PENANGANAN KATA BERIMBUHAN PADA POS TAGGER
BAHASA INDONESIA BERBASIS STATISTIK
IMPLEMENTING MORPHOLOGICAL ANALYZER FOR
AFFIXES HANDLING IN STATISTIC BASED INDONESIAN
POS TAGGER
Diajukan untuk memenuhi salah satu syarat memperoleh gelar Sarjana Teknik Informatika
Disusun Oleh :
Nama
: Umriya Afini
NIM
: A11.2012.07305
Program Studi : Teknik Informatika – S1
FAKULTAS ILMU KOMPUTER
UNIVERSITAS DIAN NUSWANTORO
SEMARANG
Nama : Umriya Afini
NIM : A11.2012.07305
Program Studi : Teknik Informatika Fakultas : Ilmu Komputer
Judul Tugas Akhir : PENERAPAN ANALISIS MORFOLOGI UNTUK PENGGUNAAN KATA BERIMBUHAN PADA POS TAGGER BAHASA INDONESIA BERBASIS STATISTIK
Tugas Akhir ini telah diperiksa dan disetujui, Semarang,
Menyetujui Pembimbing
Mengetahui
Dekan Fakultas Ilmu Komputer
Muljono,SSi, M.Kom Dr. Abdul Syukur
NIM : A11.2012.07305 Program Studi : Teknik Informatika Fakultas : Ilmu Komputer
Judul Tugas Akhir : PENERAPAN ANALISIS MORFOLOGI UNTUK PENGGUNAAN KATA BERIMBUHAN PADA POS TAGGER BAHASA INDONESIA BERBASIS STATISTIK
Tugas akhir ini telah diujikan dan dipertahankan dihadapan Dewan Penguji pada Sidang tugas akhir tanggal 3 Agustus 2016. Menurut pandangan kami, tugas akhir ini memadahi dari segi kualitas maupun kuantitas untuk tujuan penganugrahan gelar Sarjana Komputer (S.Kom)
Semarang, X 2016 Dewan Penguji :
Pembimbing Ketua Penguji
Muljono,SSi, M.Kom Hanny Haryanto,S.Kom, M.T
Sebagai mahasiswa Universitas Dian Nuswantoro, yang bertanda tangan dibawah ini, saya:
Nama : Umriya Afini NIM : A11.2012.07305
Menyatakan bahwa karya ilmiah saya berjudul:
PENERAPAN ANALISIS MORFOLOGI UNTUK PENGGUNAAN KATA BERIMBUHAN PADA POS TAGGER BAHASA INDONESIA BERBASIS STATISTIK
Merupakan karya asli (kecuali cuplikan dan ringkasan yang masing-masing telah saya jelaskan seumbernya dan perangkat pendukung seperti webcamp dll). Apabila dikemudian hari, karya saya disinyalisir bukan merupakan karya asli saya, yang disertai bukti-bukti yang cukup, maka saya bersedia untuk dibatalkan gelar saya beserta hak dan kewajiban yang melekat pada gelar tersebut. Demikian surat pernyataan ini saya buat dengan sebenarnya.
Dibuat di : Semarang Pada Tanggal : Yang Menyatakan
(Umriya Afini)
Sebagai mahasiswa Universitas Dian Nuswantoro, yang bertanda tangan dibawah ini, saya:
Nama : Umriya Afini NIM : A11.2012.07305
Demi mengembangkan Ilmu Pengetahuan, menyetujui untuk memberikan kepada Universitas Dian Nuswantoro Hak Bebas Royalti Non-Ekskusif (Non-Exclusive Royalti-Free-Right) atas karya ilmiah saya yang berjudul:
PENERAPAN ANALISIS MORFOLOGI UNTUK PENGGUNAAN KATA BERIMBUHAN PADA POS TAGGER BAHASA INDONESIA BERBASIS STATISTIK beserta perangkat yang diperlukan. Dengan Hak Bebas Royalti Non-Eksklusif ini Universitas Dian Nuswantoro berhak untuk menyimpan, mengcopy ulang (memperbanyak), menggunakan, mengelolanya dalam bentuk pangkalan data (database), mendistribusikan dan menampilkan/mempublikasi di internet atau media lain untuk kepentingan akademis tanpa perlu meminta ijin dari saya selama tetap mencantumkan nama saya sebagai penulis/pencipta.
Saya bersedia untuk menanggung secara pribadi, tanpa melibatkan pihak Universitas Dian Nuswantoro, segala bentuk hokum yang timbul atas pelanggaran Hak Cipta dalam karya ilmiah saya ini.
Demikian surat pernyataan ini saya buat dengan sebenarnya. Dibuat di : Semarang
Pada Tanggal : Yang Menyatakan
(Umriya Afini)
dan inayah-Nya kepada penulis sehingga laporan tugas akhir dengan judul “PENERAPAN ANALISIS MORFOLOGI UNTUK PENGGUNAAN KATA BERIMBUHAN PADA POS TAGGER BAHASA INDONESIA BERBASIS STATISTIK” dapat penulis selesaikan sesuai rencana karena adanya dukungan dari berbagai pihak yang tidak ternilai besarnya. Oleh karena itu penulis menyampaikan terimakasih kepada :
1. Dr. Ir. Edi Noersasongko, M.Kom selaku Rektor Universitas Dian Nuswantoro.
2. Dr. Drs. Abdul Syukur, MM selaku Dekan Fasilkom.
3. Heru Agus Santoso, Ph.D selaku Ka.Progdi Teknik Informartika.
4. Muljono, SSi, M.Kom selaku pembimbing tugas akhir yang memberikan ide penelitian, informasi referensi dan bimbingan yang berkaitan dengan penelitian penulis.
5. Kedua orang tua penulis yang telah memberikan doa, dorongan, nasehat, dan kasih sayang. Adik-adik serta teman-teman penulis yang telah mendukung dalam pembuatan laporan tugas akhir ini.
6. Pihak-pihak yang telah banyak membantu penulis, yang tidak dapat penulis sebutkan namanya satu-persatu.
Semoga Tuhan Yang Maha Esa memberikan balasan yang lebih besar kepada beliau-beliau, dan pada akhirnya penulis berharap bahwa penulisan laporan tugas akhir ini dapat bermanfaat dan berguna sabagaimana mestinya. Penulis sangat berharap penelitian ini dapat dikembangkan dan disempurnakan sehingga dapat menjadi lebih bermanfaat.
Semarang, Agustus 2016
(Umriya Afini)
POS tagging (pelabelan kelas kata) merupakan salah satu proses penting pada aplikasi-aplikasi NLP. POS tagging otomatis dibutuhkan karena POS tagging secara manual membutuhkan waktu yang lama dan biaya mahal. Masalah utama dalam POS tagging secara otomatis adalah kata ambigu dan kata Out-of-Vocabulary (OOV). Salah satu pendekatan untuk mengatasi masalah kata ambigu yang telah dikembangkan dan terbukti menghasilkan keakuratan tinggi adalah POS tagging menggunakan pendekatan statistik dengan Hidden Markov Model (HMM). Sistem POS tagger bahasa Indonesia yang menerapkan HMM adalah IPOSTAgger. Masalah lain yaitu penanganan kata OOV dalam penelitian ini digunakan penerapan metode pengalisis morfologi bahasa Indonesia. Sistem yang diterapkan adalah penganalisis morfologi Morphind. Selain untuk penanganan kata OOV, sistem Morphind juga digunakan untuk pemotongan klitik pada kata imbuhan berbentuk frasa. Dengan menggabungkan kedua sistem tersebut dihasilkan beberapa model yang dapat diterapkan untuk POS tagging pada korpus bahasa Indonesia. Korpus yang digunakan yaitu korpus latih terdiri dari 10.000 kata yang telah diberi 31 label POS dan 3 jenis korpus uji masing-masing berisi 3000 kata. Keakuratan tertinggi sebesar 95.683~% dihasilkan oleh model HMM trigram + MA pada korpus uji 1 dengan tingkat kata OOV 10%, pada korpus 2 dengan tingkat kata OOV 20% dihasilkan oleh model HMM trigram + MA dan HMM bigram + MA dengan keakuratan yang sama yaitu 92.809~%, sedangkan pada korpus 3 dengan tingkat kata OOV 30% dihasilkan oleh model HMM bigram + MA yaitu sebesar 88.3279~%.
Kata kunci : Part of Speech Tagger, Hidden Markov Model, Analisis Morfologi
POS tagging (word class tagging) is one of essential process in many NLP applications. Automatic POS tagging is needed because manually POS tagging is time consuming and costly. The main problem of automatic POS tagging is word ambiguity and Out-of-Vocabulary (OOV) word. One of approach for handling word ambiguity problem which already developed and proven give high accuracy is POS tagging using Hidden Markov Model (HMM) statistic based tagger. POS tagger system for bahasa Indonesia using HMM is IPOSTAgger. Another POS tagging problem is OOV words handling, in this research is used morphology analyzer method for bahasa Indonesia. Applied System is morphology analyzer MorphInd. In addition to handling OOV word, system MorphInd is used for clitic segmentation in affix phrase form. With combining both system resulted several models which can be used for POS tagging in corpus using bahasa Indonesia. Used corpus is training corpus which consist of 10000 words given 31 POS tag and 3 kind of test corpus each consist of 3000 words. Highest accuracy in test corpus 1 with 10% OOV is 95.683~% resulted by HMM trigram + MA model, in test corpus 2 with 20% OOV is 92.809~% resulted by HMM trigram + MA model and HMM bigram + MA model, while in test corpus 3 with 30% OOV is 88.3279~% resulted by HMM bigram + MA model. Highest accuracy in test corpus 1 with 10% OOV is 95.683~% resulted by HMM trigram + MA model, in test corpus 2 with 20% OOV is 92.809~% resulted by HMM trigram + MA model and HMM bigram + MA model, while in test corpus 3 with 30% OOV is 88.3279~% resulted by HMM bigram + MA model.
