Sistem Inferensi Fuzzy berbasis
Feedback User
dan
Ekstraksi Fitur Musik Untuk Pengenalan Emosi
Pada Musik
Ifriandi Labolo [email protected]
ABSTRACT
Music has become one of the important things in our world, because almost all the activities we did not loose connection with the music. Working while listening to music with a low volume makes a person more relaxed in completing the work. To the present understanding of music not only on human perception, but also research on how music develops computer can understand the emotions in the music.
The method is often used to analyze emotions in music including music using feature extraction. The music feature extraction results when a rule can be applicable to generate emotional information contained in the music. However, the use of the extracted features alone as parameter determining emotion emotion recognition has not been able to produce an accurate, because the extraction of the feature contains many ambiguous (dual membership), so the selection of the membership of each feature are often wrong and incompatible with human intuition. This study proposed the model of emotion recognition in music -based fuzzy inference system and user feedback to improve the accuracy of emotion recognition results. Fuzzy chosen because emotions are vague and very close to human intuition.
Eculidean measurement results using the average distance of the participants at 10:56. This proves that the value of model-based fuzzy inference system and user feedback can improve the recognition accuracy of emotion in music.
Keywords: emotional music, feature extraction, fuzzy inference system
ABSTRAK
Musik telah menjadi salah satu hal penting di dunia kita, karena hampir seluruh kegiatan kita tidak lepas kaitannya dengan musik. Bekerja sambil mendengarkan musik dengan volume yang rendah membuat seseorang lebih rileks dalam menyelesaikan pekerjaannya. Sampai pada saat ini pemahaman musik tidak hanya pada persepsi manusia saja, akan tetapi penelitian musik berkembang pada bagaimana komputer dapat memahami emosi pada musik.
Metode yang sering digunakan untuk menganalisa emosi pada musik di antaranya menggunakan ekstraksi fitur musik. Hasil ekstraksi fitur musik ini apabila diterapakan pada suatu aturan dapat menghasilkan informasi emosi yang terkandung pada musik tersebut. Akan tetapi penggunaan hasil ekstraksi fitur saja sebagai parameter penentu emosi belum dapat menghasilkan pengenalan emosi yang akurat, karena dalam ekstraksi fitur tersebut mengandung banyak ambigu (keanggotaan ganda), sehingga pemilihan keanggotan dari masing-masing fitur sering salah dan tidak sesuai dengan intuisi manusia. Penelitian ini mengusulkan model pengenalan emosi pada musik berbasis sistem inferensi fuzzy dan feedback user untuk meningkatkan akurasi hasil pengenalan emosi. Fuzzy dipilih karena emosi bersifat samar dan sangat dekat dengan intuisi manusia. Hasil pengukuran menggunakan eculidean distance dari rata-rata partisipan sebesar 10.56. Nilai ini membuktikan bahwa model berbasis sistem inferensi fuzzy dan feedback user dapat meningkatkan akurasi pengenalan emosi pada musik.
Kata Kunci: Emosi musik, Ekstraksi fitur, Sistem inferensi fuzzy
Musik telah menjadi salah satu hal penting di dunia kita [1]. Hampir seluruh kegiatan kita tidak lepas kaitannya dengan musik. Manusia
sambil mendengarkan musik dengan volume yang rendah membuat seseorang lebih rileks dalam menyelesaikan pekerjaan tersebut, atau orang yang sedang mendapatkan masalah biasanya memilih mendengarkan musik untuk menenangkan perasaannya.
Perkembangan musik digital membuat tren musik tidak berhenti sampai pada persepsi manusia saja. Beberapa tahun belakangan muncul kajian baru pada bidang Music Intelligence yaitu Music Information Retrieval (MIR) [3]. Penelitian-penelitian pada MIR di antaranya adalah tentang bagaimana komputer dapat memahami emosi yang ada pada sepotong musik (Music Emotion Recognition) [4]. Hal ini merupakan tantangan yang sulit, karena persepsi manusia terhadap emosi selalu berbeda [5]. Music Emotion Recognition
(MER) menggunakan pendekatan model
emosi psikologi untuk membantu memodelkan emosi manusia agar dapat dipahami komputer [3] [6] [7].
