PERINGKASAN TEKS BERITA SECARA OTOMATIS
MENGGUNAKAN TERM FREQUENCY INVERSE
DOCUMENT FREQUENCY (TF-IDF)
SKRIPSI
DANDUNG TRI SETIAWAN
071402054
PROGRAM STUDI TEKNOLOGI INFORMASI
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI
UNIVERSITAS SUMATERA UTARA
▸ Baca selengkapnya: teks berita dapat dianalisis menggunakan kriteria konteks opini perspektif dan sumber. apa maksudny
(2)PERINGKASAN TEKS BERITA SECARA OTOMATIS MENGGUNAKAN
TERM FREQUENCY-INVERSE DOCUMENT FREQUENCY (TF-IDF)
SKRIPSI
Diajukan untuk melengkapi tugas dan memenuhi syarat memperoleh ijazah Sarjana Teknologi Informasi
DANDUNG TRI SETIAWAN 071402054
PROGRAM STUDI TEKNOLOGI INFORMASI
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI UNIVERSITAS SUMATER UTARA
MEDAN 2014
ii
PERSETUJUAN
Judul : PERINGKASAN TEKS BERITA SECARA
OTOMATIS MENGGUNAKAN TF.IDF
Kategori : SKRIPSI
Nama : DANDUNG TRI SETIAWAN
Nomor Induk Mahasiswa : 071402054
Program Studi : SARJANA (S1) TEKNOLOGI INFORMASI
Departemen : TEKNOLOGI INFORMASI
Fakultas : ILMU KOMPUTER DAN TEKNOLOGI
INFORMASI UNIVERSITAS SUMATERA UTARA
Diluluskan di
Medan, Agustus 2014
Komisi Pembimbing :
Pembimbing 2 Pembimbing 1
M Anggia Muchtar, ST, M.MIT Prof. Dr. Opim Salim Sitompul, M.Sc
NIP. 19800110 200801 1 010 NIP. 19610817 198701 1 001
Diketahui/Disetujui oleh
Program Studi S1 Teknologi Informasi
Ketua,
M Anggia Muchtar, ST, M.MIT
iii
PERNYATAAN
PERINGKASAN TEKS BERITA SECARA OTOMATIS MENGGUNAKAN TERM
FREQUENCY INVERSE DOCUMENT FREQUENCY (TF.IDF)
SKRIPSI
Saya mengakui bahwa skripsi ini adalah hasil kerja saya sendiri, kecuali beberapa
kutipan dan ringkasan yang masing-masing telah disebutkan sumbernya.
Medan, Agustus 2014
Dandung Tri Setiawan
071402054
iv
UCAPAN TERIMA KASIH
Alhamdulillah, segala puji dan syukur penulis ucapkan kehadirat Allah SWT, serta
shalawat dan salam kepada junjungan alam nabi Muhammad SAW, karena atas
berkah, rahmat dan hidayah-Nya penulis mampu menyelesaikan skripsi ini.
Dalam penulisan skripsi ini penulis banyak mendapatkan bantuan serta
dorongan dari pihak lain. Dalam kesempatan ini dengan segala kerendahan hati,
penulis mengucapkan terima kasih sebesar-besarnya kepada:
1. Umi dan Papa selaku kedua orang tua penulis Fatimah dan M. Yahmin, karena
berkat dukungannya baik secara moril maupun materil secara terus disetiap
saat, sehingga penulis dapat menyelesaikan skripsi ini.
2. Pihak keluarga, kakak, abang, adik dan seluruh keluarga.
3. Bapak Prof. Dr. Opim Salim Sitompul, M.Sc, Bapak M. Anggia Muchtar, ST,
M.MIT selaku dosen pembimbing penulis yang telah bersedia meluangkan
waktu untuk memberikan saran dalam menyelesaikan skripsi ini.
4. Ketua dan Sekretaris Program Studi S-1 Teknologi Informasi Bapak M.
Anggia Muchtar, ST, M.MIT dan Bapak M. Fadhly Syahputra, M.Sc.
5. Dekan dan Pembantu Dekan Fakultas Ilmu Komputer dan Teknologi Informasi
Universitas Sumatera Utara serta semua dosen dan pegawai di Program Studi
S-1 Teknologi Informasi.
6. Ibu Dr. Erna Budhiarti Nababan, M.IT dan Bapak Dr. Syahril Effendi, S.Si,
M.IT selaku dosen pembanding dan penguji yang telah banyak memberikan
saran dan kritik dalam menyelesaikan skripsi ini.
7. Seluruh rekan-rekan kuliah sejawat yang tidak dapat disebutkan satu persatu.
Dalam penyusunan skripsi ini penulis menyadari bahwa masih banyak
kekurangan, untuk itu penulis mengharapkan saran dan kritik yang bersifat
membangun dari semua pihak demi kesempuranaan skripsi ini.
Akhir kata penulis mengharapkan semoga skripsi ini dapat bermanfaat dan
v
ABSTRAK
Perkembangan teknologi internet berdampak bertambahnya jumlah situs berita dan
menciptakan ledakan informasi. Hal tersebut menuntut semua informasi bisa diakses
dengan cepat dan tidak harus membutuhkan banyak waktu dalam membaca sebuah
berita. Teknologi peringkas teks otomatis menawarkan solusi untuk membantu
pencarian isi berita berupa deskripsi singkat. Penelitian diawali dengan tahap text
preprocessing, feature selection dan proses selanjutnya menghitung bobot tf-idf. Hasil
dari penelitian ini menunjukkan bahwa metode tf-idf dapat digunakan untuk
meringkas teks secara otomatis meskipun tidak sampai pada proses stemming. Sistem
dengan metode tf-idf masih memiliki kelemahan yaitu ringkasan teks yang dihasilkan
kurang mencerminkan isi berita dan secara tata bahasa masih belum baik.
Kata Kunci : ringkasan, ringkasan teks, peringkasan teks otomatis, tf-idf, berita.
vi
THE AUTOMATIC NEWS TEXT SUMMARIZATION BY USING TERM FREQUENCY INVERSE DOCUMENT FREQUENCY (TF.IDF)
ABSTRACT
The development of internet technology affect the increasing of news web and create
an information explosion. This make all information can be accessed fast and not
need so much time in reading a news. The automaic summarizaton technology of text
give solution in searching the content of news in short description. This study begins
with the processing text step, feature selection and count the amount tf-idf. The result
of this study show that tf-idf can be used to summarize text automatcally though it
cannot reach stemming process. The system of tf.idf method still has some
weaknesses that is the result of text does not interprete the content of text and there are
also some of text grammar.
Keywords : summary, teks summarization, automatic text summarization, term
vii
DAFTAR ISI
Hal.
Persetujuan ii
Pernyataan iii
Ucapan Terima Kasih iv
Abstrak v
1.1. Latar Belakang 1
1.2. Rumusan Masalah 2
1.3. Tujuan Penelitian 2
1.4. Manfaat Penelitian 2
1.5. Batasan Masalah 3
1.6. Metodologi Penelitian 3
1.7. Sistematika Penulisan 4
2 Bab 2 Landasan Teori 6
2.1. Peringkasan Teks Otomatis 6
viii
2.7. Term Frequency Inverse Document Frequency (TF-IDF) 15
2.8. Flowchart 17
2.9. Penelitian Terdahulu 18
3 Bab 3 Analisis dan Perancangan 21
3.1. Analisis Data 21
3.1.1. Data Berita 21
3.1.2. Data Stopword 23
3.1.3. Data Kata Dasar 23
3.2. Analisis Sistem 24
3.2.1. Text Preprocessing 24
3.2.2. Feature Selection 26
3.2.3. Contoh penggunaan algoritma (tf/idf) 28
3.3. Perancangan Sistem 31
3.3.1. Diagram konteks 31
3.3.2. DFD level 1 32
3.4. Perancangan Antarmuka Sistem 33
4 Bab 4 Implementasi dan Pengujian 35
4.1. Implementasi Sistem 35
4.1.1. Spesifikasi Perangkat Keras dan Perangkat Lunak 35
4.1.2. Tampilan Awal 36
4.1.3. Tampilan Proses Sistem 36
4.1.4. Tampilan Hasil Sistem 37
4.2. Pengujian Sistem 38
5 Bab 5 Kesimpulan dan Saran 40
5.1. Kesimpulan 40
5.2. Saran 40
ix
DAFTAR TABEL
Hal.
Tabel 2.1 Fungsi simbol-simbol flowchart 18
Tabel 2.2 Penelitian terdahulu 20
Tabel 3.1 Tabel Berita 22
Tabel 3.2 Tabel Stopword 23
Tabel 3.3 Tabel kata dasar 23
Tabel 3.4 Hasil dari proses text preprocessing 26
Tabel 3.5 Hasil dari proses text preprocessing yang dijadikan input. 27
Tabel 3.6 Kumpulan stopword 27
Tabel 3.7 Hasil dari proses filtering 28
Tabel 3.8 Menghitung tf 29
Tabel 3.9 Menghitung df 29
Tabel 3.10 Menghitung idf (1) 30
Tabel 3.11 Menghitung idf (2) 30
Tabel 3.12 Menghitung tf.id 31
Tabel 4.1 Rancangan Pengujian Tampilan Sistem 38
Tabel 4.2 Hasil Pengujian Tampilan Sistem 39
x
DAFTAR GAMBAR
Hal.
