Pipeline
1.1 Penjelasan Umum
Teknologi pipeline yang digunakan pada komputer bertujuan untuk mening-‐ katkan kinerja dari komputer. Secara sederhana, pipeline adalah suatu cara yang digunakan untuk melakukan sejumlah kerja secara bersamaan tetapi dalam tahap yang berbeda yang dialirkan secara kontiniu pada unit pemro-‐ sesan. Dengan cara ini, maka unit pemroses selalu bekerja. Teknik pipeline ini dapat diterapkan pada berbagai tingkatan dalam sis-‐ tem komputer. Bisa pada level yang tinggi, misalnya program aplikasi, sam-‐ pai pada tingkat yang rendah, seperti pada instruksi yang dijalankan oleh microprocessor. Teknik pipeline yang diterapkan pada microprocessor, da-‐ pat dikatakan sebuah arsitektur khusus. Ada perbedaan khusus antara model microprocessor yang tidak menggunakan arsitektur pipeline dengan microp-‐ rocessor yang menerapkan teknik ini.
Pada microprocessor yang tidak menggunakan pipeline, satu instruksi dilakukan sampai selesai, baru instruksi berikutnya dapat dilaksanakan. Se-‐ dangkan dalam microprocessor yang menggunakan teknik pipeline, ketika satu instruksi sedangkan diproses, maka instruksi yang berikutnya juga da-‐ pat diproses dalam waktu yang bersamaan. Tetapi, instruksi yang diproses secara bersamaan ini, ada dalam tahap proses yang berbeda. Jadi, ada se-‐ jumlah tahapan yang akan dilewati oleh sebuah instruksi.
Misalnya sebuah microprocessor menyelesaikan sebuah instruksi dalam 4 langkah. Ketika instruksi pertama masuk ke langkah 2, maka instruksi berikutnya diambil untuk diproses pada langkah 1 instruksi tersebut. Begitu seterusnya, ketika instruksi pertama masuk ke langkah 3, instruksi kedua masuk ke langkah 2 dan instruksi ketiga masuk ke langkah 1.
Dengan penerapan pipeline ini pada microprocessor akan didapatkan pe-‐ ningkatan dalam unjuk kerja microprocessor. Hal ini terjadi karena beberapa instruksi dapat dilakukan secara parallel dalam waktu yang bersamaan. Se-‐ cara kasarnya diharapkan akan didapatkan peningkatan sebesar K kali diban-‐ dingkan dengan microprocessor yang tidak menggunakan pipeline, apabila tahapan yang ada dalam satu kali pemrosesan instruksi adalah K tahap. Teknik pipeline ini menyebabkan ada sejumlah hal yang harus diperhatikan sehingga ketika diterapkan dapat berjalan dengan baik. Tiga kesulitan yang sering dihadapi ketika
menggunakan teknik pipeline ini adalah : Terjadinya penggunaan resource yang bersamaan, Ketergantungan terhadap data, Pengaturan Jump ke suatu lokasi memori.
Karena beberapa instruksi diproses secara bersamaan ada kemungkinan perlukan adanya pengaturan yang tepat agar proses tetap berjalan dengan benar. Sedangkan ketergantungan terhadap data, bisa muncul, misalnya in-‐ struksi yang berurutan memerlukan data dari instruksi yang sebelumnya. Kasus Jump, juga perlu perhatian, karena ketika sebuah instruksi meminta untuk melompat ke suatu lokasi memori tertentu, akan terjadi perubahan program counter, sedangkan instruksi yang sedang berada dalam salah sa-‐ tu tahap proses yang berikutnya mungkin tidak mengharapkan terjadinya perubahan program counter.
Dengan menerapkan teknik pipeline ini, akan ditemukan sejumlah per-‐ hatian yang khusus terhadap beberapa hal di atas, tetapi tetap akan meng-‐ hasilkan peningkatan yang berarti dalam kinerja microprocessor. Ada kasus tertentu yang memang sangat tepat bila memanfaatkan pipeline ini, dan juga ada kasus lain yang mungkin tidak tepat bila menggunakan teknologi pipeline.
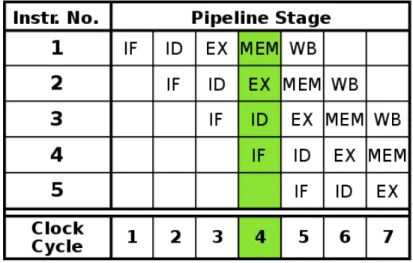
Gambar 1: Diagram Pewaktuan Pipeline
Pipeline tidak selalu berfungsi pada berbagai kasus, ada beberapa kerugian, berikut adalah kelebihan dan kekurangan pipeline:
Kekurangan Pipeline
• Mencegah penundaan cabang ini (berlaku, setiap cabang yang tertunda) dan masalah dengan serial instruksi yang dijalankan secara bersamaan, akibatnya desain yang lebih sederhana dan murah untuk pro-‐ duksi.
