DETEKSI PENJIPLAKAN KODE PROGRAM C DENGAN
METODE BISECTING K-MEANS PADA KODE YANG
MEMILIKI MAKRO
FAJAR SURYA DHARMA
DEPARTEMEN ILMU KOMPUTER
FAKULTAS ILMU PENGETAHUAN ALAM DAN MATEMATIKA INSTITUT PERTANIAN BOGOR
BOGOR 2015
PERNYATAAN MENGENAI SKRIPSI DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa skripsi berjudul Deteksi Penjiplakan Kode Program C dengan Metode Bisecting K-Means pada Kode yang Memiliki Makro adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir skripsi ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, Februari 2015
Fajar Surya Dharma
ABSTRAK
FAJAR SURYA DHARMA. Deteksi Penjiplakan Kode Program C dengan Metode Bisecting K-Means pada Kode yang Memiliki Makro. Dibimbing oleh AUZI ASFARIAN.
Pengumpulan tugas pemrograman dalam bentuk digital sangatlah rentan akan penjiplakan karena jumlah submisi yang diunggah dapat mencapai ratusan setiap minggunya sehingga proses pemeriksaan penjiplakan secara manual menjadi tidak memungkinkan. Oleh sebab itu, diperlukan suatu sistem yang dapat mendeteksi penjiplakan kode program secara otomatis. Hal ini sudah dilakukan pada penelitian sebelumnya dengan menggunakan metode K-means dan bisecting
K-means, namun penelitian sebelumnya mengasumsikan tidak adanya preprocessor directive. Padahal penggunaan preprocessor directive dapat
mengubah struktur kode program yang bisa mempengaruhi kemampuan sistem dalam deteksi penjiplakan. Tujuan penelitian ini adalah menangani kode program yang mempunyai makro dan membandingkan hasil yang didapat dengan penelitian sebelumnya. Hasil penelitian yang didapat menunjukkan adanya peningkatan akurasi dalam mendeteksi seluruh kode program dari 85% menjadi 89%. Sedangkan untuk pengujian masing-masing jenis kode program akurasinya naik dari 20%-40% menjadi 80%.
Kata kunci: deteksi penjiplakan, preprocessor directive, structure-oriented
similarity
ABSTRACT
FAJAR SURYA DHARMA. C Source Code Plagiarism Detection Using
Bisecting K-means on the Code with Macro. Supervised by AUZI ASFARIAN.
Submission of programming tasks in digital form is vulnerable to plagiarism because the number of submitted codes can reach hundreds every week, making the process of plagiarism checking manually infeasible. Therefore we need a system that can detect plagiarism program code automatically. This has been done in previous studies using the K-means and bisecting K-means, but previous research assumes no preprocessor directive in the program code. Meanwhile, the use of preprocessor directive can change the structure of the program code that could affect the ability of the system to detect plagiarism. The purpose of this study is to detect codes that uses macro and compare the results obtained with previous research. The results obtained showed an increased accuracy in detecting the whole program code from 85 % to 89 %. Testing for each type of program code result in an increase of accuracy from 20%-40% to 80%.
Keywords: plagiarism detection, preprocessor directive, structure-oriented similarity
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer
pada
Departemen Ilmu Komputer
DETEKSI PENJIPLAKAN KODE PROGRAM C DENGAN
METODE BISECTING K-MEANS PADA KODE YANG
MEMILIKI MAKRO
FAJAR SURYA DHARMA
DEPARTEMEN ILMU KOMPUTER
FAKULTAS ILMU PENGETAHUAN ALAM DAN MATEMATIKA INSTITUT PERTANIAN BOGOR
BOGOR 2015
Judul Skripsi : Deteksi Penjiplakan Kode Program C dengan Metode Bisecting
K-Means pada Kode yang Memiliki Makro
Nama : Fajar Surya Dharma NIM : G64080101
Disetujui oleh
Auzi Asfarian, SKomp MKom Pembimbing
Diketahui oleh
Dr Ir Agus Buono, MSi MKom Ketua Departemen
PRAKATA
Puji dan syukur penulis panjatkan ke hadirat Allah Subhanahu wa
Ta’alaata rahmat, hidayah, dan nikmat-Nya sehingga penulis dapat
menyelesaikan penelitian ini sebagai tugas akhir untuk memperoleh gelar Sarjana Komputer. Banyak pihak yang telah memberikan bantuan baik yang bersifat materi maupun moral kepada penulis dalam penyelesaian tugas akhir ini. Oleh karena itu, penulis ingin menyampaikan rasa terima kasih yang sebesar-besarnya kepada:
1 Bapak dan Ibu penulis yang selalu mendukung penulis.
2 Bapak Auzi Asfarian, Skomp MKom selaku dosen pembimbing.
3 Bapak Ahmad Ridha, SKom MS dan Bapak Firman Ardiansyah, SKom MSi selaku dosen penguji.
Akhir kata, penulis mohon maaf apabila dalam tulisan ini masih terdapat banyak kekurangan. Penulis berharap semoga tulisan ini dapat bermanfaat bagi para pembaca.