Gambar 2.1 Mesin Peringkas Teks 8
Gambar 2.2 Modul Peringkas Teks 9
Gambar 2.3 Anatomi Berita 11
Gambar 2.4 Tahapan-tahapan peringkasan teks otomatis metode TF-IDF 17
Gambar 3.1 Skema proses pengambilan berita 21
Gambar 3.2 Flowchart Text Preprocessing 25
Gambar 3.3 Contoh kalimat yang akan diinput 25
Gambar 3.4 Contoh kalimat setelah ToLowerCase 25
Gambar 3.5 Flowchart proses filtering 27
Gambar 3.6 Konteks Diagram Peringkas Teks Otomatis 32
Gambar 3.7 DFD peringkas teks otomatis 32
Gambar 3.8 Tampilan Antarmuka Sistem 33
Gambar 4.1 Tampilan Awal Sistem 36
Gambar 4.2 Tampilan Proses Pemilihan 37
Gambar 4.3 Tampilan Hasil Proses Pemilihan 37
v
ABSTRAK
Perkembangan teknologi internet berdampak bertambahnya jumlah situs berita dan
menciptakan ledakan informasi. Hal tersebut menuntut semua informasi bisa diakses
dengan cepat dan tidak harus membutuhkan banyak waktu dalam membaca sebuah
berita. Teknologi peringkas teks otomatis menawarkan solusi untuk membantu
pencarian isi berita berupa deskripsi singkat. Penelitian diawali dengan tahap text
preprocessing, feature selection dan proses selanjutnya menghitung bobot tf-idf. Hasil
dari penelitian ini menunjukkan bahwa metode tf-idf dapat digunakan untuk
meringkas teks secara otomatis meskipun tidak sampai pada proses stemming. Sistem
dengan metode tf-idf masih memiliki kelemahan yaitu ringkasan teks yang dihasilkan
kurang mencerminkan isi berita dan secara tata bahasa masih belum baik.
Kata Kunci : ringkasan, ringkasan teks, peringkasan teks otomatis, tf-idf, berita.
vi
THE AUTOMATIC NEWS TEXT SUMMARIZATION BY USING TERM FREQUENCY INVERSE DOCUMENT FREQUENCY (TF.IDF)
ABSTRACT
The development of internet technology affect the increasing of news web and create
an information explosion. This make all information can be accessed fast and not
need so much time in reading a news. The automaic summarizaton technology of text
give solution in searching the content of news in short description. This study begins
with the processing text step, feature selection and count the amount tf-idf. The result
of this study show that tf-idf can be used to summarize text automatcally though it
cannot reach stemming process. The system of tf.idf method still has some
weaknesses that is the result of text does not interprete the content of text and there are
also some of text grammar.
Keywords : summary, teks summarization, automatic text summarization, term
1BAB 1 PENDAHULUAN
1.1.Latar Belakang
Seiring perkembangan teknologi informasi mengakibatkan teknologi internet semakin
pesat yang berdampak pada penggunaan internet. Tujuannya adalah untuk
mendapatkan informasi dengan cepat dan akurat. Seiring bertambahnya informasi,
maka berbanding lurus dengan dokumen yang ada di dunia internet, salah satu
contohnya adalah dokumen berita.
Dokumen berita merupakan kumpulan informasi tentang banyak peristiwa
penting terjadi dan terbaru secara berkala. Memahami isi dokomen berita melalui
ringkasan teks memerlukan waktu yang lebih singkat dibandingkan membaca seluruh
isi dokumen, sehingga ringkasan teks menjadi sangat penting. Dengan adanya
ringkasan, diharapkan pembaca dapat dengan cepat dan mudah memahami makna
sebuah teks tanpa harus membaca keseluruhan teks. Selain dapat menghemat waktu,
pembaca juga dapat menghindari pembacaan teks yang tidak relevan dengan informasi
yang diharapkan oleh pembaca, terutama ketika sangat banyak informasi tersedia di
internet.
Ringkasan dibutuhkan untuk mendapatkan isi artikel secara ringkas. Konsep
sederhana ringkasan adalah mengambil bagian penting dari keseluruhan isi dari
artikel. Menurut Mani dan Maybury, ringkasan adalah mengambil isi yang paling
penting dari sumber informasi yang kemudian menyajikannya kembali dalam bentuk
yang lebih ringkas bagi penggunanya (Mani dan Maybury, 1999). Namun demikian,
membuat ringkasan manual dengan dokumen yang banyak akan memerlukan waktu
dan biaya yang besar. Sehingga diperlukan suatu sistem peringkasan secara otomatis
untuk mengatasi masalah waktu baca dan biaya.
2
Peringkasan teks otomatis (automatic text summarization) adalah proses
menghasilkan teks yang lebih pendek daripada teks aslinya menggunakan perangkat
berbasis komputer. Banyak instansi yang bergerak dalam penyaluran informasi
masyarakat atau berita yang pada awalnya menyampaikan berita melalui media
Televisi, Surat Kabar, Majalah atau Radio sudah mulai menggunakan sistem berbasis
web untuk menyampaikan beritanya secara up to date (Fajar, 2008). Aplikasi
peringkasan teks otomatis merupakan teknologi yang menawarkan solusi untuk
mencari informasi dengan menghasilkan ringkasan (summary) berita.
Term frequency inverse document frequency (TF-IDF) adalah salah satu
metode yang dapat digunakan untuk melakukan peringkasan teks. Metode TF-IDF
adalah cara pemberian bobot hubungan suatu kata (term) terhadap dokumen. Untuk
dokumen tunggal tiap kalimat dianggap sebagai dokumen. Metode ini
menggabungkan dua konsep untuk penghitungan bobot, yaitu Term Frequency (TF)
merupakan frekuensi kemunculan kata (t) pada kalimat (d). Document Frequency
(DF) adalah banyaknya kalimat dimana suatu kata (t) muncul.
Berdasarkan dari uraian latar belakang diatas, maka penulis memilih judul
“peringkasan teks berita secara otomatis menggunakan term frequency inverse
document frequency“.
1.2.Rumusan Masalah
Berdasarkan latar belakang di atas maka rumusan masalah pada penelitian ini adalah
bagaimana mendapatkan ringkasan pada sebuah berita secara otomatis.
1.3.Tujuan Penelitian
Tujuan dari penelitian ini adalah penggunaan TF-IDF (term frequency inverse
document frequency) untuk memperoleh ringkasan berita secara otomatis dan
mengetahui ringkasan dari suatu berita dengan cepat.
1.4.Manfaat Penelitian
Manfaat yang dapat diperoleh dari penelitian ini adalah:
1. Memberikan efisiensi waktu bagi para pembaca berita dalam memahami berita
3
2. Mengetahui kemampuan TF-IDF (term frequency inverse document frequency)
untuk memperoleh ringkasan berita secara otomatis.
3. Menambah ilmu pengetahuan serta menjadi bahan referensi dan perbandingan
untuk penelitian yang berkaitan dengan penggunaan term frequency inverse
document frequency.
1.5.Batasan Masalah
Guna mencegah meluasnya cakupan permasalahan yang akan dibahas dalam studi ini
dan untuk membuat studi ini lebih terarah, maka dilakukan pembatasan masalah
sebagai berikut:
1. Algoritma yang digunakan dalam peringkasan ini adalah term frequency
inverse document frequency.
2. Data yang digunakan adalah berita politik
3. Jumlah data yang digunakan 50 berita
4. Berita yang digunakan dalam penelitian ini hanya berita berbahasa Indonesia.
5. Berita yang dimasukkan ke dalam sistem peringkasan adalah berita yang sudah
dinyatakan layak untuk dipublikasikan.
6. Penelitian ini tidak melakukan perbandingan algoritma.
7. Perancangan program aplikasi sistem peringkas teks berita ini menggunakan
bahasa pemrograman PHP.
8. Sistem ini dibangun tidak disatukan dengan media berita yang sudah ada tetapi
dengan membuat homepage sendiri dan mengunakan jaringan offline.
1.6.Metodologi Penelitian
Dalam penelitian ini, penulis melakukan beberapa metode untuk memperoleh data
atau informasi dalam menyelesaikan permasalahan. Metode yang dilakukan tersebut
antara lain :
1. Studi Literatur
Dilakukan studi literatur atau studi pustaka yaitu mengumpulkan bahan-bahan
referensi baik dari buku, artikel, paper, jurnal, makalah, maupun situs internet.
2. Analisis
Hal-hal yang dilakukan tahap ini adalah :
4
a. Menganalisis tahap demi tahap dari proses peringkasan teks.
b. Cara kerja dari algoritma term frequency invers document frequency dalam
meringkas teks.
3. Perancangan
Pada tahap ini dilakukan perancangan arsitektur, perancangan data, dan
perancangan antarmuka.
4. Pengkodean
Pada tahap ini akan dilakukan proses implementasi pengkodean program
dalam aplikasi komputer menggunakan bahasa pemrograman yang telah
ditentukan.
5. Pengujian
Pada tahap ini dilakukan proses pengujian dan percobaan terhadap sistem
sesuai dengan spesifikasi yang ditentukan sebelumnya serta memastikan
program yang dibuat dapat berjalan seperti yang diharapkan.
6. Penyusunan Laporan
Pada tahap ini dilakukan penulisan dokumentasi hasil analisis dan
implementasi.
