UNTUK KLASIFIKASI PADA SISTEM TEMU KEMBALI CITRA
VITA YULIA NOORNIAWATI
G64103034
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer
pada Fakultas Matematika dan Ilmu Pengetahuan Alam
Institut Pertanian Bogor
Oleh:
VITA YULIA NOORNIAWATI
G64103034
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
VITA YULIA NOORNIAWATI. Metode Support Vector Machine untuk Klasifikasi pada Sistem Temu Kembali Citra. Dibimbing oleh YENI HERDIYENI dan AGUS BUONO.
Citra memiliki bentuk, tekstur dan warna yang sangat beragam. Hal ini menyebabkan sulitnya dilakukan pencarian citra. Klasifikasi citra merupakan salah satu tahap yang paling penting pada temu kembali berbasis citra. Penelitian ini mengimplementasikan metode Support Vector Machine
(SVM) dengan algoritma optimisasi Sequential Minimal Optimization (SMO) untuk tahap klasifikasi pada sistem temu kembali citra berdasarkan ciri warna. Penelitian juga membandingkan kinerja SVM dengan pendekatan jarak Euclidean pada sistem temu kembali citra.
Data yang digunakan diambil dari basis data Caltech dan www.flowers.vg sebanyak 300 citra untuk berbagai macam objek. Format citra adalah JPEG berukuran 50×50 piksel. Seluruh citra di dalam basis data disegmentasi menggunakan algoritma Expectation-Maximization (EM) dan diekstraksi menggunakan metode Fuzzy Color Histogram (FCH) untuk membentuk indeks warna citra di dalam basis data. Kemudian indeks warna citra ini dilatih menggunakan algoritma optimisasi SMO untuk membentuk model klasifikasi SVM. Model klasifikasi ini digunakan untuk mengklasifikasikan citra. Dari hasil klasifikasi, diambil citra di dalam basis data yang memiliki kelas yang sama dengan citra kueri dan citra dari kelas lain yang memiliki tingkat kemiripan yang tinggi dengan citra kueri sebagai citra hasil temu kembali.
Evaluasi terhadap hasil temu kembali dilakukan menggunakan rataan precision untuk setiap tingkat recall. Berdasarkan penelitian ini, temu kembali citra menggunakan metode klasifikasi SVM memiliki hasil temu kembali dengan rataan precision mencapai 76.76%, sedangkan pada temu kembali citra yang hanya berdasarkan jarak Euclidean antar citra memiliki rataan precision
50.91%.
NRP
: G64103034
Menyetujui:
Pembimbing I
Pembimbing II
Yeni Herdiyeni, S.Si., M.Kom.
Ir. Agus Buono, M.Si., M.Kom.
NIP 132 282 665
NIP 132 045 532
Mengetahui:
Dekan Fakultas Matematika dan Ilmu Pengetahuan Alam
Institut Pertanian Bogor
Prof. Dr. Ir. Yonny Koesmaryono, MS
NIP 131 473 999
Alhamdulillahirabbil ‘alamin, puji syukur penulis panjatkan kepada Allah Subhanahu wa ta’ala atas segala curahan rahmat dan karunia-Nya, sehingga penulis dapat menyelesaikan skripsi metode Support Vector Machine untuk klasifikasi pada sistem temu kembali citra ini. Shalawat serta salam juga penulis sampaikan kepada junjungan kita Nabi Muhammad Shalallahu ‘alaihi wasallam beserta seluruh keluarga, sahabat dan umatnya hingga akhir zaman.
Penulis mengucapkan terima kasih kepada Ibu Yeni Herdiyeni, S.Si., M.Kom. dan Bapak Ir. Agus Buono, M.Si., M.Kom. selaku pembimbing I dan pembimbing II yang telah banyak memberi saran, masukan dan ide-ide kepada penulis serta semangat untuk selalu berusaha yang terbaik. Penulis juga mengucapkan terima kasih kepada Bapak Irman Hermadi, S.Kom., M.S. selaku penguji yang telah memberi saran dan masukan. Selanjutnya, penulis ingin mengucapkan terima kasih kepada:
1 Ibu, Bapak, Mas Heru, Mbak Danik, Mas Yelly, dan Mas Rudhy, serta seluruh saudara di Solo yang senantiasa memberikan dukungan, doa dan kasih sayang. Untuk Bapak semoga cepat sembuh dan kembali ceria seperti dulu.
2 Fadlul Fadkur Rahman atas semuanya yang tidak bisa dijabarkan, tak lupa juga Nia ucapkan selamat atas kelulusannya, dan semoga tetap semangat dan ceria dalam menjalani hari-hari kerjanya di tanah rantau.
3 Yulia atas kerjasamanya dalam menyelesaikan tugas akhir ini, karena tanpa hasil segmentasimu, mungkin aku masih menjadi mahasiswi sejati.
4 Citha, Ghibta, Nacha dan rekan-rekan di Laboratorium Computational Intelligence (CI) atas semangat kekeluargaan serta bantuannya dalam menyelesaikan penelitian ini.
5 Meynar, Nanik, Dina dan penghuni wisma RZ lainnya yang telah banyak membantu dan memotivasi penulis melalui kebersamaan dan dukungan untuk terus berusaha yang terbaik. 6 Departemen Ilmu Komputer, dosen dan staf yang telah banyak membantu penulis pada masa
perkuliahan dan penelitian.
7 Ratih, Yayan, Sofi, Aristi, dan seluruh rekan Ilkomerz 40 yang banyak membantu penulis baik secara teknis maupun non-teknis pada masa perkuliahan hingga akhir penyusunan makalah skripsi ini.
Penulis menyadari bahwa masih banyak kekurangan dalam penelitian ini. Oleh karena itu, penulis sangat mengharapkan kritik dan saran untuk perbaikan di masa mendatang. Penulis berharap hasil dari penelitian ini dapat bermanfaat dan dapat menjadi acuan bagi penelitian berikutnya.
Bogor, Agustus 2007
Halaman
DAFTAR TABEL ... .vi
DAFTAR GAMBAR ... vi
DAFTAR LAMPIRAN ... vi
PENDAHULUAN ... 1
Latar Belakang ... 1
Tujuan... ... 1
Ruang Lingkup ... 1
TINJAUAN PUSTAKA ... 1
Content-Based Image Retrieval ... 1
Expectation-Maximization ... 1
Ektraksi Ciri Warna ... 1
Fuzzy Color Histogram ... 2
Fuzzy C-Means ... 2
Fungsi Cauchy ... 2
K-Fold Cross Validation ... 2
Support Vector Machine ... 3
Sequential MinimalOptimization ... 4
Recall dan Precision ... 5
METODE PENELITIAN ... 5
Data Penelitian ... 5
Segmentasi Warna dengan EM ... 5
Ekstraksi Ciri Warna dengan FCH ... 6
Data Latih dan Data Uji ... 6
Pelatihan dengan SVM ... 6
Pengujian dengan SVM ... 6
Hasil Temu Kembali ... 7
Evaluasi Hasil Temu Kembali ... 7
Perangkat Lunak dan Perangkat Keras yang Digunakan ... 7
HASIL DAN PEMBAHASAN ... 7
Segmentasi Citra ... 7
Ekstraksi ciri warna ... 8
Data Uji dan Data Latih ... 8
Klasifikasi... ... 8
Hasil Temu Kembali ... 9
Evaluasi Hasil Temu Kembali ... 10
KESIMPULAN DAN SARAN ... 11
Kesimpulan... ... 11
Saran ... ... 11
DAFTAR PUSTAKA ... 11
1 Rataan akurasi hasil proses pengujian untuk setiap pasangan C dan σ ... 8
2 Hasil proses pengujian dengan C = 26 dan σ= 2-1 ... 9
3 Nilai rataan precision hasil temu kembali citra ... 11
DAFTAR GAMBAR Halaman 1 Data terpisah secara linier. ... 3
2 Fungsi Φ
( )
xr memetakan data ke ruang vektor berdimensi lebih tinggi... 34 Contoh citra sebelum dan sesudah segmentasi menggunakan algoritma EM. ... 7
5 Gambar wajah... 8
6 Hasil FCH dengan FCM 25 bin. ... 8
7 Contoh hasil temu kembali tanpa menggunakan SVM. ... 9
8 Contoh hasil temu kembali menggunakan SVM. ... 9
9 Contoh hasil temu kembali citra menggunakan SVM... 10
10 Grafikrataan precision hasil temu kembali citra menggunakan SVM dan tanpa menggunakan SVM……….………...………...11 DAFTAR LAMPIRAN Halaman 1 Seluruh citra dalam basis data setelah melalui proses segmentasi ... 14
2 Warna kuantisasi untuk 25 bin histogram ... 17
3 Hasil klasifikasi SVM ... 18
4 Citra kueri yang diujicobakan pada proses temu kembali citra ... 21
5 Contoh hasil temu kembali citra berdasarkan ciri warna menggunakan SVM... 22
6 Nilai recall-precision hasil temu kembali citra menggunakan SVM untuk setiap citra kueri……26
PENDAHULUAN
Latar Belakang
Seiring dengan banyaknya aplikasi multimedia dan perkembangan internet, jumlah citra pun meningkat secara tajam. Para pengguna sangat mudah untuk mengakses ratusan bahkan ribuan citra, akan tetapi seringkali tidak mudah mendapatkan citra-citra yang sesuai dengan yang dibutuhkan pengguna. Oleh karena itu, perlu dikembangkan metode pencarian citra untuk mempermudah pencarian data. Pencarian citra dapat dilakukan berdasarkan isi citra atau sering disebut Content-Based Image Retrieval
(CBIR). CBIR ini mencari citra dengan mencocokkan isinya yang berupa tekstur, bentuk, atau warna. Salah satu metode pencarian citra yang banyak dikembangkan adalah berdasarkan warna citra.
