ARTIKEL ILMIAH
ALGORITMA
SUPPORT VECTOR MACHINE
UNTUK MEMPREDIKSI
RENTET WAKTU HARGA DAGING AYAM BROILER DAN
TELUR AYAM BROILER
Oleh
MOHAMAD ISMAIL
P31.2011.01048
PROGRAM PASCA SARJANA
MAGISTER TEKNIK INFORMATIKA
UNIVERSITAS DIAN NUSWANTORO
ALGORITMA
SUPPORT VECTOR MACHINE
UNTUK MEMPREDIKSI
RENTET WAKTU HARGA DAGING AYAM BROILER DAN
TELUR AYAM BROILER
Mohamad Ismail, Dr. Abdul Syukur, MM , H. Himawan, M.Kom
Pascasarjana Teknik Informatika Universitas Dian Nuswantoro
ABSTRACT
This thesis entitled "The Prediction of a Time-series Using Algorithm Support Vector Machine Towards Meat Chicken Broilers and Eggs Chicken Broilers". The purpose of the reseacrh is to build a prediction model of time-series based on the algorithm support vector machine (SVM). The amount of collecting data is obtained by the market of Deperindag district of Brebes, those are consists of three types : day/ date/ year, product/ market name, and price.
The data of meat chicken broilers is 640 and also 640 for eggs chicken broilers. For obtained data is the sample of 2012 and 2013. The first result shows that the prediction method of the comodity chicken broilers' price with the best RMSE are about 1863.157 + /- 1272-465. It seems by the prediction data 4 days before, using algorithm SVM with k-fold= 10, c (cost) of 0,3 and using type kernel polynomial. Both predictions method of eggs chicken broilers with RMSE are 472.169 + /- 244.893 with cost prediction which is affected by the price of eggs chicken broilers six days before, using algorithm SVM with k-fold= 10, c (cost) of 0,3 and using type kernel dot.
Key Words : Algorithm, Support vector machine, time-series, meat chicken broilers’ price, eggs chicken broilers.
1. PENDAHULUAN
Permintaan daging dan telur ayam di Indonesia meningkat seiring dengan daya beli masyarakat yang cukup tinggi. Penyediaan daging ayam dalam kuantitas yang tinggi harus diiringi dengan kualitas yang baik. Oleh karena itu, daging ayam untuk dikonsumsi manusia haruslah sehat.
Inflasi harga yang diakibatkan oleh kelebihan permintaan dari persediaan barang yang ada (demand pull inflation) umumnya terjadi pada saat menjelang hari-hari besar keagamaan (lebaran, natal dan tahun baru). Pada saat demikian permintaan daging dan telur ayam meningkat baik karena faktor peningkatan pendapatan, maupun budaya masyarakat merayakan hari besar tersebut. Kenaikan permintaan tersebut kemudian mendorong peternak dan pedagang menaikan harga daging dan telur ayam.
Sumbangan daging dan telur ayam yang cukup besar terhadap inflansi, akan berdampak signifikan pada penurunan permintaan daging dan telur ayam. Dengan nilai elastisitas pendapatan dan harga terhadap daging dan telur ayam yang bersifat elastis, maka penurunan pendapatan atau kenaikan harga berpengaruh signifikan terhadap permintaan (konsumsi) daging dan telur ayam. Keadaan ini berdampak lebih lanjut pada penurunan produksi dan investasi pada agribisnis perunggasan, yang pada akhirnya akan memperlambat laju pertumbuhan ekonomi nasional.
Berdasarkan latar belakang masalah di atas maka rumusan masalah dalam penelitian ini adalah perlunya kemampuan untuk memprediksi harga daging dan telur ayam untuk mencegah terjadinya fluktuasi harga yang terlalu ekstrim yang akan mengakibatkan inflasi dan penurunan permintaan (konsumsi) daging dan telur.