• Instruksi yang tersembunyi pada prosesor non pipelining tersebut sedikit lebih rendah daripada di papelining yang setara. Hal ini disebabkan oleh kenyataan bahwa tiba-‐tiba harus ditambahkan ke jalur data dari prosesor pipelined
• Prosesor non pipelining akan ada instruksi bandwith yang stabil. Ki-‐ nerja prosesor pipelined sangat sulit untuk memprediksi dan dapat ber-‐ variasi secara lebih luas di antara berbagai program.
Kelebihan Pipeline
• Siklus waktu dalam prosesor berkurang, sehingga secara umum menilai instruksi-‐isu • Kombinasi beberapa sirkuit seperti adders atau multipliers dapat di-‐ buat lebih cepat
dengan menambahkan lebih circuitry. Jika pipelining digunakan sebagai gantinya,ia dapat menyimpan circuity melawan yang lebih kompleks atas kombinasi sirkuit.
3. Intruksi pipeline Tahapan pipeline
· Mengambil instruksi dan membuffferkannya
· Ketika tahapn kedua bebas tahapan pertama mengirimkan instruksi yang dibufferkan
tersebut
· Pada saat tahapan kedua sedang mengeksekusi instruksi, tahapan pertama memanfaatkan
siklus memori yang tidak dipakai untuk mengambil dan membuffferkan instruksi berikutnya .
Instuksi pipeline:
Karena untuk setiap tahap pengerjaan instruksi, komponen yang bekerja berbeda, maka dimungkinkan untuk mengisi kekosongan kerja di komponen tersebut. Sebagai contoh :
Instruksi 1: ADD AX, AX Instruksi 2: ADD EX, CX
Setelah CU menjemput instruksi 1 dari memori (IF), CU akan menerjemahkan instruksi tersebut(ID). Pada menerjemahkan instruksi 1 tersebut, komponen IF tidak bekerja. Adanya teknologi pipeline menyebabkan IF akan menjemput instruksi 2 pada saat ID menerjemahkan instruksi 1. Demikian seterusnya pada saat CU menjalankan instruksi 1 (EX), instruksi 2 diterjemahkan (ID).
t = 1 2 3 4 5 6 7 8 9 10
ADD AX,AX IF DE IF DE EX
ADD BX,CX IF DE IF DE EX
ADD DX,DX IF DE IF DE EX
Contoh pengerjaan instruksi tanpa pipeline
t = 1 2 3 4 5 6 7 8 9 10
ADD AX,AX IF DE IF DE EX
ADD BX,CX IF DE IF DE EX
Disini instruksi baru akan dijemput jika instruksi sebelumnya telah selesai dilaksanakan.
pipeline
Disini instruksi baru akan dipanggil setelah tahap IF menganggur (t2).
Contoh pengerjaan instruksi dengan
Dengan adanya pipeline dua instruksi selesai dilaksanakan pada detik keenam (sedangkan pada kasus tanpa pipeline baru selesai pada detik kesepuluh). Dengan demikian telah terjadi percepatan sebanyak 1,67x dari 10T menjadi hanya 6T. Sedangkan untuk pengerjaan 3 buah instruksi terjadi percepatan sebanyak 2, 14 dari 15T menjadi hanya 7T.
Untuk kasus pipeline sendiri, 2 instruksi dapat dikerjakan dalam 6T(CPI = 3) dan instruksi dapat dikerjakan dalam 7T (CPT = 2,3) dan untuk 4 instruksi dapat dikerjakan dalam 8T (CPI =2). Ini berarti utnuk 100 instruksi akan dapat dikerjakan dalam 104T (CPI = 1,04). Pada kondisi ideal CPI akan harga 1.
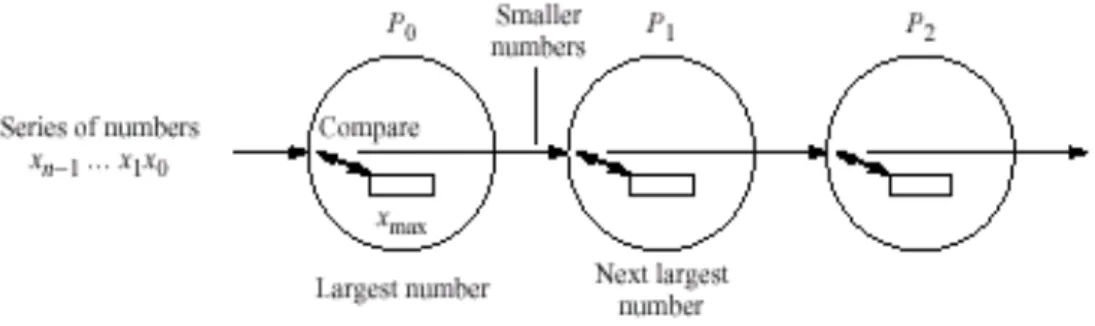
Dalam teknik pipeline, problem dibagi menjadi deretan yang harus dilaksanakan satu setelah lainnya. Setiap tugas nantinya akan dieksekusi oleh proses atau prosesor yang berbeda.