Bogor, Februari 2015
DAFTAR ISI
DAFTAR TABEL vi DAFTAR GAMBAR vi DAFTAR LAMPIRAN vi PENDAHULUAN 1 Latar Belakang 1 Perumusan Masalah 2 Tujuan Penelitian 2 Manfaat Penelitian 2Ruang Lingkup Penelitian 2
METODE 2
Pembuatan program penanganan makro 3
Pembuatan Data Plagiasi 5
Pengujian Data pada Sistem tanpa Penanganan Makro 5 Pengujian Data pada Sistem dengan Penanganan Makro 5
Perbandingan Kedua Percobaan 6
Lingkungan Pengembangan 6
HASIL DAN PEMBAHASAN 6
Pembuatan Program Penanganan Makro 6
Pembuatan Data Plagiasi 8
Pengujian Data Untuk Sistem tanpa Penanganan Makro 8 Pengujian Data Untuk Sistem dengan Penanganan Makro 9
Perbandingan Kedua Percobaan 9
SIMPULAN DAN SARAN 10
Simpulan 10
Saran 10
DAFTAR PUSTAKA 10
LAMPIRAN 11
DAFTAR TABEL
1 Contoh aturan konversi 4
2 Hasil pengujian untuk sistem tanpa penanganan makro 8 3 Hasil pengujian untuk sistem dengan penanganan makro 9
DAFTAR LAMPIRAN
1 Tabel aturan konversi 11
2 Kode program yang dimodifikasi 12
3 Clustering untuk pengujian data pada sistem tanpa penanganan makro 17 4 Clustering untuk pengujian data pada sistem dengan penanganan makro 18
PENDAHULUAN
Latar BelakangPlagiarisme atau penjiplakan sejak dulu sudah menjadi masalah dalam dunia pendidikan karena bisa mengacaukan penilaian terhadap kemampuan siswa. Penjiplakan dalam kode program biasanya dilakukan hanya dengan mengubah nama dokumen, variabel yang digunakan, nama fungsi dan sebagainya. Pengumpulan tugas dalam bentuk digital sangatlah rentan akan penjiplakan karena jumlah submisi yang diunggah dapat mencapai ratusan setiap minggunya sehingga proses pemeriksaan penjiplakan secara manual menjadi tidak memungkinkan. Oleh karena itu diperlukan suatu sistem yang dapat mendeteksi penjiplakan secara otomatis.
Burrow (2004) mengatakan ada dua kategori utama metode pendeteksian :
text-based dan code-based. Deteksi penjiplakan pada kode program biasanya
digunakan sistem berbasis kode. Pada sistem berbasis kode sendiri terdapat dua pendekatan yang digunakan, yaitu structure-oriented and attribute-oriented. Pada
attribute-oriented code-based system kesamaan antara dua program diukur dari
banyaknya operator dan operand yang digunakan. Cara ini punya keterbatasan karena hanya efektif jika program yang diperiksa sangat mirip sedangkan pada penjiplakan terkadang pelakunya menambah/mengurangi beberapa baris kode yang tak diperlukan sehingga kode programnya kadang terlihat berbeda.
Structure-oriented code-based system relatif tahan terhadap perubahan kecil yang
dilakukan pada program seperti penambahan variabel, penambahan kode program dan sebagainya, sehingga untuk menghindari pendeteksian diperlukan perubahan besar pada program untuk menghindari deteksi penjiplakan. Teknik yang digunakan adalah mengubah kode program menjadi suatu representasi yang solid lalu akan dicari kemiripan antara representasi kode program tersebut.
Notyasa (2013) dan Gumilang (2013) menggunakan structured-oriented
code-based system untuk mendeteksi penjiplakan pada kode program. Penelitian
Gumilang (2013) menggunakan metode flat clustering K-means, pada metode ini jumlah cluster yang dihasilkan harus ditentukan terlebih dahulu padahal jumlah
cluster yang akan dihasilkan belum diketahui. Maka pada penelitian gumilang
masalah ini diatasi dengan melakukan iterasi K-means secara otomatis, yaitu dengan menentukan cluster awal berjumlah satu kemudian dicek jarak antar dokumennya jika belum memuaskan maka cluster akan ditambah hingga mendapatkan jarak antar dokumen yang diinginkan. Cara ini memerlukan waktu eksekusi yang cukup lama karena setiap penambahan cluster semua jarak antar dokumen akan dihitung ulang. Pada penelitian Notyasa (2013) metode clustering yang digunakan adalah bisecting K-means, metode ini adalah suatu algoritme
clustering yang bersifat HDC (Hierarchical Divisive Clustering), algoritme clustering ini awalnya berawal dari suatu cluster besar yang akan dipecah menjadi cluster-cluster kecil, idealnya setiap cluster akan berisi satu data saja, namun
dalam penelitian ini yang ingin dihasilkan adalah suatu cluster yang berisi kumpulan data yang mirip sehingga jarak antara data dan centroid-nya dalam satu
cluster akan dibatasi. Hasil akurasi yang didapat pada penelitian tersebut sudah
2
Dalam penelitian sebelumnya diasumsikan tidak adanya makro sehingga semua preprocessor directive dihilangkan. Padahal penggunaan makro dapat mengakibatkan struktur program berubah. Hal ini juga berpengaruh pada proses tokenisasi karena preprocessor directive bisa mengakibatkan sebaris kode program dianggap sebagai sebuah variabel, sehingga kode program yang dijiplak bisa tidak terdeteksi oleh sistem. Oleh sebab itu diperlukan suatu sistem yang bisa mengatasi makro agar kode-kode program yang menggunakan makro bisa terdeteksi. Pada penelitian ini akan diimplementasikan program penanganan makro pada sistem yang telah dibuat pada penelitian sebelumnya, sehingga semua kode program dengan makro yang akan diperiksa akan terdeteksi oleh sistem.
