Fakultas Ilmu Komputer
330
Implementasi Gabungan Metode Bayesian dan Backpropagation untuk
Peramalan Jumlah Pengangguran Terbuka di Indonesia
Yure Firdaus Arifin1, Dian Eka Ratnawati2, Putra Pandu Adikara3
Program Studi Teknik Informatika, Fakultas Ilmu Komputer, Universitas Brawijaya Email: 1[email protected], 2[email protected], 3[email protected]
Abstrak
Salah satu masalah pokok yang dihadapi negara Indonesia adalah pengangguran. Penyebab terjadinya pengangguran antara lain adalah jumlah lapangan kerja yang tersedia lebih kecil dari jumlah lulusan/pencari kerja. Tidak sebandingnya jumlah lapangan kerja dengan jumlah lulusan/pencari kerja tersebut yang menyebabkan tingginnya tingkat pengangguran di Indonesia. Tingkat pengangguran yang tinggi berdampak langsung maupun tidak langsung terhadap kemiskinan, kriminalitas, dan masalah-masalah sosial. Akan tetapi pada kenyataannya berdasarkan hasil survei BPS dari tahun 2014 ke 2015 tingkat pengangguran terbuka di Indonesia justru menunjukkan peningkatan. Dengan meramalkan/memprediksi jumlah pengangguran, dapat membantu pemerintah Indonesia dalam membuat perencanaan program pemerintah ataupun kebijakan-kebijakan yang terkait tentang lapangan pekerjaan. Selain itu, data hasil prediksi dapat digunakan untuk mengukur seberapa berhasilkah program pemerintah yang telah dilaksanakan pada tahun sebelumnya.
Metode Backpropagation adalah salah satu metode yang dapat digunakan untuk memprediksi. Pada penelitian ini dilakukan optimasi nilai inisialisasi bobot pada Backpropagation menggunakan metode Bayesian yang merupakan modifikasi dari Kalman Filter. Berdasarkan hasil pengujian yang telah dilakukan dalam penelitian ini nilai Average Forecasing Error Rate (AFER) yang terendah adalah 2,1003%. Dari hasil pengujian tersebut metode gabungan Bayesian dan Backpropagation memiliki tingkat akurasi yang lebih baik dari pada metode Backpropagation dengan inisialisasi random yang memiliki nilai AFER terendah 2,5793% tetapi membutuhkan jumlah iterasi yang lebih banyak. Sistem prediksi jumlah pengangguran terbuka di Indonesia dengan metode gabungan Bayesian dan Backpropagation pada penelitian ini dapat melakukan prediksi beberapa tahun kedepan secara langsung tetapi hasil yang paling optimal adalah prediksi pada tahun pertama sedangkan pada tahun-tahun berikutnya hasil prediksi semakin tidak akurat.
Kata kunci: backpropagation, bayesian, kalman filter, time series
Abstract
One of the major problems that Indonesia has is unemployment. It happens because of the low number of the job vacancy meets the high number of the graduate and job seeker. The unbalanced number of the job vacancy to the graduate and job seeker causes an increasing in the unemployment rate in Indonesia. The high rate of unemployment will inevitably give a direct or indirect impact to the poverty, crime, and other social issues. However, according to the survey conducted by BPS, Indonesia’s unemployment rate was even increasing from the year of 2014 to 2015. It would really help the Indonesian government to make planning, program, or policy related to the job vacancy by being able to predict the number of unemployment. In addition, the data result from the prediction could be used as the measurement of the success of government’s previous programs.
Keywords: backpropagation, bayesian, kalman filter, time series
1. PENDAHULUAN
Tingginya tingkat pengangguran akan berdampak langsung maupun tidak langsung terhadap kemiskinan, kriminalitas, dan masalah-masalah sosial. Akan tetapi pada kenyataannya berdasarkan hasil survei BPS dari tahun 2014 ke 2015 tingkat pengangguran terbuka di Indonesia justru menunjukkan peningkatan. Jumlah pengangguran terbuka pada Agustus 2014 yaitu 7,24 juta orang, pada Agustus 2015 mencapai
7,56 juta orang. Dengan
meramalkan/memprediksi jumlah pengangguran, dapat membantu pemerintah Indonesia dalam membuat perencanaan program pemerintah ataupun kebijakan-kebijakan yang terkait tentang lapangan pekerjaan. Selain itu, data hasil dari prediksi nantinya dapat digunakan untuk mengukur seberapa berhasilkah program pemerintah yang telah dilaksanakan pada tahun sebelumnya.
