0 Orasi Ilmiah, Wisuda AMIK – AKPER IMELDA 30 Agustus 2016
ORASI ILMIAH
Pemanfaatan Teknologi Big Data Dalam
Perspektif Ilmu Komputer dan Kesehatan
Oleh:
Dr. Zakarias Situmorang, MT
DISAMPAIKAN PADA WISUDA
AKADEMIK MANAJEMEN INFORMATIKA KOMPUTER IMELDA
DAN AKADEMIK KEPERAWATAN IMELDA
MEDAN
1 Orasi Ilmiah, Wisuda AMIK – AKPER IMELDA 30 Agustus 2016 Intisari
Pemakaian data sudah berkembang pesat pada zaman yang dipenuhi dengan teknologi ini. Data dapat menjelaskan tren, memvalidasi klaim, dan mengurangi jumlah kesalahan manusia dalam proses pengambilan keputusan. Big Data adalah data dengan ciri berukuran sangat besar, sangat variatif, sangat cepat pertumbuhannya dan mungkin tidak terstruktur yang perlu diolah khusus dengan teknologi inovatif sehingga mendapatkan informasi yang mendalam dan dapat membantu pengambilan keputusan yang lebih baik.
Dari Pemerintahan, Industri kesehatan, Perguruan Tinggi, Perusahaan asuransi dan bank, Big data mengubah bagaimana kita memahami dunia, melakukan bisnis dan melaksanakan kebijakan publik. Karena semakin banyak perusahaan menyadari nilai dari penerapan strategi Big Data, dan akhirnya akan membentuk link terakhir dari rantai nilai yang akan membantu perusahaan meningkatkan operasional lebih efisien dari investasi yang ada.
Pemanfaatan Big data dalam dunia ilmu komputer memberikan peluang analisis data berupa pembuatan software dan bahasa pemrograman statistic, Software platform yang menghubungkan beberapa komputer sehingga dapat saling bekerja sama dan sinkron dalam menyimpan dan mengolah data sebagai satu kesatuan. Pemanfaatan Rekam Medis Elektronik sangat berkembang, yang diikuti dengan pertumbuhan data yang sangat besar, baik secara kuantitas (hasil laboratorim), kualitatif (catatan-catatan), atau transaksional (pemesanan obat), lebih dari itu, proyek-proyek genomics yang makin banyak, perubahan focus ke pelayanan pengobatan yang personal akan memaksa organisasi-organisasi kesehatan beralih ke pengelolaan data yang memanfaatkan teknik Big Data
2 Orasi Ilmiah, Wisuda AMIK – AKPER IMELDA 30 Agustus 2016 I. Pendahuluan
Perkembangan zaman hingga saat ini sangat berdampak besar terhadap kehidupan sekarang. Salah satu hal yang berubah adalah cara menggunakan data. Hal tersebut sangat dipengaruhi oleh perkembangan teknologi, karena dapat dilihat sekarang penggunaan tiap individu terhadap data sudah sangat tinggi, hampir semua orang memiliki data dalam setiap perangkatnya (komputer / laptop, smartphone, flashdisk, harddisk eksternal, dll) yang jika dijumlahkan akan menjadi besar sekali. Hal ini dipengaruhi juga dengan mudahnya tiap individu untuk mendapatkan data yang diinginkannya (film, musik, games, foto) melalui internet. Internet menghubungkan tiap individu di seluruh dunia dengan mudah tanpa memperdulikan jarak / lokasi dan waktu. Sekarang dengan terjadinya perkembangan teknologi, data menjadi hal yang penting dalam menjalankan berbagai hal, beberapa diantaranya; mengetahui tren pasar, mengetahui keinginan konsumen saat ini, meningkatkan hasil penjualan, dll. Hasil perubahan ini sangatlah besar, data pun diolah dengan lebih terkomputerisasi sehingga penyimpanan beberapa data dapat menghemat tempat dalam kantor perusahaan dengan cara penyimpanan softcopy. Data yang tersimpan ini lama kelamaan menjadi sangat banyak dan besar sehingga semakin susah untuk digunakan, hal tersebut disebut big data. Dengan perkembangan sekarang, big data ini sudah dapat diolah dan digunakan lagi, bahkan memberikan hasil yang lebih baik karena mencakup pengolahan data yang ada di dalam sosial media.
Big Data adalah lautan informasi yang kita selami tiap hari, sebesar zetabytes yang mengalir dari komputer kita, perangkat mobile, dan sensor mesin. Tetapi mungkin kejutan terbesar bagi kita adalah sangat beragam penggunaan big data, dan bagaimana hal itu sudah mengubah keseharian manusia. Banyak orang melihat big data melalui lensa ekonomi internet, karena Google dan Facebook memiliki begitu banyak data. Pengguna Facebook berbagi hampir 2,5 juta konten, Pengguna Twitter me-tweet hampir 300.000 kali, Pengguna Instagram me-posting hampir 220.000 foto baru, pengguna YouTube mengunggah 72 jam konten video baru, Apple pengguna men-download hampir 50.000 aplikasi, Pengguna email mengirim lebih dari 200 juta pesan, Amazon menghasilkan lebih dari $ 80.000 dalam penjualan online.
Dan dari analisis data ditemukan fakta baru:
1. Butuh dari awal peradaban hingga tahun 2003, dunia untuk menghasilkan 1,8 zettabytes data. Pada tahun 2011, cukup membutuhkan dua hari untuk menghasilkan jumlah data yang sama.
2. Pada tahun 2011 ada 12 juta tag RFID terjual di seluruh dunia. Angka itu diproyeksikan menjadi 209 milyar pada tahun 2021.
3. Ada 750 juta foto diunggah ke Facebook setiap dua hari
4. 1/3 dari semua data akan disimpan dalam cloud pada tahun 2020
5. Terdapat bit informasi digital di alam semesta ini sebanyak bintang di alam semesta kita yang sebenarnya.
6. Ada lebih dari 247 miliar e-mail yang dikirim setiap hari. 80% dari email tersebut adalah spam.
7. 48 jam video diunggah ke YouTube tiap menit.
3 Orasi Ilmiah, Wisuda AMIK – AKPER IMELDA 30 Agustus 2016
9. Jumlah teks pesan yang dikirim dan diterima setiap hari melebihi jumlah populasi di bumi
10. Twitter memproses 7 terabyte data setiap hari 11. Facebook memproses 10 terabyte data setiap hari
12. Decoding genom manusia membutuhkan 10 tahun untuk diproses; sekarang dapat dicapai dalam satu minggu
13. 571 situs-situs baru dibuat setiap menit
14. Google memiliki lebih dari 3 juta server pengolahan, dengan lebih dari 1,7 triliun pencarian tiap tahun pada tahun 2011 (22 juta pada tahun 2000)
15. Data center mengkonsumsi hingga 1,5 persen dari seluruh listrik di dunia. Dengan perkembangan data inilah big data muncul dan saat ini mulai berkembang. Penggunaannya pun semakin luas, hingga mencakup social media, sehingga dapat menganalisa tren pasar dengan melihat sentimen analisis pelanggan melalui social media. Dengan perkembangan saat ini, ada baiknya untuk memahami lebih dalam mengenai big data, sehingga dapat dimanfaatkan dengan lebih maksimal.
I.1. Pengertian Data, Informasi dan Pengetahuan
(R. Kelly Rainer, 2011) Data, menunjuk pada deskripsi dasar akan benda, event, aktivitas, dan transaksi yang terdokumentasi, terklasifikasi,dan tersimpan tetapi tidak terorganisasi untuk dapat memberikan suatu arti yang spesifik. Berdasarkan pengertian di atas, data merupakan hal paling mendasar yang dibutuhkan perusahaan yang dapat diperoleh dari proses-proses operasional sehari-hari maupun sumber-sumber luar yang akan diolah menurut keinginan perusahaan.
Information, merupakan data yang telah terorganisir agar dapat memberikan arti dan nilai kepada penerima. Berdasarkan pengertian di atas, hasil penyusunan dan transformasi data yang dapat memberikan makna baru kepada data tersebut.
Pengetahuan terdiri dari data atau informasi yang telah terorganisasi dan proses untuk memberikan pemahaman, pengalaman, dan pembelajaran, serta keahlian terhadap problema bisnis yang sedang dihadapi. Berdasarkan pengertian di atas, pengetahuan (knowledge) menjadi sarana bagi para manajer untuk membuat keputusan - keputusan yang crucial dan berdampak besar bagi perusahaan, dimana kesalahan atau kecacatan dalam knowledge dapat memberikan dampak buruk bagi perusahaan.
I.2. Pengertian Data Warehouse
(R. Kelly Rainer, 2011) Data Warehouse adalah repository dari data-data yang bersifat historical yang terorganisir berdasarkan subjek yang digunakan untuk mendukung pengambilan keputusan. Data warehouse memiliki beberapa karakter dasar seperti. Diatur oleh business dimension or subject dimana data disusun berdasarkan subjeknya dan memiliki informasi yang relevan dengan pemgambilan keputusan dan analisis data.consistent yaitu data memliki bentuk yang sama disetiap atau disemua database. Historical, data yang ada merupakan data yang tersimpan dan terkumupl dalam waktu yang lama yang digunakan untuk forecasting dan perbandingan untuk meliat tingakt laju suatu perusahaan. Use only analytical
4 Orasi Ilmiah, Wisuda AMIK – AKPER IMELDA 30 Agustus 2016
data-data yang ada. Multidimensional, data warehouse menyimpan data dalam lebih dari dua dimensi seperti data cube.
