DOKUMEN CERITA WAYANG
Skripsi
Diajukan untuk Memenuhi Salah Satu Syarat
Memperoleh Gelar Sarjana Teknik Jurusan Teknik Informatika
Oleh :
Angela Ami Asmarani
NIM : 055314057
PROGRAM STUDI TEKNIK INFORMATIKA
JURUSAN TEKNIK INFORMATIKA
FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA
YOGYAKARTA
2009
USING WAYANG STORY DOCUMENTS
A Thesis
Presented as Partial Fulfillment of the Requirements
To Obtain the Sarjana Teknik Degree In Department of Informatics Engineering
By :
Angela Ami Asmarani
Student ID : 055314057
INFORMATICS ENGINEERING STUDY PROGRAM INFORMATICS ENGINEERING DEPARTMENT
FACULTY OF SCIENCE AND TECHNOLOGY SANATA DHARMA UNIVERSITY
YOGYAKARTA 2009
SISTEM TANYA JAWAB DENGAN MENGGUNAKAN KOLEKSI
DOKUMEN CERITA WAYANG
Oleh :
Angela Ami Asmarani
NIM : 055314057
Telah Disetujui oleh :
Pembimbing
Sri Hartati Wijono, S.Si., M.Kom Tanggal …. Agustus 2009
DOKUMEN CERITA WAYANG
Yang dipersiapkan dan disusun oleh :
Angela Ami Asmarani
NIM : 055314057
Telah dipertahankan di depan Tim Penguji
Pada tanggal 16 Juni 2009
Dan dinyatakan memenuhi syarat.
Susunan Tim Penguji
Tanda Tangan
Ketua : Alb. Agung Hadhiatma, S.T., M.T. _ _ _ _ _ _ _ _ _
Sekretaris : Sri Hartati Wijono, S.Si., M.Kom _ _ _ _ _ _ _ _ _
Anggota : Puspaningtyas Sanjoyo Adi, S.T., M.T. _ _ _ _ _ _ _ _ _
Yogyakarta,……….
Fakultas Sains dan Teknologi
Universitas Sanata Dharma
Dekan,
(Yosef Agung Cahyanta, S.T, M.T.)
Skripsi ini kupersembahkan untuk :
untuk Tuhan Yang Maha Menakjubkan, yang selalu penuh kejutan dan selalu membuatku terkejut dengan seluruh keajaiban semestanya, baik ketika mataku terbuka maupun tertutup.
untuk keluargaku yang juga menakjubkan, untuk semua dukungan dan kehangatan
untuk almamaterku,
untuk Indonesia dan kebudayaannya,
dan, untuk setiap orang yang mampelajari Information Retrieval
Saya menyatakan dengan sesungguhnya bahwa skripsi yang saya tulis ini
tidak memuat karya/bagian karya orang lain, kecuali yang telah disebutkan dalam
kutipan dan daftar pustaka, sebagaimana layaknya karya ilmiah.
Yogyakarta, 11 Agustus 2009
Penulis
Angela Ami Asmarani
UNTUK KEPENTINGAN AKADEMIS
Yang bertanda tangan di bawah ini, saya mahasiswa Universitas Sanata Dharma :
Nama : Angela Ami Asmarani
NIM : 055314057
Demi pengembangan ilmu pengetahuan, saya memberikan kepada Perpustakaan
Universitas Sanata Dharma karya ilmiah saya yang berjudul :
SISTEM TANYA JAWAB DENGAN MENGGUNAKAN KOLEKSI
DOKUMEN CERITA WAYANG
Beserta perangkat yang diperlukan (bila ada). Dengan demikian saya memberikan
kepada Perpustakaan Universitas Sanata Dharma hak untuk menyimpan, mengalihkan
dalam bentuk media lain, mengelolanya dalam bentuk pangkalan data,
mendistribusikannya secara terbatas, dan mempublikasikannya di internet dan media
lain untuk kepentingan akademis tanpa perlu meminta izin dari saya maupun
memberikan royalti kepada saya selama tetap mencantumkan nama saya sebagai
penulis.
Demikian pernyataan ini saya buat dengan sebenarnya.
Yogyakarta, 11 Agustus 2009
Penulis,
Angela Ami Asmarani
Sistem tanya jawab adalah sistem yang menerima pertanyaan dari user dalam
bahasa alami, dan mengembalikan teks pendek sebagai jawabannya. Sistem
memperoleh jawaban dari koleksi dokumen (corpus) yang dimilikinya. Sistem tanya jawab terdiri atas beberapa tahap pemrosesan antara lain: analisa pertanyaan,
preprocessing koleksi dokumen, pencarian kandidat dokumen, dan ekstraksi jawaban. Skripsi ini membahas pembuatan sistem tanya jawab yang menggunakan
koleksi dokumen cerita wayang, sehingga pertanyaan user juga dibatasi seputar cerita wayang. Dalam menjawab pertanyaan, sistem menggunakan metode pembobotan
kueri dan formula scoring untuk me-ranking kandidat jawaban.
Sistem ini dapat menerima pertanyaan seputar cerita wayang yang dibatasi pada
lima tipe jawaban yaitu Person, Location, Relation, Weapon, dan Number. Diujicobakan pada 100 pertanyaan, sistem mampu menjawab 22 pertanyaan dengan
tepat, atau tingkat keberhasilannya adalah 22%.
Question answering system is a system that receives a user’s question in a
natural language, and returns short text as an answer. System retrieves the answer
from its corpus. Question answering system consists of some processing state i.e:
question analysis, document collection preprocessing, candidate document searching,
and answer extraction.
This paper discusses about the making of question answering system using
wayang story documents as the corpus, so that user’s question is about wayang stories
only. In answering the question, system uses query weight method and scoring
formula to rank candidate answers.
This system can receive questions around wayang story but the questions are
limited by five type of answer: Person, Location, Relation, Weapon, and Number.
Being tested on 100 questions, the system could answer 22 questions correctly. In
other words, the level of success is 22%.
Puji syukur kepada Tuhan Yang Maha Esa yang telah memberikan segala
karunia-Nya sehingga penulis dapat menyelesaikan skripsi dengan judul “Sistem
Tanya Jawab dengan Menggunakan Koleksi Dokumen Cerita Wayang”.
Dalam kesempatan ini, penulis ingin mengucapkan terima kasih yang
sebesar-besarnya kepada semua pihak yang turut memberikan dukungan, semangat dan
bantuan hingga selesainya skripsi ini :
1. Ibu Sri Hartati Wijono, S.Si., M.Kom atas semua bantuan, bimbangan,
kesabaran, waktu, dan semangat yang telah ibu berikan, membuat skripsi ini
dapat terselesaikan. Apa jadinya semua ini tanpa bantuan ibu?
2. Bapak Puspaningtyas Sanjoyo Adi, S.T., M.T. sebagai Kaprodi dan sebagai
dosen penguji, atas saran dan kritikan yang diberikan.
3. Bapak Alb. Agung Hadhiatma, S.T., M.T. dan sebagai dosen penguji, atas
saran dan kritikan yang diberikan.
4. Seluruh Dosen TI yang selama empat tahun ini telah membagikan ilmunya
yang sangat berguna kepada penulis.
5. Laboran Laboratorium Komputer yang telah membantu mempersiapkan
jalannya pendadaran.
6. Seluruh Staff Universitas Sanata Dharma, yang atas kerja kerasnya, membuat
perkuliahan menjadi terasa nyaman.
Aquino Adam Nurcahyo, kakakku, Agatha Uni Asmarani, atas kasih sayang,
perhatian, dukungan, semangat dan doa yang mengiringi proses pembuatan
skripsi ini.
8. Linus Wedar Duanto, Fenti Iskandari, dan Agnes Tyas, yang sangat banyak
membantu dalam proses pembuatan skripsi ini, atas dukungan, semangat, dan
bantuan.
9. Serta semua pihak yang telah membantu kelancaran dalam penulisan tugas
akhir ini. Penulis mengucapkan banyak terima kasih.
