DISTRIBUTED TWITTER CRAWLER
Skripsi
Diajukan untuk Memenuhi Sebagian dari Syarat untuk Memperoleh Gelar Sarjana Komputer
Program Studi Ilmu Komputer
Oleh:
WILLI NIM 0809126
PROGRAM STUDI ILMU KOMPUTER
FAKULTAS PENDIDIKAN MATEMATIKA DAN ILMU PENGETAHUAN ALAM UNIVERSITAS PENDIDIKAN INDONESIA
Distributed Twitter Crawler
Oleh Willi
Sebuah skripsi yang diajukan untuk memenuhi salah satu syarat memperoleh gelar Sarjana pada Fakultas Pendidikan Matematika dan Ilmu Pengetahuan Alam
© Willi 2015
Universitas Pendidikan Indonesia Januari 2015
Hak Cipta dilindungi undang-undang.
WILLI
DISTRIBUTED TWITTER CRAWLER
Disetujui dan disahkan oleh pembimbing:
Pembimbing I
Yudi Wibisono, M.T. NIP 197507072003121003
Pembimbing II
Asep Wahyudin, M.T. NIP 197112232006041001
Mengetahui
Ketua Program Studi Ilmu Komputer
Willi, 2015
Distributed twitter crawler
Universitas Pendidikan Indonesia | repository.upi.edu | perpustakaan.upi.edu ABSTRAK
DISTRIBUTED TWITTER CRAWLER
Twitter sebagai sebuah situs jejaring sosial memberikan akses kepada penggunanya untuk mengirimkan pesan singkat maksimal 140 karakter yang disebut dengan tweet. Tweet dapat pula berupa gambar. Berbagai macam manfaat dapat diperoleh dari tweet misalnya event detection, prediksi pergerakan saham, prediksi pemilu, penyebaran penyakit, dan sebagainya. Ide dasar pembuatan penelitian ini adalah keterbatasan untuk mendapatkan tweet jika hanya mengandalkan satu buah pengumpul tweet. Penelitian ini difokuskan pada pengembangan prototype untuk memproses pengumpulan (crawler) tweet yang terdistribusi. Pemanfaatan sistem terdistribusi digunakan untuk menangani keterbatasan permintaan pada Twitter API. Pada proses pendistribusian, kata kunci pengumpulan tweet diolah oleh node yang berperan sebagai koordinator terhadap node lain yang ada. Jika node koordinator mengalami gangguan (error), secara otomatis node lain akan melakukan pemilihan koordinator yang baru dengan menggunakan algoritma ring. Hasil uji coba menunjukkan bahwa aplikasi dapat mendistribusikan proses pengumpulan tweet ke dalam tiga buah node. Luaran dari aplikasi ini dapat berguna bagi para analis yang ingin mengolah data yang bersumber dari jejaring sosial khususnya twitter.
Kata kunci: Crawler, Twitter, Sistem Terdistribusi, Algoritma Ring
Willi, 2015
Distributed twitter crawler
Universitas Pendidikan Indonesia | repository.upi.edu | perpustakaan.upi.edu ABSTRACT
DISTRIBUTED TWITTER CRAWLER
Twitter as a social networking site provides access to users to send short messages up to 140 characters called tweets. Tweets can also be pictures. Various kinds of benefits can be obtained from the tweet such event detection, prediction of stock movement, election prediction, the spread of disease, and so on. The basic idea of making this study is limited to get a tweet if only rely on one crawler of tweet. This study is focused on the development of a prototype for distributed processing tweet collection (crawler). Utilization of a distributed system is used to handle the limitations request on Twitter API. In the process of distributing, keywords of collecting tweets processed by the node that acts as the coordinator of the other existing nodes. If the coordinator node get impaired (error), other nodes will automatically elect a new coordinator by using algorithms ring. Experimental results show that the application can distribute the process of collecting tweets into three nodes. Outcomes of these applications can be useful for analysts who want to process data from social networks, especially Twitter.
