Fakultas Ilmu Komputer
Universitas Brawijaya
2533
Optimasi Peramalan Metode Backpropagation Menggunakan Algoritme
Genetika pada Jumlah Penumpang Kereta Api di Indonesia
Muhammad Birky Auliya Akbar1, Indriati2, Ahmad Afif Supianto3
Program Studi Teknik Informatika, Fakultas Ilmu Komputer, Universitas Brawijaya Email: 1[email protected], 2[email protected], 3[email protected]
Abstrak
Kereta api adalah jenis transportasi darat masif dengan jumlah pengguna yang banyak, berdasarkan hasil yang ditunjukkan oleh data statistika untuk indeks keselamatan dan pelayanan mencapai nilai 4.09 dari 5 di tahun 2014, selain itu juga dukung denga fakta yang diungkap harian tempo (www.bisnis.tempo.co) yang menyatakan bahwa pengguna kereta api dari waktu ke waktu mengalami peningkatan. Namun dengan peningkatan jumlah penumpang kereta api tanpa adanya prediksi akan berakibat buruk bagi perkeretaapian di Indonesia. Untuk itu dibutuhkan suatu metode peramalan dengan hasil yang dapat dipertanggungjawabkan, dengan menggunakan metode yang populer seperti jaringan saraf tiruan Backpropagation dan dilakukan optimasi dalam penentuan inisialisasi bobot (w) dengan menggunakan variabel berjumlah 800 untuk populasi, 20 untuk jumlah generasi, komposisi nilai Mr = 0.3 dan Cr = 0.7, dengan variabel utama dari jaringan saraf tiruan Backpropagation yang terdiri dari jumlah iterasi sebesar 100 dan nilai alpha sebesar 0.9, juga dengan mengguanakan dataset tersusun secara bulanan, mulai dari januari 2006 hingga juni 2017 berupa data timeseries, dengan data latih 100 pola data awal dan data uji 10 pola data akhir. Sehingga menghasilkan tingkat akurasi berdasarkan nilai error (MSE) sebesar 0.065869861 dari hasil hibridisasi metode jaringan sarat tiruan backpropagation dengan menggunakan algoritme genetika, sedangkan jika tanpa menggunakan hibridisasi nilai error yang didapat sebesar 0.072517977.
Kata kunci: Kereta Api Indonesia, Peramalan. Jaringan Syaraf Tiruan (JST), Backpropagation,
Algoritme Genetika.
Abstract
The train is a kind of massive land transport with a lot of users, base on the results presented by Statistics for Safety Index and service reached 4.09 from 5 in year 2014, also supported by the fact that exposed by the daily Tempo (www.bisnis.tempo.co) indicating that the train users from time to time inCreased. However, with the inCrease in the number of passengers on top of the train without any prediction will be bad for the train in Indonesia. For this need a method of predicting the results that can be answerable, using popular methods such as artificial neural network Backpropagation and optimizations to do in determining the initial weights (W) with Using numbered variables 800 for the population, 20 for a number of generations, the composition of the value of Mr = 0.3 and Cr = 0.7, with the main variant of the Backpropagation artificial neural network that consists of multiple iterations is 100 and a value of Alpha is 0.9, also with dataset on a monthly basis, start from January 2006 to June 2017 in timeseries form data, with 100 training data pattern as initial data and 10 pattern of test data of last data. So the result is the level of precision based on error value (MSE) results 0.065869861 from the results of the hybridization method backpropagation artificially neural networks using a genetic algorithm, while without using the hybridization error value is 0.072517977.
Keywords: Indonesian’s Railway, Forecasting, Artificial Neural Networks (ANN), Backpropagation,
Genetic Algorithm.
1. PENDAHULUAN
Kereta api merupakan suatu moda transportasi masif darat di Indonesia yang cukup populer, hal ini dikarenakan hampir semua
wilayah di Indonesia memiliki moda transportasi ini sebagai alat mobilitas, sehingga sebagian besar masyarakat Indonesia pada wilayah tersebut tergantung akan transportasi kereta api ini. Hal ini diperkuat dengan nilai indeks
Fakultas Ilmu Komputer, Universitas Brawijaya keselamatan dan pelayanan yang mendekati nilai maksimal 5, yakni berada pada skala 4.09, pada tahun 2014 berdasarkan situs PT Kereta Api Indonesia (PT KAI) yakni www.kai.id. Selain itu juga didukung dengan fakta bahwa jumlah pengguna yang semakin bertambah dari tahun ke tahun dari pemaparan berita harian Tempo (www.bisnis.tempo.co) bahkan mencapai 352 juta pengguna terbilang pada tahun 2016. Sehingga seperti penumpukan penumpang KAI, kurang puasnya akan pelayanan, dan lain sebagainya mungkin dapat timbul, oleh sebab itu diperlukan metode peramalan dengan hasil yang dapat dipertanggungjawabkan.