Beberapa penelitian pada MER menggunakan ekstraksi fitur [8]. Ketepatan akurasi hasil emosi sangat dipengaruhi oleh parameter dan hasil ekstraksi fitur yang digunakan. Permasalahan yang timbul akibat ekstraksi fitur ini yaitu hasil dari proses ekstraksi tersebut berupa nilai crisp (tegas), sehingga sering terjadi ambigu atau pemaknaan ganda pada proses ekstraksi fitur ini. Misalnya setelah di ekstrak, tempo mempunyai nilai tegas 76, sedangkan menurut kamus musik Banoe-Pono [9] dan Dictionary of Music [10], tempo 76 tersebut termasuk tipe tempo Adagio (tempo lambat) dengan keanggotaan 66-76
dan Andante (tempo sedang) dengan
keanggotaan 76-108. Di sini telihat bahwa tempo 76 tersebut mempunyai keanggotaan ganda, yaitu sebagai Andante dan sebagai Adagio. Pemilihan jenis tempo dan hasil ekstraksi fitur yang salah dapat menyebabkan pengenalan emosi nanti menjadi kurang akurat. Selain itu masing-masing instrument musik memiliki warna dan emosinya sendiri, lagu yang sama tetapi dimainkan dengan instrument yang berbeda seperti piano, string, atau flute tentunya mengandung emosi yang berbeda pula, sehingga penggunaan fitur seperti tempo, mode, atau loudness saja belum
cukup untuk dijadikan parameter penentu emosi.
Penelitian ini mengembangkan model
pengenalan emosi musik berbasis sistem inferensi fuzzy dan feedback user. Sistem inferensi fuzzy dipilih karena menurut Seif El-Nasr, M. dalam penelitiannya tentang
klasifikasi musik berdasarkan emosi
berpendapat bahwa “Fuzzy logic is a more
appropriate mathematical tool for emotion detection” [11]. Sedangkan menurut Rossant [8] pada penelitiannya tentang Optical Music Recognition berpendapat bahwa, “Fuzzy sets and possibility theory offer a good framework for resolve ambiguities result from feature extraction”. Feedback user akan digunakan dalam proses training, ini dilakukan untuk memperkecil selisih perbedaan jarak antara
model yang diusulakan dengan hasil
intrepretasi user (praktisi musik) dalam menetukan emosi pada musik. Mereka berpendapat bahwa pemanfaatan isyarat akustik dalam emosi musik dapat digunakan untuk mencari hubungan korelasi antara ekspresi emosi, seperti marah, sedih, dan bahagia dengan isyarat akustik seperti tempo, spektrum, dan artikulasi.
S ong
Sistem Inferensi Fuzzy
+ feedback user
Nilai Arousal/Valence
Pengolahan awal data
Label Emosi
S ong
Rule s
Pengolahan awal data
Label Emosi fitur musik, selanjutnya mereka menggunakan
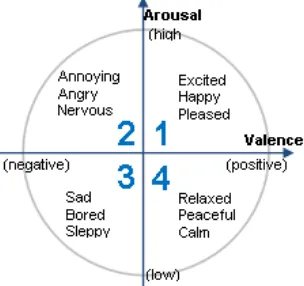
SVR (Support Vector Regression) untuk mapping ke model emosi Thayer’s (Gambar 1. Thayers emotions model). Hasil terbaik dari hasil evaluasi statistik � yang mereka peroleh yaitu 58.3% untuk arousal dan 28.1% untuk valence.
Peneliti lainnya, Han et all [4] melakukan penelitian yang serupa. Mereka menggunakan empat fitur seperti Scale, Average Energy
(AE), Rhythm,dan Harmonics sebagai
parameter penentu emosi. Penelitian ini menggunkan metode SVR, SVM, dan GMM untuk mencari nilai AV. Pengukuran pada penelitian ini dilakukan dengan dua metode, yaitu koordinat Cartesian dan Polar. Hasil terbaik yang diperoleh adalah untuk koordinat cartesian yaitu 91.52% (151 dari 165 sampel), sedangkan untuk koordinat polar yaitu 94.55% (156 dari 165 sampel). Dari hasil pengukuran ini terlihat bahwa akurasi dengan menggunakan polar lebih baik dibandingkan menggunakan koordinat cartesian.
