BAB 2
LANDASAN TEORI
2.1 Definisi Pemeliharaan
Agar suatu kegiatan produksi dapat berlangsung dengan lancar, menghasilkan produk-produk yang bermutu tinggi, maka perlu didukung oleh mesin-mesin atau peralatan yang handal dan siap bekerja setiap saat. Untuk mencapai hal itu maka mesin-mesin dan peralatan penunjang proses produksi ini membutuhkan suatu aktivitas pemeliharaan (maintenance) secara teratur dan terencana.
Definisi pemeliharaan (maintenance) adalah suatu kombinasi dari berbagai tindakan yang dilakukan untuk menjaga suatu barang atau memperbaikinya sampai pada suatu kondisi yang bisa diterima. Pemeliharaan juga dapat diartikan sebagai suatu kegiatan menjaga fasilitas pabrik serta mengadakan perbaikan, penyesuaian atau penggantian yang diperlukan agar tercapai suatu keadaan operasi produksi yang sesuai dengan yang direncanakan.
Jadi, secara umum, pemeliharaan dapat juga didefinisikan sebagai suatu aktifitas yang diperlukan untuk tetap menjaga suatu fasilitas berada dalam kondisi pengoperasian yang terbaik. Apabila kita menginginkan kondisi mesin-mesin produksi selalu dalam kondisi fungsional yang baik, maka kegiatan perawatan atau pemeliharaan mesin-mesin tersebut wajib untuk diperhatikan.
Kegiatan-kegiatan yang termasuk ke dalam pemeliharaan misalnya adalah : 1.Pemeriksaan (inspection), yaitu tindakan yang ditujukan terhadap sistem atau
mesin untuk mencegah terjadinya breakdown mendadak dan untuk mengetahui apakah sistem atau mesin bekerja dengan baik sesuai dengan fungsinya.
2.Penggantian komponen (replacement), yaitu melakukan penggantian komponen yang tidak dapat berfungsi lagi. Penggantian ini mungkin dilakukan secara mendadak atau dengan perencanaan terlebih dahulu.
3.Reparasi (repair), yaitu melakukan perbaikan secara cermat saat terjadi kerusakan. 4.Overhaul, yaitu tindakan pemeriksaan besar-besaran yang biasanya dilakukan pada
akhir periode tertentu.
Dengan adanya kegiatan pemeliharaan yang baik, maka fasilitas, mesin atau peralatan pabrik dapat dipergunakan untuk produksi sesuai dengan rencana, dan tidak mengalami kerusakan selama digunakan dalam proses produksi atau sebelum jangka waktu tertentu yang direncanakan, sehingga proses produksi berjalan dengan lancar.
2.2 Tujuan Pemeliharaan
Kegiatan pemeliharaan atau maintenance bukan saja dianggap sebagai fungsi tambahan dari sistem produksi, melainkan suatu bagian yang penting di dalam usaha peningkatan produktifitas. Kegiatan pemeliharaan sudah merupakan suatu bagian yang harus dilibatkan di dalam proses industri, dimana staf dari kegiatan pemeliharaan harus terlibat secara aktif untuk menjamin efisiensi operasi yang optimal.
Secara umum, kegiatan pemeliharaan atau maintenance memiliki beberapa tujuan sebagai berikut :
1. Memperpanjang usia kegunaan asset.
2. Menjamin ketersediaan peralatan dan kesiapan operasional perlengkapan serta peralatan yang dipasang untuk kegiatan produksi.
3. Membantu mengurangi pemakaian atau penyimpangan diluar batas serta menjaga modal yang ditanamkan selama waktu yang ditentukan.
4. Menekan tingkat biaya perawatan serendah mungkin dengan melaksanakan kegiatan perawatan secara efektif dan efisien.
5. Memenuhi kebutuhan produk dan rencana produksi tepat waktu.
6. Meningkatkan keterampilan para supervisor dan operator melalui kegiatan pelatihan yang diadakan.
7. Menjamin kesiapan operasional dari seluruh mesin dan peralatan yang diperlukan dalam keadaan darurat setiap waktu.
8. Menjamin keselamatan orang yang menggunakan sarana tersebut.
2.3 Jenis-jenis Pemeliharaan
Secara umum, aktivitas pemeliharaan (maintenance) dapat dibedakan ke dalam 3 jenis, yaitu preventive maintenance, corrective maintenance dan total productive maintenance.
2.3.1 Preventive Maintenance
Preventive maintenance atau pemeliharaan pencegahan merupakan suatu kegiatan pemeliharaan yang dilakukan secara rutin untuk mencegah terjadinya kerasakan-kerusakan pada sebuah fasilitas (mesin atau peralatan) selama proses produksi berlangsung. Kegiatan yang termasuk ke dalam preventive maintenance ini adalah pemeriksaan dan penggantian komponen
Kegiatan penggantian komponen pada preventive maintenance akan menambah biaya dalam proses produksi, karena penggantian komponen atau part dilakukan sebelum komponen tersebut rusak. Oleh sebab itu penetapan komponen-komponen yang hendak dibuat penjadwalan penggantiannya harus merupakan komponen yang kritis (critical unit) di dalam suatu sistem.
Dalam pelaksanaannya, preventive maintenance dibedakan menjadi dua kegiatan, yaitu :
1. Routine Maintenance, yaitu kegiatan pemeliharaan yang dilakukan secara rutin, sebagai contoh adalah kegiatan pembersihan fasilitas dan peralatan, pemberian minyak pelumas atau pengecekan oli, serta pengecekan bahan bakar dan sebagainya.
2. Periodic Maintenance, yaitu kegiatan pemeliharaan yang dilakukan secara berkala. Pemeliharaan berkala dilakukan berdasarkan lamanya jam kerja mesin produk tersebut sebagai jadwal kegiatan misalnya setiap seratus jam sekali.
2.3.2 Corrective Maintenance
Corrective maintenance atau pemeliharaan korektif adalah kegiatan pemeliharaan yang dilakukan ketika suatu fasilitas atau sistem mengalami kerusakan atau gangguan yang mengakibatkan fasilitas tersebut tidak dapat menjalankan fungsinya dengan sebagaimana mestinya. Kegiatan pemeliharaan korektif ini sering disebut sebagai repair maintenance atau perbaikan. Maksud dari tindakan corrective maintenance ini adalah agar fasilitas atau sistem tersebut dapat dipergunakan kembali dalam proses produksi, sehingga proses produksi dapat berjalan lancar kembali.
Secara sepintas, corrective maintenance membutuhkan biaya yang lebih murah dibandingkan preventive maintenance. Akan tetapi, apabila kerusakan terjadi selama proses produksi berlangsung, maka akan menimbulkan biaya yang jauh lebih besar karena adanya biaya kehilangan produksi akibat terhentinya proses produksi selama kerusakan tersebut masih belum diatasi atau diperbaiki. Dengan demikian, tindakan coorective maintenance memusatkan permasalahan setelah permasalahan itu terjadi, bukan menganalisa masalah untuk mencegahnya agar tidak terjadi.