Tujuan penelitian ini adalah membangun model prediksi rentet waktu harga daging ayam broiler dan telur broiler berbasis algorithma Support vector machine (SVM).
a. Sebagai tambahan referensi bagi peneliti selanjutnya yang meneliti tentang prediksi rentet waktu dengan kerangka kerja Support vector machine (SVM)
b. Hasil penelitian ini menjadi masukan dan pertimbangan bagai pihak Disperindag Kabupaten Brebes untuk melakukan prediksi rentet waktu harga daging ayam broiler dan telur broiler
2. TINJUAN PUSTAKA 2.1. Penelitian Terkait
Rohana dan Arifudin tahun 2013 melakukan penelitian tentang kajian algoritma jaringan syaraf tiruan untuk mendeteksi secara dini kepatuhan wajib pajak orang pribadi. Tujuan penelitian ini adalah menerapkan multilayer perceptron (MLP) dan support vector machine (SVM) untuk mengetahui akurasi dari tugas klasifikasi. Penerapan tersebut kemudian diuji dengan confucion matrix dan kurva
reciever operating characteristic (ROC), sehingga dapat diketahui algoritma mana yang memperoleh akurasi yang lebih tinggi. Hasil penelitian menunjukkan bahwa antara model algoritma multilayer perceptron (MLP) dan support vector machine (SVM) menghasilkan tingkat akurasi 82,15% dan nilai
the area under curve (AUC) sebesar 0,766. Sedangkan support vector machine (SVM) menghasilkan tingkat akurasi 81,91% dan nilai the area under curve 0,500. Sehingga terlihat bahwa model algoritma multilayer perceptron (MLP) menghasilkan tingkat akurasi lebih tinggi dibandingkan dengan model algoritma support vector machine (SVM) [1].
Darsyah tahun 2013 melakukan penelitian tentang menakar tingkat akurasi support vector machine study kasus kanker payudara. Tujuan penelitian adalah untuk mengetahui seberapa akurat dan efisien antara SVM, Regresi Logistik, dan CART dalam ketepatan akurasi. Data yang digunakan dalam penelitian diambil dari data pasien kanker payudara UCI Machine learning Wicoxsin University. Data untuk diagnosis kanker payudara adalah data pasien yang melakukan skrining mamografi dan melakukan biopsy. Variabel penelitian yang digunakan pada penelitian ini terdiri dari variabel respon (y) dan variabel prediktor (x). Pada penelitian ini akan membandingkan tiga metode analisis klasifikasi yaitu SVM, Regresi Logistik Biner, dan CART. Adapun Metode Kernel yang digunakan ialah Kernel RBF, dan Polynimial. Selain dengan menggunakan variabel dependen (Y) dari data asli, klasifikasi juga dicoba menggunakan variabel dependen (Y) hasil dugaan metode K-means clustering dan hasil duguan Kernel means clustering. Hasil pengelompokan dengan metode
K-means clustering setelah dicocokkan dengan variabel dependen (Y) asli diperoleh ketepatan pengelompokan sebesar 59,6%. Hasil ini menunjukkan hasil yang kurang baik karena kecilnya ketepatan pengelompokan. Kemudian, hasil pengelompokan K-means ini digunakan sebagai taksiran variabel dependen (Y) untuk selanjutnya dilakukan analisis klasifikasi. Taksiran variabel dependen (Y) juga didapatkan dari hasil analisis kernel K-means clustering yang di cocokan dengan (y) data aslinya, Ketepatan pengelompokan kernel K-means untuk masing-masing variasi kernel Polinomial dan RBF sebesar 71,1% dan 73,6%. Jadi ketepatan pengelompokan yang paling tinggi akurasinya dengan metode Kernel Kmean SVM dengan Y Kernel K- Mean memberikan akurasi 100% dalam klasifikasi, secara keseluruhan metode SVM memberikan hasil yang terbaik mungkin ini yang menjadikan SVM mendapat perhatian serius dari para peneliti karena bisa mencari hyperpline yang terbaik [2].