Gambar 1 Proses pipeline
Filter frekuensi - Menghilangkan frekuensi tertentu ( katakan f0, f1, f2, f3, dst) signal, f(t). Signal dapat dilewati pipeline dari kiri.
Gambar 3. Pipeline untuk filter frekuensi
Pipeline dapat meningkatkan kecepatan untuk problem yang sekuensial, dalam tiga tipe komputasi:
1. Jika lebih dari satu instance dari problem yang akan dieksekusi
2. Jika ada deretan item data yang harus diproses, masing-masing membutuhkan operasi ganda 3. Jika informasi untuk memulai proses berikutnya dpt diberikan sebelum proses selesai melaksanakan operasi internalnya.
Diagram Ruang-Waktu Pipeline “Tipe 1”
Gambar 5 Diagram Ruang-Waktu Alternatif Diagram Ruang-Waktu Pipeline “Tipe 2”
Diagram Ruang-Waktu Pipeline “Tipe 3”
Gambar 7 Pemrosesan pipeline, informasi di-pass sebelum proses selesai
Jika jumlah tahap lebih besar dari jumlah prosesor dalam pipeline, kelompok tahap dapat diassign untuk tiap prosesor.
Platform Komputisai untuk Aplikasi Pipeline
gambar 9 Sistem multiprosesor dengan konfigurasi Contoh Program Penjumlahan Angka
Gambar 10 Penjumlahan Pipeline Kode dasar untuk proses Pi : recv(&accumulation,
P i-1 ); accumulation = accumulation + number; send(&accumulation, P i+1 );
Kecuali untuk proses pertama, P0 , yaitu send(&number, P 1 );
Dan proses terakhir , Pn-1 , yaitu
recv(&number, P n-2 );
Program SPMD if (process > 0) {
recv(&accumulation, P i-1 );
accumulation = accumulation + number; }
if (process < n-1) send(&accumulation, P i+1 ); Hasil akhir ada di proses terakhir.
Selain penjumlahan, operasi aritmatika lainnya dapat dilakukan juga.
Gambar 11 Penjumlahan angka pipeline dengan proses master dan konfigurasi cincin.
Analisa
Contoh pertama adalah Tipe 1. Dengan asumsi bahwa tiap proses melakukan aksi serupa dalam tiap siklus pipeline. Kemudian akan dilakukan komputasi dan komunikasi yang dibutuhkan dalam siklus pipeline
Waktu total eksekusi
t total = (waktu untuk satu siklus pipeline)(jumlah siklus) t total = (t comp + t comm )(m + p - 1)
Dimana ada m instances problem dan p tahap pipeline (proses) Waktu rata-rata untuk komputasi diberikan oleh:
t a = t total /m 4. Permasalahan di (dalam) Instruksi Pipelining
· VARIASI WAKTU:
Tidak semua tahap memakan waktu yang sama. Ini berarti untuk mendapatkan kecepatan dalam intruksi pipelining sangat ditentukan oleh tahap yang paling lambat. Masalah ini sangat akut dalam memproses instruksi, sejak instruksi yang berbeda memiliki persyaratan
operand waktu proses yang berbeda. Selain itu, diperlukan mekanisme sinkronisasi untuk memastikan bahwa data lewat dari stage ke stage hanya ketika kedua stage siap.
· DATA BERBAHAYA (DATA HAZARDS):
Ketika beberapa instruksi di eksekusi secara parsial, masalah timbul jika mereka referensi data yang sama. Kita harus memastikan bahwa instruksi selanjutnya tidak berusaha untuk mengakses data lebih cepat dari instruksi sebelumnya, jika ini terjadi akan menyebabkan hasil yang salah. Sebagai contoh, instruksi N +1 tidak harus diperbolehkan untuk mengambil sebuah operand yang belum disimpan oleh instruksi N.
· PERCABANGAN (BRANCH):
untuk mengambil instruksi berikutnya, kita harus tahu mana saja yang dibutuhkan, Jika instruksi ini adalah cabang bersyarat (conditional branch) instruksi berikutnya mungkin tidak diketahui sampai saat diproses.
interupsi membuat instruksi extra yang tidak terencana untuk masuk kedalam aliran intruksi. jeda(Interrupt) harus berperan antar instruksi. yaitu, ketika satu instruksi telah selesai dan berikutnya belum dimulai. Dengan pipelining, instruksi berikutnya biasanya dimulai sebelum yang sekarang telah selesai.
Semua masalah ini harus diselesaikan dalam konteks kebutuhan kita untuk mendaatkan kinerja dengan kecepatan tinggi. Jika kita tidak dapat mencapai kecepatan yang cukup, pipelining mungkin tidak sepadan.
Instance Tunggal Problem
t comp = 1
t comm = 2(t startup + t data )
t total = (2(t startup + t data ) + 1)n
Kompleksitas waktu = O(n).
Instances Ganda Problem
t total = (2(t startup + t data ) + 1)(m + n - 1)
t a = t total /m » 2(t startup + t data ) + 1 Yaitu, satu siklus pipeline.