Selanjutnya penelitian yang dilakukan oleh Yang, Liu, dan Chen [13], melakukan komparasi terhadap metode klasifikasi berbasis fuzzy, yaitu Fuzzy K-NN Classifier dan Fuzzy Nearest-Mean. Metode klasifikasi ini digunakan untuk mengukur kekuatan emosi pada sebuah lagu. Untuk memperoleh tempo,
loudness, dan fitur lainnya, mereka
menggunakan framework PsySound. Hasil akurasi yang diperoleh untuk FKNN adalah 68.22% dengan β=0.75, sedangkan untuk FNM lebih baik dibandingkan FKNN yaitu 71.43%.
Gambar 1. Thayers emotions model
2. MODEL YANG DIUSULKAN
Pada model berbasis ekstraksi fitur secara umum (Gambar 2.a), setelah fitur dari audio diperoleh dan dengan menerapkan beberapa aturan pakar maka nilai arousal dan valence (AV value) akan langsung diketahui.
Gambar 2. (a) Model berbasis Ekstraksi Fitur. (b) Model berbasis sistem inferensi fuzzy dan feedback
user
Model berbasis ekstraksi fitur ini memiliki kelemahan pada hasil ekstraksi fitur. Karena emosi sangat dekat dengan intuisi manusia, maka penggunaan nilai ekstraksi fitur yang berupa nilai crisp atau tegas dapat mengandung banyak ambigu (keanggotaan ganda).
Untuk mengatasi permasalahan ini, maka digunakan sistem pengenalan emosi musik berbasis sistem inferensi fuzzy (Gambar 2.b), karena fuzzy dapat mengatasi ambigu pada hasil ekstaksi fitur sehingga fitur yang dijadikan parameter untuk pemetaan pada
model emosi merupakan fitur dengan
keanggotaan yang benar. Selanjutnya untuk mendapatkan hasil pengenalan emosi pada musik yang lebih akurat tidak cukup dengan menggunakan sistem inferensi fuzzy saja, oleh karena
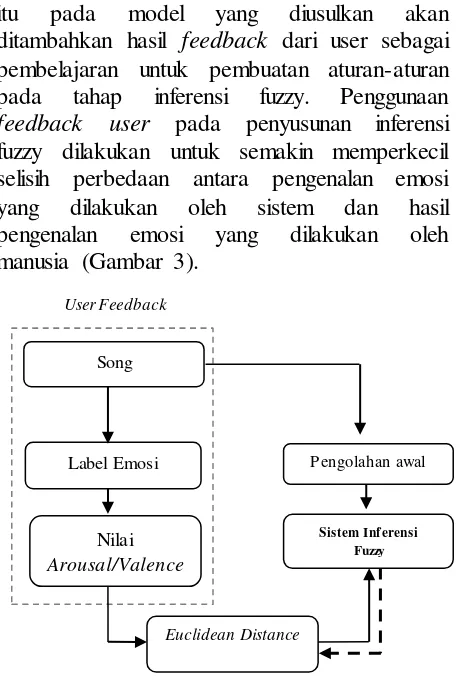
itu pada model yang diusulkan akan ditambahkan hasil feedback dari user sebagai pembelajaran untuk pembuatan aturan-aturan pada tahap inferensi fuzzy. Penggunaan feedback user pada penyusunan inferensi fuzzy dilakukan untuk semakin memperkecil selisih perbedaan antara pengenalan emosi yang dilakukan oleh sistem dan hasil pengenalan emosi yang dilakukan oleh manusia (Gambar 3).