Melihat akibat yang dapat ditimbulkan, peramalan data adalah media yang perlu digunakan dalam pencegahan hal tersebut, dengan memanfaatkan beberapa metode peramalan yang ada, sehingga dapat mengurangi permasalahan yang ada. Berdasarkan penelitian yang pernah dilakukan oleh Saleh (2015), untuk meramalkan tingkat konsumsi listrik dalam suatu keluarga dengan memanfaatkan metode naive bayes. Selain dengan metode naive bayes, Gani, Kolibu dan Tamuntuan (2016), membuktikan bahwa metode Fuzzy dapat digunakan untuk meramalkan bencana banjir dengan menggunakan mamdani sebagai model masukan dengan hasil yang baik.
Selain beberapa metode yang telah disebutkan, terdapat juga suatu metode peramalan lain, yakni jaringan saraf tiruan backpropagation, dengan salah satu kasus penelitian yang memililiki korelasi yang sama dengan penelitian ini, yakni peramalan jumlah penumpang kereta api di Semarang menghasilkan nilai keakurasian yang baik (Luthfianto, Santoso, & Christiyono, 2011). Akan tetapi dalam menghasilkan nilai yang lebih akurat dibutuhkan media lain untuk memaksimalkan hasil yang diinginkan, sepertihalnya melakukan optimasi pada metode yang dipilih.
Terdapat banyak pilihan teknik untuk memalukan optimasi yang dapat diterapkan, namun algoritme genetika merupakan algoritme yang populer dalam algoritme evolusi terkait optimasi salah satunya yakni penelitian yang dilakukan oleh Wicaksono dan Supianto (2018) terkait peramalan topik surat kabar yang populer saat ini dengan optimasi peramalan menggunakan algoritme genetika pada machine learning. Berpacu korelasi permasalahan dan metode yang memiliki kemiripan dengan kajian yang pernah dipublikasikan oleh Luthfianto,
Santoso, & Christiyono, peneliti menentukan metode jaringan syaraf tiruan backpropagation untuk meramalkan jumlah kereta api di Indonesia dan dengan dilakukan optimasi pada bobot atau sinyal informasi awal dengan menggunakan algoritme genetika.
Dan dengan dilakukanlah penentuan variabel yang berpengaruh pada kedua metode sehingga dapat diketahui nilai akurasi yang akan terbentuk dari peramalan yang dilkukan dengan mengangkat tajuk “Optimasi Metode Jaringan Syaraf Tiruan Backpropagation Menggunakan Algoritme Genetika pada Prediksi Jumlah Penumpang Kereta Api di Indonesia”.
2. METODE PENELITIAN
Penelitian yang bertujuan untuk mendapatkan informasi peramalan jumlah pengguna kereta api ini memanfaatkan data sekunder yang didapat dari laman resmi Badan Pusat Statistika (BPS) pusat, yang terdiri dari data awal bulan 2006, yakni pada bulan januari sampai dengan juni 2017. Sehingga berdasarkan parameter pola data yang dibentuk dapat digunakan untuk memprediksi jumlah penumpang pada beberapa waktu kedepan dengan memanfaatkan metode jaringan saraf tiruan backpropagation. Akan tetapi sebelum dilakukan peramalan tersebut, data tersebut akan diolah terlebih dahulu dengan menggunakan algoritme genetika, sehingga dapat terbentuk inisialisasi bobot awal yang baik.
3. ALGORITME GENETIKA
Algoritme genetika adalah suatu konsep untuk memilih dan memberi nilai pada suatu satuan yang mengindikasikan kebugaran suatu ojek, dengan meniru proses daur evolusi pada mahluk hidup dan proses seleksi alam, hanya individu yang memiliki kebugaran yang baik akan bertahan dan pada individu yang memiliki tingkat kebugaran yang lemah dari batas ambing yang ditentukan makan akan tersingkir, agar peluang untuk mengjasilkan individu baru yang lebih baik pula akan terlahir (Yandra, Seminar, & Gunawan, 2012). Selain itu algoritme genetika juga merupakan suatu algoritme yang bersifat fleksibel, sehingga dapat dihibridisasi dengan metode lain, hanya dengan menyesuaikan nilai inisialisasi atau merepresentasikan pola data pada metode tersebut (Mahmudy, 2015).
3.1. Srtuktur Algoritme Genetika
Dalam penerapan algoritme genetika, setidaknya memiliki proses umum yang wajib dilakukan yakni dengan melakukan representasi kromosom dengan cara pengkodean (encoding) nilai iInput sebagai inisialisasi data, selanjutnya proses pencarian solusi dengan menghasilkan generasi baru dengan proses crossover dan mutasi, kemudian dilanjutkan dengan pemilihan solusi atau disebut dengan proses decoding, dengan cara evaluasi dan seleksi data, sehingga menghasilkan nilai solusi yang mendekati nilai optimum (Mahmudy, 2015).
