KUALITATIF DAN CAMPURAN DALAM PEMBUATAN
POHON KEPUTUSAN DENGAN MENGGUNAKAN
ALGORITMA ID3
SKRIPSI
Diajukan Untuk Memenuhi Syarat Memperoleh Gelar Sarjana Komputer Program Studi Teknik Informatika
Oleh :
CAECILIA NOVA PATRIANA
NIM : 065314019
JURUSAN TEKNIK INFORMATIKA
FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA
YOGYAKARTA
DATA, QUALITATIVE DATA AND MIXED IN MAKING A
DECISION TREE USING ID3 ALGORITHM
A THESIS
Presented as Partial Fulfillment of the Requirements to Obtain Sarjana Komputer Degree in Informatics Engineering Department
By :
CAECILIA NOVA PATRIANA
NIM : 065314019
DEPARTMENT OF INFORMATICS ENGINEERING
FACULTY OF SCIENCE AND TECHNOLOGY
SANATA DHARMA UNIVERSITY
YOGYAKARTA
Jika kenyataan tidak sesuai dengan apa yang kamu inginkan,
jangan pernah menyerah, teruslah berjuang, berdoa dan
pasrahkanlah semua pada Tuhan, karena pasti Tuhan
memberikan yang terbaik untukmu. Ingatlah bahwa setiap
rancangan Tuhan itu indah dan penuh makna.
Jangan pernah pelit untuk saling berbagi dalam hal
apapun, karena rejeki selalu berputar dan suatu saat itu
akan kembali kepadamu.
Lakukanlah semua hal atas dasar cinta karena dengan itu akan
membuat semuanya menjadi indah.
Jangan pernah menunda pekerjaan, lakukanlah sekarang
juga karena waktu tidak akan pernah kembali sebelum kau
menyesal nantinya.
Jangan pernah merasa dirimulah yang paling hebat atau yang
paling lemah, karena di atas langit masih ada langit.
Tidak ada sesuatu yang didapatkan tanpa perjuangan dan kerja keras
Kupersembahkan karyaku ini untuk :
Papa dan Mama tercinta
Adikku tersayang
Orang-orang yang aku cintai dan mencintaiku
I love You Forever All
Permasalahan dalam tugas akhhir ini adalah bagaimana algoritma ID3 membantu pengolahan data tipe data kuantitatif (interval, rasio), kualitatif (nominal, ordinal) dan campuran sehingga diperoleh suatu pola dalam bentuk pohon keputusan yang dapat membantu dalam mengambil keputusan. Tujuan pembuatan tugas akhir ini agar tersedianya aplikasi atau model pengolahan data yang mampu menganalisis sekumpulan data dengan tipe data kuantitatif (interval, rasio), kualitatif (nominal, ordinal) dan campuran sehingga ditemukan suatu pola atau aturan yang dapat membantu dalam mengambil keputusan untuk suatu permasalahan klasifikasi serta memberikan pemodelan pengolahan data dalam menangani data kuantitatif (interval, rasio), kualitatif (nominal, ordinal) dan campuran dengan menggunakan algoritma ID3.
Decision tree adalah sebuah metode untuk memperkirakan fungsi target nilai-diskrit, dimana fungsi yang dipelajari ditampilkan dengan pohon keputusan. Dalam ID3 mengunakan kriteria information gain untuk memilih atribut. Akurasi yang didapat untuk data kuantitatif (interval, rasio) adalah 72.4%, data kualitatif (nominal, ordinal) adalah 72.92% dan data campuran adalah 77.9%
Problems in this thesis is how the algorithm helps ID3 data processing type of quantitative (interval, ratio), qualitative (nominal, ordinal) and mixed to obtain a pattern in the form of a decision tree that can assist in making decisions. Purpose of making this thesis will provide the application or the data processing model that is able to analyze a set of data with the type of quantitative (interval, ratio), qualitative (nominal, ordinal) and mixed so found a pattern or rule that can help in making decisions for a classification problem and provide a data processing modeling in dealing with quantitative (interval, ratio), qualitative (nominal, ordinal) and mixed using ID3 algorithm.
Decision tree is a method to estimate the target function of discreate values, where the functions being studied displayed with the decision tree. In the decicion tree using information gain criterion to select attributes. Accuracy is obtained for 72.4% of quantitative (interval, ratio) data, qualitative (nominal, ordinal) data was 72.92% and 77.9% are mixed data.
Puji syukur kepada Tuhan Yang Maha Esa karena atas segala berkat dan rahmat-Nya penulis dapat menyelesaikan skripsi dengan judul “Perbandingan Penanganan Data Kuantitatif, Kualitatif Dan Campuran Dalam Pembuatan Pohon Keputusan Dengan Menggunakan Algoritma ID3”.
Penulisan skripsi ini diajukan untuk memenuhi salah satu syarat memperoleh gelar Sarjana Komputer Program Studi Teknik informatika Universitas Sanata Dharma Yogyakarta.
Dengan terselesaikannya penulisan skripsi ini, penulis mengucapkan terima kasih kepada pihak-pihak yang telah membantu memberikan dukungan baik berupa masukan ataupun berupa saran. Oleh karena itu, penulis menyampaikan ucapan terima kasih yang sebesar-besarnya kepada :
1. Romo Dr. Cyprianus Kuntoro Adi, SJ, MA, M.Sc., selaku dosen pembimbing, atas kesabaran, pengarahan, dan saran yang diberikan kepada penulis selama penyusunan skripsi ini.
2. Ibu P.H. Prima Rosa, S.Si, M.Sc., selaku Dekan Fakultas Sains dan Teknologi Universitas Sanata Dharma Yogyakarta serta selaku dosen penguji atas kritik dan saran yang membangun dalam perbaikan skripsi ini.
akademik atas bantuan dan saran yang diberikan kepada penulis selama penyusunan skripsi ini.
5. Dosen-dosen Teknik Informatika Universitas Sanata Dharma. Terima kasih atas ilmu yang telah diajarkan selama ini.
6. Bapak Bele yang turut mendukung dalam persiapan ujian pendadaran.
7. Seluruh staff Fakultas Sains dan Teknologi Universitas Sanata Dharma yang banyak membantu penulis dalam urusan administratsi akademik terutama menjelang ujian tugas akhir dan yudisium.
8. Papaku FX. Harjanto dan Mamaku Agnes Dwi Sayekti tercinta yang menyertai, mendoakan dan merestui penulis selalu selama masa studi.
9. Adikku Vinsensius Nugroho Wicaksono tersayang atas doa dan dukungannya.
10. Orang-orang yang aku cintai dan mencintaiku atas doa dan dukungannya. 11. Teman-teman Teknik Informatika angkatan 2006, terima kasih atas semangat
dan bantuan yang sangat berarti sehingga akhirnya skripsi ini dapat terselesaikan.
12. Dan Semua pihak yang tidak bisa penulis sebutkan satu per satu, yang telah memberikan bantuan, bimbingan, kritik dan saran dalam penyusunan skripsi ini.
wawasan ataupun menjadi referensi bagi para pembaca sekalian khususnya pada mahasiswa Teknik Informatika.