Willi, 2015
Distributed twitter crawler
Universitas Pendidikan Indonesia | repository.upi.edu | perpustakaan.upi.edu DAFTAR ISI
ABSTRAK ... i
ABSTRACT ... ii
KATA PENGANTAR ... iii
UCAPAN TERIMA KASIH ... iv
DAFTAR ISI ... v
1.6 Sistematika Penelitian ... 5
BAB II KAJIAN PUSTAKA ... 6
2.1 Sistem Terdistribusi ... 6
2.1.1 Karakter Sistem Terdistribusi ... 7
2.1.2 Grid Computing Systems ... 8
2.1.3 Algoritma Pemilihan Koordinator ... 10
2.1.4 Fault Tolerance ... 12
2.1.5 Replikasi ... 14
2.1.6 Distributed Crawler ... 15
Willi, 2015
Distributed twitter crawler
Universitas Pendidikan Indonesia | repository.upi.edu | perpustakaan.upi.edu
BAB III METODOLOGI PENELITIAN... 22
3.1 Desain Penelitian ... 22
3.2 Persiapan Alat dan Bahan Penelitian ... 24
3.3 Studi Literatur ... 25
3.4 Proses Pengembangan Perangkat Lunak ... 27
BAB IV HASIL PENELITIAN DAN PEMBAHASAN ... 30
4.1 Hasil Pengembangan Perangkat Lunak ... 30
4.1.1 Analisis Kebutuhan Perangkat Lunak ... 30
4.1.2 Desain Sistem ... 35
4.1.3 Implementasi ... 42
4.1.4 Pengujian ... 45
4.2 Pembahasan Eksperimen ... 48
4.2.1 Pemilihan Koordinator ... 48
4.2.2 Pendistribusian Tugas Pengumpulan Tweet ... 54
4.2.3 Penggabungan Hasil Pengumpulan Tweet ... 61
4.2.4 Replikasi ... 62
BAB V KESIMPULAN DAN SARAN ... 66
5.1 Kesimpulan ... 66
5.2 Saran ... 66
Willi, 2015
Distributed twitter crawler
Universitas Pendidikan Indonesia | repository.upi.edu | perpustakaan.upi.edu BAB I
PENDAHULUAN
1.1 Latar Belakang
Twitter adalah sebuah situs jejaring sosial yang sedang berkembang pesat saat ini karena pengguna dapat berinteraksi dengan pengguna lainnya dari komputer ataupun perangkat mobile mereka dari manapun dan kapanpun. Setelah
diluncurkan pada Juli 2006, jumlah pengguna Twitter meningkat sangat pesat. Pada September 2010, diperkirakan jumlah pengguna Twitter yang terdaftar sekitar 160 juta pengguna (Chiang, 2011).
Pengguna Twitter sendiri bisa terdiri dari berbagai macam kalangan yang para penggunanya ini dapat berinteraksi dengan teman, keluarga hingga rekan kerja. Twitter sebagai sebuah situs jejaring sosial memberikan akses kepada penggunanya untuk mengirimkan sebuah pesan singkat yang terdiri dari maksimal 140 karakter (disebut tweet). Tweet sendiri bisa terdiri dari pesan teks dan foto. Melalui tweet inilah pengguna Twitter dapat berinteraksi lebih dekat dengan pengguna Twitter lainnya dengan mengirimkan tentang apa yang sedang mereka pikirkan, apa yang sedang dilakukan, tentang kejadian yang baru saja terjadi, tentang berita terkini serta hal lainnya.
Pada tahun April 2010, jumlah tweet yang diposting mencapai 55 juta
tweet/hari (Jackoway, dkk., 2011, hlm. 2), lalu kemudian pada tahun 2011,
tercatat rata-rata sekitar 140 juta tweet telah dikirimkan oleh pengguna Twitter (Twitter Blog, 2011). Berbagai macam manfaat dapat diperoleh dari tweet dimulai dari event detection (deteksi kejadian, salah satunya bencana alam), prediksi pergerakan pasar saham, prediksi pemilu hingga penyebaran penyakit di suatu
2
Willi, 2015
Distributed twitter crawler
Universitas Pendidikan Indonesia | repository.upi.edu | perpustakaan.upi.edu
yang berkaitan dengan pasar saham seperti Dow Jones, S&P 500, NASDAQ (Zhang, dkk., 2010, hlm. 3). Contoh lainya yaitu event detection. Pada event
detection (bencana alam), untuk memperoleh tweet yang akurat dan tepat sasaran,
diterapkan semantik analisis tweet terhadap keyword yang muncul pada tweet (Sakaki, dkk., 2010, hlm. 2). Untuk mendapatkan manfaat dari tweet yang jumlahnya berlimpah ini, tentu saja dibutuhkan penelitian dan analisis terhadap
tweet yang ada, salah satunya untuk penelitian data mining yang mempergunakan
data dari tweet.
