31 BAB III PEMBAHASAN
Algoritma Self Organizing Map (SOM) merupakan suatu metode NN yang diperkenalkan oleh Professor Teuvo Kohonen pada tahun 1982. Self Organizing Map merupakan salah satu bentuk topologi dari Unsupervised Artificial Neural Network (Unsupervised ANN) dimana dalam proses pelatihannya tidak memerlukan pengawasan (target output). Self Organizing Map digunakan untuk mengelompokkan (clustering) data berdasarkan karakteristik atau fitur-fitur data. (Shieh & Liao, 2012).
Dalam algoritma Self Organizing Map, data input berupa vektor yang terdiri dari n komponen (tuple) yang akan dikelompokkan dalam maksimum m buah kelompok (disebut vektor contoh). Output jaringan adalah kelompok yang paling dekat atau mirip dengan input yang diberikan. Ada beberapa ukuran kedekatan yang dapat dipakai. Ukuran yang sering dipakai adalah Eucledian distance yang paling minimum (Siang, 2009).
Vektor bobot untuk sebuah unit cluster menggambarkan sebuah contoh dari pola input yang dikumpulkan dalam cluster. Selama proses Self Organizing Map, unit cluster yang mempunyai bobot dicocokkan dengan pola input yang terdekat dan dipilih sebagai pemenang (winner). Unit pemenang dan unit tetangganya, dalam hal ini adalah topologi dari unit cluster akan memperbaiki bobot mereka masing-masing (Kristanto, 2004).
32
A. Arsitektur dan Algoritma Pembelajaran Self Organizing Map
Self Organizing Map atau SOM merupakan suatu algoritma pembelajaran yang baik dalam mengeksporasi data mining dan memiliki kemampuan cukup baik untuk pembentukan model cluster.
Self Organizing Map merupakan algoritma yang melakukan pemetaan dari data yang ada di ruang vektor berdimensi tinggi ke ruang vector dua dimensi yang terletak pada lokasi yang berdekatan. Self Organizing Map terdiri dari dua lapisan (layer), yaitu lapisan input dan lapisan output. Setiap neuron dalam lapisan input terhubung dengan setiap neuron pada lapisan output. Setiap neuron pada lapisan output merepresentasikan kelas (cluster) dari input yang telah diberikan.
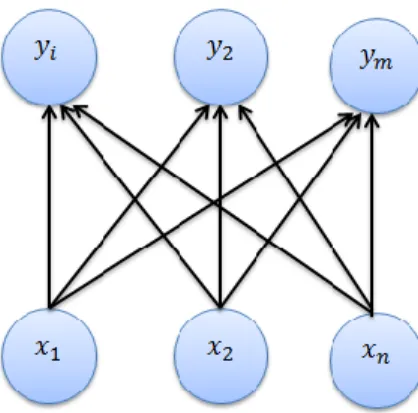
Self Organizing Map merupakan generalisasi dari jaringan kompetitif, dan merupakan jaringan tanpa supervise (Siang, 2009). Self Organizing Map disusun oleh sebuah lapisan unit input yang dihubungkan seluruhnya ke lapisan unit output, yang kemudian unit-unit diatur di dalam topologi khusus seperti struktur jaringan (Jain & Martin, 1998). Secara umum arsitektur jaringan Self Organizing Map dapat dilihat pada gambar 3.1
33
dengan adalah vektor input dengan n dimensi dan adalah vektor output dengan m dimensi.
Salah satu algoritma pembelajaran untuk Self Organizing Map adalah algoritma pembelajaran kompetitif dengan metode Kohonen (Kusumadewi, 2003). Pada algoritma pembelajaran Self Organizing Map, akumulasi sinyal yang didapat tidak perlu diaktivasi, karena fungsi aktivasi tidak memberikan pengaruh pada pemilihan winner neuron yang akan memperbarui bobotnya dan bobot tetangganya. Dengan demikian, pada proses pelatihan error tidak dihitung pada setiap iterasi pelatihan. Kriteria berhentinya proses pelatihan dalam Self Organizing Map akan menggunakan jumlah iterasi tertentu.
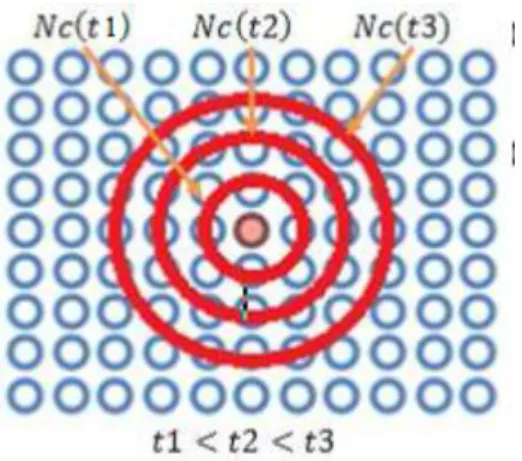
Pada Gambar 3.2, jika neuron yang di tengah adalah winner neuron untuk suatu input vektor, maka neighbor neuron untuk winner neuron ini adalah mereka yang terletak di dalam lingkaran area, yang didefinisikan dengan Nc(t1), Nc(t2), …dst. Nc(t1) adalah batas area pada iterasi ke-1, Nc(t2) adalah batas area pada iterasi ke-2, dan seterusnya. Neuron yang secara topografi terletak jauh dari winner neuron tidak diupdate.
34
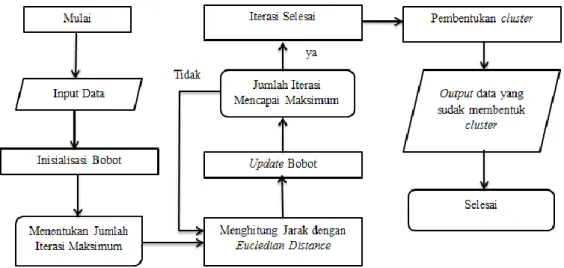
Secara ringkas algoritma Self Organizing Map digambarkan seperti tampak pada diagram alir pada Gambar 3.3.
Gambar 3.3 Diagram Alir Self Organizing Map (SOM)
Berikut adalah algoritma Self Organizing Map yang digunakan dalam pembentukan cluster berdasarkan Gambar 3.3:
1. Pada langkah awal, seluruh data dampak bencana tanah longsor dan faktor penyebab terjadinya tanah longor menurut provinsi dijadikan data input. Data input yang digunakan adalah data yang berbentuk matrik , dimana i adalah jumlah provinsi dan j adalah jumlah variabel. Selanjutnya, dilakukan proses clustering menggunakan metode Self Organizing Map.
2. Pada perhitungan menggunakan metode SOM, diawali dengan inisialisasi bobot secara random (acak). Dalam Matlab2011b digunakan sintaks
net.IW{1,1}
35
4. Untuk setiap data dilakukan perhitungan terhadap bobot menggunakan rumus Euclidean Distance. Kemudian dipilih nilai terkecil.
5. Data yang memiliki nilai terkecil dari langkah 4 digunakan untuk proses update bobot. Dalam menentukan bobot terbaru pada waktu t, maka diasumsikan obyek saat ini x(i) dan centroid yang terbentuk . Kemudian untuk menentukan centroid yang baru untuk waktu berikutnya t+1
α adalah learning rate. Pada langkah selanjutnya nilai learning rate yang digunakan adalah learning_rate_new= dimana nilai b berada di antara 0 dengan 1. Pada akhir iterasi, nilai α akan menuju nilai learning rate minimum. 6. Melakukan pengecekan syarat berhenti, Iterasi akan berhenti apabila threshold
terpenuhi, untuk mencapai nilai threshold terpenuhi. Adapun nilai treshold dikatakan terpenuhi apabila nilai parameter telah terpenuhi.
7. Selanjutnya dilakukan proses pengelompokkan atau clusterisasi, disini menggunakan rumus Euclidean.
8. Hasil akhir dari proses ini yaitu data ter-cluster
1. Membangun jaringan pada algoritma Self Organizing Map
Dalam proses membangun suatu jaringan, hal pertama yang harus dilakukan adalah dengan menentukan input jaringan. Pada software Matlab, untuk membangun jaringan pada algoritma Self Organizing Map digunakan intruksi sebagai berikut :
Net =selforgmap([a b])
Net=configure(net,NameofData)
36 dengan
[a b] : ukuran matriks neuron yang akan dihasilkan pada output. Matriks ini nantinya akan digunakan untuk menklasifikasikan vektor input.
NameofData : nama data yang digunakan ketika input
Penentuan nilai a dan b akan mempengaruhi hasil output. Hal ini disebabkan karena jumlah cluster pada akhir proses pembelajaran algoritma self organizing map akan sama banyak dengan hasil perkalian a dan b. Sebagai contoh jika ditentukan nilai a adalah 2 dan nilai b adalah 3 maka jaringan akan menghasilkan output neuron sebanyak 6 neuron. Penentuan nilai a dan b juga akan mempengaruhi topologi neuron output. Sebagai contoh, pada model dengan hasil 6 neuron, maka terdapat 2 kemungkinan bentuk jaringan yang dapat dibangun, yaitu jaringan dengan nilai a adalah 1 dan b adalah 6, dan jaringan dengan nilai a adalah 2 dan b adalah 3. Kedua jaringan ini pada hasil output akan mengelompokkan objek ke dalam 6 neuron, meskipun demikian topologi yang dihasilkan oleh kedua model jaringan ini berbeda. karena topologi yang dihasilkan oleh kedua model jaringan ini berbeda maka hasil yang diperoleh dapat berbeda, meskipun tidak ada jaminan bahwa jaringan dengan penghubung tunggal antar neuron lebih baik atau lebih buruk bila dibandingkan dengan jaringan dengan penghubung jamak antar neuron.
