Question answering system menggunakan semantic web dan algoritma Porter sebagai Stemmer kata
Bebas
104
0
0
Teks penuh
(2) H A L A M A N PE N G A J U A N. Q U E S T IO N A N S W E R IN G S Y S T E M. M E N G G U N A K A N. S E M A N T IC W E B D A N A L G O R IT M A P O R T E R SE B A G A I STE M M E R K A T A. S K R IP S I. D ia ju k a n k e p a d a : F a k u lta s S a in s d a n T e k n o lo g i U n iv e r sita s Islam N e g e r i M a u la n a M alik Ib ra h im M ala n g U n tu k M e m e n u h i S a la h S a tu P e r sy a r a ta n D a lam M e m p e r o l e h G e l a r S a r j a n a K o m p u t e r ( S .K o m ). o le h : D Z A K IY A T U R R O SY ID A H N IM . 1 0 6 5 0 0 7 7 / S -1. JU R U S A N T E K N IK IN F O R M A T IK A FA K U L T A S SA IN S D A N T E K N O L O G I U N IV E R SIT A S ISL A M. N E G E R I M A U L A N A M A L IK IB R A H IM M A L A N G 2014. ii.
(3) iii.
(4) iv.
(5) v.
(6) M O TTO. “D o yo u r b e st a t a n y m o m e n t th a t y o u h a v e , c a u se e v e ry e f f o r t h a s it r e w a r d s ”. “ T i d a k a d a u s a h a y a n g s ia - s i a ”. vi.
(7) PERSEM BA H A N. A lh a m d u lilla h , s e g a la p u ji s y u k u r a t a s r a h m a t , h id a y a h d a n in a y a h A lla h S W T , k a ry a in i k u p e r s e m b a h k a n u n t u k o r a n g - o r a n g is t im e w a d a la m. h id u p k u. | A y a h a n d a d a n Ib u n d a T e r c in ta | H a r u n N u r R a s y it d a n Z u lia t i. T e r i m a k a s i h a t a s k a s i h s a y a n g , s e m a n g a t , d a n k e i k h l a s a n h a ti t e l a h m e n d id ik d a n m e m b im b in g k u. | A d ik - a d ik k u T e r s a y a n g | A h m a d M u b a r o k u l W a jid F a iz N u r I h s a n A r if F a u z a n R o s y id i M . R iz q y R o s y id T e r im a k a s ih a ta s s e m a n g a t d a n d o a n y a. | P a r a D o s e n T I U IN M a l ik i M a l a n g | T e r i m a k a s i h t e l a h m e m b i m b i n g d a n m e n d i d i k s a y a s e m o g a il m u y a n g s a y a t e rim a b a r o k a h d u n ia a k h ira t. | IN F IN IT Y ( T I 2 0 1 0 ) |. K it a le b ih d a r i t e m a n s e p e rju a n g a n m e n u n t u t ilm u ,. k i t a a d a la h k e l u a r g a. v ii.
(8) K A T A PE N G A N T A R. A ssa la m u a’a laik u m W r. W b .. S e g a l a p u ji b a g i A l la h S W T y a n g t e l a h m e l im p a h k a n ra h m a t , h i d a y a h d a n. k a r u n i a - N y a k e p a d a p e n u l i s . S h a l a w a t s e rt a s a l a m. N abi. k i ta. M u h am m a d. SA W. yang. tela h. m e m bim b in g. m e n u ju te ra n g n y a c a h a y a Isla m . S e hin g g a. dengan. ju d u l. “ Q u e stio n. A n s w e ri n g. j u g a te t a p t e rc u r a h k a n k e p a d a. u m atn y a. d a ri k e g ela p a n. p e n ulis d a p a t m e n y ele saik a n. S y stem. M en g g u n akan. S e m a ntic. s krip si. W eb. dan. A l g o r i tm a P o rt e r s e b a g a i S t e m m e r K a t a ” d e n g a n b a i k .. S e l a n j u t n y a p e n u l is h a t u r k a n u c a p a n te r im a k a s i h s e i ri n g d o ’ a d a n h a r a p a n. ja z a k u m ulla h. a h sa n al. ja z a ’. kepada. sem ua. p iha k. yang. tela h. m e m b a ntu. t e r s e l e s a i k a n n y a s k ri p si i n i . U c a p a n t e ri m a k a s i h i n i p e n u l i s s a m p a i k a n k e p a d a :. 1.. A ’la. S y a u q i, M . K o m , sela k u. m e lu a n g k a n. w a k tu. u n tu k. d o se n. p em b im bin g. skripsi I, y a n g. m e m b i m b i n g , m e m o t i v a s i , s e rt a. tela h. m e m b e ri k a n. p e n g a ra h a n , m asu k a n d a n p e n g ala m a n b erh a rg a .. 2.. F a t c h u r r o h m a n , M .K o m , s e l a k u d o s e n p e m b im b i n g. s krip si II, y a n g tela h. m e m b e ri k a n s a r a n d a n m a s u k a n d a l a m p e n y u s u n a n s k ri p s i .. 3.. D r . C a h y o C r y s d i a n , s e l a k u K e t u a J u r u s a n T e k n i k I n f o r m a t i k a U n i v e rs i ta s. Islam. N e g e ri. M a ula n a. M a li k. I b r a h im. M ala n g ,. m e n g a r a h k a n d a l a m p e n g e rj a a n s k ri p s i i n i .. v iii. yang. m endukung. dan.
(9) 4.. S e g e n a p s i v it a s a k a d e m i k a J u r u s a n T e k n i k I n f o rm a ti k a , t e r u t a m a s e l u r u h. d o s e n , t e ri m a k a s i h a t a s s e g e n a p il m u d a n b i m b i n g a n y a n g t e l a h d i b e r i k a n .. 5.. Sem ua. p ih a k. yang. tid a k. m u n g kin. p e n u l is. se b u tk a n. s a t u - p e rs a t u ,. a ta s. s e g a l a y a n g t e l a h d i b e ri k a n k e p a d a p e n u l i s d a n d a p a t m e n j a d i p e l a j a r a n .. P e n u lis. m e n y a d ari b a h w a. d a la m. penyusu nan. s k ri p si i n i m a si h. te rd a p at. k e k u r a n g a n d a n p e n u li s b e r h a r a p s e m o g a s k r i p s i i n i d a p a t m e m b e ri k a n m a n f a a t. k e p a d a p a r a p e m b a c a . A m i n Y a R a b b a l A la m i n .. W a ssa lam u ’ala ik um W r. W b .. M a la n g , 9 N o v e m b er 2 0 1 4. P e n u lis. ix.
(10) D A F T A R ISI. H A L A M A N J U D U L .............................................................................................. i H A L A M A N P E N G A J U A N .................................................................................. i i H A L A M A N P E R S E T U J U A N ............................................................................. i i i H A L A M A N P E N G E S A H A N .............................................................................. i v H A L A M A N P E R N Y A T A A N ................................................................................v H A L A M A N M O T T O .......................................................................................... v i H A L A M A N P E R S E M B A H A N .......................................................................... v i i K A T A P E N G A N T A R ........................................................................................ v i i i D A F T A R I S I ...........................................................................................................x D A F T A R G A M B A R ........................................................................................... x i i D A F T A R T A B E L ............................................................................................... x i i i A B S T R A K .......................................................................................................... x i i i. B A B I PE N D A H U L U A N 1 .1. L a t a r B e l a k a n g ...........................................................................................1. 1 .2. R u m u s a n M a s a l a h ......................................................................................8. 1 .3. B a t a s a n M a s a l a h ........................................................................................8. 1 .4. T u j u a n P e n u l is a n ................................ ................................ ........................9. 1 .5. M a n f a a t P e n u l is a n ................................ ................................ ......................9. 1 .6. S i s t e m P e n u l is a n ................................ ................................ ........................9. 1 .7. M e t o d e P e n e l i ti a n ................................ ................................ ....................1 0. B A B II T IN J A U A N P U ST A K A 2 .1. P e n e l i ti a n T e r k a i t ................................ ................................ .....................1 1. 2 .2. S e m a n t i c W e b ...........................................................................................1 4. 2 .3. K o m p o n e n - k o m p o n e n S e m a n ti c W e b ................................ ......................1 5. 2 .4. O n t o l o g y ...................................................................................................1 8. 2 .5. T e m u K e m b a li I n f o r m a s i ( I n f o r m a ti o n R e t r i e v a l) ................................ ...1 9. 2 .6. Q u e s t i o n A n s w e r i n g .................................................................................2 0. 2 .7. D B P e d i a ...................................................................................................2 1 2 .7 .1 L i n k e d D a t a .....................................................................................2 1 2 .7 .2 S P A R Q L E n d p o i n t ..........................................................................2 1 2 .7 .3 R D F D u m p s ....................................................................................2 2. 2 .8. P a r s i n g .....................................................................................................2 2. 2 .9. S t e m m i n g ..................................................................................................2 2. 2 .1 0 S P A R Q L ..................................................................................................2 3. B A B III A N A L ISIS D A N P E R A N C A N G A N SIST E M 3 .1 D e s a i n S i s te m ................................ ............................................................2 5 3 .1 .1 T e x t P r o c e s si n g ...............................................................................2 6 3 .1 .1 .1 K a l i m a t T a n y a .......................................................................2 8 3 .1 .1 .2 C a s e f o l d i n g ...........................................................................2 8 3 .1 .1 .3 M e n g h a p u s T a n d a T a n y a ......................................................2 8 3 .1 .1 .4 P a r s i n g ..................................................................................2 8 x.
(11) 3 .1 .1 .5 M e n g h a p u s S t o p w o r d s ..........................................................2 9 3 .1 .1 .6 P o r t e r S t e m m i n g ...................................................................2 9 3 .1 .2 D a t a M i n i n g ....................................................................................3 4 3 .1 .2 .1 C a r i R e s o u r c e d i W i k i p e d i a ..................................................3 5 3 .1 .2 .2 S P A R Q L Q u e r y ....................................................................3 5 3 .1 .3 M e n a m p il k a n J a w a b a n ................................ ................................ ....3 6 3 .2 D e s a i n I n t e r f a c e ........................................................................................3 7 3 .3 K e b u t u h a n S i s t e m .....................................................................................3 8. B A B IV H A SIL D A N P E M B A H A S A N 4 .1 I m p l e m e n ta s i S i s t e m ................................ ................................ .................4 0 4 .1 .1 I m p l e m e n ta s i P o r t e r S te m m i n g ........................................................4 2 4 .1 .2 I m p l e m e n ta s i P r o s e s P e n c a r i a n R e s o u r c e ........................................4 5 4 .1 .3 I m p l e m e n ta s i S P A R Q L p a d a D B P e d i a I n d o n e s i a ...........................4 6 4 .2 I m p l e m e n ta s i T a m p i la n ................................ ................................ .............4 7 4 .3 U j i C o b a ....................................................................................................5 0 4 .4 A n a l i s a H a s il ................................ .............................................................5 1 4 .5 I n t e g r a s i Q u e s ti o n A n s w e r i n g S y s t e m d e n g a n Is l a m ................................ .6 8. B A B V PE N U T U P 5 .1 K e s i m p u l a n ...............................................................................................7 1 5 .2 S a r a n .........................................................................................................7 1 D A FT A R PU ST A K A L A M P IR A N. xi.
