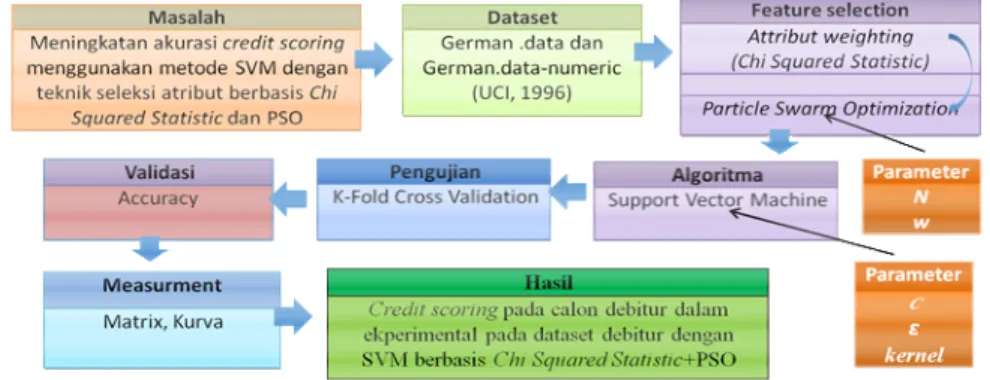
CREDIT SCORING MENGGUNAKAN
METODE
SUPPORT VECTOR MACHINE DENGAN TEKNIK SELEKSI
ATRIBUT BERBASIS
CHI SQUARED STATISTIC DAN
PARTICLE SWARM OPTIMIZATION
Suwondo, dan Stefanus Santosa
Pascasarjana Teknik Informatika Universitas Dian Nuswantoro
ABSTRACT
Credit scoring is a system used by a bank or other financial institution to determine the debtor feasible or not get a loan to avoid mancet . Many studies have been conducted to determine credit scoring . One of the most widely used methods is the SVM . SVM has an excellent generalization ability to solve problems even with limited data . One of the successes of SVM is highly dependent on the selection of attributes and parameters . Selection attributes using Chi Squared Statistic and PSO . This study uses German.data and German.data-numeric from UCI . Accuracy values obtained by using the parameter C , kernel type , epsilon , min weight , max weight , and population . Of the 20 predictor variables weighted Chi Squared Statistic selected 19 attributes then selected 14 attributes PSO process . SVM algorithm testing with Chi Squared Statistic and PSO produces 77.80 % accuracy values and AUC values of 0.786 , then the value of classification accuracy enough (fair classification) . Testing attribute selection using SVM with Chi Squared Statistic and PSO higher accuracy value than the sampling procedure in SVM , SVM + GA , BPN , GP [1], LDA , Logistic Regression , Neural Networks , Neighborhood Rough Set + SVM [8], LDA + SVM , DT + SVM , SVM + RST , F -score + SVM [10] and SVM , SVM + PSO [9] . Then Support Vector Machine ( SVM ) based Chi Squared Statistic and Particle Swarm Optimization ( PSO ) can be used for credit scoring problem solving .
Key Word: Credit scoring, selection attribute, Support Vector Machine, Chi Squared Statistic, Particle
Swarm Optimization
1. PENDAHULUAN 1.1 Latar Belakang
Credit scoring atau penilaian kredit adalah sistem atau cara yang digunakan oleh bank atau lembaga pembiayaan lainnya untuk menentukan calon debitur layak atau tidak mendapatkan pinjaman. Credit
scoring ini merupakan kumpulan data calon debitur atau data calon debitur yang pernah menjadi debitur. Data ini berisi tentang sejarah pinjaman, siklus pembayaran tagihan, dan berapa banyak kredit yang masih diangsur atau pernah debitur miliki.
Model credit scoring secara intensif digunakan dan dikembangkan untuk penilaian terhadap debitur untuk meningkatkan akurasi prediksi. Model ini mengkategorikan debitur menjadi dua kelompok yaitu kelompok pengajuan kredit diterima dan ditolak. Karakteristik penilaian seperti pendapatan, saldo rekening bank, pekerjaan/profesi, keluarga, pendidikan dan lainnya [1]. Tetapi data tersebut diatas tidak semuanya bersifat kuantitatif juga ada data yang bersifat kualitatif yang perlu dikonversi ke kuantitatif dengan beberapa standar/prosedur untuk komputasi.
Berdasarkan data [2] kredit macet hampir terjadi di seluruh dunia seperti kredit macet yang terjadi di negara-negara Eropa pada tahun 2012 yaitu 50 miliar euro atau setara dengan US$ 64,2 miliar [3]. Sedangan di negara-negara Asia seperti Indonesia menurut Bank Indonesia (BI) mengungkapkan jumlah
kredit macet perbankan mencapai Rp 33,401 triliun hingga akhir 2011 dan bulan Februari 2012 jumlah kredit macet perbankan mencapai Rp 51,42 triliun. Jumlah ini naik 4% atau Rp 2,06 triliun dibandingkan akhir Februari 2011 sebesar Rp 49,36 triliun [2].
Faktor penyebab timbulnya kredit bermasalah atau macet dikelompokkan atas 3 golongan yaitu faktor intern bank, ketidaklayakan debitur dan faktor eksternal. Faktor intern bank salah satunya penyelenggaraan credit scoring yang kurang mampu, sedangkan faktor eksternal berupa pimpinan bank mendapat tekanan dari pihak luar, sehingga credit scoring yang dilakukan oleh pihak bank tidak obyektif dan terjadian pelanggaran [4]. Maka dibuat model credit scoring dengan tujuan untuk menganalisa dan membuat keputusan yang lebih cepat, tepat dan efisien.
Penelitian dibidang credit scoring telah banyak dilakukan untuk meningkatkan akurasi credit scoring, maka berbagai metode untuk credit scoring telah banyak diusulkan. Adapun penelitian yang pernah dilakukan antara lain: penelitian dilakukan oleh Hens-Akhil Bandhu dan Tiwari-Manoj Kumar tahun 2012 berjudul Computational time reduction for credit scoring: An integrated approach based on support
vector machine and stratified sampling method [1]. Tujuan penelitian yang dilakukan oleh Hens-Akhil Bandhu dan Tiwari-Manoj Kumar adalah mempelajari pendekatan metode baru dan membuat analisis komparatif dari waktu komputasi dan akurasi dengan beberapa metode dengan menggunakan dua dataset yaitu Australia Credit dan German.data dengan pengujian algoritma Sampling procedure in SVM, SVM dan GA, BPN, dan GP. Seleksi atribut menggunakan F-score dan Sampling approach. Nilai akurasi tertinggi adalah GP sebesar 77.26%.
Penelitian selanjutnya yang dilakukan oleh Sadatrasoul, et al yang berjudul Credit scoring in banks
and financial institutions via data mining techniques : A literature review dengan melakukan review
literatur tentang credit scoring mulai tahun 2000 sampai 2012 dengan mengkategorikan data mining
credit scoring berjumlah 110 artikel dan yang digunakan 44 artikel sedang 66 artikel tidak digunakan karena tidak berhubungan dengan data mining credit scoring. Dari 44 artikel tersebut dipelajari dan dikategorikan bahwa credit scoring digunakan untuk perorangan/individu, perusahaan, dan UKM. Adapun teknik datang mining juga dikategorikan metode tunggal, metode hybrid dan ensemble. Temuan
literatur review ini menunjukan bahwa sebagian besar teknik data mining credit scoring untuk penilaian individu atau perseorangan. Metode yang digunakan ensemble, SVM, NN, GA dan lainnya. Tapi yang paling banyak digunakan adalah SVM dan NN [5].