Data mining sendiri menurut Han dan Kamber (2006, hlm. 39) adalah
sebuah upaya menemukan pola-pola yang menarik dari data yang berjumlah besar, yang dimana data-data tersebut bisa saja tersimpan di dalam database, data
warehouse, ataupun di tempat penyimpanan lainnya. Begitu juga dengan data
yang terdiri dari tweet, jumlah datanya berlimpah dan tentu saja memiliki pola-pola menarik yang bisa dimanfaatkan. Pada penelitian “Twitter mood predicts the stock market” (Bollen, dkk., 2010, hlm. 2), jumlah data tweet yang digunakan untuk menganalisis dan memprediksi pasar saham mencapai 9.853.498 tweet. Penelitian lain, “Using prediction markets and twitters to predict swine flu pandemic” (Ritterman, dkk., 2009, hlm. 3) menggunakan data tweet sebanyak 48 juta data tweet.
Untuk dapat mengumpulkan data tweet dalam jumlah yang besar tersebut, diperlukan sebuah sistem yang dapat mengumpulkan tweet yang tersedia sesuai dengan keyword tertentu. Dalam hal ini, Twitter sendiri telah menyediakan fasilitas Twitter API yang memberikan kemudahan untuk para peneliti untuk mengkoleksi dan mengumpulkan tweet. Twitter API memfasilitasi pengguna untuk dapat mengirimkan request query sebanyak 180 request/15 menit. Jika sebelum waktu 15 menit, request telah mencapai 180, maka harus menunggu 15 menit berikutnya untuk bisa melakukan request kembali.
3
Willi, 2015
Distributed twitter crawler
Universitas Pendidikan Indonesia | repository.upi.edu | perpustakaan.upi.edu
menggunakan 20 whitelist mesin dengan alamat IP yang berbeda (Kwak. dkk., 2009, hlm. 2) dan berhasil mengumpulkan 106 juta tweet. Whitelist adalah aturan yang ditetapkan Twitter (pada Twitter API v1) dengan memasukkan alamat mesin ke daftar putih Twitter dan memberikan keringanan dalam hal keterbatasan dalam melakukan permintaan dan saat ini (pada Twitter API v1.1) aturan whitelist sudah tidak berlaku.
Untuk menanggulangi keterbatasan permintaan pada Twitter API, dapat digunakan prinsip sistem terdistribusi. Prinsip sistem terdistribusi diterapkan agar di dalam satu waktu, proses pengumpulan tweet dapat dilakukan dengan lebih cepat dan mampu mengumpulkan lebih banyak tweet karena proses pengumpulan
tweet akan didistribusikan ke beberapa node. Contohnya ingin mengumpulkan
tweet dari beberapa keyword, maka sistem akan mendistribusikan beberapa
keyword ini ke beberapa node yang tersedia. Dari beberapa node ini, jika terdapat
node yang mati, maka tugasnya akan diambil alih oleh node lain sehingga sistem
yang sedang dijalankan tidak mati. Scalability sistem juga harus diperhatikan. Sistem harus dapat menambahkan node secara dinamis jika diperlukan. Penelitian
yang menerapkan sistem terdistribusi yaitu penelitian “TwitterEcho – A Distributed Focused Crawler to Support Open Research with Twitter Data” yang
dilakukan oleh Bosnjak dkk. Penelitian ini menggunakan arsitektur distribusi terpusat. (Bosnjak, dkk., 2012, hlm. 2).
Penelitian Java dkk. (pada Bosnjak., dkk., 2012, hlm. 2) yang melakukan
crawl Twitter dari tanggal 1 April hingga 30 Mei 2007 mendapatkan tweet sekitar
1,3 juta tweet. Jika dirata-ratakan, maka sekitar 15 tweet per menit yang bisa diperoleh. Dengan aplikasi twitter crawler yang akan dibuat, jika memaksimalkan parameter count dengan jumlah 100 dan distribusi menggunakan 3 mesin, maka bisa diperoleh tweet sebanyak 300 tweet dalam satu kali pencarian. Diharapkan dengan dikembangkannya aplikasi untuk pendistribusian proses pengumpulan
tweet ini dapat mengoptimalkan pengumpulan data tweet dalam jumlah besar.