Perumusan Masalah
Perumusan masalah dalam penelitian ini adalah
1 Bagaimana mengimplementasikan program penanganan makro dalam sistem pendeteksi plagiat kode program C dengan metode bisecting K-Means.
2 Apakah dengan diimplementasikannya program penanganan makro pada sistem yang sudah ada dapat menaikkan akurasi sistem dalam mendeteksi kode program yang mempunyai makro di dalamnya.
Tujuan Penelitian
Tujuan dari penelitian ini adalah mendeteksi penjiplakan kode program C yang mempunyai makro di dalamnya dengan menambahkan penanganan makro serta membandingkan hasil yang didapat dengan penelitian terdahulu terutama dalam pendeteksian penjiplakan.
Manfaat Penelitian
Penelitian ini diharapkan dapat mempermudah deteksi penjiplakan pada kode progam C yang mengandung makro di dalamnya.
Ruang Lingkup Penelitian
1 Kode program yg dideteksi hanya kode program dalam bahasa C.
2 Data yang digunakan adalah data dummy kode program C dengan makro di dalamnya.
METODE
Penilitian ini terbagi menjadi 5 tahap yaitu pembuatan program penanganan makro, pembuatan data plagiasi, pengujian data pada sistem tanpa penanganan makro, pengujian data pada sistem dengan penanganan makro, dan perbandingan kedua percobaan. Ilustrasinya dapat dilihat pada Gambar 1.
3
Gambar 1 Metode Penelitian
Pembuatan program penanganan makro
Preprocessor directive adalah suatu fitur dalam bahasa pemrograman C
yang akan memodifikasi kode program sebelum program tersebut dijalankan oleh
compiler (Banahan et al.1991). Jenis preprocessor directive yang dipakai dalam
penelitian ini adalah yang dapat mempengaruhi struktur program yaitu
preprocessor yang mendefinisikan sebuah makro. Makro adalah suatu potongan
program yang diberi sebuah identifier, setiap kali identifier tersebut digunakan dalam tubuh program maka identifier tersebut akan digantikan oleh argument dari makro. Biasanya, ada dua jenis makro yang sering digunakan, yaitu makro yang berbentuk seperti sebuah objek dan makro yang berbentuk seperti sebuah fungsi.
Preprocessor ini berada di awal kode program dan mempunyai ciri “#define” di
depannya kemudian diikuti dengan identifier dan argument yang masing-masing dipisahkan oleh whitespace. Tanda berakhirnya makro adalah baris baru dalam kode program, tetapi dengan menggunakan backslash, makro dapat ditulis lebih dari satu baris. Berikut ini adalah contoh beberapa jenis preprocessor directive yang mendefinisikan makro:
Pembuatan program penanganan makro
Pembuatan data plagiasi
Pengujian data untuk sistem tanpa penanganan
makro
Pengujian data untuk sistem dengan penanganan
makro
Perbandingan kedua percobaan
4
#define X 10000
#define Y rev[i] = rev[l - i] #define Z(x)\
strlen(x)-1
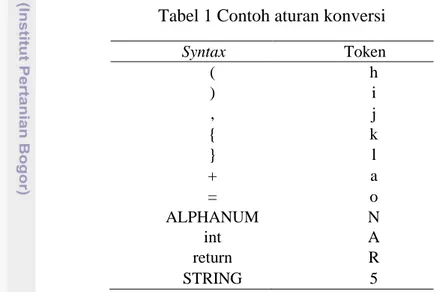
Untuk pembuatan program penangangan makro yang pertama dilakukan adalah mengidentifikasi bagian kode program yang berupa makro, kemudian seluruh makro tersebut akan diidentifikasi identifier dan argument-nya. Jika makro tersebut berbentuk sebuah fungsi maka akan ditambahkan sebuah fungsi yang mirip dengan makro tersebut ke dalam tubuh program. Jika makro tersebut berbentuks sebuah objek maka ketika identifier dari makro tersebut dipanggil dalam program hanya tinggal digantikan dengan argument-nya. Selanjutnya kode program akan dijadikan sebuah representasi yang ringkas berupa token stream agar lebih mudah dihitung kemiripan antar kode programnya, setiap syntax akan diubah menjadi token yang berbeda-beda, sedangkan nama variabel, nilai variabel, nama fungsi akan dimasukkan ke kategori yang sama. Contoh tokenisasi yang dilakukan dapat dilihat pada Tabel 1:
Tabel 1 Contoh aturan konversi Syntax Token ( h ) i , j { k } l + a = o ALPHANUM N int A return R STRING 5
Sebagai contoh kode program sederhana berikut ini jika diubah menjadi
token stream: 1 #include <stdio.h> 2 3 int main(){ 4 int a=1,b=1,c=1; 5 a=b+c; 6 printf("%d", a); 7 b=a+c; 8 printf("%d", b); 9 return 0; 10 }
Token stream kode program di atas:
5
Pembuatan Data Plagiasi
Karena pada penelitian ini ingin menguji seberapa akurat program jika diujicobakan pada kumpulan program yang dijiplak maka data pada penelitian ini adalah data dummy yang dibuat sendiri. Data yang dibuat asalnya hanya satu kode program, tetapi dimodifikasi sedemikian rupa sehingga strukturnya secara kasat mata lumayan berbeda. Jenis modifikasi yang dilakukan pada setiap kode program adalah:
1 Kode asli
2 Perubahan nama variabel 3 Penambahan fungsi di atas 4 Penambahan fungsi di bawah 5 Penggantian variabel dengan makro 6 Penggantian baris program dengan makro 7 Pembuatan fungsi dengan makro
8 Perubahan variabel dan penambahan makro
9 Penambahan Fungsi di atas dan penambahan makro 10 Penambahan Fungsi di bawah dan penambahan makro
Dalam penelitian ini akan dibuat 5 jenis kode program dengan struktur dan kompleksitas yang berbeda. Untuk setiap jenis kode progam akan diberi nama ex1 sampai dengan ex5. Setiap varian dari kode program akan diberi kode tes1 sampai dengan tes10 pada, jenis kode program yang akan diuji berjumlah 5 jenis dengan 10 varian untuk masing-masing jenis kode program sehingga ada 50 kode program. Pengelompokan manual sesuai jenis kode program juga dilakukan untuk mengukur akurasi program.