2.3.3 Total Productive Maintenance (TPM)
Total Productive Maintenance (TPM) adalah pendekatan yang digunakan sebagai usaha untuk memaksimalkan keefektifan dari fasilitas yang dipergunakan dalam menjalankan bisnis. TPM tidak hanya mengenani perawatan (maintenance), tetapi menyangkut semua aspek operasi dan instalasi dari fasilitas tersebut, dan TPM sangat mempengaruhi motivasi orang-orang yang bekerja dalam suatu perusahaan.
Definisi lengkap TPM memuat aspek-aspek sebagai berikut :
Total efektif, memaksimalkan efektifitas peralatan atau mesin secara menyeluruh.
Total sistem, menerapkan sistem preventive maintenance yang komprehensif sepanjang umur alat.
Total keterlibatan, melibatkan seluruh departemen, meliputi perencana, pemakai dan pemelihara alat.
Total partisipasi, dilakukan mulai dari operator yang paling rendah sampai kepada level Top Management.
Total usaha, mengembangkan preventive maintenance melalui manajemen motivasi aktivitas kelompok kecil mandiri.
TPM mempunyai sasaran Zero breakdown dan Zero defect. Jika breakdown dan defect dapat dikurangi, equipment operation rates meningkat, cost berkurang, inventory minimal, dan sebagai akibatnya produktifitas pekerja naik.
2.4 Konsep-konsep Pemeliharaan 2.4.1 Konsep Breakdown dan Downtime
Suatu barang atau produk dikatakan rusak ketika barang atau produk tersebut tidak dapat menjalankan fungsinya dengan baik lagi. Hal yang sama juga terjadi pada mesin atau peralatan di dalam sistem produksi pada industri manufaktur. Ketika suatu mesin atau alat tidak dapat menjalankan fungsinya dengan baik atau sebagaimana mestinya, maka mesin atau alat tersebut dikatakan mengalami kerusakan atau breakdown.
Pada dasarnya, downtime didefinisikan sebagai waktu suatu sistem atau komponen tidak dapat digunakan (tidak berada dalam kondisi yang baik) sehingga membuat fungsi sistem tidak berjalan sesuai yang diharapkan. Downtime terjadi ketika unit mengalami masalah seperti kerusakan yang dapat mengganggu performansi keseluruhan termasuk kualitas produk yang dihasilkan atau kecepatan produksinya, sehingga membutuhkan waktu untuk mengembalikan fungsi unit tersebut pada kondisi semula. Konsep downtime terdiri dari beberapa unsur, yaitu : 1. Supply delay, yaitu waktu untuk memperoleh komponen (part) yang dibutuhkan
dalam proses perbaikan. Supply delay dapat terdiri dari lead time administrasi, lead time produksi, dan waktu transportasi komponen pada lokasi perbaikan. 2. Maintenance delay, yaitu waktu untuk menunggu ketersediaan sumber daya
maintenance untuk melakukan suatu proses perbaikan. Sumber daya maintenance dapat berupa personil, alat bantu atau alat tes.
3. Access time, yaitu waktu untuk mendapatkan akses langsung ke komponen yang rusak.
4. Diagnosis time, yaitu waktu untuk menentukan penyebab kerusakan dan langkah perbaikan yang harus ditempuh untuk memperbaiki kerusakan tersebut.
5. Repair or replacement time, yaitu waktu aktual untuk menyelesaikan proses pemulihan setelah permasalahan dapat diidentifikasi dan akses ke komponen yang rusak dapat dicapai.
6. Verification and alignment, yaitu waktu untuk memastikan bahwa fungsi dari suatu unit telah kembali pada kondisi operasi semula.
2.4.2 Konsep Keandalan (Reliability)
Yang dimaksud dengan keandalan (reliability) adalah probabilitas sebuah komponen atau sistem untuk dapat beroperasi sesuai dengan fungsi yang diinginkan untuk suatu periode tertentu ketika digunakan pada kondisi operasi yang telah ditetapkan. Keandalan juga berarti probabilitas dari sebuah mesin atau peralatan untuk tidak mengalami kerusakan selama proses berlangsung. Fungsi keandalan dapat dinotasikan R(t) = P(peralatan beroperasi pada saat t). Empat elemen pokok dalam konsep reliability ini adalah :
1. Probability (peluang), dimana nilai reliability adalah berada diantara 0 dan 1. 2. Performance (kinerja), artinya bahwa keandalan merupakan suatu karakteristik
performansi sistem, dimana suatu sistem yang andal harus dapat menunjukkan performansi yang memuaskan jika dioperasikan. Dalam hal ini performansi yang diharapkan atau tujuan yang diinginkan, harus digambarkan secara jelas dan spesifik. Untuk setiap unit terdapat suatu standar untuk menentukan apa yang dimaksud dengan performansi atau tujuan yang diharapkan.
3. Time (waktu), sebagai parameter yang penting untuk melakukan penilaian kemungkinan suksesnya suatu sistem. Dalam hal ini, konsep reliability dinyatakan dalam suatu periode waktu. Peluang suatu sistem untuk digunakan selama setahun akan berbeda dengan peluang sistem tersebut untuk digunakan dalam sepuluh tahun.
4. Condition (kondisi), artinya perlakuan yang diterima suatu sistem memberikan pengaruh terhadap tingkat reliability. Dalam hal ini, kondisi lingkungan akan mempengaruhi umur sistem atau peralatan, seperti suhu, kelembaban dan kecepatan gerak. Hal ini menjelaskan bagaimana perlakuan yang diterima sistem dapat memberikan tingkat keandalan yang berbeda dalam kondisi operasionalnya.
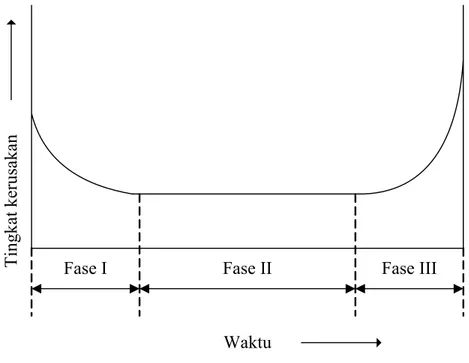
Terkait dengan reliability suatu sistem terdapat hal yang perlu diperhatikan yaitu kegagalan atau kerusakan, dimana sistem tersebut tidak dapat bekerja sebagaimana mestinya. Karakteristik kegagalan (produk, mesin, atau peralatan) dalam perjalanan sehubungan dengan waktu dapat digambarkan seperti grafik dibawah ini.
Fase I Fase II Fase III
Tingka
t kerusa
ka
n
Waktu
Fase I, disebut Burn-in Region, yaitu wilayah dimana mesin atau peralatan baru digunakan. Pada wilayah ini terjadi penurunan resiko kerusakan (Decreasing Hazard Rate). Kerusakan yang terjadi misalnya disebabkan kurangnya pengendalian kualitas produksi, pengecekan yang tidak sesuai, material di bawah standar, ketidaksempurnaan rancangan, kesalahan proses atau pemasangan awal.