(12) D A FT A R G A M B A R. G a m b a r 1 .1 H a s i l P e n c a r ia n d a ri Y a h o o S e a r c h E n g i n e ................................ .........3 G a m b a r 1 . 2 H a s i l P e n c a r ia n d a ri W o l fr a m A l p h a Q u e s t i o n A n s w e r i n g S y s t e m ......5 G a m b a r 1 .3 H a s i l P e r a n k i n g a n W i k i p e d i a d i A l e x a ................................................7 G a m b a r 1 .4 D e m o g r a f i P e n g g u n a d i W i k i p e d i a ......................................................7 G a m b a r 2 .1 L a y e r S e m a n ti c W e b ................................ ................................ ...........1 6 G a m b a r 2 .2 M e a n i n g T r i a n g l e ...............................................................................1 8 G a m b a r 3 .1 B l o k D i a g r a m Q u e s ti o n A n s w e r i n g S y s t e m ........................................2 6 G a m b a r 3 .2 B l o k D i a g r a m T e x t P r o c e s si n g ...........................................................2 7 G a m b a r 3 .3 B l o k D i a g r a m P o r t e r S t e m m i n g .........................................................3 0 G a m b a r 3 .4 B l o k D i a g r a m. D a t a M i n i n g ................................................................3 5. G a m b a r 3 .5 S t r u k t u r K u e ri S P A R Q L ....................................................................3 6 G a m b a r 3 .6 C o n t o h K u e r i S P A R Q L ......................................................................3 6 G a m b a r 3 .7 H a s i l d a r i K u e ri S P A R Q L ..................................................................3 6 G a m b a r 3 .8 D e s a i n I n t e r f a c e Q u e s ti o n A n s w e r i n g S y s t e m ................................ ....3 7 G a m b a r 4 .1 I m p l e m e n t a si U s e r I n t e rf a c e ..............................................................4 8 G a m b a r 4 .2 S i st e m M e n a m p i l k a n Ja w a b a n k e p a d a P e n g g u n a ..............................4 9. x ii.
(13) D A FT A R T A B E L. T a b e l 3 .1 A t u r a n u n t u k I n fl e c ti o n P a r ti c l e ............................................................3 1 T a b e l 3 .2 A t u r a n u n t u k I n fl e c ti o n P o s s e s i v e P r o n o u n ................................ ...........3 1 T a b e l 3 .3 A t u r a n u n t u k F i r s t O r d e r D e r i v a t i o n a l P r e fi x ................................ .......3 1 T a b e l 3 .4 A t u r a n u n t u k S e c o n d O r d e r D e r r iv a t i o n a l P r e fi x ................................ .3 2 T a b e l 3 .5 A t u r a n u n t u k D e r r i v a t i o n a l S u f fi x .........................................................3 2 T a b e l 4 .1 R e k a p i t u l a si U j i C o b a ............................................................................5 1. x iii.
(14) A B ST R A K. R o sy id a h ,. D z a k iy atu r.. 2014.. Q u e s ti o n. A n sw e r in g. S y s te m. M enggunakan. S e m a n t i c W e b d a n A l g o r i tm a P o r t e r s e b a g a i S t e m m e r K a t a . S k r i p s i . J u r u s a n T e k n ik. I n f o rm a ti k a. F a k u ltas. S a in s. dan. T e k n o lo gi. U n i v e r s it a s. Islam. N eg eri. M a u la n a M alik Ib ra him M ala n g . P e m b i m b i n g : ( I ) A ’l a S y a u q i , M . K o m ( II ) F a t c h u r r o c h m a n , M .K o m. K a ta. K u n c i:. N a tu ral. Language. P r o c e s sin g ,. Q u e stio n. A n s w e rin g ,. W ik ip e dia ,. D b p e d ia , S P A R Q L. Q u e s tio n A n s w e r in g S y s te m Language. P r o c e s s in g. k e b u tu h a n. in fo r m a s in y a. bahasa. a la m i),. ja w a b a n .. Saat. d an in i,. (Q A S ) m e ru p a k a n b a g ia n d a ri p e n e litia n m e n g e n a i N a tu r a l. (N L P ),. d im a n a. d a la m. b e n tu k. m e n g e m b a lik a n k e b u tu h a n. s is te m. n a tu ra l. k u tip a n. u n tu k. in i. m e n g iz i n k a n. la n g u a g e. te k s. m e n d a p a tk a n. pengguna. q u e s tio n. singkat. a ta u. in fo rm a s i. m e n y a ta k a n. (p e rta n y a a n. bahka n. se c a ra. fra se. cepat. d a la m se bagai. dan. a k u ra t. s e m a k in m e n i n g k a t d iiri n g i p u la d e n g a n p e n in g k a ta n d a ta y a n g a d a p a d a w e b . U n tu k in i pada. p e n e litia n. in i,. p e n e li ti. m e m bangu n. sebu ah. Q u e s tio n. A n s w e r in g. S y s te m. m e n g g u n a k a n a lg o rit m a P o rte r s e b a g a i s te m m e r k a ta . A lg o ri tm a P o rte r d ig u n a k a n u n tu k s te m m in g. pada. k a lim a t ta n y a. d ig u n a k a n. a d a la h. W ik ip e d ia. yang. D B P e d ia m enam pung. yang. d iin p u tk a n. In d o n e s ia , ju ta a n. o le h p e n g g u n a . S u m b e r d a ta. d im a n a. in fo rm a s i.. D B P edia P e n e liti. m e ru p a k a n. ju g a. b a s is. m enggun akan. yang d a ta. akan d a ri. SP A R Q L. u n tu k m e l a k u k a n k u e ri p a d a D B P e d ia In d o n e s ia u n t u k m e m p e ro le h ja w a b a n n y a . D a ri u ji c o b a y a n g te la h d ila k u k a n , Q A S y a n g d ib u a t m e m b e r ik a n n ila i a k u ra s i s e b e s a r 7 1 ,5 0 % .. x iv.
(15) A B ST R A C T. R o s y i d a h , D z a k i y a t u r . 2 0 1 4 . Q u e s ti o n A n s w e r i n g S y st e m U s i n g S e m a n t i c W e b a n d P o r te r A lg o r ith m F a c u lty. of. S cie n c e. fo r W o r d S te m m er . T h e sis. In form atics D e p a rtm e nt o f. and. T e c h n olo g y .. M a ula n a. M a li k. I b r a h im. Sta te. Isla m ic. U n i v e r s it y , M a la n g . A d v i s e r : (I ) A ’l a S y a u q i , M .K o m , M .K o m. K ey w o rd s:. N a tu ra l. Language. ( II ) F a tc h u r r o c h m a n , M .K o m. P r o c e s sin g ,. Q u e s ti o n. A n sw e rin g ,. W ikip e d ia ,. D b p e d ia , S P A R Q L. Q u e s tio n. A n s w e rin g. S y s te m. (Q A S ). P ro c e s s in g ( N L P ), w h e re th e s y s te m. is. p a rt o f. is a llo w. th e. re se a rc h. on. th e. N a tu ra l L a n g u a g e. u s e r s to e x p re s s th e ir in fo rm a tio n n e e d s in. th e fo rm o f n a t u ra l la n g u a g e q u e s tio n (q u e s tio n s i n n a tu ra l l a n g u a g e ), a n d re tu rn s t h e te x t o r a p h ra s e a s th e a n s w e r. C u rre n tl y , th e n e e d to g e t in fo rm a tio n q u ic k ly a n d a c c u ra te ly in c re a s in g l y a c c o m p a n ie d b y a n i n c re a s e in t h e e x is tin g d a ta o n th e w e b . F o r th is s tu d y , re se a rc h e rs a re s te m m in g .. b u ild i n g. P o rte r. a. Q u e s t io n. s te m m in g. A n s w e rin g. a lg o rith m. is. used. S y s te m. using. to. s e n te n c e. s te m. th e. P o rt e r a lg o rit h m e n te re d. b y. th e. fo r u se r.. S o u rc e o f d a ta to b e u s e d is th e D B P e d ia In d o n e s ia , w h e re D B P e d ia is a d a ta b a s e th a t h o ld s m il lio n s. o f W i k ip e d ia. in fo r m a tio n . R e s e a rc h e rs a ls o. D B P e d ia In d o n e s ia to g e t th e a n s w e r. F ro m. use. SPA R Q L. to. query. on. t h e e x p e rim e n ts th a t h a v e b e e n c a r rie d o u t,. Q A S g iv e a n a c c u ra c y 7 1 ,5 0 % .. xv.
(16) ال مل خ ص. ا ن ش ش ُ ذ ح ,ر ك ُ خ . 2 0 1 4 .ا ن ن ظ ب و ا ن س ؤ ا ل و ا ن ج ى ا ة ع ن ط ش َ ق ب ن ذ ال ن ٍ ا ن ى َ ت و ا ن خ ى ا س ص ي ُ ب د ث ى سر ش ين بن خ ر غُ شان كه ً خ (. أ ط ش و د خ .ق س ى ان ً عه ى ي برُ خ ،كهُ خ ان عه ى و. (s te e m e r. و ا ن ز ك ن ى ن ى ج ُ ب ،ا ن ج ب ي ع خ ا إل س ال ي ُ خ ا ن ذ ك ى ي ُ خ ي ى ال ن ب ي ب ن ك إ ث ش ا ه ُ ى ي ب ال ن ج .ا ن ً ش ش ف :أ ع ه ً ش ى ق ٍ ان ً ب ج سزُ ش و فز خ ان ش د ً ن ان ً ب ج سزُ ش ان كه ً ب د انج ذ ث :ي ع بن ج خ انه غ بر بن طجُ عُ خ ،ان س ؤا ل ان ج ىا ة ،وَ كُجُ ذَ ب ، انن ظ ب و ان س ؤا ل وان ج ىا ة انه غ بر بن طجُ عُ. خ) (N L P. ) (Q A S. S P A R Q L ، D b p e d ia. ه ى ج ض ء ين بنج ذ ث د ىن ً ع بن ج خ. ،دُ ث انن ظ ب و ه ى ان س ً ب ح نه ً سز خ ذ يُن بنز عجُ ش عن ب دزُ ب ج بر ه ى ي ن. ا ن ً ع ه ى ي ب ر ف ٍ ش ك م ي ع ب ن ج خ ا ن ه غ خ ا ن ط ج ُ ع ُ خ ( ا أل س ئ ه خ ف ٍ ا ن ه غ خ ا ن ط ج ُ ع ُ خ ) ، وإ س ج ب ع ً قز ط ف برن صُ خ ق صُ ش حأ و دز ي عج ب س ح ي بان ج ىا ة .ف ٍ ان ى ق ذ ان ذ ب ض ش ،وان ذ ب ج خ إن ً ان ذ ص ى ل عه ي بن ً عه ى ي ب د ث س ش ع خ وث ذ ق خ صا درُ شا ف ق ه ضَ ب د ح فُ بنجُ بن ب د ان ً ى ج ى د ح عه ً شج ك خ ا إل ن ز ش ن ذ .ن ه ز ه ا ن ذ س ا س خ ،و ث ن ً ا ن ج ب د ث ا ن ن ظ ب و ا ن س ؤ ا ل و ا ن ج ى ا ة ث ب س ز خ ذ ا و خ ى ا س ص ي ُ خ ث ى سر ش ي ن ان خ ر غُ ش ان كه ً خ. .ا ن خ ى ا س ص ي ُ خ ث ى س ر ش ا ن ن ب ث ع خ ا ن ً س ز خ ذ ي خ ن ه ج ً ه خ ا ال س ز ف ه ب ي ب ن ً ذ خ ه خ. ث ب ن ً س ز خ ذ و .ي ص ذ س ا ن ج ُ ب ن ب ر ال س ز خ ذ ا ي ه ب ه ى. D B P e d ia. ث ُ ب ن ب ر ً ن ى َ ك ُ ج ُ ذ َ ب ا ن ز ٍ ر ذ ً ال ن ً ال َ ُ ن ي ن ب ن ً ع ه ى ي ب د ا ال س ز ع ال ي ع ه ً. D B P e d ia. ث ه ب ،ا أل ي ش ا ن ز ٌ ج ع م. A S. انذ ونُ سُب ،دُ ث. D B P e d ia. .انج ب دث أَ ض ب ا سز خ ذا و. ه ٍ قب عذح. SPA R Q L. ان ذ ونُ سُ بنه ذ ص ى ل عه ي بن ج ىا ة .ين بنز ج ب سث بنز ٍ ر ً بن قُ ب و. Qر ع ط ُ ذ ق خ .٪ 7 1 . 5 0. xvi.
