penggabungan beberapa kategori menjadi kategori yang lebih umum. Kategori yang baru terdiri atas lima kategori yaitu:
1 : sangat tidak suka 2 : tidak suka 3 : biasa saja 4 : suka 5 : sangat suka
Metode
Tahapan yang dilakukan dalam penelitian ini adalah:
1. Membuat deskripsi data untuk melihat gambaran umum masing-masing peubah. 2. Membuat klasifikasi BN Terboboti
menggunakan algoritma Spanning Tree dan Equivalence Classes, kemudian menghitung tingkat akurasi dugaan klasifikasi dengan rumus dibawah ini:
3. Membuat klasifikasi Semi Naïve Bayesian
dengan menggunakan algoritma BSE, FSS untuk deleteting attribute, kemudian menghitung tingkat akurasi dugaan klasifikasi dengan rumus seperti pada langkah kedua.
4. Membandingkan tingkat akurasi dugaan klasifikasi Semi Naïve Bayesian, baik yang menggunakan algoritma deleting attribute terhadap tingkat akurasi dugaan klasifikasi BN Terboboti.
5. Menganalisis perubahan peluang peubah respon berdasarkan perubahan peluang yang terjadi pada setiap peubah penjelas dan sebaliknya berdasarkan struktur BN yang terbaik.
Perangkat lunak yang digunakan untuk membuat struktur BN dalam penelitian ini adalah Bayesia Lab 5.0 Evaluation Version (http://www.bayesia.com).
PEMBAHASAN
Deskripsi dataData yang digunakan merupakan data hasil survei produk biskuit yang dilakukan kepada 200 responden.
Peubah Respon
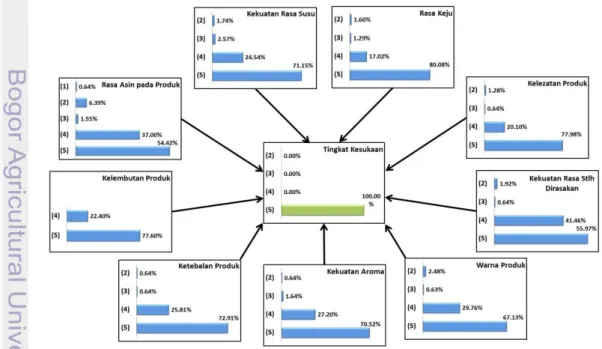
Peubah respon tingkat kesukaan (Y) merupakan penilaian seseorang terhadap keadaan produk secara keseluruhan. Penilaian ini dilihat dari berbagai aspek. Sebaran data untuk masing-masing kategori tingkat kesukaan dapat dilihat pada Gambar 3.
Gambar 3 Sebaran frekuensi tingkat kesukaan peubah respon.
Jumlah konsumen yang menyatakan tidak suka (kategori 2) sebanyak 3 (1.5%), biasa saja (kategori 3) sebanyak 5 (2.5%), suka (kategori 4) sebanyak 58 (29%), dan sangat suka (kategori 5) sebanyak 134 (67%). Sehingga secara umum dapat dilihat bahwa lebih dari 90% konsumen menyatakan kesukaannya terhadap produk biskuit tersebut.
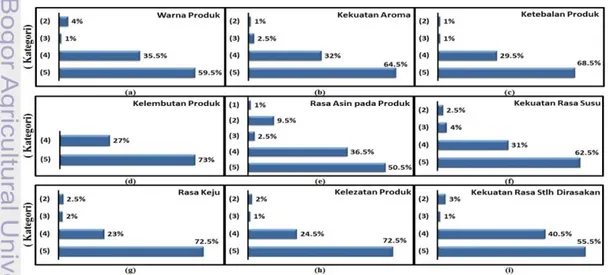
Gambar 4 Sebaran tingkat kesukaan berdasarkan (a) warna produk; (b) kekuatan aroma; (c) ketebalan produk; (d) kelembutan produk; (e) rasa asin pada produk; (f) kekuatan rasa susu; (g) rasa keju; (h) kelezatan produk; dan (i) kekuatan rasa setelah dirasakan
Peubah Penjelas
Peubah penjelas yang digunakan merupakan penilaian secara lebih detail dari berbagai aspek yang dijadikan tolak ukur. Pada penelitian ini digunakan sembilan peubah penjelas yaitu: warna produk, kekuatan aroma, ketebalan produk, kelembutan produk, rasa asin pada produk, kekuatan rasa susu, rasa keju, kelezatan produk, dan kekuatan rasa setelah dirasakan. Sebaran tingkat kesukaan setiap peubah penjelas dapat dilihat pada Gambar 4.
