Acara 1: Prinsip dan Konsep Perancangan Percobaan
Tujuan: Mahasiswa dapat menjelaskan beberapa konsep dan prinsip dasar perancangan percobaan
Mahasiswa dapat menerapkan konsep dan prinsip ini dalam merancang percobaan
Mahasiswa dapat menjelaskan prinsip dan konsep ini dalam beberapa rancangan percobaan baku dan populer
Pendahuluan
Kegiatan penelitian (research) secara umum terbagi menjadi survei dan percobaan (experiment). Dalam survei, subjek penelitian tidak diintervensi sebelumnya sehingga kondisi ketika diamati adalah “apa adanya”. Dalam percobaan, peneliti mengendalikan kondisi penelitian dengan melakukan seleksi dan intervensi lingkungansehingga pengamatan sepenuhnya diarahkan pada menjawab tujuan penelitian. Baik survei maupun percobaan akan menghasilkan data yang akan diolah. Data ini harus merupakan gambaran dari hal-hal yang akan diteliti sehingga dapat dipercaya dan layak dianalisis.
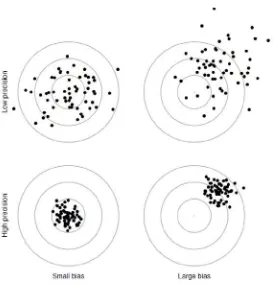
Dengan demikian, diperlukan suatu perencanaan dalam merancang percobaan. Perencanaan dilakukan dengan mempertimbangkan aspek statistika karena data akan dianalisis dengan metode statistika tertentu. Ilmu yang membahas bagaimana percobaan direncanakan atau dirancang dikenal sebagai perancangan percobaan atau experimental design. Perancangan percobaan diarahkan terutama untuk meningkatkan presisi pengukuran, bukan akurasi. Presisi tinggi berarti variasi simpangan (error) yang kecil, sementara akurasi tinggi berarti kemelesetan rendah. Presisi terkait dengan besaran varians, sedangkan akurasi terkait dengan besaran rerata.
Gambar di atas dengan jelas menggambarkan ketika presisi rendah, maka titik-titik akan menyebar dan inilah yang menggambarkan varians. Low precision artinya varians tinggi dan dalam hal ini akan menyebabkan nilai error menjadi besar. Sedangkan, ketidakakuratan (bias) artinya titik-titik berada jauh dari sasaran. Dalam statistik, sasaran adalam suatu estimate, contohnya, rerata, koefisien regresi, dan lain-lain. Yang diinginkan dari suatu percobaan jelas presisi yang tinggi dan bias yang kecil (akurasi tinggi).
Konsep-konsep dasar dalam perancangan percobaan
Perlakuan
percobaan membandingkan efek tiga cara pengendalian gulma, perlakuan misalnya adalah penyiraman herbisida, penyemprotan herbisida, dan kontrol negatif (tidak dikendalikan). Jadi, tidak diberi herbisida pun juga dianggap perlakuan. Dalam percobaan tiga dosis herbisida tertentu, perlakuan misalnya adalah dosis 0, 10, dan 20 ml per liter larutan.
Perhatikan bahwa ketiga kasus percobaan tadi dilakukan untuk tujuan penelitian yang berbeda-beda. Jadi, pemilihan perlakuan harus terkait dengan tujuan dan hipotesis yang diajukan.
Satuan percobaan dan ulangan
Perlakuan dikenakan pada satuan bahan yang memperoleh satu, dan hanya satu, perlakuan disebut satuan percobaan (experimental unit). Untuk contoh pengendalian gulma di atas, herbisida A diterapkan pada luasan lahan tertentu. Lahan inilah yang disebut sebagai satuan percobaan. Untuk percobaan lapangan semacam ini, satuan percobaan dapat disebut plot/petak percobaan, namun untuk percobaan di laboratorium atau tempat lain, istilah satuan percobaan lebih tepat. Satuan percoba-an dapat berupa kolam, individu tumbuhpercoba-an atau hewpercoba-an (jika perlakupercoba-an diterapkpercoba-an per individu, bukan populasi), cawan Petri, kandang, petak lahan, baris-baris tanam kultivar berbeda, seonggok daging, sekemas benih, sesisir pisang, sebutir buah, dan seterusnya.
Satuan pencuplikan dan pengukuran berulang
Dalam percobaan, ada kemungkinan data diambil dari keseluruhan satuan percobaan. Misalnya panen per plot, ikan per kolam, dan seterusnya, jika perlakuan diterapkan pada plot atau kolam tersebut. Untuk keadaan demikian, satuan percobaan menjadi setangkup dengan satuan pencuplikan. Namun demikian, ada keadaan lain ketika satuan pencuplikan hanya sebagian dari satuan percobaan, seperti tanaman sampel dari satu satuan percobaan berupa plot, sesendok contoh adonan, beberapa butir buah dari suatu kantung kemasan tertentu, dan sebagainya. Satuan pencuplikan (sampling unit) adalah satuan tempat data diambil. Dengan demikian, dari satu satuan percobaan dapat muncul beberapa data yang diperoleh dari mengamati sejumlah satuan pencuplikan.
Perlu disadari bahwa dari satu satuan pencuplikan dapat dilakukan beberapa pengamatan berulang pada waktu yang berbeda. Pengamatan semacam ini membangkitkan data pengukuran berulang (repeated measurements).
Rancangan lingkungan dan pengelompokan/blocking
Maksud rancangan lingkungan adalah perencanaan yang ditujukan untuk menjaga agar pengaruh luar percobaan sekecil mungkin. Ini merupakan bentuk pengendalian sesatan. Instrumen yang dipakai adalah pengelompokan atau blocking. Blocking mengelompokkan beberapa satuan percobaan ke dalam situasi yang seragam. Tiap kelompok disebut blok. Tentu saja pengelompokan tidak diperlukan bila satuan percobaan telah seragam. Sebagai misal, apabila dalam suatu lahan plot-plot percobaan berada di lahan yang tidak seragam kesuburannya, dibuatlah blocking agar sekumpulan perlakuan dapat berada pada satu blok dengan kondisi yang serupa.
Rancangan perlakuan dan faktor
Percobaan bisa memiliki satu faktor, yaitu satu seri perlakuan yang dipilih untuk menjawab beberapa hipotesis. Misalnya, untuk mengetahui perbedaan pengaruh cara pengendalian gulma, dilakukan seri perlakuan: (a) penyiangan cabut, (b) penyiangan kepras, (c) penyemprotan herbisida pratumbuh, (d) penyemprotan herbisida pascatumbuh, dan (e) tanpa pengendalian. Beberapa hipotesis yang diajukan dari seri perlakuan ini adalah (1) “Pengendalian berdampak baik terhadap pertumbuhan tanaman” (membandingkan dikendalikan vs. tanpa pengendalian); (2) “Penyiangan manual sama bersihnya dengan penyemprotan herbisida” (perlakuan a dan b versus perlakuan c dan d); (3) “Penyiangan cabut lebih baik daripada penyiangan kepras” (perlakuan a versus b); dan (4) “Penyemprotan pratumbuh lebih efektif daripada penyemprotan pascatumbuh” (perlakuan c versus d). Misal lain adalah seri perlakuan pemberian dosis berbeda untuk mengetahui dosis yang paling efektif.
Dapat terjadi pula, percobaan memiliki dua atau lebih faktor. Di sini, setiap satuan percobaan mendapat dua atau lebih perlakuan yang masing-masing tergolong pada faktor berbeda. Percobaan semacam ini, yang dikenal pula sebagai “percobaan faktorial”, memiliki keuntungan penghematan bahan dan juga kemungkinan pendugaan pengaruh bersama dari dua atau lebih faktor yang diuji (“interaksi”). Sebagai misal adalah percobaan yang mengombinasi dua macam pupuk buatan: faktor pertama adalah urea berbagai dosis dan faktor kedua adalah SP36 berbagai dosis.
Latihan. Cobalah Anda tentukan konsep-konsep yang telah dikemukakan terhadap kasus berikut.
Dari 30 tanaman semangka yang ada di setiap petak percobaan atau setiap ulangannya akan diambil 10 tanaman untuk diukur panjang tanaman, jumlah daun, jumlah buah, bobot setiap buah, dan bobot buah dalam satu tanamannya.
Sebutkan perlakuan-perlakuan yang diberikan. Apakah satuan percobaannya? Ada berapa? Apakah satuan pencuplikannya untuk setiap peubah yang diamati? Ada berapa per satuan percobaan? Berapa ulangan untuk masing-masing perlakuan? Berapa faktor perlakuan yang digunakan untuk percobaan ini?
Prinsip-prinsip pokok perancangan percobaan
Dalam perancangan percobaan hanya ada tiga prinsip dasar: 1. Pengacakan (randomisation),
2. Pengendalian sesatan (error control), dan 3. Kesetimbangan (balance).
Apabila ketiga prinsip ini dipenuhi, analisis menjadi sederhana dan hasilnya sahih (valid). Tujuan inti dari perancangan percobaan adalah mendapatkan rancangan dan analisis yang sederhana yang memenuhi prinsip-prinsip dasar namun tepat memenuhi penyimpulan yang sahih.
Pengacakan
Pengacakan adalah hal yang wajib ada dalam merancang percobaan, karena menjamin bahwa kita membentuk peubah acak dalam data pengamatan kita. Semua metode statistika bertumpu pada asumsi bahwa data merupakan peubah acak. Tanpa adanya pengacakan, asumsi itu gugur dan hasil analisis tidak bermakna.