(17) امللخص الرشيدة ,ذكية .4102 .النظام السؤال واجلواب عن طريق الداليل الويب واخلوارزميات بورتر من الة تغري الكلمة ( (stemmerأطروحة .قسم املعلوماتية ،كلية العلوم والتكنولوجيا ،اجلامعة اإلسالمية احلكومية موالنا مالك إبراهيم ماالنج .املشرف :أعلى شوقي املاجستري و فتح الرمحن املاجستري ال كلمات البحث :معاجلة اللغات الطبيعية ،السؤال اجلواب ،ويكيبيدياSPARQL ،Dbpedia ، النظام السؤال واجلواب )(QASهو جزء من البحث حول معاجلة اللغات الطبيعية)، (NLP حيث النظام هو السماح للمستخدمني التعبري عن احتياجاهتم من املعلومات يف شكل معاجلة اللغة الطبيعية (األسئلة يف اللغة الطبيعية) ،وإرجاع مقتطفات نصية قصرية أو حىت عبارة ما اجلواب .يف الوقت احلاضر ،واحلاجة إىل احلصول على املعلومات بسرعة وبدقة زادت يرافقه زيادة يف البيانات املوجودة على شبكة اإلنرتنت .هلذه الدراسة ،وبىن الباحث النظام السؤال واجلواب باستخدام خوارزمية بورتر من الة تغري الكلمة .اخلوارزمية بورتر النابعة املستخدمة للجملة االستفهام املدخلة باملستخدم .مصدر البيانات الستخدامها هو DBPediaاندونيسيا ،حيث DBPediaهي قاعدة بيانات من ويكيبيديا اليت حتمل املاليني من املعلومات .الباحث أيضا استخدام SPARQLاالستعالم على DBPediaاندونيسيا للحصول على اجلواب .من التجارب اليت مت القيام هبا ،األمر الذي جعل QASتعطي دقة .٪71.50.
(18) ABSTRACT Rosyidah, Dzakiyatur. 2014. Question Ans wering System Using Semantic Web and Porter Algorithm for Word Ste mmer. Thesis. Informatics Department of Faculty of Science and Technology. Maulana Malik Ibrahim State Islamic University, Malang. Adviser: (I) A’la Syauqi, M.Kom, M.Kom (II) Fatchurrochman, M.Kom Keywords: Natural Language Processing, Question Answering, Wikipedia, Dbpedia, SPARQL Question Answering System (QAS) is part of the research on the Natural Language Processing (NLP), where the system is allow users to express their information needs in the form of natural language question (questions in natural language), and returns the text or a phrase as the answer. Currently, the need to get information quickly and accurately increasingly accompanied by an increase in the existing data on the web. For this study, researchers are building a Question Answering System using the Porter algorithm for stemming. Porter stemming algorithm is used to stem sentence entered by the user. Source of data to be used is the DBPedia Indonesia, where DBPedia is a database that holds millions of Wikipedia information. Researchers also use SPARQL to query on DBPedia Indonesia to get the answer. From the experiments that have been carried out, QAS give an accuracy 71,50 %.. xv.
(19) ABSTRAK. Rosyidah, Dzakiyatur. 2014. Question Ans wering System Menggunakan Semantic Web dan Algoritma Porte r sebagai Stemmer Kata. Skripsi. Jurusan Teknik Informatika Fakultas Sains dan Teknologi Universitas Islam Negeri Maulana Malik Ibrahim Malang. Pembimbing: (I) A’la Syauqi, M. Kom (II) Fatchurrochman, M.Kom Kata Kunci: Natural Language Processing, Question Answering, Wikipedia, Dbpedia, SPARQL Question Answering System (QAS) merupakan bagian dari penelitian mengenai Natural Language Processing (NLP), dimana sistem ini mengizinkan pengguna menyatakan kebutuhan informasinya dalam bentuk natural language question (pertanyaan dalam bahasa alami), dan mengembalikan kutipan teks singkat atau bahkan frase sebagai jawaban. Saat ini, kebutuhan untuk mendapatkan informasi secara cepat dan akurat semakin meningkat diiringi pula dengan peningkatan data yang ada pada web. Untuk ini pada penelitian ini, peneliti membangun sebuah Question Answering System menggunakan algoritma Porter sebagai stemmer kata. Algor itma Porter digunakan untuk stemming pada kalimat tanya yang diinputkan oleh pengguna. Sumber data yang akan digunakan adalah DBPedia Indonesia, dimana DBPedia merupakan basis data dari Wikipedia yang menampung jutaan informasi. Peneliti juga menggunakan SPARQL untuk melakukan kueri pada DBPedia Indonesia untuk memperoleh jawabannya. Dari uji coba yang telah dilakukan , QAS yang dibuat memberikan nilai akurasi sebesar 71,50%.. xiv.
(20) BAB I PENDAHULUAN. 1.1 Latar Belakang Dewasa ini internet telah tumbuh menjadi media elektronik yang menyediakan berbagai kebutuhan informasi untuk segala bidang keahlian. Sebagian besar masyarakat di dunia memanfaatkan internet sebagai sarana menuntut ilmu. Agama Islam juga mengajarkan umatnya untuk senantiasa menuntut ilmu, bahkan jika menginginkan kebahagiaan dunia akhirat maka wajib menuntut ilmu, seperti hadits yang diriwayatkan oleh Turmudzi berikut ini.. َ ْ َو َم ْن أَ َرا َد, الدنْيَا ف َ َعلَيْ ِه ِب ا ْل ِعلْ ِم ُّ َم ْن أَ َرا َد َو َم ْن أَ َرا َدهُ َما ف َ َع لَيْ ِه ِبا, اخ َرة َ ف َ َعلَيْ ِه ِب ا لْ ِعلْ ِم ِ اْل لْ ِعلْ ِم Artinya: “Barang siapa yang menghendaki kehidupan dunia maka wajib baginya memiliki ilmu, dan barang siapa yang menghendaki kehidupan akhirat, maka wajib baginya memiliki ilmu, dan barang siapa menghendaki keduanya maka wajib baginya memiliki ilmu”. (HR. Turmudzi). Dari hadits tersebut jelas bahwa sebagai umat muslim wajib untuk menuntut ilmu. Ada berbagai cara untuk memperkaya ilmu pengetahuan dan memperoleh informasi, antara lain dengan membaca, berguru kepada seorang ahli, ataupun secara otodidak melalui media elektronik, seperti internet, televisi, radio, dan sebagainya. Semua hal tersebut dapat dilakukan sebaga i media pembelajaran untuk memperkaya ilmu pengetahuan dan informasi. Di dalam Al Qur’an surat Al ‘Alaq ayat 3 – 5 juga termaktub ayat mengenai media pembelajaran sebagai berikut.. 1.
(21) 2. . Artinya: 3. Bacalah, dan Tuhanmulah yang Maha pemurah, 4. Yang mengajar (manusia) dengan perantaran kalam, 5. Dia mengajar kepada manusia apa yang tidak diketahuinya.. Menurut terjemah tafsir jalalain, makna bacalah pada la fal ayat ini ialah mengukuhkan makna lafal pertama yang sama (dan Rabbmulah Yang Paling Pemurah) artinya tiada seorang pun yang dapat menandingi kemurahan-Nya. Lafal ayat ini sebagai Haal dan Dhamir yang terkandung di dalam lafal Iqra’. Selanjutnya, terjemah dari ayat keempat adalah yang mengajar (manusia) dengan perantaraan kalam, manusia pertama yang menulis dengan memakai kalam atau pena ialah Nabi Idris a.s. Pada ayat kelima, (Dia mengajarkan kepada manusia) atau jenis manusia (apa yang tidak diketahuinya) yaitu sebelum Dia mengajarkan kepadanya hidayah, menulis dan berkreasi serta hal- hal lainnya (As Suyuthi, 2008). Dari ayat tersebut, dapat diilhami bahwa proses pembelajaran atau proses pentransferan pengetahuan kepada manusia dari yang semula tidak tahu menjadi tahu menggunakan perantara berupa pena. Pena yang dimaksud disini adalah baca tulis. Sehingga ayat ini mengandung makna bahwa penyampaian ilmu pengetahuan kepada manusia tidak secara langsung begitu saja. Akan tetapi Allah memberikan. pengetahuan. melalui. perantara.. Sehingga. Allah. sudah.
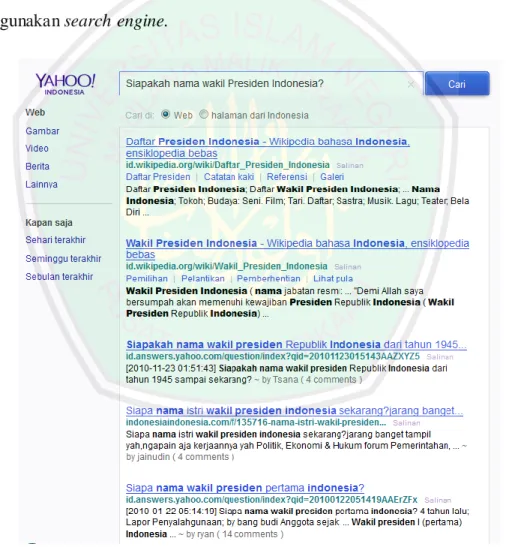
(22) 3. mengisyaratkan. melalui surat Al ‘Alaq. ini bahwa penggunaan media. pembelajaran untuk pentransferan ilmu pengetahuan memang penting. Mesin pencari (search engine) merupakan salah satu fasilitas yang sering digunakan untuk mencari informasi, contohnya: Google, Yahoo, Altavista, Bing dan lain sebagainya. Cara kerja search engine adalah sistem akan menampilkan daftar dokumen yang berkaitan dengan keyword yang telah diinput oleh pengguna (Gunawan, 2006). Gambar 1.1 menunjukkan daftar dokumen dari hasil pencarian menggunakan search engine.. Gambar 1.1 Hasil Pencarian dari Yahoo Search Engine (sumber: Yahoo, 10 Maret 2014).
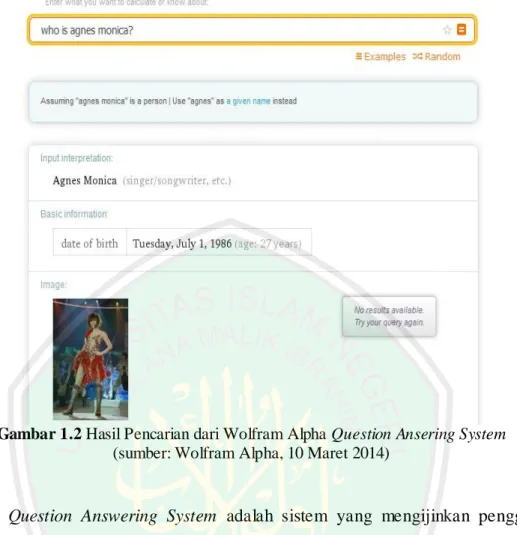
(23) 4. Search engine tidak dapat melakukan analisis linguistik terhadap teks kueri secara mendalam. Search engine akan menampilkan daftar dokumen atau website. Untuk mendapatkan informasi yang benar-benar dibutuhkan, pengguna harus memeriksa dan membaca setiap dokumen di daftar tersebut. Tidak jarang sebagai pengguna terkadang mengalami kesulitan dalam menemukan informasi yang tepat sesuai dengan keyword dicari. Hal ini dipengaruhi oleh tingginya peningkatan data pada web, sehingga semakin banyak informasi dan pengetahuan atau data yang ada pada internet, maka search engine akan mengembalikan daftar dokumen yang banyak pula. Hal yang demikian kurang efisien dari segi waktu dan akurasi informasi yang dibutuhkan pengguna. Dengan demikian, maka perlu dibangun sebuah Question Answering System (QAS). Ada beberapa faktor yang mendorong dikembangkannya Question Answering System (QAS), antara lain: tingginya peningkatan data web, kemajuan informasi dan teknologi, dan banyaknya permintaan dari pengguna untuk mendapatkan informasi dengan cepat dan akurat (Tahri, 2013, hal. 23). Gambar 1.2 menunjukkan hasil pencarian menggunakan Question Answering System yaitu Wolfram Alpha. Wolfram Alpha merupakan salah satu contoh Question Answering System menggunakan bahasa Inggris..
