Nama : SISCA DWI RAHMAWATI
NIM : 132211095
KELAS : MJS 5C
SKALA PENGUKURAN DAN METODE ANALISIS DATA
Tujuan dari analisis data adalah mendapatkan informasi relevan yang terkandung di dalam data tersebut dan menggunakan hasilnya untuk memecahkan suatu masalah. Hipotesis nol menggambarkan permasalahan dan “informasi relevan” yang terkandung di dalam data yang digunakan untuk menguji secara statistic hipotesis nol.
Skala pengukuran adalah kesepakatan yang digunakan sebagai acuan tolak ukur untuk menentukan panjang pendeknya interval yang ada pada alat ukur sehimgga alat ukur tersebut bila digunakan dalam pengukuran akan menghasilkan data.
Rasio : Pendapatan, harga barang Satu satuan real
Nominal : Gender, Religion Sama-sama identitas (tidak akan bisa ditambah) Ordinal : Tenaga Kerja, Penduduk, Juara Sama- sama identitas (tidak akan bisa ditambah) Interval : Nilai test, pengukuran sikap Memberikan nilai
Tujuan metode Dependen,!! : Menentukan apakah variable bebas mempengaruhi variable terikat secara individual dan atau bersamaan.
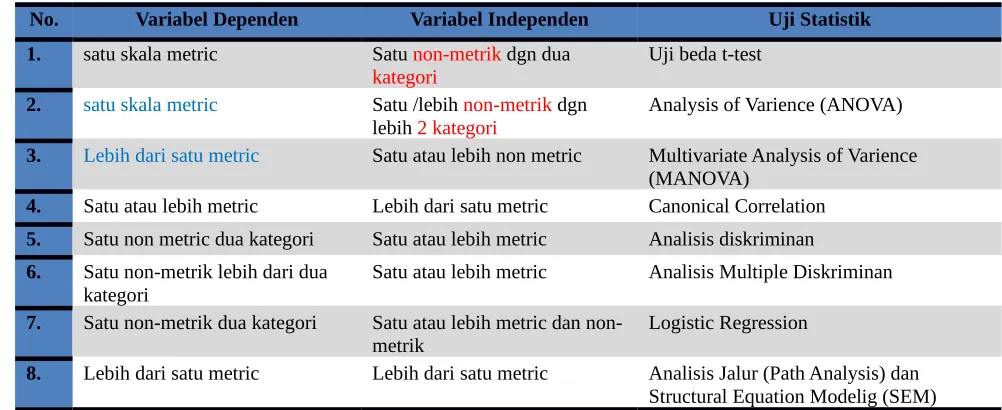
Table 1 Metode Statistik Dependen
No. Variabel Dependen Variabel Independen Uji Statistik
1. satu skala metric Satu non-metrik dgn dua kategori
Uji beda t-test
2. satu skala metric Satu /lebih non-metrik dgn lebih 2 kategori
Analysis of Varience (ANOVA)
3. Lebih dari satu metric Satu atau lebih non metric Multivariate Analysis of Varience (MANOVA)
4. Satu atau lebih metric Lebih dari satu metric Canonical Correlation 5. Satu non metric dua kategori Satu atau lebih metric Analisis diskriminan 6. Satu non-metrik lebih dari dua
kategori Satu atau lebih metric Analisis Multiple Diskriminan 7. Satu non-metrik dua kategori Satu atau lebih metric dan
non-metrik Logistic Regression
8. Lebih dari satu metric Lebih dari satu metric Analisis Jalur (Path Analysis) dan Structural Equation Modelig (SEM) Tujuan Metode Interdependen,!!: Memahami atau mengidentifikasi mengapa dan bagaimana variable” tersebut saling berkorelasi.
Tabel 2 Metode Statistik Interdependen
Jumlah variable Metric Non-metrik
Dua variable Korelasi sederhana Tabel kontjensi two-way
Loglinear models Lebih dari dua variable Principle components
Analisis factor
Table kontijensi Multiway Loglinear models
SPSS berfungsi untuk menganalisis data, melakukan perhitungan statistic baik untuk statistic parametric maupun non-parametrik dengan basis windows. Menu SPSS : file, edit, view, data, transform, analyze, graphs, utilities, add-ons, windows, help. Statistic deskriptif memberikan gambaran atau deskripsi suatu data yang dilihat dari nilai rata-rata (mean), std deviasi, variance, maksimum, minimum, sum, range, kurtosis dan skewness (kemencengan distribusi). Screening data diperlukan sebelum melakukan uji statistic. Salah satu asumsi penggunaan statistic parametric adalah asumsi multivariate normality. Asumsi ini dapat di uji dengan melihat normalitas, linearitas dan homoskedastisitas variable atau melalui residualnya.