Yogyakarta, Agustus 2009
Penulis
HALAMAN JUDUL BAHASA INDONESIA ... i
HALAMAN JUDUL BAHASA INGGRIS ... ii
HALAMAN PERSETUJUAN PEMBIMBING ... iii
HALAMAN PENGESAHAN ... iv
HALAMAN PERSEMBAHAN ... v
PERNYATAAN KEASLIAN KARYA ... vi
HALAMAN PERSETUJUAN PUBLIKASI... vii
ABSTRAK ... viii
ABSTRACT ... ix
KATA PENGANTAR ... x
DAFTAR ISI ... xii
DAFTAR TABEL ... xvii
DAFTAR GAMBAR ... xviii
BAB I PENDAHULUAN 1.1 Latar Belakang ... 1
1.2 Rumusan Masalah ... 3
1.3 Batasan Masalah ... 3
1.4 Tujuan dan Manfaat ... 4
1.5 Metodologi Penelitian ... 4
1.6 Sistematika Penulisan ... 5
2.1 Information Retrieval... 7
2.2 Sistem Tanya Jawab... 9
2.3 Ad Hoc Retrieval ... 10
2.4 Kueri... 10
2.5 Segmentasi ... 12
2.6 Stemming... 12
2.7 Parsing... 15
2.8 Stopword, Stoplist, dan StopwordRemoval... 15
2.9 Indexing... 16
2.10 Ranking... 16
2.11 Diagram Aliran Data ... 18
2.12 Perl dan XAMPP... 20
BAB III ANALISA DAN DESAIN SISTEM 3.1. Perancangan Sistem ... 25
3.1.1.Preproses (Proses 1) ... 27
a. Segmentasi dokumen (Sub Proses 1.1P)... 29
b. Pembuatan file kosakata (Sub Proses 1.2P) ... 29
c. Pembuatan file Token (Proses 1.3P) ... 32
d. StemmingFile (Sub Proses 1.4P) ... 33
e. Stemming Koleksi(Sub Proses 1.5P) ... 36
g. Membuat File Stoplist (Sub Proses 1.7P) ... 39
h. RemoveStopword (Sub Proses 1.8P) ... 40
i. Parsing / Tagging (Sub Proses 1.9P) ... 41
j. Pembuatan Passage (Sub Proses 1.10P) ... 43
3.1.2.Indexing (Proses 2)... 48
a. Pembuatan FileIndex Dokumen (Sub Proses 2.1P) ... 49
b. Pembuatan FileIndexPassage (Sub Proses 2.3P ... 51
3.1.3.Pengolahan Pertanyaan dan Pencarian Jawaban (Proses 3)... 51
a. Analisa Pertanyaan (Sub Proses 3.1) ... 52
b. Pencarian dan Ranking Dokumen (Sub Proses 3.2)... 57
c. Pencarian dan RankingPassage (Sub Proses 3.3) ... 58
d. Ekstraksi Jawaban (Sub Proses 3.4)... 60
3.1.4.Kamus Data... 70
3.2. Diagram Berjenjang Sistem ... 78
3.3. Desain Antar Muka ... 79
BAB IV IMPLEMENTASI 4.1Implementasi Fisik ... 82
4.1.1 Struktur File pada Folder Preproses... 83
4.1.2 Struktur File pada Folder Index ... 88
4.1.3 Struktur File pada Folder Koleksi ... 90
4.2Implementasi Program ... 96
4.2.2 Program Stem File ... 97
4.2.3 Program Stem Koleksi ... 99
4.2.4 Program Pembuatan Stoplist ... 100
4.2.5 Program Stopword Removal ... 101
4.2.6 Program Parsing ... 101
4.2.7 Program Pembuatan Passage... 102
4.2.8 Program Pembuatan Index Dokumen ... 105
4.2.9 Program Pembuatan Index Passage ... 106
4.2.10 Program Analisa Pertanyaan ... 107
4.2.11 Program Pencarian dan Ranking Dokumen ... 109
4.2.12 Program Pencarian dan Ranking Passage ... 110
4.2.13 Program Ekstraksi Jawaban ... 112
4.3Implementasi Antarmuka ... 116
4.3.1 Halaman Home / Form Pertanyaan ... 116
4.3.2 Halaman Jawaban... 117
4.3.3 Halaman Tentang Sistem ... 118
4.3.4 Halaman Kredit ... 119
4.3.5 Halaman Cara Kerja Sistem ... 120
4.3.6 Halaman Evaluasi ... 120
BAB V ANALISA HASIL IMPLEMENTASI 5.1Hasil Implementasi ... 121
BAB IV KESIMPULAN DAN SARAN
6.1Kesimpulan ... 126
6.2Saran... 127
DAFTAR PUSTAKA ... 128
LAMPIRAN
Tabel 1: inflectional pasrticles... 13
Tabel 2 : inflectional possessive pronouns ... 13
Tabel 3 : first order of derivational prefixes... 14
Tabel 4 : second order of derivational prefixes... 14
Tabel 5 : derivational suffixes... 15
Tabel 3.1.3 Tabel kata passage ... 65
Table 3.1.4 Kamus Data... 70
Gambar 2.1.a : Diagram proses Pemerolehan Informasi ... 8
Gambar 2.6.a desain Stemming ... 13
Gambar 2.11.a contoh DAD... 18
Gambar 2.11.b contoh DAD... 20
Gambar 3.1.a diagram konteks system ... 25
Gambar 3.1.b Diagram Aliran Data level 1 ... 26
Gambar 3.1.1.a DAD level 2 proses 1 ... 28
Gambar 3.1.1.b Flowchart Pembuatan File Kosakata ... 31
Gambar 3.1.1.c desain Stemming ... 34
Gambar 3.1.1.d desain proses Stemming ... 35
gambar 3.1.1e flowchart proses parsing ... 42
gambar 3.1.1.f gambar flowchart pembuatan passage ... 45
Gambar 3.1.1.g gambar file-file preproses ... 47
Gambar 3.1.1.h koleksi-koleksi dokumen ... 48
gambar 3.1.2.a DAD level 2 Proses 2 ... 49
gambar 3.1.2.b Flowchart pembuatan file index ... 50
Gambar 3.1.3.a DAD level 2 proses 3 ... 52
gambar 3.1.3.b DAD level 3 proses 3.1 ... 53
gambar 3.1.3.c Flowchart pengelompokkan pertanyaan jawaban ... 55
Gambar 3.1.3.d DAD level 3 proses 3.2 ... 57
gambar 3.1.3.f Flowchart skor passage 1... 61
gambar 3.1.3.g Flowchart skor passage 2 ... 62
gambar 3.1.3.h Flowchart skor passage 3... 63
gambar 3.1.3.i Flowchart skor kandidat 1... 67
gambar 3.1.3.j Flowchart skor kandidat 2 ... 68
Gambar 3.3.a Diagram berjenjang ... 78
Gambar 3.4.a Form pertanyaan ... 79
Gambar 3.4.b Jawaban Pertanyaan ... 79
Gambar 3.4.c tampilan Tentang program. ... 79
Gambar 3.4.d tampilan Kredit ... 80
Gambar 3.4.e tampilan Bagaimana Sistem bekerja ... 80
Gambar 3.4.f halaman evaluasi ... 81
Gambar 4.1.a implementasi program... 82
Gambar 4.1.b folder file ... 83
Gambar 4.1.1a folder preproses ... 83
Gambar 4.1.1.b folder sinonim ... 85
Gambar 4.1.1.c folder token ... 86
Gambar 4.1.1.d folder stem ... 87
Gambar 4.1.1.e folder suffix ... 88
Gambar 4.1.2.a. folder index ... 89
Gambar 4.1.3.a folder koleksi ... 90
Gambar 4.1.3.c folder koleksi-segmen ... 92
Gambar 4.1.3.d folder koleksi-parsing ... 94
Gambar 4.1.3e folder koleksi-passage ... 95
Gambar 4.3.1.a halaman home ... 116
Gambar 4.3.1.b form pertanyaan ... 117
Gambar 4.3.2.a halaman jawaban ... 117
Gambar 4.3.3.a halaman tentang ... 118
Gambar 4.3.4.a halaman kredit system... 119
Gambar 4.3.5.a halaman cara kerja system ... 120
Gambar 4.3.6.a halaman evaluasi... 120
PENDAHULUAN
1.1LATAR BELAKANG
Dengan adanya komputer dan internet, pertukaran informasi dapat terjadi dengan sangat cepat, dan saat ini, informasi sudah menjadi sebuah kebutuhan.
Informasi yang dapat kita peroleh sangat banyak, tetapi hanya beberapa informasi
saja yang diperlukan, dan sering terjadi kesulitan dalam mencari informasi yang
dibutuhkan dari miliaran informasi yang ada di internet. Untuk itulah maka diciptakan mesin pencari. Mesin pencari adalah sebuah sistem yang dirancang
untuk membantu seseorang menemukan file-file yang disimpan dalam komputer
maupun di dalam server.
Saat ini dengan adanya mesin pencari, pencarian dokumen yang dibutuhkan
dapat dilakukan dengan memasukkan kata-kata kunci dari dokumen yang
dimaksud. Kemudian, mesin pencari akan mengembalikan informasi mengenai
dokumen-dokumen yang relevan terhadap kata kunci yang diberikan. Tetapi,
seringkali, yang dibutuhkan bukanlah sebuah dokumen, melainkan hanya
sebagian dari dokumen itu. Misalnya saat ingin mengetahui “siapa yang menculik
Sinta?”. Bila menggunakan mesin pencari untuk menemukan jawaban dari
pertanyaan tersebut, maka mesin pencari akan mengembalikan
dokumen-dokumen Ramayana. Dokumen tersebut harus dibaca untuk mendapatkan
jawaban atas pertanyaan, padahal yang diinginkan hanyalah kata “Rahwana”,
bukan keseluruhan cerita Ramayana. Untuk menjawab permasalahan itu, maka
dibutuhkan Sistem Tanya Jawab.
Sistem Tanya Jawab menerima masukan berupa pertanyaan dengan bahasa
natural, atau bahasa sehari-hari, kemudian memproses pertanyaan tersebut
menjadi sebuah kueri, kueri tersebut digunakan untuk mencari jawaban pada
koleksi dokumen.
Saat ini sudah banyak penerapan Sistem Tanya Jawab, baik Sistem Tanya
Jawab dengan tema tertentu maupun Sistem Tanya Jawab secara umum. Beberapa
yang sudah dikerjakan di Indonesia adalah Sistem Tanya Jawab Alkitab[Gu] yang
menggunakan koleksi dokumen Alkitab berbahasa Inggris untuk mendapatkan
jawaban dari pertanyaan yang diberikan. Pertanyaannya pun juga berkisar
mengenai Alkitab dan menggunakan bahasa Inggris.