Prediksi merupakan proses memperkirakan sesuatu secara sistematis yang akan terjadi pada masa depan berdasarkan data informasi dari masa lalu dan sekarang yang dimiliki, sehingga mendapatkan hasil perkiraan yang mendekati hasil nyatanya. Terdapat dua teknik dalam memprediksi yaitu teknik prediksi kualitatif dan teknik prediksi kuantitatif. Teknik prediksi kualitatif merupakan prediksi yang hasilnya ditentukan pada individu yang menyusunnya berdasarkan pemikiran yang bersifat opini, pengetahuan dan pengalaman dari penyusunnya. Teknik kuantitatif merupakan prediksi yang hasilnya berdasarkan metode yang dipergunakan dalam prediksi tersebut (Berutu, 2013).
Salah satu metode yang dapat digunakan untuk memprediksi yaitu jaringan saraf tiruan. Jaringan saraf tiruan adalah sistem pemrosesan informasi yang didesain seperti cara kerja otak manusia dalam menyelesaikan masalah dengan melakukan proses belajar melalui perubahan bobot sinapsisnya. Jaringan saraf tiruan dapat melakukan pengenalan terhadap kegiatan berbasis data masa lalu. Data masa lalu dapat dipelajari oleh jaringan saraf tiruan sehingga memiliki kemampuan untuk memberikan keputusan terhadap data yang belum pernah dipelajari. Salah satu algoritma pada jaringan saraf tiruan yang dapat diterapkan dengan baik untuk peramalan adalah Backpropagation (K. S. Kusumadewi, 2004).
Pada penelitian sebelumnya yang telah dilakukan oleh Nadir Murru dan Rosaria Rossini yaitu menerapkan metode Bayesian untuk inisialisasi bobot pada algoritma Backpropagation untuk pengenalan karakter (character recognition). Pendekatan Bayesian yang menerapkan Kalman filter modifikasi digunakan untuk inisialisasi bobot pada Backpropagation. Bayesian merupakan sebuah teori kondisi probabilitas yang memperhitungkan probabilitas suatu kejadian bergantung pada kejadian lain (Yahdin, 2008). Pada penelitian tersebut mereka membandingkan hasil metode gabungan Bayesian dan Backpropagation yaitu menggunakan Random Weights Initialization (RI) dan Bayesian Weights Initialization (BI). Hasilnya metode BI menghasilkan persentasi tingkat akurasi yang lebih tinggi dibandingkan dengan RI. Mereka juga membandingkan metode BI dengan beberapa motode lain yang telah dilakukan oleh peneliti lainnya. Hasilnya metode BI adalah yang paling optimal untuk menyelesaikan masalah yang kompleks (Murru & Rossini, 2016).
Pada penelitian ini dilakukan prediksi jumlah pengangguran terbuka di Indonesia menggunakan gabungan metode Bayesian dan Backpropagation. Metode Bayesian pada penelitian ini merupakan modifikasi dari Kalman filter yang dilakukan pada saat proses inisialisasi bobot. Penelitian ini mempunyai tujuan pencapaian yaitu untuk mengimplementasikan metode Bayesian dan Backpropagation dalam memprediksi jumlah pengangguran terbuka di Indonesia serta untuk mengetahui bagaimana hasil dari gabungan kedua metode tersebut berdasarkan hasil pengujian.
2. DASAR TEORI
2.1. Backpropagation
lapisan tersembunyi (hidden layer). Setiap unit/neuron yang ada pada lapisan tersembunyi (hidden layer) terhubung dengan setiap unit yang ada pada lapisan output. Jaringan ini memiliki banyak lapisan (multilayer network).
Saat jaringan Backpropagation diberikan pola input sebagai pola pelatihan (training), maka pola tersebut menuju unit-unit pada lapisan tersembunyi untuk selanjutnya diteruskan pada unit-unit pada lapisan output. Unit-unit pada lapisan output akan memberikan respon sebagai output jaringan saraf tiruan. Ketika hasil output tidak sesuai dengan yang diharapkan atau target, maka output akan disebarkan mundur (backward) pada lapisan tersembunyi (hidden layer) kemudian dari lapisan tersembunyi (hidden layer) dilanjutnya menuju ke lapisan input. Arsitektur jaringan Backpropagation ditunjukkan pada Gambar 2.1 (Agustin & Prahasto, 2012).
Pelatihan jaringan Backpropagation terdiri dari 3 tahapan yaitu Umpan maju (feedforward), Umpan mundur (Backpropagation), dan update bobot. Secara rinci proses algoritma pelatihan pada jaringan Backpropagation dapat diuraikan sebagai berikut:
Langkah0 : Inisialisasi nilai bobot, menentukan konstanta laju pelatihan (α/alpha), menentukan teleransi/target error atau jumlah maksimum iterasi/epoch.
