract students ID
localize and extract the students ID and score. The
simple and effective vertical and horizontal projections are employed for extraction process.
To recognize the numeral handwriting characters, we propose to modify the handwritten recognition method used in [7]. The method [7] uses the skeleton of a character to extract the feature. This skeleton is obtained by a thinning algorithm which is rather complicated. In our research, to simplify the process we do not used the skeleten of a character, but uses a blob (binary image) of the character instead.
The paper is organized as below. Section 2 presents the proposed handwriting recognition system. The characters extraction is described in section 3. In section 4, the characters recognition is described. The experimental results and discussions are covered in section 5. Finally, the conclusion is presented in section 6.
II. PROPOSED HANDWRITING RECOGNITION SYSTEM
The proposed system is depicted in Fig. 1. A Webcam is used to capture the image of examination papers where
students ID and score to be recognized. The Webcam is
used instead of the scanner, because of the low cost, fast reading, and easy installation. However, those benefits should be paid with the following problems: the captured image is affected by the lighting changes, the appearance of characters on the paper may degrade due to the improper position of the paper, eg. not in flat position, folded, etc. Since our objective is to find and recognize
the numeral characters, i.e. the students ID and score of
the examination, not the whole handwriting texts, the problems become less difficult.
Figure 1. Hardware configuration of the proposed system.
In the research, the students ID and score to be
recognized are captured from the examination paper used in National Institute of Technology (ITN), Malang, with the specific format as depicted in Fig. 2. A box contains
the fields of name, students ID, course, etc., is printed on
the top-right corner of the examination paper. There is no field for score on that box, but usually examiner/lecturer writes the score on the left side of that box as depicted in Fig. 2.
Figure 2. Example of examination paper.
Figure 3. Block diagram of students ID and score recognition system.
The process for recognizing students ID and score is
depicted in Fig. 3. The recognition process is divided into two stages: character extraction and character recognition. First step in the character extraction stage is the
localization of students ID and score that finds the locations of students ID and score in the image. The
Score Student's ID
Examination information fields
Students ID and
Score localization Captured image
Character segmentation
Character normalization
Feature extraction
Character classification
Character extraction
locations are defined by the bounding boxes of the digits
of students ID (seven digits) and score (one to three
digits). Then the character segmentation step will separate
the individual digit of students ID and score. After each character is extracted, they will be classified in the recognition stage.
The extracted characters obtained in previous stage are scale varying and sometimes contain noise. Thus, the character normalization is required in the recognition stage. It resizes the characters in a standard size, and eliminates the outlier noise. After character is normalized, the feacture extraction using the box-method [7] is employed to extract the f eature of each character. Finally, the character classification process is used to classify the character (represented by its feature) into the reference numeral characters, i.e. 0 to 9. The details processes will be described in the following sections.
III. CHARACTER EX TRA CTION
A. Students ID and Score Localization
Since students ID is written in the provided box of the
examination information fields, we first find the box in the image. The box is defined by the left border (LB), the right border (RB), the top border (TB), and bottom border (BB). RB is assigned as the right border of the paper, TB is assigned as the top border of the paper. While LB and BB are searched by analyzing the image projections as described in the following:
1. Convert the color image (captured image) into grayscale image.
2. Find the Sobel gradient image in the horizontal direction.
3. Compute the horizontal projection of the gradient image, and identify the column of the maximum peak as the left border of the box (LB).
4. Define the left_image as the sub-image of the gradient image bounded with a short distance in the left and right of LB.
5. Compute the vertical projection of the
left_image, and perform a scanning from the top to the bottom to find the first transition from high peaks to zero indicating the bottom border of the box (BB).
After LB,RB,TB and BB are determined, the bounding
box of students ID is defined by geometric analysis as
follows:
1. Define the box_image as the gradient image bounded by LB, RB, TB and BB.
2. Compute the vertical projection of the
box_image, and perform a scanning from the top to the bottom to find the first peak. Identify the corresponding row as line_up. Then perform a scanning from the bottom to the top to find the first peak, and identify the corresponding row as
line_down.