Dari uraian penelitian diatas dapat diketahui bahwa metode Support vector Machine (SVM) banyak digunakan untuk credit scoring karena SVM mempunyai kemampuan generalisasi sangat baik untuk memecahkan masalah walau dengan data yang terbatas, tetapi salah satu keberhasilan SVM sangat tergantung pada seleksi atribut dan parameter yang akan mempengaruhi tingkat akurasi [6]. Seleksi atribut adalah adalah proses memilih dan mendapatkan informasi yang lebih berharga dari data dengan atribut yang besar. Jika database berisi sejumlah atribut, ruang berdemensi besar dan tidak bersih akan menurunkan tingkat akurasi.
Algoritma yang akan digunakan untuk seleksi atribut yaitu Chi Squared Statistic dan Particle Swarm
Optimization (PSO). Algoritma PSO memiliki kompleksitas yang lebih rendah dan sederhana serta dapat memastikan solusi optimal dengan menyesuaikan pencarian global dan lokal. Juga dapat digunakan sebagai teknik optimasi mengoptimalkan subset atribut dan parameter secara bersamaan, sehingga kinerja klasifikasi pada algoritma SVM dapat ditingkatkan [7].
Sedangkan tahapan proses penelitian ini, sebagai berikut: proses pertama menggunakan Attribut
weighting menggunakan Chi Squared Statistic untuk mendapatkan nilai pembobotan atribut setelah masing-masing atribut mendapatkan nilai w…> 0 akan diseleksi oleh Select Attributes dengan cara membuang atribut yang bernilai 0 selanjutnya hasil seleksi pembobotan dilanjutkan dengan seleksi atribut menggunakan Particle Swarm Optimization (PSO) kemudian proses pembelajaran klasifikasi dengan SVM.
1. 2. Rumusan Masalah
Berdasarkan latar belakang di atas dapat ditarik rumusan masalah sebagai berikut a. Banyaknya kredit macet di tengah masyarakat
b. Nilai akurasi credit scoring baru mencapai 77,26% pada dataset UCI German.data dan
German.data-numeric 1. 3. Tujuan Penelitian
Tujuan dari penelitian ini adalah
a. Untuk menghindari kegagalan usaha perbankan dan mengurangi kredit macet
b. Untuk meningkatkan akurasi credit scoring lebih besar dari 77,26% dengan pendekatan metode filter berbasis algoritma Support Vector Machine (SVM) berbasis Chi Squared Statistic dan Particle
Swarm Optimization (PSO)
1. 4. Manfaat Penelitian
Adapun penelitian ini dapat memberikan beberapa manfaat sebagai berikut:
a. Manfaat bagi masyarakat, hasil ini diharapkan dapat digunakan sebagai masukan bagi perbankan, khususnya membantu staf credit scoring dalam memberikan penilain debitur sehingga tepat untuk mengambil keputusan debitur ditolak atau diberi pinjaman.
b. Manfaat bagi ilmu pengetahuan dan teknologi, hasil ini diharapkan dapat memberikan sumbangan berupa model algoritma SVM dengan PSO penentukan credit scoring pada tiap debitur.
2. TINJAUAN PUSTAKA 2.1 Penelitian Terkait
Beberapa penelitian terdahulu yang menggunakan model Support Vector Machine (SVM) untuk credit
scoring secara garis besar adalah sebagai berikut:
Hens-Akhil Bandhu dan Tiwari-Manoj Kumar pada tahun 2012 berjudul Computational time
reduction for credit scoring: An integrated approach based on support vector machine and stratified sampling method [1]. Tujuan penelitian yang dilakukan oleh Hens-Akhil Bandhu dan Tiwari-Manoj Kumar adalah mempelajari pendekatan metode baru dan membuat analisis komparatif untuk efisiensi waktu komputasi dan peningkatan akurasi dengan seleksi atribut menggunakan F-score dan Sampling
approach dengan dataset yaitu Australia Credit dan German.data. Algoritma yang digunakan adalah
Sampling procedure in SVM, SVM dan GA, BPN, dan GP. Seleksi atribut menggunakan F-score dan
Sampling approach. Adapun hasilnya menujukkan bahwa GP lebih bagus yaitu 77.26% dibanding
accuray sampling procedure in SVM, SVM+GA, dan BPN.
Yao Ping, Lu Yongheng melakukan penelitian pada tahun 2011 dengan judul Neighborhood rough
set and SVM based hybrid credit scoring classifie. Penelitian ini untuk meningkatkan akurasi credit
scoring dengan membangun sebuah model credit scoring berbasis hybrid SVM sesuai inputan atribut pemohon. Dua masalah dihadapi yaitu memilih input atribut dan menentukan parameter kernel terbaik. Maka menggunakan tiga strategi: (1) menggunakan neighborhood rough set untuk memilih masukan atribut, (2) menggunakan pencarian Grid Search untuk optimal parameter kernel RBF, (3) menggunakan masukan atribut hybrid yang optimal dan model parameter untuk memecahkan masalah credit scoring dengan 10-fold cross validation, (4) membandingkan tingkat akurasi dengan metodel lain. Hasil eksperimen menunjukkan bahwa eighborhood rough set dan SVM based hybrid classifier paling bagus dengan hybrid klasifikasi lainnya yaitu linear discriminant analysis, logistic regression dan neural
networks. Nilai akurasi 76,60% [8].
Rinawati melakukan penelitian pada tahun 2012 dengan judul Penerapan particle swarm
optimization untuk seleksi atribut pada metode support vector machine untuk penentuan penilaian kredit
membahas tentang kredit macet perbankan. Penulis melakukan peningkatan akurasi penilaian kredit dengan melakukan seleksi terhadap atribut, karena seleksi atribut mengurangi dimensi dari data sehingga
operasi algoritma data mining dapat berjalan lebih efektif dan lebih cepat dengan menggunakan algoritma SVM dan seleksi atribut dengan menggunakan PSO untuk penentuan penilaian kredit dengan membandingkan algoritma SVM. Hasil yang didapat adalah algoritma support vector machines berbasis
particle swarm optimization masuk kedalam kategori klasifikasi cukup dengan nilai akurasi 77,40% [9]. Penelitian yang dilakukan oleh Fei-Long Chena dan Feng-Chia Li tahun 2010 yang berjudul
Combination of feature selection approaches with SVM in credit scoring membahas tentang credit scoring dengan metode hybrid-SVM serta mengusulkan empat pendekatan untuk seleksi atribut yaitu LDA,
Decision Tree, Rough Sets dan F-score dengan menggunakan dua dataset UCI. Dari pendekatan yang diusulkan kemudian dievaluasi dan hasilnya dibandingkan dengan pengujia menggunakan nonparametrik
Wilcoxon signed rank test untuk menunjukan apakah ada perbedaan yang signifikan. Hasilnya menunjukkan bahwa pendekatan hybrid SVM + F-core menunjungkan hasil yang besar, efektif dan optimal dengan Nilai akurasi 76,70%[10].
Disimpulkan bahwa algoritma Support Vector Machine telah banyak digunakan dan menunjukkan hasil yang lebih baik dari beberapa metode lainnya. Maka SVM akan digunakan dalam penelitian ini. Sedangkan untuk memperoleh nilai akurasi yang lebih baik dengan cara menyeleksi atribut pada dataset dengan menggunakan Chi Squared Statistic dan Particle Swarm Optimization
2.2 Landasan Teori 2.2.1 Data Mining
Data mining atau Knowledge Discovery in Databases (KDD) adalah pengambilan informasi yang tersembunyi, dimana informasi tersebut sebelumnya tidak dikenal dan berpotensi bermanfaat. Proses ini meliputi sejumlah pendekatan teknis yang berbeda, seperti clustering, data summarization, learning
classification rules [11]. Salah satu tuntutan dari data mining ketika diterapkan pada data berskala besar adalah diperlukan metodologi sistematis tidak hanya ketika melakukan analisa saja tetapi juga ketika mempersiapkan data dan juga melakukan interpretasi dari hasilnya sehingga dapat menjadi aksi ataupun keputusan yang bermanfaat [11]. Proses atau tahapan dalam data mining dapat dibagi menjadi beberapa tahap, yaitu pembersihan data, intergrasi data, transformasi data, aplikasi teknik data mining, evaluasi pola yang ditemukan, presentasi pengetahuan [11].