Langkah 1 : Ketika kondisi berhenti belum dicapai, maka dilakukan langkah ke-2 hingga langkah ke-9.
Langkah 2 : Untuk setiap pasangan pola pelatihan, dilakukan langkah ke-3 sampai langkah ke-8.
Langkah 3 : [Tahap I: Umpan maju (feedforwand)]. Setiap unit input menerima sinyal dan meneruskannya ke unit tersembunyi di atasnya.
Langkah 4 : Masing-masing unit pada lapisan tersembunyi dikalikan dengan bobotnya dan dijumlahkan serta ditambahkan dengan biasnya. Langkah 5 : Masing-masing unit output (yk,
k=1,2,3,...m) dikalikan dengan bobot dan dijumlahkan serta ditambahkan dengan biasnya. Langkah 6 : [Tahap II: Umpan mundur
(backpropagation)]. Setiap unit output (yk, k=1,2,3,...m) menerima pola target tk sesuai dengan pola
input pada saat pelatihan dan kemudian kesalahan/error lapisan output (δk) dihitung. δk dikirim ke lapisan di bawahnya dan digunakan untuk menghitung besarnya koreksi bobot dan bias (∆Wjk dan ∆Wok ) antara lapisan tersembunyi dengan lapisan output.
Langkah 7 : Setiap unit pada lapisan tersembunyi (dari unit ke-1 hingga ke-p; i=1…n; k=1…m) dilakukan perhitungan kesalahan/error untuk lapisan tersembunyi (δj). δj kemudian digunakan untuk menghitung besar koreksi bobot dan bias (∆Vji dan ∆Vjo) antara lapisan input dan sehingga menghasilkan bobot dan bias baru, demikian juga untuk setiap unit tersembunyi mulai dari unit 1 sampai dengan unit ke-p.
Langkah 9 : Uji kondisi berhenti (akhir iterasi).
Gambar 2.1. Arsitektur jaringan Backpropagation
2.2. Bayesian
Persamaan 2.2. Secara umum teorema Bayes dapat dituliskan dalam bentuk yang ditunjukkan pada Persamaan 2.3. (Lukman, 2013).
P(A|B)P(B) = P(A, B) = P(B|A)P(A) (2.1)
𝑃(𝐴|𝐵) =𝑃(𝐵𝑃(𝐵)|𝐴)𝑃(𝐴) (2.2)
P(Ai|B) =∑ 𝑃(𝐵│𝐴𝑖)𝑃(𝐴𝑖)𝑃(𝐵│𝐴𝑖)𝑃(𝐴𝑖)
𝑖 (2.3)
2.3. Kalman Filter
Kalman filter banyak diterapkan dalam berbagai aplikasi. Fungsi dari Kalman filter adalah sebagai estimator dalam berbagai sistem yang digunakan. Kalman filter memiliki model yang sederhana sehingga mudah diterapkan pada berbagai sistem. Kalman filter memperhitungkan noise yang diestimasi pada seluruh cangkupan frekuensi sehingga Kalman filter dapat digunakan sebagai estimator tanpa perlu memperhitungkan noise yang terjadi pada sistem secara detail terlebih dahulu. Kalman filter dapat digunakan untuk melakukan estimasi sistem yang linear. Dalam perkembangannya, untuk sistem yang lebih kompleks dengan persamaan matematis yang linier, Kalman filter dapat dimodifikasi agar dapat mengestimasi sistem yang non-linier. Ada beberapa contoh modifikasi Kalman filter yaitu Extended Kalman Filter (EKF), Uncented Kalman Filter (UCF), dan Franctional Kalman Filter (FKF) (Murru & Rossini, 2016).
Kalman Filter merupakan suatu metode estimasi variabel keadaan dari sistem dinamik stokastik linear diskrit yang meminimumkan nilai kovariansi error estimasi. Metode Kalman filter pertama kali diperkenalkan oleh Rudolph E. Kalman pada tahun 1960 melalui papernya yang terkenal tentang suatu penyelesaian rekursif pada masalah filtering data diskrit yang linear (Welch & Bishop, 2006). Kalman filter merupakan suatu pendekatan teknis untuk menaksir fungsi parameter dalam peramalan deret berkala (time series). Keunggulan dari metode Kalman filter adalah kemampuannya dalam mengestimasi suatu keadaan berdasarkan data yang minim. Data minim yang dimaksudkan merupakan data pengukuran (alat ukur) karena Kalman filter adalah suatu metode yang menggabungkan model dan pengukuran. Data pengukuran terbaru menjadi bagian yang penting dari algoritma Kalman filter karena data terbaru akan digunakan untuk mengoreksi hasil prediksi sehingga hasil estimasinya selalu mendekati kondisi yang sebenarnya (Masduqi & Apriliani, 2008).