Fase II, disebut wilayah Useful Life atau fase umur pakai. Dalam hal ini, fase kerusakannya konstan (Constant Hazard Rate). Pada wilayah ini, kerusakan tidak dapat diprediksi, sehingga sering disebut kerusakan acak. Contoh penyebab terjadinya kerusakan pada fase ini adalah karena karena kesalahan operasional.
Fase III, disebut wilayah Wareout, yaitu wilayah dimana umur ekonomis mesin atau peralatan telah habis atau melebihi batas yang diizinkan, sehingga resiko kerusakan akan meningkat (Increasing Hazard Rate). Penyebab kerusakannya adalah karena kurangnya perawatan, karena telah dipakai terlalu lama, terjadi karat atau perubahan fisik mesin atau peralatan tersebut. Pada wilayah ini, aktivitas preventive maintenance diperlukan untuk mengurangi tingkat kerusakan.
2.4.3 Konsep Keterawatan (Maintainability)
Keterawatan (maintainability) adalah probabilitas bahwa komponen atau sistem yang rusak akan diperbaiki ke dalam suatu kondisi tertentu dalam periode waktu tertentu sesuai dengan prosedur yang telah ditentukan. Keterawatan juga dapat didefinisikan sebagai probabilitas suatu komponen atau sistem untuk bisa diperbaiki pada waktu tertentu.
2.4.4 Konsep Ketersediaan (Availability)
Ketersediaan (availability) adalah probabilitas suatu komponen atau sistem menunjukkan fungsi yang diharapkan pada suatu waktu tertentu ketika dioperasikan dalam kondisi operasional tertentu. Ketersediaan juga dapat diinterpretasikan sebagai persentase waktu suatu komponen atau sistem dapat beroperasi pada interval waktu tertentu atau persentase pengoperasian komponen dalam waktu yang tersedia. Angka probabilitas availability menunjukkan kemampuan komponen untuk berfungsi setelah dilakukan tindakan perawatan terhadapnya. Dengan demikian semakin besar nilai availability menunjukkan semakin tinggi kemampuan komponen tesebut, atau dapat dikatakan semakin nilai availability mendekati satu, maka semakin baik keadaan komponen tersebut untuk dapat beroperasi sesuai fungsinya.
2.5 Distribusi Kerusakan
Terdapat empat macam jenis distribusi yang umum digunakan untuk mengidentifikasi pola data kerusakan yang terbentuk, yaitu distribusi Weibull, Exponential, Normal dan Lognormal.
Distribusi Weibull
Distribusi Weibull merupakan distribusi yang paling banyak digunakan untuk waktu kerusakan karena distribusi ini baik digunakan untuk laju kerusakan yang meningkat maupun laju kerusakan yang menurun. Terdapat dua parameter yang digunakan dalam distribusi ini yaitu θ yang disebut dengan parameter skala (scale parameter) dan β yang disebut dengan parameter bentuk (shape parameter).
Dalam distribusi Weibull yang menentukan tingkat kerusakan dari pola data yang terbentuk adalah parameter β. Nilai-nilai β yang menunjukkan laju kerusakan terdapat dalam tabel berikut :
Tabel 2.1 Nilai-Nilai Parameter β
Nilai Laju Kerusakan
0 < β <1 Pengurangan laju kerusakan (DFR)
β = 1 Distribusi Exponential (CFR)
1 < β < 2 Peningkatan laju kerusakan (IFR), concave
β = 2 Distribusi Rayleigh (LFR)
β > 2 Peningkatan laju kerusakan (IFR), convex
3 ≤β≤ 4 Peningkatan laju kerusakan (IFR), mendekati kurva normal
Jika parameter β mempengaruhi laju kerusakan maka parameter θ
mempengaruhi nilai tengah dari pola data.
Distribusi Exponential
Distribusi Exponential digunakan untuk menghitung keandalan dari distribusi kerusakan yang memiliki laju kerusakan konstan. Distribusi ini mempunyai laju kerusakan yang tetap terhadap waktu, dengan kata lain probabilitas terjadinya kerusakan tidak tergantung pada umur alat. Distribusi ini merupakan distribusi yang paling mudah untuk dianalisa. Parameter yang digunakan dalam distribusi Exponential adalah λ, yang menunjukkan rata-rata kedatangan kerusakan yang terjadi.
Distribusi Normal
Distribusi Normal cocok untuk digunakan dalam memodelkan fenomena keausan (kelelahan) atau kondisi wearout dari suatu item. Parameter yang digunakan adalah μ (nilai tengah) dan σ (standar deviasi). Karena hubungannya dengan distribusi Lognormal, distribusi ini dapat juga digunakan untuk menganalisa probabilitas Lognormal.
Distribusi Lognormal
Distribusi Lognormal menggunakan dua parameter yaitu s yang merupakan parameter bentuk (shape parameter) dan tmed sebagai parameter lokasi (location
parameter) yang merupakan nilai tengah dari suatu distribusi kerusakan. Distribusi ini dapat memiliki berbagai macam bentuk, sehingga sering dijumpai bahwa data yang sesuai dengan distribusi Weibull juga sesuai dengan distribusi Lognormal.
2.6 Perhitungan Index Of Fit
Untuk menentukan jenis distribusi yang paling mewakili penyebaran suatu data kerusakan dapat dilakukan dengan menggunakan metode Least-Squares Curve-Fitting. Dalam hal ini, proses yang harus dilakukan adalah mencari nilai index of fit untuk masing-masing distribusi sehingga didapatkan nilai index of fit terbesar yang kemudian akan diuji lagi menurut hipotesa distribusinya.
Index of fit dihitung dengan mencari nilai r (koefisien korelasi) yang menunjukkan kekuatan hubungan linear antara variabel x dan y. Nilai r yang semakin mendekati 1 artinya bahwa terdapat korelasi atau hubungan linear yang kuat diantara variabel x dan y. Semakin kuat hubungan diantara variabel x dan y, maka semakin menyebar membentuk garis lurus atau linear, artinya data-data tersebut semakin mendekati suatu jenis distribusi tertentu. Berikut ini adalah rumus-rumus yang digunakan dalam perhitungan nilai index of fit (r) untuk masing-masing jenis distribusi. 4 . 0 n 3 . 0 i ) t ( F i + − =
Dimana : i = data waktu ke-t
n = jumlah data kerusakan
index of fit (r) = ⎥ ⎦ ⎤ ⎢ ⎣ ⎡ ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ − ⎥ ⎦ ⎤ ⎢ ⎣ ⎡ ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ − ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ − ∑ ∑ ∑ ∑ ∑ ∑ ∑ = = = = = = = n 1 i 2 n 1 i i 2 i n 1 i 2 n 1 i i 2 i n 1 i n 1 i i n 1 i i i i y y n x x n y x y x n
Dimana nilai xi dan yi untuk masing-masing jenis distribusi adalah berbeda, yaitu :
Distribusi Weibull ) t ln( xi = i ⎥ ⎦ ⎤ ⎢ ⎣ ⎡ ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ − = ) t ( F 1 1 ln ln y i i
Distribusi Exponential i i t x = ⎥ ⎦ ⎤ ⎢ ⎣ ⎡ ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ − = ) t ( F 1 1 ln ln y i i Distribusi Normal i i t x =
yi = zi = Φ-1[F(ti)] Æ diperoleh dari Tabel Standardized Normal Probabilities
Distribusi Lognormal )
t ln(
xi = i
yi = zi = Φ-1[F(ti)] Æ diperoleh dari Tabel Standardized Normal Probabilities Perhitungan index of fit juga bisa dilakukan dengan menggunakan bantuan software minitab dengan langkah-langkah berikut ini :
- Pada worksheet baru masukkan nilai variabel x pada kolom C1 dan masukkan nilai y pada kolom C2.