Reabilitas :alat untuk mengukur suatu kuesioner yang merupakan indicator dari variable atau konstruk. Ada dua cara pengukuran reabilitas, : a. repeated measure (pengukuran ulang) b. One shot (pengukuran sekali). Validitas : digunakan untuk mengukur sah atau tidaknya suau kuesioner. Uji signifikan dilakukan dengan membandingkan nilai r hitung dengan r table untuk degree of freedom (df)= n-2, dalam hal ini n adalah jumlah sample. Analisis factor konfirmatori digunaka utuk meguji apakah suatu konstruk mempuyai uidimesioalitas atau apakah idikator-indikator (autonom1-4) yag digunaka dapat megkofirmasika sebuah kostruk atau variable (AUTONOMI)
Apabila variable independen berkategori dua, maka uji statistic yag digunakan adalah uji beda t-test, sedagka untuk variable independen yag berkategori lebih dari dua digunakan analisis of varience ( ANOVA ). Apabila jumlah variable dependen lebih dari satu maka diguaka multivariate analysis of variance ( MANOVA ).
Mengimpor data dari program Excel, Lotus, Dbase
File Open data
*pilih data excel dengan file ekstensi .xls atau lotus .wk
Membuka file dan meng-entri data baru
File New data
Menghitung statistic deskriptif
1. Buka file Crossecl.xls (file/open/data)
2. Pilih analyze – descriptive statistic – descriptive
3. Isi variabel dengan EARNS dan WEALTH 4. pilih option, kemudian pilih hanya yang ada
pada tab distribution (skewness dan kurtosis) dan variabel list pada display order lainnya abaikan
5. pilih continue dan OK *hasil ouput
Dari Ouput tersebut dapat dihitung Zskewness dan Zkurtosis nya, sbb:
Zskew (EARNS) :
2.590
√
6
/
100
= 10.575 Zskew (WEALTH) :3.030
√
6
/
100
= 12.372 Zkurt (EARNS) :8.422
√
24
/
100
= 17.192 Zkurt (WEALTH) :11.551
√
24
/
100
= 23.578Hasil perhitungan nilai z baik untuk variabel EARNS maupun WEALTH jauh diatas nilai kritisnya ±2.58 (signifikan pada α = 0.01). jadi kesimpulannya kedua variabel ini tidak terdistribusi secara normal.
3. Masukkan EARNS dan WEALTH dalam kotak Test variabel list dan OK
*hasil output
a).Nilai K-S untuk variabel EARNS = 1.859 dengan probabilitas signifikansi 0.002 < 0.05, sehingga Ho ditolak (variabel EARNS tidak terdistribusi secara normal). b) Nilai K-S untuk WEALTH = 2.271 dengan probabilitas signifikasi 0.00 < 0.05, sehingga Ho ditolak (variabel WEALTH tidak terdistribusi secara normal).
Maka harus dilakukan transformasi data sampai data tersebut normal. transformasi data = Buka file Crossecl.xls (file/open/data) > pilih Transform – compute > pada Target Variabel isikan nama baru variabel hasil transform missal SQEARNS > pada Function Group pilih all dan pada functions sepecial variabel pilih SQRT,lalu masukkan ke kotak Numeric Expression dengan panah > pada type dan label pilih variabel EARNS atau WEALTH > Ok. Kemudian uji statistic Kolmogoro-Smirnov untuk variabel yang telah ditransformasi (SQREARNS & SQRWEALTH) untuk melihat apakah data berdistribusi normal. Setelah melakukan transformasi data untuk mendapatkan normalitas dilakukan dengan mendeteksi outler dengan melihat adanya nilai lebih dari 3 untuk table ZSQREARNS & ZSQRWEALTH setelah melakukan langkah-langkah berikut : Analyze – Descriptive Statistic – Descriptive > isikan variabel SQREARNS &SQRWEALTH – pilih (tikmark) save standardize value as variable > Ok.
Uji reabilitas:
1. Buka file Jobsurvey.sav (File/Open/Data) 2. Pilih Analyze/ Scale/ Reability Analysis
3. Pada layar Reability masukkan Autonom 1-4 kedalam kotak Items,pilih model alpha lalu pilih statistic
4. Pada bagian descriptive for, pilih Item, Scale, Scale if item deleted dan inter-item Correlation 5. Pilih Continue / OK
*hasil Ouput
Uji validitas menggunakan korelasi bivariate antara masing-masing skor indicator dengan skor konstruk :
1. Buka file Jobsurvey.sav
2. pilih menu analyze, klik correlate, lalu bivariate
3. isikan dalam kotak variable ke empat indicator kostruk AUTONOM dan skor total AUTONOM
4. pilih Correlation Coefficients Pearson 5. klik Ok
*hasil output disamping
Dari tampilan output terlihat bahwa korelasi antara masing-masing indicator (autonom1-autonom4) terhadap total skor konstruk (autonom) menunjukkan hasil yang signifikan. Jadi dapat disimpulkan bahwa masing-masing indicator pertanyaan adalah Valid.