2.3. Gabungan Bayesian dan
Backpropagation
Pada penelitian sebelumnya yang telah dilakukan oleh Nadir Murru dan Rosaria Rossini yaitu menerapkan metode Bayesian untuk inisialisasi bobot pada algoritma Backpropagation untuk pengenalan karakter (character recognition). Pendekatan Bayesian yang menerapkan Kalman filter modifikasi digunakan untuk inisialisasi bobot pada Backpropagation (Murru & Rossini, 2016). Metode Kalman filter merupakan suatu metode yang dapat dipergunakan untuk mengestimasi variabel state dari sistem dinamik stokastik linier yang terkorupsi oleh white noise Gaussian. Variabel state dari suatu sistem dapat diestimasi oleh Kalman filter dengan memodelkan sistem tersebut terlebih dahulu (Palega, Wardoyo, & Wiryadinata, 2013).
Pada penelitian tersebut mereka membandingkan hasil metode gabungan Bayesian dan Backpropagation yaitu menggunakan Random Weights Initialization (RI) dan Bayesian Weights Initialization (BI). Hasilnya metode BI menghasilkan persentasi tingkat akurasi yang lebih tinggi dibandingkan dengan RI. Mereka juga membandingkan metode BI dengan beberapa motode lain yang telah dilakukan oleh peneliti lainnya. Hasilnya metode BI adalah yang paling optimal untuk menyelesaikan masalah yang kompleks. Inisialisasi bobot menggunakan pendekatan Bayesian dan modifikasi Kalman filter pada penelitian ini ditunjukkan pada Persamaan 2.4, 2.5, 2.6, 2.7, dan 2,8 (Murru & Rossini, 2016).
dengan range (-h,h). Nadir Murru dan Rosaria Rossini pada penelitiannya membatasi nilai t untuk mempercepat proses komputasi dan untuk mencegah nilai bobot yang dihasilkan mendekati 0. Mereka menentukan tmax= 2, pada penelitian ini diterapkan hal yang sama sehingga hasil dari W2 adalah nilai bobot yang telah teroptimasi untuk digunakan pada algoritma Backpropagation pada lapisan input ke hidden (V).
3. METODE
Penelitian ini menggunakan metode gabungan Bayesian dan Backpropagation dimana metode Bayesian digunakan untuk inisialisasi bobot V pada jaringan Backpropagation. Diagram alir metode gabungan ditunjukkan pada Gambar 3.1 sedangkan arsitektur jaringan yang digunakan pada penelitian ini ditunjukkan pada Gambar 3.2.
Gambar 3.1 Diagram alir sistem
Gambar 3.2 Arsitektur jaringan
3.1. Normalisasi Data
Data yang digunakan dalam penelitian ini adalah data dari Badan Pusat Statistik tentang jumlah pengangguran terbuka di Indonesia dari tahun 1986 sampai 2016. Pada penelitian ini data dinormalisasi ke range 0,1 sampai 0,9 dengan rumus yang ditunjukkan pada Persamaan 3.1 (S. Kusumadewi, 2003).
𝑥′ =0,8(𝑥−𝑎)𝑏−𝑎 + 0,1 (3.1)
Keterangan:
a : nilai minimum
b : nilai maksimum
3.2. Inisialisasi Bobot Menggunakan
Bayesian
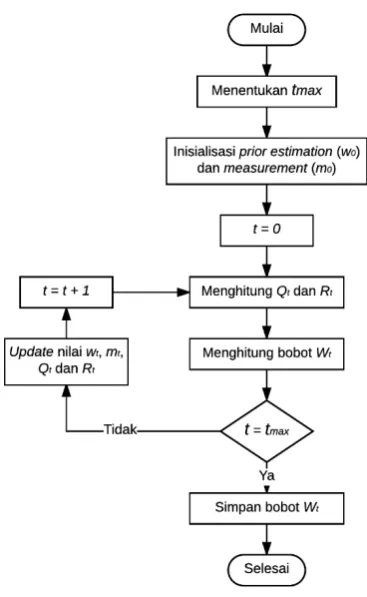
Pada penelitian ini nilai bobot V diinisialisasi menggunakan metode Bayesian dengan langkah-langkah yang ditunjukkan pada Gambar 3.3.