Data warehouse merupakan bagian penting dalam struktur / arsitektur suatu BI karena posisinya sebagai tempat penyimpanan data- data yang telah terorganisasi dan yang telah memiliki makna, maka harus memilki struktur data desain yang baik yang dapat mensupport pengambilan data-data dan informasi secara akurat dan cepat dari dalam data warehouse itu sendiri.
I.3. Pengertian Big Data
Menurut (Eaton, Dirk, Tom, George, & Paul) Big Data merupakan istilah yang berlaku untuk informasi yang tidak dapat diproses atau dianalisis menggunakan alat tradisional.
Menurut (Dumbill, 2012) , Big Data adalah data yang melebihi proses kapasitas dari kovensi sistem database yang ada. Data terlalu besar dan terlalu cepat atau tidak sesuai dengan struktur arsitektur database yang ada. Untuk mendapatkan nilai dari data, maka harus memilih jalan altenatif untuk memprosesnya.
Berdasarkan pengertian para ahli di atas, dapat disimpulkan bahwa Big Data adalah data yang memiliki volume besar sehingga tidak dapat diproses menggunakan alat tradisional biasa dan harus menggunakan cara dan alat baru untuk mendapatkan nilai dari data ini
"Big Data adalah data dengan ciri berukuran sangat besar, sangat variatif, sangat cepat pertumbuhannya dan mungkin tidak terstruktur yang perlu diolah khusus dengan teknologi inovatif sehingga mendapatkan informasi yang mendalam dan dapat membantu pengambilan keputusan yang lebih baik."
II. Big Data
Setiap hari, kita menciptakan 2,5 triliun byte data - begitu banyak bahwa 90% dari data di dunia saat ini telah dibuat dalam dua tahun terakhir saja. Data ini berasal dari mana-mana, sensor digunakan untuk mengumpulkan informasi iklim, posting ke situs media sosial, gambar digital dan video, catatan transaksi pembelian, dan sinyal ponsel GPS untuk beberapa nama. Data ini adalah Big Data. Big Data mengacu pada dataset yang ukurannya diluar kemampuan dari database software tools untuk meng-capture, menyimpan,me-manage dan menganalisis. Definisi ini sengaja dibuat subjective agar mampu digabungkan oleh definisi Big Data yang masi belum ada baku. Ukuran big data sekitar beberapa lusin TeraByte sampai ke beberapa PetaByte tergantung jenis Industri
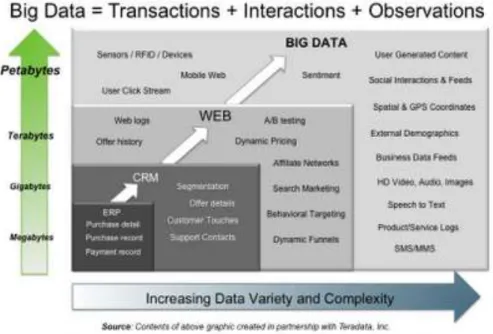
Isi dari Big Data adalah Transaksi+interaksi dan observasi atau bisa di bilang segalanya yang berhubungan dengan jaringan internet, jaringan komunikasi, dan jaringan satelit, seperti terlihat pada gambar 1. Big Data dapat juga didefinisikan sebagai sebuah masalah domain dimana teknologi tradisional seperti relasional database tidak mampu lagi untuk melayani. Big data lebih dari hanya masalah ukuran, itu adalah kesempatan untuk menemukan wawasan dalam jenis baru dan muncul data dan konten, untuk membuat bisnis Anda lebih gesit, dan menjawab pertanyaan yang sebelumnya dianggap di luar jangkauan Anda.
5 Orasi Ilmiah, Wisuda AMIK – AKPER IMELDA 30 Agustus 2016 Gambar 1. Isi Big data (Connolly, 2012)
II.1. Dimensi -Dimensi Big Data
Dimensi big data: berukuran sangat besar volume), atau sangat bervariasi
(high-variety), atau kecepatan pertumbuhan tinggi (high-velocity), dan sangat tidak jelas (high veracity) sering disebut dengan 4V's of Big Data. Teknologi Big Data diciptakan untuk
menangani keempat ciri di atas. Jadi jika data Anda memiliki satu ciri saja atau beberapa kombinasi ciri di atas, tentunya dapat memanfaatkan teknologi Big Data yang tersedia di pasaran.
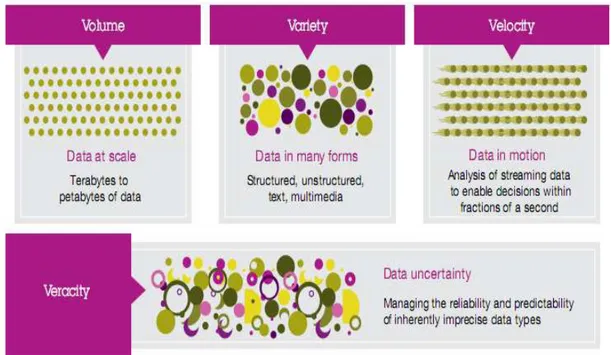
Ada 3 dimensi dari Big Data yang jelas yaitu Volume, Variety dan Velocity dn disajikan pada gambar 2.
6 Orasi Ilmiah, Wisuda AMIK – AKPER IMELDA 30 Agustus 2016
Volume
Perusahaan tertimbun dengan data yang terus tumbuh dari semua jenis sektor, dengan mudah mengumpulkan terabyte bahkan petabyte-informasi. Contoh,
Mengubah 12 terabyte Tweet dibuat setiap hari ke dalam peningkatan sentimen analisis produk.
Mengkonvert 350 milliar pembacaan tahunan untuk lebih baik dalam memprediksi kemampuan beli pasar.
Mungkin karakteristik ini yang paling mudah dimengerti karena besarnya data. Volume juga mengacu pada jumlah massa data, bahwa organisasi berusaha untuk memanfaatkan data untuk meningkatkan pengambilan keputusan yang banyak perusahaan di banyak negara. Volume data juga terus meningkat dan belum pernah terjadi sampai sethinggi ini sehingga tidak dapat diprediksi jumlah pasti dan juga ukuran dari data sekitar lebih kecil dari petabyte sampai zetabyte. Dataset big data sekitar 1 terabyte sampai 1 petabyte perperusahaan jadi jika big data digabungkan dalam sebuah organisasi / group perusahaan ukurannya mungkin bisa sampai zetabyte dan jika hari ini jumlah data sampai 1000 zetabyte, besok pasti akan lebih tinggi dari 1000 zetabyte.
Variety
Volume data yang banyak tersebut bertambah dengan kecepatan yang begitu cepat sehingga sulit bagi kita untuk mengelola hal tersebut. Kadang-kadang 2 menit sudah menjadi terlambat. Untuk proses dalam waktu sensitif seperti penangkapan penipuan, data yang besar harus digunakan sebagai aliran ke dalam perusahaan Anda untuk memaksimalkan nilainya.
Meneliti 5 juta transaksi yang dibuat setiap hari untuk mengidentifikasi potensi penipuan
Menganalisis 500 juta detail catatan panggilan setiap hari secara real-time untuk memprediksi gejolak pelanggan lebih cepat.
Berbagai jenis data dan sumber data. Variasi adalah tentang mengelolah kompleksitas beberapa jenis data, termasuk structured data, unstructured data dan semi-structured data. Organisasi perlu mengintegrasikan dan menganalisis data dari array yang kompleks dari kedua sumber informasi Traditional dan non traditional informasi, dari dalam dan luar perusahaan. Dengan begitu banyaknya sensor, perangkat pintar (smart device) dan teknologi kolaborasi sosial, data yang dihasilkan dalam bentuk yang tak terhitung jumlahnya, termasuk text, web data, tweet, sensor data, audio, video, click stream, log file dan banyak lagi.
Velocity :
Big Data adalah setiap jenis data - data baik yang terstruktur maupun tidak
terstruktur seperti teks, data sensor, audio, video, klik stream, file log dan banyak lagi. Wawasan baru ditemukan ketika menganalisis kedua jenis data ini bersama-sama.
Memantau 100 video masukan langsung dari kamera pengintai untuk menargetkan tempat tujuan.
7 Orasi Ilmiah, Wisuda AMIK – AKPER IMELDA 30 Agustus 2016
Mengeksploitasi 80% perkembangan data dalam gambar, video, dan dokumen untuk meningkatkan kepuasan pelanggan.
Data dalam gerak. Kecepatan di mana data dibuat, diolah dan dianalisis terus menerus. Berkontribusi untuk kecepatan yang lebih tinggi adalah sifat penciptaan data secara real-time, serta kebutuhan untuk memasukkan streaming data ke dalam proses bisnis dan dalam pengambilan keputusan. Dampak Velocity latency, jeda waktu antara saat data dibuat atau data yang ditangkap, dan ketika itu juga dapat diakses. Hari ini, data terus-menerus dihasilkan pada kecepatan yang mustahil untuk sistem tradisional untuk menangkap, menyimpan dan menganalisis. Jenis tertentu dari data harus dianalisis secara real time untuk menjadi nilai bagi bisnis.
II.2. Dimensi Ketidakpastian data
Gambar 3. Big Data dalam dimensi (IBM)
Dalam industri untuk meningkatan sebuah data lebih berkualitas dibutuhkan dimensi ke empat yaitu Veracity, pencantuman Veracity dapat menekankan pengelolahan dan penanganan untuk suatu ketidakpastian yang melekat dalam beberapa jenis data, seperti pada gambar 3.
Veracity
1 dari 3 pemimpin bisnis tidak mempercayai informasi yang mereka gunakan untuk membuat keputusan. Bagaimana Anda dapat bertindak atas informasi yang anda tidak percaya? Membangun kepercayaan atas big data menghadirkan tantangan besar sebagai variasi dan sumber untuk pertumbuhan perusahaan.