Pengujian Data pada Sistem tanpa Penanganan Makro
Pada tahap ini data plagiasi yang sudah dibentuk menjadi korpus akan diujikan ke program hasil dari penelitian Notyasa(2013). Validasi hasil clustering dalam mendeteksi penjiplakan akan diukur menggunakan Rand Index (RI). RI adalah suatu metode untuk mengukur persentase dari keputusan yang tepat (Manning et al. 2008) dengan formula sebagai berikut:
RI = TP + TN
TP + FP + FN + TN dengan
RI : Rand index
TP : true positive, dua dokumen yang mirip berada pada cluster yang sama FP : false positive, dua dokumen yang berbeda berada di cluster yang sama TN : true negative, dua dokumen yang berbeda berada di cluster yang berbeda FN : false negative, dua dokumen yang mirip berada di cluster yang berbeda
Pengujian Data pada Sistem dengan Penanganan Makro
Pada tahap ini data plagiasi akan diujikan pada program yang sama tetapi sudah dimodifikasi pada bagian praproses datanya sehingga bisa mendeteksi dan
6
menangani makro pada kode program. Tingkat akurasi dalam mendeteksi penjiplakan diukur menggunakan metode yang sama seperti tahap sebelumnya.
Perbandingan Kedua Percobaan
Perbandingan dari hasil kedua percobaan di atas adalah berupa perubahan
cluster pada program tanpa penangangan marko dan dengan penanganan makro.
Akurasi dari kedua percobaan tersebut juga akan dibandingkan, dan jika ada kode program yang tak terdeteksi atau keluar dari cluster aslinya akan dianalisa apa yang menyebabkan kode tersebut tak terdeteksi.
Lingkungan Pengembangan
Perangkat Keras:
Processor intel Pentium i5
Memory 4GB
Hard disk 500GB Perangkat Lunak:
Operating System Microsoft Windows 8.1 64bit
Programming language PHP 5.6.3
Apache HTTP server 2.4.10
Database Management System MySQL 5.6.21
Server Control Panel Xampp v3.2.1
Integrated Development Environtment Netbeans 8.0
Integrated Development Environtment Notepad++ v.6.6.8
Integrated Development Environtment Dev-C++ 5.6.3
HASIL DAN PEMBAHASAN
Pembuatan Program Penanganan MakroUntuk mendeteksi preprocessor directive pada kode program yang pertama dilakukan adalah mengecek ada atau tidaknya tanda “#” pada awal program, karena preprocessor directive yang dapat mempengaruhi struktur program hanya makro maka hanya preprocessor directive yang diikuti kata “define” saja yang diambil berikutnya akan diambil identifier dan argument dari makro yang masing-masing dipisahkan oleh whitespace. Jika makro pada kode program memakai
backslash agar bisa ditulis lebih dari satu baris maka akan dinormalisasi dengan
menghilangkan backslash dan menjadikannya satu baris saja. Sebagai contoh, dari kode program sebagai berikut:
1 #include <stdio.h> 2 #include <string.h> 3 #define X 10000
4 #define Y rev[i] = rev[l - i] 5 #define Z(x)\
7 6 strlen(x)-1
7
8 int reverse(char rev[], int i, int l){ 9 if(2 * i > l) return 0; 10 char temp;
11 temp = rev[i];
12 rev[i] = rev[l - i]; 13 rev[l - i] = temp; 14 reverse(rev, ++i, l); 15 } 16 17 main(){ 18 char word[10000] ; 19 scanf("%s", &word);
21 printf("entered string is %s\n", word); 22 int length = Z(word);
23 reverse(word, 0, length);
24 printf("reversed string is %s\n", word); 25 return 0;
26 }
Dari kode program di atas akan diambil makro yang sudah dinormalisasi seperti ini:
3 #define X 10000
4 #define Y rev[i] = rev[l - i] 5 #define Z(x) strlen(x)-1
Kemudian setiap makro yang didapat akan diperiksa apakah berupa fungsi atau hanya berupa objek. Jika berupa fungsi, pada tubuh program akan ditambahkan fungsi yang mirip seperti makro jika hanya berupa objek maka hanya tinggal diganti identifier yang ada pada tubuh program dengan argument yang ada pada makro. Selanjutnya semua preprocessor directive yang ada akan dihapus dari program agar tidak mempengaruhi proses tokenisasi kode program. Berikut contoh kode program yang telah diproses:
1 int reverse(char rev[], int i, int l){ 2 if(2 * i > l) return 0; 3 char temp;
4 temp = rev[i];
5 rev[i] = rev[l - i]; 6 rev[l - i] = temp; 7 reverse(rev, ++i, l); 8 } 9 10 main(){ 11 char word[1000] ; 12 scanf("%s", &word);
13 printf("entered string is %s\n", word); 14 int length = Z(word);
15 reverse(word, 0, length);
16 printf("reversed string is %s\n", word); 17 return 0;
18 }
8
Setelah kode program di atas mengalami proses tokenisasi sesuai aturan tabel konversi pada Lampiran 1, maka akan didapat token stream yang siap dihitung jarak antar dokumennya. Berikut adalah token stream yang dihasilkan dari kode program di atas:
ANhCNNNjANjANikIhNcNnNiRNCNNoNNNNNNNNoNNNbNNNNNbNNoN NhNjaaNjNilNhikCNNNNNh5jfNiNh5jNiANoNhNiNhNjNjNiNh5jNiRNlNhNik NhNibNl
Pembuatan Data Plagiasi
Untuk menguji apakah kode program penanganan makro yang sudah dibuat berfungsi atau tidak dibutuhkan data kode program yang mempunyai banyak jenis makro di dalamnya oleh karena itu penelitian ini tidak menggunakan data sebenarnya namun data dummy yang dibuat sendiri dengan mempertimbangkan bagaimana penjiplakan di dunia nyata dilakukan, dari satu kode program akan dibuat 9 jenis kode program dengan metode penjiplakan yang berbeda-beda.