(24) 5. Gambar 1.2 Hasil Pencarian dari Wolfram Alpha Question Ansering System (sumber: Wolfram Alpha, 10 Maret 2014). Question Answering System adalah sistem yang mengijinkan pengguna menyatakan kebutuhan informasinya dalam bentuk natural language question (pertanyaan dalam bahasa alami), dan mengembalikan kutipan teks singkat atau bahkan frase sebagai jawaban (Gunawan, 2006). Question Answering System (QAS) atau sistem tanya jawab berupaya mencari jawaban spesifik terhadap pertanyaan yang diajukan dalam bahasa natural. Dibandingkan dengan mesin pencari (search engine) yang memberikan himpunan dokumen hasil penelusuran, sebuah QAS harus dapat menghadirkan jawaban akhir kepada pengguna. Secara nilai kecerdasan, QAS harus memiliki intelejensia yang lebih dibandingkan dengan mesin pencari biasa (Toba, 2010)..
(25) 6. Ada. beberapa. penelitian. yang. mengembangkan. QAS. dengan. menggunakan tema atau topik tertentu, misalnya: QAS seputar NBA (National Basketball Association). QAS ini dibangun oleh Calvin Irwan, Dr. Eng. Ayu Purwarianti, S.T, M. T. QAS ini mempunyai pengetahuan (knowledge) seputar liga bola basket pria di Amerika Serikat yang paling bergengsi di dunia. QAS lain dikembangkan oleh Gunawan dan Gita Lovina. QAS ini menggunakan Alkitab sebagai pengetahuan (knowledge). Peneliti ingin mengembangkan sebuah QAS berbahasa Indonesia yang dapat menjawab pertanyaan-pertanyaan umum sehingga QAS yang akan dibangun tidak terpaku pada topik atau tema tertentu seperti pada penelitian sebelumnya. Dengan adanya data yang besar pada web dikombinasikan dengan teknologi Information Retrieval (IR) dan Natural Language Processing (NLP) dapat dikembangkan sebuah Question Answering System menggunakan Wikipedia sebagai basis pengetahuan atau knowledge-nya. Wikipedia digunakan sebagai basis pengetahuan karenea. merupakan free ensiklopedia terbesar yang. menampung berjuta-juta informasi yang dikelola oleh berjuta-juta kontributor dari seluruh dunia. Berdasarkan hasil perangkingan di Alexa.com, Wikipedia berada di peringkat keenam secara global dan di United States (US). Wikipedia masuk ke dalam top 10 sites. Hasil perankingan tersebut dapat dilihat pada Gambar 1.3..
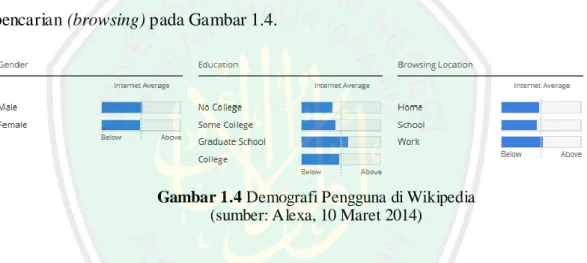
(26) 7. Gambar 1.3 Hasil Perankingan Wikipedia di Alexa (sumber: Alexa, 10 Maret 2014). Jumlah pengguna yang mengakses Wikipedia juga beragam, datanya dapat dilihat demografinya berdasarkan jenis kelamin, tingkat pendidikan dan lokasi pencarian (browsing) pada Gambar 1.4.. Gambar 1.4 Demografi Pengguna di Wikipedia (sumber: Alexa, 10 Maret 2014). Berdasarkan data tersebut, maka Wikipedia dipilih sebagai knowledge dari Question Answering System (QAS) yang akan dibuat. Resource yang akan digunakan yaitu DBPedia. DBPedia adalah sebuah komunitas yang bergerak untuk mengekstrak informasi terstruktur dari Wikipedia dan menyediakan informasi tersebut dalam sebuah web. DBPedia yang akan digunakan pada penelitian ini adalah DBPedia Indonesia. DBPedia Indonesia mer upakan web yang menyediakan data hasil ekstraksi dari Wikipedia Indonesia. Sehingga dapat dilakukan pencarian yang kompleks terhadap data di Wikipedia. Ada 3 cara yang dapat dilakukan untuk mengakses knowledge dari DBPedia Indonesia, yaitu.
(27) 8. Linked Data, SPARQL Endpoint dan RDF Dumps. Linked Data adalah mengakses sebuah entitas dengan menggunakan URI resource dari entitas tersebut, contoh URI resource yaitu http://id.dbpedia.org/resource/Indonesia. SPARQL Endpoint adalah mengakses DBPedia dengan cara melakukan query pada knowledge base. Sedangkan RDF Dumps merupakan hasil dari ekstraksi Wikipedia Indonesia, dimana ini terbagi menjadi 26 berkas dalam format NTriple. Pada pembuatan QAS ini akan dilakukan pengaksesan DBPedia Indonesia dengan menggunakan SPARQL Endpoint. Dengan adanya QAS ini diharapkan dapat membantu pengguna untuk menemukan informasi dengan cepat dan akurat.. 1.2 Rumusan Masalah Rumusan masalah pada penelitian ini sebagai berikut: a. Apakah Question Answering System yang dibuat dapat memberikan jawaban yang akurat? b. Berapa tingkat akurasi jawaban yang dihasilkan dari Question Answering System yang dibuat?. 1.3 Batasan Masalah Batasan masalah pada penelitian ini sebagai berikut: a. Pengetahuan atau knowledge yang digunakan untuk sumber jawaban adalah DBPedia b. Pertanyaan yang diajukan oleh pengguna adalah sesuatu mengenai Indonesia.
(28) 9. 1.4 Tujuan Penelitian Tujuan pada penelitian ini sebagai berikut: a. Untuk membangun Question Answering System menggunakan algoritma Porter sebagai stemmer kata. b. Untuk mengukur tingkat akurasi jawaban yang dihasilkan pada Question Answering System.. 1.5 Manfaat Penelitian Hasil dari penelitian ini diharapkan dapat membantu pengguna untuk mendapatkan informasi secara tepat dan akurat melalui Question Answering System yang telah dibuat.. 1.6 Sistematika Penulisan Penulisan. skripsi ini. tersusun dalam lima bab dengan sistematika. penulisan sebagai berikut : BAB I Pendahuluan Pendahuluan, membahas tentang latar belakang masalah, rumusan masalah, batasan masalah, tujuan penyusunan tugas akhir, metedologi, dan sistematika penyusunan tugas akhir. BAB II Landasan Teori Landasan teori berisikan beberapa teori yang mendasari dalam penyusunan tugas akhir ini. Adapun yang dibahas dalam bab ini adalah dasar teori yang berkaitan. dengan. pembahasan. tentang. penelitian terkait, semantic web,.
(29) 10. komponen-komponen. semantic web,. ontology,. temu kembali. informasi. (Information Retrieval), Question Answering, DBPedia, parsing, stemming, dan SPARQL. BAB III Analisa dan Perancangan Menganalisa kebutuhan sistem untuk membangun Question Answering System dan langkah- langkah pembuatannya. BAB IV Implementasi dan Pembahasan Menjelaskan tentang. implementasi sistem berdasarkan rancangan yang telah. disusun sebelumnya serta pengujian Question Answering System yang telah dibuat beserta pembahasannya. BAB V Penutup Berisi kesimpulan dan saran.. 1.7 Metode Penelitian Berdasarkan jenis dan analisis data,penulisan skripsi ini menggunakan metode penelitian kuantitatif untuk mengukur akurasi jawaban dari QAS yang akan dibuat..
(30) BAB II TINJAUAN PUSTAKA. 2.1 Penelitian Terkait Sebelumnya pernah dilakukan penelitian mengenai QAS dengan menggunakan metode Rule-Based pada terjemahan Al Qur’an surat Al Baqarah oleh Meynar pada tahun 2007. Proses awal pada QAS adalah dengan mengambil dokumen-dokumen (ayat-ayat) berekstensi (*.txt) yang terdapat pada satu direktori dan. menyimpan. nama. masing- masing dokumen dalam tabel. penyimpanan dokumen. Kemudian dokumen-dokumen tersebut dipecah menjadi kalimat-kalimat yang dimasukkan ke dalam tabel penyimpanan kalimat. Selanjutnya dilakukan parsing dengan menggunakan titik (.) sebagai pemisah (separator), penghilangan stopwords, dan stemming yang akan menghasilkan token-token kalimat. Token-token tersebut disimpan dalam tabel penyimpanan. Pengguna memasukkan kueri berupa kalimat pertanyaan, selanjutnya dilakukan parsing, penghilangan stopwords, dan stemming yang akan menghasilkan tokentoken kueri. Kemudian dilakukan proses WordMatch yaitu membandingkan token-token pada setiap kalimat dokumen dan kalimat kueri. Setiap token yang sama dari kalimat kueri akan memberikan nilai clue (+3) pada kalimat dokumen tersebut. Selanjutnya masuk ke dalam proses rule sesuai dengan tipe kueri yang diberikan. Dari proses tersebut, masing- masing kalimat akan memperoleh nilai berdasarkan nilai WordMatch dan rule. Kalimat yang dikembalikan sebagai jawaban adalah kalimat yang memiliki nilai paling tinggi. Akurasi rata-rata rule. 11.
(31) 12. terhadap kueri oleh peneliti adalah 85,69 % dan akurasi rata-rata rule terhadap kueri yang diberikan pengguna umum adalah 53,14 %. Kelebihan dari penelitian ini antara lain: sistem ini berbasis web, kuerinya menggunakan bahasa alami, dan indexing dokumen hanya dilakukan sekali ketika di awal pembangunan sistem. Adapun kekurangan dari penelitian ini antara la in: jika terdapat penambahan dokumen, maka harus dilakukan proses pengindeksan ulang, tidak dilakukan kajian terhadap hubungan makna semantik dalam dokumen, sehingga kandungan terjemahan yang bersifat prosedural belum dapat ditemukembalikan, dan penelitian ini belum menggunakan thesaurus dan hanya menggunakan simple matching (Dwi, 2007). Penelitian seputar QAS lainnya yaitu penelitian mengenai aplikasi Question Answering (QA) tentang National Basketball Association (NBA). QA ini merupakan aplikasi yang menjawab pertanyaan seputar NBA. Aplikasi ini dibangun dengan 4 modul, yaitu antarmuka, Question Analyzer, Query Processor, dan Database Generator. Teknik Rule Based diterapkan pada Database Generator untuk pembuatan aturan-aturan yang memanfaatkan teknik pencocokan string dilanjutkan dengan pemotongan string untuk pengambilan data basis data. Pada modul Question Analyzer, digunakan pencocokan string untuk mendeteksi stopwords, Expected Answer Type (EAT), dan keywords. Selanjutnya pada modul Query Processor digunakan query basis data biasa. Query menggunakan EAT sebagai kolom elemen tabel dan keywords untuk dicocokan pada elemen tabel untuk pengembalian jawaban. Hasil pengujian dari aplikasi ini menunjukkan bahwa akurasi kebenaran aplikasi berdasarkan skenario uji mencapai 93, 18%,.