- Proses representasi kromosom perlu dilakukan dengan cermat, hal ini disebabkan pada proses ini sangat menentukan bentuk solusi yang akan diproses dan dihasilkan (Melin, Castillo, Ramirez, Kacprzyk, & Pedrycz, 2007). Ciri dari objek yang diproses harus dapat digambarkan dengan baik oleh kromosom yang dibentuk sehingga membentuk pola nilai data yang sama. Representasi nilai yang paling sering digunakan ialah biner, integer, real-code, dan matriks. Pada pengkodean dengan teknik real-code yang digunakan pada penelitian ini, memiliki bentuk data yang berkisar antar -1 sampai dengan 1, sehingga memudahkan untuk melakukan perhitungan dan sesuai dengan nilai inisialisasi dalam proses jaringan saraf tiruan backpropagation yang digunakan. Selain itu kesamaan dan sifat dataset juga mempengaruhi bentuk representasi yang digunakan yakni dengan penggunaan data time series yang bersifat kontiyu atau memiliki jangkauan yang panjang (Mahmudy, 2015). Pada penelitian ini bentuk representasi kromosom digambarkan pada Gambar 1.
Gambar 1 Representasi Kromosom
- Crossover, secara umum dikatakan sebagai tahap utama pada proses reproduksi dalam algoritme genetika, dengan memanfaatkan dua induk untuk melakukan reproduksi segingga dapat menghasilkan individu baru yang identik namun memiliki sifat yang bebeda akan terbentuk sehingga dapat digunakan sebagai solusi baru untuk melakukan regenerasi berikutnya (Yandra,
Seminar, & Gunawan, 2012). Jumlah solusi atau individu baru dapat ditentukan dari perkalian antara Crossover rate (Cr) dengan populasi (Mahmudy, 2015). Penelitian ini memanfaatkan extended intermediate crossover dengan cara kerja mengkombinasikan nilai dari kedua induknya untuk menghasilkan offspring. Pada Tabel 1 dan Tabel 2, merupakan gambaran dari proses crossover, dengan menggunakan perhitungan pada Persamaan 1 dan 2.
Ci(1) = Pi(1) + α(Pi(2) – Pi(1))
Ci(2) = Pi(2) + α(Pi(1) – Pi(2))
(1)
(2) Keterangan :
Ci = Kromosom offspring Pi = Kromosom induk
α = Nilai acak antara [-0,25 , 1,25] Tabel 1 Kromosom Induk Terpilih (Crossover)
Tabel 2 Kromosom Offsrping (Crossover)
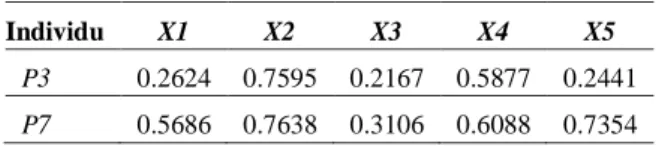
- Mutasi, pada umumnya merupakan tahapan pendukung yang juga dapat menghasilkan generasi (solusi) baru. Berbeda dengan crossover mutasi pada algoritme genetika hanya memerlukan satu induk saja untuk menghasilkan individu baru, dengan cara mutasi gen. Mutasi ini dibangkitkan agar dapat menghasilkan individu yang benar-benar baru, sehingga meningkatkan peluang mendapatkan solusi yang jauh lebih baik (Yandra, Seminar, & Gunawan, 2012). Dengan proses yang sama, populasi juga digunakan sebagai faktor pengali, namun dalam mutasi, populasi akan dikalikan dengan Mutation rate (Mr) dalam menghasilkan offspring baru, (Mahmudy, 2015). Pada Tabel 3 dan 4 merupakan representasi dari proses mutasi yang menerapkan metode random mutation berdasarkan Persamaan 3. P X1 X2 X3 X4 X5 X6 Individu X1 X2 X3 X4 X5 P3 0.2624 0.7595 0.2167 0.5877 0.2441 P7 0.5686 0.7638 0.3106 0.6088 0.7354 Offspring X1 X2 X3 X4 X5 C1 0.367 4 0.760 9 0.248 8 0.594 9 0.412 6 C2 0.463 4 0.762 2 0.278 3 0.601 5 0.566 7
Fakultas Ilmu Komputer, Universitas Brawijaya
x’i = xi + r (maxi – mini) (3)
Keterangan :
x’i = Nilai gen baru
xi = Nilai gen lama
r = Range random anatara [-0,1 , 0,1] maxi = Tingkat maksimal variabel xi
mini = Tingkat minimal variabel xi
Tabel 3 Kromosom Induk Terpilih (Mutasi)
Tabel 4 Kromosom Offspring (Mutasi)
- Proses mengevaluasi data dilakukan dengan cara memberikan nilai pada masing-masing individu, baik individu induk dan juga individu anak, yakni dengan pemberian nilai fitness pada masing-masing individu yang merupakan nilai yang menunjukkan besaran tingkat kebugaran suatu individu, yang memungkinkan digunakan sebagai induk baru (Mahmudy, 2015), salah satu solusi dalam pencarian nilai fitness berdasarkan kasus ini, menggunakan Persamaan 4.