8 Orasi Ilmiah, Wisuda AMIK – AKPER IMELDA 30 Agustus 2016
Ketidakpastian data. Veracity mengacu pada tingkat keandalan yang terkait dengan jenis tertentu dari data. Berjuang untuk kualitas data yang tinggi merupakan syarat big data penting dan tantangan, tapi bahkan metode pembersihan data yang terbaik tidak dapat menghapus ketidakpastian yang melekat pada beberapa data, seperti cuaca, ekonomi, atau aktual keputusan membeli pelanggan masa depan. Kebutuhan untuk mengakui dan merencanakan ketidakpastian adalah dimensi data besar yang telah diperkenalkan sebagai eksekutif berusaha untuk lebih memahami dunia di sekitar mereka.
Beberapa data tidak pasti, misalnya: sentimen dan kebenaran pada manusia, sensor GPS memantul antara pencakar langit Manhattan, cuaca kondisi-kondisi, faktor ekonomi, dan masa depan. Ketika berhadapan dengan jenis data, tidak ada metode pembersihan data dapat memperbaiki untuk semua itu. Namun, meski ketidakpastian, data masih mengandung informasi yang berharga. Kebutuhan untuk mengakui dan menerima ketidakpastian ini merupakan ciri dari data.Uncertainty besar memanifestasikan dirinya dalam data besar dalam banyak cara. Sekarang dalam skeptisisme yang mengelilingi data yang dibuat dalam lingkungan manusia seperti jaringan sosial, dalam ketidaktahuan bagaimana masa depan akan terungkap dan bagaimana orang-orang, alam atau kekuatan pasar yang tak terlihat akan bereaksi terhadap variabilitas dari dunia di sekitar mereka.
Untuk mengelola ketidakpastian, analis perlu menciptakan konteks sekitar data. Salah satu cara untuk mencapai ini adalah melalui data fusion, di mana menggabungkan beberapa sumber yang kurang dapat diandalkan menciptakan lebih akurat dan berguna point data, seperti komentar sosial ditambahkan ke geospasial informasi lokasi. Cara lain untuk mengelola ketidakpastian adalah melalui matematika canggih yang mencakup hal itu, seperti teknik optimasi yang kuat dan pendekatan fuzzy logic. Manusia secara alami, tidak menyukai ketidakpastian, tetapi hanya mengabaikannya dapat menciptakan lebih banyak masalah daripada ketidakpastian itu sendiri. Dalam era big data, eksekutif akan perlu pendekatan dimensi ketidakpastian berbeda. Mereka akan perlu untuk mengakuinya, menerimanya dan menentukan.
II.3. Arsitektur Big Data
Untuk memahami level aspek arsitektur yang tinggi dari Big Data, sebelumnya harus memahami arsitektur informasi logis untuk data yang terstruktur. Pada gambar 4. menunjukkan dua sumber data yang menggunakan teknik integrasi (ETL / Change Data Capture) untuk mentransfer data ke dalam DBMS data warehouse atau operational data store, lalu menyediakan bermacam-macam variasi dari kemampuan analisis untuk menampilkan data. Beberapa kemampuan analisis ini termasuk,; dashboards, laporan, EPM/BI Applications, ringkasan dan query statistic, interpretasi semantic untuk data tekstual, dan alat visualisasi untuk data yang padat. Informasi utama dalam prinsip arsitektur ini termasuk cara memperlakukan data sebagai asset melalui nilai, biaya, resiko, waktu, kualitas dan akurasi data.
9 Orasi Ilmiah, Wisuda AMIK – AKPER IMELDA 30 Agustus 2016 Gambar 4. Arsitektur Big Data terstruktur (Sun & Heller, 2012, p. 11)
Mendefinisikan kemampuan memproses untuk big data architecture, diperlukan beberapa hal yang perlu dilengkapi; volume, percepatan, variasi, dan nilai yang menjadi tuntutan. Ada strategi teknologi yang berbeda untuk real-time dan keperluan batch processing. Untuk real-time, menyimpan data nilai kunci, seperti NoSQL, memungkinkan untuk performa tinggi, dan pengambilan data berdasarkan indeks. Untuk batch processing, digunakan teknik yang dikenal sebagai Map
Reduce, memfilter data berdasarkan pada data yang spesifik pada strategi
penemuan. Setelah data yang difilter ditemukan, maka akan dianalisis secara langsung, dimasukkan ke dalam unstructured database yang lain, dikirimkan ke dalam perangkat mobile atau digabungkan ke dalam lingkungan data warehouse tradisional dan berkolerasi pada data terstruktur.
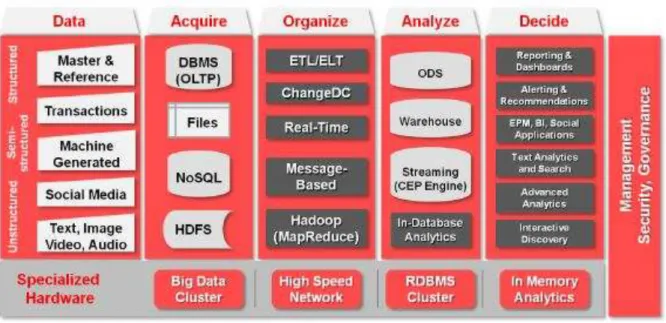
Gambar 5. Arsitektur Big Data tidak terstruktur (Sun & Heller, 2012, p. 11)
Sebagai tambahan untuk unstructured data yang baru (Gambar 5), ada dua kunci perbedaan untuk big data. Pertama, karena ukuran dari data set, raw data tidak dapat secara langsung dipindahkan ke dalam suatu data warehouse. Namun, setelah proses Map Reduce ada kemungkinan akan terjadi reduksi hasil dalam lingkungan data warehouse sehingga dapat memanfaatkan pelaporan business
intelligence, statistik, semantik, dan kemampuan korelasi yang biasa. Akan sangat
ideal untuk memiliki kemampuan analitik yang mengkombinasikan perangkat BI bersamaan dengan visualisasi big data dan kemampuan query. Kedua, untuk memfasilitasi analisis dalam laingkungan Hadoop, lingkungan sandbox dapat dibuat.
Untuk beberapa kasus, big data perlu mendapatkan data yang terus berubah dan tidak dapat diperkirakan, untuk menganilisis data tersebut, dibutuhkan arsitektur yang baru. Dalam perusahaan retail, contoh yang bagus adalah dengan menangkap jalur lalu lintas secara real-time dengan maksud untuk memasang iklan atau promosi toko di tempat strategis yang dilewati banyak orang, mengecek peletakan barang dan promosi, mengamati secara langsung pergerakan dan tingkah laku pelanggan.
Dalam kasus lain, suatu analisis tidak dapat diselesaikan sampai dihubungkan dengan data perusahaan dan data terstruktur lainnya. Sebagai contohnya, analisis perasaan pelanggan, mendapatkan respon positif atau negatif
10 Orasi Ilmiah, Wisuda AMIK – AKPER IMELDA 30 Agustus 2016
dari social media akan memiliki suatu nilai, tetapi dengan mengasosiasikannya dengan segala macam pelanggan (paling menguntungkan atau bahkan yang paling tidak menguntungkan) akan memberikan nilai yang lebih berharga. Jadi, untuk memenuhi kebutuhan yang diperlukan oleh big data BI adalah konteks dan pemahaman. Menggunakan kekuatan peralatan statistikal dan semantik akan sangat memungkinkan untuk dapat memprediksikan kemungkinan – kemungkinan di masa depan.
Salah satu tantangan yang diteliti dalam pemakaian Hadoop dalam perusahaan adalah kurangnya integrasi dengan ekosistem BI yang ada. Saat ini BI tradisional dan ekosistem big data terpisah dan menyebabkan analis data terintegrasi mengalami kebingungan. Sebagai hasilnya, hal ini tidaklah siap untuk digunakan oleh pengguna bisnis dan eksekutif biasa.
Pengguna big data yang pertama kali mencoba menggunakan, seringkali menulis kode khusus untuk memindahkan hasil big data yang telah diproses kembali ke dalam database untuk dibuat laporan dan dianalisa. Pilihan – pilihan ini mungkin tidak layak dan ekonomis untuk perusahaan IT. Pertama, karena menyebabkan penyebaran salah satu data dan standar yang berbeda, sehingga arsitekturnya mempengaruhi ekonomi IT. Big data dilakukan secara independen untuk menjalankan resiko investasi yang redundan, sebagai tambahannya, banyak bisnis yang sama sekali tidak memiliki staff dan ketrampilan yang dibutuhkan untuk pengembangan pekerjaan yang khusus.
Pilihan yang paling tepat adalah menggabungkan hasil big data ke dalam data warehouse. Kekuatan informasi ada dalam kemampuan untuk asosiasi dan korelasi. Maka yang dibutuhkan adalah kemampuan untuk membawa sumber data yang berbeda-beda, memproses kebutuhan bersama – sama secara tepat waktu dan analisis yang berharga.
Gambar 6. Proses DBMS tradisional, simple files (Sun & Heller, 2012, p. 13)
Ketika bermacam – macam data telah didapatkan, data tersebut dapat disimpan dan diproses ke dalam DBMS tradisional, simple files, atau sistem cluster terdistribusi seperti NoSQL dan Hadoop Distributed File System (HDFS).