Mem-partisi Data dengan Instances Gande Problem
t comp = d
t comm = 2(t startup + t data )
t total = (2(t startup + t data ) + d)(m + n/d - 1)
Dengan menaikkan d, partisi data, pengaruh komunikasi dihilangkan. Akan tetapi naiknya partisi data menurunkan paralelisme dan terkadang menaikkan waktu eksekusi.
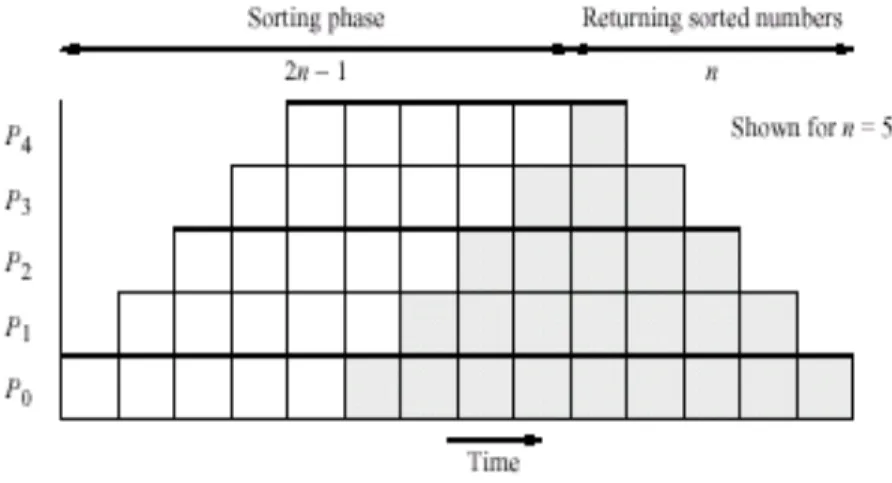
Mengurutkan Angka
Versi paralel dari insertion sort. (versi sekuensialnya adalah menempatka kartu yang dimainkan berurut dgn memindahkan kartu untuk menyisipkannya dalam posisi-nya).
Gambar 13 Langkah dalam insertion sort dengan lima angka Algortima dasar untuk proses Pi adalah
recv(&number, P i-1 ); if (number > x)
{ send(&x, P i+1 ); x = number;
} else send(&number, P i+1 );
Dengan n angka, berapa banyak proses ke yang akan diterima diketahui, diberikan oleh n - i. Berapa banyak yang di pass kedepan juga diketahui; diberikan oleh n - i - 1 karena satu dari jumlah yang diterima tidak di pass kedepan. Maka loop sederhana dapat digunakan.
Gambar 14 Pipeline untuk sorting menggunakan insertion sort.
Gambar 15 Insertion sort dengan hasil kembali ke proses master m,enggunakan konfigurasi baris dua arah
Dengan mengembalikan hasilnya, proses i dapat ditulis dalam bentuk right_procno = n -‐ i -‐ 1; /*no of processes to the right */
recv(&x, P i-‐1 ); for (j = 0; j < right_procno; j++) { recv(&number, P i-‐1 ); if (number > x) { send(&x, P i+1 ); x = number;
} else send(&number, P i+1 ); }
send(&number, P i-‐1 ); /* send number held */
for (j = 0; j < right_procno; j++) {/*pass on other nos */ recv(&x, P i+1 );
send(&x, P i-‐1 ); }
Sekuensial
Jelas merupakan algoritma sorting yang buruk dan tidak cocok kecuali untuk jumlah n yang sangat kecil
ts = (n - 1) + (n - 2) + … + 2 + 1 = n (n + 1) / 2 Paralel
Setiap siklus pipeline membutuhkan paling tidak
t comp = 1
t comm = 2(t startup + t data ) Waktu eksekusi total, t total , diberikan oleh
t total = (t comp + t comm )(2n - 1) = (1 + 2(t startup + t data ))(2n - 1)
Gambar 16 Insertion sort dengan hasil dikembalikan
Pembangkit Bilangan Prima
Deretan integer dibangkitkan dari 2 Bilangan pertama, 2 adalah prima dan disimpan. Seluruh kelipatan bilangan ini dihilangkan karena bukan merupakan bilangan prima. Proses dilakukan secara berulang untuk bilangan berikutnya. Algoritma membuang nonprima, dan menginggalkan hanya bilangan prima.
Kode Sekuensial
Umumnya menggunakan array dengan nilai awal 1 (TRUE) dan diset 0 (FALSE) jika indeks elemen bukan bilangan prima.Dengan menyatakan angka terakhir adalah n maka dapat ditulis: for (i = 2; i < n; i++)
prime[i] = 1; /* Initialize array */
for (i = 2; i <= sqrt_n; i++)/* for each number */ if (prime[i] == 1) /* identified as prime */
for (j = i + i; j < n; j = j + i)/*strike multiples */ prime[j] = 0; /* includes already done */ Loop sederhana mengakses array untuk mencari bilangan prima. Kode Sekuensial Waktu Sekuensial
Jumlah iterasi sangat tergantung dari bilangan prima tersebut. Ada [n/2-1] kelipatan dua, [n/3-1] kelipatan tiga, dan seterusnya. Sehingga total waktu sekuensial yang dibutuhkan:
Dengan asumsi komputasi pada tiap iterasi sam dengan satu langkah komputasional. Kompleksitas waktu sekuensial adalah O(n2 ).