Gambar 3.3 Diagram alir metode Bayesian
Keterangan:
1. Menentukan tmax pada sistem, pada penelitian ini tmax= 2.
3. Menghitung Qt yang merupakan matrik kovarian dari wt dan Rt yang merupakan matrik kovarian dari mt.
4. Menghitung bobot Wt menggunakan
Persamaan 2.4.
5. Jika t = tmax maka simpan bobot Wt, jika tidak maka update nilai wt, mt, Qt, dan Rt berturut-turut menggunakan Persamaan 2.5, 2.6, 2.7, dan 2.8, kemudian t = t+1 dan kembali ke proses ke-3.
3.3. Metode Backpropagation
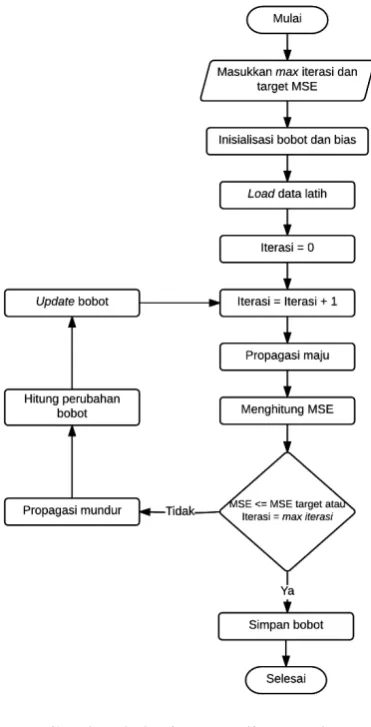
Metode Backpropagation digunakan untuk proses training data. Langkah-langkah pada metode Backpropagation ditunjukkan pada Gambar 3.4.
Gambar 3.4 Diagram alir metode Backpropagation
Keterangan:
1. Menentukan maksimum iterasi dan target MSE.
2. Inisialisasi bobot dan bias menggunakan bilangan acak kecil.
3. Mengambil data latih dari database yang telah dinormalisasi.
4. Melakukan propagasi maju kemudian menghitung MSE.
5. Jika nilai MSE kurang dari sama dengan MSE target atau jumlah iterasi sama dengan jumlah maksimum iterasi maka simpan bobot, jika tidak maka lakukan propagasi mundur.
6. Mengitung perubahan bobot lalu update bobot.
7. Iterasi bertambah 1 kemudian kembali ke langkah ke-4.
4. HASIL PENGUJIAN DAN ANALISIS
4.1. Pengujian Learning Rate (alpha) Terhadap Nilai AFER
Pengujian ini bertujuan untuk mengetahui bagaimana pengaruh nilai learning rate (alpha) terhadap nilai AFER. Learning rate adalah parameter jaringan dalam mengendalikan proses penyesuaian bobot. Untuk pengujian ini variabel yang diberi nilai tetap adalah tmax = 2dan h = 1, uji coba dilakukan sebanyak 5 kali dengan jumlah maksimum iterasi 20000, training menggunakan 10 pola data dan prediksi pada tahun 2016a. Tabel hasil pengujian ditunjukkan pada Tabel 4.1 dan grafik hasil pengujian ditunjukkan pada Gambar 4.1.
Tabel 4.1 Hasil pengujian learning rate (alpha) terhadap nilai AFER
alpha AFER (%)
0,1 6,9332
0,2 6,2637
0,3 5,5869
0,4 5,0245
0,5 4,6543
0,6 4,4691
0,7 4,4107
0,8 4,4177
Gambar 4.1 Grafik hasil pengujian Learning Rate (alpha) Terhadap Nilai AFER
Berdasarkan grafik hasil skenario pengujian 2 pada Gambar 4.1 menunjukkan nilai AFER terendah terjadi ketika alpha = 0,7 sedangkan nilai AFER tertinggi terjadi ketika alpha = 0,1, grafik tersebut menunjukkan bahwa pada penelitian ini semakin kecil nilai alpha maka semakin besar hasil nilai AFER. Nilai alpha berfungsi sebagai pengendali pada proses penyesuaian bobot. Hasil dari pengujian ini menunjukkan bahwa nilai alpha sangat mempengaruhi tingkat akurasi dari hasil prediksi. Pada pengujian ini dengan jumlah iterasi 20000 dan 10 pola data latih, nilai alpha yang paling optimal adalah 0,7, maka untuk skenario pengujian berikutnya nilai alpha akan digunakan 0,7.
