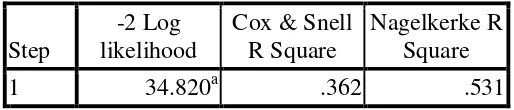PENERAPAN MODEL REGRESI LOGISTIK TERHADAP KEPEMILIKAN HP ANDROID PADA MAHASISWA FAKULTAS MATEMATIKA
DAN ILMU PENGETAHUAN ALAM USU
SKRIPSI
MARIA ULFA 120823004
DEPARTEMEN MATEMATIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM UNIVERSITAS SUMATERA UTARA
PENERAPAN MODEL REGRESI LOGISTIK TERHADAP KEPEMILIKAN HP ANDROID PADA MAHASISWA FAKULTAS MATEMATIKA
DAN ILMU PENGETAHUAN ALAM USU
SKRIPSI
Diajukan untuk melengkapi tugas dan memenuhi syarat mencapai gelar Sarjana Sains
MARIA ULFA 120823004
DEPARTEMEN MATEMATIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM UNIVERSITAS SUMATERA UTARA
PERSETUJUAN
Judul : PenerapanModel Regresi Logistik Terhadap Kepemilikan Hp Android Pada Mahasiswa Fakultas Matematika dan Ilmu Pengetahuan Alam USU
Kategori : Skripsi
Nama : Maria Ulfa
Nomor induk mahasiswa : 120823004
Program studi : Sarjana (S1) Matematika
Departemen : Matematika
Fakultas : Matematika Dan Ilmu Pengetahuan Alam Universitas Sumatera Utara
Disetujui di
Medan, Oktober2014
Komisi Pembimbing :
Pembimbing 2, Pembimbing 1,
Dr. Pasukat Sembiring, M.Si Dr. Mardiningsih, M.Si NIP. 19531113 198503 1 002 NIP.19630405 198811 2 001
Disetujui oleh
Departemen Matematika FMIPA USU Ketua,
PERNYATAAN
PENERAPAN MODEL REGRESI LOGISTIK TERHADAP KEPEMILIKAN HP ANDROID PADA MAHASISWA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM USU
SKRIPSI
Saya mengakui bahwa skripsi ini adalah hasil kerja saya sendiri.Kecuali beberapa
kutipan dan ringkasan yang masing-masing disebutkan sumbernya.
Medan, Oktober2014
PENGHARGAAN
Assalamu’alaikum Warahmatullahi Wabarakatuh
Puji dan syukur Penulis panjatkan kepada Allah SWT atas segala berkah, rahmat dan
karunia yang dilimpahkan-Nya sehingga Penulis dapat menyelesaikan penyusunan
skripsi ini dengan judulPenerapan Model Regresi Logistik Terhadap Kepemilikan Hp
Android Pada Mahasiswa Fakultas Matematika dan Ilmu Pengetahuan Alam USU.
Terimakasih Penulis sampaikan kepada kepada IbuDr. Mardiningsih,M.Si
selaku pembimbing 1 dan BapakDr. Pasukat Sembiring, M.Si pembimbing 2 yang
telah meluangkan waktunya selama penyusunan skripsi ini. Terima kasih kepada Prof.
Dr. Tulus, M. Si, Dekan dan Pembantu Dekan FMIPA USU, seluruh staff dan Dosen
Matematika FMIPA USU, pegawai FMIPA USU serta kepada Ayahanda tercinta Seni
Wira Arzaini (Alm) dan Ibunda tercinta Siti Ramlah Hsb serta rekan-rekan kuliah
yang selama ini memberikan bantuan dan dorongan yang diperlukan. Semoga Allah
SWT membalasnya.
Medan, Oktober2014
Penulis,
ABSTRAK
Peningkatan jumlah penduduk yang disertai dengan pertumbuhan ekonomi masyarakat dan perkembangan Ilmu Pengetahuan dan Teknologi (IPTEK) yang sangat maju pesat, telah mendorong tingkat kepemilikan gadget canggih khususnya Hp atau telepon seluler yang dari tahun ke tahun semakin meningkat di kalangan masyarakat. Dalam penelitian ini penerapan Model Regresi Logistik digunakan untuk mengidentifikasi faktor-faktor yang mempengaruhi kepemilikan Hp Android pada mahasiswa Fakultas MIPA USU. Data tersebut dianalisis dengan menggunakan Metode Regresi Logistik karena variabel respon dari data tersebut berupa data kategori. Diperoleh Model Regresi Logistik yang terbentuk adalah sebagai berikut:
[ ]
Persamaan menunjukkan bahwa nilai intersep = -11,295. Artinya: [
] = -11,295 pada saat semua variabel berharga 0, yaitu pada saat variabel X1, X3, X4, dan
X5 tidak berpengaruh terhadap besarnya peluang kepemilikan Hp Android (Y).
Diperoleh besaran [
] = -11,295 atau besarnya probabilitas
) 295 , 11 (
) 295 , 11 (
1 )
(
e e x
p i = 0,00001.
ABSTRACT
The increase of population coupled with economic growth of society and the development of Science and Technology highly advanced rapidly, have pushed the ownership rate gadgets especially Hp or cell phone that from year to year increasing among society. In this researches, Logistic Regression Model is used to identify the factors that influence android phone ownership in student faculty of mathematics and natural science. The data were analyzed using Logistic Regression method for the variable response of data in the form of categorical data. Thus, Logistic Regression models were formed are as follows:
[
]
Equation shows that the intercept = -11,295. Means: [
] = -11,295, when all the variables is 0, is at the moment the X1, X3, X4, and X5 variables no effect on the
android phone ownership opportunities. Magnitude obtained [
] = -11,295or
the magnitude of the probability
.
DAFTAR ISI
Halaman
Persetujuan ii
Pernyataan iii
Penghargaan iv
Abstrak v
Abstract vi
Daftar isi vii
Daftar tabel ix
BAB 1 PENDAHULUAN
1.1. Latar Belakang 1
1.2. Rumusan Masalah 2
1.3. Batasan Masalah 3
1.4. Tujuan Penelitian 3
1.5. Manfaat Penelitian 3
1.6. Tinjauan Pustaka 4
1.7. Metodologi Penelitian 7
BAB 2 LANDASAN TEORI
2.1. Gambaran Fakultas FMIPA USU 9
2.2 Pengertian Android 10
2.3 Defenisi Operasional Variabel Penelitian 10
2.4 Data 11
2.4.1 Data Menurut Sifatnya 11
2.4.2 Skala Pengukuran Data 11
2.4.3 Skala Untuk Instrumen 13
2.4.4 Mengubah Data Ordinal ke Data Interval dengan 14 Metode Suksesif Interval (MSI)
2.5 Tahapan Penelitian 15
2.6 Analisis Data 16
2.4.1 Uji Validitas 16
2.4.2 Uji Reliabilitas 16
2.5. Regresi Logistik 17
2.5.1 Model Regresi Logistik 17
2.5.2 Uji Signifikansi Parameter 18
2.5.3 Uji Kecocokan Model 20
2.5.4 Odds Rasio 21
BAB 3 PEMBAHASAN
3.1. Pengolahan Data 23
3.1.1. Tabulasi Hasil Kuesioner 23
3.2. Transformasi Data Ordinal Menjadi Data Interval 29
3.3. Pengolahan Data 32
3.4. Analisis Data 32
3.4.1 Tipe Data 32
3.5. Menjelaskan Hasil Analisis Dengan Menggunakan SPSS 33
3.5.1 Model Regresi Logistik 33
3.5.2 Uji Signifikansi Parameter Model Awal 35
3.5.3 Uji Kecocokan Model 38
3.6. Interpretasi Model Menggunakan Odds Rasio 39 3.7. Mencari Persamaan Regresi Logistik Tanpa SPSS 41
BAB IV KESIMPULAN DAN SARAN
4.1. Kesimpulan 46
4.2. Saran 47
DAFTAR TABEL
Halaman
1. Tabel 3.1 Uji Validitas Harga 24
2. Tabel 3.2 Uji Validitas Fitur 25
3. Tabel 3.3 Uji Validitas Merek 25
4. Tabel 3.4 Uji Validitas Desain 26
5. Tabel 3.5 Uji Validitas Iklan 26
6. Tabel 3.6 Uji Reliabilitas Harga 27
7. Tabel 3.7 Uji Reliabilitas Fitur 27
8. Tabel 3.8 Uji Reliabilitas Desain 28
9. Tabel 3.9 Uji Reliabilitas Merek 28
10.Tabel 3.10 Uji Reliabilitas Iklan 29
11.Tabel 3.11 Skor Jawaban Ordinal 30
12.Tabel 3.12 Rincian Hasil Perhitungan Secara Manual 32
13.Tabel 3.13 Nilai Koefisien Variabel 33
14. Tabel 3.14 Model Summary 35
15. Tabel 3.15 Model Klasifikasi 36
16. Tabel 3.16 Nilai Koefisien Variabel 37
17. Tabel 3.17 Tabel Kontingensi Untuk Uji Hoshmer-Lemeshow 39
18. Tabel 3.18 Uji Hoshmer-Lemeshow 39
19. Tabel 3.19 Kontribusi Variabel X Terhadap Variabel Y 40
20. Tabel 3.20 Data Variabel Y dan X 41
21. Tabel 3.21 Tabel Kontingensi 42
22. Tabel 3.22 Nilai Peluang 42
23. Tabel 3.23 Nilai Y 42
ABSTRAK
Peningkatan jumlah penduduk yang disertai dengan pertumbuhan ekonomi masyarakat dan perkembangan Ilmu Pengetahuan dan Teknologi (IPTEK) yang sangat maju pesat, telah mendorong tingkat kepemilikan gadget canggih khususnya Hp atau telepon seluler yang dari tahun ke tahun semakin meningkat di kalangan masyarakat. Dalam penelitian ini penerapan Model Regresi Logistik digunakan untuk mengidentifikasi faktor-faktor yang mempengaruhi kepemilikan Hp Android pada mahasiswa Fakultas MIPA USU. Data tersebut dianalisis dengan menggunakan Metode Regresi Logistik karena variabel respon dari data tersebut berupa data kategori. Diperoleh Model Regresi Logistik yang terbentuk adalah sebagai berikut:
[ ]
Persamaan menunjukkan bahwa nilai intersep = -11,295. Artinya: [
] = -11,295 pada saat semua variabel berharga 0, yaitu pada saat variabel X1, X3, X4, dan
X5 tidak berpengaruh terhadap besarnya peluang kepemilikan Hp Android (Y).