Key word : Part of Speech Tagger, Hidden Markov Model , Morphology Analysis
PERSETUJUAN SKRIPSI...ii
PENGESAHAN DEWA PENGUJI...iii
PERNYATAAN KEASLIAN SKRIPSI...iv
PERNYATAAN PERSETUJUAN PUBLIKASI KARYA ILMIAH UNTUK KEPENTINGAN AKADEMIS...v UCAPAN TERIMAKASIH...vi ABSTRAK...vii ABSTRACT...viii DAFTAR ISI...ix DAFTAR TABEL...xi DAFTAR GAMBAR...xii BAB I PENDAHULUAN...1 1.1 Latar Belakang...1 1.2 Rumusan Masalah...3 1.3 Batasan Masalah...3 1.4 Tujuan Penelitian...4 1.5 Manfaat Penelitian...4
Bab II TINJAUAN PUSTAKA...5
2.1 Tinjauan Studi...5
2.2 Tinjauan Pustaka...9
2.2.1 Karakteristik Bahasa Indonesia...9
2.2.2 Morfologi Bahasa Indonesia...9
2.2.3 Part-of-speech...15
2.2.4 Sistem Yang Diterapkan...21
2.3 Kerangka Pemikiran...23
BAB III METODE PENELITIAN...24
3.1 Instrumen Penelitian...24
3.2.1 Studi Pustaka...25
3.2.2 Eksperimen...26
3.3 Teknik Analisis Data...26
3.4 Model Atau Metode Yang Diusulkan...27
3.4.1 Preprocessing...27
3.4.2 HMM Tagging...29
3.4.3 Evaluation...32
3.5 Eksperimen Dan Cara Pengujian Model...33
3.5.1 Pengujian Data...33
3.5.2 Pengujian Keakuratan...34
Bab IV ANALISIS HASIL PENELITIAN DAN PEMBAHASAN...36
4.2 Analisis Data...36
4.3 Hasil Training...36
4.4 Hasil Preprocesing...39
4.5 Implementasi HMM...42
4.6 Implementasi Morphology Analyzer...50
4.7 Pengujian...54
BAB V KESIMPULAN DAN SARAN...57
5.1 Kesimpulan...57
5.2 Saran...57
DAFTAR PUSTAKA...58
Tabel 1: State Of The Art...7
Tabel 2: Perubahan Nada Suara...13
Tabel 3: Tagset Yang Digunakan...33
Tabel 4: Contoh Ngram...37
Tabel 5: Penerjemah Label POS...40
Tabel 6: Perhitungan Probabilitas Emisi Known Word...43
Tabel 7: Hasil Penghitungan Decoding HMM Bigram...47
Tabel 8: Hasil Penghitungan Decoding HMM Trigram...49
Tabel 9: Hasil Penghitungan Decoding HMM Bigram Dan MA...53
Tabel 10: Persentase Overall Accuracy...55
Tabel 11: Persentase Known Word Accuracy...55
Tabel 12: Persentase Unknown Word Accuracy...56
Gambar 1: Pohon Sufiks Pada Kepanjangan Tiga...20
Gambar 2: Struktur Keluaran MorphInd...22
Gambar 3: Tahapan Proses POS Tagging...27
Gambar 4: Tahap Preprocessing...28
Gambar 5: Tahap HMM Tagging...30
Gambar 6: Ilustrasi Pelabelan Decoding HMM...32
Gambar 7: File Ngram.trn Dan File Lexicon.trn...37
Gambar 8: Preprocesing Korpus Uji...39
Gambar 9: File Token-tag.txt...41
Gambar 10: Ilustrasi Decoding HMM Bigram...48
Gambar 11: Ilustrasi Decoding HMM Trigram...49
Gambar 12: Ilustrasi Decoding HMM Bigram Dan MA...54
1.1 Latar Belakang
Bahasa Indonesia adalah bahasa resmi negara Indonesa yang secara luas digunakan sebagai alat komunikasi sehari-hari oleh lebih dari 222 juta orang. Dengan lebih dari 742 bahasa daerah yang berbeda, Bahasa Indonesia merupakan bahasa pemersatu bagi penduduk Indonesia [1]. Sehingga memiliki peralatan untuk penelitian Natural Language Processing (NLP) yang tersedia untuk masyarakat luas menjadi penting.
Label Part-of-Speech (POS) adalah label kategori kelas kata yang berupa kata kerja (verb), kata benda (noun), kata sifat (adjectives), kata keterangan (adverb) dan seterusnya pada tiap kata dalam suatu kalimat. POS tagging (pelabelan kelas kata) merupakan salah satu bagian yang sangat penting dalam aplikasi NLP seperti Speech Recognition, Question Answering dan Informarion Retrieval. Melakukan palabelan POS secara manual membutuhkan waktu yang lama dan biaya yang mahal karena harus memerlukan ahli bahasa. Oleh karena itu mengembangkan POS tagging secara otomatis merupakan kebutuhan yang mendesak.
POS tagging telah secara luas dipelajari dan dikembangkan untuk bahasa Indonesia. Beberapa pendekatan telah digunakan untuk mengembangkan POS tagging diantaranya adalah pendekatan Statistic-Based [2,3,4], pendekatan Rule-Based [5] dan pendekatan Transformasion-Based learning [6]. Salah satu metode POS tagging yang telah dikembangkan dan menghasilkan keakuratan yang tinggi adalah POS tagging dengan pendekatan berbasis statistik (Statistic-Based) menggunakan metode Hidden Markov Model (HMM) dikombinasikan dengan metode lain [7]. HMM sendiri merupakan pengembangan dari Markov Model yang mengasumsikan bahwa kata secara probabilitas bergantung hanya pada
kategori POS dua kata sebelumnya.
Salah satu POS tagging untuk bahasa Indonesia yang menerapkan pendekatan statistik dengan metode HMM adalah IPOSTAgger, yang dikembangkan oleh Wicaksono dan Purwarianti [3]. Dengan menggunakan HMM bigram (urutan pertama) dan HMM trigram (urutan kedua) sebagai model dasar IPOSTAgger juga menerapkan beberapa metode lain seperti Jelinek-Mercer smoothing, Affix Tree (pohon prefix – suffix), Lexicon (kamus) dari KBBI-Kateglo dan Succeding POS tag. Metode-metode tersebut diuji untuk mengetahui konfigurasi yang menghasilkan nilai keakuratan terbaik. Adapun konfigurasi terbaik yang didapatkan kombinasi metode HMM trigram, Affix tree dan Lexicon. Masalah utama dalam POS tagging antara lain kata ambigu dan kata Out-of-Vocabulary (OOV) [8]. Kata ambigu merupakan kata yang memiliki sifat berbeda jika ditempakan pada konteks yang berbeda. Sedangkan kata OOV merupakan kata yang ada dalam korpus uji namun tidak ada dalam korpus latih, hal ini akan menyebabkan masalah sparse data. Sistem morfologi bahasa Indonesia cukup rumit, termasuk diantaranya afiksasi yang menjadi salah satu sumber dari masalah kata OOV. Bahasa Indonesia menggunakan banyak kata imbuhan untuk membuat kata jadian. Penggunaan prefik, sufiks, infiks, atau kombinasinya dapat merubah label POS dan makna dari suatu kata. Kata kerja dapat menjadi kata benda, kata keterangan maupun kata sifat. Salah satu bagian dari afiksasi adalah pengklitikan. Fenomena pengklitikan (proklitik, enklitik) sangat sering terjadi dalam bahasa sehari-hari. Kata berimbuhan yang ketambahan klitik akan menjadi kata ambigu, contohnya kata kumengirimkanmu (kata benda nama diri) yang terdiri dari kata mengirimkan (kata kerja transitif) ketambahan proklitik ku (kata benda) dan enklitik mu (kata benda). Sehingga diperlukannya proses pengolahan berupa pemotongan pada kata berklitik. Penentuan kombinasi afiks ataupun pemotongan klitik memerlukan analisis morfologi terlebih dahulu sehingga tidak menimbulkan kesalahan pemberian label POS atau kesalahan pemotongan klitik yang akan mengurangi tingkat keakuratan POS tagger.
Penerapan analisis morfologi dapat membantu pemberian kategori kelas kata karena dapat diketahui unsur-unsur pembuat kata tersebut. Salah satu metode
analisis morfologi adalah Affix tree yang diadaptasi oleh IPOSTAgger. Namun Affix tree hanya dapat melakukan pencocokan pola tidak memberikan informasi morfologi lebih jauh. Sistem yang menerapkan analisis morfologi untuk bahasa Indonesia yang dapat menangani afiksasi dan pengklitikan salah satunya adalah penganalisis morfologi (Morphology Analyzer ) MorphInd [9].
Penelitian ini menerapkan analisis morfologi pada POS tagging untuk mengatasi masalah kata ambigu dan kata OOV yang banyak disebabkan oleh kata berimbuhan. Sistem MorphInd diterapkan untuk pelabelan POS pada kata OOV dan membantu pemotongan klitik pada tahap preprocessing. Selanjutnya tahap HMM tagging dilakukan menggunakan IPOSTAgger, konfigurasi model terbaik akan dibandingkan untuk mengetahui nilai keakuratan tertinggi pada korpus uji yang telah disiapkan.
Berdasarkan analisis tersebut, penelitian ini mengambil judul “Penerapan analisis morfologi untuk penanganan kata berimbuhan pada POS Tagger bahasa Indonesia berbasis statistik”.
1.2 Rumusan Masalah
Berdasarkan uraian pada latar belakang, masalah yang ada pada POS tagging seperti penanganan kata OOV dan kata ambigu sangat penting untuk meningkatkan keakuratan pada model POS tagging. Salah satu masalah dalam POS tagging bahasa Indonesia adalah kata imbuhan. Hal ini dapat diatasi dengan menerapkan analisis morfologi pada POS tagging. Dengan demikian rumusan dari masalah tersebut adalah, “Bagaimana menerapkan analisis morfologi untuk penanganan kata berimbuhan dalam POS tagging bahasa Indonesia berbasis statistik”.
1.3 Batasan Masalah
Untuk menyelesaikan permasalahan yang ada, diperlukan adanya batasan yang dapat mencakup kajian yang berhubungan dengan masalah tersebut sehingga
penyelesaian tidak menyimpang dari masalah. Adapun batasannya adalah sebagai berikut:
1. Penelitian diterapkan pada sistem POS tagging IPOSTAgger.
2. Penelitian menggunaan MorphInd untuk penganalisis morfologi bahasa Indonesia.
3. Korpus latih dan korpus uji menggunakan bahasa Indonesia yang baku dan merupakan korpus yang telah ditentukan.
1.4 Tujuan Penelitian
Tujuan yang ingin dicapai dalam penelitian ini adalah sebagai berikut: 1. Mengimplementasikan analisis morfologi pada POS tagging berbasis
statistik.
2. Menentukan konfigurasi model POS tagging dengan penerapan analisis morfologi yang dapat meningkatkan keakuratan POS tagger.