3. The left (L), right (R), top (T) and bottom (B)
borders of the students ID are obtained using the
following formulas:
L=LB+33x(line_up-line_down)/40 (1)
R=LB+83x(line_up-line_down)/40 (2)
T=line_down+26x(line_up-line_down)/40 (3)
D=line_down+20x(line_up-line_down)/40 (4)
To localize the score, we search the area on the left side of the box of examination information fields. It is assumed that the area only contains the score. Therefore, the bounding box of the score could be determined by vertical and horizontal projection easily.
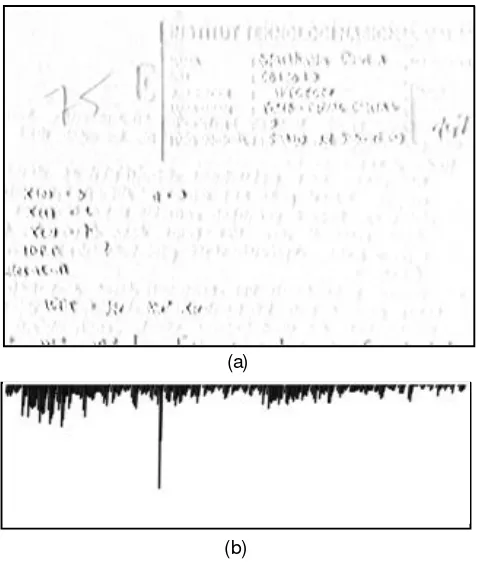
Figure 4. (a) The gradient image; (b) The horizontal projection of the gradient image.
Fig. 4(a) depitcs the gradient image obtained by Sobel operator in the horizontal direction. Since the examination paper uses the paper with horizontal lines printed on it, we could eliminate those horizontal lines by perform the gradient image only in the horizontal direction. The horizontal projection of the gradient image in Fig. 4(a) is depicted in Fig. 4(b). The peak in the figure corresponds with the left border of the box (LB).
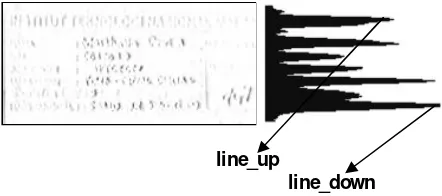
Fig. 5 depicts the box_image and the corresponding vertical projection. From the figure, it is clear that the
line_up corresponds with the first field of the examination information fields (see Fig. 2 for the details). The line_down corresponds with the last field. Hence, we could utilize the two parameters as the reference for
locating the students ID as defined by Eqs. (1)-(4). (a)
Figure 5. The box_image and the corresponding vertical projection.
B. Character Segmentation
The bounding box obtained in previous section defines
the boundarie of all seven digits of the students ID. To
classify each digit or character, we should separate each digit individually. We employ a horizontal projection technique to separate them. Here, the projection is
The horizontal projection method peforms well when the gap between two adjacent digits is clear enough. Thus create a valley in the image projection. However, in some cases two digits often touch each other, and the valley is not exist. It results a wrong segmentation. To overcome such problem, we utilize the ratio of height and width of the character to verify the segmented results.
IV. CHARACTER RECOGNITON
A. Character Normalization
The examination information fields printed in the examination paper provides a specific field with a certain
height for writing the students ID. However due to the
nature of handwriting, the size of characters written by the different students will be different. Furthermore,
without the provided field, the size of scores characters
written by the examiners will be totally different from one examiner to others. Theref ore, the size normalization should be performed before classification.
In the research, the normalized size of the character is
x is the x-coordinate of the normalized image,
y is the y-coordinate of the normalized image,
x is the x-coordinate of the original image,
y is the y-coordinate of the original image,
p is the the height of the normalized image,
q is the width of the normalized image,
m is the height of the original image,
n is is the width of the original image.