Diperoleh besaran [
] = -11,295 atau besarnya probabilitas
) 295 , 11 (
) 295 , 11 (
1 )
(
e e x
p i = 0,00001.
ABSTRACT
The increase of population coupled with economic growth of society and the development of Science and Technology highly advanced rapidly, have pushed the ownership rate gadgets especially Hp or cell phone that from year to year increasing among society. In this researches, Logistic Regression Model is used to identify the factors that influence android phone ownership in student faculty of mathematics and natural science. The data were analyzed using Logistic Regression method for the variable response of data in the form of categorical data. Thus, Logistic Regression models were formed are as follows:
[
]
Equation shows that the intercept = -11,295. Means: [
] = -11,295, when all the variables is 0, is at the moment the X1, X3, X4, and X5 variables no effect on the
android phone ownership opportunities. Magnitude obtained [
] = -11,295or
the magnitude of the probability
.
BAB I
PENDAHULUAN
1.1 Latar Belakang
Menurut sebuah riset yang dilakukan oleh GfK Asia, penjualan smartphone di wilayah Asia Tenggara mengalami kenaikan hingga 61%. Lebih jauh lagi, para konsumen dari
Singapura, Malaysia, Vietnam, Thailand, Indonesia, Kamboja dan Filipina telah
menghabiskan lebih dari US 10.8 miliar atau 127.98 triliun rupiah untuk membeli 41.5
juta smartphone. Dari deretan negara-negara tersebut Indonesia berada di urutan nomor satu sebagai negara yang paling komsumtif dalam pembelian perangkat mobile
(Republica.co.id).
Peningkatan jumlah penduduk yang disertai dengan pertumbuhan ekonomi
masyarakat dan perkembangan Ilmu Pengetahuan dan Teknologi (IPTEK) yang sangat
maju pesat telah mendorong tingkat kepemilikan gadget canggih khususnya Hp atau telepon seluler yang dari tahun ke tahun semakin meningkat di kalangan masyarakat.
Saat ini yang menjadi trend bagi kebanyakan masyarakat dari berbagai kalangan
adalah Hp Android. Hampir setiap orang memiliki Hp Android, tidak terkecuali bagi
mahasiswa di Fakultas Matematika dan Ilmu Pengetahuan Alam USU.
Android adalah sistem operasi berbasis linux yang dirancnang untuk perangkat
seluler layar sentuh seperti telepon pintar dan komputer tablet. Saat ini Hp Android
menjadi salah satu kebutuhan penting tak terkecuali bagi mahasiswa. Karena akan
mempermudah untuk memenuhi kebutuhan dalam kegiatan perkuliahan. Fungsinya
yang menyerupai komputer mini, namun pengguna tidak lagi direpotkan membawa
mouse ataupun keyboard. Mahasiswa dapat dengan mudah mengakses internet untuk keperluan belajar, seperti untuk mencari referensi buku, tugas kuliah dan keperluan
Analisis regresi dapat digunakan untuk mengetahui pengaruh dan mengukur
hubungan antara variabel dependen dan variabel independen. Pada penelitian ini,
variabel dependen model regresinya yaitu kepemilikan Hp Android pada mahasiswa
FMIPA USU. Sedangkan untuk variabel independenrnya terdiri dari harga, fitur,
merek, desain, dan iklan. Model regresi yang diterapkan pada saat variabel
dependennya bersifat kualitatif adalah model regresi logistik. Model regresi logistik
merupakan salah satu pendekatan model matematis yang digunakan untuk
menganalisis hubungan satu atau beberapa variabel dependen kategori (Hastono, S.P,
2008).
Model regresi logistik yang variabel dependen kategorinya mempunyai dua
nilai variasi disebut model regresi logistik biner. Sedangkan yang memiliki lebih dari
dua variasi disebut model regresi logistik polykotomous. Dalam penelitian ini akan dilakukan uji kecocokan pada model regresi logistik. Jika terdapat kurang cocoknya
model maka akan memberikan kesimpulan yang salah terhadap hasil data penelitian.
Uji kecocokan diperlukan untuk mengetahui apakah model statistik sudah layak
digunakan. Terdapat beberapa uji kecocokan untuk model regresi logistik, salah
satunya adalah uji Hosmer dan Lemeshow.
Berdasarkan uraian di atas penulis tertarik untuk mengetahui “Penerapan
Model Regresi Logistik Terhadap Kepemilikan Hp Android Pada Mahasiswa Fakultas Matematika dan Ilmu Pengetahuan Alam USU”
1.2 Rumusan Masalah
Memiliki Hp Android bagi mahasiswa saat ini dirasa penting, karena Hp Android
dapat membantu dan mempermudah mahasiswa dalam mengakses internet guna
mememenuhi kebutuhan dalam proses belajar. Masalah kepemilikan Hp Android
adalah masalah yang variabel dependen kategorinya bersifat kualitatif dan mempunyai
dua nilai variasi. Regresi logistik merupakan model regresi yang digunakan untuk
menganalisis hubungan satu atau beberapa variabel independen dengan sebuah
logistik adalah metode yang sesuai untuk digunakan dalam penelitian kepemilikan Hp
ini.
1.3 Batasan Masalah
Melihat luasnya cakupan permasalahan yang berhubungan dengan penelitian ini, maka
batasan masalah dalam penelitian ini adalah:
1. Variabel independen X yang digunakan dalam penelitian ini adalah harga (X1),
merek (X2), fitur (X3), desain (X4) dan iklan (X5).
2. Responden pada penelitian ini adalah mahasiswa FMIPA USU.
3. Metode analisis yang digunakan untuk menentukan model hubungan antara
variabel independen X dan variabel dependen Y dalam penelitian ini adalah
dengan pendekatan statistik, yaitu dengan regresi logistik.
1.4 Tujuan Penelitian
Menerapkan model regresi logistik terhadap kepemilikan Hp Android pada mahasiswa
FMIPA USU.
1.5 Manfaat Penelitian
Hasil penelitian ini diharapkan dapat memberikan manfaat sebagai berikut:
1. Sebagai tambahan informasi pada produsen dan memberikan gambaran
tentang faktor-faktor yang berpengaruh terhadap kepemilikan Hp Android.
2. Mengetahui penerapan model regresi logistik terhadap kepemilikan Hp
Android pada mahasiswa FMIPA USU.
3. Memberikan manfaat bagi mahasiswa dalam rangka menambah ilmu
pengetahuan dan wawasan tentang Analisis Regresi Logistik serta dapat
1.6 Tinjauan Pustaka
Pengertian teknologi sebenarnya dari bahasa prancis yaitu “la teqnique” yang berarti
semua proses yang dilaksanakan dalam upaya untuk mewujudkan sesuatu secara
rasional (http:/www.aingindra.com/pengertian-teknologi). Android adalah sistem
operasi berbasis linux yang dirancang untuk perangkat seluler layar sentuh seperti
telepon pintar dan komputer tablet.
Analisis regresi logistik adalah salah satu pendekatan model matematis yang
digunakan untuk menganalisis hubungan satu atau beberapa variabel independen
dengan sebuah variabel dependen kategori yang bersifat dikotom/binary. Variabel
kategori yang dikotomi adalah variabel yang mempunyai dua nilai variasi, misalnya
sukses atau tidak sukses. (S.P. Hastono, 2008 :167)
Regresi logistik berbeda dengan regresi linier pada penggunaan jenis variabel
dependennya. Pada regresi linier menggunakan variabel dependen numerik sedangkan
pada regresi logistik menggunakan variabel dependen kategorik yang bersifat
dikotomi. (Yasril, 2008)
Banyak topik penelitian yang menuntut variabel dependen berupa pilihan
nominal seperti terjadi atau tidak terjadi, memilih atau tidak memilih, sukses atau
gagal. Regresi dengan variabel dependen bernilai nominal tersebut dapat dilakukan
dengan menggunakan variabel dependen berupa nilai 1 atau 0. (Suharjo, 2008)
Regresi logistik merupakan model regresi yang digunakan bila variabel
responnya bersifat kualitatif (Hosmer dan Lemeshow, 1989) model regresi logistik
sederhana yaitu model regresi logistik untuk satu variabel Independen X dengan
variabel dependen Y yang bersifat dikotomi. Nilai variabel Y = 1 menyatakan adanya
suatu karakteristik dan Y = 0 menyatakan tidak adanya suatu karakteristik.