1.5 Manfaat Penelitian
Penelitian ini diharapkan dapat bermanfaat bagi: 1. Universitas Dian Nuswantoro
(a) Penelitian ini dapat menjadi tinjauan pustaka baru untuk studi pada bidang NLP khususnya POS tagging.
2. Masyarakat Umum
(a) Dapat diterapkan untuk alat preprocessing pada aplikasi-aplikasi NLP. (b) Dapat dimanfaatkan kembali untuk penelitian tentang analisis morfologi
dalam komputasi linguistik, POS tagging ataupun penelitian NLP selanjutnya.
2
2.1 Tinjauan Studi
Dasar pemikiran penelitian tentang POS tagging bahasa Indonesia yang penulis buat mengacu pada beberapa penelitian terkait sebelumnya. Pertama penelitian yang dilakukan oleh A.F. Wicaksono dan Ayu Purwarianti dalam jurnal berjudul “HMM Based Part-of-Speech Tagger for Bahasa Indonesia” membahas tentang pengembangan IPOSTAgger, sistem POS tagger bahasa Indonesia yang menerapkan pendekatan statistik dan beberapa metode lain untuk mengatasi masalah keambiguan label POS. Model dasar yang diterapkan adalah HMM bigram dan HMM trigram. Jelinek-Mercer smoothing diterapkan untuk mengatasi masalah sparse data pada probabilitas transisi. Sedangkan model Affix tree dan Lexicon seperti yang digunakan oleh Helmut Schmid juga diterapkan untuk penanganan OOV. Terakhir metode Succeeding POS tag yang diadaptasi dari penelitian Tetsuji Nakagawa juga diterapkan. Dengan menggunakan 12.000 kata korpus latih dan 3.000 kata korpus uji, pengujian dilakukan sebanyak 3 kali dengan presentasi kata OOV berbeda yaitu 15% kata OOV, 21% kata OOV dan 30% kata OOV. Dari ketiga pengujian keakuratan tertinggi dihasilkan dari kombinasi metode HMM trigram, Affix tree dan Lexicon, sedangkan penggunaan Succeeding POS tag meunjukkan penurunan keakuratan. Pada ketiga pengujian yang dilakukan tingkat keakuratan cenderung menurun pada korpus uji dengan tinggat kata OOV tinggi yaitu 96.50% pada korpus 15% kata OOV, 94.46% pada korpus 21% kata OOV, dan 91.30% pada korpus 30% kata OOV [3].
Kedua penelitian oleh H. Mohamed, N. Omar, dan M. J. Ab Aziz dalam jurnal berjudul “Statistical Malay Part-of-Speech (POS) Tagger using Hidden Markov Approach” membahas pengembangan POS tagging berbasis statistik
untuk bahasa Malaysia. Pada proses morfologi penanganan klitik dilakukan dengan cara pemotongan pada enklitik nya dan lah. Penelitian ini menggunakan metode HMM trigram, Linear Successive Abstraction smoothing dan untuk memprediksi kata OOV digunakan informasi afiks (prefiks, sufiks) seperti yang digunakan dalam TnT POS tagger, sedangakan informasi sirkumfiks menggunakan chain rule. Percobaan menggunakan 18.400 token korpus latih dan diujikan pada 1.840 token korpus uji dengan 15 % kata OOV. Keakuratan terbaik dihasilkan pada pemrediksi prefiks dengan keakuratan overall 94%, keakuratan pada known word mencapai 98,6% dan unknown word mencapai 67,9% [10].
Ketiga penelitian yang dilakukan oleh A. B. Juhaida dalam jurnal berjudul “Morphology Analysis in Malay POS Prediction” membahas pengembangan POS tagging pada bahasa Malaysia menggunakan informasi morfologi. Penelitian ini menggunakan dua algoritma machine learning yaitu Decision Tree (J48) dan Nearest Neighbor (kNN) untuk dibandingkan hasilnya. Sedangkan pada informasi morfologi digunakan pada open class word. Percobaan dilakukan menggunakan Weka 3.7.9 menunjukkan hasil keakuratan, kesalahan RMS dan waktu untuk membangun model ditunjukkan oleh Decision Tree (J48) yaitu sebesar 92.86%. Ini menunjukkan bahwa analisis morfologi terbukti berpengaruh pada hasil komputasi [11].
Keempat penelitian oleh S. D. Larasati, V. Kuboˇn, dan D. Zeman dalam jurnal berjudul “Indonesian Morphology Tool (MorphInd): Towards an Indonesian Corpus” merupakan penelitian yang dilakukan untuk perbaikan beberapa isu pada IndMA, alat analisis morfologi bahasa Indonesia sebelumnya. Penelitian ini membahas tentang pengembangan MorphInd, alat analisis morfologi untuk bahasa Indonesia yang dapat mengatasi analisis morfologi dan lexical pada bahasa Indonesia dengan lebih baik. Fenomena morfologi dalam bahasa Indonesia diantaranya karakter tidak biasa, seperti afiksasi (prefik, sufik, sirkumfik, dan infik), reduplikasi dan pengklitikan (proklitik dan enklitik). Alat berbasis finite state ini menggunakan teknologi Foma yang mengimplementasi pendekatan dua level morfologi. Pengujian menggunakan korpus paralel yang terdiri dari 39% kalimat-kalimat terjemah dari PENN Treebank, 7% subtitle film,
10% artikel olahraga, 14% artikel pengetahuan umum, 15% artikel internasional, dan 15% artikel ekonomi. Hasil menunjukkan secara overall ( rasio jumlah kata yg dianalisis dan jumlah kata dalam teks ) MorphInd menunjukkan nilai yang lebih baik dari pada IndMA ini karena MorphInd secara utama mencakup klitik, numeral alternation, dan tambahan partikel morfem yg tidak ditanggulangi oleh IndMA [9].
Semua penelitian diatas, penulis rangkum dalam tabel state of the art untuk merumuskan lingkup penelitian.
Tabel 1: State of the art
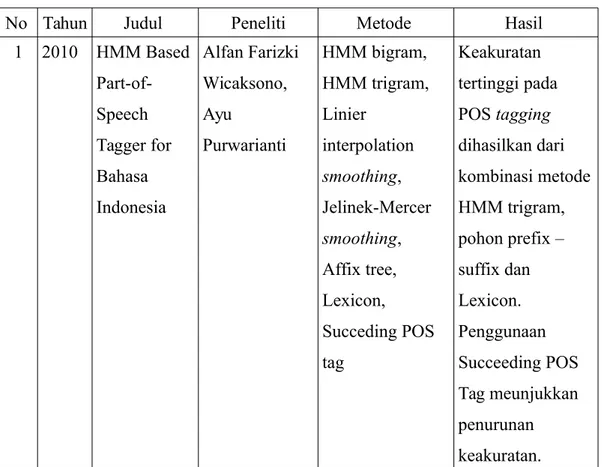
No Tahun Judul Peneliti Metode Hasil
1 2010 HMM Based Part-of-Speech Tagger for Bahasa Indonesia Alfan Farizki Wicaksono, Ayu Purwarianti HMM bigram, HMM trigram, Linier interpolation smoothing, Jelinek-Mercer smoothing, Affix tree, Lexicon, Succeding POS tag Keakuratan tertinggi pada POS tagging dihasilkan dari kombinasi metode HMM trigram, pohon prefix – suffix dan Lexicon. Penggunaan Succeeding POS Tag meunjukkan penurunan keakuratan.
(Tabel State of the art lanjutan)
No Tahun Judul Peneliti Metode Hasil
2 2011 Statistical Malay Part-of-Speech (POS) Tagger using Hidden Markov Approach Hassan Mohamed ,Nazlia Omar, Mohd Juzaidin Ab Aziz HMM trigram, Linear successive abstraction smoothing, Pemrediksi prefiks dan sufiks Keakuratan terbaik untuk penanganan kata OOV dihasilkan pada pemrediksi prefiks. 3 2013 Morphology Analysis in Malay POS Prediction Juhaida Abu Bakar, Khairuddin Omar, Mohammad Faidzul Nasrudin dan Mohd Zamri Murah Decision Tree (J48) , Nearest neighbor (kNN), informasi morfologi pada open class word
Keakuratan tertinggi dihasilkan oleh Decision Tree (J48), dan membuktikan analisis morfologi berpengaruh pada hasil komputasi 4 2011 Indonesian Morphology Tool (MorphInd): Towards an Indonesian Corpus Septiana Dian Larasati, Vladislav Kubon dan Daniel Zeman Teknologi Finite-state oleh Foma
Penganalisis morfologi bahasa Indonesia yang mencakup klitik, numeral alternation, dan tambahan partikel morfem.
2.2 Tinjauan Pustaka
2.2.1 Karakteristik Bahasa Indonesia
Bahasa Indonesia telah digunakan oleh lebih dari 222 milyar penduduk Indonesia sebagai bahasa pemersatu. Sebagai penjembatan dari lebih dari 742 bahasa daerah, kosa kata bahasa Indonesia dipengaruhi dari berbagai bahasa lain terutama bahasa Sansekerta, bahasa Arab, bahasa Cina, bahasa Belanda dan bahasa Inggris serta bahasa local seperti bahasa Jawa dan bahasa Batavia [1]. Seperti bahasa lainnya, bahasa Indonesia menggunakan abjad Romawi yaitu dibaca dari kiri ke kanan dan setiap kata dipisahkan dengan jarak atau spasi. Berbeda dengan bahasa Inggris bahasa Indonesia tidak memiliki tense, sehingga untuk ekspresi waktu suatu kejadian diggunakan kata fungsi dan kata keterangan waktu seperti akan, sudah, besok, sekarang dan sebagainya. Namun untuk struktur sederhana bahasa Indonesia memiliki pola yang sama dengan bahasa Inggis. Bahasa Indonesia juga memiliki banyak sekali kata imbuhan untuk membuat kata turunan. Kata imbuhan seperti prefiks, sufiks, infiks ataupun kombinasinya dapat merubah label POS suatu kata. Dalam bahasa Indonesia ungkapan jamak digunakan kata ganda seperti kata anak-anak.