4
Willi, 2015
Distributed twitter crawler
Universitas Pendidikan Indonesia | repository.upi.edu | perpustakaan.upi.edu
node. Komputer virtual adalah representasi logis dari sebuah komputer di dalam
perangkat lunak. (IBM Global Education White Paper., 2007, hlm. 3). Virtualisasi memungkinkan pengguna untuk menjalankan satu atau lebih mesin virtual secara bersamaan, yang masing-masing mesin virtual memiliki sistem operasinya di atas komputer fisik tunggal (Li., 2010, hlm. 12).
Skripsi ini membahas tentang pendistribusian proses pengumpulan tweet sehingga mampu mengumpulkan data tweet dalam jumlah besar yang bermanfaat untuk peneliti lainnya.
1.2 Rumusan Masalah
Berdasarkan latar belakang masalah yang ada, maka permasalahan dalam skripsi ini dirumuskan sebagai berikut:
1. Bagaimana melakukan pendistribusian proses pengumpulan tweet ke banyak
node sehingga akan bisa diperolah tweet yang lebih banyak dalam satu
waktu?
2. Bagaimana mengembangkan prototype sistem untuk memudahkan
pengumpulan data tweet dalam jumlah besar?
1.3 Batasan Masalah
Untuk memfokuskan penelitian, ada beberapa batasan masalah, yaitu sebagai berikut:
1. Twitter API yang digunakan pada penelitian adalah Search API yang merupakan bagian dari REST API.
2. Data yang diambil dari twitter hanyalah sebatas data tweets yang sesuai dengan keyword yang dimasukkan oleh pengguna.
3. Proses pendistribusian yang dilakukan menggunakan komputer virtual.
1.4 Tujuan Penelitian
5
Willi, 2015
Distributed twitter crawler
Universitas Pendidikan Indonesia | repository.upi.edu | perpustakaan.upi.edu
1. Dapat mendistribusikan proses pengumpulan tweet ke beberapa node yang tersedia sehingga dapat diperoleh jumlah tweet yang besar dalam waktu yang lebih cepat dibandingkan dengan pengambilan dengan satu node.
6
Willi, 2015
Distributed twitter crawler
Universitas Pendidikan Indonesia | repository.upi.edu | perpustakaan.upi.edu 1.5 Manfaat Penelitian
Manfaat yang ingin diperoleh dari penelitian ini adalah:
1. Mempermudah serta mempersingkat waktu proses pengumpulan tweet. 2. Menambah wawasan serta dapat menerapkan ilmu yang diperoleh di
perkuliahan.
3. Dapat menjadi bahan rujukan bagi peneliti lain dalam penelitiannya yang memiliki keterkaitan dengan penelitian ini.
1.6 Sistematika Penulisan
Sistematika penulisan skripsi ini adalah sebagai berikut: BAB I PENDAHULUAN
Bab ini berisi latar belakang, rumusan masalah, batasan masalah, tujuan penelitian, manfaat penelitian, serta sistematika penulisan.
BAB II TINJAUAN PUSTAKA
Bab ini berisi tentang teori-teori serta konsep-konsep yang berfungsi sebagai sumber atau alat dalam memahami yang akan diterapkan pada penelitian yang akan dilakukan.
BAB III METODOLOGI PENELITIAN
Bab ini berisi tentang penjelasan tahap-tahap yang akan dilakukan dalam penelitian, serta hasil penelitian, dan pembahasan dari hasil penelitian.
BAB IV HASIL PENELITIAN DAN PEMBAHASAN
Bab ini berisi pemaparan hasil penelitian pendistribusian proses pengumpulan tweet disertai fakta yang diperoleh selama penelitian.
BAB V KESIMPULAN DAN SARAN
Willi, 2015
Distributed twitter crawler
Universitas Pendidikan Indonesia | repository.upi.edu | perpustakaan.upi.edu BAB III
METODOLOGI PENELITIAN
3.1 Desain Penelitian
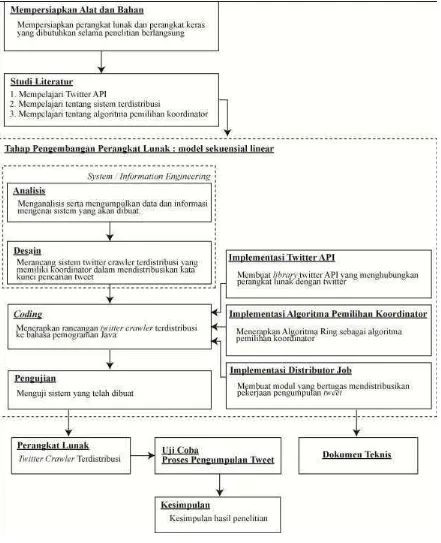
Desain penelitian merupakan tahapan yang dibutuhkan penulis untuk memberikan gambaran serta kemudahan agar penelitian dilakukan dapat berjalan dengan baik. Desain penelitian yang digunakan pada pengembangan distributed
twitter crawler adalah sebagaimana yang digambarkan pada gambar 3.1.