37
2. Prosedur Pembentukan Cluster dengan Algoritma Self Organizing Map a. Deskripsi data
Berdasarkan penelitan yang dilakukan oleh Naryanto (2011), Dinata (2013) dan Insani (2016), penanggulangan bencana yang mencakup tiga tahap, yaitu pra bencana, saat bencana, dan pasca bencana akan berjalan secara efisien jika diketahui informasi terkait tentang faktor terjadinya bencana tanah longsor dan dampak dari peristiwa bencana tanah longsor di Indonesia. Informasi terkait denga faktor terjadinya bencana tanah longsor dan dampak dari peristiwa bencana tanah longsor dapat dijadikan pertimbangan untuk menentukan jenis penanggulangan pra bencana dan pasca bencana. Oleh karena itu, pada penelitian ini faktor terjadinya bencana tanah longsor dan dampak dari peristiwa bencana tanah longsor akan digunakan sebagai variabel dengan 33 provinsi di Indonesia yang digunakan sebagai sampel. Hal ini disebabkan karena pengambilan data pada provinsi di Indonesia yang hanya mengambil pada tahun-tahun tertentu dengan yang didasarkan pada kelengkapan data dari sumber data. Variabel ditentukan dari hasil penelitian terdahulu terkait bencana tanah longsor dan berita acara yang dirilis oleh BNPB. Adapun variabel yang digunakan adalah :
Tabel 3.1 Variabel Input dan Satuan yang Digunakan
Kode Variabel Satuan Keterangan
Persentase keluarga yang tidak memiliki kendaraan bermotor
Persen (%) Kendaraan bermotor yang dihitung mencakup mobil dan motor. Data diambil pada tahun 2014 Persentase keluarga yang
memiliki kendaraan bermotor
Persen (%) Kendaraan bermotor yang dihitung mencakup mobil dan motor. Data diambil pada tahun 2014
38
Kode Variabel Satuan Keterangan
Lokasi kemiringan lahan curam
Unit Lahan curam adalah lahan dengan kemiringan lebih dari 25 derajat yang diambil pada tahun 2011.
Lokasi kemiringan lahan landai
Unit Lokasi yang masuk dalam kategori ini memiliki kemiringan kurang dari 15 derajat. Data diambil pada tahun 2011.
Lokasi kemiringan lahan sedang
Unit Lokasi yang masuk dalam kategori ini memiliki kemiringan antara 15 sampai 25 derajat. Data diambil pada tahun 2011.
Persentase keluarga yang memilah sampah dan sebagian dimanfaatkan
Persen (%) Jenis sampah yang dihitung adalah sampah organic maupun non organik. Keluarga yang masuk dalam kategori ini adalah keluarga yang secara rutin memilah dan memanfaatkan sampah. Data diambil pada tahun 2014
Persentase keluarga yang memilah sampah kemudian dibuang
Persen (%) Jenis sampah yang dihitung adalah sampah organic maupun non organik. Keluarga yang masuk dalam kategori ini adalah keluarga yang secara rutin memilah sampah. Data diambil pada tahun 2014.
Persentase keluarga yang tidak memilah sampah
Persen (%) Jenis sampah yang dihitung adalah sampah organik maupun non organik. Data diambil pada tahun 2014
39
Kode Variabel Satuan Keterangan
Frekuensi terjadinya gempa bumi
Jumlah Kejadian
Kejadian gempa bumi dihitung seluruhnya, baik tektonik maupun vulkanik.
Frekuensi jumlah hujan mm Frekuensi yang dihitung adalah kerapatan curah hujan yang dihiung dengan satuan mm
Frekuensi jumlah hari hujan Jumlah Hari Jumlah hari hujan yang dihitung adalah jumlah hari dimana hujan turun dengan mengabaikan volume curah hujan
Frekuensi terjadi kebakaran hutan dan lahan
Jumlah kejadian
Jumlah kejadian kebakaran hutan dan lahan yang dihitung adalah kejadian bencana kebakaran yang terjadi karena fenomena alam ataupun karena kesalahan manusia dengan mengabaikan besar dampak yang ditimbulkan.
Jumlah luas lahan sangat kritis Hektar (Ha) Lahan yang masuk dalam kategori sangat kritis adlah lahan yang sama sekali tidak dapat dikelola, bersifat gundul dan tingkat kesuburan sangat rendah
Jumlah luas lahan kritis Hektar (Ha) Lahan yang masuk dalam kategori lahan kritis adalah lahan yang tidak produktif mski telah dikelola, bersifat gundul dan tingkat kesuburan rendah.
40
Kode Variabel Satuan Keterangan
Persentase keluarga dengan kepemilikian sumur resapan air
Persen (%) Sumur resapan air yang dihitung adalah sumur resapan air yang berada di tanah warga dengan mengabaikan jumlah sumur resapan. Data Diambil pada tahun 2014.
Persentase keluarga dengan kepemilikian lubang resapan biopori
Persen (%) Lubang resapan biopori yang dihitung adalah lubang resapan yang berada di tanah warga dengan mengabaikan luas area lubang resapan air. Data Diambil pada tahun 2014
Persentase keluarga dengan kepemilikan taman/ tanah berumput
Persen (%) Taman/ tanah berumput yang dihitung adalah Taman/ tanah berumput yang berada di tanah warga dengan mengabaikan luas taman/ tanah berumput. Data Diambil pada tahun 2014
Frekuensi terjadinya bencana tanah longsor
Jumlah kejadian
Jumlah kejadian dihitung baik keseluruhan, baik yang menimbulkan korban dan kerusakan maupun yang tidak
Jumlah korban meninggal Jiwa Korban meninggal yang dihitung adalah yang terkena dampak bencana, tidak termasuk relawan.
Jumlah korban hilang Jiwa Korban hilang dihitung adalah korban yang tidak ditemukan baik karena tertimbun atau terisolasi
41
Kode Variabel Satuan Keterangan
Jumlah korban terluka Jiwa Korban terluka yang dihitung yaitu semua korban luka dampak bencana, baik ringan maupun berat, dan tidak termasuk relawan. Jumlah korban menderita Jiwa Korban menderita yang dihitung adalah yang
menderita secara finansial dan psikologis.
Jumlah korban mengungsi Jiwa Korban mengungsi yang dihitung adalah korban bencana yang meninggalkan lokasi bencana pada waktu pasca bencana.
Jumlah rumah rusak berat Unit Rumah rusak berat adalah rumah yang ditemukan kerusakan pada sebagian besar komponen bangunan, baik stuktural maupun non-struktural, seperti dinding rubuh, lantai retak merekah, dan lain sebagainya.
Jumlah rumah rusak sedang Unit Rumah rusak sedang adalah rumah ditemukan kerusakan pada sebagian komponen non struktural atau komponen struktural seperti, struktur atap, struktur lantai dan lain sebagainya. Jumlah rumah rusak ringan Unit Rumah rusak ringan adalah rumah yang
ditemukan kerusakan terutama pada komponen non-struktural, seperti penutup atap, langit-langit, penutup lantai, dan dinding pengisi.
42
Kode Variabel Satuan Keterangan
Jumlah fasilitas peribadatan yang rusak
Unit Fasilitas peribadatan mencakup masjid, gereja, vihara dan fasilitas peribadatan lainnya
Jumlah fasilitas pendidikan yang rusak
Unit Fasilitas pendidikan meliputi sekolah, kampus, perpustakaan, dan fasilita pendidikan lainnya Jumlah fasilitas kesehatan
yang rusak
Unit Fasilitas kesehatan meliputi rumah sakit, puskesmas, apotik dan fasilitas kesehatan lainnya.
Panjang jalan yang terkena dampak bencana
KM Panjang jalan yang dihitung adalah yang terkena dampak longsoran, dan yang terkena dampak tidak langsung (timbulnya retakan karena bencana). Adapun jalan yang diukur adalah jalan utama, seperti jalan penghubung antar desa.
b. Normalisasi Data
Sebelum dilakukan proses pembelajaran (training), data input harus dinormalisasi terlebih dahulu. Normalisasi adalah penskalaan terhadap nilai-nilai input sedemikian sehingga data-data input masuk dalam suatu range tertentu. Pada pembelajaran algoritma Self Organizing Map proses normalisasi perlu dilakukan agar rentang nilai pada masing-masing variabel tidak terpaut jauh.