- Pilih menu Stat – Basic Statistic – Correlation.
- Pada dialog box (variables), masukkan kolom C1 dan C2 kemudian pilih Select. - Pilih Ok.
2.7 Goodness Of Fit Test
Setelah perhitungan index of fit dilakukan, maka tahap selanjutnya adalah pengujian goodness of fit (uji kebaikan suai) untuk nilai index of fit (r) terbesar. Uji goodness of fit dilakukan dengan membentuk suatu hipotesis H0 dan H1. Hipotesis H0 biasanya berisi pernyataan harapan, sedangkan hipotesis H1 adalah kebalikan dari hipotesis H0.
Distribusi yang memiliki nilai r terbesar belum tentu benar-benar mewakili penyebaran suatu data, sebab ketika diuji kesesuaian data tidak selalu menghasilkan keputusan terima hipotesis harapan H0. Jika hal ini terjadi, maka pengujian dilakukan kembali terhadap distribusi lain yang memiliki nilai index of fit (r) terbesar kedua, dan seterusnya sampai dihasilkan keputusan bahwa data-data yang diuji memiliki kecocokan dengan suatu jenis distribusi tertentu. Jenis pengujian yang digunakan untuk masing-masing jenis distribusi adalah berbeda-beda, yaitu :
Mann’s Test untuk Pengujian Distribusi Weibull Hipotesa untuk melakukan uji Mann adalah :
H0 : Waktu kerusakan berdistribusi Weibull H1 : Waktu kerusakan tidak berdistribusi Weibull Uji statistiknya adalah :
(
)
(
)
∑ ∑ = + − + = + ⎥ ⎦ ⎤ ⎢ ⎣ ⎡ − ⎥ ⎦ ⎤ ⎢ ⎣ ⎡ − = 1 k 1 i i i 1 i 2 1 r 1 1 k i i i 1 i 1 M t ln t ln k M t ln t ln k MDimana : =⎢⎣⎡ ⎥⎦⎤ 2 r k1 dan =⎢⎣⎡ − ⎥⎦⎤ 2 1 r k1 Mi = Zi+1 - Zi Zi = ⎥ ⎦ ⎤ ⎢ ⎣ ⎡ ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ + − − − 25 . 0 n 5 . 0 i 1 ln ln
Jika nilai M < Mtabel (α,v1,v2) Æ maka H0 diterima.
v1 = 2k2 dan v2 = 2k1
Nilai Mtabel (α,v1,v2) diperoleh dari Tabel F-Distribution
Ket : ti = data waktu kerusakan yang ke-i r = jumlah data kerusakan
M = nilai uji statistik untuk uji Mann
Bartlett’s Test untuk Pengujian Distribusi Exponential Hipotesa untuk melakukan uji Bartlett adalah :
H0 : Data kerusakan berdistribusi Eksponential H1 : Data kerusakan tidak berdistribusi Eksponential Uji statistiknya adalah :
( )
( )
) r 6 / ) 1 r (( 1 t ln r / 1 ) t r / 1 ln( r 2 B r 1 i i r 1 i i + + ⎥⎦ ⎤ ⎢⎣ ⎡ − = ∑= ∑= Jika 2 1 r , 2 / α 2 1 r , 2 / α 1 B X X − − < < − Æ maka H0 diterima. Nilai 2 1 r , 2 / α 1 X− − dan 2 1 r , 2 / αKet : ti = data waktu kerusakan yang ke-i r = jumlah data kerusakan
B = nilai uji statistik untuk uji Bartlett
Kolmogorov-Smirnov’s Test untuk Pengujian Distribusi Normal dan Lognormal
Hipotesa untuk melakukan uji Normal atau Lognormal adalah : H0 : Data kerusakan berdistribusi Normal atau Lognormal H1 : Data kerusakan tidak berdistribusi Normal dan Lognormal Uji statistiknya adalah : Dn = max{D1,D2}
Dimana : ⎪⎭ ⎪ ⎬ ⎫ ⎪⎩ ⎪ ⎨ ⎧ − − ⎟ ⎟ ⎠ ⎞ ⎜ ⎜ ⎝ ⎛ − = ≤ ≤ n 1 i s t t Φ max D i n i 1 1 ⎪⎭ ⎪ ⎬ ⎫ ⎪⎩ ⎪ ⎨ ⎧ ⎟ ⎟ ⎠ ⎞ ⎜ ⎜ ⎝ ⎛ − − = ≤ ≤ s t t Φ n i max D i n i 1 2 ∑ = = n 1 i i n t t dan 1 n ) t t ( s n 1 i 2 i 2 − −
= ∑= (untuk distribusi Normal)
∑ = = n 1 i i n t ln t dan 1 n ) t t (ln s n 1 i 2 i 2 − −
= ∑= (untuk distribusi Lognormal) Jika nilai Dn < Dtabel (n,α) Æ maka H0 diterima.
Ket : ti = data waktu kerusakan yang ke-i t = rata-rata data waktu kerusakan n = jumlah data kerusakan
s = standar deviasi
Dn = nilai uji statistik untuk uji Kolmogorov-Smirnov
Untuk pengujian goodness of fit juga dapat dilakukan dengan menggunakan software minitab dengan langkah-langkah sebagai berikut :
- Pada worksheet baru masukkan data TTF atau TTR pada kolom C1. - Pilih menu Stat – Quality Tools – Individual Distribution Identification. - Pada dialog box, untuk single column masukkan kolom C1.
- Pada dialog box, untuk specify pilih jenis distribusi yang ingin diketahui.
- Untuk mengubah tingkat kepercayaan, klik options button, masukkan tingkat kepercayaan yang dikehendaki, lalu klik Ok.
- Pilih Ok.
2.8 Perhitungan Parameter
Setelah jenis distribusi kerusakan telah teridentifikasi, maka selanjutnya dilakukan perhitungan nilai parameter berdasarkan jenis distribusi yang terpilih. Berikut ini adalah rumus perhitungan parameter yang digunakan untuk masing-masing distribusi.