1.7.Sistematika Penulisan
Tugas akhir ini disusun dalam lima bab dengan sistematika penulisan sebagai
berikut :
BAB 1 : Pendahuluan
Pada bab ini dibahas mengenai latar belakang penulisan, rumusan masalah,
batasan masalah, tujuan, manfaat, metodologi penelitian dan sistematika
penulisan.
BAB 2 : Tinjauan Pustaka
Pada bab tinjauan pustaka berisi landasan teori, kerangka pikir dan hipotesis
yang diperoleh dari acuan yang mendasari dalam melakukan penelitian ini.
5
Pada bab ini dibahas mengenai analisis terhadap permasalahan dan
penyelesaian persoalan dalam pembuatan aplikasi serta menjelaskan tentang
rancangan struktur program dan antarmuka dari aplikasi perangkat lunak yang
akan dibuat.
BAB 4 : Implementasi dan Pengujian
Pada bab ini dibahas implementasi dari perangkat lunak serta berisikan
gambaran antarmuka dari perangkat lunak yang akan dibuat. Selain itu, juga
dilakukan pengujian untuk melihat perangkat lunak yang dibuat berhasil
dijalankan atau tidak serta untuk menemukan kesalahan (error).
BAB 5 : Kesimpulan dan Saran
Pada bab ini berisi tentang kesimpulan yang didapat dari pembuatan skripsi
dan saran-saran yang diharapkan dapat dikembangkan untuk penelitian
selanjutnya.
2BAB 2
LANDASAN TEORI
2.1.Peringkasan Teks Otomatis
Sering kali kita membutuhkan ringkasan dari sebuah bacaan untuk mendapatkan
secara ringkas dan cepat isi dari bacaan. Konsep sederhana dari ringkasan adalah
mengambil bagian penting yang menggambarkan keseluruhan isi dari dokumen asal.
Menurut Mani dan Maybury (Mani and Maybury, 1999), ringkasan adalah mengambil
isi yang paling penting dari sumber informasi yang kemudian menyajikan kembali
dalam bentuk yang lebih ringkas bagi penggunanya.Dalam Hovy (2001), summary
atau ringkasan didefinisikan sebagai sebuah teks yang dihasilkan dari satu atau lebih
teks, mengandung informasi dari teks asli dan panjangnya tidak lebih dari setengah
teks asli.
Peringkasan teks otomatis (automatic text summarization) adalah pembuatan
versi yang lebih singkat dari sebuah teks dengan memanfaatkan aplikasi yang
dijalankan pada komputer. Hasil peringkasan ini mengandung poin -poin penting dari
teks asli.
2.1.1.Tipe Ringkasan
Berdasar teknik pembuatan, suatu ringkasan diambil dari bagian terpenting dari teks
aslinya (Mani, 2001), terdapat 2 tipe yaitu :
1. Abstraktif
Tipe peringkasan abstraktif menghasilkan sebuah interpretasi terhadap teks
aslinya. Dimana sebuah kalimat akan ditransformasikan menjadi kalimat yang
lebih singkat dan kalimat baru yang tidak terdapat dalam dokumen yang asli
7
2. Ekstraktif
Tipe peringkasan ekstraktif menghasilkan suatu ringkasan dengan memilih
sebagian dari kalimat yang ada dalam dokumen asli. Metode ini menggunakan
metode statistical, linguistical dan heuristic atau kombinasi dari semuanya
dalam menetapkan ringkasan suatu teks.
Berdasarkan teori, hasil ringkasan ekstraktif lebih baik dibandingkan dengan
ringkasan abstraktif. Hal ini dikarenakan peringkasan abstraktif, seperti representasi
semantik, inferens dan pembangun natural language relatif lebih sulit, dibandingkan
pendekatan data driven, seperti ekstraksi kalimat (Erkan dan Radev, 2004). Sehingga
kebanyakan penelitian dilakukan menggunakan metode ekstraktif.
Sedangkan model peringkasan teks otomatis ada dua yaitu ringkasan yang
umum (generic summary) merupakan perwakilan dari teks asli yang mencoba untuk
mempresentasikan semua fitur penting dari sebuah teks asal. Mengikuti pendekatan
bottom up (information retrieval) dan yang kedua ringkasan berpusat pada pemakai
(query driven) yaitu peringkasan bersandar pada spesifikasi kebutuhan informasi
pemakai, seperti topik atau query dan mengikuti pendekatan top down (information
extraction).
Tujuan dari peringkasan teks (teks summarization) dapat dikategorikan
berdasarkan maksud, fokus dan cakupannya (Firmin dan Chrzanowski, 1999), sebagai
berikut :
1. Informatif
Informatif, ringkasan ini menyatakan informasi - informasi penting yang
terdapat pada dokumen asal.
2. Indikatif
Indikatif, tujuan dari ringkasan ini adalah untuk dijadikan sebuah referensi,
yang membantu pembaca untuk mengetahui isi dari teks daripada membaca
keseluruhan teks yang ada. Ringkasan ini meliputi topik kunci dari teks asal.
3. Evaluatif
Evaluatif, atau ringkasan yang melibatkan pembuatan sebuah pertimbangan
pada teks asal, seperti suatu tinjauan ulang atau opini.
8
4. User-focused (query-relevant)
User-focused, ringkasan yang dibuat berdasarkan topik yang dipilih oleh user,
sering merupakan jawaban dari query yang dimiliki oleh user.
5. Generic
Generic, disebut juga author-focused, sifatnya lebih umum dan berdasarkan
pada teks aslinya.
6. Dokumen tunggal (single document)
Dokumen tunggal, ringkasan merupakan ringkasan dari satu dokumen.
7. Banyak dokumen (multi document)
Banyak dokumen, ringkasan merupakan hasil ringkasan dari banyak dokumen.
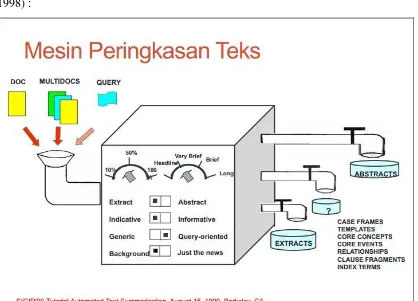
Berikut gambar mesin dan modul peringkasan teks menurut (Hovy dan Marcu,
1998) :
9
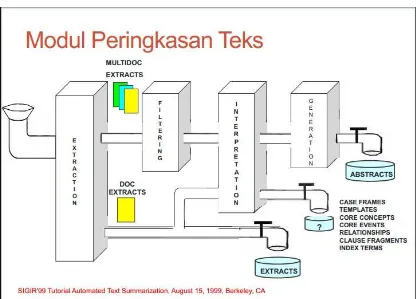
Serta gambar modul peringkasan teks :
Gambar 2.2 Modul Peringkas Teks 2.2.Berita
Kata "berita" berasal dari bahasa sansekerta yaitu dari kata "vrit" yang sebenarnya
berarti "terjadi" atau "ada" (Djuroto, 2004). Berita (news) adalah laporan mengenai
suatu peristiwa atau kejadian yang terbaru (aktual); laporan mengenai fakta-fakta yang
aktual, menarik perhatian, dinilai penting, atau luar biasa (Budiman, 2011).
Berita adalah informasi baru tentang kejadian yang baru, penting, dan
bermakna, yang berpengaruh pada para pendengarnya serta relevan dan layak
dinikmati (Maeseneer, 1999).
2.2.1.Nilai-Nilai Berita
Dalam menulis berita, ada beberapa hal yang perlu diperhatikan terkait nilai berita itu
sendiri (Djuroto, 2004). Ada beberapa nilai berita yang dapat dikelompokkan sebagai
acuan dalam sebuah penulisan. Beberapa nilai berita tesebut adalah sebagai berikut :
1. Magnitude (pengaruh) artinya seberapa luas pengaruh suatu berita terhadap
khalayak.
10
2. Significant (Arti) artinya seberapa penting arti dari suatu kejadian atau
peristiwa.
3. Actuality (Aktualitas) artinya seberapa besar tingkat aktualitas suatu kejadian
atau peristiwa.
4. Proximity (Kedekatan) artinya bertia lokal lebih pas diberitakan di daerah
bersangkutan.
5. Prominence (Keakraban) artinya akrabnya suatu peristiwa terhadap khalayak.
6. Surprise (Kejutan).
7. Clarity (Kejelasan) kejadian atau peristiwa.
8. Dampak (Impact) artinya berdampak apakah berita tersebut terhadap khalayak.
9. Konflik.
10. Human Interest artinya kemampuan suatu peristiwa menyentuh perasaan
khalayak.