Yogyakarta, Mei 2012
Penulis
HALAMAN SAMPUL (BAHASA INDONESIA) ... i
HALAMAN SAMPUL (BAHASA INGGRIS) ... ii
HALAMAN PERSETUJUAN PEMBIMBING ... iii
HALAMAN PENGESAHAN ... iv
HALAMAN MOTTO ... v
HALAMAN PERSEMBAHAN ... vi
ABSTRAK ... vii
ABSTRACT ... viii
PERNYATAAN KEASLIAN KARYA ... ix
PERNYATAAN PERSETUJUAN PUBLIKASI ... x
KATA PENGANTAR ... xi
DAFTAR ISI ... xiv
DAFTAR GAMBAR ... xvii
DAFTAR TABEL ... xix
BAB I. PENDAHULUAN ... 1
1.1. Latar Belakang... 1
1.2. Rumusan Masalah ... 2
1.3. Tujuan ... 3
1.4. Batasan Masalah ... 3
1.5. Kegunaan ... 4
1.6. Sistematika Penulisan ... 4
BAB II. LANDASAN TEORI. ... 6
2.3. Tahap-Tahap Data Mining ... 10
2.4. Jenis Atribut Suatu Data ... 13
2.5. Metode Pelatihan ... 14
2.6. Pohon Keputusan (Decision Tree)... 14
2.6.1. Macam-Macam Pohon Keputusan ... 16
2.6.2. Algoritma ID3 ... 18
2.6.2.1. 1-Rule ... 20
2.6.2.2. Entropi ... 21
2.6.2.3. Information Gain ... 22
2.6.3. Kelebihan dan Kekurangan Pohon Keputusan ... 23
BAB III. METODOLOGI PENELITIAN . ... 25
3.1. Data Histori ... 25
3.1.1. Data Kuantitatif. ... 25
3.1.2. Data Kualitatif ... 26
3.1.3. Data Campuran ... 26
3.2. Training dan Testing ... 27
3.3. Akurasi ... 28
3.4. Contoh Perhitungan Manual ID3... 29
3.4.1. Proses Pengolahan Data Campuran ... 29
3.4.1.1. Data Training Campuran ... 32
3.4.1.2. Data Testing Campuran ... 67
3.5. Desain Interface... 69
4.1. Prepocessing... 76
4.1.1. Pembersihan Data ... 76
4.1.2. Transformasi Data ... 77
4.2. Seleksi Atribut ... 77
4.3. Hasil dan Analisis ... 79
4.3.1. Data Kuantitatif ... 79
4.3.2. Data Kualitatif ... 82
4.3.2. Data Campuran. ... 85
4.4. Implementasi Antarmuka ... 91
BAB V. PENUTUP. ... 101
5.1. Kesimpulan ... 101
5.2. Saran ... 102
Gambar 2.1. Tahapan Dalam KDD. ... 10
Gambar 2.2. Contoh Pohon Keputusan. ... 15
Gambar 3.1. Root Yang Terpilih Untuk Tree Campuran... 53
Gambar 3.2. Cabang Yang Terpilih Jika fnlwgt >71420 dan ≤113317 ... 57
Gambar 3.3. Cabang Yang Terpilih Jika fnlwgt >154856.5 ... 62
Gambar 3.4. Tree Yang Terbentuk Untuk Data Campuran. ... 66
Gambar 3.5. Desain Form Utama ... 69
Gambar 3.6. Desain FormTraining dan Testing Data Kuantitatif (Bagian 1) ... 70
Gambar 3.7. Desain FormTraining dan Testing Data Kuantitatif (Bagian 2) ... 70
Gambar 3.8. Desain FormTraining dan Testing Data Kualitatif (Bagian 1) ... 71
Gambar 3.9. Desain FormTraining dan Testing Data Kualitatif (Bagian 2) ... 71
Gambar 3.10. Desain FormTraining dan Testing Data Campuran (Bagian 1) ... 72
Gambar 3.11. Desain FormTraining dan Testing Data Campuran (Bagian 2) ... 72
Gambar 3.12. Desain Form Pengenalan Data Tunggal Data Kuantitatif ... 73
Gambar 3.13. Desain Form Pengenalan Data Tunggal Data Kualitatif ... 73
Gambar 3.14. Desain Form Pengenalan Data Tunggal Data Campuran ... 74
Gambar 4.1. Sebagian Tree Yang Terbentuk Untuk Data Kuantitatif ... 81
Gambar 4.2. Sebagian Tree Yang Terbentuk Untuk Data Kualitatif ... 84
Gambar 4.3. Sebagian Tree Yang Terbentuk Untuk Data Campuran ... 90
Gambar 4.4. Form Utama ... 92
Gambar 4.5. FormTraining dan Testing Data Kuantitatif (Bagian 1) ... 93
Gambar 4.6. FormTraining dan Testing Data Kuantitatif (Bagian 2) ... 93
Gambar 4.7. FormTraining dan Testing Data Kualitatif (Bagian 1)... 94
Gambar 4.8. FormTraining dan Testing Data Kualitatif (Bagian 2)... 95
Gambar 4.9. FormTraining dan Testing Data Campuran (Bagian 1) ... 96
Gambar 4.10. FormTraining dan Testing Data Campuran (Bagian 2) ... 97
Gambar 4.11. Form Pengenalan Data Tunggal Data Kuantitatif ... 98
Tabel 3.1. Data Cencus Income... 29
Tabel 3.2. Data Testing Cencus Income ... 67
Tabel 3.3. Confusion Matriks Data Cencus Income ... 68
Tabel 4.1. Hasil Perhitungan Proses Training UntukData Kuantitatif... 80
Tabel 4.2. Confusion Matriks Untuk Data Kuantitatif ... 82
Tabel 4.3. Hasil Perhitungan Proses Training UntukData Kualitatif... 83
Tabel 4.4. Confusion Matriks Untuk Data Kualitatif ... 85
Tabel 4.5. Hasil Perhitungan Proses Training UntukData Campuran Kuantitatif ... 87
Tabel 4.6. Hasil Perhitungan Proses Training UntukData Campuran Kualitatif ... 88
Tabel 4.7. Hasil Perhitungan Proses Training UntukKeseluruhan Data Campuran ... 89
Tabel 4.8. Confusion Matriks Untuk Data Campuran ... 91
PENDAHULUAN
Pada bab ini akan dibahas hal-hal yang berkaitan dengan latar belakang, rumusan masalah, tujuan, batasan masalah, kegunaan dan sistematika penulisan.
1.1 Latar Belakang
Ukuran database dalam sebuah organisasi atau institusi boleh jadi berkembang menjadi semakin besar seiring perkembangan jaman. Akan tetapi yang menjadi masalah bukan besarnya timbunan data tersebut, melainkan bagaimana supaya aset mentah tadi menjadi sesuatu yang lebih berarti, informasi atau kesimpulan yang lebih berguna dari hasil analisis kumpulan data.
Di lain pihak, data statistika tertentu seperti rekaman hasil observasi atau pencatatan rutin sebuah institusi maupun perorangan yang dapat direpresentasikan dalam sebuah database dengan table tunggal atau database flat, disertai atribut yang cukup banyak ratusan atau bahkan ribuan baris data, akan sulit dipahami tanpa indikator-indikator yang memadai atau pengelompokkan tertentu.
gagasan klasifikasi, association rule, clustering, dan sebagainya. Salah satu model yang cukup luas digunakan adalah model pohon keputusan (decision tree). Model ini didasarkan pada gagasan klasifikasi. Beberapa aplikasi dengan model ini diterapkan untuk prediksi dalam permasalahan tertentu.
Decision tree adalah sebuah metode untuk memperkirakan fungsi target nilai diskrit, dimana fungsi yang dipelajari ditampilkan dengan pohon keputusan (decision tree). Dalam decision tree, ID3 (Iterative Dichotomiser 3) adalah algoritma yang digunakan untuk menghasilkan pohon keputusan. Decision tree ditemukan oleh Ross Quinlan. Dalam ID3 mengunakan kriteria information gain untuk memilih atribut yang akan digunakan untuk pemisahan obyek. Atribut yang mempunyai information gain paling tinggi dibanding atribut yang lain dalam suatu data, dipilih untuk melakukan pemecahan. (Mitchell,1997)
Melihat ukuran database yang semakin besar seiring perkembangan jaman, maka penulis membuat suatu aplikasi atau model pengolahan data yang mampu menangani sekumpulan data dengan tipe data kuantitatif (interval, rasio), kualitatif (nominal, ordinal) dan campuran yang ditampilkan dalam bentuk pohon keputusan untuk membantudalam mengambil keputusan.
1.2 Rumusan Masalah
dapat membantudalam mengambil keputusan.
1.3 Tujuan
Tujuan dibuatnya aplikasi ini yaitu :
1. Tersedianya aplikasi atau model pengolahan data yang mampu menganalisis sekumpulan data dengan tipe data kuantitatif (interval, rasio), kualitatif (nominal, ordinal) dan campuran sehingga ditemukan suatu pola atau aturan yang dapat membantudalam mengambil keputusan untuk suatu permasalahan klasifikasi.
2. Memberikan pemodelan pengolahan data dalam menangani data kuantitatif (interval, rasio), kualitatif (nominal, ordinal) dan campuran dengan menggunakan algoritma ID3.
1.4 Batasan Masalah
Adapun batasan-batasan masalah yang terdapat dalam pembuatan aplikasi ini adalah :
1. Data yang digunakan berupa tiga jenis tipe data yaitu data kuantitatif (data blood transfusion), data kualitatif (data car), dan data campuran (data cencus income).
Basic 6.0.
1.5 Kegunaan
Aplikasi atau model pengolahan data ini nantinya untuk membandingkan penanganan data kuantitatif (interval, rasio), kualitatif (nominal, ordinal) dan campuran dalam pembuatan pohon keputusan dengan menggunakan algoritma ID3.
1.6 Sistematika Penulisan
Sistematika yang digunakan dalam penulisan tugas akhir ini adalah sebagai berikut :
BAB I. PENDAHULUAN
Bab ini terdiri atas bagian latar belakang, rumusan masalah, tujuan, batasan masalah, metodologi penelitian, dan sistematika penulisan
BAB II. LANDASAN TEORI
Bab ini menjelaskan mengenai teori yang berkaitan dengan judul/masalah di tugas akhir.
BAB III. METODOLOGI PENELITIAN
Bab ini menyajikan gambaran mengenai cara implementasi dan pengoperasian aplikasi, serta hasil pengujian yang dilakukan terhadap aplikasi tersebut.