Sistem Tanya Jawab yang umum, biasanya menggunakan koleksi dokumen
dari world wide web, dan pertanyaannya pun dapat apa saja. Dalam skripsi ini, Tema yang dipilih adalah cerita wayang, sementara untuk koleksi dokumennya
menggunakan koleksi dokumen cerita wayang dari penyimpanan lokal (tidak
menggunakan koleksi dari world wide web). Skripsi ini memilih tema tersebut dengan harapan dapat lebih fokus dalam menangani pertanyaan dan pencarian
1.2RUMUSAN MASALAH
Dari latar belakang masalah di atas dapat dirumuskan menjadi beberapa
masalah sebagai berikut :
1. Bagaimana memproses pertanyaan menjadi sebuah kueri?
2. Bagaimana mencari dokumen yang relevan dengan kueri?
3. Bagaimana mengekstrak jawaban dari dokumen yang relevan?
1.3BATASAN MASALAH
1. Sistem ini hanya menggunakan koleksi dokumen teks cerita wayang
berbahasa Indonesia, yaitu cerita Mahabarata dan Ramayana yang disimpan di
penyimpanan local (bukan world wide web).
2. Pertanyaan yang diajukan menggunakan bahasa Indonesia dengan kalimat
sederhana.
3. Pertanyaan yang diajukan berkisar tentang cerita wayang.
4. Jawaban pertanyaan dibatasi pada tipe person, tempat, jumlah (angka), relasi, dan senjata.
5. Jawaban pertanyaan terdiri dari satu atau dua kata.
6. Untuk lebih memahami konteks, ditambahkan potongan cerita dimana
jawaban berada.
7. Sistem ini merupakan sistem Ad Hoc, dimana koleksi dokumen tidak bertambah, hanya pertanyaannya saja yang berubah.
9. Skripsi ini terfokus pada pembuatan sistem tanya jawab, sehingga pembuatan
website tidak dibahas secara detail.
1.4TUJUAN DAN MANFAAT
Tujuan dari pembuatan skripsi ini adalah membuat sebuah sistem yang
mampu menerima masukan berupa pertanyaan dalam bahasa natural dan
memberikan jawaban yang sesuai.
Manfaat dari pembuatan skripsi ini adalah untuk mengenalkan cerita wayang.
1.5METODOLOGI PENELITIAN
1. Studi pustaka mengenai Sistem Tanya Jawab, Information Retrieval dan Perl. 2. Mengumpulkan koleksi dokumen cerita wayang dalam bahasa Indonesia.
3. Membuat contoh kueri (pertanyaan) dari koleksi dokumen tersebut.
4. Pembuatan sistem menggunakan metode waterfall. Langkah-langkahnya yaitu:
• Perancangan sistem
• Implementasi Sistem
• Melakukan uji coba dengan sample kueri yang sudah dikumpulkan.
1.6SISTEMATIKA PENULISAN
BAB I PENDAHULUAN
Bab I berisi tentang penjelasan awal masalah, masalah apa yang dihadapai,
rumusan masalah, batasan masalah, dan metode penelitian.
BAB II LANDASAN TEORI
Bab II berisi landasan-landasan teori yang akan mendunkung pembuatan
skripsi antara lain mengenai Information Retrieval, Sistem Tanya Jawab, dan fungsi-fungsi bahasa Perl yang akan di gunakan dalam pembuatan program.
BAB III ANALISIS DAN PERANCANGAN SISTEM
Bab III berisi tentang analisis dan perancangan sistem yang akan dibuat,
Diagram Alir Data, flowchart, diagram berjenjang, dan disain user interface.
BAB IV IMPLEMENTASI SISTEM
Bab IV berisi pembuatan dan implementasi sistem, bahasan script (kode program) yang digunakan.
BAB V ANALISA HASIL IMPLEMENTASI
Bab V berisi penerapan dan pengujian sistem beserta hasil evaluasi sistem.
Bab V berisi kesimpulan dari keseluruhan pembuatan sistem dan saran
LANDASAN TEORI
2.1 Information Retrieval
Definisi Pemerolehan Informasi atau Information Retrieval (IR) adalah menemukan sebuah material atau informasi dari sebuah koleksi dokumen
berskala besar yang tidak terstruktur yang dapat memenuhi sebuah kebutuhan
informasi. IR digunakan untuk mengatasi "banjir informasi".
Aplikasi-Aplikasi IR antara lain digunakan untuk:
1. mesin pencari pada internet.
2. Automatic summarization, merupakan sistem yang dapat membuat sebuah ringkasan dari sebuah dokumen atau lebih.
3. Document classification, adalah sistem yang memilah-milah sekumpulan dokumen ke dalam klasifikasinya.
4. Recommender systems, adalah sistem yang memberikan rekomendasi berdasarkan data yang ada.
5. Question answering, adalah sistem yang menerima pertanyaan dan mencari jawabannya pada koleksi dokumen yang dimilikinya.
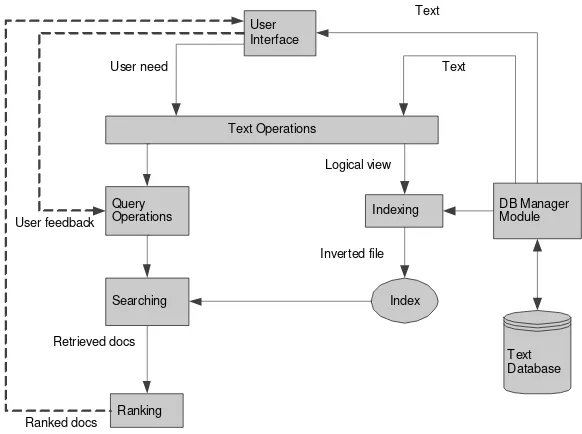
Proses dalam IR secara umum dapat dijelaskan pada gambar 2.1
User
Indexing DB Manager Module
Index
Gambar 2.1.a : Diagram proses Pemerolehan Informasi
Penjelasan proses Pemerolehan Informasi:
Dari sisi database, database diproses sebagai berikut :
1. Text database, melalui DB Manager Module diolah dalam proses text
operation.
2. Hasil dari text operation digunakan dalam proses indexing
3. Proses indexing menghasilkan sebuah fileindex.
Dari sisi user:
1. User menginputkan kebutuhan user
3. Kebutuhan user yang telah diolah kemudian dibuat menjadi kueri. 4. Dilakukan pencarian dengan menggunakan kueri pada fileindex. 5. Hasil dari pencarian kemudian di ranking dan ditampilkan pada user. 6. Pemerolehan informasi juga memungkinkan terjadinya feedback dari
user. Feedback ini kemudian digunakan untuk pembuatan kueri.
2.2 Sistem Tanya Jawab
Sistem tanya jawab (QA) adalah salah satu jenis Information Retrieval. Sistem ini mampu me-retrieve jawaban dari pertanyaan yang diajukan dalam
bahasa alami dari koleksi dokumen yang dimilikinya (dapat juga dari world
wide web). Dari seluruh jenis aplikasi Information Retrieval, QA merupakan aplikasi yang paling banyak menggunakan pemrosesan bahasa alami, dan
diyakini merupakan generasi berikutnya dari mesin pencari.
Berdasarkan koleksi dokumennya, QA terbagi menjadi dua :
• Closed-domain question answering : merupakan QA system yang
menangani pertanyaan dengan domain tertentu, contohnya adalah bidang
otomotif, kesehatan, alkitab dan lain-lain. QA system dengan closed-domain dapat dikatakan lebih mudah, karena pemrosesan bahasa alaminya dapat mengenali istilah-istilah dalam domain tersebut.
• Open-domain question answering : merupakan QA system yang
dan pengetahuan tentang dunia. Selain itu, dibandingkan dengan
closed-domain, Open-domain menangani koleksi data yang jauh lebih banyak untuk menemukan jawaban.
Proses dari QA system antara lain adalah :
1. Pemrosesan Kueri
2. Pencarian Dokumen
3. Ekstraksi Jawaban
2.3 Ad Hoc Retrieval
Merupakan tipe retrival dimana koleksi dokumen tetap sementara kueri
berubah-ubah.
2.4 Kueri
Kueri adalah bentuk lain dari pertanyaan atau kebutuhan. Kueri dalam IR
adalah kueri yang hasilnya memungkinkan untuk diurutkan (ranked). Ada
beberapa jenis kueri, di antaranya adalah Keyword-Based Querying, Pattern
Matching, dan Structural Queries.
Keyword-Based Querying adalah kueri yang terdiri dari kata kunci-kata kunci dari dokumen yang akan dicari. Keyword-Based Querying populer karena intuitive, ekspresinya mudah , dan memudahkan ranking secara cepat. Kueri ini dapat terdiri dari satu kata kunci atau beberapa susunan kata kunci yang
1. Single-word Queries
Pada kueri ini, sebuah dokumen dianggap merupakan sekumpulan
kata-kata, tidak memperhatikan kalimat atau konteks di mana suatu kata
berada. Hasil dari kueri ini adalah dokumen-dokumen yang setidaknya
memiliki atau mengandung paling tidak satu kata dari kata-kata kunci
pada kueri. Hasilnya di-ranking berdasarkan banyaknya jumlah kata kunci kueri yang ditemukan dalam dokumen itu dengan menggunakan
metode statistik “term frequency” yang akan menghitung berapa kali kata itu muncul dalam sebuah dokumen, dan “inverse document
frequency” yang akan menghitung jumlah dokumen yang mengandung kata-kata tersebut.