Pada sistem temu kembali citra yang hanya berdasarkan jarak Euclidean antar citra, citra yang ditemukembalikan adalah citra di dalam basis data yang mempunyai tingkat kemiripan yang tinggi dengan citra kueri. Banyak kemungkinan citra yang ditemukembalikan adalah citra yang bukan dari jenisnya sendiri. Hal ini dapat menyebabkan tingkat keefektifan hasil temu kembali citra menjadi kurang baik. Oleh karena itu, diperlukan sebuah model klasifikasi untuk memperbaiki tingkat keefektifan hasil temu kembali citra. Model klasifikasi tersebut dapat dibangun melalui proses pelatihan, dan digunakan untuk mengklasifikasikan citra. Citra yang ditemukembalikan pada sistem temu kembali menggunakan model klasifikasi adalah citra hasil klasifikasi di dalam basis data yang terdapat dalam kelas citra yang sama dengan citra kueri dan citra dari kelas lain yang memiliki tingkat kemiripan yang tinggi dengan citra kueri.
Platt (1998) telah menggunakan algoritma
Sequential Minimal Optimization (SMO) untuk proses pelatihan dalam metode Support Vector Machine (SVM) dengan waktu komputasi yang lebih cepat. Zhang et al.
(2001) telah menggunakan metode SVM untuk klasifikasi pada sistem temu kembali citra berdasarkan ciri warna. Berdasarkan hasil penelitian Gosselin dan Cord (2004), metode SVM memberikan hasil klasifikasi yang lebih baik dibandingkan dengan metode klasifikasi Bayes dan k-Nearest Neighbors
(kNN). Oleh karena itu, pada penelitian ini
dikembangkan sebuah sistem temu kembali citra berdasarkan ciri warna menggunakan metode klasifikasi SVM dengan algoritma optimisasi SMO.
Tujuan Penelitian
Tujuan penelitian ini adalah mengimplementasikan dan menganalisis kinerja metode SVM dengan algoritma optimisasi SMO dalam tahap klasifikasi citra dan pada sistem temu kembali citra berdasarkan ciri warna.
Ruang Lingkup
Ruang lingkup penelitian ini difokuskan pada metode klasifikasi menggunakan SVM.
TINJAUAN PUSTAKA
Content-Based Image Retrieval
Content-Based Image Retrieval (CBIR) merupakan suatu pendekatan untuk masalah temu kembali citra yang didasarkan pada ciri yang terkandung di dalam citra seperti warna, bentuk atau tekstur dari citra (Han & Ma 2002).
Expectation-Maximization
Expectation-Maximization (EM) adalah salah satu metode optimisasi untuk mencari dugaan parameter maximum likelihood ketika ada data yang hilang atau tidak lengkap. Di dalam algoritma EM, dilakukan perhitungan dugaan kemungkinan untuk mengisi data yang tidak lengkap (E-step) dan perhitungan dugaan parameter maximum likelihood dengan memaksimalkan dugaan kemungkinan yang diperoleh dari E-step (M-step). Nilai parameter yang diperoleh dari M-step
digunakan kembali untuk memulai E-step
selanjutnya. Proses ini akan berulang hingga mencapai konvergensi nilai likelihood
(Belongie et al. 1998). Ektraksi Ciri Warna
Ekstraksi ciri warna merupakan salah satu bagian dari CBIR untuk menentukan arti fisik suatu citra melalui proses pengindeksan warna. Proses ini bisa dilakukan dengan pendekatan histogram warna (Belongie et al.
1998).
mengandung N piksel dapat dirumuskan seperti H(I)=[h1,h2,...,hn] dengan
∑ =
= N
j Pi j N i h 1 | 1 ,
⎩
⎨
⎧
= selainnya ; 0 i -ke bin ke sasi terkuanti j piksel ; 1 |j i P .Histogram warna seperti ini disebut juga
conventional color histogram (CCH) (Han & Ma 2002).
Fuzzy Color Histogram
Fuzzy Color Histogram (FCH) adalah salah satu metode yang merepresentasikan informasi warna dalam citra digital ke dalam bentuk histogram. Di dalam FCH, setiap warna direpresentasikan dengan himpunan fuzzy (fuzzy set). Hubungan antar warna dimodelkan dengan fungsi keanggotaan (membership function) terhadap fuzzy set.
Fuzzy set F pada ruang ciri Rn didefinisikan oleh ηF:Rn→[0,1] yang biasa disebut
membership function. Untuk tiap vektor ciri
n
f∈ℜ , nilai dari ηF(f) disebut derajat
keanggotaan dari f terhadap fuzzy set F
(derajat keanggotaan F). Nilai dari ηF(f)
yang mendekati 1 lebih representatif terhadap vektor ciri f dan terhadap fuzzy setf (Zhang R & Zhang Z 2004).
Fuzzy C-Means
Fuzzy C-Means (FCM) adalah suatu teknik pengelompokan data (clustering) tanpa proses pelatihan (unsupervised learning). Algoritma FCM adalah sebagai berikut (Han & Ma 2002):
1 Masukkan jumlah cluster c, konstanta pembobot m, dan toleransi nilai error e.
2 Inisialisasi pusat cluster ui untuk
c i≤
≤
1 .
3 Data input X =
{
x1,x2,...,xn}
.4 Menghitung c pusat cluster{ui(l)} dengan
∑
∑
= = = 1 1 ) ( ) ( ) ( k m ik n k k m ik l i u x uv , untuk 1≤i≤c.
5 Perbaharui nilai keanggotaan U(l)dengan
∑
= − ⎟⎟ ⎟ ⎠ ⎞ ⎜⎜ ⎜ ⎝ ⎛ − − = c j m A j k A i k ik u x u x u 1 1 2 2 2 1 . ,..., 2 , 1 . ,..., 2 , 1 n k c i = =6 Jika U(l) −U(l−1) >e maka l =l+1 dan kembali ke tahap 4. Jika tidak maka berhenti.
Hasil FCM adalah sejumlah pusat cluster
dengan derajat keanggotaan setiap titik data terhadap cluster tersebut yang digambarkan sebagai matrik U =[uik]n×n'.
Fungsi Cauchy
Beberapa fungsi keanggotaan adalah fungsi Cauchy, Cone, dan Trapezoidal. Berdasarkan hasil penelitian Zhang R dan Zhang Z (2004), fungsi Cauchy lebih baik daripada fungsi keanggotaan yang lain. Fungsi
Cauchy C:Rn →[0,1] didefinisikan sebagai berikut:
(
)
, / 1 1 ) ( α d v x x C r r r − + = , 0 , 0 , , , ≥ > ∈ ∈ α α d R d R vrv
r
adalah titik tengah dari lokasi fuzzy set, dmerepresentasikan lebar dari fungsi dan α merepresentasikan tingkat fuzziness
(kekaburan).
K-Fold Cross Validation
K-Fold Cross Validation dilakukan untuk membagi data pelatihan dan data pengujian.
K-Fold Cross Validation membagi data contoh secara acak ke dalam K subset yang saling bebas. Satu subset sebagai data pengujian dan K-1 subset sebagai data pelatihan. Proses cross-validation akan diulang sampai K kali (Fu 1994).
Pada metode tersebut, data awal dibagi menjadi k subset yang saling bebas secara acak, yaitu S1,S2,…,Sk, dengan ukuran setiap
subset kira-kira sama. Pelatihan dan pengujian dilakukan sebanyak k kali. Pada proses ke-i, subset Si diperlakukan sebagai data pengujian
dan subset lainnya diperlakukan sebagai data pelatihan. Pada proses pertama S2,...,Sk
menjadi data pelatihan dan S1 menjadi data
pengujian, pada proses kedua S1,S3,...,Sk
menjadi data pelatihan dan S2 menjadi data
Support Vector Machine
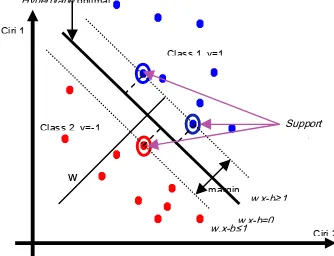
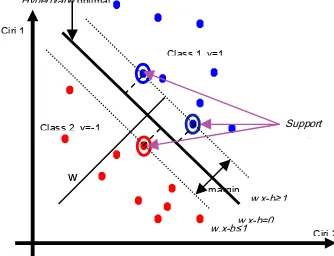
Support Vector Machine (SVM) adalah salah satu teknik klasifikasi data dengan proses pelatihan (supervised learning). Salah satu ciri dari metode klasifikasi SVM adalah menemukan garis pemisah (hyperplane) terbaik sehingga diperoleh ukuran margin
yang maksimal. Titik yang terdekat dengan
hyperplane disebut support vector. Margin
adalah dua kali jarak antara hyperplane
dengan support vector. Ilustrasi SVM untuk data yang terpisahkan secara linier dapat dilihat pada Gambar 1.
Gambar 1 Data terpisah secara linier. Diberikan data latih
( )( )
x1,y1,x2,y2,...,(
xn,yn)
,di mana x∈ℜn, y∈
{ }
+1,−1. Jika data terpisahsecara linier seperti pada Gambar 1, maka akan berlaku fungsi diskriminan linier:
b x w
u= . − , (1) dengan
w = vektor bobot yang tegak lurus terhadap
hyperplane,
x = datayang diklasifikasi, b = bias.
Hyperplane adalah garis u=0. Margin antara dua kelas adalah
2 2 w
m= . Margin dapat dimaksimalkan menggunakan fungsi optimisasi Lagrangian seperti berikut:
(
)
∑(
(
(
)
)
)
= + −
−
= l
i i yi xi w b w
b w L
1 , 1
2 2 1 ,
, r r r
r α α (2).
Dengan memperhatikan sifat gradien:
∑ = = − = ∂ ∂ l
i iyixi w
w L
1α 0
dan ∑
= =
= ∂
∂ l
i iyi b L
1α 0
,
persamaan (2) dapat dimodifikasi sebagai maksimalisasi L yang hanya mengandung αi,
sebagaimana persamaan (3).
∑ = ∑= ∑ = − = l i l
j i jyiyj xixj l
i i
L
1 1 ( . )
1 2
1 αα r r
α (3)
dengan 0≤αi ≤C,(i=1,2,...,l),∑ = =
l
i 1αiyi 0
, dan αi adalah lagrange multiplier. Data yang
berkorelasi dengan αi yang positif disebut sebagai support vector. Support vector inilah yang akan digunakan untuk menghitung bobot
∑ =
=NSV
i iyixi w
1α
dan bias b=w.xi−yi untuk
i=1,2,...,NSV. Selanjutnya, kelas dari data
input x dapat ditentukan dengan persamaan (1).
