PENENTUAN INDIKATOR PRIORITAS PEMBANGUNAN DESA MENGGUNAKAN METODE SELEKSI FITUR
Teks penuh
Gambar
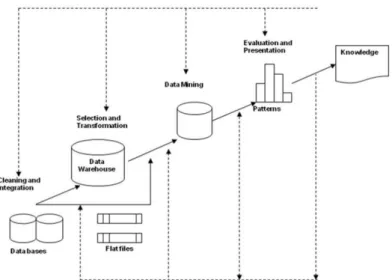
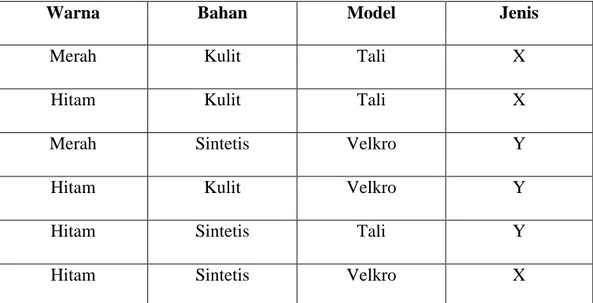

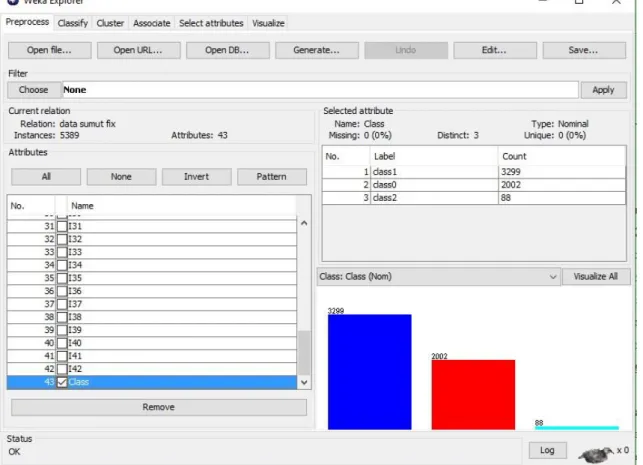
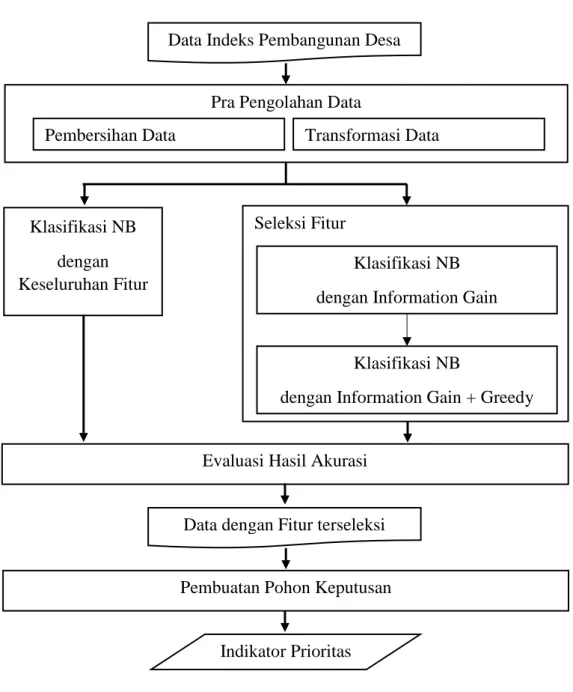
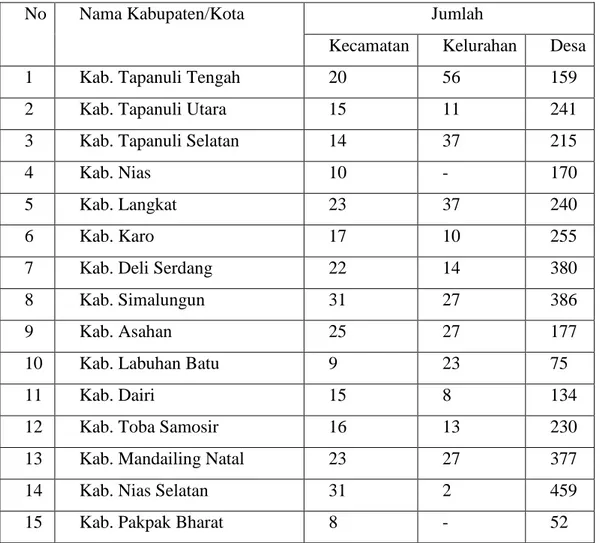
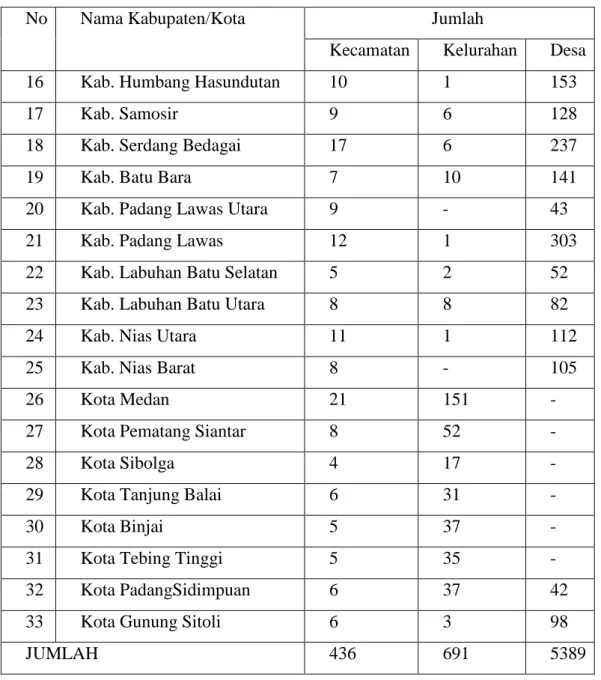
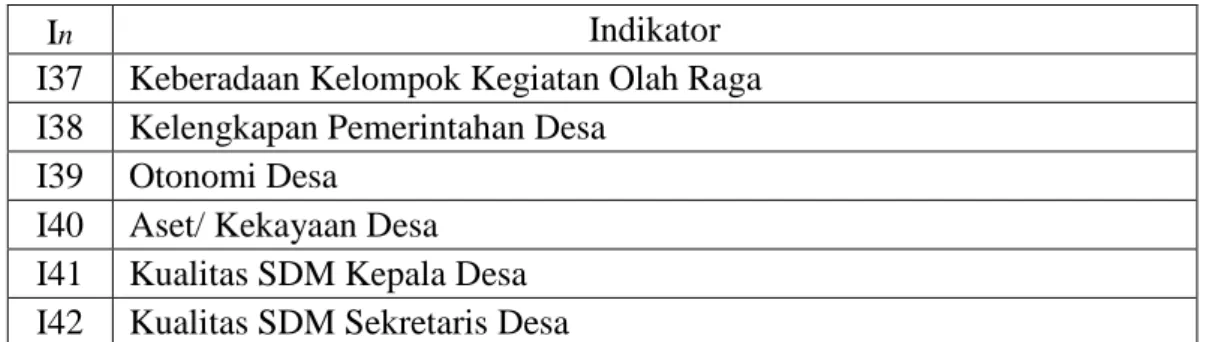
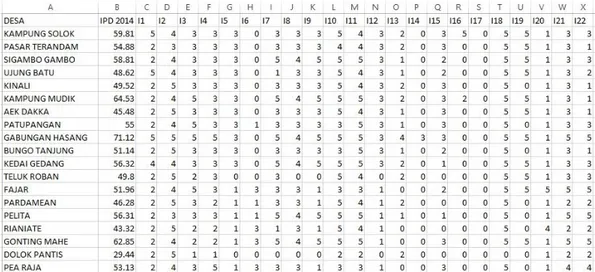
Dokumen terkait
Cardinality relationship menunjukkan berapa banyak kejadian pada suatu entity dalam relationship yang dapat dihubungkan dengan satu kejadian dari entity lain dalam
Secara aspek hukum dan sejarah, Tambrauw di mekarkan sejak tahun 2008 dengan kabupaten induk kabupaten Kabupaten Sorong yang dibentuk berdasarkan Undang-Undang No. 56
Karena Nilai Z hitung untuk variabel abnormal return saham lebih besar dari nilai Z tabel , maka pada tingkat kekeliruan 5% H 0 ditolak dan H 3 diterima, sehingga
Marah Labid li Kashf Ma’na al-Quran al-Majid. Karya ini bukan sahaja mentafsirkan ayat-ayat al-Quran dengan lengkap, bahkan beliau turut menghuraikan perbezaan
HBsAg biasanya positif selama beberapa gejala klinis dari penyakit masih ada, dan baru menghilang beberapa minggu (1-12 minggu) kemudian HBsAg yang menetap lebih dari 6 bulan
Korelasi yang kuat antara dukungan kelembagaan non formal dengan tingkat partisipasi masyarakat, artinya makin tinggi dukungan kelembagaan non formal maka makin
Hasil uji parsial nilai tukar terhadap harga saham perushaan ANTM diperoleh sig-value sebesar 0,001 <α maka nilai tukar berpengaruh secara parsial terhadap harga
Hasil penelitian menunjukan bahwa penambahan jamur tiram putih 15% memberikan karakteristik bakso terbaik yaitu Karbohidrat 25,56% , lemak 2,31%, protein 11,76% serat kasar 0,71%