Implementasi Pipeline
Kode untuk proses, Pi , berdasarkan atas recv(&x, P i-1 );
/* repeat following for each number */ recv(&number, P i-1 );
if ((number % x) != 0) send(&number, P i+1 );
Setiap proses tidak akan menerima jumlah angka yang sama dan tidak diketahui sebelumnya. Menggunakan message “terminator, yang dikirim pada akhir urutan.
recv(&x, P i-1 ); for (i = 0; i < n; i++) {
recv(&number, P i-1 );
if (number == terminator) break;
if (number % x) != 0) send(&number, P i+1 ); }
Menyelesaikan Sistem Persamaan Linier — Kasus Khusus
Contoh tipe 3 – proses dapat melanjutkan pekerjaan lain setelah mem-passing informasi Untuk menyelesaikan persamaan linier dalam bentuk upper triangular:
Subtitusi Balik
Pertama, x0 dapat dilihat dari persamaan terakhir
Nilai untuk x0 disubtitusi ke persamaan berikutnya untuk mendapatkan x1
Nilai x0 dan x1 disubtitusi ke persamaan berikutnya untuk mendapatkan x2:
X X X
X X X
X X
.
X XContoh 9.4
Lihat kembali Gambar 9-18(a), X pada baris 1, kolom
to
dan 13 mempunyai jarak kolom sebesar 3 di antara mereka; X pada baris 1, kolom t3 dan t5 mempunyai jarak kolom sebesar 2 di antara mereka; X pada baris 1, kolom to dan t5 mempunyai jarak kolom sebesar 5 di antara mereka; dan X pada baris 2, ko)om tJ dan 14 mempunyaijarak kolom sebesar 3i
terlarang, F, adalah {2, 3, 5}. Dapat kita Iihat pada Gambar 9-18(c), l tensi
inisiasi pertama dan kedua adalah 2. Karena 2 ada di daJam F maka terjadi suatu tubrukan.
Vektor tubrukan (collision vector), C, merupakan suatu representasi vektor
biner dari kumpulan latensi yang terlarang. Ia memiliki sejumlah n bit yang dimulai dari bit yang paling tidak signifikan, bit ke-i bernilai 1 jika i merupakan Iatensi terlarang danjika tidak bemilai 0; sehingga kita tulis:
(9.1)
dimana c; = I jika i ada di dalam F dan c;
=
0 jika sebaliknya.s,
3, 5,8s,
2. 3. 5s,
5s
2 FOfbtddln last: F • : 2. J. 5, 8!
Collision vector. C • ( 10010110)Gam bar 9-20
F
dan C pada
sebuah tabel reservasi
Contoh 9.7
Anggaplah Ct = (10010110) merupakan vektor tubrukan awal pada pipeline yang
T, T2 TJ T, T1 Tl r, Tl T, T2 TJ T, T2 , T2 T, T2 TJ r.. T, T2 T, T2 T3 r.. TJ T.. T, T2 T, T2 T, T2 TJ T.. TJ T.. Tl r.. Ts
Gambar 9-21 Diagram state untuk pipeline pada Gambar 9-20
s, s, Ti me 0 2 3 4 s 6 7 f a) ' Latency cycle • 1 s, 0 2 3 4 5 6 7 8 9 10 11 12 13 14 15 lbl latenCY cycle • 1,6
Gam bar 9-19 Siklus latensi yang berbeda untuk sebuah pipeline
bahwa terjadi sebuah inisiasi baru setelah 4 unit waktu. Hal ini mungkin terjadi karena setelah empat kali penggeseran Smenjadi (00001001) dan output terakhimya bemilai 0. Pengoperasian OR terhadap S dengan Ct akan menghasilkan (10011111), yang merupakan nilai S yang baru. Berdasarkan nilai S ini, suatu inisiasi baru tidak dapat terjadi pada unit waktu berikutnya. Jika terjadi maka inisiasi itu' tidak akan ber- tubrukan dengan pendahulunya, namun akan bertubrukan dengan inisiasi sebelum pendahulunya. lnilah kasus yang ditunjukkan oleh Gambar 9-19(a).