2.2.2 Credit Scoring
Kredit adalah penyediaan uang atau tagihan yang dapat dipersamakan dengan itu, berdasarkan persetujuan atau kesepakatan pinjam-meminjam antara bank dengan pihak lain yang mewajibkan pihak peminjam untuk melunasi utangnya setelah jangka waktu tertentu dengan pemberian bunga.[12]
Credit scoring ini merupakan kumpulan data nasabah yang diambil dari data aplikasi pinjaman nasabah. credit scoring mengelompokkan para calon debitur menjadi dua jenis yaitu debitur baik dan debitur buruk. Debitur baik memiliki kemungkinan besar akan membayar kewajiban keuangannya dengan lancar, sedangkan debitur buruk memiliki kemungkinan besar mengalami kredit macet [13]. Tujuannya untuk membantu bank mengukur dan mengelola risiko keuangan dalam memberikan pinjaman sehingga mereka dapat membuat keputusan yang lebih baik, cepat dan obyektif. Manfaat memberikan analisis obyektif dari kelayakan kredit seorang konsumen, untuk meningkatkan kecepatan dan konsistensi dari proses aplikasi pinjaman dan memungkinkan otomatisasi proses kredit, dapat membantu lembaga keuangan dalam membuat keputusan yang berkualitas, lebih cepat, lebih baik, dan lebih tinggi akurasinya, menetapkan tingkat bunga dan batas kredit yang akan ditetapkan untuk konsumen [14].
Selain memperhatikan dan melakukan penilaian terhadap laporan keuangan calon debitur, pihak bank juga harus memperhatikan prinsip 5C dari calon debitur tersebut. Prinsip 5C tersebut adalah : character,
capital, collateral, capacity, dan condition of economy.
Kelima prinsip tersebut sangat penting untuk menjadi penilaian sebelum bank memberikan persetujuan pemberian kredit. Bagi bank, debitur yang memenuhi semua prinsip 5C adalah nasabah yang layak untuk mendapatkan kredit.[15].
2.2.3 Metode Filter untuk Seleksi Atribut
Seleksi atribut (juga dikenal sebagai subset seleksi) adalah suatu proses yang digunakan dalam machine
learning, dimana atribut dari subset yang tersedia dari data yang dipilih untuk penerapan algoritma learning. Subset terbaik adalah berisi jumlah dimensi berkontribusi terhadap akurasi, kita membuang atribut yang tidak sesuai. Ini merupakan tahap penting dari pre processing dan merupakan salah satu dari dua cara untuk menghindari curse of dimensionality (feature extraction
Seleksi atribut terkait erat dengan pengurangan dimensi. Tujuannya untuk mengidentifikasi tingkat kepentingan atribut dalam kumpulan data, dan membuang semua atribut lain seperti informasi yang tidak relevan dan berlebihan. maka hal ini akan memungkinkan operasi algoritma data mining dapat berjalan lebih efektif dan lebih cepat [16].
Metode yang digunakan dalam penulisan ini adalah metode filter untuk pemilihan atribut karena model ini lebih cepat dalam komputasi karena tidak melibatkan induksi algoritma dalam prosesnya[17]. Maksudnya adalah dengan menggunakan pendekatan filter dilakukan secara terpisah dengan mesin klasifikasi, atau dengan kata lain seleksi atribut dijadikan tahapan pra proses sebelum data dimasukkan dalam mesin klasifikasi. Maka penerapan model filter ini cocok untuk data yang mempunyai atribut yang banyak.
Gambar 1. Filter based Feature Selection
2.2.3.1 Chi-Squared Statistic
Chi Squared Statistic adalah teknik statistik nonparameter yang digunakan untuk menentukan distribusi frekuensi yang diteliti dari yang diharapkan dengan menghitung bobot atribut yang berhubungan dengan kelas atribut. Semakin tinggi nilai bobot atribut maka semakin relevan.
Chi Squared Statistic menghitung proses komputasi setiap atribut dari masukan sampel dataset yang berhubungan dengan atribut kelas. Nilai dari Chi Squared Statistic sebagai berikut :
] (1)
adalah Chi Squared Statistic
adalah frekuensi yang diperoleh/diamati adalah frekuensi yang diharapkan Adapun langkah-langkah pengujian sebagai berikut:
a. Hipotesis Ha dan Ho yaitu apakah Ho tidak ada hubungan yang signifikan antara atribut dataset dengan credit scoring, sedangkan Ha yaitu terdapat hubungan yang signifikan antara atribut dataset dengan credit scoring
b. Buat tabel kontingensi. Setiap kotak disebut sel, setiap sebuah kolom berisi sebuah subvariabel, setiap sebuah baris berisi sebuah subvariabel.
c. Cari nilai frekuensi yang diharapkan ( dengan rumus setiap sel dengan persamaan (1) (1)
d. Hitung nilai Chi-Square
2.2.3.2 Select Attributes
Select attributes adalah operator untuk memilih atribut dari dataset yang akan digunakan atau atribut yang tidak digunakan, ketika semua atribut pada dataset tidak akan digunakan semua.
Select attributes digunakan pada dataset yang besar dan kompleks sehingga dengan mudah dapat memilih atribut yang dipergunakan lalu dikirim menjadi output dan sisanya akan dihapus dari dataset tersebut.
2.2.4 Algoritma Particle Swarm Optimization
Particle Swarm Optimization merupakan teknik komputasi evolusione r yang mampu menghasilkan solusi secara global optimal dalam ruang pencarian melalui interaksi individu dalam segerombolan partikel. Setiap partikel menyampaikan informasi berupa posisi terbaiknya kepada partikel yang lain dan menyesuaikan posisi dan kecepatan masing-masing berdasarkan informasi yang diterima mengenai posisi yang terbaik tersebut [18].
Particle Swarm Optimization dapat diasumsikan dengan sekelompok burung yang secara acak mencari makanan di suatu daerah. Hanya ada satu potong makanan di daerah yang dicari tersebut. Burung-burung tidak tahu di mana makanan tersebut. Tapi mereka tahu seberapa jauh makanan tersebut dan posisi rekan-rekan mereka. Jadi strategi terbaik untuk menemukan makanan adalah dengan mengikuti burung yang terdekat dari makanan [7].