2.2.2 Morfologi Bahasa Indonesia 2.2.2.1 Morfologi
Morfologi secara harfiah berarti "ilmu bentuk" yang mulanya biasa digunakan dalam biologi, namun sejak pertengahan abad 19, juga digunakan untuk menjelaskan tipe pada penyelidikan yang menganalisis semua elemen-elemen dasar dalam bahasa. Elemen-elemen tersebut yang secara teknis disebut sebagai morfem [12]. Morfem berarti satuan terkecil yang memiliki arti dalam pembentukan sebuah kata, dapat dibagi menjadi dua bagian yaitu morfem bebas dan morfem terikat. Morfem bebas yaitu morfem yang ketika berdiri sendiri memiliki makna atau juga dapat
diartikan sebagai stem (akar kata) contohnya tidur, makan, sendok. Sedangkan morfem terikat adalah morfem yang jika berdiri sendiri tidak memiliki makna apapun seperti kata imbuhan. Contoh pembagian morfem bebas dan terikat sebagai berikut:
Ketiduran ke tidur an Morfem terikat (prefiks) Morfem bebas (stem) Morfem terikat (sufiks) 2.2.2.2 Analisis Morfologi
Analisis morfologi merupakan proses meneliti cara suatu kata dibentuk dengan menghubungkan morfem yang satu dengan yang lainnya. Prosesnya morfologi meliputi afiksasi, reduplikasi, perubahan intern, suplisi, dan modifikasi kosong [13]. Namun dalam bahasa Indonesia hanya melalui afiksasi dan reduplikasi.
2.2.2.3 Afiksasi
Afiksasi merupakan penggabungan dari akar kata (stem) dengan afiks [14]. Dalam bahasa Indonesia terdapat empat jenis imbuhan yaitu awalah (prefiks), sisipan (infiks), akhiran (suffiks) dan imbuhan terbelah (konfiks) [15]. Penjelasan mengenai masing-masing afiks sebagai berikut:
1. Awalan atau prefiks
Awalan atau disebut juga prefiks adalah kata imbuhan yang letaknya berada di depan kata dasar atau kata jadian. Jenis awalan dalam bahasa Indonesia yaitu: ber-, per-, meng-, di-, ter-, ke-, dan se- [15]. Contoh awalan dalam bahasa Indonesia seperti berikut:
Berjalan → Ber + Jalan
Pelari → Per + Lari
Tertawa → Ter + Tawa
Ditulis → Di + Tulis
Sekota → Se + Kota
Keluar → Ke + Luar
2. Sisipan atau infiks
Sisipan atau disebut juga Infiks adalah kata imbuhan yang letaknya berada di tengah kata dasar. Jenis sisipan dalam bahasa Indonesia ada empat yaitu: -el, -em, -er, dan -in [15]. Contoh sisipan dalam bahasa Indonesia sebagai berikut:
Telapak → El + tapak
Gemetar → Em + getar
Girigi → Er + Gigi
Kinerja → In + Kerja
3. Akhiran atau sufiks
Akhiran atau disebut juga sufiks adalah kata imbuhan yang melekat pada akhir kata dasar atau kata serapan. Jenis akhiran dalam bahasa Indonesia yaitu: -i, -kan, -an, -man, -wan, -wati, -wi, -nya, -at, -in, -isme, -(is)asi, -logi, dan -tas [15]. Contoh afiksasi sufiks pada bahasa Indonesia sebagai berikut:
Potogan → Potong + an
Wisudawan → Wisuda + wan
Bukakan → Buka + kan
Duniawi → Dunia + wi
4. Imbuhan terbelah atau konfiks
melekat pada awal dan akhir kata dasar [15]. Contoh penerapan konfiks dalam bahasa Indonesia sebagai berikut:
ke- … -an : Kematian, ketiduran, kesakitan Ber- … -an : Bertabrakan, bersalaman, berdesakan Peng- … -an : Pengalaman, penghembusan, penebusan Per- … -an : Pertemuan, perjudian, perdagangan Se- … -nya : Sebesar-besarnya, sebanyak-banyaknya
Selain 4 jenis imbuhan diatas juga terdapat imbuhan gabung atau disebut juga simulfiks. Simulfiks adalah dua imbuhan atau lebih yang ditambahkan secara bertahap pada kata dasar atau kata turunan. Contoh simulfiks dalam bahasa Indonesia adalah kata imbuhan mem+ber-kan pada kata memberdayakan, memberlakukan dan sebagainya [15]. Secara afiksasi pada kata bersimulfiks sebagai berikut:
Memberdayakan mem+ber+daya+kan Memberlakukan Mem+ber+laku+kan Memperbolehkan Mem+per+boleh+kan Pemberdayaan Pem+ber+daya+an Memperkayakan Men+per+kaya+kan
Afiks dalam bahasa Indonesia berperan penting karena keberadaan kata imbuhan dapat menentukan bentuk, makna, fungsi, dan kategori kata yang dilekatinya tersebut. Contohnya suatu kata kerja (verb) dapat berubah menjadi kata benda (noun), kata keterangan (adverb), kata sifat (adjective) ataupun sebaliknya. Contoh perubahan kelas kata pada kata kirim dan makan berikut:
Kirim → Kata kerja (verb) Makan→ Kata kerja (verb)
Mengirim → Kata kerja (verb) Memakan → Kata kerja (verb)
Kiriman → kata benda (noun) Makanan → kata benda (noun)
Kumengirimnya → frasa Kumemakannya → frasa
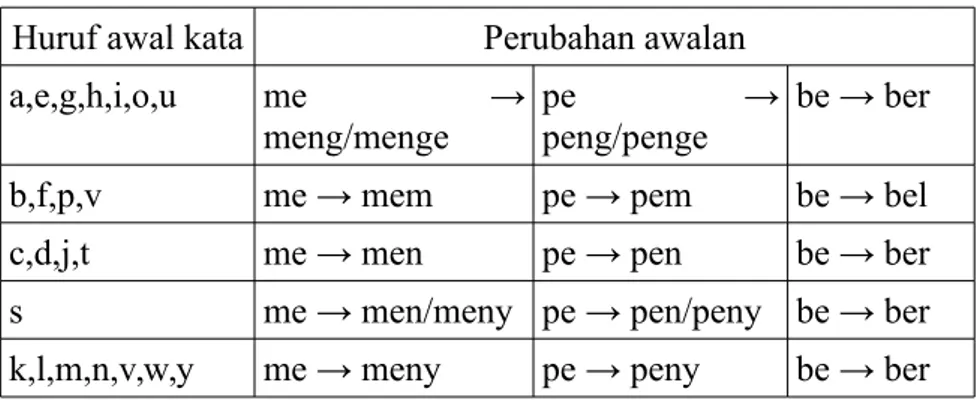
Pada contoh diatas dapat diketahui jika suatu kata dasar mendapat awalan me- kata akan masuk dalam kelas kata kerja dan jika mendapat akhiran -an masuk dalam kelas kata benda. Namun kata kumengiriminya dan kata kumemakannya merupakan kata frasa yang berasal dari kata berimbuhan dan klitik harus memerlukan proses morfologi untuk menentukan kelas kata yang tepat. Selain itu, suatu kata dapat dibuat lebih dari dua kombinasi kata imbuhan yang dapat menimbulkan keambiguan. Contohnya kata desakan berasal dari desa (kata benda) +kan atau bisa juga diartikan sebagai desak (kata kerja) +an. Keambiguan yang diakibatkan oleh afiks lainnya yaitu perubahan nada suara saat kata imbuhan tertentu bertemu dengan kata dasar berawalan huruf tertentu, misalnya awalan me- ketika bertemu dengan huruf awalan “s” pada kata sorak maka imbuhan me- berubah menjadi meny-pada kata menyorakan. Berikut tabel perubahan nada suara yang terjadi pada awalan me-, pe-, be-.
Tabel 2: Perubahan nada suara Huruf awal kata Perubahan awalan
a,e,g,h,i,o,u me →
meng/menge pepeng/penge → be → ber
b,f,p,v me → mem pe → pem be → bel
c,d,j,t me → men pe → pen be → ber
s me → men/meny pe → pen/peny be → ber
k,l,m,n,v,w,y me → meny pe → peny be → ber
2.2.2.4 Pengklitikan
bermakna bersandar. Klitik biasa dipakai untuk menyebutkan kata-kata singkat, kata-kata tidak beraksen yang selalu bersandar pada suatu kata [16]. Kridalaksana menjelaskan, klitik adalah bentuk terikat yang secara fonologis tidak memiliki tekanan sendiri atau tidak dianggap sebagai morfem terikat, tetapi memiliki ciri-ciri kata karena dapat berlaku sebagai bentuk bebas [13]. Dengan kata lain suatu klitik secara sintaksis merupakan sebuah kata yang jelas namun secara morfologi dan fonologi hanya berupa morfem [17]. Klitik dapat dibedakan menjadi dua macam, yaitu proklitik dan enklitik.
1. Proklitik
Proklitik merupakan klitik yang teletak dimuka (kata utama) misalnya ku- pada kata kuambil, kau- pada kata kauambil [18]. contoh bentuk-bentuk proklitik adalah non-, anti-, ku-, kau-, maha-, purna-, dan nir-.
2. Enklitik
Enklitik adalah klitik yang terletak dibelakang (kata utama) misalnya -ku pada kata rumahku, -mu pada kata rumahmu, dan –nya pada kata rumahnya[18]. Moeliono menulis, enklitik dalam tata bahasa baku Indonesia terdapat bentuk ku, mu, nya, lah, tah, kah, dan pun. Bentuk enklitik kah, lah, pun, tidak dapat berdiri sendiri, tetapi selalu melekat pada bentuk lain [19].