11 Orasi Ilmiah, Wisuda AMIK – AKPER IMELDA 30 Agustus 2016
Secara arsitektur, komponen kritikal yang memecah bagian tersebut adalah layer integrasi yang ada di tengah. Layer integrasi ini perlu untuk diperluas ke seluruh tipe data dan domain, dan menjadi jembatan antara data penerimaan yang baru dan tradisional, dan pengolahan kerangka. Kapabilitas integrasi data perlu untuk menutupi keseluruhan spektrum dari kecepatan dan frekuensi. Hal tersebut diperlukan untuk menangani kebutuhan ekstrim dan volume yang terus bertambah banyak. Oleh karena itu diperlukan teknologi yang memungkinkan untuk mengintegrasikan Hadoop / Map Reduce dengan data warehouse dan data transaksi.
Layer berikutnya digunakan untuk Load hasil reduksi dari big data ke dalam data warehouse untuk analisis lebih lanjut. Diperlukan juga kemampuan untuk mengakses data terstruktur seperti informasi profil pelanggan ketika memproses dalam big data untuk mendapatkan pola seperti mendeteksi aktivitas yang mencurigakan.
Hasil pemrosesan data akan dimasukkan ke dalam ODS tradisional, data warehouse, dan data marts untuk analisis lebih lanjut seperti data transaksi. Komponen tambahan dalam layer ini adalah Complex Event Processing untuk menganalisa arus data secara real-time. Layer business intelligence akan dilengkapi dengan analisis lanjutan, dalam analisis database statistik, dan visualisasi lanjutan, diterapkan dalam komponen tradisional seperti laporan, dashboards, dan query. Pemerintahan, keamanan, dan pengelolaan operasional juga mencakup seluruh spektrum data dan lanskap informasi pada tingkat enterprise.
Dengan arsitektur ini, pengguna bisnis tidak melihat suatu pemisah, bahkan tidak sadar akan perbedaan antara data transaksi tradisional dan big data. Data dan arus analisis akan terasa mulus tanpa halangan ketika dihadapkan pada bermacam – macam data dan set informasi, hipotesis, pola analisis, dan membuat keputusan.
III. Teknologi Big Data
12 Orasi Ilmiah, Wisuda AMIK – AKPER IMELDA 30 Agustus 2016
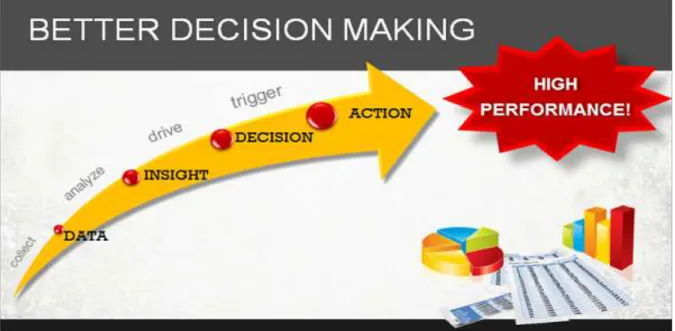
Teknologi Big Data adalah teknologi yang memungkinkan proses pengolahan data dengan empat ciri di atas. Sebelum munculnya teknologi ini, pengolahan data hampir selalu dilakukan oleh programmer dan sangat memakan waktu. Proses ini bertujuan agar setiap bisnis, organisasi ataupun individu yang mampu mengolah data tersebut bisa mendapatkan informasi lebih mendalam (insights) yang akan memicu pengambilan keputusan (decision making) dan tindakan (action) bisnis yang mengandalkan insights tersebut, bukan berdasarkan insting semata. Dari Data Menjadi Tindakan untuk Menaikkan Kinerja Perusahaan (gambar 7), dengan contoh-contoh berikut:
III.1. Analisa Perilaku Belanja Konsumen
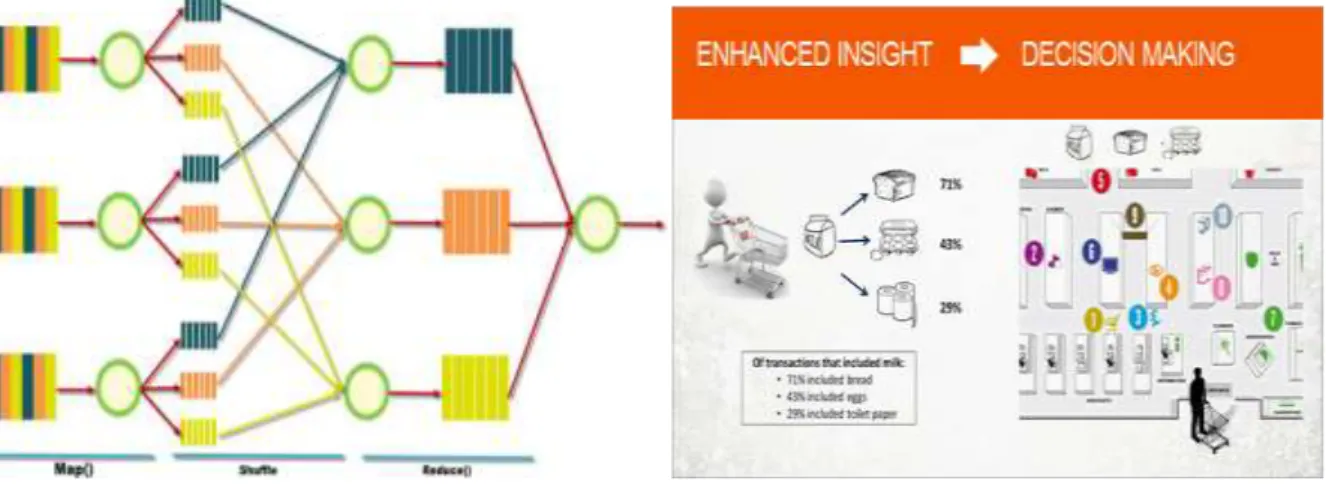
Data struk belanja yang dimiliki oleh perusahaan ritel dapat digunakan untuk meneliti perilaku konsumennya. Data dari tiap struk transaksi tentunya berisi kombinasi produk-produk yang Anda beli, jumlah dan harganya. Seluruh data transaksi tersebut kemudian dicari pola belanja untuk menjawab pertanyaan: kombinasi dua atau tiga produk apa saja yang paling sering dibeli oleh konsumen. Dari hasil informasi tersebut ada beberapa tindakan menarik yang dapat dilakukan, diantaranya: menyusun rak belanja agar dua atau tiga produk tersebut berdekatan sehingga mudah dijangkau oleh konsumen dan dapat diputuskan untuk dibeli dengan cepat. Kemudian bisa membuat paket promosi dimana kombinasi produk-produk tersebut dijual lebih murah.
Tindakan ini terbukti dapat meningkatkan penjualan secara signifikan dan mengurangi masalah inventori / stok, seperti terlihat pada gambar 8.
Gambar 8. Shopping Basket Analysis
Awalnya, permasalahan ini kelihatan mudah dan bisa dipecahkan dengan program spreadsheet seperti Excel. Namun, tahukah Anda jika Anda memiliki 1000 item SKU (produk) dari seluruh struk transaksi maka Anda sudah memiliki 999,000 kombinasi dua produk yang perlu dicek kembali ke data-data transaksi. Berapa lama waktu yang Anda perlukan dengan menggunakan spreadsheet? Dua minggu? Sebulan? Namun, jika digabungkan dengan penggunaan teknologi data mining mungkin hanya memerlukan waktu beberapa detik atau mungkin paling lama 1 jam.
13 Orasi Ilmiah, Wisuda AMIK – AKPER IMELDA 30 Agustus 2016
Sampai beberapa tahun yang lalu, solusi software dan hardware dari Big Data ini masih sangat mahal dan hanya dapat dimanfaatkan oleh perusahaan berskala besar. Tetapi, dengan kemurahan hati dari komunitas programmer seluruh dunia akhirnya lahir produk-produk teknologi Big Data yang gratis untuk digunakan dan bisa memanfaatkan server yang cukup murah harganya.
Dari pengalaman penulis dan dari berbagai data yang dirilis oleh lembaga riset, Usaha Kecil Menengah (UKM) di Indonesia saat ini sudah banyak memanfaatkan software IT dan produk internet, terutama dalam memasarkan produk mereka melalui website dan marketplace. Data produk, supplier, pelanggan, transaksi pembelian dan penjualan adalah data yang paling banyak dimiliki oleh UKM-UKM ini. Selain itu bagi yang menerapkan sistem IT lebih jauh maka akan menyimpan juga data akuntansi, kepegawaian, penggajian, dan absensi. Walaupun jauh dari besarnya data yang dimiliki perusahaan yang diceritakan di atas, usaha untuk menangani dan memahami data ini tidak kalah besar. Sebagai contoh, tim dari UMN/Kontan banyak menemukan bahwa untuk menghasilkan suatu laporan penjualan bulanan saja banyak UKM membutuhkan waktu cukup lama bahkan sampai berhari-hari. Jika masalah seperti ini masih menjadi kendala, maka ketika UKM ingin menganalisa perilaku pelanggan dari data – sebagai contoh ingin mengetahui apa yang menyebabkan pelanggan yang satu menjadi sangat loyal sedangkan yang lain tidak – tentunya akan menjadi sangat tidak mungkin.
Beruntunglah, software-software Big Data saat ini ternyata banyak dirancang untuk menangani banyak persoalan data mulai dari saat Anda “kecil” dan menggunakan satu server saja, kemudian dapat beradaptasi ketika data bertumbuh semakin besar. Solusi software yang bersahabat dengan UKM sekarang ini banyak tersedia untuk offline maupun online – mulai dari solusi mengintegrasikan data, data mining untuk menemukan perilaku pelanggan dan karyawan, menemukan persepsi positif tidaknya suatu brand di sosial media, pembersihan data kepegawaian, pemetaan sebaran pelanggan, dan lain-lain. Banyak solusi teknologi ini banyak tersedia dengan gratis, namun tetap ada tantangannya – yaitu pada kurangnya pengetahuan apa dan bagaimana pemanfaatan secara praktis. Walaupun sama-sama produk software, penggunaan Big Data ini bisa sangat berbeda dengan penggunaan software operasional bisnis lain. Dan Jika dipelajari dengan baik, maka penggunaannya untuk analisa bisnis akan jauh lebih mudah dan superior.