Gambar 2 Fungsi Φ
( )
xr memetakan data keruang vektor berdimensi lebih tinggi.
Jika data terpisah secara tidak linier, SVM dimodifikasi dengan memasukkan fungsi
( )
xrΦ . Dalam SVM yang tidak linier, pertama-tama data dipetakan oleh fungsi Φ
( )
xr keruang vektor baru yang berdimensi lebih tinggi, seperti pada Gambar 2. Selanjutnya di ruang vektor yang baru itu, SVM mencari
hyperplane yang memisahkan kedua kelas secara linier. Pencarian ini hanya bergantung pada dot product dari data yang sudah dipetakan pada ruang baru yang berdimensi lebih tinggi, yaitu
( )
( )
j x i xr Φr
Φ . . Karena
umumnya transformasi Φ
( )
xr ini tidak diketahui dan sangat sulit untuk dipahami, maka perhitungan dot product dapat digantikan dengan fungsi Kernel yang dirumuskan sebagai berikut:K(xri,xrj) = Φ(xri).Φ(xrj),
sehingga persamaan (3) menjadi seperti berikut: ∑ = ∑= ∑ = − = l i l
j i jyiyjK xixj l
i i
L
1 1 ( . )
1 2
1 α α r r
α (4)
dan persamaan (1) menjadi seperti berikut:
( )
bNSV
i iyiK xi x
u ∑ −
= =
1 ,
r r
α (5),
NSV adalah data pelatihan yang termasuk
support vector. Fungsi Kernel yang sering Ciri 2 Ciri 1 Support t Hyperplaneoptimal margin w
w x-b 1 w.x-b 1w.x-b=0
Class 1 y=1
digunakan untuk SVM adalah fungsi Kernel Gaussian RBF (Mak 2000):
⎟
⎟
⎟
⎠
⎞
⎜
⎜
⎜
⎝
⎛
− − = 2 2 2 exp ) , ( σ j x i x j x i x K r r r r .Sequential Minimal Optimization
Sequential Minimal Optimization (SMO) adalah algoritma untuk proses pelatihan SVM yang dapat memberikan solusi pada masalah optimisasi. Pada dasarnya penggunaan SVM hanya terbatas pada masalah yang kecil karena algoritma pelatihan SVM cenderung lambat, kompleks, dan sulit untuk diimplementasikan. Berdasarkan hasil penelitian sebelumnya, algoritma SMO lebih sederhana, lebih mudah diimplementasikan, dan lebih cepat waktu komputasinya daripada algoritma Chunking (Platt 1998 ).
SMO memilih menyelesaikan masalah optimisasi pada persamaan (4) seminimal mungkin untuk setiap tahapnya. Pada setiap tahap, SMO memilih dua lagrange multipliers αi untuk dioptimisasi bersama-sama, mencari
nilai yang paling optimal untuk lagrange multiplier tersebut, dan memperbaharui SVM dengan nilai optimal yang baru.
Algoritma SMO adalah sebagai berikut (Platt 1998):
1 - Masukkan data latih
( )( )
x1,y1,x2,y2,...,(
xn,yn)
,nilai parameter SMO C, dan nilai parameter kernelσ.
- Inisialisasi nilai lagrange multiplier
αdan biasb.
2 - Lakukan iterasi pada seluruh data latih, cari α1yang melanggar sifat gradien. - Jika α1diperoleh maka ke tahap 3. - Jika iterasi pada seluruh data latih
selesai, maka lakukan iterasi pada data yang tidak terdapat pada batas.
- Lakukan iterasi pada seluruh data latih dan pada data yang tidak terdapat pada batas secara bergantian untuk mencari
1
α yang melanggar sifat gradien sampai seluruh α memenuhi sifat gradien. 3 - Cari α2 dari data yang tidak terdapat
pada batas.
- Ambil α yang memberikan nilai |E1-E2|
terbesar sebagai .α2 E1 dan E2 merupakan error cache untuk α1dan α2. - Jika dua data identik, maka buang α2 ini dan ke tahap 4. Selainnya, hitung nilai L
dan H untuk
2 α : ⎪⎩ ⎪ ⎨ ⎧ ≠ − + = − = 2 1 jika ), 1 2 , 0 ( max 2 1 jika ), 1 2 , 0 ( max y y C y y L α α α α , ⎪⎩ ⎪ ⎨ ⎧ ≠ + = − + = 2 1 jika ), 1 2 , ( min 2 1 jika ), 1 2 , ( min y y C y y C C H α α α α .
- Jika L=H, maka perkembangan optimisasi tidak dapat dibuat, buang α2 ini dan ke tahap 4. Selainnya, hitung nilai η:
) 2 , 2 ( ) 1 , 1 ( ) 2 , 1 (
2K xr xr −K xr xr −K xr xr
=
η .
- Jika nilai η negatif, maka hitung nilai
2
α yang baru. Selainnya, hitung fungsi objektif pada titik L dan H dan gunakan nilai α2 yang memberikan fungsi objektif
paling tinggi sebagai nilai α2 yang baru.
- Jika lama
2 baru
2 α
α − lebih kecil dari nilai perubahan terkecil α (ε), maka buang nilaiα2 ini dan ke tahap 4. Selainnya ke tahap 5.
4 - Lakukan iterasi pada data yang tidak terdapat pada batas sampai diperoleh α2 yang dapat membuat perkembangan optimisasi di tahap 3.
- Jika tidak diperoleh, maka lakukan iterasi pada seluruh data latih sampai diperoleh α2 yang dapat membuat perkembangan optimisasi di tahap 3. - Jika α2 tidak diperoleh setelah dua iterasi
tersebut, maka lewati nilai α1 yang diperoleh dan kembali ke tahap 2 untuk mencari α1baru yang melanggar sifat gradien.
Recall dan Precision
Dua parameter utama yang dapat digunakan untuk mengukur keefektifan temu kembali citra, yaitu recall dan precision. Recall adalah perbandingan jumlah materi relevan yang ditemukembalikan terhadap jumlah materi yang relevan, sedangkan
precision adalah perbandingan jumlah materi relevan yang ditemukembalikan terhadap jumlah materi yang ditemukembalikan (Grossman 2006). data basis dalam relevan citra jumlah kembali temu hasil relevan citra jumlah = recall terambil yang citra seluruh jumlah terambil yang relevan citra jumlah = precision
Average precision adalah suatu ukuran evaluasi yang diperoleh dengan menghitung rata-rata tingkat precision pada berbagai tingkat recall (Grossman 2006).
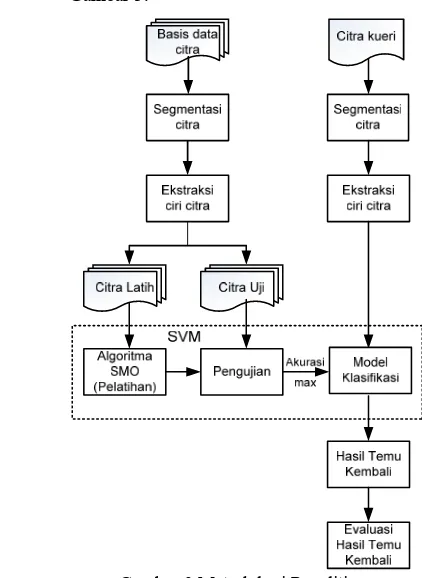
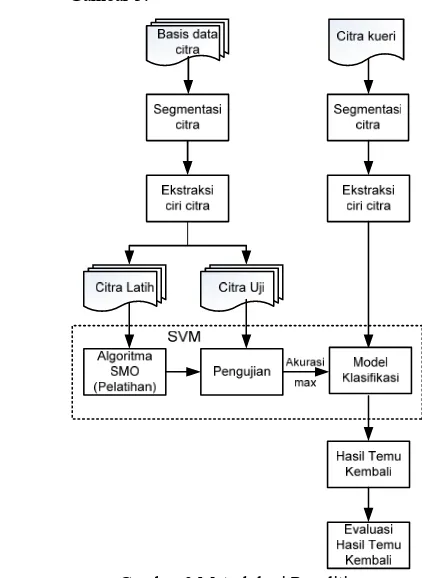
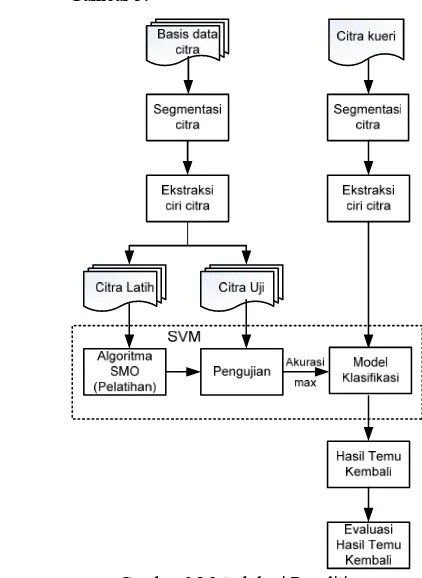
METODE PENELITIAN
Metode penelitian ini dapat dilihat pada Gambar 3.
Gambar 3 Metodologi Penelitian.
Data Penelitian
Data yang digunakan diambil dari basis data Caltech dan www.flowers.vg sebanyak 300 citra untuk berbagai macam objek. Format citra adalah JPEG berukuran 50×50 piksel.