2. Context Queries
Context Queries memiliki dasar bahwa kata-kata yang kemunculannya dekat satu sama lain mungkin lebih tinggi tingkat relevansinya
dibandingkan bila kata-kata itu muncul secara terpisah. Context Queries
dibagi menjadi Phrase Query dan Proximity Query. Phrase Query
adalah kueri yang mengijinkan kata-kata tersebut muncul dengan jarak
yang dekat atau jarak minimum yang ditentukan. Proximity adalah kueri yang memperbolehkan jarak maksimum dari kemunculan kata-kata
3. Boolean Queries
Boolean Queries merupakan kueri yang paling tua. Terdiri dari kata-kata kunci dan operator Boolean yang bekerja sebagai operand. Operator yang biasa digunakan adalah operator OR, AND, dan BUT.
2.5 Segmentasi
Segmentasi adalah membagi sesuatu menjadi bagian-bagian yang lebih kecil
dengan aturan tertentu.
2.6 Stemming
Stemming adalah proses penghilangan prefiks dan sufiks dari sebuah kata untuk
mendapatkan kata dasarnya. Stemming dilakukan atas dasar asumsi bahwa
kata-kata yang memiliki kata-kata dasar yang sama memiliki makna yang serupa sehingga
dokumen-dokumen yang di dalamnya terdapat kata-kata dengan kata dasar yang
sama juga relevan dengan kuerinya. Terdapat beberapa metode untuk melakukan
Stemming diantaranya adalah metode Porter, Lovins, Dawson, dan Krovetz. Ada
juga algoritma Proter Stemmer yang telah dimodifikasi untuk Bahasa Indonesia.
Porter Stemmer for Bahasa Indonesia dikembangkan oleh Fadillah Z. Tala pada
tahun 2003. Implementasi Porter Stemmer for Bahasa Indonesia berdasarkan
English Porter Stemmer yang dikembangkan oleh W.B. Frakes pada tahun 1992.
Karena bahasa Inggris datang dari kelas yang berbeda, beberapa modifikasi telah
bahasa Indonesia.
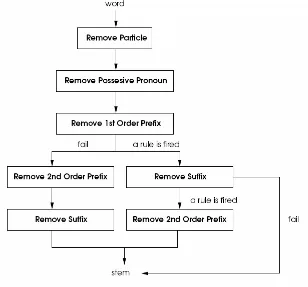
Desain Porter Stemmer for Bahasa Indonesia dapat dilihat pada gambar 2.8.a
Gambar 2.6.a desain Stemming
Pada gambar 2.8.a terlihat beberapa langkah ‘removal’ menurut aturan yang ada
pada tabel 1 sampai dengan tabel 5.
Tabel 2 : kelompok rule kedua : inflectional possessive pronouns
Tabel 3 : Kelompok rule ketiga : first order of derivational prefixes
Tabel 5 : Kelompok rule kelima : derivational suffixes
2.7 Parsing
Untuk pemrosesan, dokumen dipilah menjadi unit-unit yang lebih kecil
misalnya berupa kata, frasa atau kalimat. Unit pemrosesan tersebut disebut
sebagai token. Parsing merujuk pada proses pengenalan token yang terdapat dalam rangkaian teks. Oleh karena itu bagian dasar dalam parsing adalah algoritma pengambil token dari teks yang disebut tokenizer. Proses ini memerlukan pengetahuan bahasa untuk menangani karakter-karakter khusus,
serta menentukan batasan satuan unit dalam dokumen.
2.8 Stopword, Stoplist, dan StopwordRemoval
Stopwords adalah kata-kata yang tidak signifikan dalam sebuah dokumen seperti kata-kata “dan”, “hingga”, “di”, “ke”, “dari”. Stoplist adalah daftar
2.9 Indexing
Indexing adalah membuat sebuah struktur data dari seluruh dokumen untuk mempercepat proses pencarian. Indeks biasanya digunakan untuk koleksi
dokumen yang bersifat semi-statis. Semi-statis maksudnya adalah koleksi
dokumen tersebut dapat bertambah atau berubah jumlahnya namun dalam
interval waktu tertentu, tidak berubah setiap detik.
Salah satu metode indexing adalah : InvertedFiles (inverted index)
Inverted files adalah mekanisme dalam mengindeks sebuah koleksi dari dokumen teks yang bertujuan untuk mempercepat proses pencarian. Struktur
inverted file terbagi menjadi dua elemen : vocabulary dan occurrences.
Vocabulary adalah kumpulan dari kata yang berbeda yang terdapat di dalam teks. Occurrences adalah daftar dari semua posisi teks dimana kata-kata tersebut muncul.
2.10 Ranking
Dalam skripsi ini ranking adalah proses mengurutkan sekumpulan dokumen berdasarkan tingkat relevansinya terhadap kueri. Salah satu metodenya adalah
dengan menggunakan Term Frequency digabungkan dengan Inverse
Document Frequency.
Inverse document frequency (idf) adalah inverse document frequency dari suatu kata.
Rumus dalam penggunaan tf*idf adalah :
Dimana :
Wij = weight (bobot) dari kata i pada dokumen j
tfij = jumlah kemunculan kata I pada dokumen j
idfi = inverse document frequency dari kata i
N = jumlah seluruh dokumen
dfi = jumlah dokumen yang mengandung kata i
kemudian tingkat similiaritinya dihitung dengan menggunakan Similarity
Measure-Inner Product dengan rumus:
Dimana :
Sim (dj, q) = tingkat kesamaan dokumen j terhadap kueri
dj = dokumen j
q = kueri
t = terms (jumlah kata dalam kueri)
Wiq = bobot kata i pada kueri
2.11 Diagram Aliran Data [Whitten]
Diagram Aliran Data adalah suatu model proses yg digunakan utk
menggambarkan aliran data yg melalui sebuah sistem dan bagaimana proses
atau kerja yg dilakukan oleh sistem.
Sinonimnya adalah bubble chart, transformation graph, dan process model.
Gambar 2.11.a contoh DAD
Simbol dalam Diagram Aliran Data
• Data flow
Menggambarkan data yang bergerak atau berpindah. Sebuah data
flow dapat juga digunakan untuk merepresentasikan pembuatan (creation), pembacaan (reading), penghapusan (deletion) atau perubahan (updating) data dalam sebuah file atau database
(disebut sebagai sebuah data store).
• External Agent
Orang di luar sistem yang berinteraksi dengan sistem
• Data store
Melambangkan sebagai database atau file.
• Proses
Melambangkan sebuah proses.
Menyatukan beberapa aliran data ataupun untuk memecah aliran
data menjadi beberapa lairan data yang asalnya dari satu aliran data.
Gambar 2.11.b contoh DAD
2.12 Perl dan XAMPP
Perl adalah bahasa pemrograman yang dapat digunakan untuk lintas platform. Bahasa pemrograman ini di buat oleh Larry Wall dan pertama kali dirilis pada
tahun 1987. Perl merupakan software open source dibawah Artistic License
atau GNU General Public License (GPL).
Bahasa ini dapat digabungkan dengan HTML, XML, dan bahasa mark-up
lainnya, selain itu bahasa ini mendukung pemrograman secara procedural
maupun object-oriented. Interpreter Perl dapat digabungkan dengan sistem lain.
Perl merupakan bahasa pemrograman web yang populer untuk kemampuan
dengan web server untuk mempercepat proses, kecepatannya mencapai 2000% dari penggunaan bahasa lain. Untuk menggabungkan Interpreter Perl dengan Apache web server, dapat digunakan mod_perl.
XAMPP adalah aplikasi gabungan dari empat software server, yaitu web
server Apache, MySQL, PHP, dan Perl. XAMPP sudah memiliki fasilitas Perl,
ter Perl berada.
Un er sintaksnya adalah :
karakter ‘$’. Untuk
variabel array, dalam menggunakan awalan karakter ‘@’,
$_angka = 10;
namun secara default belum terkoneksi, untuk mengoneksikannya dilakukan
dengan mengubah konfigurasi mod_perl. Selain itu, modul-modul Perl yang
terdapat dalam XAMPP dapat di tambahi dengan modul-modul yang
diperlukan yang belum ada di XAMPP.
Suatu file Perl selalu diawali dengan sintaks: #!/usr/local/bin/perl
Yang merupakan path menuju tempat interpre
tuk menampilkan tulisan di lay
print "Hello, World!\n";
Variabel-variabel dalam Perl selalu diawali dengan
pendeklarasian
kemudian baru diakses dengan menggunakan karakter ‘$’. Untuk variable
hash, dalam pendeklarasiannya menggunakan awalan karakter ‘%’, kemudian
baru diakses dengan menggunakan karakter ‘$’ Untuk komentar
menggunakan tanda ‘#’.
@nilai = (10, 7, 6 # mencetak '6'
, 5, 9, 8);
’, 10, ‘nilai2’, 20}; ’};
Op menggunakan If dan else.