When the normalized image is bigger than the original image, there will be pixels do not have corresponding pixels in the original image. In the case, we use the nearest neighbor interpolation to interpolate those pixels.
B. Feature Extraction and Classification
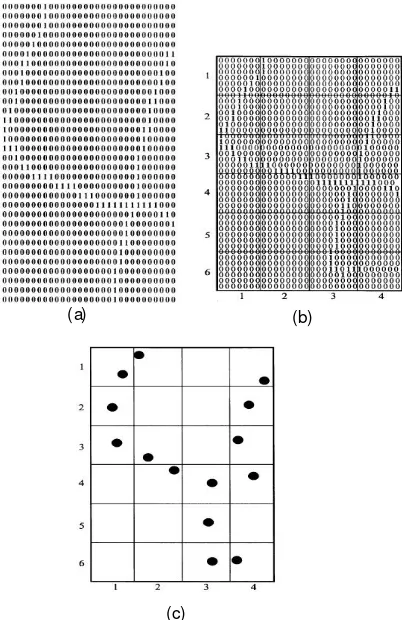
Feature extraction used in this research is the vector distance and box-method approached proposed by [7], [8]. The method divides a character image into 24 boxes of size 6 x 4 as depicted in Fig. 6(b), where a binary
character of number 4 shown in Fig. 6(a) is
superimposed on the partitioned image. By taking the bottom left corner as the origin (0,0), the vector disctance for kth pixel in bth box at location (i,j) is calcucalted as
dividing the sum of distance of all 1 pixels in a box with
the total number of pixels on the box, yields
b
depicts the extracted features for character 4, where the dot points denote the normalized vector distance for each box. directly. Since the calculation of vector distance expressed by Eq. (7) is normalized by total pixels in the box, it suggests that the non-thinned image might be used too. Further, the non-thinned image is less sensitive to the
variation of characters style or shape compared to the thinned image.
After features of the characters are extracted, the classification process is performed by calculating the distance of feature vectors between target image and the references. The distance is calculated using the following formula: the target image, and bris the normalized vector distance for bth box of the reference image. Given a target image, we calculate the distance for all reference images (digit
0 to 9), and classify the target image to the reference digit with the minimum distance.
line_up
Figure 6. (a) A binary image of digit 4; (b) Digit 4 enclosed in 6 x 4 boxes; (c) Pattern of digit 4 plotted using extracted
features[7].
V. EXPERIMENTAL RESULTS AND DISCUSSIONS
To verify our proposed algorithm, we conducted the experiments using the examination paper images captured by 2.0 Megapixels Webcam. The algorithm was implemented using C++ and the OpenCV library.
We evaluated the characters extraction and classification stages separately. Twenty examination papers captured by Webcam are used for evaluating the character extraction process. Table 1 shows the results. From the table, we could see that the proposed algorithm
is able to find the location of the students ID and score efficiently. However, the extraction rate of the students
ID is low. From the observation, it is caused by the resolution of the Webcam which is relative low, hence the quality of captured image is poor, i.e. the characters of
students ID are not clear enough. The score extraction
rate is higher than the students ID because the character size of score is usually larger, more than three times of
the students ID size.
Fig. 7 shows the typical extraction results. The box shown on the top right corner in Fig. 7(a) is the detected box of the examination information fields. The box shown on the middle in Fig. 7(b) is the bounding box of
the students ID. The digit extraction of the students ID
and score are shown in Fig. 7(c) and 7(d) respectively.
Table 1. Results of the characters extraction
Tested items Number of successed
images %
1. Box localization 19 95%
2. Students ID
localization
18 90%
3. Students ID
extraction
9 45%
4. Score extraction 14 70%
Figure 7. (a) Detected box of the examination information
fields; (b) The bounding box of students ID;(c) Extracted students ID; (d) Extracted score.