Secara singkat proses PSO dimulai dari inisialisasi populasi hingga penghentian komputasi, seperti algoritma berikut:
a. Inisialisasi populasi (posisi dan kecepatan acak) dalam hyperspace b. Evaluasi fitness partikel individu
c. Modifikasi kecepatan berdasarkan terbaik sebelumnya (previous best:pbest) dan terbaik global atau local (global or neighborhood best; gbest or lbest)
d. Hentikan berdasarkan beberapa kondisi e. Kembali ke langkah (b)
Untuk menemukan solusi yang optimal, maka setiap partikel akan bergerak kearah posisi yang terbaik sebelumnya (pbest) dan posisi terbaik secara global (gbest). Modifikasi kecepatan dan posisi tiap partikel dapat dihitung menggunakan kecepatan saat ini dan jarak ke seperti ditunjukkan oleh persamaan [19] berikut:
(2)
Untuk mencapai nilai bobot insersia yang secara imbang antara pencarian global dan lokal dan mempercepat konvergensi, suatu bobot inersia yang mengecil nilainya dengan bertambahnya iterasi dengan rumur
(3)
Keterangan :
: partikel, : iterasi, : populasi, : kecepatan partikel j pada iterasi ke i, : faktor bobot inersia, : kecepatan partikel j, : partikel atau vektor koordinat dari partikel, : learning rates untuk kemampuan individu dan pengaruh sosial, : bilangan random yang berditribusi uniformal dalam interval 0 dan 1, : posisi terbaik sebelumnya dari partikel ke-i, gbest : partikel terbaik diantara semua partikel dalam satu kelompok atau populasi, : nilai awal bobot inersia, : nilai akhir bobot inersia, : jumlah iterasi maksimum yang digunakan dan i adalah iterasi sekarang
Mengusulkan PSO biner dimana setiap partikel bergerak dalam yang terbatas 0 dan 1 pada tiap dimensi, terms berubah didalam pro-abilities yang sedikit berada dalam satu ruang atau ditempat lainnya.
2.2.5 Support Vector Machine
SVM dirancang untuk menyelesaikan permasalahan dua kelas [20]. Support Vector Machine (SVM) diperkenalkan oleh Vapnik, Boser dan Guyon serta dikembangkan oleh Boser, dan pertama kali dipresentasikan pada tahun 1992 di Annual Workshop on Computational Learning Theory. Konsep dasar SVM sebenarnya merupakan kombinasi harmonis dari teori-teori komputasi yang telah ada puluhan tahun
sebelumnya, seperti margin hyperplane (Duda & Hart tahun 1973, Cover tahun 1965, Vapnik 1964, dsb.), kernel diperkenalkan oleh Aronszajn tahun 1950, dan demikian juga dengan konsep-konsep pendukung yang lain. Akan tetapi hingga tahun 1992, belum pernah ada upaya merangkaikan komponen-komponen tersebut [21].
Support Vector Machine adalah metode learning machine yang bekerja atas prinsip Structural Risk
Minimization (SRM) dengan tujuan menemukan hyperplane terbaik yang memisahkan dua buah class pada input space [22]. Hyperplane terbaik adalah hyperplane yang terletak ditengah-tengah antara dua set obyek dari dua class. Hyperplane pemisah terbaik antara kedua class dapat ditemukan dengan mengukur
margin hyperplane tersebut dan mencari titik maksimalnya. Margin adalah jarak antara hyperplane tersebut dengan pattern terdekat dari masing-masing class. Pattern yang paling dekat ini disebut sebagai
support vector [23][9].
Yang menjadi karakteristik dari Support Vector Machine (SVM) adalah sebagai berikut: 1) Secara prinsip SVM adalah linear classifier.
2) Pattern recognition dilakukan dengan mentransformasikan data pada input space ke ruang yang berdimensi lebih tinggi, dan optimisasi dilakukan pada ruang vector yang baru tersebut. Hal ini membedakan SVM dari solusi pattern recognition pada umumnya, yang melakukan optimisasi parameter pada ruang hasil transformasi yang berdimensi lebih rendah daripada dimensi input space. 3) Menerapkan strategi Structural Risk Minimization (SRM).
4) Prinsip kerja SVM pada dasarnya hanya mampu menangani klasifikasi dua kelas.
Secara sederhana konsep SVM adalah sebagai usaha mencari hyperlane terbaik yang berfungsi sebagai pemisah dua buah kelas pada input space, dimana dapat dilihat pada gambar 2.4 dibawah ini:
Gambar 2 Alternatif bidang pemisah (kiri) dan bidang pemisah terbaik dengan margin (m) terbesar (kanan) [24].
Pada gambar diatas memperlihatkan beberapa pattern yang merupakan anggota dari dua buah class: +1 dan -1. Pattern yang tergabung pada class -1 disimbolkan dengan warna kuning. Sedangkan pattern pada class +1, disimbolkan dengan warna biru. Problem klasifikasi dapat diterjemahkan dengan usaha menemukan garis (hyperplane) yang memisahkan antara kedua kelompok tersebut. Berbagai alternatif garis pemisah (discrimination boundaries) ditunjukkan garis berwarna orange. Hyperplane pemisah terbaik antara kedua kelas dapat ditemukan dengan mengukur margin hyperplane tersebut. dan mencari titik maksimalnya.
Margin adalah jarak antara hyperplane tersebut dengan pattern terdekat dari masing-masing class.
Pattern yang paling dekat ini disebut sebagai support vector. Hyperplane yang terbaik yaitu yang terletak tepat pada tengah-tengah kedua class, sedangkan titik putih yang berada dalam garis bidang pembatas
class adalah support vector. Usaha untuk mencari lokasi hyperplane ini merupakan inti dari proses pembelajaran pada SVM [9].
Adapun data pada SVM dapat dinotasikan sebagai berikut [25]:
(4)
dan Masalah klasifikasi ini bisa dirumuskan sebagai berikut: menemukan set
parameter sehingga fungsi ini untuk menemukan
sedangkan label masing- masing dinotasikan dan menunjukkan jumlah dimensi input data serta untuk i adalah banyaknya data. Diasumsikan kedua class –1 dan +1 dapat terpisah secara sempurna oleh hyperplane berdimensi d , yang didefinisikan:
(5)
Sebuah pattern xi yang termasuk class –1 (sampel negatif) dapat dirumuskan sebagai pattern yang memenuhi pertidaksamaan:
(6) sedangkan pattern yang termasuk class +1 (sampel positif):
(7)
Margin terbesar dapat ditemukan dengan memaksimalkan nilai jarak antara hyperplane dan titik terdekatnya, yaitu 1/||w||. Hal ini dapat dirumuskan sebagai Quadratic Programming (QP) problem, yaitu mencari titik minimal persamaan (8), dengan memperhatikan constraint persamaan (9).
(8) (9)
Keterangan: adalah data input, adalah keluaran dari data adalah parameter-parameter yang dicari nilainya. Hal ini meminimalkan atau memaksimalkan atau dengan
memperhatikan pembatas Bila output , maka pembatas menjadi
Untuk kasus non-linear, SVM akan memetakan data dalam ruang dimensi yang lebih rendah ke dalam ruang dimensi yang lebih tinggi melalui trik kernel. Secara garis besar pemisah non linear, ditambahkan variabel . Parameter C ditentukan user yang menyatakan besar penalti terhadapat error : min
(10)
Subject to
Klasifikasi:
(11) (12)
Juga dapat memanfaatkan fungsi kernel (K), maka fungsi tidak perlu diketahui maka dapat diubah menjadi
(13) Fungsi kernel yang sering dipakai dalam literatur SVM [25]:
• Linear : • Polynomial :
• Radial basis function (RBF) : ,
• Tangent hyperbolic (sigmoid): , dimana
2.2.6 Pengujian K-Fold Cross Validation
Cross Validation salah satu metode yang digunakan menemukan parameter terbaik dengan cara menguji besarnya error pada data testing. Cross Validation membagi data secara acak kedalam k bagian dengan ukuran yang sama dan masing-masing bagian akan dilakukan proses klasifikasi[9][25]. Secara umum pengujian nilai k dilakukan sebanyak 10 kali untuk memperkirakan akurasi estimasi. Dalam penelitian ini nilai k yang digunakan berjumlah 10 atau 10-fold Cross Validation. tiap percobaan akan menggunakan 1 data testing dan k-1 bagian akan menjadi data training, kemudian data testing itu akan ditukar dengan satu buah data training sehingga untuk tiap percobaan akan didapatkan data testing yang berbeda-beda. Misalnya ada 10 subset data maka akan menggunakan 9 subset untuk training dan 1 subset untuk testing dilakukan untuk semua kemungkinan[25].