Distribusi Weibull Parameter : β = b dan θ = (a/b) e− Dimana : a=y−bx dan ∑ ∑ ∑ ∑ ∑ = = = = = ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ − ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ − = n 1 i 2 n 1 i i 2 i n 1 i i n 1 i n 1 i i i i x x n y x y x n b Distribusi Exponential Parameter : λ = b Dimana : ∑ ∑ = = = n 1 i 2 i n 1 i i i x y x b Distribusi Normal Parameter : b 1 σ= dan ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ − = b a μ Dimana : a=y−bx dan ∑ ∑ ∑ ∑ ∑ = = = = = ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ − ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ − = n 1 i 2 n 1 i i 2 i n 1 i i n 1 i n 1 i i i i x x n y x y x n b Distribusi Lognormal Parameter : s = b 1 dan tmed = e−sa Dimana : a=y−bx dan ∑ ∑ ∑ ∑ ∑ = = = = = ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ − ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ − = n 1 i 2 n 1 i i 2 i n 1 i i n 1 i n 1 i i i i x x n y x y x n b
2.9 Perhitungan Mean Time To Failure (MTTF)
Mean Time To Failure (MTTF) merupakan rata-rata selang waktu kerusakan dari suatu distribusi kerusakan. Perhitungan nilai MTTF berbeda-beda sesuai dengan jenis distribusi yang terpilih untuk penyebaran data Time To Failure (TTF). Rumus yang digunakan dalam perhitungan nilai MTTF untuk masing-masing jenis distribusi adalah sebagai berikut :
Distribusi Weibull MTTF = ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ + β 1 1 Γ . θ Nilai ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ + β 1 1
Γ Æ didapat dari nilai Γ(x)pada Tabel Gamma Function
Distribusi Exponential MTTF = λ 1 Distribusi Normal MTTF = μ Distribusi Lognormal MTTF = 2 s med 2 e . t
2.10 Perhitungan Mean Time To Repair (MTTR)
Mean Time To Repair (MTTR) merupakan waktu rata-rata dari interval waktu perbaikan atau TTR. Dalam perhitungan nilai MTTR, perbedaan distribusi data TTR untuk setiap komponen kritis juga akan menyebabkan adanya perbedaan untuk cara perhitungan MTTR. Parameter yang digunakan juga berbeda sesuai dengan jenis distribusinya. Berikut ini adalah rumus yang digunakan untuk perhitungan nilai MTTR berdasarkan jenis distribusi masing-masing.
Distribusi Weibull MTTR = ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ + β 1 1 Γ . θ Nilai ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ + β 1 1
Γ Æ didapat dari nilai Γ(x)pada Tabel Gamma Function
Distribusi Eksponential
MTTR =
λ
1
Distribusi Normal dan Lognormal
MTTR = 2 s med 2 e . t
2.11 Penentuan Interval Waktu Penggantian Pencegahan Optimal
Seperti telah dijelaskan sebelumnya, bahwa pada dasarnya, downtime didefinisikan sebagai waktu suatu sistem atau komponen tidak dapat digunakan (tidak berada dalam kondisi yang baik) sehingga membuat fungsi sistem tidak berjalan. Prinsip utama dalam manajemen sistem perawatan adalah untuk menekan periode kerusakan (breakdown period) sampai batas minimum, maka keputusan penggantian komponen sistem berdasarkan downtime minimum menjadi sangat penting.
Permasalahannya adalah penentuan waktu terbaik untuk mengetahui kapan penggantian harus dilakukan untuk meminimasi total downtime. Konflik yang dihadapi adalah :
1. Peningkatan frekuensi penggantian dapat meningkatkan downtime karena penggantian tersebut, tetapi dapat mengurangi waktu downtime akibat terjadi kerusakan.
2. Pengurangan frekuensi penggantian akan menurunkan downtime karena penggantian, tetapi konsekuensinya adalah kemungkinan peningkatan downtime karena kerusakan.
Dari dua kondisi di atas, diharapkan untuk dapat menghasilkan keseimbangan diantara keduanya.
Secara umum, ada dua jenis model standar bagi permasalahan penggantian yaitu :
1. Block Replacement
Pada model block replacement, tindakan penggantian dilakukan pada suatu interval yang tetap. Model ini digunakan jika diinginkan adanya konsistensi interval penggantian pencegahan yang telah ditentukan, walau sebelumnya telah terjadi penggantian yang disebabkan adanya kerusakan. Jika pada selang waktu tp tidak terdapat kerusakan, maka tindakan penggantian dilakukan pada suatu interval tp yang tetap. Jika sistem rusak sebelum jangka waktu tp, maka dilakukan penggantian kerusakan dan penggantian selanjutnya akan tetap dilakukan pada saat tp dengan mengabaikan penggantian perbaikan sebelumnya.
2. Age Replacement
Pada model ini penggantian pencegahan dilakukan tergantung pada umur pakai dari komponen. Tujuan model ini menentukan umur optimal dimana penggantian pencegahan harus dilakukan sehingga dapat meminimasi total downtime. Dalam metode ini tindakan penggantian dilakukan pada saat pengoperasiannya sudah mencapai umur yang ditetapkan yaitu sebesar tp.
Jika pada selang waktu tp tidak terdapat kerusakan, maka dilakukan penggantian sebagai tindakan korektif. Perhitungan umur tindakan penggantian tp dimulai dari awal lagi dengan mengambil acuan dari waktu mulai bekerjanya sistem kembali setelah dilakukan tindakan perawatan korektif tersebut.
Model penentuan interval waktu penggantian pencegahan berdasarkan kriteria minimasi downtime yang digunakan adalah Age Replacement. Formulasi perhitungan untuk model age replacement adalah sebagai berikut :
siklus panjang ekspektasi siklus per downtime ekspektasi Total ) tp ( D = )) tp ( R 1 ).( T ) tp ( M ( ) tp ( R ). T tp ( )) tp ( R 1 ( T ) tp ( R . T ) tp ( D f p f p − + + + − + = Dimana :
D(tp) = total downtime per unit waktu untuk penggantian preventive tp = panjang dari siklus (interval waktu) preventive
Tp = downtime karena tindakan preventive (waktu yang diperlukan untuk penggantian komponen karena tindakan preventive)
Tf = downtime karena kerusakan komponen (waktu yang diperlukan untuk penggantian komponen karena kerusakan)
R(tp) = peluang dari siklus preventive (pencegahan) M(tp) = nilai harapan panjang siklus kerusakan (kegagalan)
Nilai tingkat ketersediaan (availability) dari interval penggantian pencegahan dapat diketahui dengan rumus A(tp) = 1 - D(tp)min.
2.12 Penentuan Interval Waktu Pemeriksaan Optimal
Selain aktivitas penggantian pencegahan, juga perlu dilakukan aktivitas pemeriksaan yang dilakukan secara berkala. Langkah-langkah perhitungan interval waktu pemeriksaan yang optimal adalah :
Waktu rata-rata 1x perbaikan (1/μ) =
kerja/bln jam
MTTR
Waktu rata-rata 1x pemeriksaan (1/i) =
kerja/bln jam n pemeriksaa x 1 waktu
Rata-rata kerusakan dalam 1 bulan (k) =
bulan 12
thn kerusakan/ jumlah
Jumlah pemeriksaan optimal (n) =
μ
i k×
Interval waktu pemeriksaan (ti) =
n kerja/bln jam
Nilai tingkat ketersediaan (availability) jika dilakukan sejumlah n pemeriksaan dapat diketahui dengan rumus A(n)=1−D(n),
Dengan
( )
i n μ n k n D + × =Dimana : D(n) = total downtime
n = jumlah pemeriksaan per satuan waktu
μ = berbanding terbalik dengan 1/ μ
2.13 Perhitungan Availability Total
Perhitungan tingkat availability total komponen kritis bertujuan untuk mengetahui tingkat ketersediaan atau kesiapan mesin untuk beroperasi kembali saat mesin tersebut telah diperbaiki.