Persentase kesukaan konsumen yang menyatakan sangat suka (kategori 5) untuk semua peubah penjelas secara rata-rata berada pada persentase 64% dan konsumen yang menyatakan suka (kategori 4) berada pada persentase rata-rata sebesar 31%. Banyaknya konsumen yang menyatakan biasa saja (kategori 3) secara rata-rata untuk semua peubah sebesar 1.9%, dan banyaknya konsumen yang menyatakan tidak suka (kategori 2) sebesar 3.2%.
Pada peubah penjelas kelembutan produk (X4) tidak terdapat konsumen yang menyatakan tidak suka (kategori 2), sedangkan pada peubah penjelas yang lain masih terdapat konsumen yang menyatakan tidak suka (kategori 1 dan 2). Konsumen sudah menyukai kelembutan produk biskuit dan aspek ini perlu dipertahankan oleh produsen.
Persentase terbesar konsumen yang menyatakan tidak suka (kategori 2) terdapat pada peubah penjelas rasa asin (X5) yaitu sebesar 9.5%. Pada peubah penjelas ini juga terdapat konsumen yang menyatakan sangat tidak suka (kategori 1) yaitu sebesar 1%. Aspek rasa asin pada produk adalah aspek yang pertama harus dievaluasi oleh produsen agar konsumen tetap menyukai produk biskuit tersebut.
Klasifikasi dengan BN Terboboti Algoritma Maximum Spanning Tree
Algoritma Maximum Spanning Tree yang digunakan merupakan algoritma yang didasarkan hubungan causal relationship. Hubungan ini diperlihatkan melalui nilai korelasi spearman. Nilai korelasi antar peubah dapat dilihat pada Lampiran 1. Nilai korelasi ini selanjutnya digunakan sebagai pembobot pada setiap edge.
Langkah pertama adalah mencari edge dari peubah respon yang memiliki bobot terbesar yaitu edge antara peubah respon (Y) dan peubah rasa asin pada produk (X5). Kemudian
mencari edge dengan nilai bobot terbesar selanjutnya dari node-node yang sudah terhubungkan tetapi tidak membentuk siklus. Algoritma ini berhenti saat semua node sudah terhubungkan minimal dengan satu edge. Gambar 5 memperlihatkan struktur BN hasil algoritma Maximum Spanning Tree. Peubah tingkat kesukaan (Y) merupakan child dari peubah kekuatan rasa asin (X5) dan warna produk (X1). Peubah kelezatan produk (X8) menjadi parent bagi peubah rasa asin (X5) yang selanjutnya menjadi child bagi peubah rasa keju (X7) dan peubah kekuatan rasa setelah dirasakan (X9).
Gambar 5 Struktur BN dengan algoritma Maximum Spanning Tree
Struktur BN dengan menggunakan algoritma Maximum Spanning Tree memperlihatkan bahwa selain peubah warna produk (X1) dan rasa asin pada produk (X5), ketujuh peubah yang lain tidak mempengaruhi peubah tingkat kesukaan (Y) secara langsung. Perubahan pada peubah kekuatan aroma (X2) akan mempengaruhi peubah kekuatan rasa susu (X6) terlebih dahulu, selanjutnya perubahan peubah kekuatan rasa susu (X6) akan mempengaruhi peubah kelezatan produk (X8), dan perubahan peubah kelezatan produk ini yang akan mempengaruhi peubah rasa asin (X5) yang secara langsung berpengaruh terhadap peubah tingkat kesukaan (Y). Begitu pula dengan perubahan pada ketebalan produk (X3) dan kelembutan produk (X4). Perubahan pada peubah-peubah ini akan mempengaruhi peubah kekuatan rasa setelah dirasakan (X9), kelezatan produk (X8), kekuatan rasa asin (X5), dan akhirnya akan berpengaruh terhadap tingkat kesukaan (Y).