TABEL 9.1 SIKLUS LATENSI SEDERHANA UNTUK PIPELINE PADA GAMBAR 9-21
Siklus Sederhana Latensi Rata-rata
A A-B A-B-C A-B-e-n· A-C A-C-D A-D A-D-C
c
6,0s.o
4.33 4,25+ 6.5 5,667 5,0 5.667 7.0 C-D 5.5 • Siklus serakahContoh 9.8
Dalam diagram state pada Gambar 9-21, suatu kumpulan yang berurutan {A, C, D} membentuk suatu siklus. Dimulai dari state A, transisi 7 dapat diikutkan ke state C, transisi 4 dapat diikutkan ke stateD dan kemudian transisi 6 atau 9+ dapat diikutkan kernbali ke state A. Siklus ini sederhana dan juga dapat diwakilkan sebagai {7, 4, 6}. Perhatikan, karena state dan transisinya dalam suatu urutan tertentu memben- tuk suatu siklus, state-state yang sama dapat membentuk suatu siklus yang ber- beda dengan urutan yang berbeda. Untuk seluruh siklus, latensi rata-rata dihitung sebagai total latensi di dalam siklus dibagi jumlah state dalam siklus. Misalnya, latensi rata-rata dari siklus state A,D dan C pada Gambar 9-21 adalah (4
+
7+
6)/3 = 5,667. Perhatikan bahwa suatu siklus tidak harus dimulai dari state awal. Pada Gambar 9-21, ada suatu siklus antara state D dan C yang latensi rata-ratanya sebesar (7+
4)/2 = 5,5. Untuk mengoptimalkan strategi pengendalian pada pipeline tersebut, siklus latensi terbaik yang akan digunakan adalah siklus latensi yang mempunyailateosi rata-rata
palingrendah
(MAL atau minimum average latency). Tabel 9.1 memperlihatkan semua siklus sederhana untuk diagram state pada Gambar 9-21. MAL untuk pipeline ini adalah sebesar 4,25 unit waktu.Meskipun strategi itu benar untuk diagram state
pada
Gambar 9-21, pemilihan path latensi terpendek dari setiap state;dikena] sebagai siklus serakah (greedy cycle),tidak selalu merupakan siklus yang optimal. Sebagai contoh, perhatikan tabel reser- vasi pada Gambar 9-22(a). Dapat kita lihat dalam diagram state pada Gambar 9-22(b) dan tabel yang berhubungan dengan Gambar 9-22(c), siklus {4} mempunyai latensi rata-rata yang lebih ndah
panjang lebih efisien bagi kita untuk menunggu latensi keempat sebelum membuat inisiasi kedua daripada memulainya pada latensi ketiga.
F•\1.2.S.6.i
c •
f1110011) 1110011 11111ll 4 Simpll! A Cvctes Latencv {b) State d• ram •Grwdy cycle 3.s
·
5..5 'MAL 8 8 4 4' 4, 8 6M M M s s s
s
Shorntop OpenndA Operand 8 Parttal wmMulttply Parttai carry
I Sign•hcance Result C
como•ement
..n.n
Input Dlvtde and S.gn•f•cano!
complement !iC;uan: root count
Gam bar 9-25 Pipeline perkalian floating-point pada CYBER 205 (Courtesy of Control Data Corporation)
Jika operand A dan B akan dikalikan, pertama-tama kedua operand tersebut melewati stage perkalian, yang menghasilkan produk mantissa. Kemudian stage
penggabunganlkomplemen (merge/complement)
menambahkan eksponen-ekspo-nen mereka. Terakhir, angka floating point yang dihasilkan kita nonnalisir di dalam stage
pergeseran
signifikan
(significant shift).
Baik operasi pembagian ataupun akar pangkat dua memerlukan pengurangan mantissa suatu operand dari operand lainnya (lihat algorithma pem bagian pada Bagian 2.3). Untuk memungkinkan hal tersebut, operand yang sesuai
dikomple-Multiply
Input complement Drvlde ¥ld squant mot Men)elcomplemen t S'9"4r.ance count Sigrnficanashtft (t) Mulhply D 0 0 D (b) Dcv!de
Gambar 9-26 TabeJ reservasi untuk pipeline pada Gambar 9-25 (M = multiply (perkalian), D =divide (pembagian), S = square root (akar kuadrat)
z,
z,
z3z.
z5z&
z,
X, xlxl
x.
)( X x,x,
x2
xl
x.
Xx,
x,
x,
xl
x.
I
x5
x. x.,z,
Zzzl
x,
X2 / Z,T
x,.z2
x,
X1i Z, 1x,
:z,
x,
X:,'Z, xl .'Zlr
x.,.z,
• lGambar 9-27 Masalah perulangan
s, 0 2 3 4 5 6 7 8 9
z
.
!.t Bloctd s, 0 2 3 4 s 6 7 8 9 10 Timez.
:1 Pi1)eline wtd\ connection (dl Rewlting timeX.
l
Func:uon g-
··
zj_:-:7
Functton f: 1 stageS Z,[!]