Klitik dalam sebuah kalimat dapat mengubah kalimat menjadi kategori lain atau kelas lain. Klitik ku yang berkategori nomina (noun) apabila melekat pada kata ambil yang berkategori verba (verb) akan menjadi kategori verba dengan kalimat kuambil. Sehingga walaupun dieja seperti afiks, tetapi secara kelas kata berada di tingkat frasa.
pada klitik pronomina. Icuk prayogi dalam hasil tesisnya menyimpulkan bahwa terdapat tiga suku kata yang termasuk klitik pronomina yaitu proklitik ku- dan enklitik -ku, -mu, serta -nya. Untuk penyebarannya proklitik hanya melekat pada kata kerja atau kata jadian dari kata kerja, sementara enklitik melekat pada kata kerja trasitif dan kata benda [20]. Contoh keambiguan pada pengklitikan sebagai berikut:
Antar (kata kerja)
Kuantar (frasa) Ku (kata ganti) + antar (kata kerja)
Kuantarmu (frasa) Ku (kata ganti) + antar (kata kerja) + mu
(kata ganti)
Jalan (kata benda)
Jalannya (frasa) Jalan (kata benda) + nya (kata ganti)
Kujalaninya (frasa) Ku (kata ganti) + jalani (kata kerja) +
nya (kata ganti)
2.2.3 Part-of-speech
Secara kategori tata bahasa kata dapat dibagi menjadi 2 yaitu kelas terbuka (open class) dan kelas tertutup (closed class). Kelas terbuka merupakan kategori kelas yang kata-katanya selalu meningkat sepanjang waktu sedangkan kelas tertutup yang katanya tidak bertambah. Anggota dari kelas-kelas ini biasa disebut Part-of-Speech yang juga dikenal sebagai POS, kelas kata, atau kategori sintaksis [21]. POS sendiri dalam bahasa Indonesia terbagi menjadi: kata kerja (verb), kata benda (noun), kata sifat (adjective), kata angka (word number), kata ganti (pronoun), kata keterangan (adverb), kata penunjuk (demonstrative), kata tanya (interrogatives), artikulasi (articulatory), kata depan (preposition), kata seru (interjection), kata sambung (conjunction) dan kata ganda (reduplication) [22].
2.2.3.1 Part-of-speech Tagging
Pelabelan kelas kata atau yang disebut POS tagging berarti proses memberikan tanda Part-of-Speech pada tiap kata yang diinputkan. Permasalahan dalam POS tagging ini adalah suatu kata berkemungkinan memiliki lebih dari satu label POS yang membuat kata menjadi ambigu, sehingga tujuan tagging ini adalah sebagai tugas disambiguasi untuk mencari label POS yang benar untuk kata tersebut [23]. Kebanyakan proses POS tagging yaitu menyelesaikan dua langkah dasar yaitu analisis morfologi dan disambiguaisi. Disambiguaisi ini dapat dilakkan menggunakan beberapa pendekatan seperti Statistic-Based, pendekatan Rule-Based dan pendekatan Transformasion-Based learning. Dari ketiga pendekatan tersebut, pendekatan berbasis statistik banyak diminati karena tidak memerlukan banyak sumber daya linguistik dan terbukti memberi tingkat keakuratan yang tinggi pada penelitian-penelitian sebelumnya [2, 3, 4, 7].
2.2.3.2 Tagset
Pada komputasi linguistik POS digunakan untuk memberi label suatu kata yang diberikan, urutan label yang mungkin diberikan biasa disebut tagset. Tagset memiliki banyak versi, contohnya tagset untuk bahasa Inggris versi Penn Treebank tagset yang terdiri 45 label POS. Tagset ini telah banyak digunakan untuk keperluan komputasi linguistik seperti digunakan pada Brown corpus, Switchboard corpus,danStreet Journal Corpus [23]. Varian tagset untuk bahasa-bahasa lain juga teredia seperti tagset untuk bahasa Arab oleh O. Hajic memiliki 21 label POS, K. Simov menggunakan 54 label POS untuk bahasa Bulgaria, S. Brants menggunakan 54 label POS untuk bahasa Jerman dan M. A. Mart menggunakan 47 label POS untuk bahasa Spayol [24, 25, 26, 27].
Sedangkan tagset bahasa Indonesia juga memiliki banyak versi diantaranya POS versi PAN Localization Project mengembangkan tagset dari Penn Treebank yang tersidi dari 29 label POS, F. Pisceldo mengembangkan 37 label POS, A.F. Wicaksono dan Ayu Purwarianti menggunakan tagset yang terdiri 35 label POS untuk pengembangan IPOSTAgger, S. D. Larasati menggunakan 19 label POS pada pengembangan MorphInd dan A. Dinakaramani menggunakan 22 label POS untuk melabeli 250.000 korpus bahasa Indonesia secara manual [2, 3, 9, 28].
2.2.3.3 Teknik POS Tagging 2.3.3.1.1 HMM Part-of-speech
Hidden Markov Model (HMM) merupakan kelanjutan dari Markov Chain yang menyatakan bahwa probabilitas dari state tertentu hanya bergantung pada state sebelumnya. Markov chain berguna saat perhitungan probabilitas urutan kejadian yang dapat diamati, sedangkan HMM dapat melakukan perhitungan probabilitas urutan yang dapat diamati dan yang tersembunyi (hidden) seperti label Part-of-Speech (kelas kata). Menurut Daniel Jurafsky, HMM adalah urutan probabilitas urutan model: diberikan urutan dari suatu kesatuan (kata, huruf, morfem, kalimat dll) lalu meghitung probabilitas distribusi melalui urutan label yang mungkin dan memilih urutan label terbaik [23]. Adapun persamaan dasar HMM seperti ditunjukkan pada persamaan (1) di bawah ini.
λ=(Λ,Β,π) (1)
menunjukkan sebuah HMM, simbol Λ menunjukkan vektor probabilitas transisi, simbol Β sebagai vektor probabilitas emisi dan π sebagai distribusi state awal.
Berdasarkan tutorial dari Jack Ferguson di tahun 1960, dalam HMM terdapat tiga masalah dasar yaitu masalah likelihood, decoding, dan learning. Dari ketiga masalah tersebut, yang digunakan untuk POS tagging adalah masalah decoding. Masalah decoding ini yaitu ketika diberikan input berupa sebuah HMM λ=(Λ,Β) dan urutan pengamatan Ο=o1, o2,..., oT lalu akan mencari urutan state yang paling mungkin. Sehingga tujuan dari HMM decoding pada POS tagging adalah mencari urutan label POS yang paling mungkin ketika diberikan sejumlah urutan kata-kata. Adapun persamaan HMM decoding untuk POS tagging yang diadaptasi dari milik A.F Wicaksono ditunjukkan pada persamaan (2) untuk bigram dan persamaan (3) untuk trigram.
t1−n=arg maxt 1...tnΡ(t1)×
∏
i=2 n Ρ (ti∣ti−1)×∏
i=1 n Ρ (wi∣ti) (2) t1−n=arg maxt1...tnΡ(t1)Ρ(t2∣t1)×∏
i=3 n Ρ(ti∣ti−1,ti−2)×∏
i=1 n Ρ(wi∣ti) (3)Pada persamaan diatas t1−n merupakan urutan label POS terbaik dari tagset, w1...wn merupakan urutan kata-kata. Ρ(t1) dan Ρ(t2∣t1) bukan merupakan unigram
dan bigram merupakan token pertama dalam suatu kalimat.
Ρ(ti∣ti−1) dan Ρ(ti∣ti−1, ti−2) adalah probabilitas transisi.
2.3.3.1.2 Teknik Smoothing
HMM POS tagging menggunakan korpus latih untuk mendapatkan vektor probabilitas transisi, namun korpus latih ini jumlahnya terbatas sehingga memungkinkan pada kondisi tertentu keadaan tidak pernah terpenuhi sehingga nilai akan menjadi nol, masalah ini sering disebut sebagai masalah sparse data. Teknik untuk mengatasi masalah spase data adalah dengan teknik smoothing. Salah satu teknik smoothing yang dapat digunakan adalah Jelinek-Mercer smoothing untuk probabilitas transisi HMM bigram seperti yang ditunjukkan pada persamaan (4). Sedangkan teknik Linier Interpolation smoothing dapat digunakan untuk probabilitas transisi pada HMM trigram seperti pada persamaan (5).
Ρ(ti∣ti−1)=λ Ρ'(ti∣ti−1)+(1−λ)Ρ'(ti) (4)
Ρ(ti∣ti−1, ti−2)=λ1Ρ'(ti)+λ2Ρ'(ti∣ti−1)+λ3Ρ'(ti∣ti−1,ti−2) (5)
Pada kedua persamaan di atas Ρ adalah probabilitas transisi HMM sedangakan Ρ' adalah MLE. Pada persamaan (4) λ1+λ2+λ3=1 di mana λ1,λ2,λ3
didapatkan menggunakan algoritma deleted interpolation. Sedangkan masalah sparse data pada probabilitas emisi yang timbul akibat kata OOV dapat dilakukan dengan salah satunya analisis morfologi.
2.3.3.1.3 Teknik Penanganan Kata OOV
Untuk menghasilkan keakuratan yang tinggi, suatu model POS tagging penting memiliki penanganan terhadap
kata Out-of-Vocabulary (OOV). Beberapa teknik penanganan kata OOV pada POS tagging diantaranya adalah teknik Affixs tree dan teknik analisis morfologi.
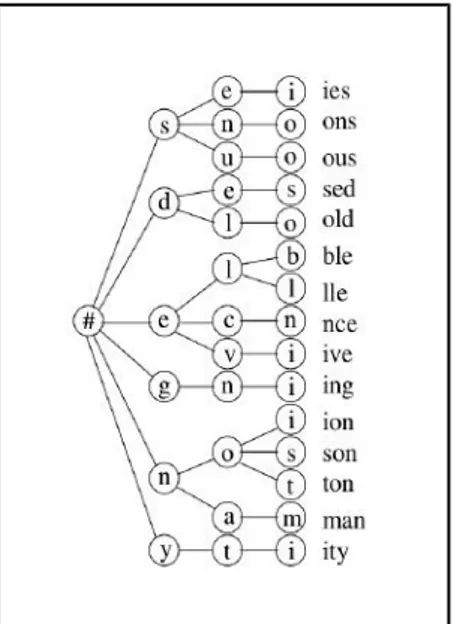
1. Affix tree
Affix tree disebut juga pohon afiks pertama diusulkan oleh Helmut Schmid pada TreeTagger. Pohon afiks diatur seperti sebuah pohon, tiap simpul pohon (kecuali pada simpul akar) dilabeli dengan sebuah karakter. Pada simpul daun, probabilitas vektor label disematkan. Pohon afiks dapat berupa pohon prefiks, sufiks maupun gabungan prefiks, dan sufiks. Pada proses pencarian pohon sufiks, pencarian dimulai pada simpul akar. Pada tiap langkahnya, ranting yang di lebeli dengan karakter berikutnya dari akhir kata akhiran sampai
Gambar 1: Pohon sufiks pada kepanjangan tiga
seterusnya. Pada gambar 1 ditunjukkan contoh pohon sufiks dengan tiga tingkat kepanjangan [29].