Adapun tahap penelitian yang dilakukan adalah sebagai berikut:
1. Mempersiapkan alat dan bahan penelitian berupa perangkat lunak dan perangkat keras yang digunakan untuk penelitian dan mengembangkan perangkat lunak.
2. Melakukan studi literatur terhadap hal-hal yang dibutuhkan dalam penelitian. 3. Membangun perangkat lunak berdasarkan analisa kebutuhan yang diperoleh
dari hasil penelaahan bahan penelitian yaitu menerapkan sistem terdistribusi pada twitter crawler. Metode pengembangan perangkat lunak yang digunakan dalam mengembangkan perangkat lunak menggunakan metode sekuensial linear yang terdiri dari analisis kebutuhan perangkat lunak, desain,
implementasi, dan pengujian.
4. Mengoperasikan perangkat lunak yang telah dibuat dan melakukan uji coba
23
Willi, 2015
Distributed twitter crawler
Universitas Pendidikan Indonesia | repository.upi.edu | perpustakaan.upi.edu Gambar 3.1 Desain Penelitian
24
Willi, 2015
Distributed twitter crawler
Universitas Pendidikan Indonesia | repository.upi.edu | perpustakaan.upi.edu
membangun perangkat lunak sebagai produk dari penelitian ini dengan menggunakan metode pengembangan sekuensial linear. Tahap berikutnya yaitu setelah perangkat lunak selesai dibangun, dilanjutkan ke tahap uji coba atau eksperimen untuk mengetahui hasil penelitian. Data yang diperoleh dari tahap uji coba akan digunakan untuk membuat kesimpulan terhadap hasil dari penelitian ini.
3.2 Persiapan Alat dan Bahan Penelitian
Pada penelitian ini, digunakan alat penelitian berupa perangkat keras dan juga perangkat lunak. Kebutuhan perangkat keras yang digunakan di dalam
penelitian ini adalah komputer dengan spesifikasi sebagai berikut: 1. Processor Intel Core i3 @ 2.53 GHz
2. RAM 2 Gb 3. Harddisk 250 Gb
Adapun kebutuhan perangkat lunak yang digunakan pada penelitian ini adalah sebagai berikut:
1. Sistem Operasi Windows 7 2. Eclipse Helios JEE & Notepad++ 3. XAMPP 1.7.4 (MySQL)
4. JDK 1.6.0_07
5. Oracle Virtual Machine VirtualBox 4.0.4
6. Sistem Operasi Windows XP SP3 untuk sistem operasi pada mesin virtual pada aplikasi VirtualBox.
25
Willi, 2015
Distributed twitter crawler
Universitas Pendidikan Indonesia | repository.upi.edu | perpustakaan.upi.edu
Bahan penelitian yang digunakan di dalam penelitian ini adalah berupa
paper, buku, dan dokumentasi lainnya yang diperoleh dari world wide web.
3.3 Studi Literatur
Proses pengumpulan data yang dilakukan adalah studi literatur yang dilakukan dengan cara mempelajari tentang sistem terdistribusi khususnya grid
computing, algoritma ring untuk pemilihan koordinator, dan Twitter API melalui
buku, jurnal, karya ilmiah, paper, dan sumber lainnya.
a. Mempelajari Konsep Sistem Terdistribusi
Sistem terdistribusi adalah kumpulan komputer-komputer yang bersifat
independen yang terlihat oleh pengguna sebagai suatu sistem tunggal. (Tanenbaum dan van Steen, 2006, hlm. 2). Dari komputer-komputer independen ini, dibutuhkan kolaborasi sehingga setiap komputer ini dapat berkomunikasi, berkoordinasi dan bekerja sama dengan saling bertukar pesan. Salah satu jenis sistem terdistribusi adalah distributed computing system. Salah satu bagian dari
distributed computing system adalah grid computing. Inti dari konsep grid
computing adalah sekumpulan komputer yang saling berinteraksi untuk
26
Willi, 2015
Distributed twitter crawler
Universitas Pendidikan Indonesia | repository.upi.edu | perpustakaan.upi.edu
pekerjaan pencarian tweet akan ditangani oleh komputer tunggal. Jika salah satu komputer pada sistem mengalami kegagalan, pengguna pun tidak mengetahui hal tersebut. Hal ini sesuai dengan transparansi yang terdapat pada sistem terdistribusi.