Pengacakan dapat dilakukan dengan penggunaan alat bantu seperti pengocokan undian/arisan, dadu, kartu, atau daftar tabel bilangan acak. Perangkat lunak seperti MSExcel atau LibreOffice memiliki fungsi acak pula.
teracak. Petak B pada susunan kiri selalu memiliki pola sama, yaitu di sebelah kirinya ada A dan di kanannya C. Hal ini memunculkan “sesatan sistematik”, karena semua A bersebelahan dengan A dan B, sementara semua B bersebelahan dengan A, B, dan C. Ketika kita hendak membandingkan efek A dengan efek B, yang terjadi malah membandingkan efek A-yang-bersebelahan-dengan-A-dan-B dan efek B-yang-bersebelahan-dengan-A-B-dan-C. Pada susunan di kanan, meskipun masih terdapat pola serupa (A di sebelah kiri B) derajat sistemiknya berubah (misalnya, di sebelah C dapat A atau B). Pengacakan paling baik terjadi ketika pola-pola sistematik tidak ada sama sekali.
A B C A B C
A B C C A B
Tidak diacak Diacak
Pengendalian sesatan
Sesatan yang besar mengganggu presisi sehingga perlu dikendalikan. Ada tiga strategi untuk mengendalikannya: (1) penggunaan rancangan percobaan yang tepat, (2) penyeragaman satuan percobaan, dan (3) penggunaan peubah pengendali (konkomitan).
Rancangan percobaan yang tepat dapat ditentukan dengan ketajaman dalam mengenali sumber-sumber keragaman dan nalar yang baik. Mengenali lingkungan percobaan dan memperkirakan keragaman yang dapat muncul adalah keterampilan yang diperlukan. Penyeragaman satuan percobaan merupakan pilihan lain yang mudah untuk mengendalikan sesatan.
meningkatkan presisi, karena pembandingan kedua cara pengolahan dilakukan terhadap tiga kemungkinan tekstur yang berbeda.
Untuk penyeragaman satuan percobaan dapat dilihat contoh berikut ini. Bandingkan gambar bawah di kiri dan di kanan. Gambar di kiri menunjukkan satu cara pengolahan dilakukan terhadap setiap kelompok ukuran yang seragam masing-masing. Gambar di kanan menunjukkan jika cara pengolahan diterapkan tanpa pengelompokan. Pilihan di kiri lebih baik karena seragam di dalam setiap kumpulannya sehingga sumber keragaman internalnya minimal dan ujungnya penduga varians sesatan lebih kecil.
Kesetimbangan
Prinsip kesetimbangan menyarankan agar ukuran ulangan dan sampel hendaknya sama untuk setiap kelompok perlakuan. Namun demikian, apabila terpaksa terjadi perbedaan di antara kelompok perlakuan, diusahakan tidak terjadi perbedaan ukuran yang terlalu besar. Penjelasan secara statistik dijelaskan kelak karena prinsip ini lebih bermakna pada aneka rancangan rumit.
Latihan. Buatlah sketsa pengacakan yang dilakukan untuk kasus percobaan semangka di lahan pantai di atas. Kapan perlu melakukan pengelompokkan dan kapan/pada situasi apa tidak perlu?
Beberapa rancangan percobaan baku yang populer
Rancangan Acak Lengkap (RAL)/ Completely Randomised Design (CRD)
Rancangan Acak Lengkap merupakan rancangan lingkungan paling sederhana dan paling dianjurkan apabila peneliti dapat menjamin bahwa lingkungan percobaan terkendali dengan baik dan bahan percobaan relatif seragam. Pengacakan dilakukan sekali terhadap seluruh satuan percobaan yang ada. Sebagai misal, untuk suatu percobaan dengan empat perlakuan, masing-masing tiga ulangan, akan diperlukan 12 satuan percobaan. Penentuan satuan percobaan mana yang akan memperoleh perlakuan tertentu dilakukan melalui pengacakan terhadap ke-12 satuan percobaan tersebut. Contoh pengacakan dapat ditunjukkan dengan layout untuk percobaan dengan empat perlakuan (A – D), masing-masing dengan tiga ulangan.
A B C D A B C D
A B C D B A C C
A B C D D B A D
Sebelum pengacakan
Sesudah pengacakan
Rancangan Berblok Lengkap Teracak (RBLT)/ Randomised Complete Block Design (RCBD) Skema tidak jelas
Blok 1 Blok 2 Blok 3
A B C
B A D
C D A
D C B
Gradien lingkungan
Perhatikan bahwa pembagian blok didasarkan pada gradien lingkungan, contohnya, kemiringan lahan, intensitas penyinararan, kesuburan tanah, dan lain-lain.
Rancangan Segiempat Latin (RSL)/ Latin Square Design (LS)
Rancangan Segiempat Latin (Latin Square Design) tidak lain daripada Rancangan Berblok Lengkap Teracak dengan blocking dua arah yang saling tegak lurus. Penggunaannya merupakan modifikasi RBLT apabila diketahui ada dua sumber keragaman penyebab satuan percobaan tidak seragam. Rancangan ini amat menerapkan prinsip kesetimbangan, karena suatu ulangan-ulangan dalam setiap perlakuan tidak boleh menempati urutan yang sama (itulah sebabnya dinamakan Segiempat Latin). Konsekuensinya, banyaknya perlakuan akan sama dengan banyaknya ulangan.
Pengacakan dilakukan tiga tahap: pertama untuk blok arah pertama, kedua untuk blok arah kedua, dan terakhir adalah pengacak satuan percobaan untuk setiap rangkaian perlakuan.
Berikut layout yang menunjukkan hasil pengacakan:
Perhatikan bahwa dalam setiap baris maupun kolom tidak terdapat perlakuan yang sama. Penomoran ulangan dihapuskan karena nomor ulangan menjadi tidak relevan.
sebelum sesudah pengacakan blok datar, pengacakan blok tegak, lalu
Rancangan Faktorial Penuh (RFP)/ Factorial Design
Rancangan Faktorial Penuh bukanlah rancangan lingkungan seperti tiga rancangan sebelumnya, tetapi merupakan rancangan perlakuan. Dengan demikian, Rancangan Faktorial Penuh bisa dilakukan dalam Rancangan Acak Lengkap, RBLT, maupun RSL. Tujuan utama kita melakukan RFP adalah untuk menghemat satuan percobaan, sekaligus juga mendapatkan informasi mengenai ada-tidaknya interaksi antara faktor-faktor yang diuji.
Pengacakan dilakukan sama, sesuai dengan rancangan lingkungan yang dipakai. Yang perlu diperhatikan adalah setiap kombinasi perlakuan dalam masing-masing faktor (“level”) dianggap sebagai perlakuan tunggal.
Berikut contoh layout pengacakan untuk RFP 2 faktor, masing-masing 2 dan 3 level dalam RBLT dua ulangan dalam hal ini blok.
sebelum pengacakan
sesudah pengacakan blok lalu satuan percobaan (kombinasi perlakuan) dalam tiap blok
faktor pertama (disebut faktor utama) memiliki ukuran satuan percobaan yang lebih besar. Satuan percobaan bagi faktor pertama ini berfungsi sebagai blok bagi faktor kedua (disebut anak-faktor atau subfaktor). Faktor kedua dengan demikian memiliki ukuran satuan percobaan yang kecil dan merupakan bagian dari satuan percobaan faktor utama.
Sebagai misal, umpamanya kita melakukan percobaan faktorial dua faktor, masing-masing dengan dua dan tiga level, dengan rancangan lingkungan RBLT menggunakan tiga blok. Pengacakan pertama dilakukan terhadap ketiga blok. Selanjutnya, setiap perlakuan/level pada faktor utama diacak di dalam satuan percobaan (utama) dalam masing-masing blok (dibagi dua). Berikutnya, setiap satuan percobaan dibagi sebanyak perlakuan pada anak-faktor (dibagi tiga). Dilakukanlah pengacakan satuan percobaan bagi tiap perlakuan anak-faktor pada setiap satuan percobaan faktor utama. Layout berikut memberi gambaran proses itu.
Perhatikan layout split-plot di atas sesudah pengacakan blok lalu satuan percobaan faktor utama (A) dengan level perlakuan A, B, dan C, lalu diikuti pengacakan satuan percobaan anakfaktor (B) dengan level perlakuan V1, V2, dan V3 dalam tiap satuan percobaan faktor utama.
Blok 1 Blok 2 Blok 3
Main plot A B C C B A B C A
V1 V2 V3 V2 V3 V1 V3 V1 V2
Sub plot V2 V3 V1 V3 V1 V2 V1 V2 V3
Model linear matematis
Suatu rancangan percobaan tertentu akan menghasilkan data pengamatan yang akan dianalisis sesuai dengan kaidah tertentu untuk menguji dan menghasilkan kesimpulan atas suatu hipotesis yang telah ditentukan.
Perhatikan suatu hipotesis formal: H0: μ1 = μ2. Ini berarti kita ingin menguji hipotesis nol bahwa rerata pengamatan akibat pengaruh perlakuan 1 sama dengan rerata pengamatan akibat pengaruh perlakuan 2. Untuk menguji H0 ini, kita mengambil n1 satuan percobaan untuk dikenakan perlakuan 1 dan mengambil n2 satuan percobaan untuk dikenakan perlakuan 2. Ini berarti perlakuan 1 memiliki n1 ulangan dan perlakuan 2 memiliki n2 ulangan. Perhatikan bahwa apabila kita mengambil satu pengamatan dari satu satuan percobaan, maka satuan percobaan ini juga merupakan satuan pencuplikan (sampling unit).