Tabel 1 memperlihatkan hasil perbandingan klasifikasi aktual dan dugaan tingkat kesukaan dengan menggunakan algoritma Maximum Spanning Tree. Hasil klasifikasi dengan menggunakan algoritma tersebut memiliki tingkat akurasi dugaan klasifikasi sebesar 75.5%.
Hasil klasifikasi yang tidak sesuai antara hasil dugaan dan aktual banyak terdapat pada kategori sangat suka (5) yaitu sebesar 25%. Sedangkan untuk kategori tidak suka (2) dan
biasa saja (3) tidak ada satu pun hasil dugaan yang diklasifikasi pada kategori ini.
Tabel 1 Dugaan klasifikasi algoritma Maximum Spanning Tree
Aktual Total 2 3 4 5 Du g aa n 2 0 0 0 0 0 3 0 0 0 0 0 4 2 1 20 3 26 5 1 4 38 131 174 Total 3 5 58 134 200 Algoritma Equivalence Classes
Algoritma Equivalence Classes merupakan algoritma yang didasarkan pada tingkat kesamaan (Equivalence) peubah. Peubah yang memiliki kesamaan akan memiliki hubungan yang erat dan tingkat kebebasan yang kecil. Hubungan kesamaan dan kebebasan antar peubah ini ditunjukkan dengan nilai khi-kuadrat yang dapat dilihat pada Lampiran 3. Jika pada uji khi-kuadrat kedua peubah dinyatakan saling bebas, maka kedua peubah tersebut tidak dihubungkan dengan edge. Gambar 6 memperlihatkan struktur BN yang dibangun dengan menggunakan algoritma equivalence classes.
Gambar 6 Struktur BN dengan algoritma Equivalence Classes
Struktur BN dengan menggunakan algoritma equivalence classes memperlihatkan bahwa hanya peubah kelezatan produk (X8) yang berpengaruh langsung terhadap peubah tingkat kesukaan (Y). Selain peubah tersebut, peubah lain memiliki pengaruh tidak langsung terhadap peubah tingkat kesukaan.
Perubahan pada peubah kelembutan produk (X5) akan terlebih dahulu mempengaruhi peubah ketebalan produk (X4). Selanjutnya perubahan pada peubah ini akan berpengaruh terhadap peubah rasa keju (X7) dan perubahan pada peubah ini akan mempengaruhi peubah kelezatan produk (X8) yang secara langsung berpengaruh pada tingkat kesukaan (Y).
Begitu pula dengan perubahan pada peubah warna produk (X1). Perubahan pada peubah ini secara berturut-turut akan berpengaruh terhadap peubah rasa asin pada
produk (X5), kekuatan rasa susu (X6), rasa keju (X7), kelezatan produk (X8), dan akhirnya akan berpengaruh terhadap tingkat kesukaan (Y). Sedangkan perubahan pada peubah kekuatan aroma (X2) dan kekuatan rasa setelah dirasakan (X9) akan terlebih dahulu berpengaruh pada peubah rasa keju (X7) dan kelezatan produk (X8) yang pada akhirnya berpengaruh terhadap peubah tingkat kesukaan (Y).
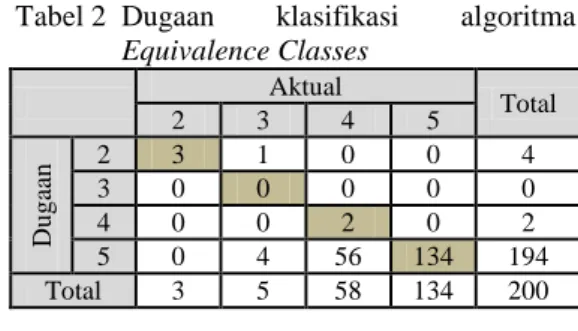
Hasil klasifikasi nilai dugaan tingkat kesukaan menggunakan struktur BN dengan algoritma Equivalence Classes yang dibandingkan dengan nilai aktual dapat dilihat pada Tabel 2. Hasil klasifikasi dengan menggunakan algoritma tersebut memiliki tingkat akurasi dugaan klasifikasi sebesar 69.5%.