𝑓𝑖𝑡𝑛𝑒𝑠𝑠 = 1
𝑀𝑆𝐸 (4)
MSE merupakan hasil dari perhitungan yang dihasilkan dari proses jaringan saraf tiruan, pada fase feedforward.
- Seleksi, merupakan tahap lanjutan dari proses pelabelan di tahap evaluasi, sehingga pada tahapan ini akan mengurutkan label tersebut dengan teknik tertentu, diantaranya elitism, binary tournament, dan roulette wheel. Dengan menggunakan teknik elitism individu yang memiliki nilai fitness yang tertinggi sepanjang data populasi awal akan dipilih menjadi induk baru untuk menghasilkan solusi baru berikutnya.
Ketiga tahapan tersebut, mulai dari tahapan 2 sampai dengan tahapan 4, akan dilakukan perulangan sampai mencapai nilai konvergen, dan ditentukan nilai kromosom yang paling baik, sehingga dapat digunakan sebagai nilai
inisialisasi pada bobot (w), pada metode jaringan saraf tiruan Backpropagation.
4. BACKPROPAGATION NEURAL NETWORK (BPNN)
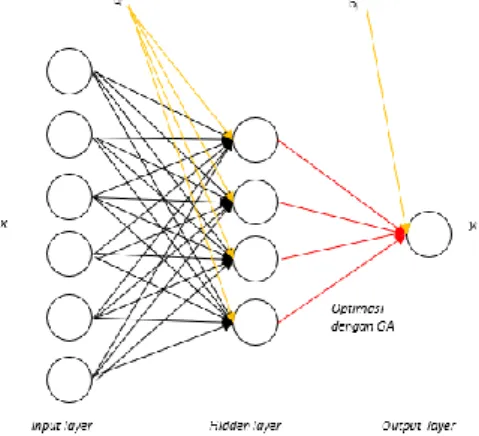
Jaringan Saraf Tiruan backpropagation ialah salah satu bentuk pengembangan dari jaringan saraf tiruan. Metode BPNN pada dasarnya mengelola informasi berdasarkan beberapa perulangan dengan melakukan pembenahan nilai pada tiap prosesnya. Dengan memodifikasi sinyal atau bobot dari pelatihan peramalan untuk menentukan letak kesalahan yang terjadi lalu dilakukan pembenahan bobot secara mundur, sehingga metode ini disebut sebagai metode backpropagation, (Kusrini & Luthfi, 2009). Dengan menggunakan pemodelan proses backpropagation digambarkan pada Gambar 2.
Gambar 2 Arsitektur Backpropagation
4.1. Proses Backpropagation
Dalam metode Backpropagation tebagi menjadi tiga bagian pokok yaitu, tahap feedforward, backpropagation, dan weight update. Namun terdapat juga proses penunjang tiga tahap tersebut salah satunya yakni proses normalisasi data yang bertujuan untuk membentuk nilai awal sehingga mempermudah untuk dilakukan pemrosesan berdasarkan Persamaan 5.
x’ = (0.8 x 𝑥−min 𝑣𝑎𝑙𝑢𝑒
max 𝑣𝑎𝑙𝑢𝑒−min 𝑣𝑎𝑙𝑢𝑒) (5)
Penjelasan :
x = Bentuk awal data
x’ = Bentuk data hasil normalisasi min value = Skala minimum pola data max value = Skala maksimim pola data
Individu X1 X2 X3 X4 X5 P3 0.9386 0.5727 0.2264 0.2308 0.4357 Offspring X1 X2 X3 X4 X5 C3 0.9386 0. 6083 0.2264 0.2308 0.4357
Selanjutnya hasil normalisasi data tersebut diproses pada tiga tahap yang telah disebutkan, yakni :
- Tahap I Feedforward
Menghitung besaran unit Hidden Layer.
𝑧_𝑛𝑒𝑡𝑗= 𝑣𝑗0∑ 𝑥𝑖. 𝑣𝑖𝑗 𝑛
𝑖=1 (6)
Penjelasan:
z_net = Besaran unit Hidden Layer xi = Besaran pola data training
vj0 = Nilai bias Input Layer
vij =Nilai bobot dari unit Input
menuju Hidden Layer
Membangkitkan nilai Hidden Layer dengan fungsi sigmoid.
𝑧𝑗= 𝑓 (𝑧𝑛𝑒𝑡𝑗) =1+𝑒𝑥𝑝(−𝑧_𝑛𝑒𝑡𝑗)1 (7)
Penjelasan:
zj = Besaran Hidden Layer yang
diaktivasi
exp = Nilai euler (2.71828)
Menghitung besaran unit Output Layer 𝑦_𝑛𝑒𝑡𝑘= 𝑤𝑘0+ ∑𝑝𝑗=1𝑧𝑗. 𝑤𝑘𝑗 (8)
Penjelasan:
y_netk = Besaran unit Output Layer
wko = Nilai bias Hidden Layer
zj = Besaran Hidden Layer yang
diaktivasi
wkj = Nilai bobot dari unit Hidden
menuju Output Layer
Membangkitkan nilai Output Layer dengan fungsi sigmoid.