Adapun bentuk umum model regresi logistik adalah:
∑
Keterangan:
= peluang sukses = intersep
parameter-parameter regresi
variabel ke- dari variabel independen bilangan natural (2,7183)
Model ini merupakan model peluang suatu kejadian yang dipengaruhi oleh
faktor–faktor . Persamaan ini bersifat nonlinier dalam parameter. Tidak seperti pada regresi linier dengan metode Ordinary Least Squares atau kuadrat terkecil, regresi logistik tidak mengasumsikan hubungan linier antara variabel
dependen dengan variabel independen. Akan tetapi, variabel independen memiliki
hubungan linear dengan logit variabel dependen. Selanjutnya, untuk menjadikan
model tersebut linier proses yang dinamakan logit transformation perlu dilakukan
seperti berikut ini:
| | ∑ (1.2)
Keterangan:
= peluang sukses = intersep
parameter-parameter regresi
variabel ke- dari variabel independen
Sebelum membentuk model regresi logistik terlebih dahulu dilakukan uji
signifikansi parameter. Uji yang pertama dilakukan adalah pengujian peranan
parameter di dalam model secara keseluruhan atau uji signifikansi secara overall. Menurut Hosmer-Lemeshow, (1989) suatu statistik uji rasio likelihood G adalah fungsi dari dan yang berdistribusi (Chi-square) dengan derajat bebas yang didefenisikan sebagai berikut:
Keterangan:
nilai maksimum fungsi kemungkinan untuk model di bawah H0
nilai maksimum fungsi kemungkinan untuk model di bawah H1
= nilai maksimum fungsi log kemungkinan untuk model di bawah H0
= nilai maksimum fungsi log kemungkinan untuk model di bawah H1
Uji Wald Chi-square digunakan untuk menguji signifikansi parameter model secara terpisah. Didefenisikan dengan:
[ ̂ ̂ ] dengan i = 1,2,...,n (1.5)
Keterangan:
̂ = Nilai dari estimasi parameter regresi untuk variabel ke-i
( ̂) = Nilai standard error untuk variabel ke-i n = variabel bebas yang digunakan
Uji kecocokan model digunakan untuk mengevaluasi cocok tidaknya model
dengan data, nilai observasi yang diperoleh sama atau mendekati dengan yang
diharapkan dalam model. Alat yang digunakan untuk menguji kecocokan dalam
regresi logistik adalah uji Hosmer dan Lemeshow, mengikuti distribusi Chi-square
dengan dimana adalah banyaknya kelompok, dengan rumus sebagai
berikut :
∑ ̅ ̅ ̅ (1.6)
Keterangan :
= total sampel kelompok
= Jumlah sampel kejadian sukses pada kelompok
ke-Dalam regresi logistik juga ada rasio peluang (odds ratio) yang digunakan untuk melihat asosiasi antara variabel independen dengan variabel dependen dan juga
untuk menginterpretasikan regresi logistik. Peluang (odds) dari suatu kejadian diartikan sebagai probabilitas hasil yang muncul dibagi dengan probabilitas suatu
kejadian yang tidak terjadi. Secara umum rasio peluang merupakan sekumpulan
peluang yang dibagi oleh peluang lainnya. Rasio peluang bagi independen diartikan
sebagai jumlah relatif dimana peluang hasil meningkat (rasio peluang > 1) atau turun
(rasio peluang < 1) ketika nilai variabel independen meningkat sebesar 1 unit. Untuk
menentukan odds ratio rumusnya sebagai berikut:
) 0 ( 1 ) 0 ( ) 1 ( 1 ) 1 ( ) 0 ( 1 ) 0 ( ) 1 ( 1 ) 1 ( p p p p p p p p (1.7) Keterangan: 1
p : Peluang kejadian kelompok pertama.
0
p : Peluang kejadian kelompok kedua.
1.7 Metodologi Penelitian
Metode penelitian adalah salah satu cara yang terdiri dari langkah-langkah atau urutan
kegiatan yang berfungsi sebagai pedoman umum yang digunakan untuk melaksanakan
penelitian sehingga apa yang menjadi tujuan dari penelitian itu terwujud. Penulis
melakukan beberapa langkah-langkah untuk menyelesaikan penelitian antara lain :
1. Pengambilan sampel dilakukan sebagai berikut :
a. Dalam penelitian ini metode pengambilan sampel yang digunakan adalah
sampling kemudahan (Convenience Sampling), yaitu responden yang terpilih adalah yang sesuai dengan teori penelitian dan dianggap cocok
sebagai sumber data. Jumlah sampel yang diambil sebanyak 50 responden
dengan pertimbangan penentuan ukuran sampel tersebut dapat memberikan
b. Menentukan variabel-variabel yang akan diteliti yaitu kepemilikan Hp
Android (Y), harga (X1), fitur (X2), merek (X3), desain (X4), dan iklan
(X5).
c. Merancang kuesioner.
d. Melakukan survey dan mengumpulkan data primer pada mahasiswa
FMIPA USU.
2. Mengubah data ordinal ke data interval dengan menggunakan Metode Suksesif
Interval (MSI).
3. Perumusan model regresi logistik dengan membuat persamaan logistik
berganda.
4. Menerapkan model regresi logistik pada data sampel yang diperoleh, yaitu :
a. Menguji signifikansi parameter yang diperoleh dari hasil penaksiran
b. Menerapkan uji kecocokan model regresi logistik dengan uji Hosmer dan
Lemeshow.
BAB 2
LANDASAN TEORI
2.1 Gambaran umum Fakultas MIPA USU
Pendirian fakultas Matematika dan Ilmu Pengetahuan Alam (FMIPA) mulai dirintis
sejak tahun 1959 melalui berbagai pembahasan dalam sidang pimpinan USU yang
ketika itu disebut Rapat Presidium dan Asesor dengan nama Fakultas Ilmu Pasti dan
Ilmu Alam (FIPIA). Rencana pendirian FIPIA USU pernah terhenti karena adanya
pergolakan di USU, namun akhirnya mendapat persetujuan dari menteri dengan Surat
Keputusan Nomor 9638/Sekret/BUP/1965. Peresmian berdirinya FIPIA USU ditandai
dengan dibukanya tiga jurusan yaitu: Jurusan Matematika, Fisika dan Kimia. Pada
tahun 1969, FIPIA USU membuka Jurusan Farmasi pada tahun 1969 dan pada tahun
1981 membuka Program Diploma-3 Pendidikan Ahli Kimia Analis (PAKA) melalui
Surat Keputusan Rektor USU Nomor: 3491/PT05/SK/C/1981. Pada tahun 1974 FIPIA
USU berubah nama menjadi Fakultas Ilmu Pasti dan Ilmu Pengetahuan Alam USU,
namun beberapa tahun kemudian yaitu pada tahun 1982 kembali merubah nama
dengan Fakultas Matematika dan Ilmu Pengetahuan Alam (FMIPA) USU. Pada tahun
1985 FMIPA USU dipercayakan Pemerintah Republik Indonesia untuk
menyelenggarakan Program Diploma-3 Kependidikan meliputi Program Studi :
Matematika, Fisika, Kimia dan Biologi. Program ini dimaksudkan untuk pengadaan
guru-guru dalam bidang eksakta akan ditempatkan di daerah dan seluruh
mahasiswanya memperoleh beasiswa. Peringatan Dies Natalis FMIPA diperingati
setiap tahunnya pada tanggal 25 Agustus yaitu pada saat pelantikan pertama sekali
pimpinan FIPIA. Jurusan Farmasi berubah status menjadi Fakultas Farmasi
2.2 Pengertian Android
Android adalah sistem operasi berbasis linux yang dirancang untuk perangkat seluler
layar sentuh seperti telepon pintar dan komputer tablet. Hp Android memiliki fungsi
yang menyerupai kompuer mini, namun pengguna tidak lagi direpotkan membawa
mouse ataupun keyboard. Layaknya sebuah handphone masa kini dimana ponsel Android memiliki bentuk yang simpel. Hp Android bentuknya sangat sederhana
namun memiliki kemampuan yang sangat banyak. Diantaranya:
1. Telepon.
2. SMS.
3. Video Call. 4. Browsing. 5. Dll.
Pada Hp Android terdapat berbagai fitur yang bisa digunakan. Sesuai dengan
pengertian fitur yang merupakan aspek-aspek keistimewaan, karakteristik, layanan
khusus, ragam keuntungan yang dibawa dalam suatu produk terpapar kepada
pelanggan/sosial/umum.
2.3 Defenisi Operasional Variabel Penelitian
Untuk memudahkan gambaran yang jelas dan memudahkan pelaksanaan penelitian,
maka variabel-variabel yang akan diteliti adalah sebagai berikut:
a. Variabel independen (bebas) adalah variabel yang mempengaruhi atau menjadi
sebab timbulnya variabel terikat. Dalam penelitian ini yang menjadi variabel
independen X adalah harga (X1), fitur (X2), merek (X3), desain (X4), dan iklan
(X5).
b. Variabel dependen (terikat) adalah variabel yang dipengaruhi atau menjadi
akibat karena adanya perubahan variabel independen. Dalam penelitian ini
2.4 Data
Pengertian data menurut Webster New World Dictionary, data adalah things known or assumed, yang berarti bahwa data itu adalah sesuatu yang diketahui atau dianggap. Diketahui artinya yang sudah terjadi merupakan fakta (bukti). Data dapat memberikan
gambaran tentang suatu keadaan atau persoalan.