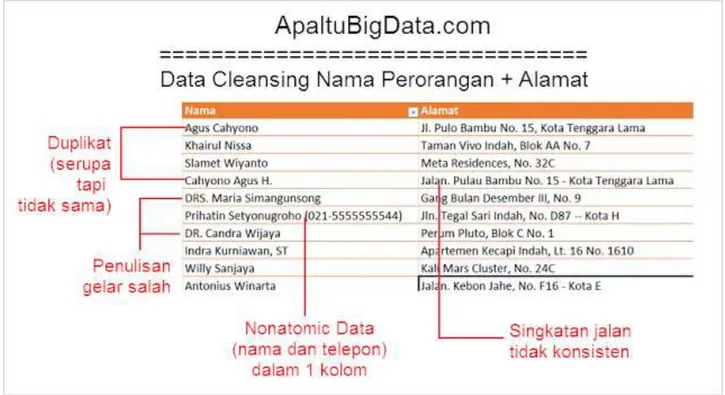
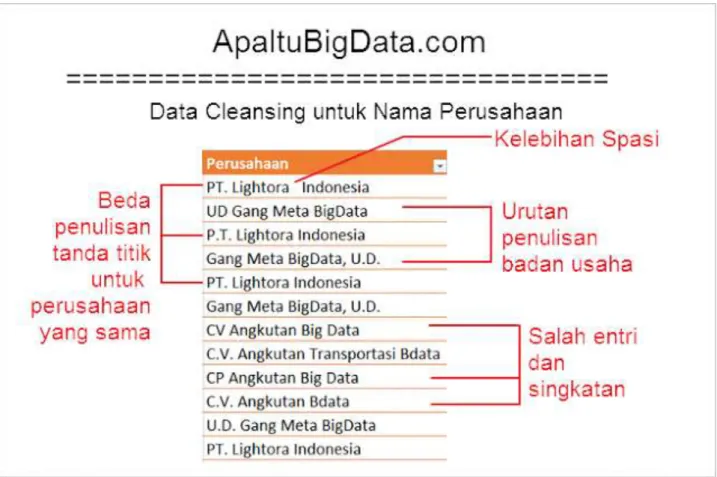
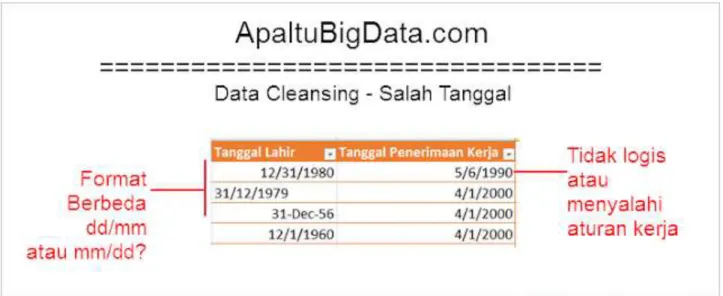
III.2. Proses data cleansing
Data cleansing yang telah ditangani umumnya data mayoritas berasal dari file
Excel. Masih banyak kasus lainnya seperti kesalahan penulisan email, sekolah, nomor KTP, nama ibu kandung, tempat pelatihan, nomor rekening, dan lain-lain. Tapi kasus di atas adalah kasus standar yang dapat memberikan gambaran apa saja tantangan-tantangan di dalam proses data cleansing. Dengan pengalaman berbagai project, kita dapat mempersingkat proses data cleansing dengan sangat signifikan - dari jumlah data puluhan ribu sampai jutaan baris. Proses otomatisasi pembersihan 60% data dari waktu standar 2 minggu menjadi hanya 2 menit, tentunya setelah semua rule didefinisikan dengan baik bersama user. Penghematan dari sisi produktivitas waktu yang digunakan SDM menjadi luar biasa bukan?
14 Orasi Ilmiah, Wisuda AMIK – AKPER IMELDA 30 Agustus 2016 Gambar 9. Nomor Telepon (ApaItuBigData.com)
15 Orasi Ilmiah, Wisuda AMIK – AKPER IMELDA 30 Agustus 2016 Gambar 11. Nama Perusahaan (ApaItuBigData.com)
16 Orasi Ilmiah, Wisuda AMIK – AKPER IMELDA 30 Agustus 2016 Gambar 13. Tanggal (ApaItuBigData.com)
III.3. Proses Big Data Kesehatan
Sebelum Big Data diperkenalkan ke sistem kesehatan, peran data dalam pengobatan pasien terbatas. Rumah sakit akan mengumpulkan data pasien seperti nama, usia, deskripsi penyakit, profil diabetes, laporan medis dan riwayat keluarga penyakit, mana yang berlaku. Data tersebut memberikan pandangan dibatasi dari masalah kesehatan pasien. Sebagai contoh. untuk pasien yang telah didiagnosis dengan penyakit jantung, informasi khas yang dikumpulkan akan sejarah keluarga, diet, gejala, usia dan penyakit lain yang ada. Sementara informasi tersebut memberikan tampilan rinci penyakit, data tidak dapat memberikan perspektif lain dalam masalah. Ada cara lain juga untuk melihat masalah dari yang rencana pengobatan yang lebih baik dapat berpotensi muncul.
Pemanfaatan Rekam Medis Elektronik sangat berkembang akhir-akhir ini, yang diikuti dengan pertumbuhan data yang sangat besar, baik secara kuantitas (misal hasil lab), kualitatif (misal catatan-catatan), atau transaksional (misal pemesanan obat). Lebih dari itu, proyek-proyek genomics yang makin banyak, perubahan focus ke pelayanan pengobatan yang personal akan memaksa organisasi-organisasi kesehatan beralih ke pengelolaan data yang memanfaatkan teknik Big Data.
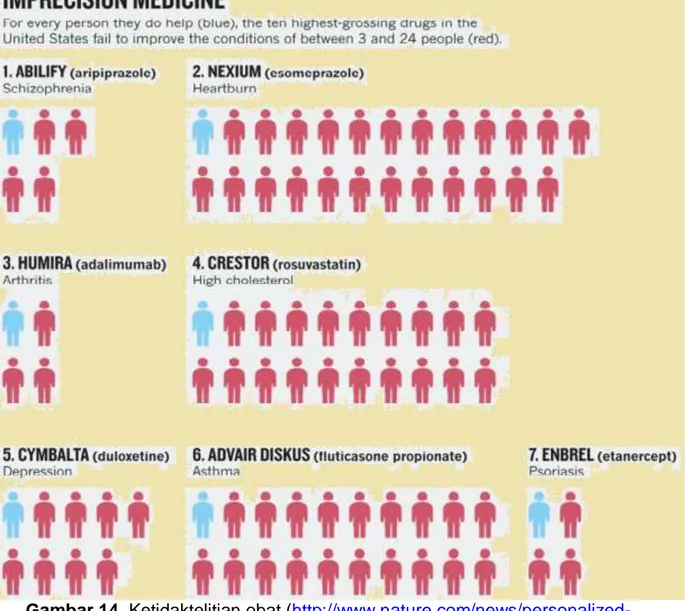
Dalam statistik yang diterbitkan dalam majalah ALAM, telah ditemukan bahwa di antara 10 tertinggi obat terlaris diresepkan di AS hanya membantu 1 di 25 atau 1 dari 4 pasien. Dan untuk obat kolesterol, tingkat keberhasilan hanya 1 dari 50 pasien. Jadi probabilitas keberhasilan sangat rendah dibandingkan dengan pengeluaran yang dilakukan pada penelitian, persetujuan dan kegiatan lainnya, Gambar 14. Gambar 14. di atas menunjukkan efek obat ketidaktepatan pada pasien. Tapi sekarang paradigma tersebut berubah dengan cepat dengan bantuan data besar dan IT.
17 Orasi Ilmiah, Wisuda AMIK – AKPER IMELDA 30 Agustus 2016 Gambar 14. Ketidaktelitian obat (
http://www.nature.com/news/personalized-medicine-time-for-one-person-trials-1.17411)
Big Data telah menambahkan dimensi untuk pengobatan penyakit. Dokter sekarang mampu memahami penyakit yang lebih baik dan memberikan akurat, perawatan pribadi. Mereka juga dapat memprediksi kekambuhan dan menyarankan langkah-langkah preventif. Big Data telah membantu lembaga-lembaga kesehatan mengambil 360 derajat dari masalah kesehatan pasien. Hal ini telah menyebabkan temuan baru, rencana pengobatan baru dan diagnosis yang lebih akurat. Ketersediaan data telah dibawa ke perhatian faktor yang sampai sekarang belum yang berkaitan dengan masalah kesehatan. For example, ras tertentu secara genetik lebih cenderung untuk penyakit jantung daripada ras lain. Now, ketika seorang pasien merupakan salah satu ras seperti menderita penyakit jantung, saatnya untuk memeriksa data pasien milik ras yang sama yang telah mengeluhkan masalah jantung. Ini membantu untuk mengetahui lebih lanjut tentang pasien tersebut - kebiasaan diet, gaya hidup, struktur genetik, DNA keluarga, protein, metabolit ke sel, jaringan, organ, organisme, dan ekosistem. Ini mengikuti perubahan pertama sebenarnya. Ketika seorang pasien dirawat, lembaga kesehatan dapat memperoleh volume besar data yang berarti tentang pasien. Data dapat digunakan untuk memprediksi kekambuhan penyakit dengan tingkat tertentu presisi.