𝑦𝑘 = 𝑓(𝑦_𝑛𝑒𝑡𝑘) =1+𝑒𝑥𝑝(−𝑦_𝑛𝑒𝑡𝑘)1 (9)
Penjelasan:
yk = Besaran Output Layer yang
diaktivasi
exp = Nilai euler (2.71828)
- Tahap II Backpropagation
Menghitung nilai kesalahan
berdasarkan perbandingan nilai peramalan dengan nilai aktual. dengan menggunakan Persamaan 10.
δk = (tk – yk) yk (1 – yk) (10)
Penjelasan:
δk = Perbandingan nilai kesalahan
antara ouput Layer dengan nilai aktual.
tk = Target atau nilai aktual
yk = Besaran Output Layer yang
diaktivasi
Menghitung faktor kesalahan bobot menuju ke Hidden Layer.
∆wjk = α . δk . zj (11)
Penjelasan:
∆wjk = Nilai faktor kesalahan bobot
yang menuju ke Hidden Layer.
α = Nilai jangkauan pelatihan (learning rate) berada antara 0 sampai 1.
δk = Nilai kesalahan pada Output
Layer
zj = Besaran Hidden Layer yang
diaktivasi
Menghitung nilai kesalahan pada Hidden Layer berdasarkan nilai kesalahan pada Output Layer (δk).
𝛿_𝑛𝑒𝑡𝑗 = ∑𝑚 𝛿𝑘
𝑘=1 . 𝑤𝑘𝑗 (12)
Penjelasan:
δ_netj = Nilai kesalahan pada Layer
tersembunyi atau Hidden Layer
δk = Nilai kesalahan pada Layer
keluaran atau Output Layer wkj = Nilai sinyal atau bobot dari
Hidden Layer ke Output Layer.
Menghitung selisih nilai kesalahan pada Hidden Layer
δj = δ_netj . zj (1-zj) (13)
Penjelasan:
δj = Selisih nilai kesalahan pada
Fakultas Ilmu Komputer, Universitas Brawijaya
δ_netj = Nilai kesalahan dari Output ke
Hidden Layer
zj = Besaran Hidden Layer yang
diaktivasi
Menghitung faktor kesalahan bobot menuju ke Input Layer.
∆vij = α . δj . xi (14)
Penjelasan:
∆vij = Nilai faktor kesalahan bobot
yang menuju ke Input Layer. α = Nilai jangkauan pelatihan (learning rate) berada antara 0
sampai 1.
δj = Selisih nilai kesalahan pada
unit Hidden Layer
xi = Besaran pola data training
- Tahap III Weight Update
Pembenahan nilai bobot unit Hidden Layer
wkj(t+1) = wkj(lama) + ∆wjk (15)
Penjelasan:
wkj(t+1) = Bobot w yang baru
wkj(lama) = Bobot w yang lama
∆wjk = Nilai faktor kesalahan bobot
menuju ke Hidden Layer
Pembenahan nilai bobot unit Input Layer
vji(Baru) = vji(lama) + ∆vji (16)
Penjelasan:
vji (Baru) = Bobot v yang baru
vji (lama) = Bobot v yang lama
∆vij = Nilai faktor kesalahan bobot
menuju ke Input Layer
Pada akhir pengoperasian ketiga fase tersebut, selanjutnya perhitungan untuk menentukan nilai akurasi berdasarkan rerata nilai kesalahannya (MSE) dilakukan dengan Persamaan 17.
MSE = ∑𝑛𝑘=1(𝑦𝑘− 𝑡𝑘)2 (17)
Penjelasan:
yk = Nilai OutputLayer tk = Nilai pada target
Kemudian pola data akan dikembalikan dalam bentuk semula, dengan cara melakukan dinormalisasi data dengan Persamaan 18.