2.2.2.Unsur-Unsur Berita
Dalam penulisan berita kita harus memahami unsur dari suatu berita supaya memberi
kemudahan kita dalam mendeskripsikan berita tersebut dan berita yang kita buat
mudah untuk dipahami oleh khalayak ramai (Olii, 2007). Unsur-unsur berita tersebut
adalah:
1. What (apa) artinya apa yang tengah terjadi. Peristiwa apa yang tengah terjadi.
2. Who (siapa) artinya siapa saja yang terlibat dalam peristiwa itu.
3. Where (dimana) artinya dimana lokasi terjadinya peristiwa itu.
4. When (kapan) artinya kapan perisitiwa itu berlangsung.
5. Why (mengapa) artinya mengapa kejadian itu bisa terjadi.
6. How (bagaimana) artinya bagaimana kejadian itu bisa berlangsung.
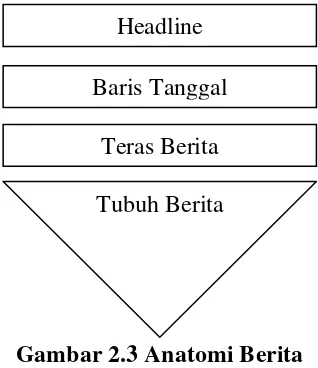
2.2.3.Anatomi Berita
Seperti tubuh manusia, berita juga mempunyai bagian-bagian, diantaranya adalah
sebagai berikut (Budiman, 2011) :
1. Judul atau Kepala Berita (Headline)
Headline mewakili isi berita yang ingin disampaikan dan memiliki daya tarik
11
2. Baris Tanggal (Dateline)
Dateline terdiri atas nama media massa, tempat kejadian dan tanggal kejadian.
Tujuannya adalah untuk menunjukkan tempat kejadian dan inisial media.
3. Teras Berita (Lead atau Intro)
Lead biasanya ditulis pada paragrap pertama sebuah berita. Lead merupakan
unsur yang paling penting dari sebuah berita, yang menentukan apakah isi
berita akan dibaca atau tidak.
4. Tubuh Berita (Body)
Body isinya menceritakan peristiwa yang dilaporkan dengan bahasa yang
singkat, padat, dan jelas baik yang sudah dikemukakan dalam teras maupun
yang belum diungkapkan.
Gambar 2.3 Anatomi Berita
Bagian yang disebutkan membentuk anatomi yang tersusun sebagai sebuah
struktur yang utuh dan terpadu, yang sering dinamakan sebagai gaya piramida terbalik
(inverted pyramid style) seperti yang terlihat pada Gambar 2.3. Disebut demikian
karena bagian tubuh berita disusun dengan pola pengembangan umum ke khusus
(dimulai dari hal umum, lalu secara berangsur-angsur menuju ke hal-hal yang semakin
khusus) atau klimaks-antiklimaks (dari yang paling pokok atau penting beralih secara
berturut-turut ke yang kurang pokok atau penting). Tujuannya adalah untuk
memudahkan atau mempercepat pembaca dalam mengetahui apa yang diberitakan. Headline
Baris Tanggal
Teras Berita
Tubuh Berita
12
2.3.Text Mining
Text mining (penambangan teks) adalah penambangan yang dilakukan oleh komputer
untuk mendapatkan sesuatu yang baru, sesuatu yang tidak diketahui sebelumnya atau
menemukan kembali informasi yang tersirat secara implisit, yang berasal dari
informasi yang di-ekstrak secara otomatis dari sumber-sumber data teks yang
berbeda-beda (Feldman & Sanger, 2007). Text mining merupakan teknik yang digunakan untuk
menangani masalah klasifikasi, clustering, information extraction dan information
retrival (Berry & Kogan, 2010).
Pada dasarnya proses kerja dari text mining banyak mengapdopsi dari
penelitian data mining namun yang menjadi perbedaan adalah pola yang digunakan
oleh text mining diambil dari sekumpulan bahasa alami yang tidak terstruktur
sedangkan dalam data mining pola yang diambil dari database yang terstruktur (Han
& Kamber, 2006).
2.3.1.Tahap – Tahap Text Mining
Tahap-tahap text mining secara umum adalah text preprocessing dan feature selection
(Feldman & Sanger 2007, Berry & Kogan 2010) . Dimana penjelasan dari
tahap-tahap tersebut adalah sebagai berikut :
1. Text Preprocessing
Tahap text preprocessing adalah tahap awal dari text mining. Tahap ini
mencakup semua rutinitas, dan proses untuk mempersiapkan data yang akan
digunakan pada operasi knowledge discovery sistem text mining (Feldman &
Sanger, 2007). Tindakan yang dilakukan pada tahap ini adalah toLowerCase,
yaitu mengubah semua karakter huruf menjadi huruf kecil, dan Tokenizing
yaitu proses penguraian deskripsi yang semula berupa kalimat – kalimat
menjadi kata-kata dan menghilangkan delimiter-delimiter seperti tanda titik (.),
koma (,), spasi dan karakter angka yang ada pada kata tersebut (Weiss et al,
2005).
2. Feature Selection
Tahap seleksi fitur (feature selection) bertujuan untuk mengurangi dimensi
dari suatu kumpulan teks, atau dengan kata lain menghapus kata-kata yang
13
proses pengklasifikasian lebih efektif dan akurat (Do et al, 2006., Feldman &
Sanger, 2007., Berry & Kogan 2010). Pada tahap ini tindakan yang dilakukan
adalah menghilangkan stopword ( stopword removal ) dan stemming terhadap
kata yang berimbuhan (Berry & Kogan 2010., Feldman & Sanger 2007).
Namun pada penelitian ini proses stemming tidak dilakukan.
Stopword adalah kosakata yang bukan merupakan ciri ( kata unik ) dari suatu
dokumen (Dragut et al. 2009). Misalnya “di”, “oleh”, “pada”, “sebuah”, “karena” dan
lain sebagainya. Sebelum proses stopword removal dilakukan, harus dibuat daftar
stopword (stoplist). Jika termasuk di dalam stoplist maka kata-kata tersebut akan
dihapus dari deskripsi sehingga kata-kata yang tersisa di dalam deskripsi dianggap
sebagai kata-kata yang mencirikan isi dari suatu dokumen atau keywords. Daftar kata
stopword di penelitian ini bersumber dari Tala (2003).
2.4.Kata
Kata adalah kesatuan terkecil yang diperoleh sesudah kalimat dibagi atas
bagian-bagiannya dan mengandung suatu ide.
Kategori kata berdasarkan sintaksisnya terdiri dari lima kata (Putrayasa, 2007),
yaitu :
1. Kata Benda (Nomina)
Kata benda adalah kata yang mengacu pada manusia, binatang, benda dan
konsep atau pengertian.
2. Kata Kerja (Verba)
Kata kerja adalah kata yang menyatakan tindakan.
3. Kata Sifat (Adjektiva)
Kata sifat adalah kata yang memberi keterangan yang lebih khusus tentang
sesuatu yang dinyatakan oleh nomina dalam kalimat.
4. Kata Keterangan (adverbia)
Kata keterangan adalah kategori yang dapat mendampingi adjektiva, numeralia
atau preposisi dalam konstruksi sintaksis.
5. Kata Tugas
Kata tugas adalah kata yang hanya memiliki arti gramatikal dan tidak memiliki
arti leksikal.
14
2.5.Kalimat
Kalimat adalah satuan bahasa terkecil dalam wujud lisan atau tulisan, yang
mengungkapkan pikiran yang utuh. Kalimat terdiri atas deret kata yang dimulai
dengan huruf kapital dan diakhiri dengan tanda titik (.), tanda tanya (?), atau tanda
seru (!).
Unsur-unsur kalimat terdiri dari kata, kelompok kata dan lagu kalimat. Di
dalam kalimat terdapat pengaturan hubungan kedudukan antara bagian-bagiannya.
Ada bagian didalam kalimat yang menunjukkan sebagai “pelaku”, ada bagian yang
menunjukkan sebagai “perbuatan”, ada bagian yang menunjukkan “bagaimana
perbuatan itu dilakukan”. Berdasarkan jabatannya kalimat terdiri dari :
1. Subyek, yaitu bagian yang menjadi pangkal atau pokok pembicaraan.
2. Predikat, yaitu bagian yang menerangkan subyek, biasanya berdiri sesudah
subyek.
3. Obyek, yaitu bagian yang menjadi tujuan.
4. Keterangan, yaitu bagian yang menunjukkan waktu (keterangan waktu),
tempat (keterangan tempat), alat (keterangan alat) dan sebagainya.
Sedangkan kalimat berdasarkan fungsinya, dapat dikategorikan sebagai
berikut:
Paragraf disebut juga alinea. Kata paragraf merupakan kata serapan dari bahasa
Inggris paragraph, sedangkan kata alinea dari bahasa Belanda dengan ejaan yang
sama. Paragraf adalah seperangkat kalimat yang membicarakan suatu gagasan atau
topik. Terdapat dua syarat dalam membentuk paragraf :
1. Menulis pernyataan (kalimat) tentang pokok bahasan dengan baik.
15
2.7.Term Frequency Inverse Document Frequency (TF-IDF)
Metode Term Frequency-Inverse Document Frequency (TF-IDF) adalah cara
pemberian bobot hubungan suatu kata (term) terhadap dokumen. Untuk dokumen
tunggal tiap kalimat dianggap sebagai dokumen. Metode ini menggabungkan dua
konsep untuk perhitungan bobot, yaitu Term frequency (TF) merupakan frekuensi
kemunculan kata (t) pada kalimat (d). Document frequency (DF) adalah banyaknya
kalimat dimana suatu kata (t) muncul. Frekuensi kemunculan kata di dalam dokumen
yang diberikan menunjukkan seberapa penting kata itu di dalam dokumen tersebut.