18 Orasi Ilmiah, Wisuda AMIK – AKPER IMELDA 30 Agustus 2016
For example, jika pasien telah menderita stroke, rumah sakit dapat memiliki data pada waktu stroke, kesenjangan antara stroke dalam beberapa kasus stroke di masa lalu, mempengaruhi peristiwa sebelum stroke seperti peristiwa stres psikologis atau kegiatan fisik yang berat. Rumah sakit dapat memberikan langkah-langkah yang jelas untuk mencegah stroke berdasarkan data yang.
Perangkat Wearable : dapat melakukan pekerjaan yang baik dalam mendeteksi
masalah kesehatan potensial bahkan jika tidak ada gejala yang jelas. Untuk mengevaluasi kesehatan dari orang yang tampak sehat, dokter perlu meresepkan serangkaian pemeriksaan medis yang panjang dan mahal. perangkat Wearable dapat mengungkapkan sejumlah indikator kesehatan berdasarkan yang seorang dokter dapat membuat kesimpulan tertentu dan memutuskan masa depan saja tindakan. Sudah, sejumlah perangkat dpt dipakai dan aplikasi yang mampu mengukur parameter seperti detak jantung Anda, nadi, kadar glukosa dan kadar kalori. Meskipun sebagian besar perangkat yang tersedia saat ini sedang digunakan untuk tujuan rekreasi, mereka metamorphosing menjadi gadget yang serius. Sudah, Administrasi Makanan dan Obat AS (FDA) telah menyetujui sejumlah monitor glukosa.
Dampak data besar pada obat-obatan pribadi : Para ahli percaya bahwa data
yang besar akan meningkatkan efektivitas obat-obatan pribadi secara signifikan. Sejumlah inisiatif sedang berjalan untuk mengetahui cara-cara untuk meningkatkan efektivitas obat-obatan pribadi.
Salah satu inisiatif tersebut telah menjadi program penelitian kanker dikenal sebagai Analisis NCI-Molekuler untuk Terapi Penghargaan (NCI-MATCH) Percobaan. uji coba ini merupakan bagian penting dari Institut Nasional Kesehatan Presisi Kedokteran Initiative. inisiatif ini akan mendaftarkan diri sekitar 1000 orang dan pertandingan spesifik jenis tumor dengan obat-obatan tertentu. Orang-orang yang mendaftar telah memiliki tumor yang belum merespons pengobatan kanker standar. Tumor akan dicocokkan dengan obat yang dikenal untuk menghasilkan hasil yang lebih baik atas dasar penanda genetik tertentu. Berdasarkan hasil pencocokan, database obat akan dibuat sehingga daftar obat diketahui efektif untuk tumor yang sesuai tersedia. Inisiatif ini merupakan salah satu yang sedang berlangsung dan jenis baru dari tumor akan dipelajari dan obat-obatan yang sesuai akan diidentifikasi. persidangan memiliki potensi untuk membuka rahasia menyembuhkan jenis kanker langka dan mematikan dengan mencocokkan genom individu dengan obat yang tepat. Seorang pasien dengan jenis kanker memenuhi syarat untuk mendaftar untuk sidang meskipun program ini bertujuan untuk memiliki minimal 25% dari total pasien memiliki kanker langka. Ada sejumlah parameter untuk mengevaluasi apakah obat-obatan bekerja. Salah satu parameter untuk mengamati jika ukuran tumor menyusut, parameter kedua adalah untuk mengetahui apakah kondisi pasien memburuk di masa lalu 6 months. Para peneliti juga akan memperhitungkan efek samping dari pengobatan. Obat presisi adalah mendapatkan popularitas besar dan mengemudi dari semua sektor. AS juga telah mengumumkan US $ 215-juta nasional Presisi Pengobatan Initiative. Ini akan mencakup pembentukan database nasional data genetik dan lainnya dari satu juta orang di Amerika Serikat.
19 Orasi Ilmiah, Wisuda AMIK – AKPER IMELDA 30 Agustus 2016
Seperti data pergudangan, toko web atau platform TI, infrastruktur untuk data yang besar memiliki kebutuhan yang unik. Dalam mempertimbangkan semua komponen platform data yang besar, penting untuk diingat bahwa tujuan akhir adalah untuk dengan mudah mengintegrasikan data yang besar dengan data perusahaan Anda untuk memungkinkan Anda untuk melakukan analisis mendalam pada set data gabungan.
Gambar 15. Big Data Platform
Requirement dalam big data infrastruktur :
data acquisition,
data organization
data analysis
Data acquisition
Tahap akuisisi adalah salah satu perubahan besar dalam infrastruktur pada hari-hari sebelum big data. Karena big data mengacu pada aliran data dengan kecepatan yang lebih tinggi dan ragam yang bervariasi, infrastruktur yang diperlukan untuk mendukung akuisisi data yang besar harus disampaikan secara perlahan, dapat diprediksi baik di dalam menangkap data dan dalam memprosesnya secara cepat dan sederhana, dapat menangani volume transaksi yang sangat tinggi , sering dalam lingkungan terdistribusi, dan dukungan yang fleksibel, struktur data dinamis. Database NoSQL sering digunakan untuk mengambil dan menyimpan big data. Mereka cocok untuk struktur data dinamis dan sangat terukur. Data yang disimpan dalam database NoSQL biasanya dari berbagai variasi/ragam karena sistem dimaksudkan untuk hanya menangkap semua data tanpa mengelompokkan dan
parsing data.
Sebagai contoh, database NoSQL sering digunakan untuk mengumpulkan dan menyimpan data media sosial. Ketika aplikasi yang digunakan pelanggan sering
20 Orasi Ilmiah, Wisuda AMIK – AKPER IMELDA 30 Agustus 2016
berubah, struktur penyimpanan dibuat tetap sederhana. Alih-alih merancang skema dengan hubungan antar entitas, struktur sederhana sering hanya berisi kunci utama untuk mengidentifikasi titik data, dan kemudian wadah konten memegang data yang relevan. Struktur sederhana dan dinamis ini memungkinkan perubahan berlangsung tanpa reorganisasi pada lapisan penyimpanan.
Data Organization
Dalam istilah Data pergudangan klasik, pengorganisasian data disebut integrasi data. Karena ada volume/jumlah data yang sangat besar, ada kecenderungan untuk mengatur data pada lokasi penyimpanan aslinya, sehingga menghemat waktu dan uang dengan tidak memindah-midahkan data dengen volume yang besar. Infrastruktur yang diperlukan untuk mengatur data yang besar harus mampu mengolah dan memanipulasi data di lokasi penyimpanan asli. Biasanya diproses didalam batch untuk memproses data yang besar, beragam format, dari tidak terstruktur menjadi terstruktur.
Apache Hadoop adalah sebuah teknologi baru yang memungkinkan volume data yang besar untuk diatur dan diproses sambil menjaga data pada cluster penyimpanan data asli. Hadoop Distributed File System (HDFS) adalah sistem penyimpanan jangka panjang untuk log web misalnya. Log web ini berubah menjadi perilaku browsing dengan menjalankan program MapReduce di cluster dan menghasilkan hasil yang dikumpulkan di dalam cluster yang sama. Hasil ini dikumpulkan kemudian dimuat ke dalam sistem DBMS relasional.
Data Analysis
Karena data tidak selalu bergerak selama fase organisasi, analisis ini juga dapat dilakukan dalam lingkungan terdistribusi, di mana beberapa data akan tinggal di mana data itu awalnya disimpan dan diakses secara transparan dari sebuah data warehouse. Infrastruktur yang diperlukan untuk menganalisis data yang besar harus mampu mendukung analisis yang lebih dalam seperti analisis statistik dan data mining, pada data dengan jenis yang beragam dan disimpan dalam sistem yang terpisah, memberikan waktu respon lebih cepat didorong oleh perubahan perilaku; dan mengotomatisasi keputusan berdasarkan model analitis. Yang paling penting, infrastruktur harus mampu mengintegrasikan analisis pada kombinasi data yang besar dan data perusahaan tradisional. Wawasan baru datang bukan hanya dari analisis data baru, tapi dari menganalisisnya dalam konteks yang lama untuk memberikan perspektif baru tentang masalah lama.
Misalnya, menganalisis data persediaan dari mesin penjual otomatis cerdas dalam kombinasi dengan acara kalender untuk tempat di mana mesin penjual otomatis berada, akan menentukan kombinasi produk yang optimal dan jadwal pengisian untuk mesin penjual otomatis. Kenyataannya adalah sebagian besar bisnis ini bergantung pada kemampuan platform Hadoop. Namun, keilmuan big data dan analitik berkembang begitu cepat sehingga perusahaan perlu masuk “permainan” big data atau beresiko tertinggal. Di masa lalu, teknologi muncul mungkin membutuhkan waktu tahunan untuk menjadi mature, namun sekarang, solusi akan didapatkan dalam hitungan bulanan, atau mingguan. Jadi, perkembangan dan tren teknologi harus jadi perhatian. Dalam sebuah wawancara antara Computerworld dan pimpinan IT, konsultan dan analis industri terfapat beberapa hasil tentang trend teknologi Big Data:
21 Orasi Ilmiah, Wisuda AMIK – AKPER IMELDA 30 Agustus 2016 1. Big Data Analytics in The Cloud
Hadoop, sebuah kerangka dan kumpulan alat untuk memproses kumpulan data yang sangat besar, yang awalnya dirancang untuk berkerja pada kelompok mesin fisik. Namun kini, pertambahan jumlah teknologi, tersedia untuk pemrosesan data pada cloud. Contohnya BI data warehouse pada Amazon Redshift, Google’s BigQuery data analytics service, IBM’s Bluemix cloud platform dan Amazon’s Kinesis data processing service. Smarter Remarketer, sebuah penyedia SaaS berbasis retail analytics, segmentasi dan jasa pemasaran, baru-baru ini berpindah dari in-house Hadoop dan Mongo DB database infrastructure ke Amazon Redshift, data warehouse berbasis cloud. Indianapolis-based company mengumpulkan data online, penjualan toko bangunan, data demografi pelanggan, serta data perilaku yang real time, kemudian menganalisis informasi untuk membantu retailer membuat rekomendasi bagaimana mendapatkan pembeli. Redshift lebih baik dalam hal biaya untuk kebutuhan data Smart Remarketer, khususnya sejak memiliki kemampuan pelaporan yang ekstensif untuk data terstruktur. Selain itu, juga lebih terukur dan relatif mudah digunakan.