𝑥" = (max 𝑣𝑎𝑙𝑢𝑒−min 𝑣𝑎𝑙𝑢𝑒)∗(𝑥′−0,1)
0,8 + min 𝑣𝑎𝑙𝑢𝑒
(18) Penjelasan:
x” = Hasil denormalisasi x’ = Data olahan normalisasi min value = Skala minimum dataset max value = Skala maksimim dataset
5. HASIL EKSPERIMEN
Dalah hasil eksperimen peramalan jumlah penumpang kereta api dengan menggunakan metode jaringan saraf tiruan backpropagation dan algoritme genetika dihasilkan bentuk solusi berdasarkan beberapa pengujian variabel dengan didukung variabel lain yang dibuat statis kecuali variabel yang diujikan, dengan ketentuan variabel statis pendukung populasi berjumlah 10, generasi berjumlah 10, kombinasi Cr = 0.2 dan Mr = 0.2, serta variabel statis pada BPNN dengan 10 iterasi dan nilai alpha = 0.9, yang masing-masing dilakukan 10 kali percobaan, dengan detail hasil eksperimen diantaranya :
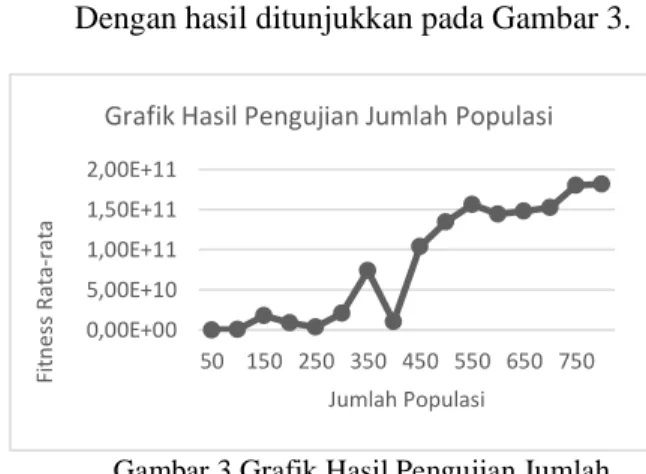
- Hasil pengujian jumlah populasi, dengan menggunakan variabel statis, namun untuk populasi dibuat percobaan dengan menggunakan 50 populasi dan kelipatannya, sampai mencapai nilai 800. Dengan hasil ditunjukkan pada Gambar 3.
Gambar 3 Grafik Hasil Pengujian Jumlah Populasi
Hasil yang didapat dari pengujian menghasilkan bahwa semakin banyak populasi yang digunakan maka semakin besar peluang
0,00E+00 5,00E+10 1,00E+11 1,50E+11 2,00E+11 50 150 250 350 450 550 650 750 Fi tnes s R at a-rat a Jumlah Populasi
untuk menghasilkan nilai fitness yang tinggi, terbukti dalam penelitian ini, nilai fitness yang tertinggi berada pada jumlah populasi pada titik 800, namun seperti yang ditunjukkan pula pada Gambar 3 bahwa pada titik 400 memiliki nilai fitness tidak lebih baik daripada nilai fitness pada titik 300 dan 350, hal ini mungkin saja terjadi disebabkan proses pencarian dengan menggunakan populasi sejumlah 400 tidak atau belum menemukan nilai terbaiknya dan juga dapat disebabkan variabel dalam pengujian kurang memungkinkan hal tersebut terjadi, sehingga hal itu sangat mungkin terjadi.
- Hasil pengujian jumlah generasi, dengan menggunakan variabel statis, namun untuk generasi dibuat percobaan dengan menggunakan 2 generasi dan kelipatannya, sampai mencapai 20. Dengan hasil yang direpresentasikan seperti pada Gambar 4.
Gambar 4 Hasil Pengujian Jumlah Generasi Pada Gambar 4, menunjukkan pergerakan pola nilai fitness memiliki tren naik, bahkan pada generasi ke-20 menghasilkan nilai fitness tertinggi yang memungkinkan untuk mempertahankan tren tersebut. Dengan hasil tersebut, menunjukkan jumlah generasi sangat mempengaruhi pada besar fitness yang dihasilkan.
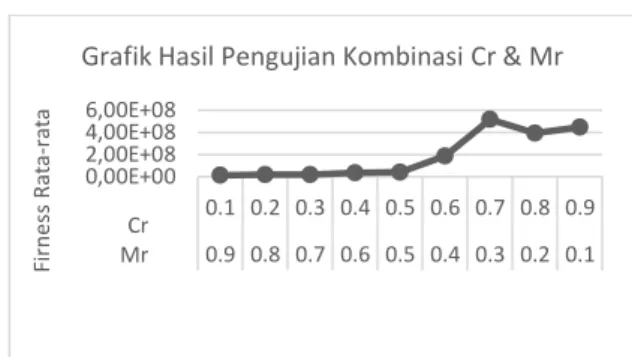
- Kombinasi Cr dan Mr dilakukan pengujian secara terbalik antara ascending dan descending dengan range nilai antara (0.1,0.9), hasil pengujian jumlah kombinasi Cr dan Mr, dengan menggunakan variabel bantuan statis yang telah ditentukan sebelumnya. Dengan perolehan nilai pengujian seperti pada Gambar 5.
Gambar 5 Hasil Pengujian Kombinasi Cr & Mr Dengan hasil yang direpresentasikan pada Gambar 5 tren yang menghasilkan nilai fitness terbaik muncul saat nilai Cr lebih besar daripada nilai Mr, lebih tepatnya pada titik nilai Cr = 0.7 dan nilai Mr = 0.3, tidak hanya itu, pada Gambar 5 juga menunjukkan tren nilai fitness jauh membaik mulai dari nilai Cr itu lebih besar daripada nilai Mr, meskipun pada nilai Cr = 0.8 dan Mr = 0.2 sempat terjadi penurunan nilai, namun pola fitness yang naik tidak berubah, berdasarkan hal tersebut menunjukkan bahwa nilai Cr ini mempengaruhi dalam menghasilkan nilai fitness dalam perhitungan algoritme genetika ini.