Frekuensi dokumen yang mengandung kata tersebut menunjukkan seberapa umum
kata tersebut. Bobot kata semakin besar jika sering muncul dalam suatu dokumen dan
semakin kecil jika muncul dalam banyak dokumen (Robertson, 2004). Pada Metode
ini pembobotan kata dalam sebuah dokumen dilakukan dengan mengalikan nilai TF
dan IDF.
Pada penelitian ini, peringkasan teks otomatis yang di kembangkan merupakan
sistem peringkasan dengan inputan berupa single dokumen dan secara otomatis
menghasilkan ringkasan (summary). Proses text preprosessing yang dilakukan pada
peringkasan teks otomatis ini hanya proses tokenizing yaitu proses pemotongan string
input berdasarkan tiap kata yang menyusunnya. Pemecahan kalimat menjadi kata-kata
tunggal dilakukan dengan me-scan kalimat dengan pemisah (delimiter) white space
(spasi, tab dan newline)( Tala, 2003).
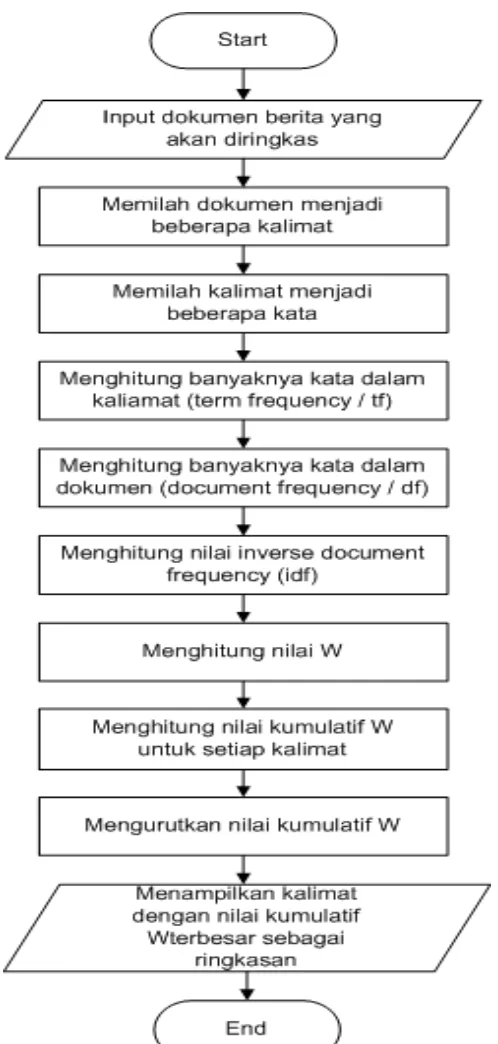
Adapun tahapan-tahapan peringkasan teks otomatis metode TF-IDF adalah
sebagai berikut :
1. Menginput dokumen yang akan dibuat ringkasannya
2. Memilah dokumen menjadi beberapa kalimat.
Pemilahan kalimat dilakukan dengan memecah string teks dari dokumen yang
panjang menjadi kalaimat-kalimat mengunakan fungsi split(), dengan tanda
titik ”.”, tanda tanya ”?” dan tanda seru ”!” sebagai delimiter untuk memotong
string dokumen.
3. Memilah kalimat yang terbentuk menjadi beberapa kata dan simpan dalam
variable array. Untuk memilah kalimat menjadi kata digunakan proses
tokenizing.
16
4. Pembobotan TF-IDF
Pembobotan diperoleh berdasarkan jumlah kemunculan term dalam kalimat
(TF) dan jumlah kemunculan term pada seluruh kalimat dalam dokumen
(IDF). Bobot suatu istilah semakin besar jika istilah tersebut sering muncul
dalam suatu dokumen dan semakin kecil jika istilah tersebut muncul dalam
banyak dokumen (Grossman, 1998). Nilai IDF sebuah term dihitung
menggunakan persamaan 1.
(1)
dengan:
N = jumlah kalimat yang berisi term(t)
dfi = jumlah kemunculan kata (term) terhadap D
5. Menghitung bobot (W) masing-masing dokumen dengan persamaan 2
(Mustaqhfiri, 2011).
(2)
dengan :
d = kalimat ke-d
t = kata(term) ke –t
TF = term freqency
W = bobot kalimat ke-d terhadap kata(term)ke- t
IDF = inverse document f reqency
6. Melakukan proses pengurutan (sorting) nilai kumulatif dari W untuk setiap
kalimat.
7. Tiga kalimat dengan nilai W terbesar dijadikan sebagai hasil dari ringkasan
atau sebagai output dari peringkasan teks otomatis.
Tahapan-tahapan Peringkasan Teks Otomatis dengan metode TF -IDF di atas
17
Gambar 2.4 Tahapan-tahapan peringkasan teks otomatis metode TF-IDF 2.8.Flowchart
Flowchart adalah penggambaran secara grafik dari langkah-langkah dan urutan-urutan
prosedur suatu program (Setiawan, 2006). Simbol-simbol dari flowchart memiliki
fungsi yang berbeda antara satu simbol dengan simbol lainnya (Davis, 1999). Fungsi
dari simbol-simbol flowchart adalah sebagai berikut :
18
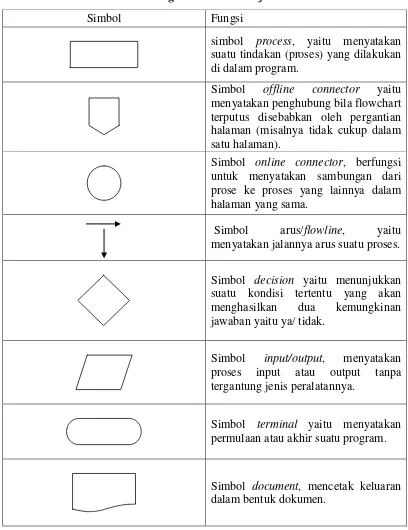
Tabel 2.1 Fungsi simbol-simbol flowchart.
Simbol Fungsi
simbol process, yaitu menyatakan suatu tindakan (proses) yang dilakukan di dalam program.
Simbol offline connector yaitu menyatakan penghubung bila flowchart terputus disebabkan oleh pergantian halaman (misalnya tidak cukup dalam satu halaman).
Simbol online connector, berfungsi untuk menyatakan sambungan dari prose ke proses yang lainnya dalam halaman yang sama.
Simbol arus/flowline, yaitu
menyatakan jalannya arus suatu proses.
Simbol decision yaitu menunjukkan suatu kondisi tertentu yang akan menghasilkan dua kemungkinan jawaban yaitu ya/ tidak.
Simbol input/output, menyatakan proses input atau output tanpa tergantung jenis peralatannya.
Simbol terminal yaitu menyatakan permulaan atau akhir suatu program.
Simbol document, mencetak keluaran dalam bentuk dokumen.
2.9.Penelitian Terdahulu
Metode Term Frequency Inverse Document Frequency telah banyak digunakan dalam
menyelesaikan berbagai macam permasalahan dalam hal pembobotan kata. Dari
permasalahan yang kecil hingga permasalahan yang cukup kompleks dengan berbagai
19
Zafikri, (2008) melakukan penelitian untuk menyelesaikan permasalahan
dalam pencarian informasi yang akurat dan efektif pada mesin pencari. Dalam
penelitiannya mencoba menerapkangabungan antara metode Term Frequency Inverse
Document Frequency (TF-IDF) dan model ruang vektor (vector space model) pada
mesin pencari. Hasilnya metode pembobotan dokumen TF-IDF tidak selalu
memberikan hasil performansi yang baik.
Akbar (2011) dalam penelitiannya menyelesaikan permasalahan dalam
menentukan nilai tes esai online. Dalam halini Akbar (2011) menggunakan algoritma
Latent Semantic Analysis (LSA) dengan pembobotan Term Frequency/Inverse
Document Frequency (TF/IDF) untuk menyelesaikan permasalahannya yakni sebagai
alternatif solusi penilaian esai kepada user ssecara konsisten tanpa mengikutsertakan
subjektivitas penilai, seperti suasana hati dan tingkat pengetahuan. Algoritma
TF/IDF-LSA memiliki tingkat keakuratan cukup tinggi dalam pemeriksaan jawaban esai
dengan jumlah kata yang banyak.
Sulthan (2012) menggunakan algoritma Hill Climbing dalam meringkas teks,
hasil dari peringkasan menggunakan algoritma Hill Climbing cukup baik. Metode text
mining juga pernah dilakukan Kurniawan (2012) dalam klasifikasi berita, dan hasil
dari metode text mining cukup berhasil.
Aristoteles (2013) melakukan penelitian peringkasan teks dokumen bahasa
Indonesia menggunakan algoritma genetika, hasilnya bahwa algoritma genetika dapat
digunakan untuk mencari tingkat kepentingan yang optimal dari tiap fitur teks. Nilai
akurasi 47.46% pada pemampatan 30%. Sedangkan hasil tidak optimal pada
pemampatan 10%.
20
Tabel 2.2 Penelitian terdahulu
No Peneliti / Tahun Judul Keterangan
1 Zafikri (2008) Implementasi Metode Term Frequency Inverse Document Frequency (TF-IDF) pada Sistem Temu Kembali informasi.