BAB V. PENUTUP
Bab ini berisi kesimpulan dari pembahasan tugas akhir secara keseluruhan yang tentunya berkaitan dengan rumusan masalah dan tujuan tugas akhir. Bab ini juga akan berisi saran dari penulis untuk pengembangan lebih lanjut aplikasi yang dibuat.
BAB II
LANDASAN TEORI
Pada bab ini akan dibahas hal-hal yang berkaitan dengan pengertian datamining, pengelompokan data mining, tahap-tahap data mining, jenis atribut suatu data, metode pelatihan, pohon keputusan (decision tree), macam-macam pohon keputusan, algoritma ID3, 1-rule, entropi, information gain, kelebihan dan kekurangan pohon keputusan.
2.1 Pengertian DataMining
Beberapa pengertian datamining dari beberapa pendapat adalah sebagai berikut : 1. Secara sederhana dapat didefinisikan bahwa data mining adalah ekstraksi informasi atau pola yang penting atau menarik dari data yang ada di database yang besar sehingga menjadi informasi yang sangat berharga. (Larose, 2005) 2. Data mining merupakan proses semi otomatik yang menggunakan teknik
statistik, matematika, kecerdasan buatan, dan machine learning untuk mengekstraksi dan mengidentifikasi informasi pengetahuan potensial dan berguna yang bermanfaat yang tersimpan di dalam database. (Turban, 2005 ) 3. Datamining adalah suatu pola yang menguntungkan dalam melakukan pencarian
4. Datamining adalah sebuah class dari suatu aplikasi database yang mencari pola-pola yang tersembunyi di dalam sebuah group data yang dapat digunakan untuk memprediksi prilaku yang akan datang. (Thomas, 2004)
Berdasarkan beberapa pengertian diatas dapat ditarik kesimpulan bahwa data mining adalah analisa otomatis dari data yang berjumlah besar atau kompleks dengan tujuan untuk menemukan pola atau kecenderungan yang penting yang sebelumnya tidak diketahui. Istilah data mining sering disalahgunakan untuk menggambarkan perangkat lunak yang mengolah data dengan cara yang baru. Sebenarnya perangkat lunak datamining bukan hanya mengganti presentasi, tetapi benar-benar menemukan sesuatu yang sebelumnya belum diketahui menjadi muncul diantara sekumpulan data yang ada. Bahkan dengan menggunakan data mining dapat memprediksikan prilaku dan trend yang akan terjadi kemudian, sehingga dapat mengambil keputusan dengan benar.
2.2 Pengelompokan Data Mining
Data mining dibagi menjadi beberapa kelompok berdasarkan tugas yang dapat dilakukan, yaitu (Larose, 2005) :
1. Description
trend. Model data mining harus dibuat sejelas (transparan) mungkin, yang berarti hasil dari model data mining harus mendeskripsikan pola jelas yang sesuai dengan interpretasi dan penjelasan intuitif. Metode data mining tertentu lebih sesuai dari metode lain dalam hal interpretasi transparan. Deskripsi yang berkualitas tinggi seringkali diperoleh melalui exploratory data analysis, metode grafis dalam eksplorasi data dalam pencarian pola dan trend.
2. Estimation
Estimasi hampir sama dengan klasifikasi kecuali bahwa variabel targetnya berupa numerik bukan kategori. Metode estimasi pada umumnya menggunakan analisis statistik termasuk point estimation dan confidence interval estimation, simple linear regression and correlation dan multiple regression.
3. Prediction
Prediksi hampir sama dengan klasifikasi dan estimasi. Perbedaan mendasar yaitu, hasil dari prediksi adalah di masa depan. Contoh dari prediksi adalah memprediksi harga saham selama 3 bulan mendatang. Semua metode dan teknik yang digunakan untuk klasifikasi dan estimasi dapat pula digunakan untuk prediksi dalam situasi yang sesuai.
4. Classification
target serta satu set input. Metode data mining yang umum untuk klasifikasi adalah k‐nearest neighbor, decision tree, dan neural network.
5. Clustering
Clustering merupakan pengelompokkan record, observasi, atau kasus ke dalam kelas‐kelas dengan objek yang serupa. Sebuah cluster adalah koleksi record yang sama satu sama lain, dan tidak sama dengan record di cluster lain. Clustering berbeda dengan classification karena tidak ada variabel target dalam clustering. Clustering tidak mengklasifikasi, estimasi ataupun prediksi nilai dari variabel target. Akan tetapi algoritma clustering mencari segmen dari keseluruhan set data ke dalam subgrup yang relatif homogen atau cluster di mana keserupaan (similarity) record dalam cluster adalah maksimal dan keserupaan record di luar cluster adalah minimal. Contoh clustering adalah target pemasaran produk dari bisnis kecil dengan budget marketing yang terbatas.
6. Assosiation
2.3 Tahap-Tahap Data Mining
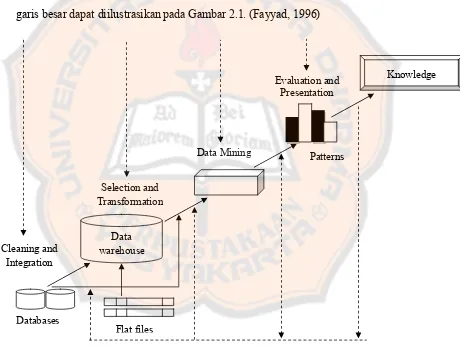
Istilah data mining dan Knowledge Discovery in Database (KDD) sering kali digunakan secara bergantian untuk menjelaskan proses penggalian informasi tersembunyi dalam suatu basis data yang besar. Sebenarnya kedua istilah tersebut memiliki konsep yang berbeda, tetapi berkaitan satu sama lain. Dan salah satu tahapan dalam keseluruhan proses KDD adalah data mining. Proses KDD secara garis besar dapat diilustrasikan pada Gambar 2.1. (Fayyad, 1996)
Gambar 2.1. Tahapan Dalam KDD Databases
Flat files Cleaning and
Integration
Data Mining
Evaluation and Presentation
Data warehouse
Selection and Transformation
Patterns
1. Pembersihan data (untuk membuang data yang tidak konsisten dan noise)
Pada umumnya data yang diperoleh, baik dari database suatu perusahaan maupun hasil eksperimen, memiliki isian-isian yang tidak relevan dengan hipotesa data mining yang kita miliki. Pembersihan data yang tidak relevan akan mempengaruhi performasi dari sistem data mining karena data yang ditangani akan berkurang jumlah dan kompleksitasnya.
2. Integrasi data (penggabungan data dari beberapa sumber)
Integrasi data dilakukan pada atribut-aribut yang mengidentifikasikan entitas-entitas yang unik. Integrasi data perlu dilakukan secara cermat karena kesalahan pada integrasi data bisa menghasilkan hasil yang menyimpang dan bahkan menyesatkan pengambilan aksi nantinya. Dalam integrasi data ini juga perlu dilakukan transformasi dan pembersihan data karena seringkali data dari dua database berbeda tidak sama cara penulisannya atau bahkan data yang ada di satu database ternyata tidak ada di database lainnya. Hasil integrasi data sering diwujudkan dalam sebuah data warehouse.
4. Aplikasi teknik data mining
Aplikasi teknik data mining sendiri hanya merupakan salah satu bagian dari proses data mining. Beberapa teknik data mining sudah umum dipakai. Ada kalanya teknik-teknik data mining umum yang tersedia di pasar tidak mencukupi untuk melaksanakan data mining di bidang tertentu atau untuk data tertentu. 5. Evaluasi pola yang ditemukan (untuk menemukan yang menarik/bernilai)
Dalam tahap ini hasil dari teknik data mining berupa pola-pola yang khas maupun model prediksi dievaluasi untuk menilai apakah hipotesa yang ada memang tercapai. Bila ternyata hasil yang diperoleh tidak sesuai hipotesa ada beberapa alternatif yang dapat diambil seperti : menjadikannya umpan balik untuk memperbaiki proses data mining, mencoba teknik data mining lain yang lebih sesuai, atau menerima hasil ini sebagai suatu hasil yang di luar dugaan yang mungkin bermanfaat.
6. Presentasi pola yang ditemukan untuk menghasilkan aksi
2.4 Jenis Atribut Suatu Data
Atribut suatu data berdasarkan jenisnya dapat dikelompokkan sebagai berikut (Tan, Steinbach, Kumar, 2006) :
1. Kualitatif Nominal
Variabel yang nilainya berupa simbol, nilainya sendiri hanya berfungsi sebagai label atau memberi nama, tidak ada hubungan antar nilai nominal, tidak bisa diurutkan atau diukur jaraknya dan hanya uji persamaan yang bisa dilakukan. Contoh data nominal adalah kode pos, nomor ID pegawai, warna mata, jenis kelamin.