Tabel 2 Dugaan klasifikasi algoritma Equivalence Classes Aktual Total 2 3 4 5 Du g aa n 2 3 1 0 0 4 3 0 0 0 0 0 4 0 0 2 0 2 5 0 4 56 134 194 Total 3 5 58 134 200 Hasil klasifikasi nilai dugaan tingkat kesukaan yang tidak sesuai dengan aktual untuk kategori sangat suka (5) sebesar 30%. Nilai ini merupakan nilai terbesar ketidak sesuaian antara hasil dugaan dengan aktualnya. Hasil klasifikasi terkecil terdapat pada kategori suka (4) yaitu hanya diduga sebanyak 4 dari 58 pada nilai aktual.
Klasifikasi dengan Semi Naïve Bayesian Algoritma BSE
Penerapan algoritma BSE diawali dengan proses klasifikasi dengan metode simple-naïve Bayesian yaitu menggunakan seluruh peubah penjelas dan menghubungkan semua peubah tersebut dengan peubah tingkat kesukaan (Y) sebagai peubah respon. Tingkat akurasi dugaan klasifikasi yang dihasilkan dengan proses klasifikasi ini sebesar 94%. Nilai akurasi klasifikasi ini selanjutnya digunakan sebagai dasar untuk melakukan eliminasi peubah penjelas.
Tingkat akurasi klasifikasi terbesar hasil proses eliminasi salah satu peubah penjelas yaitu sebesar 93%. Nilai tersebut terjadi saat proses eliminasi untuk peubah penjelas kelembutan produk (X4), rasa keju (X7), dan kekuatan rasa setelah dirasakan (X9). Karena nilai tingkat akurasi klasifikasi hasil proses eliminasi tersebut lebih kecil dari nilai tingkat
akurasi klasifikasi proses klasifikasi simple-naïve Bayesian (Ci≤ C0), maka proses
eliminasi peubah selesai.
Struktur BN yang diperoleh dengan menerapkan algoritma BSE sama dengan struktur BN hasil proses klasifikasi simple-naïve Bayesian yaitu menggunakan seluruh peubah penjelas. Struktur BN dengan menggunakan algoritma BSE dapat dilihat pada Gambar 7.
Gambar 7 Struktur BN dengan algoritma BSE
Tingkat akurasi dugaan klasifikasi hasil Semi Naïve Bayesian dengan penerapan algoritma BSE dapat dilihat pada Tabel 3. Hasil klasifikasi dengan menggunakan algoritma tersebut memiliki tingkat akurasi dugaan klasifikasi sebesar 94%.
Tabel 3 Dugaan klasifikasi Semi Naïve Bayesian dengan algoritma BSE
Aktual Total 2 3 4 5 Du g aa n 2 3 0 0 0 3 3 0 4 0 0 4 4 0 0 48 1 49 5 0 1 10 133 144 Total 3 5 58 134 200 Hasil klasifikasi pada Tabel 3 menunjukkan banyaknya klasifikasi yang tidak sesuai untuk kategori sangat suka (5) sebesar 7.6%, dan untuk kategori suka (4) relatif kecil yaitu sebesar 2%. Sedangkan untuk kategori tidak suka (2) hasil dugaan sama dengan nilai aktual.
Algoritma FSS
Penerapan algoritma FSS pada prinsipnya sama dengan penerapan algoritma BSE yaitu menentukan peubah penjelas yang meningkatkan akurasi klasifikasi. Berlawanan dengan penerapan algoritma BSE yang melakukan eliminasi, algoritma ini diawali dengan gugus himpunan peubah penjelas yang kosong, kemudian dilakukan proses penambahan peubah penjelas yang dapat meningkatkan tingkat akurasi klasifikasi paling besar.