2 Akbar (2011) Menentukan Nilai Tes Esai Online Menggunakan AlgoritmaLatent Semantic Analysis (LSA) dengan Pembobotan Term Frequency/ Inverse Document Frequency
3 Sulthan (2012) Peringkasan Teks Otomatis Berbasis Web Menggunakan AlgoritmaHill Climbing
4 Kurniawan (2012) Klasifikasi Konten Berita menggunakan
Text Mining
3BAB 3
ANALISIS DAN PERANCANGAN
Pada bab ini akan membahas beberapa hal diantaranya data yang digunakan, flowchart
system, tampilan antar-muka serta analisis perancangan yang bertujuan untuk
mengindentifikasi permasalahan yang ada pada sistem tersebut. Analisis ini
diperlukan sebagai dasar perancangan sistem untuk mengimplementasikan tf-idf
dalam meringkas teks.
3.1.Analisis Data
Dalam penelitian ini data terdiri dari 3 bagian yaitu data berita, data stopword dan data
kata dasar.
3.1.1.Data Berita
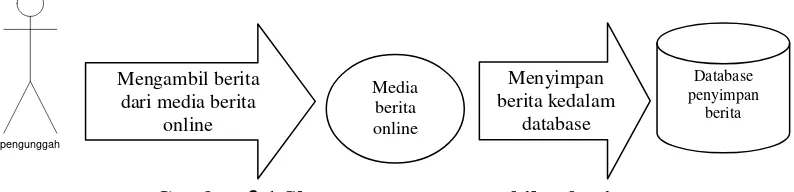
Data berita dalam penelitian ini didapat dari beberapa media berita online yang
kemudian dimasukkan kedalam database. Skema dari proses pengambilan berita dapat
dilihat pada gambar 3.1.
Data berita berjumlah 50 dokumen berita politik.Untuk memperoleh ketepatan
dan mempermudah proses pengujian maka berita diambil dari situs media berita
online. Berikut tabel 3.1.
Database
Gambar 3.1 Skema proses pengambilan berita
22
Tabel 3.1 Tabel Berita
id_berita Judul Berita Isi Berita
1 Kontras Kritik Penunjukan Hendropriyono
Koordinator Komisi untuk Orang Hilang dan Korban Tindak Kekerasan (Kontras),
Haris Azhar mengatakan dipilihnya AM Hendropriyono sebagai penasihat tim
transisi Jokowi-JK tidak mendukung penuntasan kasus hak asasi manusia di
Indonesia.
Kontras menilai terpilihnya
Hendropriyono mencerminkan sikap Joko Widodo yang kurang serius terhadap persoalan HAM. “Antara tidak serius, tidak mengerti, atau rentan diintervensi (berbagai kepentingan),” ujarnya dikutip
BBC, Kamis (14/8). .... 2 Presiden Baru, Rakyat
Akan Kembali Kecewa
KH M Shoffar Mawardi menyatakan rakyat akan kembali kecewa pasca pemilu 2014 lantaran harapan presiden yang baru
akan membawa Indonesia menuju kehidupan yang adil dan makmur tidak
akan tercapai. “Pada akhirnya, banyak rakyat yang sedih dan kecewa saat harapannya tidak kunjung menjadi nyata,”
ungkap Pengasuh Ma’had Daarul Muwahhid Srengseng Jakarta Barat tersebut seperti dilansir tabloid Media Umat Edisi 132: Presiden Baru, Umat Siap
Kecewa, Jum’at (18 Juli-21 Agustus)...
3 Israel Gunakan Bom
Fosfor Putih di Gaza
Laporan terakhir mengatakan pasukan udara dan darat Israel menggunakan bom fosfor putih untuk menghantam beberapa wilayah pemukiman di Jalur Gaza yang
terkepung.
Bom-bom mematikan itu melanggar semua konvensi internasional dan dianggap sebagai senjata terlarang untuk
digunakan di wilayah penduduk sipil. 4 Sengketa PLN Pertamina
Ancam Listrik Padam
Perusahaan Listrik Negara mengatakan berkurangnya pasokan solar dari Pertamina sekitar 50% akan diatasi dengan
23
3.1.2.Data Stopword
Data stopword didapat dari jurnal Tala (2003) dimana datanya berjumlah 753 data dan
dari berita-berita yang digunakan dalam penelitian. Data stopword di dalam database.
Rancangan tabel stopword dapat dilihat pada Tabel 3.2
Tabel 3.2 Tabel Stopword
id_stopword Stopword
3.1.3.Data Kata Dasar
Data kata dasar didapat dari kamus bahasa Indonesia online dimana datanya
berjumlah 28533 data. Data kata dasar disimpan di dalam database. Rancangan tabel
kata dasar dapat dilihat pada Tabel 3.3.
Tabel 3.3 Tabel kata dasar
24
3.2.Analisis Sistem
Analisis sistem bertujuan untuk mengidentifikasi permasalahan-permasalahan yang
ada pada sistem yang meliputi perangkat lunak (software), pengguna (user) serta hasil
analisis terhadap sistem dan elemen-elemen yang terkait. Analisis ini diperlukan
sebagai dasar bagi tahapan perancangan sistem. Analisis sistem ini meliputi desain
data, deskripsi sistem, dan implementasi desain dan semua yang diperlukan dalam
aplikasi peringkasan teks otomatis.
Dalam penelitian ini sistem mempunyai 2 tahapan proses yaitu tahapan
pertama adalah tahap text Preprocessing yaitu tahap awal dari text mining. Tahap ini
mencakup semua rutinitas, dan proses untuk mempersiapkan data yang akan
digunakan pada operasi knowledge discovery sistem text mining (Feldman & Sanger,
2007). Tindakan yang dilakukan pada tahap ini adalah toLowerCase, yaitu mengubah
semua karakter huruf menjadi huruf kecil dan Tokenizing yaitu proses penguraian
deskripsi yang semula berupa kalimat-kalimat menjadi kata-kata dan menghilangkan
delimiter-delimiter seperti tanda titik (.), koma (,), spasi dan karakter angka yang ada
pada kata tersebut (Weiss et al, 2005). Sedangkan tahap kedua adalah Tahap seleksi
fitur (feature selection) bertujuan untuk mengurangi dimensi dari suatu kumpulan
teks, atau dengan kata lain menghapus kata-kata yang dianggap tidak penting atau
tidak menggambarkan isi dokumen sehingga proses pengklasifikasian lebih efektif
dan akurat (Do et al, 2006., Feldman & Sanger, 2007., Berry & Kogan 2010). Pada
tahap ini tindakan yang dilakukan adalah menghilangkan stopword (stopword
removal) dan stemming terhadap kata yang berimbuhan (Berry & Kogan 2010.,
Feldman & Sanger 2007).
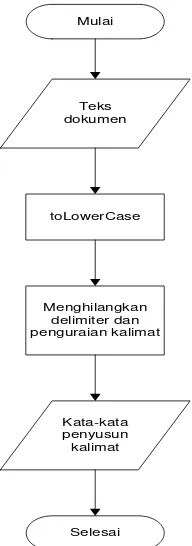
3.2.1.Text Preprocessing
Langkah-langkah proses text preprocessing adalah sebagai berikut :
1. Setelah teks dokumen dimasukkan maka sistem akan merubah semua karakter
huruf menjadi huruf kecil melalui proses toLowerCase.
2. Kemudian dilakukan penghapusan delimiter yaitu karakter angka dan karakter
simbol kecuali karakter huruf serta penguraian terhadap kalimat-kalimat yang
ada di teks dokumen tersebut.
25
4. Proses text preprocessing selesai. Flowchart dari proses text preprocessing
adalah sebagai berikut:
Gambar 3.2 Flowchart Text Preprocessing
Contoh :
Misal terdapat input kalimat seperti :
Maka setelah melalui proses ToLowerCase maka huruf besar dalam kalimat
tersebut berubah menjadi huruf kecil :
Kemudian setelah proses penghilangan delimiter dan penguraian kalimat maka
Kemudian setelah proses penghilangan delimiter dan penguraian kalimat maka
hasilnya adalah sebagai berikut :
Gambar 3.4 Contoh kalimat setelah ToLowerCase
dalam penelitian ini data terdiri 3 bagian yaitu data berita, data unik, dan data kata dasar.
Dalam penelitian ini data terdiri 3 bagian yaitu data berita, data unik, dan data kata
dasar.