Segmentasi Warna dengan EM
Pada tahapan segmentasi ini, setiap citra akan disegmentasi untuk mengelompokkan warna yang dikandung oleh setiap piksel dari citra ke beberapa segmen yang sudah ditentukan jumlahnya, yaitu dua, tiga, empat, dan lima. Segmen ini merupakan representasi dari warna-warna dominan citra. Setiap piksel dari citra dibangkitkan dari salah satu G segmen. Peluang sebuah piksel masuk ke dalam segmen adalah sebagai berikut:
(
)
( )
.1 |
| l
g
l p x l
x
p ∑ θ π
= = Θ
Masing-masing segmen diasumsikan mempunyai distribusi normal Gauss, sehingga peluang piksel dari segmen l dapat dihitung dengan formulasi sebagai berikut:
( )
( ) 1( ).2 1 exp 2 1 ) det( 2 ) 2 ( 1 | ⎭ ⎬ ⎫ ⎩ ⎨ ⎧− − Σ− − Σ
= x lT l x l
l d l x
p μ μ
π θ
Algoritma EM mempunyai dua tahapan utama yaitu tahapan Expectation (E-step) dan
Maximization (M-step). Pada tahapan
Expectation, data Xdiasumsikan sebagai data yang tidak lengkap dengan missing value
berupa label yang menyatakan keanggotaan tiap piksel dari X ke dalam salah satu G segmen. Yang dilakukan pada tahapan ini adalah menghitung peluang tiap piksel dari tiap segmen dan membentuk matriks Z yang akan melengkapi data X, sehingga data yang lengkap dapat dinyatakan sebagai
(
X Z)
Y = , . Label tiap piksel didapatkan dari segmen yang mempunyai peluang tertinggi dalam Z . Nilai likelihood dari data yang lengkap adalah
(
)
. 1 1 | ) | ( ∑ = ∑= Θ = Θ n i g l p x Yp
∑ = ∑ = = + N i i l z N
i xi
i l z t l 1 1 1 μ ,
(
)(
)
. 1 1 1 1 1 ∑ = ∑ = + − + − = + ∑ N i i l z N i T t l i x t l i x i l z t l μ μNilai parameter yang baru dari M-step ini akan digunakan kembali untuk E-step pada iterasi berikutnya. Proses E-step dan M-step
akan terus berulang sampai didapatkan nilai
likelihood yang kecil sehingga hasil perhitungan sudah tidak terlalu banyak mengalami perubahan. Ketika nilai likelihood
hanya sedikit berubah, maka hasil dianggap konvergen.
Ekstraksi Ciri Warna dengan FCH
Proses ekstraksi warna dengan FCH tidak terlalu beragam hasilnya pada perbedaan ruang warna (RGB, HSV, Lab) (Vertan & Boujemaa 2000). Oleh karena itu, pengolahan citra pada penelitian ini dilakukan pada ruang warna RGB untuk mempermudah pengolahan citra.
Langkah pertama yang dilakukan untuk menghitung FCH adalah menghitung histogram awal. Pada penelitian ini, nilai warna kuantisasi awal tersebut didasarkan pada sebaran warna citra dalam basis data yang memiliki 10 kelas citra dengan jenis dan warna yang bervariasi. Untuk tiap kelas citra diambil 10 warna piksel yang muncul terbanyak sehingga dihasilkan 100 warna semesta tanpa ada warna yang sama.
Dari histogram awal dihasilkan jumlah ciri yang terlalu banyak sehingga diperlukan waktu komputasi yang besar untuk ekstraksi ciri sebuah citra. Oleh karena itu perlu dilakukan pengelompokan warna (clustering) dari 100 warna semesta tersebut ke dalam beberapa pusat cluster warna menggunakan
Fuzzy C-Means (FCM). Setiap pusat cluster
FCM merepresentasikan bin FCH. Jumlah bin
FCH yang digunakan sebanyak 25.
Untuk perhitungan FCH selanjutnya diperlukan matriks derajat keanggotaan, dimana nilai keanggotaannya dapat diperoleh menggunakan fungsi Cauchy:
α σ μ ) / ) , ' ( ( 1 1 ) ( ' c c d c
c = + , dengan
d(c’,c) = jarak Euclid antara warna c dengan
c’,
c’ = warna pada bin FCH,
c = warna semesta,
α = untuk menentukan kehalusan dari fungsi,
σ = untuk menentukan lebar dari fungsi keanggotaan.
Nilai parameter
α
=2 danσ
=15 diperoleh dari hasil percobaan sebelumnya (Balqis 2006).Perhitungan akhir FCH dengan FCM dinotasikan sebagai berikut:
∑
∈ = μ μ cc c hc
c
h2( ') '( )* ( ) , dengan
2
h = fuzzy color histogram,
) (c
h = conventional color histogram, )
( ' c
c
μ = nilai keanggotaan dari warna c ke warna c’.
Data Latih dan Data Uji
Sesuai dengan metode 10-fold cross validation, seluruh data hasil ekstraksi ciri warna yang terdapat di dalam basis data dibagi menjadi 10 subset, yaitu S1,S3,...,S10.
Masing-masing subset memiliki ukuran yang sama. Pembagian data dilakukan secara acak dengan mempertahankan perbandingan jumlah citra setiap kelas. Pada proses pertama
S2,...,S10 menjadi data pelatihan dan S1
menjadi data pengujian, pada proses kedua
S1,S3,...,S10 menjadi data pelatihan dan S2
menjadi data pengujian, dan seterusnya. Pelatihan dengan SVM
Pada proses pelatihan SVM digunakan algoritma SMO dengan fungsi Kernel Gaussian RBF untuk membangun model klasifikasi. Di dalam algoritma SMO diperlukan nilai konstanta C dan nilai parameter kernel σ. Oleh karena itu perlu dilakukan proses pelatihan untuk setiap pasangan nilai C (20,21,...,29) dan σ (2-2,2-1, dan 20) untuk mendapatkan model klasifikasi terbaik. Data yang dimasukkan pada proses pelatihan ini adalah data citra pelatihan yang sudah ditentukan sebelumnya. Karena SVM bersifat supervised learning, maka setiap citra mengandung vektor ciri citra dan label kelas. Pengujian dengan SVM
Proses pengujian dilakukan dengan memprediksi terlebih dahulu data pengujian dengan persamaan (5). Persamaan (5) tersebut juga menggunakan fungsi Kernel Gaussian
dengan nilai σ yang digunakan pada tahap pelatihan sebelumnya. Selanjutnya dilakukan perhitungan tingkat akurasi SVM terhadap citra yang telah diprediksi secara benar dan tidak benar oleh model klasifikasi. Proses pengujian dilakukan berdasarkan metode 10-fold cross validation. Model klasifikasi dikatakan terbaik jika mencapai nilai akurasi yang paling tinggi ketika diaplikasikan ke data uji dengan nilai C dan σ terbaik. Model klasifikasi inilah yang akan digunakan untuk menentukan hasil klasifikasi akhir.
Hasil Temu Kembali
Dari hasil klasifikasi akhir, diambil citra di dalam basis data yang memiliki kelas yang sama dengan citra kueri dan citra dari kelas lain yang memiliki tingkat kemiripan yang tinggi dengan citra kueri sebagai citra hasil temu kembali. Pengukuran tingkat kemiripan citra kueri terhadap citra dari kelas lain menggunakan perhitungan jarak Euclidean. Jarak Euclidean antara citra a dan b dirumuskan dengan formula:
[
]
,1
2 ) ( ) ( , = ∑= −
B
i fcha i fchb i b
a d
dengan
fch = hasil ekstraksi ciri warna dengan menggunakan FCH,
B = jumlah bin pada histogram warna. Evaluasi Hasil Temu Kembali
Pada tahap evaluasi dilakukan penilaian tingkat keefektifan proses temu kembali terhadap sejumlah koleksi pengujian. Evaluasi menggunakan nilai recall dan precision dari hasil temu kembali citra berdasarkan penilaian relevansinya. Recall adalah perbandingan jumlah citra relevan yang terambil terhadap jumlah citra relevan di dalam basis data, sedangkan precision adalah perbandingan jumlah citra relevan yang terambil terhadap jumlah seluruh citra yang terambil.
Perangkat Lunak dan Perangkat Keras yang Digunakan
Perangkat lunak yang digunakan pada penelitian ini adalah Matlab 7.0.1 dan sistem operasi Windows XP Professional SP 1, sedangkan spesifikasi perangkat keras yang mendukung adalah komputer dengan
processor Pentium IV 1.8 GHz dan memori 512 MB.
HASIL DAN PEMBAHASAN
Penelitian ini menekankan pada penerapan metode SVM untuk mengklasifikasikan citra berdasarkan ciri warna citra. Citra yang digunakan sebanyak 300 dengan format JPG yang kemudian distandarkan ke dalam ukuran 50×50 piksel. Terdapat 10 kelas citra yang berbeda yang digunakan dalam penelitian ini yaitu buaya, bonsai, macan, pesawat, kapal, wajah, bunga, kura-kura, gentong, dan budha. Segmentasi Citra
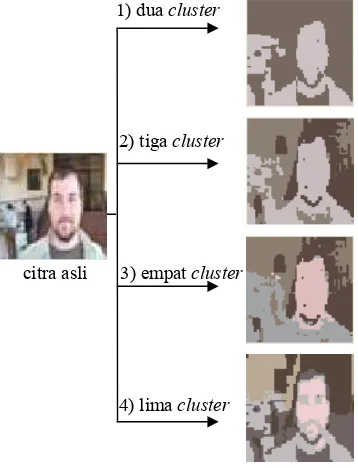
Pada tahapan segmentasi ini, setiap citra akan disegmentasi untuk mengelompokkan warna yang dikandung oleh setiap piksel dari citra ke beberapa segmen (cluster) yang sudah ditentukan jumlahnya, yaitu dua, tiga, empat, dan lima. Cluster ini merupakan representasi dari warna-warna dominan citra. Tahapan segmentasi ini bertujuan mendapatkan kelompok-kelompok warna dominan dan mengurangi jumlah warna citra asli seperti yang terlihat pada Gambar 4.
1) dua cluster
2) tiga cluster
citra asli 3) empat cluster
4) lima cluster
Gambar 4 Contoh citra sebelum dan sesudah
segmentasi menggunakan algoritma EM.
segmentensi yang sudah terpilih sebagai masukan pada tahap ekstraksi warna untuk seluruh citra di dalam basis data dapat dilihat pada Lampiran 1.
Ekstraksi ciri warna
Pada tahapan ekstraksi ini, setiap piksel pada citra akan direpresentasikan dengan peluang atau frekuensi piksel-piksel tersebut terhadap nilai warna (bin) yang sudah ditentukan sebanyak 25. Bin tersebut diperoleh dari FCH menggunakan FCM. Bin
FCH yang digunakan pada penelitian ini dapat dilihat pada Lampiran 2.
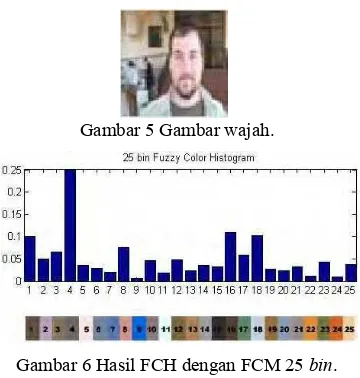
Gambar 5 Gambar wajah.