Dalam penelitian yang berjudul Penerapan Particle Swarm Optimization untuk Seleksi Atribut pada Metode Support Vector Machine relink Prediksi Penyakit Diabetes, peneliti melakukan prediksi terjadinya penyakit diabetes melitus. Data penelitian yang diperoleh adalah data sekunder karena diperoleh dari Pinia Indian diabetes database. Masalah yang harus dipecahkan di sini adalah prediksi terjadinya penyakit diabetes melitus dalam waktu 5 tahun dengan menggunakan data Pima yang berisi 786 orang yang diperiksa dan sebanyak 500 pasien tidak terdeteksi terkena penyakit diabetes melitus, sehingga 268 pasien terdeteksi penyakit diabetes melitus. Atribut penyakit diabetes melitus adalah berapa kali hamil, konsentrasi glukosa, tekanan darah, ketebalan lipatan kulit, serum insulin, indeks massa tubuh, fangsi silsilah diabetes melitus, dan umur serta kelas sebagai label yang terdiri atas ya dan tidak. Penelitian ini berusaha membandingkan prediksi terjadinya penyakit diabetes melitus antara algoritma Support Vector Machine (SVM) dan Support Vector Machine (SVM) berbasis
Particle Swarm Optimization (PSO). Perangkat lunak yang digunakan adalah RapidMiner 5.2. Penelitian diawali dengan melakukan data training terhadap kedua algoritma. Selanjutnya, keduanya dievaluasi dan diuji dengan confusion matrix dan kurva Receiver Operating Characteristic
Heru Supriyanto memprediksi arah pergerakan harga harian valuta asing menggunakan Support Vector Machines dengan metode Kernel Trick menggunakan fungsi Kernel Radial Basis Function. Dalam penelitian tersebut dikemukakan bahwa SVM dengan metode kernel trick menggunakan fungsi kernel RBF dapat digunakan untuk memprediksi arah pergerakan harga harian perdagangan valuta asing dengan akurat. Hal ini ditunjukkan dengan akurasi prediksi terhadap USD/JPY untuk periode bulan Juni 2012 yang mencapai 100% (21 data dapat diprediksi dengan benar seluruhnya) dan pada EUR/USD maupun GBP/USD yang mencapai 95.24% (20 dari 21 data dapat diprediksi dengan benar) [4].
Melihat dari penelitian-penelitian tersebut di atas dapat diketahui bahwa algoritma Support Vector Machine (SVM) memiliki tingkat akurasi yang lebih baik dibandingkan dengan metode algoritma lainnya dalam memprediksi harga.
2.2. Landasan Teori 2.2.1. Data mining
Data mining merupakan teknologi yang menggabungkan metoda analisis tradisional dengan algoritma yang canggih untuk memproses data dengan volume besar. Data mining adalah suatu istilah yang digunakan untuk menemukan pengetahuan yang tersembunyi di dalam database. Data mining merupakan proses semi otomatik yang menggunakan teknik statistik, matematika, kecerdasan buatan, dan machine learning untuk mengekstraksi dan mengidentifikasi informasi pengetahuan potensial dan berguna yang bermanfaat yang tersimpan di dalam database besar [20].
Beberapa definisi awal dari data mining meyertakan focus pada proses otomatisasi. Berry dan Linoff, [5] dalam buku Data Mining Technique for Marketing, Sales, and Customer Support rangkaian harmonis konsep-konsep unggulan dalam bidang pattern recognition. Sebagai salah satu metode pattern recognition, usia SVM terbilang masih relatif muda. Walaupun demikian, evaluasi kemampuannya dalam berbagai aplikasinya menempatkannya sebagai state of the art dalam pattern recognition. SVM adalah metode learning machine yang bekerja atas prinsip Structural Risk Minimization (SRM) dengan tujuan menemukan hyperplane terbaik yang memisahkan dua buah class
pada inputspace [7][8].
Hyperplane pemisah terbaik antara kedua kelas diperoleh dengan cara mengukur margin dari
hyperplane dan mencari margin terbesar. Margin adalah jarak antara hyperplane tersebut dengan data terdekat dari masing-masing kelas. Data yang paling dekat dengan hyperplane disebut sebagai support vector. hyperplane yang terbaik yaitu yang terletak tepat pada tengah-tengah kedua class, sedangkan titik kotak dan lingkaran yang berada dalam lingkaran hitam adalah support vector. Usaha untuk mencari lokasi hyperplane ini merupakan inti dari proses pembelajaran pada SVM.