Proses penambahan peubah penjelas dengan menggunakan peubah penjelas rasa asin pada produk (X5) menghasilkan tingkat akurasi klasifikasi sebesar 73%. Nilai ini merupakan nilai ketepatan klasifikasi terbesar di antara kombinasi penambahan peubah penjelas yang lain, sehingga peubah penjelas ini menjadi dasar klasifikasi (C0) untuk proses
penambahan peubah penjelas selanjutnya. Susunan peubah penjelas yang terbentuk dari penerapan algoritma FSS adalah sebagai berikut. Peubah penjelas kekuatan rasa setelah dirasakan (X9) merupakan peubah penjelas yang selanjutnya bergabung dengan peubah respon karena memiliki nilai tingkat akurasi klasifikasi terbesar dibandingkan dengan kombinasi peubah penjelas lain, yaitu sebesar 76.5%. Nilai ini lebih besar dari nilai tingkat ketepatan klasifikasi dasar (C0) = 73.5%.
Proses penambahan peubah penjelas secara berturut-turut yaitu: warna produk (X1), kelezatan produk (X8), kekuatan rasa susu (X6), kekuatan aroma (X2), ketebalan produk (X3), dan rasa keju (X7). Proses penambahan peubah penjelas berhenti saat nilai tingkat akurasi klasifikasi hasil penambahan peubah penjelas lebih kecil dari tingkat akurasi klasifikasi dasar (Ci ≤ C0). Peubah penjelas
kelembutan produk (X4) tidak dimasukan karena penambahan peubah penjelas ini tidak meningkatkan ketepatan klasifikasi.
Gambar 8 Struktur BN dengan menggunakan algoritma FSS Tabel tingkat ketepatan klasifikasi hasil Semi-Naïve Bayesian dengan penerapan algoritma FSS disajikan pada Tabel 4.
Tabel 4 Dugaan klasifikasi Semi Naïve Bayesian dengan algoritma FSS
Aktual Total 2 3 4 5 Du g aa n 2 3 0 0 0 3 3 0 4 0 0 4 4 0 0 48 3 51 5 0 1 10 131 142 Total 3 5 58 134 200 Tingkat akurasi dugaan klasifikasi akhir yang dihasilkan dengan penerapan algoritma FSS yaitu sebesar 93%. Hasil klasifikasi yang
tidak sesuai banyak terdapat pada kategori sangat suka (5) yaitu sebesar 8%.
Perbandingan Tingkat Akurasi Dugaan klasifikasi dinyatakan memiliki hasil yang baik jika memiliki tingkat akurasi klasifikasi yang besar. Tingkat akurasi klasifikasi yang dihasilkan dengan metode klasifikasi BN Terboboti dan Semi Naïve Bayesian disajikan pada Tabel 5.
Secara umum metode Semi Naïve Bayesian memiliki tingkat akurasi dugaan klasifikasi yang lebih baik dibandingkan metode BN Terboboti. Penerapan kedua algoritma pada metode Semi Naïve Bayesian memiliki nilai akurasi dugaan klasifikasi lebih dari 90%, sedangkan algoritma BN Terboboti memberikan akurasi dugaan klasifikasinya kurang dari 80%.
Tabel 5 Perbandingan Tingkat Akurasi
Metode Tingkat
Akurasi BN Terboboti
-Maximum Spaning Tree 75.5% -Equilavence Classes 69.5% Semi-Naïve Bayesian
-Backward Sequential Elimination 94% -Forward Sequential Selection 93% Tingkat akurasi dugaan klasifikasi yang dihasilkan metode Semi-Naïve Bayesian dengan algoritma BSE memiliki nilai yang sama dengan Simple Naïve Bayesian. Tingkat akurasi dugaan klasifikasi yang dihasilkan dalam penelitian ini bernilai maksimum saat semua peubah penjelas dihubungkan dengan peubah respon.