Gambar 6 Hasil FCH dengan FCM 25 bin. Gambar 6 adalah hasil FCH dengan FCM dari Gambar 5. Berdasarkan Gambar 6, dapat dilihat bahwa bin 4 yang cenderung berwarna hijau merupakan warna yang paling banyak muncul.
Data Uji dan Data Latih
Seluruh data citra hasil ekstraksi ciri warna di dalam basis data sebanyak 300 citra, dibagi secara acak ke dalam 10 subset. Setiap subset memiliki jumlah citra yang sama, yaitu 30 citra. Subset-subset tersebut akan digunakan sebagai data latih dan data uji sesuai dengan metode validasi silang, yaitu metode 10-fold cross validation.
Klasifikasi
Di dalam proses pelatihan SVM yang menggunakan algoritma SMO dan fungsi
KernelGaussian RBF diperlukan parameter C
dan σ. Sedangkan di dalam proses pengujian SVM yang menggunakan fungsi Kernel Gaussian RBF juga diperlukan parameter σ. Untuk memilih nilai parameter C dan σ terbaik digunakan metode 10-fold cross validation. Pada penelitian ini, dicobakan
beberapa nilai C dan σ untuk dicari yang terbaik, yaitu untuk nilai C (20,21,...,29)dan σ (2-2,2-1, dan 20).
Di dalam metode 10-fold cross validation, dilakukan proses pelatihan dan proses pengujian terhadap data latih dan data uji. Proses pelatihan dan pengujian ini bertujuan membangun model klasifikasi dan menghitung tingkat akurasi SVM dalam memprediksi citra uji. Model klasifikasi dikatakan terbaik jika mencapai nilai akurasi yang paling tinggi ketika diaplikasikan ke data uji dengan nilai C dan σ terbaik. Nilai C dan σ dikatakan terbaik jika mencapai rataan akurasi yang paling tinggi ketika digunakan dalam klasifikasi SVM.
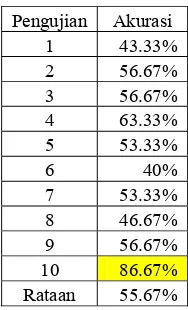
Akurasi adalah perbandingan jumlah citra yang telah diprediksi benar terhadap jumlah data uji. Rataan akurasi adalah nilai rata-rata dari akurasi di setiap pasangan nilai C dan σ. Rataan akurasi hasil proses pengujian untuk setiap pasangan nilai parameter C (20,21,...,29) dan σ(2-2,2-1, dan 20) dapat dilihat pada Tabel 1.
Tabel 1 Rataan akurasi hasil proses pengujian untuk setiap pasangan C dan σ
σ
C 2
-2
2-1 20 20 53.67% 52% 51.33% 21 54.33% 52.66% 51.33% 22 53.67% 53.67% 52%
23 54% 53% 53%
24 51% 53.33% 53% 25 51% 53.67% 52.03% 26 51.33% 55.67% 54% 27 52.33% 53.70% 55.33% 28 52.33% 51.67% 52.50% 29 52.33% 51.67% 54.67%
Berdasarkan Tabel 1, dapat dilihat bahwa untuk pasangan nilai parameter C = 26 dan σ= 2-1 dihasilkan rataan akurasi yang paling tinggi, yaitu 55.67%. Hal itu menunjukkan bahwa nilai C = 26 dan σ = 2-1 merupakan pasangan nilai C dan σ terbaik. Rincian akurasi untuk setiap tahap pengujian dengan menggunakan C = 26 dan σ= 2-1 dapat dilihat
pada Tabel 2.
klasifikasi ini mengandung bias (b), 240 buah citra dari data latih ke-10 yang terpilih sebagai
support vector, dan
α
iy
i,
(
i
=
1
,
2
,...,
240
)
. Citra yang termasuk support vector ini memiliki nilai lagrange multiplier0≤α≤C. Tabel 2 Hasil proses pengujian dengan C = 26dan σ= 2-1 Pengujian Akurasi
1 43.33% 2 56.67% 3 56.67% 4 63.33% 5 53.33% 6 40% 7 53.33% 8 46.67% 9 56.67% 10 86.67% Rataan 55.67%
Model klasifikasi terbaik digunakan untuk menentukan hasil klasifikasi akhir dengan menghitung nilai fungsi diskriminan seperti pada persamaan (5). Dalam perhitungan nilai fungsi diskriminan tersebut tidak digunakan seluruh citra di dalam basis data, akan tetapi hanya digunakan citra di dalam basis data yang termasuk support vector. Hasil klasifikasi akhir untuk seluruh citra di dalam basis data dapat dilihat pada Lampiran 3. Hasil Temu Kembali
Pada penelitian ini, temu kembali citra diujicobakan ke dua metode yang berbeda untuk melihat perbedaan tingkat keefektifan hasil temu kembali citra. Dua metode ini adalah temu kembali citra tanpa menggunakan SVM dan temu kembali citra menggunakan SVM. Citra di dalam basis data yang digunakan sebagai citra kueri adalah citra yang termasuk data uji ke-10 (Lampiran 4). Hal ini dikarenakan hasil proses pengujian yang paling baik dicapai saat model klasifikasi diaplikasikan terhadap data uji ke-10.
Hasil temu kembali citra tanpa menggunakan SVM hanya didasarkan pada kemiripan ciri warna menggunakan perhitungan jarak Euclidean. Contoh hasil temu kembali tanpa menggunakan SVM dapat dilihat pada Gambar 7.
Gambar 7 memperlihatkaan bahwa citra hasil temu kembali tidak sepenuhnya berasal dari jenis citra yang sama dengan citra kueri.
Citra yang relevan di dalam basis data yang ditemukembalikan sampai 30 citra teratas hanya sebanyak 10 dari 30 citra yang relevan di dalam basis data. Terdapat beberapa citra yang ditemukembalikan memiliki warna berbeda sekali dengan warna citra kueri, yaitu citra pada peringkat 4, 5, 8, 10, 11, 12, 14, 18, 22, 23, 26, 27, 28, dan 30. Citra-citra tersebut cenderung berwarna biru, berbeda sekali dengan warna citra kueri yang cenderung berwarna hijau kekuningan. Hal ini dikarenakan sistem tidak mengenal kelas citra dan sistem hanya menemukembalikan citra di dalam basis data yang mempunyai tingkat kemiripan yang tinggi dengan citra kueri. Kekurangan sistem ini diperbaiki oleh temu kembali citra menggunakan SVM yang dapat dilihat pada Gambar 8.
Gambar 7 Contoh hasil temu kembali tanpa menggunakan SVM.
Gambar 8 Contoh hasil temu kembali menggunakan SVM.
21. Citra tersebut tidak sejenis dengan citra kueri, akan tetapi memiliki warna yang cenderung sama dengan citra kueri. Hasil temu kembali citra yang sangat baik ini dikarenakan sistem mengenal kelas citra dan melakukan prediksi baik terhadap citra kueri maupun terhadap seluruh citra di dalam basis data sehingga diperoleh kelas yang baru untuk setiap citra. Citra yang ditemukembalikan adalah citra hasil klasifikasi di dalam basis data yang terdapat dalam kelas citra yang sama dengan citra kueri dan citra dari kelas lain yang memiliki tingkat kemiripan yang tinggi dengan citra kueri. Hasil temu kembali menggunakan SVM yang baik ini juga dipengaruhi oleh model klasifikasi yang terbaik. Pada tahap klasifikasi sebelumnya, telah dipilih model klasifikasi terbaik yang mencapai nilai akurasi 86.67% setelah diaplikasikan terhadap data uji ke-10. Nilai akurasi SVM yang baik ini, menyebabkan hasil temu kembali citra juga baik.
Gambar 9 Contoh hasil temu kembali citra menggunakan SVM.
Gambar 9 adalah contoh hasil temu kembali menggunakan SVM. Berdasarkan Gambar 9, dapat dilihat bahwa warna citra yang ditemukembalikan cenderung mirip dengan warna pada citra kueri, meskipun hanya dua citra yang relevan di dalam basis data yang ditemukembalikan sampai 30 citra teratas. Hal ini disebabkan hasil perhitungan fungsi diskriminan dengan SVM menunjukkan bahwa indeks warna citra kueri masuk ke kelas citra lain, yaitu citra buaya. Kesalahan klasifikasi ini menyebabkan hasil temu kembali citra menjadi kurang baik. Oleh karena itu, untuk penelitian selanjutnya dapat digunakan metode relevance feedback dalam temu kembali citra agar hasil temu kembali citra menjadi lebih baik. Dalam penggunaan metode relevance feedback, model klasifikasi SVM dapat dibentuk dari citra yang relevan dan yang tidak relevan dengan citra kueri
yang merupakan hasil penandaan oleh pengguna. Dengan model klasifikasi tersebut, sistem dapat menemukembalikan lebih banyak citra di dalam basis data yang relevan dengan citra kueri. Contoh hasil temu kembali citra berdasarkan ciri warna menggunakan SVM untuk setiap kelas citra dapat dilihat pada Lampiran 5.
Evaluasi Hasil Temu Kembali
Pada tahap evaluasi dilakukan penilaian tingkat keefektifan dalam proses temu kembali terhadap sejumlah koleksi pengujian dengan menghitung nilai recall dan precision
dari proses temu kembali citra berdasarkan penilaian relevansinya. Penentuan relevansi citra hasil temu kembali dibuat berdasarkan kelas citra di dalam basis data, di mana terdapat 10 kelas citra yang berbeda, yaitu: 1 Buaya,
2 Bonsai, 3 Macan, 4 Pesawat, 5 Kapal, 6 Wajah, 7 Bunga, 8 Kura-kura, 9 Genthong, 10 Budha.
Di dalam basis data terdapat 300 citra dari 10 kelas citra dengan 30 citra untuk setiap kelas citra. Dengan demikian untuk setiap kueri citra terdapat 30 citra relevan di dalam basis data yang penilaian relevansinya didasarkan atas kesamaan kelas citra. Penilaian relevansi tersebut kemudian digunakan sebagai acuan pada saat melakukan evaluasi terhadap hasil temu kembali untuk setiap citra kueri.