Data yang tersedia dinotasikan sebagai x ∈ R d sedangkan label masing-masing dinotasikan yi
∈{-1+1} untuk i = 1,2,....,1 yang mana l adalah banyaknya data. Diasumsikan kedua class –1 dan +1 dapat terpisah secara sempurna oleh hyperplane berdimensi d , yang didefinisikan:
Diasumsikan kedua class –1 dan +1 dapat terpisah secara sempurna oleh hyperplane berdimensi
d , yang didefinisikan:
... (1)
Sebuah pattern xi yang termasuk class –1 (sampel negatif) dapat dirumuskan sebagai pattern
yang memenuhi pertidaksamaan:
... (2) sedangkan pattern yang termasuk class +1 (sampel positif):
Margin terbesar dapat ditemukan dengan memaksimalkan nilai jarak antara hyperplane dan titik terdekatnya, yaitu 1/||w||. Hal ini dapat dirumuskan sebagai Quadratic Programming (QP) problem, yaitu mencari titik minimal dengan memperhatikan constraint :
... (4)
... (5)
Problem ini dapat dipecahkan dengan berbagai teknik komputasi, diantaranya Lagrange Multiplier sebagaimana ditunjukkan pada persamaan di bawah ini :
... (6)
αi adalah Lagrange multipliers, yang bernilai nol atau positif (αi0). Nilai optimal dari persamaan diatas
dapat dihitung dengan meminimalkan L terhadap w dan b , dan memaksimalkan L terhadap αi. Dengan memperhatikan sifat bahwa pada titik optimal gradient L=0, persamaan dapat dimodifikasi sebagai maksimalisasi problem yang hanya mengandung αi saja, sebagaimana persamaan :
Maximize :
... (7)
Subject to :
... (8)
Dari hasil dari perhitungan ini diperoleh αi yang kebanyakan bernilai positif. Data yang berkorelasi dengan αi yang positif inilah yang disebut sebagai support vector.
2.2.3. Time series
Time series atau runtun waktu adalah himpunan observasi data terurut dalam waktu [9]. Metode time series adalah metode peramalan dengan menggunakan analisa pola hubungan antara variabel yang akan dipekirakan dengan variabel waktu. Peramalan suatu data time series perlu memperhatikan tipe atau pola data. Secara umum terdapat empat macam pola data time series, yaitu horizontal, trend, musiman, dan siklis [9]. Pola horizontal merupakan kejadian yang tidak terduga dan bersifat acak, tetapi kemunculannya dapat memepengaruhi fluktuasi data time series. Pola trend merupakan kecenderungan arah data dalam jangka panjang, dapat berupa kenaikan maupun penurunan. Pola musiman merupakan fluktuasi dari data yang terjadi secara periodik dalam kurun waktu satu tahun, seperti triwulan, kuartalan, bulanan, mingguan, atau harian. Sedangkan pola siklis merupakan fluktuasi dari data untuk waktu yang lebih dari satu tahun.
Sedangkan Box & Jenkins, 1976 menyatakan bahwa time series adalah himpunan nilai-nilai hasil pengamatan berdasarkan periode waktu dan disusun untuk melihat pengaruh perubahan dalam rentang waktu tertentu. Sedangkan data time series merupakan data yagn dikumpulkan, dicatat atau diobservasi secara berurutan. Periode observasi dapat berupa tahun, bulan, minggu dan untuk beberapa kasus ada pula periode dalam hari ataupun jam. Prediksi data time series adalah pendugaan data yang akan datang yang dilakukan berdasarkan nilai data masa lalu dari suatu variabel. Tujuannya adalah menemukan pola dalam deret data historis dan menggunakan pola tersebut untuk prediksi data yang akan datang. Prediksi data dapat diterapkan bila terdapat tiga kondisi berikut : a) Tersedia informasi tentang masa lalu. b) Informasi dapat dikuantitatifkan dalam bentuk data numerik, c) Dapat diasumsikan bahwa beberapa aspek pola masa lalu akan terus berlanjut di masa datang [10].