Gambar 3.3 Contoh kalimat yang akan diinput
26
Tabel 3.4 Hasil dari proses text preprocessing
dalam penelitian ini terdiri
bagian yaitu data berita
data unik dan data
kata dasar
3.2.2.Feature Selection
Pada tahap ini terdapat dua proses yang dilakukan, adalah sebagai berikut :
1. Stopword Removal (Filtering)
Langkah-langkah untuk proses filtering adalah sebagai berikut :
a. Kata-kata penyusun kalimat hasil dari tahap text preprocessing dijadikan
sebagai masukkan.
b. Kemudian dibandingkan dengan kata-kata yang ada di database stopword.
c. Jika kata yang dimasukkan sama dengan kata di database stopword maka
kata yang dimasukkan dihapus. Namun jika kata yang dimasukkan tidak
sama dengan kata yang ada di database stopword maka tersebut tidak
dihapus
d. Proses filtering selesai. Flowchart dari proses filtering adalah sebagai
27
Kata yang diinput = kata yang ada didatabase stopword
Gambar 3.5 Flowchart proses filtering
Contoh :
Misalkan terdapat masukkanyang merupakan hasil dari proses text processing
sebagai berikut :
Tabel 3.5 Hasil dari proses text preprocessing yang dijadikan input.
dalam penelitian ini terdiri
bagian yaitu data berita
data unik dan data
kata dasar
Dan misalnya terdapat stopword yang dalam database stopword sebagai
berikut :
Tabel 3.6 Kumpulan stopword
dan dari ingin ini
kepada dalam selalu lalu
yaitu bahwa terdiri sekali
dulu sekalian enggak bagian
28
Kemudian sistem akan membandingkan antara kata-kata yang dimasukkan
dengan kata-kata yang ada di dalam database stopword. Selanjutnya sistem akan
menghapus kata-kata yang dimasukkan apabila kata-kata yang dimasukkan sama
dengan kata-kata yang ada di database stopword. Maka ouput-nya menjadi sebagai
berikut :
Tabel 3.7 Hasil dari proses filtering
penelitian data berita data
unik data kata dasar
3.2.3.Contoh penggunaan algoritma (tf/idf)
Berikut simulasi perhitungan nilai tf*idf bisa dilihat pada bagian dibawah ini :
Terdapat kalimat:
Saya sedang belajar menghitung tf.idf. Tf.idf merupakan frekuensi
kemunculan term pada dokumen. Langkah awal perhitungan tersebut adalah
menghitung tf, kemudian menghitung df dan idf. Langkah terakhir menghitung nilai
tf.idf. Mari kita belajar!
Catatan: tiap kalimat dianggap sebagai dokumen.
Setelah di pisah akan menjadi seperti berikut :
D1 Saya sedang belajar menghitung tf.idf.
D2 Tf.idf merupakan frekuensi kemunculan term pada dokumen.
D3 Langkah awal perhitungan tersebut adalah menghitung tf, kemudian menghitung
df dan idf.
D4 Langkah terakhir menghitung nilai tf.idf.
D5 Mari kita belajar!
Menghitung Term Frequency (tf)
Term frequency (tf) merupakan frekuensi kemunculan term (t) pada dokumen (d).
Data tulisan tersebut mengalami proses tokenisasi, stop words dan steaming sehingga
29
Tabel 3.8 Menghitung tf
Term (t) D1 D2 D3 D4 D5
Menghitung document frequency (df)
Document frequency (df) adalah banyaknya dokumen dimana suatu term (t) muncul.
30
Menghitung invers document frequency (idf) Menggunakan rumus (1)
IDF = 1 / df
Tabel 3.10 Menghitung idf (1)
Term (t) df idf
Tabel 3.11 Menghitung idf (2)
31
Menghitung tf.idf Hasil kali tf x idf
Tabel 3.12 Menghitung tf.idf
Term (t) D1 D2 D3 D4 D5 idf tf.idf
Perancangan proses perlu dilakukan untuk mengetahui proses-proses yang diperlukan
dalampembuatan aplikasi, aliran data pada tiap-tiap proses hingga aktor yang terlibat
di dalamnya. Perancangan ini bertujuan untuk mengetahui proses transformasi data
dari input berupa dokumen hingga menjadi output berupa hasil ringkasan.
3.3.1.Diagram konteks
Diagram konteks dibuat untuk menggambarkan sistem secara umum dan
entitas-entitas yangterlibat di dalamnya. Dalam konteks diagram Peringkas Teks Otomatis
pada Bahasa Indonesia terdapat satu eksternal yakni pengguna, yakni orang yang
menggunakan sistem. Pengguna memasukkan dokumen, kemudian sistem akan
memberikan output berupa hasil ringkasan.
Diagram konteks ini seperti gambar 3.6 berikut.
32
Gambar 3.6 Konteks Diagram Peringkas Teks Otomatis
3.3.2.DFD level 1
Dari konteks diagram gambar 3.6, dijabarkan menjadi DFD Level 1 seperti terlihat
pada gambar 3.7. Dari gambar tersebut terdapat 5 proses yakni Pra Proses, Pembagian
dokumen menjadi topik, penghitungan bobot relatif topik, dan pemilihan kalimat
paling penting dari topik. Dokumen dari pengguna akan diproses pada pra proses,
kemudian representasi dokumen yang dihasilkan pada proses ini akan dijadikan
masukan pada proses pembagian dokumen menjadi topik. Keluaran dari proses
sebelumnya yang berupa topik dijadikan sebagai masukan untuk dilakukan proses
perhitungan bobot topik. Kemudian proses terakhir pada level ini adalah pemilihan
kalimat paling penting dari topik. Masing-masing proses terdapat sub proses yang
merupakan dekomposisi dari proses tersebut, kecuali untuk proses penghitungan bobot
topik yang tidak memiliki sub proses karena sudah cukup ditangani pada proses itu.
33
Pilih File
Set Kompresi %
Teks Asli Ringkasan
Proses
3.4.Perancangan Antarmuka Sistem
3.4.1.Antarmuka Sistem
Antar muka sistem merupakan tampilan sistem yang berfungsi untuk membantu
pengguna dalam menggunakan sistem.
Antarmuka sistem pada penelitian ini dibuat sesederhana mungkin dengan
tujuan untuk mengurangi penggunaan waktu yang tidak relevan pada proses sistem
serta membantu pengguna dalam memahami dan menggunakan sistem. Adapun
rancangan antarmuka sistem terdiri atas beberapa komponen dasar, yaitu : tombol
pilih file, kolom set tingkat kompresi, kolom teks asli, kolom ringkasan dan tombol
proses.
Adapun bentuk ataupun gambaran dari antarmuka sistem yang akan dibuat
dapat dilihat pada Gambar 3.8 berikut :
Gambar 3.8 Tampilan Antarmuka Sistem
34
Berikut ini merupakan rincian dari rancangan tampilan antarmuka sistem pada
Gambar 3.8 yang akan dibuat, yaitu :
a. Tombol Pilih File, dimana user dapat memilih salah satu file berita yang
telah di simpan di direktori.
b. Kolom set tingkat kompresi, dimana user dapat menentukan berapa persen
tingkat dari hasil ringkasan. Interval yang diberikan 0 sampai 100 persen.
c. Kolom teks asli, akan menampilkan teks asli dari berita yang dipilih.
d. Kolom ringkasan, akan menampilkan hasil ringkasan dari berita yang
dipilih.
e. Tombol proses, setelah user memilih file berita dan menentukan tingkat
4BAB 4
IMPLEMENTASI DAN PENGUJIAN
Dalam bab ini akan dibahas mengenai implementasi peringkasan teks berita secara
otomatis menggunakan term frequency inverse document frequency. Untuk
mengetahui apakah implementasi aplikasi tersebut berhasil atau tidak, serta dilakukan
pengujian terhadap sistem. Berikut ini hasil implementasi dari aplikasi yang telah
dibangun.
4.1.Implementasi Sistem
Berdasarkan hasil analisis dan perancangan sistem yang telah dilakukan, maka
dilakukan implementasi sistem peringkasan teks berita secara otomatis menggunakan
term frequency inverse document frequency ke dalam bentuk program dengan
menggunakan bahasa pemrograman PHP. Artinya sistem akan dijalankan pada
browser sebagai media pemrosesan dan interface sistem dengan menggunakan
software XAMPP.
4.1.1.Spesifikasi Perangkat Keras dan Perangkat Lunak
Lingkungan implementasi merupakan lingkungan perangkat lunak yang digunakan
untuk membangun dan mengoperasikan perangkat lunak. Berikut ini merupakan
spesifikasi perangkat keras dan perangkat lunak yang digunakan dalam pembuatan
sistem, yaitu:
Spesifikasi perangkat keras yang digunakan :
1. Processor AMD C60 APU with Radeon(tm) HD Graphics 1.00 GHz
2. Memory RAM yang digunakan 2 GB
3. Kapasitas Hardisk 320GB
Spesifikasi perangkat lunak yang digunakan :
1. Sistem Operasi yang digunakan Windows 7 Ultimate 32-bit
36
2. XAMPP win32-1.8.3-4-VC11
3. PHP 5.6
4. Mozilla Firefox 30.0
4.1.2.Tampilan Awal
Pada tampilan awal sistem dibuat sederhana agar mudah dalam menggunakan
sistem serta membuang waktu yang tidak relevan, dengan rincian sebagai berikut :
1. Tombol Pilih File untuk mencari dan memilih file txt yang akan diuji
2. Kolom Set Tingkat Kompresi untuk membatasi jumlah maksimum kalimat
hasil ringkasan.
3. Kolom Teks Asli sebagai media untuk menampilkan teks berita hasil dari
pemilihan file berita.
4. Kolom Ringkasan sebagai media untuk menampilkan ringkasan teks hasil
dari proses peringkasan teks berita.
5. Tombol Proses untuk memulai eksekusi proses peringkasan.
Tampilan awal sistem dapat dilihat pada Gambar 4.1 berikut:
Gambar 4.1 Tampilan Awal Sistem
4.1.3.Tampilan Proses Sistem
Pada Gambar 4.2 menampilkan proses pemilihan dari peringkasan teks berita
37
Gambar 4.2 Tampilan Proses Pemilihan
Setelah kita memilih file teks berita dan menentukan tingkat kompresi
ringkasan, maka akan didapat tampilan hasil proses pemilihan seperti terlihat pada
Gambar 4.1 berikut :
Gambar 4.3 Tampilan Hasil Proses Pemilihan
4.1.4.Tampilan Hasil Sistem
Setelah kita melewati tahap pemilihan file berita dan menentukan tingkat
kompresi hasil ringkasan, kemudian eksekusi proses peringkasan dengan
tombol proses maka hasil ringkasan akan terlihat seperti Gambar 4.4 berikut :
38
Gambar 4.4 Tampilan Hasil Ringkasan 4.2.Pengujian Sistem
Pengujian yang dilakukan pada sistem adalah melihat hasil ringkasan teks berita yang
menggunakan term frequency inverse document frequency. Hal ini dilakukan untuk
mengetahui seberapa besar pengaruhnya dan perbedaan teks asli terhadap hasil
ringkasan.