Jenis kode program yang dipakai adalah sebanyak 5 jenis kode program, dengan demikian akan didapatkan 50 kode program, setiap jenis program akan dinamakan ex1 sampai dengan ex5. Varian dari masing-masing jenis program akan dinamai tes1 sampai dengan tes10. Berbagai macam modifikasi yang dilakukan pada jenis program ex1 dapat dilihat pada Lampiran 2. Selanjutnya data tersebut akan dijadikan korpus dan akan dikelompokkan secara manual sesuai dengan jenis kode programnya untuk memeriksa akurasi dari program pendeteksi penjiplakan.
Pengujian Data Untuk Sistem tanpa Penanganan Makro
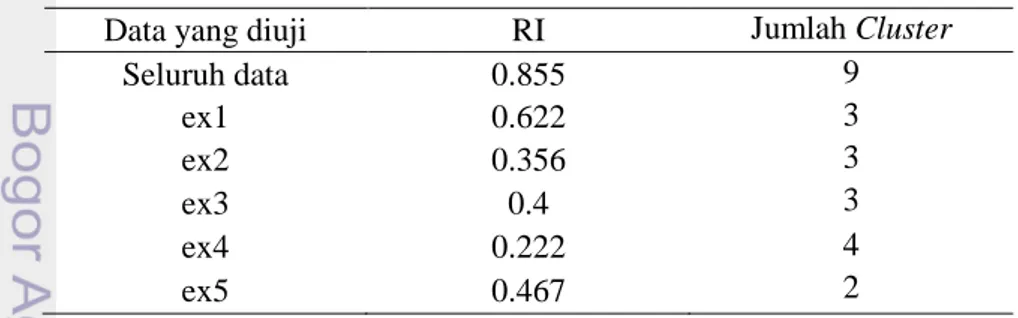
Pada penelitian Notyasa (2013) nilai i (rata-rata jarak setiap anggota cluster ke centroid cluster-nya) terbaik yang di dapat adalah adalah 0.95-0.97. Untuk pengujian awal akan diuji seluruh data yang ada pada korpus dengan i=0.97 sehingga didapat hasil clustering dan RI yang dapat dilihat pada Tabel 2:
Tabel 2 Hasil pengujian untuk sistem tanpa penanganan makro Data yang diuji RI Jumlah Cluster
Seluruh data 0.855 9 ex1 0.622 3 ex2 0.356 3 ex3 0.4 3 ex4 0.222 4 ex5 0.467 2
Hasil clustering dari pengujian ini dapat dilihat pada Lampiran 3. Dari hasil RI yang didapat dari hasil pengujian setiap jenis kode program dapat dilihat nilainya cukup rendah dan jumlah cluster yang dihasilkan juga cukup banyak, sehingga cukup banyak kode program yang tidak berada dalam satu cluster padahal, semua kode program yang ada hanya berasal dari satu kode program dan
9 pada kondisi ideal untuk pengujian seluruh data cluster-nya berjumlah 5 dan untuk pengujian setiap jenis data hanya menghasilkan 1 cluster.
Pengujian Data Untuk Sistem dengan Penanganan Makro
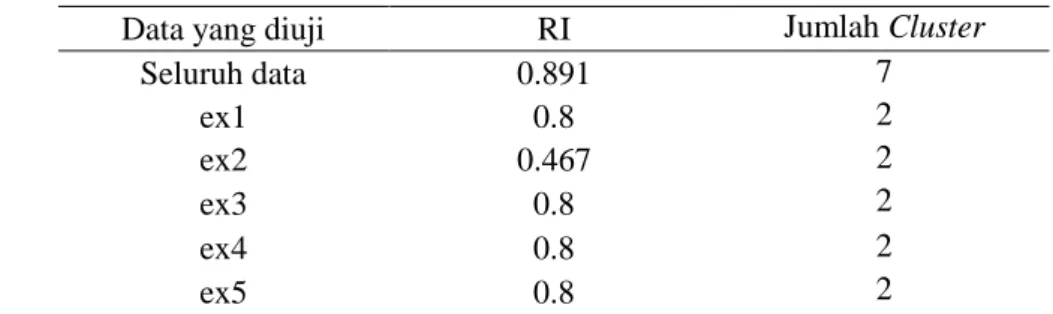
Pada pengujian ini nilai i yang digunakan sama yaitu 0.97. Dari hasil pengujian didapat clustering dan RI yang dapat dilhat pada Tabel 3:
Tabel 3 Hasil pengujian untuk sistem dengan penanganan makro Data yang diuji RI Jumlah Cluster
Seluruh data 0.891 7 ex1 0.8 2 ex2 0.467 2 ex3 0.8 2 ex4 0.8 2 ex5 0.8 2
Hasil clustering dari pengujian ini dapat dilihat pada Lampiran 4. Hasil RI yang didapat pada pengujian ini mengalami kenaikan dan kode program yang diuji sudah berkumpul ke dalam satu cluster walaupun ada beberapa pengecualian.