Tingkat ketersediaan berdasarkan interval waktu penggantian pencegahan dan tingkat ketersediaan berdasarkan interval pemeriksaan merupakan dua kejadian yang saling bebas dan tidak saling mempengaruhi. Sehingga berdasarkan teori peluang dua kejadian bebas, nilai peluang kejadian saling bebas sama dengan hasil perkalian kedua availability tersebut.
2.14 Perhitungan Reliability
Peningkatan keandalan (reliability) dapat ditempuh dengan cara preventive maintenance. Dengan menerapkan preventive maintenance maka dapat mengurangi pengaruh umur atau wearout mesin atau komponen dan memberikan hasil yang signifikan terhadap umur sistem. Model keandalan berikut mengasumsikan bahwa sistem kembali ke kondisi baru setelah dilakukannya tindakan preventive maintenance :
( )
⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎣ ⎡ ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ − = β θ t exp t R( )
⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎣ ⎡ ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ − = β n θ T n exp T R(
)
⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎣ ⎡ ⎟ ⎠ ⎞ ⎜ ⎝ ⎛ − − = − β θ nT t exp nT t R( )
t R( )
T R(
t nT)
Rm = n× − Dimana :T = interval waktu pemeliharaan (penggantian pencegahan atau service) n = jumlah pemeliharaan yang telah dilakukan sampai kurun waktu t
( )
tR = keandalan pada kondisi berjalan (saat ini)
( )
T nR = probabilitas keandalan dengan n kali preventive maintenance
(
t nT)
R − = probabilitas keandalan untuk waktu (t-nT) dari tindakan preventive maintenance yang terakhir
( )
tRm = probabilitas keandalan setelah diterapkannya usulan preventive maintenance
2.15 Perhitungan Biaya Failure dan Biaya Preventive
Pemeliharaan yang baik akan dilakukan dalam setiap interval waktu tertentu dan pada waktu proses produksi sedang tidak berjalan. Semakin sering pemeliharaan suatu mesin dilakukan akan meningkatkan biaya pemeliharaan. Disisi lain, jika pemeliharaan tidak dilakukan akan mengurangi performance kerja dari mesin tersebut. Pola maintenance yang optimal perlu dicari supaya antara biaya pemeliharaan dan biaya kerusakan bisa seimbang pada total cost yang paling minimal.
Berdasarkan penjelasan tersebut, maka biaya failure (Cf) dapat didefinisikan sebagai biaya yang timbul karena terjadi kerusakan pada mesin di luar perkiraan yang menyebabkan mesin produksi terhenti ketika produksi sedang berjalan. Sedangkan biaya preventive (Cp) merupakan biaya yang timbul karena adanya pemeliharaan pencegahan terhadap mesin yang memang sudah dijadwalkan. Perhitungan biaya satu siklus failure dan satu siklus preventive dapat dilakukan dengan menggunakan rumus berikut ini :
Cf = biaya satu siklus failure
= ((biaya tenaga kerja/jam + biaya kehilangan produksi) × Tf) + harga komponen
Cp = biaya satu siklus preventive
= (biaya tenaga kerja/jam × Tp) + harga komponen Dimana : Tf = waktu standar perbaikan failure
Tp = waktu standar perbaikan preventive
Untuk menghitung total biaya failure (Tc(tf)) dan total biaya preventive (Tc(tp)) rumus yang digunakan adalah :
Total Biaya Failure
tf Cf ) tf ( Tc =
Dimana : Cf = biaya satu siklus failure tf = merupakan nilai MTTF
Sedangkan untuk total biaya failure per bulan didapatkan dengan menggunakan rumus : Tc(tf) per bulan = Tc(tf) × tf × kf kf = MTTF n Kerja/bula Jam
Dimana : kf = frekuensi pemeliharaan kondisi berjalan
Total Biaya Preventive
) R 1 ( tf R tp ) R 1 ( Cf R Cp ) tp ( Tc − + × − + × =
Dimana : Cp = biaya preventive Cf = biaya failure
tp = interval waktu preventive tf = merupakan nilai MTTF
R = merupakan nilai reliability saat R(tp)
Sedangkan untuk total biaya preventive per bulan didapatkan dengan menggunakan rumus : Tc(tp) per bulan = Tc(tp) × tp × kp kp = MTTF n Kerja/bula Jam
2.16 Fault Tree Analysis (FTA)
FTA (Fault Tree Analysis) berorientasi pada fungsi (function oriented) atau yang lebih dikenal dengan “top down“ approach karena analisa ini berawal dari sistem level (top) dan meneruskannya ke bawah. Titik awal dari analisa ini adalah pengidentifikasikan mode kegagalan fungsional pada top level dari suatu sistem atau subsistem.
FTA adalah teknik yang banyak dipakai untuk studi yang berkaitan dengan resiko dan keandalan dari suatu sistem engineering. Event potensial yang menyebabkan kegagalan dari suatu sistem engineering dan probabilitas terjadinya event tersebut dapat ditentukan dengan FTA. Sebuah top event yang merupakan definisi dari kegagalan suatu sistem (system failure), harus ditentukan terlebih dahulu dalam mengkonstrusikan FTA. Sistem kemudian dianalisa untuk menemukan semua kemungkinan yang didefinesikan pada top event. FT adalah sebuah model grafis yang terdiri dari beberapa kombinasi kesalahan (fault) secara pararel dan secara berurutan yang mungkin menyebabkan awal dari failure event yang sudah ditetapkan.
Setelah mengidentifikasi top event, event-event yang memberi kontribusi secara langsung terjadinya top event diidentifikasi dan dihubungkan ke top event dengan memakai hubungan logika (logical link) sampai dicapai event dasar yang idependent (mutually independent basic event). Analisa yang dilakukan dalam metode FTA ini menunjukan analisa kualitatif dan kuantitatif dari sistem engineering yang dianalisa.