2.2.4. Komponen Penghitungan Prediksi dalam SVM a. K-fold cross-validation
Dalam pendekatan cross-validation, setiap record digunakan beberapa kali dalam jumlah yang sama untuk training dan tepat sekali untuk testing. Untuk mengilustrasikan metode ini, anggaplah kita mempartisi data ke dalam dua subset yang berukuran sama. Pertama, kita pilih satu dari kedua subset
tersebut untuk training dan satu lagi untuk testing. Kemudian dilakukan pertukaran fungsi dari subset
Setiap record digunakan tepat satu kali untuk training dan satu kali untuk testing. Metode k-fold cross-validation mengeneralisasi pendekatan ini dengan mensegmentasi data ke dalam k partisi berukuran sama. Selama proses, salah satu dari partisi dipilih untuk testing, sedangkan sisanya digunakan untuk training. Prosedur ini diulangi k kali sedemikian sehingga setiap partisi digunakan untuk testing tepat satu kali. Total error ditentukan dengan menjumlahkan error untuk semua k proses tersebut [11].
Metode k-fold cross-validation menetapkan k = N, ukuran dari data set. Metode ini dinamakan pendekatan leave-one-out, setiap test set hanya mengandung satu record. Pendekatan ini memiliki keuntungan dalam pengunaan sebanyak mungkin data untuk training. Test set bersifat mutually exclusive dan secara efektif mencakup keseluruhan data set. Kekurangan dari pendekatan ini adalah banyaknya komputasi untuk mengulangi prosedur sebanyak N kali.
K-fold cross-validation adalah salah satu teknik untuk mengevaluasi keakuratan model, dengan ciri-ciri [12]:
1. Mempartisi data secara random ke dalam k buah himpunan/fold yaitu D1, D2, ..Dk. Setiap kelompok
mempunyai jumlah yang hampir sama.
2. Pada perulangan i, gunakan Di sebagai data uji dan himpunan lainnya sebagai data pelatihan Contoh :
Pada perulangan ke-1 : D1 sebagai data uji dan D2 s.d.Dk sebagai data pelatihan
Pada perulangan ke-2 : D2 sebagai data uji dan D1, D3s.d. Dk sebagai data pelatihanan dan
seterusnya
3. Melakukan training dan pengujian sebanyak k kali 4. Menghitung keakuratan dengan rumus.
b. C (cost)
Pada penghitungan SVM diberikan penalti dengan menambahkan nilai cost C. Nilai cost C dipilih untuk mengontrol keseimbangan antara nilai margin dan errorprediksi. Semakin besar nilai C, maka penalti yang diberikan terhadap data error juga semakin besar.
c. Kernel
Asumsi data mining adalah kelinieran. Sehingga algorithma yang dihasilkan terbatas untuk kasus-kasus yang linier. Karena itu, bila suatu kasus-kasus klasifikasi memperlihatkan ketidaklinieran, algorithma seperti perceptron tidak bisa mengatasinya. Secara umum, kasus-kasus di dunia nyata adalah kasus yang tidak linier. Semisal data yang sulit dipisahkan secara linier, metode kernel adalah salah satu untuk mengatasinya. Dengan metode kernel suatu data x di input space dimapping ke feature space F
dengan dimensi yang lebih tinggi melalui map sebagai berikut : x _→ (x). Karena itu data x di
input space menjadi (x) di feature space.
Fungsi kernel yang biasanya dipakai pada penelitian adalah:
Dot : K(x,xi) = (xi).( xj)………. (9) bergantung pada data. Biasanya metode cross-validation digunakan untuk pemilihan fungsi kernel ini. Pemilihan fungsi kernel yang tepat adalah hal yang sangat penting. Karena fungsi kernel ini akan menentukan feature space di mana fungsi prediksi yang akan dicari [12].
d. RMSE (Root Mean Square Error)
Keakuratan keseluruhan dari setiap model peramalan baik itu rata-rata bergerak, eksponensial smoothing atau lainnya dapat dijelaskan dengan membandingkan nilai yang diproyeksikan dengan nilai aktual atau nilai yang diamati. Untuk tingkat akurasi peramalan dapat diukur dari nilai berikut, adapun rumus dari RMSE adalah sebagai berikut :
MSE (Mean Squared Error) Merupakan rata-rata jumlah kuadrat kesalahan peramalan, yang rumusnya adalah sebagai berikut :
... (13)
Semakin kecil nilai RMSE, semakin baik tingkat akurasi prediksinya. Keakuratan sebuah model peramalan dalam melakukan prediksi ditentukan oleh nilai terkecil dari masing-masing metode akurasi data.