4.2. Pengujian Variabel Tmax Terhadap Nilai
AFER
Pengujian ini bertujuan untuk mengetahui bagaimana pengaruh nilai variabel tmaxterhadap
nilai AFER. Variabel tmax digunakan untuk menentukan batas iterasi pada saat inisialisasi bobot V menggunakan metode Bayesian. Untuk pengujian ini variabel yang diberi nilai tetap adalah alpha= 0,7dan h = 1, uji coba dilakukan sebanyak 5 kali dengan jumlah maksimum iterasi 20000, training menggunakan 10 pola data dan prediksi pada tahun 2016a. Tabel hasil pengujian ditunjukkan pada Tabel 4.2 dan grafik hasil pengujian ditunjukkan pada Gambar 4.2.
Tabel 4.2 Hasil pengujian variabel Tmax Terhadap Nilai AFER
tmax AFER (%)
2 4,6662
4 4,6731
6 4,6981
8 4,6932
10 4,6683
tmax AFER (%)
12 4,6688
14 4,6733
16 4,6843
18 4,6993
Gambar 4.2 Grafik hasil pengujian variabel tmax terhadap nilai AFER
Berdasarkan grafik hasil skenario pengujian 3 pada Gambar 4.2 menunjukkan bahwa nilai AFER terendah adalah ketika nilai tmax= 2 dan nilai AFER tertinggi adalah ketika nilai tmax = 18, tetapi perbedaan rata-rata nilai AFER dari pengujian ini sangat kecil. Berdasarkan hasil tersebut maka dapat dikatakan pada penelitian ini pengaruh nilai variabel tmax tidak terlalu besar terhadap hasil prediksi karena pada inisialisasi bobot V menggunakan metode Bayesian proses iterasi selanjutnya tetap akan dilakukan perhitungan matrik kovarian sehingga perbedaan hasil inisialisasi bobot pada satu iterasi dengan iterasi lainnya tidak terlalu besar. Jadi dapat disimpulkan pada pengujian ini nilai variabel tmax yang optimal adalah 2, maka untuk skenario pengujian selanjutnya akan digunakan nilai tmax = 2.
4.3. Pengujian Variabel h Terhadap Nilai AFER
pada Tabel 4.3 dan grafik hasil pengujian ditunjukkan pada Gambar 4.3.
Tabel 4.3 Hasil pengujian variabel h terhadap nilai AFER
h AFER (%)
0,6 4,6949
0,8 4,7114
1 4,7212
1,2 4,7345
1,4 4,7412
1,6 4,7497
Gambar 4.3 Grafik hasil pengujian variabel h terhadap nilai AFER
Berdasarkan grafik hasil skenario pengujian 4 pada Gambar 4.3 menunjukkan bahwa nilai AFER terendah adalah ketika nilai h= 0,6 dan nilai rata-rata AFER tertinggi adalah ketika nilai h = 1,6, tetapi perbedaan nilai AFER dari pengujian ini sangat kecil. Hal tersebut terjadi karena semakin besar nilai h maka variasi akan semakin besar sehingga menghasilkan nilai bobot yang semakin besar pula dan menyebabkan nilai AFER semakin besar. Pada pengujian ini nilai h yang optimal adalah 0,6, maka untuk skenario pengujian selanjutnya akan digunakan nilai h = 0,6.
4.4. Pengujian Pengaruh Jumlah Pola Data
Training Terhadap Nilai AFER
Pengujian ini bertujuan untuk mengetahui apakah jumlah pola data training dan bentuk distribusi data mempengaruhi nilai AFER. Untuk pengujian ini nilai variabel yang tetap adalah alpha = 0.7, tmax= 2, h = 0,6, maksimum iterasi = 20000, dan tahun prediksi adalah 2016a. Hasil pengujian ini ditunjukkan pada Tabel 4.4 dan grafik hasil pengujian ditunjukkan pada Gambar 4.4.
Tabel 4.4 Hasil pengujian pengaruh jumlah pola data training terhadap nilai AFER Jumlah Pola
Data Data Training AFER (%) 10 2011a – 2015b 3.2216 15 2008b – 2015b 2.2448 20 2006a – 2015b 7.0553 25 2002 – 2015b 7,8518 30 1997 – 2015b 8,2191
Gambar 4.4 Grafik hasil pengujian pengaruh jumlah pola data training terhadap nilai AFER
Berdasarkan grafik hasil skenario pengujian 5 pada Gambar 4.4 menunjukkan bahwa nilai AFER terendah adalah ketika jumlah pola data training= 15 dan nilai rata-rata AFER tertinggi adalah ketika jumlah pola data training = 30. Pola data yang digunakan untuk training pada pengujian ini adalah data terdekat dari tahun yang akan diprediksi. Jadi dapat disimpulkan pada pengujian ini bentuk distribusi data yang dilatih sangat berpengaruh terhadap hasil prediksi, semakin banyak variasi data maka tingkat akurasi semakin rendah. Pada pengujian ini jumlah pola data training yang optimal adalah 15, maka untuk skenario pengujian selanjutnya jumlah pola data training menggunakan 15 pola data.