Ordinal
Nilai dari suatu atribut ordinal memberikan informasi yang cukup untuk urutan objek. Contoh data ordinal adalah nilai.
2. Kuantitatif Interval
Variabel yang nilainya bisa diurutkan, dan diukur dengan tetap dan unit yang sama. Contoh data interval adalah kalender, temperatur dalam Celcius atau Fahrenheit.
Rasio
penjumlahan, pengurangan, pembagian dan sebagainya, bisa dilakukan terhadap nilai rasio. Contoh data rasio adalah temperatur dalam Kelvin, umur.
2.5 Metode Pelatihan
Metode pelatihan adalah cara berlangsungnya pembelajaran atau pelatihan dalam data mining. Secara garis besar metode pelatihan dibedakan ke dalam dua pendekatan:
1. Pelatihan yang terawasi (Supervised Learning)
Pada pembelajaran terawasi, kumpulan input yang digunakan, output-outputnya telah diketahui.
2. Pelatihan Tak terawasi (Unsupervised Learning)
Dalam pelatihan tak terawasi, metode diterapkan tanpa adanya latihan (training) dan tanpa ada guru (teacher). Guru disini adalah label dari data.
2.6 Pohon Keputusan (Decision Tree)
Decision tree merupakan salah satu model dalam data mining. Decision tree adalah sebuah metode untuk memperkirakan fungsi target nilai diskrit, dimana fungsi yang dipelajari ditampilkan dengan pohon keputusan (decision tree).
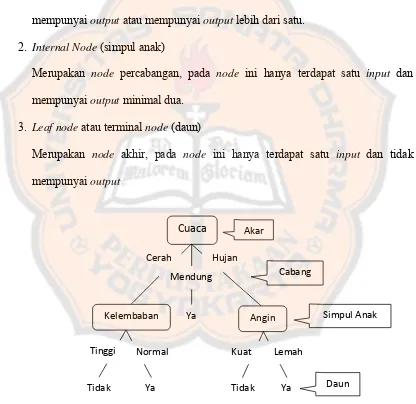
Pohon keputusan merupakan metode klasifikasi yang paling populer digunakan. Selain karena pembangunannya relatif cepat, hasil dari model yang dibangun mudah untuk dipahami. Pada pohon keputusanterdapat 3 jenis node , yaitu :
1. Root Node (akar)
Merupakan node paling atas, pada node ini tidak ada input dan bisa tidak mempunyai output atau mempunyai output lebih dari satu.
2. Internal Node (simpul anak)
Merupakan node percabangan, pada node ini hanya terdapat satu input dan mempunyai output minimal dua.
3. Leaf node atau terminal node (daun)
Merupakan node akhir, pada node ini hanya terdapat satu input dan tidak mempunyai output
Gambar 2.2. Contoh Pohon Keputusan Cuaca
Cerah
Mendung Hujan
Kelembaban Ya Angin Akar
Cabang
Simpul Anak
Tinggi Normal
Tidak Ya Tidak Ya Kuat Lemah
Pembentukan pohon keputusanterdiri dari beberapa tahap, yaitu (Han & Kamber 2001) :
1. Konstruksi pohon, yaitu pembuatan pohon yang diawali dengan pembentukan bagian akar, kemudian data terbagi berdasarkan atribut – atribut yang cocok untuk dijadikan leaf node.
2. Pemangkasan pohon (tree pruning), yaitu mengidentifikasi dan membuang cabang yang tidak diperlukan pada pohon yang telah terbentuk. Ada dua metode dalam melakukan pemangkasan dalam pohon keputusan, yaitu :
a. prepruning : pemangkasan dilakukan sejak awal pembentukan pohon. b. postpruning : pemangkasan dilakukan saat pohon telah terbentuk secara utuh 3. Pembentukan aturan keputusan, yaitu membuat aturan keputusan dari pohon
yang telah dibentuk.
2.6.1 Macam-Macam Pohon Keputusan Macam-macam pohon keputusan adalah : 1. ID3 (Iterative Dichotomiser 3)
CART (Classification And Regresion Trees) merupakan metode partisi rekursif yang digunakan baik untuk regresi maupun klasifikasi. CART dibangun dengan melakukan pemecahan subset-subset dari dataset menggunakan variable prediktor untuk membuat dua child node secara berulang, dimulai dari keseluruhan dataset. Tujuannya adalah menghasilkan subset data yang sehomogen mungkin untuk mengklasifikasikan variable target.
3. CHAID (Chi-Squared Automatic Interaction Detection)
Metode CHAID (Chi-Squared Automatic Interaction Detection) adalah berdasarkan tes chi-square terhadap asosiasi. Pohon CHAID adalah decision tree yang dibangun dengan memecah/splitting subset-subset secara berulang ke dalam dua atau lebih child node yang dimulai dari keseluruhan dataset.
4. C4.5
2.6.2 Algoritma ID3
Dalam pohon keputusan, ID3 (Iterative Dichotomiser 3) adalah algoritma yang digunakan untuk menghasilkan pohon keputusan. Ditemukan oleh Ross Quinlan. ID3 adalah awal dari algoritma C4.5.
Dalam ID3 mengunakan kriteria information gain untuk memilih atribut yang akan digunakan untuk pemisahan obyek. Atribut yang mempunyai information gain paling tinggi dibanding atribut yang lain relatif terhadap set y dalam suatu data, dipilih untuk melakukan pemecahan. (Mitchell, 1997)
Algoritma ID3 (Iterative Dichotomiser 3) mempelajari pohon keputusan dengan membangunnya dari atas ke bawah, dimulai dengan pertanyaan “atribut mana yang harus di uji pada simpul akar?”. Untuk menjawab pertanyaan tersebut, tiap atributinstans dievaluasi dengan menggunakan pengujian statistik untuk menentukan seberapa baik suatu atribut mengklasifikasikan sampel-pelatihan. Atribut terbaik kemudian dipilih dan digunakan sebagai pengujian pada simpul akar. Menurun dari simpul akar, selanjutnya dibuat untuk tiap kemungkinan nilai pada atribut, dan sampel-pelatihan yang diasosiasikan dengan tiap simpul, menurun untuk memilih atribut terbaik untuk diuji pada titik itu.
Algoritma ID3 dapat dijelaskan sebagai berikut :
Jika semua sampel positif, berhenti dengan suatu pohon dengan satu simpul akar, beri label +
Jika semua sampel negatif, berhenti dengan suatu pohon dengan satu simpul akar, beri label –
Jika atribut kosong, berhenti dengan suatu pohon dengan satu simpul akar dengan label sesuai.
Nilai yang terbanyak yang ada pada label training. Untuk yang lain,
Mulai
A ←atribut yang mengklasifikasikan sampel dengan hasil terbaik (berdasarkan information gain).
Atribut keputusan untuk simpul akar ← A. Untuk setiap nilai, vi, yang mungkin untuk A.
Tambahkan cabang di bawah akar yang berhubungan dengan A = vi.
Tentukan sampel Svi sebagai subset dari sampel yang mempunyai nilai vi untuk atribut A.
Jika sampel Svi kosong,
Di bawah cabang tambahkan simpul daun dengan label = nilai yang terbanyak yang ada pada label training.
ID3 (sampel training, label training, atribut – [A]). Berhenti
2.6.2.11-Rule
2.6.2.2Entropi
Algoritma ID3 berangkat dari pemilihan atribut mana yang paling baik untuk mengklasifikasikan sampel information gain sebagai property statistik, mampu mengukur seberapa baik atribut yang diberikan, membagi sampel-pelatihan berdasarkan klasifikasi targetnya.
Atribut yang harus ditanyakan di suatu simpul adalah atribut yang memungkinkan untuk mendapatkan pohon keputusan yang paling kecil ukurannya. Atau ukuran lain adalah atribut yang bisa memisahkan obyek menurut kelasnya. Secara heuristic, dipilih atribut yang menghasilkan simpul yang paling “purest” (paling bersih). Kalau dalam suatu cabang anggotanya berasal dari satu kelas maka cabang ini disebut pure. Semakin pure suatu cabang, semakin baik. Ukuran purity dinyatakan dengan tingkat impurity. Kriteria impurity adalah information gain. Jadi dalam memilih atribut untuk memecah obyek dalam beberapa kelas harus dipilih atribut yang menghasilkan information gain yang paling besar.