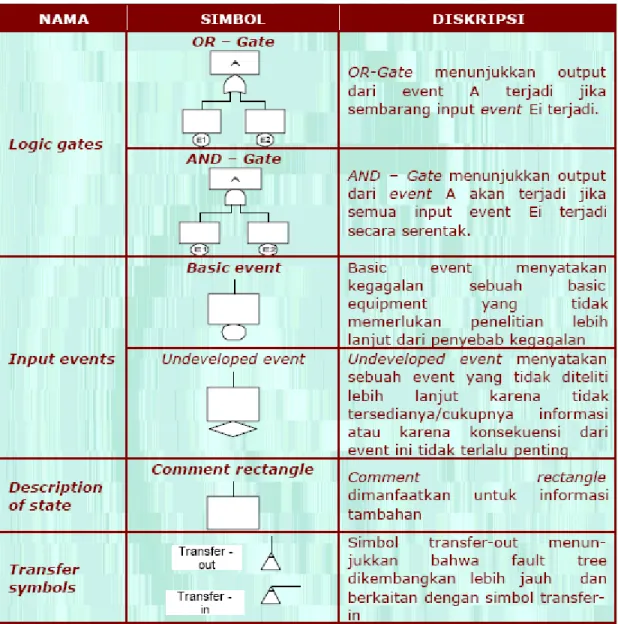
Sebuah fault tree mengilustrasikan keadaan dari komponen-komponen sistem (basic event) dan hubungan antara basic event dan top event. Simbol grafis yang dipakai untuk menyatakan hubungan disebut gerbang logika (logic gate). Output dari sebuah gerbang logika ditentukan oleh event yang masuk ke gerbang tersebut. Sebuah FTA secara umum dilakukan dalam 5 tahapan, yaitu :
1. Mendefinisikan problem dan kondisi batas (boundary condition) dari sistem. 2. Pengkontruksian fault tree.
3. Mengidentifikasi minimal cut set. 4. Analisa kualitatif dari fault tree. 5. Analisa kuantitatif fault tree.
2.16.1 Definisi Problem dan Kondisi Batas
Aktivitas pertama dari fault tree analysis terdiri dari dua step, yaitu : 1. Mendefinisikan critical event yang akan dianalisa
2. Mendefinisikan boundary condition untuk analisa
Critical event yang akan dianalisa secara normal disebut dengan top event. Penting kiranya untuk bahwa top event harus didefinisikan secara jelas dan tidak kabur (unambiguous). Diskripsi dari top event seharusnya selalu memberikan jawaban terhadap pertanyaan apa (what), dimana (where), dan kapan (when).
What : Mendiskripsikan tipe dari critical event yang sedang terjadi, sebagai contoh kebakaran (fire).
Where : Mendiskripsikan dimana critical event terjadi, sebagai contoh critical event terjadi di process oxidation reactor.
When : Mendiskripsikan dimana critical event terjadi, sebagai contoh critical event terjadi pada saat pengoperasian normal.
Jadi, sebagai contoh top event yang melibatkan ketiga kriteria di atas adalah : “Kebakaran yang terjadi di process oxidation reactor pada saat pengoperasian normal”.
Agar analisis dapat dilakukan secara konsisten, adalah hal yang penting bahwa kondisi batas bagi analisa didefinisikan secara hati–hati. Dari kondisi batas, kita akan memilliki beberpa pemahaman sebagai berikut :
1. Batas fisik sistem : Bagian mana dari sistem yang akan dimasukkan dalam analisa dan bagian mana yang tidak ?
2. Kondisi awal : Kondisi pengoperasian sistem yang bagaimana pada saat top event terjadi ? Apakah sistem bekerja pada kapasitas yang penuh atau sebagian ?
3. Kondisi batas yang berhubungan dengan stres eksternal : Apa tipe stres eksternal yang seharusnya disertakan dalam analisa ?
4. Level dari resolusi : Seberapa detail kita akan mengidentifikasi berbagai alasan potensial yang menyebabkan kegagalan ?
2.16.2 Pengkontruksian Fault Tree
Pengkonstruksian fault tree selalu bermula dari top event. Oleh karena itu, berbagai fault event yang secara langsung, penting, dan berbagai penyebab terjadinya top event harus secara teliti diidentifikasi. Berbagai penyebab ini dikoneksikan ke top event oleh sebuah gerbang logika (lihat Tabel 2.2). Penting kiranya bahwa penyebab level pertama di bawah top event harus disusun secara terstruktur. Level pertama ini sering disebut dengan top structure dari sebuah fault tree. Top structure ini sering diambil dari kegagalan modul–modul utama sistem, atau fungsi utama dari sistem. Analisa dilanjutkan level demi level samapai semua fault event telah dikembangkan sampai pada resolusi yang ditentukan. Analisa ini merupakan analisa deduktif dan dilakukan dengan mengulang pertanyaan “Apa alasan terjadinya event ini ?”.
Ada beberapa aturan yang harus dipenuhi dalam mengkonstruksi sebuah fault tree. Berikut ini beberapa aturan yang dipakai untuk mengkonstruksi sebuah fault tree.
1. Diskripsikan fault event.
Masing–masing basic event harus didefiniskan secara teliti dalam sebuah kotak.. 2. Evaluasi fault event.
Sebuah normal basic event di dalam sebuah fault tree merupakan sebuah primary failures yang menunjukkan bahwa komponen merupakan penyebab dari dari kegagalan. Secondary failures dan command faults merupakan intermediate event yang membutuhkan investigasi lebih mendalam untuk mengidentifikasi alasan utama.
Pada saat mengevaluasi sebuah fault event, seorang analis akan bertanya, “Dapatkah fault ini dikategorikan dalam primary failure ?” Jika jawabannya adalah YA, maka analis tersebut dapat mengkalsifikasikan fault event sebagai normal basic event. Jika jawabannya adalah TIDAK, maka analis tersebut dapat mengkalsifikasikan fault event sebagai intermediate event, yang harus dikaji lebih jauh, atau sebagai secondary basic event. Secondary basic event sering disebut dengan undeveloped event dan menunjukkan sebuah fault event yang tidak dikaji lebih jauh karena informasinya tidak tersedia atau karena dampak yang ditimbulkan tidak signifikan.
3. Lengkapi semua gerbang logika.
Semua input ke gate tertentu harus didefiniskan dengan lengkap dan didiskripsikan sebelum memproses gate lainnya. Fault tree harus diselesaikan pada masing–masing level sebelum memulai level berikutnya.
2.16.3 Pengidentifikasian Minimal Cut Set
Sebuah fault tree memberikan informasi yang berharga tentang berbagai kombinasi dari fault event yang mengarah pada critical failure sistem. Kombinasi dari berbagai fault event disebut dengan cut set. Pada terminologi fault tree, sebuah cut set adalah sekumpulan dari komponen yang bila komponen-komponen itu mengalami kegagalan, maka akan menyebabkan seluruh sistem akan mengalami kegagalan pula. Sebuah cut set dikatakan sebagai minimal cut set bila salah satu komponen yang terdapat di dalam minimal cut set itu mengalami kegagalan, maka akan menyebabkan seluruh sistem akan mengalami kegagalan pula, tetapi bila salah satu komponen yang terdapat di dalam mininimal cut set bekerja, maka tidak mengakibatkan sistem menjadi gagal.
Jumlah basic event yang berbeda di dalam sebuah minimal cut set disebut dengan orde cut set. Untuk fault tree yang sederhana adalah mungkin untuk mendapatkan minimal cut set dengan tanpa menggunakan prosedur formal atau algoritma. Untuk fault tree yang lebih besar, maka diperlukan sebuah algoritma untuk mendapatkan minimal cut set pada fault tree. MOCUS (method for obtaining cut sets) merupakan sebuah algoritma yang dapat dipakai untuk mendapatkan minimal cut set dalam sebuah fault tree.