Simbol dari suatu pengamatan terhadap salah satu satuan pencuplikan kita sebut saja Yijdengan i = nomor perlakuan (i =1 atau 2) dan j = nomor ulangan dari
masing-masing nomor perlakuan. Jadi, sebagai misal, Y23 adalah data pengamatan dari satuan
pencuplikan perlakuan 2 ulangan 3. Di bawah hipotesis nol, nilai suatu pengamatan Yij
dapat dianggap berasal dari gabungan pengaruh rerata populasi μi dan sesatan εij atau
Yij= μi + εij [1]
Jelas bahwa di sini sesatan melekat pada data. Bentuk [1] ini disebut sebagai model linear matematis. Karena dalam perancangan percobaan satuan percobaan untuk semua perlakuan diusahakan seragam, maka [1] dapat ditulis ulang sebagai
Yij= μ + τi + εij, [2]
dengan μ adalah rerata umum yang berasal dari satuan percobaan (yang seragam, karena itu tidak memiliki nomor) dan τi adalah pengaruh perlakuan ke-i. Di bawah
Skema rancangan percobaan dan analisisnya
Sebagai contoh ketika percobaan menguji jenis pupuk pada satu jenis tanaman maka rancangan perlakuannya satu faktor. Kemudian jika percobaan dilakukan pada lingkungan yang relatif homogen berarti rancangan lingkungannya bisa menggunakan CRD sehingga rancangan percobaannya adalah CRD satu faktor. Analisis yang sesuai untuk percobaan tersebut adalah ANOVA klasik karena jenis pupuk bersifat kategori. Namun, jika jenis pupuk tersebut diberikan pada beberapa jenis tanaman maka rancangan perlakuannya menjadi factorial. Contoh lain, ketika perlakuan berupa dosis pupuk pada suatu tanaman, maka analisis yang digunakan adalah regresi. Khusus untuk split-plot, rancangan ini termasuk rancangan lingkungan bersyarat karena mengharuskan rancangan perlakuannya merupakan rancangan factorial.
Tanggal: Nama & Ttd Asisten: Jenis Perlakuan
dan analisisnya
Perlakuan bersifat kuantitatif
(Dosis, I ntensitas Cahaya, Suhu)
Regresi liner (sederhana atau
berganda)
ANOVA klasik dengan kontras polinomial
Perlakuan bersifat kualitatif/ kategorikal (Jenis varietas, herbisida,
pupuk, lokasi)
ANOVA Klasik
Jenis Rancangan
Rancangan
lingkungan CRD, RCBD, LS
Rancangan Perlakuan
Satu faktor atau lebih dari satu faktor
Acara 2. Asosiasi Antara Dua Himpunan Data Tujuan: Mengulang dan mempelajari analisis asosiasi lebih lanjut
Mengenalkan cara menguji percobaan dengan dua grup perlakuan Mengenalkan program R untuk keperluan itu
Analisis Asosiasi
Sebelum mendalami lebih lanjut mengenai perluasan percobaan dua perlakuan, ada baiknya kita mempelajari lebih lanjut bagaimana melakukan analisis statistik antara dua atau lebih peubah yang saling berkaitan (berasosiasi). Penelitian di bidang pertanian banyak menggunakan kerangka metodologi ini.
Analisis mengenai keterkaitan (asosiasi) antara satu peubah (variable) dengan satu atau lebih peubah lain merupakan analisis mendasar dalam banyak penelitian hayati maupun sosial. Data yang dipakai berasal dari penelitian non-percobaan, seperti survei dan sensus, maupun penelitian percobaan, baik percobaan semu maupun percobaan dengan perlakuan terkendali penuh. Dalam penelitian survei atau deskriptif (bukan penelitian rekomendasi), peubah yang dilihat keterkaitannya biasanya berasal dari pengamatan langsung. Dalam percobaan untuk memberi rekomendasi, beberapa peubah merupakan perlakuan. Tabel 1 memberikan rangkuman mengenai pendekatan analisis yang dilakukan.
Tabel 1. Tipe peubah data dan pendekatan analisisnya. Tipe data
Hubungan X
dan Y Pendekatan
Peubah I (X) Peubah II (Y)
Kategorik Kategorik Tidak selalu kausal
Analisis frekuensi (non parametrik)
Numerik acak Numerik
acak
Tidak selalu kausal
Analisis korelasi (Y~X)
Numerik acak atau fixed Numerik acak
Kausal (X → Y) Analisis regresi (Y~X)
Kategorik fixed Numerik acak
Kausal (X → Y) Uji-t dan analisis varians (Y~X)
Kategorik fixed dan numerik acak atau fixed
Analisis regresi dan varians untuk peubah Y yang bersifat kategorik sebenarnya tersedia, tetapi tidak menjadi lingkup mata praktikum ini. Dalam acara praktikum ini, akan dibahas analisis frekuensi (kesesuaian model & independensi), korelasi, dan regresi.
Statistik Non Parametrik Analisis frekuensi
Analisis frekuensi dilakukan untuk mengetahui keterkaitan antara dua atau lebih peubah kategorik, misalnya antara jenis kelamin dan kebiasaan merokok. Ada atau tidaknya hubungan sebab-akibat (kausal) antara peubah2 yang dilibatkan tidak diberi perhatian dalam analisis ini.
Pengujian independensi
Pengujian ini menguji hipotesis nol bahwa dua (atau lebih) peubah saling bebas (independen). Kebebasan ini diukur dari apakah frekuensi kombinasi sama dengan perkalian frekuensi marginal masing-masing peubah, atau dapat ditulis Ho: pAB = pA .
pB. Pengujian menggunakan MsExcel dapat dilihat kembali pada Panduan Praktikum Statistika. Berikut ini latihan yang dapat dilakukan pada program R. Bukalah file R dengan nama Acara-2-non-parametrik.R untuk latihan pengujian independensi.
sex smoke asthma sex smoke asthma
f smoker asthma f nonsm asthma
m nonsm nonasht f nonsm nonasht m smoker nonasht m smoker asthma
f nonsm asthma f nonsm nonasht
m smoker asthma f nonsm nonasht m smoker asthma m smoker asthma
f nonsm nonasht f nonsm nonasht m smoker asthma m nonsm nonasht
Pengujian kesesuaian (goodness-of-fit test)
Kesesuaian dengan perbandingan atau sebaran tertentu biasa dilakukan, misalnya perbandingan Mendel atau distribusi Binomial. Sebagai contoh adalah pengujian perbandingan generasi pertama silang balik (BC1) dengan tetua resesif rentan memberikan hasil 70 tahan : 80 rentan. Hipotesis untuk diuji (H0): 1:1. Jalankan syntax untuk uji goodness-of-fit pada file R yang sama. Apakah hasilnya mendukung H0 (mengikuti nisbah Mendel)?
Statistik Parametrik
Statistik parametrik yang diberikan di sini terbatas hanya pada model liner untuk korelasi, regresi, dan ANOVA klasik. Statistik parametrik lainnya seperti regresi logistik, model liner campuran (linear mixed model) tidak diberikan di sini.
Analisis korelasi
Pengamatan terhadap dua atau lebih peubah seringkali berangkat dari minat untuk mengetahui keterkaitan antara peubah-peubah tersebut. Sebagai contoh, pengamatan terhadap umur berbunga, tinggi tanaman, panjang tongkol, dan hasil pada jagung. Apabila orang mengetahui keterkaitan antara umur berbunga dan tinggi tanaman terhadap panjang tongkol dan hasil jagung, sebelum panen sudah dapat diperkirakan besar-kecil tongkol atau tinggi rendahnya hasil. Hubungan ini belum tentu dapat dijelaskan secara sebab-akibat, kecuali ada dasar teori yang dapat menegakkan hubungan sebab-akibat tersebut. Sebagai misal, hubungan antara bobot dan lingkar lengan bayi, tingkat konsumsi ikan mentah dan panjang usia, dan sebagainya.
Plot matriks korelasi (korelogram) memudahkan kita untuk melihat korelasi antar variabel. Plot sebelah kanan langsung menunjukkan angka dan warna yang menunjukkan koefisien korelasi. Semakin merah artinya korelasinya positif dan kuat. Sedangkan, semakin biru berarti korelasi antar variabel negatif dan kuat. Korelasi yang lemah ditunjukkan dengan warna yang relatif pudar. Plot di sebelah kanan menggunakan lingkaran dan warna untuk menunjukkan koefisien korelasi. Semakin besar lingkaran artinya korelasi antar variabel semakin kuat. Jika lingkaran semakin kecil berarti korelasi mendekati 0. Warna pada lingkaran menunjukkan sifat korelasi. Jika berwarna merah berarti sifatnya positif dan jika berwarna biru berarti sifatnya negatif.
Analisis korelasi parsial (boleh dilewati/opsional)
Dalam analisis korelasi biasa (simple), hubungan antara dua peubah dilakukan sambil mengabaikan peubah-peubah lainnya. Analisis korelasi parsial dilakukan dengan membuat peubah(-peubah) lain seakan-akan konstan (tidak berubah nilainya) sehingga muncul gambaran hubungan antarpeubah yang lebih jelas.
> pcor(nama)
> pcor.test(nama$hasil,nama$gbhpmalai,nama[,c("anakan")]) > pcor.test(nama$hasil,nama$gbhpmalai,nama[,c("anakan",
"b1000gbh")])
Perhatikan perubahan nilai korelasi parsial dengan korelasi sebelumnya. Peubah mana yang sebenarnya berkaitan secara langsung dengan hasil? (Petunjuk: yaitu peubah yang tetap signifikan, baik pada korelasi biasa maupun korelasi parsial).
Koefisien korelasi biasa yang nyata, tetapi kemudian koefisien korelasi parsialnya menjadi tidak nyata menunjukkan bahwa hubungan korelasionalnya sebenarnya terjadi melalui peubah lain yang nyata. Sebaliknya, koefisien korelasi biasa yang tidak nyata, tetapi kemudian koefisien korelasi parsialnya menjadi nyata menunjukkan adanya hubungan relasional yang ”tertutupi” oleh peubah lainnya.
Analisis regresi liner (sederhana dan berganda)
Apabila hubungan peubah X mempengaruhi Y dapat ditegakkan secara teoretis, analisis regresi layak (valid) dilakukan, dengan meregresi Y ke X. Analisis regresi digunakan di berbagai bidang dan mudah untuk dirampatkan (generalised). Perampatannya dikenal sebagai model linear.