Data bisa juga didefenisikan sekumpulan informasi atau nilai yang diperoleh
dari pengamatan (observasi) suatu objek, data dapat berupa angka dan dapat pula
merupakan angka atau sifat. Beberapa macam data antara lain: data populasi dan
sampel, data observasi, data primer dan data sekunder.
Pada dasarnya kegunaan data (setelah diolah dan dianalisis) ialah sebagai dasar
yang objektif di dalam proses pembuatan keputusan-keputusan dalam rangka untuk
memecahkan persoalan oleh pengambilan keputusan. Keputusan yang baik hanya bisa
dieroleh dari pengambilan keputusan yang objektif, dan didasarkan atas data yang
baik.
Data yang baik adalah data yang bisa dipercaya kebenarannya (reliable), tepat waktu dan mencakup ruang lingkup yang luas atau bisa memberikan gambaran
tentang suatu masalah secara menyeluruh merupakan data relevan.
Riset akan menghasilkan data. Ada tiga peringkat data yaitu data mentah, hasil
pengumpulan, data hasil pengolahan berupa jumlah, rata-rata, dan data hasil analisis
berupa kesimpulan. Yang terakhir ini mempunyai peringkat tertinggi sebab langsung
dapat dipergunakan untuk menyusun saran atau usul untuk dapat keputusan.
2.4.1 Data Menurut Sifatnya
Menurut sifatnya, data dapat dibagi dua:
a. Data kualitatif yaitu data yang tidak berbentuk angka, misalnya: kuesioner
b. Data kuantitatif yaitu data yang berbentuk angka, misalnya: harga suatu
produk, besar pendapatan, dan sebagainya.
2.4.2 Skala Pengukuran Data
Skala merupakan suatu prosedur pemberian angka atau simbol lain kepada sejumlah
ciri dari suatu objek agar dapat menyatakan karakteristik angka pada ciri tersebut.
Skala pengukuran oleh S.S Steven (1976) terbagi atas 4 bagian yaitu:
a. Skala Nominal: skal nominal tingatan pengukuran yang paling sederhana.
Dasar penggolongan ini agar kategori yang tidak tumpang tindih (mutually exclutive) dan tuntas (exhaustive). Angka yang ditunjuk untuk suatu kategori tidak merefleksikan bagaimana kedudukan kategori tersebut terhadap kategori
lainnya, tetapi hanyalah sekedar label atau kode sehingga skala yang
diterapkan pada data yang hanya dibagi ke dalam kelompok-kelompok tertentu
dan pengelompokan tersebut hanya dilakukan untuk tujuan identifikasi.
b. Skala Ordinal: skala ini memungkinkan peneliti untuk mengurutkan
respondennya dari tingkatan paling rendah ke tingkatan paling tinggi menurut
atribut tertentu. Skala yang diterapkan pada data yang dapat dibagi dalam
berbagai kelompok dan kita bisa membuat peringkat diantara kelompok
tersebut.
c. Skala Interval: seperti hal ukuran ordinal, ukuran interval adalah mengurutkan
orang atau objek berdasarkan suatu atribut. Interval atau jarak yang sama pada
skala interval dipandang sebagai mewakili interval atau jarak yang sama pula
pada objek yang diukur. Skala yang diterapkan pada data yang dapat
dirangking dan dengan peringkat tersebut kita bisa mengetahui perbedaan
diantara peringkat-peringkat tersebut dan kita bisa menghitung besarnya
perbedaan itu. Namun harus diperhaikan bahwa dalam skala ini perbandingan
d. Skala Rasio: suatu bentuk interval yang jaraknya (interval) tidak dinyatakan
sebagai perbedaan nilai antar responden, tetapi antara seorang dengan nilai
absolute, karena ada titik 0 maka perbandingan rasio dapat ditentukan.
2.4.3 Skala untuk Instrumen (Skala Sikap)
Bentuk-bentuk model skala sikap sering digunakan dalam penelitian ada 5 macam
yaitu:
a. Skala Likert
Digunakan untuk mengukur sikap, pendapat dan persepsi seseorang atau
sekelompok orang tentang fenomena sosial (Situmorang et al, 2010). Pada penelitian ini responden memilih salah satu dari jawaban yang diberi skor
tertentu. Skor responden kemudian dijumlahkan dan jumlah ini merupakan
total skor. Skala likert digunakan tergantung kebutuhan.
b. Skala Gutman
Digunakan untuk mengukur dimensi saja dari suatu variabel multidimensi.
Skala gutman dilakukan jika peneliti ingin mendapatkan jawaban tegas
terhadap suatu permasalahan yang ditanyakan.
c. Skala Diferensial Semantik
Berisikan serangkaian bipolar (dua kutub). Skala ini digunakan untuk
mengukur sikap, hanya bentuknya bukan pilihan ganda atau checklist, tetapi tersusun dalam satu garis kontinum yang jawaban positifnya terletak di bagian
kiri dan jawaban negatif terletak di bagian kanan atau sebaliknya.
d. Rating Scale
Merupakan data mentah yang didapat berupa angka kemudian ditafsirkan
e. Skala Thurtone
Skala ini meminta responden untuk memilih jawaban pertanyaan yang ia
setujui dari beberapa pertanyaan yang menyajikan pandangan-pandangan yang
berbeda-beda. Pada umumnya setiap item mempunyai asosiasi antara 1 sampai
10 tetapi nilai-nilainya tidak diketahui oleh responden.
2.4.4 Mengubah Data Ordinal ke Data Interval Dengan Metode Suksesif Interval (MSI)
Metode suksesif interval merupakan proses mengubah data ordinal menjadi data
interval. Mengapa data ordinal harus diubah dalam bentuk interval? Data ordinal
sebenarnya adalah data kualitatif atau bukan angka sebenarnya. Data ordinal
menggunakan angka sebagai simbol data kualitatif. Dalam contoh di bawah ini
misalnya:
- Angka 1 mewakili “sangat tidak setuju” - Angka 2 mewakili “tidak setuju” - Angka 3 mewakili “netral” - Angka 4 mewakili “setuju”
- Angka 5 mewakili “sangat setuju”
Proses mengubah data berskala ordinal menjadi data berskala interval,
mempunyai beberapa ahapan yang harus dilakukan, yaitu:
a. Menghitung frekuensi
b. Menghitung proporsi
c. Menghitung proporsi kumulatif
d. Menghitung nilai z
e. Menghitung nilai densitas fungsi z
f. Menghitung scale value
2.5 Tahapan Penelitian
Studi Pendahuluan: - Identifikasi/penentuan lokasi studi - Identifikasi data
- Identifikasi pustaka
- Identifikasi alat bantu (perangkat lunak)
Latar Belakang dan Rumusan Masalah
Tujuan Penelitian
Pengumpulan Data dengan Menggunakan Kuesioner
Tabulasi Data
Uji Validitas dan Reliabilitas
Transformasi Data Ordinal ke Data Interval
Uji Statistika dengan Menggunakan Model Regresi Logistik
2.6 Analisis Data 2.6.1 Uji Validitas
Uji validitas adalah uji yang dilakukan untuk mengetahui apakah sebuah
pertanyaan-pertanyaan tersebut valid atau tidak. Untuk mengetahui hal tersebut perlu dilakukan
perbandingan antara rhit dengan rtab. Apabila rhit >rtabmaka item-item pertanyaan
tersebut dinyatakan valid.
2 2 2 2 Y Y n X X n Y X XY n rxy (2.1) Keterangan: xyr : Koefisien korelasi pearson
n : Banyaknya responden
X : Skor yang yang diperoleh subjek dari seluruh item
Y : Skor total yang diperoleh dari seluruh item
X
: Jumlah skor dalam distribusi X
Y
: Jumlah skor dalam distribusi Y
2
X
: Jumlah kuadrat dalam skor distribusi X
2
Y
: Jumlah kuadrat dalam skor distribusi Y
2.6.2 Uji Reliabilitas
Uji reliabilitas adalah uji yang dilakukan untuk mengetahui apakah sebuah pertanyaan
atau pernyataan sudah reliabel atau belum. Menurut Ghozali (2005), suatu variabel
dikatakan reliabel jika memberikan nilai Alpha Cronbach > 0,60. Rumus yang
digunakan untuk menghitung nilai Alpha Cronbabach adalah sebagai berikut:
2Keterangan:
r
: Koefisien reabilitas instrumen (cronbach alpha)k
: Jumlah item pertanyaan yang di uji
2b
: Jumlah varians skor tiap- tiap item pertanyaan
2 t
: Varians total2.7 Regresi Logistik
Regresi logistik adalah suatu model matematik yang digunakan untuk mempelajari
hubungan antara satu atau beberapa variabel independen dengan satu variabel
dependen yang bersifat dikotomus (binary). Variabel yang bersifat dikotomus adalah variabel yang hanya memiliki dua nilai, misalnya hidup/mati, sakit/sehat,
merokok/tidak merokok dan sebagainya.