b. Mempelajari Konsep Algoritma Ring
Konsep algoritma ring pemilihan koordinator adalah memilih koordinator dari sekumpulan proses. Diasumsikan setiap proses terurut secara logika dan fisik. Setiap proses yang ada mengetahui proses mana yang menjadi koordinator. Jika proses yang ada mengetahui koordinator tidak berfungsi, maka proses tersebut akan membuat election message yang berisi nomor proses itu sendiri dan mengirimkannya ke proses berikutnya. Jika proses yang dikirimi election message mengetahui bahwa di dalam election message tidak berisi nomor prosesnya, maka
election message tersebut akan diteruskan ke proses berikutnya. Jika election
message telah kembali kepada proses yang mengirimnya, proses tersebut akan
memilih salah satu proses dari data nomor proses di election message untuk menjadi koordinator. Yang dipilih sebagai koordinator adalah nomor proses
tertinggi.
c. Mempelajari Mengenai Twitter API
Twitter menyediakan layanan API yang memberikan sejumlah fungsi untuk melakukan pengakesan data di twitter. Yang digunakan pada penelitian ini adalah Search API. Pada Twitter API v.1, Search API tidak membutuhkan otentikasi, tetapi berbeda dengan Twitter API v.1.1, Search API sudah menggunakan otentikasi sehingga membutuhkan consumer key dan consumer
secret key yang terdaftar untuk setiap aplikasi yang didaftarkan di
http://dev.twitter.com. Jenis otentikasi yang digunakan adalah application-only
authentication. Dengan otentikasi jenis ini, pengguna tak perlu melakukan login
27
Willi, 2015
Distributed twitter crawler
Universitas Pendidikan Indonesia | repository.upi.edu | perpustakaan.upi.edu
untuk melakukan permintaan untuk mencari tweet, mengakses data teman dan pengikut dari setiap akun ataupun mengambil informasi pengguna.
d. Mempelajari Konsep Pengembangan Perangkat Lunak Model Sekuensial Linear
Konsep metode pengembangan perangkat lunak model sekuensial linear adalah metode yang menggunakan pendekatan secara sistematis dan terurut. Dimulai dari analisis, kemudian tahap desain, tahap coding, dan tahap pengujian. Setiap tahap yang dilakukan harus menunggu selesainya tahap yang ada sebelumnya. Misalnya, untuk dapat melakukan tahap desain, harus menunggu selesainya tahap analisis. Begitu juga dengan tahap coding, jika ingin melakukan tahap coding, maka harus menyelesaikan tahap desain.
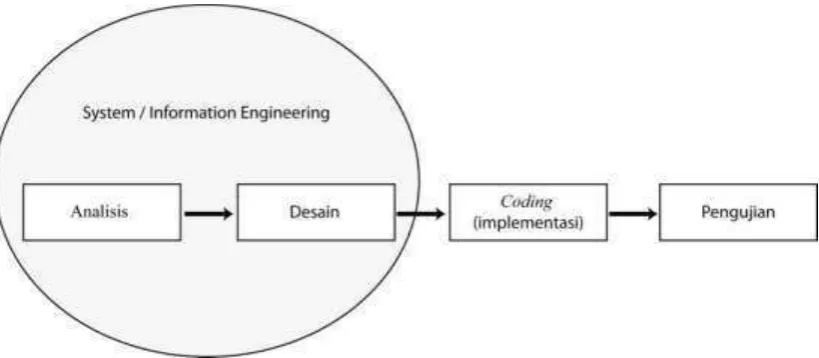
3.4 Proses Pengembangan Perangkat Lunak
Proses pengembangan perangkat lunak yang digunakan di dalam pengembangan perangkat lunak ini adalah model sekuensial linear. Pada model sekuensial linear, terdapat beberapa tahapan yaitu analisis, desain, coding (implementasi), dan pengujian.
