Sketch-guided filtering support for detecting
superspreaders in high-speed networks
T. Wellem and Y.-K. Lai
✉A sketch-guidedfiltering scheme for assisting superspreader detection
in the measurement of high-speed network traffic is proposed. The
scheme comprises of an array of linear-counting sketches that
rapidly eliminatesflows with potentially low fan-out during a
measure-ment interval. Based on the results of simulations obtained using
real-world network traces, thefilter can eliminate up to 90% of theflows of
non-superspreader sources and improve the accuracy of superspreader
identification. Furthermore, the proposed scheme has a smaller fan-out
estimation error and consumes less memory than previously developed
approaches. The hardware implementation can process network traffic
at a throughput of 27 Gbit/s.
Introduction: Identifying hosts that communicate with more than a pre-defined number of distinct destinations during a measurement interval is important for detecting network anomalies. These hosts are also known as super sources [1] or superspreaders [2]. To detect superspreaders, network device must count the number of connections from each source to its distinct destinations (the fan-out of the source) in the measurement interval. In high-speed links, since the number of distinct sources is large, accurately identifying each distinct source and its number of connections in an online setting with limited fast memory space is difficult. Available real-world Internet traces [3], clearly reveal that most sources have few connections to distinct destinations. Therefore, the tracking of sources with low fan-out is unnecessary and wastes memory. While most of previous studies have developed algor-ithms detecting superspreader, this work proposes a sketch-guidedfi lter-ing scheme for removlter-ing non-superspreader sources with high probability. The goal is to keep tracking only the potential supersprea-ders with limited memory and improve the accuracy of fan-out esti-mation. Thefilter mechanism can be easily implemented in hardware eliminating most low fan-out sources at wirespeed.
Background: The goal of superspreader detection is tofind sources with fan-out that exceeds a predefined threshold and estimate their fan-out. Fan-out of a host is defined as the number of distinct destinations to which the host connects in a measurement interval [1]. Some network monitoring applications, such as the detection of distributed denial-of-service (DDoS) attack and port scans, require the counting of connections of a host. Conversely, detecting destinations that are con-tacted by many distinct sources (or super destinations) can be useful in detecting victims of DDoS attack.
Previous works in thefield [1,2,4,5] have developed methods to detect superspreaders and estimate their fan-outs. Most focus on the algorithm and not hardware implementation. The method of Venkataramanet al. [2] requires a large memory because it requires two hash tables, of which one stores all distinct source–destination pairs and the other stores the source address–counter pairs for each source address. Estan et al. [4] utilised bitmaps to store the source– destination pairs and thereby reduce the memory requirement. Each source address has its own bitmap, from which the fan-out can be esti-mated. Still a large memory is required to allocate the bitmap for a large number of sources. Zhaoet al.[1] presented bitmap sharing from a 2D bit array. The bit array stores information concerning the fan-out of each source; each column of the bit array is a bitmap that is shared by many sources. Sampling is utilised to obtain the source addresses. These sampled sources are then used to query the bit array to obtain their esti-mated fan-outs. Yoonet al.[5] developed a scheme based on a virtual bit vector for each source by selecting bits uniformly at random from a large 1D bit array. Like Zhaoet al.[1], they conducted sampling to collect the sources. The problem with the sampling method is that it either misses the superspreaders or it samples too many sources, include those that have low fan-out. If the number of samples is too large, then more storage is needed. The time that is required for estimat-ing fan-out increases because the virtual vector needs to be computed for each source in the sample table.
System design: In general, a superspreader detection system has the fol-lowing two main functions: (i) to store or encode information about the source–destination pairs in the measurement interval, in such a form that it can be used for detection and (ii) to identify the superspreaders and
estimate the fan-outs of the collected sources from the information that is stored in memory.
The main innovation of the proposed system is to utilise the
sketch-guided filtering mechanism to remove sources with potentially low
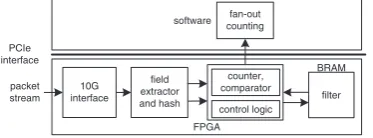
fan-out. The superspreader detection system, as shown in Fig.1, com-prises of two stages, thefiltering stage and the fan-out counting stage.
packet
Fig. 1Superspreader detection system consists of two stages:filtering stage implemented in FPGA hardware and fan-out counting stage in host CPU
In thefirst stage, there is afilter of two dimensional bit array. Each row of the array is a linear-counting (LC) sketch [6]. It is initialised to zero at the beginning of each measurement interval. The filtering stage proceeds as follows. Upon arrival of a packet, theflow ID (the source–destination pair 〈s, d〉) and source sare hashed by different hash functions to the column and row of thefilter, respectively. The bit in the corresponding [row, col] position is then set to‘1’ during this filter update process. For each incoming high-speed packet source, the filter can be used to estimate the number of distinct source–destinationflows from the number of zeros in the LC sketch at a coarse-grained fashion. As the number of zeros in a particular row is less than a prespecified number, the sources that are hashed to that row have potentially high fan-outs. Theseflows are then passed to the fan-out counting stage. Therefore, sources with high-probability of low fan-out are removed by thefilter.