2.3. Kerangka Pemikiran
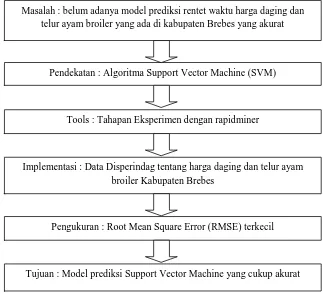
Pengolahan data dengan menggunakan Algoritma SVM didasarkan pada k-fold validation, c (cost) dan
kernel-nya, kemudian dicari tingkat RMSE (root mean square error) yang terkecil. RMSE yang terkecil itulah yang dijadikan desain dalam memprediksi harga komoditas emas dan batubara. Untuk lebih memperjelas kerangka pikir, penulis membuat langkah-langkah berupa gambar di bawah ini :
Gambar 1 Kerangka Pemikiran
2.4. Kerangka Teori dan Hipotesis
Dalam mendesain prediksi tersebut langkah yang dilakukan peneliti dengan eksperimen dataset yang ada, yaitu dengan mengubah bentuk data set yang semula univariate diubah menjadi multivariate, kemudian dataset multivariate tersebut di pisahkan menjadi inputan data yang bertujuan sebagai data training dalam algoritma SVM. Data training dan data testing disimpan dalam satu file Excell. Data tersebut kemudian divalidasi dengan perbadingan data training dan data testing adalah 90:10.
Data training yang digunakan adalah inputan data berdasarkan harga periode yang lalu, yaitu harga 2 hari sebelumnya hingga 7 hari periode sebelumnya. Kemudian dataset tersebut diolah dengan Algoritma Support Vector Machine menggunakan tool rapidminer, dalam pengolahannya ditentukan terlebih dahulu pada k-fold validation, c (cost) dan kernel-nya, kemudian dicari tingkat RMSE (root mean square error) yang terkecil. RMSE yang terkecil itulah yang dijadikan desain dalam memprediksi harga daging dan telur ayam broiler.
Masalah : belum adanya model prediksi rentet waktu harga daging dan telur ayam broiler yang ada di kabupaten Brebes yang akurat
Pendekatan : Algoritma Support Vector Machine (SVM)
Tools : Tahapan Eksperimen dengan rapidminer
Implementasi : Data Disperindag tentang harga daging dan telur ayam broiler Kabupaten Brebes
Pengukuran : Root Mean Square Error (RMSE) terkecil
3. METODE PENELITIAN
Pada penelitian ini data diperoleh dari Dinas Perindustrian dan Perdagangan (DISPERINDAG) Kabupaten Brebes. Berikut adalah data informasi harga Daging Ayam Broiler dan harga Telur Ayam Broiler per kg di Pasar Tradisional di Wilayah Kabupaten Brebes (terlampir), informasi data ini adalah data harga pada tanggal 1 Maret 2012 s.d. tanggal 30 November 2013.
Data yang akan diolah berupa data time series harga daging ayam broiler dan harga telur ayam disajikan harian dan berbentuk univariat. Dalam memprediksi harga daging ayam bolier dan harga telur ayam didasarkan pada harga-harga periode sebelumnya, dimana harga-harga sebelumnya merupakan variabel yang mempengaruhi harga periode berikutnya.
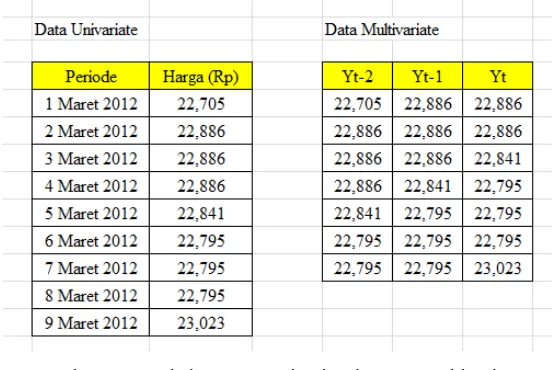
Pengolahan data awal menggunakan aplikasi Microsoft Excel dimana data univariat yang terdiri satu kolom harga dibuat menjadi beberapa kolom yang termasuk variable yang mempengaruhi kolom harga periode berikutnya. Untuk lebih jelasnya dapat dilihat pada gambar dibawah ini :
Gambar 4.1 Perubahan Data Univariate ke Data Multivariate
Dari gambar di atas dapat dilihat perubahan bentuk univariate ke bentuk multivariate dimana data multivariate tersebut menjelaskan bahwa harga yang akan datang / target (Yt) dipengaruhi oleh harga dari 2 periode sebelumnya.