Analisis Perubahan Peubah Penjelas Dugaan klasifikasi BN dapat digunakan dalam melihat perubahan peluang yang terjadi pada peubah respon ketika peluang peubah penjelas berubah. Hal ini dapat dilakukan dengan cara merubah peluang pada kategori-kategori peubah penjelas dan dilihat sejauh mana perubahan peluang yang terjadi pada peubah respon. Struktur BN yang digunakan adalah struktur yang memiliki tingkat akurasi yang tertinggi yaitu Semi-Naïve Bayesian, dengan algoritma BSE.
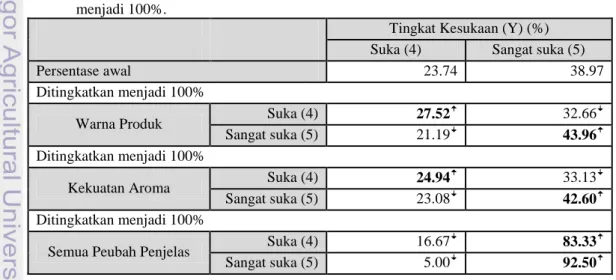
Pembahasan selanjutnya akan difokuskan analisis perubahan persentase pada kategori suka (4) dan sangat suka (5), baik pada peubah penjelas maupun peubah respon. Tabel 6 memperlihatkan contoh perubahan yang terjadi pada peubah tingkat kesukaan (Y) saat persentase kategori-kategori pada peubah warna produk (X1), kekuatan aroma (X2), dan semua peubah penjelas ditingkatkan menjadi 100%. Saat kategori suka (4) pada peubah penjelas ditingkatkan menjadi 100% akan berdampak pada peningkatan persentase kategori suka (4) dan penurunan persentase kategori sangat suka (5) pada peubah tingkat kesukaan (Y). Sedangkan saat persentase kategori sangat suka (5) pada peubah penjelas ditingkatkan menjadi 100% akan berdampak pada penurunan persentase kategori suka (4) dan peningkatan persentase sangat suka (5) pada peubah tingkat kesukaan (Y). Perubahan yang terjadi pada peubah respon saat setiap kategori - kategori peubah penjelas ditingkatkan menjadi 100% disajikan dengan lengkap pada Lampiran 5.
Tabel 6 Perubahan persentase peubah respon saat persentase kategori suka (4) dan sangat suka (5) pada peubah warna produk, kekuatan aroma, dan semua peubah penjelas ditingkatkan menjadi 100%.
Tingkat Kesukaan (Y) (%)
Suka (4) Sangat suka (5)
Persentase awal 23.74 38.97
Ditingkatkan menjadi 100%
Warna Produk Suka (4) 27.52ꜛ 32.66ꜜ
Sangat suka (5) 21.19ꜜ 43.96ꜛ
Ditingkatkan menjadi 100%
Kekuatan Aroma Suka (4) 24.94ꜛ 33.13ꜜ
Sangat suka (5) 23.08ꜜ 42.60ꜛ
Ditingkatkan menjadi 100%
Semua Peubah Penjelas Suka (4) 16.67ꜜ 83.33ꜛ
Ga m b ar 9 . P er u b ah an y a n g ter jad i p ad a p eu b ah r esp o n s aa t p er sen tase k ate g o ri san g at su k a ( 5 ) p ad a p eu b ah p en jelas d itin g k at k an m e n jad i 100%
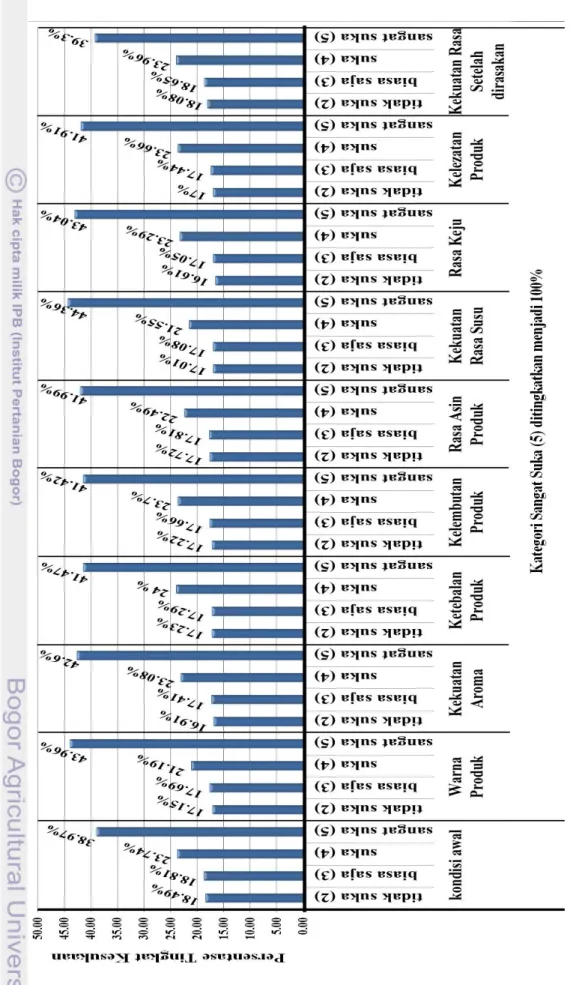