(32) 13. sementara hasil pengujian responden menunjukkan akurasi 91, 67% (Irwan, 2012). Penelitian lain seputar Question Answering yaitu Question Answering System pada Alkitab menggunakan metode Rule Based. Arsitektur aplikasinya menggunakan arsitektur umum dari QAS yang dibuat oleh Monz, yaitu Question Analysis, Document Collection Preprocessing, Candidate Document Selection, Candidate Document Analysis, Answer Extraction, dan Response Generation (Monz, 2003). Pada tahap Question Analysis menghasilkan dua buah representasi pertanyaan sebagai output. Representasi pertama berupa sebuah query yang akan diteruskan pada tahap Candidate Document Selection dan representasi kedua adalah representasi semantik yang mengarah pada jenis informasi atau tipe jawaban yang diinginkan oleh pertanyaan yang dijadikan input. Tahap Candidate Document Selection akan mengidentifikasi dokumen-dokumen yang mengandung jawaban menggunakan metode SurfaceText Patterns. Lalu tahap Candidate Document Analysis dilakukan untuk memperkecil ukuran dokumen. Kemudian tahap Answer Extraction bertugas mencocokkan kandidat dokumen dengan representasi semantik dari pertanyaan sehingga menghasilkan daftar jawaban. Selanjutnya menyajikan jawaban, contoh penyajiaannya bisa berupa daftar dokumen, daftar paragraf, daftar kalimat, atau daftar frase jawaban sebagai respon. Berdasarkan hasil pengujian melalui kuisioner, prosentase rata-rata evaluasi program adalah 77.2% (Handojo, 2012). Penelitian. terkait. lainnya. yaitu. sebuah. arsitektur. baru. untuk. mengembangkan factoid Question Answering System menggunakan DBPedia.
(33) 14. ontologi dan DBPedia extraction framework. Arsitektur dari Question Answering System ini terdiri dari 3 proses utama, yaitu Question Classification and Decision Model Generation, Question Processing dan Query Formulation and Execution. Question Classification adalah tahap awal untuk mengklasifikasikan pertanyaan. Ada 7 kelas utama untuk klasifikasi pertanyaan, yaitu human, location, entity, description, abbreviation, number, dan boolean. Karena ada beberapa kelas untuk mengklasifikan pertanyaan, maka peneliti menggunakan algoritma Support Vector Machine (SVM) untuk multi-class SVM yaitu Directed Acrylic Graph. Tahap selanjutnya yaitu memproses pertanyaan, mengekstraksi resource, mengekstraksi keywords, formulasi query menggunakan SPARQL dan eksekusi. Kernel SVM yang digunakan pada penelitian ini adalah linear karena kernel ini mampu bekerja dengan cepat dalam menangani data yang besar. Penggunaan kernel ini memiliki tingkat akurasi 87% untuk pengklasifikasian pertanyaan. Dari penelitian yang dilakukan, masih ada beberapa kekurangan, yaitu kurangnya informasi yang tersedia pada DBPedia ontologi dan terkadang terjadi kesalahan dalam pengklasifikasian pertanyan (Tahri, 2013).. 2.2 Semantic Web Semantik di dalam bahasa Indonesia berasal dari bahasa Inggris semantics, dari bahasa Yunani sema (nomina) ‘tanda’: atau dari verba samaino ‘menandai’, ‘berarti’. Istilah tersebut digunakan para pakar bahasa untuk menyebut bagian Ilmu bahasa yang mempelajari tentang makna (Djajasudarman, 1993). Sedangkan web sendiri yaitu bagian visual dari internet. Web didasarkan pada prinsip-prinsip Web page multimedia yang bentuknya seperti halaman-.
(34) 15. halaman majalah yang dilengkapi dengan gambar, teks, dan foto. Pembuat web, European Particle Physics Laboratory (CERN) mengembangkan bahasa komputer yang disebut dengan Hypertext Markup Languange atau HTML, yang mana menjadi dasar dari web (Ause, 1995). Semantic Web merupakan perluasan dari World Wide Web yang memungkinkan orang untuk berbagi konten melampaui batas-batas suatu aplikasi dan website. Semantic web merupakan web data yang memungkinkan mesin untuk memahami suatu informasi pada World Wide Web sesuai maknanya atau secara struktural. Ini dapat memperluas jaringan hyperlink suatu halaman web dengan memasukkan mesin pembaca metadata mengenai halaman yang terdapat dalam web tersebut dan bagaimana mereka saling berhubungan satu sama lain. Hal tersebut memungkinkan suatu agen untuk otomatis mengakses web secara lebih cerdas dan melakukan tugas-tugas atas nama pengguna (Berneers, 2001). Semantic web sedikit berbeda apabila digambarkan seperti web pada umumnya. Penggunaan semantic web merupakan suatu pergeseran paradigma saat ini dalam penggunaan web sehari-hari. Maka dari itu, semantic web telah mengilhami banyak orang untuk menciptakan aplikasi dan teknologi semantik yang inovatif.. 2.3 Komponen-komponen Semantic Web Terdapat beberapa standar yang memungkinkan dalam pembuatan Semantic Web yang telah dikoordinasi oleh World Wide Web Consortium (W3C). Beberapa standar pokok dalam pembangunan suatu Semantic Web adalah Extensible Markup Lanuage (XML), XML Schema, Resource Description Framework (RDF), RDF Schema, Web Ontology Language (OWL), dan SPARQL. Layer dari.
(35) 16. Semantic Web sebagaimana direkomendasikan oleh W3C dapat dlihat pada Gambar 2.1 (Koivunen, 2002).. Gambar 2.1 Layer Semantic Web. a. Unicode dan URI Unicode adalah standar representasi karakter komputer. Dalam hal ini, Semantic Web seharusnya dapat merepresentasikan dokumen dalam bahasa manusia yang berbeda dengan pemahaman mesin. URI (Uniform Resource Identifier) merupakan standar untuk lokasi dan identitas suatu resource (misalnya web page) dimana URI sebagai suatu penamaan unik untuk identifikasi semantic web. b. XML dan Namespaces Extensible Markup Language (XML) dan Namespaces serta Schema, merupakan sintaks yang berfungsi untuk menyajikan struktur data pada web. XML sendiri merupakan Markup Language yang memungkinkan penciptaan dokumen-dokumen yang tersusun dari struktur data dan Namespaces yang menyediakan caranya untuk me-markup dari banyak sources. Semantic web.
(36) 17. merupakan sistem yang menghubungkan banyak data sehingga memerlukan source dalam pengolahan dokumen-dokumen tersebut. c. RDF dan RDF Schema Resource Description Framework (RDF) adalah sebuah framework yang. dibuat oleh W3C. untuk. merepresentasikan. informasi dengan. menggunakan sekumpulan format sintaks. Ide dasar dari RDF adalah bagaimana dapat membuat pernyataan mengenai sebuah resource Web dalam bentuk ekspresi tertentu. “Subjet-Predikat-Objek”. Dalam terminology RDF, SPO ini seringkali disebut dengan istilah N-triple. Subjek mengacu pada resource yang ingin dideksripsikan. Predikat menggambarkan kelakuan atau karakteristik dari resource tersebut dan mengekspresikan hubungan antara subjek dan objek. RDF Schema merupakan sebuah kamus data yang menyediakan dasardasar vocabulary untuk mendeskripsikan properties dan classes dari resources RDF. Hal ini dapat digunakan dalam pembuatan hirarki properties dan classesnya. d. Query Sebuah query digunakan untuk mengakses data pada repository yang tersedia. e. Ontology Vocabulary Bahasa ontology yang direkomendasikan oleh W3C pada 10 Februari 2004 adalah OWL Web Ontology Language, merupakan bahasa yang lebih kaya dan kompleks untuk mendeskripsikan resource..
(37) 18. f. Logic dan Proof Layer ini berupa rule dan sistem untuk melakukan reasoning pada ontology sehingga dapat disimpulkan apakah suatu resource memenuhi syarat tertentu. g. Trust Layer dari semantic web yang memungkinkan pengguna web untuk mempercayai suatu informasi pada web (Pollock, 2009).. 2.4 Ontology Definisi ontologi dalam ilmu komputer yang sering dirujuk berasal dari Tom Gruber (2007) yang menyatakan “An ontology is an explicit and formal specification of a conceptualization of domain of interest”. Dalam memahami definisi tersebut digunakan istilah semantic, logic, controlled vocabulary, taxonomy dan thesauri sebagai sudut pandang untuk memulai pembahasan tentang pengertian ontologi. Untuk memberikan pengertian semantic, dirujuk permasalahan dalam konteks komunikasi. Dalam konteks komunikasi dengan ataupun tanpa ontology dikenal suatu penggambaran yang disebut meaning triangle yang dapat dilihat pada Gambar 2.2.. evokes. Concept. Symbol. refers to. Thing stands for. Gambar 2.2 Meaning Triangle (sumber: Sarno, 2012).
(38) 19. Ada tiga komponen pada meaning triangle yang berupa symbol, concept dan thing. Symbol merupakan kata atau istilah yang digunakan dalam bahasa (syntax). Thing (referent) adalah sesuatu yang diwakilkan oleh symbol, namun tidak terdapat relasi langsung dari symbol menuju thing. Untuk memahami thing yang dimaksud, diperlukan concept yang memberikan meaning (semantic) sehingga terdapat reference menuju thing tersebut. Suatu kosakata terkontrol (controlled vocabulary) adalah suatu daftar istilah (term) atau konsep yang dinyatakan secara eksplisit. Semua istilah dalam kosakata terkontrol memiliki definisi yang jelas dan tidak redudansi. Taxonomy adalah koleksi dari kosakata terkontrol yang diorganisasikan secara hierarki berdasarkan hubungan generalisasi. Thesauri adalah jaringan koleksi dari kata atau frase dengan satu set relasi linguistic. Thesauri juga menggunakan relasi asosiatif selain menggunakan relasi induk-anak sehingga thesauri lebih kuat dalam memberikan semantic bila dibandingkan dengan taxonomy. Relasi asosiatif dalam thesauri misalnya “related-to”, “broader”, “narrower” dan sebagainya. Tujuan dibuatnya ontology semantic adalah untuk meningkatkan otomatisasi pemrosesan teks dengan menyediakan representasi konsep yang ada di dunia secara language independent dan meaning-based (Sarno, 2012).. 2.5 Temu Ke mbali Informasi (Information Retrieval) Temu kembali informasi berkaitan dengan representasi, penyimpanan, pengorganisasian, dan pengaksesan informasi. Sistem temu kembali informasi.
(39) 20. menyediakan kemudahan akses informasi bagi pengguna. Pengguna harus menerjemahkan kebutuhan informasinya dalam bentuk kueri. Dengan adanya kueri yang diberikan pengguna, tujuan utama dari sistem temu kembali informasi adalah mengembalikan informasi yang relevan dengan kueri dan informasi yang tidak relevan sesedikit mungkin.. 2.6 Question Answering Question Answering merupakan aplikasi nyata dari teknologi Natural Language Processing (NLP). Tujuan utama dari Question Answering (QA) adalah menampilkan jawaban atas pertanyaan yang diberikan pengguna. Ide utama QA adalah (Dolarosa, 2008): -. Menentukan tipe semantik jawaban yang diharapkan. -. Menentukan tipe dokumen-dokumen yang memiliki keywords seperti pada pertanyaan. -. Mencari entitas dengan tipe yang sesuai dengan pertanyaan, yang dekat dengan keywords. 2.7 DBPedia DBPedia Indonesia merupakan sebuah komunitas yang bergerak untuk mengekstrak informasi terstruktur dari Wikipedia dan menyediakan informasi tersebut dalam sebuah web. DBPedia Indonesia merupakan sebuah web yang menyediakan data hasil ekstraksi dari Wikipedia Indonesia. Dengan DBPedia dapat dilakukan pencarian yang kompleks terhadap data dari Wikipedia. Adapun.