Perbandingan Kedua Percobaan
Dari kedua percobaan tersebut dapat dilihat bahwa penambahan penangangan makro pada praproses data dapat meningkatkan nilai RI. Pada pengujian keseluruhan data, nilai RI yang didapat bertambah dari 85% menjadi 89% dan cluster-nya berkurang dari 9 menjadi 7. Pada pengujian keseluruhan data jika tidak ada penangangan makro dapat dilihat dokumen menyebar tidak pada
cluster-nya sedangkan pada yang memakai penangangan makro dokumen mulai
menyebar pada cluster-nya masing-masing pengecualian terdapat pada cluster ex2 yang seharusnya sejenis namun terbagi menjadi dua cluster hal ini nampaknya disebabkan karena pada dokumen ex2 penambahan fungsi yang ada cukup signifikan sehingga mempengaruhi keseluruhan struktur program.
Pada pengujian masing-masing jenis kode program nilai RI yang didapat meningkat dari 20-40% menjadi 80%. Pengecualian terjadi lagi pada beberapa kode program ex2, yang mendapatkan penambahan jumlah fungsi yang signifikan yaitu tes 3,4,9, dan 10, sehingga terbagi menjadi dua cluster. Pada setiap jenis program dapat dilihat bahwa tes7 selalu terpisah dengan tes1 yang merupakan kode program yang asli, hal ini terjadi karena pada tes7 terdapat preprocessor
directive yang berbentuk makro fungsi sehingga ketika diproses akan
menambahkan fungsi pada tubuh program hal ini dapat menyebabkan tes7 dapat keluar dari cluster aslinya.
10
SIMPULAN DAN SARAN
SimpulanDari hasil perbandingan kedua pengujian, dapat dilihat dengan ditambahkannya penanganan makro pada praproses data dapat meningkatkan akurasi RI yang didapat baik pada keseluruhan data maupun pada setiap jenis data. Tetapi penambahan fungsi yang signifikan pada kode program dapat menyebabkan struktur kode program berubah sehingga menyebabkan kode yang diberi tambahan fungsi tapi merupakan penjiplakan tidak masuk ke cluster aslinya.
Saran
Penambahan fungsi yang signifikan dapat mengakibatkan struktur program berubah cukup drastis sehingga mengakibatkan kode program tersebut keluar dari
cluster aslinya, hal ini mungkin dapat menjadi pertimbangan untuk penelitian
selanjutnya. Program penanganan makro yang dibuat juga belum bisa menangani makro yang di dalam argument-nya terdapat identifier dari makro lain. Saran lainnya adalah penambahan variasi pada kode program plagiasi agar data yang diuji semakin beragam.
DAFTAR PUSTAKA
Burrow S. 2004. Efficient and effective plagiarism detection for large code repositories [tesis]. Melbourne (AU): RMIT University.
Gumilang AP. 2013. Pendeteksian penjiplakan kode program C dengan K-means [skripsi]. Bogor (ID): Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor
Notyasa Arizal. 2013. Pendeteksian penjiplakan kode program C dengan Bisecting K-means [skripsi]. Bogor (ID): Fakultas Matematika dan Ilmu Pengetahuan Alam,Institut Pertanian Bogor.