Gambar 3. Tahap learning menggunakan feedback user untuk penyusunan inferensi
Model yang diusulkan dibagi menjadi dua tahapan, yang pertama adalah tahap learning menggunakan feedback user dan tahap selanjutnya adalah tahap pengenalan emosi musik itu sendiri. Sebuah lagu yang sama akan diujikan kepada tiga orang praktisi musik yang telah dipilih sebelumnya. Dari hasil pengenalan emosi oleh tiga praktisi musik ini kemudian akan dibandingkan dengan sistem pengenalan emosi musik berbasis sistem inferensi fuzzy menggunakan pengukuran euclidean distance. Jika terdapat perbedaan antara nilai arousal dan valence oleh sistem dan hasil feedback oleh user tersebut maka akan dicari rata-rata nilai arousal dan valence dari tiga orang partisipan, dan hasil yang diperoleh akan diterapkan pada aturan yang telah dibuat sebelumnya.
2.1 Sistem Inferensi Fuzzy
Sistem Inferensi Fuzzy atau Fuzzy Inference System (FIS) merupakan bagian dari fuzzy
system yang memungkinkan pengetahuan
seorang pakar dapat ditransfer ke dalam suatu perangkat lunak, sehingga perangkat lunak tersebut dapat memetakan suatu input menjadi output berdasarkan IF-THEN rule yang diberikan [14]. Berbeda dengan logika digital yang hanya memiliki dua nilai yaitu 1 (Satu) atau 0 (Nol), logika fuzzy memiliki nilai yang disebut derajat keanggotaan dalam rentang 0 (Nol) sampai 1 (Satu), sehingga dengan logika fuzzy kita dapat merepresentasikan keadaan yang ada di dunia nyata menggunakan bahasa (linguistic).
Secara umum suatu sistem berbasis aturan fuzzy terdiri dari tiga komponen utama, yaitu: Fuzzification, Inference, dan Defuzzyfication.
1. Fuzzification
Fuzzification atau fuzzifikasi merupakan proses pengubahan nilai input yang berada dalam suatu himpunan tegas menjadi nilai input yang berada dalam suatu himpunan fuzzy [15]. Dalam menentukan apakah suatu elemen merupakan anggota dari suatu himpunan fuzzy tidak semudah himpunan tegas. Derajat keanggotaan berupa bilangan real dalam interval tertutup [0, 1], dengan demikian fungsi keanggotaan dari suatu himpunan fuzzy dalam semesta x adalah pemetaan µ� dari x ke
Input untuk fuzzifikasi pada penelitian ini adalah empat hasil ekstraksi fitur musik, yaitu tempo, loudness, mode, dan timbre.
2. Inference
setiap nilai variabel tidak bebas menyatakan ukuran kompabilitas terhadap variabel bebas (pada antecedent).
3. Defuzzyfication
Defuzzification atau penegasan berfungsi untuk mengubah fuzzy output menjadi crisp value berdasarkan fungsi keanggotaan yang telah ditentukan [15]. Penelitian ini menggunakan metode Centroid Method untuk medapatkan nilai hasil defuzzyfication. Persamaan untuk centroid method adalah sebagai berikut:
y* = ∑ ��� � ∑ �� �
Persamaan di atas digunakan apabila y berupa nilai diskrit.
2.2 Ekstraksi Fitur Musik
Ekstraksi fitur merupakan langkah penting dalam pembelejaran mesin (machine learning) [16]. Ekstraksi fitur digunakan untuk memperoleh informasi musik dari analisa dan perhitungan yang dilakukan pada sinyal audio. Hasil ekstraksi berpengaruh besar terhadap hasil pengenalan emosi nanti. Fitur dari musik yang akan diekstraksi adalah tempo, loudness, mode, dan timbre.