(40) 21. cara pengaksesan knowledge DBPedia Indonesia ada 3 cara, yaitu Linked Data, SPARQL Endpoint dan RDF Dumps. 2.7.1 Linked Data Cara pengaksesan entitas dengan menggunakan URI resource dari entitas. tersebut.. Setiap. artikel. Wikipedia. http://id.wikipedia.org/wiki/JUDULARTIKEL. akan. dengan. URL. memiliki. URI. resource http://id.dbpedia.org/resource/JUDULARTIKEL. Di bawah ini contoh dari beberapa URI resource, antara lain: o http://id.dbpedia.org/resource/Universitas_Indonesia o http://id.dbpedia.org/resource/Indonesia o http://id.dbpedia.org/resource/Soekarno o http://id.dbpedia.org/resource/Jawa_Tengah o http://id.dbpedia.org/resource/The_Beatles 2.7.2 SPARQL Endpoint Ini merupakan cara pengaksesan knowledge base DBPedia Indonesia dengan menggunakan query. Dalam hal ini, untuk melakukan query sebaiknya mempelajari ontology dan property-property yang digunakan di DBPedia. Berikut contoh struktur query SPARQL. select ?gubernur ?wakilGubernur where { dbpedia-id:Daerah_Khusus_Ibukota_Jakarta dbpedia-owl:leaderName ?gubernur. dbpedia-id:Daerah_Khusus_Ibukota_Jakarta dbpedia-owl:viceLeader ?wakilGubernur. }. Hasil dari query tersebut akan menampilkan nama dari gubernur dan wakil gubernur DKI Jakarta..
(41) 22. 2.7.3 RDF Dumps DBPedia Indonesia. juga. menyediakan. RDF. dumps. yang. merupakan hasil ekstraksi dari Wikipedia Indonesia. RDF dumps terbagi menjadi 26 berkas dalam format N-Triple yang dikompresi dengan gzip.. 2.8 Parsing Parsing adalah proses untuk menguraikan kalimat menjadi per kata. Atau dengan kata lain parsing adalah proses parser atau pemisahan dari elemen-elemen pembentuk dokumen ke dalam satuan terkecil, yaitu kata (Zainal, 2009). Pemisah antar kata yang umum digunakan dalam sebuah kalimat adalah spasi. Sehingga pada penelitian ini akan digunakan spasi sebagai pemisah untuk menguraikan kalimat tanya yang diinputkan oleh pengguna menjadi per kata.. 2.9 Stemming Stemming merupakan suatu proses yang terdapat dalam sistem Information Retrieval (IR). yang mentransformasi kata-kata yang terdapat dalam suatu. dokumen ke kata-kata akarnya (root word) dengan menggunakan aturan-aturan tertentu. Sebagai contoh, kata bersama, kebersamaam, menyamai, akan distem ke root wordnya yaitu “sama”. Proses stemming pada teks berbahasa Indonesia berbeda dengan stemming pada teks berbahasa Inggris (Keke, 2012). Pada umumnya kata dasar pada bahasa Indonesia terdiri dari kombinasi: Prefiks 1 + Prefiks 2 + Kata dasar + Sufiks 3 + Sufiks 2 + Sufiks 1.
(42) 23. Pada teks berbahasa Inggris, proses yang diperlukan hanya proses menghilangkan sufiks. Sedangkan pada teks berbahasa Indonesia, selain sufiks, prefiks, dan konfiks juga dihilangkan (Agusta, 2009).. 2.10 SPARQL SPARQL Protocol and RDF Query Language (SPARQL) adalah sebuah protocol dan bahasa query untuk Semantic Web’s resources. Sebuah query yang menggunakan SPARQL dapat terdiri atas triple patterns, konjungsi (or) dan disjungsi (and). Berikut ini adalah contoh query yang menghasilkan semua ibu kota di Indonesia: PREFIX abc: <http://mynamespace.com/exampleOntologie#> SELECT ?capital ?province WHERE { ?x abc:cityname ?capital. ?y abc:provincename ?province. ?x abc:isCapitalOf ?y. ?y abc:isInCountry abc:indonesia. }. Untuk menjalankan SPARQL dapat menggunakan beberapa tools dan APIs seperti: ARQ, Rasqal, RDF::Query, twingql, Pellet, dan KAON2. Tools tersebut memiliki API yang memampukan pemrogram untuk memanipulasi hasil query dengan berbagai aplikasi. yang ada. Namun, sebagai standar dapat. digunakan SPARQL Query Results XML Fomat yang direkomendasikan oleh W3C (Beckett, 2013). Hasil dari query di atas adalah (Ibrahim, 2007): <?xml version="1.0"?> <sparql xmlns="http://www.w3.org/2005/sparql-results#"> <head> <variable name="capital"/> <variable name="province"/>.
(43) 24. </head> <results> <result> <binding name="capital"> <literal datatype="http://www.w3.org/2001/XMLSchema#string"> Bandung </literal> </binding> <binding name="province"> <literal datatype="http://www.w3.org/2001/XMLSchema#string"> Jawa Barat </literal> </binding> </result> <!-- more results --> </results> </sparql>.
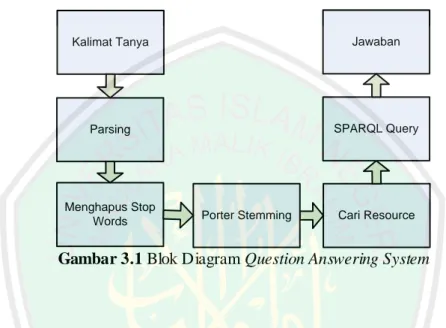
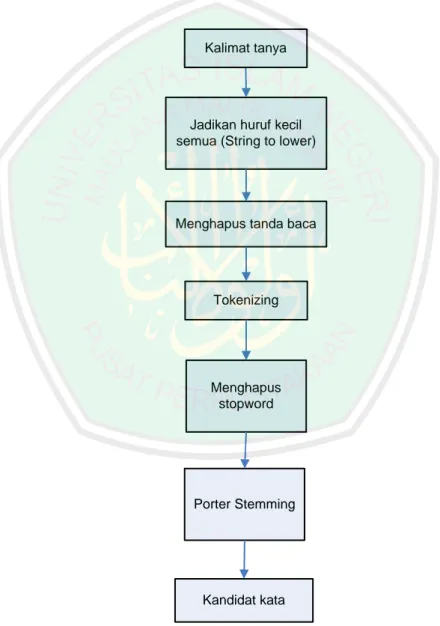
(44) BAB III ANALISIS DAN PERANCANGAN SISTEM. 3.1 Desain Sistem Question Answering System (QAS) merupakan sistem yang mengijinkan pengguna menyatakan kebutuhan informasinya dalam bentuk natural language question (pertanyaan dalam bahasa alami), dan mengembalika n kutipan teks singkat atau bahkan frase sebagai jawaban. Sistem yang akan dibuat menggunakan DBPedia Indonesia sebagai sumber pengetahuan. Ada 3 proses utama di dalamnya, yaitu: 1. Text Processing Ini merupakan tahap awal untuk mengolah kalimat tanya yang d iinput oleh pengguna. Kalimat tersebut diubah menjadi huruf kecil semua (lower), dihilangkan tanda bacanya, dihapus stopwords-nya, kemudian dicari bentuk kata dasarnya menggunakan algoritma Porter stemming. 2. Data Mining Data mining merupakan proses untuk menggali kata-kata yang akan digunakan dalam kueri SPARQL. Kandidat kata-kata yang digunakan adalah kata yang telah dilakukan text processing pada tahap pertama. Data mining digunakan untuk mencari resource di DBPedia Indonesia yang sesuai dengan pertanyaan yang diinputkan oleh pengguna.. 25.
(45) 26. 3. Menampilkan jawaban Setelah ditemukan resource di DBPedia yang sesuai dengan pertanyaan dari pengguna. Maka selanjutnya adalah menampilkan hasil jawaban kepada pengguna. Blok diagram dari Question Answering System yang akan dibuat dapat dilihat pada Gambar 3.1.. Kalimat Tanya. Jawaban. Parsing. SPARQL Query. Menghapus Stop Words. Porter Stemming. Cari Resource. Gambar 3.1 Blok Diagram Question Answering System. Gambar 3.1 merupakan blok diagram dari Question Answering System yang akan dibangun. Penjelasan dari masing- masing proses pada blok diagram di atas dijelaskan pada subbab berikutnya. 3.1.1. Text Processing Pada Question Answering System (QAS), yang dijadikan inputan adalah string pertanyaan yang diinputkan oleh pengguna. String ini diolah terlebih dahulu untuk mempermudah proses pencarian kandidat kata yang dapat digunakan sebagai resource. Pengolahan string meliputi: -. Mengubah string menjadi huruf kecil semua (lower). -. Menghilangkan tanda tanya (?).
(46) 27. -. Memecah kalimat tersebut menjadi per kata (tokenizing). -. Melakukan penghapusan stopwords. Stopwords adalah kata yang tidak memiliki makna dan sebaiknya dihilangkan saja.. -. Mencari kata dasar dari masing- masing kata dengan menggunakan algoritma Porter Stemming. Blok diagram dari text processing dapat dilihat pada Gambar 3.2.. Kalimat tanya. Jadikan huruf kecil semua (String to lower). Menghapus tanda baca. Tokenizing. Menghapus stopword. Porter Stemming. Kandidat kata. Gambar 3.2 Blok Diagram Text Processing.
(47) 28. 3.1.1.1 Kalimat tanya Ini merupakan tahap dimana pengguna menginputkan kalimat tanya ke dalam sistem. Kalimat tanya yang diinputkan dapat menggunakan beberapa macam kata tanya, antara lain: apa atau apakah, siapa atau siapakah, dimana atau dimanakah, kapan atau kapankah, mengapa, bagaimana dan berapa. Misalnya: Siapakah Presiden Indonesia?. 3.1.1.2 Casefolding String pertanyaan dari pengguna diubah menjadi huruf kecil semua. Proses ini juga dapat dinamakan sebagai case folding (membuat semua huruf pada teks menjadi huruf kecil). 3.1.1.3 Menghapus Tanda Tanya Setelah diubah menjadi huruf kecil semua, tanda tanya (?) yang ada pada pertanyaan akan dihapus. 3.1.1.4 Parsing Proses yang ada dalam parsing adalah tokenizing, yaitu memecah kalimat yang telah diinput oleh pengguna menjadi per kata. Proses parsing menggunakan spasi sebagai separator. Sebelum dilakukan parsing, dilakukan penghapusan tanda tanya (?) untuk memudahkan proses selanjutnya jika pengguna memasukkan tanda tanya ketika menginputkan pertanyaan. Proses ini akan menghasilkan token-token untuk kemudian dilanjutkan dengan proses penghapusan stopwords..