4.5. Pengujian Jumlah Iterasi dan
Perbandingan Inisialisasi Random dengan Inisialisasi Bayesian
prediksi adalah 2016a. Hasil pengujian dintunjukkan pada Tabel 4.5 serta grafik pada Gambar 4.5.
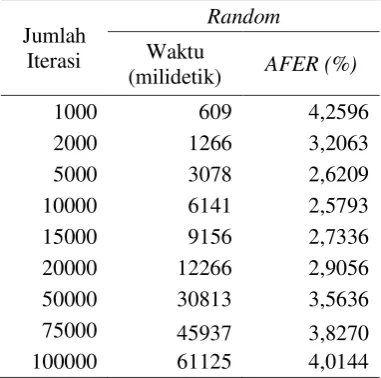
Tabel 4.5 Hasil pengujian jumlah iterasi dan perbandingan inisialisasi Random dengan
inisialisasi Bayesian (Random)
Jumlah Iterasi
Random
Waktu
(milidetik) AFER (%)
1000 609 4,2596
2000 1266 3,2063
5000 3078 2,6209
10000 6141 2,5793
15000 9156 2,7336
20000 12266 2,9056 50000 30813 3,5636 75000 45937 3,8270 100000 61125 4,0144
Tabel 4.6 Hasil pengujian jumlah iterasi dan perbandingan inisialisasi Random dengan
inisialisasi Bayesian (Bayesian)
Jumlah Iterasi
Bayesian
Waktu
(milidetik) AFER (%)
1000 703 6,1292
2000 1719 4,2450
5000 4234 2,4509
10000 7516 2,1003
15000 9250 2,1197
20000 15438 2,2448 50000 37312 3,0517 75000 46094 3,6718 100000 76828 3,8609
Gambar 4.5 Grafik hasil pengujian jumlah iterasi dan perbandingan inisialisasi random
dengan inisialisasi Bayesian terhadap waktu training
Gambar 4.6 Grafik hasil pengujian jumlah iterasi dan perbandingan inisialisasi random
dengan inisialisasi Bayesian terhadap nilai AFER
Berdasarkan Grafik hasil pengujian jumlah iterasi dan perbandingan inisialisasi random dengan inisialisasi Bayesian terhadap waktu training pada Gambar 4.5 menujukkan bahwa semakin besar jumlah iterasi maka waktu proses training akan semakin besar. Selisih waktu proses training pada sistem antara inisialisasi random dengan inisialisasi menggunakan metode Bayesian sangat kecil. Dari 9 uji coba, inisialisasi random selalu lebih cepat dari pada inisialisasi Bayesian meskipun selisihnya sangat kecil.
4.6. Pengujian Prediksi Beberapa Jangka Waktu Ke Depan
Pengujian ini melakukan prediksi dengan jangka waktu 5 tahun sekaligus yaitu tahun 2016a dengan 3 macam data latih yaitu 15 pola adalah tahun 2006b sampai 2013b, 20 pola adalah tahun 2003 sampai 2013b, dan 25 pola adalah tahun 1998 sampai 2013b. Pengujian ini dilakukan dengan cara data hasil prediksi pada tahun pertama digunakan untuk memprediksi tahun kedua begitu juga seterusnya. Hasil dari prediksi 5 tahun ke depan akan dibandingkan dengan hasil prediksi jangka waktu 1 tahun ke depan. Pengujian ini dilakukan sampai iterasi ke 10000 dengan menggunakan variabel alpha = 0,7, tmax = 2, dan h = 0,6. Pengujian ini bertujuan untuk mengetahui apakah sistem ini dapat digunakan untuk memprediksi beberapa jangka waktu ke depan. Pada pengujian ini hasil prediksi akan dibandingkan dengan data asli yang ditunjukkan pada Tabel 4.7 serta grafik yang ditunjukkan pada Gambar 4.7 dan 4.8.