In the second stage, there is a Bloomfilter to check the presence of a source, and a hash table to store the source and its fan-out count within a measurement interval. When aflow is passed into the second stage, if the source IP address does not exist, then theflow is recorded in the Bloomfilter, added to the hash table and its fan-out counter is updated.
packet
Fig. 2 Block diagrams of superspreader detection system on NetFPGA platform
Implementation: The proposed system is implemented using a
NetFPGA-10G platform with a Xilinx Virtex-5 field programmable gate array (FPGA). Thefiltering stage is implemented in FPGA hard-ware, while the fan-out counting stage is implemented in software on the host CPU. The implementation of the counting stage in software has two advantages: (i) it simplifies hardware implementation and (ii) it ensures flexibility of the counting stage (meaning that different fan-out counting algorithms can be used). Moreover, after the super-spreaders are detected, the software can take the predetermined actions (such as sending notification to hardware to block and redirect the sources, for example). Implementing the filter is straightforward and can be stored in FPGA on-chip block RAM (BRAM). The BRAM capacity of 1.42 MB is more than enough to implement the
filter. Thefilter update operation requires two hash computations and memory access (write) to set the bit. These operations can be performed very rapidly using a hardware-friendly hash function (such as the one from H3 family [7]). The hash computations, memory writing, and
threshold comparison can be completed in four clock cycles. With a 160 MHz system clock, networking traffic can be processed at a throughput of 27 Gbit/s assuming a 64 byte minimum Ethernet frame
size plus a 20 byte interframe gap. In each measurement interval, the
filter is updated and passes theflows to be read by the software. In the software, the flows are processed to identify the superspreaders and estimate their fan-outs. Fig. 2 shows a block diagram of the system on the NetFPGA platform.
Evaluation: The proposed scheme was validated using trace-driven
simulations. The trace is available from CAIDA [3]; it comprises of 30 million packets with a duration of 60 s. The total number of distinct source–destination pairs and distinct source IP addresses are one million and 450 k, respectively. The observation interval was set to 15 s. In this interval, the number of distinct source–destination pairs is∼360–410 k, and the number of distinct sources is∼192–210 k. The proposed system was compared to online streaming module (OSM) [1]. The OSM scheme was simulated in software that was written in C. The two par-ameters in OSM are the number of rows in the bitmap (m) and the column size (n). Herein,mis set to 16,384 andn is set to 128 bits (256 kB). Another 528 kB is allocated for the sampling process that is required by OSM, and a maximum of 128 k sources can be accommo-dated in the sample table. The total memory size is 784 kB. For our pro-posed system, the LC sketchfilter size is 256 kB (16,384 rows and 128 bits columns). The Bloomfilter and hash table are implemented in the software part of the system. Consequently, their sizes can be adjusted independently of FPGA hardware resource. Bloom filter and hash table sizes of 128 and 256 kB, respectively, are chosen herein.
A hash table of this size is large enough to store the potential super-spreaders and the fan-out counters. The proposed system requires a total memory of 640 kB. The parameter offilter threshold, which determines the number offlows to be processed in the second stage and the
identi-fication accuracy is set to be 64 ensure good identification accuracy. This based on an assumption where a superspreader is regarded as a source whose fan-out exceeds 200. The number of sources that pass through thefilter in the presented scheme and the number of sources that are sampled by the sampling module (in the OSM scheme) influence the accuracy of identification of the superspreaders. The identification accu-racy is measured herein by the negative ratio (FNR) and the false-positive ratio (FPR). The FNR is the number of superspreaders that fail to be identified divided by the number of actual superspreaders. The FPR is the number of non-superspreaders that are incorrectly identified as superspreaders divided by the number of actual superspreaders. As indicated in Table1, the proposed system can accurately identify the superspreaders.