Pada IPOSTAgger, wicaksono mengadaptasi model Affix tree milik Schmid untuk bahasa Indonesia dengan membuat tiga tipe pohon yang dapat menangani kata berkapital, kata tak berkapital, dan kata kardinal (ke-5, 100, dst). Pada percobaaan terdapat tiga konfigurasi pohon afiks yang diujikan yaitu pohon prefiks, pohon sufiks, dan pohon prefiks-sufiks. Pohon afiks ini dibangun berdasarkan pada korpus latih dan memanfaatkan informasi Lexicon dari KBBI dan Kateglo untuk mengurangi jumlah vektor probabilitas emisi yang dihasilkan pada pohon afiks tersebut [3].
2. Analisis Morfologi
Analisis morfologi (Morphological Analyzer) pada POS tagging digunakan untuk memberi informasi morfologi kepada kata-kata. Teknik ini digunakan oleh Fam Rashel dalam pembuatan POS tagging bahasa Indonesia dengan pendekatan Rule-Based dan Abu Bakar pada POS tagging bahasa Malaysia [5, 11]. Teknik analisis morfologi ini digunakan untuk memberikan label POS pada kata yang masuk dalam kategori open class words.
2.2.4 Sistem Yang Diterapkan 2.2.4.1 IPOSTAgger
IPOSTAgger merupakan sistem POS tagging berbasis statistik untuk bahasa Indonesia yang dikembangkan oleh A. F.
Wicaksono dengan bahasa pemrograman Java. Adapun metode yang diterapkan pada IPOSTAgger adalah Hidden Markov Model (HMM) bigram dan trigram, metode smoothing, metode Affix tree, metode Lexicon dan Succeeding POS tag. Sistem dapat melakukan training pada korpus latih dan mengujikannya pada korpus uji. Hasil keluaran berupa dokumen yang berisi urutan kata diikuti dengan label POSnya, contohnya pelabelan dengan konfigurasi terbaik sesuai penelitian dengan 35 label POS sebagai berikut: Mengapa/WP lebah/NN betina/NN sering/JJ pergi/VBI keluar/VBI sarangnya/NNG ?/.
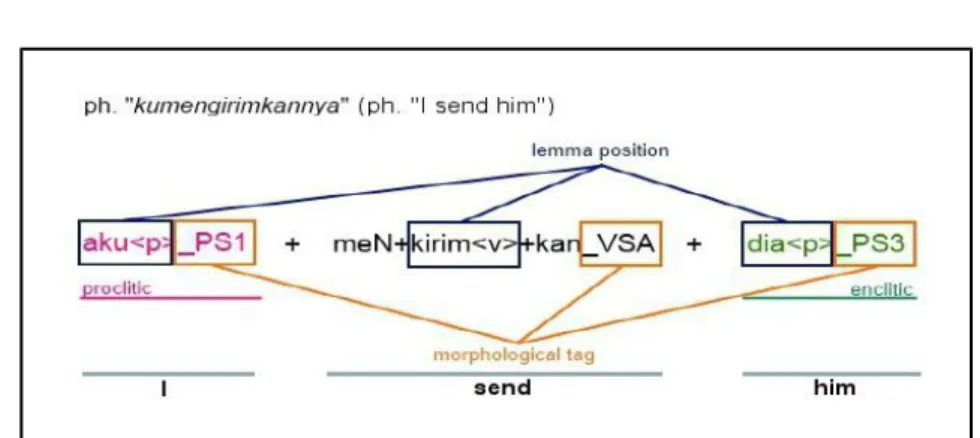
2.2.4.2 Morphind
MorphInd merupakan tool analisis morfologi untuk bahasa Indonesia berbasis finite state, yang dapat menangani analisis morfologi, lemmatization untuk bentuk kata permukaan yang diberikan sehingga dapat dilakukan pengolahan kata selanjutnya. MorphInd terdiri aturan-aturan morfosintaktis dan morfofonemik untuk kata turunan atau infleksi kata permukaan pada bahasa Indonesia. Hasil keluaran yang ditunjukan pada gambar 2 terdiri
dari tiga label berbeda yang ditempatakan setelah morfem.
2.3 Kerangka Pemikiran
Masalah
Kata OOV yang disebabkan oleh kata berimbuhan pada POS tagging bahasa Indonesia berbasis statistik.
Tujuan
Menerapkan analisis morfologi pada POS tagging bahasa Indonesia berbasis statistik untuk penanganan kata OOV yang disebabkan oleh kata berimbuhan
Eksperimen
Data Metode
Korpus latih terdiri dari 10000 token, korpus uji terdiri dari kurang lebih 3000 token dengan masing-masing 10% kata OOV, 20% kata ambigu, 30% kata berimbuhan.
HMM bigram, HMM trigram, Teknik smoothing, Morpholgy Analyzer. Hasil
Perbandingan persentase keakuratan POS tagging antar model yang diajukan serta dengan metode pada IPOSTAgger.
Manfaat
Sebagai pembanding POS tagging bahasa Indonesia yang telah ada khususnya POS tagging berbasis statistik.
BAB III
METODE PENELITIAN
2.4
3
3.1 Instrumen Penelitian
Dalam penelitian ini diperlukan beberapa perangakat agar penelitian berjalan lancar dan sesuai yang diharapkan. Perangkat yang digunakan dalam penelitian ini dibagi menjadi dua, yaitu bahan dan peralatan.
3.1.1 Bahan
Bahan-bahan yang digunakan penulis dalam penelitian ini adalah korpus dalam bahasa Indonesia diambil dari korpus A. Dinakaramani yang telah melabeli lebih dari 250.000 token secara manual dengan 23 jenis label POS [28]. Korpus tersebut kemudian akan diolah menjadi korpus latih untuk proses training dan korpus uji untuk pengujian.
3.1.2 Peralatan
Peralatan yang digunakan penulis dalam penelitian ini adalah perangakat keras (hardware) dan perangkat lunak (software), meliputi :
1. Perangkat keras
(a) Processor Inter Core i5 (b) RAM 4GB
(c) Harddisk 1TB (d) Monitor LCD 14'' 2. Perangkat lunak
(a) Sistem Operasi : Elementary OS Freya (b) Sublime Text Editor 3
(c) IPOSTagger 1.1 (d) MorphInd 1.4
3.2 Prosedur Pengumpulan Data
Prosedur pengumpulan data yang dilakukan dalam penelitian ini menggunakan 2 metode yaitu studi pustaka dan eksperimen.
3.2.1 Studi Pustaka
Metode studi pustaka dilakukan dengan cara mencari referensi dari berbagai sumber yang mendukung penelitian, diantaranya:
1. Materi tentang POS tagging beserta metode-metode dan tagset didapat dari buku dan jurnal penelitian.
2. Materi tentang morfologi, kata imbuhan dan klitik pada bahasa Indonesia didapat dari beberapa buku bahasa Indonesia.
3. Materi tentang Hidden Markov Model (HMM) didapat dari buku dan jurnal penelitian.
4. Materi penelitian penggunaan metode HMM pada POS tagging didapat dari jurnal penelitian.
Selain informasi dari jurnal dan buku-buku informasi ataupun materi-materi juga penulis dapatkan dari berbagai sumber di internet diantaranya: 1. http://books.google.com/ 2. http://scholar.google.com/ 3. http://septinalarasati.com/work/morphind/ 4. http://www.panl10n.net/ 5. http://jedlik.phy.bme.hu/~gerjanos/HMM/node2.html 6. https://web.stanford.edu/~jurafsky/slp3/
Hasil dari studi pustaka yang dikumpulkan diantaranya adalah referensi tentang morfologi bahasa Indonesia, POS tagging beserta metode-metode pengembangannya, dan pengaruh morfologi pada bahasa Indonesia seperti kata imbuhan dan pengklitikan pada POS tagging khususnya POS tagging dengan pendekatan statistik menggunakan HMM.
3.2.2 Eksperimen
Metode eksperimen dilakukan dengan pencatatan percobaan menggunakan perangkat-perangkat terkait yaitu IPOSTagger dan MorphInd berupa hasil keluaran perangkat tersebut. Pada percobaan disiapkan 3 jenis korpus uji yang memiliki tingkan kata OOV berbeda untuk kemudian diujikan pada tiap model sistem untuk mengetahui hasil dan tingkat keakuratan yang didapatkan pada perangkat dari tiap korpus.
3.3 Teknik Analisis Data
Pada penelitian ini menggunakan teknik analisis data untuk mendapatkan metode yang tepat untuk diterapkan pada POS tagging bahasa Indonesia. Pada POS tagging berbasis statistik proses utama yang dilakukan adalah proses morfologi dan proses ambiguasi. Pada beberapa jurnal proses morfologi yang dilakukan adalah penanganan kata imbuhan. Adapun metode yang digunakan diantaranya adalah pemrediksi afiks [10], dan pohon afiks (Affix tree) [3]. Sedangkan proses ambiguasi pada pendekatan statistik dilakukan dengan penghitungan probabilitas. Beberapa metode yang digunakan untuk proses ambiguasi dalam POS tagging ini seperti HMM, MEMM, Decision Tree, kNN dan sebagainya.
Pada penelitian sebelumnya, POS tagging menggunakan metode HMM yang digabungkan dengan beberapa metode sebagai fitur terbukti selain memiliki tingkat keakuratan yang tinggi juga memilki waktu pemrosesan yang rendah [7]. Adapun metode-metode yang ditambahkan sebagai fitur HMM adalah untuk
penanganan masalah sparse data dan penanganan kata OOV. Metode penanganan masalah sparse data yang digunakan adalah metode smoothing sedangkan penanganan kata OOV diantaranya adalah Affix tree, Succeding POS tag, Lexicon, Morphology Analyzer dan sebagainya.
Dalam penelitian ini peneliti menggabungkan metode HMM dengan beberapa metode lain antara lain adalah metode smoothing menggunakan Jelinek-Mercer smoothing dan Linier Interpolation smoothing serta menggunakan penganalisi morfologi untuk penanganan kata OOV.