Uji dengan CFA
1. buka file Job Survey.sav dengan peritah File/Open/Data
2. klik Analyze /data reduction / factor
3. pada kotak variable, masukkan semua indicator autonom 1-4 dan routine 1-4
4. klik Descriptive dan pilih KMO and Bartlett’s test of sphericity, kemudian Continue
5. klik Rotation dan klik Varimax dan tekan indicator routine1-4 mengelompok pada factor 2. Jadi,kesimpulannya konstruk AUTONOMI memiliki unidimensionalitas begitu juga dengan kontruk ROUTINE dengan kata lain indicator autonom dan routine semuanya valid.
Uji beda t-test
1. Buka file Employee data.sav dengan perintah File/Open/Data
2. Analyze / Compare Means / Independent Sample T Test (karena lk dan pr berasal dari populasi berbeda)
3. Isikan kedalam kotak variabel Previous Experience dan pada Grouping Variable bertipe kualitatif yaitu Gender
4. Pada Define Group isikan m(male) pada Group satu dan f(female) pada Group dua
5. Continues / OK
Ho : variance populasi pengalaman kerja sebelumnya antara responden laki-laki dan wanita adalah sama
Ha : variance populasi pengalaman kerja sebelumnya antara responden laki-laki dan wanita adalah berbeda
*hasil Output :
F : 2.582 dengan sig : 0.109 = p>0.05 maka kesimpulannya adalah Terima Ho (variance sama). t= 3.361 dengan probabilitas signifikan sig: 0.00. jadi kesimpulannya adalah rata-rata pengalaman kerja sebelumnya dengan bulan lalu berbeda signifikan anatara responden lk dengan pr.
UJi ANOVA
1. Buka file Employee data.sav dengan perintah File/Open/Data
*hasil output
2. Analyze/ General Linear Model/ Univariate 3. Pada kotakDependent variable isikan Previous
experience
4. Pada kotak fixed factor isikan variabel kategori yaitu Employment category (jobcat)
5. Option/Homogeneyty Test (untuk menguji apakah variabel sama atau tidak)
6. Klik Post Hoc, pindahkan variable jobcat ke kotak post hoc test for
7. Pilih bonferoni dan Tukey 8. Klik continue dan OK
Sebelum analisis di ANOVA maka harus memenuhi asumsi-asumsi sbb :
1. Multivariate normality (uji normalitas data menggunakan Kolmogorof smirnov, histogram atau skewness kurtosis)
2. Homogenity test asumsi (dilihat pada Levene test)
3. Test of between subjek (hasil akhir)
Jika telah terdistribusi secara normal maka dilanjutkan uji ANOVA nya, kalau belum normal maka dilakukan transformasi data (compute variable, yaitu dengan membuat data baru). Jika masih tetap tidak normal maka diberi keterangan bahwa data tidak terdistribusi secara normal lalu lanjut ke ANOVA, hal ini juga berlaku di uji MANOVA .
P<0.05 maka tidak terdistribusi secara normal Melakukan transform, lalu di uji kembali dan hasilnya masih tidak normal yaitu p= 0.03.
Levene test menunjukkan F : 2.544 sig : 0.80 maka p> 0.05 (Ho diterima)
Test of between-subject effects diketahui F = 483.709 untuk intercept dan signifikan pada 0.05. pada jobcat F= 69.192 dan signifikan pada 0.05. maka jobcat mempengaruhi kerja sebelumnya.
Uji MANOVA
1. bukafile employee data.sav
2. Klik Analyze > General Linear Model > Multivariate
3. pada dependen Variabel diisi 2 variabel metrik gaji akhir dan pengalaman kerja sebelumnya 4. pada fixed factor isikan kategori pekerjaan
(Jobcat)
5. pada kotak options klik homogeneity tests 6. klik Post Hoc test > bonferoni > Turkey 7. Klik Continue dan OK
Asumsi MANOVA:
1. Multivariate normality
2. Matrik Variance/Covariance (harus sama)
3. Test of Between subject effects
Box’s M test : 220.377 , F test : 36.046 , sig : 0.000 maka P<0.05 (Ho ditolak). Berarti matrik variance/ covariance dari table dependen berbeda. Hasil uji ini menyalahi asumsi MANOVA, tapi analisis masih dapat diteruskan.
F test : 434.481 sig :0.000 maka P<0.05 (signifikan dan Ho ditolak) berarti terdapat perbedaan gaji akhir antara kategori pekerjaan. Untukhubungan antara jobcat dan pengalaman kerja didapat F: 69.192 dan signifikan pada 0.05 hal ini berarti terdapat perbedaan lama pengalaman kerja sebelumnya antar kategori pekerjaan.