2.16.4 Evaluasi Kualitatif Fault Tree
Evaluasi kualitatif dari sebuah fault tree dapat dilakukan berdasarkan minimal cut set. Kekritisan dari sebuah cut set jelas tergantung pada jumlah basic event di dalam cut set (orde dari cut set). Sebuah cut set dengan orde satu umumnya lebih kritis daripada sebuah cut set dengan orde dua atau lebih. Jika sebuah fault tree memiliki cut set dengan orde satu, maka top event akan terjadi sesaat setelah basic event yang bersangkutan terjadi. Jika sebuah cut set memiliki dua basic event, kedua event ini harus terjadi secara serentak agar top event dapat terjadi.
2.16.5 Evaluasi Kuantitatif Fault Tree
Evaluasi kuantitatif fault tree yang dilakukan dengan menggunakan pendekatan perhitungan langsung (direct numerical approach) yang bersifat bottom-up approach. Pendekatan numerik ini berawal dari level hirarki yang paling rendah dan mengkombinasikan semua probabilitas dari event yang ada pada level ini dengan menggunakan logic gate yang tepat dimana event–event ini dikaitkan. Kombinasi probabilitas ini akan memberikan nilai probabilitas dari intermediate event pada level hirarki diatasnya sampai top event dicapai. Rumus yang digunakan adalah :
(
)
( )
(
)
(
)
( )
(
1 2 n)
1 n n 3 i 1 i 2 j 1 j 1 k i j k n 1 i 1 i 1 j i j n 1 i i n i 2 1 s C ... C C P 1 ... C C C P C C P C P C ... C ... C C P Q ∩ ∩ ∩ − + + ∩ ∩ + ∩ − = ∪ ∪ ∪ = − = − = − = = − = = ∑ ∑ ∑ ∑ ∑ ∑Dimana : Ci= minimal cut set ke-i
2.17 Simulasi Monte Carlo
Simulasi merupakan salah satu cara untuk memecahkan berbagai persoalan yang dihadapi di dunia nyata, dan dapat memberikan hasil yang cukup baik bila digunakan untuk memecahkan berbagai persoalan, termasuk dalam pembuatan perencanaan kegiatan. Simulasi merupakan pendekatan yang dapat digunakan untuk memecahkan berbagai masalah yang mengandung ketidakpastian dan kemungkinan jangka panjang yang tidak dapat diperhitungkan dengan seksama. Dengan demikian, secara umum simulasi dapat diartikan sebagai suatu sistem yang digunakan untuk memecahkan atau menguraikan persoalan-persoalan dalam kehidupan nyata yang penuh dengan ketidakpastian dengan tidak atau menggunakan model atau metode tertentu dan lebih ditekankan pada pemakaian komputer untuk mendapatkan solusinya.
Ada beberapa keuntungan yang bisa diperoleh dengan memanfaatkan simulasi, yaitu :
1. Menghemat waktu
Kemampuan di dalam menghemat waktu ini dapat dilihat dari pekerjaan yang bila dikerjakan dapat memakan waktu tahunan, namun dapat disimulasikan hanya dalam beberapa menit atau bahkan dalam hitungan detik. Kemampuan ini dipakai oleh para peneliti untuk melakukan berbagai pekerjaan desain operasional yang juga memperhatikan bagian terkecil dari waktu untuk kemudian dibandingkan dengan yang terdapat pada sistem yang sebenarnya.
2. Dapat melebar-luaskan waktu
Simulasi dapat digunakan untuk menunjukkan perubahan struktur dari suatu sistem nyata (real system) yang sebenarnya tidak dapat diteliti pada waktu yang seharusnya (real time). Dengan demikian, simulasi dapat membantu mengubah sistem nyata dengan memasukkan sedikit data.
3. Dapat mengendalikan sumber-sumber variasi
Kemampuan pengendalian dalam simulasi ini tampak apabila statistik digunakan untuk meninjau hubungan antara variabel bebas (independent) dengan variabel terkait (dependent) yang merupakan faktor-faktor yang akan dibentuk dalam percobaan. Dalam simulasi pengambilan data dan pengolahannya pada komputer, ada beberapa sumber yang dapat dihilangkan atau sengaja ditiadakan.
4. Memperbaiki kesalahan perhitungan
Dalam prakteknya, pada suatu kegiatan ataupun percobaan dapat saja muncul kesalahan dalam mencatat hasil-hasilnya. Sebaliknya, dalam simulasi komputer jarang ditemukan kesalahan perhitungan terutama bila angka-angka diambil dari komputer secara teratur dan bebas. Komputer mempunyai kemampuan untuk melakukan penghitungan dengan akurat.
5. Dapat dihentikan dan dijalankan kembali
Simulasi komputer dapat dihentikan untuk kepentingan peninjauan ataupun pencatatan semua keadaan yang relevan tanpa berakibat buruk terhadap program simulasi tersebut. Dalam dunia nyata, percobaan tidak dapat dihentikan begitu saja, namun dalam simulasi komputer, setelah dilakukan penghentian maka kemudian dapat dengan cepat dijalankan kembali.
6. Mudah diperbanyak
Dengan simulasi komputer, percobaan dapa dilakukan setiap saat dan dapat diulang-ulang. Pengulangan dilakukan terutama untuk mengubah berbagai komponen dan variabelnya, seperti perubahan parameter, perubahan kondisi operasi, atau perubahan jumlah output.
Simulasi Monte Carlo dikenal juga dengan istilah Sampling Simulation atau Monte Carlo Sampling Technique. Simulasi ini menggambarkan kemungkinan penggunaan data sample dalam metode Monte Carlo yang juga juga sudah dapat diketahui atau diperkirakan distribusinya. Simulasi ini menggunakan data yang sudah ada (historical data) yang sebenarnya dipakai untuk tujuan lain. Dengan kata lain apabila menghendaki model simulasi yang mengikut sertakan random dan sampling dengan distribusi probabilitas yang dapat diketahui dan ditentukan, maka cara simulasi ini dapat dipergunakan.
Kunci dari metode Monte Carlo terletak pada pembangkitan bilangan random yang digunakan untuk mewakili ketidakpastian atau risiko yang diamati. Sebelum hal ini dilakukan terlebih dahulu pendefinisian tingkat probabilitas yang ada pada setiap elemen yang mengandung unsur risiko. Tingkat probabilitas tersebut kemudian diterjemahkan dalam bilangan random yang dihasilkan dari generator bilangan acak (random). Langkah-langkah untuk melakukan simulasi Monte Carlo adalah sebagai berikut :
1. Tentukan distribusi probabilitas untuk variabel yang penting. 2. Membangun distribusi kumulatif untuk masing-masing variabel. 3. Menentukan interval bilangan random umtuk setiap variabel. 4. Bangkitkan bilangan random.