Pengolahan data menggunakan Support Vector Machine (SVM), ini dilakukan untuk menghitung prediksi harga yang akan datang / target (Yt), dan penentuan harga yang akan datang dipengaruhi oleh harga-harga pada periode-periode sebelumnya, adapun input data yang digunakan sebanyak 6 (enam) buah data set, yaitu dari inputan 1 hari sebelumnya sampai inputan harga 6 hari sebelumnya.
Pengolahan data pada penelitian ini menggunakan Algoritma SVM dengan konstruksi penghitungan data sebagai berikut : Penghitungan data menggunakan tools rapidminer, yang terlebih dahulu menentukan data inputan (sebanyak 6 inputan) sebagai data training dalam memproses data tersebut, setelah itu eksperimen berlanjut ke penentuan type kernel, nilai C (cost) dan k-fold-nya.
Type kernel yang digunakan adalah : type kernel dot, radial dan polynomial, dan nilai C (cost) berdasarkan 0,1, 0,2, dan 0,3 serta besarnya k-fold (number of validation) range k =5 dan k = 10. Berikut ini hasil dari percobaan yang telah dilakukan dengan beberapa fungsi kernel dan memasukkan nilai C (cost) serta nilai range (k-fold) yang telah ditentukan untuk menguji masing-masing kelompok tersebut.
5. KESIMPULAN DAN SARAN 5.1 Kesimpulan
Setelah melakukan percobaan dengan jumlah input data harga komoditas Daging Ayam Broiler dan Telur Ayam Broiler dan data ini adalah harga selama 2 tahun dari tanggal 1 Maret 2012 s.d. tanggal 30 November 2013, maka didapatkan konfigurasi prediksi harga komoditas sebagai berikut :
1. Metode prediksi harga komoditas Daging Ayam Broiler dengan RMSE terbaik adalah sebesar 1863.157 +/- 1272.465 dengan prediksi harga Daging Ayam Broiler dilihat dari harga Daging Ayam Broiler 4 (empat) hari sebelumnya. Dengan menggunakan algoritma SVM dengan k-fold 10, C (cost) sebesar 0,3 dan dengan menggunakan type kernel Polynomial. Dengan bobot prediksi w[yt-4] = 129.673, w[yt-3] = 130.505. w[yt-2] = 131.539. w[yt-1] = 132.569
2. Metode prediksi harga Telur Ayam Briiler dengan RMSE terbaik adalah sebesar 472.169 +/- 244.893 dengan prediksi harga yang dipengaruhi dari harga Telur Ayam Broiler 6 (enam) hari sebelumnya. Dengan menggunakan algoritma SVM dengan k-fold 10, C (cost) sebesar 0,3 dan dengan menggunakan tipe kernel dot. Dengan bobot prediksi w[yt-6] = 129.141, w[yt-5] = 131.347, w[yt-4] = 133.125, w[yt-3] = 135.395. w[yt-2] = 137.599, w[yt-1] = 141.530
5.2 Saran-saran
Dalam penelitian ini telah menghasilkan prediksi yang optimal dan akurat, namun demikian untuk penelitian selanjutnya agar mendapatkan hasil yang lebihbaik, perlu memperhatikan hal-hal sebagi berikut :
2. Untuk mendapatkan hasil prediksi yang lebih baik dapat dilakukan penelitian lebih lanjut dengan melakukan optimasi pada SVM (support Vector Machine) yaitu dengan memanfaatkan fungsi-fungsi linear dalam sebuah ruang fitur (feature space) dan mengimplementasikan learning bias
6. PENUTUP
Syukur Alhamdulillah, berkat dan anugerah Allah SWT, penulis dapat tmenyelesaikan penyusunan tesis dengan judul “Algoritma Support Vector Machine Untuk Memperediksi Rentet Waktu Harga Daging Ayam Broiler dan Telur Ayam Broiler”. Penyusunan tesis ini berhasil berkat adanya bantuan dan dukungan dari berbagai pihak. Pada kesempatan ini perkenankan penulis menyampaikan ucapan terima kasih yang setulus-tulusnya kepada :
1. Bapak Dr.Abdul Syukur selaku Direktur Magister Teknik Informatika yang telah memfasilitasi selama perkuliahan berlangsung hingga terselesaikannya penulisan tesis ini.