2.2.7 Evaluasi dan Validasi Hasil 2.2.7.1 Confusion matrix
Confusion matrix memberikan keputusan yang diperoleh dalam traning dan testing, confusion matrix memberikan penilaian performance klasifikasi berdasarkan objek dengan benar atau salah [26]. Confusion matrix berisi informasi aktual (actual) dan prediksi (predicted) pada sistem klasifikasi.
Tabel 1 Confusion Matrix [26]
Clasification Predicted Class
Observed Class
Class = Yes Class = No
Class = Yes a (true positive – TP) b (false negative – FN) Class = No c (false positive – FP) d (true negatif – TN)
Berikut adalah persamaan model confusion matrix:
a. Nilai Accuracy adalah proporsi jumlah prediksi yang benar. Dapat dihitung dengan menggunakan persamaan:
(14)
b. Sensitivity digunakan untuk membandingkan proporsi TP terhadap tupel yang positif, yang dihitung dengan menggunakan persamaan:
(15)
c. Specificity digunakan untuk membandingan proporsi TN terhadap tupel yang negatif, yang dihitung dengan menggunakan persamaan:
(16)
d. PPV (positive predictive value) adalah proporsi kasus dengan hasil diagnosa positif, yang dihitung dengan menggunakan persamaan:
(17)
e. NPV (negative predictive value) adalah proporsi kasus dengan hasil diagnosa negatif, yang dihitung dengan menggunakan persamaan:
(18)
2.2.7.2 Kurva ROC
Kurva ROC (Receiver Operating Characteristic) adalah alat visual yang berguna untuk membandingkan dua model klasifikasi. ROC mengekspresikan confusion matrix. ROC adalah grafik dua dimensi dengan
false positives sebagai garis horisontal dan true positives sebagai garis vertikal [26]. Dengan kurva ROC, kita dapat melihat trade off antara tingkat dimana suatu model dapat mengenali tuple positif secara akurat dan tingkat dimana model tersebut salah mengenali tuple negatif sebagai tuple positif. Sebuah grafik ROC adalah plot dua dimensi dengan proporsi positif salah (fp) pada sumbu X dan proporsi positif benar (tp) pada sumbu Y. Titik (0,1) merupakan klasifikasi yang sempurna terhadap semua kasus positif dan kasus negatif. Nilai positif salah adalah tidak ada (fp = 0) dan nilai positif benar adalah tinggi (tp = 1). Titik (0,0) adalah klasifikasi yang memprediksi setiap kasus menjadi negatif {-1}, dan titik (1,1) adalah klasifikasi yang memprediksi setiap kasus menjadi positif {1}. Grafik ROC menggambarkan trade-off antara manfaat (true positive) dan biaya (false positives). Berikut tampilan dua jenis kurva ROC (discrete dan continous).
Untuk tingkat akuransi nilai AUC dalam klasifikasi data mining dibagi menjadi lima kelompok [26], yaitu:
a. 0.90 - 1.00 = klasifikasi sangat baik (excellent classification) b. 0.80 - 0.90 = klasifikasi baik (good classification)
c. 0.70 - 0.80 = klasifikasi cukup (fair classification) d. 0.60 - 0.70 = klasifikasi buruk (poor classification) e. 0.50 - 0.60 = klasifikasi salah (failure)
3. CREDIT SCORING MENGGUNAKAN SVM DENGAN TEKNIK SELEKSI ATRIBUT BERBASIS CHI SQUARED STATISTIC DAN PSO
Penelitian ini adalah untuk meningkatkan akurasi credit scoring pada German.data dan
German.data-numeric dengan pendekatan Support Vector Machine dan menggunakan Chi Squared Statistic dan
Particle Swarm Optimization untuk seleksi atribut. SVM dirancang untuk menyelesaikan permasalahan dua kelas dengan metode learning machine yang bekerja atas prinsip Structural Risk Minimization (SRM) dengan tujuan menemukan hyperplane terbaik yang memisahkan dua buah class pada input
space[25][26][27].
German.data dan German.data-numeric merupakan data yang mempunyai banyak atribut sehingga akan mengurangi akurasi dan menambah kompleksitas dari algoritma Support Vector Machine. Untuk itu perlu adanya seleksi atribut supaya SVM dapat berkerja secara maksimal. Algoritma yang digunakan untuk seleksi atribut adalah Chi Squared Statistic dan Particle Swarm Optimization.
Chi Squared Statistic untuk menghitung bobot setiap atribut yang berhubungan dengan kelas atribut sehingga mendapatkan bobot nilai tiap atribut. Setelah setiap atribut mendapatkan bobot nilai maka dilakukan pemilihan atribut yang bernilai X > 0 oleh Select Attributes. Proses Select Attributes adalah menghasilkan atribut untuk digunakan pembelajaran lebih lanjut. Kemudian menggunakan Particle
Swarm Optimization untuk optimasi pembobotan atribut mendapatkan solusi optimal secara global dan atribut yang digunakan untuk proses SVM adalah bernilai X > 0.
Tahapan seleksi atribut sebelum pengujian dataset dengan SVM sebagai berikut :
1) Menentukan Attribut weighting dengan rumus Chi Squared Statistic dengan menggunakan parameter yaitu normalize, sort weights, sort direction (ascending) dan number of bins untuk mendapat nilai bobot atribut.
2) Setelah mendapat nilai bobot atribut maka dilakukan select attributes. Select attributes untuk memilih atribut dataset yang digunakan dan membuang atribut tidak digunakan atau atribut bernilai 0. Select
attributes digunakan untuk kasus ketika atribut dari dataset tidak digunakan . Parameter select
attributes yaitu attribute filter type (parameter ini untuk memilih pilihan filter yang digunakan untuk memilih atribut).
3) Mendapatkan atribut yang bernilai/berbobot maka dilanjutkan dengan proses Particle Swarm
Optimization untuk optimasi pembobotan atribut mendapatkan solusi optimal secara global. Hasil proses tersebut mendapatkan bobot/nilai Untuk mendapatkan bobot/nilai dipengaruhi oeleh parameter/variabel yang dipilih. Adapun parameter PSO adalah ukuran partikel dalam populasi, jumlah maksimun generasi/partikel, dan nilai bobot inersia (nilai awal dan nilai akhir bobot).
4) Bobot/nilai ,...> 0 hasil seleksi dari PSO selanjutnya diproses dengan algoritma SVM untuk mendapatkan nilai akurasi dengan mencari parameter yang sesuai
5) Kemudian dilakukan pengujian dengan Cross validation terhadap kinerja dari kedua metode tersebut, hasil ditunjukkan oleh Confusion matrix dan Kurva ROC.
Gambar 3 Model Credit Scoring Berbasis SVM, Chi Squared Statistic dan PSO
4. METODE PENELITIAN 4.1 Pengumpulan Data
Pengumpulan data yang digunakan dalam penelitian ini menggunakan data sekunder yang diperoleh dari database dalam UCI machine learning responsitory [27]. Data tersebut berupa German.data memuat 1.000 nasabah terdiri dari 21 atribut dan German.data-numeric merupakan hasil edit dataset German.data dari universitas Strathclyde dengan menambah beberapa variabel indikator supaya dapat mengatasi algoritma tidak dapat mengenali variabel kategorikal seperti pada antribut 17 yang berbentuk integer sehingga atributnya bertambah menjadi 24 atribut. Atribut tersebut ada yang tergolong atribut prediktor atau prediksi yaitu atribut yang dijadikan sebagai penentu hasil penilaian kredit, dan atribut tujuan yaitu atribut yang dijadikan sebagai hasil penilaian kredit.