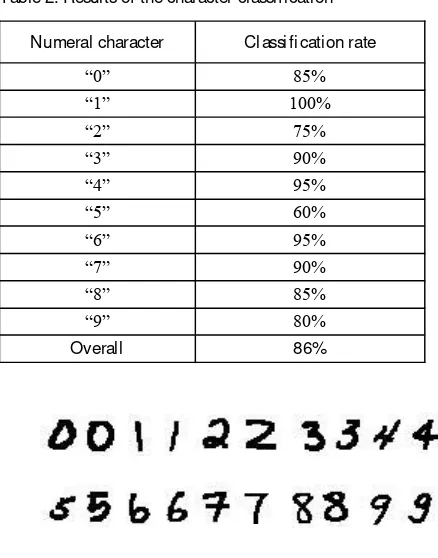
The character classificati on algorithm was tested on two hundred images of the numeral characters collected from Internet, contain twenty images for each numeral character. The classification rate is shown in Table 2. It could be clearly understood that the classification rate of
(a) (b)
(c)
(a)
(b)
(c)
numeral 1 is very high, because there are no many variations in the writing of number 1. Fig. 8 depitcs the
samples of tested numeral character images.
Table 2. Results of the character classification
Numeral character Classification rate
0 85%
1 100%
2 75%
3 90%
4 95%
5 60%
6 95%
7 90%
8 85%
9 80%
Overall 86%
Figure 8. Some of the tested numeral character images.
VI. CONCLUSION
This paper presents the application of handwriting
recognition technique to recognize students ID and score
written on the examination paper. The proposed technique using image projection for locating those characters and vectore distance calculated using box-method, shows a good results on a limited test images.
In future, we will investigate with the complex and a huge numbers of test images. Furthermore, the technique will be extended to deal with the general case of the examination paper.
REFERENCES
[1] M.M. Thin and M.M. Sein, Implementation Automatic Data Entry
of Passport With Handwritten Recognition System, Proceedings of 28th Asi an Conference on Remote Sensing, Kuala Lumpur,
Malaysia, 2007.
[2] E. Kavallieratos, N. Antoniades, N. Fakotakis and G. Kookinakis,
Extraction and Recognition of Handwritten Alphanumeric
Characters From Application Forms, Proceedi ngs of 13th
International Conference on Digital Signal Processing, Santorini, Greece, 1997.
[3] A.S.M .M. Morshed, M d. S. Islam, M d. A. Faisal, M d. A. Sattar,
and M. Ishizuka, Automatic Sorting of Mails by Recognizing
Handwritten Postal Codes Using Neural Network Architectures, Proceedi ngs of International Conference on Computer and Information Technology, Dhaka, Banglasdesh, 2007.
[4] G. Koch, L. Heutte, and T. Paquet, Numerical Field Extraction in
Hanwritten Incoming Mail Documets, Proceedings of the 3rd
International Workshop on Pattern Recognition in Information
Systems, PRIS2003, pp. 167-172.
[5] K. Wang and J.A. Kangas, Character location in scene images
from digital camera, Pattern Recognition, Vol. 36, pp. 2287-2299.
[6] C. Liu, K. Nakashima,H. Sako, and H. Fujisawa, Handwritten digit recognition: benchmarking of state-of-the-art techniques, Pattern Recognition, Vol. 36, pp. 2271-2285.
[7] M . Hanmandlu, K.R.M . M ohan, S. Chakraborty, S. Goyal, and
D.R. Choudhury, Unconstrained handwritten character
recognition based on fuzzy logic, Pattern Recognition, Vol. 36, pp. 603-623.
[8] V.K. Madasu, B.C. Lovell, M. Hanmandlu, Hand Printed
Character Recognition Using Neural Networks, Proceedings of
International Conference on Cogniti on and Recognition, M ysore, India.
[9] N.J. Naccache, R. Shinghal, SPTA: a proposed algorithm for
thinning binary patterns, IEEE Trans. Systems Man Cybernet. Vol