Ada beberapa macam regresi linear:
1. Regresi linear sederhana adalah apabila peubah Y diregresi ke satu peubah X. Regresi ini membentuk garis lurus pada proyeksi Descartes (Cartesius).
2. Regresi berganda digunakan apabila peubah Y diregresi secara simultan (sekaligus) ke dua atau lebih peubah X. Bentuk analisis ini sangat popular di bidang ilmu-ilmu sosial.
3. Regresi linear polinom kuadratik meregresikan peubah Y ke peubah X dan X2 untuk melihat pengaruh X yang bukan garis lurus tetapi polinomial derajat dua.
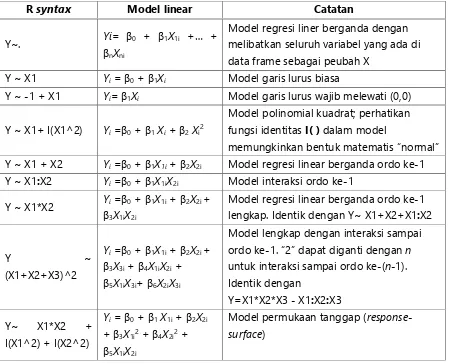
Tabel 2. Beberapa syntax dalam R dan model matematika eksplisitnya
R syntax Model linear Catatan
Y~. Yi= β0 + β1X1i +… + βnXni
Model regresi liner berganda dengan melibatkan seluruh variabel yang ada di data frame sebagai peubah X
Y ~ X1 Yi = β0+ β1Xi Model garis lurus biasa
Y ~ -1 + X1 Yi= β1Xi Model garis lurus wajib melewati (0,0)
Y ~ X1+ I(X1^2) Yi=β0+ β1Xi+ β2Xi2
Model polinomial kuadrat; perhatikan fungsi identitas I( ) dalam model
memungkinkan bentuk matematis “normal” Y ~ X1 + X2 Yi=β0+ β1X1i+ β2X2i Model regresi linear berganda ordo ke-1
Y ~ X1:X2 Yi=β0+ β1X1iX2i Model interaksi ordo ke-1
Y ~ X1*X2 Yi=β0+ β1X1i+ β2X2i + β3X1iX2i
Model regresi linear berganda ordo ke-1 lengkap. Identik dengan Y~ X1+X2+X1:X2
Y ~ (X1+X2+X3)^2
Yi=β0+ β1X1i+ β2X2i +
β3X3i+ β4X1iX2i +
β5X1iX3i+ β6X2iX3i
Model lengkap dengan interaksi sampai ordo ke-1. “2” dapat diganti dengan n untuk interaksi sampai ordo ke-(n-1). Identik dengan
Model permukaan tanggap ( response-surface)
Asumsi model liner (regresi dan anova klasik)
Pernyataan εij ~ N (0,σ2) merupakan asumsi dasar dalam model liner (baik regresi
Asumsi sesatan menyebar mengikuti distribusi normal
Untuk menguji asumsi bahwa sesatan mengikuti distribusi normal diperlukan banyaknya ulangan yang cukup banyak dari setiap grup perlakuan. Hal ini kerap tidak mudah dijumpai apabila ulangan hanya tiga atau empat. Karena itu, uji kenormalan sebaran sesatan biasanya dilakukan dengan menggabungkan semua komponen penduga sesatan dari semua perlakuan. Untuk menguji asumsi tersebut, dapat digunakan berbagai cara seperti uji goodness-of-fit untuk kenormalan sebaran menggunakan Shapiro-Wilk’s test atau dengan membuat plot kuantil v. kuantil (quantile-to-quantile plot/QQ plot).
Cara 1. Uji goodness-of-fit untuk kenormalan sebaran
Uji ini dilakukan dengan membandingkan peluang munculnya suatu nilai data (atau penduga sesatannya) dengan peluang distribusi normal untuk nilai tersebut. Jika selalu berdekatan peluangnya, maka distribusinya normal. Pengujian yang biasa dipakai adalah uji Shapiro-Wilk.
Dari suatu kolom analisis varians, ambillah data asli dan simpan sebagai data berkas tersendiri (tanpa menyertakan kolom-kolom lainnya). Ambillah juga kolom penduga sesatan dan simpan sebagai data tersendiri (menggunakan permintaan namaoutput$residual setelah ANOVA) dengan nama berkas yang berbeda. Berikut syntax untuk menguji normalitas residual dengan R.
> shapiro.test(namaoutput$residual)
Cara 2. Menggunakan plot kurva
Teknik lain, yang berbasis kurva, adalah dengan membuat plot kuantil vs. kuantil (quantile-to-quantile plot). Kita telah mengenal median, kuartil, atau persentil. Kesemuanya ini adalah kuantil. Dengan membandingkan sebaran data pada kurva kuantil dapat dinilai kenormalan sebaran. Apabila sebaran data mengikuti garis lurus, maka sebaran itu mendekati normal. Ketiklah baris perintah berikut dan simpan grafik yang muncul ke dalam format gambar (TIFF atau .jpg). Berikut perintah di R untuk menghasilkan QQ plot dengan package car.
> car::qqPlot(namadata$namavar,dist=”norm”)
Berikut ada contoh QQ plot yang mengindikasikan asumsi normalitas tidak terpenuhi. Perrhatikan titik-titik yang ada tidak mengikuti garis merah yang miring ke kanan dan banyak titik-titik berada di luar garis selang kepercayaan (garis putus-putus/dashed line)
Jika data tidak mengikuti distribusi normal, lakukan analisis varians untuk distribusi data yang sesuai, namun topik ini tidak akan dibahas.
Asumsi homoskedastisitas tiap grup perlakuan
Asumsi ini cukup mempengaruhi kekuatan uji analisis varians. Penyimpangan dari asumsi kehomogenan varians-varians grup perlakuan akan membuat kita perlu melakukan bentuk analisis alternatif. Untuk data yang menggunakan uji t, pengujian homoskedasitas dapat dilakukan dengan uji F jika perlakuannya dua. Namun, untuk ANOVA klasik yang perlakuannya lebih dari dua, maka uji homoskedatisitas dilakukan dengan Uji Hartley (jika ulangannya sama) atau Uji Bartlett (ulangan bebas). Selain itu, terdapat pula Uji Levene dapat digunakan untuk data dengan rancangan apa saja.
> car::ncvTest(model)
Cara lain adalah dengan melihat plot diagnostik pada bagian Residual vs. Fitted value atau Standardised residual vs. Fitted value. Jika titik-titik pada grafik ini menyebar tanpa pola, maka asumsi terpenuhi. Jika terdapat pola tertentu, terutama pola loudspeaker, maka asumsi homoskedastisitas varians tidak terpenuhi. Perhatikan contoh grafik di bawah ini.
Asumsi homoskedastisitas terpenuhi Asumsi homoskedastisitas tidak terpenuhi
Hal yang dilakukan jika asumsi tidak terpenuhi
Apabila uji homoskedastisitas menunjukkan varians-varians tidak homogen, perlu dilihat apakah ada hubungan fungsional antara rerata-rerata dengan variansnya masing-masing. Jika hubungan ini terdeteksi, lakukanlah transformasi data. Jika tidak ada hubungan antara rerata dan varians, analisis varians untuk varians tidak homogen (tidak dibahas dalam mata kuliah ini, tapi tersedia di R), atau uji-uji nonparametrik dilakukan (misalnya Uji Kruskal-Wallis untuk ANOVA satu-arah).
Uji Kruskal-Wallis (optional, diberikan atau tidak dalam praktikum)
secara acak; (2) kasus masing-masing kelompok independen; (3) skala pengukuran yang digunakan biasanya ordinal.
Perhitungan yang dilakukan menggunakan statistik uji yang mengikuti distribusi khi-kuadrat ( χ2). Jika nilai uji lebih kecil daripada nilai tabel atau probabilitas lebih besar daripada α, maka Ho diterima, artinya median beberapa populasi seragam.
>kruskal.test(model)
Praktik Analisis Data
Lakukan analisis korelasi dan regresi sesuai suplemen Acara 2. Bukalah file R bernama Korelasi Regresi.R.
Skema Penggunaan Model Liner Secara Umum
Regresi Liner
Peubah Y kuantitatif (tinggi tanaman, hasil)
Peubah X kuantitatif (dosis, suhu)
Yang menjadi perhatian adalah uji parameter setiap variabel
peubah X untuk peubah Y
Uji asumsi normalitas dan homoskedasitas varians
Jika asumsi tidak terpenuhi, dapat menggunakan metode
generalisasi model liner (generalized linear model). Tidak
dibahas di sini
ANOVA Klasik
Peubah Y kuantitatif (tinggi tanaman, hasil)
Peubah X kualitatif/kategorikal (jenis varietas, pupuk, lokasi)
Yang menjadi perhatian adalah uji F antar sumber ragam
Uji asumsi normalitas dan homoskedasitas varians
Jika asumsi tidak terpenuhi, dapat menggunakan metode lain sepertiKruskal Wallis (CRD), Friedman(RCBD), atau yang lain.
Acara 3: Analisis CRD dan CRD sub-sampling Tujuan: Menguji asumsi-asumsi dalam analisis varians
Mengerjakan perancangan percobaan teracak lengkap dan melakukan analisis varians berbasis cuplikan (contoh)
Menganalisis data dari rancangan tsb. dan menafsirkan hasilnya
A. Rancangan Percobaan Sederhana
Pada acara sebelumnya kita mengenal susunan data dari percobaan-percobaan yang dirancang secara sederhana, seperti bagaimana sepasang grup perlakuan diuji, tergantung dari bagaimana cuplikan untuk setiap perlakuan diambil, bagaimana hubungan antara peubah-peubah yang diamati dipelajari (mengabaikan perlakuan, dengan analisis frekuensi dan korelasi) atau bagaimana pengaruh suatu seri perlakuan kuantitatif terhadap suatu peubah diukur (dengan regresi). Acara 3 ini membahas per-luasan Acara 2, yaitu bagaimana merancang dan menganalisis lebih daripada dua grup perlakuan.