3.4 Model Atau Metode Yang Diusulkan
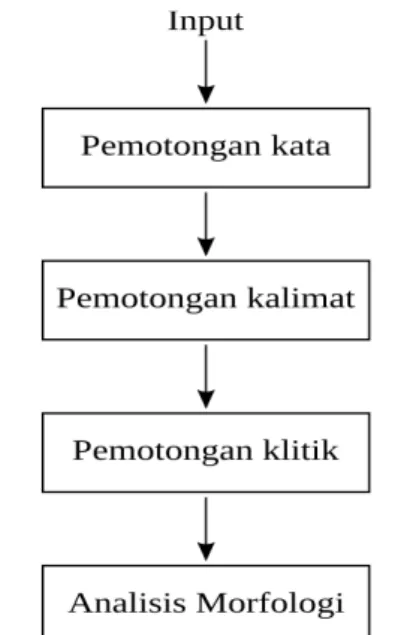
Berdasarkan hasil dari analisis data metode yang diusulkan dalam penelitian ini adalah penerapan metode penganalisis morfologi untuk penanganan kata OOV berupa kata imbuhan pada POS tagging berbasis statistik. Tahap pemrosesan yang didapatkan berdasar analisis tersebut ditunjukan pada gambar 3 sebagai berikut:
Dari gambar diatas, Tahapan proses tagging meliputi proses preprocessing, HMM tagging dan evaluation.
3.4.1 Preprocessing
Proses preprocessing dilakukan untuk menyiapkan korpus uji Gambar 3: Tahapan proses POS tagging
proses ini terdiri dari tiga tahap yaitu pemotongan kata, pemotongan kalimat, pemotongan klitik dan analisis morfologi sebagai berikut :
3.4.1.1 Pemotongan Kata
Pemotongan kata atau word segmentation hanya dilakukan pada tanda baca pada akhir kalimat seperti tanda “.” (titik), “,” (koma), “?” (tanya), “!” (seru) “””” (petik dua) dan sebagainya. Tanda baca pada tengah kalimat seperti pada kata buah-buahan dan 0.5 tidak dipisah.
3.4.1.2 Pemotongan Kalimat
Pemotongan kalimat atau sentence segmentation dilakukan untuk memisahkan kalimat satu dengan kalimat lain. Tiap kalimat akan diberi jarak satu baris baru.
3.4.1.3 Pemotongan Klitik
Pemotongan klitik atau clitic segmentation dilakukan untuk memisahkan kata dengan klitik yang bersifat pronomina. Pemotongan ini dibantu dengan sistem Morphind.
3.4.1.4 Analisis Morfologi
Tahap analisis morfologi pada preprocessing ini dilakukan dengan menerapkan sistem MorphInd sebagai penganalisis morfologi bahasa Indonesia yang akan digunakan untuk mendapatkan informasi morfologi berupa label POS pada tiap kata di korpus uji yang telah melewati tahapan preprocessing sebelumnya. Label POS hasil sistem Morphind akan diubah menjadi label POS yang digunakan untuk sistem dan digunakan untuk penghitungan probabilitas emisi pada kata OOV saat proses HMM tagging.
3.4.2 HMM Tagging
Proses HMM tagging yaitu pelabelan POS secara otomatis menggunakan metode Hidden Markov Model (HMM). Dalam HMM terdapat beberapa komponen penting yaitu urutan state ( Q ), vektor probabilitas transisi ( Λ ), urutan pengamatan ( Ο ), vektor probabilitas emisi ( Β ) dan state awal ( π ). Urutan state merupakan urutan label POS di korpus latih dan urutan pengamatan merupakan urutan kata-kata di korpus latih. Sistem akan menerapkan dua model HMM untuk POS tagging yaitu HMM bigram (first order) dan HMM trigram (second order) seperti gambar 5 dibawah.
Probabilitas transisi, probabilitas emisi, dan state awal dihitung dari korpus latih melalui persamaan berikut :
Λ=
{
∏
i=2 n Ρ(t1∣ti−1)}
(6) Λ={
∏
i=2 n Ρ(t1∣ti−1,ti−2)}
(7) Β={
∏
i=1 n Ρ(wi∣ti)}
(8) π={
Ρ (⟨STARTTAG⟩)}
(9)Probabilitas transisi untuk bigram ditunjukan oleh persamaan (6) dan persamaan untuk trigram (7). Probabilitas emisi menghitung probabilitas kata yang diamati dengan label POS ditunjukan pada persamaan (8). Sedangakan state awal ditunjukan pada persamaan (9).
Setelah komponen telah dipenuhi, proses decoding HMM dilakukan untuk mendapatkan urutan label POS paling mungkin.
Persamaan decoding HMM bigram dan trigram yang diterapkan pada IPOSTAgger ditunjukan pada persamaan (2) dan (3) sebelumnya.
Perhitungan probabilitas transisi dan probabilitas emisi dilakukan menggunakan Maximum Likelihood Estimation (MLE) sebagai berikut:
Ρ'(ti∣ti−1)=Count(ti−1, ti)
Count(ti−1)
(10)
Ρ'(ti∣ti−1, ti−2)=Count(ti−2, ti−1, ti)
Count(ti−2, ti−1)
(11)
Ρ'(wi∣ti)=Count(ti, wi)
Count(ti)
(12)
Pada pelabelan decoding HMM metode smoothing diterapkan untuk mengatasi sparse data pada probabilitas transisi. Metode smoothing yang diterapkan adalah Jelinek-Mercer smoothing ditunjukan pada persamaan (4) dan metode Linier Interpolation smoothing ditunjukan pada persamaan (5).
Kata OOV menyebabkan sparse data pada probabilitas emisi, untuk menghindari masalah tersebut perhitungan probabilitas emisi dilakukan dengan menghitung unigram label POS hasil dari proses preprocessing menggunakan MorpInd. Label POS dari MorphInd kemudian akan diterjemahkan kedalam tagset yang digunakan dan dihitung bentuk unigramnya sesuai persamaan (13).
Ρ'(ti)=Count(ti)
N
(13)
Pada persamaan unigram diatas nilai ti adalah label POS dari Morphind pada ururtan ke i sedangkan N adalah jumlah token dalam korpus latih.
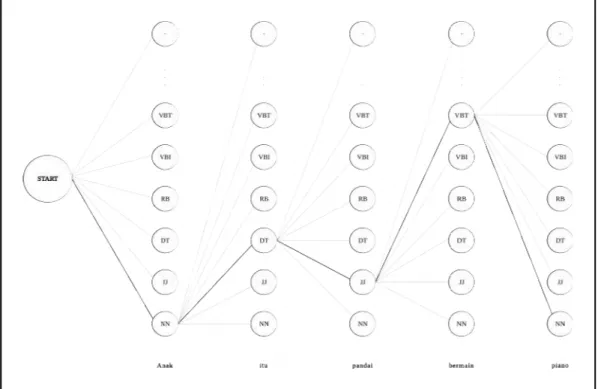
Ilustrasi proses pelabelan menggunakan decoding HMM ditunjukan pada diagram trellis pada gambar 6 dibawah ini.
Pada gambar 6 diatas START mewakilkan state awal, label-label POS sebagai hidden state ditunjukkan pada lingkaran, dan garis paling jelas mewakilkan jalur urutan terbaik.
3.4.3 Evaluation
Proses evaluation ditujukan untuk mengetahui tingkat keakuratan tiap model yang diujikan. Tiap model akan dibandingkan dengan hasil baseline. Baseline ini merupakan model yang hanya menggunakan HMM bigram dan Jelinek-Mercer smoothing tanpa menerapkan penanganan kata OOV, sehingga kata yang termasuk kata OOV akan langsung diberi label (NN) Noun. Nilai keakuratan dari baseline ini akan dibandingkan dari model yang diterapkan pada sistem, sehingga dapat diketahui kinerja model terbaik.
3.5 Eksperimen Dan Cara Pengujian Model 3.5.1 Pengujian Data
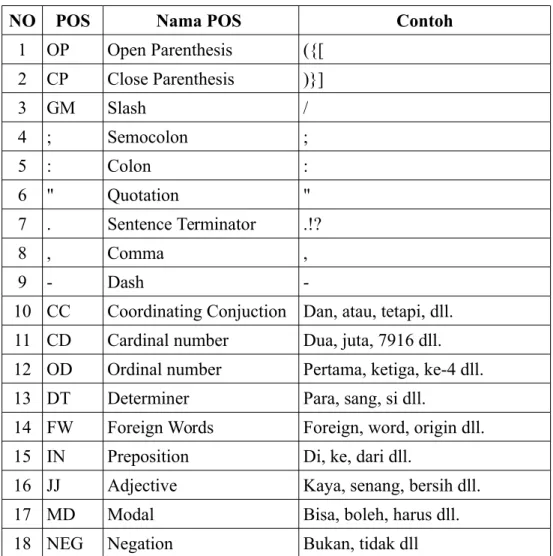
Penelitian ini menggunakan dua macam korpus yaitu korpus latih dan korpus uji. Korpus diadaptasi dari korpus POS bahasa Indonesia milik A. Dinakaramani yang melabeli lebih dari 250.000 token secara manual dengan 23 jenis label POS [28]. Korpus latih terdiri dari kurang lebih 10.000 token diambil dari korpus tersebut namun dengan mengganti dan menambah beberapa jenis tagset. Tagset yang digunakan penulis dalam penelitian ini berjumlah 31 label POS yang dimodifikasi dari tagset asli dari korpus A. Dinakaramani dan tagset dari A. Wicaksono, tagset ditunjukkan pada tabel 3.
Tabel 3: Tagset yang digunakan
NO POS Nama POS Contoh
1 OP Open Parenthesis ({[ 2 CP Close Parenthesis )}] 3 GM Slash / 4 ; Semocolon ; 5 : Colon : 6 " Quotation " 7 . Sentence Terminator .!? 8 , Comma , 9 - Dash
-10 CC Coordinating Conjuction Dan, atau, tetapi, dll. 11 CD Cardinal number Dua, juta, 7916 dll. 12 OD Ordinal number Pertama, ketiga, ke-4 dll. 13 DT Determiner Para, sang, si dll.
14 FW Foreign Words Foreign, word, origin dll. 15 IN Preposition Di, ke, dari dll.
16 JJ Adjective Kaya, senang, bersih dll.
17 MD Modal Bisa, boleh, harus dll.
(Tabel Tagset yang digunakan lanjutan)
NO POS Nama POS Contoh
19 NN Common Noun Mobil, kertas, rupiah dll. 20 NNP Proper Noun Semarang, Indonesia, Jawa dll. 21 NND Classifier, partitive, and
measurement noun
Orang, helai, lembar dll. 22 PR Demonstrative pronoun Ini, itu, sini dll.