Pada regresi logistik, variabel independen yang digunakan dapat berupa
variabel katagorik maupun numerik. Namun sebaiknya menggnakan variabel
katagorik agar lebih mudah dalam menginterpretasikan hasil analisisnya. Bila salah
satu atau beberapa variabel independen merupakan variabel dengan skala nominal
dengan 3 atau lebih kategori, maka harus dibuat dummy variable yang menggambarkan kategori dari variabel tersebut dengan referrence group-nya salah satu dari kategori tersebut.
Regresi logistik merupakan regresi yang digunakan bila dependennya bersifat
kualitatf (Hosmer dan Lemeshow, 1989) model regresi logistik sederhana yaitu model
regresi logistik untuk satu variabel independen X dengan variabel dependen Y yang
bersifat dikotomi. Nilai variabel Y = 1 menyatakan adanya suatu karakteristik dan Y =
0 menyatakan tidak adanya suatu karakteristik.
2.7.1 Model Regresi Logistik
Adapun bentuk umum dari model regresi logistik adalah:
∑
Keterangan:
= Peluang sukses = intersep
parameter-parameter regresi
pengamatan variabel ke- dari variabel independen bilangan natural (2,7183)
Selanjutnya, untuk menjadikan model tersebut linier proses yang dinamakan
logit transformation perlu dilakukan seperti berikut ini:
| | ∑ (2.4)
Keterangan:
= Peluang sukses = intersep
parameter-parameter regresi
pengamatan variabel ke- dari variabel independen
2.7.2 Uji Signifikansi Parameter
Sebelum membentuk model regresi logistik terlebih dahulu dilakukan uji signifikansi
parameter. Uji yang pertama dilakukan adalah pengujian peranan parameter di dalam
model secara keseluruhan atau uji signifikansi secara overall yaitu dengan hipotesis sebagai berikut :
H0 : (tidak ada perbedaan antara model dengan data
sehingga model dapat dikatakan baik)
H1 : paling sedikit koefisien (ada perbedaan antara model dengan data
Menurut Hosmer-Lemeshow, (1989) suatu statistik uji rasio likelihood G adalah fungsi dari dan yang berdistribusi (Chi-square) dengan derajat bebas
yang didefenisikan sebagai:
[ ] (2.5)
keterangan:
nilai maksimum fungsi kemungkinan untuk model di bawah H0
nilai maksimum fungsi kemungkinan untuk model di bawah H1
= nilai maksimum fungsi log kemungkinan untuk model di bawah H0
= nilai maksimum fungsi log kemungkinan untuk model di bawah H1
Nilai tersebut mengikuti distribusi Chi-square dengan . Jika menggunakan taraf nyata sebesar , maka kriteria ujinya adalah tolak H0 jika
atau , dan terima dalam hal lainnya.
Uji signifikansi parameter secara terpisah dilakukan dengan menggunakan
Wald Chi-square dengan rumusan hipotesis sebagai berikut:
0
:
0 i
H
0
:
1 i
H
atau
:
0
H
Koefisien logistik tidak signifikan terhadap model (tidak ada perbedaanantara model dengan koefisien sehingga model dapat dikatakan baik).
:
1
H Koefisien logistik signifikan terhadap model (ada perbedaan antara model
dengan koefisien sehingga model tidak dapat dikatakan baik).
Uji Wald Chi-square digunakan untuk menguji signifikansi parameter model secara terpisah. Didefeinisikan dengan:
Keterangan:
̂ = Nilai dari estimasi parameter regresi untuk variabel ke-i
( ̂) = Nilai standard error untuk variabel ke=i i = variabel bebas yang digunakan
Statistik uji mendekati distribusi Chi-square dengan derajat bebas 1. H0
nya adalah ̂ , untuk setiap yang berarti bahwa variabel independen
ke- tidak signifikan terhadap model. H0 ditolak jika
2.7.3 Uji kecocokan Model
Uji kecocokan model digunakan untuk mengevaluasi cocok tidaknya model dengan
data, nilai observasi yang diperoleh sama atau mendekati dengan yang diharapkan
dalam model. Alat yang digunakan untuk menguji kecocokan dalam regresi logistik
adalah uji Hosmer dan Lemeshow, mengikuti distribusi Chi-square dengan dimana adalah banyaknya kelompok.
Uji Hosmer dan Lemeshow yang ditulis dengan uji ̂, dihitung berdasarkan
taksiran probabilitas (Hosmer danLemeshow, 1989). Pada uji ini sampel dimasukkan
ke sejumlah kelompok dengan tiap-tiap kelompok memuat sampel
pengamatan, dengan adalah jumlah sampel. Jumlah kelompok sekitar 10. Idealnya,
kelompok pertama memuat sampel yang memiliki taksiran probabilitas
sukses terkecilyang diperoleh dari model taksiran. Kelompok kedua memuat
sampel yang memiliki taksiran probabilitas sukses terkecil kedua, dan seterusnya, dengan rumus sebagai berikut:
∑ ̅ ̅ ̅ (2.7)
Keterangan:
= total sampel kelompok
̅ = rata-rata taksiran probabilitas kelompok
ke-Untuk menguji kecocokan model, bandingkan nilai Chi-square pada tabel
Chi-square dengan . Jika maka H0 ditolak.
2.7.4 Odds Rasio
Regresi logistik juga menghasilkan rasio peluang (odds ratio) terkait dengan nilai setiap independen. Peluang dari suatu kejadian diartikan sebagai probabilitas hasil
yang muncul yang dibagi dengan probabilitas suatu kejadian yang tidak terjadi. Secara
umum rasio peluang merupakan sekumpulan peluang yang dibagi oleh peluang
lainnya. Rasio peluang bagi independen diartikan sebagai jumlah relatif dimana
peluang hasil meningkat (rasio peluang > 1) atau turun (rasio peluang < 1) ketika nilai
variabel independen meningkat sebesar 1 unit. Untuk menentukan odds ratio
rumusnya sebagai berikut:
) 0 ( 1 ) 0 ( ) 1 ( 1 ) 1 ( ) 0 ( 1 ) 0 ( ) 1 ( 1 ) 1 ( p p p p p p p p (2.8)
Odds ratio didefinisikan sebagai perbandingan dari nilai variabel sukses terhadap variabel bernilai gagal. Dengan kata lain odds rasio menjelaskan seberapa besar pengaruh variabel sukses dibanding variabel gagal terhadap suatu eksperimen
atau observasi. Pada kasus penelitian dengan regresi logistik, nilai ini dapat dilihat
dari nilai Exp(B)pada hasil analisis data atau ei dengan
i
adalah estimasi
parameter variabel independen pertama, kedua, dan seterusnya. Hasil tersebut akan
menunjukkan pengaruh setiap variabel-variabel independen terhadap variabel
BAB 3
PEMBAHASAN
3.1 Pengolahan Data
3.1.1 Tabulasi Hasil Kuesioner
Untuk melakukan analisis pada penelitian ini data pengamatan hasil survey terhadap
masing-masing variabel independen yaitu harga (X1), fitur (X2), merek (X3), desain
(X4), iklan (X5) dan variabel dependen kepemilikan Hp Android (Y) ditabulasi dengan
menggunakan skala likert. Pemberian skor dari setiap pertanyaan dilakukan dengan
cara sangat setuju diberi skor 5, setuju diberi skor 4, cukup setuju diberi skor 3, tidak
setuju diberi skor 2, dan sangat tidak setuju diberi skor 1. Hasil tabulasi kuesioner
dapat dilihat pada Lampiran 1.
3.1.2 Nilai Total Skor Variabel Hasil Penelitian
Setelah data pengamatan hasil survey ditabulasi, langkah selanjutnya adalah
mengumpulkan data yang sudah ditabulasi dalam bentuk nilai total skor
masing-masing variabel independen X1, X2, X3, X4 dan X5 serta variabel dependen Y. Bentuk
total nilai skor tersebut dapat dilihat pada Lampiran 2.
3.1.3 Uji Instrumen Kuesioner Menggunakan Uji Validitas
Uji validitas adalah uji yang dilakukan untuk mengetahui apakah sebuah
pertanyaan-pertanyaan tersebut valid atau tidak. Untuk mengetahui hal tersebut perlu dilakukan
perbandingan antara rhit dengan rtab. Apabila rhit >rtabmaka item-item pertanyaan
tersebut dinyatakan valid.
n XY X Y
Keterangan:
xy
r : Koefisien korelasi pearson
n : Banyaknya responden
X : Skor yang yang diperoleh subjek dari seluruh item
Y : Skor total yang diperoleh dari seluruh item
X
: Jumlah skor dalam distribusi X
Y
: Jumlah skor dalam distribusi Y
2
X
: Jumlah kuadrat dalam skor distribusi X
2
Y
: Jumlah kuadrat dalam skor distribusi Y
a. Variabel Harga (X1)
berdasarkan kuesioner yang ada, maka jumlah butir pertayaan berjumlah 3 butir,
pengujian validitas dilakukan pada 50 responden. Setelah dilakukan uji validitas
[image:35.595.148.487.422.511.2]dengan bantuan program SPSS 16 diperoleh hasil sebagai berikut:
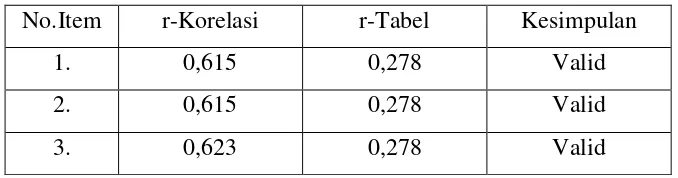
Tabel 3.1 Uji Validitas Harga
No.Item r-Korelasi r-Tabel Kesimpulan
1. 0,615 0,278 Valid
2. 0,615 0,278 Valid
3. 0,623 0,278 Valid
Berdasarkan hasil uji validitas dari tabel 3.1, terlihat bahwa seluruh butir item
pertanyaan dinyatakan valid karena nilai r korelasinya lebih besar dari 0.278 (r-tabel).