Sebelum menghitung information gain, perlu menghitung dulu nilai informasi dalam satuan bits dari suatu kumpulan obyek. Cara menghitung dilakukan dengan menggunakan konsep entropi. Entropi menyatakan suatu impurity suatu kumpulan obyek. Jika diberikan sekumpulan obyek dengan label atau output y yang terdiri dari obyek berlabel 1, 2 sampai n, entropi dari obyek dengan n kelas ini dihitung dengan rumus berikut
2.6.2.3Information Gain
Information gain bisa dihitung dari output data atau variable depedent y yang dikelompokkan berdasarkan atribut A, dinotasikan dengan gain (y,A). Information gain, gain (y,A), dari atribut A relatif terhadap output data y adalah :
gain(y,A)=entropi(y) - ∑ entropi (yc)………..(2.2)
dimana nilai (A) adalah semua nilai yang mungkin dari atribut A, dan yc adalah subset dari y dimana A mempunyai nilai c. Term pertama dalam persamaan di atas adalah entropi total y dan term kedua adalah entropi sesudah dilakukan pemisahan data berdasarkan atribut A.
Secara umum terdapat mekanisme untuk melakukan perhitungan information gain, yaitu (Kantardzic 2003) :
1. Standar test yang dilakukan pada data atribut dengan tipe diskrit, dengan satu nilai keluaran dan satu cabang untuk setiap nilai atribut yang mungkin.
2. Jika atribut Y adalah atribut dengan tipe numerik, perhitungan akan dilakukan dengan Y <= Z dan Y > Z, dimana Z merupakan nilai perbandingan. Untuk mencari nilai perbandingan dapat digunakan nilai tengah dari tiap interval dari data yang digunakan
……...………..(2.3)
(v
i+ v
i+1)Dari formula tersebut, vi adalah nilai ke -i dari data yang digunakan.
3. Pengujian yang lebih kompleks juga terjadi pada atribut diskrit, dimana nilai yang mungkin dialokasikan untuk setiap kelompok variabel dengan satu keluaran dan cabang untuk setiap grup.
2.6.3 Kelebihan dan Kekuranga Pohon Keputusan Kelebihan pohon keputusan adalah :
1. Daerah pengambilan keputusan yang sebelumnya kompleks dan sangat global, dapat diubah menjadi lebih simpel dan spesifik.
2. Eliminasi perhitungan-perhitungan yang tidak diperlukan, karena ketika menggunakan metode pohon keputusan maka sample diuji hanya berdasarkan kriteria atau kelas tertentu.
3. Fleksibel untuk memilih fitur dari internal node yang berbeda, fitur yang terpilih akan membedakan suatu kriteria dibandingkan kriteria yang lain dalam node yang sama. Kefleksibelan metode pohon keputusan ini meningkatkan kualitas keputusan yang dihasilkan jika dibandingkan ketika menggunakan metode penghitungan satu tahap yang lebih konvensional.
ini dengan menggunakan kriteria yang jumlahnya lebih sedikit pada setiap node internal tanpa banyak mengurangi kualitas keputusan yang dihasilkan.
Kekurangan pohon keputusan adalah :
1. Terjadi overlap terutama ketika kelas-kelas dan kriteria yang digunakan jumlahnya sangat banyak. Hal tersebut juga dapat menyebabkan meningkatnya waktu pengambilan keputusan dan jumlah memori yang diperlukan.
2. Pengakumulasian jumlah error dari setiap tingkat dalam sebuah pohon keputusan yang besar.
METODOLOGI PENELITIAN
Pada bab ini akan dibahas hal-hal yang berkaitan dengan data histori untuk data kuantitatif, kualitatif dan campuran, training dan testing, akurasi, contoh perhitungan manual ID3 data campuran, desain interface, spesifikasi perangkat lunak.
3.1 Data Histori
Dalam pembuatan aplikasi ini, data yang digunakan ada 3 macam jenis data, yaitu data kuantitatif (blood transfusion), data kualitatif (car), dan data campuran (cencus income).
3.1.1 Data Kuantitatif
Data kualitatif menggunakan data car. Data diambil dari Car Evaluation Database. Data kualitatif terdiri dari 6 atribut yaitu buying, maint, doors, persons, lug_boot dan safety. Atribut buying memiliki nilai vhigh, high, med dan low. Atribut maint memiliki nilai vhigh, high, med dan low. Atribut doors memiliki nilai 2, 3, 4 dan 5more. Atribut persons memiliki nilai 2, 4 dan more. Atribut lug_boot memiliki nilai small, med dan big. Atribut safety memiliki nilai low, med dan high. Outputnya dari data car ada empat yaitu acc, good, unacc dan vgood. Jumlah data car adalah 1728.
3.1.3 Data Campuran
diambil secara acak seperempat dari 45222 data yaitu 11306 data.
3.2 Training dan Testing
Data training dan data testing adalah sejumlah instansi dalam database yang akan dipelajari oleh perangkat lunak untuk diklasifikasikan berdasarkan algoritma ID3. Data training dan data testing mempunyai sejumlah atribut dan fungsi target/output. Atribut adalah nilai-nilai kolom suatu instans yang menentukan nilai fungsi target/output. Nilai atribut dan nilai fungsi target tentu saja telah ditentukan berdasarkan kenyataan yang sebenarnya. Sedangkan fungsi target inilah yang akan menjadi nilai-nilai keputusan pada tiap-tiap simpul daun dalam representasi pohon keputusan.
Adapun dalam implementasinya, data training dan data testing akan berupa sejumlah instans yang tersimpan dalam database MySQL. Data training diambil dari 2/3 total data secara keseluruhan, sedangkan data testing diambil dari 1/3 total data secara keseluruhan.
Akurasi dihitung berdasarkan jumlah nilai yang sama antara nilai dalam test set dengan nilai yang dihasilkan oleh pohon dengan menggunakan keseluruhan aturan yang terbentuk, perhitungan akurasi adalah sebagai berikut
3.4.1 Proses Pengolahan Data Campuran
Cencus Income
6 atribut kuantitatif : age, fnlwgt, education-num, capital-gain, capital-loss, hours-per-week
8 atribut kualitatif : workclass, education, marital-status, occupation, relationship, race, sex, native-country
Tabel 3.1. Data Cencus Income
No. age workclass fnlwgt education education - num
marital - status
occupation relationship race sex capital - gain
adm-clerical not-in-family white male 2174 0 40 united-states
other-service own-child black male 0 0 35 united-states
other-service husband white male 0 1887 50 canada >50K
6. 20 private 111697
some-college
10 never-married
adm-clerical own-child white female 0 1719 28 united-states
8. 38 federal-gov
95432 HS-grad 9
married-civ-spouse
adm-clerical husband white male 0 0 40 united-states
not-in-family white female 14084 0 55 united-states
other-service husband white male 0 0 40 united-states
craft-repair husband white male 0 0 20 united-states
sales not-in-family white male 0 0 35 united-states
<=50K
16. 30 private 118551 bachelors 13
married-civ-spouse
tech-support wife white female 0 0 16 united-states
20. 32 private 97429 bachelors 13 divorced
exec-managerial
unmarried white female 0 0 40 canada <=50K
21. 49 private 160187 9th 5
married- spouse-absent
23. 41 private 122215 masters 14 married-civ-spouse
prof-speciality
husband white male 15024 0 40 united-states
adm-clerical own-child white male 0 0 40 united-states
craft-repair husband white male 0 0 40 united-states
craft-repair husband white male 0 0 40 united-states
<=50K
28. 27 private 106758 HS-grad 9 divorced adm-clerical unmarried white female 0 0 45
united-states
<=50K
29. 46 private 146919 HS-grad 9
married-civ-spouse
Untuk data training campuran, diambil 2/3 dari total data secara keseluruhan. Dalam contoh ini data campuran yang digunakan berjumlah 30 data. Untuk data training campuran, data yang digunakan ada 20 data. Data campuran terdiri dari atribut kuantitatif dan atribut kualitatif.
Untuk melakukan proses training pada atribut kuantitatif, dilakukan dengan menggunakan 1-rule untuk memecah-mecah data menjadi aturan-aturan. Untuk memproses 1-rule, pertama-tama data dari setiap atribut diurutkan terlebih dahulu dari yang terkecil sampai yang terbesar. Setelah data diurutkan, output dari data tersebut yang berubah dipecah-pecah. Dari output data yang sudah dipecah-pecah, kemudian output data tersebut dikelompokan sesuai minimum member
yang telah ditentukan dari setiap atribut. Minimum member yang dipilih yang memberikan total error paling optimal. Dari kelompok-kelompok tersebut kemudian dipilih nilai yang paling dominan untuk dijadikan nilai output rulenya. Setelah didapat nilai output rulenya dari masing-masing kelompok, maka jika ada nilai output yang sama dapat digabungkan dan kemudian terbentuklah rule /aturan-aturan dari setiap atribut. Setelah dilakukan proses 1-rule, maka dicari entropinya untuk setiap rule dari masing-masing atribut. Setelah didapatkan entropi dari masing-masing atribut, maka kemudian akan dicari information gainya.
akan dicari information gainya. Rootnya dipilih berdasarkan information gain
yang paling tinggi.