4.2.1.Pengujian Tampilan Sistem
Pengujian yang dilakukan pada tampilan sistem berupa fungsi dari tiap komponen,
algoritma serta teknik yang digunakan. Rancanagn pengujian dapat dilihat pada Tabel
4.1 dan dilanjutkan dengan hasil pengujian pada Tabel 4.2 berikut ini :
Tabel 4.1 Rancangan Pengujian Tampilan Sistem
No Komponen Sistem Yang Diuji Butir Uji
1 Tombol Pilih File mencari dan memilih file txt yang akan
diuji
2 Kolom Set Tingkat Kompresi membatasi jumlah maksimum kalimat
hasil ringkasan
3 Kolom Teks Asli menampilkan teks berita hasil dari
pemilihan file berita
4 Kolom Ringkasan menampilkan ringkasan teks hasil dari
proses peringkasan teks berita
5 Tombol Proses memulai eksekusi proses peringkasan
39
No Komponen Sistem Yang Diuji Hasil Pengujian
1 Tombol Pilih File Berhasil
2 Kolom Set Tingkat Kompresi Berhasil
3 Kolom Teks Asli Berhasil
4 Kolom Ringkasan Berhasil
5 Tombol Proses Berhasil
Berdasarkan pada Gambar 4.4 terlihat hasil implementasi dan pengujian sistem, maka
dapat disimpulkan bahwa algoritma term frequency inverse document frequency dapat
digunakan untuk meringkas teks.
5BAB 5
KESIMPULAN DAN SARAN
Pada bab ini akan dibahas mengenai kesimpulan dan saran berdasarkan analisis dan
pengujian yang dilakukan dalam menyelesaikan permasalahannya, yaitu meringkas
teks berita secara otomatis menggunakan term frequency inverse document frequency.
5.1.Kesimpulan
Dari penelitian yang telah dilakukan dapat disimpulkan bahwa metode TF-IDF (Term
Frequency and Inverse Document Frequency) dapat digunakan untuk meringkas teks
secara otomatis meskipun tidak melalui proses stemming. Dan menghasilkan
ringkasan teks yang tetap memiliki bagian-bagian yang penting dan dominan dari teks
asli meskipun secara makna dan tata bahasa belum baik.
5.2.Saran
Pada penelitian selanjutnya disarankan untuk menggunakan metode dan algoritma
yang lebih baik lagi. Hasil ringkasan teks otomatis perlu dilakukan perbandingan
terhadap hasil ringkasan secara manual serta tidak hanya untuk meringkas teks
berbahasa Indonesia saja melainkan bahasa asing yang lain, seperti bahasa Inggris dan
DAFTAR PUSTAKA
Adriani, M., Asian, J., Nazief, B., Tahaghoghi, S.M.M. & Williams, H.E. 2007. Stemming Indonesian : A Confix-Stripping Approach. Transaction on Asian Langeage Information Processing. Vol. 6, No. 4, Articel 13. Association for Computing Machinery : New York .
Agusta, L. 2009. Perbandingan Algoritma stemming Porter dengan algoritma Nazief & Adriani untuk Stemming Dokumen Teks Bahasa Indonesia.Prosiding
Konferensi Nasional Sistem dan Informatika, pp. 196-201.
Akbar, Fakhreza. 2011. Menentukan Nilai Tes Esai Online Menggunakan Algoritma Latent Semantic Analysis (LSA) dengan Pembobotan Term Frequency/
Inverse Document Frequency. Skripsi. Medan, Indonesia: Universitas
Sumatera Utara.
Alwi, H., Dardjowidjojo, S. &Lapoliwa, A.M., 2003. Tata Bahasa Baku Bahasa Indonesia.Edisi Ketiga. Balai Pustaka : Jakarta.
Aristoteles. 2013. Penerapan Algoritma Genetika pada Peringkasan Teks Dokumen
Bahasa Indonesia. Skripsi. Lampung. Indonesia: Universitas Lampung.
Asian, J., Williams, H.E. & Tahaghoghi, S.M.M. 2005. Stemming Indonesia.
Proceedings of the Twenty-eighth Australasian conference on Computer
Science.Vol. 38, hal. Australia : Association for Computing Machinery.
Berry, M.W. & Kogan, J. 2010. Text Mining Aplication and theory. WILEY : United Kingdom.
Budiman, K. 2011. Dasar-dasar Jurnalistik. (Online)
http://www.akirahmedia.com/main/articledetail/7 (24 Desember 2013).
Djuroto, Totok. 2004. Manajemen Penerbitan Pers. Bandung : PT Remaja Rosdakarya.
Dragut, E., Fang, F., Sistla, P., Yu, S. & Meng, W. 2009. Stop Word and Related
Problems in Web Interface Integration.(Online)http://www.vldb.org/pvldb/2/vldb09-384.pdf (24
Desember 2013).
Dharwiyanti, S dan Wahono, S.R., 2003. Pengantar Unified Modeling Language.
(Online) http://IlmuKomputer.com.
Davis, S.T. 1999. Chapter-Five : Logic (process) Flowchart. CRC Press : United State.
42
Erkan, Gunes & Radev Dragomir R.. “LexRank : Graph-Based Centrality as Salience in Text Summarization.” Journal of Artificial Intelegence Research 22, 2004: 1-23.
Fajar, M. 2008. Media cetak era digital. (Online) www.emfajar.net/internet/media-cetak-di-era-digital/(24Desember 2013).
Feldman, R & Sanger, J. 2007. The Text Mining Handbook : Advanced Approaches in Analyzing Unstructured Data. Cambridge University Press : New York.
Firmin, T. &M.J Chrzanowski. 1999. An Evaluation of Automatic Text Summarization System. The MIT Press : Cambrige.
Han, J & Kamber, M. 2006 Data Mining: Concepts and Techniques Second Edition. Morgan Kaufmann publisher : San Francisco.
Hariyanto, B., 2004. Rekayasa Sistem Berorientasi Objek. Bandung: Informatika Bandung.
Hovy, E. 2001. Automated Text Summarization. In R. Mitkov. (Eds).Handbook of
computation linguistics. Oxford:Oxford University Press.
Hovy, E & Marcu, D. 1998. Automated Text summarization Tutorial, Information Sciences Institute, University of Southern California.
Kurniawan, Bambang. 2012. Klasifikasi Konten Berita Menggunakan Text Mining.
Skripsi. Medan. Indonesia: Universitas Sumatera Utara.
Kridalaksana, H. 2009. Pembentukkan Kata dalam Bahasa Indonesia. Gramedia Pustaka Utama : Jakarta.
Maeseener, P. D. 1999. Here’s The News : A Radio News Manual. United States : Unesco Asosiate.
Mani, Inderjeet. 2001. Summarization Evaluation: An Overview. The MITRE Corporation, W640 11493 Sunset Hills Road Reston, VA 20190-5214 USA.
Mani, I. &Maybury, M. T. 1999. Advance in Automatic Text Summarization. The MIT Press: Cambrige.
Muslich, M., 2008. Tata Bentuk Bahasa Indonesia : Kajian ke Arah Tata Bahasa Deskriptif. Bumi Aksara : Jakarta.
Mustaqhfiri, M., Abidin Z. &Kusumawati, R.2011. Peringkasan Teks Otomatis Berbahasa Indonesia Menggunakan Metode Maximum Marginal Relevance.Ejournal Matics4(4) : 135-147.
43
Robertson, S., 2004. “Understanding Inverse Document Frequency: On theoretical arguments for IDF”, Journal ofDocumentation, Vol.60, no.5, pp. 503-520.
Setiawan, I. 2006. Progrmmable Logic Controller dan Teknik Perancangan Sistem Kontrol. Andi : Yogyakarta.
Sulthan, Aniesma. 2012. Peringkasan Teks Otomatis Berbasis Web Menggunakan
Algoritma Hill Climbing. Skripsi. Jakarta, Indonesia: Universitas Mercu Buana.
Tala, Fadillah Z. 2003. A Study of Stemming Efects on Information Retrieval in Bahasa Indonesia. Institute for Logic, Language and ComputationUniversiteit van Amsterdam The Netherlands.
(Online)http://www.illc.uva.nl/Research/Reports/MoL-2003-02.text.pdf. (04 Januari
2014).
Weiss, S.M., Indurkhya, N., Zhang, T. &Damerau, F.J. (Editor). 2005. Text Mining :
Predictive Methods fo Analyzing Unstructered Information. Springer : New
York.
Zafikri, Atika. 2008. Implementasi Metode Term Frequency Inverse Document
Frequency (TF-IDF) pada Sistem Temu Kembali informasi. Skripsi. Medan.
Indonesia: Universitas Sumatera Utara.