23 PRP Personal Pronouns Saya, kamu, dia dll.
24 RB Adverb Sementara, nanti, sangat dll.
25 RP Practicles Pun, kah, lah
26 SC Subordinating conjunction Jika, ketika, supaya, dll.
27 SYM Symbols @#$%^&
28 UH Interjection Wah, aduh, Oi, oh, hai dll.
29 VB Verb Membeli, memakan, tidur dll.
30 WH WH-Pronouns Apa, siapa, kapan dll.
31 X Unknown Bangedd, G0k!L, jus+ice dll.
Pengujian dilakukan pada tiga korpus uji yang berbeda masing-masing berisi kurang lebih 3.000 token. Pengujian pertama pada korpus uji yang mengandung 10% kata OOV, kedua menggunakan korpus dengan 20% kata OOV dan ketiga menggunakan korpus dengan 30% kata OOV.
3.5.2 Pengujian Keakuratan
Pengujian POS tagging dengan pengubahan variabel data akan dihitung prosentase keakuratannya pada tiap model. Prosentase yang dihitung adalah prosentase keseluruhan keakuratan (Overall accuracy), keakuratan kata yang diketahui (Known word accuracy) dan keakuratan kata OOV (Unknown word accuracy). Hasil prosentase tiap model akan dibandingkan
satu sama lain untuk mengetahui keakuratan tertinggi yang didapatkan. Pada model dengan keakuratan tertinggi akan dibandingkan dengan model IPOSTagger yaitu dengan metode Affix tree dan Lexicon.
4.1
4.2 Analisis Data
Penelitian ini menggunakan data berupa korpus yang telah diberi 31 jenis label POS yang ditunjukkan pada tabel 3. Korpus diadaptasi dari korpus A. Dinakaramani yang telah mengalami perubahan pada tagset dan pelabelan. Perubahan tagset yang dilakukan seperti perubahan dari label “Z” dibagi menjadi label ., ,, “, :, ;, OP, CP, dan GM. Perubahan pelabelan yang dilakukan seperti merubah semua kata asing menjadi berlabel “FW”.
Data dipilih dan dibagi menjadi dua untuk korpus latih dan korpus uji. Korpus latih terdiri dari kurang lebih 10.000 kata, sedangakan korpus uji terdiri dari kurang lebih 3.000 kata. Terdapat tiga macam korpus yang diujikan dengan tingkat kata OOV yang berbeda pada tiap korpusnya. Korpus uji pertama berisi 10% kata OOV, korpus uji kedua berisi 20% kata OOV dan korpus ketiga berisi 30% kata OOV.
4.3 Hasil Training
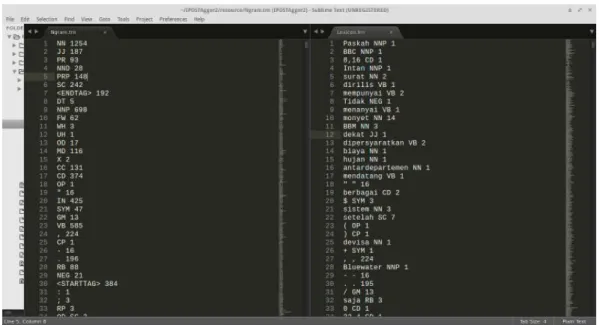
Proses training (pelatihan) dilakukan dengan menggunakan sistem IPOSTAgger dengan menggunakan korpus latih yang telah disiapkan. Proses ini dilakukan untuk mencari persebaran kemunculan label POS dan persebaran kemunculan kata dengan label POS yang mengikutinya. Saat proses training berlangsung sistem akan menghasilkan dua file yaitu Ngram.trn pada dan Lexicon.trn seperti gambar dibawah ini.
Gambar 7 diatas merupakan hasil proses training oleh sistem IPOSTAgger, yaitu file Ngram.trn (kiri) dan Lexicon.trn (kanan). File Ngram.trn berisi persebaran urutan label kata unigram, bigram dan trigram beserta jumlah kemunculannya. Nilai kemunculan ini akan digunakan untuk menghitung probabilitas transisi menggunakan MLE, masing-masing pada unigram seperti persamaan (13), bigram seperti persamaan (10) dan trigram seperti persamaan (11). Sebagai contoh pada tabel yang berisi urutan label POS dan frekuensinya sebagai berikut:
Tabel 4: Contoh Ngram
Jenis Ngram Urutan Label POS Frekuensi
Unigram NN 1254
Bigram NN PR 70 Trigram NN PR VB 25
Pada tabel 4 yang didapatkan dari file Ngram.trn hasil proses training korpus latih yang terdiri dari 5577 kata, akan dihitung probabilitas transisi masing-masing Ngram sebagai berikut:
Perhitungan unigram: Ρ'(NN)=Count(NN) 5577 Ρ'(NN)=1254 5577 Ρ'(NN)=0,224852071 Perhitungan bigram: Ρ'(PR∣NN)=Count(NN , PR) Count(NN) Ρ'(PR∣NN)= 70 1254 Ρ'(PR∣NN)=0,055821372 Perhitungan Trigram: Ρ'(VB∣PR , NN)=Count(NN , PR , VB) Count(NN , PR) Ρ'(VB∣PR , NN)=25 70 Ρ'(VB∣PR , NN)=0,357142857
Sesuai perhitungan diatas masing-masing hasil probabilitas transisi unigram NN adalah 0,224852071, bigram NN PR adalah 0,055821372 dan trigram NN PR VB adalah 0,357142857.
Sedangkan file Lexicon.trn berisi persebaran kata, label, dan jumlahnya dalam korpus latih. Nilai jumlah ini yang akan digunakan untuk mendapatkan probabilitas emisi pada masing-masing kata. Kata yang tidak ada dalam file Lexicon.trn ini akan dianggap sebagai kata OOV. Sebagai contoh perhitungan probabilitas emisi sesuai persamaan (12) pada kata Paskah berlabel NNP yang muncul sebanyak sekali dengan jumlah label NNP sebanyak 698 pada korpus latih, sebagai berikut:
Perhitungan probabilitas emisi kata Paskah
Ρ'(Paskah∣NNP)=Count(NNP , Paskah)
Count(NNP) Ρ'(Paskah∣NNP)= 1
698
Ρ'(Paskah∣NNP)=0,001432665
Sesuai perhitungan di atas, maka hasil dari probabilitas emisi pada kata Paskah adalah 0,001432665.
4.4 Hasil Preprocesing
Preprocesing dilakukan dengan menyiapkan korpus uji melalui beberapa tahap yaitu word segmentation, sentence segmentation dan terakhir analisis morfologi seperti yang ditunjukkan pada gambar 4 tahapan preprocessing. Analisis morfologi ini diantaranya adalah pemotongan klitik yang bersifat pronomina. Pemotongan kata dan pemotongan kalimat dilakukan dengan menerapkan sistem tokenizer-id [30] sedangkan pemotongan klitik dengan penganalisis morfologi menggunakan sistem MorphInd.
Gambar 8 menunjukkan contoh korpus uji sebelum preprocessing (kiri) dan setelah preprocesing (kanan). Korpus hasil preprocesing ini disimpan dalam file bernama korpus-final.txt (kanan) menjadi korpus uji yang siap untuk proses POS tagging menggunakan HMM selanjutnya.
Penerapan Morphind selain untuk pemotongan klitik juga untuk penanganan kata OOV pada korpus uji. Tiap kata pada korpus uji akan diterjemahkan dalam bentuk MorphInd lalu diberi label POS yang sesuai. Namun karena tagset Morphind berbeda dengan tagset yang digunakan pada penelitian ini maka digunakan tabel penerjemah label POS seperti yang ditunjukkan pada tabel 5 dibawah ini.
Tabel 5: Penerjemah label POS
NO Label Morphind Label POS
1 A JJ 2 B DT 3 CD CD 4 CC CD 5 CO OD 6 D RB 7 G NEG 8 H CC 9 I UH 10 M MD 11 N NN,NNP,NND 12 O VB 13 P PR,PRP 14 R IN 15 S SC 16 T RP 17 V VB 18 W WH
(Tabel Penerjemah Label POS lanjutan)
NO Label Morphind Label POS
19 X X
20 Z .,,,-,\",;,:,GM,OP,CP
Hasil dari kata yang telah diberi label MorphInd dan telah diterjemahkan tersebut nantinya akan digunakan sebagai label kandidat pada kata OOV. Setiap kata dalam korpus uji yang telah dilabeli dengan label kandidat kemudian dimasukkan kedalam file token-tag.txt.
Gambar 9 diatas menunjukkan file token-tag.txt pada contoh korpus uji yang diinputkan sebelumnya. File ini digunakan pada perhitungan probabilitas emisi untuk kata OOV pada proses POS tagging menggunakan Morpholgy Analyzer selajutnya.
4.5 Implementasi HMM
Sistem IPOSTagger menerapkan Hidden Markov Model (HMM) untuk POS tagging. Algorima decoding yang diterapkan adalah algoritma viterbi. Algoritma viterbi digunakan untuk menentukan urutan label POS terbaik pada kalimat yang diinputkan. Proses decoding seperti pada persamaan (2) untuk decoding HMM bigram dan persamaan (3) decoding HMM trigram dilakukan dalam bentuk penjumlahan logaritma.
Sebelum sistem melakukan proses decoding HMM, sistem terlebih dulu melakukan beberapa persiapan sebagai berikut :
1. Memilih model HMM yang akan digunakan yaitu model HMM bigram atau HMM trigram.
2. Menyiapkan tagset yang akan digunakan untuk pelabelan yang didapatkan dari proses training korpus latih. Tagset yang digunakan ditunjukan pada tabel 3.
3. Menyiapkan urutan kata perkalimat yang diambil dari korpus uji dalam file korpus-final.txt yaitu korpus uji yang telah melewati proses preprocessing. Sebagi contoh kalimat dalam korpus uji yang akan diberi label misalnya adalah kalimat “Perebutan jamrud Bahia raksasa .”
4. Menyiapkan urutan kata perkalimat dengan memberikan label POS <STARTTAG> pada awal kalimat dan label POS <ENDTAG> pada akhir tiap kalimat pada model bigram dan memberikan label POS <STARTTAG>, <STARTTAG> pada awal kalimat dan label POS <ENDTAG> pada akhir kalimat pada model trigram.
Contoh (bigram): “<STARTTAG> Perebutan jamrud Bahia raksasa . <ENDTAG> ”
Contoh (trigram): “<STARTTAG> <STARTTAG> Perebutan jamrud Bahia raksasa . <ENDTAG> ”
5. Menyiapkan probabilitas emisi untuk known word (kata yang ada dalam korpus latih) dengan menggunakan file Lexicon.trn hasil dari proses