Banahan M, Brady D, Doran M. 1991. The C Book. United Kingdom : GBDirect. Manning CD, Raghavan P, Schütze H. 2008. An Introduction to Information
11 Lampiran 1 Tabel aturan konversi
Syntax Token + a - b * c / d % e & f | g ( h ) i , j { k } l < m > n = o . p ! q : r int A float B char C double D Syntax Token short E long F signed G unsigned H if I else J while K do L for M ALPHANUM N goto O case P break Q return R switch S const T continue U sizeof W struct X enum Y typedef Z STRING 5
12
Lampiran 2 Kode program yang dimodifikasi 1 Kode asli
1 #include <stdio.h> 2 #include <string.h> 3
4 int reverse(char v[], int index, int length){ 5 if(2 * index > length) return 0; 6 char temp;
7 temp = v[index];
8 v[index] = v[length - index]; 9 v[length - index] = temp; 10 reverse(v, ++index, length); 11 } 12 13 main(){ 14 15 char test[10000]; 16 scanf("%s", &test);
17 printf("entered string is %s\n", test); 18 reverse(test, 0, strlen(test) - 1); 19 printf("reversed string is %s\n", test); 20 return 0;
21 }
2 Perubahan nama variabel 1 #include <stdio.h> 2 #include <string.h> 3
4 int reverse(char rev[], int i, int l){ 5 if(2 * i > l) return 0; 6 char temp;
7 temp = rev[i];
8 rev[i] = rev[l - i]; 9 rev[l - i] = temp; 10 reverse(rev, ++i, l); 11 } 12 13 main(){ 14 char word[10000] ; 15 scanf("%s", &word);
16 printf("entered string is %s\n", word); 17 int length = strlen(word)-1;
18 reverse(word, 0, length);
19 printf("reversed string is %s\n", word); 20 return 0;
13
Lampiran 2 Lanjutan
3 Penambahan fungsi di atas 1 #include <stdio.h> 2
3 int reverse(char rev[], int i, int l){ 4 if(2 * i > l) return 0; 5 char temp;
6 temp = rev[i];
7 rev[i] = rev[l - i]; 8 rev[l - i] = temp; 9 reverse(rev, ++i, l); 10 }
11
12 int calculate_length(char *string) { 13 int l = 0; 14 while (string[l] != '\0') { 15 l++; 16 } 17 return l; 18 } 19 20 main(){ 21 char word[10000] ; 22 scanf("%s", &word);
23 printf("entered string is %s\n", word); 24 int length = calculate_length(word)-1; 25 reverse(word, 0, length);
26 printf("reversed string is %s\n", word); 27 return 0;
28 }
14
1 #include <stdio.h> 2 #include <string.h> 3
4 int reverse(char v[], int index, int length); 5
6 main(){
7 char test[] = ""; 8 scanf("%s", &test);
9 printf("entered string is %s\n", test); 10 reverse(test, 0, strlen(test) - 1); 11 printf("reversed string is %s\n", test); 12 return 0;
13 } 14
15 int reverse(char v[], int index, int length){ 16 if(2 * index > length) return 0; 17 char temp;
18 temp = v[index];
19 v[index] = v[length - index]; 20 v[length - index] = temp; 21 reverse(v, ++index, length); 22 }
Lampiran 2 Lanjutan
5 Penggantian variabel dengan makro 1 #include <stdio.h> 2 #include <string.h> 3 #define X 10000 4 #define Y 2 5 #define Z 0 6
7 int reverse(char v[], int index, int length){ 8 if(Y * index > length) return Z; 9 char temp;
10 temp = v[index];
11 v[index] = v[length - index]; 12 v[length - index] = temp; 13 reverse(v, ++index, length); 14 }
15
16 main(){
17 char test[X];
18 scanf("%s", &test);
19 printf("entered string is %s\n", test); 20 reverse(test, Z, strlen(test) - 1); 21 printf("reversed string is %s\n", test); 22 return Z;
23 }
15 1 #include <stdio.h>
2 #include <string.h>
3 #define X reverse(test,0,strlen(test)-1) 4 #define Y reverse(v,++index,length)
5 #define Z if(2 * index > length) return 0 6 #define A temp = v[index]
7 #define B v[index] = v[length - index] 8
9
10 int reverse(char v[], int index, int length){ 11 Z;
12 char temp; 13 A;
14 B;
15 v[length - index] = temp; 16 Y; 17 } 18 19 main(){ 20 21 char test[10000]; 22 scanf("%s", &test);
23 printf("entered string is %s\n", test); 24 X;
25 printf("reversed string is %s\n", test); 26 return 0;
27 }
Lampiran 2 Lanjutan
7 Pembuatan fungsi dengan makro 1 #include <stdio.h>
2 #include <string.h> 3 #define X(x,y) x-y 4 #define Y(x) ++x
5 #define Z(x,y) 2 * x > y 6 #define A(x) strlen(x)-1 7
8 int reverse(char v[], int index, int length){
9 if(Z(index,length)) return 0;
10 char temp;
11 temp = v[index];
12 v[index] = v[X(length,index)];
13 v[X(length,index)] = temp;
14 reverse(v, Y(index), length);
15 } 16 17 main(){ 18 19 char test[] = ""; 20 scanf("%s", &test);
21 printf("entered string is %s\n", test);
22 reverse(test, 0, A(test));