Nilai recall yang digunakan adalah 0,0.1,0.2,...,1. Nilai ini menunjukkan jumlah bagian citra dari seluruh citra terambil untuk perhitungan nilai precision. Misalkan untuk nilai recall 0.1 berarti jumlah citra yang digunakan untuk perhitungan nilai precision
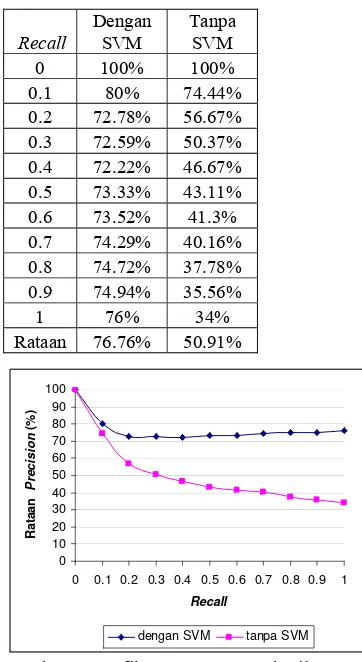
adalah 10% dari seluruh citra yang terambil. Nilai precision untuk nilai recall 0.1 adalah perbandingan banyaknya citra relevan yang terambil dari seluruh citra dengan jumlah tersebut. Nilai rataan precision hasil temu kembali citra dapat dilihat pada Tabel 3.Nilai
recall-precision hasil temu kembali citra tanpa menggunakan SVM untuk setiap citra kueri dapat dilihat pada Lampiran 7.
Tabel 3 Nilai rataan precision hasil temu kembali citra
Recall
Dengan SVM
Tanpa SVM 0 100% 100% 0.1 80% 74.44% 0.2 72.78% 56.67% 0.3 72.59% 50.37% 0.4 72.22% 46.67% 0.5 73.33% 43.11% 0.6 73.52% 41.3% 0.7 74.29% 40.16% 0.8 74.72% 37.78% 0.9 74.94% 35.56% 1 76% 34% Rataan 76.76% 50.91%
0 10 20 30 40 50 60 70 80 90 100
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Recall
R
at
aan
Pr
e
c
is
io
n
(%
)
dengan SVM tanpa SVM
Gambar 10 Grafik rataan precision hasil temu kembali citra menggunakan SVM dan tanpa menggunakan SVM. Berdasarkan Gambar 10, dapat dilihat bahwa nilai rataan precision temu kembali citra menggunakan SVM cenderung lebih besar daripada nilai rataan precision temu kembali citra tanpa menggunakan SVM pada setiap nilai recall lebih dari nol. Hal ini menunjukkan bahwa tingkat keefektifan hasil temu kembali citra menggunakan SVM cenderung selalu lebih tinggi daripada hasil temu kembali citra tanpa menggunakan SVM. Untuk temu kembali citra menggunakan SVM, dapat dilihat bahwa nilai rataan precision
mengalami penurunan pada nilai recall 0.1, sedangkan pada nilai recall lainnya cenderung stabil. Hal ini dikarenakan pada peringkat
recall 0.1 banyak kueri citra yang tidak menemukan citra yang relevan di dalam basis data. Untuk temu kembali citra tanpa
menggunakan SVM, dapat dilihat bahwa nilai rataan precision cenderung selalu mengalami penurunan pada setiap nilai recall. Hal ini dikarenakan banyak kueri citra yang menemukan sedikit citra yang relevan di dalam basis data.
KESIMPULAN DAN SARAN
Kesimpulan
Hasil penelitian menunjukkan bahwa metode SVM telah memberikan hasil temu kembali citra yang lebih baik daripada hasil temu kembali citra tanpa menggunakan metode SVM. Dengan metode 10-fold cross validation, didapatkan model klasifikasi terbaik dan citra kueri dari proses pelatihan dan pengujian ke-10, dengan akurasi SVM sebesar 86.67%. Nilai rataan precision untuk hasil temu kembali menggunakan SVM mencapai 76.76%, sedangkan nilai rataan
precision untuk hasil temu kembali tanpa menggunakan SVM mencapai 50.91%. Saran
Pada sistem temu kembali citra berdasarkan isi citra, pencarian citra dilakukan dengan mencocokkan isinya yang berupa warna, bentuk, ataupun tekstur. Berdasarkan penelitian, untuk memperbaiki hasil temu kembali diperlukan informasi selain warna, seperti bentuk dan tekstur. Isi citra meliputi warna, bentuk, dan tekstur. Oleh karena itu, untuk penelitian selanjutnya dapat dikembangkan sistem temu kembali citra berdasarkan ciri warna, bentuk, dan tekstur.
Berdasarkan penelitian, terdapat beberapa kesalahan klasifikasi yang dapat menyebabkan hasil temu kembali citra menjadi kurang baik. Oleh karena itu, untuk penelitian selanjutnya dapat digunakan metode relevance feedback dalam temu kembali citra agar hasil temu kembali citra menjadi lebih baik.
DAFTAR PUSTAKA
Balqis, DP. 2006. Metode Fuzzy Color Histogram untuk Temu Kembali Citra Bunga. [Skripsi]. Bogor:Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor.
http://elib.cs.berkeley.edu/carson/papers/I CCV98.pdf [6 Mei 2007].
Fu L. 1994. Neural Network In Computer Intelligence. Singapura : McGraw Hill. Gosselin PH, Cord M. 2004. A Comparison of
Active Clasification Methods for Content-Based Image Retrieval. http://perso-etis.ensea.fr/~gosselin/gosselin04cvdb.pdf [28 Oktober 2006].
Grossman D. IR Book. http://www.ir.iit.edu/~dagr/cs529/files/ir_ book/ [30 Oktober 2006].
Han J, Ma KK, Fuzzy Color Histogram and Its Use in Color Image Retrieval. IEEE Transaction on Image Processing, vol. 11, no. 8, 2002.
Mak G. 2000. The Implementation of Support Vector Machines Using The Sequential Minimal Optimization Algorithm.
http://www.cs.mcgill.ca/~hu/publications/ 99.04.McGill.thesis.gmak.pdf [28 Oktober 2006].
Platt JC. 1998. Sequential Minimal Optimization: A Fast Algorithm for Training Support Vector Machines.
http://reseach.microsoft.com/users/jplatt/s moTR.pdf [28 Oktober 2006].
Vertan C, Boujemaa N. 2000. Using Fuzzy Histogram and Distance for Color Image
Retrieval.
http://www-rocq.inria.fr/imedia/Articles/cir2000.pdf [28 Oktober 2006].
Zang Lei, et al. 2001. Support Vector Machine Learning for Image Retrieval. http://research.microsoft.com/users/leizhan g/Paper/ICIP01.pdf [28 Oktober 2006]. Zhang R, Zhang Z. A Robust Color Object
Analysis Approach to Efficient Image Retrieval.
Lampiran 2 Warna kuantisasi untuk 25 bin histogram
warna R G B
98 78 66
181 161 184
129 117 97
105 106 106 246 227 221 114 132 155
88 117 173
209 147 136
6 100 216
138 118 123 227 251 254
119 104 67
170 128 87
157 159 158 44 45 49
82 64 49
91 133 105
198 204 223
150 111 66
135 157 181 154 140 135
224 141 60
118 116 67
213 99 33
Lampiran 3 Hasil klasifikasi SVM ID
Citra Kelas Awal
Kelas Akhir
ID Citra
Kelas Awal
Kelas Akhir
ID Citra
Kelas Awal
Kelas Akhir
1 1 8 46 2 2 91 4 4
2 1 1 47 2 2 92 4 4
3 1 7 48 2 2 93 4 4
4 1 3 49 2 2 94 4 4
5 1 1 50 2 2 95 4 8
6 1 1 51 2 2 96 4 4
7 1 1 52 2 2 97 4 4
8 1 1 53 2 2 98 4 5
9 1 1 54 2 2 99 4 4
10 1 1 55 2 2 100 4 4
11 1 1 56 2 2 101 4 4
12 1 1 57 2 2 102 4 8
13 1 1 58 2 2 103 4 8
14 1 1 59 2 2 104 4 4
15 1 2 60 2 2 105 4 4
16 1 1 61 3 3 106 4 4
17 1 1 62 3 3 107 4 8
18 1 1 63 3 3 108 4 5
19 1 1 64 3 3 109 4 8
20 1 1 65 3 3 110 4 5
21 1 1 66 3 3 111 4 5
22 1 1 67 3 3 112 4 4
23 1 1 68 3 3 113 4 4
24 1 1 69 3 3 114 4 4
25 1 10 70 3 3 115 4 4
26 1 1 71 3 3 116 4 8
27 1 1 72 3 3 117 4 4
28 1 9 73 3 3 118 4 4
29 1 8 74 3 3 119 4 8
30 1 1 75 3 3 120 4 5
31 2 2 76 3 3 121 5 5
32 2 2 77 3 3 122 5 4
33 2 2 78 3 3 123 5 5
34 2 2 79 3 3 124 5 5
35 2 2 80 3 3 125 5 5
36 2 2 81 3 3 126 5 5
37 2 2 82 3 3 127 5 5
38 2 2 83 3 3 128 5 5
39 2 2 84 3 3 129 5 5
40 2 2 85 3 3 130 5 5
41 2 2 86 3 3 131 5 8
42 2 2 87 3 3 132 5 5
43 2 2 88 3 3 133 5 5
44 2 2 89 3 3 134 5 5
Lampiran 3 Lanjutan ID
Citra Kelas Awal
Kelas Akhir
ID Citra
Kelas Awal
Kelas Akhir
ID Citra
Kelas Awal
Kelas Akhir
136 5 5 181 7 7 226 8 8
137 5 5 182 7 7 227 8 8
138 5 5 183 7 7 228 8 8
139 5 5 184 7 7 229 8 8
140 5 5 185 7 7 230 8 8
141 5 5 186 7 7 231 8 8
142 5 5 187 7 7 232 8 8
143 5 5 188 7 7 233 8 8
144 5 5 189 7 7 234 8 8
145 5 5 190 7 7 235 8 8
146 5 5 191 7 7 236 8 8
147 5 5 192 7 7 237 8 8
148 5 5 193 7 7 238 8 8
149 5 5 194 7 7 239 8 8
150 5 5 195 7 7 240 8 8
151 6 6 196 7 7 241 9 9
152 6 6 197 7 7 242 9 9
153 6 6 198 7 7 243 9 9
154 6 6 199 7 7 244 9 9
155 6 6 200 7 7 245 9 9
156 6 6 201 7 7 246 9 9
157 6 6 202 7 7 247 9 9
158 6 6 203 7 7 248 9 9
159 6 6 204 7 7 249 9 9
160 6 6 205 7 7 250 9 3
161 6 6 206 7 7 251 9 6
162 6 6 207 7 7 252 9 9
163 6 6 208 7 7 253 9 9
164 6 6 209 7 7 254 9 9
165 6 6 210 7 7 255 9 3
166 6 6 211 8 8 256 9 9
167 6 6 212 8 8 257 9 9
168 6 6 213 8 8 258 9 9
169 6 6 214 8 8 259 9 9
170 6 6 215 8 8 260 9 1
171 6 6 216 8 8 261 9 9
172 6 6 217 8 8 262 9 9
173 6 6 218 8 8 263 9 10
174 6 6 219 8 8 264 9 1
175 6 6 220 8 8 265 9 9
176 6 6 221 8 8 266 9 9
177 6 6 222 8 8 267 9 2
178 6 6 223 8 8 268 9 10
179 6 6 224 8 8 269 9 9
Lampiran 3 Lanjutan ID
Citra Kelas Awal
Lampiran 4 Citra kueri yang diujicobakan pada proses temu kembali citra
No
Kueri Citra
ID Citra
No
Kueri Citra
ID Citra
No Kueri Citra
ID Citra
1 6 11 102 21 206
2 10 12 104 22 214
3 15 13 129 23 220
4 33 14 133 24 233
5 37 15 150 25 246
6 43 16 158 26 255
7 62 17 175 27 264
8 66 18 177 28 276
9 85 19 185 29 282
Lampiran 5 Contoh hasil temu kembali citra berdasarkan ciri warna menggunakan SVM
(a) Contoh kelas bonsai.