- Iterasi diuji dengan bantuan variabel statis namun untuk iterasi dilakukan pengujian 10 iterasi selanjutnya dengan 25 dan kelipatannya, sampai dengan 350 iterasi. Dengan perolehan nilai pengujian seperti pada Gambar 6.
Gambar 6 Grafik Hasil Pengujian Jumlah Iterasi Berdasarkan ujicoba jumlah iterasi yang terlihat pada Gambar 6 menghasilkan pola yang stabil, terlihat pada proes peramalan informasi menggunakan 10 percobaan, memeiliki tren yang hampir sama pada iterasi ke-100 menghasilkan pola yang stabil, sehingga pada iterasi ke-100 ini dapat dikatakan sebagai titik balik dari pencarian jumlah iterasi yang baik untuk menghasilkan solusi yang baik dalam peramalan suatu informasi.
0,00E+00 1,00E+08 2,00E+08 3,00E+08 2 4 6 8 10 12 14 16 18 20 Fi tnes s R at a-rat a Jumlah Generasi
Grafik Hasil Pengujian Jumlah Generasi
0,00E+00 2,00E+08 4,00E+08 6,00E+08 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 0.9 0.8 0.7 0.6 0.5 0.4 0.3 0.2 0.1 Fi rne ss R at a-rat a Cr Mr
Grafik Hasil Pengujian Kombinasi Cr & Mr
1,00E-02 2,50E-02 10 25 50 75 100 125 150 175 200 225 250 275 300 325 350 R ata -r ata M SE Jumlah Iterasi
Grafik Pengujian Jumlah Iterasi
P1 P2 P3 P4 P5
Fakultas Ilmu Komputer, Universitas Brawijaya - Pengujian nilai alpha diuji dengan bantuan
variabel statis dengan modifikasi nilai alpha yang diuji memiliki rentang nilai antara (0.1,0.9). Dengan hasil pengujian akan ditunjukkan pada Tabel 5 dan Gambar 7.
Tabel 5 Pengujina Nilai Alpha
Gambar 7 Grafik Hasil Pegujian Nilai Learning Rate
Berdasarkan Tabel 9 menunjukkan hasil
dari penggunaan nilai alpha yang baik dalam
peramalan memiliki tren yang cukup stabil
anatar percobaan ke-1 sampai dengan
percobaan ke-10. Dan berdasarkan hasil
pengujian seperti yang terlihat pada Gambar
7, hasil MSE terbaik dihasilkan pada
learning rate dititik 0.9, berdasarkan dari
hasil yang didapat, dapat diambil suatu
kesimpulan bahwa penentuan nilai learning
rate hanya bergantung pada pola data yang
digunakan, hal ini dikarenakan perubahan
nilai antar percobaan tidak berubah terlalu
signifikan yang biasanya harus distabilkan
dengan variabel-variabel lain sehingga pola
dapat terlihat lebih teratur dan stabil.
- Selain menggunakan kelima variabel
pengujian
tersebut,
pengujian
perbandingan akurasi berdasarkan nilai
error
juga
dilakukan.
Dengan
menggunakan berbagai parameter yang
telah diuji, pengujian nilai keakurasian
berdasarkan nilai MSE dan MAD juga
diperhitungkan, dengan representasi yang
ditunjukkan oleh Tabel 6, Tabel 7, dan
Gambar 8.