Proses normalisasi dapat dilakukan dengan metode Min-Max Normalization (Martiana, 2013). Pada metode ini, untuk memetakan suatu nilai pada variabel
43
dengan range nilai minimum dan nilai maksimum dari atribut tersebut ke range nilai yang baru, dilakukan perhitungan sebagai berikut
dengan :
: nilai yang baru setelah dinormalisasi : nilai yang lama sebelum dinormalisasi : nilai maksimum dari variabel
: nilai minimum dari variabel
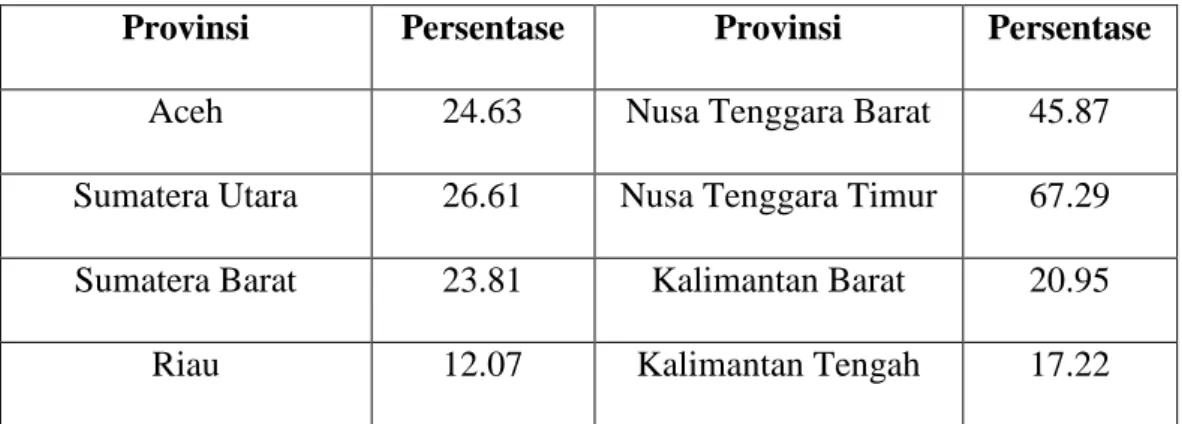
: nilai maksimum yang baru pada variabel : nilai minimum yang baru pada variabel Berikut akan digunakan persamaan 3.2 dengan memanfaatkan variabel persentase keluarga yang tidak memiliki kendaraan bermotor di Indonesia ( ). Berikut adalah data persentase keluarga yang tidak memiliki kendaraan bermotor:
Tabel 3.2 Persentase Keluarga yang tidak memiliki kendaraan bermotor
Provinsi Persentase Provinsi Persentase
Aceh 24.63 Nusa Tenggara Barat 45.87
Sumatera Utara 26.61 Nusa Tenggara Timur 67.29 Sumatera Barat 23.81 Kalimantan Barat 20.95
Riau 12.07 Kalimantan Tengah 17.22
44
Provinsi Persentase Provinsi Persentase
Jambi 16.06 Kalimantan Selatan 16.29
Sumatera Selatan 19.92 Kalimantan Timur 8.68
Bengkulu 18.94 Sulawesi Utara 49.42
Lampung 18.90 Sulawesi Tengah 30.02
Kep, Bangka Belitung 9.51 Sulawesi Selatan 29.56 Kepulauan Riau 9.53 Sulawesi Tenggara 33.10
DKI Jakarta 18.75 Gorontalo 45.43
Jawa Barat 36.08 Sulawesi Barat 38.37
Jawa Tengah 26.85 Maluku 58.08
DI Yogyakarta 18.54 Maluku Utara 49.19
Jawa Timur 23.20 Papua Barat 44.54
Banten 24.09 Papua 71.39
Bali 13.69
Dari tabel 3.2 diperoleh persentase keluarga yang tidak memiliki kendaraan bermotor dengan nilai minimum 8.68 persen dan nilai maksimum 71.39 persen. Dengan menggunakan persamaan 3.2 data akan dinormalkan dengan nilai maksimum 1 dan nilai minimum 0. Maka untuk normalisasi data variabel pada Provinsi Aceh adalah sebagai berikut :
45
Sehingga diperoleh bahwa hasil normalisasi data variabel pada Provinsi Aceh adalah 0.23453. Hasil selanjutnya untuk normalisasi data pada variabel
adalah sebagai berikut
Tabel 3.3 Hasil Normalisasi Data Variabel
Provinsi Persentase Provinsi Persentase
Aceh 0.254345 Nusa Tenggara Barat 0.593047 Sumatera Utara 0.285919 Nusa Tenggara Timur 0.93462 Sumatera Barat 0.241269 Kalimantan Barat 0.195663
Riau 0.054058 Kalimantan Tengah 0.136182
Jambi 0.117685 Kalimantan Selatan 0.121352 Sumatera Selatan 0.179238 Kalimantan Timur 0
Bengkulu 0.16361 Sulawesi Utara 0.649657
Lampung 0.162972 Sulawesi Tengah 0.340297
Kep, Bangka Belitung 0.013236 Sulawesi Selatan 0.332961 Kepulauan Riau 0.013554 Sulawesi Tenggara 0.389412
DKI Jakarta 0.16058 Gorontalo 0.586031
Jawa Barat 0.436932 Sulawesi Barat 0.473449
Jawa Tengah 0.289746 Maluku 0.787753
DI Yogyakarta 0.157232 Maluku Utara 0.645989
Jawa Timur 0.231542 Papua Barat 0.571839
Banten 0.245734 Papua 1
46
Penentuan nilai maksimum dan minimum yang baru untuk variabel akan disamakan pada rentang 0 sampai dengan 1. Hasil selanjutnya untuk normalisasi seluruh variabel data input akan ditampilkan pada lampiran 2.
c. Pembentukan Cluster
Pembentukan cluser terbaik meliputi penentuan jumlah neuron output yang akan digunakan dalam mengklasifikasikan data input. Penentuan jumlah neuron ini menjadi penting karena pada output, data akan diklasifikasi menjadi cluster-cluster yang jumlahnya sama dengan jumlah neuron input. Tidak ada aturan pasti dalam menentukan jumlah neuron, maka dari itu penentuan jumlah neuron dilakukan dengan cara mengelompokkan data dengan pembentukan kelompok yang mungkin dilakukan pada data input.
Setelah menentukan banyak neuron, melakukan pelatihan (training) pada jaringan yang telah dibangun dan dikonfigurasikan dengan data input. Hal ini dilakukan agar bobot awal yang sebelumnya ditentukan secara random (acak) akan diupdate bobotnya dengan dilakukan pelatihan (training) pada jaringan. Pelatihan jaringan pada algoritma Self Organizing Map akan berhenti apabila telah mencapai iterasi maksimum. Pada skripsi ini, iterasi maksimum ditentukan sebanyak 1000 iterasi untuk seluruh model yang akan dibentuk. Untuk pelatihan jaringan dengan 1000 iterasi pada software Matlab digunakan sintaks
net.trainparam.epochs=1000;
47
Setelah pelatihan jaringan telah mencapai iterasi maksimum, maka dapat dimunculkan nilai dari bobot akhir. Kemudian langkah selanjutnya adalah menentukan jarak antara salah satu data input ke masing-masing neuron yang telah ditentukan. Masing-masing input dihitung jaraknya dengan neuron dengan menggunakan persamaan eucledian distance. Setelah diperoleh jarak antara input dengan masing-masing neuron, kemudian jarak antara data input dengan salah satu neuron dibandingkan dengan jarak antara data input dengan neuron lainnya yang masih dalam satu pelatihan (training). Pemilihan cluster terbaik dilakukan dengan menentukan nilai Davies Bouldin Index dari masing masing model, kemudian dibandingkan dengan nilai Davies Bouldin Index dari model yang lainnya.
Dalam rangka penentuan jarak, diperlukan bobot akhir yang telah memenuhi treshold pelatihan (training). Pada Matlab2011b, digunakan sintaks net.WI{1,1} untuk memunculkan bobot akhir. Dalam penelitian ini, akan dijelaskan lebih lanjut mengenai penentuan jarak dan penentuan nilai Davies Bouldin Index. Indeks ini menjadi penting nantinya karena meskipun tidak ada aturan dalam menentukan jumlah cluster, akan tetapi dengan menggunakan indeks ini maka akan ditentukan satu model pembentukan cluster terbaik dari proses algoritma Self Organizing Map.
Pada algoritma Self Organizing Map, pembentukan cluster didasarkan pada pengukuran jarak dari data input menuju neuron yang ditentukan untuk meminimumkan jarak. Pengukuran jarak dilakukan pada seluruh data input dengan memanfaatkan nilai dari normalisasi data dan bobot akhir dari model
48
pembentukan cluster. Berikut ini akan digunakan persamaan 2.3 dengan memanfaatkan hasil normalisasi data pada lampiran 2. Berikut adalah data hasil normalisasi untuk Provinsi Aceh (lampiran 2)
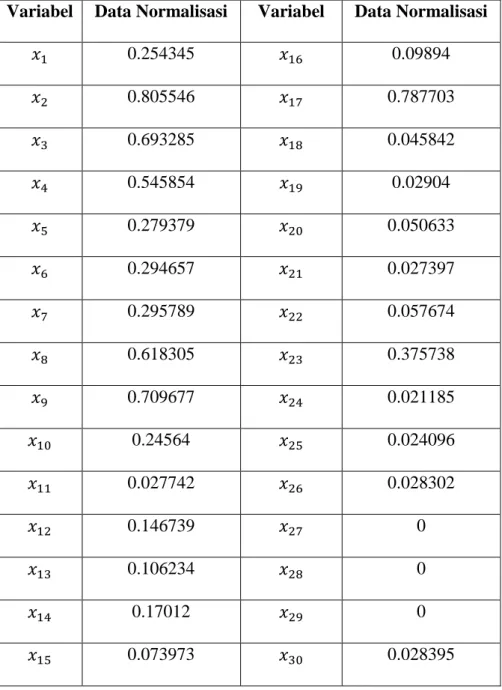
Tabel 3.4 Data Hasil Normalisasi untuk Provinsi Aceh Variabel Data Normalisasi Variabel Data Normalisasi
0.254345 0.09894 0.805546 0.787703 0.693285 0.045842 0.545854 0.02904 0.279379 0.050633 0.294657 0.027397 0.295789 0.057674 0.618305 0.375738 0.709677 0.021185 0.24564 0.024096 0.027742 0.028302 0.146739 0 0.106234 0 0.17012 0 0.073973 0.028395
Kemudian berikut adalah bobot akhir untuk model 2 cluster yang diperoleh dengan menggunakan sintaks net.IW{1,1} pada Matlab R2011b (lampiran 3):
49
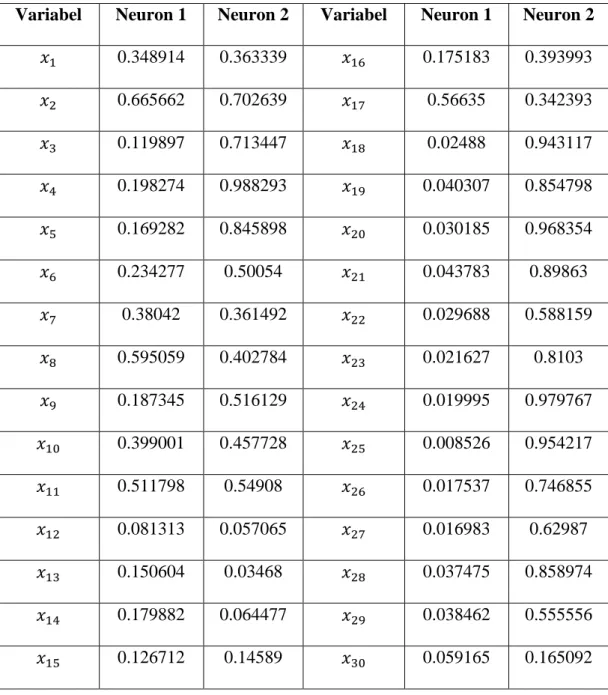
Tabel 3.5 Bobot Akhir untuk Model 2 Cluster
Variabel Neuron 1 Neuron 2 Variabel Neuron 1 Neuron 2
0.348914 0.363339 0.175183 0.393993 0.665662 0.702639 0.56635 0.342393 0.119897 0.713447 0.02488 0.943117 0.198274 0.988293 0.040307 0.854798 0.169282 0.845898 0.030185 0.968354 0.234277 0.50054 0.043783 0.89863 0.38042 0.361492 0.029688 0.588159 0.595059 0.402784 0.021627 0.8103 0.187345 0.516129 0.019995 0.979767 0.399001 0.457728 0.008526 0.954217 0.511798 0.54908 0.017537 0.746855 0.081313 0.057065 0.016983 0.62987 0.150604 0.03468 0.037475 0.858974 0.179882 0.064477 0.038462 0.555556 0.126712 0.14589 0.059165 0.165092
Berdasarkan data hasil normalisasi dan bobot akhir dari data input Provinsi Aceh, maka dapat ditentukan jarak antara neuron 1 dan neuron 2 dengan data input Provinsi Aceh. Dengan menggunakan Eulcedian Distance maka dapat ditentukan jarak inter-cluster data pada Provinsi Aceh ke masing-masing cluster.