2. Bapak Dr.Abdul Syukur dan Bapak H. Himawan, M.Kom selaku pembimbing tesis, yang telah meluangkan waktu dan mengarahkan penulisan tesis ini.
3. Seluruh Staf Pengajar Magister Teknik Informatika Universitas Dian Nuswantoro, yang telah membagi pengetahuannya selama proses perkuliahan.
4. Seluruh Staf Administrasi Magister Teknik Informatika Universitas Dian Nuswantoro yang telah membantu urusan administrasi selama proses perkuliahan dan penyusunan tesis ini.
5. Istri dan anak-anakku tercinta yang senantiasa memberi semangat dalam penulisan tesis ini.
6. Semua keluarga dan kawan-kawan yang telah membantu secara moril dan materil selama perkuliahan dan penyusunan tesis ini
7. Semua pihak yang telah membantu dalam pemulisam tesis ini yang tidak dapat saya sebut satu persatu.
Disadari dalam penelitian ini masih banyak kekurangan, sehingga saran dan koreksi sangat dibutuhkan untuk kesempurnaannya. Semoga tesis ini memberikan manfaat dalam pengembangan ilmu pengetahuan
PERNYATAAN ORIGINALITAS
“Saya menyatakan dan bertanggung jawab dengan sebenarnya bahwa Artikel ini adalah hasil karya saya sendiri kecuali cuplikan dan ringkasan yang masing-masing telah saya jelaskan sumbernya” [Mohamad Ismail – P31.2011. 01048]
DAFTAR PUSTAKA
[1] Rohana dan Arifudin, Kajian Algoritma Jaringan Syaraf Tiruan Untuk Mendeteksi Secara Dini Kepatuhan Wajib Pajak Orang Pribadi, Jurnal Snati, Yogyakarta, 15 Juni 2013
[2] Darsyah, Menakar Tingkat Akurasi Support Vector Machine Study Kasus Kanker Payudara, Jurnal Statistika, Vol. 1, No. 1, Mei 2013
[3] Sardiarinto, Komparasi Penerapan Algoritma C 4.5, K-Nearest Neighbor, dan Naive Bayes dalam Penentuan Kelayakan Pinjaman Kredit Nasabah Koperasi, Tesis, Sekolah Tinggi Manajemen Informatika dan Komputer Nusa Mandiri, Jakarta, 2012.
[4] Handayana, Prisma, Penerapan Particle Swarm Optimization untuk Seleksi Atribut pada Metode Support Vector Machine relink Prediksi Penyakit Diabetes, Tesis, Sekolah Tinggi Manajemen Informatika dan Komputer Nusa Mandiri, Jakarta. 2012.
[5] Berry, Michael J.A dan Linoff, Gordon S. Data Mining Techniques For Marketing, Sales, Customer Relationship Management, Second Editon, United States of America: Wiley Publishing, Inc, 2004.
[6] Larose D, T., Data Mining Methods and Models, Jhon Wiley & Sons, Inc. Hoboken New Jersey. 2006.
[8] Tsuda K., Overview of Support Vector Machine, Journal of IEICE, Vol. 83, No.6, 2000, pp.460-466 (in Japanese).
[9] Subagyo, Pangestu, 1986, Forecasting Konsep dan Aplikasi, BPFE UGM, Yogyakarta
[10] Makridakis, S, Wheelwright, SC, dan Hyndman, RJ., 1998, Forecasting: methods and applications. 3rd ed New York
[11] J. Han, Data Mining : Concepts and techniques, Morgan Kaufman, 2006.