Perulangan dapat digunakan dengan statement for, foreach maupun while.
foreach () {# statemen}
Me
maka harus file dibuka dengan fungsi open, contoh:
ariable $fh adalah filehandle yang diperlukan untuk membaca dan menutup
jutnya setiap baris dibaca dengan operator <>. sebagai berikut: print $prima1[2];
%hash = {‘nilai1 Print $hash{‘nilai1
erator kondisional dalam Perl
if ( kondisi1) {# statemen} elsif (kondisi2) {
# statemen
} elsif (kondisi3) { # statemen
} else { # statemen }
for ( ; ; ) { # statemen }
while(kondisi) {# statemen }
mbaca dari file teks
Sebelum file dapat dibaca
open($fh, '/etc/passwd');
V
while($line = <$fh>) { # memproses $line }
Setelah selesai file ditutup dengan fungsi close, contoh: close($fh);
Menulis ke file teks
Perintah yang sama dengan program di atas dapat digunakan untuk menulis ke
file. Pertama, file dibuka dengan mode 'tulis': open($fh, “> /path/ke/file”);
selanjutnya dapat ditulis dengan perintah print, menggunakan file handle, sbb: print $fh “baris teks yang ditulis ...\n”;
Seperti halnya dalam hal membaca, maka filehandle harus ditutup dengan close.
Berikut ini contoh membaca dari file dan menulis ke file baru, atau mengcopy
file:
# mengcopy /etc/profile $fnam = '/etc/profile';
$fbaru = '/home/copyprofile';
open($fh1, $fnam) or die “gagal baca $fnam, $!”;
open($fh2, “>$fbaru”) or die “gagal menulis $fbaru, $!”; while($line = <$fh1>) {
print $fh2 $line; }
close($fh2);
Ekspresi “or die ... “ digunakan sebagai error handler jika file tidak dapat dibuka. Variabel khusus $! digunakan untuk menampilkan pesan error dari
ANALISA DAN DESAIN SISTEM
3.1. Perancangan Sistem
Sistem tanya jawab wayang ini menerima input pertanyaan dalam Bahasa Indonesia berupa teks dan memberi output berupa jawaban dalam bentuk teks singkat beserta potongan dokumen tempat ditemukannya jawaban. Secara umum, diagram
konteksnya seperti pada gambar 3.1.a
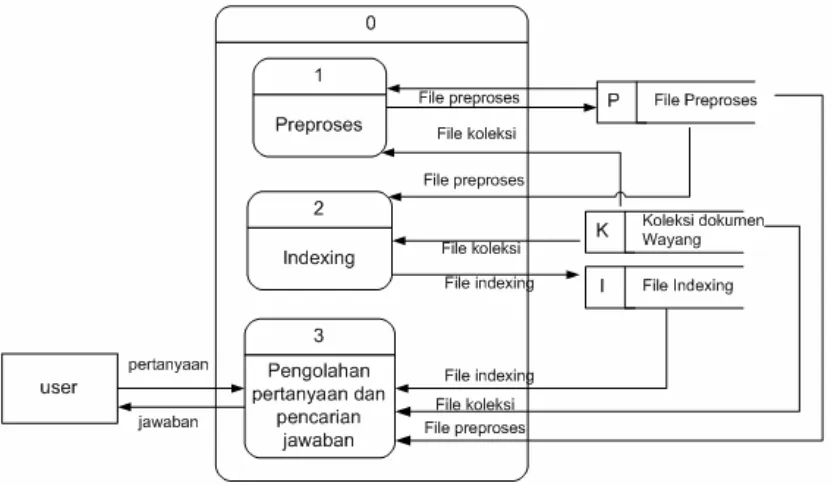
Gambar 3.1.a diagram konteks sistem
Dalam sistem ini hanya terdapat satu tipe pengguna, yaitu user yang memanfaatkan sistem ini untuk bertanya seputar wayang. Sistem tanya jawab wayang ini
merupakan bagian dari IR dengan tipe Ad Hoc, di mana hanya pertanyaannya saja yang berubah, sementara bagian koleksi tetap, maka dari itu tidak terdapat user
yang memiliki akses untuk menambah koleksi.
Sebelum sebuah sistem tanya jawab dapat menjawab pertanyaan, perlu dilakukan
pengolahan pada koleksi dokumen. Pengolahan ini disebut tahap preproses. Setelah
dilakukan tahap preproses maka akan dilakukan proses indexing, yang akan memudahkan dan mempercepat proses pencarian untuk menemukan jawaban. Baru
setelah itu, sistem tanya jawab dapat menggunakan koleksi untuk menemukan
jawaban dari pertanyaan user. Gambar 3.1.b Diagram Aliran Data (DAD) level 1
akan menjelaskan proses-proses ini.
Gambar 3.1.b Diagram Aliran Data level 1
Tahap preproses mengubah koleksi dokumen wayang yang masih mentah menjadi
dokumen yang terstruktur. Tahap ini menghasilkan beberapa file preproses yang akan digunakan pada tahap indexing. Tahap preproses akan dibahas pada sub bab 3.1.1
Tahap indexing adalah tahap dimana file-file koleksi di-index untuk mempercepat proses pencarian jawaban. Tahap ini menggunakan file koleksi dan file preproses yang akan menghasilkan file index. Tahap indexing akan dibahas pada sub bab 3.1.2
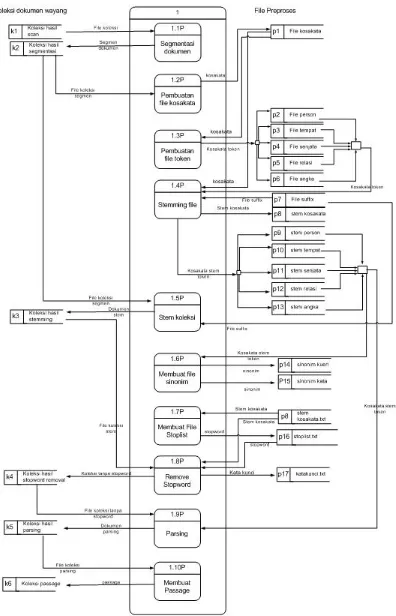
3.1.1. Preproses (Proses 1)
Karena sistem ini bertipe Ad Hoc, maka tahap preproses ini hanya dilakukan satu kali saja, setelah itu dapat dilakukan proses tanya berulang-ulang.
Tahap preproses terdiri dari segmentasi dokumen, pembuatan file kosakata,
file token, stopword removal, Stemming dan parsing, dan pembuatan
passage.
Diagram Alir Data level 2 untuk tahap preproses digambarkan pada Gambar
a. Segmentasi dokumen (Sub Proses 1.1P)
Koleksi yang dimiliki sistem ini terdiri dari dokumen-dokumen cerita
yang panjang setiap dokumennya berbeda-beda. Dokumen yang
memiliki jumlah kalimat atau kata yang banyak, akan dibagi menjadi
beberapa dokumen. Pembagian menjadi beberapa dokumen ini akan
dilakukan secara manual. Pembagian ini tidak berdasarkan pada jumlah
paragraf maupun kalimat. Pembagian dilakukan perbabak cerita, di mana
suatu babak biasanya memiliki subyek tertentu. Bila menggunakan
pembagian perjumlah paragraf, paragraf satu dan yang lainnya mungkin
memiliki satu subyek yang sama yang hanya di ceritakan pada paragraf
pertama, sehingga bila paragraf kedua dipisah dari paragraf pertama,
maka pragraf ini akan kehilangan subyeknya. Setelah dibagi ke dalam
beberapa bagian, seluruh koleksi akan diberi nama file berupa angka dari 1 sampai N (jumlah seluruh dokumen). Jumlah dokumen tersebut
disimpan dalam sebuah file index.txt sebagai file info.
Input-an untuk proses ini adalah koleksi dokumen wayang hasil scan dan
output-nya adalah koleksi dokumen wayang yang telah disegmentasi.
b. Pembuatan file kosakata (Sub Proses 1.2P)
Daftar kosakata dapat diambil dari Kamus Besar Bahasa Indonesia
(KBBI), namun tidak semua kosakata yang ada dalam KBBI digunakan
dalam koleksi dokumen. Maka dari itu, akan lebih relevan bila daftar
kosakata diambil dari kosakata yang digunakan dalam koleksi.
Proses ini membuat daftar seluruh kosakata yang ada dalam koleksi
dokumen. Input-an dari proses ini adalah koleksi hasil segmentasi dan
File ini akan disimpan dalam nama kosakata.txt dengan format sebagai berikut:
kosakata1:cacah_kosakata1 kosakata2:cacah_kosakata2
…
…
…
Contoh isi file kosakata.txt adalah sebagai berikut:
Abadi:120 Abu:53 … …
c. Pembuatan file Token (Proses 1.3P)
Seperti yang telah dijelaskan pada pembatasan masalah, bahwa topik
pertanyaan dibatasi pada person, tempat, senjata, jumlah(angka) dan
relasi, maka kosakata tersebut merupakan kosakata yang merupakan
kandidat jawaban yang disebut sebagai token. File ini akan berguna dalam proses parsing atau yang juga biasa disebut sebagai tagging atau
tokenisasi.
yang telah dibuat dalam proses sebelumnya. Input dari sub proses ini adalah file kosakata. Output-nya adalah file token person.txt, tempat.txt, senjata.txt, angka.txt, dan relasi.txt.