(b) Contoh kelas wajah.
Lampiran 5 Lanjutan
(d) Contoh kelas bunga.
(e) Contoh kelas kapal.
Lampiran 5 Lanjutan
(g) Contoh kelas budha.
(h) Contoh kelas kura-kura.
Lampiran 5 Lanjutan
Lampiran 6 Nilai recall-precision hasil temu kembali citra menggunakan SVM untuk setiap citra kueri
Recall
No kueri
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
1 100 66.67 33.33 55.56 66.67 73.33 72.22 76.19 75 77.78 80 2 100 33.33 16.67 22.22 41.67 53.33 61.11 66.67 70.83 74.07 76.67 3 100 33.33 16.67 11.11 8.33 6.67 5.56 4.76 4.17 3.7 3.33 4 100 100 100 100 100 100 100 95.24 95.83 96.3 96.67 5 100 100 100 100 100 93.33 94.44 95.24 95.83 92.59 93.33 6 100 100 100 100 100 100 100 95.24 95.83 96.3 96.67 7 100 100 100 100 100 100 88.89 90.48 87.5 88.89 90 8 100 100 83.33 77.78 83.33 86.67 88.89 85.71 87.5 88.89 90 9 100 100 100 88.89 91.67 86.67 88.89 90.48 91.67 88.89 90 10 100 33.33 33.33 33.33 50 40 50 57.14 62.5 66.67 70 11 100 66.67 66.67 55.56 41.67 33.33 33.33 28.57 25 25.93 23.33 12 100 100 83.33 66.67 58.33 60 61.11 66.67 70.83 74.07 76.67 13 100 100 83.33 88.89 83.33 86.67 83.33 80.95 83.33 81.48 83.33 14 100 66.67 66.67 77.78 66.67 73.33 77.78 80.95 83.33 81.48 83.33 15 100 100 83.33 88.89 83.33 86.67 77.78 80.95 83.33 81.48 83.33 16 100 100 100 100 100 100 94.44 95.24 95.83 96.3 96.67 17 100 100 100 100 100 100 94.44 95.24 95.83 96.3 96.67 18 100 100 83.33 88.89 91.67 93.33 94.44 95.24 95.83 96.3 96.67 19 100 100 100 100 100 100 100 100 95.83 96.3 96.67 20 100 100 100 100 100 100 100 95.24 95.83 96.3 96.67 21 100 100 100 100 100 100 100 100 95.83 96.3 96.67 22 100 100 100 88.89 83.33 86.67 88.89 80.95 75 74.07 73.33 23 100 100 50 55.56 50 60 61.11 66.67 70.83 62.96 66.67 24 100 66.67 33.33 55.56 58.33 60 61.11 66.67 62.5 62.96 66.67 25 100 66.67 50 33.33 41.67 53.33 55.56 61.9 66.67 70.37 73.33 26 100 33.33 16.67 22.22 16.67 13.33 11.11 9.52 8.33 7.41 6.67 27 100 33.33 33.33 22.22 16.67 13.33 11.11 9.52 8.33 7.41 6.67 28 100 66.67 83.33 77.78 75 80 83.33 85.71 87.5 88.89 90 29 100 66.67 83.33 77.78 75 80 83.33 85.71 87.5 88.89 90 30 100 66.67 83.33 88.89 83.33 80 83.33 85.71 87.5 88.89 90
Rataan 100 80 72.78 72.59 72.22 73.33 73.52 74.29 74.72 74.94 76
Keterangan:
Lampiran 7 Nilai recall-precision hasil temu kembali citra tanpa menggunakan SVM untuk setiap citra kueri
Recall
No kueri
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
1 100 66.67 33.33 22.22 25 20 22.22 19.05 20.83 18.52 20 2 100 33.33 16.67 22.22 25 20 16.67 28.57 25 25.93 23.33 3 100 66.67 33.33 22.22 16.67 13.33 22.22 19.05 16.67 14.81 16.67 4 100 100 100 88.89 75 60 55.56 52.38 54.17 48.15 43.33 5 100 33.33 50 44.44 50 40 38.89 33.33 33.33 29.63 30 6 100 100 66.67 44.44 33.33 40 38.89 42.86 37.5 33.33 33.33 7 100 66.67 33.33 44.44 41.67 33.33 27.78 28.57 29.17 25.93 23.33 8 100 100 83.33 77.78 83.33 73.33 77.78 76.19 70.83 70.37 66.67 9 100 100 83.33 66.67 50 46.67 38.89 42.86 37.5 37.04 33.33 10 100 33.33 33.33 33.33 50 40 38.89 33.33 33.33 29.63 36.67 11 100 66.67 66.67 55.56 41.67 40 38.89 38.1 33.33 33.33 30 12 100 100 83.33 66.67 58.33 53.33 61.11 57.14 50 44.44 43.33 13 100 100 66.67 44.44 50 46.67 50 42.86 41.67 37.04 36.67 14 100 66.67 50 66.67 66.67 53.33 50 52.38 45.83 44.44 43.33 15 100 100 66.67 55.56 50 46.67 44.44 38.1 41.67 37.04 40 16 100 66.67 50 33.33 25 26.67 22.22 23.81 20.83 18.52 20 17 100 100 83.33 88.89 75 66.67 55.56 52.38 45.83 44.44 43.33 18 100 66.67 33.33 33.33 33.33 33.33 33.33 33.33 33.33 33.33 30 19 100 66.67 33.33 22.22 25 20 16.67 19.05 16.67 14.81 16.67 20 100 100 100 100 91.67 86.67 83.33 80.95 75 66.67 60 21 100 100 100 100 83.33 80 77.78 71.43 62.5 55.56 56.67 22 100 100 83.33 66.67 50 60 55.56 52.38 50 51.85 46.67 23 100 100 50 55.56 50 60 55.56 52.38 54.17 59.26 53.33 24 100 66.67 33.33 55.56 50 53.33 50 57.14 58.33 51.85 46.67 25 100 66.67 50 33.33 25 26.67 22.22 23.81 25 22.22 20 26 100 33.33 16.67 11.11 25 20 22.22 19.05 16.67 14.81 13.33 27 100 33.33 33.33 22.22 16.67 13.33 16.67 19.05 20.83 25.93 23.33 28 100 66.67 66.67 55.56 50 40 33.33 33.33 29.17 25.93 23.33 29 100 66.67 66.67 44.44 41.67 40 33.33 28.57 25 22.22 20 30 100 66.67 33.33 33.33 41.67 40 38.89 33.33 29.17 29.63 26.67
Rataan 100 74.44 56.67 50.37 46.67 43.11 41.3 40.16 37.78 35.56 34
Keterangan:
VITA YULIA NOORNIAWATI
G64103034
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
VITA YULIA NOORNIAWATI. Metode Support Vector Machine untuk Klasifikasi pada Sistem Temu Kembali Citra. Dibimbing oleh YENI HERDIYENI dan AGUS BUONO.
Citra memiliki bentuk, tekstur dan warna yang sangat beragam. Hal ini menyebabkan sulitnya dilakukan pencarian citra. Klasifikasi citra merupakan salah satu tahap yang paling penting pada temu kembali berbasis citra. Penelitian ini mengimplementasikan metode Support Vector Machine
(SVM) dengan algoritma optimisasi Sequential Minimal Optimization (SMO) untuk tahap klasifikasi pada sistem temu kembali citra berdasarkan ciri warna. Penelitian juga membandingkan kinerja SVM dengan pendekatan jarak Euclidean pada sistem temu kembali citra.
Data yang digunakan diambil dari basis data Caltech dan www.flowers.vg sebanyak 300 citra untuk berbagai macam objek. Format citra adalah JPEG berukuran 50×50 piksel. Seluruh citra di dalam basis data disegmentasi menggunakan algoritma Expectation-Maximization (EM) dan diekstraksi menggunakan metode Fuzzy Color Histogram (FCH) untuk membentuk indeks warna citra di dalam basis data. Kemudian indeks warna citra ini dilatih menggunakan algoritma optimisasi SMO untuk membentuk model klasifikasi SVM. Model klasifikasi ini digunakan untuk mengklasifikasikan citra. Dari hasil klasifikasi, diambil citra di dalam basis data yang memiliki kelas yang sama dengan citra kueri dan citra dari kelas lain yang memiliki tingkat kemiripan yang tinggi dengan citra kueri sebagai citra hasil temu kembali.