Tabel 6 Perbandingan Nilai Error MSE Menggunakan dan Tanpa Optimasi Tabel 7 Pengujian Coba Perbandingan Hasil
ANN-BP dan Algoritme Genetika Data Aktual ANN-BP ANN-BP + GA Selisih ANN-BP Selisih ANN-BP + GA 30263 32491. 091 30103.0 59 2228.091 159.941 … … … … … 34310 32579. 800 30130.1 32 1730.200 4179.868 MAD 1824.973 1806.742
Gambar 8 Grafik Perbandingan Nilai Peramalan ANN-BP dengan Optimasi GA pada ANN-BP
Berdasarkan hasil yang diperoleh dari perbandingan peramalan informasi tanpa menggunakan optimasi bobot (w) menghasilkan nilai kesalahan sebesar 0.072517977, sedangkan jika bobot (w) dilakukan proses optimasi dengan mengunakan algoritme genetika dapat mencapai nilai MSE sebesar 0.065869861, seperti pada hasil yang dijabarkan pada Tabel 7, selain itu juga dari hasil perbandingan penggunaan metede tersebut menghasilkan nilai Median absolute deviation (MAD) pada metode ANN-BP tanpa 2,0E-02 2,5E-02 3,0E-02 3,5E-02 4,0E-02 4,5E-02 0,1 0,2 0,3 0,4 0,5 0,6 0,7 0,8 0,9 R at a-rat a M SE
Nilai Learning Rate
Grafik Hasil Pengujian Nilai Learning Rate
13000 18000 23000 28000 33000 38000 1 2 3 4 5 6 7 8 9 10
Grafik Perbandingan Nilai Peramalan ANN-BP dengan Optimasi GA pada ANN-BP
Data Aktual ANN-BP ANN-BP + GA
Alpha Percobaan ke-n Rata-rata MSE
1 … 10 0.1 0.0468266 … 0.0367718 0.0415057 0.2 0.0472402 … 0.0382427 0.0423816 0.3 0.0430346 … 0.0321924 0.0367656 0.4 0.0399704 … 0.0238269 0.0289548 0.5 0.0453919 … 0.0237496 0.0312248 0.6 0.0470315 … 0.0326475 0.0379417 0.7 0.0484848 … 0.0219497 0.0281518 0.8 0.0453497 … 0.0236434 0.0286190 0.9 0.0359332 … 0.0201550 0.0242369 Pelatiha n
Percobaan ke-n Rata-rata MSE 1 … 10 ANN-BP 0.07834 1 … 0.06996920 6 0.07251797 7 ANN-BP + GA 0.06539 3 … 0.06961890 4 0.06586986 1
optimasi menggunakan algoritme genetika menghasilkan nilai sebesar 1806.74 yang nilainya lebih kecil dari pada tanpa mengunakan optimasi, yang juga telah dijabarkan pada Tabel 8. Dan berdasarkan Gambar 8 menunjukkan bahwa pola dari data permasalahan merupakan jenis pola trend, yang mengartikan bahwa pola terdiri dari data dengan pola yang memiliki jangkauan waktu yang panjang sehingga terbentuklah pola trend yang dihasilkan dari perbandingan nilai aktual dan pola hasil prediksi.
6. KESIMPULAN DAN SARAN
Dengan topik penelitian peramalan
jumlah
penumpang
PT
KAI
yang
menggunakan
variabel
yang
berupa
penentuan nilai iterasi pada metode
ANN-BP dengan hasil nilai iterasi yang optimum
berada pada nilai 100 dan nilai learning rate
yang optimim dengan nilai 0.9, sedangkan
parameter penentu dari proses algoritme
genetika hasil pencarian solusi yang
optimum
dengan
memakai
parameter
banyak populasi yang digunakan yakni
sebanyak 800, jumlah generasi sebanyak 20,
dan dengan kombinasi nilai Cr = 0.7 dan Mr
= 0.3. Yang menghasilkan peramalan
dengan niali MSE = 0.065869861 dengan
menggunakan nilai optimasi dari proses
algoritme genetika, sedangkan jika tanpa
menggunakan optimasi menghasilkan nilai
MSE = 0.072517977. Dengan hasil MAD
lebih baik 18.231 jika menggunakan
optimasi.
7. REFRENSI
Gani, E., Kolibu, H. S., & Tamuntuan, G. H. (2016). Pemanfaatan Logika Fuzzy Untuk Sistem Prediksi Banjir. JURNAL MIPA UNSRAT, 81–84 .
Kusrini, & Luthfi, E. T. (2009). Algoritma Data Mining. Yogyakarta: ANDI.
Luthfianto, R., Santoso, I., & Christiyono, Y. (2011). Peramalan Jumlah Penumpang Kereta Api dengan Jaringan Saraf Tiruan Metode Perambatan Balik (Backpropagation). Reserarch gate, 1-9. Mahmudy, W. F. (2015). Dasar-Dasar Algoritma Evolusi. Malang: Program Teknologi Informasi dan Ilmu Komputer (PTIIK) Universitas Brawijaya.
Saleh, A. (2015). Implementasi Metode Klasifikasi Naïve Bayes. Citec Journal, 207.
Wicaksono, A., & Supianto, A. (2018). Hyper Pamarameter optimization using Genetic Algorithm on Machine Learning Methods for Online News Popularity Prediction. (IJACSA) International Journal of Advance Computer Science and Applications, 263-267.
Wiharto, Palgunadi, Y., & Nugroho, M. A. (2013). Analisis Penanggulangan Algoritma Genetika Untuk Perbaikan Jaringan Syaraf Tiruan Radial Basis Function. Seminar Nasional Teknologi Informasi dan Komunikasi 2013 (SENTIKA 2013) (pp. 181-188). Surakarta: Riset Group Ilmu Rekayasa dan Komputasi FMIPA Universitas Sebelas Maret.
Yandra, A., Seminar, K. B., & Gunawan, H. (2012). Algoritma Genetika Teori dan Aplikasinya Untuk Bisnis dan Industri. Bogor: PT Penerbit IPB Press.
Yohannes, E., Mahmudy, W. F., & Rahmi, A. (2015). Penentuan Upah Minimum Kota Berdasarkan Tingkat Inflasi Menggunakan Backpropagation Neural Network (BPNN). Jurnal Teknologi Informasi dan Ilmu Komputer (JTIIK), 34-40.