Setiap filenya memiliki format yang sama yaitu :
kosakata1:cacah_kosakata1 kosakata2:cacah_kosakata2
…
…
…
Contohnya pada person.txt adalah
arimbi:98 arjuna:230
…
…
…
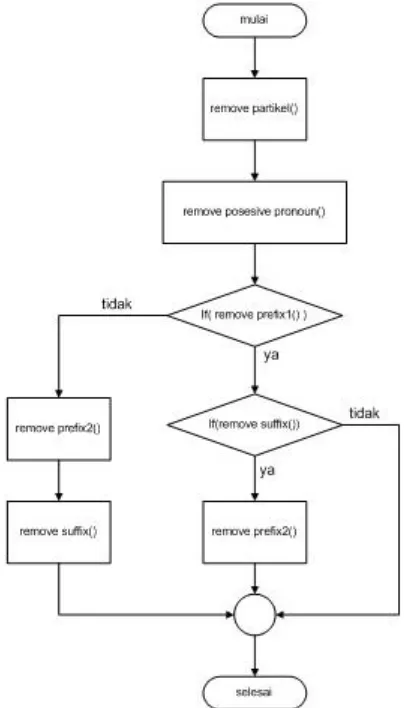
d. StemmingFile (Sub Proses 1.4P)
Proses Stemming ini menggunakan file suffix yang sudah disiapkan terlebih dahulu secara manual. Proses ini melakukan operasi stem pada
file-file kosakata, antara lain : file kosakata, person, senjata, relasi, tempat, dan angka. Tujuan proses stem ini adalah untuk mendapatkan kata dasar dari setiap kosakata yang ada. Stem juga dilakukan pada file
koleksi 1.5P) seluruh kata yang ada di dokumen akan di stem, termasuk kata-kata atau nama-nama yang merupakan kata-kata token. Bila file-file
token tidak di-stem, maka akan terjadi ketidakkonsistenan data.
Proses stem-nya menggunakan porter stemmer yang telah dijelaskan pada bab II. Pada Gambar3.1.1c diperlihatkan flowchart proses
Stemming.
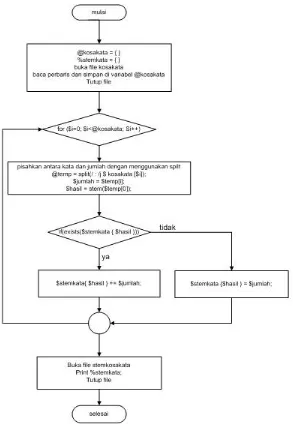
Gambar 3.1.1.c desain Stemming
Dalam proses pembuatan file kosakata, bila terdapat kata “rumahku” dan “rumah”, kedua kata tersebut dianggap berbeda. Sementara, setelah
“rumah”, dan dianggap sama dengan kata yang kedua. Kedua kata
tersebut harus digabungkan, dan jumlah (cacah) katanya harus
dijumlahkan, maka dari itu, proses Stemming file keseluruhan digambarkan pada flowchart pada gambar 3.1.1d
Contoh file sebelum di stem : arjuna:1028
akankah:301 akan:200 anak:459 ... ...
Setelah dilakukan proses stem : arjuna:1028
akan:501 anak:459 ... ...
e. Stemming Koleksi(Sub Proses 1.5P)
Proses Stemming pada koleksi dilakukan seperti pada proses Stemming file , hanya saja input-annya adalah koleksi dokumen tanpa stopword
dan output-nya adalah koleksi hasil Stemming. Contoh dokumen sebelum di-stem:
Abimanyu Terjebak Perangkap Mahadigda. Dia putra Arjuna yang lahir dari cintanya yang pertama kepada seorang wanita yang bernama Sumbadra putri Raja Basudewa dari Dewi Badraini. Abimanyu kekasihnya satria muda usia, sopan tutur bahasanya, hormat kepada orang tua dan tak segan menolong sesamanya...
Contoh dokumen setelah di-stem:
abimanyu jebak angkap mahadigda
dia putra arjuna yang lahir dari cinta yang tama pada seorang wanita yang nama sumbadra putri raja basudewa dari dewi badrain. abimanyu kasih satria muda usia, sopan tutur bahasa, hormat pada orang tua dan tak segan tolong sesama....
...
f. Pembuatan File Sinonim(Sub Proses 1.6P)
Pada proses ini akan dibuat dua buah file yaitu file sinonim kata dan file
sinonim kueri.
Dalam Bahasa Indonesia terdapat kata-kata yang berbeda tetapi memiliki
arti yang sama. Kata-kata ini dapat digunakan untuk membuat kueri,
agar dokumen-dokumen yang memiliki kata yang sama artinya juga
ditemukan.
Selain kata-kata dalam Bahasa Indonesia, juga terdapat istilah wayang
yang memiliki arti yang sama atau cara penulisan yang berbeda, seperti
penulisan ‘Kurawa’ ada yang menulis ‘Korawa’, ada yang menulis
‘Kurowo’. Secara umum penulisannya adalah ‘Kurawa’. Kata-kata
tersebut juga akan dimasukkan dalam file sinonim kata.
Karena koleksi yang dimiliki adalah dokumen-dokumen cerita sastra,
maka jarang ditemui bahasa yang memiliki arti langsung. Contohnya
adalah kueri “Siapa ayah gatotkaca?” dalam koleksi tidak ditemukan
dokumen yang mengandung “ayah gatotkaca adalah Bima”. Dalam
koleksi lebih banyak ditemukan dokumen-dokumen yang mengandung :
“Bima menikah dengan Hidimbi. Dari perkawinan mereka, lahirlah
seorang putera yang diberi nama Gatotkaca.”
“Ghattotkacha adalah seorang tokoh dalam wiracarita Mahabarata yang
dikenal sebagai putra Bimasena atau Wrekodara dari keluarga
Pandawa.”
Dari dua kalimat tersebut kata ‘ayah’ maupun ‘bapak’ tidak ditemukan,
padahal kedua kalimat tersebut mengandung jawaban dari pertanyaan
user. Dalam domain ini, hubungan ayah anak lebih sering dinyatakan dalam kata ‘putera’ atau ‘putra’ atau dapat juga diberi sinonim ‘anak’,
sehingga dalam pembentukkan kuerinya, kata ‘ayah’, ‘putra’, maupun
‘anak’ diikutsertakan. Begitu juga dengan hubungan relasi kakek dan
cucu, suami dan istri.
Kata-kata yang seperti ini akan dimasukkan dalam file sinonim kueri. Saat pembentukan kueri kata-kata yang memiliki sinonim ini akan
diikutsertakan.
sinonimkueri.txt dengan format yang sama yaitu :
kosakata1, sinonim1_kosakata1, sinonim2_kosakata1,….. kosakata2, sinonim1_kosakata2
… … …
Contoh pada sinonim kata:
arjuna, harjuna, arjuno …. putra, putera, anak
… … …
Contoh pada sinonim kueri:
Suami, istri Ayah, anak …
… …
g. Membuat File Stoplist (Sub Proses 1.7P)
berikut :
Pertama, file stem kosakata dibersihkan terlebih dahulu dari kata-kata yang terdapat pada file-filestem token. Hal ini dilakukan agar kata-kata token tidak dianggap sebagai stopword.
Kedua, hitung jumlah kosakta yang tersisa dari proses pertama.
Kemudian, jumlahkan seluruh cacah setiapkata. Setelah mendapatkan
jumlahkata dan jumlah seluruh cacah kata, kita dapat mencari rata-rata
kemunculan setiap kata :
Rata-rata kemunculan kata = jumlah seluruh cacah kata dibagi dengan
jumlah seluruh kata yang ada.
Ketiga, setiap kata yang kemunculan (dilihat dari cacah katanya) lebih
dari 5 (lima) kali kemunculan kata rata-rata, akan dianggap sebagai
stopword.
Kata-kata yang dianggap stopword disimpan di dalam file stoplist.txt
h. RemoveStopword (Sub Proses 1.8P)
Proses ini menghilangkan stopword pada koleksi dokumen dan filestem
kosakata, caranya adalah membuka setiap file koleksi yang ada, dan menghapus setiap kata yang termasuk dalam stoplist. Hasil dari proses
ini adalah koleksi hasil removestopword dan file katakunci. Dokumen awal (dari koleksi stem):
abimanyu kasih satria muda usia, sopan tutur bahasa, hormat pada orang tua dan tak segan tolong sesama..