50
Berdasarkan hasil perhitungan diatas, dapat ditentukan bahwa jarak data input Provinsi Aceh dengan neuron 1 adalah 1.22873 dan 8.355261987 menuju neuron 2. Hasil selanjutnya untuk pengukuran jarak inter-cluster dengan model 2 cluster pada data Provinsi di Indonesia ditampilkan pada tabel 3.6
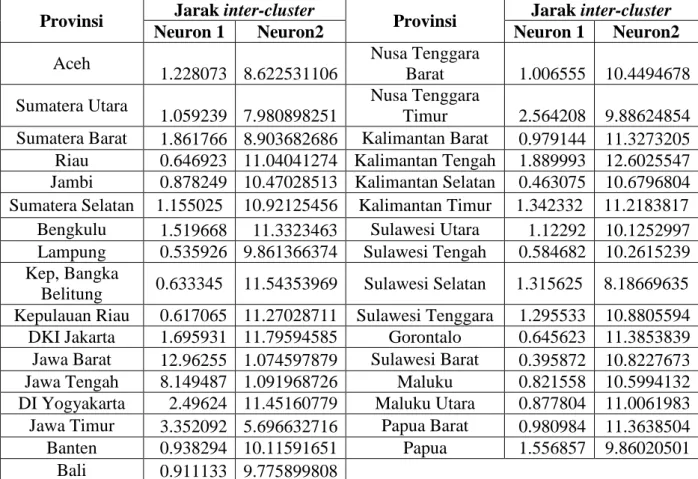
Tabel 3.6 Hasil Penentuan jarak inter-cluster untuk model 2 Cluster
Provinsi Jarak inter-cluster Provinsi Jarak inter-cluster
Neuron 1 Neuron2 Neuron 1 Neuron2
Aceh 1.228073 8.622531106 Nusa Tenggara Barat 1.006555 10.4494678 Sumatera Utara 1.059239 7.980898251 Nusa Tenggara Timur 2.564208 9.88624854 Sumatera Barat 1.861766 8.903682686 Kalimantan Barat 0.979144 11.3273205 Riau 0.646923 11.04041274 Kalimantan Tengah 1.889993 12.6025547 Jambi 0.878249 10.47028513 Kalimantan Selatan 0.463075 10.6796804 Sumatera Selatan 1.155025 10.92125456 Kalimantan Timur 1.342332 11.2183817 Bengkulu 1.519668 11.3323463 Sulawesi Utara 1.12292 10.1252997 Lampung 0.535926 9.861366374 Sulawesi Tengah 0.584682 10.2615239 Kep, Bangka
Belitung 0.633345 11.54353969 Sulawesi Selatan 1.315625 8.18669635 Kepulauan Riau 0.617065 11.27028711 Sulawesi Tenggara 1.295533 10.8805594 DKI Jakarta 1.695931 11.79594585 Gorontalo 0.645623 11.3853839 Jawa Barat 12.96255 1.074597879 Sulawesi Barat 0.395872 10.8227673 Jawa Tengah 8.149487 1.091968726 Maluku 0.821558 10.5994132 DI Yogyakarta 2.49624 11.45160779 Maluku Utara 0.877804 11.0061983 Jawa Timur 3.352092 5.696632716 Papua Barat 0.980984 11.3638504 Banten 0.938294 10.11591651 Papua 1.556857 9.86020501
51 dengan bentuk topologi bobot sebagai berikut
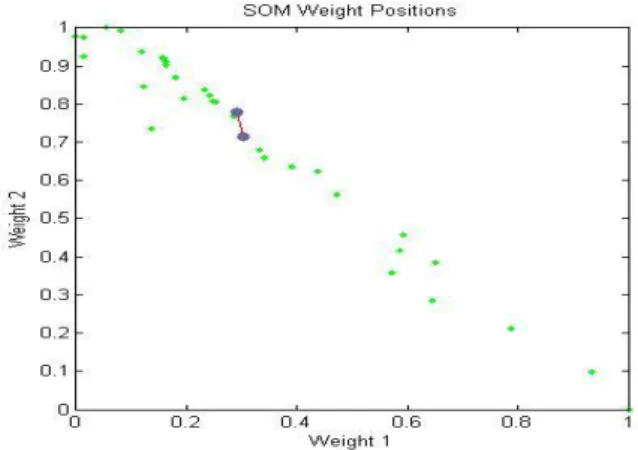
Gambar 3. 4. Topologi Bobot Model 2 cluster
Berdasarkan gambar 3.4, dapat terlihat bahwa neuron dan data input provinsi di Indonesia di representasikan ke dalam dua dimensi. Pada gambar 3.4, neuron ditampilkan dalam bentuk dot berwarna biru, sedangkan untuk data input provinsi di Indonesia ditampilkan dalam bentuk dot berwarna hijau. Adapun bobot penghubung antar neuron ditampilkan dalam bentuk garis berwarna merah.
Berdasarkan tabel 3.6 diketahui jarak inter-cluster untuk masing masing neuron pada model pembentukan cluster dengan 2 cluster. Karena tujuan pembentukan cluster sendiri adalah untuk mengelompokkan unit-unit yang hampir sama pada suatu daerah tertentu dan memaksimumkan perbedaan antar cluster yang dibentuk. Sehingga unit-unit input akan dikelompokkan ke neuron yang paling dekat dengan unit input.
Tabel 3.7 Hasil Pembentukan Model 2 Cluster Provinsi Eucledian
distance Cluster Provinsi
Eucledian
distance Cluster
Aceh 1.228073 1 Nusa Tenggara Barat 1.006555 1 Sumatera Utara 1.059239 1 Nusa Tenggara
52 Provinsi Eucledian
distance Cluster Provinsi
Eucledian
distance Cluster
Sumatera Barat 1.861766 1 Kalimantan Barat 0.979144 1
Riau 0.646923 1 Kalimantan Tengah 1.889993 1
Jambi 0.878249 1 Kalimantan Selatan 0.463075 1 Sumatera Selatan 1.155025 1 Kalimantan Timur 1.342332 1
Bengkulu 1.519668 1 Sulawesi Utara 1.12292 1
Lampung 0.535926 1 Sulawesi Tengah 0.584682 1
Kep, Bangka
Belitung 0.633345 1 Sulawesi Selatan 1.315625 1 Kepulauan Riau 0.617065 1 Sulawesi Tenggara 1.295533 1
DKI Jakarta 1.695931 1 Gorontalo 0.645623 1
Jawa Barat 1.074597879 2 Sulawesi Barat 0.395872 1
Jawa Tengah 1.091968726 2 Maluku 0.821558 1
DI Yogyakarta 2.49624 1 Maluku Utara 0.877804 1
Jawa Timur 3.352092 1 Papua Barat 0.980984 1
Banten 0.938294 1 Papua 1.556857 1
Bali 0.911133 1
Tabel 3.7 menunjukkan model pembentukan cluster dengan 2 cluster. Pada cluster 1, terdapat 31 anggota dan untuk cluster 2 terdapat 2 anggota. Hasil selanjutnya untuk model pembentukan cluster ditampilkan pada lampiran 4.
B. Penerapan Metode Davies Bouldin Index (DBI) dalam Menentukan
Cluster Terbaik dari Proses Algoritma Self Organizing Map
Davies Bouldin Index digunakan untuk validasi cluster, yaitu prosedur yang mengevaluasi hasil analisis cluster secara kuantitatif dan objektif sehingga dihasilkan kelompok optimum. Dalam skripsi ini, Davies Bouldin Index (DBI) akan digunakan untuk mendeteksi outlier pada masing-masing cluster yang terbentuk. Pengukuran ini bertujuan untuk memaksimalkan jarak inter-cluster antara satu cluster dengan cluster yang lain.
53
Berikut ini persamaan Davies Bouldin Index yang diperoleh dengan menggunakan hasil penghitungan jarak inter-cluster pada model pembentukan cluster dengan 2 cluster (lampiran 4).
Maka diperoleh nilai pada model 2 cluster
‖ ̅ ̅ ‖
‖ ‖ Sehingga dapat ditentukan nilai dan IDB
Untuk hasil penentuan nilai Davies Bouldin Index selengkapnya akan ditampilkan pada lampiran 5.
C. Analisis Pembentukan Cluster dengan metode Self Organizing Map
Pemilihan model pembentukan cluster terbaik dilakukan dengan melihat hasil penghitungan nilai Davies Bouldin Index. Untuk menentukan model pembentukan
54
cluster terbaik, maka dibentuk beberapa model pembentukan cluster dengan jumlah cluster yang berbeda. Dalam penelitian ini, dibentuk 9 model pembentukan cluster yang dimulai dengan membentuk model 2 cluster hingga membentuk model 10 cluster menggunakan Matlab (lampiran 7). Berdasarkan hasil penghitungan nilai Davies Bouldin Index untuk masing masing model (lampiran 5), dapat dilihat bahwa dengan pembentukan model lebih dari 4 cluster, terdapat cluster yang hanya memiliki satu anggota saja. Hal ini mungkin terjadi apabila anggota input tersebut tidak sama dengan yang lainnya. Dengan kata lain, dalam pembentukan cluster, terdapat input yang memiliki karateristik khusus sehingga tidak dapat dikelompokkan dengan yang lainnya. Dalam penelitian lain, hal ini disebut dengan kasus khusus. Meski hanya memiliki satu anggota, kelompok tersebut tetap dihitung sebagai cluster. Akan tetapi pada perhitungan nilai Davies Bouldin Index¸ nilai akan selalu bernilai nol jika salah satu dari atau menunjukkan cluster ke- atau cluster ke- yang hanya memiliki satu anggota.