1-rule
age
Data diurutkan terlebih dahulu
age output
Setiap output data yang berubah dipecah-pecah
fnlwgt
Data diurutkan terlebih dahulu
fnlwgt output
Setiap output data yang berubah dipecah-pecah
Data diurutkan terlebih dahulu
Setiap output data yang berubah dipecah-pecah
14 >50K
Nilai 9 mempunyai kelas yang berbeda, tetapi masih dalam nilai yang sama. Oleh karena itu diberi tanda sampai diatas 9, yaitu antara 9 dan 10 = 9.5.
Nilai 10 mempunyai kelas yang berbeda, tetapi masih dalam nilai yang sama. Oleh karena itu diberi tanda sampai diatas 10, yaitu antara 10 dan 12 = 11.
Nilai 13 mempunyai kelas yang berbeda, tetapi masih dalam nilai yang sama. Oleh karena itu diberi tanda sampai diatas 13, yaitu antara 13 dan 14 = 13.5.
> 13.5 >50K [0,3]
capital-gain
Data diurutkan terlebih dahulu
capital-gain output
Setiap output data yang berubah dipecah-pecah
0 >50K
Nilai 0 mempunyai kelas yang berbeda, tetapi masih dalam nilai yang sama. Oleh karena itu diberi tanda sampai diatas 0, yaitu antara 0 dan 2174 = 1087.
Data diurutkan terlebih dahulu
Setiap output data yang berubah dipecah-pecah
0 <=50K
Nilai 0 mempunyai kelas yang berbeda, tetapi masih dalam nilai yang sama. Oleh karena itu diberi tanda sampai diatas 0, yaitu antara 0 dan 1719 = 859.5.
Data diurutkan terlebih dahulu
Setiap output data yang berubah dipecah-pecah
40 <=50K
Nilai 40 mempunyai kelas yang berbeda, tetapi masih dalam nilai yang sama. Oleh karena itu diberi tanda sampai diatas 40, yaitu antara 40 dan 50 = 45.
[<=50K, >50K]
workclass
federal-gov [0,2]
local-gov [1,0]
private [8,5]
self-emp-not-inc [1,1]
state-gov [2,0]
education
11th [1,0]
assoc-acmd [0,1]
bachelors [3,1]
HS-grad [4,2]
masters [0,2]
prof-school [0,1]
college [4,1]
marital-status
divorced [1,0]
married-civ-spouse [4,7]
married-spouse-absent [1,0]
never-married [6,1]
occupation
exec-managerial [1,2]
farming-fishing [1,0]
handle-cleaners [1,0]
other-service [2,1]
prof-speciality [1,2]
sales [2,0]
tech-support [0,1]
relationship
husband [4,5]
not-in-family [3,1]
other-relative [0,1]
own-child [3,0]
unmarried [2,0]
wife [0,1]
race
asian-pac-slander [1,0]
black [2,0]
white [9,8]
sex
female [4,2]
canada [1,1]
poland [2,0]
united-states [9,7]
Entropi
age :
Entropi [5,0] = - 5 log2(5) - 0 log2(0) = 0 Entropi [2,6] = - log2 - log2 = 0.811 Entropi [5,2] = - log2 - log2 = 0.863 workclass :
Entropi [0,2] = - 0 log2(0) - 2 log2(2) = 0 Entropi [1,0] = - 1 log2(1) - 0 log2(0) = 0 Entropi [8,5] = - log2 - log2 = 0.961 Entropi [1,1] = - log2 - log2 = 1
Entropi [2,0] = - 2 log2(2) - 0 log2(0) = 0 fnlwgt :
Entropi [1,0] = - 1 log2(1) - 0 log2(0) = 0 Entropi [0,1] = - 0 log2(0) - 1 log2(1) = 0 Entropi [3,1] = - log2 - log2 = 0.811 Entropi [4,2] = - log2 - log2 = 0.918 Entropi [0,2] = - 0 log2(0) - 2 log2(2) = 0 Entropi [0,1] = - 0 log2(0) - 1 log2(1) = 0 Entropi [4,1] = - log2 - log2 = 0.721 education-num :
Entropi [12,5] = - log2 - log2 = 0.873 Entropi [0,3] = - 0 log2(0) - 3 log2(3) = 0 marital-status :
Entropi [1,0] = - 1 log2(1) - 0 log2(0) = 0 Entropi [4,7] = - log2 - log2 = 0.945 Entropi [1,0] = - 1 log2(1) - 0 log2(0) = 0 Entropi [6,1] = - log2 - log2 = 0.591 occupation :
Entropi [2,1] = - log2 - log2 = 0.918 Entropi [1,2] = - log2 - log2 = 0.918 Entropi [2,0] = - 2 log2(2) - 0 log2(0) = 0 Entropi [0,1] = - 0 log2(0) - 1 log2(1) = 0 relationship :
Entropi [4,5] = - log2 - log2 = 0.991 Entropi [3,1] = - log2 - log2 = 0.811 Entropi [0,1] = - 0 log2(0) - 1 log2(1) = 0 Entropi [3,0] = - 3 log2(3) - 0 log2(0) = 0 Entropi [2,0] = - 2 log2(2) - 0 log2(0) = 0 Entropi [0,1] = - 0 log2(0) - 1 log2(1) = 0 race :
Entropi [1,0] = - 1 log2(1) - 0 log2(0) = 0 Entropi [2,0] = - 2 log2(2) - 0 log2(0) = 0 Entropi [9,8] = - log2 - log2 = 0.997 sex :
Entropi [4,2] = - log2 - log2 = 0.918 Entropi [8,6] = - log2 - log2 = 0.985 capital-gain :
capital-loss :
Entropi [11,7] = - log2 - log2 = 0.964 Entropi [1,1] = - log2 - log2 = 1
hours-per-week :
Entropi [12,6] = - log2 - log2 = 0.918 Entropi [0,2] = - 0 log2(0) - 2 log2(2) = 0 native-country :
Entropi [1,1] = - log2 - log2 = 1 Entropi [2,0] = - 2 log2(2) - 0 log2(0) = 0 Entropi [9,7] = - log2 - log2 = 0.988
Information Gain
age :
Gain(y,A) = Entropi [12,8] - Entropi [5,0] - Entropi [2,6] - Entropi [5,2] = 0.344
workclass :
Gain(y,A) = Entropi [12,8] - Entropi [0,2] - Entropi [1,0] - Entropi [8,5] - Entropi [1,1] - Entropi [2,0]
Gain(y,A) = Entropi [12,8] - Entropi [0,2] - Entropi [4,1] - Entropi [0,3] - Entropi [8,2]
= 0.429
education :
Gain(y,A) = Entropi [12,8] - Entropi [1,0] - Entropi [0,1] - Entropi [3,1] - Entropi [4,2] - Entropi [0,2] - Entropi [0,1]
- Entropi [4,1] = 0.352
education-num :
Gain(y,A) = Entropi [12,8] - Entropi [12,5] - Entropi [0,3] = 0.228
marital-status :
Gain(y,A) = Entropi [12,8] - Entropi [1,0] - Entropi [4,7] - Entropi [1,0] - Entropi [6,1]
= 0.243
occupation :
Gain(y,A) = Entropi [12,8] - Entropi [2,2] - Entropi [2,0] - Entropi [1,2] - Entropi [1,0] - Entropi [1,0] - Entropi [2,1]
Gain(y,A) = Entropi [12,8] - Entropi [4,5] - Entropi [3,1] - Entropi [0,1] - Entropi [3,0] - Entropi [2,0] - Entropi [0,1]
= 0.362
race :
Gain(y,A) = Entropi [12,8] - Entropi [1,0] - Entropi [2,0] - Entropi [9,8] = 0.123
sex :
Gain(y,A) = Entropi [12,8] - Entropi [4,2] - Entropi [8,6] = 0.005
capital-gain :
Gain(y,A) = Entropi [12,8] - Entropi [11,6] - Entropi [1,2] = 0.037
capital-loss :
Gain(y,A) = Entropi [12,8] - Entropi [11,7] - Entropi [1,1] = 0.003
hours-per-week :
Gain(y,A) = Entropi [12,8] - Entropi [1,1] - Entropi [2,0] - Entropi [9,7] = 0.079
Tree
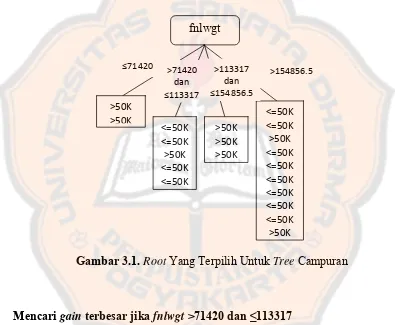
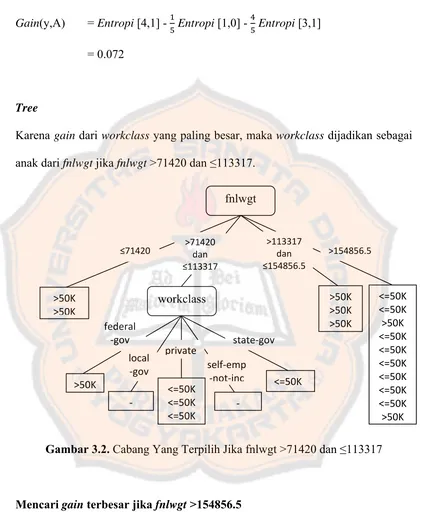
Karena gain dari fnlwgt yang paling besar, maka fnlwgt dijadikan sebagai root.