Dokumen setelah stopword removal
abimanyu jebak angkap mahadigda. putra arjuna lahir cinta tama wanita nama sumbadra putri raja basudewa dewi badrain. abimanyu kasih satria muda usia, sopan tutur bahasa, hormat tua segan tolong sesama..
i. Parsing / Tagging (Sub Proses 1.9P)
Proses parsing adalah memberi tag pada kata-kata yang penting yang nantinya setelah diberi tag disebut dengan token. Pemberian tag ini membuat format file dokumen menjadi format XML. Formatnya adalah sebagai berikut :
<?XML VERSION =”1.0” ?> <document no=” ”>
<paragraf> <kalimat>
<person> </person> <tempat> </tempat> <relasi> </relasi> <senjata> </senjata> <angka> </angka>
</kalimat> </paragraf> </document>
dokumen tersebut memiliki kata yang terdapat dalam file person. Untuk pemberian tag person, tempat dan lain-lain dapat menggunakan file-file
token yang sudah dikelompokkan. Prosesnya ditunjukkan dalam gambar
flowchart 3.1.1e
Contoh sebuah file dokumen yang telah di parsing adalah sebagai berikut: <?XML VERSION =”1.0” ?>
<document no=”54”> <paragraf>
<kalimat> <person> Arjuna </person> karakter mulia, jiwa satria, iman kuat, tahan goda dunia, gagah berani, rebut jaya beri juluk <person> Dananjaya </person>. </kalimat> <kalimat> Musuh takluk, ia beri juluk <person>Parantapa</person>, arti takluk musuh. </kalimat> <kalimat> turun <person> Kuru </person> silsi Dinasti <person> Kuru </person>, ia juluk <person> Kurunandana </person>, arti putera sayang <person> Kuru </person>. </kalimat> <kalimat> Ia nama <person> Kuruprawira </person>, arti satria Dinasti <person> Kuru </person> baik, arti harfiah Perwira <person> Kuru </person>.</kalimat>
</paragraf> </document>
Input dari proses ini adalah file koleksi dokumen yang telah di-stem dan
file-file token. Output-nya adalah koleksi hasil parsing dengan format XML.
j. Pembuatan Passage (Sub Proses 1.0P)
Setelah dilakukan proses pemberian tag, selanjutnya dokumen-dokumen tersebut dipecah lagi menjadi passage-passage. Passage akan digunakan dalam mempersempit pencarian jawaban dalam proses ekstraksi jawaban.
Passage dipecah berdasarkan paragraf. Satu paragraf akan menjadi satu
maka akan dipecah lagi menjadi beberapa passage dengan maksimal jumlah kalimat adalah 10. Langkah-langkah pembuatan passage
digambarkan dalam gambar 3.1.1f.
Filepassage akan diberinama dengan format
No_dokumen_awal-no_passage_dari_dokumen
Contohnya bila passage itu berasal dari dokumen no 54 dan passage itu merupakan passage pertama dari dokumen tersebut, makan nama filenya adalah
54-1.xml
Passage akan di simpan dalam format seperti berikut ini: <?XML VERSION =”1.0” ?>
<passage docno=“ “ no=” ”>
<kalimat>
<person> </person> <tempat> </tempat> <relasi>
</relasi> <senjata> </senjata> <angka> </angka>
</sentence>
</passage>
Contoh sebuah passage :
<?XML VERSION =”1.0” ?> <passage docno=“54“ no=”7”>
Kuruprawira </person>, arti satria Dinasti <person> Kuru </person> baik, arti harfiah Perwira <person> Kuru </person>.</sentence> </passage>
Input-an dari proses ini adalah koleksi dokumen hasil parsing dan
output-nya adalah koleksi passage.
Gambar 3.1.1.g gambar file-file preproses
Gambar 3.1.1.h koleksi-koleksi dokumen
Tidak semua dari file-file atau koleksi ini akan digunakan. File-file atau koleksi yang akan digunakan akan terlihat pada proses 3. Selain dari file
atau koleksi yang digunakan di proses 3, file-file dan koleksi tersebut dapat dihapus.
3.1.2. Indexing (Proses 2)
Proses index terdiri dari empat sub proses yang dapat dilihat pada gambar 3.1.2.a
a. Pembuatan FileIndex Dokumen (Sub Proses 2.1P)
File index akan berisi kata kunci, jumlah munculnya katakunci dalam seluruh koleksi, jumlah dokomen yang mengandung kata kunci tersebut
dan dokumen apa saja yang mengandung kata kunci tersebut dan jumlah
munculnya dalam dokumen itu.
Format filenya adalah sebagai berikut :
kosakata1:jml_kosakata:jml_dokumen&doc:jml_kosakata;…;… kosakata2:jml_kosakata:jml_dokumen&doc:jml_kosakata;…;… …
… …
Contoh
Arjuna:20:5&6:10;9:4;13:2;15:4 Arimbi:10:3&3:2;4:5;7:3
… … …
Langkah-langkah pembuatan file index ini akan ditunjukkan pada
gambar 3.1.2.b Flowchart pembuatan file index
Input-an dari proses ini adalah file preindex dan koleksi hasil parsing.
b. Pembuatan FileIndexPassage (Sub Proses 2.3P)
Proses ini sama dengan proses pembuatan file index dokumen, hanya saja, yang di-index kali ini bukanlah dokumen melainkan passage. Cara pembuatan file index ini juga sama dengan cara pembuatan file index
dokumen, begitu juga dengan format file-nya. File index passage ini akan digunakan saat merankingpassage pada proses 3. Input dari proses ini adalah file pre-index dan koleksi passage, output-nya adalah file
indexpassage.
3.1.3. Pengolahan Pertanyaan dan Pencarian Jawaban (Proses 3)
Proses pengolahan pertanyaan dan Pencarian Jawaban adalah proses utama
dari Sistem tanya jawab. Proses ini berhubungan langsung dengan user, namun proses ini tidak dapat berjalan bila tidak dilakukan preproses dan
indexing. Proses ini akan dijalankan setiap user mengajukan pertanyaan. Terdapat empat sub proses dalam proses ini yang dapat dilihat pada gambar
Gambar 3.1.3.a DAD level 2 proses 3
a. Analisa Pertanyaan (Sub Proses 3.1)
Terdapat empat buah sub proses dalam proses ini yang dapat dilihat pada
gambar 3.1.3.b DAD level 3 proses 3.1
1. Pengelompokan Pertanyaan (Sub Proses 3.1.1P)
Pada blok proses ini terjadi proses pengelompokan pertanyaan.
Setiap pertanyaan akan dikelompokkan berdasarkan kata tanyanya :
• Apa
Mewakili pertanyaan mengenai senjata, dan hubungan
Contoh pertanyaannya adalah :
Senjata apa yang Arjuna dapat dari dewa Indra?
Apa hubungan Pandu dan Kunti?
• Siapa
Mewakili pertanyaan mengenai person
Siapa yang menculik Sinta?
Siapa ayah Gatotkaca?
• Di mana
Mewakili pertanyaan mengenai tempat / lokasi
Contoh pertanyaannya adalah :
Di mana Yudhistira moksa?
• Berapa
Mewakili pertanyaan mengenai jumlah / tanggal
Contoh pertanyaannya adalah :
Berapa jumlah pasukkan pandawa saat berperang di kuruksetra?
Abimanyu tewas pada hari keberapa dalam perang di kuruksetra?
Bila ada pertanyaan yang tidak menggunakan kata tanya diatas maka
dianggap bahwa “sistem tidak mampu atau belum mendukung
pertanyaan user”.
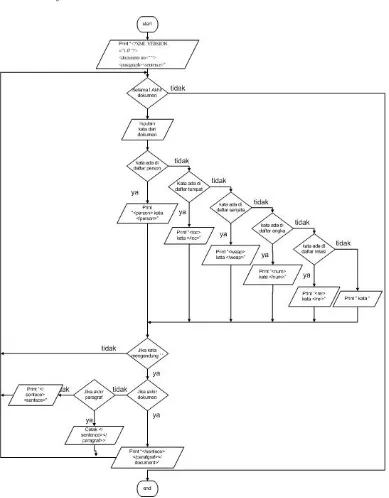
gambar 3.1.3.c Flowchart pengelompokkan pertanyaan jawaban
2. Stemming (Sub Proses 3.1.2P)
Stemming pada proses ini langkah-langkahnya sama dengan proses
Stemming pada proses 1.4.1P.
3.1.2P dan output-nya adalah pertanyaan yang telah di Stemming
menuju ke proses 3.1.4P
3. Stopword removal (Sub Proses 3.1.3P)
Stopword removal dilakukan dengan cara yang sama dengan proses 1.3.3P.
Input-an proses ini adalah pertanyaan tanpa kata tanya dari proses 3.1.1P, output-nya adalah pertanyaan tanpa stopword menuju ke proses 3.1.4P
4. Pembuatan Kueri (Sub Proses 3.1.4P)
Pembuatan kueri dilakukan dengan melihat pada file sinonim kueri dan file sinonim kata. Urutan pembuatannya adalah :
1. seluruh kata kunci diberi bobot 4.
2. kemudian seluruh kata kunci dicari persamaan kuerinya
dengan melihat file sinonim kueri. Kata-kata sinonim tersebut ditambahkan pada kata kunci, tetapi dengan bobot lebih kecil,
yaitu 1.
3. setelah itu, dengan menggunakan sinonim kata, apakah ada
kata-kata dalam pertanyaan yang memiliki sinonim, bila ada
masukkan juga sinonimnya sebagai kata kunci kueri dengan
bobot 1.
contohnya adalah pertanyaan “Siapa ayah gatotkaca?” Setelah
“ayah gatotkaca”.
1. setelah ditambah dengan sinonim kueri maka akan
menghasilkan : ayah, gatotkaca, anak.