2. Hadoop: The New Enterprise Data Operating System
Distributed analytic frameworks, seperti MapReduce, yang berkembang menjadi distributed resource managers secara bertahap mengubah Hadoop menjadi general-purpose data operating system. Dengan sistem ini maka dapat melakukan banyak manipulasi data yang berbeda dan analisis operasi dengan memasukkannya ke dalam Hadoop sebagai distributed file storage system. Apa artinya ini bagi perusahaan? Seperti SQL, MapReduce, in-memory, stream processing, graph analytic dan tipe workload lainnya dapat diaplikasikan dengan Hadoop. Dengan performansi yang memadai, perusahaan menggunakan Hadoop sebagai pusat datanya. Kemampuan untuk menjalankan berbagai macam [query dan data operations] data dalam Hadoop akan membuat biaya lebih murah, dan mempermudah mengelola data yang akan dianalisis.
3. Big Data Lakes
Teori database tradisional menyatakan bahwa merancang kumpulan data terlebih dahulu sebelum memasukkan data. Sebuah data lake, juga disebut sebagai enterprise data lake atau enterprise data hub, digunakan perusahaan untuk mengumpulkan datanya. Karena sebelum memasukkan data dan membangun model, analis akan melihat informasi apa yang dapat diambil dari data dengan skala besar tersebut, agar tidak sia-sia ketika data akan dimasukkan. Tantangannya, dibutuhkan analis yang memiliki kemampuan tinggi untuk melakukannya.
4. More Predictive Analytics
Dengan Big Data, analis tidak hanya memiliki data untuk dikerjakan namun juga kekuatan proses untuk mengelola data berukuran besar dan dengan banyak karakteristik. Kombinasi dari Big Data dan kekuatan komputasi memungkinkan analis mengeksplorasi data perilaku baru sepanjang hari, seperti website yang dikunjungi atau lokasi. Hal ini seperti sparse data, karena untuk menemukan sesuatu yang menarik maka harus memahami banyak data. Menggunakan cara algoritma
22 Orasi Ilmiah, Wisuda AMIK – AKPER IMELDA 30 Agustus 2016
lama untuk menyelesaikan komputasi banyak tipe data akan sia-sia. Menemukan variabel data yang menarik dan best analytic terlebih dahulu akan mengurangi permasalahan komputasi ini. Yang menarik adalah bagaimana dapat menjalankan real-time analysis dengan predictive modeling. Namun masalahnya adalah dengan Hadoop akan membutuhkan waktu 20 kali lebih lama dalam menyelesaikan masalah ini. Di sisi lain, Intuit menguji Apache Sparke, processing engine data skala besar dan mengaitkan dengan SQL query tool, Spark SQL. Spark memiliki kecepatan interactive query sebaik graph services dan kemampuan streaming. Sehingga, Intuit menggunakan Hadoop dan Spark, karena keduanya memiliki kinerja yang cukup baik terutama dalam mengisi kekurangan satu sama lain.
5. SQL on Hadoop: Faster, better
Dengan menggunakan Hadoop, maka hanya tinggal memindahkan data dan melakukan analisis di dalamnya. Namun masalahnya, dibutuhkan data dengan format dan stuktur bahasa yang mudah dikenal. Oleh karena itu, dengan SQL di Hadoop, yaitu tools yang dapat membantu melakukan query pada umumnya yang mempermudah penggunanya dalam mengelola data.
Namun, tools ini sesungguhnya bukan hal yang baru. Apache Hive hal yang sama yaitu berupa SQL, seperti bahasa query pada Hadoop. Alternatif dari Cloudera, Pivotal Software, IBM dan vendor lainnya tidak hanya menawarkan tools yang hanya memiliki kinerja lebih baik namun juga lebih cepat. Hal ini lah yang membuat teknologi cocok disebut sebagai iterative analytics, dimana ketika ada pertanyaan, diberikan jawaban, kemudian yang lainnya bertanya kembali. Seperti halnya dalam data warehouse. SQL di Hadoop tidak akan menggantikan data warehouse, setidaknya tidak dalam waktu dekat. Namun, akan ada penawaran software alternatif lain yang lebih murah dan aplikatif untuk analitik tipe tertentu.
6. More, better NoSQL
Relational database berbasis traditional SQL atau biasa disebut NoSQL (Not only SQL) database, kini memiliki peningkatan populatitas yang cukup pesat sebagai tools yang digunakan untuk aplikasi spesifik analitik. Aka nada sekitar 15 sampai 20 opensource NoSQL database yang memiliki masing-masing spesialisasi. Contohnya, produk NoSQL dengan kemampuan database grafik sepeti ArangoDB, yang memberikan analisis jaringan hubungan antara pelanggan dan salespeople lebih cepat dari pada relational database.
7. Deep learning
Deep learning, sekumpulan teknik machine-learning berbasis neural networking, yang kini masih dikembangkan namun telah menunjukkan potensi yang besar dalam menyelesaikan masalah bisnis. Deep learning memungkinkan computer hal-hal menarik dalam data tidak terstruktur dalam jumlah besar dan biner, serta menyimpulkan hubungannya tanpa membutuhkan model tertentu atau instruksi pemrograman. Contohnya, algoritma deep learning dalam memeriksa data dari Wikipedia, dimana California dan Texas berada di AS. Hal ini tidak perlu dimodelkan untuk mengetahui konsep mengenai sebuah Negara. Inilah perbedaan mendasar antara machine learning lama dengan metode deep learning.
23 Orasi Ilmiah, Wisuda AMIK – AKPER IMELDA 30 Agustus 2016 8. In-Memory Analytics
Penggunaan in-memory database dala mempercepat proses analitik, kini semakin popular dan bermanfaat dalam pengaturan kecepatan. Nyatanya, banyak bisnis yang siap menggunakan Hybrid Transactional/Analytical Processing (HTAP), dimana memperbolehkan transaksi dan proses analitik pada tempat yang sama, yaitu pada in-memory database. Namun telah banyak bisnis yang menggunakannya secara berlebihan. Untuk sistem dimana kebutuhan user dalam melihat data yang sama dan bentuk yang sama dalam seharian, akan tidak ada perubahan data yang signifikan. Dalam hal ini, in-memory akan menghabiskan biaya. Dan ketika akan melakukan analitik yang lebih cepat dengan HTAP, seluruh transaksi harus ditempatkan pada database yang sama. Masalahnya, kini sebagian besar usaha analitik akan menempatkan transaksi pada banyak sistem yang berbeda secara bersamaan. Dengan begitu, apabila ada in-memory database, maka ada juga produk lain yang akan mengelola, menjaga dan menampilkan bagaimana menyatukan dan mengukurnya.
V. Tantangan dalam pemanfaatan Big Data
Dalam usaha pemanfaatan Big Data dapat terdapat banyak hambatan dan tantangan, beberapa hal diantaranya berhubungan dengan data dimana melibatkan acquisition, sharing dan privasi data, serta dalam analisis dan pengolahan data
Privasi :merupakan isu yang paling sensitif, dengan konseptual, hukum, dan
teknologi, Privasi dapat dipahami dalam arti luas sebagai usaha perusahaan untuk melindungi daya saing dan konsumen mereka. Data-data yang digunakan / disimpan sebagai big data
Access dan sharing : Akses terhadap data, baik data lama maupun data baru
dapat menjadi hambatan dalam mendapatkan data untuk big data, terlebih pada data lama dimana data- data tersimpan dalam bentuk – bentuk yang berbeda-beda dan beragam ataupun dalam bentuk fisik, akses terhadap data baru juga membutuhkan usaha yang lebih kerana diperlukannya izin dan lisensi untuk mengakses data-data non-public secara legal.
Analisis : Bekerja dengan sumber data baru membawa sejumlah tantangan analitis.
relevansi dan tingkat keparahan tantangan akan bervariasi tergantung pada jenis analisis sedang dilakukan, dan pada jenis keputusan yang akhirnya akan bisa diinformasikan oleh data.