1.Tempo
Menurut kamus Banoe Pono [9] dan Dictionary of Music [10], pembagian tempo dapat dikategorikan menjadi tiga bagian, yaitu tempo pelan (slow), tempo sedang (middle), dan tempo cepat (fast). Tempo diukur dengan satuan beat per minute (bpm). Tempo digunakan untuk mengukur tingkat energi atau
arousal pada sebuah lagu. Ekspresi
keanggotaan untuk tempo adalah sebagai berikut:
2. Loudness
Loudness dikelompokan menjadi dua kategori yaitu loudness pelan (silent) dan keras (loud) [17]. Pengelompokan ini didasarkan atas tingkatan bunyi yang mampu didengar oleh manusia. Fitur ini digunakan untuk mengukur tingkat energi atau arousal pada sebuah lagu. Ekspresi keanggotaan untuk loudness adalah sebagai berikut:
3. Mode
Mode dikelompokan menjadi dua, yaitu mode minor dan mode mayor. Dimana mode minor memiliki nilai lebih kecil dari 0, sedangkan mode mayor memiliki nilai lebih besar dari 0. Fitur ini digunakan untuk mengukur tingkat stress atatu valence pada model emosi. Pengelompokan ini didasarkan atas panduan manual MIRToolBox oleh Lartillot [18]. Ekspresi keanggotaan untuk mode adalah sebagai berikut:
4. Timbre
Timbre dikelompokan ke dalam dua kategori, yaitu timbre gelap (dark) dan timbre terang (bright). Pengelompokan ini didasarkan atas Wapnick dan Freeman dalam Collier [19]. Wapnick berpendapat bahwa alat musik seperti brass, string dengan oktav tinggi, saxophone, flute, dan clarinet cenderung
memiliki warna suara yang terang
digunakan untuk mengukur tingkat stress atau
valence pada sebuah lagu. Ekspresi
keanggotaan untuk timbre adalah sebagai berikut:
2.3 Eksperimen dan Pengujian Model Secara keseluruhan sistem ini terbagi atas dua bagian, bagian yang pertama adalah ekstraksi fitur yang dibangun menggunakan tool programing Matrix Labolatory (MATLAB)
R2009b. MATLAB menyediakan banyak
library fungsi matematika di antaranya untuk
keperluan signal processing, audio
processing, transformasi domain, dan lain sebagainya. Pada bagian ini digunakan
framework MIRToolBox untuk melakukan
ekstraksi fitur musik.
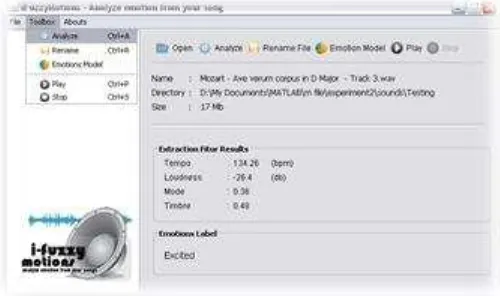
Bagian yang kedua adalah sistem inferensi fuzzy untuk pengenalan emosi, pada bagian ini dikembangkan sebuah framework sistem inferensi fuzzy yang disebut dengan FuzzyBox. Framework ini dibangun untuk lingkup pemrograman Java. Paket Java yang digunakan merupakan include dari Netbeans 6.9.1. Rancangan program utama dibuat dengan menggunakan java. Walaupun sistem ini dirancang dengan menggunakan dua tool pemrograman, tetapi kita hanya cukup menjalankan satu file *.jar yang merupakan hasil kompiler dari program utama tersebut.
Gambar 4. GUI iFuzzyMotions
Metode pengukuran yang digunakan pada penelitian ini yaitu Euclidean Distance. Teknik ini akan menghitung jarak antara hasil pengenalan emosi oleh prototipe sistem ini dan hasil pengenalan emosi oleh beberapa praktisi musik. Rumus untuk mencari euclidean distance adalah sebagai berikut:
� = √ − + −
Dimana x1 merupakan koordinat x dari titik
pertama, x2 merupakan koordinat x dari titik
kedua, y1 merupakan koordinat y dari titik
pertama dan y2 merupakan koordinat y dari
titik kedua. Dari persamaan ini akan dicari nilai d yang paling kecil, karena semakin kecil jarak antara keduanya maka semakin akurat pula hasil pengenalan emosi antara partisipan dan model.
Sampel musik yang digunakan untuk
pengujian yaitu 30 lagu tanpa vokal dengan genre Classic Symphony dan 20 lagu dengan vokal ber-genre POP, Kroncong, dan Latin.