Rancangan Teracak Lengkap (Completely Randomized Design, CRD) dapat dipandang sebagai pengambilan t (t > 1) cuplikan yang saling bebas (independent) (atau pengukuran terhadap sejumlah cuplikan dari t grup perlakuan) dengan ukuran masing-masing ri (i = 1, 2, ..., t). Jika ri besarnya sama, dapat disimbol ulang r (r1= r2=
rt= r). Perhatikan, CRD tidak mensyaratkan banyaknya ulangan sama untuk setiap
perlakuan.
Perlu diperhatikan bahwa dalam CRD, tiap objek cuplikan harus sedapat mungkin dalam kondisi yang seragam (homogen), baik cara mendapatkannya maupun keadaannya. Setiap kegagalan menjaga keseragaman akan memperbesar varians dan mengurangi daya uji analisis.
Analisis varians untuk CRD
Dalam menganalisis varians untuk percobaan dengan Rancangan Teracak Lengkap, banyak cara dapat dilakukan. Analisisnya dalam literatur statistika dikenal sebagai analisis varians satu arah (one-way analysis of variance). Untuk latihan, akan digunakan set data berikut.
Analisis dilakukan lewat model linear dan cara ini lebih berguna untuk rancangan yang lebih rumit kelak. Data dapat disimbolkan dengan Yij , maka suatu data yang
muncul dari suatu satuan percobaan ke-j dari perlakuan ke-i adalah
Y
ij=
μ + τ
i+ ε
ij,
dengan εij = (Yij – μ + τi) ~ NID (0, σ2). NID artinya Normally and Independently
Distributed, residualnya independen dan mengikuti distribusi normal. Besaran τi= (μi
– μ), disebut pengaruh perlakuan. Bentuk ini disebut sebagai model linear matematis. Hipotesis nol yang digunakan adalah H0: μ1 = μ2 = ... = μt= μ dapat ditulis H0: τ1 = τ 2 = ... = τ t = 0. Melalui metode kuadrat terkecil (least squares), kita mendapatkan
penduga-penduga (diberi simbol “topi“) bagi, berturut-turut¸ μ, τi , dan εij :
�̂
=
�
�
�.�
�
�=
��
�.− ��
…�
�
��=
�
��− �̂ − �
�
�Selanjutnya, menghitung Jumlah Kuadrat (JK) dan derajat bebas (db). JK Antargrup perlakuan (=JK Perlakuan) = ΣΣ
τ
ˆ
i2 dengan derajat bebas (db) sebesar t - 1 dan JK Dalam Grup (= JK Sesatan) = ΣΣ εˆ2ij dengan derajat bebas sebesar Σ (ri – 1) atau t(r –Dalam latihan ini, data disusun dalam format kategoris, yaitu nama grup perlakuan dan nomor ulangan masing-masing disusun dalam kolom tunggal dan data hasil pengamatan disusun pada kolom berikutnya, pada tempat yang bersesuaian dengan perlakuan dan nomor ulangan yang menjadi labelnya.
Buatlah kolom-kolom dalam MSExcel seperti contoh di bawah ini dan isilah sesuai dengan data anda. Hitunglah JK masing-masing kolom. Bandingkan dengan hasil perhitungan sebelumnya! Sebagai petunjuk: Fungsi ΣΣ ( ) dapat dilakukan dengan memasukkan rumus =SUM( ) dan ΣΣ ( )2 dengan rumus =SUMSQ( ).
Biasakanlah untuk seterusnya menyusun data dalam format demikian (turun ke bawah). Selanjutnya buatlah di MS Excel tabel analisis varians berikut.
Apakah nilai Fhit ini mendekati satu (H0 benar) atau tidak, dapat dilihat dari
peluangnya untuk mendapatkan nilai sebesar itu atau lebih, dilambangkan dengan Prob, yang dapat diperoleh dari MSExcel sbb.: Ketik = FDIST(nilai Fhit, db pembilang,
db penyebut). Jika nilai ini kecil, Fhitnya dikatakan mendekati satu. Seberapa yang
disebut kecil terserah kita; biasanya sebagai batas adalah 0,05 atau 0,01 dan disebut tingkat signifikansi, dilambangkan dengan α. Apa kesimpulannya: H0 diterima atau H0 ditolak; dan bagaimana hasil eksperimen anda, apakah perlakuan-perlakuan memberikan pengaruh yang nyata?
Sekarang, cobalah melakukan analisis data yang sama dengan menggunakan R dalam file syntax Acara CRD.R.
Koefisien keragaman (Coefficient of Variation, CV)
Koefisien keragaman (CV) adalah ukuran keragaman sesatan terhadap satuan pengukuran. Koefisien tersebut dihitung dengan membagi akar kuadrat tengah sesatan dan rerata umum. Nilai CV dalam % dapat dipakai untuk membandingkan antarpercobaan yang serupa. Apabila nilai CV lebih dari 100%, maka banyaknya ulangan perlu ditambahkan jika percobaan tersebut ingin diulang dengan tujuan melihat perbedaan perlakuan yang nyata. Jika nilai CV% yang didapat dari percobaan di luar dari kisaran ekspektasinya, maka dapat diduga bahwa percobaan dilakukan dengan tidak semestinya atau kaidah-kaidah percobaan tidak ditaati. CV% wajar biasanya 5% sampai 20%. Untuk mengetahui nilai CV%, pakailah package agricolae dengan fungsi sebagai berikut:
B. Analisis varians berbasis cuplikan (pengamatan berganda)
Dalam praktik sering terjadi, lebih dari satu data dapat diperoleh dari satu peubah dalam satu unit percobaan. Sebagai contoh, jika unit percobaan berupa petak dengan sejumlah tanaman jagung dan data tinggi tongkol diukur dari sejumlah tanaman. Contoh lain, unit percobaan berupa seekor ayam dan datanya berupa kadar hemoglobin darah yang tentu saja dapat diukur lebih dari sekali. Dalam hal demikian, yaitu pengukuran dilakukan di sebagian unit percobaan. Percobaan dikatakan berbasis data cuplikan. Namun demikian, rancangan lingkungan pada dasarnya tentu saja dapat sama seperti sebelumnya. Kita akan pelajari RAL dengan subsampel, tetapi cara analisisnya dapat diterapkan pula untuk rancangan lain.
Perhatikan data percobaan yang dirancang untuk mengetahui hubungan dosis N (1 pot tanpa N, 2 pot N sedang, dan 3 pot N tinggi) dengan kandungan protein padi yang diukur dari dua contoh masing-masing 1 g dari setiap pot berikut ini. Model yang dipakai tentu saja serupa dengan model untuk RAL hanya ada tambahan faktor kebetulan untuk contoh pengukuran protein:
Y
ijk=
µ
+
τ
i+
ε
ij+
δ
ijk,
i = 1,2, …, t, j = 1,2, …, ri, dan k = 1,2, …, mij
dengan mij = banyaknya cuplikan yang diambil dari unit percobaan ke-j yang
mendapat perlakuan i. Indeks k dibutuhkan untuk menunjukkan banyaknya cuplikan. Pada ilustrasi ini t = 3, r1 = 1, r2 = 2, r3 = 3. dan mij= 2 untuk setiap i dan j. Penduga
setiap komponen model serupa dengan pendugaan komponen model rancangan dasarnya dengan satu data dari tiap unit percobaan: µˆ =Y... (rerata seluruh data),
... .. ˆi =Yi −Y
τ (rerata perlakuan dikurangi rerata seluruh data), εˆij =Yij.−Yi.. dan
. ˆ ˆ ˆ ˆ
ij i ijk
ijk =Y −µ−τ −ε
δ Di bawah hipotesis nol seperti biasa, H0: μ1 = μ2 = ... = μt = μ, analisis
varians dilakukan.
Gunakan MSExcel! Untuk mendapatkan
ε
ˆ
ij kita perlu menghitung Yij. (rerata tiapi j Yij. μˆ τˆi εˆij
dan δˆijk sekarang dapat dihitung dengan mengisi tabel ini:
i j k Yijk μˆ τˆi
ε
ˆ
ij δˆijkJKS merupakan JK antarulangan dalam perlakuan, sedangkan JKC merupakan JK
antarcuplikan dalam ulangan. JKT adalah JKData–FK. Tabel ANOVA-nya sbb. Pengujian
untuk “Ulangan dalam perlakuan” menguji H0: (σ2 + cσ2w) = σ2w. Selanjutnya buatlah
tabel di bawah ini dan lakukan pengujian!
Sumber Keragaman db JK RK Fhit
Perlakuan
Ulangan dalam perlakuan (E) Cuplikan dalam ulangan (S)
t–1
Acara 4: Rancangan Berblok Lengkap (RCBD) dan Segiempat Latin (LS)
Tujuan: Mengerjakan analisis varians untuk rancangan berblok lengkap teracak searah (RCBD) dan dua arah (LS Design) dan menafsirkan hasilnya
Menerapkan uji asumsi keaditifan model menurut Tukey Mengerjakan analisis RCBD dengan data hilang
Apabila kita dapat mengidentifikasi sumber keragaman/sesatan secara sistematis pada satuan percobaan sebelum percobaan dijalankan, diperlukan suatu strategi untuk dapat memisahkannya dari sumber sesatan yang muncul secara tak disengaja. Dalam uji-t (Acara 2) kita mengenal pengambilan cuplikan (samples) secara ber-pasangan, seperti pada kasus data sebelum-sesudah, sepasang perlakuan pada pot/ kandang yang sama, dan sebagainya. Itu adalah satu strategi untuk memisahkan sumber sesatan sistematis. Tentu saja jika grup perlakuannya lebih daripada dua, strategi tersebut perlu diubah karena kita akan kesulitan menghitung selisih lebih daripada dua perlakuan.