Gambar 3.1. Root Yang Terpilih Untuk Tree Campuran
Mencari gain terbesar jika fnlwgt >71420 dan ≤113317
= 0.321
Akan dicari gain dari workclass jika fnlwgt >71420 dan ≤113317 :
Entropi [0,1] = - 0 log2(0) - 1 log2(1) = 0 Entropi [3,0] = - 3 log2(3) - 0 log2(0) = 0 Entropi [1,0] = - 1 log2(1) - 0 log2(0) = 0
Gain(y,A) = Entropi [4,1] - Entropi [0,1] - Entropi [3,0] - Entropi [1,0] = 0.721
Akan dicari gain dari education jika fnlwgt >71420 dan ≤113317 :
Entropi [2,0] = - 2 log2(2) - 0 log2(0) = 0 Entropi [1,1] = - log2 - log2 = 1 Entropi [1,0] = - 1 log2(1) - 0 log2(0) = 0
Gain(y,A) = Entropi [4,1] - Entropi [2,0] - Entropi [1,1] - Entropi [1,0]
= 0.321
Akan dicari gain dari education-num jika fnlwgt >71420 dan ≤113317 :
Entropi [4,1] = - log2 - log2 = 1
Gain(y,A) = Entropi [4,1] - Entropi [4,1] = 0
Akan dicari gain dari marital-status jika fnlwgt >71420 dan ≤113317 :
= 0.321
Akan dicari gain dari occupation jika fnlwgt >71420 dan ≤113317 :
Entropi [2,1] = - log2 - log2 = 0.918 Entropi [1,0] = - 1 log2(1) - 0 log2(0) = 0 Entropi [1,0] = - 1 log2(1) - 0 log2(0) = 0
Gain(y,A) = Entropi [4,1] - Entropi [2,1] - Entropi [1,0] - Entropi [1,0] = 0.170
Akan dicari gain dari relationship jika fnlwgt >71420 dan ≤113317 :
Entropi [1,1] = - log2 - log2 = 1 Entropi [1,0] = - 1 log2(1) - 0 log2(0) = 0 Entropi [1,0] = - 1 log2(1) - 0 log2(0) = 0 Entropi [1,0] = - 1 log2(1) - 0 log2(0) = 0
Gain(y,A) = Entropi [4,1] - Entropi [1,1] - Entropi [1,0] - Entropi [1,0] - Entropi [1,0]
= 0.321
Akan dicari gain dari race jika fnlwgt >71420 dan ≤113317 :
Entropi [1,0] = - 1 log2(1) - 0 log2(0) = 0 Entropi [3,1] = - log2 - log2 = 0.811
Entropi [2,0] = - 2 log2(2) - 0 log2(0) = 0 Entropi [2,1] = - log2 - log2 = 0.918
Gain(y,A) = Entropi [4,1] - Entropi [2,0] - Entropi [2,1] = 0.170
Akan dicari gain dari capital-gain jika fnlwgt >71420 dan ≤113317 :
Entropi [3,1] = - log2 - log2 = 0.811 Entropi [1,0] = - 1 log2(1) - 0 log2(0) = 0
Gain(y,A) = Entropi [4,1] - Entropi [3,1] - Entropi [1,0] = 0.072
Akan dicari gain dari capital-loss jika fnlwgt >71420 dan ≤113317 :
Entropi [3,1] = - log2 - log2 = 0.811 Entropi [1,0] = - 1 log2(1) - 0 log2(0) = 0
Gain(y,A) = Entropi [4,1] - Entropi [3,1] - Entropi [1,0] = 0.072
Akan dicari gain dari hours-per-week jika fnlwgt >71420 dan ≤113317 :
Entropi [4,1] = - log2 - log2 = 1
Gain(y,A) = Entropi [4,1] - Entropi [4,1] = 0
Akan dicari gain dari native-country jika fnlwgt >71420 dan ≤113317 :
Gain(y,A) = Entropi [4,1] - Entropi [1,0] - Entropi [3,1] = 0.072
Tree
Karena gain dari workclass yang paling besar, maka workclass dijadikan sebagai anak dari fnlwgt jika fnlwgt >71420 dan ≤113317.
Gambar 3.2. Cabang Yang Terpilih Jika fnlwgt >71420 dan ≤113317
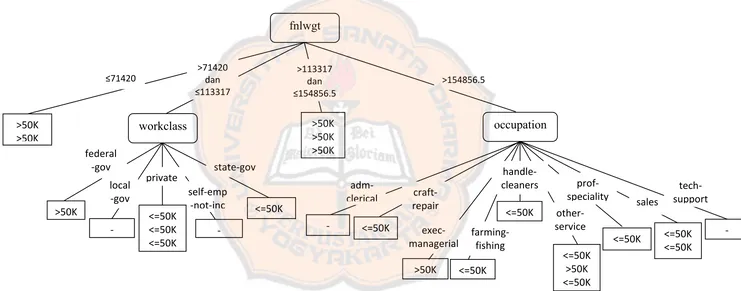
Mencari gain terbesar jika fnlwgt >154856.5
Gain(y,A) = Entropi [8,2] - Entropi [4,0] - Entropi [1,1] - Entropi [3,1]
= 0.197
Akan dicari gain dari education jika fnlwgt >154856.5 :
Entropi [1,0] = - 1 log2(1) - 0 log2(0) = 0 Entropi [1,0] = - 1 log2(1) - 0 log2(0) = 0 Entropi [3,1] = - log2 - log2 = 0.811 Entropi [3,1] = - log2 - log2 = 0.811
Gain(y,A) = Entropi [8,2] - Entropi [1,0] - Entropi [1,0] - Entropi [3,1] - Entropi [3,1]
= 0.072
Akan dicari gain dari education-num jika fnlwgt >154856.5 :
Entropi [8,2] = - log2 - log2 = 0.721 Gain(y,A) = Entropi [8,2] - Entropi [8,2] = 0
Akan dicari gain dari marital-status jika fnlwgt >154856.5 :
- Entropi [4,0] = 0.236
Akan dicari gain dari occupation jika fnlwgt >154856.5 :
Entropi [1,0] = - 1 log2(1) - 0 log2(0) = 0 Entropi [0,1] = - 0 log2(0) - 1 log2(1) = 0 Entropi [1,0] = - 1 log2(1) - 0 log2(0) = 0 Entropi [1,0] = - 1 log2(1) - 0 log2(0) = 0 Entropi [3,1] = - log2 - log2 = 0.811 Entropi [1,0] = - 1 log2(1) - 0 log2(0) = 0 Entropi [2,0] = - 2 log2(2) - 0 log2(0) = 0
Gain(y,A) = Entropi [8,2] - Entropi [1,0] - Entropi [0,1] - Entropi [1,0] - Entropi [1,0] - Entropi [3,1] - Entropi [1,0] - Entropi [2,0]
= 0.397
Akan dicari gain dari relationship jika fnlwgt >154856.5 :
- Entropi [2,0] - Entropi [1,0]
= 0.236
Akan dicari gain dari race jika fnlwgt >154856.5 :
Entropi [2,0] = - 2 log2(2) - 0 log2(0) = 0 Entropi [6,2] = - log2 - log2 = 0.811
Gain(y,A) = Entropi [8,2] - Entropi [2,0] - Entropi [6,2] = 0.072
Akan dicari gain dari sex jika fnlwgt >154856.5 :
Entropi [1,0] = - 1 log2(1) - 0 log2(0) = 0 Entropi [7,2] = - log2 - log2 = 0.764
Gain(y,A) = Entropi [8,2] - Entropi [1,0] - Entropi [7,2] = 0.034
Akan dicari gain dari capital-gain jika fnlwgt >154856.5 :
Entropi [8,2] = - log2 - log2 = 0.721 Gain(y,A) = Entropi [8,2] - Entropi [8,2] = 0
Akan dicari gain dari capital-loss jika fnlwgt >154856.5 :
= 0.268
Akan dicari gain dari hours-per-week jika fnlwgt >154856.5 :
Entropi [8,1] = - log2 - log2 = 0.503 Entropi [0,1] = - 0 log2(0) - 1 log2(1) = 0
Gain(y,A) = Entropi [8,2] - Entropi [8,1] - Entropi [0,1] = 0.268
Akan dicari gain dari native-country jika fnlwgt >154856.5 :
Entropi [0,1] = - 0 log2(0) - 1 log2(1) = 0 Entropi [2,0] = - 2 log2(2) - 0 log2(0) = 0 Entropi [6,1] = - log2 - log2 = 0.591
Gain(y,A) = Entropi [8,2] - Entropi [0,1] - Entropi [2,0] - Entropi [6,1]
Karena gain dari occupation yang paling besar, maka occupation dijadikan sebagai anak dari fnlwgt jika fnlwgt >154856.5.