3. EVALUASI DAN VALIDASI HASIL
Pada ekperimen pertama dilakukan
perbandingan model pengenalan emosi
berbasis ekstraksi fitur dengan hasil pengenalan emosi yang dilakukan oleh partisipan. Hasil yang diperoleh adalah sebagai berikut:
Tabel 1. Evaluasi model deteksi emosi berbasis ekstraksi fitur
Partisipan 1 Partisipan
2 Partisipan 3
Kasus
terbaik
0.75 - Lagu
ke 42
1.05 -
Lagu ke
49
0.75 – Lagu
ke 33
Kasus
terburuk
70.16 - Lagu
ke 3
61.99 -
Lagu ke 3
58.67 – Lagu
ke 3
Rata-rata 17.23 16.75 12.08
Gambar 5. Perbandingan model berbasis ekstraksi fitur dengan partisipan
Dari hasil tabel 1 diketahui nilai rata-rata dari ke tiga partisipan untuk kasus terbaik diperoleh sebesar 0.85, dan kasus terburuk dari ke tiga partisipan diperoleh sebesar 63.60. Hasil rata-rata dari ke tiga partisipan adalah 15.35. Nilai ini menunjukan bahwa pengenalan emosi berbasis ekstraksi fitur belum dapat menghasilkan pengenalan emosi yang akurat, karena nilai rata-rata yang diperoleh masih cukup tinggi.
Pada eksperimen kedua dilakukan perbandingan antara model pengenalan emosi berbasis sistem inferensi fuzzy
dengan hasil pengenalan emosi dari partisipan, dan hasil yang diperoleh adalah sebagai berikut:
Tabel 2. Evaluasi model deteksi emosi berbasis sistem inferensi fuzzy
Partisipan 1 Partisipan 2 Partisipan 3
Kasus
terbaik
0.75 - Lagu
ke 42
0.72 – Lagu
ke 38
0.67 - Lagu
ke 41
Kasus
terburuk
47.67 -
Lagu ke 14
46.08 - Lagu
ke 14
48.29 -
Lagu ke 13
Rata-rata 12.10 15.45 12.57
Dari hasil tabel 2 diketahui nilai rata-rata ke tiga partisipan untuk kasus terbaik diperoleh 0.71, untuk kasus terburuk diperoleh 47.34, dan hasil rata-rata dari ketiga partisipan adalah
13.37. Nilai ini menunjukan bahwa
pengenalan emosi berbasis sistem inferensi fuzzy lebih tinggi akurasinya dibandingkan dengan model berbasis ekstraksi fitur. Hasil visualisasi dapat dilihat pada gambar 6.
Gambar 6. Perbandingan model berbasis sistem inferensi fuzzy dengan partisipan
Pada eksperimen terakhir dilakukan
Tabel 3. Evaluasi model deteksi emosi berbasis sistem inferensi fuzzy + feedback user
Partisipan 1 Partisipan 2 Partisipan 3
Kasus Nilai rata-rata yang diperoleh adalah 10.56. Dari nilai ini diperoleh kesimpulan, bahwa pengenalan emosi berbasis sistem inferensi fuzzy dengan penambahan feedback user dapat meningkatkan akurasi pengenalan emosi pada musik. Hasil visualisasi perbandingan model pengenalan emosi berbasis sistem inferensi fuzzy dan feedback user dapat dilihat pada gambar 7.
Gambar 7. Perbandingan model berbasis sistem inferensi fuzzy + feedback user dengan partisipan
4. KESIMPULAN
Dari hasil analisis, eksperimen, serta pengujian yang dilakukan, terlihat bahwa pengenalan emosi berbasis ekstraksi fitur saja memiliki tingkat pengenalan emosi yang kurang akurat dibanding dengan pengenalan
emosi menggunakan sistem inferensi fuzzy. Ini dibuktikan dengan tingginya nilai rata-rata selisih jarak oleh tiap partisipannya, yaitu 15.35. Ini membuktikan bahwa ambigu (keanggotaan ganda) pada hasil ekstraksi fitur sangat mempengaruhi hasil pengenalan emosi.