Pengacakan (randomisation)
Berbeda dari CRD yang pengacakannya langsung terhadap satuan percobaan, pengacakan dalam dalam rancangan berblok dilakukan untuk bloknya dan untuk satuan-satuan percobaan di dalam setiap blok. Dengan demikian, jika kita meng-gunakan tiga blok, pengacakan yang perlu dilakukan adalah satu antarblok, dan tiga untuk antarsatuan percobaan dalam setiap blok. Sesungguhnya, dalam uji-t untuk data berpasangan, yang disebut sebagai blok ini adalah objek yang menyatukan setiap pasangan perlakuan yang diujikan.
Berikut contoh ilustrasi. Untuk mengetahui keefektifan lima cara pengemasan jambu air, Udin memerlukan 40 kg jambu air bagi lima grup-perlakuan pengemasan dan empat ulangan yang direncanakan-nya. Ternyata dari satu pemasok ia hanya dapat memperoleh 20 kg, dari pemasok lain 10 kg, dan dari pemasok ketiga 10 kg. Tampak olehnya bahwa jambu air dari ketiga sumber ini berbeda-beda kondisinya. Apabila Udin nekad menggunakan CRD untuk penelitiannya, ia akan mencampur semua jambu air miliknya terlebih dahulu kemudian membaginya menjadi 20 satuan percobaan @ 2 kg, yang kemudian diacaknya kepada lima cara pengemasan yang direncanakannya. Keragaman yang terdeteksi karena sumber yang berbeda itu menyumbang sesatan dalam analisis datanya kelak.
Cara analisis
Cara analisis untuk RCBD biasa disebut sebagai analisis varians klasifikasi dua-arah tanpa interaksi (two-way classification without interaction) dalam literatur statistika. Model linear yang dipakai adalah
Y
ij=
µ
+
ρ
j+
τ
i+
ε
ij.
Keterangan masing-masing suku sama seperti pada Acara 3, dengan tambahan di sini ρj, yang merupakan pengaruh blok ke-j (j= 1,2, … , n). Perhatikan bahwa ada tiga
sumber keragaman data di sini, yaitu perlakuan, blok, dan sesatan.
Asumsi bahwa sesatan berdistribusi normal, saling independen, dan variansnya homogen (yaitu sebesar σ2) tetap berlaku. Hipotesis yang diuji sama dengan hipotesis pada CRD, yaitu H0: μi= μ (untuk i = 1,2, …, t; t = banyaknya perlakuan), yang juga bisa
dituliskan H0: τi = 0 ∀i = 1,2, …, t. ∀i artinya untuk semua i.
Jika datanya seimbang (balanced), sebagaimana yang terjadi bila setiap perlakuan dicobakan di tiap blok sehingga cacah ulangannya sama, melalui metode kuadrat terkecil didapatkan penduga-penduga bagi μ, τi, ρj, dan εij yaitu:
μˆ = Y..,
i
τ
ˆ = Yi.–Y.. ,j
ρˆ = Y.j–Y.. , dan
j i ij
ij
Y
μ
ˆ
τ
ˆ
ρ
ˆ
ε
ˆ
=
−
−
−
.Jumlah kuadrat tiap sumber keragaman diperoleh dengan cara yang sama seperti pada Acara 3. Sebagai contoh, JK Perlakuan = ΣΣ
τ
ˆ
i2.Sebagai teladan untuk praktik, berikut adalah data hasil uji tiga bahan pengawet dan kontrol sbb. Data ini sudah disiapkan pada syntax R.
Perlakuan Blok
1 2 3
Kontrol 4 8 9
Pengawet X 7 14 9
Pengawet Y 11 13 12
Masukkanlah data dan nilai duga bagi setiap suku dalam model ke dalam tabel berikut di spreadsheet MSExcel atau OpenOfficeCalc.
Derajat bebas (db) data adalah sebanyak data (tr), db FK adalah 1, db Total adalah tr – 1, db Perlakuan adalah banyaknya perlakuan (t) dikurang satu atau (t – 1), db Blok adalah banyaknya blok atau ulangan (b) dikurang satu atau (b – 1), dan derajat bebas sesatan sama dengan (t – 1) (b – 1).
Analisis varians untuk RCBD memiliki tiga sumber keragaman: Blok atau Ulangan, Grup Perlakuan, dan Sesatan.
Analisis dengan Perangkat Lunak
MSExcel dilengkapi dengan perangkat untuk menganalisis RCBD, melalui Tools > Data Analysis, dan pilih Anova: Two-Factor Without Replication. Kita tidak akan melakukannya di kelas, tetapi dsarankan Anda mencobanya di rumah. Namun, tidak disarankan untuk mengerjakan analisis menggunakan MS Excel pada aplikasi nyata.
Perangkat lunak R dapat dengan mudah melakukan analisis varians untuk RCBD. Dengan prosedur yang sama seperti CRD, siapkan kolom Perlakuan dan Blok sebagai factor, menggunakan baris perintah. Bukalah program RStudio dan buka file Acara RCBD.R sebagai latihan. Perhatikan bahwa kolom blok harus diubah menjadi faktor karena berupa numerik dengan fungsi as.factor( ) atau factor( ).
2. Keaditifan model matematis
Satu asumsi lain dalam analisis varians yang tidak menyangkut sesatan adalah keaditifan (kesalingjumlahan) komponen model. Maksudnya adalah bahwa pengaruh-pengaruh komponen perlakuan, blok, dan sesatan saling menjumlah, seperti pada model regresi linear, bukan seperti pada model non-linear semacam model logaritmik atau eksponensial.
Tukey mengajukan satu uji bagi ketakaditifan, dengan hipotesis nol bahwa model aditif, dengan memasukkan satu komponen non-aditif pada model dan mencoba melihat apakah komponen non-aditif ini dapat meregresi komponen sesatan.
Perhatikan model linear untuk RCBD: Yij = µ + τi + ρj + εij. Model yang diajukan
Tukey adalah Yij = µ + τi + ρj + βτiρj + eij, dengan melihat εij = βτiρj + eij. Bentuk
perkalianτiρjadalah komponen non-aditif. Dengan mengajukan H0: β = 0 melawan
H1: β≠ 0, kita menguji regresi Yij ke βτiρj . Jika H0 diterima, kenonaditifan ditolak. Uji
3. Rancangan Segiempat Latin (Latin Square Design, LS)
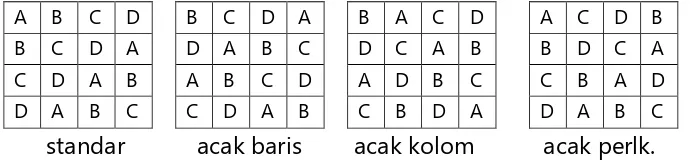
Rancangan ini, seperti halnya RCBD, dipakai jika kita dapat mengenali sumber keragaman sistematis yang muncul. Perbedaannya, LS mengendalikan dua sumber keragaman sistematis sekaligus dalam dua blok yang arahnya saling bersilangan. Lihat gambar!
A B C D B C D A B A C D A C D B B C D A D A B C D C A B B D C A C D A B A B C D A D B C C B A D D A B C C D A B C B D A D A B C
standar acak baris acak kolom acak perlk.
Gambar kiri menunjukkan situasi standar sebelum pengacakan. Pengacakan dilaku-kan untuk setiap arah blok, diikuti dengan pengacadilaku-kan perlakuan. Diagram kedua menunjukkan hasil pengacakan blok mendatar (“baris”), diagram ketiga hasil acakan blok vertikal (“kolom”), dan paling kanan hasil acakan perlakuan. Perhatikan perubahan-perubahan yang terjadi.
Akibat dari ketatnya blocking, dalam LS banyaknya baris (= blok dalam RAKL) dan banyaknya kolom sama dengan banyaknya perlakuan yang diberikan. Modifikasi rancangan segiempat latin untuk banyaknya perlakuan yang tidak sama dengan blok tersedia, tetapi di luar lingkup acara ini.
Model linear yang dipakai adalah
Y
(i)jk= μ + κ
k+ ρ
j+ τ
(i)+ ε
(i)jkAsumsi yang dipakai dan arti dari lambang sama seperti sebelumnya, hanya ada tambahan satu suku, κk , yang berarti pengaruh kolom ke-k (k = 1,2, ..., t; t = banyaknya
perlakuan). Melalui metode kuadrat terkecil (least squares), penduga tak bias bagi suku-suku pada model tersebut, yaitu
μˆ = Y.., ) (
ˆi
τ = Y(i)..−Y... ,
j
ρˆ = Y.j.−Y... ,
k
j i ijk
ijk
Y
μ
ˆ
τ
ˆ
ρ
ˆ
ε
ˆ
=
−
−
−
- κˆk .Untuk teladan, berikut ini adalah data hasil penelitian dengan rancangan segiempat latin menguji empat takaran pupuk dilambangkan dengan huruf A (= 50 kg per ha), B (= 100 kg per ha), C (= 150 kg per ha), dan D (= 200 kg per ha).
A=7 C=7 B=9 D=9
C=13 B=11 D=13 A=7 D=13 A=9 C=17 B=13 B=11 D=5 A=5 C=11
Masukkanlah data dan nilai duga bagi setiap suku dalam model ke dalam tabel berikut di spreadsheet MSExcel atau OpenOfficeCalc, seperti sebelumnya.
i j k Yijk μˆ τˆi ρˆj κˆk
ε
ˆ
ijDerajat bebas (db) data adalah sebanyak data (tr), db FK adalah 1, db Total adalah tr – 1, db Perlakuan adalah banyaknya perlakuan (t) dikurang satu atau (t – 1), db Blok-Baris adalah banyaknya blok atau ulangan (r = t) dikurang satu atau (t – 1), db Blok-Kolom adalah banyaknya blok atau ulangan (r = t) dikurang satu atau (t – 1), dan derajat bebas sesatan sama dengan (t – 1) (t – 2).