Tabel 2 Karakteristik German.data dan German.data-numeric [27]
Dataset Classes Instances Qualitative Feature Numeric Feature Total Feature Binomial Feature(respond) Total Features + respon German.data 2 1000 13 7 20 1 21 German.data-numeric 2 1000 0 24 24 1 25
Deskripsi dataset yang bersumber dari Professor Dr. Hans Hofmann Institut f"ur Statistik und "Okonometrie Universit"at Hamburg. Berjumlah 1000 dataset terdiri jumlah atribut German.data adalah 21 atribut yang terdiri dari 7 numerik, 13 katagorikal dan 1 binominal. German.data-numeric terdiri dari 25 atribut yang terdiri 24 numerik dan 1 binominal.
4.2 Pengolahan Awal Data
Pengolahan awal data meliputi proses input data ke format yang dibutuhkan, pengelompokan dan penentuan atribut data, serta pemecahan data (split) untuk digunakan dalam proses pembelajaran (training) dan pengujian (testing).
German.data memuat 1.000 data/nasabah yang mempunyai 20 atribut dan 1 atribut respon/tujuan sedangkan German.data-numeric mempunyai 24 atribut dan 1 atribut respon/tujuan. Tetapi jumlah atribut tersebut tidak semua digunakan karena harus melalui beberapa tahap pengolahan awal data supaya mendapatkan data yang berkualitas dengan beberapa teknik [28] yaitu: data validation , data integration dan transformationi menggunakan program software Rapidminer 5.3, data size reduction dan
4.3 Eksperimen dan Pengujian
Eksperimen dan pengujian dalam penelitian ini menggunakan program RapidMiner 5.3. Setelah dilakukan proses seleksi atribut Chi Squared Statistic dan Particle Swarm Optimization. German.data terdiri dari 20 atribut prediktor menghasilkan 14 atribut dan 1 atribut sebagai label/klas yaitu Response. Sedangkan
German.data-numeric dari 24 atribut diperoleh 18 atribut dan 1 atribut sebagai label/klas yaitu Response. Kemudian dilakukan proses pembelajaran SVM.
Sebelum pengujian dilakukan terlebih dahulu mencari parameter yang sesuai sebagai atribut masukan untuk meningkatkan akurasi. Adapun parameter yang digunakan dalam pengujian terdiri dari C, Epsilon,
kernel, number of bins, dan population. Hasil SVM, Chi Squared Statistic dan PSO akan diuji dengan menggunakan K-Fold Cross Validation .
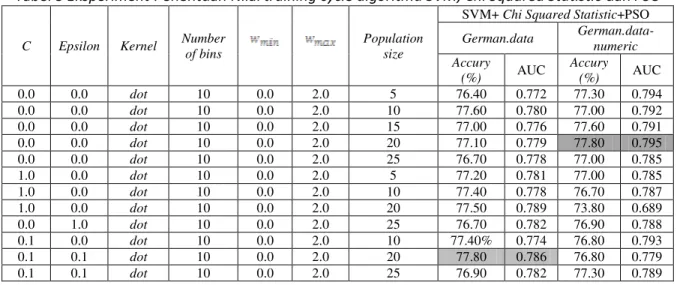
Tabel 3 Eksperiment Penentuan Nilai training cycle algoritma SVM, Chi Squared Statistic dan PSO
C Epsilon Kernel Number of bins
Population size
SVM+ Chi Squared Statistic+PSO
German.data German.data-numeric Accury (%) AUC Accury (%) AUC 0.0 0.0 dot 10 0.0 2.0 5 76.40 0.772 77.30 0.794 0.0 0.0 dot 10 0.0 2.0 10 77.60 0.780 77.00 0.792 0.0 0.0 dot 10 0.0 2.0 15 77.00 0.776 77.60 0.791 0.0 0.0 dot 10 0.0 2.0 20 77.10 0.779 77.80 0.795 0.0 0.0 dot 10 0.0 2.0 25 76.70 0.778 77.00 0.785 1.0 0.0 dot 10 0.0 2.0 5 77.20 0.781 77.00 0.785 1.0 0.0 dot 10 0.0 2.0 10 77.40 0.778 76.70 0.787 1.0 0.0 dot 10 0.0 2.0 20 77.50 0.789 73.80 0.689 0.0 1.0 dot 10 0.0 2.0 25 76.70 0.782 76.90 0.788 0.1 0.0 dot 10 0.0 2.0 10 77.40% 0.774 76.80 0.793 0.1 0.1 dot 10 0.0 2.0 20 77.80 0.786 76.80 0.779 0.1 0.1 dot 10 0.0 2.0 25 76.90 0.782 77.30 0.789
Hasil eksperiment SVM berbasis Chi Squared Statistic dan PSO diatas dengan C = 0.1, Epsilon = 0.1, kernel = dot, number of bins = 10, dan population = 20 menghasilkan nilai
accuracy sebesar 77.80% dan AUC sebesar 0.786 merupakan nilai accuracy yang paling besar dalam proses ekperiment dengan dataset German.data. Sedangkan menggunakan dataset German.data-numeric dengan nilai parameter C = 0.0, Epsilon = 0.0, kernel = dot, number of bins = 10,
dan population = 20 menghasilkan nilai accuracy sebesar 77.80% dan AUC sebesar 0.795.
4.4 Evaluasi dan Validasi Hasil
Hasil dari pengujian model yang dilakukan untuk German.data untuk credit scoring dengan menggunakan algoritma SVM berbasis Chi Squared Statistic dan PSO untuk menentukan nilai accuracy dan AUC (Area
Under Curve) dan menggunakan metode Cross Validation untuk penggujiannya.
4.4.1 Confusion Matrix
Berdasarkan tabel 4 menggunakan dataset German.data diketahui dari 1000 data, 635 ‘ya’.sesuai dengan prediksi yang dilakukan dengan metode SVM berbasis Chi Squared Statistic dan PSO, lalu 157 data diprediksi ‘ya’ tetapi ternyata hasilnya ‘tidak’, 143 data class tidak diprediksi sesuai, dan 65 data diprediksi ‘tidak’ ternyata hasil prediksinya ‘ya’.
Tabel 4. Model Confusion Matrix untuk Metode SVM Berbasis Chi Squared Statistic dan PSO Dataset
German.data Accuracy : 77.80% +/-3.12% (mikro: 77.80%)
True Ya True Tidak Class Precission
Pred. Ya 635 157 80,18%
Pred. Tidak 65 143 68,75%
Class Recall 90,71% 47,67%
Tabel 5. Nilai accuracy, sensitivity, specificity, ppv, dan npv untuk Metode SVM Berbasis Chi Squared
Statistic dan PSO Dataset German.data
Nilai (%) Accuracy 77,80 sensitivity 80,17 specificity 68,75 ppv 90,71 npv 47,66
Berdasarkan tabel 6 dataset German.data-numeric diketahui dari 1000 data, 635 ‘ya’.sesuai dengan prediksi yang dilakukan dengan metode SVM berbasis Chi Squared Statistic dan PSO, lalu 157 data diprediksi ‘ya’.tetapi ternyata hasilnya ‘tidak’, 143 data class tidak diprediksi sesuai, dan 65 data diprediksi ‘tidak’ ternyata hasil prediksinya ‘ya’.