Gambar 3.2 Model Sekuensial Linear (Pressman, 2002: hal. 29)
28
Willi, 2015
Distributed twitter crawler
Universitas Pendidikan Indonesia | repository.upi.edu | perpustakaan.upi.edu 1. System Information/Engineering
Dikarenakan perangkat lunak selalu menjadi dari sebuah sistem yang lebih besar, pekerjaan dimulai dari membuat kebutuhan-kebutuhan untuk semua bagian sistem dan kemudian mengalokasikan beberapa kelompok kebutuhan dari keseluruhan kebutuhan untuk perangkat lunak. Jadi pada tahap ini menyangkut proses pengumpulan kebutuhan-kebutuhan (requirement gathering) sistem.
2. Analisis
Tahap analisis merupakan tahap awal dalam membangun sebuah perangkat lunak yang dimulai dengan mengumpulkan segala kebutuhan yang dibutuhkan oleh perangkat lunak. Pada tahap ini dianalisis kebutuhan-kebutuhan yang telah dikumpulkan agar dapat difokuskan pada kebutuhan perangkat lunak yang akan dibangun. Kebutuhan-kebutuhan yang dianalisis pada penelitian ini meliputi bagaimana alur perangkat lunak yang diinginkan, algoritma yang digunakan, antarmuka yang diinginkan, dan bahasa pemrograman yang akan digunakan sehingga diperlukan pemahaman dari analis dalam hal ini penulis dalam memahami informasi, tingkah laku, dan antar muka perangkat lunak yang akan
dikembangkan.
Pada tahap ini, dipelajari tentang data twitter beserta Twitter API, dipelajari juga mengenai perangkat lunak sistem terdistribusi, tentang twitter
crawler, dan juga algoritma apa yang akan digunakan pada perangkat lunak
distributed twitter crawler (jika ada algoritma yang digunakan) yang akan
dibangun. Pada perangkat lunak yang dibangun, digunakan algoritma ring untuk algoritma pemilihan koordinator.
3. Desain
Tahap desain difokuskan pada empat hal, yaitu desain basis data, arsitektur perangkat lunak, antarmuka, dan algoritma yang digunakan pada perangkat lunak. Pada tahap ini, data-data yang diperoleh dari tahap analisis diterjemahkan ke dalam representasi perangkat lunak untuk dilanjutkan ke tahap selanjutnya, yaitu tahap coding atau implementasi.
29
Willi, 2015
Distributed twitter crawler
Universitas Pendidikan Indonesia | repository.upi.edu | perpustakaan.upi.edu
Coding, tahap pembuatan aplikasi yang merupakan tindak lanjut dari tahap
desain. Merupakan tahap menterjemahkan desain perangkat lunak yang telah dibuat sebelumnya pada tahap desain. Pada tahap ini, desain yang telah dibuat tersebut diimplementasikan ke baris-baris kode program. Dalam penelitian ini, bahasa pemrograman yang digunakan adalah Java untuk aplikasi pemprosesan tugas pengumpulan tweet sedangkan untuk aplikasi berbasis web yang menjadi antarmuka untuk pengguna menggunakan bahasa pemrograman php.
5. Pengujian
Willi, 2015
Distributed twitter crawler
Universitas Pendidikan Indonesia | repository.upi.edu | perpustakaan.upi.edu BAB V
KESIMPULAN DAN SARAN
5.1 Kesimpulan
Adapun kesimpulan akhir dari penelitian Distributed Twitter Crawler adalah sebagai berikut:
1. Pendistribusian proses pengumpulan tweet yang dilakukan bersifat serial. Dapat dilakukan ke beberapa node sehingga dapat diperoleh tweet dengan jumlah yang lebih banyak dibanding hanya menggunakan satu node. Dalam penelitian ini, pendistribusian tugas pengumpulan tweet dapat dilakukan ke dua node.
2. Pengembangan prototype aplikasi dtcapp untuk memudahkan pengumpulan data tweet dapat dilakukan dengan memanfaatkan prinsip sistem terdistribusi.
5.2 Saran
Untuk pengembangan lebih lanjut terhadap penelitian yang telah dilakukan, saran-saran yang diberikan pada penelitian ini adalah:
1. Proses pendistribusian tweet yang dapat dilakukan masih bersifat serial untuk menghindari duplikasi tweet. Oleh karena itu disarankan proses pendistribusian pengumpulan tweet dapat dikembangkan dari proses pendistribusian serial menjadi proses pendistribusian secara paralel.