2. kemudian dengan melihat pada sinonim kata, maka akan
menjadi : ayah, gatotkaca, anak, bapak, wrekudara, putra.
b. Pencarian dan Ranking Dokumen (Sub Proses 3.2)
Terdapat dua buah sub proses dalam proses ini yang dapat dilihat pada
gambar 3.1.3.c
Gambar 3.1.3.d DAD level 3 proses 3.2
1. Pencarian dokumen (Sub Proses 3.2.1P)
Proses ini menerima input-an berupa kueri dari proses 3.1, kueri tersebut kemudian di lakukan pada file index. Contoh setelah kueri dilakukan pada file index adalah sebagai berikut:
Ayah:5:2&2:2;6:3
Gatotkaca:4:3&1:2;5:1;6:1 Anak:12:3&2:3;6:7;9:2 Bapak:1:1&2:1
Putera:3:2&7:1;9:1 Putra3:1&10:3
Hasil pencarian dokumen tersebut kemudian digunakan untuk proses
berikutnya
2. Ranking dokumen (Sub Proses 3.2.2P)
Setelah mendapatkan dokumen yang relevan, maka akan dibuat
ranking relevansi dari tiap dokumen. Ranking dibuat melihat jumlah kata kunci yang terdapat pada dokumen itu dan dihitung
menggunakan perhitungan TF-IDF. Hasil perhitungan TF-IDF setiap
kata kunci kemudian dikalikan dengan bobotnya. Setelah selesai
dihuting, kemudian diurutkan yang terbersar dan diambil 10
dokumen teratas.
Output proses ini adalah urutan dokumen yang relevan terhadap pertanyaan.
c. Pencarian dan RankingPassage (Sub Proses 3.3)
Terdapat dua buah sub proses dalam proses ini yang dapat dilihat pada
gambar 3.1.3.e DAD level 3 proses 3.3
1. Pencarian Passage (Sub Proses 3.3.1P)
Dalam proses ini yang dilakukan adalah sama dengan yang
dilakukan pada proses 3.2.1P yaitu pencarian, bedanya pada proses
ini index yang digunakan adalah index passage. Contoh hasil dari kueri pada index passage:
Ayah:2:5&2-1:2;6-1:1;6-2:3
Gatotkaca:4:4&1-1:2;5-1:1;6-1:1;6-2:1 Anak:3:12&2-1:3;6-1:7;9-1:2
Bapak:1:1&2-2:1 Wrekudara:1:1&9-3:1 Putera:2:3&7-4:1;9-3:1 Putra:1:3&10-2:3
Dari setiap kata kunci akan didapatkan baris index yang berisi
passage mana saja yang mengandung kata tersebut. Passage-passage
ini kemudian diperiksa dengan top-10 ranking dokumen hasil dari
passage itu akan dibuang.
Passage-passage yang merupakan bagian dari top-10 ranking dokumen akan digunakan untuk proses selanjutnya.
2. RankingPassage (Sub Proses 3.3.2P)
Setelah mendapatkan sekumpulan passage yang mengandung kandidat jawaban, kemudian passage ini di ranking juga menggunakan metode TF-IDF yang kemudian dikalikan dengan
bobot kata kuncinya. Input dari proses ini adalah kandidat passage
yang relevan. Output dari proses ini adalah urutan passage yang mengandung kandidat jawaban.
d. Ekstraksi Jawaban (Sub Proses 3.4)
Proses ini menerima input-an berupa urutan passage yang mengandung kandidat jawaban dari proses 3.3 dan jenis pertanyaan dari proses 3.1.
Ekstraksi jawaban dilakukan dengan memberikan skor pada setiap
passage berdasarkan :
1. Passage akan mendapatkan skor tambahan 1, bila memiliki
gambar 3.1.3.f Flowchart skor passage 1
Contoh :
Pertanyaan : “Apa hubungan subali dan sugriwa?”
Pertanyaan diatas akan dikategorikan sebagai pertanyaan mengenai
“relation”, maka QToken = “relation”.
Contoh passage yang ditemukan :
Passage 110-5 :
<?XML VERSION ="1.0" ?> <passage docno=110 no=5>
<sentence> sungguh hati <person>subal</person> <person>sugriwa</person> angkat goa
<location>kiskenda</location>..</sentence>
<sentence> mulut gua <person>subal</person> pesan <relation>adik</relation> waspada jaga
jaga..</sentence>
<sentence> apabila cair darah warna merah seluruh musuh sirna muka..</sentence>
Di mana :
QToken = token dari
pengelompokan
pertanyaan
Pi = Passsage ke i
<sentence> apabila genang darah putih alir gua
<person>sugriwa</person> utup pintu gua..</sentence>
<sentence> <person>sugriwa</person> sanggup <person>subal</person> labrak
<person>maesasura</person>
<person>lembusura</person>.</sentence>
</passage>
Maka passage ini akan mendapat skor +1, Spi += 1.
2. Bila di dalam passage terdapat kata kunci kueri, maka passage
akan mendapatkan skor 1 untuk setiap kata kunci yang ada.
gambar 3.1.3.g Flowchart skor passage 2
Contoh pada passage 110-5 di atas, terdapat kata “subali” dan sugriwa”, tetapi tidak terdapat kata ”hubungan”, maka passage akan mendapatkan skor +2.
Di mana :
Q = kata kunci kueri
Qj = kata kunci kueri ke j
Pi = Passsage ke i
SPi = Skor Passage i
3. Bila dalam satu kalimat terdapat kata kunci kueri yang berbeda,
1.
Di mana :
P = Passage
Q = kata kunci kueri
Si = Kalimat dari Passage i
Sik = Kalimat ke k dari
Passage ke i
Qj = kata kunci kueri ke j
SPi = Skor Passage i
gambar 3.1.3.h Flowchart skor passage 3
Contoh pada passage 110-5 di atas, pada kalimat ke-1 dan kalimat ke-5, dalam satu kalimat terdapat lebih dari 1 kata kunci kueri. Maka
passage ini mendapat skor +2.
Skor total dari passage 110-5 ini adalah 1+2+2 = 5.
Untuk setiap kandidat dalam passage juga diberi penilaian dengan ketentuan :
1. Setiap kandidat jawaban (token yang sesuai dengan jenis pertanyaan),
dihitung jaraknya dengan setiap kata kunci kueri yang terdapat
dalam passage tersebut. Jaraknya dihitung secara absolute (tidak ada negative). Jarak kandidat jawaban dengan setiap kata kunci dihitung
dari jumlah kata yang ada diantara kandidat dan kata kunci. Jarak
tersebut kemudian dibagi dengan bobot katakunci. Setelah itu
dijumlah dengan seluruh jarak kata kunci yang ada, kemudian dibagi
dengan kuadrat kata kunci yang ditemukan.
(
C
Q
BQ
)
n
DCil = Jarak kandidat dan kata kunci kueri
Cil = Kandidat passage i ke l
Qim = Kata kunci kueri pada passage i ke m
BQim = Bobot kata kunci kueri pada passage i ke m
n = jumlah kata kunci kueri yang terdapat dalam passage i Contoh :
1 2 3 4 5 6 7
sungguh Hati subal sugriwa angkat goa kiskenda
8 9 10 11 12 13 14
mulut Gua subal pesan adik waspada jaga
15 16 17 18 19 20 21
jaga Apabila cair darah warna merah seluruh
22 23 24 25 26 27 28 musuh Sirna muka apabila genang darah putih
29 30 31 32 33 34 35
alir Gua sugriwa utup pintu gua sugriwa
36 37 38 39 40
sanggup Subal labrak maesasura lembusura Tabel 3.1.3 Tabel kata passage
Pada array passage 110-5 dapat dilihat bahwa kandidat jawaban yang
ditemukan adalah ”adik” pada array index 12. Selain itu ditemukan
juga kata kunci kueri pada array indeks 3, 4, 10, 31, 35, dan 37.
Sehingga bila dimasukkan ke dalam rumus akan menjadi :
Cil = Kandidat passage i ke l
Kata kunci kueri yang terdapat pada pertanyaan akan mendapat
hasil pencarian sinonim, bobotnya yaitu 4.
BQ110-5 1 = 4
BQ110-5 2 = 4
BQ110-5 3 = 4
BQ110-5 4 = 4
BQ110-5 5 = 4
BQ110-5 6 = 4
n = jumlah kata kunci kueri yang terdapat dalam passage i
n = 6.
Sehingga :
DC110-5 1 = ( (| C110-5 1 - Q110-5 1| / BQ110-5 1) + (| C110-5 1 - Q110-5 2| /
BQ110-5 2) + (| C110-5 1 - Q110-5 3| / BQ110-5 3) + (| C110-5 1 -
Q110-5 4| / BQ110-5 4) + (| C110-5 1 - Q110-5 5| / BQ110-5 5) + (|
C110-5 1 - Q110-5 6| / BQ110-5 6)) / n2
DC110-5 1 = ( (| 12 - 3 | / 4 ) + (| 12 - 4 | / 4 ) + (| 12 - 10 | / 4 ) + (| 12 -
31 | / 4 ) + (| 12 - 35 | / 4 ) + (| 12 - 37 | / 4 )) / 62
DC110-5 1 =( (9/4) + (8/4) + (2/4) + (19/4) + (23/4) + (25/4)) / 36
DC110-5 1 =( 2.25 + 2 + 0.5 + 4.75 + 5.75 + 6.25) / 36
DC110-5 1 = 21.5 / 36
DC110-5 1 = 0.597
dibagi dengan kuadrat jumlah kandidat jawaban sama.
Di mana :
Cij = Kandidat passage i ke j
Cik = Kandidat passage i ke k
gambar 3.1.3.i Flowchart skor kandidat 1
Untuk contoh menggunakan passage 110-5, karena tidak terdapat kandidat jawaban sama, maka :
DCij = DCij
DC110-5 1 = 0.597
3. Kemudian skor setiap kandidat jawaban dibagi dengan skor
passagenya.
SP
DC
SC
i il il =
Di mana :
SCil = Skor kandidat passage i ke l