Tabel 6 Model Confusion Matrix untuk Metode SVM Berbasis Chi Squared Statistic dan PSO Dataset
German.data-numeric Accuracy : 77.80% +/-2.14% (mikro: 77.80%)
True Ya True Tidak Class Precission
Pred. Ya 635 157 80.18%
Pred. Tidak 65 143 68.75%
Class Recall 90.71% 47.67%
Tabel 7. Nilai accuracy, sensitivity, specificity, ppv, dan npv untuk Metode SVM Berbasis Chi Squared
Statistic dan PSO Dataset German.data-numeric
Nilai (%) Accuracy 77,80 sensitivity 80,17 specificity 68,75 ppv 90,71 npv 47,66 4.4.2 Kurva ROC
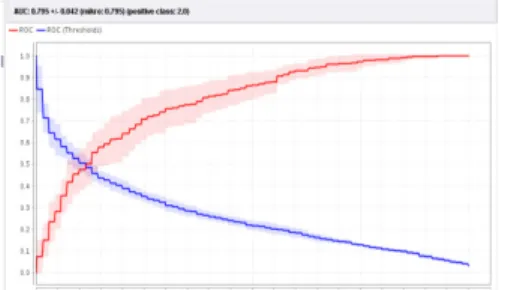
Hasil perhitungan diatas dapat divisualisasikan dengan kurva ROC. German.data. menghasilkan Kurva ROC pada gambar 4 mengekspesikan confusion matrix dari tabel 4. Garis horizontal adalah false positives dan garis vertikal true positives. Menghasilkan nilai AUC (Area Under Curve) sebesar 0,786 dengan nilai akurasi klasifikasi cukup (fair classification) pada dataset German.data.
Gambar 4 Kurva ROC dengan Metode SVM Berbasis Chi Squared Statistic dan PSO Dataset German.data Sedangkan hasil perhitungan untuk dataset German.data-numeric divisualisasikan dengan kurva ROC dapat dilihat pada gambar 5 mengekspesikan confusion matrix dari tabel 6. Garis horizontal adalah
false positives dan garis vertikal true positives. Menghasilkan nilai AUC (Area Under Curve) sebesar 0.795 dengan nilai akurasi klasifikasi cukup (fair classification) pada dataset German.data-numeric
Gambar 5 Kurva ROC dengan Metode SVM Berbasis Chi Squared Statistic dan PSO Dataset
German.data-numeric 4.4.3 Analisis Evaluasi dan Validasi Model
Dari hasil pengujian diatas baik evaluasi menggunakan Confusion Matrix dan kurva ROC terbukti bahwa hasil pengujian algoritma SVM berbasis Chi Squared Statistic dan PSO memiliki nilai akurasi yang lebih tinggi dibandingkan dengan algoritma [1][8][9][10]. Hasil perbandingan dapat dilihat pada tabel 8.
Tabel 8 Hasil Akurasi Masing-masing Metode
Metode Dataset Akurasi (%)
German.data German.data-numeric Sampling Procedure in SVM [1] √ 75.08 SVM + GA [1] √ 76.84 BPN [1] √ 76.69 GP [1] √ 77.26 LDA [5] √ 66.00 Logistic Regression [8] √ 72.40 Neural Networks [8] √ 75.20
Neighborhood Rough set +SVM [8] √ 76.60
LDA+SVM [10] √ 76.10 DT + SVM [10] √ 73.70 RST + SVM [10] √ 75.60 F-score + SVM [10] √ 76.70 SVM [9] √ 75.30 SVM+PSO [9] √ 77.40
SVM + Chi Squa + PSO √ √ 77.80
Tabel 8 merupakan hasil rangkuman dari hasil penelitian terdahulu [1][8][10][9] dan hasil eksperiment algoritma SVM berbasis Chi Squa dan PSO yang dilakukan penulis dengan menggunakan dataset
5. HASIL EKSPERIMEN DAN PEMBAHASAN
Eksperimen algoritma SVM berbasis Chi Squared Statistic dan PSO dalam penelitian ini memiliki nilai akurasi lebih tinggi dibanding [1][8][10][9] . Lebih jelasnya lihat pada tabel 9.
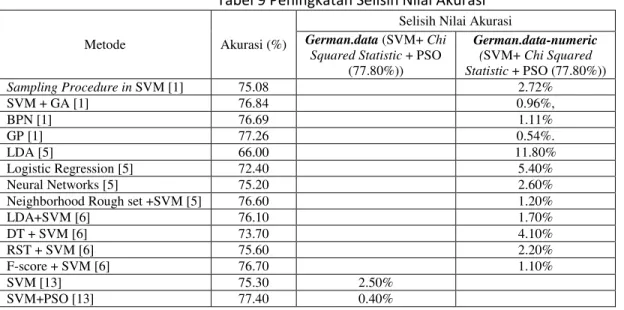
Tabel 9 Peningkatan Selisih Nilai Akurasi
Metode Akurasi (%)
Selisih Nilai Akurasi
German.data (SVM+ Chi
Squared Statistic + PSO (77.80%)) German.data-numeric (SVM+ Chi Squared Statistic + PSO (77.80%)) Sampling Procedure in SVM [1] 75.08 2.72% SVM + GA [1] 76.84 0.96%, BPN [1] 76.69 1.11% GP [1] 77.26 0.54%. LDA [5] 66.00 11.80% Logistic Regression [5] 72.40 5.40% Neural Networks [5] 75.20 2.60% Neighborhood Rough set +SVM [5] 76.60 1.20%
LDA+SVM [6] 76.10 1.70% DT + SVM [6] 73.70 4.10% RST + SVM [6] 75.60 2.20% F-score + SVM [6] 76.70 1.10% SVM [13] 75.30 2.50% SVM+PSO [13] 77.40 0.40%
Berdasarkan tabel 9 menunjukan bahwa seleksi atribut menggunakan Chi Squared Statistic dan
Particle Swarm Optimization (PSO) dalam penelitian ini menujukan hasil yang lebih baik. Karena Chi
Squared Statistic memberikan nilai bobot pada atribut sebelum dilanjutkan ketahap seleksi oleh PSO. Sedangkan PSO mempunyai kemampuan memecahkan masalah secara optimal dan global dalam ruang pencarian melalui interaksi individu dalam segerombolan partikel. Setiap partikel memberikan informasi berupa posisi terbaiknya terhadap partikel yang lain dan menyesuaikan posisi dan kecepatan masing-masing berdasarkan informasi yang diterima mengenai posisi yang terbaik dan memiliki kompleksitas yang lebih rendah serta sederhana, sehingga kinerja klasifikasi pada algoritma SVM dapat ditingkatkan.
Berdasarkan algoritma SVM berbasis Chi Squared Statistic dan PSO untuk credit scoring dengan menggunakan German.data dan German.data-numeric masing-masing menunjukan nilai akurasi sebesar 77.80% lebih tinggi dibandingkan dengan algoritma [1][8][10][9]. Adapun algoritma SVM berbasis Chi
Squared Statistic dan PSO menghasilkan nilai akurasi sebesar 77.80% dan nilai AUC (Area Under Curve) sebesar 0,786 dengan dataset German.data dan German.data-numeric menghasilkan nilai akurasi sebesar 77.80% dan nilai AUC (Area Under Curve) sebesar 0,795. Sehingga nilai akurasi klasifikasi cukup (fair
classification).
6. PENUTUP 6.1. Kesimpulan
Penelitian ini merupakan jenis penelitian eksperimen yang melibatkan perlakuan pada parameter atau atribut. Pengujian model menggunakan Support Vector Machine (SVM) berbasis Chi Squared Statistic dan Particle Swarm Optimization (PSO) dengan German.data dan German.data-numeric pada UCI. Dari dataset German.data mempunyai 20 atribut prediktor dilakukan seleksi atribut dengan Chi Squared
Statistic dan PSO terpilih 14 atribut, sedangkan dataset German.data-numeric mempunyai 24 atribut prediktor terpilih 18 atribut. Kemudian model yang dihasilkan lalu diuji untuk mendapatkan nilai akurasi dan AUC. Adapun hasil eksperiment SVM berbasis Chi Squared Statistic dan PSO dengan parameter C = 0.1, Epsilon = 0.1, kernel = dot, number of bins = 10, dan population = 20 menghasilkan nilai accuracy sebesar 77.80% dan AUC sebesar 0.786 dengan dataset German.data.