Akan dicari gain dari age jika fnlwgt >154856.5 dan occupation = other-service :
Entropi [1,0] = - 1 log2(1) - 0 log2(0) = 0 Entropi [1,1] = - log2 - log2 = 1
Gain(y,A) = Entropi [2,1] - Entropi [1,0] - Entropi [1,1] = 0.251
Akan dicari gain dari education jika fnlwgt >154856.5 dan occupation = other-service :
Entropi [1,1] = - log2 - log2 = 1 Entropi [1,0] = - 1 log2(1) - 0 log2(0) = 0
Gain(y,A) = Entropi [2,1] - Entropi [1,1] - Entropi [1,0] = 0.251
Akan dicari gain dari education-num jika fnlwgt >154856.5 dan occupation =
other-service :
Entropi [2,1] = - log2 - log2 = 0.918 Gain(y,A) = Entropi [2,1] - Entropi [2,1] = 0
Akan dicari gain dari marital-status jika fnlwgt >154856.5 dan occupation =
other-service :
= 0.251
Akan dicari gain dari relationship jika fnlwgt >154856.5 dan occupation = other-service :
Entropi [1,1] = - log2 - log2 = 1 Entropi [1,0] = - 1 log2(1) - 0 log2(0) = 0
Gain(y,A) = Entropi [2,1] - Entropi [1,1] - Entropi [1,0] = 0.251
Akan dicari gain dari race jika fnlwgt >154856.5 dan occupation = other-service :
Entropi [1,0] = - 1 log2(1) - 0 log2(0) = 0 Entropi [1,1] = - log2 - log2 = 1
Gain(y,A) = Entropi [2,1] - Entropi [1,0] - Entropi [1,1] = 0.251
Akan dicari gain dari sex jika fnlwgt >154856.5 dan occupation = other-service :
Entropi [2,1] = - log2 - log2 = 0.918 Gain(y,A) = Entropi [2,1] - Entropi [2,1] = 0
Akan dicari gain dari capital-gain jika fnlwgt >154856.5 dan occupation = other-service :
= 0
Akan dicari gain dari capital-loss jika fnlwgt >154856.5 dan occupation = other-service :
Entropi [2,0] = - 2 log2(2) - 0 log2(0) = 0 Entropi [0,1] = - 0 log2(0) - 1 log2(1) = 0
Gain(y,A) = Entropi [2,1] - Entropi [2,0] - Entropi [0,1] = 0.918
Akan dicari gain dari hours-per-week jika fnlwgt >154856.5 dan occupation =
other-service :
Entropi [2,0] = - 2 log2(2) - 0 log2(0) = 0 Entropi [0,1] = - 0 log2(0) - 1 log2(1) = 0
Gain(y,A) = Entropi [2,1] - Entropi [2,0] - Entropi [0,1] = 0.918
Akan dicari gain dari native-country jika fnlwgt >154856.5 dan occupation =
other-service :
Entropi [0,1] = - 0 log2(0) - 1 log2(1) = 0 Entropi [2,0] = - 2 log2(2) - 0 log2(0) = 0
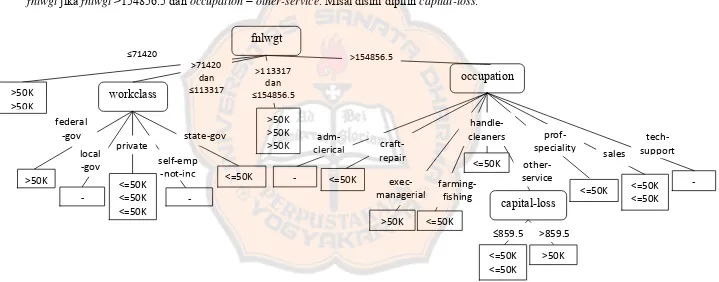
Karena gain dari capital-loss, hours-per-week dan native-country yang paling besar, maka salah satunya dijadikan sebagai anak dari
fnlwgt jika fnlwgt >154856.5 dan occupation = other-service. Misal disini dipilih capital-loss.
Gambar 3.4. Tree Yang Terbentuk Untuk Data Campuran
Untuk data testing campuran, diambil 1/3 dari total data secara keseluruhan. Dalam contoh ini data campuran yang digunakan berjumlah 30 data. Untuk data testing campuran, data yang digunakan ada 10 data. Proses data testing ini dilakukan dengan cara membandingkan output dari data testing dengan pohon keputusan/tree yang sudah terbentuk. Hasil dari perbandingan ini nantinya akan ditampilkan dalam bentuk confusion matriks dan dari confusion matriks ini akan diperoleh akurasinya.
Tabel 3.2. Data Testing Cencus Income age workclass fnlwgt education
education-num
marital-status
occupation relations race sex
capital-gain
49 private 160187 9th
5
married-45 private 155093 10th
6 divorced other-service not-in-family
black female 0 0 38 dominican -republic
<=50K <=50K √
41 private 122215 masters 14 married-civ-spouse
30 federal-gov 59951 some-college
25 private 209428 some-college
10 married-civ-spouse
sales husband white male 0 0 25 el-salvador <=50K <=50K √
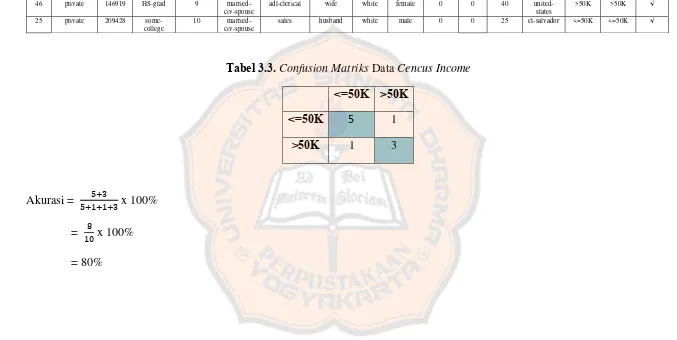
Tabel 3.3. Confusion Matriks Data Cencus Income <=50K >50K
<=50K 5 1 >50K 1 3
Desain interface merupakan tampilan dari aplikasi data mining yang akan dibuat. Desain interface terdiri dari formtraining dan testing data kuantitatif, form training dan testing data kualitatif, formtraining dan testing data campuran, form pengenalan data tunggal data kuantitatif, form pengenalan data tunggal data kualitatif, form pengenalan data tunggal data campuran.
a) Form Utama
Gambar 3.5. Desain Form Utama Menu Utama - Aplikasi Data Mining
Kuantitatif Kualitatif Campuran
Kuantitatif Kualitatif Campuran
Keluar Pengenalan Data Tunggal
Gambar 3.6. Desain FormTraining dan Testing Data Kuantitatif (Bagian 1)
Gambar 3.7. Desain FormTraining dan Testing Data Kuantitatif (Bagian 2)
Training dan Testing Data Kuantitatif
Atribut
Training dan Testing Data Kuantitatif
Gambar 3.8. Desain FormTraining dan Testing Data Kualitatif (Bagian 1)
Gambar 3.9. Desain FormTraining dan Testing Data Kualitatif (Bagian 2)
Training dan Testing Data Kualitatif
Atribut TRAINING
Training dan Testing Data Kualitatif
Gambar 3.10. Desain FormTraining dan Testing Data Campuran (Bagian 1)
Gambar 3.11. Desain FormTraining dan Testing Data Campuran (Bagian 2)
Training dan Testing Data Campuran
Atribut
Training dan Testing Data Campuran
Gambar 3.12. Desain Form Pengenalan Data Tunggal Data Kuantitatif
f) Form Pengenalan Data Tunggal Data Kualitatif
Gambar 3.13. Desain Form Pengenalan Data Tunggal Data Kualitatif Pengenalan Data Tunggal Data Kuantitatif
PROSES TREE
Tree
Time Monetary Frequency Recency
Output
CEK CLEAR KELUAR
Pengenalan Data Tunggal Data Kualitatif
PROSES TREE
Tree
Doors Maint Buying
Lug_Boot
Output Safety Persons