Berdasarkan nilai Davies Bouldin Index, diperoleh bahwa nilai Davies Bouldin Index untuk model 8 cluster memiliki nilai minimum dengan nilai sebesar 0.173808643. hasil penentuan jarak inter-cluster dan pembentukan cluster untuk model 8 cluster ditampilkan pada tabel 3.8.
55
Tabel 3.8 Penentuan Jarak Inter-Cluster dan Pembentukan Cluster untuk Model 9 Cluster
Provinsi Eucledian
distance Cluster Provinsi
Eucledian
distance Cluster
Aceh 0.875 5 Nusa Tenggara Barat 0.755604 5
Sumatera Utara 0.824781 5 Nusa Tenggara Timur 9.7 6
Sumatera Barat 1.08 7 Kalimantan Barat 0.478437 4
Riau 0.283553 2 Kalimantan Tengah 1.17E-30 3
Jambi 0.4201 2 Kalimantan Selatan 0.167562 2
Sumatera Selatan 0.820101 2 Kalimantan Timur 1.217905 2
Bengkulu 1.37E-30 4 Sulawesi Utara 0.708464 5
Lampung 0.182669 2 Sulawesi Tengah 0.254085 5
Kep, Bangka Belitung 0.170635 2 Sulawesi Selatan 1.008522 5
Kepulauan Riau 0.158978 2 Sulawesi Tenggara 1.016041 5
DKI Jakarta 1.153046 2 Gorontalo 0.333477 5
Jawa Barat 0.838334 9 Sulawesi Barat 0.249417 5
Jawa Tengah 0.838334 9 Maluku 0.339403 5
DI Yogyakarta 0.001898 1 Maluku Utara 0.533828 5
Jawa Timur 2.09E-30 8 Papua Barat 0.559245 5
Banten 0.555936 2 Papua 0.710331 5
Bali 0.594471 2
Untuk penentuan kategori tingkat kerawanan bencana tanah longsor didasarkan pada mean dari faktor-faktor terjadinya bencana tanah longsor dan dampak dari bencana tanah longor dari seluruh anggota cluster. Mean yang diperoleh kemudian digunakan sebagai dasar untuk menganalisis karakteristik dari suatu cluster secara umum. Maka untuk melihat karateristik dari masing-masing cluster dilakukan penghitungan dan analisis terhadap nilai mean dari faktor-faktor terjadinya bencana tanah longsor dan dampak dari bencana tanah longor dari seluruh anggota cluster (lampiran 7).
56
1. Analisis Faktor dan Dampak Terjadinya tanah longsor pada masing-masing Cluster
Analisis pada hasil pembentukan cluster akan difokuskan ke dua hal, yaitu faktor penyebab terjadinya bencana tanah longsor dan dampak dari terjadinya bencana tanah longsor. Adapun variabel sampai dengan adalah variabel yang menunjukkan faktor penyebab terjadinya bencana tanah longsor dan variabel sampai dengan menunjukkan dampak dari terjadinya bencana tanah longsor. Analisis hasil pembentukan cluster adalah sebagai berikut
a. Kepemilikan Kendaraan Bermotor
Gambar 3. 5 Diagram Persentase Kepemilikan Kendaraan Bermotor
Dalam kategori kepemilikan kendaraan bermotor, terdapat dua variabel input yang akan dianalisis, yaitu persentase keluarga yang memililiki kendaraan bermotor dan persentase keluarga yang tidak memiliki kendaraan bermotor. Secara umum, hampir seluruh cluster menunjukkan persentase keluarga yang memiliki kendaraan bermotor lebih besar daripada persentase keluarga yang tidak
0 20 40 60 80 100
Persentase Kepemilikan Kendaraan
Bermotor
Tidak Memiliki Kendaraan Bermotor Memiliki Kendaraan Bermotor
57
memiliki kendaraan bermotor dengan perbandingan yang berbeda-beda, hanya pada cluster 6 yang memiliki kondisi yang sedikit berbeda. Pada wilayah cluster 6, persentase rata-rata keluarga yang memiliki kendaraan bermotor lebih kecil daripada persentase rata-rata keluarga yang tidak memiliki kendaraan bermotor. Adapun provinsi yang termasuk ke dalam cluster 6 adalah Provinsi Nusa Tenggara Timur.
b. Kemiringan Lahan
Gambar 3.6 Diagram Jumlah Lokasi Lahan Berkemiringan Curam, Landai dan Sedang
Pada kategori kemiringan lahan, terdapat 3 variabel input yang dianalisis, yaitu jumlah lokasi untuk lahan dengan kemiringan curam, landai dan sedang. Secara umum, hampir pada seluruh wilayah cluster didominasi oleh lahan dengan kemiringan curam, hanya pada cluster 6 jumlah lokasi lahan curam lebh sedikit daripada jumlah lahan landai. Tentu saja banyaknya lahan dengan kemiringan curam lebih berpotensi untuk menimbulkan bencana tanah longsor. Artinya lebih dari separuh provinsi di Indonesia memiliki potensi yang cukup besar untuk
0 1000 2000 3000 4000 5000 6000 7000 Cluster 1 Cluster 2 Cluster 3 Cluster 4 Cluster 5 Cluster 6 Cluster 7 Cluster 8 Cluster 9
Kemiringan Lahan
Curam Landai Sedang58
menimbulkan bencana tanah longsor. Adapun provinsi yang termasuk ke dalam cluster 6 adalah Provinsi Nusa Tenggara Timur.
Secara umum, dari diagram diatas terlihat bahwa seluruh provinsi di Indonesia memiliki jumlah lahan dengan kemiringan sedang yang sangat sedikit. Dapat diambil informasi pula bahwa hampir seluruh cluster memiliki jumlah lokasi lahan curam yang lebih banyak dari pada lahan landai dan lahan sedang, hanya pada cluster 6 yang memiliki jumlah lokasi lahan curam yang lebih sedikit dari pada lahan landai. Adapun pada wilayah cluster 8 dan cluster 9 memiliki rata-rata jumlah lokasi lahan curam yang berbeda cukup signifikan dengan wilayah cluster lainnya dengan rata-rata jumlah lokasi lahan curam lebih dari 4000 lokasi. Adapun provinsi yang termasuk ke dalam cluster 8 adalah Provinsi Jawa Timur dan provinsi yang termasuk ke dalam cluster 9 adalah Provinsi Jawa Barat dan Provinsi Jawa Tengah.
Dari sembilan cluster yang terbentuk, cluster 1 dan cluster 7 memiliki kondisi yang paling baik diantara cluster lainnya bila dilihat dari faktor kemiringan lahan. Jumlah lokasi lahan curam pada wilayah-wilayah ini kurang dari 400 lokasi, sedangkan bila membandingkan keberadaan lahan landai dan lahan sedang maka cluster 7 memiliki kondisi yang lebih baik karena jumlah lahan curam pada wilayah ini lebih sedikit bila dibandingkan dengan wilayah cluster 1. Sedangkan pada wilayah cluster lainnya cenderung memiliki karakteristik kemiringan lahan yang hampir sama. Adapun provinsi yang termasuk ke dalam cluster 1 adalah Provinsi DI Yogyakarta dan provinsi yang termasuk ke dalam cluster 7 adalah Provinsi Sumatera Barat.
59
Dari hasil analisis diatas dapat disimpulkan bahwa :
1) Cluster 8 dan cluster 9 adalah wilayah dengan jumlah lahan curam, lahan landai dan lahan sedang yang paling banyak bila dibandingkan dengan wilayah cluster lainnya, namun yang paling signifikan perbedaanya adalah jumlah lokasi lahan curam yang dapat menjadi potensi terjadi bencana tanah longsor.
2) Cluster 1 dan cluster 7 memiliki kondisi yang paling baik diantara cluster lainnya bila dilihat dari faktor kemiringan lahan. Jumlah lokasi lahan curam pada wilayah-wilayah ini kurang dari 400 lokasi, sedangkan bila membandingkan keberadaan lahan landai dan lahan sedang maka cluster 7 memiliki kondisi yang lebih baik karena jumlah lahan curam pada wilayah ini lebih sedikit bila dibandingkan dengan wilayah cluster 1.
3) Wilayah cluster 2, cluster 3, cluster 4, cluster 5 dan cluster 6 cenderung memiliki karakteristik kondisi kemiringan lahan yang hampir sama.
c. Pemilahan Sampah
Gambar 3.7 Diagram Persentase Keluarga berdasarkan Pemilahan Sampah
0 20 40 60 80 100
Persentase Keluarga berdasarkan
Pemilahan Sampah
Sampah Dipilah dan Sebagian Dimanfaatkan Sampah Dipilah Kemudian Dibuang Sampah Tidak Dipilah
60
Pada kategori pemilahan sampah, terdapat 3 variabel input yang dianalisis, yaitu persentase keluarga yang memilah sampah dan sebagian dimanfaatkan, persentase keluarga yang memilah sampah kemudian dibuang dan persentase keluarga yang tidak memilah sampah. Secara umum, dapat terlihat seperti yang tertera pada diagram, bahwa persentase keluarga yang tidak memilah sampah pada seluruh cluster lebih banyak dari pada persentase keluarga yang memilah, baik yang memilah kemudian dimanfaatkan ataupun yang memilah kemudian dibuang. Artinya kesadaran masyarakat akan pentingnya memilah sampah masih rendah. Hal ini cukup mengkhawatirkan, mengingat tidak terkelolanya sampah dengan baik dapat mengakibatkan masalah lingkungan yang beragam, salah satunya adalah tanah longsor.
Apabila melihat dari persentase pemanfaatan sampah, maka hampir persentase keluarga yang memanfaatkan sampah setelah dipilah di seluruh provinsi di Indonesia lebih rendah daripada persetase keluarga yang memanfaatkan sampah setelah dipilah, hanya pada cluster 1 dan cluster 6, dan cluster 8 memiliki kondisi yang paling baik karena persentase keluarga yang memanfaatkan sampah setelah dipilah lebih tinggi daripada persentase keluarga yang membuang sampah setelah dipilah. Adapun provinsi yang termasuk ke dalam cluster 1 adalah Provinsi DI Yogyakarta, provinsi yang masuk ke dalam cluster 8 adalah Provinsi Jawa Timur dan provinsi yang termasuk ke dalam cluster 6 adalah Provinsi Nusa Tenggara Timur.