Tabel 4.7 Hasil pengujian prediksi beberapa jangka waktu ke depan
Jumlah
Pola Hasil
1 Tahun Kedepan
5 Tahun Ke depan
15
Hasil
Prediksi 7174869 7587810 AFER (%) 2,1003 7,4282
20
Hasil
Prediksi 7543560 8023116 AFER (%) 6,8852 12,4508
25
Hasil
Prediksi 7593353 8078095 AFER (%) 7,4958 13,0467
Gambar 4.7 Grafik hasil pengujian prediksi beberapa jangka waktu ke depan
Gambar 4.7 Grafik hasil pengujian prediksi beberapa jangka waktu ke depan (AFER)
Berdasarkan grafik hasil pengujian prediksi beberapa jangka waktu ke depan pada Gambar 4.7 dan 4.8 menunjukkan bahwa sistem prediksi pada penelitian ini dapat digunakan untuk memprediksi 5 tahun ke depan secara langsung tetapi tingkat akurasi dari hasil prediksi lebih rendah dibandingkan dengan prediksi jangka waktu 1 tahun, hal tersebut terjadi karena data hasil prediksi pada tahun pertama digunakan untuk memprediksi tahun berikutnya. Dari hasil pengujian ini dapat disimpulkan bahwa sistem prediksi pada penelitian ini dapat digunakan untuk memprediksi beberapa tahun ke depan secara langsung tetapi hasil yang paling optimal adalah pada tahun pertama sedangkan tahun-tahun berikutnya akan semakin tidak akurat.
5. KESIMPULAN
Berdasarkan hasil dari penelitian yang telah dilakukan tentang sistem prediksi jumlah pengangguran terbuka di Indonesia menggunakan gabungan metode Bayesian dan Backpropagation, dapat diambil kesimpulan sebagai berikut:
menerapkan tahap propagasi maju (Feedforward).
2. Berdasarkan hasil pengujian yang telah dilakukan dalam penelitian ini nilai Average Forecasing Error Rate (AFER) yang terendah adalah 2,1003%. Sistem prediksi jumlah pengangguran terbuka di Indonesia pada penelitian ini dapat melakukan prediksi beberapa jangka waktu tahun kedepan secara langsung, tetapi hasil yang paling optimal adalah pada tahun pertama sedangkan pada tahun-tahun berikutnya hasil prediksi akan semakin tidak akurat.
3. Berdasarkan hasil pengujian pada penelitian ini, perbandingan antara inisialisasi random dengan inisialisasi Bayesian adalah waktu komputasi lebih cepat inisialisasi random tetapi dari kedua metode tersebut memiliki rata-rata selisih yang sangat kecil yaitu sekitar 500 milidetik, sedangkan untuk tingkat akurasi pada jumlah iterasi diatas 5000 inisialisasi Bayesian lebih akurat dari pada inisialisasi random sehingga proses komputasi lebih lama.
6. DAFTAR PUSTAKA
Agustin, M., & Prahasto, T. (2012). Penggunaan Jaringan Syaraf Tiruan Backpropagation Untuk Seleksi Penerimaan Mahasiswa Baru Pada Jurusan Teknik Komputer Di Politeknik Negeri Sriwijaya. Jurnal Sistem Informasi Bisnis, 2, 89–97.
Berutu, S. S. (2013). Peramalan Penjualan Dengan Metode Fuzzy Time Series Ruey Chyn Tsaur. Universitas Diponegoro.
Kusumadewi, K. S. (2004). Analisis Jaringan Saraf Tiruan dengan Metode
Backpropagation Untuk Mendeteksi Gangguan Psikologi. Media Informatika, 2, 1–14.
Kusumadewi, S. (2003). Artificial Intelligence (Teknik dan Aplikasinya). Yogyakarta: Graha Ilmu.
Lukman, A. (2013). Algoritma Bayesian Network Untuk Simulasi Prediksi Pemenang PILKADA Menggunakan MSBNx. Jurnal Informatika Multimedia (JIM) STIMED NUSA PALAPA, 2(1). Masduqi, A., & Apriliani, E. (2008). Estimation
of Surabaya River Water Quality Using Kalman Filter Algorithm. IPTEK, The Journal for Technology and Science, 19(3), 87–91.
Murru, N., & Rossini, R. (2016).
Neurocomputing A Bayesian approach for initialization of weights in
backpropagation neural net with application to character recognition. Neurocomputing, 193, 92–105.
https://doi.org/10.1016/j.neucom.2016.01. 063
Palega, O., Wardoyo, S., & Wiryadinata, R. (2013). Estimasi Kecepatan Kendaraan Menggunakan Kalman Filter. SETRUM, 2(2), 60–65.