Tergantung dari jenis data terdapat 3 kategori dalam analisis data o Penentuan gambaran yang benar
Masalah ini biasanya ditemukan dalam penanganan unstructured
user-generated text-based data dimana data yang didapatkan belum tentu benar
karena data atau sumber yang salah. o Interpreting Data
Kesalahan –kesalahan seperti Sampling selection bias merupakan hal yang sering ditemukan dimana data yang ada tidak dapat digunakan untuk mepresentasikan semua populasi yang ada, dan apophenia, melihat adanya
24 Orasi Ilmiah, Wisuda AMIK – AKPER IMELDA 30 Agustus 2016
pola walaupun tidak benar-benar ada dikarenakan jumlah data yang besar, dan kesalahan dalam menginterpreasikan hubungan dalam data.
o Defining and detecting anomalies
tantangan sensitivitas terhadap spesifisitas pemantauansistem. Sensitivitas mengacu pada kemampuan sistem pemantauan untuk mendeteksi semua kasus sudah diatur untuk mendeteksi sementara spesifisitas mengacu pada kemampuannya untuk mendeteksi hanya kasus-kasus yang relevan. kegagalan untukmencapai hasil yang terakhir "Tipe I kesalahan keputusan", juga dikenal sebagai "positif palsu"; kegagalanuntuk mencapai mantan "Type II error", atau "negatif palsu." Kedua kesalahan yang tidak diinginkan ketika mencoba untuk mendeteksi malfungsi atau anomali, bagaimanapun didefinisikan, untuk berbagai alasan. Positif palsu merusak kredibilitas sistem sementara negatif palsu dilemparkan ragu pada relevansinya. Tapi apakah negatif palsu lebih atau kurang bermasalah daripada positif palsu tergantung pada apa yang sedang dipantau, dan mengapa itu sedang dipantau.
Analisis Diagnostik : BDA memberikan peluang untuk tidak sekedar melakukan analisa
diskriptif, tetapi juga mampu melakukan analisis diagnostik, analisi prediktif dan analisa prescriptive. Berbagai macam tujuan BDA di kesehatan dapat dilakukan seperti melihat pola pelayanan kesehatan, kuantitas, kualitas dan distribusi yang dikaitkan dengan equity. Khususnya di era post MDG’s, dimana beberapa poin MDG’s yang direncanakan selesai di tahun 2015 belum mencapai target sehingga masih diperlukan upaya strategis untuk mendukung pencapaian target paska 2015. Data survey yang dilakukan secara rutin (Riskesdas), data klaim dari rumah sakit (INA-CBGs), data laporan rutin fasilitas kesehatan (RL, LB), laporan kegiatan program kesehatan yang dilakukan setiap tahun dan bahkan data sosial media (twitter, facebook) dapat dianalisa menggunakan pendekatan BDA untuk melihat konteks kinerja pelayanan kesehatan dan menghasilkan pengetahuan kesehatan baru. Pendekatan ini telah dimanfaatkan di berbagai organisasi, untuk menghasilkan pemahaman yang mendalam, rekomendasi serta pengetahuan untuk memperbaiki mutu pelayanankesehatan, meningkatkan outcome pelayanan, memberikan umpan balik untuk peningkatan kinerja, maupun sampai dengan usulan kebijakan untuk menghindari pemborosan biaya karena pelayanan kesehatan yang tidak efektif.
Negara berkembang seperti Indonesia masih menemui tantangan dalam mengaplikasikan BDA seperti data capture, infrastruktur,capacity building SDM yang ada, integrasi data dari berbagai sumber data berbeda, isu privasi dan sekuriti data, serta membangun kerjasama antara public dan private sector yang ahli dalam big data. Isu-isu tersebut dapat dijelaskan sebagai berikut.
Data Capture: Tantangan terbesar dari data itu sendiri adalah besarnya data yang
dihasilkan dari berbagai sumber. Bahkan boleh dibilang, perkembangan mobile network dan penetrasi mobile phone yang sangat tinggi menjadi sumber terbesar dari data yang dihasilkan di negera berkembang seperti Indonesia. Sebagai contoh, program SMS for Life menggunakan kombinasi mobile phone, SMS, Internet dan teknologi pemetaan elektronik untuk melacak level stok obat malaria setiap minggu di berbagai fasilitas kesehatan publik. Program ini banyak diadopsi di beberapa negara di Afrika. Link terkait ada di : https://www.malarianomore.org/news/blog/sms-for-life-improving-lives-through-mobile-phones
25 Orasi Ilmiah, Wisuda AMIK – AKPER IMELDA 30 Agustus 2016 Infrastruktur: Adanya infrastruktur yang handal secara fisik adalah kata kunci yang
sangat penting dalam operasional dan skalabilitas proyek2 Big Data. Hal tersebut berbasis pada model penyimpanan yang terdistribusi, kualitas jaringan telekomunikasi, server dengan arsitektur khusus dan aplikasi spesifik yang mampu mengelola Big Data. Negara berkembang yang belum mampu mempunyai infrastuktur seperti itu harus mampu memilih strategi yang sesuai. Salah satunya adalah menyewa layanan dari perusahaan-perusahaan IT besar seperti Google, Microsoft, Yahoo dan Amazon dengan konsep IaaS (Infrastructure as a Service). Contoh pemanfaatan IaaS di negara berkembang adalah DHIS2 (District Health Information System 2), sebuah alat bantu yang bisa digunakan untuk mengumpulkan, validasi, analisis, dan presentasi untuk agregrat data statistik dari berbagai aktivitas pengelolaan informasi kesehatan. DHIS2 sudah banyak diterapkan secara luas seperti di banyak negara berkembang. Link terkait ada di:
https://www.dhis2.org/
VI. Penutup
Pemakaian data sudah berkembang pesat pada zaman yang dipenuhi dengan teknologi ini. Data dapat menjelaskan dan menganalisis tren penjualan, memvalidasi klaim data pelanggan, dan mengurangi jumlah kesalahan manusia dalam proses pengambilan keputusan bidang kesehatan. Big Data adalah data dengan ciri berukuran sangat besar, sangat variatif, sangat cepat pertumbuhannya dan mungkin tidak terstruktur yang perlu diolah khusus dengan teknologi inovatif sehingga mendapatkan informasi yang mendalam dan dapat membantu pengambilan keputusan yang lebih baik.
Pemanfaatan Big data dalam dunia ilmu komputer memberikan peluang analisis data berupa pembuatan software dan bahasa pemrograman statistic, Software platform yang menghubungkan beberapa komputer sehingga dapat saling bekerja sama dan sinkron dalam menyimpan dan mengolah data sebagai satu kesatuan. Pemanfaatan Rekam Medis Elektronik sangat berkembang, yang diikuti dengan pertumbuhan data yang sangat besar, baik secara kuantitas (hasil laboratorim), kualitatif (catatan-catatan), atau transaksional (pemesanan obat), lebih dari itu, proyek-proyek genomics yang makin banyak, perubahan focus ke pelayanan pengobatan yang personal akan memaksa organisasi-organisasi kesehatan beralih ke pengelolaan data yang memanfaatkan teknik Big Data.
Dari Pemerintahan, Industri kesehatan, Perguruan Tinggi, Perusahaan asuransi dan bank, Big data mengubah bagaimana kita memahami dunia, melakukan bisnis dan melaksanakan kebijakan publik. Karena semakin banyak perusahaan menyadari nilai dari penerapan strategi Big Data, dan akhirnya akan membentuk link terakhir dari rantai nilai yang akan membantu perusahaan meningkatkan operasional lebih efisien dari investasi yang ada.
26 Orasi Ilmiah, Wisuda AMIK – AKPER IMELDA 30 Agustus 2016
Dumbill, E. (2012). Big Data Now Current Perspective. O'Reilly Media.
Eaton, C., Dirk, D., Tom, D., George, L., & Paul, Z. (n.d.). Understanding Big Data. Mc Graw Hill.
Global Pulse. (2012). Big Data for Development:Challenges & Opportunities. Global Pulse.
H., I. (2006). METADATA – CENTRALIZED AND DISTRIBUTED IN DW2.0. 3-5. H.Immon, W. (2005). Building the Data Warehouse, 4th Edition. Indianapolis,
Indiana: Wiley Publishing, Inc.
IBM. (n.d.). Analytics: The real-world use of big data. Retrieved from How innovative enterprises extract value from uncertain data: http://www-935.ibm.com/services/us/gbs/thoughtleadership/ibv-big-data-at-work.html R. Kelly Rainer, C. (2011). Introduction to Information Systems. John Wiley & Sons
(Asia) Pte Ltd.
Sun, H., & Heller, P. (2012). Oracle Information Architecture. Oracle Information
Architecture. http://www-01.ibm.com/software/data/bigdata/ http://www.zdnet.com/top-10-categories-for-big-data-sources-and-mining-technologies-7000000926/ http://bigdata.blogdetik.com/ http://www.oracle.com/us/products/database/big-data-for-enterprise-519135.pdf http://www-01.ibm.com/common/ssi/cgi-bin/ssialias?subtype=BK&infotype=PM&appname=SWGE_IM_DD_USEN&ht mlfid=IMM14100USEN&attachment=IMM14100USEN.PDF http://www.mckinsey.com/~/media/McKinsey/dotcom/Insights%20and%20pubs/MGI/ Research/Technology%20and%20Innovation/Big%20Data/MGI_big_data_full _report.ashx http://connollyshaun.blogspot.com/2012/05/7-key-drivers-for-big-data-market.html http://www.mckinsey.com/~/media/McKinsey/dotcom/Insights%20and%20pubs/MGI/ Research/Technology%20and%20Innovation/Big%20Data/MGI_big_data_full _report.ashx Biography
Dr. Zakarias Situmorang, MT ([email protected]) Lahir di Binjai, 14 April 1965.
Menyelesaikan Pendidikan S-1 Fisika Komputasi dari USU Tahun 1989, Pendidikan S-2 Instrumentasi dan Kontrol ITB Tahun 1998 dan Pendidikan S-3 Ilmu Komputer UGM Tahun 2009. Aktif di Assosiasi Pendidikan Tinggi Informatika dan Komputer (APTIKOM), Tenaga Edukatif Fakultas Ilmu Komputer Unika Santo Thomas, S-2 dan S-3 Teknik Informatika USU. Ketua Umum IHAN Batak. Ada 10 tulisan jurnal internasional, 40 tulisan jurnal nasional, Dosen Berprestasi Tahun 2015 se-Kopertis Wil I. Aktif meneliti di Kemeritekdikti dan LIPI.