61
Kondisi yang sedikit berbeda juga ditemukan pada wilayah cluster 9. Pada wilayah cluster 9 persentase keluarga yang memanfaatkan sampah dan yang membuang sampah setelah dipilah hampir sama. Adapun provinsi yang masuk ke dalam cluster 9 adalah Provinsi Jawa Tengah dan Jawa Barat.
Dari hasil analisis diatas maka dapat disimpulkan bahwa :
1) Persentase keluarga yang tidak memilah sampah pada seluruh cluster lebih banyak dari pada persentase keluarga yang memilah, baik yang memilah kemudian dimanfaatkan ataupun yang memilah kemudian dibuang.
2) Pada cluster 1 dan cluster 6, dan cluster 8 memiliki persentase keluarga yang memanfaatkan sampah setelah dipilah lebih tinggi daripada persentase keluarga yang membuang sampah setelah dipilah.
3) Pada wilayah cluster 9 persentase keluarga yang memanfaatkan sampah dan yang membuang sampah setelah dipilah hampir sama.
4) Pada wilayah cluster 2, cluster 3, cluster 4, cluster 5, dan cluster 7 memiliki karakteristik wilayah yang hampir sama bila dilihat dari faktor pemilahan sampah.
d. Bencana Gempa Bumi
Gambar 3.8 Diargam Frekuensi Terjadinya Bencana Gempa Bumi
0 20 40 60 80
Cluster 1Cluster 2Cluster 3Cluster 4Cluster 5Cluster 6Cluster 7Cluster 8Cluster 9
62
Pada kategori bencana gempa bumi, terdapat satu variabel input yang dianalisis, yaitu frekuensi terjadinya bencana gempa bumi. Dari diagram diatas terlihat bahwa karakteristik wilayah pada cluster 7 adalah wilayah yang rawan terjadi bencana gempa bumi. Tercatat ada rata-rata 62 kasus terjadinya bencana gempa bumi. Hal ini tentu menjadi pertimbangan dalam penanganan pra bencana karena semakin tinggi frekuensi terjadi bencana tanah longsor maka tinggi pula potensi terjadinya bencana tanah longsor.
Adapun wilayah yang memiliki frekuensi terjadi bencana tanah longsor terendah adalah wilayah cluster 2 dan cluster 3 dengan jumlah kasus kejadian bencana gempa bumi kurang dari 5 kasus. Sedangkan pada wilayah cluster lainnya cenderung memiliki potensi terjadi gempa bumi yang cukup tinggi dengan rata-rata lebih dari 10 kejadian.
e. Curah Hujan
Gambar 3.9 Diagram Jumlah Curah Hujan
0 500 1000 1500 2000 2500 3000 3500 4000 4500 5000
Jumlah Curah Hujan
63
Gambar 3.10 Diagram Jumlah Hari Hujan
Pada kategori curah hujan, terdapat 2 variabel yang dianalisis, yaitu jumlah curah hujan dan jumlah hari hujan.
Apabila melihat jumlah curah hujan pada diagram diatas terlihat bahwa karakteristik wilayah pada cluster 3, cluster 4 dan cluster 7 adalah wilayah yang memiliki jumlah hujan cukup tertinggi bila dibandingkan dengan jumlah curah hujan pada cluster lainnya dengan rata-rata jumlah curah hujan lebih dari 2500 mm yang beranggotakan Kalimantan Tengah pada cluster 3, Provinsi Bengkulu pada cluster 4 dan Provinsi Sumatera Barat pada cluster 7. Adapun wilayah yang memiliki jumlah curah hujan terendah adalah cluster 6 yang beranggotakan Provinsi Nusa Tenggara Timur. Sedangkan pada wilayah cluster lainnya cenderung memiliki karakteristik curah hujan yang hampir sama dengan rata-rata curah hujan kurang dari 2000mm.
0 50 100 150 200 250
Jumlah Hari Hujan
64
Apabila melihat dari jumlah hari hujan, maka cluster 4, cluster 7 dan cluster 8 memiliki jumlah hujan yang sangat banyak dengan rata-rata jumlah hari hujan lebih dari 200 hari. Provinsi-provinsi yang masuk ke dalam cluster-cluster ini adalah Provinsi Bengkulu, Provinsi Sumatera Barat, dan Provinsi Jawa Timur. Adapun cluster yang memiliki jumlah hari hujan yang paling sedikit adalah cluster 6 yang beranggotakan Provinsi Nusa Tenggara Timur dengan rata-rata 98 hari hujan. sedangkan pada wilayah cluster lainnya memiliki karakteristik jumlah hari hujan yang hampir sama dengan rata-rata jumlah hari hujan sekitar 180 hari.
f. Bencana Kebakaran
Gambar 3.11 Jumlah Frekuensi Terjadinya Bencana Kebakaran
Pada kategori bencana kebakaran, terdapat satu variabel input yang dianalisis, yaitu frekuansi terjadi bencana kebakaran hutan dan lahan. Secara umum dapat dikatakan hampir seluruh wilayah di provinsi-provinsi di Indonesia memiliki potensi untuk terjadi bencana kebakaran, hanya pada cluster 1 saja, kasus
0 5 10 15 20 25 30 35
Frekuensi Terjadi Bencana Kebakaran
65
kebakaran hutan dan lahan tidak pernah terjadi. Adapun provinsi yang termasuk ke dalam cluster 1 adalah provinsi DI Yogyakarta.
Dari diagram diatas yang tersaji, terlihat bahwa wilayah yang masuk ke dalam cluster 2, cluster 3, cluster 7 dan cluster 8 memiliki jumlah kejadian bencana kebakaran hutan dan lahan yang cukup signifikan apabila dibandingkan dengan wilayah cluster lainnya rata-rata kurang dari 15 kejadian. Dapat dikatakan juga bahwa provinsi-provinsi yang masuk ke dalam cluster 2, cluster 3, cluster 7 dan cluster 8 memiliki potensi terjadi bencana kebakaran hutan dan lahan yang cukup tinggi bila dibandingkan dengan wilayah cluster lainnya. Sedangkan wilayah cluster 4, cluster 5 dan cluster 6 memiliki potensi terjadi kebakaran hutan dan lahan yang cenderung sama dengan rata-rata kurang dari 11 kejadian.
g. Lahan Kritis
Gambar 3.12 Diagram Keberadaan Lahan Kritis
Pada kategori lahan kritis, terdapat dua variabel input yang dianalisis, yaitu luas lahan kritis dan luas lahan sangat kritis. Secara umum dapat dikatakan bahwa di seluruh wilayah provinsi di Indonesia didominasi oleh lahan kritis. Hal ini
0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% Lahan Kritis Lahan Sangat Kritis
66
terlihat dari lahan kritis pada masing-maisng cluster memiliki luas rata-rata yang lebih tinggi daripada luas rata-rata lahan sangat kritis, bahkan pada cluster 8 tidak memiliki lahan yang masuk dalam kategori lahan sangat kritis.
Bila melihat luas lahan kritis maupun lahan sangat kritis pada masing masing wilayah cluster 3, cluster 4 dan cluster 6 menjadi wilayah yang memiliki kondisi lahan yang paling buruk dengan luas lahan kritis lebih dari 1000 hektar. Untuk cluster 2, cluster 5 dan cluster 7 memiliki kondisi lahan yang cukup buruk dengan rata-rata luas lahan kritis berkisar 500 hektar, sedangkan untuk cluster 1 dan cluster 9 memiliki kondisi lahan yang lebih baik dengan luas rata-rata lahan kritis tidak lebih dari 300 hektar. Dari seluruh cluster yang terbentuk, cluster 8 menjadi wilayah dengan kondisi lahan yang paling baik karena memiliki lahan kritis dengan luas tersempit, yaitu hanya 33 hektar.
Bila membandingkan keberadaan lahan sangat kritis antar wilayah cluster, maka cluster 3 dan cluster 4 memiliki kondisi terburuk dengan luas lahan sangat kritis yang yang cukup signifikan bila dibandingkan dengan wilayah cluster lainnya. Kondisi lahan pada wilayah cluster 2 dan cluster 5 sedikit lebih baik dengan rata-rata luas lahan kritis berkisar pada angka 100 sampai 170 hektar, sedangkan pada wilayah cluster lainnya memiliki rata-rata luas lahan kritis tidak lebih dari 100 hektar. dari seluruh cluster yang terbentuk, bila keberadaan lahan sangat kritis maka cluster 1 dan cluster 8 memiliki kondisi yang paling baik , bahkan pada wilayah cluster 8 tidak ditemukan lahan yang masuk ke dalam kategori lahan sangat kritis.
67
1) Cluster 3 dan cluster 4, dan cluster 6 memiliki kondisi lahan yang sangat buruk dengan rata-rata luas lahan kritis mencapai lebih dari 1000 hektar. 2) Cluster 2, cluster 5 dan cluster 7 memiliki kondisi lahan cukup buruk dengan
luas rata-rata lahan kritis dan lahan kritis sangat kritis berkisar 500 hektar. Meskipun demikian, kondisi lahan pada cluster 2 sedikit lebih buruk daripada cluster 5 dan cluster 7 dengan keberadaan lahan sangat kritis yang lebih luas. Sedangkan kondisi lahan pada cluster 5 dan cluster 7 relatif sama.
3) Cluster 1 dan cluster 9 memiliki kondisi lahan yang cukup baik dengan keberadaan lahan kritis tidak lebih dari 300 hektar dan luas lahan sangat kritis yang tidak lebih dari 40 hektar. Meski begitu, bila melihat pada luas lahan kritis dan luas lahan sangat kritis pada masing masing cluster, cluster 9 memiliki kondisi yang lebih buruk daripada wilayah cluster 1 karena baik luas lahan kritis maupun luas lahan sangat kritis pada wilayah cluster 9 lebih luas daripada luas lahan krits dan lahan sangat kritis pada wilayah cluster 1. 4) Cluster 8 memiliki kondisi yang paling baik bila dibandingkan wilayah
cluster lainnya karena wilayah ini memiliki luas lahan kritis tersempit dan tidak ditemukannya lahan yang masuk ke dalam kategori lahan sangat kritis.