b. Variabel Fitur (X2)
berdasarkan kuesioner yang ada, maka jumlah butir pertayaan berjumlah 3 butir,
pengujian validitas dilakukan pada 50 responden. Setelah dilakukan uji validitas
Tabel 3.2 Uji Validitas Fitur
No.Item r-Korelasi r-Tabel Kesimpulan
1. 0,611 0,278 Valid
2. 0,640 0,278 Valid
3. 0,669 0,278 Valid
Berdasarkan hasil uji validitas dari tabel 3.2, terlihat bahwa seluruh butir item
pertanyaan dinyatakan valid karena nilai r korelasinya lebih besar dari 0.278 (r-tabel).
c. Variabel Merek (X3)
berdasarkan kuesioner yang ada, maka jumlah butir pertayaan berjumlah 4 butir,
pengujian validitas dilakukan pada 50 responden. Setelah dilakukan uji validitas
dengan bantuan program SPSS 16 diperoleh hasil sebagai berikut:
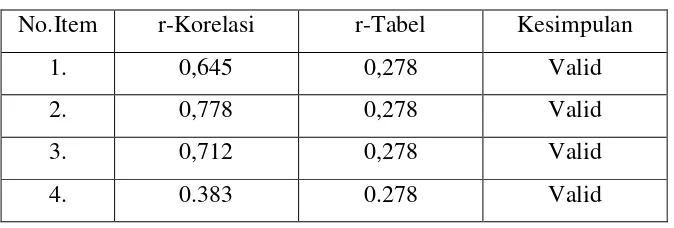
Tabel 3.3 Uji Validitas Merek
No.Item r-Korelasi r-Tabel Kesimpulan
1. 0,645 0,278 Valid
2. 0,778 0,278 Valid
3. 0,712 0,278 Valid
4. 0.383 0.278 Valid
Berdasarkan hasil uji validitas dari tabel 3.3, terlihat bahwa seluruh butir item
pertanyaan dinyatakan valid karena nilai r korelasinya lebih besar dari 0.278 (r-tabel).
c. Variabel Desain (X4)
berdasarkan kuesioner yang ada, maka jumlah butir pertayaan berjumlah 4 butir,
pengujian validitas dilakukan pada 50 responden. Setelah dilakukan uji validitas
[image:36.595.150.487.393.507.2]Tabel 3.4 Uji Validitas Desain
No.Item r-Korelasi r-Tabel Kesimpulan
1. 0,769 0,278 Valid
2. 0,542 0,278 Valid
3. 0,701 0,278 Valid
4. 0.586 0.278 Valid
Berdasarkan hasil uji validitas dari tabel 3.4, terlihat bahwa seluruh butir item
pertanyaan dinyatakan valid karena nilai r korelasinya lebih besar dari 0.278 (r-tabel).
c. Variabel Iklan (X5)
berdasarkan kuesioner yang ada, maka jumlah butir pertayaan berjumlah 4 butir,
pengujian validitas dilakukan pada 50 responden. Setelah dilakukan uji validitas
dengan bantuan program SPSS 16 diperoleh hasil sebagai berikut:
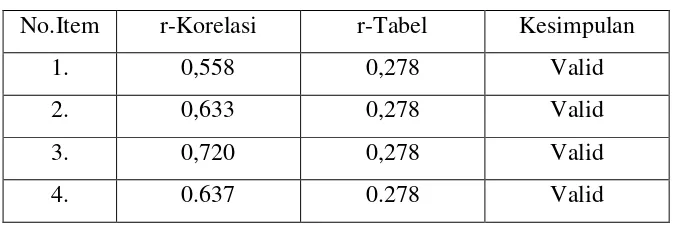
Tabel 3.5 Uji Validitas Iklan
No.Item r-Korelasi r-Tabel Kesimpulan
1. 0,558 0,278 Valid
2. 0,633 0,278 Valid
3. 0,720 0,278 Valid
4. 0.637 0.278 Valid
Berdasarkan hasil uji validitas dari tabel 3.5, terlihat bahwa seluruh butir item
pertanyaan dinyatakan valid karena nilai r korelasinya lebih besar dari 0.278 (r-tabel).
3.1.4 Uji Instrumen Kuesioner Menggunakan Uji Reliabilitas
Uji reliabilitas adalah uji yang dilakukan untuk mengetahui apakah sebuah pertanyaan
atau pernyataan sudah reliabel atau belum. Menurut Ghozali (2005), suatu variabel
dikatakan reliabel jika memberikan nilai Alpha Cronbach > 0,60. Rumus yang
[image:37.595.149.487.414.528.2]
22
1
1 t
b
k k r
(3.2)
Keterangan:
r
: Koefisien reabilitas instrumen (cronbach alpha)k
: Jumlahitem pertanyaan yang di uji
2b
: Jumlah variansskor tiap- tiap item pertanyaan
2 t
: VarianstotalUntuk lebih mudah melakukan uji reliabilitas dalam penelitian ini dapat
dilakukan dengan bantuan program SPSS.16. Berikut adalah hasil perhitungan Alpha
Cronbach dari variabel-variabel bebas berdasarkan item-item pertanyaan.
[image:38.595.193.439.429.521.2]a. Variabel Harga (X1)
Tabel 3.6 Uji Reliabilitas Harga
No. Item Alpha Cronbach Kesimpulan
1 0.703 Reliabel
2 0.676 Reliabel
3 0.688 Reliabel
Berdasarkan tabel 3.6 terlihat bahwa seluruh butir item pertanyaan reliabilitas
karena item-item pertanyaan tersebut memberikan nilai Cronbach Alpha > 0.60.
dengan demikian variabel Harga (X1) adalah reliabel.
b. Variabel Fitur (X2)
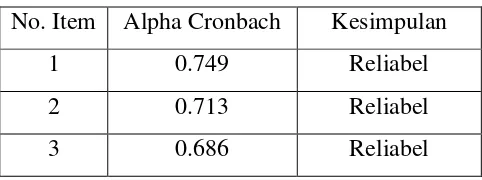
Tabel 3.7 Uji Reliabilitas Fitur
No. Item Alpha Cronbach Kesimpulan
1 0.749 Reliabel
[image:38.595.196.437.681.771.2]Berdasarkan tabel 3.7 terlihat bahwa seluruh butir item pertanyaan reliabilitas
karena item-item pertanyaan tersebut memberikan nilai Cronbach Alpha > 0.60.
dengan demikian variabel Harga (X2) adalah reliabel.
[image:39.595.196.436.223.339.2]c. Variabel Merek (X3)
Tabel 3.8 Uji Reliabilitas Desain
No. Item Alpha Cronbach Kesimpulan
1 0.743 Reliabel
2 0.674 Reliabel
3 0.702 Reliabel
4. 0.867 Reliabel
Berdasarkan tabel 3.8 terlihat bahwa seluruh butir item pertanyaan reliabilitas
karena item-item pertanyaan tersebut memberikan nilai Cronbach Alpha > 0.60.
dengan demikian variabel Harga (X3) adalah reliabel.
d. Variabel Desain (X4)
Tabel 3.9 Uji Reliabilitas Merek
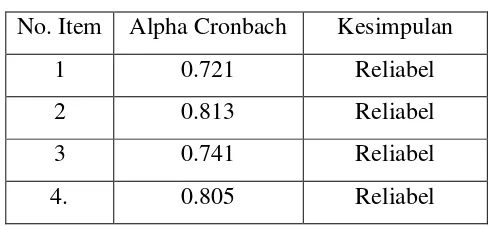
No. Item Alpha Cronbach Kesimpulan
1 0.721 Reliabel
2 0.813 Reliabel
3 0.741 Reliabel
4. 0.805 Reliabel
Berdasarkan tabel 3.9 terlihat bahwa seluruh butir item pertanyaan reliabilitas
karena item-item pertanyaan tersebut memberikan nilai Cronbach Alpha > 0.60.
[image:39.595.193.439.496.609.2]e. Variabel Iklan (X5)
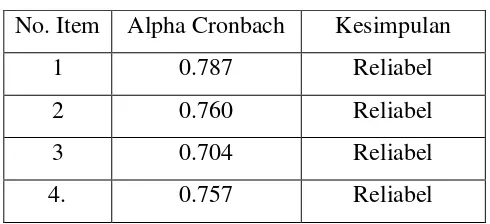
Tabel 3.10 Uji Reliabilitas Iklan
No. Item Alpha Cronbach Kesimpulan
1 0.787 Reliabel
2 0.760 Reliabel
3 0.704 Reliabel
4. 0.757 Reliabel
Berdasarkan tabel 3.10 terlihat bahwa seluruh butir item pertanyaan reliabilitas
karena item-item pertanyaan tersebut memberikan nilai Cronbach Alpha > 0.60.
dengan demikian variabel Harga (X5) adalah reliabel.