Sumber
Analisis varian untuk LSDesign secara lebih cepat dapat digunakan perangkat lunak R. Siapkan kolom Perlakuan, Blok-Baris, dan Blok-Kolom sebagai factor (memakai pilihan as.factor() atau factor(), lihat sebelumnya).
Model Matematika dan Syntax R Berbagai Rancangan Lingkungan
Rancangan
Berikut Skema Rancangan Lingkungan
4. Data hilang (Missing data/unequal sample size/unbalanced)
Data hilang merupakan hal yang dapat atau bahkan sering terjadi dalam suatu percobaan. Percobaan yang berkaitan dengan organisme/makhluk hidup sangat rentan dengan data hilang yang diakibatkan, sebagai contoh, unit eksperimen mati
Rancangan Perlakuan ANOVA Klasik (Balanced
atau hilang, atau unit eksperimen rusak karena faktor alam. Data hilang mengakibatkan sample size menjadi unequal dan rancangan menjadi unbalanced sehingga tidak ortogonal lagi.
Data hilang berbeda dengan rancangan tidak lengkap. Data hilang artinya suatu percobaan dirancang dengan rancangan yang lengkap (complete, balanced, dan ortogonal), tetapi tidak seluruh perlakuan ataupun kombinasi perlakuan bisa didapatkan datanya sehingga tidak diketahui nilainya. Sedangkan, rancangan tidak lengkap terjadi karena keterbatasan bahan ataupun tempat. Contoh rancangan tidak lengkap seperti, blok tidak lengkap (incomplete block design), lattice design, alpha design, dsb.
Untuk rancangan CRD satu faktor, data hilang tidak mempengaruhi nilai rerata per perlakuan maupun penghitungan jumlah kuadrat karena hanya ada satu sumber ragam yaitu perlakuan. Akan tetapi, data hilang akan mengakibatkan nilai residual menjadi lebih besar. Lebih lanjut, data hilang bisa mengakibatkan homoskedastisitas tidak terpenuhi karena varians antar perlakuan menjadi tidak homogen akibat data hilang.
Ketidakortoganalan mengakibatkan estimate/nilai rerata dan penghitungan jumlah kuadrat (sum of squares/SS) menjadi berbeda ketika rancangan sudah memiliki lebih dari satu sumber ragam, seperti, CRD dua faktor, RCBD (satu faktor dan faktorial), dan split-plot. Ketidakortogonalan juga terjadi pada rancangan percobaan tidak lengkap seperti incomplete block, lattice design, alpha design, dan rancangan tidak lengkap lainnya. Dengan demikian, diperlukan metode penghitungan rerata yang lebih baik, yaitu dengan rerata kuadarat terkecil (Least Squars Mean/LSMEANS) dan untuk jumlah kuadrat/SS juga terdapat berbagai pilihan.
Dalam praktikum ini, jumlah kuadrat/SS yang sering dipakai adalah SS type I atau sequential SS. Penghitungan SS ini adalah berurutan. Sebagai contoh, ketika dalam model dituliskan hasil~blok+perlakuan, maka SS blok akan dihitung terlebih
akan dihitung terlebih dahulu (SS perlakuan), kemudian SS blok akan dhitung setelah efek perlakuan (SS blok | perlakuan). Jika data lengkap, maka penulisan model pada SS type I tidak akan memberikan hasil berbeda. Khusus untuk CRD, kejadian data hilang juga tidak berpengaruh terhadap SS Karena walaupun data tidak lengkap karena bentuk model hanya hasil~perlakuan sehingga penghitungan SS hanya SS
perlakuan.
Namun, hal tersebut tidak berlaku ketika data hilang terjadi pada rancangan CRD faktorial, RCBD (satu faktor dan faktorial), dan rancangan lainnya. Sebagai contoh, pada RCBD, model hasil~blok+perlakuan (A), akan memberikan hasil ANOVA yang berbeda dengan hasil~perlakuan+blok (B), ketika SS yang digunakan ada SS type I. Pada model A, SS perlakuan akan dihitung setelah efek blok (perlakuan adjusted dan blok unadjusted) sehingga SS yang benar hanyalah SS perlakuan. Untuk model B, SS yang benar hanyalah SS blok karena SS blok dihitung setelah efek perlakuan (SS blok adjusted, SS perlakuan unadjusted). Dengan demikian, penggunaan SS type I tidak dianjurkan karena urutan faktor pada model berpengaruh dan menyebabkan hasil yang kurang tepat seandainya salah memasukkan model.
Tipe SS yang sesuai untuk rancangan yang unbalanced dan tidak orthogonal adalah SS type II. SS type II, akan memberikan hasil yang benar walaupun urutan faktor dalam model dibolak-balik. SS pada model A maupun model B di atas akan menghasilkan SS yang sama (adjusted untuk kedua faktor) karena penghitungan SS type II sebagai berikut.
Jika model A dimasukkan, maka SS type II akan menghitung SS blok setelah efek perlakuan (SS blok | perlakuan) dan SS perlakuan setelah efek blok (SS perlakuan | blok). Begitu juga untuk model B sehingga urutan faktor menjadi tidak persoalan. Oleh karena itu, ketika data unbalanced dan tidak ortogonal, gunakan SS type II.
maka SS yang digunakan adalah SS type II. SS type III baru akan digunakan jika ada interaksi dalam model. Berikut tabel ringkasan jenis SS.
Tipe SS Model Sumber
hanya jika data lengkap. Ketika digunakan pada data tak lengkap, SS untuk faktor yang masuk pertama akan unadjusted dan hanya SS untuk faktor yang kedua yang adjusted. model yang lebih dari satu faktor (RCBD satu faktor, lattice satu faktor, blok tidak lengkap satu faktor, dll.)
(hierarchical) SS A SS A | B
Skema Rancangan dan SS yang Sesuai
Rancangan dan data
Rancangan lengkap, data
lengkap
SS Type I, II, III tidak berbeda
Rancangan ataupun data tidak lengkap
CRD satu faktor
Tidak ada pengaruh untuk
tipe SS, semua dibuang ke
residual
Bisa bermasalah pada homoskedastisitas
RCBD, LS, lattice SS type II
CRD dan RCBD dengan interaksi,
split-plot
Acara 5: Uji Post-hoc dan Kontras Ortogonal
Tujuan: Melakukan perbandingan antarrerata
Melakukan kontras orthogonal dan kontras polinomial Mengenal transformasi data
Uji Lanjutan Pembandingan Antarrerata
Pembandingan antarrerata posthoc
Pembandingan antarrerata yang tidak direncanakan sebelumnya dikenal sebagai pembandingan antarrerata posthoc. Pembandingan ini tidak terstruktur, hanya berdasarkan pasangan-pasangan rerata. Untuk tujuan ini tersedia sejumlah metode, tetapi dasar semua metode adalah sama, yaitu dua perlakuan atau populasi berbeda reratanya jika selisih rerata contohnya melebihi suatu nilai tertentu, disebut nilai kritis. Berdasarkan cara mendapatkan nilai kritis ini muncul bermacam metode. Untuk latihan, gunakan data CRD dan RCBD.
Perangkat lunak R melalui library (agricolae) dapat mendukung sebagian besar pembandingan antarrerata di atas. Untuk contoh data CRD dan RCBD, nama peubah dihitung adalah hasil dan nama peubah pengelompok adalah perlakuan. Sebelum memanggil package yang sesuai, perlu dilakukan analisis varians terlebih dahulu. Selanjutnya dimasukkan beberapa parameter yang diambil dari analisis varians tersebut. Dalam acara praktikum berikut, hanya BNT-Fisher, BNJ-Tukey, dan Uji Duncan yang dipraktikkan. Uji pembandingan rerata yang lain dapat Anda coba sebagai tugas yang wajib Anda kumpulkan pada pertemuan berikutnya.
Memilih metode pembandingan antarrerata yang tepat adalah memilih satu metode yang memberikan hasil yang dapat menjawab hipotesis awal. Idealnya, anda merencanakan
metode sebelum penelitian dilakukan, bukan setelah mendapatkan data!
a. Beda Nyata Terkecil (BNT)atau Least Significant Difference (LSD)
Pada dasarnya, metode ini serupa dengan uji-t untuk dua rerata dari cuplikan independen dengan asumsi varians homogen yang telah kita pelajari pada Acara 1. Uji ini
menggunakan distribusi t-Student. Kita menghitung �ℎ�� = ��1−��2
���1−��2. H0 ditolak jika thit > ttabel.
Jadi, H0 ditolak jika Y1−Y2>������.���1−��2; nilai suku kanan disebut batas kritis BNT. H0
digabungkan, �2��1−��2 =������1
r2. Batas kritis BNT mengalikan varians selisih rerata dengan ttabel dua sisi, memakai derajat
bebas sesatan pada analisis varians.
BNT-Fisher. Fisher menasehatkan agar metode ini digunakan hanya apabila hasil analisis varians menolak hipotesis nol dan pembandingan tidak dilakukan untuk seluruh pembandingan yang mungkin.
BNT-Bonferroni. Bonferroni menyarankan agar ttabel tidak diperoleh dengan α dibagi 2, tapi dibagi 2k, karena semula hanya ada satu perbandingan antara dua perlakuan, tetapi
perbandingannya akan sebanyak
dimungkinkan untuk pembandingan keseluruhan set pasangan.