68 h. Daerah Resapan Air
Gambar 3.13 Diagram Persentase Keberadaan Daerah Resapan Air
Gambar 3.14 Diagram Persentase Keberadaan Taman/ Tanah Berumput
Pada kategori daerah resapan air, terdapat 3 variabel input yang dianalisis, yaitu luas daerah sumur resapan, luas daerah lubang resapan/ biopori, dan luas daerah taman/ tanah berumput. Secara umum, daerah resapan air diseluruh provinsi di Indonesia didomiasi oleh taman/ tanah berumput dengan persentase mencapai 90 persen dari luas daerah resapan air. Namun apabila dibandingkan
0 1 2 3 4 5 6 7 8
Daerah Resapan Air
Sumur Resapan
Lubang Resapan Biopori
0 10 20 30 40 50 60
Taman/ Tanah Berumput
69
dengan rata-rata luas wilayah untuk masing-masing cluster, maka cluster 3 dan cluster 7 memiliki kondisi yang paling baik. Hal ini terlihat dari jumlah daerah resapan air masing masing cluster yang mencapai 44.36 persen dan 41.43 persen. Persentase ini lebih besar dari pada persentase daerah resapan air di wilayah lain yang bahkan tidak mencapai angka 30 persen.
Bila melihat dari data persentase luas daerah resapan air, masyakarat di wilayah yang masuk ke dalam cluster 1 memiliki kesadaran akan penyediaan daerah resapan air yang cukup tinggi. Persentase rata-rata luas daerah sumur resapan air pada cluster 1 mencapai angka 7.3 persen, sedangkan untuk persentase rata-rata luas daerah lubang resapan/ biopori mencapai angka 2.81 persen. persentase ini lebih baik bila dibandingkan dengan persentase luas wilayah daerah resapan air di cluster lain yang bahkan tidak mencapai 1 persen untuk kategori sumur resapan dan lubang resapan air/biopori.
Secara umum, penanganan pra bencana apabila melihat dari masalah ketersediaan daerah resapan air, maka untuk seluruh wilayah dapat difokuskan kepada peningkatan kesadaran masyarakat akan pentingnya penyediaan daerah sumur resapan dan lubang resapan/ biopori. Sedangkan untuk penanganan ketersediaan daerah taman/ tanah berumput dapat difokuskan ke wilayah-wilayah yang masuk ke dalam cluster 1 yang memiliki persentase daerah taman/ tanah berumput yang kecil.
70 i. Bencana Tanah Longsor
Gambar 3.15 Frekuensti Terjadinya Bencana Tanah Longsor
Pada kategori bencana tanah longsor terdapat 1 variabel input yang dianalisis, yaitu frekuensi terjadinya bencana tanah longsor. Dari data nilai mean faktor-faktor terjadinya bencana tanah longsor, wilayah cluster 7, cluster 8 dan cluster 9 menjadi wilayah yang paling berpotensi terjadi tanah longsor dengan rata-rata kejadian bencana tanah longsor mencapai lebih dari 100 kejadian. Bahkan frekuensi terjadi bencana tanah longsor pada wilayah cluster 9 mencapai 1113 peristiwa.
Kemudian wilayah lain yang memiiki frekuensi terjadi bencana tanah longsor yang cukup signifikan adalah cluster 8 dengan 336 peristiwa dan wilayah cluster 7 dengan 172 peristiwa. Cluster 1 dan cluster 6 memiliki rata-rata jumlah peristiwa bencana tanah longsor yang cukup banyak dengan rata-rata kejadian bencana
0 200 400 600 800 1000 1200
Frekuensi Terjadi Bencana Tanah Longsor
71
tanah longsor mencapai lebih dari 50 peristiwa. Adapun cluster 2 dan cluster 5 memiliki frekuensi terjadi bencana tanah longsor yang cukup rendah dengan rata-rata 27 kejadian. Sedangkan pada cluster 4 frekuensi terjadi bencana tanah longsor rata-rata mencapai 17 kejadian. Dari seluruh cluster, yang terbentuk, cluster 3 adalah wilayah yang memiliki frekuensi terjadi tanah longsor yang terendah dengan rata-rata 4 kejadian.
Dari hasil analisis diatas dapat disimpulkan bahwa :
1) Wilayah cluster 7, cluster 8 dan cluster 9 adalah wilayah dengan frekuensi kejadian bencana tanah longsor yang sangat tinggi dengan jumlah kejadian lebih dari 100 peristiwa. Adapun cluster 4 menjadi wilayah yang paling tinggi frekuensi terjadinya bencana tanah longsor dengan rata-rata 1113 peristiwa tanah longsor.
2) Wilayah cluster 1 dan cluster 6 adalah wilayah dengan frekuensi bencana tanah longsor sedang dengan rata-rata jumlah peristiwa bencana tanah longsor lebih dari 50 kejadian. Meskipun pada kenyataanya jumlah frekuensi terjadi bencana tanah longsor di wilayah cluster 1 dan cluster 6 cukup berbeda, namun pada proses pra bencana kedua cluster ini dapat dikategorikan pada karakteristik yang sama.
3) Wilayah cluster 2 dan cluster 8 adalah wilayah dengan frekuensi bencana tanah longsor yang rendah karena rata-rata jumlah kejadian rata-rata 27 kejadian. Sedangkan di bawah kedua cluster ini ada cluster 4 dengan 17 kejadian.
72
4) Wilayah cluster 6 adalah wilayah dengan frekuensi bencana tanah longsor terendah dengan rata-rata 13 peristiwa tanah longsor
j. Korban Bencana
Gambar 3. 16 Diagram Jumlah Korban Akibat Bencana Tanah Longsor Pada kategori korban bencana tanah longsor, terdapat 5 variabel input yang dianalisis, yaitu jumlah korban mengungsi, korban menderita, korban terluka, korban hilang dan korban meninggal. Secara umum, dapat terlilhat bahwa potensi timbulnya korban hilang dan terluka akibat dari bencana tanah longsor sangat kecil. Hal ini dapat terlihat dari sedikitnya jumlah korban hilang dan terluka yang ditimbulkan dari bencana tanah longsor. Sebaliknya, potensi timbulnya korban mengungsi, korban menderita, dan korban meninggal cukup tinggi. Bila melihat jumlah korban pada masing masing-masing wilayah cluster, maka cluster 2, cluster 3, cluster 4, cluster 6, dan cluster 8 didominasi oleh korban menderita, sedangkan pada wilayah cluster1, cluster 5, cluster 7 dan cluster 9 didominasi oleh korban mengungsi.
0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% Cluster 1 Cluster 2 Cluster 3 Cluster 4 Cluster 5 Cluster 6 Cluster 7 Cluster 8 Cluster 9 Mengungsi Menderita Terluka Hilang Meninggal
73
Bila melihat dari jumlah korban yang ditimbulkan maka cluster 5 menjadi wilayah yang terkena dampak korban jiwa yang paling besar dibandingkan dengan wilayah cluster lainnya. Rata-rata setiap kejadian bencana tanah longsor menimbulkan 89 korban jiwa, diikuti dengan cluster 8 dengan rata-rata 75 korban per kejadian bencana. Adapun pada cluster 6 dan cluster 7 jumlah korban yang jatuh akibat bencana tanah longsor rata-rata berjumlah 50 korban jiwa, cluster 2 dan cluster 9 dengan rata-rata 33 korban jiwa, sedangkan pada cluster 1, cluster 3 jumlah korban yang jatuh rata-rata 24 korban jiwa. Dari seluruh cluster yang terbentuk, cluster 4 memiliki rata-rata jumlah korban jiwa yang paling sedikit dengan 15 korban jiwa di setiap kejadian bencana tanah longsor.
Dari hasil analisis di atas maka disimpulkan bahwa :
1) Potensi timbulnya korban hilang dan terluka akibat dari bencana tanah longsor cukup kecil, sedangkan potensi timbulnya korban mengungsi, korban menderita, dan korban meninggal cukup tinggi. Adapun kondisi pada cluster 9 sedikit berbeda, karena pada wilayah ini potensi adanya korban terluka sama besar dengan potensi adanya korban meninggal.
2) Wilayah cluster 2, cluster 3, cluster 4, cluster 6 dan cluster 8 didominasi oleh korban menderita
3) Wilayah cluster 1, cluster 5, cluster 7 dan cluster 9 didominasi oleh korban mengungsi.
4) Wilayah cluster 5 menjadi wilayah yang terkena dampak korban jiwa yang paling besar dibandingkan dengan wilayah cluster lainnya dengan rata-rata
74
setiap kejadian bencana tanah longsor menimbulkan korban sebanyak 89 korban jiwa, diikuti oleh wilayah cluster 8 dengan 75 korban jiwa.
5) Pada wilayah cluster 6 dan cluster 7 jumlah korban yang jatuh akibat bencana tanah longsor rata-rata berjumlah 50 korban jiwa
6) Pada wilayah cluster 2 dan cluster 9 jumlah korban yang jatuh rata-rata 33 korban jiwa.