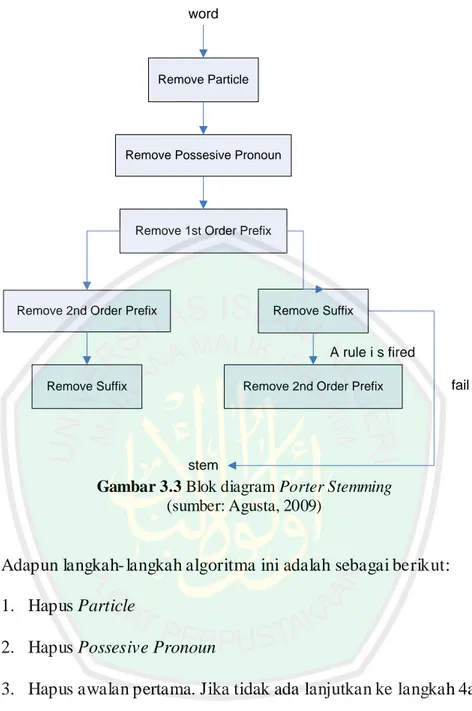
(48) 29. 3.1.1.5 Menghapus Stopwords Proses penghapusan stopwords dilakukan untuk menghilangkan kata-kata yang tidak mempunyai makna, misalnya: di, yang, pada, ke, dan lain sebagainya. Kata-kata yang termasuk ke dalam stopwords tersebut disimpan ke dalam suatu tabel pada database dan dicocokkan satu persatu dengan kata yang diinputkan oleh pengguna. Daftar stopwords dapat dilihat pada lampiran. Apabila terdapat kata-kata yang mengandung stopwords dari kalimat yang diinput oleh pengguna maka kata tersebut akan dihapus. 3.1.1.6 Porter Stemming Stemming adalah proses untuk mentransformasikan kata-kata yang telah dipecah sebelumnya menjadi root word (kata dasarnya). Pada penelitian ini, stemming menggunakan algoritma Porter. Algoritma ini ditemukan oleh Martin Porter pada tahun 1980. Algoritma tersebut digunakan untuk stemming kata berbahasa Inggris, kemudian karena proses stemming bahasa Inggris berbeda dengan bahasa Indonesia, maka dikembangkan algoritma Porter khusus untuk bahasa Indonesia oleh W.B. Frakes pada tahun 1992. Stemming kata dilakukan pada kata yang diindikasi sebagai keyword. Blok diagram dari algoritma Porter dapat dilihat pada Gambar 3.3 (Agusta, 2009):.
(49) 30. word. Remove Particle. Remove Possesive Pronoun. Remove 1st Order Prefix. Remove 2nd Order Prefix. Remove Suffix. A rule i s fired Remove Suffix. Remove 2nd Order Prefix. fail. stem. Gambar 3.3 Blok diagram Porter Stemming (sumber: Agusta, 2009). Adapun langkah- langkah algoritma ini adalah sebagai berikut: 1. Hapus Particle 2. Hapus Possesive Pronoun 3. Hapus awalan pertama. Jika tidak ada lanjutkan ke langkah 4a, jika ada cari maka lanjutkan ke langkah 4b 4. (a) Hapus awalan kedua, lanjutkan ke langkah 5a (b) Hapus akhiran, jika tidak ditemukan maka kata tersebut diasumsikan sebagai root word. Jika ditemukan maka lanjutkan ke langkah 5b.
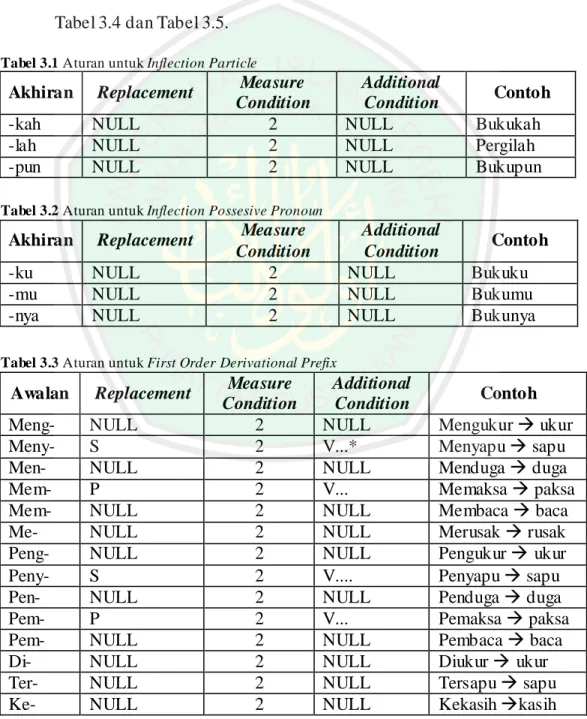
(50) 31. 5. (a) Hapus akhiran. Kemudian kata akhir diasumsikan sebagai root word (b) Hapus awalan kedua. Kemudian kata akhir diasumsikan sebagai root word Terdapat 5 kelompok aturan pada algoritma Porter untuk bahasa Indonesia ini. Aturan tersebut dapat dilihat pada Tabel 3.1, Tabel 3.2, Tabel 3.3, Tabel 3.4 dan Tabel 3.5. Tabel 3.1 Aturan untuk Inflection Particle. Akhiran -kah -lah -pun. Replacement NULL NULL NULL. Measure Condition 2 2 2. Additional Condition NULL NULL NULL. Contoh Bukukah Pergilah Bukupun. Tabel 3.2 Aturan untuk Inflection Possesive Pronoun. Akhiran -ku -mu -nya. Replacement NULL NULL NULL. Measure Condition 2 2 2. Additional Condition NULL NULL NULL. Contoh Bukuku Bukumu Bukunya. Tabel 3.3 Aturan untuk First Order Derivational Prefix. Awalan MengMenyMenMemMemMePengPenyPenPemPemDiTerKe-. Replacement NULL S NULL P NULL NULL NULL S NULL P NULL NULL NULL NULL. Measure Condition 2 2 2 2 2 2 2 2 2 2 2 2 2 2. Additional Condition NULL V...* NULL V... NULL NULL NULL V.... NULL V... NULL NULL NULL NULL. Contoh Mengukur ukur Menyapu sapu Menduga duga Memaksa paksa Membaca baca Merusak rusak Pengukur ukur Penyapu sapu Penduga duga Pemaksa paksa Pembaca baca Diukur ukur Tersapu sapu Kekasih kasih.
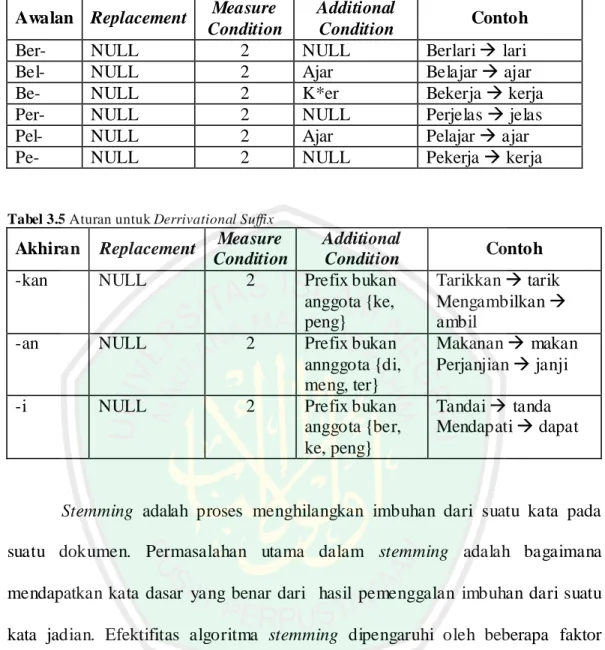
(51) 32. Tabel 3.4 Aturan untuk Second Order Derivational Prefix. Awalan Replacement BerBelBePerPelPe-. NULL NULL NULL NULL NULL NULL. Measure Condition 2 2 2 2 2 2. Additional Condition NULL Ajar K*er NULL Ajar NULL. Contoh Berlari lari Belajar ajar Bekerja kerja Perjelas jelas Pelajar ajar Pekerja kerja. Tabel 3.5 Aturan untuk Derrivational Suffix. Akhiran. Replacement. -kan. NULL. -an. NULL. -i. NULL. Measure Additional Condition Condition 2 Prefix bukan anggota {ke, peng} 2 Prefix bukan annggota {di, meng, ter} 2 Prefix bukan anggota {ber, ke, peng}. Contoh Tarikkan tarik Mengambilkan ambil Makanan makan Perjanjian janji Tandai tanda Mendapati dapat. Stemming adalah proses menghilangkan imbuhan dari suatu kata pada suatu dokumen. Permasalahan utama dalam stemming adalah bagaimana mendapatkan kata dasar yang benar dari hasil pemenggalan imbuhan dari suatu kata jadian. Efektifitas algoritma stemming dipengaruhi oleh beberapa faktor (Mandala, 2004): a. Kesalahan dalam proses pemenggalan imbuhan dari kata dasarnya. Kesalahan ini dapat berupa: . Overstemming: yaitu pemenggalan imbuhan yang melebihi dari yang seharusnya. Contoh: kata masalah menjadi masa. Kesalahan ini dapat timbul karena bentuk kata dasar yang menyerupai imbuhan..
(52) 33. . Understemming: yaitu pemenggalan imbuhan yang terlalu sedikit dari yang seharusnya. Contoh: kata belajar menjadi lajar. Kesalahan ini dapat timbul karena kekurangan pada aturan pola imbuhan yang didefinisikan.. . Unchange: yaitu kasus khusus dari understemming, dimana tidak terjadi pemenggalan. imbuhan. sama. sekali.. Contoh: kata. telapak,. setelah. pemenggalan kata dasar yang didapat tetap telapak. Kesalahan ini dapat ditimbulkan karena kekurangan pada aturan pola imbuhan yang didefinisikan. . Spelling exception: yaitu huruf pertama kata dasar yang didapat tidak benar yang diakibatkan dari pemenggalan awalan. Contoh: kata memukul menjadi ukul. Kesalahan ini dapat timbul karena ada beberapa imbuhan yang berubah bentuk ketika ditempelkan pada suatu kata dasar. Misalnya awalan berR-, meN-, teR-, peR-, akan bergantung pada huruf pertama kata dasar dimana imbuhan tersebut ditempelkan. Contoh: ber- + ajar = belajar, pen- + lihat = penglihatan, pen- + sakit = penyakit. Atau sebaliknya ada imbuhan yang mengakibatkan huruf pertama kata dasar yang ditempelinya menjadi luluh. Misalnya meng- / peng- meluluhkan huruf ‘k’. Contoh: mengarang menjadi meng- dan karang atau men- / pen- meluluhkan huruf ‘p’. Contoh: menuai dari men- dan tuai.. b.. Kekurangan dalam perumusan aturan penambahan imbuhan pada kata dasar. Hal ini dapat terjadi karena morfologi bahasa Indonesia yang kompleks, sehingga sangat sulit atau bahkan tidak mungkin untuk merumuskan aturan yang sempurna..
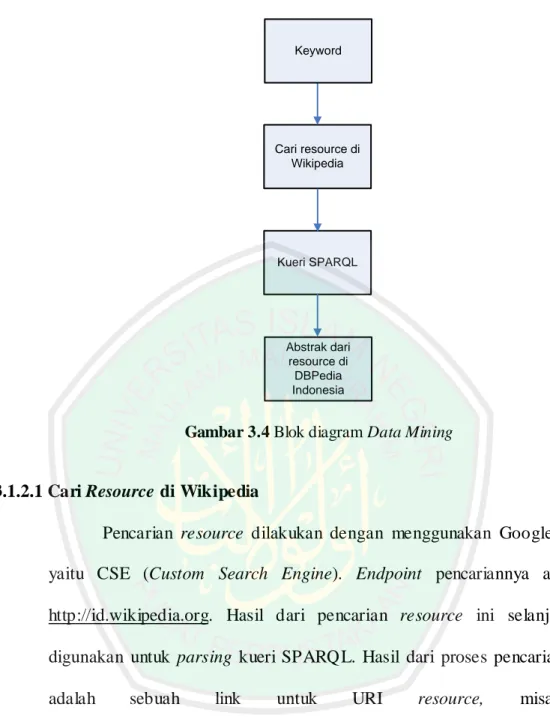
(53) 34. c.. Jumlah total aturan imbuhan yang didapat berhubungan dengan efektifitas proses temu kembali. Dimana semakin banyak pola penambahan imbuhan yang dapat dirumuskan, maka proses temu kembali akan semakin efektif. Kata-kata yang di-stemming adalah kata-kata yang bukan termasuk ke. dalam stopwords. Setelah dilakukan stemming, maka akan diperoleh kata dasar atau akar kata yang akan diproses ke tahap selanjutnya. Dari beberapa langkah pada text processing ini selanjutnya diperoleh kandidat kata. Kandidat kata ini selanjutnya digunakan sebagai keywords untuk melakukan proses selanjutnya yaitu data mining. Data mining ini dilakukan untuk mencari resource di Wikipedia.. 3.1.2. Data Mining Data mining adalah proses penggalian data, data mining yang dimaksud pada QAS ini adalah untuk menemukan kata yang dapat digunakan sebagai resource dari pertanyaan yang diinputkan oleh pengguna. Data yang akan di-mining adalah data pada DBPedia Indonesia. Pencarian resource pada DBPedia Indonesia menggunakan kandidat kata dari text processing pada proses sebelumnya. Sehingga pada tahap ini dibagi lagi menjadi 2 proses di dalamnya, yaitu: mencari link resource terlebih dahulu di Wikipedia Indonesia dan kueri SPARQL dengan endpoint DBPedia Indonesia. Blok diagram dari data mining dapat dilihat pada Gambar 3.4:.