Sedangkan menggunakan dataset German.data-numeric dengan nilai parameter C = 0.0, Epsilon = 0.0,
kernel = dot, number of bins = 10, dan population = 20 menghasilkan nilai
accuracy sebesar 77.80% dan AUC sebesar 0.795 lebih baik dibandingkan dengan Sampling Procedure in SVM, SVM + GA,BPN, GP[1], LDA, Logistic Regression, Neural Networks, Neighborhood Rough Set +SVM [8], LDA+SVM, DT + SVM , RST + SVM, F-score + SVM [10] dan SVM , SVM+PSO [9]. Hasil nilai akurasi penelitian ini bernilai klasifikasi cukup (fair classification). Disimpulkan bahwa pengujian German.data dan German.data-numeric pada UCI untuk credit scoring menggunakan Support
Vector Machine (SVM) berbasis Chi Squared Statistic dan Particle Swarm Optimization (PSO) memberikan pemecahan masalah credit scoring dengan nilai klasifikasi cukup (fair classification).
6.2. Saran
Berdasarkan kemampuan dalam penelitian ini, penulis menyarankan masih besar peluang untuk penelitian di bidang ini untuk meningkatkan akurasi atau waktu komputasi di bidang credit scoring.
DAFTAR PUSTAKA
[1] A. B. Hens and M. K. Tiwari, “Computational time reduction for credit scoring: An integrated approach based on support vector machine and stratified sampling method,” Expert Systems with
Applications, vol. 39, no. 8, pp. 6774–6781, Jun. 2012.
[2] H. Purnomo, “Kredit macet bank di Februari 2012 Capai Rp 51,42 Triliun,”
http://finance.detik.com/read/2012/04/16/135221/1893386/5/%20kredit-macet-bank-di-februari-2012-capai-rp-5142-triliun, 2012.
[3] D. Megasari, “Kredit macet perbankan Eropa kembali mengkhawatirkan,”
http://internasional.kontan.co.id/news/kredit-macet-perbankan-eropa-kembali-mengkhawatirkan, no. September 2010, p. 2780, 2013.
[4] H. Sjafitri, “Faktor-faktor yang mempengaruhi kualitas kredit dalam dunia perbankan,” vol. 2, pp. 106–120, 2011.
[5] S. M. Sadatrasoul, M. R. Gholamian, M. Siami, and Z. Hajimohammadi, “Credit scoring in banks and financial institutions via data mining techniques : A literature review,” vol. 1, no. 2, pp. 119– 129, 2013.
[6] M. Zhao, C. Fu, L. Ji, K. Tang, and M. Zhou, “Feature selection and parameter optimization for support vector machines: A new approach based on genetic algorithm with feature chromosomes,”
Expert Systems with Applications, vol. 38, no. 5, pp. 5197–5204, May 2011.
[7] L. Yun, Q. Cao, and H. Zhang, “Application of the PSO-SVM Model for Credit Scoring,” 2011
Seventh International Conference on Computational Intelligence and Security, pp. 47–51, Dec. 2011.
[8] Y. Ping and L. Yongheng, “Neighborhood rough set and SVM based hybrid credit scoring classifier,” Expert Systems with Applications, vol. 38, no. 9, pp. 11300–11304, Sep. 2011.
[9] Rinawati, “Penerapan particle swarm optimization untuk seleksi atribut pada metode support vector machine untuk penentuan penilaian kredit,” vol. Program Pa, 2012.
[10] F.-L. Chen and F.-C. Li, “Combination of feature selection approaches with SVM in credit scoring,” Expert Systems with Applications, vol. 37, no. 7, pp. 4902–4909, Jul. 2010.
[11] Kusnawi, “Pengantar solusi data mining,” Seminar Nasional Teknologi 2007 (SNT 2007)
Yogyakarta, 24 November 2007 ISSN : 1978 – 9777, vol. 2007, no. November, pp. 1–9, 2007.
[12] “Undang Republik Indonesia nomor 10 tahun 1998 tentang Perubahan atas Undang-Undang Nomor 7 Tahun 1992 tentang Perbankan,” 1992.
[13] G. Wang, J. Hao, J. Ma, and H. Jiang, “A comparative assessment of ensemble learning for credit scoring,” Expert Systems with Applications, vol. 38, no. 1, pp. 223–230, Jan. 2011.
[14] H. C. Koh and W. C. Tan, “A Two-step Method to Construct Credit Scoring Models with Data Mining Techniques,” vol. 1, no. 1, pp. 96–118, 2006.
[15] R. A. Saraswati, “Peranan Analisis Laporan Keuangan, Penilaian Prinsip 5c Calon Debitur Dan Pengawasan Kredit Terhadap Efektivitas Pemberian Kredit Pada PD BPR Bank Pasar Kabupaten Temanggung,” vol. I, no. 5, 2012.
[16] O. Maimon and L. Rokac, Data Mining and Knowledge Discovery Handbook edition2. Springer New York Dordrecht Heidelberg London, 2010.
[17] Z. Zhu, Y.-S. Ong, and M. Dash, “Wrapper-filter feature selection algorithm using a memetic framework.,” IEEE transactions on systems, man, and cybernetics. Part B, Cybernetics : a
publication of the IEEE Systems, Man, and Cybernetics Society, vol. 37, no. 1, pp. 70–6, Feb. 2007.
[18] R. Poli, J. Kennedy, and T. Blackwell, “Particle swarm optimization,” Swarm Intelligence, vol. 1, no. 1, pp. 33–57, Aug. 2007.
[19] B. Santosa, Metode Metaheuristik, Konsep dan Implementasi. Penerbit Guna Widya, 2011, p. Bab 10–11.
[20] Y. Liu, G. Wang, H. Chen, H. Dong, X. Zhu, and S. Wang, “An Improved Particle Swarm Optimization for Feature Selection,” Journal of Bionic Engineering, vol. 8, no. 2, pp. 191–200, Jun. 2011.
[21] A. S. Nugroho, A. B. Witarto, and D. Handoko, “Support Vector Machine: teori dan aplikasinya dlam Bioinformatika,” 2003.
[22] T. Bellotti and J. Crook, “Support vector machines for credit scoring and discovery of significant features,” Expert Systems with Applications, vol. 36, no. 2, pp. 3302–3308, Mar. 2009.
[23] I. Aydin, M. Karakose, and E. Akin, “A multi-objective artificial immune algorithm for parameter optimization in support vector machine,” Applied Soft Computing, vol. 11, no. 1, pp. 120–129, Jan. 2011.
[24] K. Sembiring, “Penerapan teknik support vector machine untuk pendeteksian intrusi pada jaringan,” PROGRAM STUDI TEKNIK INFORMATIKA SEKOLAH TEKNIK ELEKTRO DAN
INFORMATIKA INSTITUT TEKNOLOGI BANDUNG, no. September, pp. 1–28, 2007.
[25] B. Santosa, Data mining: teknik pemanfaatan data untuk keperluan bisnis, Edisi pert. Yogyakarta: Graha Ilmu, 2007, pp. 141–205.
[26] F. Gorunescu, Data Mining: Concepts, Models, and Techniques. Springer, 2011.
[27] P. D. H. Hofmann, “German Credit data (17-Nov-1994).” UCI Machine Learning Repository, 1996.
[28] Carlo Vercellis, Busine ss I nte llige nc e : Data Mining and Optimization for Decision Making. India: John Wiley & Sons, 2009.