Untuk lebih memperkecil perbedaan hasil pengenalan emosi, maka untuk penyusunan inferensi fuzzy dibutuhkan pembelajaran dari hasil feedback user. Penerapan metode ini menghasilkan nilai rata-rata yang lebih kecil
yaitu 10.56 dari ketiga partisipan
dibandingkan menggunakan model yang
berbasis sistem inferensi fuzzy saja yang nilai rata-ratanya adalah 13.37.
Nilai yang diperoleh untuk model pengenalan emosi berbasis sistem inferensi fuzzy dan feedback user ini masih belum terlalu tinggi, karena ketepatan akurasi pengenalan emosi pada musik berbasis ekstraksi fitur sangat bergantung pada hasil ekstraksi fitur tersebut. Semakin akurat hasil fitur yang diekstrak, maka semakin akurat pula pengenalan emosinya. Berikut juga dengan sampel musik yang digunakan sangat mempengaruhi hasil ekstraksi fitur dan emosi yang terkandung dalam musik tersebut.
5. REFERENSI
[1] Thomas Lidy, "Evaluation of New Audio Features and Their Utilization in Novel Music Retrieval Applications," Viena University of Technology, Austria, PhD Thesis Dec. 2006.
[2] Patrik N. Juslin and Daniel Vastfjall, "Emotional responses to music:The need to consider underlying mechanisms," in University Press, Cambridge, 2008, pp. 559-621.
[3] Jun Sanghoon, Rho Seungmin, Han Byeong -jun, and Hwang Eenjun, "A Fuzzy Inference-based Music Emotion Recognition System," in
International Society for Music Information Retrieval (ISMIR), Korea, 2008, pp. 673-677.
651-656.
[5] Yi-Hsuan Yang, Chia-Chu Liu, and Homer H. Chen, "Music Emotion Recognition: The Role of Individuality," in International Society for Music Information Retrieval (ISMIR), Germany, 2007, pp. 21-29.
[6] Yi-Hsuan Yang, Yu-Ching Lin, Ya-Fan Su, and Homer H. Chen, "Music Emotion Clasification: A Regression Approach," in National Science Council, Taiwan, 2006.
[7] Yi-Hsuan Yang, Yu-Ching Lin, Ya-Fan Su, and Homer H. Chen, "A Regression Approach to Music Emotion Recognition," Audio, Speech, and Language Processing, vol. 16, no. 2, pp. 449-457, February 2008.
[8] Florence Rossant and Isabelle Bloch, "Optical Music Recognition Based on Fuzzy Modeling of Sysmbol Classes and Music Writing Rules," in
International Society for Music Information Retrieval (ISMIR), Paris, 2005.
[9] Pono Banoe, Kamus Musik. Jogjakarta, Indonesia: Kanisius, 2003.
[10] Christine Ammer, Dictionary Of Music. New York, United States of America: Acid-Free Paper, 2004.
[11] El-Nasr M. Seif, J. Yen, and T. Loerger, "FLAME – Fuzzy Logic Adaptive Mode Of Emotions,"
Autonomous Agents and Multi Agent Systems, vol. 3, pp. 219-257, 2000.
[12] P. N. Juslin and J. A. Sloboda, Music and Emotion: Theory and Research. New York: Oxford University Press, 2001.
[13] Yi-Hsuan Yang, Chia-Chu Liu, and Homer H. Chen, "Music Emotion Classification: A Fuzzy Approach," in National Science Council, Taiwan, 2006.
[14] Agus Naba, Belajar Cepat Fuzzy Logic Menggunak an MATLAB. Jakarta: Andy Offset, 2009.
[15] Suyanto, Soft Computing: Membangun Mesin Ber-IQ Tinggi. Bandung, Indonesia: Informatika Bandung, 2008.
[16] Alberto Zuccato, "Content-based Music Similarity, Visualization and Automatic Playlist Generation," in Audio Processing and Indexing, New York, January 2011.
[17] Mary Florentine, Arthur N. Popper, and Richard R. Fay, Loudness. New York, USA: Springer, 2011.
[18] Olivier Lartillot. (2011, January) MIR toolbox 1.3.2 Users Manual. Document.