(54) 35. Keyword. Cari resource di Wikipedia. Kueri SPARQL. Abstrak dari resource di DBPedia Indonesia. Gambar 3.4 Blok diagram Data Mining. 3.1.2.1 Cari Resource di Wikipedia Pencarian resource dilakukan dengan menggunakan Google API yaitu CSE (Custom Search Engine). Endpoint pencariannya adalah http://id.wikipedia.org. Hasil dari pencarian resource ini selanjutnya digunakan untuk parsing kueri SPARQL. Hasil dari proses pencarian ini adalah. sebuah. link. untuk. URI. resource,. misalnya:. http://id.wikipedia.org/wiki/Indonesia. Yang dibutuhkan untuk proses selanjutnya adalah kata Indonesia nya. 3.1.2.2 SPARQL Query Struktur dari kueri SPARQL yang akan d igunakan dapat dilihat pada Gambar 3.5..
(55) 36. select distinct ?Concept where {[] a ?Concept} Gambar 3.5 Struktur Kueri SPARQL. Contoh kueri SPARQL dengan menggunakan endpoint DBPedia Indonesia dapat dilihat pada Gambar 3.6. select ?jawaban where { dbpedia-id:Ekosistem dbpedia-owl:abstract ?jawaban. } Gambar 3.6 Contoh Kueri SPARQL. 3.1.3. Menampilkan Jawaban Setelah dilakukan kueri menggunakan SPARQL, maka akan diperoleh jawaban yang akan ditampilkan ke pengguna. Jawaban yang ditampilkan kepada pengguna adalah abstract Wikipedia dari resource yang telah ditemukan. Hasil dari kueri pada Gambar 3.6 dapat dilihat pada Gambar 3.7.. Gambar 3.7 Hasil dari Kueri SPARQL.
(56) 37. 3.2 Desain Interface Desain interface untuk tampilan awal dari sistem dapat dilihat pada Gambar 3.8 ini:. Gambar 3.8 Desain Interface Question Answering System. Pada bagian pertama, terdapat input field untuk menginputkan pertanyaan ke dalam sistem. Berikut penjelasan untuk kolom Your Question, Keyword Found, Document on Wikipedia, Wikipedia Endpoint dan Document Extraction: Your Question. : menampilkan pertanyaan yang diinputkan oleh pengguna. Keyword Found. : menampilkan. kandidat. kata. yang. digunakan. sebagai keyword untuk pencarian resource di Wikipedia Indonesia.. Kata yang ditampilkan. diperoleh dari proses text processing yaitu: case folding, parsing, menghapus stopwords dan Porter.
(57) 38. stemming. Document on. : menampilkan link resource URI dari Wikipedia. Wikipedia Wikipedia Endpoint. : menampilkan kata yang akan diproses untuk SPARQL. Document Extraction. : menampilkan abstract DBPedia Indonesia dari kata pada Wikipedia endpoint.. 3.3 Kebutuhan Sistem Berikut ini beberapa perangkat keras maupun lunak yang dibutuhkan untuk mendukung pembuatan dan uji coba Question Answering System (QAS). a) Perangkat Keras (Hardware) -. Peneliti menggunakan PC / Laptop dengan spesifikasi processor Intel(R) Core(TM) i3-2328M CPU @2.20GHz 2.20 GHz dan RAM 2,00 GB. b) Perangkat Lunak (Software) -. XAMPP versi 1.8.3 XAMPP digunakan sebagai web server yang berdiri sendiri (localhost), yang terdiri atas program Apache HTTP Server, MySQL database dan penerjemah bahasa yang ditulis dengan bahasa pemrograman PHP dan Perl.. -. Notepad++ Notepad++ digunakan sebagai text editor.. -. Mozilla Firefox.
(58) 39. Mozilla Firefox merupakan browser yang digunakan untuk mengeksekusi aplikasi -. Adobe Photoshop Photoshop digunakan untuk membuat desain logo dan tampilan web..
(59) BAB IV HASIL DAN PEMBAHASAN. Pada bab ini membahas tentang implementasi dari perancangan yang telah dibuat sebelumnya. 4.1 Implementasi Sistem Sistem yang dibuat terdiri dari 3 proses utama, yaitu text processing, data mining dan menampilkan jawaban. Text processing terdiri dari beberapa langkah, yaitu: -. Mengubah string menjadi huruf kecil semua (lower) atau case folding. -. Menghilangkan tanda tanya (?). -. Memecah kalimat tersebut menjadi per kata (tokenizing). -. Melakukan penghapusan stopwords. Stopwords adalah kata yang tidak memiliki makna dan sebaiknya dihilangkan saja.. -. Mencari kata dasar dari masing- masing kata yang telah di-parsing dengan menggunakan algoritma Porter stemming.. Berikut ini kode program dari text processing: $soal = $_POST['soal']; //jadikan huruf kecil semua $lower = strtolower($soal); //menghilangkan tanda tanya $ubah = str_replace("?"," ",$lower); //memecah kalimat menjadi per kata (tokenizing) $pecah = explode(" ", $ubah); $i = 0; while($split[$i] != null) {. 40.
(60) 41. $dicari= hapussStopword(hapusakhiran(hapusawalan2(hapusawalan1(hap uspp(hapuspartikel($pecah[0])))))).' '.hapusStopword(hapusakhiran(hapusawalan2(hapusawalan1(ha puspp(hapuspartikel($pecah[1])))))).' '.hapusStopword(hapusakhiran(hapusawalan2(hapusawalan1(ha puspp(hapuspartikel($pecah[2])))))).' '.hapusStopword(hapusakhiran(hapusawalan2(hapusawalan1(ha puspp(hapuspartikel($pecah[3])))))).' '.hapusStopword(hapusakhiran(hapusawalan2(hapusawalan1(ha puspp(hapuspartikel($pecah[4])))))).' '.hapusStopword(hapusakhiran(hapusawalan2(hapusawalan1(ha puspp(hapuspartikel($pecah[5])))))).' '.hapusStopword(hapusakhiran(hapusawalan2(hapusawalan1(ha puspp(hapuspartikel($pecah[6])))))).' '.hapusStopword(hapusakhiran(hapusawalan2(hapusawalan1(ha puspp(hapuspartikel($pecah[7])))))).' '.hapusStopword(hapusakhiran(hapusawalan2(hapusawalan1(ha puspp(hapuspartikel($pecah[8])))))).' '.hapusStopword(hapusakhiran(hapusawalan2(hapusawalan1(ha puspp(hapuspartikel($pecah[9])))))); $i++; }. Berikut kode program untuk menghapus stopwords: function hapusStopword ($kata) { // cari di database $sql = mysql_query("SELECT * from stoplist ='$kata'");. tb_stoplist. if(mysql_num_rows($sql) == 1) { $stopword = $kata; $katabaru = str_replace($kata," ",$kata); return $katabaru; } else { $katabaru = $kata; return $katabaru; }}. where.
(61) 42. 4.1.1 Implementasi Porter Stemming Stemming pada QAS ini digunakan untuk mentransformasikan kata-kata yang telah dipecah sebelumnya menjadi root word (kata dasarnya). Blok diagram dari Porter stemming dapat dilihat pada Gambar 3.3.Langkah-langkah algoritma ini adalah sebagai berikut: 1. Hapus Particle 2. Hapus Possesive Pronoun 3. Hapus awalan pertama. Jika tidak ada lanjutkan ke langkah 4a, jika ada cari maka lanjutkan ke langkah 4b 4. (a) Hapus awalan kedua, lanjutkan ke langkah 5a (b) Hapus akhiran, jika tidak ditemukan maka kata tersebut diasumsikan sebagai root word. Jika ditemukan maka lanjutkan ke langkah 5b 5. (a) Hapus akhiran. Kemudian kata akhir diasumsikan sebagai root word (b) Hapus awalan kedua. Kemudian kata akhir diasumsikan sebagai root word Berikut kode program dari Porter stemming: <?php function cari($kata){ include "koneksi.php"; $hasil = mysql_num_rows(mysql_query("SELECT * FROM tb_katadasar WHERE katadasar='$kata'")); return $hasil; } //langkah 1 - hapus partikel function hapuspartikel($kata){ if(cari($kata)!=1){.
(62) 43. if((substr($kata, -3) == 'kah' )||( substr($kata, 3) == 'lah' )||( substr($kata, -3) == 'pun' )){ $kata = substr($kata, 0, -3); } } return $kata; } //langkah 2 - hapus possesive pronoun function hapuspp($kata){ if(cari($kata)!=1){ if(strlen($kata) > 4){ if((substr($kata, -2)== 'ku')||(substr($kata, -2)== 'mu')){ $kata = substr($kata, 0, -2); }else if((substr($kata, -3)== 'nya')){ $kata = substr($kata,0, -3); } } } return $kata; } //langkah 3 hapus first order pertama) function hapusawalan1($kata){ if(cari($kata)!=1){. prefiks. (awalan. if(substr($kata,0,4)=="meng"){ if(substr($kata,4,1)=="e"||substr($kata,4,1)= ="u"){ $kata = "k".substr($kata,4); }else{ $kata = substr($kata,4); } }else if(substr($kata,0,4)=="meny"){ $kata = "s".substr($kata,4); }else if(substr($kata,0,3)=="men"){ $kata = substr($kata,3); }else if(substr($kata,0,3)=="mem"){ if(substr($kata,3,1)=="a" || substr($kata,3,1)=="i" || substr($kata,3,1)=="e" || substr($kata,3,1)=="u" || substr($kata,3,1)=="o"){ $kata = "p".substr($kata,3); }else{ $kata = substr($kata,3); }.
Gambar

+7
Dokumen terkait
Menimbang, bahwa berdasarkan fakta – fakta yang terungkap dipersidangan bahwa 1 (satu) unit sepeda motor Honda Vario warna pink, yang diambil oleh terdakwa bersama Rian (DPO)
Berdasarkan latar belakang diatas, maka rumusan masalah yang dibuat pada penelitian ini adalah “Bagaimana merancang dan mengimplementasikan pendekatan triangular
BAB 1 PENDAHULUAN Latar Belakang Masalah. Keberhasilan perusahaan dapat diukur berdasarkan kemampuan
Pengaruh current ratio terhadap perubahan laba adalah semakin tinggi nilai current ratio maka laba bersih yang dihasilkan perusahaan semakin sedikit, karena rasio
Berdasarkan hasil Moran’s I dengan menggunakan pembobot costumized contiguity menunjukkan bahwa untuk variabel crime rate (Y), kepadatan penduduk (X1), jumlah
Struktur biaya produksi usahatani pada ketiga komoditas pangan utama, yaitu padi, jagung dan kedelai relatif sama dengan proporsi terbesar pada upah, disusul sewa
With respect to the interaction between expresser’s group membership and typicality of judgment item, post-hoc analyses showed that when facial expressions were neutral,
Statistics of elevation differences over stable terrain at Lindblad Cove Upper glacier study site between FIDASE 1957 and WorldView-2 2014 before and after surface matching... On
Perawatan saluran akar pada sisa akar gigi dengan restorasi akhir resin komposit direk yang diperkuat pasak dapat menjadi satu alternatif metode perawatan untuk