BNT-Dunnett. Apabila pembandingan selalu ke salah satu perlakuan acuan, biasanya
berupa kontrol atau pembanding, Dunnett mengajukan metode ini. Batas kritisnya mirip dengan BNT tetapi tidak menggunakan distribusi t-Student melainkan distribusi Dunnett (dapat dilihat pada Daftar Tabel Statistika).
b. Beda Nyata Jujur (BNJ) atau Honestly Significant Difference (HSD)
Metode ini disebut juga metode Tukey. Di sini, batas kritisnya disebut sebagai batas kritis BNJ. Nilai tabel diperoleh dari tabel Tukey atau “Titik Persentil Atas dari Kisaran Ter-Student-kan” yang nilainya ditentukan oleh taraf nyata (alpha), derajat bebas Sesatan, dan banyaknya grup perlakuan. Selain itu, pengali tidak menggunakan varians selisih rerata melainkan varians rerata (artinya tidak dikalikan 2 dan KTSes dibagi langsung dengan rerata harmonik banyaknya data tiap grup perlakuan). Jika tidak terdapat tabel Tukey, kita dapat menghitung nilai tabelnya menggunakan perangkat lunak R, dengan perintah qtukey((1-alpha), banyakperlakuan, lower.tail=T, df=dbSes. Argumen banyakperlakuan adalah banyaknya perlakuan yang dibandingkan dan dbSes adalah derajat bebas Sesatan.
c. Metode Scheffé
bagian berikutnya. Metode Scheffé merupakan metode yang dirancang untuk perbandingan demikian. Untuk perbandingan sepasang perlakuan, batas kritisnya adalah
�� =�2×�������(� −1)��,(�−1),�. .
d. Uji Duncan atau Duncan’s New Multiple Range Test (DMRT)
Berlainan dengan metode sebelumnya, ada banyak (multiple) batas kritis pada uji Duncan, karena batas kritis yang dipakai untuk suatu pembandingan tergantung jarak dua rerata grup perlakuan yang dibandingkan. Dua rerata grup perlakuan yang berdekatan langsung setelah diurutkan dari terkecil menurut besarnya dikatakan ber”jarak” dua. Jika bersela satu disebut berjarak tiga; dengan dua penyela disebut berjarak empat, dan seterusnya. Batas kritis untuk dua perlakuan berjarak p (p = 2, 3, ... , t) adalah LSRp = SSRdbSes,p*√(RKSes/r). Nilai SSR didapat dari tabel Duncan (silakan lihat Tabel Statistika), yang besarnya tergantung α, dbSes, dan p. DMRT sebenarnya sudah lama dianjurkan untuk tidak digunakan karena selang kepercayaan yang beraneka ragam.
e. Uji SNK (Student-Newman-Keuls)
Metode ini merupakan gabungan antara metode Tukey dan Uji Duncan dalam artifak nilai tabel yang digunakan diambil dari tabel Tukey tetapi batas kritisnya lebih dari satu tergantung jarak rerata perlakuan yang diperbandingkan seperti halnya DMRT. Batas kritisnya adalah SNKα= qα, ν,p . sx .
Cara Penyajian Uji Posthoc
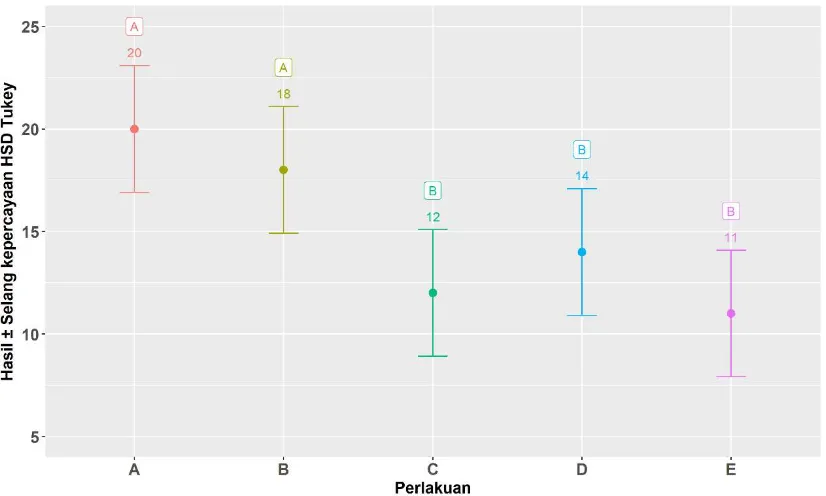
Penyajian hasil posthoc dapat dilakukan dengan menggunakan tabel seperti di bawah ini.
Perlakuan Rerata hasil
A 20 a
B 18 a
D 14 b
C 12 b
E 11 b
Keterangan: Angka yang diikuti oleh huruf yang sama tidak berbeda nyata pada uji HSD-Tukey (α = 5%).
jenis uji posthoc. Jenis uji akan menentukan lebar errorbar. Di bawah ini adalah uji dengan errorbar menurut HSD Tukey.
Gambar 1. Peubah hasil di bawah pengaruh perlakuan berdasarkan uji lanjut HSD-Tukey (α = 5%). Keterangan: angka merupakan rerata dan error bars menunjukkan selang kepercayaan.
Ringkasan tabel uji posthoc disajikan pada tabel berikut.
Posthoc test Batas kritis Ulangan (r) Keterangan LSD
= Sama Hanya digunakan ketika n perlakuan tidak lebih dari 3 dan hasil ANOVA signifikan
= Sama Hanya digunakan ketika membandingkan masing-masing
= Sama Digunakan untuk membandingkan setiap pasangan perlakuan
= Sama Digunakan untuk membandingkan group
perlakuan yang tidak
Kontras dan Keortogonalan
Bentuk pembandingan sepasang-sepasang dapat dipandang sebagai berikut. H0: (1)*μ1 + (–1)*μ2 = 0
Perhatikan koefisien di muka rerata. Jumlahnya adalah nol (1 dijumlah dengan -1 menghasilkan nol). Bentuk pembandingan berkelompok dapat ditulis ulang sebagai berikut.
H0: 2*μ1 + (–1)*μ2 + (–1)*μ3 = 0.
Penjumlahan koefisien-koefisien tersebut menghasilkan nol pula. Koefisien-koefisien yang menjumlah dan menghasilkan nol disebut sebagai koefisien kontras. Pembandingan yang menggunakan koefisien kontras disebut kontras. Dua kontras disebut saling ortogonal bila penjumlahan terhadap hasil kali (sum of products) koefisien-koefisien yang bersesuaian adalah nol. Jadi, mengambil contoh seri hipotesis nol kita di atas, kontras μ1 = μ2 vs. kontras μ2 = μ3
tidaklah saling ortogonal sebagaimana terlihat di tabel berikut.
Hipotesis nol c1 c2 c3 jumlah
μ1 – μ2 = 0 1 –1 0 0
μ2 – μ3 = 0 0 1 –1 0
Perkalian 0 –1 0 –1
Sebaliknya, kontras μ1 – (μ2 + μ3)/2 = 0 vs. kontras μ2 = μ3 saling ortogonal:
Hipotesis nol c1 c2 c3 jumlah μ1 – (μ2 + μ3)/2 = 0 1 –0.5 –0.5 0 μ2 – μ3 = 0 0 1 –1 0
Perkalian 0 –0.5 0.5 0
Perhatikan baik-baik, bagaimana kontras yang saling ortogonal dapat timbul. Secara umum, pembandingan tiap rerata sepasang-sepasang tidak menghasilkan kontras-kontras yang saling ortogonal, sedangkan pembandingan rerata grup secara berkelompok dapat menghasilkan kontras-kontras yang saling ortogonal.
Sebagai ilustrasi, suatu penelitian dengan ulangan sama mengenai pemberantasan lumut pada perdu teh, menguji perlakuan sebagai berikut: kerik lumut, disemprot glifosat, disemprot fentin-asetat, disemprot bentiokarp, dan tidak diapa-apakan sebagai kontrol. Rerata populasi lima perlakuan dilambangkan dengan µ1, µ2, µ3, µ4, dan µ5. Perhatikan bahwa perlakuannya
adalah perlakuan kualitatif!
H0: 1 2 3 4 5
4 µ
µ µ µ
H0: 2 3 4 1
3 µ
µ µ
µ + + = menguji seberapa efektif pemberantasan kimia dibanding dengan cara
manual.
H0: 2 4 3
2 µ
µ
µ + = dibuat untuk membandingkan herbisida non-asam versus asam.
H0: μ2=μ4, yaitu apakah dua herbisida non-asam yang diujikan berbeda. Perhatikan bahwa lima
perlakuan yang diuji disini dapat digolong-golongkan, seperti golongan perlakuan dengan dan tanpa pengendalian lumut, golongan perlakuan dimana pengendalian lumut dilakukan secara manual dan secara kimiawi. Jadi, perlakuannya berstruktur.
Percobaan dengan perlakuan berstruktur hampir selalu menghasilkan penelitian yang baik nalarnya, karena itu pikirkan baik-baik grup-grup perlakuan yang diberikan pada saat merancang penelitian. Buatlah tabel seperti di atas pada MSExcel anda dan berikan koefisien kontras untuk masing-masing hipotesis. Tunjukkan bahwa setiap pasang kontras tersebut saling ortogonal.
R mampu membantu dalam menemukan koefisien yang kontras dan ortogonal. Ikuti perintah berikut dan pahami keluaran yang muncul! Keterangan: x adalah banyaknya grup
perlakuan dengan perintah contr.helmert(x). Untuk menguji apakah kontras dan saling ortogonal, silakan ikuti perintah berikut.
> apply(namauji,2,sum)
> crossprod (namauji)
> contr.helmert (x, contrasts=F)
No. kontras Hipotesis nol c1 c2 c3 c4 c5 jumlah
1 2 3 4
Catatan: c1adalah koefisien untuk μ1 dst.