Table 1:Comparison of FPR/FNR for superspreader identification (LC sketchfilter threshold = 64)
Interval OSM [1]
Proposed system FPR FNR FPR FNR 1 0.075 0.025 0 0 2 0.036 0.012 0 0.012 3 0.038 0.012 0 0 4 0.013 0.013 0 0
The number of sources that is sampled by the sampling module of OSM exceeds 100,000, which is much larger than the number of actual superspreaders. These sampled sources are used to query the bitmap to estimate their fan-outs. To reduce the number of sampled sources in OSM, the sampling rate can be adjusted. However, at a low sampling rate, the superspreaders may be missed. In the system, redu-cing the threshold (setting more bits in thefilter), reduces the number of sources that pass thefilter. Therefore, the sources that are hashed to a row with more bits set are more likely to be superspreaders. The threshold must be set carefully to achieve the desired identification accu-racy according to the definition of superspreaders by system administra-tor. Using a threshold of 64 causes thefilter to drop∼90% of theflows, allowing only 10%flows, which belong to the potential superspreaders to pass to the second stage. Therefore, the number offlows that must be
processed in the software part is greatly reduced. By using thefiltering mechanism, the system also reduces the number of sources that must be stored in the hash table. The simulation shows that only 1% of the number of sources in each interval (or∼2,000 of 200,000 sources) is stored in the hash table. Compared to the large number of sources that are sampled to query the bitmap for fan-out estimation in OSM, the pro-posed system can achieve higher processing speed with less memory space. The mean fan-out estimation error of the system is 10%, which is approximately as that of the OSM with the above parameters. To further reduce the mean fan-out estimation error in the system, only the threshold has to be adjusted. The memory required does not have to be changed. In contrast, the parameters ofm and n in the OSM scheme must be changed to reduce fan-out estimation error. For example, with threshold = 96, the fan-out estimation error of the system is 6%, while OSM requires a larger bitmap size of 512 kB (m
= 16384 andn= 256) to achieve a similar estimation error.
Apart from thefilter size and thefilter threshold, another important parameter that must be considered in using thefilter is the observation interval. In the experiments herein, thefilter size was 256 kB (16,384 rows and 128 bit columns) and the observation interval was 15 s. As the observation interval is increased, more bits are set until all bits in thefilterfinally become‘1’. Then, in this case, thefiltering mechanism does not work. The easiest way to prevent this problem is to increase the
filter size. Another method, which does not involve increasing thefilter size is to refresh thefilter or reset the bits when the number of bits set in thefilter reaches a certain threshold.
Conclusion: This work presents a scheme of sketch-guidedfiltering to eliminate low fan-out sources for detecting superspreaders. Trace-driven simulations were performed to evaluate the performance of the system in terms of the accuracy of superspreader identification. The filter can reduce the number of sources that must be processed much below that of the sampling method that has been used in the previous approach, while improving the identification accuracy and mean fan-out estimation error. When only a few sources need to be processed for fan-out count-ing, only a small amount of memory required for the hash table to store the sources (256 kB). Thefilter hardware is implemented on a Xilinx Virtex-5 FPGA and can process traffic at a throughput of 27 Gbit/s.
Acknowledgment: This work was supported in part by the Taiwan
Ministry of Science and Technology under contract no. MOST 104-2221-E-033-007, 103-2221-E-033-030 and 103-2632-E-033-001.
© The Institution of Engineering and Technology 2016 Submitted:23 October 2015 E-first:4 July 2016
doi: 10.1049/el.2015.3748
T. Wellem and Y.-K. Lai (Department of Electrical Engineering,
CYCU, Chung-Li, Taiwan)
✉E-mail: [email protected]
References
1 Zhao, Q., Kumar, A., and Xu, J.:‘Joint data streaming and sampling
techniques for detection of super sources and destinations’. Proc. of the
Fifth ACM SIGCOMM Conf. on Internet Measurement, Berkeley, CA,
USA, October 19–21, 2005, pp. 77–90
2 Venkataraman, S., Song, D., Gibbons, P.B.,et al.:‘New streaming
algor-ithms for fast detection of superspreaders’. Proc. of Network and
Distributed System Security Symp., San Diego, CA, USA, February
3–4, 2005, pp. 149–166
3 ‘CAIDA UCSD Anonymized Internet Traces,’2012
4 Estan, C., Varghese, G., and Fisk, M.:‘Bitmap algorithms for counting
active flows on high-speed links’, Trans. Netw., 2006, 14, (5),
pp. 925–937
5 Yoon, M., Li, T., Chen, S.,et al.:‘Fit a compact spread estimator in small
high-speed memory’,Trans. Netw., 2011,19, (5), pp. 1253–1264
6 Whang, K.Y., Vander-Zanden, B.T., and Taylor, H.M.:‘A linear-time
probabilistic counting algorithm for database applications’, ACM
Trans. Database Syst., 1990,15, (2), pp. 208–229
7 Carter, J., and Wegman, M.: ‘Universal classes of hash functions’,
J. Comput. Syst. Sci., 1979,18, (2), pp. 143–154