31 AA[l- 121 ..-All- t3l - A[l - 141 +AU- 15] A[I1
l
A(I) Four·ttage adder r:l• K suga ofL.:J
noncompute del1ys A[l- 5] A[l - 6\ - A[I - 71 A[l - 81A(l-9] +A(I-101 -All-111
Four-nq ldde1'
---+---
Clll'
(Bll- 41l8(1- 151 • A(]- 15] + A(l- 16] ,.. Ali- 17] + A(l- 18] + BU- 191
Multithreading
Sistem SMP mengizinkan beberapa thread untuk berjalan secara bersamaan dengan menyediakan banyak physical processor. Ada sebuah strategi alternatif yang lebih cenderung untuk menyediakan logical processor daripada physical processor. Strategi ini dikenal sebagai SMT (Symetric Multithreading). SMT juga biasa disebut teknologi hyperthreading dalam prosesor intel.
Ide dari SMT adalah untuk menciptakan banyak logical processor dalam suatu physical processor yang sama dan mempresentasikan beberapa prosesor kepada sistem operasi. Setiap logical processor mempunyai state arsitekturnya sendiri yang mencakup general purpose dan machine state register. Lebih jauh lagi, setiap logical prosesor bertanggung jawab pada penanganan interupsinya sendiri, yang berarti bahwa interupsi cenderung dikirimkan ke logical processor dan ditangani oleh logical processor bukan physical processor. Dengan kata lain, setiap logical processor men-‐ share resource dari physical processor-‐nya, seperti cache dan bus.
Gambar di atas mengilustrasikan suatu tipe arsitektur SMT dengan dua physical processor dengan masing-‐masing punya dua logical processor. Dari sudut pandang sistem operasi, pada sistem ini terdapat empat prosesor.
Perlu diketahui bahwa SMT adalah fitur yang disediakan dalam hardware, bukan software, sehingga hardware harus menyediakan representasi state arsitektur dari setiap logical processor sebagaimana representasi dari penanganan interupsinya.
Sistem operasi tidak perlu didesain khusus jika berjalan pada sistem SMT, akan tetapi performa yang diharapkan tidak selalu terjadi pada sistem operasi yang berjalan pada SMT. Misalnya, suatu sistem memiliki 2 physical processor, keduanya idle, penjadwal pertama kali akan lebih memilih untuk membagi thread ke physical processor daripada membaginya ke logical processor dalam physical processor yang sama, sehingga logical processor pada satu physical processor bisa menjadi sibuk sedangkan physical processor yang lain menjadi idle.
2.7. Multicore
Multicore microprocessor adalah kombinasi dua atau lebih prosesor independen ke dalam sebuah integrated circuit (IC). Pada umumnya, multicore mengizinkan perangkat komputasi untuk memeragakan suatu bentuk thread-‐level paralelism (TLP) tanpa mengikutsertakan banyak prosesor terpisah. TLP lebih dikenal sebagai chip-‐level multiprocessing.
Keuntungan Multicore
? Meningkatkan performa dari operasi cache snoop (bus snooping). Bus snooping adalah suatu teknik yang digunakan dalam sistem pembagian memori terdistribusi dan multiprocessor yang ditujukan untuk mendapatkan koherensi pada cache. Hal ini dikarenakan sinyal antara CPU yang berbeda mengalir pada jarak yang lebih dekat, sehingga kekuatan sinyal hanya berkurang sedikit. Sinyal
dengan kualitas baik ini memungkinkan lebih banyak data yang dikirimkan dalam satu periode waktu dan tidak perlu sering di-‐repeat .
? Secara fisik, desain CPU multicore menggunakan ruang yang lebih kecil pada PCB (Printed Circuit Board) dibandingkan dengan desain multichip SMP.
? Prosesor dual-‐core menggunakan sumber daya lebih kecil dibandingkan dengan sepasang prosesor dual-‐core.
? Desain multicore memiliki resiko design error yang lebih rendah daripada desain single-‐core
2.7.2. Kerugian Multicore
? Dalam hal sistem operasi, dibutuhkan penyesuaian pada software yang ada untuk memaksimalkan kegunaan dari sumber daya komputasi yang disediakan oleh prosesor multicore. Kemampuan prosesor multicore untuk meningkatkan performa aplikasi juga bergantung pada jumlah penggunaan thread dalam aplikasi tersebut.
? Dari sudut pandang arsitektur, pemanfaatan daerah permukaan silikon dari desain single-‐core lebih baik daripada desain multicore.
? Pengembangan chip multicore membuat produksinya menjadi turun karena bertambahnya tingkat kesulitan untuk mengatur suhu pada chip yang padat.
2.7.3. Pengaruh Multicore Terhadap Software.
Keuntungan software dari arsitektur multicore adalah kode-‐kode dapat dieksekusi secara paralel. Dalam sistem operasi, kode-‐kode tersebut dieksekusi dalam thread-‐ thread atau proses-‐proses yang terpisah. Setiap aplikasi pada sistem berjalan pada prosesnya sendiri sehingga aplikasi paralel akan mendapatkan keuntungan dari arsitektur multicore. Setiap aplikasi harus tertulis secara spesifik untuk memaksimalkan penggunaan dari banyak thread.