7) Wilayah cluster 4 memiliki rata-rata jumlah korban jiwa yang paling sedikit dengan 15 korban jiwa di setiap kejadian bencana tanah longsor
k. Kerusakan Rumah
Gambar 3.17 Diagram Jumlah Kerusakan Rumah
Pada kategori kerusakan rumah, terdapat 3 variabel yang akan dianalisis, yaitu jumlah rumah rusak ringan, jumlah rumah rusak sedang dan jumlah rumah rusak berat. Secara umum, dampak kerusakan yang diberikan oleh bencana tanah
0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% Cluster 1 Cluster 2 Cluster 3 Cluster 4 Cluster 5 Cluster 6 Cluster 7 Cluster 8 Cluster 9 Rusak Ringan Rusak Sedang Rusak Berat
75
longsor pada rumah warga cukup besar. Hal ini terlihat dari 9 cluster yang terbentuk, hanya cluster 5 dan cluster 8 yang memiliki rumah rusak berat yang lebih sedikit dari pada jumlah rumah rusak ringan maupun rumah rusak sedang. Bila melihat jumlah korban pada masing-masing wilayah cluster, maka kerusakan rumah yang ditimbulkan oleh bencana tanah longsor didominasi oleh kerusakan berat dan kerusakan ringan, dengan jumlah rata-rata rumah rusak berat lebih banyak daripada jumlah rumah rusak ringan. Sehingga pada rencana pra bencana, potensi dampak kerusakan pada rumah perlu menjadi prioritas dalam penanganannya. Namun secara umum, jumlah kerusakan yang ditimbulkan oleh bencana tanah longsor pada rumah warga cukup besar, dengan minimal ada 3 rumah warga yang rusak di setiap kejadian bencana tanah longsor.
l. Fasilitas Umum
Gambar 3.18 Diagram Jumlah Kerusakan Pada Fasilitas Umum
0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% Fasilitas Kesehatan Fasilitas Pendidikan Fasilitas Peribadatan
76
Pada kategori kerusakan pada fasilitas umum, terdapat 3 variabel yang dianalisis yaitu kerusakan pada fasilitas kesehatan, kerusakan pada fasilitas pendidikan dan kerusakan pada fasilitas peribadatan. Bila melihat dari jumlah kerusakan pada masing-masing fasilitas umum, potensi timbulnya kerusakan pada fasilitas umum, baik fasilitas kesehatan, pendidikan, maupun peribadatan sangat kecil. Hal ini dapat dilihat dari sedikitnya jumlah fasilitas umum yang rusak akibat bencana tanah longsor. Dengan kata lain, tidak setiap kejadian bencana tanah longsor menimbulkan kerusakan pada fasilitas umum. Namun meski begitu, kemungkinan timbulnya kerusakan pada fasilitas umum tetap ada, meski dengan potensi yang sangat kecil.
m. Kerusakan Jalan
Gambar 3.19 Diagram Panjang Jalan yang Terkena Dampak Tanah Longsor
0 20 40 60 80 100 120 140 160 180 200
Panjang Jalan (km)
Panjang Jalan (km)77
Pada kategori kerusakan pada jalan, terdapat 1 variabel yang dianalisis yaitu kerusakan pada jalan. Secara umum, potensi adanya kerusakan pada jalan akibat dari bencana tanah longsor cukup tinggi.
Bila melihat panjang jalan yang rusak akibat bencana tanah longsor pada masing-masing wilayah cluster, maka kerusakan pada jalan yang ditimbulkan oleh bencana tanah longsor pada wilayah cluster 7 menjadi yang paling besar dengan panjang jalan yang rusak mencapai 178.99 km. Pada wilayah cluster 8 dan cluster 9 dampak kerusakan pada jalan cukup besar dengan rata-rata hampir mencapai 111 km, sedangkan pada cluster 1 dan cluster 6 jumlah kerusakan pada jalan tergolong sedang dengan panjang rata-rata jalan yang rusak mencapai 72.6 km. Dari seluruh cluster yang terbentuk, cluster 2, cluster 3 dan cluster 4 memiliki panjang jalan rusak yang paling pendek dengan panjang jalan yang rusak bahkan tidak mencapai 4 km.
Bila membandingkan frekuensi terjadi bencana tanah longsor dan panjang jalan yang rusak, maka cluster 5, cluster 6 dan cluster 7 menjadi wilayah dengan potensi kerusakan pada jalan yang paling tinggi bila dibandingkan dengan wilayah cluster lainnya. Namun meski begitu, kemungkinan timbulnya kerusakan pada jalan tetap ada. Hal ini perlu menjadi pertimbangan karena pada proses penanggulangan pasca bencana, akses jalan yang baik menjadi faktor penting dalam kelancaran penanggulangan bencana.
78
2. Analisis Cluster Berdasarkan Faktor dan Dampak Terjadinya Bencana Tanah Longsor di Indonesia
Dari hasil analisis variabel input diatas maka dapat ditentukan karakter dari masing-masing wilayah cluster. Adapun analisis karakter cluster dari pembentukan model 8 cluster adalah sebagai berikut :
a. Cluster 1
Cluster 1 memiliki satu anggota yaitu Provinsi Daerah Istimewa Yogyakarta dengan nilai Eucledian Distance sebesar 0.001898. Karena cluster 1 hanya memiliki satu anggota maka karakteristiknya akan sama dengan karakteristik wilayah provinsi Daerah Istimewa Yogyakarta.
1) Analisis faktor-faktor terjadinya bencana tanah longsor
Berdasarkan hasil analisis data input faktor-faktor terjadinya bencana tanah longsor, faktor yang paling mempengaruhi terjadinya bencana tanah longsor adalah minimnya daerah tanah berumput. Hal ini diperparah dengan rendahnya kesadaran masyakarat akan pemilahan sampah. Meskipun begitu luas daerah sumur resapan dan lubang resapan pada wilayah cluster ini lebih tinggi daripada wilayah cluster lainnya. Untuk faktor yang masuk ke dalam kategori kepemilikan kendaraan bermotor, keberadaan lahan dengan kemiringan curam, luas lahan kritis masih berada dalam jumlah yang tidak begitu besar sehingga dampak yang diberikan tidak terlalu besar. Adapun potensi bencana gempa bumi dan kebakaran hutan dan lahan di wilayah cluster 1 sangat rendah.
79
Berdasarkan hasil analisis data input dampak terjadinya bencana tanah longsor, wilayah cluster 1 adalah wilayah dengan potensi bencana tanah longsor yang cukup tinggi dengan rata-rata mencapai 74 kejadian. Meskipun demikian, rata-rata jumlah korban jiwa yang ditimbulkan dari bencana tanah cukup sedikit dengan 24 korban jiwa yang didominasi oleh korban mengungsi pada setiap kejadian bencana. Bencana tanah longsor juga tidak berdampak begitu besar pada fasilitas umum dan kerusakan jalan. Adapun kerusakan pada rumah warga cukup banyak dengan jumlah rata-rata rumah rusak mencapai 3 unit.
b. Cluster 2
Dari hasil output Minitab, Cluster 2 memiliki 11 anggota. Anggota dari cluster 2 ditunjukkan pada tabel berikut.
Provinsi Eucledian Distance Provinsi Eucledian Distance
Riau 0.283553 DKI Jakarta 1.153046
Jambi 0.4201 Banten 0.555936
Sumatera Selatan 0.820101 Bali 0.594471
Lampung 0.182669 Kalimantan Selatan 0.167562
Kep, Bangka Belitung 0.170635 Kalimantan Timur 1.217905 Kepulauan Riau 0.158978
1) Analisis faktor-faktor terjadinya bencana tanah longsor
Berdasarkan hasil analisis data input faktor-faktor terjadinya bencana tanah longsor, faktor yang paling berpengaruh akan terjadinya bencana tanah longsor
80
adalah kepemilikan kendaraan bermotor, tingginya frekuensi terjadinya kebakaran, minimnya daerah resapan air dan tingginya jumlah curah hujan. Adapun untuk faktor yang masuk ke dalam kategori keberadaan lahan dengan kemiringan curam, pengolahan sampah, keberadaan lahan kritis dan persentase daerah resapan air masih berada pada jumlah yang tidak begitu besar bila dibandingkan dengan wilayah cluster lainnya sehingga dampak yang diberikan tidak begitu besar. Adapun potensi bencana gempa bumi di wilayah cluster 2 paling rendah bila dibandingkan dengan wilayah cluster lain.
2) Analisis dampak terjadinya bencana tanah longsor
Berdasarkan hasil analisis data input dampak terjadinya bencana tanah longsor, wilayah cluster 2 adalah wilayah dengan potensi bencana tanah longsor yang cukup rendah. Meski begitu, jumlah rumah rusak yang diakibatkan oleh bencana tanah longsor cukup tinggi dengan rata-rata rumah rusak mencapai 6 unit. Adapun jumlah korban jiwa yang ditimbulkan dari bencana tanah cukup sedikit dengan rata-rata 28 korban jiwa per kejadian tanah longsor yang didominasi oleh korban menderita. Bencana tanah longsor juga tidak berdampak begitu besar pada fasilitas umum dan kerusakan jalan.
c. Cluster 3
Cluster 3 memiliki satu anggota yaitu Provinsi Kalimantan Tengah dengan nilai Eucledian Distance sebesar 9.7 . Karena cluster 3 hanya memiliki
81
satu anggota maka karakteristiknya akan sama dengan karakteristik wilayah Provinsi Kalimantan Tengah
1) Analisis faktor-faktor terjadinya bencana alam tanah longsor
Berdasarkan hasil analisis data input faktor-faktor terjadinya bencana tanah longsor, faktor yang paling berpengaruh akan terjadinya bencana tanah longsor adalah curah hujan yang tinggi, potensi terjadi kebakaran hutan dan lahan yang cukup tinggi, dan keberadaan lahan kritis. Adapun faktor yang masuk ke dalam kategori kepemilikan kendaraan bermotor, keberadaan lahan curam, daerah resapan air, pemilahan sampah serta ketersediaan daerah resapan air berada pada jumlah yang tidak begitu besar bila dibandingkan dengan wilayah cluster lainnya sehingga tidak memberikan dampak yang begitu besar. Wilayah cluster ini juga memiliki tingkat pemilahan sampah yang sangat baik dengan lebih dari 20 persen warganya memilah sampah. Adapun wilayah cluster 3 memiliki frekuensi terjadi gempa bumi paling rendah bila dibandingkan dengan wilayah cluster lainnya.
2) Analisis dampak terjadinya bencana tanah longsor
Berdasarkan hasil analisis data input dampak terjadinya bencana tanah longsor, wilayah cluster 3 adalah wilayah dengan potensi bencana tanah longsor yang paling rendah dengan rata-rata 4 kejadian. Jumlah korban jiwa yang ditimbulkan dari bencana tanah cukup paling banyak dengan rata-rata 25 korban jiwa per peristiwa yang didominasi oleh korban menderita. Bencana tanah longsor juga tidak memberikan dampak kerusakan pada akses jalan .Meskipun demikian, bencana tanah longsor tidak berdampak begitu besar pada fasilitas umum dan rumah warga bila dibandingkan dengan wilayah cluster lain.