3.2 Transformasi Data Ordinal Menjadi Data Interval
pada penelitian ini instrumen penelitiannya berupa kuesioner yang memiliki jawaban
skala likert yang berupa data ordinal. Perlu dilakukan transformasi data ordinal ke
data interval dengan menggunakan MSI (Method of Successive Interval). Berikut ini akan dilakukan perhitungan manual MSI untuk variabel harga dengan mengambil satu
item pertanyaan. Langkah-langkahnya adalah:
1. Menghitung Frekuensi
Frekuensi merupakan banyaknya tanggapan responden dalam memilih jawaban
dengan data ordinal 1 s/d 5 dengan jumlah responden 50 orang. Frekuensi dari
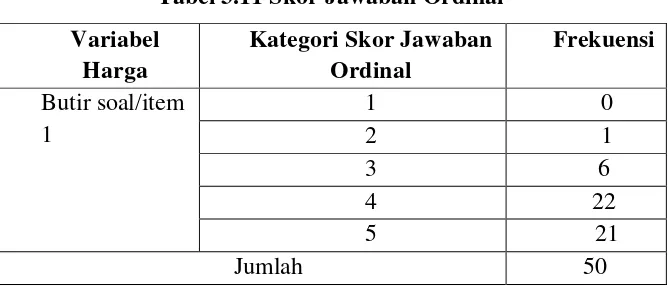
Tabel 3.11 Skor Jawaban Ordinal Variabel
Harga
Kategori Skor Jawaban Ordinal
Frekuensi
Butir soal/item 1
1 0
2 1
3 6
4 22
5 21
Jumlah 50
2. Menentukan Proporsi
Proporsi dieroleh dari hasil perbandingan antara jumlah frekuensi perpoin dengan total
frekuensi, sehingga diperoleh proporsi sebagai berikut:
3. Menentukan Proporsi Kumulatif
Proporsi kumulatif diperoleh dengan menjumlahkan secara berurutan untuk setiap
nilai, sehingga nilai diperoleh sebagai berikut:
4. Menentukan Nilai Z
Nilai proporsi kumulatif dianggap mengikuti distribusi normal baku dengan melihat
tabel berdistribusi normal kumulatif. Maka dapat ditentukan nilai Z untuk setiap
kategori sebagai berikut:
disesuaikan dengan Tabel Z diperoleh: 2,05 disesuaikan dengan Tabel Z diperoleh: 1,08 disesuaikan dengan Tabel Z diperoleh: 0,20
disesuaikan dengan Tabel Z diperoleh: ∞
5. Menentukan Densitas
Nilai densitas diperoleh dari tabel Koordinat Kurve Normal Baku untuk nilai:
6. Menentukan Scale Value (Skala Nilai)
Rumus:
7. Menentukan Transformasi (Skala Akhir)
Transformasi data interval diperoleh dengan jalan mengambil nilai negatif yang paling
besar dan diubah menjadi = 1, yaitu: [ | |]
Sa2 = (-2,44 + 3,44) = 1
Sa3 = (-1,449 + 3,44) = 1,99
Sa4 = (-0,383 + 3,44) = 3,06
[image:43.595.81.550.309.445.2]Sa5 = (0,931 + 3,44) = 4,37
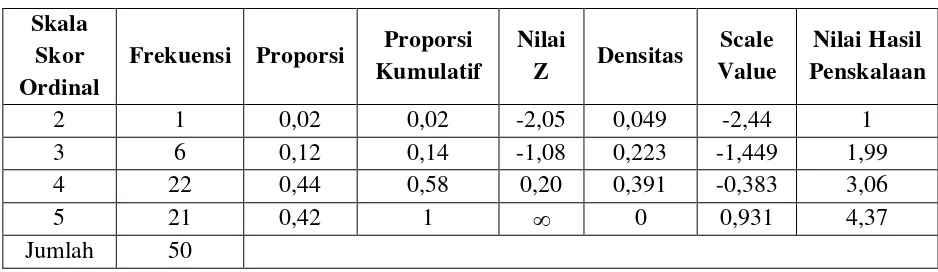
Tabel 3.12 Rincian Hasil Perhitungan Secara Manual Skala
Skor Ordinal
Frekuensi Proporsi Proporsi Kumulatif
Nilai
Z Densitas
Scale Value
Nilai Hasil Penskalaan
2 1 0,02 0,02 -2,05 0,049 -2,44 1
3 6 0,12 0,14 -1,08 0,223 -1,449 1,99
4 22 0,44 0,58 0,20 0,391 -0,383 3,06
5 21 0,42 1 0 0,931 4,37
Jumlah 50
3.3 Pengolahan Data
berdasarkan kuesioner yang telah dibagikan kepada 50 orang responden,
keseluruhannya memiliki Hp Android dan menjadi subjek penelitian. Seperti yang
telah dijelaskan sebelumnya, data yang diperoleh dalam penelitian ini akan dianalisis
dengan menggunakan analisis regresi logistik.
3.4 Analisis Data 3.3.1 Tipe Data
Data variabel independen pada penelitian ini terdiri atas dua tipe data. Data variabel
independen adalah X1, X2, X3, X4 dan X5 merupakan data ordinal. Data ini diperoleh
menggunakan skala likert. Akan tetapi data variabel dependen pada penelitian ini yang
merupakan Y adalah tipe data nominal.
3.5 Menjelaskan Hasil Analisis Data Menggunakan SPSS 3.5.1 Model Regresi Logistik
Berdasarkan analisis data yang telah dilakukan dengan regresi logistik dengan pada
[image:44.595.189.444.272.404.2]SPSS 16.0 dan hasil output dapat dilihat pada lampiran 4.
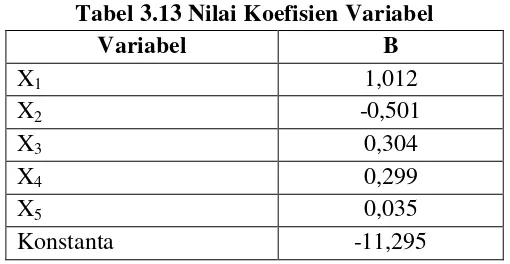
Tabel 3.13 Nilai Koefisien Variabel
Variabel B
X1 1,012
X2 -0,501
X3 0,304
X4 0,299
X5 0,035
Konstanta -11,295
Dari hasil analisis diperoleh nilai-nilai estimasi parameter untuk persamaan
regresi logistik pada penelitian ini. Persamaan logistik penelitian ini memiliki nilai
konstanta -11,295. Selain itu, dari tabel juga dapat dilihat besar masing-masing
koefisien variabel independen persamaan logistik tersebut, yaitu:
1. Variabel X1 ( = 1,012)
Variabel harga (X1) berpengaruh secara positif dan signifikan terhadap
kepemilikan Hp Android (Y), artinya jika variabel harga(X1) ditingkatkan
sebesar 1 point maka kepemilikan Hp Android (Y) akan meningkat sebesar
1,012point.
2. Variabel X2( = -0,501)
Variabel fitur (X2) berpengaruh secara negatif dan tidak signifikan terhadap
kepemilikan Hp Android (Y), artinya jika variabel fitur (X2) ditingkatkan
sebesar 1 point maka kepemilikan Hp Android(Y) akan menurun sebesar
3. Variabel X3( = 0,304)
Variabel desain (X3) berpengaruh secara positif dan signifikan terhadap
kepemilikan Hp Android (Y), artinya jika variabel desain (X3) ditingkatkan
sebesar 1 point maka kepemilikan Hp Android (Y) akan meningkat sebesar
0,304point.
4. Variabel X4( = 0,299)
Variabel merek (X4) berpengaruh secara positif dan signifikan terhadap
kepemilikan Hp Android (Y), artinya jika variabel merek (X4) ditingkatkan
sebesar 1 point maka kepemilikan Hp Android (Y) akan meningkat sebesar
0,299point.
5. Variabel X5( = 0,035)
Variabel iklan (X5) berpengaruh secara positif dan signifikan terhadap
kepemilikan Hp Android (Y), artinya jika variabel iklan (X5) ditingkatkan
sebesar 1 point maka kepemilikan Hp Android (Y) akan meningkat sebesar
0,035point.
Berdasarkan nilai-nilai koefisien hasil analisis tersebut maka taksiran model
regresi logistik yang diperoleh adalah:
Keterangan:
) (xi
p = peluang sukses kepemilikan Hp Android
= variabel harga = variabel fitur
= variabel Merek = variabel Desain
3.5.2Uji Signifikansi Parameter Model Awal
Sebelum membentuk model regresi logistik terlebih dahulu dilakukan uji signifikansi
parameter. Uji yang pertama kali dilakukan adalah pengujian peranan parameter
didalam model secara keseluruhan (overall) yaitu dengan hipotesis sebagai berikut:
,
0
:
0 k
H
Dengan k 1,2,...,n.(Secara simultan variabel independen tidakberpengaruh terhadap variabel dependen).
:
1
H k 0,Dengan k 1,2,...,n.(Minimal ada satu variabel independen yang
berpengaruh secara simultanterhadap varibel dependen).
Statistik uji yang digunakan adalah:
log( ) log( )
2( ) 2log
2 0 1 0 1
1 0 L L l l l l
G
Nilai2(L0L1)tersebut mengikuti distribusi chi-square dengan derajat bebas
banyaknya parameter dalam model df p. Keputusan 2. Kriteria ujinya adalah H0
terima jika G2,p dan H0 tolak jikaG2,p.uji diperoleh dengan
membandingkan nilai G dan dan 2.
