BAB II LANDASAN TEORI
Bebas
11
0
0
Teks penuh
(2)
(3)
(4)
(5)
(6)
(7)
(8)
(9)
(10)
(11)
Gambar
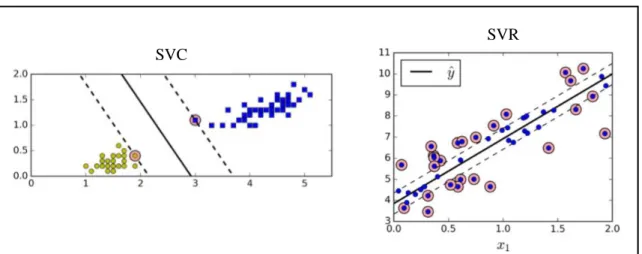
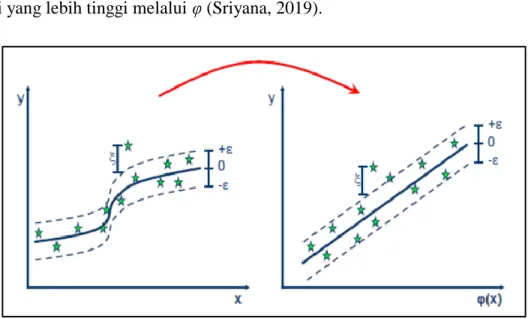
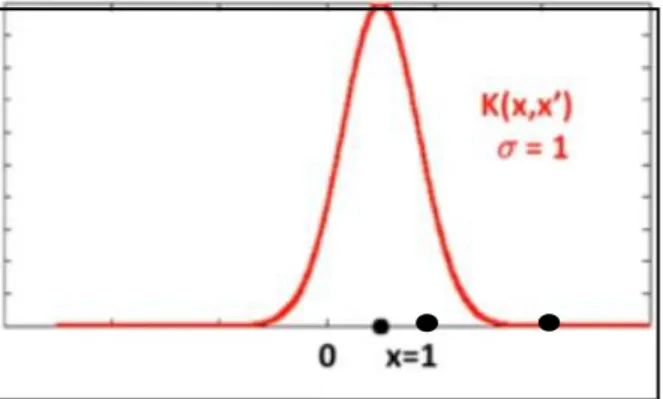
Dokumen terkait
Menurut Wikipedia.org, basis data (bahasa inggris : database) adalah kumpulan informasi yang disimpan didalam komputer secara sistematik sehingga dapat diperiksa
- Menurut Tanenbaum (2000:2), Jaringan Komputer merupakan kumpulan dari perangkat keras dan lunak di dalam suatu sistem yang memiliki aturan tertentu untuk mengatur
Basis data (Database) adalah kumpulan informasi yang disimpan di dalam komputer secara sistematik, sehingga data digunakan oleh suatu program komupter untuk
Quality of service (Qos) adalah sebuah tata cara atau protocol untuk memberikan kemampuan kepada seorang admin jaringan komputer pada sebuah jaringan komputer yang telah
Oleh karena itu, sumber data yang digunakan dalam text mining adalah kumpulan teks dengan format tidak terstruktur atau minimal semi terstruktur [18].. Adapun tugas
Virtual machine adalah perangkat lunak yang dapat mengisolasi sebuah mesin komputer serta dapat menjalankan semua program seperti komputer aslinya atau duplikat
Basis data (Database) adalah kumpulan informasi yang disimpan di dalam komputer secara sistematik, sehingga data digunakan oleh suatu program komupter untuk
Dynamic Host Configuration Protokol (DHPC) adalah layanan yang secara otomatis memberikan nomor IP kepada komputer yang memintanya. Komputer yang memberikan nomor IP