23 printf("reversed string is %s\n", test);
24 return 0;
16
8 Perubahan variabel dan penambahan makro 1 #include <stdio.h>
2 #include <string.h> 3 #define X 10000
4 #define Y rev[i] = rev[l - i] 5 #define Z(x) strlen(x)-1 6
7 int reverse(char rev[], int i, int l){
8 if(2 * i > l) return 0;
9 char temp;
10 temp = rev[i];
11 rev[i] = rev[l - i];
12 rev[l - i] = temp; 13 reverse(rev, ++i, l); 14 } 15 16 main(){ 17 char word[10000] ; 18 scanf("%s", &word);
19 printf("entered string is %s\n", word);
20 int length = Z(word);
21 reverse(word, 0, length);
22 printf("reversed string is %s\n", word);
23 return 0;
24 }
Lampiran 2 Lanjutan
9 Penambahan fungsi di atas dan penambahan makro 1 #include <stdio.h>
2 #define X 10000
3 #define Y string[l] != '\0' 4 #define Z(x) ++x
5
6 int reverse(char rev[], int i, int l){
7 if(2 * i > l) return 0;
8 char temp;
9 temp = rev[i];
10 rev[i] = rev[l - i];
11 rev[l - i] = temp;
12 reverse(rev, Z(i), l);
13 } 14
15 int calculate_length(char *string) { 16 int l = 0; 17 while (Y) { 18 l++; 19 } 20 return l; 21 } 22 23 main(){ 24 char word[X] ; 25 scanf("%s", &word);
26 printf("entered string is %s\n", word);
27 int length = calculate_length(word)-1;
28 reverse(word, 0, length);
29 printf("reversed string is %s\n", word);
30 return 0;
17
10 Penambahan fungsi di bawah dan penambahan makro 1 #include <stdio.h>
2 #include <string.h> 3 #define X 10000
4 #define Y reverse(rev, ++i, l) 5 #define Z(x,y) (x-y)
6
7 int reverse(char rev[], int i, int l); 8
9 main(){
10 char word[X];
11 scanf("%s", &word);
12 printf("entered string is %s\n", word);
13 int length = strlen(word)-1;
14 reverse(word, 0, length);
15 printf("reversed string is %s\n", word);
16 return 0;
17 } 18
19 int reverse(char rev[], int i, int l){
20 if(2 * i > l) return 0; 21 char temp; 22 temp = rev[i]; 23 rev[i] = rev[Z(l,i)]; 24 rev[Z(l,i)] = temp; 25 Y; 26 }
Lampiran 3 Clustering untuk pengujian data pada sistem tanpa penanganan makro Keseluruhan data
C1 ex4.tes1 ex4.tes10 ex4.tes2 ex4.tes3 ex4.tes4 ex4.tes5 ex4.tes6
ex4.tes7 ex4.tes8 ex4.tes9
C2 ex2.tes1 ex2.tes2 ex2.tes5 ex2.tes6 ex2.tes7 ex2.tes8
C3 ex2.tes10 ex2.tes3 ex2.tes4 ex2.tes9
C4 ex1.tes1 ex1.tes10 ex1.tes2 ex1.tes3 ex1.tes4 ex1.tes5 ex1.tes7
ex1.tes8 ex1.tes9
C5 ex1.tes6
C6 ex5.tes1 ex5.tes2 ex5.tes3 ex5.tes4 ex5.tes5 ex5.tes7
C7 ex5.tes10 ex5.tes6 ex5.tes8 ex5.tes9
C8 ex3.tes1 ex3.tes2 ex3.tes3 ex3.tes5 ex3.tes6 ex3.tes7 ex3.tes8
C9 ex3.tes10 ex3.tes4 ex3.tes9 Data ex1
C1 tes6
C2 tes1 tes10 tes2 tes3 tes4 tes5 tes8 tes9
C3 tes7
18
C1 tes10 tes3 tes4 tes9
C2 tes1 tes2 tes5 tes6 tes8 C3 tes7
Data ex3 C1 tes10 tes4 tes9
C2 tes1 tes2 tes3 tes5 tes6 tes8
C3 tes7 Data ex4 C1 tes10 tes4 tes9
C2 tes6 tes8
C3 tes1 tes2 tes3 tes5 C4 tes7
Data ex5
C1 tes1 tes2 tes3 tes4 tes5 tes7
C2 tes10 tes6 tes8 tes9
Lampiran 4 Clustering untuk pengujian data pada sistem dengan penanganan makro Keseluruhan data
C1 ex4.tes1 ex4.tes10 ex4.tes2 ex4.tes3 ex4.tes4 ex4.tes5 ex4.tes6
ex4.tes7 ex4.tes8 ex4.tes9
C2 ex3.tes1 ex3.tes10 ex3.tes2 ex3.tes3 ex3.tes4 ex3.tes5 ex3.tes6
ex3.tes7 ex3.tes8 ex3.tes9
C3 ex5.tes1 ex5.tes10 ex5.tes2 ex5.tes3 ex5.tes4 ex5.tes5 ex5.tes6
ex5.tes7 ex5.tes8 ex5.tes9
C4 ex2.tes1 ex2.tes2 ex2.tes5 ex2.tes6 ex2.tes7 ex2.tes8
C5 ex2.tes10 ex2.tes3 ex2.tes4 ex2.tes9
C6 ex1.tes1 ex1.tes10 ex1.tes2 ex1.tes3 ex1.tes4 ex1.tes5 ex1.tes6
ex1.tes8 ex1.tes9
C7 ex1.tes7
Data ex1
C1 tes1 tes10 tes2 tes3 tes4 tes5 tes6 tes8 tes9
C2 tes7
Data ex2
C1 tes1 tes2 tes5 tes6 tes7 tes8
19 Data ex3
C1 tes1 tes10 tes2 tes3 tes4 tes5 tes6 tes8 tes9
C2 tes7
Data ex4
C1 tes1 tes10 tes2 tes3 tes4 tes5 tes6 tes8 tes9
C2 tes7
Data ex5
C1 tes1 tes10 tes2 tes3 tes4 tes5 tes6 tes8 tes9
C2 tes7
RIWAYAT HIDUP
Penulis dilahirkan di Jakarta pada tanggal 29 September 1990, merupakan anak ketiga dari Bapak Sri Mulyono dan Ibu Herminie Soemitro.Pada Tahun 2002 sampai 2005 penulis menempuh pendidikan sekolah menengah pertama di SMP Negeri 166 Jakarta. Kemudian penulis melanjutkan pendidikannya di SMA Negeri 49 Jakarta pada tahun 2005 sampai 2008. Lulus dari sekolah menengah atas, penulis diterima di Departemen Ilmu Komputer Fakultas Matematika dan Ilmu Pengetahuan Alam Institut Pertanian Bogor melalui jalur Seleksi Nasional Masuk Perguruan Tinggi Negeri (SNMPTN) pada tahun 2008.