[image:46.595.188.445.586.641.2]Untuk melihat tingkat variasi data menggunakan Cox & Snell R Square pada tabelModel Summary berikut:
Tabel 3.14Model Summary
Step
-2 Log likelihood
Cox & Snell R Square
Nagelkerke R Square
1 34.820a .362 .531
a. Estimation terminated at iteration number 6 because parameter estimates changed by less than ,001.
Hasil pada tabel model summary di atas dapat kita peroleh dengan
menggunakan software SPSS 16.0, dari perhitungan tersebut maka diperoleh nilai
chi-Dengan demikian dapat dilihat bahwa, G2,pyaitu 34,820 ≥ 11,070 sehingga H0 ditolak, ini berarti bahwa paling sedikit ada satu variabel independen yang berpengaruh secara simultanterhadap varibel dependen pada 0,05. Tabel
diatas menunjukkan koefisien determinasi regresi logistik yakni 0,531 sehingga dapat
dikatakan variabel-variabel independen dalam penelitian ini sudah menjelaskan 53,1%
terhadap variabel dependennya. Dan sisanya 46,9% dapat dijelaskan oleh variabel lain
[image:47.595.132.503.286.428.2]di luar model.
Tabel 3.15 Tabel Klasifikasi
Observed
Predicted
Kepemilikan Hp
Android Percentage
Correct <1 bulan >1 bulan
Step 1 Kepemilik an Hp Android
<1 bulan 8 5 .61.5
>1 bulan 2 35 94.6
Overall Percentage 86.0
a. The cut value is ,500
Pada tabel 3.15 memperlihatkan bahwa ketepatan prediksi dalam penelitian ini
adalah sebesar 86% untuk mengetahui koefisien dari parameter mana yang berarti
tersebut, maka dilakukan uji secara individual. Uji ini dapat dilakukan dengan uji wald
dengan hipotesis sebagai berikut:
,
0
:
0 k
H
Dengan k 1,2,...,n.(Tidak ada pengaruh variabel independen ke-kterhadap variabel dependen).
,
0
:
1 k
H
Dengan k 1,2,...,n.(Ada pengaruh variabel independen ke-kterhadap variabel dependen).
Statistik Uji: ) ˆ ( ˆ 2 i i i SE W
Statistik Wald mengikuti distribusi normal sehingga untuk memperoleh
keputusan pengujian, dibandingkan nilai W dengan nilai Z/2 (H0 ditolak jika nilai
2 /
Z
W atau p-value < α).
Dengan menggunakan software SPSS 16.0 dapat kita peroleh nilai-nilai
[image:48.595.106.514.259.420.2]statistik uji wald sebagai berikut:
Tabel 3.16 Nilai Koefisien Variabel
B S.E. Wald Df Sig. Exp(B)
Step 1a X1 1.012 .487 4.313 1 .038 2.752
X2 -.501 .443 .1.278 1 .258 .606
X3 .304 .198 2.343 1 .126 1.355
X4 .299 .196 2.336 1 .126 1.349
X5 .035 .159 .050 1 .824 1.036
Constant -11.295 3.711 9.264 1 .002 .000
a. Variable(s) entered on step 1: X1, X2, X3, X4, X5.
Dengan 0,05dan df 1 pada tabel chi-square diperoleh nilai
chi-squaretabel = 3,841. Dari hasil uji statistik wald di tabel, nilai uji statistik wald pada variabel X2, X3, X4, dan X5 lebih kecil dari nilai chi-square tabel. Sedangkan untuk
nilai uji statistik wald pada variabel X1 lebih besar dari nilai chi-square tabel.Dari
nilai uji statistik wald tersebut dapat disimpulkan bahwa H0 ditolak, ini berarti bahwa variabel X1 berpengaruh secara signifikan terhadap kepemilikan Hp Android (Y) pada
mahasiswa F MIPA USU.
Setelah dilakukan uji signifikansi parameter pada tabel di atas maka model
regresi logistik dapat dibentuk dengan menggunakan nilai taksiran persamaan
transformasi logistik yaitu sebagai berikut:
Persamaan menunjukkan bahwa nilai intersep = -11,295. Artinya: [
] =
-11,295 pada saat semua variabel berharga 0, yaitu pada saat variabel X1, X3, X4, dan
X5 tidak berpengaruh terhadap besarnya peluang kepemilikan Hp Android (Y).
Diperoleh besaran [
] = -11,295atau besarnya probabilitas
) 295 , 11 (
) 295 , 11 (
1 )
(
e e x
p i = 0,00001.
3.5.3 Uji Kecocokan Model
Uji kecocokan model ini dilakukan dengan mengunakan uji Hosmer-Lemeshow
dengan hipotesis sebagai berikut:
atau
0
H : Data empiris cocok atau sesuai dengan model (tidak ada perbedaan antara
model dengan data sehingga model dapat dikatakan fit).
1
H : Data empiris tidak cocok atau tidak sesuai dengan model (ada perbedaan
antara model dengan data sehingga model dapat dikatakan fit).
Statistik Uji:
∑ ̅ ̅ ̅
Tabel 3.17 Tabel Kontingensi untuk Uji Hosmer- Lemeshow
Kepemilikan Hp Android = <1 bulan
Kepemilikan Hp Android = >1 bulan
Total Observed Expected Observed Expected
Step 1 1 5 4.490 0 .510 5
2 3 3.121 2 1.879 5
3 1 2.210 4 2.790 5
4 1 1.201 4 3.799 5
5 1 .823 4 4.177 5
6 1 .574 4 4.426 5
7 1 .309 4 4.691 5
8 0 .151 5 4.849 5
9 0 .098 5 4.902 5
[image:50.595.147.487.109.355.2]10 0 .024 5 4.976 5
Tabel 3.18 Uji Hosmer- Lemeshow
Step Chi-square df Sig.
1 4.144 8 .844
Dari tabel 3.18chi-square diperoleh (2,g2) 12,592dengang 8kelompok.
Nilai ini lebih besar dari HL2 4,144yang diperoleh dari uji Hosmer-Lemeshow dengan perhitungan menggunakan SPSS 16.0. Jadi dapat disimpulkan bahwa H0
terima (4,14412,592 atau 0,844> 0,05) yang artinya tidak ada perbedaan antara
model dengan data sehingga model dapat dikatakan fit atau layak untuk digunakan.
3.6 Interpretasi Model Menggunakan Odds Rasio
Berdasarkan analisis data yang telah dilakukan dengan menggunakan rumus
(2.8)diperoleh nilai Odds Ratio seperti tabel 3.19 dan hasil output dengan
Tabel 3.19 Kontribusi Variabel X terhadap Variabel Y Variabel Exp(Bi)
2,752
1,355
1,349
1,036
Konstan 0,000
Berdasarkan tabel 3.19 dapat disimpulkan sebagai berikut :
a. Variabel Harga (X1) (Exp(B1)=2,752)
Dari nilai ini dapat disimpulkan bahwa jika variabel merek(X3), variabel desain (X4) dan variabel iklan (X5) dianggap nol maka harga (X1) yang sesuai akan
mempengaruhi mahasiswa di Fakultas MIPA USU untuk memiliki Hp
Android 2,752 kali lebih besar dibandingkan dengan harga yang tidak sesuai.
b. Variabel Merek(X3) (Exp(B3)=1,355)
Dari nilai ini dapat disimpulkan bahwa jika variabel harga (X1), variabel desain (X4) dan variabel iklan (X5) dianggap nol maka merek(X3) yang
terkenalakan mempengaruhi mahasiswa Fakltas MIPA USU untuk memiliki
Hp Android 1,355 kali lebih besar dibandingkan dengan merek yang tidak
terkenal.
c. Variabel Desain(X4)(Exp(B4)= 1,349)
Dari nilai ini dapat disimpulkan bahwa jika variabel harga (X1), variabel merek (X3) dan variabel iklan (X5) dianggap nol maka desain(X4) yang
terkenal baik akan mempengaruhi mahasiswa Fakultas MIPA USU untuk
memiliki Hp Android tersebut 1,349 kali lebih besar dibandingkan dengan
merek produk yang tidak terkenal baik.
d. Variabel Iklan (X5) (Exp(B5)= 1,036)
menarik dan baik akan mempengaruhi mahasiswa Fakultas MIPA USU untuk
memiliki Hp Android tersebut 1,036 kali lebih besar dibandingkan dengan
iklan produk yang tidak menarik dan baik.
3.7 Mencari Persamaan Regresi Logistik Tanpa SPSS
Misalnya suatu penelitian tentang harga produk terhadap kepemilikan Hp Android
pada mahasiswa FMIPA USU, dengan pengambilan sampel sebanyak 20 responden.
Dengan variabel dependennya bersifat nominal yaitu bernilai 0 jika kepemilikan < 1
bulan dan bernilai 1 jika kepemilikan > 1 bulan. Sedangkan variabel independennya
[image:52.595.189.445.347.699.2]bersifat interval. Data yang diperoleh sebagai berikut:
Tabel 3.20 Data Variabel Y dan X
No Kepemilikan Hp (Y) Skor Variabel X
1 1 4,35
2 1 4,35