Perubahan persentase kategori-kategori peubah tingkat kesukaan (Y) saat kategori sangat suka (5) pada setiap peubah penjelas ditingkatkan menjadi 100% dapat dilihat pada Gambar 9. Pengaruh terhadap kategori tidak suka (2), biasa saja (3), dan suka (4) pada peubah tingkat kesukaan (Y) bernilai negatif, sedangkan pada kategori sangat suka (5) bernilai positif. Artinya jika terjadi perubahan persentase pada kategori sangat suka (5) peubah penjelas, maka akan menurunkan persentase kategori tidak suka (2), biasa saja (3), dan suka (4) pada peubah tingkat kesukaan (Y). Sedangkan perubahan tersebut akan meningkatkan persentase kategori sangat suka (5) pada peubah tingkat kesukaan (Y).
Besarnya kontribusi peubah penjelas terhadap perubahan persentase kategori sangat suka (5) pada tingkat kesukaan (Y) disajikan pada Tabel 7. Nilai tersebut diperoleh dari selisih persentase kategori sangat suka (5) pada peubah respon saat persentase kategori sangat suka (5) dan suka (4) peubah penjelas ditingkatkan menjadi 100%.
Pada Tabel 7 dapat dilihat bahwa peubah penjelas yang memiliki kontribusi paling besar adalah peubah rasa keju (X5) dengan kontribusi sebesar 18.49%, sedangkan peubah rasa asin pada produk (X5) adalah peubah yang memiliki kontribusi terkecil terhadap perubahan persentase kategori sangat suka (5). Peubah kekuatan rasa setelah dirasakan (X9) bernilai negatif, artinya saat kategori suka (4)
ditingkatkan menjadi kategori sangat suka (5) pada peubah ini maka kategori sangat suka (5) pada peubah tingkat kesukaan (Y) akan mengalami penurunan.
Tabel 7 Kontribusi setiap peubah penjelas. Peubah Penjelas Persentase
Kontribusi
Rasa Keju (X7) 18.49%
Kekuatan Rasa Susu (X6) 17.59% Warna dari Produk (X1) 14.72% Kelezatan Produk (X8) 12.94%
Kekuatan Aroma (X2) 12.33%
Kelembutan Produk (X4) 11.85% Ketebalan Produk (X3) 9.60% Rasa Asin pada Produk (X5) 3.24% Kekuatan Rasa Setelah
dirasakan (X9) -0.77%
Analisis Perubahan Peubah Respon Perubahan persentase pada peubah respon merupakan akibat dari perubahan persentase pada peubah-peubah penjelas. Analisis perubahan peubah penjelas terhadap respon sudah kita bicarakan pada pembahasan sebelumnya. Dalam analisis perubahan peubah respon akan diteliti kondisi-kondisi peubah penjelas yang dapat menyebabkan tingkat kesukaan berada pada kondisi tertentu. Analisis ini melibatkan semua peubah penjelas yang terhubungkan dengan peubah tingkat kesukaan (Y).
Gambar 10 Kondisi peubah-peubah penjelas saat kategori sangat suka (5) pada peubah tingkat kesukaan (Y) ditingkatkan menjadi 100%.