Banyak aplikasi software tidak dituliskan dengan menggunakan thread-‐thread yang concurrent karena tingkat kesulitan yang tinggi dalam pembuatannya. Concurrency memegang peranan utama dalam aplikasi paralel yang sebenarnya. Langkah-‐langkah dalam mendesain aplikasi paralel adalah sebagai berikut: 2.7.3.1. Partioning
Tahap desain ini dimaksudkan untuk membuka peluang awal pengeksekusian secara paralel. Fokus dari tahap ini adalah mempartisi sejumlah besar tugas dalam ukuran kecil dengan tujuan menguraikan suatu masalah menjadi butiran-‐ butiran kecil.
2.7.3.2. Communication
Tugas-‐tugas yang telah terpartisi diharapkan dapat langsung dieksekusi secara parallel. Akan tetapi, pada umumnya tidak bisa, karena eksekusi berjalan secara independen. Pelaksanaan komputasi dalam satu tugas membutuhkan asosiasi data antara masing-‐masing tugas. Kemudian data harus berpindah-‐pindah antar tugas dalam melangsungkan komputasi. Aliran informasi inilah yang dispesifikasi dalam fase communication.
2.7.3.3. Agglomeration
Pada tahap ini kita pindah dari sesuatu yang abstrak ke sesuatu yang konkret. Kita tinjau kembali kedua tahap di atas dengan tujuan untuk mendapatkan algoritma pengeksekusian yang lebih efisien. Kita pertimbangkan juga apakah perlu untuk menggumpalkan (agglomerate) tugas-‐tugas pada fase partition menjadi lebih sedikit, dengan masing-‐masing tugas berukuran lebih besar.
Mapping
Dalam tahap yang keempat dan terakhir ini, kita menspesifikasi di mana tiap tugas akan dieksekusi. Masalah mapping ini tidak muncul pada uniprocessor yang menyediakan penjadwalan tugas.
Pada sisi server, prosesor multicore menjadi ideal karena server mengizinkan banyak user untuk melakukan koneksi ke server secara simultan. Oleh karena itu, Web server dan application server mempunyai throughput yang lebih baik.
Intel Hyper-Threading Technology merupakan sebuah teknologi mikroprose- sor yang diciptakan oleh Intel Corporation pada beberapa prosesor dengan arsitektur Intel NetBurst dan Core, semacam Intel Pentium 4, Pentium D, Xeon, dan Core 2. Teknologi ini diperkenalkan pada bulan Maret 2002 dan mulanya hanya diperkenalkan pada prosesor Xeon (Prestonia).
Prosesor dengan teknologi ini akan dilihat oleh sistem operasi yang men- dukung banyak prosesor seperti Windows NT, Windows 2000, Windows XP Professional, Windows Vista, dan GNU/Linux sebagai dua buah prosesor, meski secara fisik hanya tersedia satu prosesor. Dengan dua buah prosesor dikenali oleh sistem operasi, maka kerja sistem dalam melakukan eksekusi setiap thread pun akan lebih efisien, karena meskipun sistem-sistem opera- si tersebut bersifat multitasking, sistem-sistem operasi tersebut melakukan eksekusi terhadap proses secara sekuensial (berurutan), dengan sebuah algo- ritma antrean yang disebut dengan dispatching algorithm.
2.2.1 Kebutuhan Sistem Hyper-Threading
Sebuah prosesor yang mendukung teknologi Hyper-Threading membutuhkan beberapa komponen berikut ini:
• chipset motherboard yang mendukung teknologi Intel Hyper-Threading. Chipset yang dimaksud adalah Intel 845PE, Intel 865, Intel 875P, Intel 915, Intel 920, Intel 945, Intel 950, Intel 965, Intel 975.
Gambar 10: Hyper-threaded CPU
• BIOS yang mendukung teknologi Hyper-Threading.
• Sistem operasi yang mendukung banyak prosesor seperti Windows 2000, Windows XP, serta GNU/Linux versi 2.4.18 ke atas. Pada sistem yang mendukung, sebagai contoh, Device Manager Windows XP akan me- nampilkan 2 buah prosesor dengan spesifikasi yang sama.
Referesi
Henderson, Harry. Encyclopedia of Computer Science and Technology, Facts on File. 2003
Stallings, William. Computer Organization and Architecture, Prentice Hall. 2000
Wikipedia.org
http://id.wikipedia.org/wiki/MultipengolahanMultipengolahan Diakses 10 Desember 2011.
http://en.wikipedia.org/wiki/Multiprocessing. Multiprocesing-english language Diakses 8 Desember 2011.
http://syahrie.files.wordpress.com/2009/01/multiprocessor.pdf.Multiprocesor Diakses 10 Desember 2011.
http://amutiara.staff.gunadarma.ac.id/Downloads/files/262/ArKompPar1.pdf Materi Arkom Smt.3-gunadarma
Diakses 9 Desember 2011.
Stalling William, 2010 “Computer Organization and Architecture : Designing Fpr Performance “ 8th edition. Prentice Hall
http://elearning.gunadarma.ac.id/docmodul/organisasi_sistem_komputer/bab9-komputer_pipeline.pdf