Evaluasi terhadap hasil temu kembali dilakukan menggunakan rataan precision untuk setiap tingkat recall. Berdasarkan penelitian ini, temu kembali citra menggunakan metode klasifikasi SVM memiliki hasil temu kembali dengan rataan precision mencapai 76.76%, sedangkan pada temu kembali citra yang hanya berdasarkan jarak Euclidean antar citra memiliki rataan precision
50.91%.
PENDAHULUAN
Latar Belakang
Seiring dengan banyaknya aplikasi multimedia dan perkembangan internet, jumlah citra pun meningkat secara tajam. Para pengguna sangat mudah untuk mengakses ratusan bahkan ribuan citra, akan tetapi seringkali tidak mudah mendapatkan citra-citra yang sesuai dengan yang dibutuhkan pengguna. Oleh karena itu, perlu dikembangkan metode pencarian citra untuk mempermudah pencarian data. Pencarian citra dapat dilakukan berdasarkan isi citra atau sering disebut Content-Based Image Retrieval
(CBIR). CBIR ini mencari citra dengan mencocokkan isinya yang berupa tekstur, bentuk, atau warna. Salah satu metode pencarian citra yang banyak dikembangkan adalah berdasarkan warna citra.
Pada sistem temu kembali citra yang hanya berdasarkan jarak Euclidean antar citra, citra yang ditemukembalikan adalah citra di dalam basis data yang mempunyai tingkat kemiripan yang tinggi dengan citra kueri. Banyak kemungkinan citra yang ditemukembalikan adalah citra yang bukan dari jenisnya sendiri. Hal ini dapat menyebabkan tingkat keefektifan hasil temu kembali citra menjadi kurang baik. Oleh karena itu, diperlukan sebuah model klasifikasi untuk memperbaiki tingkat keefektifan hasil temu kembali citra. Model klasifikasi tersebut dapat dibangun melalui proses pelatihan, dan digunakan untuk mengklasifikasikan citra. Citra yang ditemukembalikan pada sistem temu kembali menggunakan model klasifikasi adalah citra hasil klasifikasi di dalam basis data yang terdapat dalam kelas citra yang sama dengan citra kueri dan citra dari kelas lain yang memiliki tingkat kemiripan yang tinggi dengan citra kueri.
Platt (1998) telah menggunakan algoritma
Sequential Minimal Optimization (SMO) untuk proses pelatihan dalam metode Support Vector Machine (SVM) dengan waktu komputasi yang lebih cepat. Zhang et al.
(2001) telah menggunakan metode SVM untuk klasifikasi pada sistem temu kembali citra berdasarkan ciri warna. Berdasarkan hasil penelitian Gosselin dan Cord (2004), metode SVM memberikan hasil klasifikasi yang lebih baik dibandingkan dengan metode klasifikasi Bayes dan k-Nearest Neighbors
(kNN). Oleh karena itu, pada penelitian ini
dikembangkan sebuah sistem temu kembali citra berdasarkan ciri warna menggunakan metode klasifikasi SVM dengan algoritma optimisasi SMO.
Tujuan Penelitian
Tujuan penelitian ini adalah mengimplementasikan dan menganalisis kinerja metode SVM dengan algoritma optimisasi SMO dalam tahap klasifikasi citra dan pada sistem temu kembali citra berdasarkan ciri warna.
Ruang Lingkup
Ruang lingkup penelitian ini difokuskan pada metode klasifikasi menggunakan SVM.
TINJAUAN PUSTAKA
Content-Based Image Retrieval
Content-Based Image Retrieval (CBIR) merupakan suatu pendekatan untuk masalah temu kembali citra yang didasarkan pada ciri yang terkandung di dalam citra seperti warna, bentuk atau tekstur dari citra (Han & Ma 2002).
Expectation-Maximization
Expectation-Maximization (EM) adalah salah satu metode optimisasi untuk mencari dugaan parameter maximum likelihood ketika ada data yang hilang atau tidak lengkap. Di dalam algoritma EM, dilakukan perhitungan dugaan kemungkinan untuk mengisi data yang tidak lengkap (E-step) dan perhitungan dugaan parameter maximum likelihood dengan memaksimalkan dugaan kemungkinan yang diperoleh dari E-step (M-step). Nilai parameter yang diperoleh dari M-step
digunakan kembali untuk memulai E-step
selanjutnya. Proses ini akan berulang hingga mencapai konvergensi nilai likelihood
(Belongie et al. 1998). Ektraksi Ciri Warna
Ekstraksi ciri warna merupakan salah satu bagian dari CBIR untuk menentukan arti fisik suatu citra melalui proses pengindeksan warna. Proses ini bisa dilakukan dengan pendekatan histogram warna (Belongie et al.
1998).
PENDAHULUAN
Latar Belakang
Seiring dengan banyaknya aplikasi multimedia dan perkembangan internet, jumlah citra pun meningkat secara tajam. Para pengguna sangat mudah untuk mengakses ratusan bahkan ribuan citra, akan tetapi seringkali tidak mudah mendapatkan citra-citra yang sesuai dengan yang dibutuhkan pengguna. Oleh karena itu, perlu dikembangkan metode pencarian citra untuk mempermudah pencarian data. Pencarian citra dapat dilakukan berdasarkan isi citra atau sering disebut Content-Based Image Retrieval
(CBIR). CBIR ini mencari citra dengan mencocokkan isinya yang berupa tekstur, bentuk, atau warna. Salah satu metode pencarian citra yang banyak dikembangkan adalah berdasarkan warna citra.
Pada sistem temu kembali citra yang hanya berdasarkan jarak Euclidean antar citra, citra yang ditemukembalikan adalah citra di dalam basis data yang mempunyai tingkat kemiripan yang tinggi dengan citra kueri. Banyak kemungkinan citra yang ditemukembalikan adalah citra yang bukan dari jenisnya sendiri. Hal ini dapat menyebabkan tingkat keefektifan hasil temu kembali citra menjadi kurang baik. Oleh karena itu, diperlukan sebuah model klasifikasi untuk memperbaiki tingkat keefektifan hasil temu kembali citra. Model klasifikasi tersebut dapat dibangun melalui proses pelatihan, dan digunakan untuk mengklasifikasikan citra. Citra yang ditemukembalikan pada sistem temu kembali menggunakan model klasifikasi adalah citra hasil klasifikasi di dalam basis data yang terdapat dalam kelas citra yang sama dengan citra kueri dan citra dari kelas lain yang memiliki tingkat kemiripan yang tinggi dengan citra kueri.
Platt (1998) telah menggunakan algoritma
Sequential Minimal Optimization (SMO) untuk proses pelatihan dalam metode Support Vector Machine (SVM) dengan waktu komputasi yang lebih cepat. Zhang et al.
(2001) telah menggunakan metode SVM untuk klasifikasi pada sistem temu kembali citra berdasarkan ciri warna. Berdasarkan hasil penelitian Gosselin dan Cord (2004), metode SVM memberikan hasil klasifikasi yang lebih baik dibandingkan dengan metode klasifikasi Bayes dan k-Nearest Neighbors
(kNN). Oleh karena itu, pada penelitian ini
dikembangkan sebuah sistem temu kembali citra berdasarkan ciri warna menggunakan metode klasifikasi SVM dengan algoritma optimisasi SMO.
Tujuan Penelitian
Tujuan penelitian ini adalah mengimplementasikan dan menganalisis kinerja metode SVM dengan algoritma optimisasi SMO dalam tahap klasifikasi citra dan pada sistem temu kembali citra berdasarkan ciri warna.
Ruang Lingkup
Ruang lingkup penelitian ini difokuskan pada metode klasifikasi menggunakan SVM.
TINJAUAN PUSTAKA
Content-Based Image Retrieval
Content-Based Image Retrieval (CBIR) merupakan suatu pendekatan untuk masalah temu kembali citra yang didasarkan pada ciri yang terkandung di dalam citra seperti warna, bentuk atau tekstur dari citra (Han & Ma 2002).
Expectation-Maximization
Expectation-Maximization (EM) adalah salah satu metode optimisasi untuk mencari dugaan parameter maximum likelihood ketika ada data yang hilang atau tidak lengkap. Di dalam algoritma EM, dilakukan perhitungan dugaan kemungkinan untuk mengisi data yang tidak lengkap (E-step) dan perhitungan dugaan parameter maximum likelihood dengan memaksimalkan dugaan kemungkinan yang diperoleh dari E-step (M-step). Nilai parameter yang diperoleh dari M-step
digunakan kembali untuk memulai E-step
selanjutnya. Proses ini akan berulang hingga mencapai konvergensi nilai likelihood
(Belongie et al. 1998). Ektraksi Ciri Warna
Ekstraksi ciri warna merupakan salah satu bagian dari CBIR untuk menentukan arti fisik suatu citra melalui proses pengindeksan warna. Proses ini bisa dilakukan dengan pendekatan histogram warna (Belongie et al.
1998).
mengandung N piksel dapat dirumuskan seperti H(I)=[h1,h2,...,hn] dengan
∑ =
= N
j Pi j N i h 1 | 1 ,
⎩
⎨
⎧
= selainnya ; 0 i -ke bin ke sasi terkuanti j piksel ; 1 |j i P .Histogram warna seperti ini disebut juga
conventional color histogram (CCH) (Han & Ma 2002).
Fuzzy Color Histogram
Fuzzy Color Histogram (FCH) adalah salah satu metode yang merepresentasikan informasi warna dalam citra digital ke dalam bentuk histogram. Di dalam FCH, setiap warna direpresentasikan dengan himpunan fuzzy (fuzzy set). Hubungan antar warna dimodelkan dengan fungsi keanggotaan (membership function) terhadap fuzzy set.
Fuzzy set F pada ruang ciri Rn didefinisikan oleh ηF:Rn→[0,1] yang biasa disebut
membership function. Untuk tiap vektor ciri
n
f∈ℜ , nilai dari ηF(f) disebut derajat
keanggotaan dari f terhadap fuzzy set F
(derajat keanggotaan F). Nilai dari ηF(f)
yang mendekati 1 lebih representatif terhadap vektor ciri f dan terhadap fuzzy setf (Zhang R & Zhang Z 2004).